Fakultas Ilmu Komputer
Universitas Brawijaya
3912
Penerapan Named Entity Recognition Untuk Mengenali Fitur Produk Pada
E-Commerce Menggunakan Rule Template Dan Hidden Markov Model
M. Yusron Syauqi Dirgantara1, Mochammas Ali Fauzi2, Rizal Setya Perdana3 Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Teknologi informasi dengan adanya internet memberikan dampak perkembangan perdagangan elektronik atau e-commerce yang memperoleh banyak popularitas. Data APJII tahun 2016 menyatakan sebanyak 130,8 juta penduduk Indonesia menggunakan internet untuk menawarkan barang dan jasa. Di dalam manajemen e-commerce terdapat customer service yang bertugas untuk menangani segala macam pertanyaan yang disampaikan oleh pelanggan. Penyampaian informasi oleh customer service biasanya melalui call center atau aplikasi chatting. Di dorong kemampuan intelligent digital assistants chatbot banyak digunakan untuk membantu pekerjaan customer services. Dibutuhkan suatu analisis terhadap bahasa pelanggan pada chatbot agar dapat dikenali informasi apa saja yang terdapat pada pertanyaan tersebut, sehingga dibutuhkan klasifikasi dan ektrasi informasi agar mendapatkan informasi penting yang dibutuhkan oleh chatbot dalam menjawab pertanyaan dari pelanggan. Named Entity Recognition (NER) merupakan bagian dari ekstraksi informasi yang bertugas untuk pengklasifikasi teks dari sebuah dokumen atau korpus yang dikategorikan kedalam beberapa kelas seperti nama orang, lokasi, bulan, tanggal, waktu dan sebagainya. Ekstrasi nama secara otomatis dapat berguna untuk mengatasi beberapa permasalahan seperti pada mesin terjemahan, pencarian informasi, tanya jawab dan peringkasan teks. Pada penelitian ini NER yang dilakukan menggunakan metode Hidden Markov Model dan Rule
Template dengan 6 entitas yaitu MEREK, TIPE, HARGA, SPEK, N_SPEK dan N_TAG. Secara
keseluruhan pengenalan entitas yang dilakukan pada penelitian ini menghasilkan nilai akurasi pada Rule
Template sebesar 97.20% dan nilai akurasi pada Hidden Markov Model sebesar 92.23%.
Kata kunci: e-commerce, Named Entity Recognition, Hidden Markov Model, Rule Template, information
extraction
Abstract
Information technology with the Internet gives the impact of the development of electronic commerce or e-commerce that gained a lot of popularity. APJII data in 2016 states as many as 130.8 million Indonesians use the internet to offer goods and services. In e-commerce management there is customer service that is tasked to handle all of questions submitted by customers. Submission of information by customer service is usually through a call center or chat application. In thrust the ability of intelligent digital assistants chatbot is widely used to help the work of customer services. It takes an analysis of the customer's language on chatbot in order to be able to recognize what information is contained in the question, so it takes the classification and extracting of information in order to get important information needed by chatbot in answering questions from customers. Named Entity Recognition (NER) is part of the extraction of information assigned to the classification of text from a document or corpus categorized into classes such as person's name, location, month, date, time and so on. Automatic name extraction can be useful for addressing some issues such as translation engines, information retrieval, frequently asked questions and text summary. In this study NER is done using the method of Hidden Markov Model and Rule Template with 6 entities i.e. BRAND, TYPE, PRICE, SPEK, N_SPEK and N_TAG. Overall introduction of entities conducted in this study resulted in accuracy value in the Rule Template of 97.20% and the accuracy value in the Hidden Markov Model of 92.23%.
Keywords: e-commerce, Named Entity Recognition, Hidden Markov Model, Rule Template, information
1. PENDAHULUAN
Internet adalah jaringan informasi komputer mancanegara yang berkembang sangat pesat. Bedasarkan data Asosiasi Penyelenggara Jasa Internet Indonesia (APJII) tahun 2016 menyatakan 132,7 dari 256,2 juta penduduk Indonesia menggunakan internet. Teknologi messaging telah menyebar dengan cepat selama beberapa tahun terakhir menjadi salah satu layanan smartphone yang paling banyak digunakan. Sejalan dengan meningkatnya peranan teknologi informasi juga berdampak dalam bidang bisnis. Line, WeChat dan Facebook mereka telah berevolusi untuk menyertakan fitur seperti pembayaran, pemesanan yang tidak memerlukan aplikasi atau situs web yang terpisah. Teknologi informasi saat ini telah mengakibatkan perkembangan perdagangan elektronik atau e-commerce yang memperoleh banyak popularitas. Data APJII tahun 2016 menyatakan sebanyak 130,8 juta penduduk Indonesia menggunakan internet untuk menawarkan barang dan jasa (Guzman & Panthania, 2016). Di dalam manajemen
e-commerce terdapat customer service yang
bertugas untuk menangani segala macam pertanyaan yang disampaikan oleh pelanggan.
customer service diharuskan merespon secara
cepat jika ada yang bertanya mengenai produk, sistem pembayaran, maupun permasalahan lainnya. Penyampaian informasi oleh customer
service biasanya melalui call center atau aplikasi chatting. Akan tetapi, jumlah customer service
yang terbatas dengan jumlah pelanggan yang lebih banyak menjadi suatu kendala. Untuk itu diperlukan suatu teknologi media layanan informasi yang dapat merespon setiap pertanyaan pelanggan tanpa ada keterbatasan waktu dan jumlah customer service. Di dalam
customer service, terdapat minat yang kuat
dalam perkembangan chatbot, didorong oleh kemampuan intelligent digital assistans yang selalu tersedia untuk memenuhi permintaan pelanggan dengan murah, cepat dan konsisten (Guzman & Panthania, 2016).
Named Entity Recognition (NER)
merupakan bagian dari ekstraksi informasi yang bertugas untuk pengklasifikasi teks dari sebuah dokumen atau korpus yang dikategorikan kedalam beberapa kelas seperti nama orang, lokasi, organisasi, bulan, tanggal, waktu dan sebagainya. Ekstrasi nama secara otomatis dapat berguna untuk mengatasi beberapa
permasalahan seperti pada mesin terjemahan, pencarian informasi, tanya jawab dan peringkasan teks. Misalnya, pertanyaan untuk mengidentifikasi kata tanya (siapa, apa, kapan, dimana, dll), jadi kebanyakan kata tanya sesuai dengan entitasnya. Tujuan yang diharapkan dari proses dari NER adalah untuk melakukan ekstraksi dan klasifikasi entitas ke dalam beberapa kategori dengan mengacu kepada makna yang tepat (Mansouri, et al., 2008).
Penelitian ini akan menggunakan metode
Rule Template dan Hidden Markov Model
(HMM). Pemilihan Rule Template dan HMM sebagai algoritme pada penelitian ini didasari karena pada penelitian yang dilakukan (Chopra, et al., 2012) menggunakan HMM mendapatkan akurasi 89.78% dan 94.61% dengan penambahan algoritme Rule based Heuristics, dibandingkan dengan penelitian yang dilakukan oleh (Mansouri, et al., 2008) menggunakan metode Support Vector Machine (SVM) dengan akurasi 86.40% dan metode HMM juga unggul pada penelitian (Dey, et al., 2014) dengan penambahan algoritme Rule Based Approaches dengan akurasi 90.69%. Menggunakan metode HMM dalam perhitungan dikenal dengan
Maximum likelihood estimate. Menggunakan
estimasi Maximum likelihood dapat menyebabkan masalah karena transisi yang tidak terlihat diberi probabilitas nol. Untuk menghindari hal tersebut dapat menggunakan
Additive Smoothing dalam melakukan
perhitungan HMM (Haulrich, 2009).
2. STUDI PUSTAKA 2.1. E-Commerce
Perdagangan elektronik atau e-commerce merupakan sebuah aktivitas bisnis seperti pertukaran informasi, sistem manajemen inventaris otomatis, pengumpulan data otomatis dan transaksi yang menggunakan teknologi informasi dan komunikasi. Fasilitas internet yang memiliki layanan get and deliver pada website dapat digunakan untuk berdagang maupun berbelanja secara direct selling. Dapat diambil kesimpulan bahwa e-commerce adalah aktivitas penjualan dan pembelian suatu produk baik jasa maupun benda melalui jaringan internet sebagai media pertukaran informasi dan transaksi. Menurut (Nickerson, 2002) fungsi atau fitur e-commerce secara umum meliputi
product presentation, electronic catalogs, order entry, order confirmation, electronic payment,
order fulfillment, and customer service. Pada
saat sebelum, selama, atau setelah pembelian produk, pelanggan mungkin membutuhkan pelayanan khusus.
2.2. Text Mining
Text mining merupakan suatu proses untuk
mengekstrak pola dalam mengeksplorasi pengetahuan dari sumber data yang berbentuk teks. Proses Text mining dimulai dengan mengumpulkan data dari berbagai sumber yang tersedia dalam berbagai format file seperti teks biasa, halaman web, file pdf dan sebagainya. Kemudian melakukan pre-processing dan pembersihan data dilakukan untuk mendeteksi dan menghapus anomali pada data. Proses pembersiha harus memastikan untuk menangkap esensi teks sebenarnya yang tersedia. Pemrosesan dan pengedalian diterapkan untuk mengaudit kemudian membersihkan data dengan pemrosesan otomatis. Setelah itu dilakukan analisis pola pada data guna memperoleh informasi yang berharga dan relevan (Talib, et al., 2016).
2.3. Named Entity Recognition
Named Entity Recognition (NER)
merupakan bagian dari ekstraksi informasi yang bertugas untuk pengklasifikasi teks dari sebuah dokumen atau korpus yang dikategorikan seperti nama orang, lokasi, organisasi, tanggal, waktu dan sebagainya. NER diimplementasikan dalam banyak bidang, antara lain dalam machine
translation, question-answering machine
system, indexing pada information retrieval,
klasifikasi dan juga dalam automatic summarization. Tujuan yang diharapkan dari
proses dalam NER adalah untuk melakukan ekstraksi dan klasifikasi nama ke dalam beberapa kategori dengan mengacu kepada makna yang tepat (Mansouri, et al., 2008). Bukan hal sulit dalam menerapkan NER, karena banyak named entity diawali dengan huruf kapital sehingga mudah dikenali. Sebagai contoh pengenalan NER pada Bahasa Indonesia:
“Sabrina Nurfadilla/PERSON pada jam 07:00/TIME pergi menuju kampus Universitas Brawijaya/ORGANIZATION di Malang/LOC”
Pada NER Terdapat dua jenis model
machine learning atau pembelajaran mesin yang
dapat digunakan, yaitu supervised learning dan
unsupervised learning. Pada Supervised
learning yaitu menggunakan program yang
dapat belajar untuk mengklasifikasikan kumpulan data yang diberikan berdasarkan label yang telah dibuat dengan jumlah fitur yang sama. Pembelajaran ini disebut terbimbing karena data latih yang ada digunakan untuk ‘mengajari’ komputer agar dapat mengenali data. Pada unsupervised learning model belajar tanpa umpan balik apapun, di dalam
unsupervised bertujuan untuk membangun
representasi data yang kumudian dapat digunakan untuk kompresi data, klasifikasi, pengambilan keputusan dan keperluan lainnya (Mansouri, et al., 2008).
2.4. Hidden Markov Model
Hidden Markov Model (HMM) dapat
dikatakan sebagai model urutan yang mana tugasnya memberikan label atau kelas ke masing-masing unit secara berurutan. HMM adalah model urutan probabilistik urutan dari unit-unit (kata, huruf, morfem, kalimat dan lain sebagainya) yang kemudian dihitung nilai distribusi probabilitas untuk didapatkan urutan label yang memungkinkan dan memilih urutan label yang terbaik. HMM ditentukan oleh komponen-komponen berikut, yaitu (Jurafsky & Martin, 2017) :
1. Q = q1q2…qN, sebagai kumpulan N
kondisi.
2. A = a01a02…an1…ann, A merupakan
matriks transition probability. Setiap aij
mewakili probabilitas perpindahan dari kondisi i ke kondisi j.
3. O = o1o2…ot, merupakan urutan dari t
pengamatan masing-masing diambil dari kosakata.
4. B = bi(ot), merupakan urutan
pengamatan likelihood, disebut juga
emission probabilities yang mana
masing-masing mewakili probabilitas dari pengamatan ot yang dihasilkan dari
kondisi i.
5. qo,qf, sebagai kondisi awal dan kondisi
akhir (final) yang tidak berhubungan dengan pengamatan.
Maximum likelihood estimate untuk
mengitung transition probability:
𝑃(𝑡𝑖|𝑡𝑖−1) = 𝐶(𝑡𝐶(𝑡𝑖−1𝑖−1,𝑡)𝑖) (1)
𝑃(𝑡𝑖|𝑡𝑖−1) merupakan nilai transition
probability atau probabilitas kemunculan tag ke
i setelah tag ke i-1. C(ti-1,ti) adalah jumlah tag ke
i-1 diikuti dengan tag ke i dan C(t-1) adalah
jumlah kemunculan tag ke i-1 pada data latih. Persamaan 2 untuk menghitung emission
probability:
𝑃(𝑤𝑖|𝑡𝑖) = 𝐶(𝑡𝐶(𝑡𝑖,𝑤𝑖)
𝑖) (2)
Keterangan:
𝑃(𝑤𝑖|𝑡𝑖) merupakan nilai dari emission
nprobability atau probabilitas kata ke i yang
memiliki tag ke i, C(ti,wi) adalah jumlah
kemunculan kata ke i dengan tag ke i pada data latih dan C(ti) adalah jumlah kemunculan tag ke
i pada data latih.
Diagram Hidden Markov Model menurut (Chopra, et al., 2012):
Gambar 1. Diagram HMM
2.5. Algoritme Viterbi
Viterbi merupakan pemrograman dinamis yang bekerja seperti algoritme forward. Algoritme Viterbi memiliki satu komponen yang tidak dimiliki Algoritme forward yaitu
backpointers. Alasannya adalah bahwa
algoritme forward perlu menghasilkan kemungkinan observasi, algoritme Viterbi harus menghasilkan probabilitas dan juga urutan kondisi yang paling baik. Perhitungan urutan kondisi terbaik ini dengan mencatat jalur hidden
state yang menyebabkan masing-masing
kondisi. Proses yang dilakukan dalam algoritme Viterbi ini ialah dengan mencari nilai tag optimum untuk suatu kata. Proses ini dilakukan dengan mencari nilai maksimum dari hasil perhitungan transition probability dengan
emission probability yang telah didapatkan pada
pemodelan Hidden Markov Model. Algoritme Viterbi ini dilakukan secara rekursif sebanyak kata yang akan dikenali pada data uji. Seperti pada Persamaan 3 (Jurafsky & Martin, 2017):
𝑉𝑡(𝑗) = 𝑁 max 𝑉𝑡−1 𝑖 = 1 (𝑖)𝑎𝑖𝑗𝑏𝑗(𝑜𝑡) (3) Keterangan:
Vt-1(i) : probabilitas jalur Viterbi sebelumnya
dari langkah waktu sebelumnya
𝑎𝑖𝑗 : probabilitas transisi dari kondisi
sebelumnya ai ke kondisi sekarang aj
bj(ot) : kemungkinan kondisi pengamatan dari
ot berdasarkan kondisi j sekarang
2.6 Additive Smoothing
Mungkin metode smoothing yang paling sederhana dikenal adalah Additive smoothing dimana terdiri dari penambahan konstanta c untuk semua frekuensi (termasuk frekuensi nol dari kata yang tidak terlihat) dan kemudian menghasilkan estimasi maximum likelihood yang baru. Bergantung pada nilai c, metode ini mempunyai nama yang berbeda. Untuk c yang bernilai 1 dikenal sebagai Laplace dan c yang yang bernilai 0.5 disebut sebagai Lidstone atau
Expected Likelihood Estimation (Nivre, 2000).
Pada penelitian yang dilakukan Haulrich tahun 2009 Menggunakan estimasi maximum
likelihood dapat menyebabkan masalah karena
transisi yang tidak terlihat diberi probabilitas nol. Untuk Menghindari hal tersebut menggunakan penambahan smoothing dalam perhitungan pada Hidden Markov Model ketika menghitung probabilitas (Haulrich, 2009). Penerapan Additive smoothing pada transition
probability dapat dilakukan menggunakan
Persamaan 4.
𝑎𝑘𝑚= |𝑞𝑘 𝑞𝑚|+𝐶
|𝑞𝑘|+|𝑄𝐴| (4)
Keterangan:
qkqm merupakan nilai transition probability dari
kondisi qk ke kondisi qm dan C merupakan nilai
additive smoothing, dalam penelitian ini
menggunakan lidstone yaitu 0.5 sedangkan QA merupakan jumlah entitas yang akan dikenali. Penerapan Additive smoothing pada emission
probability dapat dilakukan menggunakan
Persamaan 5.
𝑏𝑖(𝑜𝑡) =|𝑜|𝑞𝑡,𝑞𝑖|+𝐶
𝑖|+|𝑉| (5) Keterangan:
bi(ot) adalah nilai emission probability, dengan ot
adalah kata ke t dan qi adalah
smoothing sedangkan nilai V adalah jumlah
keseluruhan kata yang berbeda.
2.7. Rule Template
Metode Rule Template bekerja dengan cara mengatur rule agar kandidatnya dapat dikenali. Entitas yang relevan teridentifikasi oleh setiap
rule. Misalnya, perusahaan Nokia memiliki seri
ponsel yang diberi nama ‘N#’ dimana ‘#’ mewakili sebuah nomor, seperti ‘N97’. Terdapat beberapa contoh rule yang dapat digunakan seperti Special Words, Semantics Pattern dan
General List. Special Words merupakan nama
unik atau kreatif yang diberikan oleh pabrik untuk hasil produksinya seperti iPhone, ThinkPad dan lain sebagainya. Semantics
Pattern merupakan pola kebiasaan masyarakat
dalam memberi nama suatu produk, yaitu terdiri dari tiga pola diantaranya:
1. Sebuah nama produk selalu diikuti oleh kata milik, preposisi, atau kuantifier seperti my MacBook, the Xbox dan lain sebagainya.
2. Terdapat kalimat yang menyebutkan beberapa produk dan mengandung preposisi ‘untuk’ atau ‘for’ di dalamnya memiliki nilai probabilitas yang tinggi untuk menjadi kandidat nama produk, baik itu sesudah atau sebelum. Contohnya, Seidio Inocase 360 untuk BlackBerry Curve 8900.
General List merupakan metode yang
digunakan untuk mengidentifikasi nama produk dengan cara mengumpulkan beberapa kategori kata yang jarang digunakan dalam pemberian nama produk Dalam mengidentifikasi nama produk dengan tujuan Rule Template, model yang digunakan bersifat cascade. Setiap rule terdiri atas classifier dan seluruh model yang berdasarkan rangkaian dari semua classifier. Semua kata yang telah diklasifikasikan secara benar oleh cascade rule adalah simbol dari beberapa produk (Wu, et al., 2012).
2.8. Regular Expression
Salah satu keberhasilan dalam standardisasi dalam ilmu komputer adalah
regular expression (RE), sebuah bahasa untuk
menentukan string pencarian teks. Implementasi ini digunakan dalam setiap bahasa komputer, pengolah kata, dan alat pengolah teks seperti alat Unix grep atau Emacs. Secara formal, regular
expression adalah notasi aljabar untuk menandai
satu set string yang sangat berguna untuk mencari teks, ketika memiliki pola untuk mencari dan korpus teks untuk dicari. Fungsi pencarian regular expression akan mencari melalui korpus, mengembalikan semua teks yang sesuai dengan polanya. Korpus bisa jadi satu koleksi dokumen. Contoh, Untuk mencari ‘woodchuck’, kita mengetik ‘/woodchuck’. (Jurafsky & Martin, 2017).
2.9. Pengukuran Evaluasi
Untuk mengetahui performance hasil klasifikasi Named Entity Recognition (NER), diperlukan sebuah teknik untuk pengukuran evaluasi. Pengukuran ini dilakukan menggunakan confusion matrix dan accuracy, dimana confusion matrix sangat penting karena menunjukkan kinerja NER berdasarkan sistem dalam hal Precision, Recall, dan F-Measure. Berikut ini adalah pengukuran confusion matrix dan accuracy menurut (Roman & Christoph, 2009):
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛,
(
𝑃)
= 𝑇𝑃 𝑇𝑃+𝐹𝑃 (4) 𝑅𝑒𝑐𝑎𝑙𝑙, (𝑅) =𝑇𝑃+𝐹𝑁𝑇𝑃 (5)𝐹 − 𝑀𝑒𝑎𝑠𝑢𝑟𝑒 =2∗𝑃∗𝑅 𝑃+𝑅 (6) 𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦 =𝑇𝑃+𝐹𝑃+𝑇𝑁+𝐹𝑁𝑇𝑃+𝑇𝑁 (7) Dimana:
1. TP, merupakan true positive. 2. FP, merupakan false positive. 3. FN, merupakan false negative. 4. TN, merupakan true negative.
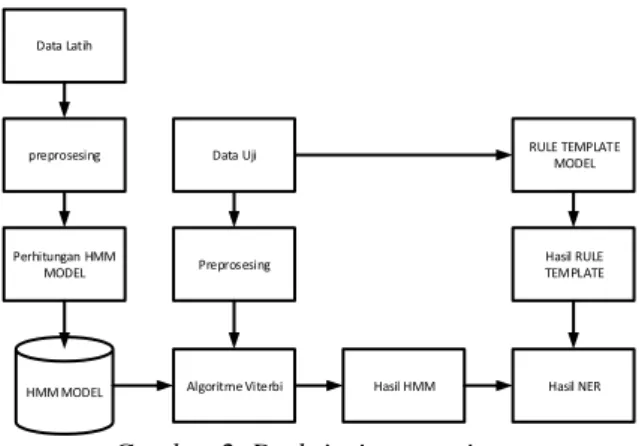
3. PERANCANGAN SISTEM
Penelitian penerapan named entity
recognition pada e-commerce menggunakan rule template dan hidden Markov model
dibangun dengan tujuan untuk melakukan ektraksi informasi, sehingga diharapkan dapat mengenali nama entitas pada teks percakapan atau pertanyaan mengenai produk terutama produk ponsel.
Data Latih
preprosesing Data Uji
Preprosesing Perhitungan HMM
MODEL
HMM MODEL Algoritme Viterbi
RULE TEMPLATE MODEL Hasil HMM Hasil RULE TEMPLATE Hasil NER
Gambar 2. Deskripsi umum sistem
Gambar 2 merupakan gambaran umum tahapan pengenalan menggunakan Rule Template dan Hidden Markov Model (HMM).
Pengenalan ini menggunakan pendekatan secara
Supervised learning dengan melakukan pre-processing kemudian melakukan
tahapan-tahapan metode rule template dan HMM hingga perancangan additive smoothing. Hasil akhir sistem ini yaitu merupakan pemberian entitas pada percakapan atau pertanyaan mengenai produk ponsel, entitas tersebut antara lain yaitu
MEREK, TIPE, HARGA, SPEK, N_SPEK dan N_TAG. Tabel 1 menunjukan beberapa contoh
pengenalan entitas pada penelitian ini. Tabel 1. Contoh Entitas yang akan dikenali
ENTITAS CONTOH
MEREK samsung, apple, xiaomi, sony, nokia TIPE galaxy, iphone, N70, S7, 5S HARGA 3 juta, 500, 300 ribu, 2jutaan SPEK memori, cpu, ram, kamera, layar N_SPEK merah, 4G, 32GB, 64GB, 15MP N_TAG Kata yang tidak dikenali atau tidak
memiliki entitas
4. PENGUJIAN DAN ANALISIS
Pengujian terhadap hasil implementasi ini dilakukan sebanyak lima skenario pengujian. Tabel 2 menunjukkan skenario pengujian yang dilakukan pada penelitian ini.
Tabel 2 Skenario Pengujian
No. Pengujian
1 Rule Template
2 Hidden Markov Model
3 Hidden Markov Model dengan Additive Smoothing
4 Rule Template dan Hidden Markov Model 5 Rule Template dan Hidden Markov Model dengan penambahan Additive Smoothing
Pengujian ini untuk mendapatkan nilai
performance berdasarkan dari precision, recall,
dan f-measure. Pengujian ini juga untuk mendapatkan nilai Accuracy yang dihasikan dalam mengenali entitas. Pengujian yang dilakukan menggunakan data uji yang berbeda pada data latih. Data uji yang digunakan sebanyak 30 data yang dipilih secara random, sedangkan jumlah data latih yang digunakan adalah 120.
4.1. Pengujian Rule Template
Tabel 3. Hasil pengujian Rule Template
E Pr Rc Fm A MEREK 1 0.9444 0.9714 0.9968 TIPE 1 0.8125 0.8965 0.9906 HARGA 1 1 1 1 SPEK 1 1 1 1 N_SPEK 1 0.7368 0.8484 0.9844 N_TAG 0.9620 1 0.9806 0.9720 Rata-rata 0.99366 0.91561 0.94948 Keterangan: E : Entitas Pr : Precision Rc : Recall Fm : F-Measure A : Akurasi
4.2. Pengujian Hidden Markov Model
Tabel 4. Hasil Pengujian Hidden Markov Model
E Pr Rc Fm A MEREK 1 0.9444 0.9714 0.9968 TIPE 1 0.6875 0.8148 0.9844 HARGA 1 0.9166 0.9565 0.9968 SPEK 1 1 1 1 N_SPEK 1 1 1 1 N_TAG 1 0.9210 0.9589 0.9440 Rata-rata 1 0.91158 0.95026 Keterangan: E : Entitas Pr : Precision Rc : Recall Fm : F-Measure A : Akurasi
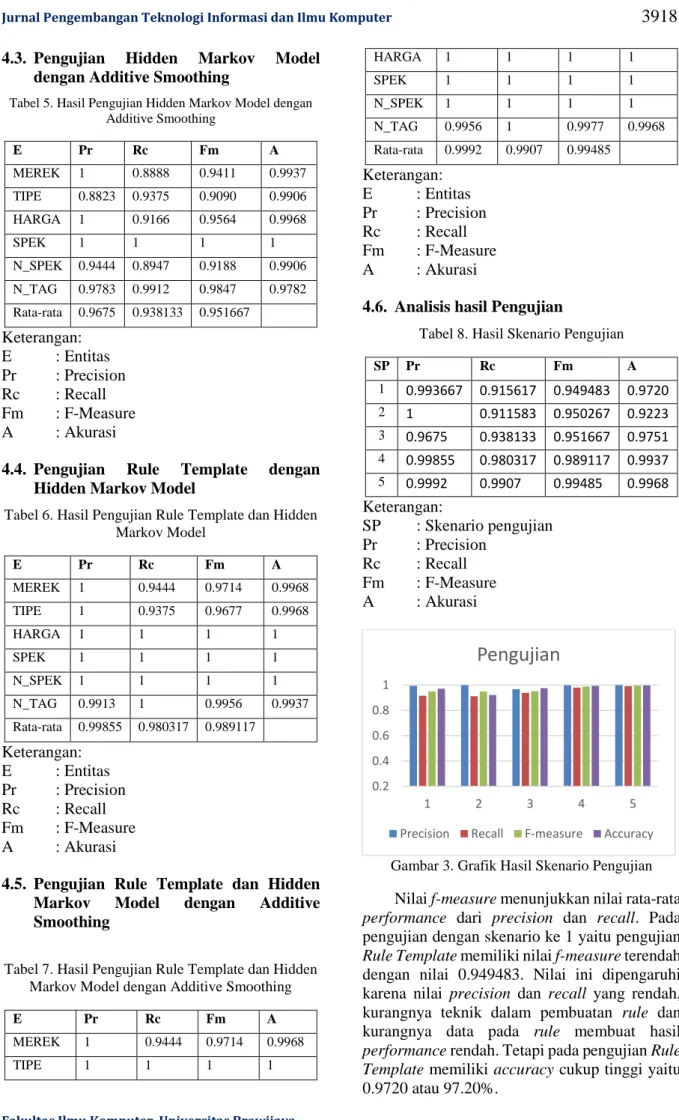
4.3. Pengujian Hidden Markov Model dengan Additive Smoothing
Tabel 5. Hasil Pengujian Hidden Markov Model dengan Additive Smoothing E Pr Rc Fm A MEREK 1 0.8888 0.9411 0.9937 TIPE 0.8823 0.9375 0.9090 0.9906 HARGA 1 0.9166 0.9564 0.9968 SPEK 1 1 1 1 N_SPEK 0.9444 0.8947 0.9188 0.9906 N_TAG 0.9783 0.9912 0.9847 0.9782 Rata-rata 0.9675 0.938133 0.951667 Keterangan: E : Entitas Pr : Precision Rc : Recall Fm : F-Measure A : Akurasi
4.4. Pengujian Rule Template dengan Hidden Markov Model
Tabel 6. Hasil Pengujian Rule Template dan Hidden Markov Model E Pr Rc Fm A MEREK 1 0.9444 0.9714 0.9968 TIPE 1 0.9375 0.9677 0.9968 HARGA 1 1 1 1 SPEK 1 1 1 1 N_SPEK 1 1 1 1 N_TAG 0.9913 1 0.9956 0.9937 Rata-rata 0.99855 0.980317 0.989117 Keterangan: E : Entitas Pr : Precision Rc : Recall Fm : F-Measure A : Akurasi
4.5. Pengujian Rule Template dan Hidden Markov Model dengan Additive Smoothing
Tabel 7. Hasil Pengujian Rule Template dan Hidden Markov Model dengan Additive Smoothing
E Pr Rc Fm A MEREK 1 0.9444 0.9714 0.9968 TIPE 1 1 1 1 HARGA 1 1 1 1 SPEK 1 1 1 1 N_SPEK 1 1 1 1 N_TAG 0.9956 1 0.9977 0.9968 Rata-rata 0.9992 0.9907 0.99485 Keterangan: E : Entitas Pr : Precision Rc : Recall Fm : F-Measure A : Akurasi
4.6. Analisis hasil Pengujian
Tabel 8. Hasil Skenario Pengujian
SP Pr Rc Fm A 1 0.993667 0.915617 0.949483 0.9720 2 1 0.911583 0.950267 0.9223 3 0.9675 0.938133 0.951667 0.9751 4 0.99855 0.980317 0.989117 0.9937 5 0.9992 0.9907 0.99485 0.9968 Keterangan: SP : Skenario pengujian Pr : Precision Rc : Recall Fm : F-Measure A : Akurasi
Gambar 3. Grafik Hasil Skenario Pengujian Nilai f-measure menunjukkan nilai rata-rata
performance dari precision dan recall. Pada
pengujian dengan skenario ke 1 yaitu pengujian
Rule Template memiliki nilai f-measure terendah
dengan nilai 0.949483. Nilai ini dipengaruhi karena nilai precision dan recall yang rendah, kurangnya teknik dalam pembuatan rule dan kurangnya data pada rule membuat hasil
performance rendah. Tetapi pada pengujian Rule Template memiliki accuracy cukup tinggi yaitu
0.9720 atau 97.20%. 0.2 0.4 0.6 0.8 1 1 2 3 4 5
Pengujian
Pada pengujian ke 2 yaitu pengujian Hidden
Markov Model menghasilkan nilai rata-rata f-measure dengan nilai 0.950267. Tingginya nilai f-measure ini dikarenakan nilai precision yang
tinggi. Pada pengujian skenario ke 2 memiliki
accuracy terendah dibandingkan pengujian yang
lain yaitu 0.9223 atau 92.23% ini dikarenakan pada pengujian 2 data uji yang tidak terdapat pada data latih tidak akan dikenali sehingga dapat mengakibatkan kesalahan dalam pemberian entitas oleh sistem.
Pada pengujian skenario 3 Hidden Markov
Model dengan penambahan Additive Smoothing
menghasilkan nilai rata-rata f-measure
0.951667. Pada skenario tiga terjadinya penurunan nilai precision sehingga berdampak pada niilai f-measure. Penurunan nilai precision ini dikarenakan kesalahan sistem dalam memberikan entitas yang benar, kesalahan ini terjadi karena nilai transition probability yang kurang optimal dalam mengenali data uji, tetapi pada pengujian ini memiliki nilai accuracy lebih tinggi yaitu 0.9751 atau 97.51%, hal ini menunjukkan bahwa dengan menambahkan
Additive Smoothing pada Hidden Markov Model
dapat meningkatkan nilai performance, accuracy dan mampu menangani kata-kata yang
belum pernah dikenali sebelumnya.
Pada pengujian skenario 4 penggabungan hasil Rule template dengan Hidden Markov
Model menghasilkan performance dan accuracy
yang lebih baik dibandingkan dengan pengujian sebelumnya. Penggabungan ini meningkatkan sistem dalam memberikan entitas. Hidden
Markov Model memiliki kelamahan dimana jika
perpindahan state tidak terlihat atau kata pada data uji tidak terdapat pada data latih akan memberikan kata tanpa entitas, jika menggunakan Rule template kata yang tidak dikenali akan memiliki entitas tetapi pemberian entitas ini bergantung dengan dengan Rule
Template dalam mengenali kata tersebut.
Pada pengujian skenario 5 memiliki
performance dan accuracy yang lebih baik
dibandingkan pada skenario 4. Meningkatnya hasil ini dikarenakan pada skenario 5 pengenalan entitas yang salah pada skenario 4 dapat diatasi dengan menambahkan additive smoothing sehingga menghasilkan performance dan
accuracy yang lebih baik.
5. KESIMPULAN
Untuk mengetahui Performance dari sistem NER dapat menggunakan precision, recall dan
f-measure. Nilai rata-rata performance yang
didapatkan dari implementasi Rule Template ialah sebesar 99.36%, 91.56% dan 94.94% sedangkan nilai performance HMM ialah sebesar 100%, 91.15% dan 95.02% dengan nilai
accuracy Rule template 97.20% dan accuracy
HMM 92.23%. Pada penelitian ini nilai tertinggi didapatkan pada skenario 5 yaitu penggabungan
rule template dengan HMM dengan nilai f-measure 0.99485 dengan accuracy 99.68% dan
nilai terendah pada skenario 2 yaitu HMM dengan accuracy 92.23%.
Penambahan teknik Additive Smoothing terbukti mampu meningkatkan hasil pada metode Hidden Markov Model dalam menangani probabilitas 0 atau kata yang tidak dikenali pada data latih. Serta penambahan teknik ini dapat meningkatkan akurasi dalam pengenalan entitas dimana sebelumnya akurasi 92.10% menjadi 97.51%.
6. DAFTAR PUSTAKA
Chopra, D., Jahan, N. & Morwal, S., 2012. Hindi Named Entity Recognition by Aggregating Rule Based Heuristics and Hidden Markov Model.
International Journal of Information Sciences and Techniques, II(6).
Dey, A., Paul, A. & Purkayastha, S. B., 2014. Named Entity Recognition for Nepali language: A Semi Hybrid Approach. International Journal
of Engineering and Innovative Technology,
III(8).
Guzman, I. & Panthania, A., 2016. Accenture
Interactive. [Online] Available at: https://www.accenture.com/t00010101T000000 __w__/br-pt/_acnmedia/PDF-45/Accenture-Chatbots-Customer-Service.pdf [Accessed 5 september 2017].
Haulrich, M., 2009. Different Approaches to Uknown Words in a Hidden Markov Model Part-of-Speech Tagger.
Jurafsky, D. & Martin, J. H., 2017. Speech And
Language Processing. 3nd ed. Silicon Valley:
stanford.
Mansouri, A., Affendey, S. L. & Mamat, A., 2008. Named Entity Recognition Approaches.
International Journal of Computer Science and Network Security, Volume VIII.
Nickerson, R. C., 2002. AN E-COMMERCE
SYSTEM MODEL, San Francisco State
University: Eighth Americas Conference on Information Systems.
Probabilistic Part-of-Speech Tagging, sweden:
Vaxjo University.
Roman, K. & Christoph, F., 2009. User’s Choice
of Precision and Recall in Named Entity
Recognition. Germany, International
Conference RANLP.
Talib, R., Hanif, M. K., Ayesha, S. & Fatima, F., 2016. Text Mining: Techniques Applications
and Issues. International Journal of Advanced
Computer Science and Applications, Volume
VII.
Wu, S., Fang, Z. & Tang, J., 2012. Accurate Product Name Recognition from User Generated Content.