Sebelum melakukan pembahasan mengenai permasalahan dalam skripsi, dalam bab ini akan dijelaskan beberapa teori penunjang yang dapat membantu dalam penulisan skripsi. Teori penunjang tersebut antara lain : Analisis deret waktu (time series), stasioner dan non-stasioner, Pengujian kestasioneran data deret waktu, differencing, Autocorrelation Function/Fungsi Autokorealsi (ACF),
Partial Autocorrelation Function/Fungsi Autokorelasi Parsial (PACF), proses
White Noise, uji normalitas, model Autoregressive Integrated Moving Average
(ARIMA), proses Pemodelan Autoregressive Integrated Moving Average (ARIMA) dan Artificial Neural Network (ANN).
2.2 Analisis Deret Waktu (Time Series)
Time series atau runtun waktu adalah himpunan observasi data terurut
dalam waktu (Hanke&Winchern, 2005). Metode time series adalah metode peramalan dengan menggunakan analisa pola hubungan antara variabel yang akan dipekirakan dengan variabel waktu. Peramalan suatu data time series perlu memperhatikan tipe atau pola data. Secara umum terdapat empat macam pola data
time series, yaitu horizontal, trend, musiman, dan siklis (Hanke dan Wichren,
2005).
Pola horizontal merupakan kejadian yang tidak terduga dan bersifat acak, tetapi kemunculannya dapat mempengaruhi fluktuasi data time series. Pola trend merupakan kecenderungan arah data dalam jangka panjang, dapat berupa
kenaikan maupun penurunan. Pola musiman merupakan fluktuasi dari data yang terjadi secara periodik dalam kurun waktu satu tahun, seperti triwulan, kuartalan, bulanan, mingguan, atau harian. Sedangkan pola siklis merupakan fluktuasi dari data untuk waktu yang lebih dari satu tahun.
Time series adalah catatan dari nilai-nilai yang diamati dari sebuah proses
atau fenomena yang diambil secara berturut-turut dari waktu ke waktu. Nilai-nilai yang diamati tersebut dapat bersifat deterministik (dapat dijelaskan secara eksplisit dengan rumus matematika) ataupun non-deterministik (tidak dapat dinyatakan dengan rumus matematika) atau data acak. Proses-proses yang sifatnya non-deterministik disebut sebagai stokastik dimana nilai-nilai yang diamati, dimodelkan sebagai urutan variabel-variabel acak. secara formal :
Proses stokastik adalah sekumpulan variabel acak dimana T adalah indeks yang ditetapkan untuk semua variabel acak , didefenisikan pada sampel yang sama. Apabila indeks yang ditepakan T menunjukan waktu, maka proses stokastik disebut sebagai time series.
Time series pada umumnya dapat diklasifikasi menjadi dua yaitu stasioner
dan non-stasioner. Secara sederhana, suatu deret pengamatan dikatakan stasioner apabila proses tidak berubah seiring dengan adanya perubahan time series. Jika suatu time series Xtstasioner maka nilai tengah (mean), varian dan kovarian deret
tersebut tidak dipengaruhi oleh berubahnya waktu pengamatan, sehingga proses berada dalam keseimbangan statistik (Soejoeti, 1987). Sebaliknya, untuk time
oleh model-model analitis terhadap ralaman-ramalan yang dihasilkan. Model-model non-stasioner melalui proses defferencing dapat diubah menjadi time series stasioner dengan demikian analisis yang diterapkan sebagai proses stasioner. 2.3 Stasioner dan Non-stasioner
Time series stasioner terkait dengan konsistensi pergerakan data time series. Suatu data time series dikatakan non-stasioner bila nilai rata-rata dan
variansinya bervariasi sepanjang waktu atau dengan kata lain data dikatakan stasioner bila data bergerak stabil dan konvergen sekitar nilai rata-ratanya tanpa mengalami fluktuasi pergerakan trend positif maupun negatif. Kestasioneran data haruslah memenuhi asumsi homoskedastis dan tidak adanya autokorelasi. Properti data stasioner adalah sebagai berikut :
1. Mean : (konstan)
2. Varians :
3. Kovarians : (tidak tergantung t)
4. Distribusi bersama X adalah identik dengan
{X untuk setiap .
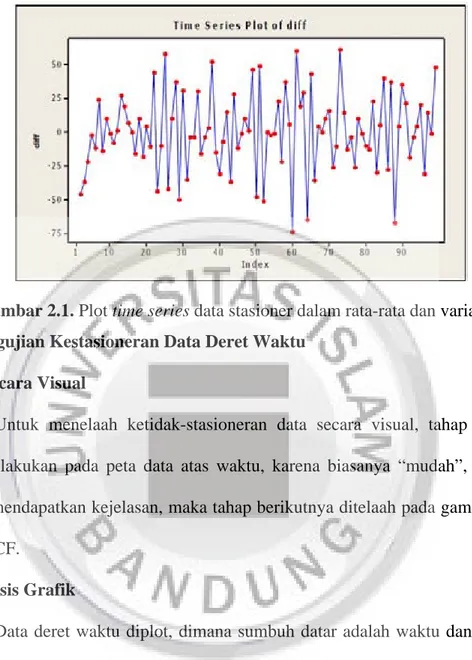
Stasioneritas berarti tidak terjadinya pertumbuhan dan penurunan data. Suatu data dapat dikatakan stasioner apabila pola data tersebut berada pada kesetimbangan disekitar nilai rata yang konstan dan variansi disekitar rata-rata tersebut konstan selama waktu tertentu (Makridakis, 1999). Time series dikatakan stasioner apabila tidak ada unsur trend dalam data dan tidak ada unsur musiman atau rata-rata dan variannya tetap, seperti pada Gambar 2.1.
Gambar 2.1. Plot time series data stasioner dalam rata-rata dan variansi 2.4 Pengujian Kestasioneran Data Deret Waktu
2.4.1 Secara Visual
Untuk menelaah ketidak-stasioneran data secara visual, tahap pertama dapat dilakukan pada peta data atas waktu, karena biasanya “mudah”, dan jika belum mendapatkan kejelasan, maka tahap berikutnya ditelaah pada gambar ACF dan PACF.
1. Analisis Grafik
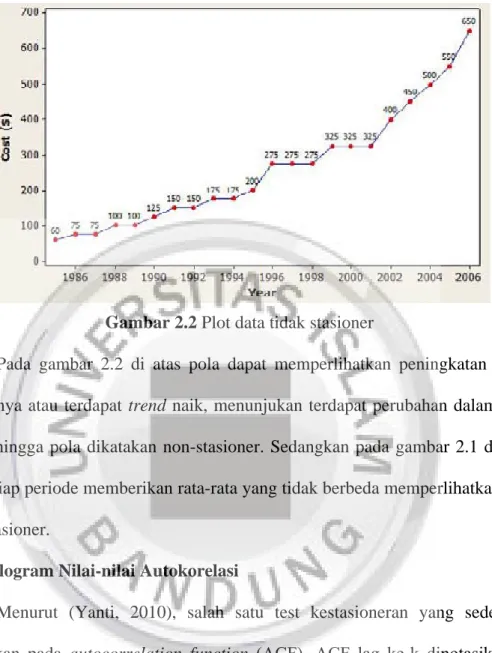
Data deret waktu diplot, dimana sumbuh datar adalah waktu dan sumbuh tegak nilai dari data. Jika plot data untuk setiap periode waktu meningkat dan menurun membentuk suatu trend maka data deret tersebut non-stasioner.
Gambar 2.2 Plot data tidak stasioner
Pada gambar 2.2 di atas pola dapat memperlihatkan peningkatan setiap periodenya atau terdapat trend naik, menunjukan terdapat perubahan dalam rata-rata, sehingga pola dikatakan non-stasioner. Sedangkan pada gambar 2.1 di atas, pola setiap periode memberikan rata-rata yang tidak berbeda memperlihatkan pola yang stasioner.
2. Korelogram Nilai-nilai Autokorelasi
Menurut (Yanti, 2010), salah satu test kestasioneran yang sederhana didasarkan pada autocorrelation function (ACF). ACF lag ke-k dinotasikan ρk, yaitu :
...(2.1) dimana
...(2.2) nilai ditaksir oleh rk
Telaahan pada gambar ACF adalah :
a. Jika data stasioner maka gambarnya akan membangun pola yaitu nilai-nilai autokorelasi pada correlogram akan turun sampai nol mulai time-lag kedua atau ketiga.
b. Jika data tidak stasioner maka gambar dari ACF akan membangun pola, Menurun secara perlahan, jika data tidak stasioner dalam rata-rata
hitung (trend naik atau turun). Data yang tidak stasioner maka nilai-nilai autokorelasi tersebut berbeda signifikan dari nol.
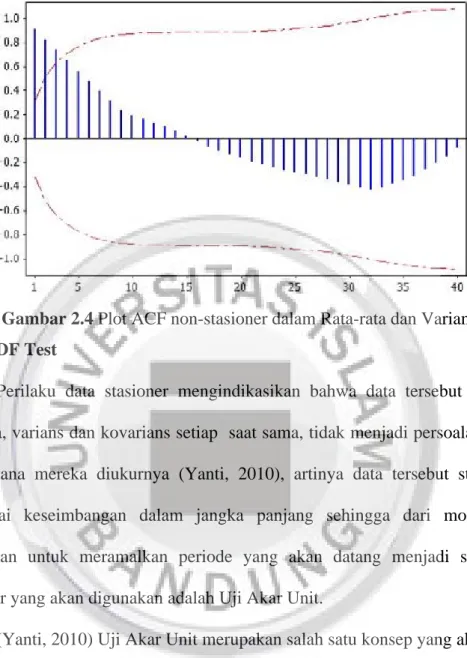
Gambar 2.3 Plot ACF non-stasioner dalam rata-rata Alternating, jika data tidak stasioner dalam varians
Gelombang, jika data tidak stasioner dalam rata-rata dan varians. Terlihat pada gambar
Gambar 2.4 Plot ACF non-stasioner dalam Rata-rata dan Varians 2.4.2 ADF Test
Perilaku data stasioner mengindikasikan bahwa data tersebut memiliki rata-rata, varians dan kovarians setiap saat sama, tidak menjadi persoalan di titik yang mana mereka diukurnya (Yanti, 2010), artinya data tersebut stabil atau mencapai keseimbangan dalam jangka panjang sehingga dari model yang digunakan untuk meramalkan periode yang akan datang menjadi sahih. Uji stasioner yang akan digunakan adalah Uji Akar Unit.
(Yanti, 2010) Uji Akar Unit merupakan salah satu konsep yang akhir-akhir ini makin populer dipakai untuk menguji kestasioneran data time series. Uji ini dikembangkan oleh Dickey dan Fuller, dengan menggunakan Augmented Dickey
Fuller Test (ADF). Terdapat tiga kemungkinan dimana ADF test ditaksir dari tiga
Data level
: tanpa Intersep ...(2.3) : Intersep ...(2.4) : Intersep dan trend ...(2.5) Langkah-langkah pengujiannya adalah sebagai berikut :
1) Menguji variabel dengan ADF test
Hipotesis yang digunakan adalah :
H0 : δ = 0 (non stasioner), melawan H1 : δ < 0 (stasioner) Statistik uji yang digunakan adalah
Tolak H0 jika τ hasil perhitungan lebih besar dari τ tabel atau jika probabilitas hasil perhitungan lebih kecil dari derajat kepercayaan yang kita inginkan. Perhitungan prosedur di atas menggunakan perangkat software Eviews
2) Bila variabel yang kita uji ternyata tidak stasioner maka data dilakukan
differencing atau pembedaan, kemudian dilakukan pengujian terhadap data
tersebut seperti langkah 1).
2.5 Metode Pembedaan (Differencing)
Differencing (pembedaan) dilakukan untuk menstasionerkan data
non-stasioner. Operator shift mundur (backward shift) sangat tepat untuk menggambarkan proses differencing (Makridakis, 1999). Notasi yang sangat
...(2.6) Dengan : nilai variabel X pada waktu t
: nilai variabel X pada waktu t-1 B : backward shift
Pada persamaan (2.6) diatas, notasi B yang dipasang pada memiliki efek menggeser data satu periode ke belakang. Sedangkan dua aplikasi dari B terhadap akan menggeser data tersebut dua periode ke belakang, sebagai berikut :
...(2.7) Apabila suatu time series non-stasioner, maka data tersebut dapat dibuat lebih mendekati stasioner dengan melakukan pembedaan pertama. Operator ini memedahkan proses diferensiasi. Deffersiasi pertama/turunan tingkat satu dapat dituliskan sebagai berikut :
= ...(2.8)
Menggunakan operator shift mundur, persamaan (2.8) dapat ditulis kembali menjadi (Makridakis, 1995) :
= ...(2.9)
Pembedaan pertama dinyatakan oleh (1-B) sama halnya apabila perbedaan orde kedua (yaitu perbedaan pertama dari perbedaan pertama sebelumnya) harus dihitung, maka pembedaan orde kedua :
... (2.10) Pembedaan orde kedua diberi notasi (1-B)2. Pembedaan orde kedua tidak
sama dengan pembedaan kedua yang diberi notasi 1-B2. Sedangkan pembedaan
pertama (1-B) sama dengan pembedaan orde pertama (1-B). Pembedaan kedua
Tujuan dari menghitung pembedaan adalah mencapai stasioneritas dan secara umum apabila terdapat pembedaan orde ke-d untuk mencapai stasioneritas, ditulias sebagai berikut :
Pembedaan orde ke-d
...(2.11) 2.6 Autocorrelation Function/Fungsi Autokorealsi (ACF)
Pada proses stasioner suatu data time series diperoleh dan
variansi , yang konstan dan kovariansi
, fungsinya hanya pada pembedaan waktu . Oleh karena itu, hasil tersebut dapat ditulis sebagai kovariansi antara dan sebagai berikut (Wei, 1989) :
...(2.12) ...(2.13) Autokorelasi merupakan korelasi atau hubungan antar data pengamatan suatu data time series. Menurut Wei (2006), koefisien autokorelasi untuk lag–k dari data runtun waktu dinyatakan sebagai berikut:
...(2.14)
Dengan :
= rata-rata
= autokovariansi pada lag-k = autokorelasi pada lag-k
t = waktu pengamatan, t = 1,2,3,...
Dimana notasi . Sebagai fungsi k, maka
disebut fungsi autokorelasi dan menggambarkan kovariansi (ACF), dalam analisis time series, dan menggambarkan kovarian dan korelasi antara dan dari proses yang sama, hanya dipisahkan oleh lag ke-k.
Dengan menggunakan asumsi-asumsi diatas, maka taksiran parameter diatas dapat disederhanakan menjadi :
...(2.15)
Dengan :
= koefisien autokorelasi pada lag-k
k = selisih waktu
n = jumlah observasi
= rata-rata dari pengamatan = pengamatan pada waktu ke-t
Untuk mengetahui apakah koefisien autokorelasi signifikan atau tidak, perlu dilakukan uji. Pengujian dapat dilakukan hipotesis :
H0: = 0 (koefisien autokorelasi tidak signifikan) H1: ≠ 0 (koefisien autokorelasi signifikan) Statistik uji yang digunakan adalah :
dengan .
Kriteria uji keputusan H0ditolak jika .
2.7 Partial Autocorrelation Function/Fungsi Autokorelasi Parsial (PACF) Autokorelasi parsial merupakan korelasi antara dan dengan mengabaikan ketidakbebasan . Autokorelasi parsial digunakan untuk mengukur derajat asosiasi antara dan , ketika efek dari rentang/jangka waktu (time lag) 1,2,3,...,k-1 dianggap terpisah. Ada beberapa prosedur untuk menentukan bentuk PACF yang salah satunya akan dijelaskan sebagai berikut. Menurut (Wei, 1989) fungsi autokorelasi parsial dapat dinotasikan dengan :
... (2.16) Misalkan adalah proses yang stasioner dengan , selanjutnya dapat dinyatakan sebagai proses linier :
...(2.17) Dengan adalah parameter regresi ke-i dan adalah nilai kesalahan yang tidak berkorelasi dengan untuk j=1,2,...,k. Dengan mengalikan
pada kedua ruas persaman (2.18) dan menghitung nilai nol harapannya (expected value), diperoleh :
...(2.18) dan
untuk j=1,2,...k, diperoleh sistem persamaan berikut :
Karena merupakan fungsi atas k, maka disebut fungsi autokorelasi parsial. Hipotesis untuk menguji koefisien autokorelasi parsial sebagai berikut :
H0: = 0
H1: 0
Statistik uji yang digunakan : dengan . Kriteria
uji : tolak H0 jika , dengan derajat bebas df=n-1, n adalah
banyaknya data (Wei, 2006). 2.8 Proses White Noise
Suatu proses {εt} disebut white noise jika merupakan barisan variabel acak
yang tidak berkorelasi dengan rata-rata E(εt) = 0, varians konstan Var(εt) =
Oleh karena itu, suatu proses white noise {εt} adalah stasioner dengan fungsi
autokovariansi (Wei, 2006).
Sedangkan, proses white noise dengan fungsi autokorelasi parsial sebagai berikut :
Langkah-langka pengujian white noise :
0 (residu memenuhi proses white noise) (residu tidak memenuhi proses white noise) Statistik uji yang digunakan yaitu uji Ljung Box-pierce. Rumus uji Ljung-Box atau Box-pierce (Wei,2006) :
...(2.19) dengan
n = banyaknya observasi dalam runtun waktu k = banyaknya lag yang diuji
= nilai koefisien autokorelasi pada lag-k
Kriteria uji : H0 ditolak jika Q > tabel dengan derajat bebas (db) = k - p atau
p-value < dengan p adalah banyaknya parameter.
Selain itu, autokorelasi residual dapat dilihat dari plot ACF residual. Apabila tidak ada lag yang keluar dari garis signifikansi, maka dapat dikatakan bahwa tidak ada autokorelasi.
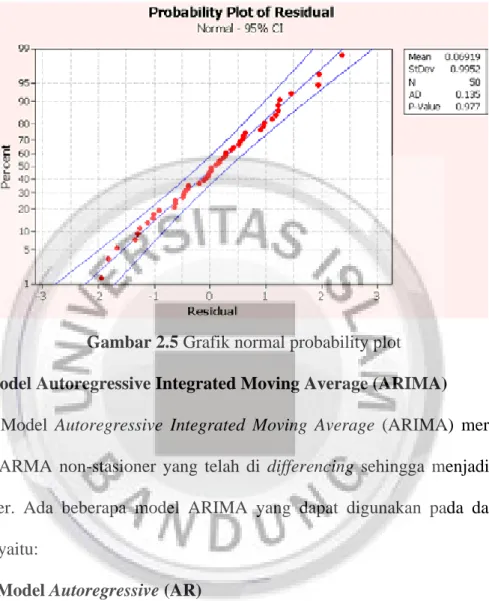
2.9 Uji Normalitas Residu
Uji normalitas residu dilakukan untuk mengetahui apakah galat berdistribusi normal atau tidak. Pengujian dapat dilakukan dengan analisis grafik normal probability plot. Jika residu berada di sekitar garis diagonal maka galat
berdistribusi normal. Sebaliknya, jika residu tidak berdistribusi normal, maka residu akan menyebar seperti pada gambar berikut ini.
Gambar 2.5 Grafik normal probability plot 2.10 Model Autoregressive Integrated Moving Average (ARIMA)
Model Autoregressive Integrated Moving Average (ARIMA) merupakan model ARMA non-stasioner yang telah di differencing sehingga menjadi model stasioner. Ada beberapa model ARIMA yang dapat digunakan pada data time
series, yaitu:
2.10.1 Model Autoregressive (AR)
Autoregressive adalah suatu bentuk regresi tetapi bukan yang
menghubungkan variabel tak bebas, melainkan menghubungkan nilai-nilai sebelumnya pada time lag (selang waktu) yang bermacam-macam. Jadi suatu model Autoregressive akan menyatakan suatu ramalan sebagai fungsi nilai-nilai sebelumnya dari time series tertentu (Makridakis, 1995).
Model Autogressive (AR) dengan order p dinotasikan dengan AR (p). Bentuk umum model AR(p) adalah:
...(2.20) Dengan :
= nilai variabel pada waktu ke-t = nilai masa lalu dari time series yang
bersangkutan pada waktu t. = koefisien regresi
= nilai error pada waktu ke-t
p = orde AR
Persamaan (2.21) dapat ditulis dengan menggunakan operator B (back
shift) :
...(2.21) dengan mengalikan kedua ruas pada persamaan (2.16) dengan dan berdasarkan rumus (2.13) maka diperoleh :
...(2.22) karena, = dan = , maka k=0 diperoleh dari :
...(2.23)
yang merupakan variansi dari autoregressive.
Proses AR (p) terjadi jika terdapat parameter yang bernilai tidak nol berbeda secara signifikan dengan nol, sedangkan (tidak berbeda secara nyata dengan nol) untuk k > p.
Orde AR yang sering digunakan dalam analisis time series adalah p=1 atau p=2, yaitu model AR(1) dan AR(2).
a. Model AR(1)
Bentuk umum model AR(1) adalah :
...(2.24) Karena independen dengan , maka variansinya adalah :
Atau ( dan supaya berhingga dan tidak negatif, maka haruslah . Ketidaksamaan inilah yang merupakan syarat agar runtun waktunya stasioner.
Dengan mengambil nilai harapan dari persamaan umum AR(1) diatas maka diperoleh :
...(2.25) Fungsi autokorelasinya adalah yang menjamin bahwa dan independen. Persamaan tersebut merupakan persamaan differensi derajat satu yang mempunyai penyelesaian dan untuk maka
Fungsi autokorelasi parsial dari AR(1) adalah untuk k=1 dan untuk k > 1, maka Persamaan (2.23) dapat ditulis dengan operator
back shift (B), menjadi :
b. Model AR(2)
Bentuk umum model Autoregressive orde 2 atau AR(2), yaitu :
...(2.27) Dengan mengambil ekspektasi dari persamaan (2.28), maka diperoleh :
Untuk stasioneritas dapat disimpulkan bahwa . Dengan mengalikan persamaan (2.28) dengan dan mengambil ekspektasinya diperoleh untuk k =
0.
atau , dan untuk , maka
atau yang merupakan persamaan
differensi derajat dua yang dapat diselesaikan. Tetapi dalam praktiknya akan lebih
mudah jika dimulai dengan :
...(2.28)
...(2.29) Dengan menstabilkan persamaan (2.30) pada persamaan variansinya, maka diperoleh :
persamaan (2.30) dapat ditulis dengan operator back shift (B), menjadi :
...(2.30) 2.10.2 Model Moving Average (MA)
Moving Average (MA) merupakan nilai time series pada waktu t yang
dipengaruhi oleh unsur kesalahan pada saat ini dan unsur kesalahan terbobot pada masa lalu (Makridakis, 1999).
Model Moving Average (MA) order q, dinotasikan menjadi MA(q). Secara umum, model MA(q) adalah:
...(2.31) Dengan :
= nilai variabel pada waktu ke-t
= nilai-nilai pada error pada waktu t, t-1,t-2,...,t-q dan diasumsikan white noise dan normal. = koefisien regresi, i=1,2,3,...,q
= nilai error pada waktu ke-t
q = orde MA
Persamaan (2.32) dapat ditulis menggunakan operator back shift (B), menjadi :
dengan merupakan operator
Oleh karena itu, variansi dari proses ini adalah : . dan
...(2.32)
Jadi fungsi autokorelasinya dari proses MA(q) adalah :
...(2.33)
Karena , proses moving average berhingga
selalu stasioner. Proses moving average invertible jika akar-akar dari berada diluar lingkaran satuan.
Secara umum, orde MA yang sering digunakan dalam analisis time series adalah q=1 atau q=2. yaitu MA(1) dan MA(2).
Sehingga model Moving Average MA(1) adalah :
...(2.34) Persamaan (2.35) dapat ditulis dengan operator B (back shift), menjadi :
Rata-rata ( adalah dan untuk semua k.
Sedangkan model Moving Average orde 2, MA(2) adalah :
...(2.35) Persamaan (2.36) dapat ditulis dengan operator B (back shift), menjadi :
Sebagai model moving average orde berhingga, proses MA(2) selalu stasioner. 2.10.3 Model Campuran AR(p) dan MA(q) / ARMA(p,q)
Unsur dasar dari model AR dan MA dapat dikombinasikan untuk menghasilkan berbagai macam model yang merupakan gabungan kedua model
Autoregressive (AR) dan Moving Average (MA). Bentuk umum dari
Autoregressive (AR) dengan Moving Average (MA) yang dinotasikan ARMA
(p,q) adalah sebagai berikut:
...(2.36) Dengan :
= nilai variabel pada wakyu ke-t
= koefisien autoregressive ke-i, i=1,2,3,...,p p = orde AR
q = orde MA
= parameter model MA ke-i, i= 1,2,3,...,q = nilai galat pada waktu ke-t
Model ini dapat ditulis dalam bentuk : untuk stasioneritas memerlukan akar-akar terletak diluar lingkaran satuan
lingkaran. Dengan mengambil ekspektasi persamaan diatas, diperoleh karena
2.10.4 Model Autoregressive Integrated Moving Average (ARIMA)
Hasil modifikasi model ARMA (p,q) dengan memasukkan operator
differencing menghasilkan persamaan model ARIMA, adanya unsur differencing
karena merupakan syarat untuk menstasionerkan data, dalam notasi operator shift mundur, differencing dapat ditulis , dimana merupakan data hasil differencing sebanyak d kali dan operator differencing. Yang dinotasikan dengan model ARIMA (p,d,q) :
Dimana : Dengan p = orde dari AR q = orde dari MA = koefisien orde p = koefisien orde q B = backward shift
= orde differencing non musiman
= besarnya pengamatan (kejadian) pada waktu ke-t
= suatu proses white noise atau galat pada waktu ke-t yang diasumsikan mempunyai mean 0 dan variansi konstan 2.11 Proses Pemodelan Autoregressive Integrated Moving Average (ARIMA)
Metode ARIMA berbeda dengan metode peramalan lain karena metode ini tidak menyaratkan suatu pola data tertentu, sehingga model dapat dipakai untuk semua tipe pola data. Metode ARIMA akan bekerja dengan baik jika data dalam
time series yang digunakan bersifat dependen atau berhubungan satu sama lain
secara statistik. Secara umum model ARIMA ditulis dengan ARIMA (p,d,q) yang artinya model ARIMA dengan derajat AR(p), derejat pembeda d, dan derajat MA(q). Langkah-langkah pembentukan model secara iteratif adalah sebagai berikut :
1. Identifikasi Model
Langkah pertama dalam pembentukan model Autoregressive Integrated
Moving Average (ARIMA) adalah pembentukan plot data time series. Pembuatan
plot data time series bertujuan untuk mendeteksi stasioneritas data time series. Data dikatakan stasioner jika pola data tersebut berada disekitar nilai rata-rata dan variansi yang konstan selama waktu tertentu. Selain itu, stasioneritas dapat dilihat dari plot Autocorrelation Function (ACF) data tersebut (Gambar 2.2). Kestasioneran suatu time series dapat dilihat dari plot ACF yaitu koefisien autokorelasinya menurun menuju nol dengan cepat, biasanya setelah lag ke-2 atau
differencing, orde pembedaan sampai deret menjadi stasioner dapat digunakan untuk menentukan nilai d pada ARIMA (p,d,q)
2. Menentukan Orde Autoregressive (AR) dan Moving Average (MA)
Model AR dan MA dari suatu time series dapat dilakukan dengan melihat grafik ACF dan PACF.
a. Jika terdapat lag autokorelasi sebanyak q yang berbeda dari nol secara signifikan maka prosesnya adalah MA (q).
b. Jika terdapat lag autokorelasi parsial sebanyak p yang berbeda dari nol secara signifikan maka prosesnya adalah AR (p). Secara umum jika terdapat
lag autokorelasi sebanyak q yang berbeda dari nol secara signifikan dan d
pembedaan maka prosesnya adala ARIMA (p,d,q)
c. Jika terdapat lag PACF sebanyak p, lag ACF sebanyak q yang berbeda dari nol secara signifikan maka prosesnya adalah ARMA (p,q), dan d sebagai pembedaan maka prosesnya adalah ARIMA (p,d,q)
3. Estimasi Parameter
Ada dua cara yang mendasar untuk mendapatkan parameter-parameter tersebut :
a. Dengan cara mencoba-coba (trial and error), menguji beberapa nilai yang berbeda dan memilih satu nilai tersebut (atau sekumpulan nilai, apabila terdapat lebih dari satu parameter yang akan ditaksir) yang meminimumkan jumlah kuadrat nilai sisa (sum of squared residual).
b. Perbaikan secara iteratif, memilih taksiran awal dan kemudian membiarkan program komputer memperhalus penaksiran tersebut secara iteratif.
Metode yang digunakan untuk mengestimasi parameter autoregressive yaitu metode kuadrat terkecil (least squared method). Model AR (p) dinyatakan dalam bentuk:
...(2.37) Dari n observasi parameter dapat diestimasi dengan meminimumkan jumlah kuadrat residual Sum Squared Error (SSE)
...(2.38) Sebagai contoh, diketahui model AR(1)
...(2.39) Sehingga di peroleh galat
untuk mengestimasi parameter dengan meminimumkan jumlah kuadrat residual
...(2.40)
4. Pemeriksaan Diagnostik
Setelah berhasil mengestimasi nilai-nilai parameter dari model ARIMA yang ditetapkan sementara, selanjutnya perlu dilakukan pemeriksaan diagnostik untuk membuktikan bahwa model tersebut cukup memadai dan menentukan model mana yang terbaik digunakan untuk peramalan (Makridakis, 1999).
Pemeriksaan diagnostik ini dapat dilakukan dengan mengamati apakah residual dari model terestimasi merupakan proses white noise atau tidak. Model dikatakan baik jika nilai error bersifat random, artinya sudah tidak mempunyai pola tertentu lagi. Dengan kata lain model yang diperoleh dapat menangkap dengan baik pola data yang ada. Statistika uji Q Box- Pierce dapat digunakan untuk menguji kelayakan model, yaitu dengan menguji apakah sekumpulan korelasi diri untuk nilai sisa tersebut tidak nol. Statistik uji Q Box-Pierce menyebar mengikuti sebaran dengan derajat bebas (m – p - q), dimana m adalah maksimum yang diamati, p adalah ordo AR, dan q adalah ordo MA. Jika nilai Q lebih besar dari nilai untuk tingkat kepercayaan tertentu atau nilai peluang statistik Q lebih kecil dari taraf nyata , maka dapat disimpulkan bahwa model tidak layak. persamaan statistik uji Box dan Pierce menurut (Makridakis, 1995) adalah :
...(2.42) Dengan :
= nilai korelasi diri pada lag ke-k n = banyaknya amatan pada data awal d = ordo pembedaan
m = lag maksimal 5. Kriteria Pemilihan Model Terbaik
Salah satu kriteria pemilihan model yang dapat digunakan untuk model terbaik adalah berdasarkan kesalahan peramalan, semakin kecil nilai MSE maka semakin baik model itu untuk dipilih yaitu :
...(2.43) Dengan :
n = Jumlah sampel
= Nilai aktual harga open emas = Nilai Prediksi harga open emas
Pada pemilihan metode terbaik (metode yang paling sesuai) yang digunakan untuk meramalkan suatu data dapat dipertimbangkan dengan meminimumkan kesalahan (error) yang mempunyai ukuran kesalahan model terkecil.
6. Peramalan dengan Model ARIMA
Notasi yang digunakan dalam ARIMA adalah notasi yang mudah dan umum. Misalkan model ARIMA (0,1,1)(0,1,1)12dijabarkan sebagai berikut :
...(2.44) Tetapi untuk menggunakannya dalam peramalan mengharuskan dilakukan sesuatu penjabaran dari persamaan tersebut dan menjadikannya sebuah persamaan regresi yang lebih umum. untuk model diatas bentuknya adalah :
Untuk meramalkan satu periode ke depan, yaitu maka seperti pada persamaan berikut :
...(2.46) Nilai tidak akan diketahui, karena nilai yang diharapkan untuk kesalahan random pada masa yang akan datang harus ditetapkan sama dengan nol. Akan tetapi dari model yang disesuaikan (fitted model) kita boleh mengganti nilai dengan nilai-nilai yang ditetapkan secara empiris (seperti yang diperoleh setelah iterasi terakhir algoritma Marquardt). Tentu saja bila kita meramalkan jauh ke depan, tidak akan kita peroleh nilai empiris untuk “ ” sesudah beberapa waktu, dan oleh sebab itu nilai harapan mereka akan seluruhnya nol.
Untuk nilai X, pada awal proses peramalan, kita akan mengetahui nilai . Akan tetapi sesudah beberapa saat, nilai X akan berupa nilai ramalan (forecasted value), bukan nilai-nilai masa lalu yang telah diketahui. 2.12 Artificial Neural Network (ANN)
Artificial neural network atau juga disebut dengan jaringan syaraf tiruan (JST) adalah sistem pemroses informasi yang memiliki karakteristik mirip dengan jaringan syaraf biologi. Neural network telah diaplikasikan dalam berbagai bidang diantaranya pattern recognition, medical diagnostic, signal processing, dan peramalan. Meskipun banyak aplikasi menjanjikan yang dapat dilakukan oleh
neural network, namun neural network juga memiliki beberapa keterbatasan
umum, yaitu ketidak akuratan hasil yang diperoleh. Neural network bekerja berdasarkan pola yang terbentuk pada inputnya.
Neural network terdiri atas elemen-elemen untuk pemrosesan informasi
yang disebut dengan neuron, unit, sel atau node (Fausset , 1994). Setiap neuron dihubungkan dengan neuron lainnya dengan suatu connection link, yang direpresentasikan dengan weight/bobot. Metode untuk menentukan nilai weight disebut dengan training, learning atau algoritma. Setiap neuron menggunakan fungsi aktivasi pada net input untuk menentukan prediksi output.
Neuron-neuron dalam neural network disusun dalam grup, yang disebut
dengan layer (lapis) . Susunan neuron-neuron dalam lapis dan pola koneksi di dalam dan antar lapis disebut dengan arsitektur jaringan. Arsitektur ini merupakan salah satu karakteristik penting yang membedakan neural network. Secara umum ada tiga lapis yang membentuk neural network :
1. Lapis input
Unit-unit di lapisan input disebut unit-unit input. Unit-unit input tersebut menerima pola inputan dari luar yang menggambarkan suatu permasalahan. banyak node atau neuron dalam lapis input tergantung pada banyaknya input dalam model dan setiap input menentukan satu neuron. 2. Lapis tersembunyi (hidden layer)
Unit-unit dalam lapisan tersembunyi disebut unit-unit tersembunyi, dimana outputnya tidak dapat diamati secara langsung. Lapis tersembunyi terletak di antara lapis input dan lapis output, yang dapat terdiri atas beberapa lapis tersembunyi.
3. Lapis output
Unit-unit dalam lapisan output disebut unit-unit output. Output dari lapisan ini merupakan solusi neural network terhadap suatu permasalahan. Setelah melalui proses training, network merespon input baru untuk menghasilkan
output yang merupakan hasil peramalan.
2.12.1 Arsitektur Neural Network
Pengaturan neuron ke dalam lapisan, pola hubungan dalam lapisan, dan diantara lapisan disebut arsitektur neural network (Fausset, 1994). Arsitektur jaringan neural network diilustrasikan dalam Gambar 2.6 yang terdiri dari unit
input, unit output, dan satu unit tersembunyi. Neural network sering
diklasifikasikan sebagai single layer dan multilayer
Gambar 2.6 Arsitektur jaringan neural network sederhana a. Single layer
Sebuah jaringan single layer memiliki satu lapisan bobot koneksi (Fausset, 1994). Ciri khas dari single layer terlihat dalam Gambar 2.6, dimana unit input yang menerima sinyal dari dunia luar terhubung ke unit output tetapi tidak
terhubung ke unit input lain, dan unit-unit output yang terhubung ke unit output lainnya.
Gambar 2.7 Arsitektur jaringan neural network single layer b. Multilayer
Jaringan multilayer adalah jaringan dengan satu atau lebih lapisan tersembunyi antara unit input dan unit output (Fausset, 1994). Biasanya, ada lapisan bobot antara dua tingkat yang berdekatan unit (input, tersembunyi, atau
output). Jaringan multilayer yang di illustrasikan pada Gambar 2.8 memecahkan
masalah yang lebih rumit dari pada jaring single layer, dan juga pelatihannya mungkin lebih sulit.
2.12.2 Metode Pelatihan
Selain arsitektur, metode pengaturan nilai bobot (training) merupakan karakteristik yang penting dalam jaringan neural network (Fausset, 1994). Metode pelatihan pada neural network dibagi menjadi dua jenis, yaitu :
a. Pelatihan Terawasi
Pelatihan ini dilakukan dengan adanya urutan vektor pelatihan, atau pola yang masing-masing terkait dengan vektor target output. Bobot kemudian disesuaikan untuk algoritma pembelajaran. Proses ini dikenal sebagai pelatihan terawasi.
b. Pelatihan tak Terawasi
Pada pelatihan ini jaring saraf mengatur segala kinerja dirinya sendiri, mulai dari masukan vektor hingga menggunakan data training untuk melakukan pembelajaran.
2.12.3 Fungsi Aktivasi
Fungsi aktivasi yang akan menentukan apakah sinyal dari input neuron akan diteruskan atau tidak. Ada beberapa fungsi aktivasi yang sering digunakan dalam neural network, antara lain:
a. Fungsi undak biner (Threshold)
Fungsi undak biner dengan menggunakan nilai ambang sering juga disebut dengan fungsi nilai ambang (Threshold) atau fungsi Heaviside.
Gambar 2.9 fungsi aktivasi undak biner (threshold) Fungsi undak biner (dengna nilai ambar θ) dirumuskan sebagai :
b. Fungsi Linear (Identitas)
Fungsi linear memiliki nilai output yang sama dengan nilai inputnya. Fungsi ini dirumuskan sebagai :
=
c. Fungsi Sigmoid Biner
Fungsi ini digunakan untuk jaringan syaraf yang dilatih dengan menggunakan metode backpropagation. Fungsi sigmoid biner memiliki nilai pada
range 0 sampai 1. Oleh karena itu, fungsi ini sering digunakan untuk jaringan
syaraf yang membutuhkan nilai output yang terletak pada interval 0 sampai 1. Namun, fungsi ini bisa juga digunakan oleh jaringan syaraf yang nilai outputnya 0 atau 1. Fungsi sigmoid biner dirumuskan sebagai :
...(2.47) dengan :
...(2.48) d. Fungsi Sigmoid Bipolar
Fungsi sigmoid bipolar hampir sama dengan fungsi sigmoid biner, hanya saja output dari fungsi ini memiliki range antara 1 sampai -1. Fungsi sigmoid
bipolar dirumuskan sebagai :
...(2.49) dengan :
...(2.50) Fungsi ini sangat dekat dengan fungsi hyperbolic tangent. Keduanya memiliki range antara -1 sampai 1. Untuk fungsi hyperbolic tangent, dirumuskan sebagai :
...(2.51) atau :
...(2.52) dengan :
...(2.53) 2.12.4 Model Feedforward Neural Network dengan Algoritma backpropagation
Secara umum, proses bekerjanya jaringan neural network menyerupai cara otak manusia memproses data input sensorik, diterima sebagai neuron input. Selanjutnya neuron saling berhubungan dengan sinapsis (node), dan sinyal dari
neuron bekerja secara paralel digabungkan untuk menghasilkan informasi maupun
reaksi. Feedforward Neural Network (FFNN) merupakan salah satu model neural
network yang banyak dipakai dalam berbagai bidang. Arsitektur model FFNN
terdiri atas satu lapis input, satu atau lebih lapis tersembunyi, dan satu lapis
output. Dalam model ini, perhitungan respon atau output dilakukan dengan
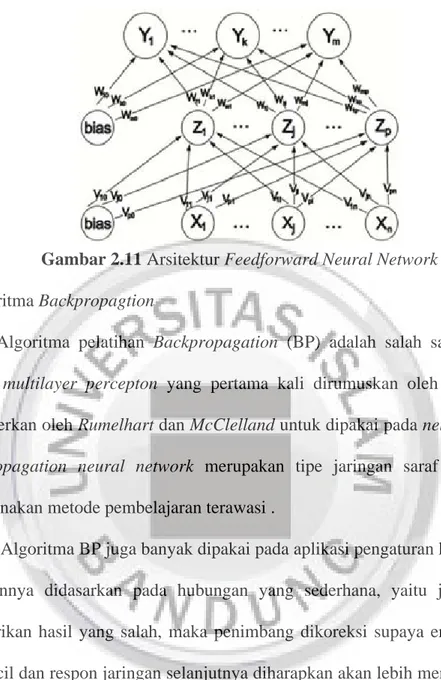
memproses input x mengalir dari satu lapis maju ke lapis berikutnya secara berurutan. Single layer feedforward dengan satu neuron pada lapisan tersembunyi adalah jaringan saraf yang paling dasar dan umum digunakan dalam ekonomi dan aplikasi keuangan. Kompleksitas dari arsitektur FFNN tergantung pada jumlah lapis tersembunyi dan jumlah neuron pada masing-masing lapis. Gambar 2.11 adalah arsitektur feedforward neural network dengan n buah masukan (ditambah sebuah bias), sebuah lapisan tersembunyi yang terdiri dari p unit (ditambah sebuah bias), serta m buah unit keluaran.
Gambar 2.11 Arsitektur Feedforward Neural Network 1. Algoritma Backpropagtion
Algoritma pelatihan Backpropagation (BP) adalah salah satu algoritma dengan multilayer percepton yang pertama kali dirumuskan oleh Werbos dan dipopulerkan oleh Rumelhart dan McClelland untuk dipakai pada neural network.
Backpropagation neural network merupakan tipe jaringan saraf tiruan yang
menggunakan metode pembelajaran terawasi .
Algoritma BP juga banyak dipakai pada aplikasi pengaturan karena proses pelatihannya didasarkan pada hubungan yang sederhana, yaitu jika keluaran memberikan hasil yang salah, maka penimbang dikoreksi supaya errornya dapat diperkecil dan respon jaringan selanjutnya diharapkan akan lebih mendekati harga yang benar. BP juga berkemampuan untuk memperbaiki penimbang pada lapisan tersembunyi (hidden layer).
Algoritma Backpropagation disebut sebagai propagasi balik karena ketika jaringan diberikan pola masukan sebagai pola pelatihan maka pola tersebut menuju ke unit-unit pada lapisan tersembunyi untuk diteruskan ke unit-unit. lapisan keluaran. Selanjutnya, unit-unit lapisan keluaran memberikan tanggapan
yang disebut sebagai keluaran jaringan. Saat keluaran jaringan tidak sama dengan keluaran yang diharapkan maka keluaran akan menyebar mundur (backward) pada lapisan tersembunyi diteruskan ke unit pada lapisan masukan. Oleh karenanya mekanisme pelatihan tersebut dinamakan backpropagation.
Tahap pelatihan ini merupakan langkah bagaimana suatu jaringan saraf itu berlatih, yaitu dengan cara melakukan perubahan penimbang (sambungan antar lapisan yang membentuk jaringan melalui masing-masing unitnya). Sedangkan pemecahan masalah baru akan dilakukan jika proses pelatihan tersebut selesai, fase tersebut adalah fase mapping atau proses pengujian/testing. Algoritma Pelatihan Backpropagation terdiri dari dua proses, feedforward dan
backpropagation dari errornya. Algoritmanya sebagai berikut (Fausset, 1994):
Terdapat tiga fase dalam pelatihan backpropagation yaitu : 1. Fase 1, yaitu Feedforward atau propagasi maju
Dalam propagasi maju, setiap sinyal masukan dipropagasi (dihitung maju) ke layar tersembunyi hingga layar keluaran dengan menggunakan fungsi aktivasi yang ditentukan.
2. Fase 2, yaitu backpropagation atau propagasi mundur
Kesalahan (selisih antara keluaran jaringan dengan target yang diinginkan) yang terjadi dipropagasi mundur mulai dari garis yang berhubungan langsung dengan unit-unit di layar keluaran.
3. Fase 3, yaitu perubahan bobot
Pada fase ini dilakukan modifikasi bobot untuk menurunkan kesalahan yang terjadi. Ketiga fase tersebut diulang-ulang terus hingga kondisi penghentian dipenuhi.
Algoritma pelatihan untuk jaringan dengan satu layar tersembunyi (dengan fungsi aktivasi sigmoid biner) adalah sebagai berikut :
Langkah 1 : Inisialisasi semua bobot dengan bilangan acak kecil.
Langkah 2 : Jika kondisi penghentian belum terpenuhi, lakukan langkah 2 sampai langkah 9.
Langkah 3 : Untuk setiap pasang data pelatihan lakukan langkah 3 sampai langkah 8.
Fase I : Feedforward
Langkah 4 : Tiap unit masukan menerima sinyal dan meneruskannya ke unit tersembunyi diatasnya.
Langkah 5 : Hitung semua keluaran di unit tersembunyi .
...(2.54) gunakan fungsi aktivasi untuk menghitung sinyal outputnya :
...(2.55) dan kirimkan sinyal tersebut ke semua unit lapisan atasnya (unit-unit output). Langkah ini dilakukan sebanyak jumlah lapisan tersebunyi.
Langkag 6 :Hitung semua keluaran jaringan unit
gunakan fungsi aktivasi untuk menghitung sinyal outputnya :
...(2.57) Fase II : Backpropagation
Langkah 7 : Hitung faktor δ unit keluaran berdasarkan kesalahan disetiap unit keluaran
...(2.58) merupakan unit kesalahan yang akan diperbaiki dalam perubahan bobot layar dibawahnya (langkah 7). kemudian hitung suku perubahan bobot (yang akan dipakai nanti untuk merubah bobot ) dengan laju percepatan
...(2.59) kemudian hitung suku perubahan bias (yang akan dipakai nanti untuk memperbaiki )
...(2.60) Langkah 8 : Hitung faktor unit δ tersembunyi berdasarkan kesalahan di setiap
unit tersembunyi
...(2.61) Faktor unit tersembunyi :
...(2.62) Hitung suku perubahan bobot (yang akan dipakai nanti untuk merubah bobot
)
kemudian hitung suku perubahan bias (yang akan dipakai nanti untuk merubah bobot )
...(2.64) Fase III : Perubahan bobot
Langkah 9 : Tiap-tiap unit output memperbaiki
bobotnya
...(2.65) Perubahan bobot garis yang menuju unit tersembunyi :
...(2.66) Langkah 10 : Setelah diperoleh bobot yang baru dari hasil perubahan bobot,
fase pertama dilakukan kembali kemudian dibandingkan hasil keluaran dengan target apabila hasil keluaran telah sama dengan target dan toleransi error maka proses dihentikan.
Model FFNN algoritma backpropagation secara sistematis dapat dituliskan sebagai berikut :
...(2.67) 2.12.5 Membangun Jaringan Feedforward Neural Network dengan algoritma
backpropagation
Membangun jaringan feedforward neural network dengan algoritma
backpropagation memerlukan beberapa langkah. Penulis membagi
a. Menentukan input Jaringan
Dalam menentukan input jaringan dari data open emas, yang menjadi variabel input yaitu harga open emas hari kemarin sebagai x1, dan harga open emas berupa data hari sekarang sebagai x2. Sedangkan data target adalah data hari esok. Data input yang telah dipilih dinormalisasi dengan perintah prestd dalam MATLAB. Fungsi aktivasi yang digunakan pada lapis tersembunyi yaitu sigmoid
biner (tansig), sedangkan pada lapis output menggunakan fungsi aktivasi linier
(purelin). Pembelajaran backpropagation dilakukan dengan menentukan banyaknya neuron pada lapis tersembunyi.
b. Pembagian data
Data yang ada dibagi menjadi 2 yaitu training dan data testing. Beberapa komposisi data training dan testing yang sering digunakan adalah 80% untuk
training dan 20% untuk data testing, 75% untuk data training dan 25% untuk data testing, atau 50% data training dan 50% untuk data testing. Komposisi ini bersifat
bebas.
c. Normalisasi data
Sebelum melakukan pembelajaran maka data perlu dinormalisasikan. Normalisasi data dilakukan karena normalisasi sangat dibutuhkan pada jaringan syaraf tiruan yang menggunakan fungsi aktifasi sigmoid. Hal ini dapat dilakukan dengan meletakkan data-data input dan target pada range tertentu. Proses normalisasi dapat dilakukan dengan bantuan mean dan standar deviasi.
Perhitungan nilai variansi ...(2.69) Perhitungan normalisasi ...(2.70) dengan : n = Banyaknya data = rata-rata data
= pengamatan pada waktu t = variansi
s = simpangan baku
Proses normalisasi data dengan bantuan mean dan standar deviasi menggunakan perintah prestd pada MATLAB yang akan membawa data ke dalam bentuk normal. Berikut perintahnya:
[pn, meanp, stdp, tn, meant, stdt] = prestd (P,T) dengan
P = matriks input T = matriks target
Fungsi pada matlab akan menghasilkan:
Pn = matriks input yang ternormalisasi (mean = 0, deviasi standar = 1) tn = matriks target yang ternormalisasi (mean=0,deviasi standar = 1) meanp = mean pada matriks input asli (p)
stdt = deviasi standar pada matriks target asli (t)
d. Menentukan Model FFNN yang Optimal dengan Algorit backpropagation Sebuah jaringan harus dibentuk dengan menentukan input dari jaringan tersebut. Input diketahui dari plot ACF dan PACF yang telah dijelaskan sebelumnya. Jika input sudah diketahui, maka neuron pada lapis tersembunyi harus ditentukan. Penentuan neuron pada lapis tersembunyi dengan cara mengestimasi. Arsitektur jaringan yang sering digunakan oleh algoritma
backpropagation adalah jaringan feedforward dengan banyak lapisan. Untuk
membangun suatu jaringan feedforward digunakan perintah newff pada MATLAB, yaitu
net = newff(PR,[S1 S2 ... SN1],{TF1 TF2 ...
TFN1},BTF,BLF,PF) dengan :
PR = matriks berukuran Rx2 yang berisi nilai minimum dan maksimum, dengan R adalah jumlah variabel input Si = jumlah neuron pada lapisan ke-i, dengan = 1,2, . . . , 1 TFi = fungsi aktivasi pada lapisan ke-i, dengan = 1,2, . . . , 1 BTF = fungsi pelatihan jaringan (default :trainlm)
BLF = fungsi pelatihan untuk bobot (default : learngdm) PF = fungsi kinerja (default: mse)
Fungsi aktivasi TFi harus merupakan fungsi yang dapat dideferensialkan, seperti tansig, logsig atau purelin. Fungsi pelatihan BTF dapat digunakan
fungsi-fungsi pelatihan untuk backpropagation, seperti trainlm, trainbfg, trainrp atau
traind.
Proses membangun jaringan feedforward neural network dengan algoritma
backpropagation terdiri atas :
1) Menentukan banyaknya neuron pada lapis tersembunyi
Jaringan yang dibangun akan dinilai keakuratannya dengan menentukan
neuron terbaik pada lapisan tersembunyi. Indikator pemilihan penilaian yang
digunakan adalah MAPE, MSE dan MAD. Berdasarkan nilai indikator yang terendah dari proses pembelajaran, maka diperoleh jaringan yang terbaik. Dalam skripsi ini, penulis menggunakan MSE sebagai indikatornya. Rumus MSE bisa dilihat pada persamaan (2.44)
2) Menentukan input yang optimal
Jaringan yang akan dibangun seharusnya berdasarkan input yang sederhana namun optimal, untuk itu perlu dilalukan pengecekan terhadap input jaringan. Untuk mendapatkan input yang optimal perlu dilakukan pengeliminasian terhadap input. Indikator dari optimalnya dilihat dari MSE yang diperoleh setelah melakukan pelatihan. Input yang optimal yaitu ketika MSE yang diperoleh sangat kecil atau paling kecil.
3) Menentukan bobot model
Penentuan bobot model bergantung pada pemilihan parameter pembelajaran.Pemilihan parameter pembelajaran adalah proses yang penting ketika melakukan pembelajaran. Dalam membentuk suatu jaringan, model yang kurang baik dapat diperbaiki dengan paramerer-parameter secara trial and error
untuk mendapatkan nilai bobot optimum supaya MSE jaringan dapat diperbarui. Adapun untuk parameter-parameter yang perlu diatur ketika melakukan pembelajaran traingdx adalah (Sri Kusumadewi, 2004) :
a) Maksimum epoh
Maksimum epoh adalah jumlah epoh maksimum yang boleh dilakukan selama proses pelatihan. Iterasi akan terhenti apabila nilai epoh melebihi maksimum epoh.
Perintah di MATLAB : net.trainParam.epochs = MaxEpoh Nilai default untuk maksimum epoh adalah 10
b) Kinerja tujuan
Kinerja tujuan adalah target nilai fungsi kinerja. Iterasi akan dihentikan apabila nilai fungsi kinerja kurang dari atau sama dengan kinerja tujuan.
Perintah di MATLAB : net.trainParam.goal = TargetError Nilai default untuk kinerja tujuan adalah 0.
c) Learning rate
Learning rate adalah laju pembelajaran. Semakin besar learning rate akan
berimplikasi pada semakin besar langkah pembelajaran.
Perintah di MATLAB : net.trainParam.Ir = LearningRate. Nilai default untuk learning rate adalah 0,01.
d) Rasio untuk menaikkan learning rate
Rasio yang berguna sebagai faktor pengali untuk menaikkan learning rate apabila learning rate yang ada terlalu rendah atau mencapai kekonvergenan.
Nilai default untuk rasio menaikkan learning rate adalah 1,05. e) Rasio untuk menurunkan learning rate
Rasio yang berguna sebagai faktor pengali untuk menurunkan learning
rate apabila learning rate yang ada terlalu tinggi atau menuju ke ketidakstabilan.
Perintah di MATLAB : net.trainParam.Ir_decc =DecLearningRate Nilai default untuk rasio penurunan learning rate adalah 0,7.
f) Maksimum kegagalan
Maksimum kegagalan diperlukan apabila pada algoritma disertai dengan validitas (optional). Maksimum kegagalan adalah ketidakvalitan terbesar yang diperbolehkan. Apabila gradient pada iterasi ke-k lebih besar daripada gradien iterasi ke-(k-1), maka kegagalannya akan bertambah 1. Iterasi akan dihentikan apabila jumlah kegagalan lebih dari maksimum kegagalan.
Perintah di MATLAB : net.trainParam.max_fail =MaxFaile Nilai default untuk maksimum kegagalan adalah 5.
g) Maksimum kenaikan kerja
Maksimum kenaikan kerja adalah nilai maksimum kenaikan error yang diijinkan, antara error saat ini dan error sebelumnya.
PerintahdiMATLAB : net.trainParam.max_perf_inc =MaxPerfInc Nilai default untuk maksimum kenaikan kinerja adalah 1,04.
h) Gradien minimum
Gradien minumum adalah akar dari jumlah kuadrat semua gradien (bobot input, bobot lapisan, bobot bias) terkecil yang diperbolehkan. Iterasi akan
dihentikan apabila nilai akar kuadrat semua gradien ini kurang dari gradien minimum.
Perintah di MATLAB : net.trainParam.min_grad =MinGradien Nilai default untuk gradien minimum adalah 10-10.
i) Momentum
Momentum adalah perubahan bobot yang baru dengan dasar bobot sebelumnya. Besarnya momentum antara 0 sampai 1. Apabila besarnya momentum = 0 maka perubahan bobot hanya akan dipengaruhi oleh gradiennya. Sedangkan, apabila besarnya momentum = 1 maka perubahan bobot akan sama dengan perubahan bobot sebelumnya.
Perintah di MATLAB : net.trainParam.mc =Momentum Nilai default untuk momentum adalah 0,9.
j) Jumlah epoh yang akan ditunjukkan kemajuannya
Parameter ini menunjukkan berapa jumlah epoh yang berselang yang akan ditunjukkan kemajuannya.
Perintah di MATLAB : net.trainParam.show =EpohShow Nilai default untuk jumlah epoh yang akan ditunjukkan adalah 25. k) Waktu maksimum untuk pelatihan
Parameter ini menunjukkan waktu maksimum yang diijinkan untuk melakukan pelatihan. Iterasi akan dihentikan apabila waktu pelatihan melebihi waktu maksimum.
Algoritma pelatihan dilakukan untuk pengaturan bobot, sehingga pada akhir pelatihan mendapatkan bobot-bobot yang baik. Selama proses pelatihan, bobot diatur secara iteratif untuk meminimumkan fungsi kinerja jaringan. Fungsi kinerja jaringan yang sering digunakan dalam backpropagation adalah mean
square error (MSE), fungsi ini akan mengambil rata-rata kuadrat error yang
terjadi antara output jaringan dengan target. Algoritma pelatihan yang dasar ada 2 macam (Sri Kusumadewi, 2004), yaitu:
a. Incremental Mode
Dalam MATLAB, perintah Incremental Mode ada 2 yaitu learngd dan
learngdm.
b. Batch Mode
Dalam MATLAB, perintah Batch Mode ada 2 yaitu traingd dan traingdm. Dari kedua algoritma tersebut, algoritma pelatihan dasar Batch Mode yang sering digunakan. Pelatihan sederhana dengan Batch Mode menggunakan fungsi train dalam matlab sebagai berikut:
net = train (net,P,T) e. Denormalisasi
Setelah proses pelatihan selesai, maka data yang telah dinormalisasi dikembalikan seperti semula yang disebut denormalisasi data. Data akan di denormalisasi dengan fungsi poststd pada matlab, dengan perintah sebagai berikut : [P,T]= poststd (pn, meanp, stdp, tn, meant, stdt).
f. Uji kesesuaian model
Untuk mengecek error pada struktur jaringan yang telah dibentuk dengan uji white noise. Pengujian ini dilihat dari plot ACF dan PACF dari error training apakah bersifat random atau tidak. Jika error bersifat random maka proses white
noise terpenuhi sehingga jaringan layak digunakan untuk peramalan. Model backpropagation dengan p neuron tersembunyi dan input xi, secara sistematis dapat ditulis sebagai berikut :