BAB 2
LANDASAN TEORI
2.1 Algoritma
Algoritma adalah urutan langkah logis tertentu untuk memecahkan suatu masalah. Yang ditekankan adalah urutan langkah logis, yang berarti algoritma harus mengikuti suatu urutan tertentu, tidak boleh melompat-lompat dan disusun secara sistematis. Sedangkan yang dimaksud dengan langkah-langkah logis adalah kita harus dapat mengetahui dengan pasti setiap langkah yang kita buat. (Microsoft Press Computer and Internet Dictionary, 1998). Algoritma adalah alur pemikiran dalam menyelesaikan suatu pekerjaan yang dituangkan secara tertulis. Pertama yang ditekankan adalah alur pikiran, sehingga algoritma seseorang dapat berbeda dari algoritma orang lain. Sedangkan penekanan kedua adalah tertulis, yang artinya dapat berupa kalimat, gambar, atau tabel tertentu (sjukani,2005). Berdasarkan definisi diatas dapat disimpulkan bahwa Algoritma adalah ilmu yang mempelajari cara penyelesaian suatu masalah dengan langkah-langkah yang disusun secara sistematis dan menggunakan bahasa yang logis untuk tujuan tertentu.
Pertimbangan dalam pemilihan algoritma yaitu pertama, algoritma haruslah benar. Artinya algoritma harus menghasilkan sebuah jawaban dari permasalahan yang didapat. Pertimbangan kedua yaitu algoritma bisa dikatakan berhasil apabila algoritma tersebut sudah menghasilkan satu atau lebih dari permasalahan yang dihadapi. Pendekatan ketiga adalah efisiensi algoritma. Efisiensi yang dimaksud yaitu dari segi waktu dan memori. Namun, efisiensi penelitian ini lebih fokus dalam segi waktu.
2.2 Algoritma Pencocokan String
Pengertian string menurut Dictionary of Algorithms and Data Structures, National Institute of Standards and Technology (NIST) adalah susunan dari karakter-karakter (angka, alfabet atau karakter yang lain) dan biasanya direpresentasikan sebagai struktur data array.
Pencocokan string atau string matching adalah proses pencarian semua kemunculan string pendek P[0..n-1] yang disebut pattern di string yang lebih panjang T[0..m-1] yang disebut teks(Charras, 2004).Pencockan string merupakan masalah paling sederhana dari semua permasalahan string lainnya, dan merupakan bagian dari pemrosesan data, pengkompresian data, lexical analysis, dan temu balik informasi. Teknik untuk menyelesaikan permasalahan pencocokan string biasanya akan menghasilkan implikasi langsung ke aplikasi string lainnya (Breslaur,1992).
Persoalan pencarian string dirumuskan sebagai berikut: 1. teks (text), yaitu (long) string yang panjangnya n karakter
2. Diberikan pattern, yaitu string dengan panjang m karakter (m<n) yang akan dicari di dalam teks.
Setelah itu, dicari lokasi pertama di dalam teks yang bersesuaian dengan pattern. Carilah (find atau locate) lokasi pertama di dalam teks yang bersesuaian dengan pattern.untuk bisa memahami persoalan diatas maka akan saya berikan contoh dibawah in :
Teks
Pattern
Pola (Pattern) dinotasikan dengan x = x[0..m- 1]; panjangnya adalah m. Teks dinotasikan dengan y = y[0..n– 1]; panjangnya adalah n. Kedua string membangun lebih dari satu set terbatas karakter yang disebut alfabet, dinotasikan dengan ∑ dengan ukuran yang sama dengan σ (Charras, 2004).
Pencocokan string (string matching) secara garis besar dapat dibedakan menjadi dua yaitu:
1. Exact string matching, merupakan pencocokan string secara tepat dengan susunan karakter yang sama dalam string yang dicocokkan memiliki kemiripan dalam
K A M U S I S L A M
jumlah maupun urutan karakter dalam string yang sama. Contoh : kata sleep akan menunjukkan kecocokan hanya dengan kata sleep.
2. Inexact string matching atau Fuzzy string matching, merupakan pencocokan string secara samar, maksudnya pencocokan string dimana string yang dicocokkan memiliki kemiripan dimana keduanya memiliki susunan karakter yang berbeda (mungkin jumlah atau urutannya) tetapi string-string tersebut memiliki kemiripan baik kemiripan tekstual/penulisan (approximate string matching) atau kemiripan ucapan (phonetic string matching).
Inexact string matching masih dapat dibagi lagi menjadi dua yaitu :
a. Pencocokan string berdasarkan kemiripan penulisan (approximate string matching)
adalah masalah di ilmu komputer yang diaplikasikan dalam pencarian teks(Akhtar & Tiwari, 2012). Approximate string matching merupakan pencocokan string dengan dasar kemiripan dari segi penulisannya (jumlah karakter, susunan karakter dalam dokumen). Tingkat kemiripan ditentukan dengan jauh tidaknya beda penulisan dua buah string yang dibandingkan tersebut dan nilai tingkat kemiripan ini ditentukan oleh pemrogram (programmer). Contoh c mpuler dengan compiler, memiliki jumlah karakter yang sama tetapi ada dua karakter yang berbeda. Jika perbedaan dua karakter ini dapat ditoleransi sebagai sebuah kesalahan penulisan maka dua string tersebut dikatakan cocok
b. Pencocokan string berdasarkan kemiripan ucapan (phonetic string matching) merupakan pencocokan string dengan dasar kemiripan dari segi pengucapannya meskipun ada perbedaan penulisan dua string yang dibandingkan tersebut. Contoh step dengan steb dari tulisan berbeda tetapi dalam pengucapannya mirip sehingga dua string tersebut dianggap cocok. Contoh yang lain adalah step, dengan steppe, sttep, stepp, stepe.
Exact string matching bermanfaat jika pengguna ingin mencari string dalam dokumen yang sama persis dengan string masukan. Tetapi jika pengguna menginginkan pencocokan string yang mendekati dengan string masukan atau terjadi kesalahan penulisan string masukan maupun dokumen objek pencarian, maka inexact string matching yang bermanfaat,mesin pencarian google merupakan mesin pencarian yang menggunakan dua metode tersebut dalam pencariannya.
2.3 Algoritma Bitap
Algoritma Bitap yang juga dikenal dengan nama shift-and, shift or atau Baeza-Yates-Gonnet adalah algoritma pencarian fuzzy string (Sun wu, 1991). Algoritma Bitap untuk pencarian string ditemukan oleh Balint Domolki pada tahun 1964(Domolki, 1964) kemudian dikembangkan oleh R.K Shyamasundar pada tahun 1977 sebelum ditemukan kembali untuk pencarian string fuzzy oleh Menber dan Wu pada tahun 1991. Berdasarkan kerja yang dilakukan oleh Ricardo Baeza-Yates dan Gaston Gonnet. Karakterikstik utama algoritma Bitap :
1. Menggunakan teknik perhitungan level bit.
2. Algoritma ini efisien jika pola yang digunakan tidak lebih panjang dari ukuruan memory komputer yag digunakan.
3. Fase prepocessing memerlukan waktu dengan kompleksitas O(m + σ ) 4. Fase pencarian dengan kompleksitas O(n)
5. Dapat digunakan untuk pendekatan pencarian string
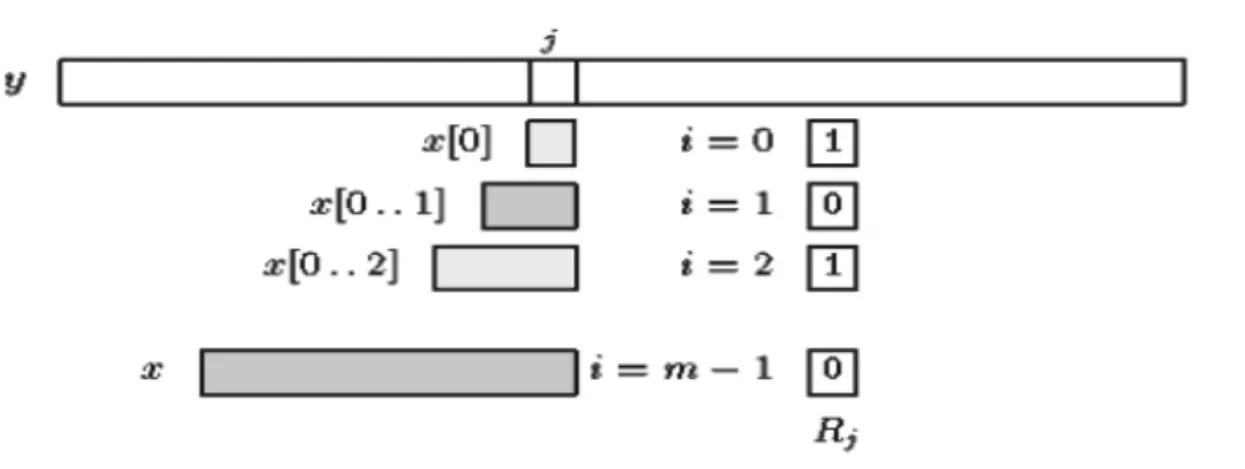
Algoritma Bitap menggunakan level bit misalkan R adalah array level bit of bit dengan ukuran m. Vektor Rj adalah nilai dari vektor R seteleh karakter teks y[j] di proses (lihat gambar 1). Vektor Rj mengandung informasi tentang semua kecocokan dari awal dari x yang berakhir di posisi j di dalam teks untuk 0 < i <= m-1 yaitu :
Gambar 2.1.Vektor Rj dari teks y pada karakter ke j ( Charras, 2004)
Jika Rj+1[m-1] = 0 maka kecocokan yang lengkap telah didapatkan. Perubahan dari Rj ke Rj+1 dapat dihitung dengan sangat cepat sebagai berikut : untuk setiap c di ∑, misalkan Sc adalah array of bit dengan ukuran m sehingga untuk 0 <= I <m-1, maka
Sc[i] = 0 jika dan hanya jika x[i]= c. Array Sc menyatakan posisi dari karakter c di dalam pattern x . Setiap Sc dapat dihitung dahulu sebelum dilakukan fase pencarian. Perhitungan dari Rj+1 mengurangi dua buah operasi, shift dan or : Rj+1 = SHIFT(Rj) OR Sy[j+1]. Misalkan bahwa panjang pattern tidak lebih panjang dari tempat penyimpanan 1 word (8 bit) di komputer, maka kompleksitas perhitungan ruang dan waktu dari fase perhitungannya adalah O(m+ σ) dan kompleksitas waktu untuk fase pencarian adalah O(n) karena tidak bergantung pada ukuran alfabet dan panjang pattern (Fernando, 2009).
2.3.1. Fase Pencarian Algoritma Bitap
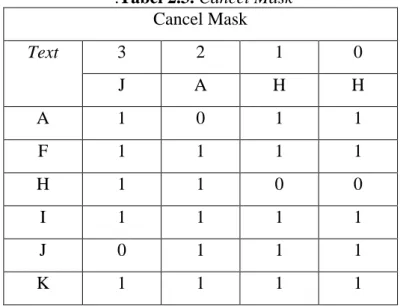
Pada fase pencarian algoritma Bitap menggunakan tabel cancel mask dan variabel match register terlebih dahulu . Fungsi tabel cancel mask untuk mencatat kumpulan karakter alfabetik pada pattern yang muncul. Algoritma Bitap membutuhkan tabel cancel mask yang berisi karakter sejumlah karakter yang ada pada karakter alfabet. Alfabet menentukan jumlah dan sifat karakter dalam teks dan pola (Feigl, 2015). Pada tabel cancel mask ini, nilai benar diwakili dengan 0 dan nilai salah diwakili dengan 1. Kita misalkan pola HHAJ yang akan dicari dari teks FIKIHHAJI.
Tabel 2.1. Urutan index text
0 1 2 3 4 5 6 7 8
F I K I H H A J I
Tabel 2.2. Urutan index pola
0 1 2 3
2.3.2 Tabel Cancel Mask
Fungsi tabel cancel mask untuk mencatat kumpulan karakter alfabetik pada pattern yang muncul. Pada tabel cancel mask ini, nilai benar diwakili dengan 0 dan nilai salah diwakili dengan 1. Cara membangun tabel cancel mask adalah sebagai berikut:
1. Panjang pattern (banyak karakter) menentukan banyak kolom tabel. kolom dinomori dengan urutan mulai dari kanan ke kiri (jadi 1 berada di sudut kanan tabel).
2. Banyaknya alfabet menentukan banyakya baris tabel. Jika pada pattern, karakter x berada pada urutan ke y (kemunculan karakter tersebut pada urutan ke-y bernilai benar) maka pada tabel baris karakter tersebut pada urutan ke-y diisi dengan 0. Lakukan untuk semua karakter pada pattern, isi dengan 1 kolom yang kosong.
.Tabel 2.3. Cancel Mask Cancel Mask Text 3 2 1 0 J A H H A 1 0 1 1 F 1 1 1 1 H 1 1 0 0 I 1 1 1 1 J 0 1 1 1 K 1 1 1 1
2.3.3 Tabel Match Register
Tabel Match Register adalah tabel yang berfungsi untuk mencatat kecocokan karakter yang mucul pada pattern. Cara membangun match register :
1. Buat tabel match register dengan kolom sepanjang jumlah karakter pada pattern. 2. Isi tabel match register dengan 1.
Tabel 2.4. Match Register
J A H H
3 2 1 0
1 1 1 1
Langkah selanjutnya lakukan shift ke kiri sekali. Shift kiti bertujuan untuk memindahkan setiap bit diregister pada posisi paling kiri untuk menempatkan 0 pada posisi paling kanan atau least significant bit.
Tabel 2.5. Match Register setelah dilakukan shift
J A H H
3 2 1 0
1 1 1 0
Cara kerja algoritma Bitap :
1. Gunakan logika OR terhadap match register dan tabel cancel mask untuk karakter pertama pada teks.
2. Simpan hasilnya pada match register. Variabel match register baru ini menjadi match register y ang di-OR-kan dengan cancel mask untuk karakter berikutnya 3. Dan langkah di atas dilakukan pada semua karakter pada teks sampai terdapat
pada teks paling kiri match register.
4. Lakukan pengecekan pada posisi pattern dengan rumus [shift [i] ] = j – m +1, j adalah posisi terakhir pattern yang terdapat pada text dan m adalah panjang patternnya dan hasilnya adalah posisi awal pattern pada text.
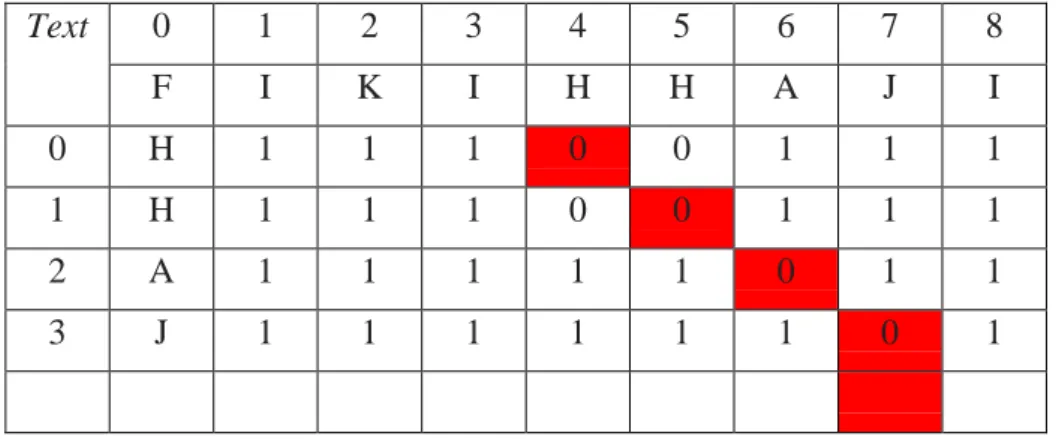
Tabel 2.6. Fase Pencarian Algoritma Bitap
Text 0 1 2 3 4 5 6 7 8 F I K I H H A J I 0 H 1 1 1 0 0 1 1 1 1 H 1 1 1 0 0 1 1 1 2 A 1 1 1 1 1 0 1 1 3 J 1 1 1 1 1 1 0 1
Y7[4] = 0 berarti X telah ditemukan pada posisi 7 -4 + 1 = 4. Maka pattern HHAJ telah ditemukan pada uritan indext ke 4 hingga ke 8 pada text.
2.4 Algoritma Not So Naϊve
Algoritma Not So Naϊve merupakan algoritma turunan dari algoritma Naϊve yang cukup efisien dalam memecahkan beberapa kasus. Algoritma ini pertama kali diperkenalkan oleh Christophe Hancart pada tahun 1992. Cara kerja algoritma Not So Naϊve mirip dengan cara kerja algoritma Naive yaitu pada fase pencarian dilakukan dengan memindai teks dan pola dari kiri ke kanan. Pada algoritma Not So Naϊve setiap akhir fase pencocokan dapat dilakukan pergeseran sebanyak dua kali ke sebelah kanan sedangkan pada algoritma Naive pergeseran hanya bisa dilakukan sebanyak satu kali. Karakteristik umum algoritma Not So Naϊve :
1. Fase preprocessing dalam kompleksitas waktu yang konstan. 2. Kompleksitas ruang eksta konstan.
3. Waktu yang konstan pada fase pencarian O(mxn). 4. Sub liniernya sedikit dalam rata-rata kasus.
Kita asumsikan bahwa P[0]≠P[1]. Jika P[0] = T[s] dan P[1] = T[s+1], maka di akhir fase pencocokan pergeseran s bisa dilakukan sebanyak 2 posisi, karena P[0]≠P[1] = pergesaran s dapat dilakukan sebanyak 2 posisi (Cantone & Faro, 2004).
2.4.1 Fase Pencarian Algoritma Not So Naϊve
Pada saat proses pencarian algoritma Not So Naϊve melakukan perbandingan karakter dengan menetapkan posisi urutan pola sebagai berikut, 1,2 .. m-2, m-1,0 . Pada setiap percobaan jendela diletakan pada teks faktor y[i..j + m-1]. Jika x[0] = x[1] dan x[1]≠y[j+1] atau jika x[0]≠x[1] dan x[1] = y[j+1]. polanya akan digeser sebanyak 2 posisi di setiap akhir percobaan dan sebanyak 1 posisi jika kondisi di atas tidak terpenuhi (Alapati & Mannava, 2011). Y kita asumsikan sebagai teks dan x sebagai pattern. Jika karakter urutan 0 dan 1 mengalami kecocokan (x[0] != x[1] maka nilai variabel ell akan diinisialisasi dengan 2. Jika karakter urutan 0 dan 1 mengalami ketidak cocokan (x[1] != y[j+1]) maka nilia variabel k akan diinisialisasi dengan 1. Kita misalkan pola HHAJ yang akan dicari dari teks FIKIHHAJI.
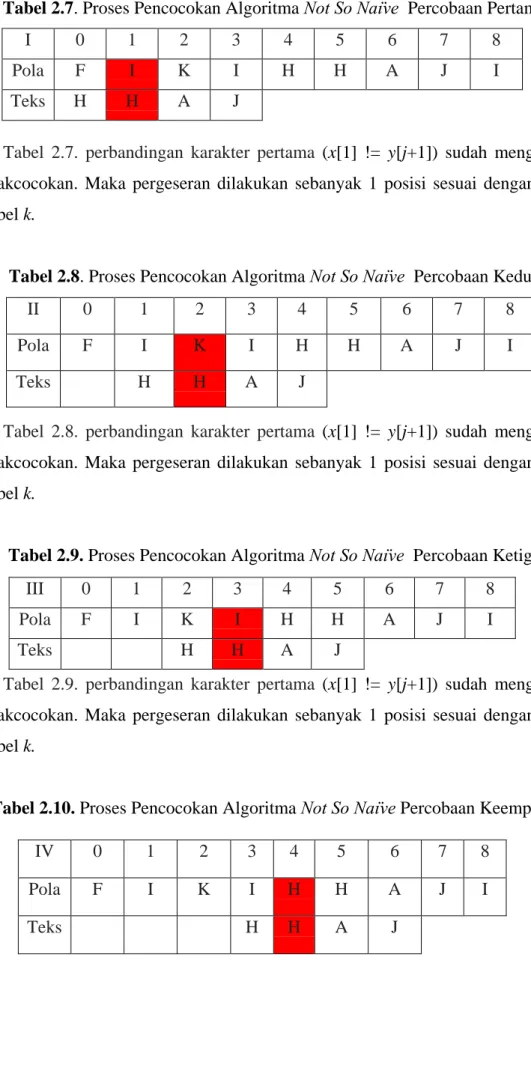
Tabel 2.7. Proses Pencocokan Algoritma Not So Naϊve Percobaan Pertama
I 0 1 2 3 4 5 6 7 8
Pola F I K I H H A J I
Teks H H A J
Pada Tabel 2.7. perbandingan karakter pertama (x[1] != y[j+1]) sudah mengalami ketidakcocokan. Maka pergeseran dilakukan sebanyak 1 posisi sesuai dengan nilai variabel k.
Tabel 2.8. Proses Pencocokan Algoritma Not So Naϊve Percobaan Kedua
Pada Tabel 2.8. perbandingan karakter pertama (x[1] != y[j+1]) sudah mengalami ketidakcocokan. Maka pergeseran dilakukan sebanyak 1 posisi sesuai dengan nilai variabel k.
Tabel 2.9. Proses Pencocokan Algoritma Not So Naϊve Percobaan Ketiga
Pada Tabel 2.9. perbandingan karakter pertama (x[1] != y[j+1]) sudah mengalami ketidakcocokan. Maka pergeseran dilakukan sebanyak 1 posisi sesuai dengan nilai variabel k.
Tabel 2.10. Proses Pencocokan Algoritma Not So Naϊve Percobaan Keempat
II 0 1 2 3 4 5 6 7 8 Pola F I K I H H A J I Teks H H A J III 0 1 2 3 4 5 6 7 8 Pola F I K I H H A J I Teks H H A J IV 0 1 2 3 4 5 6 7 8 Pola F I K I H H A J I Teks H H A J
perbandingan karakter pertama (x[1] != y[j+1]) sudah mengalami ketidakcocokan. Maka pergeseran dilakukan sebanyak 1 posisi sesuai dengan nilai variabel k.
Tabel 2.11. Proses Pencocokan Algoritma Not So Naϊve di Percobaan Kelima
perbandingan karakter mengalami kecocokan (x[1] == y[j+1]) semua karakter mengalami kecocokan dimulai dari H,H,A, dan J. Maka teks akan dikeluarkan. Namun algoritma Not So Naϊve tidak berhenti melakukan pengecekan sampai sisa teks lebih sedikit dari pola, barulah berhenti. Pergeseran dilakukan sebanyak 2 posisi sesuai dengan nilai variabel ell
Tabel 2.12. Proses Pencocokan Algoritma Not So Naϊve Percobaan Keenam
Sisa teks sudah lebih kecil dari panjang pola maka fase pencarian berhenti sampai di percobaan kelima.
2.5. Kompleksitas Algoritma
Algoritma adalah metode untuk memecahkan masalah pada komputer. Kompleksitas algoritma adalah biaya, running time, atau apa pun yang relevan terhadap algoritma tersebut untuk menyelesaikan salah satu masalah tersebut (wilf, 1994). Algoritma yang bagus bukan hanya algoritma yang bisa menyelesaikan masalah tapi juga algoritma yang mampu menyelesaiakn masalah secara mangkus. Suatu algoritma akan memerlukan masukan (input) tertentu untuk memulainya, dan akan menghasilkan keluaran (output) tertentu pada akhirnya. Hal-hal yang perlu diperhatikan dalam algoritma adalah mencari langkah-langkah yang paling sesuai untuk penyelesaian
V 0 1 2 3 4 5 6 7 8 Pola F I K I H H A J I Teks H H A J VI 0 1 2 3 4 5 6 7 8 Pola F I K I H H A J I Teks H H
suatu masalah, karena setiap algoritma memiliki karakteristik tertentu yang memiliki kelebihan dan kekurangan. (Nugraha, 2011).
Kompleksitas dari suatu algoritma merupakan seberapa banyak komputasi yang dibutuhkan algoritma tersebut untuk menyelesaikan masalah. Secara informal, algoritma yang dapat menyelesaikan suatu permasalahan dalam waktu yang singkat memiliki kompleksitas yang rendah, sementara algoritma yang membutuhkan waktu lama untuk menyelesaikan masalahnya mempunyai kompleksitas yang tinggi. (Azizah, 2013). Kompleksitas waktu yang dihasilakan sengat bergantung pada baik buruknya algoritma tersebut. Jika komputer dapat menyelesaikan perhitungan dengan cepat dan benar maka algoritma tersebut adalah algoritma yang efisien. Untuk mengukur efektivitas algortima dapat dibedakan menjadi dua macam yaitu kompleksitas ruang dinyatakan oleh S(n) dan kompleksitas waktu dinyatakan oleh T(n) . Kompleksitas ruang berkaitan dengan sistem memori yang dibutuhkan dalam eksekusi program. Kompleksitas waktu dari algoritma berisi ekspresi bilangan dan jumlah langkah yang dibutuhkan sebagai fungsi dari ukuran permasalahan.
Kompleksitas waktu asimptotik terdiri dari tiga macam. Pertama keadaan terbaik (best case) dinotasikan dengan Ω (g(n)) (Big-Omega), keadaan rata-rata (average case) dilambangkan dengan notasi ϴ (g(n)) (Big-Theta) dan keadaan terburuk (worst case) dilambangkan dengan O (g(n)) (Big-O).
2.6. Kamus
Menurut Kamus Besar Bahasa Indonesia ( KBBI), Kamus adalah buku acuan yang memuat kata dan ungkapan, biasanya disusun menurut abjad berikut keterangan tentang makna, pemakaian, atau terjemahannya. Buku yang memuat kumpulan istilah atau nama yang disusun menurut abjad beserta penjelasan tentang makna dan pemakaiannya. Kata kamus diserap dari bahasa Arab qamus (قاموس), dengan bentuk jamaknya qawamis. Kata Arab itu sendiri berasal dari kata Yunani Ωκεανός (okeanos) yang berarti samudra. Sejarah kata itu jelas memperlihatkan makna dasar yang terkandung dalam kata kamus, yaitu wadah pengetahuan, khususnya pengetahuan bahasa, yang tidak terhingga dalam dan luasnya. Dewasa ini kamus merupakan khazanah yang memuat perbendaharaan kata suatu bahasa, yang secara ideal tidak terbatas jumlahnya.
Secara fisik, kamus terbagi menjadi dua jenis yaitu kamus yang berbentuk buku dan kamus elektronik (digital). Kamus berbentuk buku terdiri dari puluhan bahkan ratusan lembar halaman kata. Berbeda dengan kamus buku yang cenderung besar dan tebal, kamus elektronik atau kamus digital merupakan sebuah fasilitas yang membantu pengguna mencari kata dengan cara mengetikkan kata yang diinginkan pada kolom pencarian. Penggunaan kamus elektronik atau kamus digital ini lebih efisien dalam hal waktu dibandingkan dengan kamus buku. (Tania, 2015).
2.7 Agama Islam
Islam adalah agama yang mengimani satu Tuhan, yaitu Allah. Dengan lebih dari satu seperempat miliar orang pengikut di seluruh dunia, menjadikan Islam sebagai agama terbesar kedua di dunia setelah agama Kristen. Islam memiliki arti "penyerahan", atau penyerahan diri sepenuhnya kepada Tuhan (Arab: الله, Allāh). Pengikut ajaran Islam dikenal dengan sebutan muslim yang berarti "seorang yang tunduk kepada Tuhan, atau lebih lengkapnya adalah Muslimin bagi laki-laki dan Muslimat bagi perempuan. Islam mengajarkan bahwa Allah menurunkan firman-Nya kepada manusia melalui para nabi dan rasul utusan-Nya, dan meyakini dengan sungguh-sungguh bahwa Muhammad adalah nabi dan rasul terakhir yang diutus ke dunia oleh Allah. Sebagai umat Islam, kita harus mengetahui pengertian Islam, karakteristik Islam maupun sumber ajaran Islam itu sendiri sehingga dapat dihasilkan pemahaman Islam yang komprehensif. Hal ini diperlukan supaya agama ini tidak hanya sekedar “status”, tetapi dapat di jalankan dengan penuh keyakinan demi mewujudkan muslim dan muslimah yang nantinya dapat menyebarkan agama Islam walau hanya satu ayat (Yudyawati, 2015). Berikut beberapa contoh istilah agama Islam dapat dilihat pada Tabel 2.13.
Tabel 2.13. Istilah agama Islam
No Kata Arti Kata
1 Dalil Keterangan dari nash yang dijadikan sebagai bukti atau alasan untuk suatu kebenaran.
2 Fuqoha Ulama-ulama fikih
3 Ghanimah Harta rampasan yang diperoleh kaum Muslimin melalui pertempuran.
4 Istbat Penetapan
5 Hujjah Dalil dan bukti nyata. Hujjah merupakan dasar dan sandaran yang dijadikan pegangan dalam berkeyakinan dan beramal.
7 Nadzhar Janji seorang mukallaf dengan kemauan sendiri untuk mewajibkan sesuatu atas dirinya yang sebenarnya tidak wajib secara syar'i.
2.8 Penelitian yang relevan
Berikut ini beberapa penelitian yang terkait dengan algoritma Bitap dan algortitma Not So Naϊve :
1. Pada penelitian terdahulu yang dilakukan oleh (Cantone, D. & Faro, S., 2004) tentang “Searching for a Substring with Constant Extra Space Complexity”, menyimpulkan bahwa algoritma pencocokan string Not So Naϊve adalah algoritma yang baik untuk menyelesaikan beberapa kasus dalam pencarian kata.
2. Pada penelitian terdahulu yang dilakukan oleh (Fernando, 2009) tentang “Perbandingan dan Pengujian Beberapa Algoritma Pencocokan String”, menyimpulkan bahwa Algoritma Bitap menggunakan pengoperasian bit untuk mencari kesamaan pattern dan teks.
3. Pada penenlitian terdahulu yang dilakukan oleh (Aprita, 2015) tentang “Implementasi Metode Fuzzy String Matching Menggunakan Algoritma String Matching Bitap pada Aplikasi Pencarian Berkas di Komputer”, menyimpulkan bahwa kelebihan algoritma Bitap adalah preprocessing dan pencariannya sangat sederhana, menghasilkan waktu proses yang real time dan tidak adanya proses penyimpanan file.
4. Pada penenlitian terdahulu yang dilakukan oleh (Wijaya, 2016) tentang “ Perbandingan Algoritma String Matching Not So Naϊve dan Skip Search Pada Platform Android”, menyimpulkan bahwa algoritma Not So Naϊve hanya efisien untuk pencarian kata namun tidak efisien untuk pencarian kalimat karena semakin panjang teks maka semakin lama proses pengecekan yang dilakukan