METODE SMOOTHING DALAM NAÏVE BAYES UNTUK
KLASIFIKASI EMAIL SPAM
MUTIA HAFILIZARA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2014
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Metode Smoothing dalam Naïve Bayes untuk Klasifikasi Email Spam adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Desember 2014 Mutia Hafilizara NIM G64124007
ABSTRAK
MUTIA HAFILIZARA. Metode Smoothing dalam Naïve Bayes untuk Klasifikasi Email Spam. Dibimbing oleh JULIO ADISANTOSO.
Kehadiran spam pada email menyebabkan penelitian terhadap pembangunan piranti lunak spam filter untuk mengklasifikasikan email meningkat. Naïve Bayes banyak digunakan sebagai fungsi klasifikasi oleh pengembang spam filter. Pada fungsi klasifikasi Naïve Bayes terdapat metode smoothing yang telah umum digunakan yaitu Add-One smoothing atau Laplace smoothing. Disamping itu terdapat metode smoothing lainnya yaitu Jelinek-Mercer smoothing, Dirichlet smoothing, Absolute Discounting smoothing, dan Two-Stage smoothing yang diduga mampu meningkatkan akurasi melebihi Laplace smoothing. Hasil percobaan menunjukkan bahwa akurasi yang dihasilkan fungsi Naïve Bayes menggunakan metode Laplace smoothing sebesar 93.72% lebih rendah dari penggunaan metode smoothing lainnya yang mencapai nilai akurasi melebihi 94%. Fungsi klasifikasi Naïve Bayes yang menggunakan metode Dirichlet smoothing memberikan nilai akurasi terbaik dengan nilai akurasi 94.82%.
Kata kunci: akurasi, metode smoothing naïve bayes, spam filter
ABSTRACT
MUTIA HAFILIZARA. Naïve Bayes Smoothing Methods for Spam Email Classification. Supervised by JULIO ADISANTOSO.
The presence of spam in email lead research on the development of software to classify email spam filter increases. Naïve Bayes is widely used as classification function by spam filter developer. Smoothing method on Naïve Bayes classification function that has been commonly used, namely Add-One smoothing or Laplace smoothing. There are another methods such as Jelinek-Mercer smoothing, Dirichlet smoothing, Absolute Discounting smoothing, and Two –Stage which allegedly able to improve classification accuracy exceeds Laplace smoothing. The experimental results shown accuracy for Naïve Bayes classification function using Laplace smoothing method is 93.72% lower than other smoothing methods which accuration results more than 94%. Naïve Bayes classification function which using Dirichlet smoothing method that gives the best results with accuracy 94.82%.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
METODE SMOOTHING DALAM NAÏVE BAYES UNTUK
KLASIFIKASI EMAIL SPAM
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2014
Penguji:
1. Ahmad Ridha, SKom MS
Judul Skripsi : Metode Smoothing dalam Naïve Bayes untuk Klasifikasi Email Spam
Nama : Mutia Hafilizara NIM : G64124007
Disetujui oleh
Ir Julio Adisantoso, MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Juni 2014 ini ialah spam filter, dengan judul Metode Smoothing dalam Naïve Bayes untuk Klasifikasi Email Spam.
Terima kasih penulis ucapkan kepada Bapak Ir. Julio Adisantoso M.Kom selaku pembimbing. Ungkapan terima kasih juga disampaikan kepada kedua orangtua, Iqbal, Mute, serta seluruh keluarga dan teman, atas segala doa dan kasih sayangnya. Begitu pula rasa terima kasih penulis ucapkan pada rekan-rekan Ekstenerz 7 yang menjadi bagian hidup penulis selama menempuh pendidikan di Ekstensi Ilmu Komputer IPB .
Semoga karya ilmiah ini bermanfaat.
Bogor, Desember 2014 Mutia Hafilizara
DAFTAR ISI
DAFTAR TABEL vi DAFTAR GAMBAR vi DAFTAR LAMPIRAN vi PENDAHULUAN 1 Latar Belakang 1 Perumusan Masalah 2 Tujuan Penelitian 2 Manfaat Penelitian 2Ruang Lingkup Penelitian 2
METODE 2
Pengumpulan Dokumen Email 3
Ekstraksi Dokumen Email 3
Praproses 4
Fungsi Smoothing Naïve Bayes 6
Evaluasi 7
HASIL DAN PEMBAHASAN 8
Pengumpulan Dokumen Email 8
Ekstraksi Dokumen Email 9
Praproses 9
Fungsi Smoothing Naïve Bayes 10
Evaluasi 12
SIMPULAN DAN SARAN 15
Simpulan 15
Saran 15
DAFTAR PUSTAKA 15
LAMPIRAN 17
DAFTAR TABEL
1 Komponen Header dan Body 4
2 Tabel Kontingensi 5
3 Nilai Kritis 𝜒2 untuk taraf nyata α dengan derajat bebas = 1 (Walpole
1993) 5
4 Pendugaan parameter empat metode smoothing (Yuan et al. 2012) 7 5 Confussion Matrix dari klasifikasi dokumen email 7 6 Jumlah token, persentase token terambil, dan persentase token reduksi
pada 5 nilai taraf nyata (α) 10
7 Inverted index hasil seleksi fitur pada beberapa token penciri spam, dan frekuensi kemunculannya pada dokumen ham dan spam 10 8 Pengaruh koefisien kontrol dari metode smoothing Naïve Bayes terhadap
akurasi yang dihasilkan pada penggunaan vocabulary taraf nyata(α) =
0.100 11
9 Jumlah token penciri spam yang dihasilkan dari metode perhitungan
smoothing Naive Bayes 12
DAFTAR GAMBAR
1 Diagram Alir Penelitian 3
2 Tingkat akurasi pengujian dokumen email menggunakan metode smoothing dengan seleksi fitur chi-square pada 5 nilai taraf nyata (α) 13 3 Nilai miss rate dari pengujian dokumen email menggunakan metode
smoothing dengan seleksi fitur chi-square pada 5 nilai taraf nyata (α) 14 4 Nilai false alarm rate dari pengujian dokumen email menggunakan
metode smoothing dengan seleksi fitur chi-square pada 5 nilai taraf
nyata (α) 14
DAFTAR LAMPIRAN
1 Tingkat akurasi, miss rate, false alarm rate dari proses klasifikasi dokumen email menggunakan metode smoothing Naïve Bayes pada 5
nilai taraf nyata (α) 17
2 Tingkat akurasi tanpa menggunakan seleksi fitur chi-square 18 3 Waktu eksekusi metode smoothing pada nilai taraf nyata (α)= 0.1 dan
nilai koefisien kontrol metode smoothing 19
4 Tingkat akurasi, miss rate, false alarm rate dari proses klasifikasi email yang tidak menggunakan token ekstraksi html pada 5 nilai taraf nyata
PENDAHULUAN
Latar Belakang
Berkirim surat merupakan hal yang sering dilakukan oleh semua orang. Salah satu sarana mengirim surat adalah melalui pos. Namun seiring dengan kemajuan teknologi, kemunculan email menjadi alternatif sarana mengirim surat yang lebih cepat dan hemat biaya dibandingkan melalui pos. Keunggulan yang dimiliki email ternyata banyak disalahgunakan sebagai sarana pengiriman pesan massal yang bersifat komersial atau pesan lain yang tidak diinginkan biasa disebut dengan spam. Spam yang terkirim kepada pengguna layanan email dapat menimbulkan masalah berupa meningkatnya kapasitas penyimpanan dan menghabiskan waktu pengguna untuk menghapus spam. Seperti hasil analisis spam tahunan yang tersedia pada website Securelist (2014) terdapat 69.9% spam yang terkirim di seluruh dunia pada tahun 2013. Angka ini menurun 2.5% dari tahun sebelumnya.
Dengan adanya masalah kehadiran spam, maka muncul piranti lunak spam filter untuk mengklasifikasikan email yang dikembangkan dengan berbagai macam metode, salah satunya menggunakan fungsi klasifikasi Naïve Bayes. Naïve Bayes banyak digunakan sebagai metode dalam klasifikasi oleh pengembang spam filter komersial maupun open-source karena kesederhanaan algoritmenya dan mudah dalam mengimplementasikannya (Metsis et al. 2006). Pada penelitan pemodelan spam filter sebelumnya Rachman (2011) melakukan pengukuran kinerja spam filter menggunakan fungsi klasifikasi Naïve Bayes Multinomial dan Graham.
Pada proses penghitungan Naïve Bayes terdapat masalah apabila ada peluang yang bernilai nol. Oleh karena itu digunakan Laplace smoothing yaitu penambahan dengan angka 1 sehingga tidak ada peluang yang akan bernilai nol. Selain Laplace smoothing ada beberapa metode smoothing lainnya. Pada penelitian Yuan et al. (2012) dilakukan klasifikasi teks pendek menggunakan empat jenis metode smoothing dalam Naïve Bayes yaitu Jelinek-Mercer smoothing, Dirichlet smoothing, Absolute Discounting smoothing, dan Two-Stage smoothing. Hasil penelitian ini memperlihatkan bahwa metode smoothing tersebut mampu meningkatkan tingkat akurasi dari Naïve Bayes untuk proses klasifikasi teks.
Selain penggunaan metode smoothing ada juga seleksi fitur. Seleksi fitur dilakukan untuk mendapatkan daftar term yang efektif dan meningkatkan akurasi klasifikasi salah satunya adalah menggunakan chi-square karena performanya yang lebih baik dibandingkan seleksi fitur berbasis frekuensi dan Mutual Information (Manning et al. 2009). Oleh karena itu, penelitian ini mengimplementasikan metode-metode smoothing dalam Naive Bayes dan seleksi fitur chi-square pada proses klasifikasi dokumen email spam.
2
Perumusan Masalah
Perumusan masalah penelitian ini adalah :
1. Bagaimana empat metode smoothing dalam Naïve Bayes digunakan dalam proses klasifikasi dokumen email spam?
2. Bagaimana seleksi fitur chi-square dapat mempengaruhi tingkat akurasi? 3. Bagaimana tingkat akurasi yang dihasilkan dari metode Jelinek-Mercer,
Dirichlet, Absolute Discounting, dan Two Stage smoothing jika dibandingkan dengan metode Laplace smoothing?
Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1. Mengimplementasikan metode smoothing dalam Naïve Bayes yaitu Laplace, Jelinek-Mercer, Dirichlet, Absolute Discounting, dan Two Stage pada proses klasifikasi dokumen email spam.
2. Mengimplementasikan seleksi fitur chi-square pada proses klasifikasi dokumen email spam.
3. Membandingkan tingkat akurasi dari metode Jelinek-Mercer, Dirichlet, Absolute Discounting, Two Stage smoothing, dan Laplace smoothing.
Manfaat Penelitian
Penelitian ini diharapkan dapat menghasilkan pemodelan klasifikasi spam yang tingkat akurasinya lebih baik.
Ruang Lingkup Penelitian
Ruang lingkup pada penelitian ini antara lain:
1. Korpus yang digunakan adalah dokumen email berbahasa inggris dengan standar MIME dalam format raw.
2. Seleksi fitur yang digunakan adalah metode chi-square.
3. Data email yang digunakan diekstrak untuk mendapatkan header dan body. Untuk bagian header yang diambil adalah subject untuk dilakukan tokenisasi 4. Proses stemming tidak dilakukan karena hanya menurunkan jumlah vocabulary.
METODE
Tahapan penelitian dimulai dari pengumpulan data email, ekstraksi dokumen email, praproses, melakukan pemodelan menggunakan beberapa fungsi klasifikasi, pengujian, dan evaluasi hasil. Gambar 1 menunjukkan diagram alir penelitian yang dilakukan.
3
Gambar 1 Diagram Alir Penelitian
Pengumpulan Dokumen Email
Data yang digunakan dalam penelitian adalah korpus email publik yang tersedia pada halaman web Spamassassin1 dengan kode prefix “20030228”. Data yang didapatkan masih berupa campuran dari 3 tipe email yaitu easy ham, hard ham, dan spam. Email tersebut terdiri atas 1897 spam, 250 hard ham dan 3900 easy ham.
Tipe easy ham merupakan pesan ham yang tidak memiliki cukup ciri untuk dikategorikan sebagai spam. Sedangkan tipe hard ham merupakan pesan ham yang memiliki cukup ciri untuk dikategorikan sebagai spam. Selanjutnya pada penelitian ini pesan yang termasuk kategori easy ham dan hard ham digabungkan menjadi tipe ham. Dengan demikian korpus yang digunakan adalah kumpulan email bertipe ham dan spam. Setiap data email tersebut akan diberi label sesuai dengan kelasnya masing-masing secara manual.
Ekstraksi Dokumen Email
Ekstraksi dokumen email untuk mendapatkan bagian email yang akan dimasukkan dalam proses tokenisasi. Isi dari sebuah dokumen email terdiri atas header dan diikuti dengan body (opsional). Tabel 1 menampilkan komponen header dan body berdasarkan The Internet Society (2005), sedangkan komponen header yang digunakan untuk mendapatkan ekstraksi dokumen email dalam penelitian adalah subject saja.
4
Tabel 1 Komponen Header dan Body Jenis
Komponen
Nama Sintaks Definisi Sintaks
Header
MIME-version Menunjukkan versi MIME yang digunakan Form Nama dan alamat pengirim pesan
Received Daftar semua server / komputer dimana pesan dapat sampai kepada penerimanya Date Menunjukkan tanggal dan waktu pesan
email dibuat
Delivered-To Alamat penerima email
Message-ID Sebuah string unik yang diberikan oleh sistem mail saat pesan tersebut pertama kali dibuat
Subject Subjek dari pesan
To Alamat yang digunakan untuk mengirim pesan
X-Mailer Aplikasi yang digunakan untuk mengirimkan pesan
Return - Path Alamat pengembalian pesan jika alamat penerima tidak ditemukan
Body
Plain text Isi pesan dengan format penulisan dalam teks ASCII biasa
HTML text Isi pesan yang mengandung tag HTML Attachment Informasi yang memberikan lampiran dari
sebuah pesan.
Praproses
Dokumen email yang telah diekstraksi kemudian dilakukan tokenisasi. Tokenisasi adalah proses memotong teks menjadi bagian-bagian kecil yang disebut dengan token (Manning et al. 2008). Selain pemotongan teks, pada tahap praproses juga dilakukan pembuangan karakter-karakter tertentu dan seleksi fitur ciri. Pembuangan karakter-karakter tertentu dalam tahap ini adalah membuang bagian kata yang termasuk ke dalam stopwords. Pada penelitian ini stopwords dibuang untuk mengoptimalkan dalam memunculkan token yang berguna dalam proses seleksi fitur ciri. Proses stemming tidak dilakukan karena pada penelitian sebelumnya Drucker et al. (1999) menyatakan stemming hanya menurunkan besar vocabulary.
Seleksi fitur ciri adalah proses memilih sebuah subset dari token-token yang muncul, dan hanya subset ini yang digunakan sebagai fitur dalam proses klasifikasi. Dengan adanya seleksi fitur ciri dapat mengoptimalkan proses klasifikasi karena dapat meminimumkan jumlah token yang efektif saja, dan dapat meningkatkan tingkat akurasi dalam mengklasifikasi karena dapat menghilangkan noise feature. Secara lebih sederhananya tidak semua kata unik dapat menjadi penciri, oleh karena itu dilakukan seleksi fitur ciri. Terdapat 3 seleksi fitur ciri, yaitu Mutual Information, Chi-Square, dan Frequency Based (Manning et al. 2009).
5 Untuk menentukan subset dari token yang muncul, pada penelitian ini menggunakan seleksi fitur ciri chi-square. Nilai chi-square kata t pada kelas c dihitung menggunakan persamaan (Manning et al. 2009)
𝜒2(𝑡, 𝑐) = ∑ ∑ (𝑁𝑒𝑡𝑒𝑐−𝐸𝑒𝑡𝑒𝑐) 2
𝐸𝑒𝑡𝑒𝑐 𝑒𝑐∈{0,1}
𝑒𝑡∈{0,1} (1)
dengan N adalah frekuensi yang diamati, E adalah frekuensi yang diharapkan, 𝑒𝑡
adalah dokumen yang terkait dengan token t, dan 𝑒𝑐 adalah dokumen yang tidak
terkait dengan kelas c. Penghitungan nilai chi-square pada setiap kata t yang muncul pada setiap kelas c dapat dibantu dengan menggunakan tabel kontingensi pada Tabel 2. Isi dari Tabel 2 terdiri atas N merupakan jumlah dokumen latih, A merupakan banyaknya dokumen pada kelas c yang memuat kata t, B merupakan banyaknya dokumen yang bukan kelas c namun memuat kata t, C merupakan banyaknya dokumen yang ada di kelas c namun tidak memiliki kata t, serta D merupakan banyaknya dokumen yang bukan kelas c dan tidak memuat kata t.
Tabel 2 Tabel Kontingensi
Kata Kelas
c ̚ c
t A B
̚ t C D
Tabel kontingensi membantu persamaan 1 lebih sederhana menjadi bentuk persamaan
𝜒2(𝑡, 𝑐) = 𝑁(𝐴𝐷−𝐶𝐵)2
(𝐴+𝐶)(𝐵+𝐷)(𝐴+𝐵)(𝐶+𝐷) (2)
Pengambilan keputusan dilakukan berdasarkan nilai 𝜒2 dari masing-masing kata. Kata yang memiliki nilai 𝜒2 lebih besar dari nilai kritis pada taraf nyata α
adalah kata yang akan dipilih sebagai penciri dokumen. Kata yang dipilih sebagai penciri merupakan kata yang memiliki pengaruh terhadap kelas c. Beberapa nilai kritis 𝜒2untuk taraf nyata α yang digunakan dalam penelitian (Walpole 1993) ditunjukkan pada Tabel 3.
Tabel 3 Nilai Kritis 𝜒2 untuk taraf nyata α dengan derajat bebas = 1 (Walpole 1993) α Nilai kritis 0.100 2.710 0.050 3.840 0.010 6.630 0.005 7.830 0.001 10.830
Hasil dari proses tokenisasi adalah inverted index dari korpus email yang telah memiliki bobot. Penelitian Anagnostopoulos et al. (2006) menunjukkan bahwa inverted index dapat mengefisienkan klasifikasi. Pada tahapan seleksi fitur menggunakan chi-square dengan nilai kritis tertentu telah terpilih term yang menjadi subset kemudian diboboti berupa term frequency (TF). Subset tersebut
6
dijadikan matriks dengan memisalkan TFij adalah banyaknya token i yang muncul
pada dokumen j, yaitu
( 𝑇𝐹11 𝑇𝐹12 𝑇𝐹1… 𝑇𝐹1𝑗 𝑇𝐹21 𝑇𝐹22 𝑇𝐹2… 𝑇𝐹2𝑗 … … … … 𝑇𝐹𝑖𝑗 𝑇𝐹𝑖𝑗 𝑇𝐹𝑖𝑗 𝑇𝐹𝑖𝑗 ).
Fungsi Smoothing Naïve Bayes
Token penciri dokumen yang masuk suatu kelas tertentu telah didapatkan pada tahap tokenisasi, sehingga tahap selanjutnya adalah menentukan fungsi klasifikasi. Pada penelitian ini pemodelan klasifikasi menggunakan metode supervised learning berbasis peluang. Perhitungan peluang tersebut berdasarkan kaidah peluang Naïve Bayes yaitu
𝑃(𝑐|𝑑) ∝ 𝑃(𝑐) ∏1≤𝑘<𝑛𝑑𝑃(𝑡𝑘|𝑐) (3)
dengan parameter 𝑃(𝑐) adalah peluang dokumen ada pada kelas c, 𝑃(𝑡𝑘|𝑐) adalah peluang token 𝑡𝑘 muncul pada dokumen c, dan 𝑛𝑑 adalah jumlah token unik pada dokumen. Pendugaan parameter 𝑃̂(𝑐) dan 𝑃̂(𝑡𝑘|𝑐) pada persamaan
𝑃̂(𝑐) =𝑁𝑐
𝑁 , 𝑃̂(𝑡|𝑐) = 𝑇𝑐𝑡
∑𝑡′∈𝑉𝑇𝑐𝑡′ (4)
dimana 𝑁𝑐 adalah banyaknya dokumen dalam kelas c, N adalah total dokumen,
𝑇𝑐𝑡 adalah banyaknya token t dalam dokumen training dari kelas c (Manning et al.
2009).
Pendugaan parameter 𝑃̂(𝑡𝑘|𝑐) memiliki kelemahan apabila bernilai nol.
Untuk menghilangkan hal tersebut dapat diatasi dengan adanya metode smoothing pada Naïve Bayes. Metode yang sudah umum dipakai adalah Add-One Smoothing atau selanjutnya disebut sebagai Laplace Smoothing. Metode tersebut memiliki persamaan (Manning et al. 2009)
𝑃̂(𝑡|𝑐) = 𝑇𝑐𝑡+1
(∑𝑡′∈𝑉𝑇𝑐𝑡′)+|𝐵| (5)
dengan |𝐵| = banyaknya term dalam vocabulary.
Penggunaan Laplace Smoothing sebagai metode penghitungan peluang setiap token adalah yang paling sederhana dengan menambahkan 1 pada setiap frekuensi token yang didapat. Walaupun sederhana ternyata metode Laplace Smoothing masih rentan terhadap noise. Oleh karena itu dilakukan penelitian yang dilakukan Yuan et al. (2012) terkait dengan klasifikasi teks pendek dengan menggunakan empat metode smoothing yaitu Jelinek - Mercer, Dirichlet, Absolute Discounting, dan Two-Stage smoothing. Penggunaan empat metode smoothing tersebut terbukti dapat meningkatkan hasil akurasi melebihi metode Laplace Smoothing.
Perhitungan peluang setiap dokumen menggunakan empat metode smoothing ini masih mengacu kaidah Naïve Bayes pada persamaan (3) namun berbeda pada persamaan pendugaan parameter 𝑃̂(𝑡𝑘|𝑐) seperti yang ditampilkan
7 Tabel 4 Pendugaan parameter empat metode smoothing (Yuan et al. 2012)
Metode 𝑃̂(𝑡𝑘|𝑐) Jelinek-Mercer 𝑃 ̂ 𝜆(𝑡|𝑐) = (1 − 𝜆) 𝑇𝑐𝑡 ∑𝑡′∈𝑉𝑇𝑐𝑡′+ 𝜆 𝑃(𝑡|𝐶) Dirichlet 𝑃̂𝜇(𝑡|𝑐) =𝑇𝑐𝑡+ 𝜇 𝑃(𝑡|𝐶) ∑𝑡′∈𝑉𝑇𝑐𝑡′+ 𝜇 Absolute Discounting 𝑃̂𝛿(𝑡|𝑐) =max(𝑇𝑐𝑡− 𝛿, 0) + 𝛿 |𝐵𝑐| 𝑃(𝑡|𝐶) ∑𝑡′∈𝑉𝑇𝑐𝑡′ Two-Stage 𝑃̂𝜆, 𝜇(𝑡|𝑐) = (1 − 𝜆)𝑇𝑐𝑡+ 𝜇 𝑃(𝑡|𝐶) ∑𝑡′∈𝑉𝑇𝑐𝑡′ + 𝜇 + 𝜆 𝑃(𝑡|𝐶) Niai 𝜆 , 𝜇 , dan 𝛿 merupakan koefisien kontrol yang bersifat relatif hingga menghasilkan akurasi paling optimum pada klasifikasi, |𝐵𝑐| jumlah kata unik pada
kelas c, 𝑃(𝑡|𝐶) merupakan penduga kemungkinan maksimum dihitung dengan persamaan
𝑃(𝑡|𝐶) = ∑ 𝑐𝑜𝑢𝑛𝑡 (𝑡,𝑐𝑗) 𝑚
𝑗=1
∑ ∑ 𝑐𝑜𝑢𝑛𝑡 (𝑡𝑘 𝑗 𝑘,𝑐𝑗) (10)
dimana ∑𝑚𝑗=1𝑐𝑜𝑢𝑛𝑡 (𝑡, 𝑐𝑗) adalah jumlah token t pada kelas 𝑐𝑗 hingga 𝑐𝑚, dan ∑ ∑ 𝑐𝑜𝑢𝑛𝑡 (𝑡𝑘 𝑗 𝑘, 𝑐𝑗) adalah jumlah seluruh token yang ada pada kelas 𝑐𝑗 hingga 𝑐𝑚
(Chharia dan Gupta 2013).
Pada metode smoothing Absolute Discounting perhitungan penduga kemungkinan maksimum 𝑃(𝑡|𝐶) dilakukan berbeda, yaitu menggunakan persamaan 𝑃(𝑡|𝐶) = 1 |𝐵|× ∑ 𝑐𝑜𝑢𝑛𝑡 (𝑡, 𝑐𝑗) 𝑚 𝑗=1
dengan |𝐵| = banyaknya term dalam vocabulary (Chharia dan Gupta 2013).
Evaluasi
Pemodelan yang telah dilakukan dengan cara supervised learning berbasis peluang Naïve Bayes pada data latih, selanjutnya diuji dan dievaluasi menggunakan data uji yang tersedia. Data tersebut masuk ke proses tokenisasi untuk mendapatkan token setiap dokumen, kemudian dihitung peluang dokumen pada persamaan (3) dengan menggunakan pendugaan parameter pada persamaan (5), (6), (7), (8), dan (9). Evaluasi dilakukan dengan cara membandingkan kelas aktual dari dari data uji dan kelas hasil prediksi dengan menggunakan Confusion Matrix (Tabel 5).
Tabel 5 Confussion Matrix dari klasifikasi dokumen email
Kelas Aktual Kelas Prediksi
Spam ̚ Spam
Spam TP FN
8
TP (True Positive) pada Tabel 5 merupakan banyaknya dokumen yang kelas aktualnya adalah kelas spam dengan kelas prediksinya kelas spam, FN (False Negative) merupakan banyaknya dokumen yang kelas aktualnya adalah kelas spam dengan kelas prediksinya kelas bukan spam, FP (False Positive) merupakan banyaknya dokumen yang ada kelas aktualnya adalah kelas bukan spam dengan kelas prediksinya kelas spam serta TN merupakan banyaknya dokumen yang ada kelas aktualnya adalah kelas bukan spam dengan kelas prediksinya kelas bukan spam. Berdasarkan Tabel 5, maka nilai akurasi dapat dihitung dengan menggunakan persamaan (Manning et al. 2009)
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = 𝑇𝑃+𝑇𝑁
𝑇𝑃+𝐹𝑁+𝐹𝑃+𝑇𝑁 . (11)
Selain dari pengukuran akurasi, evaluasi dilakukan terhadap False Alarm
Rate dan Miss Rate. False Alarm adalah ukuran dokumen spam yang salah terklasifikasi pada persamaan
𝐹𝑎𝑙𝑠𝑒 𝐴𝑙𝑎𝑟𝑚 𝑅𝑎𝑡𝑒 = 𝑠𝑝𝑎𝑚 𝑑𝑜𝑐𝑢𝑚𝑒𝑛𝑡 𝑚𝑖𝑠𝑐𝑙𝑎𝑠𝑠𝑖𝑓𝑖𝑒𝑑
𝑡𝑜𝑡𝑎𝑙 𝑠𝑝𝑎𝑚 𝑑𝑜𝑐𝑢𝑚𝑒𝑛𝑡 (12)
sedangkan Miss Rate adalah ukuran dokumen ham yang salah terklasifikasi pada persamaan
𝑀𝑖𝑠𝑠 𝑟𝑎𝑡𝑒 = 𝑛𝑜𝑛𝑠𝑝𝑎𝑚 𝑑𝑜𝑐𝑢𝑚𝑒𝑛𝑡 𝑚𝑖𝑠𝑐𝑙𝑎𝑠𝑠𝑖𝑓𝑖𝑒𝑑
𝑡𝑜𝑡𝑎𝑙 𝑛𝑜𝑛𝑠𝑝𝑎𝑚 𝑑𝑜𝑐𝑢𝑚𝑒𝑛𝑡 . (13)
Keuntungan dari penggunaan False Alarm Rate dan Miss Rate dapat mengindikasikan tingkat kesalahan klasifikasi setiap kategori (Harris et al. 1999).
HASIL DAN PEMBAHASAN
Pengumpulan Dokumen Email
Korpus email yang telah didapatkan sebelumnya, yaitu 1897 spam, 250 hard ham, dan 3900 easy ham kemudian digabungkan dan dikategorikan menjadi 2 jenis yaitu ham dan spam. Ham merupakan gabungan dari data hard ham dan easy ham. Korpus dimasukkan dalam folder mails sebagai sumber data yang digunakan dalam pembuatan program klasifikasi dan masing-masing dibagi menjadi data latih sebanyak 70%, dan data uji sebanyak 30%. Komposisi dari pembagian korpus adalah sebagai berikut :
1. Total dari dokumen ham 4150. Komposisi yang digunakan sebagai data latih sebanyak 2905 dokumen dan data uji sebanyak 1245 dokumen. 2. Total dari dokumen spam 1897. Komposisi yang digunakan sebagai data
latih sebanyak 1328 dokumen dan data uji sebanyak 569 dokumen. Bahasa yang digunakan dalam korpus email adalah Bahasa Inggris. Bahasa yang digunakan tersebut mengacu pada data email yang didapat dari laman spamassasin. Penomoran serta ekstensi file yang berbeda-beda pada korpus menyulitkan pada saat training maupun testing sehingga harus dilakukan penamaan ulang berupa penomoran secara berurut, beserta dengan penggantian ekstensi file menjadi file email . Hal tersebut dilakukan menggunakan software Bulk Rename dengan tujuan mempermudah mengolah korpus dalam pemrograman sehingga lebih jelas dalam penamaan dan ekstensi setiap dokumennya.
Dari korpus yang ada, terlihat bahwa ukuran email yang masuk kategori spam memiliki ukuran yang besar dibandingkan dengan email kategori ham. Ukuran terbesar dari korpus email spam adalah 227 KB, sedangkan ukuran korpus email
9 ham terbesar adalah 192 KB. Email pada korpus memiliki sistem encoding dan charset yang berbeda-beda. Charset adalah set karakter yang digunakan dan encoding adalah cara yang digunakan untuk penyimpanan karakter di dalam memori. Korpus email spam cenderung menggunakan encoding BASE64 yang merepresentasikan karakter not humanly readable.
Ekstraksi Dokumen Email
Korpus email yang telah didapatkan kemudian dilakukan ekstraksi untuk mendapatkan bagian-bagian tertentu dari bagian header dan body. Ekstraksi dilakukan dengan menggunakan program MIME Mailparser. Komponen yang diekstraksi dari bagian header adalah bagian subject karena baik dokumen spam maupun ham selalu memiliki bagian tersebut. Subject lebih berpeluang menghasilkan token yang optimum untuk klasifikasi dibandingkan komponen header lainnya seperti from, to, return path, dan X-mailer tidak banyak mempengaruhi klasifikasi karena sifatnya hanya informatif dan cocok digunakan pada pengembangan klasifikasi berbasis aturan.
Proses ekstraksi pada bagian body mengambil isi dokumen yang termasuk ke dalam text dan html. Bagian text merupakan teks biasa (plain text), sedangkan bagian html merupakan isi dari body yang mengandung tag html. Tag tersebut diekstraksi namun yang masuk sebagai data ekstraksi adalah atribut dan value dari tag html-nya. Bagian email yang berupa attachment tidak diekstraksi karena tidak menghasilkan token yang berguna untuk klasifikasi. Dari hasil pengamatan, dokumen spam paling banyak mengandung html dan multipart (dokumen email yang mengandung attachment).
Praproses
Proses tokenisasi dilakukan pada teks hasil dari ekstraksi bagian subject, text, dan html sehingga menghasilkan token-token yang berupa kata tunggal. Selanjutnya dilakukan penghilangan token yang termasuk ke dalam kategori stop words 2. Setelah melalui proses penghilangan stop words didapat sejumlah 419 286 token dari seluruh dokumen data latih spam dan ham. Dengan total token unik 50 419, sejumlah 37 768 kata unik terdapat pada dokumen ham dan 21 378 kata unik terdapat pada dokumen spam.
Token yang digunakan memiliki panjang minimum 3 karakter dan
selanjutnya dilakukan seleksi fitur dengan melakukan penghitungan nilai chi-square setiap token pada persamaan (1), sehingga dapat ditentukan token yang
optimum masuk sebagai penciri dokumen spam berdasarkan nilai taraf nyata (α) yang digunakan. Jumlah token unik yang masuk ke fungsi chi-square sejumlah 50 419. Nilai chi-square yang dihasilkan setiap token menunjukkan tingkat kepentingan setiap token menjadi penciri suatu dokumen spam.
Dari nilai chi-square yang dihitung maka dapat ditentukan pengambilan token penciri sesuai batas nilai taraf nyata (α). Tabel 6 memperlihatkan jumlah token, persentase jumlah token yang terambil, dan persentase reduksi token yang didapat pada beberapa taraf nyata (α).
2 Daftar stopwords dapat diunduh pada http://jmlr.org/papers/volume5/lewis04a/a11-smart-stop-list/english.stop
10
Tabel 6 Jumlah token, persentase token terambil, dan persentase token reduksi pada 5 nilai taraf nyata (α)
Taraf Nyata (α) Nilai kritis Jumlah Token (Vocabulary) Persentase Token Terambil Persentase Reduksi Token 0.100 2.710 9 361 18.57 81.43 0.050 3.840 7 733 15.34 84.66 0.010 6.630 3 851 7.64 93.36 0.005 7.830 3 399 6.74 93.26 0.001 10.830 2 559 5.08 94.93
Pada Tabel 6 terlihat bahwa semakin kecil nilai taraf nyata (α) yang digunakan, maka jumlah token penciri yang digunakan (vocabulary) semakin sedikit, dan hal ini berpengaruh pada hasil klasifikasi. Lampiran 1 menunjukkan pengaruh dari jumlah vocabulary yang diambil dari penggunaan 5 nilai taraf nyata (α) terhadap nilai akurasi, miss rate, dan false alarm rate yang dihasilkan dari proses klasifikasi.
Seleksi fitur mengoptimalkan perolehan token penciri spam agar sebuah dokumen email dapat dihitung nilai peluang masuk ke dalam kelas spam dan ham. Tabel 7 menunjukkan inverted index yang dihasilkan dari seleksi fitur pada beberapa token diambil secara acak yang menjadi penciri spam dengan nilai chi-square tinggi, dan frekuensi kemunculannya pada dokumen ham dan spam.
Tabel 7 Inverted index hasil seleksi fitur pada beberapa token penciri spam, dan frekuensi kemunculannya pada dokumen ham dan spam
Token Dokumen ham Dokumen spam
opportunity 61 314 offer 115 524 deathtospamdeathtospamdeathtospam 0 128 reply 124 390 money 236 1111 removed 78 608 arial 2880 6267 align 1659 6317 face 3729 8572 color 2124 9213
Fungsi Smoothing Naïve Bayes
Berdasarkan perhitungan peluang dokumen pada persamaan (3), maka pendugaan parameter 𝑃̂(𝑡𝑘|𝑐) dapat dihitung menggunakan masing-masing
metode smoothing (5), (6), (7), (8), dan (9) dengan 𝑇𝑐𝑡 adalah banyaknya term t
dalam dokumen training dari kelas c yang diperoleh dari inverted index hasil praproses.
Tabel 8 menunjukkan pengaruh koefisien metode smoothing terhadap akurasi pada penggunaan vocabulary hasil seleksi fitur dengan taraf nyata (α) = 0.100. Pada
11 tabel tersebut terdapat koefisien yang digunakan oleh setiap persamaan metode smoothing. Jelinek-mercer menggunakan koefisien 𝜆 pada persamaan (6), Dirichlet menggunakan koefisien 𝜇 pada persamaan (7), Absolute-discounting menggunakan koefisien 𝜗 pada persamaan (8), dan Two-stage menggunakan koefisien 𝜆 dan 𝜇 pada persamaan (9). Nilai koefisien yang diujikan pada penelitian ini terbatas pada nilai yang tertera pada Tabel 8.
Tabel 8 Pengaruh koefisien kontrol dari metode smoothing Naïve Bayes terhadap akurasi yang dihasilkan pada penggunaan vocabulary taraf nyata(α) = 0.100
Metode Koefisien Kontrol Akurasi (%)
Jelinek-mercer 𝜆 = 0.1 94.16 𝜆 = 0.3 94.93 𝜆 = 0.5 94.76 𝜆 = 0.7 94.49 𝜆 = 0.9 93.88 Dirichlet 𝜇 = 0.1 94.82 𝜇 = 0.3 93.77 𝜇 = 0.5 93.83 𝜇 = 0.7 93.94 𝜇 = 0.9 94.10 Absolute -discounting 𝜗 = 0.1 94.60 𝜗 = 0.3 93.83 𝜗 = 0.5 93.00 𝜗 = 0.7 92.06 𝜗 = 0.9 89.91 Two-stage 𝜆 = 0.1 𝜇 = 25 210 𝜇 = 50 419 𝜇 = 75 629 94.87 92.94 93.83 𝜆 = 0.3 𝜇 = 25 210 𝜇 = 50 419 𝜇 = 75 629 94.76 93.50 93.83 𝜆 = 0.5 𝜇 = 25 210 𝜇 = 50 419 𝜇 = 75 629 94.71 93.83 93.66 𝜆 = 0.7 𝜇 = 25 210 𝜇 = 50 419 𝜇 = 75 629 94.38 93.50 93.50 𝜆 = 0.9 𝜇 = 25 210 𝜇 = 50 419 𝜇 = 75 629 93.72 93.88 92.89 Laplace 1 93.72
12
Nilai Koefisen tersebut dapat di rubah sesuai dengan rentang nilainya. Semua koefisien kontrol memiliki nilai dengan rentang 0 – 1, kecuali untuk 𝜇 pada Two-Stage yang sesuai dengan jumlah vocabulary dalam penelitian, sehingga digunakan nilai 25 210, 50 419, dan 75 629.
Proses klasifikasi juga dilakukan dengan tidak menggunakan seleksi fitur chi-square. Lampiran 2 menunjukkan akurasi tanpa menggunakan seleksi fitur sedikit lebih tinggi dibandingkan yang menggunakan seleksi fitur namun terdapat kelemahan pada waktu eksekusi yang lebih lama dua kali lipat oleh karena itu penggunaan seleksi fitur selain mempengaruhi akurasi juga mempersingkat waktu eksekusi (Lampiran 3).
Perhitungan pendugaan parameter menggunakan empat metode smoothing Naïve Bayes pada Tabel 4 dan Laplace pada persamaan (5) menghasilkan nilai peluang yang berbeda sehingga menimbulkan perbedaan jumlah token penciri spam yang terambil. Tabel 9 menunjukkan jumlah token penciri spam yang terambil dari masing-masing metode smoothing.
Tabel 9 Jumlah token penciri spam yang dihasilkan dari metode perhitungan smoothing Naive Bayes
Metode Jumlah token penciri spam
Jelinek-mercer 5687
Dirichlet 5687
Absolute -discounting 5879
Two-stage 5687
Laplace 5685
Dari Tabel 9 dapat disimpulkan bahwa perhitungan pendugaan parameter empat metode smoothing dapat menghasilkan jumlah token penciri spam yang lebih banyak dibandingkan metode Laplace.
Evaluasi
Evaluasi dilakukan setelah pengujian terhadap dokumen uji, dengan menghitung nilai peluang dokumen pada persamaan (3). Karena perkalian peluang dokumen menghasilkan nilai yang sangat kecil sehingga dapat menghasilkan kesalahan presisi, maka dilakukan perhitungan menggunakan logaritma untuk menghitung peluang dokumen pada persamaan (Manning et al. 2009)
log𝑃(𝑐|𝑑) 𝑃(𝑐̃|𝑑)= log 𝑃(𝑐) 𝑃(𝑐̃)∏ 𝑃(𝑡𝑘|𝑐) 𝑃(𝑡𝑘|𝑐̃) k 1 log𝑃(𝑐|𝑑) 𝑃(𝑐̃|𝑑)= log 𝑃(𝑐) 𝑃(𝑐̃)+ ∑ log 𝑃(𝑡𝑘|𝑐) 𝑃(𝑡𝑘|𝑐̃) 𝑘 1
dengan 𝑃(𝑐|𝑑) adalah nilai peluang masuk kedalam dokumen spam, dan 𝑃(𝑐̃|𝑑) adalah nilai peluang masuk kedalam dokumen ham.
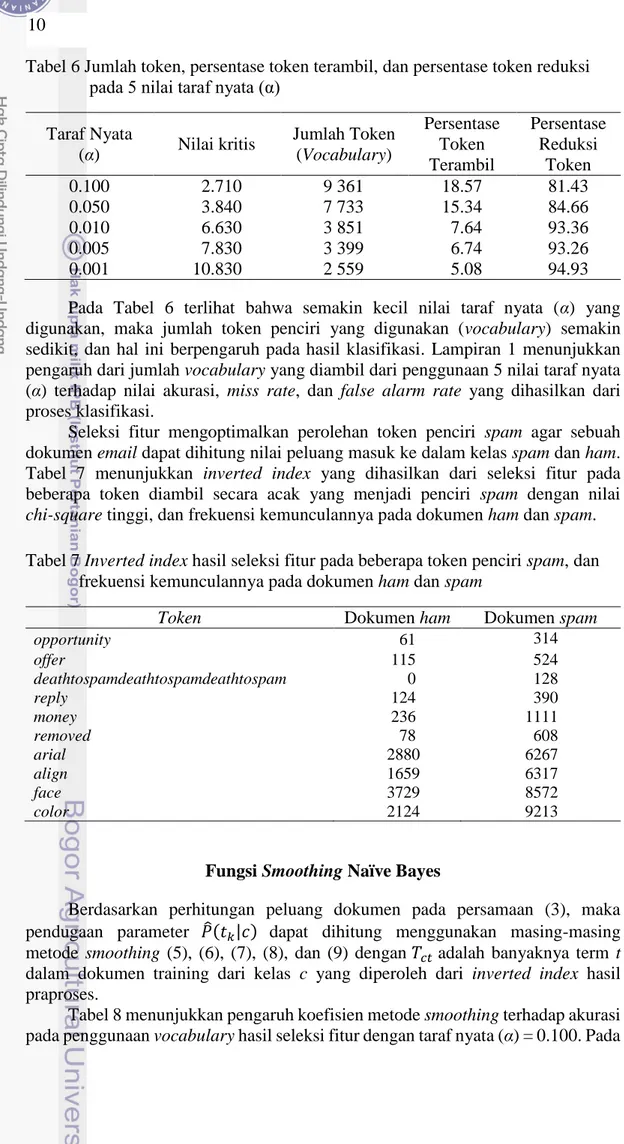
Dari hasil perhitungan nilai peluang pada dokumen uji maka dokumen hasil klasifikasi dapat dimasukkan kedalam confussion matrix merujuk pada Tabel 5. Gambar 2 yang menunjukkan tingkat akurasi masing-masing metode smoothing
13 terhadap 5 nilai taraf nyata (α) dengan metode perhitungan merujuk pada persamaan (11). Terlihat bahwa akurasi lebih tinggi pada peggunaan niai taraf nyata 0.1.
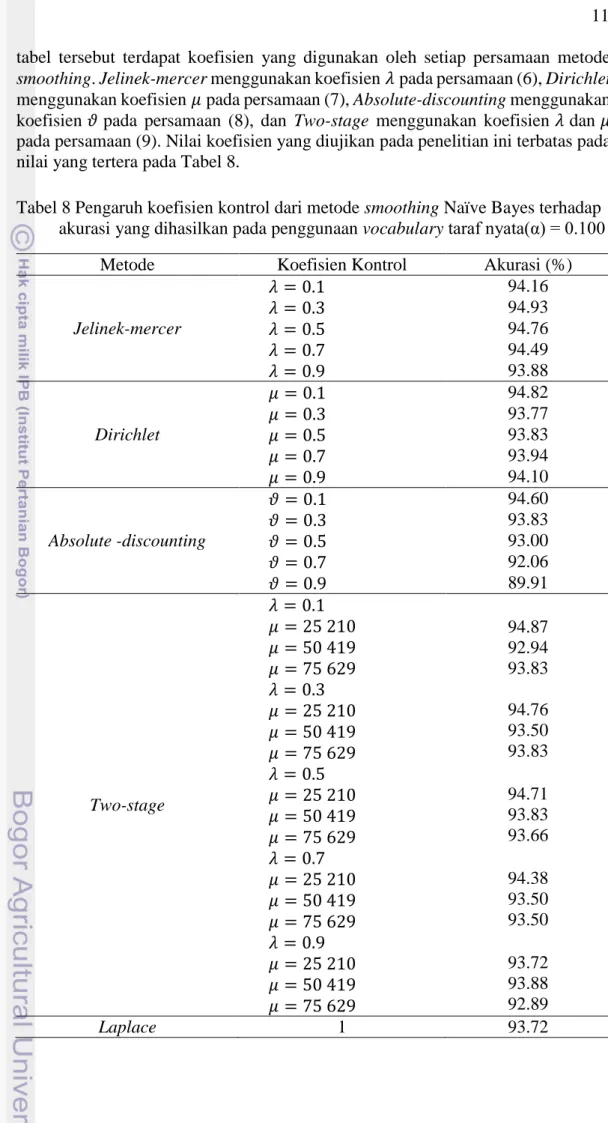
Gambar 3 menunjukkan nilai miss rate yaitu persentase dari dokumen ham yang salah terklasifikasi pada setiap metode smoothing, nilai yang dihasilkan merujuk pada persamaan (13). Terlihat bahwa nilai miss rate terendah dihasilkan dari penggunaan nilai taraf nyata 0.1.
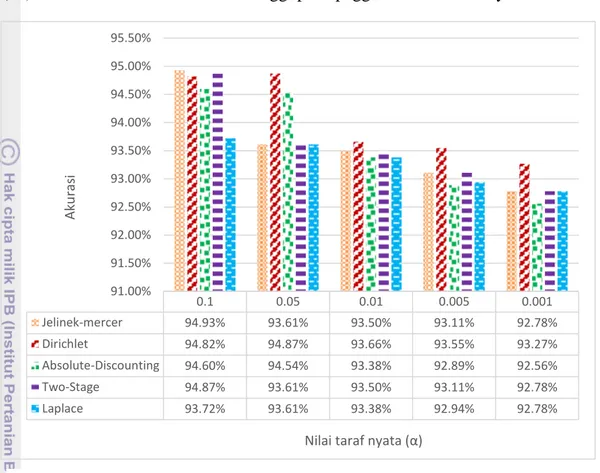
Gambar 4 menunjukkan nilai false alarm yaitu persentase dari dokumen spam yang salah terklasifikasi pada setiap metode smoothing seperti pada persamaan (12). Terlihat bahwa nilai fase alarm rate terendah dihasilkan dari penggunaan nilai taraf nyata 0.1.
Nilai false alarm rate tertinggi dimiliki oleh metode Laplace, yang menunjukkan metode Laplace masih rentan dalam kesalahan klasifikasi email spam ke dalam kelas ham yaitu sebesar 16%. Sedangkan nilai miss rate tertinggi dimiliki oleh metode Absolute-Discounting yang menunjukkan bahwa metode smoothing ini masih rentan dalam kesalahan klasifikasi email ham ke dalam kelas spam yaitu sebesar 2.4%. Nilai miss rate yang tinggi pada metode Absolute-Discounting bisa saja tidak diperhitungkan apabila kesalahan klasifikasi email ham tersebut adalah email dengan kategori hard ham yang hampir menyerupai email spam.
Evaluasi tambahan dilakukan pada klasifikasi yang hanya menggunakan token hasil ekstraksi bagian subject dan text. Lampiran 4 menunjukkan nilai akurasi, miss rate, dan false alarm rate yang dihasilkan dari proses klasifikasi yang hanya menggunakan bagian subject dan text. Nilai akurasi yang dihasilkan memang lebih
Gambar 2 Tingkat akurasi pengujian dokumen email menggunakan metode smoothing dengan seleksi fitur chi-square pada 5 nilai taraf nyata (α) 0.1 0.05 0.01 0.005 0.001 Jelinek-mercer 94.93% 93.61% 93.50% 93.11% 92.78% Dirichlet 94.82% 94.87% 93.66% 93.55% 93.27% Absolute-Discounting 94.60% 94.54% 93.38% 92.89% 92.56% Two-Stage 94.87% 93.61% 93.50% 93.11% 92.78% Laplace 93.72% 93.61% 93.38% 92.94% 92.78% 91.00% 91.50% 92.00% 92.50% 93.00% 93.50% 94.00% 94.50% 95.00% 95.50% Aku ra si
14
tinggi namun menghasilkan nilai miss rate juga tinggi sehingga masih lebih baik menggunakan klasifikasi yang menggunakan bagian subject, text, dan html
0.1 0.05 0.01 0.005 0.001 Jelinek-Mercer 1.90% 2.30% 2.60% 3.10% 3.70% Dirichlet 1.40% 1.60% 2.40% 2.60% 3.10% Absolute-Discounting 2.40% 2.90% 3.60% 4.20% 4.60% Two-Stage 1.90% 2.30% 2.60% 3.10% 3.70% Laplace 1.80% 2.00% 2.50% 2.80% 3.30% 0.00% 0.50% 1.00% 1.50% 2.00% 2.50% 3.00% 3.50% 4.00% 4.50% 5.00% N ilai M is s Rat e
Nilai taraf nyata (α)
Gambar 3 Nilai miss rate dari pengujian dokumen email menggunakan metode smoothing dengan seleksi fitur chi-square pada 5 nilai taraf nyata (α) 0.1 0.05 0.01 0.005 0.001 Jelinek-Mercer 14.40% 15.30% 15.10% 15.10% 14.90% Dirichlet 13.40% 12.80% 14.90% 14.90% 14.60% Absolute-Discounting 12.30% 11.10% 13.20% 13.50% 13.70% Two-Stage 14.40% 15.30% 15.10% 15.10% 14.90% Laplace 16.00% 16.00% 15.60% 16.30% 15.80% 0.00% 2.00% 4.00% 6.00% 8.00% 10.00% 12.00% 14.00% 16.00% 18.00% 20.00% N ilai Fa ls e Alarm
Nilai taraf nyata (α)
Gambar 4 Nilai false alarm rate dari pengujian dokumen email menggunakan metode smoothing dengan seleksi fitur chi-square pada 5 nilai taraf nyata (α)
15
SIMPULAN DAN SARAN
Simpulan
Implementasi metode smoothing pada penghitungan peluang token adalah untuk mengatasi permasalahan peluang token yang bernilai nol. Pada proses klasifikasi Naïve Bayes menggunakan laplace smoothing hal tersebut dapat diatasi dengan penambahan konstanta 1 sehingga dapat menghasilkan akurasi sebesar 93.72%. Namun dengan adanya metode smoothing lainnya yaitu Jelinek-Mercer, Dirichlet, Absolute Discounting, dan Two-Stage peluang nol tersebut diatasi dengan penambahan koefisien tertentu sesuai dengan formula setiap metode, dan menghasilkan akurasi rata-rata maksimum dari empat metode smoothing sebesar 94.24%, lebih tinggi dibandingkan metode Laplace dan terbukti meningkatkan akurasi. Dari hasil evaluasi terhadap nilai akurasi, false rate, dan miss rate terlihat metode Dirichlet memiliki nilai miss rate yang paling rendah sebesar 1.4%, nilai false rate 12.3%, dan akurasi 94.82%. Dari hasil penelitian memperlihatkan metode Dirichlet merupakan metode paling baik pada implementasi proses klasifikasi email spam.
Saran
Penelitian ini menghasilkan akurasi terbaik dari Naïve Bayes yang menggunakan metode smoothing Dirichlet, oleh karena itu pengembangan lebih lanjut dapat dilakukan dengan mengoptimalkan penggunaan metode smoothing Dirichlet. Pengoptimalan tersebut dapat dilakukan antara lain dengan percobaan koefisien kontrol hingga mendapatkan akurasi, false alarm, dan miss rate terbaik. Penelitian lebih lanjut juga dapat dilakukan dengan mengikutsertakan ekstraksi bagian images attachment yang banyak dimiliki dokumen spam, karena bagian tersebut bisa dianalisis jika ada informasi teks yang tertanam didalamnya (Fumera et al. 2006). Dengan adanya token yang dihasilkan dari images attachment, maka vocabulary token penciri spam akan semakin bertambah sumbernya tidak hanya pada bagian yang memiliki teks murni.
DAFTAR PUSTAKA
Anagnostopoulos A, Andrei ZB, and Kunal P. 2006. Effective and efficient classification on a search-engine model. Publication in Knowledge and Information System [Internet]. [diunduh pada 2014 Agustus 12]. Tersedia pada : http://aris.me/pubs/index-classifier-kais.pdf.
Chharia A, Gupta RK. 2013. Enhancing Naïve Bayes Performance with Modified Absolute Discount Smoothing Method in Spam Classification. International Journal of Advanced Research in Computer Science and Software Engineering
[Internet]. [diunduh pada 2014 Agutus 12]. 3(3):424-429. ISSN:2277-128X. Tersedia pada: http://www.ijarcsse.com/docs/papers
16
Drucker H, Donghui W. 1999. Support Vector Machine for Spam Categorization. IEEE Transactions On Neurak Networks. [Internet]. [diunduh pada 2014 Juli 2]. 10(5):1048-1054. Tersedia pada : http://www.site.uottawa.ca/~diana/csi5180/ paper-itnn_1999_09_1048.pdf.
Fumera G, Pillai I, Roli F. 2006. Spam Filtering Based On The Analysis Of Text Information Embedded Into Images. Journal of Machine Learning Research 7 [Internet]. [diunduh pada 2014 Desember 2]. 7 (2006): 2699-2720. Tersedia pada : http://www.jmlr.org/papers/volume7/fumera06a/fumera06a.pdf.
Manning CD, Raghavan P, Schütze H. 2009. Introduction to Information Retrieval. Cambridge University press [Internet]. [diunduh pada 2014 Juni 27]. New York (US): Cambridge University press . Tersedia pada : http://nlp.stanford.edu/IR-book/pdf/irbookprint.pdf.
Metsis V, Androutsopolous I, Paliouras G. 2006. Spam Filtering with Naive Bayes – Which Naive Bayes?. Third Conference on Email and Anti-Spam [Internet]. [diunduh pada 2014 Juli 2]. California (US) : CEAS. Tersedia pada: http://www.aueb.gr/users/ion/docs/ceas2006_paper.pdf.
Rachman W. 2011. Pengukuran Kinerja Spam Filter Menggunakan Metode Naive Bayes Classifier Graham [Skripsi]. Bogor (ID): Institut Pertanian Bogor. Sahami M, Dumais S, Heckerman D, Horvitz E. 1998. A Bayes Approach to
Filtering Junk E-Mail. [Internet].[diunduh pada 2014 Juli 1]. Tersedia pada : http://robotics.stanford.edu/users/sahami/papers-dir/spam.pdf.
[Securelist] Securelist. 2014. Kaspersky Security Bulletin Spam evolution 2013 [Internet]. [diacu 2014 Juli 1]. Tersedia pada : https://securelist.com/analysis/ kaspersky-security-bulletin/58274/kaspersky-security-bulletin-spam-evolution-2013/.
[The Internet Society] The Internet Society. 2005. Registration of Mail and MIME Header Fields [Internet]. [diacu 2014 Juli 1]. Tersedia pada : http://tools.ietf.org/ html/rfc4021.
Walpole RE. 1993. Pengantar Statistika Edisi ke-3. Sumantri B, penerjemah. Jakarta (ID): Gramedia Pustaka Utama. Terjemahan dari : Introduction to Statistic 3rd Edition.
Yuan Q, Chong G, Thalmann NM. 2012. Enhancing Naïve Bayes with various
smoothing methods for short text classification. ACM [Internet]. [diunduh pada 2014 Juni 27]. Lyon (FR): WWW 2012 Companion. Doi:
978-1-4503-1230-1/12/04. Tersedia pada: http://www3.ntu.edu.sg/home/gaocong/ papers/wpp095-yuan.pdf.
17 Lampiran 1 Tingkat akurasi, miss rate, false alarm rate dari proses klasifikasi
dokumen email menggunakan metode smoothing Naïve Bayes pada 5 nilai taraf nyata (α)
Metode Smoothing Nilai taraf
nyata (α) Akurasi (%) Miss rate (%) False alarm rate (%) Laplace 0.100 93.72 1.80 14.40 Jelinek-mercer 94.93 1.60 12.70 Dirichlet 94.82 1.40 12.30 Absolute-discounting 94.60 1.10 14.80 Two-stage 94.87 1.60 12.80 Laplace 0.050 93.61 2.00 16.00 Jelinek-mercer 93.61 2.30 15.30 Dirichlet 94.87 1.60 12.80 Absolute-discounting 94.54 2.90 11.10 Two-stage 93.61 2.30 15.30 Laplace 0.010 93.38 2.50 15.60 Jelinek-mercer 93.50 2.60 15.10 Dirichlet 93.66 2.40 14.90 Absolute-discounting 93.38 3.60 13.20 Two-stage 93.50 2.60 15.10 Laplace 0.005 92.94 2.80 16.30 Jelinek-mercer 93.11 3.10 15.10 Dirichlet 93.55 2.60 14.90 Absolute-discounting 92.89 4.20 13.50 Two-stage 93.11 3.10 15.10 Laplace 0.001 92.78 3.30 15.80 Jelinek-mercer 92.78 3.70 14.90 Dirichlet 93.72 3.10 14.90 Absolute-discounting 92.56 4.60 13.70 Two-stage 92.78 3.70 14.90
18
Lampiran 2 Tingkat akurasi tanpa menggunakan seleksi fitur chi-square Metode Koefisien Kontrol Akuras (%)
Jelinek-mercer 𝜆 = 0.1 94.76 𝜆 = 0.3 94.93 𝜆 = 0.5 94.76 𝜆 = 0.7 94.49 𝜆 = 0.9 93.88 Dirichlet 𝜇 = 0.1 93.55 𝜇 = 0.3 93.77 𝜇 = 0.5 93.83 𝜇 = 0.7 93.94 𝜇 = 0.9 94.10 Absolute -discounting 𝜗 = 0.1 94.60 𝜗 = 0.3 93.83 𝜗 = 0.5 93.00 𝜗 = 0.7 92.06 𝜗 = 0.9 89.91 Two-stage 𝜆 = 0.1 𝜇 = 25 210 𝜇 = 50 419 𝜇 = 75 629 94.87 94.87 94.87 𝜆 = 0.3 𝜇 = 25 210 𝜇 = 50 419 𝜇 = 75 629 94.93 94.82 94.76 𝜆 = 0.5 𝜇 = 25 210 𝜇 = 50 419 𝜇 = 75 629 94.76 94.71 94.71 𝜆 = 0.7 𝜇 = 25 210 𝜇 = 50 419 𝜇 = 75 629 94.38 94.38 94.38 𝜆 = 0.9 𝜇 = 25 210 𝜇 = 50 419 𝜇 = 75 629 93.83 93.77 93.72 Laplace 1 94.54
19 Lampiran 3 Waktu eksekusi metode smoothing pada nilai taraf nyata (α)= 0.1 dan
nilai koefisien kontrol metode smoothing
Metode Koefisien Kontrol Waktu (detik)
Jelinek-mercer 𝜆 = 0.1 8.34 𝜆 = 0.3 8.58 𝜆 = 0.5 8.59 𝜆 = 0.7 8.72 𝜆 = 0.9 8.37 Dirichlet 𝜇 = 0.1 8.60 𝜇 = 0.3 8.76 𝜇 = 0.5 8.38 𝜇 = 0.7 8.38 𝜇 = 0.9 8.54 Absolute -discounting 𝜗 = 0.1 8.40 𝜗 = 0.3 8.61 𝜗 = 0.5 8.67 𝜗 = 0.7 8.84 𝜗 = 0.9 8.63 Two-stage 𝜆 = 0.1 𝜇 = 25 210 𝜇 = 50 419 𝜇 = 75 629 8.99 8.58 8.72 𝜆 = 0.3 𝜇 = 25 210 𝜇 = 50 419 𝜇 = 75 629 8.32 8.65 8.50 𝜆 = 0.5 𝜇 = 25 210 𝜇 = 50 419 𝜇 = 75 629 8.45 8.68 8.58 𝜆 = 0.7 𝜇 = 25 210 𝜇 = 50 419 𝜇 = 75 629 8.53 8.69 8.38 𝜆 = 0.9 𝜇 = 25 210 𝜇 = 50 419 𝜇 = 75 629 8.65 8.40 8.40 Laplace 1 8.45
20
Lampiran 4 Tingkat akurasi, miss rate, false alarm rate dari proses klasifikasi email yang tidak menggunakan token ekstraksi html pada 5 nilai taraf nyata (α)
Metode Smoothing Nilai taraf
nyata (α) Akurasi (%) Miss rate (%) False alarm rate (%) Laplace 0.100 94.43 2.60 12.10 Jelinek-mercer 94.65 2.40 11.80 Dirichlet 94.93 1.70 12.50 Absolute-discounting 95.15 3.40 8.10 Two-stage 94.43 2.40 11.80 Laplace 0.050 94.21 2.70 12.70 Jelinek-mercer 94.38 2.70 12.00 Dirichlet 94.87 2.00 12.00 Absolute-discounting 94.16 2.70 7.60 Two-stage 94.38 2.70 12.00 Laplace 0.010 93.44 3.90 12.30 Jelinek-mercer 93.50 4.10 11.80 Dirichlet 93.99 3.00 12.70 Absolute-discounting 92.50 6.70 9.10 Two-stage 93.50 4.10 11.80 Laplace 0.005 93.27 4.20 12.30 Jelinek-mercer 93.38 4.30 11.60 Dirichlet 93.88 3.20 12.50 Absolute-discounting 92.39 6.90 9.10 Two-stage 93.44 4.30 11.60 Laplace 0.001 92.39 5.20 12.80 Jelinek-mercer 92.34 5.50 12.50 Dirichlet 93.44 4.10 12.00 Absolute-discounting 91.90 7.90 8.60 Two-stage 92.34 5.50 12.50
21
RIWAYAT HIDUP
Penulis dilahirkan dengan nama Mutia Hafilizara di kota Subang, Provinsi Jawa Barat pada tanggal 26 Mei 1991. Penulis merupakan anak pertama dari dua bersaudara, pasangan Bapak Jajang Juhara dan Ibu Lilis Sumiati.
Penulis mulai mengenal pendidikan dari TK An-Nida di Binong dan lulus pada tahun 1997, kemudian melanjutkan pendidikan ke Sekolah Dasar di Sekolah Dasar Negeri 1 Binong dan lulus pada tahun 2003. Pendidikan menengah penulis diselesaikan pada tahun 2006 di SMP Negeri 1 Binong. Kemudian melanjutkan pendidikan tingkat atas yang dapat diselesaikan pada tahun 2009 di SMA Negeri 1 Subang dan pada tahun yang sama penulis melanjutkan pendidikan di Institut Pertanian Bogor Program Diploma, Program Keahlian Manajemen Informatika. Setelah menempuh pendidikan pada program Diploma penulis melanjutkan pendidikan tingkat sarjana pada program Ekstensi Ilmu Komputer IPB angkatan ke-7.