Vol 4, No 1
Maret 2021
Named-Entity Recognition pada Teks Berbahasa
Indonesia menggunakan Metode Hidden Markov
Model dan POS-Tagging
Novi Yusliani#1, M. Ridho Putra Sufa#2, Ari Firdaus#3, Abdiansah#4, Yoppy Sazaki#5 #Universitas Sriwijaya
Jl. Raya Palembang – Prabumulih Km. 32 Indralaya, Ogan Ilir, Sumatera Selatan 1[email protected]
2[email protected] 3[email protected]
4[email protected] 5[email protected]
Abstrak— Named entity recognition adalah salah satu tool yang
berfungsi untuk mengenali entitas bernama suatu kata dan banyak digunakan dalam aplikasi di bidang pemrosesan bahasa alami. Hidden markov model (HMM) adalah salah satu metode yang dapat digunakan untuk mengenali entitas bernama suatu kata. Metode ini terdiri dari tahap pelatihan dan tahap pengujian. Pada tahap pelatihan metode ini membutuhkan sekumpulan data berlabel untuk mendapatkan model pengetahuan berupa nilai probabilitas setiap kata yang ada di dalam data latih. Nilai probabilitas ini berfungsi untuk mengenali kata-kata yang belum diketahui labelnya. Apabila kata yang akan dikenali tidak ada di dalam data latih, maka kata tersebut akan memiliki nilai probabilitas nol (zero probability). Nilai probabilitas nol pada suatu kata menyebabkan kata tersebut tidak bisa diketahui label entitas bernamanya. Karena itu, penelitian ini menggunakan part-of-speech tagging agar tidak ada kata yang memiliki nilai probabilitas nol. Pengujian dilakukan pada teks berbahasa Indonesia dengan jumlah kalimat sebanyak 511 kalimat. Hasil pengujian menunjukkan nilai rata-rata
recall sebesar 83.82%, nilai rata-rata precision sebesar
89.31%, dan nilai rata-rata f-measure sebesar 86.14%.
Kata kunci
—
Named Entity Recognition (NER), Hidden Markov Model (HMM), Zero Probability, Part-of-Speech TaggingI. PENDAHULUAN
Named Entity Recognition (NER) adalah salah satu
topik penelitian di bidang Natural Language Processing (NLP). Penelitian ini bertujuan untuk mengidentifikasi entitas bernama (named entity) kata di dalam kalimat. NER merupakan subsistem terpenting di dalam Information
Extraction (IE) [1]. NER juga dapat menjadi bagian dari question answering system [2], sistem pengolahan
informasi di bidang biomedis [3], atau question generation
system [4].
Menurut [5], penggunaan kata ‘bernama’ (named) di dalam named entity menunjukkan bahwa penelitian di bidang NER merupakan penelitian untuk mengetahui entitas kata dalam suatu dokumen, dalam bentuk ‘proper
names’ atau istilah-istilah tertentu, seperti nama spesies. [2]
membagi ‘entitas bernama’ (named entity) ke dalam dua kategori, yaitu ‘generic named entity (NE)’ (seperti orang dan lokasi) dan ‘domain-specific NE’ (seperti protein, enzim, dan GEN). Pada penelitian ini, kategori named
entity yang digunakan adalah ‘generic NE’.
Proses pengenalan entitas bernama di dalam NER terdiri dari dua, yaitu identifikasi entitas kata yang tepat di dalam dokumen dan pengklasifikasian entitas-entitas tersebut ke dalam beberapa kategori, seperti person,
location, dan organization [6]. Menurut [6], secara umum,
ada empat permasalahan dalam proses pengenalan entitas bernama, yaitu:
1. Deteksi batasan dari entitas bernama (NE boundary
detection), jika entitas bernama berupa gabungan dua
atau lebih kata.
2. Homonim, kata yang memiliki lafal dan ejaan yang sama dengan kata lain tetapi berbeda maknanya. Kedua kata ini memungkinkan untuk memiliki entitas bernama yang berbeda.
3. Spelling mistakes, biasanya permasalahan ini ada jika teks merupakan hasil dari forum diskusi online, bahasa yang tidak formal dan kurang terstruktur.
4. Struktur kalimat yang tidak baku.
Menurut [7], ada dua pendekatan yang dapat digunakan untuk menyelesaikan permasalahan NER, yaitu rule based
dan corpus based. Pendekatan rule based adalah pendekatan yang sangat tergantung pada aturan yang dibangkitkan [2]. Sedangkan corpus based merupakan pendekatan yang membutuhkan data sebagai sumber basis pengetahuan sistem. Algoritma hidden markov model (HMM) termasuk algoritma yang menggunakan pendekatan corpus based. Algoritma ini merupakan algoritma yang menggunakan pendekatan probabilistik, terdiri dari dua bagian yaitu observed state dan hidden
state. Menurut [8], algoritma HMM merupakan algoritma
yang sederhana dan proses pembelajarannya cepat (quick
learning) .
Kinerja dari algoritma HMM sangat bergantung pada data, yaitu data latih. Data latih adalah data yang telah memiliki label, seperti label entitas bernama pada kasus
named entity recognition. Data berlabel ini digunakan pada
tahap pelatihan. Algoritma HMM merupakan algoritma
supervised learning. Karena itu, algoritma ini terdiri dari
dua tahap, yaitu tahap pelatihan dan tahap pengklasifikasian. Tahap pelatihan merupakan tahap pembelajaran yang berfungsi untuk membuat model pengetahuan. Model ini akan menjadi sumber pengetahuan pada tahap pengklasifikasian sehingga dapat melakukan klasifikasi terhadap data yang belum memiliki label.
Permasalahan utama algoritma HMM adalah algoritma ini tidak dapat mengklasifikasikan suatu kata atau kalimat apabila kata atau kalimat tersebut tidak ada di dalam data latih. Pada kasus named entity recognition, apabila kata yang akan dikenali tidak ada di dalam data latih (out of
vocabulary) maka kata tersebut tidak akan dikenali
entitasnya. Karena itu, pada tahap pelatihan penting untuk mempelajari fitur-fitur yang membedakan (discriminative
features) antara data satu dengan data lainnya [8]. Salah
satu fitur yang dapat digunakan untuk membedakan data satu dengan data lainnya adalah word level feature. Word
level feature adalah fitur-fitur yang ada pada kata [9].
Menurut [9], word level feature terdiri dari kind,
orthography, HasPeriod, HasAposthrope, HasHypen, HasDigit, SummarizedPattern, dan Part-of-Speech (POS). Tool untuk mengenali of-speech dari kata adalah part-of-speech tagging. Part-part-of-speech tagging merupakan
salah satu tool yang digunakan di hampir setiap aplikasi pemrosesan bahasa alami diantaranya NER [7][10].
Part-of-Speech tagging merupakan tool yang berfungsi untuk
memberi label pada kata berupa kelas kata, seperti kata benda, kata kerja, kata ganti, kata sifat, kata keterangan, dan kelas kata lainnya.
[9] dan [11] melakukan penelitian NER untuk dokumen berbahasa Indonesia dengan menggunakan pendekatan
corpus based dan part-of-speech tagging sebagai salah satu
fiturnya. [9] menggunakan tiga algoritma pembelajaran mesin, yaitu Support Vector Machine, Naive Bayes, dan
Simple Logistic. Pengujian dilakukan dengan menggunakan dua skenario berdasarkan kombinasi fitur yang digunakan. Hasil pengujian menunjukkan bahwa pengembangan sistem NER cukup dengan menggunakan
part-of-speech tagging sebagai fitur [9]. Penelitian [11]
menggunakan algoritma Multinomial Naive Bayes dan hasil pengujian menunjukkan bahwa penggunaan
part-of-speech tagging pada sistem named entity recognition dapat
meningkatkan persentase nilai f-1 sebesar 19%.
Penelitian lain terkait penanganan kata yang tidak ada di dalam data latih pada metode HMM adalah penelitian [18]. Penelitian [18] menggunakan analisis morfologi untuk menangani kata-kata yang tidak ada di dalam data latih. Analisis morfologi adalah analisis yang dilakukan terkait proses pembentukan kata dari bentuk dasarnya. Pada kata “membantu”, proses morfologi dari kata tersebut adalah kata dasar “bantu” mendapat imbuhan berupa awalan “mem-“ [18]. Hasil pengujian menunjukkan
POS-Tagger menggunakan metode HMM memiliki akurasi
sebesar 97,54% sedangkan dengan menggunakan metode HMM dan analisis morfologi tingkat akurasi meningkat menjadi 99,14%. Akan tetapi pada NER, analisis morfologi tidak dapat diterapkan karena kata-kata yang berlabel
person, location, dan organization merupakan kata-kata
yang tidak akan mengalami proses morfologi.
Pada penelitian ini pendekatan yang digunakan adalah
corpus based dengan menggunakan algoritma Hidden Markov Model (HMM) dan fitur part-of-speech tagging
untuk mengatasi permasalahan dari algoritma HMM.
II. METODE
A. Preprocessing
Preprocessing teks merupakan tahap awal yang
bertujuan untuk mengubah bentuk teks tidak terstruktur menjadi bentuk yang terstruktur sesuai kebutuhan. Secara umum, tahap preprocessing terdiri dari data cleaning, tokenisasi, stopword removal, stemming, sentence
boundary detection, spelling, dan case normalization [12].
Penggunaannya di dalam aplikasi pemrosesan bahasa alami beragam, tergantung pada kebutuhan dari setiap aplikasi.
Pada penelitian ini, tahap preprocessing terdiri dari tokenisasi dan stemming. Tokenisasi adalah proses memecah kalimat atau teks menjadi kata-kata. Pemecahan kalimat menjadi kata dilakukan berdasarkan pemisah antar kata yaitu spasi. Selanjutnya, kata-kata tersebut dicari bentuk akar katanya menggunakan algoritma stemming Nazief-Andriani [13].
B. Part-of-Speech Tagging
Part-of-speech tagging merupakan salah satu tool yang
digunakan oleh hampir semua aplikasi pemrosesan bahasa alami. Tool ini berfungsi untuk mengenali kelas kata suatu kata, seperti kata benda, kata kerja, kata keterangan, kata sifat, dan kelas kata lainnya.
Ada 35 kelas kata yang digunakan dalam penelitian ini. Kelas kata yang digunakan dapat dilihat pada tabel I. Penelitian ini menggunakan part-of-speech tagging
berbasiskan probabilistic, yaitu penentuan kelas kata berdasarkan nilai probabilitas kata menggunakan algoritma
hidden markov model. Part-of-speech tagging yang
digunakan dalam penelitian ini merupakan tool yang telah dikembangkan oleh [14] dengan tingkat akurasi sebesar 96,50%.
Pada penelitian ini, kelas kata digunakan untuk menghilangkan probabilitas 0 (zero-probability) sebuah kata dikarenakan kata tersebut tidak ada di dalam data latih sehingga nilai probabilitas emisi dari kata tersebut tidak diketahui. Zero-probability pada kata menyebabkan kata tersebut tidak dapat diketahui kelas katanya.
TABELI DAFTAR KELAS KATA
No. Label Kelas Kata Contoh
1 JJ Adjective Kaya, Manis
2 RB Adverb Sementara, Nanti
3 NN Common Noun Mobil
4 NNP Proper Noun Soekarno, Bekasi,
Indonesia
5 NNG Genitive Noun Bukunya
6 VBI Intransitive Verb Pergi
7 VBT Transitive Verb Membeli
8 IN Preposition Di, Ke, Dari
9 MD Modal Bisa
10 CC Coor-Conjunction Dan, Atau, Tetapi
11 SC
Subor-Conjunction
Jika, Ketika
12 DT Determiner Para, Ini, Itu
13 UH Interjection Wah, Aduh, Oi
14 CDO Ordinal Numerals Pertama, Kedua
15 CDC Collective
Numerals
Bertiga
16 CDP Primary Numerals Satu, Dua
17 CDI Irregular Numerals Beberapa 18 PRP Personal Pronouns Saya, Kamu
19 WP WH-Pronouns Apa, Siapa
20 PRN Number Pronouns Kedua-duanya
21 PRL Locative Pronouns Sini, Situ, Sana
22 NEG Negationt Bukan, Tidak
23 SYM Symbols @#$%^&
24 RP Particles Pun, Kah
25 FW Foreign Words Foreign, Word
26 OP Open Parenthesis ({[ 27 CP Close Parenthesis )}] 28 GM Slash / 29 ; Semicolon ; 30 : Colon : 31 " Quotation " ' 32 . Sentence Terminator . ! ? 33 , Comma , 34 - Dash - 35 …. Ellipsis ….
C. Hidden Markov Model
Hidden Markov Model (HMM) adalah salah satu
algoritma pembelajaran mesin yang menggunakan model
statistik. Algoritma ini menggunakan rangkaian nilai probabilitas untuk menyelesaikan suatu permasalahan. Nilai probabilitas dihitung dengan menggunakan bagian-bagian yang dapat diamati secara langsung disebut
observed state. Sedangkan bagian yang tidak dapat diamati
secara langsung atau tersembunyi disebut hidden state. HMM terdiri atas lima komponen [15], yaitu: 1. Himpunan observed state: O = o1, o2, …,oN 2. Himpunan hidden state: Q = q1, q2, …, qN
3. Probabilitas transisi: A = a01, a02, ...., an1, …, anm; aij adalah probabilitas untuk pindah dari state i ke state j 4. Probabilitas emisi atau observation likelihood:
B = bi(ot), merupakan probabilitas observasi ot dibangkitkan oleh state i
5. State awal dan akhir: q0, qend, yang tidak terkait dengan observasi.
Perhitungan nilai probabilitas transisi (A) ditunjukkan pada persamaan 1 dan probabilitas emisi (B) ditunjukkan pada persamaan 2 [16]. 𝑃(𝑡𝑖|𝑡𝑖−1) = 𝐶𝑜𝑢𝑛𝑡(𝑡𝑖,𝑡𝑖−1) 𝐶𝑜𝑢𝑛𝑡(𝑡𝑖) (1) 𝑃(𝑤𝑖|𝑡𝑖) = 𝐶𝑜𝑢𝑛𝑡(𝑡𝑖,𝑤𝑖) 𝐶𝑜𝑢𝑛𝑡(𝑡𝑖) (2)
𝑃(𝑡𝑖|𝑡𝑖−1) merupakan nilai probabilitas transisi atau
probabilitas kemunculan label ke-i setelah label ke-(i-1). 𝐶𝑜𝑢𝑛𝑡(𝑡𝑖, 𝑡𝑖−1) adalah jumlah kemunculan label ke-i
setelah label ke-(i-1) dan 𝐶𝑜𝑢𝑛𝑡(𝑡𝑖) adalah jumlah
kemunculan label ke-i pada data latih. 𝑃(𝑤𝑖|𝑡𝑖) merupakan
nilai probabilitas emisi atau probabilitas kata memiliki label tertentu. 𝐶𝑜𝑢𝑛𝑡(𝑡𝑖, 𝑤𝑖) adalah jumlah kemunculan
label pada kata tertentu dan 𝐶𝑜𝑢𝑛𝑡(𝑡𝑖) adalah jumlah
kemunculan label ke-i di dalam data latih.
D. Word Features
Word Features adalah fitur kata yang akan digunakan
jika ditemukan kata yang tidak diketahui pada saat tahap pengujian. Fitur kata tersebut adalah kelas kata. Tujuan dari penggunaan Word Features adalah untuk membantu kata yang memiliki nilai probabilitas emisi 0 (zero-probability). Nilai probabilitas emisi nol pada suatu kata mengakibatkan sistem tidak dapat menentukan label dari kata tersebut [17].
Probabilitas emisi word features adalah probabilitas kelas kata dari kata yang akan dihitung dengan kelas kata pada kata sebelumnya yang dinotasikan dengan (𝑃𝑂𝑆 − 𝑡𝑎𝑔𝑖| 𝑃𝑂𝑆 − 𝑡𝑎𝑔𝑖−1) . Nilai probabilitas emisi word feature dihitung berdasarkan jumlah kemunculan sebuah
label NER pada sebuah kata, dengan melihat kelas kata dari kata tersebut, dan kelas kata pada kata sebelumnya, lalu dibagi dengan kemunculan sebuah label NER. Perhitungan nilai probabilitas emisi word feature ditunjukkan pada persamaan 4.
P((POS − Tagj|POS − Tagj−1)|ti) =Count(ti,(POS−Tagj|POS−Tagj−1))
Count(ti)
(3)
Contoh word features pada penelitian ini ditunjukkan pada tabel II. Pada tabel II dicontohkan sebuah kalimat “Tika pergi ke Kotabumi setiap minggu” yang telah diberi label berupa kelas kata. Pada contoh “ke Kotabumi”, kata “ke” adalah kata yang memiliki label kelas kata IN dan kata “Kotabumi” merupakan kata yang memiliki label kelas kata NNP. Misal kata “Kotabumi” tidak ada di dalam data latih, maka nilai probabilitas emisi untuk kata “Kotabumi” adalah probabilitas emisi NNP-IN yang dihitung dengan menggunakan persamaan 4. Word feature VB-NNP artinya adalah fitur yang diperoleh dari sebuah kata yang memiliki label kelas kata NNP dan label kelas kata sebelumnya adalah VB. Sedangkan NNP-IN adalah fitur yang diperoleh dari sebuah kata berlabel kelas kata IN dan kata sebelumnya berlabel kelas kata NNP dan word feature NNP-CD adalah fitur yang diperoleh dari sebuah kata berlabel kelas kata CD dimana kata sebelumnya berlabel kelas kata NNP.
TABELII CONTOH WORD FEATURES
Word Features
Contoh Keterangan Hasil ganti
Word Features
VB-NNP Tika pergi NNP VB
Jika kelas kata yang diuji adalah VB dan kelas kata sebelumnya adalah NNP Tika VB-NNP NNP-IN ke Kotabumi IN NNP
Jike kelas kata yang diuji adalah NNP dan kelas kata sebelumnya ada IN ke NNP-IN NNP-CD setiap Minggu CD NNP
Jika kelas kata yang diuji adalah NNP dan kelas kata sebelumnya adalah CD setiap NNP-CD E. Algoritma Viterbi
Pada penelitian ini, pemilihan nilai probabilitas terbaik untuk menentukan label NER dilakukan dengan menggunakan algoritma viterbi. Algoritma viterbi merupakan salah satu algoritma dynamic programming yang berfungsi untuk mendapatkan jalur hidden state yang paling optimal. Pemilihan jalur paling optimal dilakukan dengan menggunakan persamaan 3.
𝑣𝑡(𝑗) = max
𝑖=1≤𝑁𝑣𝑡−1(𝑖)𝑎𝑖𝑗𝑏𝑗(𝑜𝑡) (4)
Keterangan:
𝑣𝑡(𝑗) = Viterbi Path pada state saat ini yaitu state ke-j
max
𝑖=1≤𝑁 = Nilai maksimum untuk state ke-i sampai state
ke-N
𝑣𝑡−1(𝑖) = Viterbi Path pada state ke-i yang merupakan
state sebelumnya
𝑎𝑖𝑗 = Probabilitas transisi dari state sebelumnya
yaitu state ke-i ke state saat ini yaitu state ke-j 𝑏𝑗(𝑜𝑡) = Probabilitas emisi untuk observation state (Ot)
pada state ke-j, probabilitas emisi yang akan dipakai yaitu probabilitas emisi HMM, dan probabilitas emisi word features (jika kata yang diuji, adalah kata yang tidak diketahui)
F. Confusion Matrix
Confusion Matrix adalah tabel yang sering digunakan
untuk menggambarkan kinerja sebuah model klasifikasi (classifier) pada serangkaian data uji yang sebenarnya sudah diketahui label atau kelas-nya. Pada penelitian ini, akan digunakan multi-class confusion matrix, yaitu
confusion matrix untuk label lebih dari satu, dengan label
yang digunakan yaitu nama orang (PER), nama lokasi (LOC), nama organisasi (ORG), satuan waktu (TIME), dan bukan entitas kata (OTH). Tabel multi-class confusion
matrix ditunjukkan pada tabel III.
TABELIII
TABEL MULTI-CLASS CONFUSION MATRIX
Predicted Class
Actual Class
PER LOC ORG TIME OTH
PER True False False False False
LOC False True False False False
ORG False False True False False
TIME False False False True False
OTH False False False False True
Selanjutnya, dengan menggunakan tabel Confusion
Matrix, dapat dihitung pengukuran kinerja suatu model
klasifikasi, yang disebut dengan Performance Measures, yaitu recall, precision, dan f-measure. Masing-masing penjelasan dari Performance Measure adalah sebagai berikut:
1) Recall adalah rasio jumlah data bernilai positif
yang diprediksi bernilai positif, dengan jumlah data yang bernilai positif. Dengan rumus ditunjukkan pada persamaan 5.
𝑅𝑒𝑐𝑎𝑙𝑙 = 𝑇𝑃
𝑇𝑃+𝐹𝑁 (5)
Nilai Recall yang tinggi dapat diindikasikan bahwa dari jumlah seluruh data yang bernilai positif, sudah banyak data yang terdeteksi dengan bernilai positif.
2) Precision adalah rasio jumlah data bernilai positif
yang diprediksi bernilai positif, dengan jumlah prediksi bernilai positif. Dengan rumus ditunjukkan pada persamaan 6.
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = 𝑇𝑃
𝑇𝑃+𝐹𝑃 (6)
Nilai Precision yang tinggi dapat diindikasikan bahwa dari jumlah prediksi yang bernilai positif, hanya sedikit jumlah prediksi yang salah.
3) F-Measure adalah rata-rata dari hasil pengukuran
Precision dan Recall, dengan menggunakan fungsi Harmonic Mean. Dengan rumus ditunjukkan pada
persamaan 7.
𝐹 − 𝑀𝑒𝑎𝑠𝑢𝑟𝑒 = 2 ×𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛∗𝑅𝑒𝑐𝑎𝑙𝑙
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛+𝑅𝑒𝑐𝑎𝑙𝑙 (7) Performance Measure berdasarkan nilai F-Measure
lebih baik dari nilai Accuracy untuk digunakan sebagai tolak ukur performa sebuah model klasifikasi, khususnya jika data yang dipakai memiliki distribusi nilai Positive dan
Negative yang tidak seimbang.
III. HASIL DAN PEMBAHASAN
Pengujian dilakukan menggunakan data uji berupa sekumpulan kalimat yang telah memiliki label NER di setiap katanya. Total kalimat yang digunakan adalah 511 kalimat, terdiri dari 740 kata berlabel PER (orang), 218 kata berlabel LOC (lokasi), 699 kata berlabel ORG (organisasi), dan 217 kata berlabel TIME (waktu). Data uji yang digunakan merupakan data yang telah digunakan dalam penelitian [19]. Pada penelitian ini, skenario pengujian ada dua. Skenario pertama, pengujian dilakukan pada sistem NER yang menggunakan metode Hidden
Markov Model (HMM) dan POS-Tagging. Skenario kedua
dilakukan pengujian pada sistem NER yang hanya menggunakan metode HMM.
TABELIV
TABEL CONFUSION MATRIX SISTEM NERMENGGUNAKAN HMM DAN POS-TAGGING
Predicted Class
PER LOC ORG TIME OTH
Actual Class PER 548 9 44 0 139 LOC 8 169 15 0 26 ORG 8 1 643 0 47 TIME 0 0 0 199 18 OTH 41 8 91 10 7.217
Tabel IV adalah tabel confusion matrix hasil pengujian sistem NER menggunakan HMM dan POS-Tagging. Nilai elemen pada diagonal utama dalam tabel IV menunjukkan jumlah kata yang berhasil diklasifikasi oleh sistem dengan benar. Pada kategori PER, jumlah kata yang berhasil diklasifikasi adalah 548 dari 740 kata dalam data uji. Total kata yang berhasil dikenali memiliki label LOC adalah 169 dari 218 kata di dalam data uji. Pada kategori ORG, kata yang berhasil dikenali adalah 643 dari 699 kata dalam data uji. Sedangkan kategori TIME, kata yang berhasil dikenali adalah 199 dari 217 kata dalam data uji. Hasil perhitungan nilai recall, precision, dan f-measure untuk setiap kategori pada sistem NER menggunakan HMM dan POS-Tagging berdasarkan tabel IV dapat dilihat pada tabel V.
TABELV TABEL HASIL PENGUJIAN
Label Evaluasi
Recall Precision F-Measure
PER 74.05% 90.58% 81.49%
LOC 77.52% 90.37% 83.46%
ORG 91.99% 81.08% 86.19%
TIME 91.71% 95.22% 93.43%
Rata-rata 83.82% 89.31% 86.14%
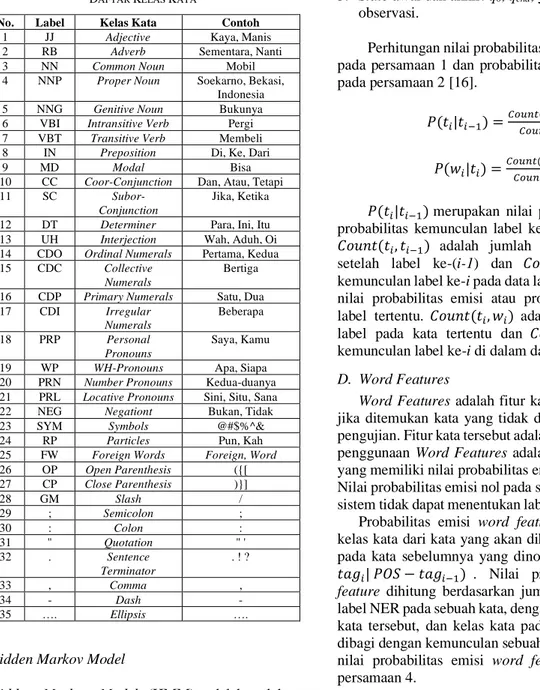
Gambar 1. Perbandingan Nilai F-Measure setiap Label NER
Grafik pada gambar 1 menunjukkan bahwa label TIME memiliki nilai f-measure tertinggi. Urutan nilai tertinggi setelah label TIME yaitu label ORG, label LOC, dan nilai terendah pada label PER. Berdasarkan persamaan (7), nilai
f-measure adalah nilai yang dipengaruhi oleh nilai recall
dan precision. Gambar 2 menunjukkan perbandingan nilai
recall dan precision pada masing-masing kategori Named-Entity Recognition (NER). Perbandingan nilai recall dan
81.49% 83.46% 86.19% 93.43% 0.00% 10.00% 20.00% 30.00% 40.00% 50.00% 60.00% 70.00% 80.00% 90.00% 100.00%
PER LOC ORG TIME
Perbandingan Nilai F-measure Pada Masing-masing Label NER
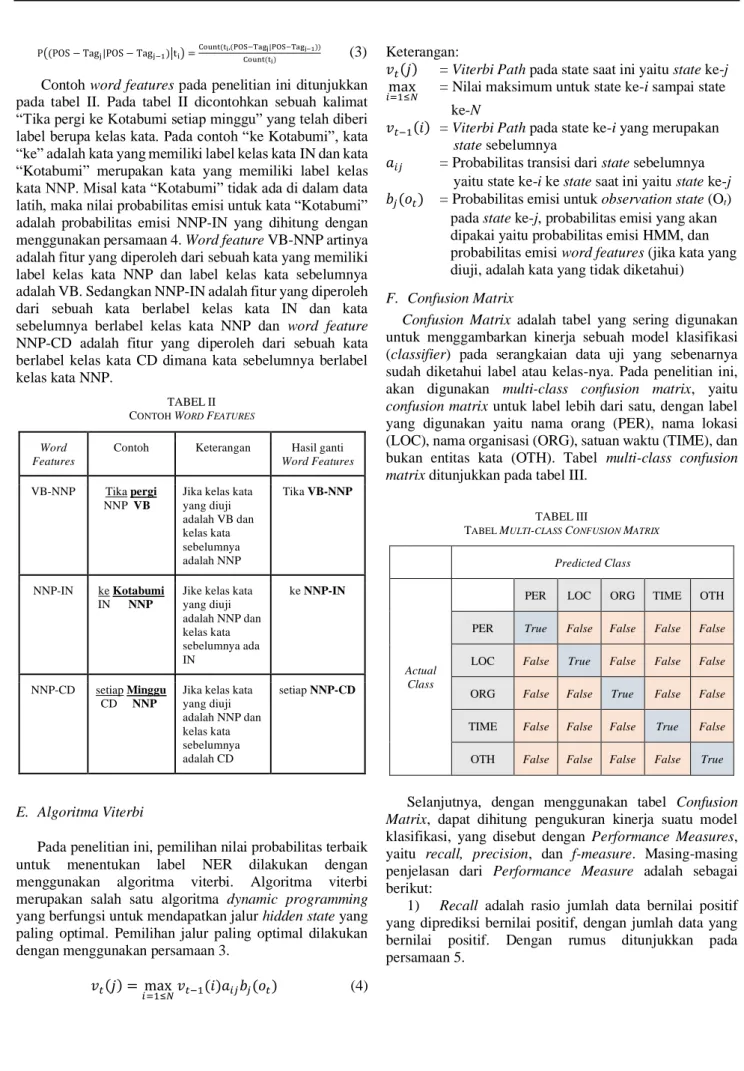
precision ditunjukkan dalam bentuk grafik batang.
Berdasarkan gambar 2, nilai recall dan nilai precision pada label TIME diatas 90%. Hasil yang tinggi ini bisa didapatkan karena kata yang merujuk pada label TIME adalah kata yang tidak ambigu. Pada penelitian ini, kata yang menunjukkan waktu, tanggal, dan tahun berupa angka diberi label TIME. Karena itu, POS-Tagging secara konsisten memberikan label kelas kata CDP (Primary
Numerals).
Gambar 2. Perbandingan Nilai Recall dan Precision pada Label NER
TABELVI
TABEL CONFUSION MATRIX SISTEM NERMENGGUNAKAN HMM
Predicted Class
PER LOC ORG TIME OTH
Actual Class PER 209 2 0 0 529 LOC 0 18 1 0 199 ORG 0 0 286 0 413 TIME 0 0 0 39 178 OTH 4 0 17 3 7343
Nilai recall pada label PER dan label LOC masih belum maksimal dikarenakan kelas kata yang dihasilkan dari POS-Tagging terkadang masih belum tepat, masih ada beberapa nama orang atau nama lokasi yang diberi label kelas kata yaitu NN. Berdasarkan tabel I, NNP adalah kelas kata yang lebih tepat untuk nama orang dan nama lokasi, contohnya seperti kata “Airlangga” dan kata “Jakarta”. Pada sistem NER menggunakan Hidden Markov Model (HMM) dan POS-Tagging, keluaran POS-Tagging sangat mempengaruhi perhitungan nilai probabilitas emisi word
features dan akan mempengaruhi kinerja sistem pada saat
melakukan pelabelan NER. Hal ini dikarenakan sistem melihat kelas kata dari kata yang diuji, jika kata yang diuji adalah kata yang tidak diketahui atau tidak ada di dalam data latih.
Sementara itu, nilai precision pada label ORG masih belum maksimal dikarenakan adanya beberapa nama orang atau nama lokasi yang diberi label kelas kata yaitu NN. Pada daftar kata word features yang dibuat dalam penelitian ini, POS-Tagging dengan kelas kata NN memiliki nilai probabilitas yang lebih tinggi untuk kata berlabel ORG, sehingga kata yang tidak diketahui dan memiliki label kelas kata NN akan diberi label ORG.
Berdasarkan uraian diatas, dapat dikatakan bahwa kinerja yang dihasilkan oleh sistem dipengaruhi oleh dua hal, yaitu ambigu atau tidaknya kata yang dihasilkan oleh sistem pada saat pelatihan, dan tepat atau tidaknya proses POS-Tagging dalam memberikan label kelas kata. Pada penelitian ini, kata dikatakan ambigu apabila kata tersebut memiliki lebih dari satu label entitas bernama, seperti kata “Komisi”.
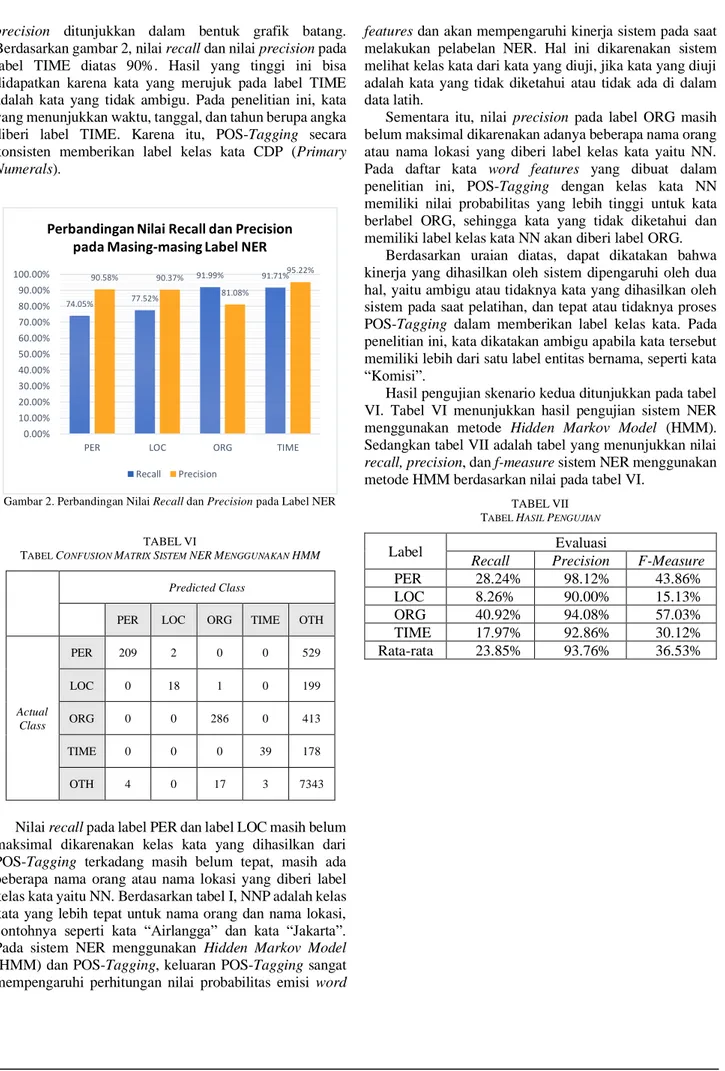
Hasil pengujian skenario kedua ditunjukkan pada tabel VI. Tabel VI menunjukkan hasil pengujian sistem NER menggunakan metode Hidden Markov Model (HMM). Sedangkan tabel VII adalah tabel yang menunjukkan nilai
recall, precision, dan f-measure sistem NER menggunakan
metode HMM berdasarkan nilai pada tabel VI.
TABELVII TABEL HASIL PENGUJIAN
Label Evaluasi
Recall Precision F-Measure
PER 28.24% 98.12% 43.86% LOC 8.26% 90.00% 15.13% ORG 40.92% 94.08% 57.03% TIME 17.97% 92.86% 30.12% Rata-rata 23.85% 93.76% 36.53% 74.05% 77.52% 91.99% 91.71% 90.58% 90.37% 81.08% 95.22% 0.00% 10.00% 20.00% 30.00% 40.00% 50.00% 60.00% 70.00% 80.00% 90.00% 100.00%
PER LOC ORG TIME
Perbandingan Nilai Recall dan Precision pada Masing-masing Label NER
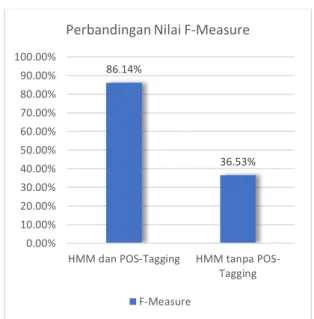
Gambar 3. Grafik Perbandingan Nilai F-Measure
Berdasarkan tabel V dan tabel VII, nilai f-measure rata-rata untuk sistem NER menggunakan Hidden Markov
Model (HMM) dan POS-Tagging memiliki nilai yang lebih
tinggi dibandingkan dengan nilai f-measure pada sistem NER menggunakan HMM. F-measure menggambarkan ketepatan sistem dalam memberikan label entitas bernama pada kata. Nilai ini ditentukan oleh nilai precision dan
recall. Nilai precision dan recall ditentukan oleh total kata
yang berhasil diberikan label dengan benar, total kata yang memiliki label yang salah, dan total kata berdasarkan kategori label pada data uji. Pada sistem NER menggunakan HMM dan POS-Tagging, total kata yang memiliki label yang benar lebih banyak dibandingkan dengan sistem NER menggunakan HMM. Jumlah label yang benar tiap kategori untuk sistem NER menggunakan HMM dan POS-Tagging dapat dilihat pada tabel IV dan jumlah label yang benar tiap kategori untuk sistem NER menggunakan HMM dapat dilihat pada tabel VI.
Pada gambar 3, ditunjukkan perbandingan nilai
f-measure pada sistem NER menggunakan Hidden Markov Model (HMM) dan POS-Tagging dan nilai f-measure pada
sistem NER menggunakan HMM. Berdasarkan gambar 4, disimpulkan bahwa kinerja metode Hidden Markov Model (HMM) dan POS-Tagging lebih baik daripada hanya menggunakan metode Hidden Markov Model (HMM) untuk menyelesaikan permasalahan NER. POS-Tagging merupakan salah satu word feature yang dapat digunakan untuk menangani kata-kata yang tidak ada di dalam data latih sehingga kata-kata tersebut tidak memiliki nilai probabilitas nol.
IV. KESIMPULAN
Penambahan POS-Tagging pada sistem named entity
recognition (NER) menggunakan hidden markov model
(HMM) dapat membantu sistem dalam mengenali kata-kata yang tidak ada di dalam latih. Hasil pengujian menunjukkan bahwa penambahan POS-Tagging di dalam sistem NER menggunakan HMM dapat meningkatkan kinerja sistem NER. Peningkatan kinerja terjadi dikarenakan POS-Tagging menjadikan kata-kata yang tidak ada di dalam latih memiliki nilai, yaitu berupa nilai probabilitas emisi word feature. Pada penelitian ini, kinerja sistem diukur berdasarkan nilai f-measure. Nilai f-measure dari sistem NER menggunakan HMM dan POS-Tagging adalah 86,14% dan nilai f-measure sistem NER menggunakan HMM adalah 36,53%.
UCAPAN TERIMA KASIH /ACKNOWLEDGMENT
Terima kasih kepada Universitas Sriwijaya yang telah mendanai penelitian ini.
DAFTAR PUSTAKA
[1] A. Setiyoaji, L. Muflikhah, and M. A. Fauzi, “Named Entity Recognition Menggunakan Hidden Markov Model dan Algoritma Viterbi pada Teks Tanaman Obat,” J. Pengemb.
Teknol. Inf. dan Ilmu Komput., vol. 1, no. 12, pp. 1858–1864,
2017, [Online]. Available: http://j-ptiik.ub.ac.id/index.php/j-ptiik/article/view/673.
[2] J. Li, A. Sun, J. Han, and C. Li, “A Survey on Deep Learning for Named Entity Recognition,” IEEE Trans. Knowl. Data Eng., pp. 1–1, 2020, doi: 10.1109/tkde.2020.2981314.
[3] L. Yao, H. Liu, Y. Liu, X. Li, and M. W. Anwar, “Biomedical Named Entity Recognition based on Deep Neutral Network,”
Int. J. Hybrid Inf. Technol., vol. 8, no. 8, pp. 279–288, 2015, doi:
10.14257/ijhit.2015.8.8.29.
[4] A. S. M. Nibras, M. F. F. Mohamed, I. S. M. Arham, A. M. M. Mafaris, and M. P. A. W. Gamage, “Automatic Question and Answer Generation from Course Materials .,” vol. 7, no. 11, pp. 224–231, 2017.
[5] D. Nadeau and S. Sekine, “A survey of named entity recognition and classification,” Lingvisticae Investig. Investig. Investig. Int.
J. Linguist. Lang. Resour., vol. 30, no. 1, pp. 3–26, 2007, doi:
10.1075/li.30.1.03nad.
[6] S. Keretna, C. P. Lim, D. Creighton, and K. B. Shaban, “Classification ensemble to improve medical named entity recognition,” Conf. Proc. - IEEE Int. Conf. Syst. Man Cybern., vol. 2014-January, no. January, pp. 2630–2636, 2014, doi: 10.1109/smc.2014.6974324.
[7] Ankita and K. A. Abdul Nazeer, “Part-of-speech tagging and named entity recognition using improved hidden markov model and bloom filter,” 2018 Int. Conf. Comput. Power Commun.
Technol. GUCON 2018, pp. 1072–1077, 2019, doi:
10.1109/GUCON.2018.8674901.
[8] M. L. Patawar and M. A. Potey, “Approaches to Named Entity Recognition: A Survey,” Int. J. Innov. Res. Comput. Commun.
Eng., vol. 3, no. 12, pp. 12201–12208, 2015, doi:
10.15680/IJIRCCE.2015.
[9] A. S. Wibawa and A. Purwarianti, “Indonesian Named-entity Recognition for 15 Classes Using Ensemble Supervised Learning,” Procedia Comput. Sci., vol. 81, no. May, pp. 221– 228, 2016, doi: 10.1016/j.procs.2016.04.053.
[10] S. R. Kundeti, J. Vijayananda, S. Mujjiga, and M. Kalyan, “Clinical named entity recognition: Challenges and
86.14% 36.53% 0.00% 10.00% 20.00% 30.00% 40.00% 50.00% 60.00% 70.00% 80.00% 90.00% 100.00%
HMM dan POS-Tagging HMM tanpa POS-Tagging
Perbandingan Nilai F-Measure
opportunities,” Proc. - 2016 IEEE Int. Conf. Big Data, Big Data
2016, pp. 1937–1945, 2016, doi:
10.1109/BigData.2016.7840814.
[11] R. Rifani, M. A. Bijaksana, and I. Asror, “Named Entity Recognition for an Indonesian Based Language Tweet using Multinomial Naive Bayes Classifier,” Indones. J. Comput., vol. 4, no. 2, pp. 119–126, 2019, doi: 10.21108/indojc.2019.4.2.330. [12] G. Miner, J. Elder, T. Hill, R. Nisbet, D. Delen, and A. Fast, “Practical Text Mining and Statistical Analysis for Non-Structured Text Data Applications”, 1st ed. USA: Academic Press, Inc., 2012.
[13] N. Yusliani, R. Primatha, and M. D. Marieska, “Multiprocessing Stemming: A Case Study of Indonesian Stemming,”
International Journal of Computer Science, vol. 182, no. 40,
February, pp. 15-16, 2019, doi: 10.5120/ijca2019918476. [14] A. F. Wicaksono and A. Purwarianti, “HMM Based
Part-of-Speech Tagger for Bahasa Indonesia,” Proceedings of 4th International MALINDO (Malaysian-Indonesian Language) Workshop, January 2010, 2014.
[15] Y. Wibisono, “Penggunaan Hidden Markov Model untuk Kompresi Kalimat,” pp. 5–17, Tesis, Institut Teknologi
Bandung, 2008, [Online]. Available:
http://digilib.itb.ac.id/files/disk1/627/jbptitbpp-gdl-yudiwibiso-1314-1-2008ts-r.pdf.
[16] D. Jurafsky and J. H. Martin, “Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition”, 3rd Ed.,
2000.
[17] M. Haulrich, “Different Approaches to Unknown Words in a Hidden Markov Model Part-of-Speech Tagger Tagging with HMMs,” pp. 1–8, 2009, [Online]. Available:
http://stp.lingfil.uu.se/~nivre/statmet/haulrich.
[18] F. Ramadhanti, Y. Wibisono, dan R. A. Sukamto, “Analisis Morfologi untuk Menangani Out-of-Vocabulary Words pada Part-of-Speech Tagger Bahasa Indonesia menggunakan Hidden Markov Model,” Jurnal Linguistik Komputasional, vol. 2, no.1, pp. 6-12, 2019.
[19] Y. Syaifudin and A. Nurwidyantoro, “Quotations Identification from Indonesin Online News using Rule-Based Method,”
International Seminar on Intelligent Technology and Its Application, 2016.