DATA WAREHOUSE
“BIG DATA”
Oleh :
1. Ni Komang Sutiari
(1304505041)
2. Anisa Rahmi
(1304505043)
JURUSAN TEKNOLOGI INFORMASI
FAKULTAS TEKNIK
UNIVERSITAS UDAYANA
2015
BAB I PENDAHULUAN
1.1 Latar Belakang
Perkembangan jaman hingga saat ini sangat berdampak besar terhadap kehidupan sekarang. Salah satu hal yang berubah adalah cara menggunakan data. Hal tersebut sangat dipengaruhi oleh perkembangan teknologi, karena dapat dilihat sekarang penggunaan tiap individu terhadap data sudah sangat tinggi, hampir semua orang memiliki data dalam setiap perangkatnya (komputer / laptop, smartphone, flashdisk, harddisk eksternal, dll) yang jika dijumlahkan akan menjadi besar sekali. Hal ini dipengaruhi juga dengan mudahnya tiap individu untuk mendapatkan data yang diinginkannya (film, musik, games, dan lain- lain) melalui internet.
Internet menghubungkan tiap individu di seluruh dunia dengan mudah tanpa memperdulikan jarak / lokasi dan waktu. Sekarang dengan terjadinya perkembangan teknologi, data menjadi hal yang penting dalam menjalankan berbagai hal, beberapa diantaranya; mengetahui tren pasar, mengetahui keinginan konsumen saat ini, meningkatkan hasil penjualan, dll. Hasil perubahan ini sangatlah besar, data pun diolah dengan lebih terkomputerisasi sehingga penyimpanan beberapa data dapat menghemat tempat dalam kantor perusahaan dengan cara penyimpanan softcopy. Data yang tersimpan ini lama kelamaan menjadi sangat banyak dan besar sehingga semakin susah untuk digunakan, hal tersebut disebut big data. Dengan perkembangan sekarang, big data ini sudah dapat diolah dan digunakan lagi, bahkan memberikan hasil yang lebih baik karena mencakup pengolahan data yang ada di dalam social media.
Dengan perkembangan data inilah big data muncul dan saat ini mulai berkembang. Penggunaannya pun semakin luas, hingga mencakup social media, sehingga dapat menganalisa tren pasar dengan melihat sentimen analisis pelanggan melalui social media. Dengan perkembangan saat ini, ada baiknya untuk memahami lebih dalam mengenai big data, sehingga dapat dimanfaatkan dengan lebih maksimal.
Rumusan masalah dari pendekatan dengan metode hybrid yaitu sebagai berikut:
1. Bagaimana definisi dari big data? 2. Bagaimana arsitektur big data?
1.3 Tujuan
Tujuan yang dapat diperoleh dari pembuatan makalah pendekatan hybrid untuk data warehouse:
1. Mahasiswa memahami definisi dari big data.
2. Mahasiswa mengetahui dan memahami arsitektur dari big data.
BAB II
TINJAUAN PUSTAKA 2.1.Definisi Big Data
Menurut (Eaton, Dirk, Tom, George, & Paul) Big Data merupakan istilah yang berlaku untuk informasi yang tidak dapat diproses atau dianalisis menggunakan alat tradisional.
Menurut (Dumbill, 2012) , Big Data adalah data yang melebihi proses kapasitas dari kovensi sistem database yang ada. Data terlalu besar dan terlalu
cepat atau tidak sesuai dengan struktur arsitektur database yang ada. Untuk mendapatkan nilai dari data, maka harus memilih jalan altenatif untuk memprosesnya.
Berdasarkan pengertian para ahli di atas, dapat disimpulkan bahwa Big Data adalah data yang memiliki volume besar sehingga tidak dapat diproses atau diolah menggunakan alat tradisional biasa dan harus menggunakan cara dan alat baru untuk mendapatkan nilai dari data ini.
2.2.Karakteristik Big Data
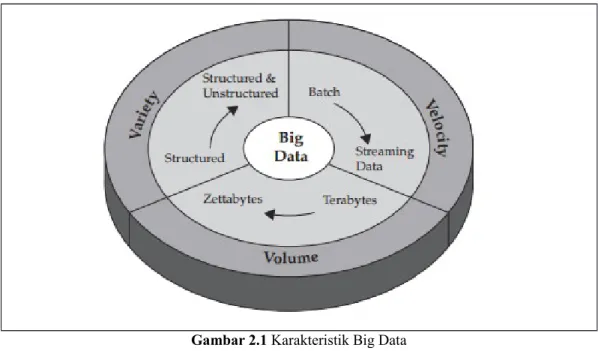
Tiga karakteristik yang dimiliki oleh Big Data yaitu Volume, velocity dan variety. Berikut ini merupakan gambar dari karakteristik big data.
Gambar 2.1 Karakteristik Big Data
1. Volume
Perusahaan tertimbun dengan data yang terus tumbuh dari semua jenis sektor, dengan mudah mengumpulkan terabyte bahkan petabyte-informasi.
Mengubah 12 terabyte Tweet dibuat setiap hari ke dalam peningkatan sentimen analisis produk.
Mengkonvert 350 milliar pembacaan tahunan untuk lebih baik dalam memprediksi kemampuan beli pasar.
Karakteristik ini yang paling mudah dimengerti karena besarnya data. Volume juga mengacu pada jumlah massa data, bahwa organisasi berusaha untuk memanfaatkan data untuk meningkatkan pengambilan keputusan yang banyak
perusahaan di banyak negara. Volume data juga terus meningkat dan belum pernah terjadi sampai sethinggi ini sehingga tidak dapat diprediksi jumlah pasti dan juga ukuran dari data sekitar lebih kecil dari petabyte sampai zetabyte. Dataset big data sekitar 1 terabyte sampai 1 petabyte perperusahaan jadi jika big data digabungkan dalam sebuah organisasi / group perusahaan ukurannya mungkin bisa sampai zetabyte dan jika hari ini jumlah data sampai 1000 zetabyte, besok pasti akan lebih tinggi dari 1000 zetabyte.
2. Velocity
Big Data adalah setiap jenis data baik yang terstruktur maupun tidak terstruktur seperti teks, data sensor, audio, video, klik stream, file log dan banyak lagi. Wawasan baru ditemukan ketika menganalisis kedua jenis data ini bersama-sama yaitu:
Memantau 100 video masukan langsung dari kamera pengintai untuk menargetkan tempat tujuan.
Mengeksploitasi 80% perkembangan data dalam gambar, video, dan dokumen untuk meningkatkan kepuasan pelanggan.
Data dalam gerak. Kecepatan di mana data dibuat, diolah dan dianalisis terus menerus. Berkontribusi untuk kecepatan yang lebih tinggi adalah sifat penciptaan data secara real-time, serta kebutuhan untuk memasukkan streaming data ke dalam proses bisnis dan dalam pengambilan keputusan. Dampak Velocity latency, jeda waktu antara saat data dibuat atau data yang ditangkap, dan ketika itu juga dapat diakses. Hari ini, data terus-menerus dihasilkan pada kecepatan yang mustahil untuk sistem tradisional untuk menangkap, menyimpan dan menganalisis. Jenis tertentu dari data harus dianalisis secara real time untuk menjadi nilai bagi bisnis.
3. Variety
Volume data yang banyak tersebut bertambah dengan kecepatan yang begitu cepat sehingga sulit bagi kita untuk mengelola hal tersebut. Kadang-kadang 2 menit sudah menjadi terlambat. Untuk proses dalam waktu sensitif seperti
penangkapan penipuan, data yang besar harus digunakan sebagai aliran ke dalam perusahaan Anda untuk memaksimalkan nilainya.
Meneliti 5 juta transaksi yang dibuat setiap hari untuk mengidentifikasi potensi penipuan
Menganalisis 500 juta detail catatan panggilan setiap hari secara real-time untuk memprediksi gejolak pelanggan lebih cepat.
Berbagai jenis data dan sumber data. Variasi adalah tentang mengelolah kompleksitas beberapa jenis data, termasuk structured data, unstructured data dan semi-structured data. Organisasi perlu mengintegrasikan dan menganalisis data dari array yang kompleks dari kedua sumber informasi Traditional dan non traditional informasi, dari dalam dan luar perusahaan. Dengan begitu banyaknya sensor, perangkat pintar (smart device) dan teknologi kolaborasi sosial, data yang dihasilkan dalam bentuk yang tak terhitung jumlahnya, termasuk text, web data, tweet, sensor data, audio, video, click stream, log file dan banyak lagi.
2.3.Arsitektur Big Data
Berikut ini merupakan arsitektur dari big data yang terdiri dari Traditional Information Architecture Capabilities dan Adding Big Data Capabilities.
2.3.1. Traditional Information Architecture Capabilities
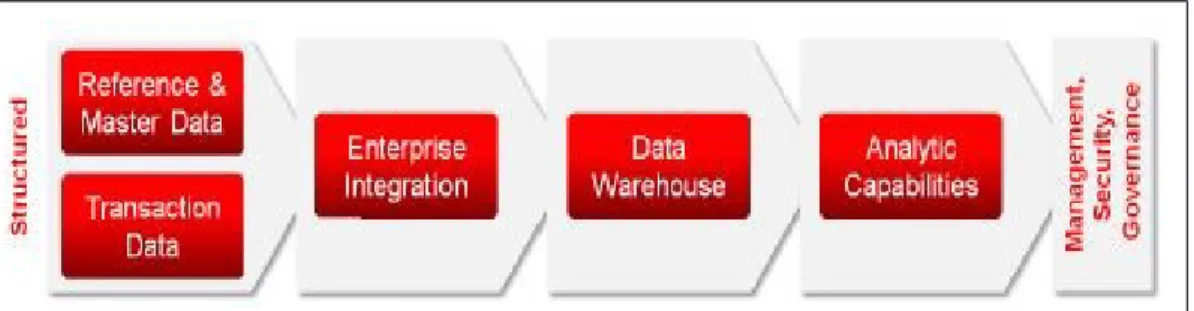
Untuk memahami level aspek arsitektur yang tinggi dari Big Data, sebelumnya harus memahami arsitektur informasi logis untuk data yang terstruktur. Pada gambar di bawah ini menunjukkan dua sumber data yang menggunakan teknik integrasi (ETL / Change Data Capture) untuk mentransfer data ke dalam DBMS data warehouse atau operational data store, lalu menyediakan bermacam-macam variasi dari kemampuan analisis untuk menampilkan data. Beberapa kemampuan analisis ini termasuk,; dashboards, laporan, EPM/BI Applications, ringkasan dan query statistic, interpretasi semantic untuk data tekstual, dan alat visualisasi untuk data yang padat. Informasi utama dalam prinsip arsitektur ini termasuk cara memperlakukan data sebagai asset melalui nilai, biaya, resiko, waktu, kualitas dan akurasi data.
Gambar 2.2 Traditional Information Architecture Capabilities
(Sun & Heller, 2012, p. 11)
2.3.2. Adding Big Data Capabilities
Mendefinisikan kemampuan memproses untuk big data architecture, diperlukan beberapa hal yang perlu dilengkapi; volume, percepatan, variasi, dan nilai yang menjadi tuntutan. Ada strategi teknologi yang berbeda untuk real-time dan keperluan batch processing. Untuk real-time, menyimpan data nilai kunci, seperti NoSQL, memungkinkan untuk performa tinggi, dan pengambilan data berdasarkan indeks. Untuk batch processing, digunakan teknik yang dikenal sebagai Map Reduce, memfilter data berdasarkan pada data yang spesifik pada strategi penemuan. Setelah data yang difilter ditemukan, maka akan dianalisis secara langsung, dimasukkan ke dalam unstructured database yang lain, dikirimkan ke dalam perangkat mobile atau digabungkan ke dalam lingkungan data warehouse tradisional dan berkolerasi pada data terstruktur.
Gambar 2.3 Adding Big Data Capabilities
(Sun & Heller, 2012, p. 11)
Sebagai tambahan untuk unstructured data yang baru, ada dua kunci perbedaan untuk big data. Pertama, karena ukuran dari data set, raw data tidak dapat secara langsung dipindahkan ke dalam suatu data warehouse. Namun, setelah proses Map Reduce ada kemungkinan akan terjadi reduksi hasil dalam lingkungan data warehouse sehingga dapat memanfaatkan pelaporan business
intelligence, statistik, semantik, dan kemampuan korelasi yang biasa. Akan sangat ideal untuk memiliki kemampuan analitik yang mengkombinasikan perangkat BI bersamaan dengan visualisasi big data dan kemampuan query. Kedua, untuk memfasilitasi analisis dalam laingkungan Hadoop, lingkungan sandbox dapat dibuat.
Untuk beberapa kasus, big data perlu mendapatkan data yang terus berubah dan tidak dapat diperkirakan, untuk menganilisis data tersebut, dibutuhkan arsitektur yang baru. Dalam perusahaan retail, contoh yang bagus adalah dengan menangkap jalur lalu lintas secara real-time dengan maksud untuk memasang iklan atau promosi toko di tempat strategis yang dilewati banyak orang, mengecek peletakan barang dan promosi, mengamati secara langsung pergerakan dan tingkah laku pelanggan.
Dalam kasus lain, suatu analisis tidak dapat diselesaikan sampai dihubungkan dengan data perusahaan dan data terstruktur lainnya. Sebagai contohnya, analisis perasaan pelanggan, mendapatkan respon positif atau negatif dari social media akan memiliki suatu nilai, tetapi dengan mengasosiasikannya dengan segala macam pelanggan (paling menguntungkan atau bahkan yang paling tidak menguntungkan) akan memberikan nilai yang lebih berharga. Jadi, untuk memenuhi kebutuhan yang diperlukan oleh big data BI adalah konteks dan pemahaman. Menggunakan kekuatan peralatan statistikal dan semantik akan sangat memungkinkan untuk dapat memprediksikan kemungkinan – kemungkinan di masa depan.
2.4 Evolusi Data Warehouse terhadap Big Data
Big data merupakan evolusi dari data warehouse dimana big data mencakup semua data warehouse namun data warehaose tidak bisa disebut sebagai big data. Data berasal dari beberapa database yaitu, data warehouse suatu perusahaan yang berisi data dari sistem yang keuangan perusahaan, sistem pemasaran pelanggan, sistem penagihan, yang point-of-sales sistem, dan sebagainya. Organisasi baru-baru ini mengakui bahwa ada peningkatan jumlah data dalam dunia digitalisasi cepat saat ini yang tidak ditangkap di database operasional seperti log clickstream, data sensor, data lokasi dari perangkat mobile,
email dukungan pelanggan dan chatting transkrip, dan video surveillance. Sistem big data memanfaatkan sumber-sumber data baru dan memungkinkan perusahaan untuk menganalisis dan mengambil nilai bisnis dari set data besar.
Teknologi yang digunakan untuk big data seperti Hadoop dan Database NoSQL. Apache Hadoop adalah sebuah teknologi baru yang memungkinkan volume data yang besar untuk diatur dan diproses sambil menjaga data pada cluster penyimpanan data asli. Hadoop Distributed File System (HDFS) adalah sistem penyimpanan jangka panjang untuk log web misalnya. Log web ini berubah menjadi perilaku browsing dengan menjalankan program MapReduce di cluster dan menghasilkan hasil yang dikumpulkan di dalam cluster yang sama. Hasil ini dikumpulkan kemudian dimuat ke dalam sistem DBMS relasional. Database NoSQL digunakan untuk mengambil dan menyimpan big data yang cocok untuk struktur data dinamis dan sangat terukur. Data yang disimpan dalam database NoSQL biasanya dari berbagai variasi untuk menangkap semua data tanpa mengelompokkan dan parsing data.
Big data memerlukan arsitektur untuk memperoleh data dari berbagai sumber data, mengatur dan menyimpan data dalam format yang sesuai untuk analisis, memungkinkan pengguna untuk secara efisien menganalisis data dan akhirnya membantu untuk mendorong keputusan bisnis.
Gambar 2.4. Big Data architecture using Oracle Engineered Systems
sumber (Oracle White Paper. 2014. Oracle Database 12c For Data Warehousing And Big Data)
Arsitektur informasi big data merupakan pengembangan arsitektur data warehouse dimana data warehouse dibangun dalam sebuah database relasional yang menjadi database utama untuk menyimpan banyak data perusahaan yang menjadi inti transaksional seperti catatan keuangan, data pelanggan, data point of sel dan sebagainya. Data warehouse akan ditambahkan dengan sistem big data yang berfungsi sebagai ‘Data Reservoir’ yang akan menjadi repositori untuk sumber-sumber baru yang memiliki volume data yang besar: file log, data-media sosial, video dan gambar serta repositori untuk data transaksional yang lebih rinci atau data transaksional lama yang tidak disimpan dalam data warehouse.
BAB III PEMBAHASAN 3.1.Analisa
Big Data berasal dari jenis yang relatif baru dari sumber data seperti media sosial, pengajuan publik, konten yang tersedia dalam domain publik melalui lembaga atau langganan, dokumen dan e-mail termasuk teks terstruktur dan tidak terstruktur, perangkat digital dan sensor termasuk lokasi berdasarkan smartphone, cuaca dan data telematika.
Perusahaan tidak terbiasa mengumpulkan informasi dari sumber-sumber ini, mereka juga tidak berurusan dengan volume besar seperti data terstruktur. Oleh karena itu, banyak informasi yang tersedia untuk perusahaan yang tidak
ditangkap atau disimpan untuk analisis jangka panjang, dan kesempatan untuk mendapatkan pengetahuan yang dalam terlewatkan. Karena volume data yang besar, banyak perusahaan tidak menyimpan data besar mereka, dan dengan demikian tidak menyadari apapun tentang ini.
Perusahaan besar yang ingin benar-benar mendapatkan keuntungan dari data besar juga harus mengintegrasikan informasi jenis baru dengan data perusahaan tradisional, dan menyesuaikan dengan bisnis proses yag ada juga operasinya. Ada beberapa pendekatan untuk mengumpulkan, menyimpan, mengolah, dan menganalisis data yang besar. Fokus utama dari makalah ini adalah analisis data tidak terstruktur. Data yang tidak terstruktur mengacu pada informasi baik itu tidak memiliki model data yang telah ditetapkan atau tidak cocok pada tabel relasional. Data tidak terstruktur adalah jenis data yang paling cepat berkembang. Beberapa contohnya adalah citra, sensor, telemetri, video, dokumen, file log, dan file data email. Ada beberapa teknik untuk mengatasi problem analisa data tidak terstruktur. Teknik-teknik tersebut berbagi karakteristik umum dari scale-out, elastisitas, dan ketersediaan tinggi.
MapReduce, dalam hubungannya dengan Hadoop Distributed File System (HDFS) dan database yang HBase, sebagai bagian dari proyek Apache Hadoop adalah pendekatan modern untuk data yang tidak terstruktur. Cluster Hadoop adalah cara yang efektif untuk pengolahan volume besar data, dan dapat ditingkatkan dengan pendekatan arsitektur yang tepat.
Sebagai perusahaan yang mengadopsi kerangka Hadoop untuk analisis data tidak terstruktur, pertimbangan utama adalah untuk mengintegrasikan dan berhadapan dengan data data warehouse dan sistem database relasional. Makalah ini berfokus pada aspek data besar yang tidak terstruktur, fitur dari Hadoop, keuntungan dan kerugian dari Hadoop. Makalah ini juga membahas apakah Hadoop adalah pengganti data warehouse. Tulisan ini memperlihatkan data besar non-relasional (NoSQL) seperti asrsitektur terdistribusi / shared nothing, penskalaan horisontal, kunci toko / nilai, dan konsistensi akhirnya. Bagian dari makalah ini juga membedakan antara terstruktur dibandingkan data terstruktur. Makalah ini menjelaskan berbagai blok bangunan dan teknik untuk Map Reduce dan HDFS, HBase dan pelaksanaannya di sumber Hadoop terbuka
3.1.1.
Teknologi Big Data
3.1.4.1 HadoopHadoop adalah, kerangka pemrograman berbasis Java gratis yang mendukung pengolahan dataset besar dalam lingkungan komputasi terdistribusi. Ini adalah bagian dari proyek Apache yang disponsori oleh Apache Software Foundation. Hadoop menyediakan penyimpanan dan pengolahan kerangka secara parallel. Itu menjalankan setumpuk program MapReduce dalam parallel dari ribuan node. Hadoop adalah semacam sistem MAD berarti bahwa (i) mampu menarik semua sumber data (M berdiri untuk Magnetism), (ii) ia mampu mengadaptasikan mesin untuk evolusi dimana mungkin terjadi di sumber data besar (A berdiri untuk Agility), (iii) itu mampu mendukung analisis secara mendalam atas sumber data yang besar jauh lebih luar kemungkinan alat analisis berbasis SQL tradisional (D berdiri untuk Depth).
1. File Sistem Terdistribusi Hadoop
The Hadoop Distributed File system (HDFS) adalah file sistem terdistribusi yang bersifat scalable yang menyediakan akses data aplikasi yang
high-throughput. HDFS ditulis dalam bahasa pemrograman Java. Sebuah cluster
HDFS beroperasi dalam pola masterslave, yang terdiri dari simpul nama induk dan sejumlah node Data slave. Nama node bertanggung jawab untuk mengelola pohon sistem file, metadata untuk semua file dan direktori tersimpan di pohon, dan lokasi dari semuau bloks tersimpan pada node data. Node Data bertanggung jawab untuk menyimpan dan mengambil data yang diblokir ketika nama node atau klien memintanya.
2. MapReduce
MapReduce adalah pemrograman model di atas HDFS untuk pengolahan dan menghasilkan set data yang besar yang dikembangkan sebagai abstraksi dari peta dan mengurangi primitif yang hadir dalam banyak bahasa fungsional. Abstraksi dari paralelisasi, toleransi kesalahan, distribusi data dan load balancing memungkinkan pengguna untuk memparalelkan perhitungan besar dengan mudah. Pemetaan dan mengurangi model bekerja dengan baik untuk analisis Big Data karena inheren paralel dan dapat dengan mudah menangani dataset yang mencakup di beberapa mesin. Setiap program MapReduce berjalan dalam dua
fase, fase pemetaan dan fase pengurangan. Programmer hanya mendefinisikan fungsi untuk setiap tahap dan Hadoop menangani agregasi data, menyortir, dan mengantar pesan antara node. Ada beberapa peta dan fase pengurangan dalam program analisis data tunggal dengan kemungkinan dependensi antara mereka. Tahap peta. Input untuk fase peta adalah data mentah. Sebuah fungsi peta harus mempersiapkan data untuk input ke reducer dengan pemetaan kunci nilai untuk setiap "baris" input. Output nilai kunci yang dihasilkan dari fungsi pemetaan diurut dan di grup oleh kunci sebelum dikirim ke fase pengurangan. Input untuk fase pengurangan adalah output dari fase pemetaan, dimana nilainya adalah list nilai dengan kunci yang sesuai yang dapat berulang. Fungsi pengurangan harus mengulang melalui daftar dan melakukan beberapa operasi pada data sebelum keluaran hasil akhir.
3.1.2. Data Warehouse Sekarang
Di tahun 1990, Bill Inmon menperkenalkan sebuah design yang dikenal dengan data warehouse. Berdasarkan itu, data warehous adalah sebuah kumpulan data yang berorientasi subjek, terintegrasi, memiliki variasi waktu, dan berifat non-volatile atau tetap. Metode tradisional mengelola data terstruktur mencakup database relasional dan skema untuk mengelola penyimpanan dan pengambilan dataset. Untuk mengelola dataset besar secara terstruktur, pendekatan utama adalah gudang data dan data mart. Sebuah gudang data adalah sistem database relasional yang digunakan untuk menyimpan, menganalisis, dan pelaporan fungsi. Data mart adalah lapisan yang digunakan untuk mengakses data warehouse. Sebuah gudang data berfokus pada data penyimpanan. Data dari sumber yang berbeda dibersihkan, diubah, dimuat ke gudang sehingga dibuat tersedia untuk data mining dan secara online fungsi analitis. Data warehouse dan Mart adalah SQL (Standard Query Language) berbasis sistem database. Dua pendekatan utama untuk menyimpan data dalam data warehouse adalah sebagai berikut :
Dimensional : Data transaksi yang dipartisi menjadi tabel "fakta" , yang umumnya untuk data transaksi dan tabel dimensi, yang merupakan informasi referensi yang memberikan konteks untuk fakta
Normalized : Tabel yang dikelompokkan secara bersama-sama berdasarkan area subjek yang mencerminkan kategori seperti data produk, pelanggan, dan sejenisnya. Struktur yang ternormalisasi membagi data menjadi entitas yang membuat beberapa tabel di database relasional.
3.1.3. Keterbatasan praktek DWH Saat Ini
1. Kemampuan terbatas dalam menangani data tidak terstruktur. Data terstruktur memiliki skema tetap sehingga cocok menjadi model relasional yang dapat dirancang [9]. Di sisi lain data tidak terstruktur dan semi terstruktur tidak memiliki skema tetap. Saat ini di perusahaan jenis data tersebut menjadi data yang umum. Data tersebut juga menyembunyikan informasi yang sensitif. Jadi proses pengambilan keputusan di perusahaan tidak akan efektif karena data tidak terstruktur tersebut tidak sedang diperhitungkan saat pengambilan keputusan. Namun, engine data warehouse tradisional memiliki keterbatasan dalam bidang ini.
2. Ekstraksi informasi dari data besar dan mencocokkan dengan data yang ada. Data besar datang dalam berbagai format. Sebagian besar data merupakan data tidak terstruktur. Ada variasi format yang signifikan dalam teks tidak terstruktur dan entitas dalam database. Query data tidak terstruktur juga bukan tugas yang mudah. Data tidak terstruktur dapat disimpan di LOB, tetapi tidak ada query yang efektif dalam lob. Meskipun sekarang SQL mendukung pencarian kata kunci berdasarkan teks lengkap, tetapi terbatas hanya pada pencarian teks saja. Dari teks tidak terstruktur, informasi yang diekstrak diperoleh sebagai urutan token tetapi database adalah bentuk dari suatu hubungan entitas. Tidak ada informasi dalam database tentang pengurutan antar entitas.
3.1.4. Mengintegrasikan Data yang Besar dengan Data Warehouse
Sebagian besar organisasi termasuk jutaan pelanggan memproses petabyte data perhari memiliki persyaratan sebagai berikut :
1. Loading data yang cepat 2. Pemrosesan query yang cepat
3. Pemanfaatan penyimpanan yang sangat efisien
4. Adaptasi yang kuat untuk pola beban kerja yang sangat dinamis 3.1.4.1 Hadoop dan Data Warehouse
Hadoop dapat cukup dianggap sebagai evolusi pada sistem Data Warehousing generasi berikutnya, khususnya berkaitan dengan fase ETL dari sistem tersebut. MapReduce adalah inti dari Hadoop. MapReduce merupakan model pemrograman dengan kerangka komputasi terkait yang terinspirasi dari bahasa fungsional Map
and Reduce terdahulu.
MapReduce is a programming model with the associated computational framework that is inspired to the primitives Map and Reduce of functional languages. Beberapa poin kunci dari teknologi berbasis Hadoop:
1. Pure-store merupakan sebuah write-once, read-many solution misal, tidak ada update dan perubahan dari struktur/file yang ada
2. Merupakan sebuah tempat penyimpanan data yang penuh tanpa integritas referensial. Hal tersebut membantu dalam mendapatkan kinerja yang cepat.
3. Pemartisian sangat baik, tetapi kolom yang telah terpartisi tidak terdapat lagi pada data set. Kolom tersebut diletakkan sebagai bagian dari struktur direktori
4. Partisi benar-benar terpisah dalam direktori fisik yang terpisah (terkadang mesin yang terpisah)
5. Hadoop merupakan sistem manajemen file “load and go”- yang berarti anda dapat menyalin file mentah ke dalam platform hadoop; tidak ada yang namanya “etl” dalam mendapatkan data ke dalam hadoop. File terkopi dan aturan transformasi pasti tertulis dalam kode program. 6. Pendekatan elt sebagai transformasi dilakukan setelah proses pemuatan.
Hal itu sama dengan “penyalinan file (el), diikuti dengan memasukkan ke dalam file baru dari file lama dikombinasikan dengan aturan transformasi.
7. Hadoop bukan sebuah tools ekstrak-transform-load(etl) melainkan sebuah platform yang mendukung etl.
Beberapa Manfaat dari pendekatan ini meliputi
Loading yang cepat dalam penyalinan data
Siap dalam mengaplikasikan transfomasi dan tidak ada integritas referensial dan mudah dalam membandingkan data.
Kompresi data otomatis. Pada beberapa implementasi Hadoop, kompresi file sudah termasuk di dalamnya, mengurangi jumlah tempat penyimpanan yang diperlukan dalam mengakomodasi data.
Tempat penyimpanan tanpa skema. Anda masih harus menentukan kolom, dan pada beberapa kasus tipe data dasar untuk file dalam hal untuk kode pada pemetaan elemen. Di lain hal, terdapat beberapa tipe file yang bekerja secara native (sudah dipetakan), seperti XML. Dan tetap, untuk dokumen lain (TXT file) yang bekerja berdasarkan pencarian tags. Penyimpanan tanpa skema memiliki kelemahan dan kelebihan.
Tanpa SQL, tidak ada batasan pada apa yang SQL butuhkan.
Tidak perlu adanya normalisasi data set untuk menghindari join antara node set.
3.1.4.2 Arsitektur
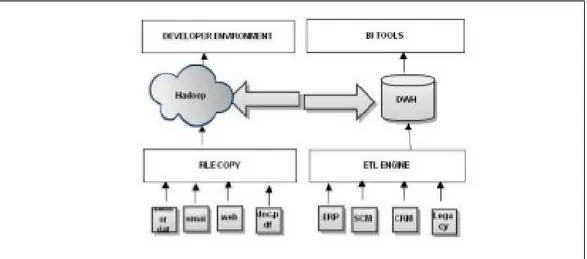
Solusi Hadoop dan MapReduce sedang digunakan dalam perusahaan bersama dengan data warehouse. Gambar 1 menunjukkan bagaimana data dibagi antara proses yang berbeda dan pembagian dari ahli data yang dapat mengakses keduanya.
Gambar 3.1. Interface antara Hadoop dan Data Warehouse
`Fungsi Hadoop kompleks dapat menggunakan data warehouse sebagai sumber data, secara bersamaan memanfaatkan kemampuan massal paralel dari dua sistem. Semua program MapReduce dapat memberikan perintah SQL ke data
warehouse. Dalam konteks yang sama, sebuah program MapReduce hanya lah sebuah program lainnya dan data warehouse adalah database lainnya.
3.1.4.3 Solusi yang diajukan
Data besar (sebagian besar merupakan format tak terstruktur) dimuat sebagai file ke HDFS. Input data diambil sebagai write-once fashion. Kemudian diproses oleh MapReduce ke dalam dua tahap, Tahap Map dan Tahap Reduce. Hasil dari proses tersebut ditulis ke HDFS. Terdapat 2 tipe HDFS node, data node yang menyimpan blok data dari file dan name node yang terdiri dari metadata.[2] Bagian berikut memberikan pengenalan langkah MapReduce saat memproses tugas.
1. Input step : muat data ke HDFS dengan memisahkan data ke dalam blok dan juga mendistribusikan ke node data cluster. Blok-blok tersebut direplikasi untuk ketersediaan apabila terjadi kegagalan. Name node melacak blok dan node data.
2. Job step : mengajukan tugas MapReduce dan detailnya ke JobTracker. 3. Job Init Step : JobTracker berinteraksi dengan TaskTracker di setiap node
data untuk menjadwalkan tugas MapReduce.
4. Map Step : Mapper memproses blok data dan menghasilkan sebuah daftar dari pasangan key dan value
5. Sort step : Mapper menyortir daftar dari pasangan key dan value
6. Shuffle step : mentransfer luaran pemetaan ke Reducers dalam kondisi tersortir
7. Reduce step : Reducers menggabungkan daftar pasangan key value untuk menghasilkan hasil akhir
Terakhir, hasil tersebut disimpan di HDFS. Hasil tersebut kemudian diterima dari HDFS oleh user dengan menulis program Java. Selanjutnya, data dimuat ke tabel berdimensi besar dari data warehouse dengan mekanisme pemuatan data seperti umumnya. Dengan data tidak mempunyai skema tetap untuk masuk ke data warehouse, untuk menangani perubahan skema yang terjadi pada table fakta yang sangat besar, dilakukan versioning terhadap perubahan skema basis pada tabel fakta. Missal setiap baris pada tabel fakta memliki id pengikut untuk versi skema. Dari sana kita dapet mengetahui kolom mana yang
tesedia untuk versi tersebut sehingga menambah atau menghapus kolom dapat dilakukan dengan mudah.
BAB IV PENUTUP