ANALISA PENCARIAN FREQUENT ITEMSETS MENGGUNAKAN
ALGORITMA FP-MAX
Suhatati Tjandra
Dosen Teknik Informatika Sekolah Tinggi Teknik Surabaya
e-mail : [email protected]
ABSTRAK
Association rule mining
merupakan sub bab dari data mining yang bertujuan untuk mencari
frequent itemset
dan menemukan hubungan di antara item-item dalam suatu database. Tujuan
utama dari association rule mining adalah menemukan frequent itemset dan men-generate
association rule
. Karena banyaknya jumlah frequent itemset yang dihasilkan jika menggunakan
frequent itemset mining
, maka dikembangkan
maximal frequent itemset mining
yang hanya
menghasilkan frequent itemset yang maximal. Sebuah frequent itemset disebut maximal jika
tidak ada frequent itemset lain yang merupakan superset dari itemset tersebut. Algoritma
FP-MAX menggunakan dasar struktur tree yang dikenal dengan FP-Tree.
Kata kunci : Data Mining, FP-Max, FP-Tree, Itemset
ABSTRACT
Association rule mining
is a part of data mining that has purposes to look for
frequent
itemsets
and to find the relation among items in a database. The main purposes of association
rule mining are to find frequent itemsets and to generate
association rule
. There are many
frequent itemsets being resulted when using
frequent itemset mining
, then
maximal frequent
itemset mining
is developed, where it only results maximal frequent itemset. A frequent itemset
is maximal if there is no other frequent itemset that is a superset for it. FP-MAX use the tree
structures which called FP-Tree.
Keywords :Data Mining, FP-Max, FP-Tree, Itemset
PENDAHULUAN
Perkembangan teknologi informasi yang cukup pesat menyebabkan penyimpanan dan pengolahan data menjadi suatu hal yang cukup vital. Data yang telah tersimpan dalam database tidak dapat digunakan secara maksimal tanpa diamati lebih dalam, mengenai fakta-fakta yang tersimpan dalam data tersebut. Data mining, bertujuan untuk mencari pengetahuan atau fakta-fakta yang tersimpan dalam data, oleh karenanya data mining ini terus dikembangkan dan diteliti.
Data mining bukanlah suatu bidang yang berdiri sendiri, melainkan terdiri dari gabungan beberapa disiplin ilmu, seperti halnya machine learning, statistika, dan database. Tidak seperti halnya classical statistic, pada data mining, lebih
ditekankan untuk mencari dan menemukan pengetahuan yang tidak hanya akurat, tetapi juga dapat dipahami oleh user. Comprehensibility (tingkat pemahaman) sangatlah penting ketika pengetahuan yang ditemukan akan digunakan sebagai bahan pertimbangan dalam pengambilan suatu keputusan. Jika pengetahuan yang ditemukan tidak dapat dipahami oleh user, user tidak mendapat gambaran mengenai apa yang sedang terjadi. Pada kasus ini, sangat besar kemungkinan user tidak mempercayai pengetahuan yang didapatkan dari hasil data mining sebagai bahan pertimbangan dalam pengambilan keputusan. Hal ini akan berakibat pada pengambilan keputusan yang buruk atau kurang baik.
preparation (data selection, data preprocessing), data transformation, data mining, dan analisis of knowledge. Setiap langkah harus diterapkan dan harus diselesaikan terlebih dahulu untuk mencapai tahap atau langkah berikutnya. Tahapan pada data mining merupakan langkah yang menunjukkan kecerdasan sistem komputer dalam mengambil pengetahuan atau keputusan.
Frequent Itemset
Frequent itemset mining adalah algoritma yang digunakan untuk mencari frequent itemset. Frequent itemset mining dapat diklasikasifikan menjadi tiga kelompok yaitu: algoritma mining Frequent Itemset (FI), algoritma mining Frequent Closed Itemset (FCI), dan algoritma mining Maka sebuah itemset X dapat didefinisikan sebagai X
I dan sebuah tidset Y dapat didefinisikan sebagai Y
T. Support sebuah itemset X adalah jumlah transaksi dimana terdapat item X didefinisikan sebagai
(X). Sebuah itemset X disebut frequent itemset apabila support X lebih besar atau sama dengan nilai minimum support yang dispesifikasikan (
(X)
min_supp ). Minimum support adalah suatu nilai yang menentukan sebuah itemset frequent atau tidak, dimana minimum support ditentukan oleh user. Misalkan nilai minimum support adalah 40% dan jumlah transaksi dalam database ada lima transaksi. Maka suatu itemset dikatakan frequent bila itemset tersebut minimal terdapat pada dua transaksi ( 40% * 5 = 2 ).Maximal Frequent Itemset
Sebuah frequent itemset X disebut bersifat maximal apabila tidak ada frequent itemset lain yang merupakan superset dari itemset X. MFI ini dikembangkan untuk mengatasi kelemahan dari association rule mining yaitu banyaknya frequent itemset yang dihasilkan apabila nilai support yang diberikan kecil atau rendah.
Akan tetapi jumlah MFI yang lebih sedikit ini tidak mengurangi informasi yang seharusnya diperoleh. Dengan adanya MFI maka diharapkan rule yang dihasilkan sedikit tapi dapat memberikan informasi yang diinginkan.
Generate Association Rule
Setelah mengetahui frequent itemset, maka langkah selanjutnya adalah menghasilkan rule yang confident. Sebuah rule dapat dinyatakan dalam ekspresi X’ X – X’ untuk semua frequent itemset X, dimana X' X dan X {}. Sebuah rule disebut confident rule apabila nilai confident dari rule tersebut lebih besar atau sama dengan nilai minimum confident yang dispesifikasikan (
p
minconf). Nilai confident ( p ) dihitung dengan rumus p =
(X)/
(X )' atau dapat dikatakan nilai confident ( p ) adalah nilai support X dibagi nilai support X’.Untuk sebuah itemset X dengan panjang k dapat dihasilkan rule sebanyak 2k-2. Dengan kata lain,
sebuah rule dihasilkan dengan mengkombinasikan item-item penyusun rule tersebut.
FP-Tree
Pembuatan FP-Tree dikerjakan dalam dua fase, dimana dalam setiap fase diperlukan satu kali membaca database. Fase yang pertama membaca database untuk mengenali frequent 1-itemset. Tujuannya adalah untuk menghasilkan order list dari frequent itemset yang dapat digunakan ketika membuat tree pada fase kedua.
Tabel 1
Transaksi item yang sudah diutkan digunakan untuk membuat FP-Tree.
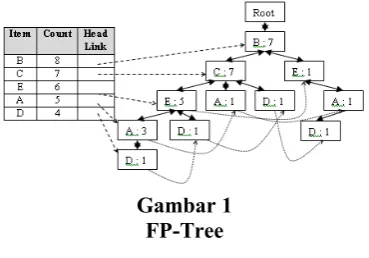
Setiap sub-transaksi yang sudah di urutkan dibandingkan dengan prefix tree mulai dari root. Jika ada kesesuaian di antara prefix tree dan path dalam tree yang dimulai dari root, support dalam node yang sesuai ditambah satu. Sebaliknya node yang baru akan ditambahkan untuk item dalam suffix dari transaksi untuk melanjutkan path yang baru dimana tiap node baru tersebut nilai supportnya di inisialisasi satu. Selama proses penambahan node baru pada FP-Tree, link di buat di antara node dalam tree dan di masukkan ke dalam tabel header. Tabel header memegang satu pointer per item yaitu pointer untuk kejadian pertama dari item tersebut dalam struktur data FP-Tree. FP-Tree yang digunakan adalah FP-Tree yang sudah dimodifikasi yaitu linknya bi-directional [2]. Gambar 1 merupakan contoh FP-Tree, dimana dataset yang digunakan adalah dataset pada tabel 1.
Gambar 1 FP-Tree
Algoritma FP-MAX
Algoritma FP-MAX ini digunakan untuk mencari semua maximal frequent itemsets di dalam sebuah transaksi atau dalam sebuah dataset. Maximal Frequent itemset ini digunakan untuk memperkecil jumlah informasi yang diperoleh dari hasil mining suatu dataset atau transaksi yang besar tanpa mengurangi informasi yang di dapatkan dari proses mining tersebut.
Sebuah frequent itemset X disebut bersifat maximal apabila tidak ada frequent itemset lain yang merupakan superset dari itemset X. MFI ini dikembangkan untuk mengatasi kelemahan dari association rule mining yaitu banyaknya frequent itemset yang dihasilkan apabila nilai support yang diberikan kecil atau rendah.
Algoritma FP-MAX ini merupakan pengembangan dari algoritma FP-Growth. Algortima FP-Growth merupakan dasar yang digunakan dalam
pengembangan algoritma FP-MAX ini. Algoritma FP-MAX ini sama seperti algoritma FP-Growth prosesnya rekursif. Pada proses awal yang dilakukan algoritma FP-MAX yaitu mencari frequent 1 itemset dengan menggunakan FP-Tree, dari pembacaan pertama suatu dataset atau transaksi, dari FP-Tree yang sudah terbetuk kemudian dicari conditional FP-Treenya setelah itu baru dibentuk MFI-Treenya. Dari MFI-Tree baru bisa didapatkan maximal frequent itemsetnya.
Langkah langkah yang di lakukan dalam
algoritma FP-MAX dapat dilihat pada gambar
2.
Gambar 2 Blok Diagram FP-MAX
Proses yang dilakukan dalam algoritma FP-MAX sampai mendapatkan maximal frequent itemsets:
1. Persiapan dataset yang akan dimining, sebelum proses mining dataset di olah dengan data preparation, agar pengetahuan yang didapatkan dari dataset sesuai dengan kebutuhan.
2. Pembentukan FP-Tree, dari dataset yang sudah diolah kemudian dibentuk FP-Treenya, sehingga mendapatkan frequent 1 itemset.
3. Pencarian Conditional Pattern Base dari FP-Tree yang terbentuk dengan menelusuri semua cabang dari FP-Tree.
4. Pembentukan Conditional FP-Tree, dari Conditional Pattern Base yang sudah di dapatkan dari FP-Tree diolah lebih lanjut untuk mendapatkan Conditional FP-Tree. 5. Setelah mendapatkan Conditional FP-Tree
maka dapat dibentuk menjadi Tree lagi yaitu MFI-Tree.
Proses yang dilakukan algoritma FP-Max adalah mengolah FP-Tree yang merupakan masukan awal, kemudian mencari Conditional Frequent Pattern Base, dari Conditional Frequent Pattern Base kemudian dibentuk Conditional FP-Treenya, dari Conditional FP-Tree kemudian barulah dibetuk Maximal Frequent Itemset Tree (MFI-Tree). MFI-Tree yang terbentuk kemudian dicari Pattern - patternnya, pattern yang terbentuk dari MFI-Tree itulah yang menjadi Maximal Frequent Itemset. FP-Tree mempunyai header table yang berhubungan dengan Treenya. Item dan jumlah itemnya ditampung pada header table yang diurutkan berdasarkan jumlahnya. Header table pada FP-Tree ini dihubungkan dengan semua node yang ada pada FP-Tree. Dibandingkan dengan algoritma Apriori yang membutuhkan proses scan database berulang ulang, algoritma FP-Growth hanya membutuhkan dua kali scan dataset untuk proses mining semua frequent itemset. Proses scan pertama untuk mencari semua frequent item yang ada pada dataset, proses scan yang kedua untuk membentuk struktur FP-Tree.
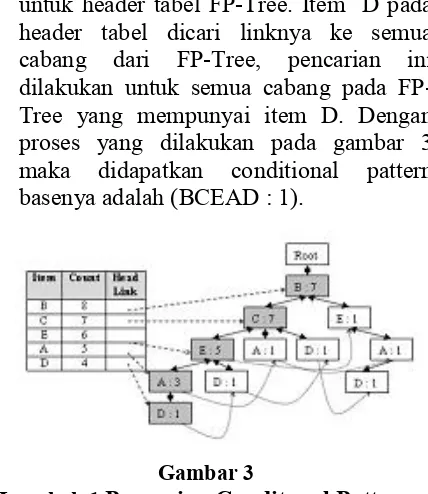
Setelah FP-tree terbentuk maka proses untuk memining dataset dapat diwakilkan dengan hanya memining FP-Treenya saja. FP-Tree yang terbentuk kemudian dicari Conditional Pattern Basenya. Proses pencarian Conditional Pattern Base dari FP-Tree gambar 1 adalah:
1.
Pembentukan Conditional Pattern base
untuk header tabel FP-Tree. Item D pada
header tabel dicari linknya ke semua
cabang dari FP-Tree, pencarian ini
dilakukan untuk semua cabang pada
FP-Tree yang mempunyai item D. Dengan
proses yang dilakukan pada gambar 3
maka didapatkan conditional pattern
basenya adalah (BCEAD : 1).
Gambar 3
Langkah 1
Pencarian Conditonal Pattern
2.
Proses pencarian selanjutnya adalah
mencari cabang dari FP-Tree yang
mempunyai item D yang lain, proses ini
dapat dilakukan dengan melakukan
penelusuran dari cabang FP-Tree yang
pertama. Proses pencarian item D kedua
dari FP-Tree didapatkan conditional
pattern basenya adalah (BCED : 1).
Gambar 4
Langkah 2
Pencarian Conditonal Pattern
3. Proses pencarian selanjutnya adalah mencari cabang dari FP-Tree yang mempunyai item D yang lain, proses ini dapat dilakukan dengan melakukan penelusuran dari cabang FP-Tree yang kedua. proses pencarian item D ketiga dari FP-Tree didapatkan conditional pattern basenya adalah (BCD : 1).
Gambar 5
Langkah 3
Pencarian Conditonal Pattern
4. Proses pencarian item D pada cabang terakhir FP-Tree didapatkan conditional pattern basenya adalah (BEAD : 1).
Gambar 6
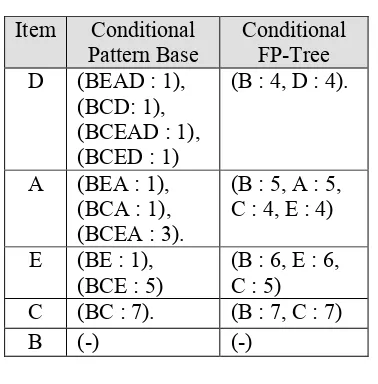
5. Proses selanjutnya adalah mencari conditional pattern base untuk item A, E, C, B, langkah yang dilakukan sama dengan langkah pencarian conditional pattern base untuk item D. Conditional pattern base untuk item A adalah (BEA : 1), (BCA : 1), (BCEA : 3). Conditional pattern base untuk item E adalah (BE : 1), (BCE : 5). Conditional pattern base untuk item C adalah (BC : 7). Conditional pattern base untuk item B adalah (-), item B tidak mempunyai conditional pattern base karena setelah item B adalah Root.
Tabel 2
Conditional Pattern Base
Item Conditional Pattern base D (BEAD : 1), (BCD: 1), (BCEAD : 1),
Conditional FP-Tree dibentuk setelah Conditional Pattern base dari semua item pada header table FP-Tree didapatkan. Conditional FP-FP-Tree dibuat dengan tujuan untuk proses pembentukan MFI-Tree. Langkah langkah untuk mendapatkan Conditional FP-Tree dengan minimum support 4 adalah sebagai berikut :
1. Conditional FP-Tree item D, cek apakah pattern pattern yang ada pada conditional pattern base merupakan subset atau bukan , jika merupakan subset dari pattern yang lain maka di kelompokkan menjadi satu, pada Tabel 5.1 item D mempunyai Conditional Pattern (BEAD : 1), (BCD: 1), (BCED : 1), karena semuanya merupakan subset dari pattern (BCEAD : 1), maka Conditional FP-Treenya akan menjadi (B : 4, D : 4).
2. Conditional FP-Tree item A, cek apakah pattern pattern yang ada pada conditional pattern base merupakan subset atau bukan , jika merupakan subset dari pattern yang lain maka di kelompokkan menjadi satu, pada Tabel 5.1 item A mempunyai Conditional Pattern (BEA : 1), (BCA : 1). Karena semuanya merupakan subset dari pattern (BCEA : 3), conditional FP-Tree yang terbentuk adalah (B : 5, A : 5, C : 4, E : 4).
3. Conditional FP-Tree item E, cek apakah pattern pattern yang ada pada conditional pattern base merupakan subset atau bukan , jika merupakan subset dari pattern yang lain maka di kelompokkan menjadi satu, pada Tabel 5.1 item E mempunyai Conditional Pattern (BE : 1). Karena semuanya merupakan subset dari pattern (BCE : 5), conditional FP-Tree yang terbentuk adalah (B : 6, E : 6, C : 5). 4. Conditional FP-Tree item C karena item C hanya mempunyai sebuah pattern pada Conditional Pattern Basenya dan pattern itu memenuhi minimum support yang ditentukan maka maka Conditional FP-Treenya yang dihasilkan dari Conditional Pattern Basennya adalah (B : 7, C : 7).
Semua Conditional FP-Tree yang terbentuk di simpan ke dalam sebuah List Conditional FP-Tree, dari proses di atas maka didapatkan semua
Pattern Base Conditional FP-Tree D (BEAD : 1),
Setelah semua proses pencarian Conditional FP-Tree selesai dilakukan maka proses selanjutnya adalah proses mining untuk mendapatkan (maximal frequent itemset) MFI dari semua conditional FP-Tree yang terbentuk.
Dengan menggunakan struktur Maximal Frequent itemset maka tidak diperlukan pengecekan lagi pada Conditional FP-Tree apakah pattern tersebut merupakan subset dari pattern yang lainnya, karena dengan struktur tree, pattern yang sama tidak dibentuk node yang baru, hanya pattern yang tidak sama yang dibentuk node baru pada tree.
Maximal Frequent Itemset tree (MFI-Tree) mirip seperti Frequent Pattern Tree (FP-Tree), mempunyai root yang di beri label “ROOT”, dan cabang dari root disebut prefix subtrees. Tiap node pada subtree mempunyai dua buah field yaitu item-name dan node-link. Semua node dengan item yang sama dihubungkan semua. Node link itu menunjuk ke node berikutnya yang mempunyai item sama pada Maximal Frequent Itemset tree (MFI-Tree). Header tabel pada Maximal Frequent Itemset tree (MFI-Tree) sama dengan header tabel pada FP-Tree pada scan pertama dataset. Header tabel pada Maximal Frequent Itemset tree (MFI-Tree) mempunyai dua buah field, yaitu item-name dan head of a node link. Node link menunjuk pada salah satu cabang dari Maximal Frequent Itemset tree (MFI-Tree) yang mempunyai item-name yang sama.
Dengan menggunakan Maximal Frequent Itemset tree (MFI-Tree) maka pattern pattern yang didapatkan dari pembacaan node node yang ada pada Maximal Frequent Itemset tree (MFI-Tree) menghasilkan pattern pattern yang sudah maximal, dan tiap patternnya tidak ada yang merupakan subset dari pattern yang lainnya.
MFI-Tree (Maximal Frequent Itemset Tree) merupakan struktur tree yang dibentuk untuk menampung Maximal Frequent Itemset yang didapat dari frequent pattern tree (FP-Tree), struktur tree yang dipakai sama dengan struktur FP-Tree, MFI-Tree mempunyai header tabel yang dihubungkan dengan node pada tree yang mempunyai item sama dengan yang ada pada header tabel, tiap nodenya yang mempunyai item sama juga dihubungkan.
MFI-Tree dibuat berdasarkan Conditional FP-Tree, dari conditional FP-Tree item itemnya di baca satu persatu kemudian di masukkan ke dalam MFI-Tree. Header tabel yang digunakan sama dengan header tabel pada FP-Tree. Berikut ini akan ditunjukkan langkah langkah pembentukan MFI-Tree dari conditional FP-MFI-Tree. Langkah langkah pembentukan MFI dari conditional FP-Tree adalah sebagai berikut:
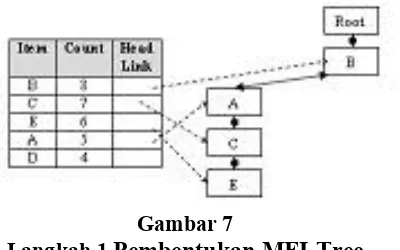
1.
Dari pembacaan pertama conditional
FP-Tree akan didapatkan pattern (BACE),
pattern ini kemudian dimasukkan ke dalan
Tree.
Gambar 7
Langkah 1
Pembentukan MFI-Tree
2.
Dari pembacaan kedua conditional
FP-Tree akan didapatkan pattern (BEC),
pattern ini kemudian dimasukkan ke dalan
Tree.
Gambar 8
Langkah 2
Pembentukan MFI-Tree
3.
Dari pembacaan ketiga conditional
FP-Tree akan didapatkan pattern (BC), pattern
ini kemudian dimasukkan ke dalan Tree.
Gambar 9
Langkah 3
Pembentukan MFI-Tree
Gambar 10
Langkah 4
Pembentukan MFI-Tree
PENUTUP
Semakin tinggi nilai minimum support yang diberikan semakin sedikit waktu yang diperlukan dan semakin sedikit memori yang dipakai. Hal ini disebabkan karena nilai minimum support berguna untuk memotong jumlah transaksi yang di baca, sehingga proses yang dilakukan semakin sedikit jika minimum support tinggi.
Algoritma FP-MAX pada saat melakukan mining pada dataset yang besar waktu dan memori yang dipakai semakin besar, karena struktur tree yang dipakai adalah struktur FP-Tree, dan proses mining dilakukan apabila keseluruhan tree sudah terbentuk, hal inilah yang menyebabkan penggunaan memori yang besar.
DAFTAR PUSTAKA
1. Jiawei Han dan Micheline Kamber, Data Mining, Concepts and Techniques, Morgan Kaufmann Publishers. 340 Pine Street, Sixth Floor, San Fransisco, USA, 2001.
2. R. Agrawal dan R. Srikant, Fast Algorithms for Mining Association Rules, Proceedings of the 20th International Conference on Very Large Databases, Santiago, Chile, 1994.
3. B. Goethals and M. Zaki. Advances in frequent itemset mining implementations: Introduction to fimi03. In Workshop on Frequent Itemset Mining Implementations (FIMI’03) in conjunction with IEEE-ICDM, 2003.