22
III.1 Analisis Konseptual Teknik Pengolahan Data
Data sudah menjadi bagian penting dalam pengambilan keputusan. Data telah banyak terkumpul baik itu data transaksi perbankan, data kependudukan, data transaksi penjualan barang di sebuah toko, data aktivitas perkuliahan dan data-data lain. Umumnya data-data tersebut telah disimpan dalam penyimpanan berupa basis data.
Seiringan dengan lamanya penggunaan basis data, maka data yang terkumpul juga akan semakin banyak. Untuk melakukan suatu proses pengambilan keputusan yang bersumber dari basis data tentunya memerlukan waktu. Semakin besar data yang akan diolah maka akan memerlukan waktu yang lama juga untuk mengolahnya sehingga menghasilkan suatu informasi yang berguna untuk pengambilan keputusan.
Karena banyaknya data yang akan diolah, seorang peneliti biasanya melakukan penelitian terhadap sekelompok data saja. Dengan aturan tertentu kelompok data tersebut diidentifikasi dari keseluruhan data yang ada. Salah satu teknik yang biasanya digunakan untuk melakukan identifikasi suatu kelompok data adalah teknik clustering.
Teknik clustering adalah suatu teknik yang dapat digunakan untuk mengidentifikasi kelompok data dari sekumpulan data tanpa ada acuan tertentu.
Inilah sebabnya teknik clustering termasuk sebagai teknik yang unsupervised.
Dengan tanpa ada acuan yang menjadi dasar pengelompokkan data, maka
clustering dianggap dapat mengidentifikasikan hubungan alamiah antar data yang
ada. Teknik clustering tidak membutuhkan pengetahuan awal terlebih dahulu
sebelum melakukan proses clustering, justru hasil akhir dari teknik clustering ini
yang berupa cluster-cluster dapat dijadikan sebagai pengetahuan awal pada
teknik-teknik pengolahan data lain.
Suatu clustering data akan menghasilkan cluster-cluster. Ciri dari suatu proses clustering yang baik adalah :
1. Tingkat kemiripan/similaritas (homogenitas) dari data-data yang ada dalam suatu cluster mempunyai derajat yang besar.
2. Tingkat ketidakmiripan/dissimilaritas (heterogenitas) antar cluster mempunyai derajat yang besar.
Setiap proses clustering selalu melibatkan cara mengukur kemiripan antar data atau antar cluster. Pengukuran tingkat kemiripan biasa dilakukan dengan melakukan perbandingan antara atribut milik sebuah data dengan data lain atau atribut suatu cluster dengan cluster lain. Sebagai contoh pengukuran tingkat kemiripan dapat dilihat pada Gambar III.1.
A=(3) B=(5)
Jarak=|A – B|=|3-5|=2
Gambar III.1. Contoh pengukuran tingkat kemiripan
Pada Gambar III.1 dapat dilihat ada dua buah data/obyek yaitu A dan B.
Obyek A mempunyai nilai atribut yaitu 3 dan obyek B mempunyai nilai atribut yaitu 3. Untuk obyek data yang hanya mempunyai 1 atribut, pengukuran tingkat kemiripan dilakukan dengan menghitung jarak antara obyek A dan B yaitu mengambil nilai absolute selisih kedua obyek tersebut (|3-5| = 2). Cara perhitungan di atas hanya berlaku jika obyek hanya memiliki 1 atribut saja. Tetapi jika obyek memiliki lebih dari 1 atribut, maka cara yang digunakan untuk melakukan pengukuran jarak adalah Euclidean Distance dan Manhattan Distance (City Block Distance) yang cara perhitungannya dapat dilihat pada Gambar II.11.
Penggunaan Euclidean distance sering digunakan karena pengukuran ini
dapat menghasilkan suatu nilai jarak terdekat antar obyek yang diambil dari nilai
akar dari kuadrat selisih antara atribut milik obyek. Sedangkan Manhattan
distance digunakan karena pengukuran ini dihasilkan berdasarkan penjumlahan
jarak selisih tiap atribut yang dimiliki oleh obyek, sehingga pengukuran dengan
metode Manhattan distance dapat mencerminkan jarak sebenarnya antar suatu obyek.
Perhitungan pengukuran jarak menggunakan Euclidean distance atau Manhattan distance mempunyai keterbatasan yaitu hanya mampu melakukan perhitungan pada data yang berbentuk numerik. Jika data obyek uji berupa data yang tidak numerik, maka perhitungan pengukuran jarak tidak dapat digunakan.
Ada cara alternatif yang bisa digunakan agar data yang bukan numerik dapat diproses yaitu dengan mengkonversikannya (transformasi nilai) ke dalam bentuk numerik. Dengan cara ini setiap nilai yang bukan numerik akan diberi angka pengganti yang sesuai dengan penelitian yang dilakukan.
Selain adanya ketidaksesuaian format data (numerik/bukan numerik), ada juga masalah yang perlu diperhatikan terhadap data obyek uji yaitu data yang tidak lengkap. Tidak semua obyek uji memiliki nilai untuk semua variable yang akan diobservasi. Adanya nilai variable yang hilang dapat berpengaruh besar terhadap hasil penelitian. Berdasarkan Joseph F. Hair dkk, ada beberapa cara yang dapat digunakan untuk menangani data yang hilang yaitu :
1. Obyek yang diteliti hanya yang mempunyai data lengkap
2. Menghapus variable yang mempunyai data tidak lengkap yang banyak 3. Melakukan metode penaksiran. Penaksiran nilai dapat dilakukan dengan
menggunakan karakteristik distribusi dari semua nilai yang ada, atau melakukan substitusi dengan nilai tertentu, nilai rata-rata, atau nilai tertentu yang didapatkan dari penelitian-penelitian sebelumnya.
Berdasarkan hal di atas maka cara pertama yang hanya akan melakukan penelitian terhadap obyek uji yang mempunyai data yang lengkap merupakan cara yang baik karena cara ini akan mengukur semua karakteristik yang dimiliki oleh obyek uji.
Selain teknik pengukuran kemiripan, ada hal lain yang dapat
mempengaruhi hasil suatu clustering, yaitu teknik bagaimana suatu obyek
dimasukkan/didaftarkan/dilokasikan ke suatu cluster. Beberapa cara yang
dilakukan untuk menentukan pelokasian suatu obyek ke suatu cluster dapat dilihat pada sub Bab II.3.3.1.1 sampai II.3.3.1.5.
Penggunaan cara pelokasian obyek ke cluster yang menggunakan teknik Average Linkage dan Centroid Linkage akan menghasilkan cluster-cluster yang lebih baik jika dibandingkan dengan yang menggunakan Single Linkage atau Complete Linkage. Hal ini disebabkan karena perbandingan jarak dilakukan terhadap seluruh obyek yang ada dalam cluster dengan obyek uji sehingga diharapkan menghasilkan tingkat homogenitas obyek dalam cluster yang lebih baik.
Walaupun Average Linkage atau Centroid Linkage dianggap dapat menghasilkan cluster yang baik tapi jika dilihat dari beban proses perhitungan yang dilakukan, proses Centroid Linkage mempunyai beban perhitungan yang lebih ringan karena perhitungan jarak hanya dilakukan terhadap centroidnya saja, sedangkan pada proses average linkage perhitungan jarak dilakukan terhadap semua obyek dalam suatu cluster.
Ada juga hal lain yang harus dilakukan dalam suatu proses clustering yaitu algoritma clustering yang akan digunakan. Umumnya ada 2 cara yang sering digunakan yaitu algoritma clustering hierarki dan non hierarki. Perbandingan antara 2 algoritma itu dapat dilihat pada Tabel III.1 di bawah ini.
Tabel III.1 Perbandingan Algoritma Clustering Hierarki dan Non Hierarki
Hierarki Non Hierarki
Proses Clustering:
- Penyusunan cluster dilakukan dengan menyusun tree.
- Setiap obyek akan dianggap sebuah cluster.
- Setiap pasangan cluster yang mempunyai jarak yang dekat akan digabungkan.
- Proses penggabungan akan dilakukan sampai dihasilkan 1 cluster.
Proses Clustering :
- Banyaknya cluster ditentukan diawal - Secara acak akan dibuat cluster
sebanyak banyak cluster yang diinginkan sebagai cluster awal (initial cluster).
- Tempatkan sebuah obyek di cluster yang mempunyai jarak terdekat.
- Proses penempatan dilakukan sampai
semua obyek telah ditempatkan ke
suatu cluster.
Kelebihan :
- Tidak ada penentuan banyaknya cluster yang diinginkan, karena cluster yang diinginkan dapat diambil dengan mengambil sub tree yang sesuai.
- Mudah digunakan dengan bentuk similaritas apapun.
- Dapat diaplikasikan untuk atribut yang tidak sejenis.
Kelebihan :
- Hasil cluster bisa lebih cepat dihasilkan.
- Dimungkinkan adanya relokasi obyek ke cluster lain.
- Dimungkinkan untuk melakukan optimalisasi terhadap hasil cluster.
Kekurangan :
- Penyusunan cluster akan dilakukan terus sampai didapatkan 1 cluster yang mencakup semua obyek.
- Pelokasian suatu obyek ke suatu cluster umumnya hanya dilakukan 1 kali, sehingga bisa saja menghasilkan obyek yang berada pada cluster yang bukan seharusnya.
- Tidak dimungkinkan adanya perpindahan suatu obyek ke cluster lain. Hal ini bisa menyebabkan hasil yang tidak optimal.
Kekurangan :
- Penentuan banyaknya cluster dilakukan diawal sebelum proses cluster dilakukan. Jika menginginkan banyak cluster yang berbeda, maka proses clustering harus diulang.
- Hasil cluster akan berbeda-beda tergantung dengan penentuan centroid awal yang dibuat random.
Berdasarkan Tabel III.1 dapat diambil kesimpulan bahwa algoritma non
hierarki dapat menghasilkan cluster yang baik karena memiliki sifat yang bisa
dioptimalkan dan dapat menghasilkan cluster dengan lebih cepat. Tetapi algoritma
ini mempunyai kelemahan yaitu ketergantungan terhadap pemilihan cluster awal
sangat besar. Sebagai ilustrasi dapat dilihat pada Gambar III.2 di bawah ini.
Centroid Awal
Cluster 1
Cluster 2
(a) Hasil Clustering Tanpa Optimalisasi Cluster
Centroid Awal
Cluster 1
Cluster 2
(b) Hasil Cluster Setelah Optimalisasi Cluster Gambar III.2 Ilustrasi Kelemahan Algoritma Non Hierarki
Pada Gambar III.2a dapat dilihat bahwa hasil cluster kurang baik karena ada obyek yang seharusnya berada di cluster 1 berada di cluster 2. Ini dikarenakan obyek tersebut merupakan centroid awal dari cluster 2. Oleh karena itu diperlukan suatu langkah optimalisasi hasil cluster yang dapat melakukan relokasi suatu obyek agar benar-benar berada pada cluster yang lebih baik seperti yang dapat dilihat pada Gambar III.2b.
Berdasarkan pada teknik clustering non hierarki yang biasa digunakan, ada satu algoritma yang mempunyai kemampuan untuk optimalisasi hasil cluster yaitu teknik Optimized Procedure. Dengan teknik ini, maka obyek yang berlokasi di suatu cluster dapat direlokasi ke cluster lain jika mempunyai tingkat kemiripan lebih baik dengan cluster barunya. Bahkan obyek yang direlokasikan mungkin saja obyek yang menjadi centroid awal suatu cluster. Teknik ini akan dapat mengurangi ketergantungan cluster terhadap penentuan centroid awalnya yang dilakukan umumnya secara acak.
Proses terakhir dalam analisis clustering adalah proses validasi cluster
yang sudah dihasilkan. Langkah ini digunakan untuk memeriksa apakah cluster
telah mempunyai tingkat validasi yang baik yang ditunjukan dengan tingkat konsistensi clusternya. Validasi dilakukan dengan membandingkan hasil cluster dengan hasil cluster yang menggunakan algoritma atau pengukuran yang berbeda.
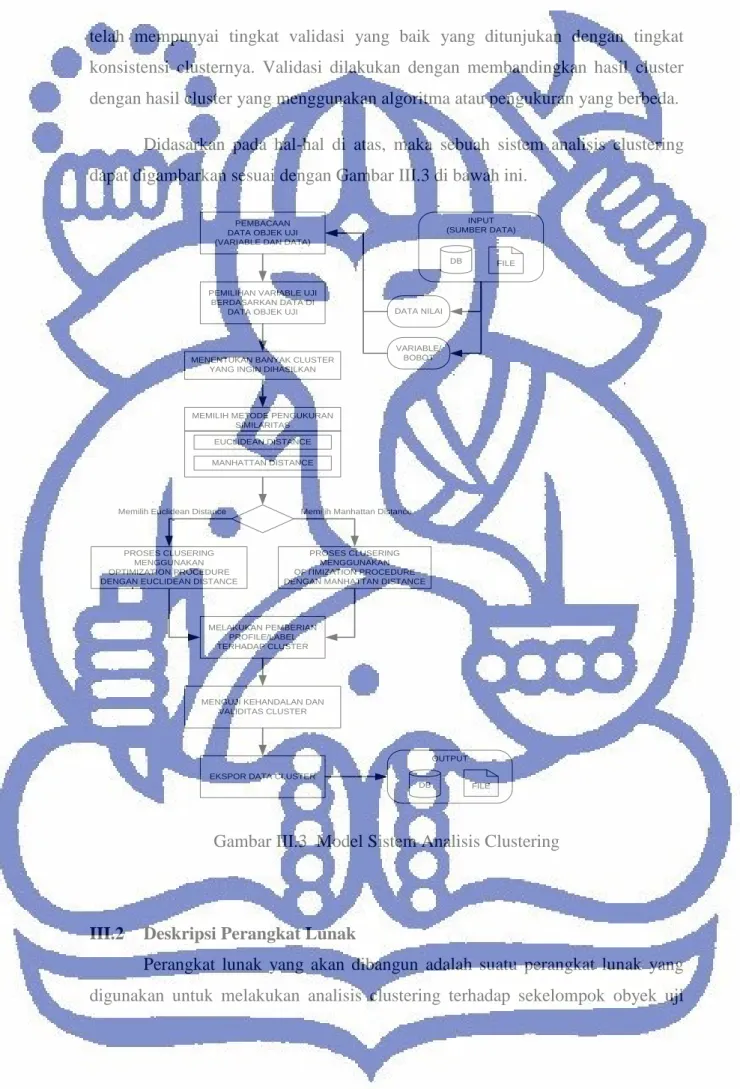
Didasarkan pada hal-hal di atas, maka sebuah sistem analisis clustering dapat digambarkan sesuai dengan Gambar III.3 di bawah ini.
INPUT (SUMBER DATA) PEMBACAAN
DATA OBJEK UJI (VARIABLE DAN DATA)
PEMILIHAN VARIABLE UJI BERDASARKAN DATA DI
DATA OBJEK UJI
MEMILIH METODE PENGUKURAN SIMILARITAS EUCLIDEAN DISTANCE MANHATTAN DISTANCE MENENTUKAN BANYAK CLUSTER
YANG INGIN DIHASILKAN
MELAKUKAN PEMBERIAN PROFILE/LABEL TERHADAP CLUSTER
MENGUJI KEHANDALAN DAN VALIDITAS CLUSTER PROSES CLUSERING
MENGGUNAKAN OPTIMIZATION PROCEDURE DENGAN EUCLIDEAN DISTANCE
DATA NILAI
VARIABLE/
BOBOT
DB FILE
PROSES CLUSERING MENGGUNAKAN OPTIMIZATION PROCEDURE DENGAN MANHATTAN DISTANCE Memilih Euclidean Distance Memilih Manhattan Distance
EKSPOR DATA CLUSTER
OUTPUT
DB FILE
Gambar III.3 Model Sistem Analisis Clustering
III.2 Deskripsi Perangkat Lunak
Perangkat lunak yang akan dibangun adalah suatu perangkat lunak yang
digunakan untuk melakukan analisis clustering terhadap sekelompok obyek uji
sehingga menghasilkan cluster-cluster yang dapat mewakili seluruh obyek uji tersebut.
Data hasil proses clustering mungkin saja dijadikan sebagai masukan bagi proses lain misalnya untuk pengambilan keputusan. Dengan melakukan proses analisis clustering terlebih dahulu, seorang pengambil keputusan dapat lebih mudah untuk mengambil keputusan karena obyek penelitian yang diteliti telah tereduksi oleh proses clustering.
Cara kerja dari perangkat lunak ini dapat dilihat pada Gambar III.4 di bawah ini.
PERANGKAT LUNAK ANALISIS CLUSTERING
Data Objek Uji, Variable Uji,
Banyak Cluster yang dihasilkan, Metode Pengukuran Kemiripan
Cluster-Cluster Hasil Analisis
PROSES PENGAMBILAN
KEPUTUSAN Cluster-Cluster, Pertimbangan, Pengetahuan, Prosedur Keputusan
Sistem Pendukung Keputusan
Gambar III.4 Cara kerja perangkat lunak analisis clustering
Berdasarkan Gambar III.4 secara garis besar cara kerja perangkat lunak analisis clustering ini adalah :
1. User memasukkan data obyek uji ke sistem. Data obyek uji adalah data suatu
entitas yang akan diclusterkan. Setiap data obyek uji terdiri dari variable yang
dimiliki dan bobot variablenya. Variable-variable inilah yang akan dijadikan
dasar proses clustering. Data obyek uji bisa berasal dari suatu file atau data
dari suatu basis data. User juga memasukkan parameter clustering yang akan
digunakan oleh proses clustering. Parameter clustering terdiri dari pemilihan
variable yang akan digunakan untuk pengujian, banyaknya cluster yang ingin dihasilkan dan metode pengukuran kemiripan yang akan digunakan.
2. Sistem melakukan proses analisis clustering sesuai dengan data obyek uji dan parameter clusteringnya. Proses ini akan menghasilkan cluster-cluster hasil proses clustering. Setelah proses clustering dilakukan, maka cluster-cluster itu harus diuji tingkat kevalidannya. Tingkat kevalidan data digunakan untuk memastikan bahwa cluster-cluster dapat mewakili kasus yang dihadapi.
3. Cluster-cluster hasil analisis dikeluarkan oleh perangkat lunak ke pengguna.
4. Cluster-cluster hasil analisis digunakan oleh pengguna sebagai bahan masukan dan diproses dengan menggunakan pertimbangan, aturan-aturan atau prosedur yang ada pada proses pengambilan keputusan. Proses inilah akan menghasilkan keputusan.
Dengan melakukan proses clustering terlebih dahulu, maka proses pengambilan keputusan bisa dilakukan dengan lebih cepat karena data uji telah menjadi lebih sederhana karena telah dikelompokkan berdasarkan karakteristik datanya. Hal ini memungkinkan peneliti hanya melakukan pengambilan keputusan terhadap data uji pada sebagian cluster saja.
III.3 Batasan-batasan dan Asumsi
Batasan-batasan dan asumsi yang berlaku dalam pengembangan perangkat lunak ini diantaranya adalah :
1. Perangkat lunak ini hanya akan melakukan proses clustering saja, sedangkan untuk pengambilan keputusan tetap dilakukan oleh pengguna sendiri, terutama pada bagian profiling cluster (pemberian label terhadap suatu cluster). Oleh karena itu kemampuan penguasaan pengguna terhadap kasus yang dihadapi sangat diperlukan.
2. Pengguna hanya dapat melakukan pengisian obyek data dari file atau dari
basis data. Pengisian obyek data secara manual tidak disediakan. File masukan
bisa berupa file text atau file Microsoft Excel. Pembacaan data dari basis data
dapat dilakukan dari basis data apapun dengan melalui koneksi ODBC (Open Database Connectivity).
3. Nilai-nilai variable obyek harus dapat dihitung. Nilai-nilai variable obyek harus berupa bilangan atau setidaknya dapat ditransformasikan ke dalam bentuk bilangan.
4. Perangkat lunak yang akan dibangun akan menggunakan clustering dengan algoritma Optimized Procedure dengan metode pengukuran similaritasnya menggunakan pengukuran Euclidean Distance atau Manhattan Distance.
Algoritma Optimized Procedure dipilih karena algoritma ini memungkinkan sebuah obyek uji berpindah cluster jika memiliki tingkat similaritas yang lebih baik. Jadi tingkat similaritasnya lebih baik.
5. Validasi cluster akan dilakukan dengan melakukan clustering ulang terhadap data obyek uji yang sama tetapi menggunakan teknik pengukuran yang berbeda dengan yang digunakan sebelumnya. Kedua cluster tersebut kemudian dibandingkan untuk melihat tingkat validasi clusternya.
III.4 Analisis Kebutuhan Fungsional
Perangkat lunak yang akan dibangun adalah perangkat lunak bantu untuk pengambilan keputusan menggunakan metode analisis clustering sebagai teknik pengolahan datanya.
Perangkat lunak ini hanya akan memberikan informasi hasil proses clustering saja, sedangkan pengambilan keputusan diambil secara manual oleh pengguna. Perangkat lunak ini tidak memberikan solusi yang harus diambil, tetapi hanya memberikan informasi yang dapat menjadi pertimbangan pengambilan keputusan.
Spesifikasi kebutuhan sistem perangkat lunak ini dapat dilihat pada Table III.2.
Tabel III.2 Daftar Spesifikasi Kebutuhan Fungsional
NO SRS DESKRIPSI
SRS-F-01 Sistem harus menyediakan fasilitas login ketika pengguna akan
NO SRS DESKRIPSI menggunakan sistem ini.
SRS-F-02 Sistem harus dapat menerima masukan data obyek uji yang bersumber dari file yaitu file text dan file Microsoft Excel yang tersimpan dalam format tertentu
SRS-F-03 Sistem harus dapat menerima masukan data obyek uji yang bersumber dari basis data
SRS-F-04 Sistem harus dapat menerima data nilai variable obyek uji dalam berbagai format baik numerik atau non numerik.
SRS-F-05 Sistem harus dapat menyimpan data obyek uji agar dapat dipergunakan kembali
SRS-F-06 Sistem harus dapat menyediakan pemilihan variable uji yang akan dijadikan sebagai kriteria analisis clustering
SRS-F-07 Sistem harus dapat menyediakan pembobotan variable yang mempunyai pengaruh yang menentukan
SRS-F-08 Sistem harus dapat melakukan transformasi nilai obyek uji jika nilai tersebut berupa non numerik
SRS-F-09 Sistem menyediakan fasilitas pemilihan metode pengukuran similaritas menggunakan Euclidean Distance atau Manhattan Distance.
SRS-F-10 Sistem harus dapat melakukan proses clustering menggunakan algoritma Optimized Procedure.
SRS-F-11 Sistem harus dapat menyediakan fasilitas pemberian label pada cluster.
SRS-F-12 Sistem harus dapat menyediakan fasilitas untuk memvalidasi cluster hasil clustering
SRS-F-13 Sistem harus dapat menyediakan fasilitas melihat kembali analisis clustering yang telah dilakukan
SRS-F-14 Sistem harus dapat menyediakan fasilitas menghapus data analisis clustering yang telah dilakukan
SRS-F-15 Sistem harus dapat mengekspor cluster hasil clustering ke dalam format ke
file seperti file Microsoft Excel, file text, dan file SQL (untuk digunakan
dalam basis data)
III.5 Analisis Kebutuhan Non Fungsional
Kebutuhan non fungsional dari perangkat lunak yang akan dibangun dapat dilihat pada Tabel III.3 di bawah ini.
Tabel III.3 Daftar Spesifikasi Kebutuhan Non Fungsional
NO SRS DESKRIPSI
SRS-NF-01
Performansisistem harus dapat melakukan clustering sesuai dengan data yang disediakan oleh pengguna. Sistem harus dapat menangani banyaknya dimensi dan banyaknya obyek penelitian yang diberikan oleh pengguna.
SRS-NF-02
PortabilitasSistem harus dapat melakukan pemasukan data dari beberapa sumber seperti dari file text atau basis data. Sumber data berupa basis data boleh berasal dari basis data yang terkoneksi dengan layanan ODBC (Open Database Connectivity). Sistem bisa berada dalam komputer yang sama dengan komputer server atau terpisah dari komputer server datanya.
SRS-NF-03
KetepatanSistem harus dapat melakukan cluster dengan benar. Hasil cluster harus konsisten. Hal ini dilakukan dengan melakukan validasi cluster ketika proses clustering dilakukan. Salah satu proses yang dilakukan agar sistem dapat menjamin tingkat ketepatan ini adalah dengan membandingkan clustering dari clustering yang menggunakan teknik pengukuran yang berbeda.
SRS-NF-04
ReuseabilitySistem harus dapat menghasilkan cluster yang dapat digunakan dalam sistem lain. Hal ini dilakukan dengan melakukan proses ekspor data hasil cluster ke dalam beberapa format misalnya file text, file Microsoft excel dan dalam file SQL yang dapat digunakan dalam basis data lain.
SRS-NF-05
FlexibilitySistem harus dapat melakukan clustering terhadap obyek data sesuai
dengan aturan dan variable-variable yang terlibat. Pemilihan variable yang
terlibat dalam suatu proses clustering dapat dipilih oleh pengguna. Sistem
harus dapat menyediakan layar untuk pemilihan variable.
III.6 Arsitektur Sistem Yang Akan Dibangun
Secara garis besar arsitektur perangkat lunak yang akan dibangun terdiri dari 4 modul yaitu :
1. Modul Pendefinisian Proyek Clustering
Modul ini berguna untuk mengelola proyek clustering. Ada beberapa proses yang ada dalam modul ini, yaitu :
a. Penambahan Proyek Clustering
Proses ini berguna untuk melakukan pembuatan proyek clustering baru.
b. Pengolahan Proyek Clustering
Proses ini berguna untuk mengolah proyek cluster yang telah dilakukan.
Proses ini mempunyai relasi ke modul Input Data Obyek Uji untuk melakukan pembacaan data, modul Proses Analisis Clustering untuk melakukan proses clustering, dan modul Output Data Cluster untuk melakukan penyimpanan cluster hasil clustering ke basis data atau ke target lain seperti ke file text atau file Microsoft Excel.
c. Penghapusan Proyek Clustering
Proses ini berguna untuk menghapus data proyek cluster yang telah dilakukan yang telah tidak diperlukan lagi. Penghapusan dilakukan terhadap data uji dan data clusternya.
2. Modul Input Data Obyek Uji
Modul ini berguna untuk mengatur input data obyek uji. Modul ini terdiri dari beberapa proses, yaitu :
a. Pembacaan Data dari Database Lain
Proses ini berguna untuk melakukan pembacaan data obyek uji yang bersumber dari suatu database. Pembacaan dilakukan dengan melakukan query data ke database tersebut.
b. Pembacaan Data dari File
Proses ini berguna untuk melakukan pembacaan data dari file. Format file yang bisa dibaca adalah file text atau file Microsoft Excel.
c. Pengaturan Nilai Transformasi
Proses ini berguna untuk melakukan pengaturan nilai transformasi nilai untuk nilai-nilai variable data yang bersifat bukan numerik.
d. Pengaturan Variable
Proses ini berguna untuk melakukan pengaturan variable beserta bobotnya yang akan digunakan untuk proses clustering.
3. Modul Proses Analisis Clustering
Modul ini berguna untuk melakukan proses analisis clustering. Modul ini terdiri dari beberapa proses yaitu :
a. Pengaturan Parameter Clustering
Proses ini berguna untuk melakukan pengaturan parameter-parameter clustering yang akan dilakukan. Pengaturan dilakukan untuk menentukan parameter clustering seperti banyak cluster yang diinginkan dan algoritma pengukuran similaritas.
b. Proses Clustering
Proses ini berguna untuk melakukan proses clustering sesuai dengan parameter yang telah ditentukan dengan menggunakan algoritma Optimizing Procedure.
c. Interpretasi Cluster
Proses ini berguna untuk menginterpretasi cluster misalnya dengan memberkan label terhadap suatu cluster. Pemberian label diperlukan dalam proses analisis clustering karena analisis cluster merupakan analisis data multivariate yang bersifat unsupervised.
d. Validasi Cluster
Proses ini dilakukan untuk untuk memvalidasi cluster hasil clustering.
4. Modul Output Data Cluster
Modul ini berguna untuk melakukan pengaturan terhadap data cluster hasil proses clustering. Proses yang ada dalam modul ini adalah :
a. Penyimpanan Data Cluster ke Database
Proses ini digunakan untuk melakukan penyimpanan data cluster ke basis data milik sistem ini. Data yang disimpan ke basis data ini dapat diolah kembali atau dihapus.
b. Export Data Cluster
Export data cluster terbagi menjadi 2 yaitu export data ke basis data lain yaitu dengan menyusun perintah SQL dan ekspor data ke file misalnya ke file text atau file Microsoft Excel.
Hubungan antar modul – modul yang terlibat dalam sistem ini dapat dilihat dengan lengkap pada Gambar III.5 di bawah ini.
PENDEFINISIAN PROYEK CLUSTERING INPUT DATA OBYEK UJI
PEMBACAAN DATA DARI DATABASE
PEMBACAAN DATA DARI FILE (FILE TEXT /
MS EXCEL)
OUTPUT DATA CLUSTER
KE DATABASE LAIN (FILE SQL)
KE FILE (FILE TEXT / MS
EXCEL) EXPORT DATA CLUSTER TAMBAH PROYEK CLUSTERING BARU
DATA OBYEK UJI
DATA OBYEK UJI
DATA CLUSTER
ANALISA CLUSTERING
PENGATURAN PARAMETER CLUSTERING
PROSES CLUSTERING MENGGUNAKAN ALGORITMA
OPTIMIZING PROCEDURE
INTERPRETASI CLUSTER
VALIDASI CLUSTER LOGIN
DATA CLUSTER PENGOLAHAN PROYEK CLUSTERING
HAPUS PROYEK CLUSTERING LAMA PENGATURAN VARIABLE DAN
BOBOT
PENGATURAN NILAI TRANSFORMASI DB SUMBER
OBYEK UJI FILE TEXT/
EXCEL SUMBER OBYEK UJI
Gambar III.5 Arsitektur Perangkat Lunak Yang Akan Dibangun
III.7 Diagram Use Case
Diagram use case sistem yang akan dibangun dapat dilihat pada Gambar III.6 di bawah ini.
Gambar III.6 Diagram Use Case Sistem
Berdasarkan pada gambar III.6, ada 12 use case utama yang ada dalam sistem yang akan dikembangkan, yaitu :
1. Use Case Login
2. Use Case Pendefinisian Proyek Clustering 3. Use Case Penambahan Proyek Clustering 4. Use Case Pengolahan Proyek Clustering 5. Use Case Penghapusan Proyek Clustering 6. Use Case Input Obyek Uji
7. Use Case Pengaturan Variable
8. Use Case Pengaturan Nilai Transformasi 9. Use Case Clustering
10. Use Case Validasi Cluster
11. Use Case Pelabelan Cluster
12. Use Case Output Cluster
III.7.1 Skenario Use Case Login
Nama Login
Deskripsi Use case ini menggambarkan pemeriksaan autentifikasi pengguna.
Aktor Pengguna
Skenario Utama
Kondisi awal Sistem menampilkan layar pengisian nama user dan password
Aksi Aktor Reaksi Sistem
Pengguna mengisi nama user dan password
Sistem memvalidasi nama user dan password. Jika status loginnya valid, maka sistem akan menampilkan pendefinisian proyek. Jika tidak valid, maka sistem akan menampilkan layar pengisian nama user dan password kembali.
Kondisi akhir Status validasi login pengguna telah teridentifikasi.
III.7.2 Skenario Use Case Pendefinisian Proyek Clustering
Nama Pendefinisian Proyek Clustering
Deskripsi Use case ini menggambarkan pendefinisian proyek clustering yang baru atau yang telah dilakukan.
Aktor Pengguna
Skenario Utama
Kondisi awal - Pengguna telah melakukan login dengan status login valid - Sistem menampilkan pilihan operasi proyek clustering yang
bisa dilakukan oleh pengguna yaitu penambahan, pengolahan dan hapus proyek clustering.
Aksi Aktor Reaksi Sistem
Pengguna memilih operasi proyek clustering yang ingin dilakukan
Skenario Alternatif : Pengguna memilih penambahan data
Sistem akan menampilkan layar penambahan proyek clustering
Pengguna mengisi data identitas proyek clustering.
Data identitas proyek clustering disimpan ke basis data
Sistem membuka layar pengolahan proyek clustering.
Skenario Alternatif : Pengguna memilih pengolahan proyek clustering
Sistem membuka layar pengolahan proyek clustering.
Skenario Alternatif : Pengguna memilih Penghapusan proyek clustering
Sistem menampilkan konfirmasi penghapusan data proyek clustering Pengguna memilih konfirmasi
penghapusan.
Jika dikonfirmasi, maka data proyek clustering dihapus dari basis data.
Kondisi akhir Pengguna memilih operasi proyek clustering yang akan dilakukan
III.7.3 Skenario Use Case Penambahan Proyek Clustering
Nama Penambahan Proyek Clustering
Deskripsi Use case ini menggambarkan proses penambahan suatu proyek clustering.
Aktor Pengguna
Skenario Utama
Kondisi awal Pengguna sedang berada pada pengelolaan proyek clustering
Aksi Aktor Reaksi Sistem Pengguna memilih untuk melakukan
penambahan proyek clustering.
Sistem menampilkan layar pembuatan proyek clustering baru
Pengguna mengisi data proyek clustering baru (Nama Proyek, Deskripsi).
Sistem akan menyimpan data proyek clustering baru tersebut ke basis data, kemudian sistem akan memanggil sub sistem pendefinisian proyek clustering.
Kondisi akhir Proyek clustering baru telah tersimpan di basis data (data yang akan dianalisis dan data hasil analisis clustering)
III.7.4 Skenario Use Case Pengolahan Proyek Clustering
Nama Pengolahan Proyek Clustering
Deskripsi Use case ini menggambarkan proses pengolahan sebuah proyek clustering. Dalam proses ini pengguna boleh melakukan input data obyek uji, proses clustering, dan output data cluster.
Aktor Pengguna
Skenario Utama
Kondisi awal - Proyek clustering tersimpan dalam basis data.
- Sistem menampilkan operasi yang bisa dilakukan
Aksi Aktor Reaksi Sistem
Pengguna memilih input data obyek uji.
Sistem memanggil use case input data obyek uji
Pengguna memilih pengaturan variable
Sistem memanggil use case pengaturan variable
Pengguna memilih pengaturan nilai
transformasi
Sistem memanggil use case pengaturan nilai transformasi
Pengguna memilih proses clustering
Sistem memanggi use case clustering.
Pengguna memilih pelabelan cluster
Sistem memanggil use case pelabelan cluster
Pengguna memilih validasi cluster
Sistem memanggil use case validasi cluster
Pengguna memilih output data cluster
Sistem memanggil use case output data cluster.
Kondisi akhir Pengguna dapat melihat data proyek clustering dan dapat melakukan proses clustering ulang.
III.7.5 Skenario Use Case Penghapusan Proyek Clustering
Nama Penghapusan Proyek Clustering
Deskripsi Use case ini menggambarkan proses menghapus data proyek clustering yang telah dilakukan. Penghapusan suatu proyek clustering akan menghapus semua data yang berelasi dengan project tersebut.
Aktor Pengguna
Skenario Utama
Kondisi awal Data proyek clustering yang pernah dilakukan ada di basis data
Aksi Aktor Reaksi Sistem
Pengguna memilih proyek clustering yang akan dihapus.
Sistem menampilkan konfirmasi
penghapusan data proyek clustering.
Pengguna memilih apakah akan menghapus data proyek clustering atau membatalkannya.
- Jika pengguna memilih untuk menghapus data proyek clustering, maka sistem akan menghapus semua data yang berelasi dengan proyek tersebut.
- Jika pengguna membatalkan penghapusan, maka sistem akan kembali ke pendefinisian proyek clustering.
Kondisi akhir Data proyek clustering terhapus dari basis data jika pengguna memilih untuk melakukan penghapusan.
III.7.6 Skenario Use Case Input Obyek Uji
Nama Input Obyek Uji
Deskripsi Use case ini menggambarkan proses input data obyek uji.
Aktor Pengguna
Skenario Utama Kondisi awal - Proyek clustering telah dibuat.
- Sistem menampilkan layar pembacaan data obyek uji.
- Sistem menampilkan pilihan sumber data obyek uji.
Aksi Aktor Reaksi Sistem
Pengguna memilih sumber obyek uji
Sistem membaca data dan menampilkannya di layar pembacaan data.
Sistem menampilkan pilihan menyimpan data obyek uji atau membatalkan pembacaan datanya.
Pengguna memilih menyimpan data
obyek uji.
Sistem menyimpan data obyek uji ke basis data, dan layar pembacaan data ditutup dan kembali ke pengolahan proyek clustering.
Skenario Alternatif : Pemilih memilih pembatalan pembacaan data
Sistem tidak menyimpan data obyek uji ke basis data, dan kembali ke pengolahan proyek clustering.
Kondisi akhir Data obyek uji untuk proses analisis cluster telah tersimpan di basis data sehingga dapat digunakan untuk proses clustering.
III.7.7 Skenario Use Case Pengaturan Variable
Nama Pengaturan Variable
Deskripsi Use case ini menggambarkan proses pengaturan variable yang akan digunakan dalam analisis clustering. Pengaturan variable dilakukan dengan mengupdate bobot variable.
Aktor Pengguna
Skenario Utama Kondisi awal - Data obyek uji telah dibaca.
- Sistem menampilkan variable yang dibaca dari obyek uji.
Aksi Aktor Reaksi Sistem
Pengguna memilih variable yang akan diatur/diedit.
Sistem menampilkan layar pengeditan bobot variable.
Pengguna mengisi bobot variable.
Sistem menyimpan bobot variable ke basis data.
Kondisi akhir Bobot variable telah diatur dan disimpan dalam basis data dan
dapat dalam proses clustering.
III.7.8 Skenario Use Case Pengaturan Nilai Transformasi
Nama Pengaturan Nilai Transformasi
Deskripsi Use case ini menggambarkan proses pengaturan nilai transformasi yang akan digunakan dalam analisis clustering.
Aktor Pengguna
Skenario Utama
Kondisi awal - Data obyek uji telah dibaca, dan memiliki nilai variable yang bukan numerik.
- Sistem menampilkan data variable yang bukan numerik yang dibaca dari obyek uji.
Aksi Aktor Reaksi Sistem
Pengguna memilih data variable bukan numerik yang akan diatur/diedit.
Sistem menampilkan layar pengisian nilai transformasi untuk data variable yang bukan numerik.
Pengguna mengisi nilai
transformasinya.
Sistem menyimpan nilai transforamsi ke basis data.
Kondisi akhir Nilai transformasi telah diatur dan disimpan dalam basis data dan dapat dalam proses clustering.
III.7.9 Skenario Use Case Clustering
Nama Clustering
Deskripsi Use case ini menggambarkan proses clustering
Aktor Pengguna
Skenario Utama
Kondisi awal Data yang akan dianalisis telah tersedia, variable, dan nilai transformasi telah diatur.
Aksi Aktor Reaksi Sistem
Pengguna memilih untuk melakukan clustering
Sistem akan menampilkan layar pengaturan parameter clustering.
Pengguna mengisi parameter clustering
Sistem akan melakukan clustering sesuai parameter clustering.
Sistem menyimpan cluster hasil clustering ke basis data.
Sistem menampilkan cluster hasil clustering di layar output cluster.
Kondisi akhir Proses clustering telah dilakukan, data cluster telah disimpan di basis data dan pengguna dapat melihatnya di layar output cluster.
III.7.10 Skenario Use Case Validasi Cluster
Nama Validasi cluster
Deskripsi Use case ini menggambarkan proses validasi cluster
Aktor Pengguna
Skenario Utama Kondisi awal Proses clustering telah dilakukan.
Aksi Aktor Reaksi Sistem
Pengguna memilih untuk melakukan validasi cluster
Sistem akan melakukan clustering
untuk membuat cluster-cluster
pembanding sesuai parameter clustering
yang telah dilakukan sebelumnya, tetapi
menggunakan metode pengukuran yang
berbeda.
Sistem menampilkan cluster hasil clustering dan cluster-cluster pembandingnya di layar validasi cluster.
Pengguna mengisi status validasi cluster.
Sistem menyimpan status validasi cluster ke basis data.
Kondisi akhir Pengguna telah memvalidasi cluster dan menyimpan status validasinya di basis data.
III.7.11 Skenario Use Case Pelabelan Cluster
Nama Pelabelan Cluster
Deskripsi Use case ini menggambarkan proses pemberian label terhadap cluster hasil clustering.
Aktor Pengguna
Skenario Utama Kondisi awal - Proses clustering telah dilakukan.
- Sistem menampilkan cluster hasil proses clustering.
Aksi Aktor Reaksi Sistem
Pengguna memilih cluster yang akan diberi label.
Sistem menampilkan layar pengisian label cluster.
Pengguna mengisi label cluster.
Sistem menyimpan label cluster ke basis data.
Kondisi akhir Cluster telah diberi label dan disimpan dalam basis data.
III.7.12 Skenario Use Case Output Data Cluster
Nama Output Data Cluster
Deskripsi Use case menggambarkan proses output data cluster hasil proses clustering. Data cluster dapat disimpan/diexport ke basis data lain atau ke file.
Aktor Pengguna
Skenario Utama
Kondisi awal - Data cluster yang berasal dari proses analisis clutering telah didapatkan.
- Sistem akan menampilkan pilihan format export data yang akan dilakukan (file teks, file excel atau file sql).
Aksi Aktor Reaksi Sistem
Pengguna memilih format ekspor data yang dilakukan dan nama file tujuan ekspor.
Skenario Alternatif : Pengguna memilih eksport ke file SQL
Sistem akan menyimpan data cluster ke file text,
Skenario Alternatif : Pengguna memilih eksport ke file Excel
Sistem akan menyimpan data cluster ke file excel
Skenario Alternatif : Pengguna memilih eksport ke file Text
sistem akan menyimpan data cluster ke file text
Kondisi akhir Data cluster telah diekspor sesuai format yang dipilih.
III.8 Realisasi Use Case
III.8.1 Realisasi Use Case Login
Use case login melibatkan 3 kelas yaitu TLayarLogin sebagai kelas boundary, TLogin dan TDBAkses sebagai kelas control.
Gambar III.7 Diagram Kelas Use Case Login
Kelas TLayarLogin menerima masukan username dan password dari pengguna. Kelas TLogin melakukan pemeriksaan login ke basis data menggunakan kelas TDBAkses. Pemeriksaan ini akan menghasilkan status login valid atau tidak valid.
Gambar III.8 Sequence Diagram Login III.8.2 Realisasi Use Case Pendefinisian Proyek Clustering
Use case ini melibatkan 3 kelas yaitu TPengelolaanProyekClustering dan TFTambahProyek sebagai kelas boundary, dan kelas TAnalisisClustering sebagai kelas control.
Gambar III.9 Diagram Kelas Use Case Pendefinisian Proyek Clustering
Pengguna memilih operasi yang akan dilakukan pada kelas
TPengelolaanProyekClustering. Jika akan melakukan penambahan proyek
clustering baru, maka pengisian data proyek clusteringnya dilakukan pada kelas
TFTambahProyek. Pengolahan data dilakukan pada kelas TAnalisisClustering.
Gambar III.10 Sequence Diagram Pendefinisian Proyek Clustering III.8.3 Realisasi Use Case Penambahan Proyek Clustering Baru
Use case ini melibatkan 4 kelas yaitu TPengelolaanProyekClustering dan FTambahProyek sebagai boundary, TProyekClustering sebagai kelas entity dan TAnalisisClustering sebagai kelas control.
Gambar III.11 Diagram Kelas Use Case Penambahan Proyek Clustering
Ketika pengguna memilih tambah proyek, maka akan diminta untuk
memasukan data proyek di kelas FTambahProyek. Kemudian data proyek akan
disimpan di kelas TProyekClustering dan kemudian data proyek tersebut akan
diolah menggunakan kelas TAnalisisClustering.
Gambar III.12 Sequence Diagram Penambahan Proyek Clustering Baru III.8.4 Realisasi Use Case Pengolahan Proyek Clustering
Use case ini melibatkan 8 kelas. Ada 7 kelas boundary yang terlibat yaitu TDataReader, TLayarUpdateVariable, TLayarUpdateNilaiTransformasi, TClusterValidator, TLayarAturParameter, TLayarLabelCluster dan TDataEksporter. Semua kelas boundary dikendalikan oleh sebuah kelas control yaitu TAnalisisClustering.
Gambar III.13 Diagram Kelas Use Case Pengolahan Proyek Clustering
Pada use case ini, pengguna memulai dengan mengisikan data obyek uji
pada kelas TDataReader, kemudian pengguna melakukan pengaturan variable
pada kelas TLayarUpdateVariable. Pengguna dapat mengatur nilai transformasi
pada kelas boundary TLayarUpdateNilaiTransformasi. Kemudian untuk
melakukan proses clustering, pengguna mengisi parameter clustering di kelas
TLayarAturParameter. Kemudian dilakukan proses clustering. Hasil clustering ditampilkan dan label cluster dapat diupdate menggunakan kelas TLayarLabelCluster. Hasil clustering yang divalidasi dengan menggunakan TClusterValidator. Hasil akhir cluster diekspor dengan memanfaatkan kelas TDataExporter.
Gambar III.14 Sequence Diagram Pengolahan Proyek Clustering III.8.5 Realisasi Use Case Penghapusan Proyek Clustering
Use case ini melibatkan 2 kelas yaitu TPengelolaanProyekClustering sebagai kelas boundary dan TDBAkses sebagai kelas control.
Gambar III.15 Kelas Diagram Use Case Penghapusan Proyek Clustering
Pada use case ini, urutan proses dilakukan ketika pengguna memilih untuk
menghapus proyek clustering. Kemudian kelas TPengelolaanProyekClustering
akan memberikan konfirmasi mengenai penghapusan. Jika penghapusan telah
dikonfirmasi, maka sistem akan melakukan penghapusan data obyek uji dan data
cluster dari basis data dengan menggunakan kelas TDBAkses.
Gambar III.16 Sequence Diagram Penghapusan Proyek Clustering
III.8.6 Realisasi Use Case Input Data Obyek Uji
Use case ini melibatkan 8 kelas yaitu TAnalisisClustering, TDataReader, TObyekUji, TObyekUjiVarList, TObyekUjiList, TVariableList, TNilaiTransformasiList dan TDBAkses.
Gambar III.17 Diagram Kelas Use Case Input Data Obyek Uji
Urutan proses dalam use case ini dimulai ketika pengguna melakukan
pemilihan sumber data obyek uji. Obyek uji dibaca dengan menggunakan kelas
TDataReader. Ketika pembacaan data dilakukan, maka data-data tersebut akan
disimpan dalam kelas entitas TObyekUji, TObyekUjiVarList, TObyekUjiList,
TVariableList, TNilaiTransformasiList dan kemudian akan disimpan ke basis data
dengan perantaraan kelas TDBAkses.
Gambar III.18 Sequence Diagram Input Data Obyek Uji III.8.7 Realisasi Use Case Pengaturan Variable
Use case pengaturan variable melibatkan 4 kelas yaitu TAnalisisClustering, TLayarUpdateVariable, TVariableList dan TDBAkses.
Gambar III.19 Sequence Diagram Pengaturan Variable
Urutan proses yang terjadi dalam use case ini dimulai ketika pengguna
memilih variable yang akan diupdate di kelas TAnalisisClustering. Kemudian
sistem akan menampilkan kelas TLayarUpdateVariable untuk melakukan
pengisian bobot variable. Kemudian data bobot baru variable akan diupdate ke
kelas entitas TVariableList dan diupdate ke basis data dengan menggunakan kelas TDBAkses.
Gambar III.20 Sequence Diagram Pengaturan Variable III.8.8 Realisasi Use Case Pengaturan Nilai Transformasi
Use case pengaturan nilai transformasi melibatkan 4 kelas yaitu TAnalisisClustering, TLayarUpdateNilaiTransformasi, TNilaiTransformasiList dan TDBAkses.
Gambar III.21 Kelas Diagram Use Case Pengaturan Nilai Transforamsi Urutan proses yang terjadi dalam use case ini dimulai ketika pengguna memilih nilai transformasi yang akan diupdate di kelas TAnalisisClustering.
Kemudian sistem akan menampilkan kelas TLayarUpdateNilaiTransformasi untuk
melakukan pengisian nilai transformasi baru. Kemudian data nilai transformasi
baru akan diupdate ke kelas entitas TNilaiTransformasiList dan diupdate ke basis
data dengan menggunakan kelas TDBAkses.
Gambar III.22 Sequence Diagram Pengaturan Nilai Transformasi III.8.9 Realisasi Use Case Clustering
Use case ini melibatkan 6 kelas yaitu TAnalisis Clustering, TObyekUjiList, TClusterList, TClusterMemberList, dan TDBAkses.
Gambar III.23 Kelas Diagram Use Case Clustering
Urutan proses dalam realisasi use case ini adalah dimulai dengan pengisian
parameter clustering di kelas TLayarAturParameter, kemudian dilakukan proses
clustering. Proses clustering akan mengupdate cluster-cluster dalam TClusterList
dan TClusterListMember. Cluster-cluster hasil clustering disimpan ke basis data
dengan perantaraan kelas TDBAkses.
Gambar III.24 Sequence Diagram Clustering III.8.10 Realisasi Use Case Validasi Cluster
Realisasi use case ini melibatkan 3 kelas yaitu TAnalisisClustering, TClusterValidator dan TDBAkses.
Gambar III.25 Kelas Diagram Use Case Validasi Cluster
Proses validasi cluster dimulai ketika pengguna memilih validasi cluster.
Hal ini akan menyebabkan pengeksekusian proses clustering untuk mencari
cluster pembanding. Hasil cluster pembanding dan hasil clustering asli
ditampilkan dalam kelas TClusterValidator. Pengguna kemudian mengisi status
validasi. Status validasi akan diupdate ke basis data melalui TDBAkses.
Gambar III.26 Sequence Diagram Validasi Cluster III.8.11 Realisasi Use Case Pelabelan Cluster
Realisasi use case pelabelan cluster melibatkan 4 kelas yaitu TAnalisisClustering, TLayarLabelCluster, TClusterList dan TDBAkses.
Gambar III.27 Kelas Diagram Use Case Pelabelan Cluster
Urutan proses yang terjadi dalam realisasi use case ini dimulai ketika
pengguna menampilkan cluster, kemudian pengguna memilih untuk mengupdate
nama cluster. Sistem akan menampilkan kelas TLayarLabelCluster untuk tempat
pengisian nama cluster. Setelah nama baru cluster diisi, maka nama baru cluster
tersebut diupdatekan ke TClusterList dan disimpan ke basis data melalui kelas
TDBAkses.
Gambar III.28 Sequence Diagram Pelabelan Cluster III.8.12 Realisasi Use Case Output Data Cluster
Use case output data cluster melibatkan 4 kelas yaitu TAnalisisClustering, TDataExporter, TClusterList dan TClusterMemberList.
Gambar III.29 Diagram Kelas Use Case Output Data Cluster
Urutan proses yang terjadi di use case ini adalah ketika pengguna memilih
format tujuan ekspor cluster. Ketika memilih untuk ekspor cluster, maka sistem
akan menampilkan kelas TDataExporter untuk melakukan proses cluster. Kelas
ini akan mengambil data dari TClusterList dan TClusterMember yang kemudian
akan disimpan dalam file tujuan ekspor cluster.
Gambar III.30. Sequence Diagram Output Data Cluster
III.9 Diagram Kelas Keseluruhan Tahap Analisis
Gambar III.31 Diagram Kelas Keseluruhan Tahap Analisis
Berdasarkan kepada Gambar III.31, kelas-kelas yang digunakan dalam sistem yang akan dibangun dapat dilihat pada Tabel III.4.
Tabel III.4. Deskripsi Kelas
No Nama Kelas Jenis Daftar Tanggung-Jawab
1. TVariable Entity Menyimpan data sebuah variable dan bobotnya.
2. TVariableList Entity Menyimpan data sekumpulan variable.
3. TObyekUjiVarList Entity Menyimpan sebuah variable dan nilai yang dimiliki oleh sebuah obyek uji 4. TObyekUji Entity Menyimpan sebuah data obyek uji.
5. TObyekUjiList Entity Menyimpan sekumpulan obyek uji 6. TNilaiTransformasi Entity Menyimpan sebuah nilai transformasi.
7. TNilaiTransformasiList Entity Menyimpan sekumpulan nilai-nilai transformasi.
8. TClusterVarList Entity Menyimpan variable dan nilai yang dimiliki oleh sebuah cluster
9. TCluster Entity Menyimpan sebuah data cluster hasil proses clustering.
10. TClusterList Entity Menyimpan semua data cluster hasil proses clustering
11. TClusterMemberList Entity Menyimpan data obyek uji yang menjadi anggota suatu cluster
12. TProyekClustering Entity Menyimpan data sebuah proyek clustering.
13. TDBAkses Control Melakukan hubungan dengan basis data
No Nama Kelas Jenis Daftar Tanggung-Jawab