BAB 2
TINJAUAN PUSTAKA
Pada bab ini, akan dibahas landasan teori mengenai pendeteksian kemiripan dokumen teks yang mengkhususkan pada pengertian dari keaslian dokumen, plagiarisme, kemiripan dokumen, dan penjelasan mengenai algoritma yang digunakan yaitu algoritma Manber serta teknik pendukung berupa stemming dan Synonym Recognition. Pada akhir bab ini akan dipaparkan penelitian-penelitian terdahulu mengenai pendeteksian kemiripan dokumen teks.
2.1 Keaslian Dokumen Teks
Keaslian sebuah dokumen teks merupakan naskah yang berasal dari ide pengarang tanpa adanya penambahan ide dari pengarang lainnya. Jika pun ada, nama pengarang harus dicantumkan di dalam referensi serta tidak menuliskan secara utuh kutipan ide tersebut melainkan menuliskannya ke dalam bahasa sendiri. Hal ini dilakukan untuk menghindari tindak plagiarisme.
2.2 Penjiplakan
Berdasarkan hasil penelitian yang dilakukan oleh Gipp & Meuschke (2011), dijelaskan bahwa teknik plagiat memiliki ragam bentuk, diantaranya:
1. Copy & Paste Plagiarism, yaitu menyalin seluruh kata tanpa adanya perubahan konten dari naskah aslinya.
2. Disguised Plagiarism, yaitu menutupi beberapa bagian yang telah disalin dari naskah aslinya dengan menggunakan konten bermakna sama.
3. Technical Disguise, yaitu menyembunyikan serta melakukan peringkasan pada beberapa konten dari naskah yang telah disalin.
4. Undue Paraphrasing, yaitu mengubah susunan serta bahasa yang digunakan (dari bahasa yang satu ke bahasa lainnya) dengan menggunakan gaya penulisannya sendiri tanpa menuliskan sumber aslinya.
5. Translated Plagiarism, yaitu mengubah dari bahasa satu ke bahasa lainnya tanpa menuliskan sumber aslinya.
6. Idea Plagiarism, yaitu menggunakan ide orang lain tanpa menuliskan sumber darimana ide berasal.
2.3 Kemiripan Dokumen Teks
Pendeteksian plagiarisme pada dokumen teks dilakukan dengan cara membandingkan isi dari dokumen yang akan diuji dengan dokumen yang dijadikan sebagai pembandingnya. Adapun syarat dokumen pembanding adalah sudah dinyatakan keasliannya sehingga pengujian kemiripan dokumen menjadi valid.
Dalam menentukan hasil akhir pendeteksian kemiripan dokumen teks, biasanya digunakan persentase similaritas sehingga pembacaan hasil akhir menjadi lebih mudah. Adapun teknik pendeteksian kemiripan dokumen teks menurut Stein & Eissen (2006) adalah:
1. Perbandingan Teks Lengkap, yaitu membandingkan seluruh kata yang terdapat di dalam dokumen teks.
2. Kesamaan Kata Kunci, yaitu membandingkan seluruh kata yang merupakan perwakilan isi dokumen.
2.4 Text Mining
Text Mining diartikan sebagai penambangan data berupa teks yang bersumber dari dokumen untuk mencari kata-kata yang merupakan perwakilan isi atau pembentuk dokumen teks sehingga penganalisisan dapat dilakukan.
Berikut ini merupakan tahapan umum pada proses Text Mining, yaitu (Nugroho, 2011):
1. Text Preprocessing, yaitu pemrosesan awal yang ditujukan untuk membentuk teks menjadi data siap olah pada proses selanjutnya.
a. Case Folding, yaitu pengubahan seluruh karakter yang merupakan huruf kapital menjadi huruf kecil.
b. Filtering, yaitu pengambilan kata-kata yang penting sesuai dengan kondisi yang diinginkan.
c. Tokenizing, yaitu tahap pemecahan kalimat yang di-input berdasarkan kata yang menyusunnya, biasanya dipisah oleh karakter whitespace.
2. Text Transformation, yaitu pembentukan teks yang mengacu pada proses untuk mendapatkan representasi dokumen yang sesuai.
a. Stemming, yaitu pencarian kata dasar dari setiap kata hasil tokenizing. b. Synonym Recognition, yaitu pengubahan kata yang memiliki makna yang
sama dengan penulisan berbeda.
3. Feature Selection, yaitu pengurangan dimensi teks sehingga nantinya akan dihasilkan kata-kata yang merupakan dasar dari isi teks.
4. Pattern Discovery, yaitu penemuan pola atau pengetahuan dari keseluruhan teks.
2.5 Algoritma Manber
Algoritma Manber merupakan salah satu dari tiga algoritma yang menggunakan
fingerprint dalam proses penyelesaian permasalahannya, selain algoritma Winnowing
Setiap algoritma memiliki penyelesaian permasalahan yang berbeda, namun algoritma Manber dan Winnowing memiliki langkah penyelesaian yang hampir sama. Adapun perbedaan algoritma Manber dari algoritma Winnowing adalah sebagai berikut (Kurniawati & Wicaksana, 2008):
1. Jumlah langkah yang lebih sedikit sehingga waktu pemrosesan dokumen menjadi lebih cepat.
2. Tidak memberikan informasi dimana posisi fingerprint berada.
3. Pemilihan fingerprint yang berbeda. Pada Algoritma Manber, fingerprint dipilih dari setiap nilai hash yang memenuhi persyaratan H mod P = 0, di
mana H adalah nilai hash dan P adalah nilai pembagi yang digunakan,
sementara pada Algoritma Winnowing dipilih nilai hash minimum dalam
setiap window.
Adapun secara singkat, konsep dasar algoritma Manber dimulai dari tahap awal baik penghapusan noise dan whitespace hingga hasil akhirnya berupa persentase adalah :
1. Penghapusan noise dan whitespace.
2. Pembentukan rangkaian gram dengan panjang N karakter.
3. Penghitungan nilai hash dari setiap gram menggunakan fungsi hash. 4. Pemilihan beberapa nilai hash menjadi fingerprint dokumen.
5. Menentukan persentase kemiripan antar dokumen menggunakan persamaan
Jaccard Coefficient.
2.5.1 Penghapusan Noise & Whitespace
Banyak algoritma atau metode yang dapat digunakan untuk mendeteksi kemiripan dokumen teks. Ada beberapa persyaratan yang harus dipenuhi oleh algoritma pendeteksi kemiripan dokumen teks (Pratama, 2012), yaitu:
2. Noise Surpression, artinya dalam melakukan pendeteksian, algoritma harus dapat menghindari adanya kata yang tidak penting, misal: “di”, “ke”, dan sebagainya. Panjang kata yang ditengarai harus cukup untuk membuktikan bahwa kata-kata tersebut telah dijiplak dan bukan merupakan kata yang umum digunakan.
3. Position Independence, artinya pendeteksian tidak boleh bergantung pada posisi kata sehingga apabila posisi kata berbeda maka pendeteksian tetap dapat dilakukan.
2.5.2 Metode N-Gram
Algoritma yang menggunakan fingerprint seperti algoritma Manber memiliki satu metode utama yaitu metode N-Gram. Metode N-Gram merupakan metode yang berfungsi untuk memecah kata ataupun kalimat menjadi sebuah rangkaian dengan panjang N karakter. Sebagai contoh :
“KEMEJA”
Dengan menggunakan nilai N = 2, maka akan dihasilkan : “KE”, “EM”, “ME”, “EJ”, “JA”
Metode N-Gram memunyai peran yang cukup penting karena merupakan langkah awal dalam proses pembentukan fingerprint. Dengan kata lain, metode N-Gram memiliki pengaruh terbesar pertama pada hasil akhir yang dikeluarkan.
Pengaruh dari nilai N pada metode N-Gram yaitu semakin kecil nilai N yang digunakan akan semakin besar pula persentase yang dihasilkan nantinya. Namun, tidak selalu dengan menggunakan nilai N = 1, hasil yang didapatkan lebih baik. Alasannya adalah jika kalimat terdiri dari huruf yang sama dengan kalimat bandingnya, maka akan menghasilkan persentase kemiripan sebesar 100%. Sebagai contoh :
“RAMAH” : “R”,”A”,”M”,”H” “MARAH” : “M”,”A”,”R”,”H”
2.5.3 Hash
Hash merupakan teknik untuk mengubah sebuah string menjadi nilai unik dengan panjang tertentu yang nantinya akan berfungsi sebagai penanda string tersebut (Pratama, et al. 2012)
Hash terdiri dari dua elemen, yaitu fungsi hash dan nilai hash. Hubungan kedua elemen tersebut adalah rangkaian gram yang dihasilkan dari proses N-Gram kemudian diolah menggunakan fungsi hash sehingga terbentuklah rangkaian nilai
hash yang nantinya akan dipilih menjadi fingerprint dokumen (Purwitasari, et al. 2009).
Fungsi hash yang digunakan pada algoritma Manber adalah fungsi hash yang mengubah setiap karakter pada rangkaian string ke dalam bentuk kode ASCII dan memrosesnya ke dalam persamaan (2.1) berikut :
k ini dapat dikatakan pula sebagai rangkaian pembentuk atau dasar dari dokumen tersebut. Fingerprint berasal dari rangkaian nilai hash yang sudah memenuhi persyaratan.
Fingerprint merupakan tujuan pertama dari algoritma yang menggunakan
fingerprint sebagai langkah penyelesaiannya. Masing-masing algoritma memiliki cara yang berbeda dalam memilih fingerprint. Pada algoritma Manber, pemilihan
H Mod P = 0 (2.2)
Ada tiga faktor yang mempengaruhi pemilihan fingerprint, yaitu :
1. Nilai N pada metode N-Gram, perubahan panjang karakter yang terbentuk akan mengubah fingerprint yang dipilih.
2. Basis pada fungsi hash, tentunya perubahan basis akan mengubah nilai hash
yang dihasilkan serta fingerprint yang dipilih.
3. Nilai pembagi pada persamaan (2.2). Perubahan pada nilai pembagi akan mengubah nilai hash yang akan dipilih menjadi fingerprint. Penggunaan nilai pembagi ini harus disesuaikan dengan kondisi dokumen teks.
2.5.5 Persamaan Jaccard Coefficient
Persamaan Jaccard Coefficient merupakan persamaan yang digunakan untuk mengukur nilai similaritas atau kemiripan. Banyak hal yang dapat diukur nilai similaritasnya, seperti similaritas dokumen teks. Oleh karena itu, persamaan ini diimplementasikan ke dalam algoritma Manber sebagai pengukur persentase similaritas dokumen teks. Persamaan Jaccard Coefficient dapat ditulis sesuai dengan persamaan (2.3) berikut: 3. Similaritas (di,dj) : Hasil bagi irisan dengan gabungan fingerprint yang
2.6 Stemming
Stemming adalah teknik pencarian kata dasar dari setiap kata hasil tokenizing. Di dalam bahasa Indonesia, stemming digunakan untuk menghilangkan bubuhan yang melekat pada kata dasar baik imbuhan (awalan, akhiran, sisipan), partikel, dan kata ganti orang. Sebagai contoh :
“mempermainkannya” = “mem” + ”per” + “main” + “kan” + “nya” Kata “mempermainkannya” merupakan hasil gabungan dari :
1. Satu kata dasar (root word) : “main”
2. Dua imbuhan awal (prefiks) : “mem” dan “per” 3. Satu imbuhan akhir (sufiks) : “kan”
4. Satu kata ganti orang (possessive pronoun) : “nya”
Stemming lebih susah diimplementasikan ke dalam teks berbahasa Indonesia karena bahasa Indonesia tidak memiliki rumus bentuk baku yang permanen (Triawati, 2009). Banyak penelitian mengenai teknik stemming, salah satunya adalah Stemming Porter yang akan digunakan pada penelitian ini. Secara singkat langkah penyelesaian pada Stemming Porter adalah sebagai berikut:
1. Menghapus partikel,
2. Menghapus kata ganti (possessive pronoun),
3. Menghapus awalan pertama. Jika tidak ditemukan, maka lanjut ke langkah 4a, dan jika ada, maka lanjut ke langkah 4b,
4. a. Menghapus awalan kedua, dan dilanjutkan pada langkah 5a,
b. Menghapus akhiran, jika tidak ditemukan, maka kata diasumsikan sebagai kata dasar. Jika ditemukan lanjut ke langkah 5b,
5. a. Menghapus akhiran dan kata akhir diasumsikan sebagai kata dasar. b. Menghapus awalan kedua dan kata akhir diasumsikan sebagai kata dasar.
2.7 Synonym Recognition
Synonym Recognition atau pengenalan kata bersinonim adalah teknik yang digunakan untuk mengenali kata dengan penulisan berbeda namun memiliki makna yang sama.
Teknik penjiplakan dokumen teks tidak lepas dari penggunaan kata bersinonim sehingga dokumen teks hasil penjiplakan berbeda secara penulisan dari dokumen teks aslinya meskipun makna yang dihasilkan tetaplah sama. Jenis penjiplakan tersebut dapat digolongkan ke dalam Disguised Plagiarism dan Technical Disguise. Jenis penjiplakan ini sangat sulit dideteksi oleh sistem yang tidak mengimplementasikan teknik Synonym Recognition.
Di dalam bahasa Indonesia, hampir setiap kata memiliki sinonim, tentu hal ini semakin menyulitkan pendeteksian. Apabila sistem penyimpan kata hanya memiliki sedikit kata bersinonim, maka semakin kecil pula keakuratan pendeteksian. Hal ini juga dipersulit dengan adanya penulisan kata bersinonim yang sama meskipun maknanya berbeda, serta sinonim kata yang menggunakan imbuhan.
Synonym Recognition merupakan kunci kedua terpenting setelah stemming. Hal ini diakibatkan karena banyaknya kata sinonim yang berasal dari kata dasar, meskipun beberapa sinonim kata memang memiliki imbuhan. Apabila proses
stemming tidak berjalan dengan baik, maka pengenalan kata bersinonim juga menjadi tidak sesuai, dan berdampak pada berkurangnya keakuratan pendeteksian.
2.8 Penelitian Terdahulu
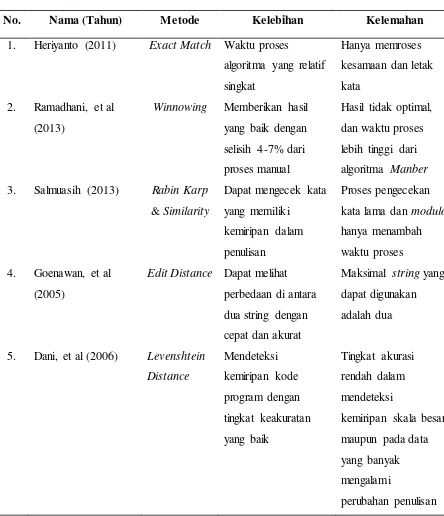
Pendeteksian kemiripan dokumen teks sudah banyak dilakukan oleh peneliti-peneliti sebelumnya, baik dengan menggunakan algoritma pendeteksi kemiripan teks yang berbeda, teknik pendukung yang berbeda maupun pengimplementasian dalam bentuk yang berbeda, dan lain sebagainya.
Ramadhani, et al (2013) menggunakan algoritma Winnowing, dimana algoritma ini memiliki langkah yang hampir sama dengan algoritma Manber. Sesuai dengan kesimpulan yang dituliskan bahwa keakuratan pendeteksian cukup baik, yaitu memberikan selisih perbedaan sebesar 4-7% dengan responden yang mencari kesamaan dokumen secara manual, namun kecepatan proses algoritma masih kalah dari algoritma Manber, meskipun dari segi keakuratan Winnowing lebih unggul.
Salmuasih (2013) yang menggunakan algoritma Rabin-Karp dan konsep
similarity menyimpulkan bahwa penggunaan teknik stemming sangat berpengaruh pada persentase hasil yang didapatkan, serta perlu ditambahkan teknik pengenalan sinonim. Modulo yang digunakan dalam penelitiannya tidak berpengaruh pada hasil persentase, namun berpengaruh pada waktu proses.
Goenawan, et al (2005) menyimpulkan bahwa algoritma Edit Distance lebih tepat digunakan untuk mencari kecocokan antara dua string. Dimana dalam proses perbandingannya , string kedua dimanipulasi sehingga pada akhirnya serupa dengan
string pertama. Dalam proses pengubahan string tersebut, dibuat sebuah tabel dua dimensi dengan baris sesuai dengan panjang string terpanjang dan jumlah kolom sebanyak panjang string terpendek. Keunggulan algoritma Edit Distance yaitu dapat melihat perbedaan di antara dua string dengan cepat dan akurat.
Dani, et al (2006) lebih meneliti pada kompleksitas waktu algoritma
Levenshtein Distance dan pendeteksian pada kemiripan kode program. Disimpulkan bahwa kemiripan antar kode program yang diimplementasi dengan bahasa pemrograman yang berbeda, sebelumnya dapat dilakukan proses deteksi bahasa dan konversi ke dalam satu bahasa standar yang dipilih. Dalam kata lain, diperlukan pengubahan bahasa pemrograman satu ke bahasa lain tanpa mengubah inti dari program tersebut atau dapat disebut sebagai sinonim bahasa pemrograman.
Oleh karena itu, diperlukan sebuah pengembangan sistem menggunakan algoritma dengan kompleksitas waktu yang baik serta menambahkan teknik stemming
Tabel 2.1 Penelitian Terdahulu
No. Nama (Tahun) Metode Kelebihan Kelemahan