Peningkatan Akurasi pada Algoritma Support Vector Machine
dengan Penerapan Information Gain untuk
Mendiagnosa Chronic Kidney Disease
Kiki Prima Wijaya1, Much Aziz Muslim212
Jurusan Ilmu Komputer, FMIPA, Universitas Negeri Semarang Email : [email protected], [email protected]
Abstrak
Perkembangan database dalam bidang kesehatan tumbuh sangat pesat. Data tersebut sangat penting untuk dapat diolah supaya bermanfaat. Data mining merupakan bidang ilmu penelitian yang dapat mengolah database menjadi pengetahuan yang dapat dimanfaatkan untuk mendiagnosa penyakit, diantaranya chronic kidney disease. Salah satu teknik data mining yang digunakan untuk memprediksi suatu hal adalah klasifikasi. Algoritma support vector
machine termasuk dalam algoritma klasifikasi data mining yang baik digunakan untuk mendiagnosa penyakit chronic kidney disease. Kelemahan support vector machine adalah sulit digunakan pada data berskala besar dan sulit
untuk membedakan antara atribut yang berpengaruh dan yang tidak berpengaruh dalam proses prediksi. Tujuan utama dari riset ini adalah untuk mengoptimalisasi atribut pada dataset untuk meningkatkan akurasi algoritma Support
vector machine dalam mendiagnosa chronic kidney disease dengan menggunakan information gain. Dari hasil
percobaan, dengan menerapkan Information Gain pada algoritma support vector machine menunjukan bahwa tingkat akurasi meningkat 0,75% dari 97,75% menjadi 98,50% dalam mendiagnosa chronic kidney disease.
Kata Kunci: Data mining, SVM, Information gain, Prediksi penyakit, Chronic kidney disease Abstract
Database development in the health field is growing very rapidly. Such data are essential in order to be processed helpful. Data mining is a field of science research database that can process it into knowledge that can be used to diagnose diseases, including chronic kidney disease. One of data minings techniques used to predict something is classification. Support vector machine algorithm included in the classification of data mining algorithms are well used to diagnose the disease chronic kidney disease. Weakness support vector machine is hard to use in large-scale data and it is difficult to distinguish between the attributes that influence and that are not influential in the prediction process. The main objective of this research is to optimize the attributes of the dataset to improve the accuracy of the algorithms Support vector machine in diagnosing chronic kidney disease by using Information Gain. From the experimental results, by applying Information Gain on support vector machine algorithm showed that the accuracy rate rose 0.75% from 97,75% to 98.50% in diagnosing chronic kidney disease.
Keywords: Data mining, SVM, Information gain, prediction of disease, Chronic kidney disease
1. PENDAHULUAN
Pada masa kini, perkembangan database dalam bidang kesehatan tumbuh sangat pesat. Semakin banyaknya data yang tersimpan dalam database, sangat penting data tersebut untuk dapat diolah supaya lebih bermanfaat. Bidang ilmu yang dapat mengolah data menjadi pengetahuan sering disebut dengan istilah data mining. Data mining adalah proses yang mempekerjakan satu atau lebih teknik pembelajaran komputer (machine learning) untuk menganalisis dan mengekstraksi pengetahuan (knowledge) secara otomatis. Salah satu fungsi dasar data mining adalah klasifikasi [1].
Klasifikasi merupakan teknik data mining yang dapat digunakan untuk memprediksi keanggotaan kelompok untuk data instance. Klasifikasi adalah proses menemukan model (atau fungsi) yang menggambarkan dan membedakan kelas data atau konsep [2]. Beberapa algoritma dalam teknik klasifikasi antara lain adalah support vector machine. Support vector machine merupakan metode baru untuk klasifikasi baik itu data linier dan nonlinier [3]. Support vector machine memetakan data input non-liner ke beberapa ruang dimensi yang lebih tinggi, dimana data dapat dipisahkan secara linier, sehingga memberikan kinerja klasifikasi atau regresi yang besar [4].
Algoritma support vector machine dapat dimanfaatkan dan membantu ahli medis dalam mendiagnosa suatu penyakit, salah satunya adalah chronic kidney disease. Chronic kidney disease (CKD) merupakan suatu kondisi dimana kinerja fungsi ginjal mulai mengalami penurunan secara bertahap, dimana kondisi tersebut mempunyai sifat yang permanen dan dapat berakhir dengan gagal ginjal. Pada umumnya, CKD
merupakan suatu penyakit yang dapat dideteksi melalui tes urin dan darah dalam uji laboratorium. Gejala yang bersifat umum membuat pengidap penyakit ginjal ini tidak mengetahui dan menyadari bahwa gejalanya telah menuju stadium lanjut. Penyakit gagal ginjal ini merupakan penyakit yang sukar untuk disembuhkan maka dari itu diperlukan pengobatan yang teratur untuk menetralisir dan memperlambat proses menuju stadium akhir. Penyakit ginjal kronis merupakan masalah kesehatan masyarakat di seluruh dunia. Di amerika serikat, insiden ini terus meningkat dan tidak sedikit jumlah orang yang terjangkit gagal ginjal pada saat ini, dengan hasil yang buruk dan biaya yang tinggi [5].
Penelitian diagnosa ini dilakukan dengan menggunakan dataset chronic kidney disease. Dataset yang digunakan dalam penelitian ini adalah dataset chronic kidney disease yang diperoleh dari UCI repository of machine learning datasets. Dataset merupakan kumpulan dari objek dan sifat atau karakteristik dari suatu objek itu sendiri (atribut) [1]. Kemungkinan ada banyak atibut yang tidak relevan dalam suatu data yang akan digunakan sehingga perlu dihapus. Banyak juga algoritma mining yang tidak melakukan tugasnya dengan baik karena jumlah fitur dan atribut yang besar [6]. Oleh karena itu perlu menerapkan teknik yang dapat mengevaluasi atribut pada dataset. Salah satu teknik tersebut adalah feature selection. Feature selection adalah proses pemilihan fitur yang relevan, atau subset calon fitur. Kriteria evaluasi yang digunakan untuk mendapatkan bagian fitur optimal [4]. Feature selection yang akan digunakan adalah information gain. Information gain merupakan ekspektasi dari pengurangan entropi yang dihasilkan dari partisi objek dataset berdasarkan fitur tertentu [7].
Tujuan utama dari riset ini adalah untuk meningkatkan akurasi dari algoritma support vector machine dengan menerapkan information gain dalam memprediksi chronic kidney disease. Bagian dalam paper ini disusun sebagai berikut. Metode yang diusulkan dicantumkan dalam Bagian 2. Bagian 3 hasil dan pembahasan. Bagian 4 kesimpulan.
2. METODE
Tujuan penelitian ini adalah untuk mengoptimalisasi atribut dari dataset yang digunakan guna meningkatkan akurasi dengan menerapkan information gain. Penelitian ini diterapkan pada algoritma support vector machine untuk mendiagnosa chronic kidney disease, agar dapat membuktikan bahwa information gain dapat meningkatkan akurasi, maka penelitian akan mengkomparasikan performa akurasi dari algoritma support vector machine yang tidak diterapkan information gain dan yang menerapkan information gain. Information gain dilakukan untuk mengurangi fitur yang tidak relevan dan mengurangi dimensi fitur pada data, fitur dihapus satu persatu dari fitur yang memiliki nilai atribut yang paling rendah dan pengurangan di hentikan sampai hasil diagnosa mengalami penurunan, kemudian diambil hasil akurasi tertinggi. Pada Gambar 1 dijelaskan dua pendekatan berbeda pada algoritma support vector machine yang dilakukan a) tanpa menerapkan information gain dan b) dengan menerapkan information gain.
MULAI
DATASET CHRONIC KIDNEY DISEASE
SUPPORT VECTOR MACHINE
FINAL RESULT
MULAI DATASET CHRONIC KIDNEY DISEASE
FITURE SELECTION : INFORMATION GAIN
FEATURE EVALUATION METHOD : RANKER
SUPPORT VECTOR MACHINE
Akurasi sebelum > Akurasi setelah STOP FINAL RESULT NO YES (FITUR -1)
a) Tanpa information gain b) Dengan information gain Gambar 1. Arsitektur Sistem
2.1. Support Vector Machine (SVM)
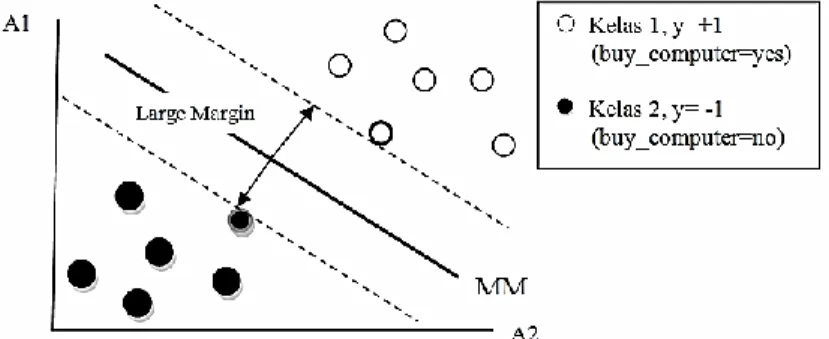
SVM dikembangkan pada tahun 1992 oleh Vladimir Vapnik dan rekannya, Bernhard Boser dan Isabelle Guyon yang dikembangkan dari teori structural risk minimaization. Dengan menggunakan trik kernel untuk memetakan sampel pelatihan dari ruang input ke ruang fitur dimensi tinggi [8]. Metode SVM menjadi sebuah metode baru yang menjanjikan untuk mengklasifikasi data, baik data linier maupun nonlinier. Sebuah SVM adalah sebuah algoritma yang bekerja menggunakan pemetaan nonlinier untuk mengubah data pelatihan asli ke dimensi yang lebih tinggi. Dalam dimensi yang baru, kemudian akan mencari linier optimal pemisah hyperplane (yaitu, “decision boundary” yang memisahkan tupel dari satu kelas dengan kelas lainnya) [2]. Dengan pemetaan nonlinier yang tepat untuk dimensi yang cukup tinggi, data dari dua kelas selalu dapat dipisahkan dengan hyperplane. SVM menemukan hyperplane ini menggunakan support vector (“essential” training tupels) dan margins (didefinisikan oleh support vectors). Pada Gambar 2, SVM menemukan hyperlane pemisah maksimum, yaitu hyperlane yang mempunyai jarak maksimum antara tupel pelatihan terdekat. Support vector ditunjukkan dengan batasan tebal pada titik tupel.
Gambar 2. Pemisahan dua kelas data dengan margin maksimum
Langkah awal suatu algoritma SVM adalah pendefinisian persamaan suatu hyperplane pemisah yang dituliskan dengan Persamaan (1).
(1)
dimana w merupakan suatu bobot vektor, yaitu { } n adalah jumlah atribut dan b merupakan suatu skalar yang disebut dengan bias. Jika berdasarkan pada atribut A1, A2 dengan permisalan tupel pelatihan X = ( , x1 dan x2 merupakan nilai dari atribut A1 dan A2, dan jika b dianggap sebagai suatu bobot tambahan , maka persamaan suatu hyperplane pemisah dapat ditulis ulang seperti pada Persamaan (2).
(2)
Setelah persamaan dapat didefinisikan, nilai dan dapat dimasukkan ke dalam persamaan untuk mencari bobot , dan atau b. Grafik pemisahan dua kelas data dengan margin maksimum dapat dilihat pada Gambar 1. Dengan demikian, setiap titik yang terletak di atas hyperplane pemisah memenuhi Persamaan 3.
(3)
Sedangkan, titik yang terletak dibawah hyperlane pemisah memenuhi rumus seperti pada Persamaan 4.
(4)
Melihat dua kondisi di atas, maka didapatkan dua persamaan hyperplane, seperti pada Persamaan (5) dan (6).
untuk yi = +1, (5) untuk yi = -1. (6) Artinya, setiap tuple yang berada di atas H1 memikiki kelas +1, dan setiap tuple yang berada di bawah H2 memiliki kelas -1. Perumusan model SVM menggunakan trik matematika yaitu Lagrangian Formulation. Berdasarkan Lagrangian formulation, Maksimum Margin Hyperplane (MMH) dapat ditulis ulang sebagai suatu batas keputusan (decision boundary) yaitu:
∑ (7) adalah label kelas dari support vector merupakan suatu tupel test. dan adalah parameter numerik yang ditentukan secara otomatis oleh optimalisasi algoritma SVM dan adalah jumlah vector support.
2.2. Feature Selection
Feature Selection adalah proses pemilihan fitur yang relevan, atau subset calon fitur. Kriteria evaluasi yang digunakan untuk mendapatkan bagian fitur optimal [9]. Feature selection merupakan teknik yang secara umum digunakan untuk mengurangi dimensi dikalangan praktisi [10]. Hal ini bertujuan untuk memilih subset kecil dari fitur yang relevan dari yang asli menurut kriteria evaluasi relevansi tertentu, yang biasanya menyebabkan kinerja learning yang lebih baik (misalnya, akurasi yang lebih tinggi untuk klasifikasi), biaya komputasi yang lebih rendah, dan model interpretability yang lebih baik. Penerapan metode fiture selection digunakan untuk mengurangi dimensi dari set fitur dengan menghapus fitur yang tidak relevan [11].
Fiture selection memiliki sejumlah keunggulan seperti ukuran dataset yang lebih kecil, menyusutnya ruang pencarian, dan kebutuhan komputasi ynag lebih rendah. Tujuannya adalah pengurangan ukuran dimensi untuk menghasilkan peningkatan akurasi klasifikasi. Metode untuk fiture subset selection untuk klasifikasi dokumen teks menggunakan fungsi evaluasi yang diterapkan untuk satu kata. Scoring dari kata-kata individu (Fitur individu terbaik) dapat dilakukan menggunakan beberapa tindakan, salah satunya information gain (IG). Metode fiture-scoring ini, peringkat fitur dan skor ditentukan secara independen.
2.3. Information Gain
Information gain merupakan ekspektasi dari pengurangan entropi yang dihasilkan dari partisi objek dataset berdasarkan fitur tertentu [7]. Entropi dari koleksi label benda S didefinisikan pada Persamaan (8). ∑ (8) Dimana Pi adalah proporsi S milik kelas i. Berdasarkan ini, matrik IG seperti pada Persamaan (9).
∑ | | || (9) Dimana nilai-nilai (A) adalah himpunan nilai untuk fitur A, S himpunan contoh training, Sv himpunan objek training set dimana A memiliki v.
2.4. Dataset
Kata „data‟ dalam terminologi statistik adalah kumpulan objek dengan atribut-atribut tertentu, di mana objek tersebut adalah individu berupa data di mana setiap data memilih sejumlah atribut. Atribut tersebut berpengaruh pada dimensi dari data, semakin banyak atribut/fitur maka semakin besar dimensi data. Kumpulan data-data membentuk dataset [12].
Dataset merupakan kumpulan dari objek dan atributnya. Atribut merupakan sifat atau karakteristik dari suatu objek. Contohnya: warna mata seseorang, suhu, dsb. Atribut juga dikenal sebagai variabel, field, karakteristik atau fitur. Kumpulan dari atribut menggambarkan sebuah objek. Objek juga disebut record, titik, kasus, sample, entitas atau instance [1]. Dataset yang diolah dalam data mining adalah keluaran dari sistem data warehouse yang menggunakan query untuk melakukan pengambilan data dari sejumlah tabel dalam sistem basis data [12].
3. HASIL DAN PEMBAHASAN
Penelitian ini diimplementasikan kedalam tool weka. Weka adalah koleksi dari algoritma learning machine yang digunakan untuk tugas-tugas data mining. Weka berisi tool untuk data pra-processing, klasifikasi, regresi, klustering, rule association, dan memvisualisasikan data tersebut menjadi mudah untuk dapat dipahami. Pada bagian ini, hasil eksperimen dianalisis untuk mengevaluasi kinerja algoritma data mining yang diusulkan. Fitur yang dipilih dengan metode optimalisasi atribut menggunakan information gain guna meningkatkan akurasi dari algoritma support vector machine dalam mendiagnosa chronic kidney disease.
Tabel 1 menunjukan presentase keakuratan dari algoritma support vector machine dalam mendiagnosa chronic kidney disease dengan tidak menggunakan penerapan information gain. Sedangkan Tabel 2 menunjukan hasil akurasi dari algoritma support vector machine dengan menggunakan penerapan information gain. Hasil dari Tabel 2 diperoleh dari menghapus satu persatu fitur dalam dataset yang memiliki nilai atribut terendah yang tidak terlalu berpengaruh. Dan pada saat hasil presentase akurasi mengalami penurunan maka pada penelitian ini, penghapusan fitur dihentikan dan mengambil tingkat akurasi maksimal sebelum mengalami penurunan tersebut.
Tabel 1. Tingkat akurasi support vector machine Algoritma Tanpa Information Gain
SVM 97.75 %
Tabel 2. Tingkat akurasi support vector machine dengan information gain Penghapusan
fitur
akurasi
awal ke-1 ke-2 ke-3 ke-4 ke-5 ke-6 ke-7 ke-8 ke-9 ke-10 ke-11 ke-12 Akurasi (%) 97.75 97.75 97.75 98.25 98.25 98.25 98.25 98.50 98.50 98.50 98.50 98.50 97.75
Gambar 3 menunjukan proses peningkatan akurasi algoritma support vector machine menggunakan penerapan information gain dengan menghapus satu persatu fitur dengan nilai atribut terrendah. Dan tingkat akurasi maksimal pada penghapusan atribut ke-11.
Gambar 3: Tingkat akurasi SVM dengan penerapan information gain
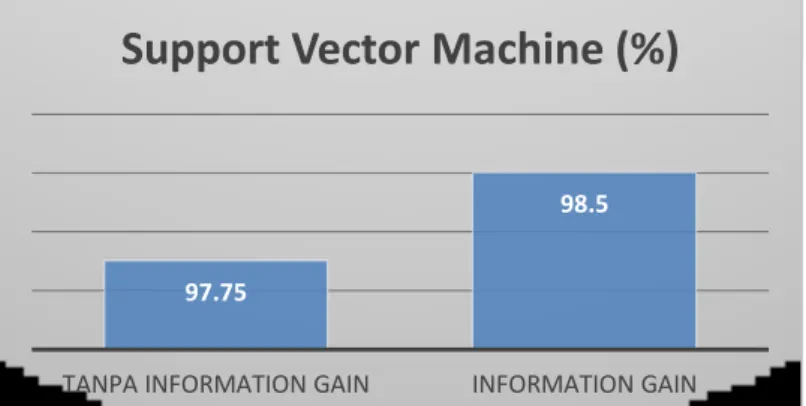
Tabel 3 menunjukan bahwa dengan menerapkan information gain pada algoritma support vector machine telah terjadi perubahan presentase akurasi algoritma support vector machine dalam mendiagnosa chronic kidney disease. Dan pada Gambar 4, diagram menunjukan peningkatan akurasi dari algoritma support vector machine sebelum dan setelah menerapkan information gain.
Tabel 3: Perbandingan tingkat akurasi support vector machine Algoritma Tanpa Information Gain Information Gain
SVM 97.75 % 98.50% 97.75 97.75 97.75 98.25 98.25 98.25 98.25 98.5 98.5 98.5 98.5 98.5 97.75 97.2 97.4 97.6 97.898 98.2 98.4 98.6
PRESENTASI AKURASI SVM DENGAN INFORMATION GAIN (%)
Gambar 4: Tingkat akurasi algoritma support vector machine 4. SIMPULAN
Dalam proses penelitian ini, peneliti menggunakan dataset chronic kidney disease yang diperoleh dari UCI repository of machine learning datasets. Dari hasil percobaan dengan menggunakan information gain, algoritma support vector machine menunjukan peningkatan 0,75% pada akurasi dari 97,75% menjadi 98,5% dalam proses diagnosa. Dapat disimpulkan bahwa penerapan information gain dapat meningkatkan akurasi algoritma support vector machine dalam mendiagnosa chronic kidney disease. 5. REFERENSI
[1] Hermawati, F. A. 2013. Data mining. CV. Andi Offset, Yogyakarta.
[2] Han, J., Jian, P., dan Micheline, K. 2012. Data mining: Concepts and Techniques (3th ed.). MA: Elsevier/Morgan Kaufmann, Waltham.
[3] Dhayanand, M, S., & Vijayarani, S. 2015. Data Mining Classification Algorithms for Kidney Disease Prediction. International Journal on Cybernetics & Informatics (IJCI). Vol. 4(4): 13-25. [4] Chezian, D. R. M., & Kumar, K. S. 2014. Support Vector Machine and K-Nearest Neighbor Based
Analysis for the Prediction of Hypothyroid. International Journal of Pharma and Bio Sciences, 5(4): (B) 447-453.
[5] Bolton, K., Culleton, B., & Harvey, K. 2002. K/DOQI Clinical Practice Guidelines for Chronic Kidney Disease: Evaluation, Classification, and Stratification. Kidney Disease Outcome Quality Initiative. Am JKidney Dis, 39(2 Suppl 1), S1-246.
[6] Arora, J., & Beniwal, S. 2012. Classification and Feature Selection Techniques in Data Mining. International Journal of Engineering Research & Technology (IJERT). 1-6.
[7] Jensen, R., & Shen, Q. 2008. Computational Intelligence and Feature Selection: Rough and Fuzzy Approaches Vol. 8. John Wiley & Sons, New Jersey.
[8] Li, X., Sung, E., & Wang, L. 2008. AdaBoost with SVM-based Component Classifiers. Engineering Applications of Artificial Intelligence. Vol. 21 (5): 785-795.
[9] Kumar, V., & Minz, S. 2014. Feature Selection: A Literature Review. Smart Computing Review. Vol 4(3): 211-229.
[10] Alelyani, S., Liu, H., & Tang, J. 2014. Feature selection for classification: A review. Data Classification: Algorithms and Applications. (37).
[11] Jain, A., Jindal, R., & Malhotra, R. 2015. Techniques for Text Classification: Literature Review and Current Trends. Weobology. Vol. 12(2): 1-28.
[12] Prasetyo, E. 2014. Data Mining: Mengolah Data Menjadi Informasi Menggunakan Matlab. CV. Andi Offset, Yogyakarta.
97.75
98.5
TANPA INFORMATION GAIN INFORMATION GAIN