i
SISTEM PENGENALAN SUARA UNTUK MENGENALI
PERINTAH SUARA MENGGUNAKAN JARINGAN SYARAF
TIRUAN BACKPROPAGATION
SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer Program Studi Teknik Informatika
Oleh : I Putu Desyanndana
145314065
TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
VOICE RECOGNITION SYSTEM FOR RECOGNIZE VOICE
COMMAND USING BACKPROPAGATION NEURAL NETWORK
FINAL PROJECT
Presented as Partial Fulfillment of Requirements to Obtain Sarjana Komputer Degree in Informatics Engineering Department
By :
I Putu Desyandana 145314065
INFORMATICS ENGINEERING STUDY PROGRAM FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY YOGYAKARTA
v
MOTO
JIKA KAMU TIDAK MENYUKAI SESUATU, UBAHLAH.
JIKA TIDAK BISA MENGUBAHNYA, UBAH SIKAPMU
MAYA ANGELOU
SATU-SATUNYA CARA UNTUK MENCINTAI
PEKERJAAN YANG HEBAT ADALAH DENGAN
MENCINTAI APA YANG KAMU LAKUKAN
vi
PERNYATAAN KEASLIAN KARYA
Saya menyatakan sesungguhnya bahwa di dalam skripsi yang saya tulis ini tidak memuat karya atau bagian karya orang lain, kecuali telah disebutkan dalam kutipan dan daftar pustaka, sebagaimana layaknya karya ilmiah.
Yogyakarta, 31 Januari 2019 Penulis
vii
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI
ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan dibawah ini, saya mahasiswa Universitas Sanata Dharma: Nama : I Putu Desyanndana
NIM : 145314065
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan Universitas Sanata Dharma karya ilmiah yang berjudul :
SISTEM PENGENALAN SUARA UNTUK MENGENALI PERINTAH SUARA MENGGUNAKAN JARINGAN SYARAF TIRUAN
BACKPROPAGATION
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada perpustakaan Universitas Sanata Dharma hak untuk menyimpan, mengalihkan daam bentuk media lain, mengelolanya dalam bentuk pangkalan data, mendistribusikan secara terbatas, dan mempublikasikannya di internet atau media lain untuk kepentingan akademis tanpa perlu meminta izin dari saya maupun memberikan royalti kepada saya selama tetap mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya.
Dibuat di Yogyakarta
Pada Tanggal 31 Januari 2019 Yang Menyatakan
viii
INTISARI
Suara manusia merupakan gelombang yang sangat unik. Hal itu dikarenakan setiap manusia memiliki gelombang suara yang berbeda. Telinga manusia normal dapat mendengarkan berbagai jenis ucapan sehingga mampu mendefinisikan huruf, kalimat atau kata yang diucapkan. Berdasarkan hal tersebut dibentuklah sistem yang mampu mengenali suara manusia. Secara khusus lagi, penulis membuat sistem pengenalan perintah suara dalam mengendalikan peralatan elektronik di rumah.
Penelitian ini memproses suara yang merupakan file rekaman dari kalimat perintah suara. Menggunakan metode Mel Frequency Cepstral Coefficients dalam melakukan ekstraksi ciri suara. Hasil ekstraksi ciri suara dimasukkan ke Jaringan Syaraf Tiruan Backpropagation untuk klasifikasi.
Percobaan klasifikasi dengan Jaringan Syaraf Tiruan Backpropagation, dengan optimalisasi arsitektur jaringan, dihasilkan akurasi terbaik menggunakan dua hidden layer dengan 15 neuron untuk setiap hidden layer sebesar 71,52%.
ix
ABSTRACT
Human voice is a very unique wave. That is because every human being has different sound waves. Normal human ears can listen to various types of speech so they are able to define letters, sentences or words that are spoken. Based on this, a system is formed that is able to recognize human voices. In particular again, the author made a system of recognition of voice commands in controlling electronic equipment at home.
This research processes sound which is a recording file from a voice command sentence. Using the Mel Frequency Cepstral Coefficients method in performing voice feature extraction. The feature extraction results are entered into Backpropagation Artificial Neural Networks for classification.
Classification experiments with Backpropagation Artificial Neural Networks, by optimizing network architecture, produced the best accuracy using two hidden layers with 15 neurons for each hidden layer at 71.52%.
x
KATA PENGANTAR
Puji syukur penulis panjatkan kepada Ida Sang Hyang Widhi Wasa, Tuhan Yang Maha Esa, yang telah memberikan karunia berlimpah sehingga penulis dapat menyelesaikan tugas akhir dengan sangat baik.
Penulis menyadari bahwa pada saat pengerjaan tugas akhir ini penulis mendapatkan banyak bantuan dari berbagai pihak, baik berupa perhatian, kritik, dan saran yang sangat penulis butuhkan untuk kelancaran dan mendapatkan hasil yang baik. Pada kesempatan ini penulis akan menyampaikan ucapan terima kasih kepada:
1. Sudi Mungkasi, S.Si., M.Math.Sc., Ph.D. selaku Dekan Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta.
2. Dr. Cyprianus Kuntoro Adi, S.J., M.A., M.Sc., selaku dosen pembimbing tugas akhir yang telah sabar dan penuh perhatian membimbing saya dalam penyusunan tugas akhir.
3. Dr. Anastasia Rita Widiarti, M.Kom., selaku Ketua Program Studi Teknik Informatika yang selalu memberikan dukungan dan perhatian serta saran kepada mahasiswa tugas akhir dan pengerjaan tugas akhir.
4. Kedua orang tua tercinta yang selalu mendoakan dan memberikan dukungan berupa moral maupun materi kepada penulis, sehingga penulis dapat menyelesaikan tugas akhir ini.
5. Seluruh dosen Teknik Informatika atas ilmu yang telah diberikan selama perkuliahan dan pengalaman yang sangat berarti bagi penulis.
6. Seluruh anggota grup line Keluarga Ya-Ampun yang selalu bertanya kapan lulus.
7. Keluarga Besar Teknik Informatika 2014 yang selalu mendukung penulis, serta seluruh teman – teman yang berjuang bersama dan saling mendukung dalam penyusunan tugas akhir ini.
xi
8. Teman-teman Game Online yang menemani setiap malam penulis.
Yogyakarta, 20 Januari 2019 Penulis
xii DAFTAR ISI
SAMPUL………..i
COVER………ii
HALAMAN PERSETUJUAN PEMBIMBING……….iii
MOTO………..v
PERNYATAAN KEASLIAN KARYA……….vi
LEMBAR PERNYATAAN………...vii
ABSTRAK………viii
ABSTRACT………ix
KATA PENGATAR………x
DAFTAR ISI………..xii
DAFTAR TABEL……….xiv
DAFTAR GAMBAR………xiv
BAB I PENDAHULUAN….………...1
1.1. Latar Belakang……….1
1.2. Rumusan Masalah………2
1.3. Tujuan Penelitian……….3
1.4. Batasan Masalah………..3
1.5. Metodologi Penelitian………..3
1.6. Sistematika Penulisan………..4
BAB II DASAR TEORI.……….6
2.1. Pengenalan Suara……….6
2.2. Mel Frequency Cepstral Coefficients………..6
2.3. Jaringan Syaraf Tiruan………12
2.4. K-Fold Cross Validation……….18
2.5. Confussion Matrix………..18
BAB III METODOLOGI PENELITIAN ……… ....19
3.1. Gambaran Penelitian………...19
3.2. Data……….22
3.3. Preprocessing………..25
3.4. Ekstraksi Ciri………..29
3.5. Jaringan Syaraf Tiruan………32
3.6. Metode Pengujian………...38
3.7. Model Pengenalan Data Tungga ………...38
3.8. Algoritma…….………...41
3.8. Kebutuhan Sistem………. 43
BAB IV IMPLEMENTASI DAN ANALISA ………..46
4.1. Preprocessing………..46
4.1.1. Merubah Format File Suara……….46
4.1.2. Pemotongan File Suara………47
4.1.3. Normalisasi Data Sample Suara………..49
xiii
4.1.5. Feature Data (MFCC)………..…54
4.1.6. 3-Fold Cross Validation ………..56
4.2. Klasifikasi………...56
4.3. Uji Data Tunggal………49
BAB V PENUTUP ………69
5.1. Kesimpulan……….69
5.2. Saran………...70
DAFTAR PUSTAKA………71
xiv DAFTAR TABEL
Tabel 3.2 Tabel Kata dalam Kalimat Perintah Suara………19
Tabel 3.4 3-Fold Cross Validation………23
Tabel 4.1 Tabel Persentase Hasil Potongan Suara………53
Tabel 4.1.5 Tabel Label Ciri Data……….…………55
Tabel 4.2.1 Tabel Fold Pertama………61
Tabel 4.2.2 Tabel Fold Kedua……….. 62
Tabel 4.2.3 Tabel Fold Ketiga………..62
DAFTAR GAMBAR Gambar 2.3.1 Ilustrasi Jaringan Lapis Tunggal………...13
Gambar 2.3.2 Ilustrasi Jaringan Lapis Majemuk……….13
Gambar 2.3.2.1 Jaringan Fungsi Aproksimasi……….14
Gambar 2.3.4.1 Jaringan 3 Lapis Notasi Ringkas………15
Gambar 3.1 Diagram Blok Sistem………..………..21
Gambar 3.2.1 Contoh Sinyal Digital………24
Gambar 3.2.2 Contoh Sinyal Spectogram………24
Gambar 3.3.1 Deteksi Energy………...26
Gambar 3.3.2 Gambar Hasil Deteksi Energi Potongan ………..26
Gambar 3.3.3 Contoh Deteksi Zero-Crossing Dari Potongan Suara 1…27 Gambar 3.3.4 Contoh Deteksi Zero-Crossing Dari Potongan Suara 2…28 Gambar 3.4 Hasil Ekstraksi ciri MFCC………...24
xv
Gambar 3.7 Diagram Blok Sistem Pengenalan Data Tunggal ………….38
Gambar 3.8 Flow Chart Sistem ………41
Gambar 3.9 Rancangan Antarmuka Sistem ………..34
Gambar 4.1.1 Merubah Format Suara dengan Format Factory………….47
Gambar 4.1.2.1 Pemotongan File Kalimat dengan Wavepad……...…….48
Gambar 4.1.2.2 Block diagram Sistem Pemotongan Manual……...…….49
Gambar 4.1.4.1 Deteksi Silence Voice dengan Energy…….………50
Gambar 4.1.4.2 Deteksi Silence Voice dengan ZeroCrossing...…………51
Gambar 4.1.4.3 Deteksi Silence Voice dengan ZeroCrossing…………...51
Gambar 4.1.4.4 Deteksi Silence Voice dengan ZeroCrossing…………...52
Gambar 4.1.4.5 Deteksi Silence Voice dengan ZeroCrossing……...……52
Gambar 4.1.4.6 Deteksi Silence Voice dengan ZeroCrossing…...………52
Gambar 4.1.5 Diagram Blok MFCC………..54
Gambar 4.2.1 Arsitektur JST Satu Hidden Layer………..56
Gambar 4.2.2 Grafik Klasifikasi dengan 1 Hidden Layer……….57
Gambar 4.2.3 Arsitektur satu Hidden Layer Variasi Bobot & Bias …….57
Gambar 4.2.4 Grafil Klasifikasi 1 Hidden Layer Variasi Bobot & Bias...58
Gambar 4.2.5 Arsitektur JST Dua Hidden Layer………..59
Gambar 4.2.6 Grafik Klasifikasi dengan 2 Hidden Layer……….59
Gambar 4.2.7 Grafik Arsitektur JST Optimal………60
Gambar 4.2.8 Arsitektur JST optimal ………...…60
xvi
Gambar 4.3.2 Uji Data 2………64
Gambar 4.3.3 Uji Data 3………65
Gambar 4..3.4 Uji Data 4………...…………65
Gambar 4.3.5 Uji Data 5………66
1 BAB I PENDAHULUAN
1.1. Latar Belakang Masalah
Di zaman yang sudah modern ini sistem kendali jarak jauh telah banyak digunakan. Salah satu contohnya adalah dalam melakukan pengendalian perangkat elektronik di dalam rumah dengan menggunakan perintah suara. Namun, karena suara manusia memiliki keunikan tersendiri maka ada beberapa hal yang harus diatasi dalam mengimplementasikan pengenalan suara seperti derau (noise), frekuensi ucapan yang berubah-ubah, pola kata yang diucapkan, serta mengklasifikasi kata-kata yang diucapkan tersebut. Maka dari itu, dalam melakukan pengendalian perangkat elektronik di dalam rumah dengan perintah suara dibutuhkan sebuah sistem pengenalan suara yang mampu mengenali perintah suara yang diucapkan manusia.
Pada tahun 2013 terdapat penelitian dengan judul “Pengenalan Suara
Manusia Menggunakan Metode Linear Predictive Coding”(Khoirul, 2013). Pada penelitian tersebut dikatakan bahwa pengenalan suara pembicara (speec recognition) tidak membutuhkan biaya yang besar dan tidak membutuhkan
peralatan khusus. Pada tahun 2014 juga terdapat penelitian dengan judul “Aplikasi Pengenalan Suara Untuk Rumah Pintar Menggunakan Algoritma
yang dihasilkan pada penelitian tersebut adalah 70% dengan waktu proses rata-rata 2,67 detik. Selain itu pada tahun 2016 juga terdapat penelitian dengan judul “Klasifikasi Burung Berdasarkan Suara Kicau Burung Menggunakan Jaringan Syaraf Tiruan Propagasi Balik” (Echo, 2016). Penelitian ini bertujuan untuk melakukan klasifikasi burung berdasarkan suara kicau. Dimana nilai akurasi yang dihasilkan pada penelitian ini sebesar 85,28% untuk klasisfikasi menggunakan 3 fold, 98,61% untuk klasifikasi menggunakan 5 fold dan sebesar 99,17% untuk klasifikasi menggunakan 10 fold.
Pada tugas akhir ini penulis akan mencoba untuk membuat suatu sistem yang dapat melakukan klasifikasi dalam pengenalan perintah suara dengan menggunakan metode Jaringan Syaraf Tiruan Backpropagation.
1.2. Rumusan Masalah
Berdasarkan latar belakang di atas, rumusan masalah dalam penelitian ini adalah :
1.2.1. Bagaimana metode Jaringan Syaraf Tiruan Back Propagation mampu mengklasifikasi perintah suara?
1.2.2. Berapakah akurasi yang dihasilkan oleh metode Jaringan Syaraf Tiruan dalam melakukan klasifikasi perintah suara? 1.3. Tujuan Penelitian
1.4. Batasan Masalah
Agar pengerjaan tugas akhir ini lebih terfokus pada tujuan yangtelah ditetapkan maka perlu adanya batasan-batasan masalah. Dalam Batasan-batasan tersebut yaitu : terdapat 4 ( Empat ) jenis perintah yang aplikasi dapat kenali yaitu : hidup (on), mati (off), buka (open) dan tutup (close). Dalam melakukan ekstraksi ciri penulis menggunakan Mell Frequency Cepstral Coefficient (MFCC). Sedangkan untuk melakukan pengenalan
pola suara peneliti menggunakan metode Jaringan Syaraf Tiruan (JST). Sedangkan untuk proses perekaman suara dilakukan dari jarak sejauh 3 hinggan 5 sentimeter dari bibir pembicara.
1.5. Metodologi Penelitian
Langkah-langkah dalam penelitian :
1.5.1. Pengumpulan referensi berupa buku-buku dan jurnal-jurnal ilmiah mengenai pengolahan suara, metode Jaringan Syaraf Tiruan (JST) dan ekstraksi ciri MCFF ( Mell Frequency Cepstral Coefficient ).
1.5.2. Pembuatan Sistem
Sistem yang dibuat akan berjalan di perangkat komputer dengan sistem operasi windows. Pembuatan sistem menggunakan Matlab 2014.b.
kirimkan ke software yang ada di komputer untuk di deteksi nilai dari setiap data ucapan yang ada.
1.5.4. Analisa dan penyimpulan hasil percobaan.
Analisa data dilakukan dengan cara meneliti jumlah variasi perintah suara yang dimasukkan ke sistem. Sedangkan dalam mengambil kesimpulan dilakukan dengan cara mencari jumlah data perintah yang dapat dikenali dengan benar oleh sistem.
1.5.1. Pengujian secara real time
Pengujian secara real time adalah pengujian dengan memberikan masukan berupa perintah suara kedalam sistem secara langsung. Setelah perintah dimasukkan sistem akan secara lansung meneruskan ke sistem dan akan diproses sehingga sistem akan mengeluarkan output berupa perintah untuk mengendalikan barang elektronik. Pengujian ini bertujuan untuk menguji kinerja sistem pada saat real time.
1.6. Sistematika Penulisan
Sistematika penulisan tugas akhir ini dibagi menjadi beberapa bab dengan susunan sebagai berikut :
BAB I : PENDAHULUAN
BAB II : LANDASAN TEORI
Bab ini membahas teori-teori yang mendukung dan menjadi dasar pemecahan masalah, antara lain teori mengenai rumah pintar dan voice recognition. Pada bab ini juga membahas mengenai metode-metode seperti:
Mell Frequency Cepstral Coefficient (MFCC) dan Jaringan Syaraf Tiruan
(JST).
BAB III : METODOLOGI PENELITIAN
Bab ini membahas mengenai perancangan aplikasi pengenalan suara. Bab ini juga membahas mengenai analisa komponen-komponen yang akan digunakan untuk pengerjaan tugas akhir.
BAB IV : IMPLEMENTASI DAN ANALISIS HASIL
Bab ini membahas analisa hasil perancangan sistem dan pengujian rekaman perintah suara.
BAB V : KESIMPULAN DAN SARAN
6 BAB II DASAR TEORI
Bab ini membahas teori-teori yang bersangkutan dengan penulisan proposal Tugas Akhir ini. Teori-teori tersebut adalah Pengenalan Suara (Voice Recognition), Mel Frequency Cepstral Coefficients, Jarigan Saraf Tiruan (Artificial Neural
Network), K-Fold Cross Validation, Confusion Matrix.
2.1. Pengenalan Suara (Voice Recognition)
Pengenalan suara (Voice Recognition) merupakan proses atau metode dalam menterjemahkan signal suara menjadi tulisan dengan menggunakan alat berupa komputer (T. Ginnakopoulos, 2014). Pengenalan suara bertujuan untuk mengidentifikasi atau mengenali suara dimana dalam prosesnya komputer akan menerima input berupa kata yang diucapkan. Kata-kata tersebut kemudian diubah menjadi sinyal digital dengan cara merubah gelombang suara menjadi sekumpulan angka lalu disesuaikan dengan kode tertentu dan dicocokkan dengan suatu pola yang tersimpan dalam sistem. Hasil identifikasi kata kemudian ditampilkan dalam bentuk tulisan atau kode yang dapat dibaca oleh perangkat teknologi (A. Astri, 2016).
2.2. Mel Frequency Cepstral Coefficients
frekuensi telinga manusia. Dimana telinga manusia merupakan filter yang bekerja secara linier pada frekuensi rendah dan bekerja secara logaritmik pada frekuensi tinggi. Untuk meniru kondisi telinga, karakteristik ini digambarkan dalam skala mel-frekuensi, yang merupakan frekuensi linier di bawah 1000Hz dan frekuensi logaritmik di atas 1000Hz(Setiawan, dkk 2011). Tujuan dari pre-emphasis adalah untuk mengkompensasi bagian frekuensi tinggi yang ditekan pada saat produksi suara manusia. Selain itu juga dapat memperkuat forman penting dari frekuensi tinggi.
2.2.2. Frame Blocking
Pada tahap ini sinyal suara kontinyu diblok menjadi frame-frame N sample, dengan frame-frame berdekatan
frame pertama, dan overlap dengan N-M sampel. Dengan cara yang sama, frame ketiga dimulai 2M sampel setelah frame pertama (atau M sampel setelah frame kedua) dan overlap dengan N-2M sampel. Proses ini berlanjut hingga
semua suara dihitung dalam satu atau banyak frame. Nilai tipikal untuk N = 256 dan M = 100 (Mustofa,2007).
2.2.3. Hamming Windowing
Tahap selanjutnya adalah pemrosesan dengan window pada masing-masing frame individual untuk
meminimalisasi sinyal yang tidak kuntinyu pada awal dan akhir frame. Window dinyatakan dengan w(n), 0 < n < N-1, dengan N adalah jumlah sampel dalam masing-masing frame, X1(n) adalah sinyal input dan hasil windowing adalah
Y1(n).
Y1(n) = X1(n)w(n), 0 < n < N-1
… (2.2.3.1)
Jenis window yang digunakan adalah window Hamming.
w(n) = 0.54 – 0.46 cos [ (2πn)/(N-1) ] , 0 < n < N-1
… (2.2.3.2)
2.2.4. Fast Fourier Transform
Tahap ini bertujuan untuk mengubah masing-masing frame N sample dari domain waktu menjadi domain frekuensi. FFT merupakan algoritma cepat untuk mengimplementasikan discrete fourier transform (DFT) dengan didefinisikan pada kumpulan N sampel.
… (2.2.4.1)
Dengan :
Xk = Deretan aperiodik dengan nilai N
N = Jumlah sampel
2.2.5. Triangular Bandpass Filter
Persepsi manusia dari kandungan frekuensi suara pada sinyal wicara tidak mengikuti skala linier. Untuk masing-masing nada dengan frekuensi aktual, f dalam Hz, pitch diukur dengan skala ‘mel’. Skala mel-frequency
merupakan frekuensi linear yang berada dibawah 1000Hz dan bentuk logaritmik berada diatas 1000Hz. Sebagai titik referensi adalah pitch dengan tone 1 kHz, 40dB diatas nilai batas ambang pendengaran, ini dinyatakan 1000mel. Pendekatan persamaan untuk menghitung mel dalam frekuensi adalah :
Salah satu pendekatan simulasi spektrum yaitu menggunakan filter bank, satu filter untuk masing-masing komponen mel-frequency yang diinginkan. Filter bank mempunyai respon frekuensi bandpass segitiga dan jarak bandwidth ditentukan oleh konstanta interval mel-frequency.
2.2.6. Discrete Cosine Transform
Langkah selanjutnya yaitu merubah spektrum log mel menjadi domain waktu. Hasil ini disebut mel frequency
cepstrum coefficient (MFCC). Representasi cepstral dari
spectrum suara memberikan representasi baik dari sifat-sifat
spektral lokal sinyal untuk analisis frame yang diketahui. Karena koefisien mel spectrum adalah bilangan nyata. Dengan mengubahnya menjadi domain waktu menggunakan discrete cosine transform (DCT). Jika koefisien spektrum
daya mel hasilnya adalah
… (2.2.6.1) Maka MFCC dapat dihitung sebagai :
… (2.2.6.2)
Dimana :
2.2.7. Log Energy
Merupakan salah satu cara untuk menambah nilai koefisien yang dihitung dari linear prediction atau mel-cepstrum, nilai tersebut merupakan log energy signal. Ini
berarti pada setiap frame terdapat nilai energi yang ditambahkan.
2.2.8. Delta Cepstrum
Secara umum metode yang digunakan untuk mendapat informasi dari ciri yang dinamis biasa disebut dengan delta-features. Turunan waktu dari ciri dapat dihitung dengan beberapa metode, hasil perhitungan delta akan ditambahkan ke vector ciri, sehingga menghasilkan vektor ciri yang lebih besar. Nilai delta akan diturunkan sekali lagi terhadap waktu menjadi nilai delta-delta pada beberapa kasus delta-delta disebut dengan koefisien percepatan, karena nilai tersebut merupakan turunan dari kuadrat waktu dari koefisien. Persamaannya adalah :
… (2.2.8.1)
umumnya sistem pengenalan suara menggunakan 39 feature untuk mengenali ( Jang, 2005 ).
2.3. Jaringan Saraf Tiruan ( Artificial Neural Network )
Jaringan Saraf Tiruan atau sering disebut Artificial Neural Network merupakan sistem komputasi yang memiliki arsitekstur dan cara kerja seperti layaknya sel saraf biologis dalam otak manusia. Jaringan Saraf Tiruan dapat digambarkan sebagai model matematis dan komputasi untuk fungsi aprokimasi non-linier, klasifikasi data cluster, dan regresi non-parametrik atau sebuah simulasi dari model saraf biologi. Jaringan Saraf Tiruan mampu menangani sistem yang kompleks, rumit dan tidak linier serta mamp belajar dengan variabel-variabel keputusan (decision variable).(Mittal & Zang, 2001;Hermawan, 2006 ;Siang,2005).
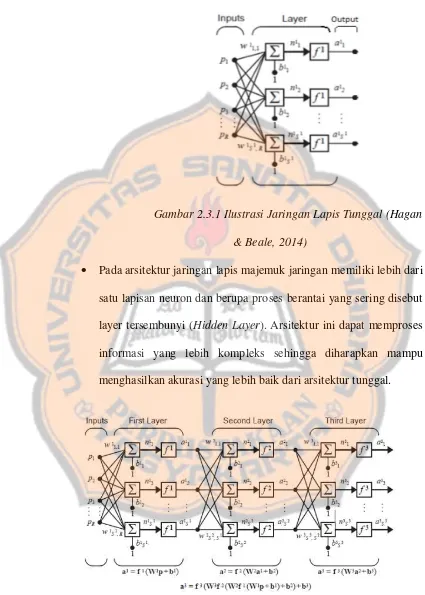
Jaringan Saraf Tiruan memiliki 2 jenis arsitektur yakni lapis tunggal dan lapis majemuk.
Gambar 2.3.1 Ilustrasi Jaringan Lapis Tunggal (Hagan
& Beale, 2014)
• Pada arsitektur jaringan lapis majemuk jaringan memiliki lebih dari satu lapisan neuron dan berupa proses berantai yang sering disebut layer tersembunyi (Hidden Layer). Arsitektur ini dapat memproses informasi yang lebih kompleks sehingga diharapkan mampu menghasilkan akurasi yang lebih baik dari arsitektur tunggal.
2.3.1. Backpropagation
Backpropagation digunakan dalam melatih jaringan untuk
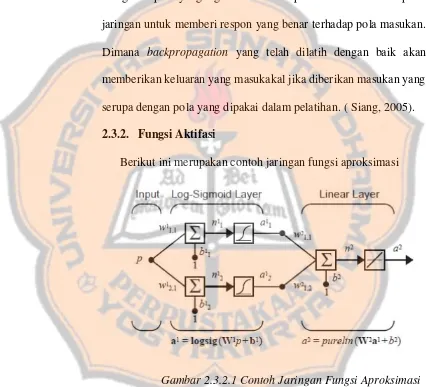
mendapatkan keseimbangan antara kemampuan jaringan dalam mengenali pola yang digunakan selama pelatihan serta kemampuan jaringan untuk memberi respon yang benar terhadap pola masukan. Dimana backpropagation yang telah dilatih dengan baik akan memberikan keluaran yang masukakal jika diberikan masukan yang serupa dengan pola yang dipakai dalam pelatihan. ( Siang, 2005). 2.3.2. Fungsi Aktifasi
Berikut ini merupakan contoh jaringan fungsi aproksimasi
Gambar 2.3.2.1 Contoh Jaringan Fungsi Aproksimasi
(Hagan & Beale, 2014)
2.3.3. Propagasi Maju
menggunakan fungsi aktivasi yang telah di tentukan. Dimana keluaran-nya akan di propagasikan maju lagi ke lapisan tersembunyi selanjutnya dan akan terus berlanjut sampai menghasilkan hasil. Hasil luaran akan dibandingkan dengan ouput atau target minimum dan perbaikan dilakukan bila hasil tidak mencapai target minimum.
2.3.4. Propagasi Mundur
Propagasi mundur digunakan untuk melakukan perbaikan dari hasil luaran propagasi maju yang tidak mencapai target minimum.
Algoritma backpropagation digambarkan dengan rumus :
Am+1= fm+1(Wm+1am+ bm+1) untuk m = 0, 1,.. M-1
...(2.3.4.1)
Dimana m merupakan jumlah layer dari jaringan tersebut.
Gambar 2.3.4.1 Gambar Jaringan 3 Lapis, dengan
2.3.5. Perbaikan Bobot
Setelah semua faktor 𝛿 dihitung, bobot semua garis dimodifikasi bersamaan. Perubahan bobot suatu garis didasarkan atas faktor 𝛿 neuron di lapis atasnya.
Secara umum algoritma pelatihan untuk jaringan backpropagation adalah sebagai berikut :
1. Ini sialisasi bilangan bobot dengan nilai kecil
2. Jika kondisi untuk pemberhentian belum terpenuhi, lakukan langkah 3-10
3. Untuk setiap pasang data pelatihan, lakukan langkah 4-9 4. Setiap neuron menerima sinyal dan meneruskannya ke
neuron tersembunyi selanjutnya
𝛿𝑘 = (𝑡𝑘− 𝑦𝑘)𝑓′(𝑦𝑛𝑒𝑡𝑘) = (𝑡𝑘− 𝑦𝑘)𝑦𝑘(1 −
Faktor δ neuron tersembunyi :
𝛿𝑗 = 𝛿_𝑛𝑒𝑡𝑗𝑓′(𝑧𝑛𝑒𝑡𝑗) = 𝛿𝑛𝑒𝑡𝑗𝑧𝑗(1 − 𝑧𝑗)
… ( 2.3.5.7 )
Hitung suku perubahan bobot v_ij
∆𝑣𝑖𝑗 = 𝛼𝛿𝑗𝑥𝑖 ; 𝑗 = 1, 2, … , 𝑝 ; 𝑥 = 0, 1, … , 𝑛
… ( 2.3.5.8 )
9. Hitung semua perubahan bobot
𝑣𝑗𝑖(𝑏𝑎𝑟𝑢) = 𝑣𝑗𝑖(𝑙𝑎𝑚𝑎)∆𝑣𝑗𝑖(𝑗 = 1, 2, … , 𝑝 ; 𝑖 = 0, 1, … , 𝑛)…(2.3.5.10)
10.Bandingkan kondisi penghentian. 2.4. K-Fold Cross Validation
K-Fold Cross Validation merupakan teknik umum untuk menguji kenerja dari klasifikasi. Data dibagi menjadi k bagian ( fold ), kemudian selama I = 1,…,k dilakukan pelatihan terhadap data selain fold ke-I dan dilakukan pengujian terhadap data fold ke-I tersebut. Kemudian menghitung jumlah pengujian yang mengalami kesalahan klasifikasi.
2.5. Confusion Matrix
19 BAB III
METODOLOGI PENELITIAN
Bab ini membahas analsisa kebutuhan sistem mencangkup metode yang digunakan untuk ekstraksi ciri, klasisfikasi, dan pengujian sistem. Bab ini juga berisi perancangan sistem mencangkup preprocessing, ekstraksi ciri, klasifikasi, metode pengujian, algoritma, dan perancangan antar muka sistem.
3.1.Gambaran Penelitian
Sesuai dengan gambar 3.1 pada penelitian ini data hasil rekaman kalimat suara akan di proses dengan melakukan tahap pre-processing terlebih dahulu. Pada tahap ini data suara akan dirubah format dan frekuensinya menjadi .WAV dengan frekuensi 11025Hz mono channel. Kemudian sistem akan melakukan normalisasi nilai sampel suara yang selanjutnya dicari nilai energi dan zero-crossing dari data suara. Nilai energi dan zero-crossing kemudian digunakan dalam proses pemotongan file kalimat suara menjadi potongan kata.
Setelah kalimat suara dipotong menjadi beberapa kata, proses selanjunya yang dilakukan adalah proses ekstraksi ciri. Pada proses ini hasil potongan kata akan di cari ciri atau feature dari setiap potongan kata dimana dalam prosesnya dilakukan dengan metode Mel Frequency Cepstral Coefficients (MFCC). Adapun tahapan yang dilakukan adalah
triangular bandpass filter, discrete cosine transform, log energy dan delta
cepstrum.
3.2.Data
Data suara yang dipakai merupakan data suara hasil rekaman 14 jenis perintah suara berupa kalimat perintah dari 10 orang berbeda yang direkam dengan menggunakan HandPhone dan disimpan dalam format .mp3 . Untuk setiap jenis perintah suara akan dikumpulkan maksimal sebanyak 6 data rekaman suara per-orang (3 rekaman dari depan & 3 rekaman dari samping) yang akan dijadikan sebagai data training. Data rekaman yang didapat haruslah bersih dari noise (gangguan suara) atau sekurang-kurangnya memiliki noise yang masih dapat di toleransi. Adapun jenis perintah kalimat suara yang digunakan adalah sebagai berikut :
➢ Hidupkan lampu ruang tamu
➢ Hidupkan lampu kamar
➢ Hidupkan lampu garasi
➢ Matikan lampu ruang tamu
➢ Matikan lampu kamar
➢ Matikan lampu garasi
➢ Hidupkan TV ruang tamu
➢ Hidupkan TV kamar
➢ Matikan TV kamar
➢ Buka pintu
➢ Buka jendela
➢ Tutup pintu
➢ Tutup jendela
Tabel 3.2: Tabel Kata dalam Kalimat Perintah Suara
Perintah Objek Lokasi
Hidupkan Lampu Ruang Tamu
Matikan Televisi Kamar
Garasi
Buka Pintu
Tutup Jendela
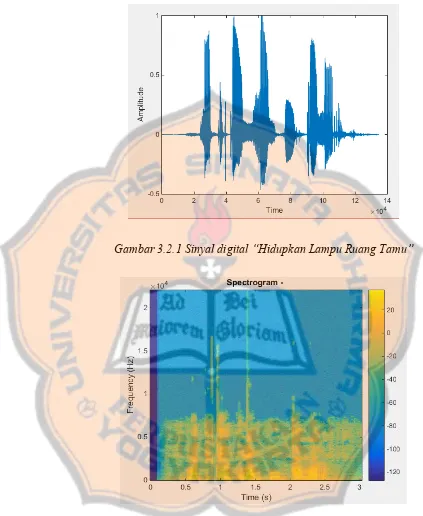
Gambar 3.2.1 Sinyal digital “Hidupkan Lampu Ruang Tamu”
3.3.Preprocessing
Terdapat beberapa tahapan dalam preprocessing yakni : merubah file ke format .WAV, melakukan proses deteksi silence voice, normalisasi nilai data, dan memotong suara per-kata.
3.3.1. Merubah Format File Suara
Pada tahap ini file suara dalam format .WAV di konversi dari frekuensi 44100Hz stereo channel ke dalam bentuk file .WAV dengan format Pulse-Code Modulation (PCM), 11025Hz, 8 bit, mono channel. Dalam proses ini membutuhkan aplikasi Format Factory 4.1.0.
3.3.2. Normalisasi
Proses ini dilakukan dengan metode min-max yang bertujuan untuk menyetarakan nilai tertinggi dan terendah dari suatu kesatuan nilai signal data suara. Pada proses ini nilai tertinggi dan terendah dari nilai signal ditetapkan secara konstan. Dimana pada proses ini menggunakan rumus :
Zi = [ max(𝑋) − min(𝑋)𝑋𝑖 − min(𝑋) ]
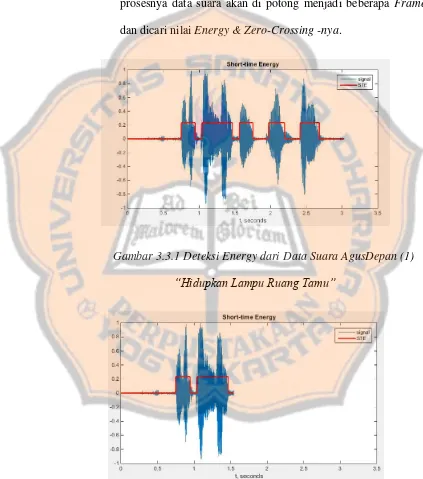
3.3.3. Deteksi Silence Voice
Proses deteksi Silence Voice dilakukan dengan cara mencari Energy & Zero-Crossing dari suatu data suara. Dalam prosesnya data suara akan di potong menjadi beberapa Frame dan dicari nilai Energy & Zero-Crossing -nya.
Gambar 3.3.1 Deteksi Energy dari Data Suara AgusDepan (1)
Gambar 3.3.2 Gambar hasil deteksi energi potongan pertama dan
ke-2 yang masih memiliki kemungkinan terdapat potongan kata di
dalamnya
Dalam prosesnya pertama-tama sistem akan mencari Energy dari data suara sehingga didapatkan energy seperti pada gambar 3.3.1 diatas. Dimana pada gambar bisa di dapatkan 5 potongan suara dimana potongan pertama dan ke-2 masih memiliki kemungkinan untuk adanya potongan suara (kata) di dalamnya.
Gambar 3.3.3 Deteksi Zero-Crossing Dari Potongan Suara
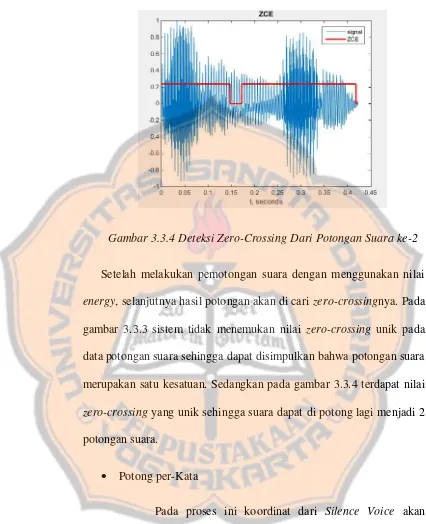
Gambar 3.3.4 Deteksi Zero-Crossing Dari Potongan Suara ke-2
Setelah melakukan pemotongan suara dengan menggunakan nilai energy, selanjutnya hasil potongan akan di cari zero-crossingnya. Pada
gambar 3.3.3 sistem tidak menemukan nilai zero-crossing unik pada data potongan suara sehingga dapat disimpulkan bahwa potongan suara merupakan satu kesatuan. Sedangkan pada gambar 3.3.4 terdapat nilai zero-crossing yang unik sehingga suara dapat di potong lagi menjadi 2
potongan suara.
• Potong per-Kata
3.4.Ekstraksi Ciri
Ekstraksi ciri menggunakan metode MFCC (Mel Frequency Cepstral Coefficient). Dimana metode tersebut dipilih karena sering digunakan
dalam speech recognition. Salah satu contohnya adalah pada penelitian
dengan judul “Klasifikasi Burung Berdasarkan Suara Kicau Burung
Menggunakan Jaringan Syaraf Tiruan Propagasi Balik” (Lorencious Echo,
2016) dimana pada penelitian tersebut didaptkan akurasi yang cukup tinggi dalam melakukan klasifikasi yakni berkisar dari 85,28% hingga 99,17%. Namun dari penelitian tersebut juga dapat dilihat kekurangan dari metode jaringan syaraf tiruan yakni proses klasifikasi yang lama dan peneliti harus mencoba-coba kombinasi secara manual hingga mendapatkan kombinasi model yang optimal.
Untuk proses ekstraksi ciri dilakukan pada semua file suara dengan menentukan terlebih dahulu ukuran frame dan overlap yang akan digunakan pada saat proses perhitungan nilai MFCC. Kemudian nilai MFCC yang dihasilkan dari setiap rekaman direduksi ciri dengan menghitung nilai statistic berupa nilai mean, variance, standart-deviasi, dan standar deviasi by mean dari nilai MFCC yang nantinya akan digunakan sebagai nilai input
Gambar 3.4 Gambar Tabel hasil ekstraksi ciri MFCC ( Tabel lengkap
dapat dilihat pada bagian lampiran dokumen )
Pada gambar 3.4 diatas nilai 13 merupakan jumlah koefisien MFCC yang dihasilkan, sedangkan 27 merupakan jumlah frame yang dihasilkan pada saat proses frame blocking. Jumlah frame sebanyak 27 dihasilkan melalui perhitungan sebagai berikut :
Sample Rate = 11025 Hz
Frame Size = 15ms = (15/1000)*11025 = 165.375 sample point
Overlap = 10ms = (10/1000)*11025 = 110.25 sample point
Step = 165.375 – 110.25 = 55.125
Sample Total = 0.1486*11025 = 1638.315 , Dibulatkan = 1638
Sample
Jumlah Frame = (1638-110.25)/55.125 = 27.714
Proses reduksi ciri dilakukan dengan menghitung nilai mean, median, standar deviasi dan standar deviasi by mean setiap baris
koefisien MFCC (baris 1-13) yang nantinya akan menghasilkan sebanyak 52x1 ciri untuk masing-masing potongan file suara.
Ada 9 tahap yang dilakukan pada proses ekstraksi ciri, dengan 8 tahap merupakan proses dari MFCC dan 1 tahap lainnya merupakan perhitungan terhadap nilai MFCC yang telah dihasilkan. Tahap-tahap tersebut adalah :
➢ Pre-Emphasis
➢ Frame Blocking
➢ Hamming Windowing
➢ Fast Fourier Transform ( FFT )
➢ Triangular Bandpass Filter
➢ Discrete Cosine Transform ( DCT )
➢ Log Energy
➢ Menghitung nilai mean, median, standar deviasi dan standar deviasi by mean
Kemudian data dibagi menjadi 3 kelompok data ciri yang berisikan ciri dari potongan kata kalimat suara. Kelompok data ini kemudian akan dijadikan sebagai data training sebanyak 2 kelompok data ciri dan data testing sebanyak 1 kelompok data ciri.
Tabel 3.4 : 3-Fold Cross Validation Percobaa sebagai input pada jaringan saraf tiruan.
3.5.Jaringan Syaraf Tiruan
Ada 2 jenis arsitektur jaringan syaraf tiruan yang akan digunakan untuk proses pelatihan dan pengujian, yaitu arsitektur jaringan syaraf tiruan dengan 1 hidden layer dan 2 hidden layer. Setiap arsitektur akan dilakukan percobaan dengan mengkombinasikan beberapa parameter yakni jumlah neuron input yang bervariasi serta fungsi aktivasi purelin.
Gambar 3.5 : Arsitektur Jaringan untuk Pelatihan dan Pengujian
Arsitektur jaringan yang digunakan pada proses pelatihan dan pengujian arsitektur memiliki kombinasi 1 hingga 25 neuron pada setiap hidden layer-nya. Pada sistem ini menggunakan 12 input sehingga luaran yang dihasilkan adalah [0 0 0 1] hingga [1 1 0 0] jadi akan ada 4 neuron output untuk mendapatkan luaran yang diinginkan.
Adapun percobaan perhitungan, jika gambar sebelumnya
akan menghasilkan perintah “Hidup” maka hasil tersebut akan
diberikan nilai. Pada percobaan ini akan diberi nilai W = [1 0 0 0], setelah itu masuk ke dalam jaringan syaraf tiruan dengan bobot dan bias bilangan random dengan nilai terkecil. Dilakukan pelatihan hingga mendapatkan nilai mendekati target yang diinginkan yakni sesuai dengan label asli.
Adapun percobaan perhitungannya adalah sebagai berikut ,
=
Langkah selanjutnya dari algoritma yakni sensitivitas backpropagation, untuk memanggil kembali diperlukan turunan
= (1 − 𝑎1)(𝑎1)
Backpropagation dimulai dari lapis ketiga
𝑠3 = −2𝐹3(𝑛3)(𝑡 − 𝑎) = −2[𝑓3(𝑛3)] [
Sensitifitas layer pertama dan kedua merupakan komputasi dari backpropagation sensitifitas lapis ketiga.
= [
Langkah terakhir yakni memperbaharui bobot dengan menggunakan laju pembelajaran α =1.
3.6.Metode Pengujian
Metode pengujian akan menggunakan K-Fold Cross Validation, dengan k=3. Metode ini dipakai karena menghasilkan data yang berbeda untuk proses pelatihan dan pengujian, sehingga dapat diketahui rata-rata akurasi yang dihasilkan pada percobaan berdasarkan confusion matrix yang dihasilkan.
3.7. Pengenalan Data Tunggal
Pada proses pengenalan data tunggal data suara yang digunakan sebagai masukan merupakan file suara dari kalimat perintah suara dimana seperti pada gambar 3.7 pertama-tama data suara masukan atau data input akan dibaca oleh sistem. Setelah data terbaca sistem akan melakukan proses normalisasi dari sampel data masukan. Hasil normalisasi tersebut kemudian akan digunakan dalam proses pemotongan kalimat suara menjadi beberapa kata.
Dalam proses pemotongan kalimat suara terdapat beberapa tahap yang dilakukan. Tahap pertama adalah mencari nilai energi dari sampel suara yang telah di normalisasi dimana nilai energi tersebut akan digunakan untuk mencari letak jeda atau suara hening dengan menggunakan metode horizontal projecting. Ketika jeda suara telah di dapatkan maka sistem akan melakukan pemotongan sampel kalimat suara menjadi beberapa sampel kata. Tahap kedua adalah mencari nilai zero-crossing dari hasil pemotongan sampel kata dengan energi. Nilai
zero-crossing ini nantinya akan digunakan untuk mencari jeda atau
suara hening dari sampel suara potongan kata dengan metode horizontal projecting. Bila dalam sampel suara potongan kata ditemukan jeda maka
Proses Ekstraksi ciri dilakukan dengan metode Mel Frequency Cepstral Coefficient (MFCC) dimana nanti hasil MFCC akan diambil
nilai mean, median, standar deviasi dan standar deviasi by mean nya yang kemudian digunakan sebagai ciri dari sampel suara. Ciri suara yang didapatkan diberikan label ciri.
Setelah ciri suara beserta labelnya ada maka proses selanjutnya adalah membagi ciri suara menjadi 3 kelompok data dimana dua kelompok data akan digunakan sebagai data training dan satu kelompok data akan digunakan sebagai data testing.
3.7.Algoritma
Gambar 3.8 Flow Chart Sistem
min-max. Setelah sampel suara ter-normalisasi sistem melakukan proses Deteksi Energi yakni menghitung intensitas gelombang suara pada setiap frame dari sampel suara hasil normalisasi dalam satuan waktu. Hasil deteksi energi kemudian digunakan dalam proses pemotongan sampel suara menjadi beberapa sampel suara baru yang merupakan potongan kata dari kalimat suara masukan. Setelah sampel kalimat suara terpotong menjadi beberapa sampel kata, sistem melakukan proses Deteksi Zero-Crossing yakni menghitung berapa kali suatu gelombang suara dari sampel kata hasil potongan melewati titik 0 dalam satuan waktu.
Hasil deteksi zero-crossing akan diperiksa kembali oleh sistem untuk mencari suara hening dalam sampel kata. Ketika sistem masih menemukan suara hening dari sampel kata, sistem akan kembali melakukan proses pemotongan sampel suara dimana sampel suara yang digunakan dalam proses pemotongan adalah sampel kata hasil deteksi zero-crossing. Namun bila setelah memeriksa sampel kata sistem tidak menemukan suara hening, sistem akan melakukan proses ekstraksi ciri dengan metode Mel Frequency Cepstral Coefficients.
kemudian diambil dan digunakan dalam proses terkahir pada sistem yakni proses menghitung akurasi hasil klasifikasi.
3.8.Kebutuhan Sistem
Alat yang akan digunakan dalam proses perancangan sistem : 1. Perangkat keras :
1.1Komputer :
Processor : Intel Core i5 4590 – Quad Core, 3.3GHz
Memory : 16 GB
Hard Drive : 1500 GB
VGA : GTX 1050 TI – 4 GB, 1303MHz/1417MHz 1.2SmartPhone (Vivo Y65):
CPU : Snapdragon 425 – Quad Core, 1.4 GHz GPU : Adreno 308
Storage : 16 GB
RAM : 3 GB
2. Perangkat Lunak :
1.3Matlab 2014b
3.9. Perancangan Antarmuka Sistem
Gambar 3.9 Rancangan Antarmuka Jendela Awal Sistem
Gambar diatas merupakan rancangan antarmuka untuk jendela awal sistem dimana dibagi menjadi 3 panel yakni panel Uji Data, panel Masukan Ciri Suara, dan panel Graph yang berfungsi untuk memunculkan grafik serta hasil akurasi dan hasil uji data tunggal.
➢ Panel Uji Data
Pada panel ini terdapat 2 buah tombol. Tombol “Uji Data
Tunggal” yang berfungsi untuk melakukan uji data tunggal.
Tombol “Lihat Akurasi Database” berfungsi untuk mengetahui
akurasi dari database file ciri yang telah dimiliki dan hasil akurasi akan ditampilkan pada panel Graph.
➢ Panel Masukan Ciri Data Suara
Panel ini berfungsi untuk memasukkan data ciri baru kedalam sistem dimana prosesnya dimulai dengan cara menekan tombol cari file. User kemudian memilih file .WAV yang akan di ambil cirinya untuk disimpan kedalam database. Didalamnya terdapat listbox untuk melihat nama file yang akan diambil cirinya. Terdapat pula 2 buah popupmenu yang berfungsi untuk memberi label dan keterangan dari file yang digunakan.
➢ Panel Graph
Panel ini berfungsi untuk mengeluarkan output atau luaran dari proses pada sistem. Pada panel ini terdapat sebuah axes yang berfungsi untuk menampilkan grafik dari proses yang
46 BAB IV
IMPLEMENTASI DAN ANALISA
Bab ini membahas uraian implementasi perancangan sistem berupa hasil penelitian dalam melakukan pengujian kombinasi data feature, kombinasi neuron dan hidden layer, serta pengujian data tunggal dan uraian mengenai analisa hasil output terkait dengan keberhasilan pemilihan atribut feature dan akurasinya.
4.1.Preprocessing
Ada beberapa tahapan yang dilakukan dalam preprocessing sebagaimana digambarkan pada Gambar 3.1 dimana data akan diproses sehingga didapatkan feature atau ciri dari data suara. Dimana feature itu sendiri didapatkan dengan
melalui proses merubah format file suara, normalisasi data sampel suara, deteksi silence voice, memotong file suara, memotong sampel suara menjadi beberapa
kelompok sampel berdasarkan letak suara hening yang kemudian dilanjutkan dengan ekstraksi ciri menggunakan Mel-Frequency Cepstral Coefficients.
4.1.1. Merubah Format File Suara
Gambar 4.1.1: Proses Merubah Format File Suara dengan Format
Factory
4.1.2. Pemotongan File Suara
• Pemotongan File Suara dari Kalimat Perintah
Gambar 4.1.2.1 : Pemotongan File Kalimat “Buka Pintu” dengan
Wavepad Sound Editor
Gambar 4.1.2.2 : Diagram Block Sistem dalam melakukan pemotongan
data secara manual menggunakan Wavepad Sound Editor
• Pemotongan Sample Suara dari Kalimat Perintah
Proses ini digambarkan pada Gambar 3.1 dimana pemotongan dilakukan secara otomatis dengan cara mencari suara hening atau silence voice dari sample suara dari kalimat perintah. Setelah suara hening ditemukan sistem akan memotong-motong sample suara menjadi beberapa bagian berdasarkan suara heningnya seperti yang dijelaskan pada bagian 4.1.4. Hasil potongan sample suara diambil cirinya dan digunakan untuk uji data tunggal pada sistem.
4.1.3. Normalisasi Data Sample Suara
(maximum) dan nilai terendah (minimum) yang sama. Dimana nilai tertinggi adalah 1 (Satu) dan nilai terendah adalah -1 (Minus Satu). 4.1.4. Deteksi Silence Voice atau Suara Hening
Pada tahap ini dilakukan deteksi silence voice dari file suara. Silence voice yang dimaksud adalah jeda antar kata dari satu kalimat
dalam file suara. Tahap ini terbagi menjadi 2 proses yakni deteksi silence voice dengan menggunakan Energi dan deteksi silence voice
dengan menggunakan zero-crossing. Dimana pada proses awal sistem akan mencari energi dari data hasil normalisasi dengan fungsi energy.m yang kemudian sampel data akan di potong sesuai hasil deteksi energy.
Gambar 4.1.4.1 : Grafik Deteksi Silence Voice menggunakan Energy
(Data : SAM – Hidupkan Lampu Kamar)
kembali. Potongan-potongan suara ini kemudian akan dicari zero-crossing-nya guna untuk menemukan silence voice dari hasil setiap
potongan suara.
Gambar 4.1.4.2 : Grafik Deteksi Silence Voice menggunakan
Zero-Crossing (Potongan ke-1)
Gambar 4.1.4.3 : Grafik Deteksi Silence Voice menggunakan
Gambar 4.1.4.4 : Grafik Deteksi Silence Voice menggunakan
Zero-Crossing (Potongan ke-3)
Gambar 4.1.4.5 : Grafik Deteksi Silence Voice menggunakan
Gambar 4.1.4.6 : Grafik Deteksi Silence Voice menggunakan
Zero-Crossing (Potongan ke-5)
Dari gambar hasil deteksi silence voice menggunakan Zero-Crossing (Gambar 4.1.4.2 hingga Gambar 4.1.4.6) didapatkan hasil
potongan pertama,ke-2 dan ke-4 dengan menggunakan energi sudah optimal karena setelah di deteksi kembali dengan zero-crossing hasil potongan tidak memiliki potongan suara baru didalamnya. Berbeda dengan potongan ke-3 dan ke-5 dimana setelah deteksi zero-crossing hasil potongan ini dapat di potong kembali menjadi masing-masing 2 potongan suara baru.
Uji data dilakukan demi mendapatkan akurasi yang baik untuk memperoleh hasil potongan yang akurat. Data uji yang digunakan dalam proses ini adalah sebanyak 320 file suara berupa rekaman dari arah depan dan samping pembicara yang akan di uji satu per-satu kedalam sistem untuk mengambil potongan kata dari file kalimat perintah tersebut. Adapun hasil uji adalah sebagai berikut :
4.1.5. FEATURE DATA (Mel-Frequency Cepstral Coefficients)
Tahap ini dilakukan untuk mendapatkan ciri atau feature dari potongan suara. Pada tahap ini semua potongan suara akan dicari matriks mfcc nya menggunakan fungsi mfcc yang ada pada Matlab. Matriks tersebut nantinya akan digunakan dalam mencari nilai mean, varian, standar deviasi, dan standar deviasi by mean yang merupakan
nilai feature dari data suara. Setelah data ciri di dapatkan, label dari ciri data diberikan secara manual. Terdapat 12 label yang merupakan kata-kata dalam kalimat perintah suara yakni : hidup, mati, buka, tutup, lampu, tv, pintu, jendela, ruang, tamu,kamar dan garasi. Setelah label diberikan sistem akan merubah label ciri menjadi bilangan biner yang kemudian digunakan dalam klasifikasi pada jaringan syaraf tiruan. Label pada tabel 4.2 digunakan sebagai label data ciri suara. Karena label ciri merupakan 4 digit angka maka proses klasifikasi jaringan syaraf tiruan memerlukan sebanyak 4 luaran.
Tabel 4.1.5 : Tabel Label Ciri Data
LABEL KATA LABEL BINER
4.1.6. 3-Fold Cross Validation
Dari hasil pemotongan kalimat suara didapatkan sebanyak 2760 file suara baru yang merupakan kata dari hasil pemotongan kalimat perintah suara. 2760 file suara berupa kata ini kemudian direduksi dan diambil hanya file suara yang tidak cacat atau suara kata didalamnya tidak terpotong dan terdengar jelas. Setelah melalui proses reduksi didapatkan sebanyak 1970 file suara berupa kata. Ekstraksi ciri kemudian dilakukan demi mendapatkan ciri suara dan label dari 1970 file suara tersebut. Kemudian semua data ciri tersebut dibagi menjadi 12 kelompok berdasarkan labelnya. Kelompok data berdasarkan 12 label ciri dibagi kembali menjadi 3 kelompok data baru untuk kemudian dijadikan sebagai data training dan data testing seperti pada Tabel 3.4.
4.2.Klasifikasi
Pada proses klasifikasi menggunakan Jaringan Syaraf Tiruan dengan fungsi aktivasi purelin, komputasi paralel dan kombinasi 1 hingga 25 neuron dalam satu hidden layer dan dua hidden layer.
➢ Satu Hidden Layer
Gambar 4.2.1 : Arsitektur JST satu Hidden Layer
algoritma backpropagation, satu hidden layer serta 4 luaran. Dimana pada layer lakukan kombinasi neuron dengan menggunakan 5 ,10, 15, 20 dan 25 neuron.
Gambar 4.2.2 : Grafik hasil klasifikasi dengan menggunakan 1 hidden
layer
Kombinasi neuron pada 1 hidden layer menghasilkan hasil tertinggi pada neuron 25 dengan hasil 63,49% .
➢ Satu Hidden Layer dengan variasi bobot dan bias
Gambar 4.2.3 : Arsitektur JST satu Hidden Layer dengan variasi bobot
dan bias
Dimana pada layer lakukan kombinasi neuron dengan menggunakan 5 ,10, 15, 20 dan 25 neuron dengan nilai bobot masukan divariasikan dengan ketentuan nilai di antara -1 hingga 1. Berikut merupakan variasi yang digunakan:
o Variasi 1 : Nilai bobot bersifat random dengan rentang nilai dari
-1 hingga 1 sedangkan nilai bias bersifat random dengan rentang -1,5 hingga 1,5
o Variasi 2 : Nilai bobot dan bias bersifat random dengan rentang
nilai dari -1 hingga 1
Gambar 4.2.4 : Grafik hasil klasifikasi dengan menggunakan 1 hidden
layer yang telah divariasikan bobot dan biasnya
➢ Dua Hidden Layer
Gambar 4.2.5 : Arsitektur JST dua Hidden Layer
Pada gambar 4.2.5 menggunakan 52 input ciri suara yang merupakan nilai mean, median, standar deviasi dan standar deviasi by mean, algoritma backpropagation, dua hidden layer serta 4 luaran. Dimana pada layer lakukan kombinasi neuron dengan menggunakan 5, 10, 15, 20, 25 neuron.
Gambar 4.2.6 : Grafik hasil klasifikasi dengan menggunakan 2 hidden layer
➢ Arsitektur Optimal
Gambar 4.2.7 : Grafik perbandingan seluruh hasil akurasi JST
dengan 1 dan 2 hidden layer beserta variasi dari 1 hidden layer
Pada gambar 4.2.7 dapat dilihat arsitektur dari 2 hidden layer memiliki nilai akurasi yang lebih optimal dibandingkan dengan arsitektur lainnya yakni sebesar 71,52% pada jumlah neuron 15 untuk setiap hidden layernya.
Gambar 4.2.8 : Arsitektur JST optimal
Berdasarkan hasil penelitian dengan menggunakan kombinasi hidden layer dan neuron didapatkan arsitektur optimal dengan input
Arsitektur optimal ini menggunakan algoritma backpropagation dengan fungsi aktivasi purelin.
Berikut merupakan confusion matriks dari arsitektur optimal untuk 3-Fold Cross Validation.
Tabel 4.2.1 : Tabel Fold Pertama
Tabel 4.2.2 : Tabel Fold Kedua
Pada tabel 4.2.2 dapat dilihat bahwa pada proses klasifikasi dengan kelompok data ciri satu sebagai data testing system mampu mengenali sebanyak 357 data dari total 453 data masukan. Hal ini dapat dilihat pada tabel 4.2.2 dimana system mengenali sebanyak 51 data yang memiliki label 2, 52 data yang memiliki label 3, 11 data yang memiliki label 4, 19 data yang memiliki label 5, 41 data yang memiliki label 6, 35 data yang memiliki label 7, 13 data yang memiliki data dengan label 8, 15 data yang memiliki label 9, 38 data yang memiliki label 10, 29 data yang memiliki label 11, 40 data yang memiliki label 12, dan sebanyak 13 data yang memiliki label 13.
Pada tabel 4.2.3 dapat dilihat bahwa pada proses klasifikasi dengan kelompok data ciri satu sebagai data testing system mampu mengenali sebanyak 292 data dari total 361 data masukan. Hal ini dapat dilihat pada tabel 4.2.3 dimana system mengenali sebanyak 37 data yang memiliki label 2, 35 data yang memiliki label 3, 12 data yang memiliki label 4, 8 data yang memiliki label 5, 58 data yang memiliki label 6, 37 data yang memiliki label 7, 11 data yang memiliki data dengan label 8, 7 data yang memiliki label 9, 26 data yang memiliki label 10, 20 data yang memiliki label 11, 32 data yang memiliki label 12, dan sebanyak 9 data yang memiliki label 13.
4.3.Uji Data Tunggal
Uji data tunggal ini menggunakan 5 data suara untuk pengujian, berikut merupakan hasil uji dari data tunggal.
➢ Data 1
Pada uji data 1 dapat di klasifikasikan dengan benar, dimana kalimat perintah yang terdeteksi sama dengan kalimat pada file suara yakni Hidupkan Lampu Kamar.
➢ Data 2
Gambar 4.3.2 : Gambar Uji Data 2
➢ Data 3
Gambar 4.3.3 : Gambar Uji Data 3
Pada uji data 3 dapat di klasifikasikan dengan benar, dimana kalimat perintah yang terdeteksi sama dengan kalimat pada file suara yakni Hidupkan TV Ruang Tamu.
➢ Data 4
Pada uji data 4 dapat di klasifikasikan dengan benar, dimana kalimat perintah yang terdeteksi sama dengan kalimat pada file suara yakni Buka Jendela. Namun terdapat tambahan kata perintah etc di belakangnya yang merupakan kata tidak terdeteksi atau noise yang tersisa pada hasil preprocessing file suara.
➢ Data 5
Gambar 4.3.5 : Gambar Uji Data 5
4.4.Analisa Hasil
Dalam hasil pengujian dengan menggunakan beberapa variasi arsitektur dari jaringan syaraf tiruan seperti yang dijelaskan pada bagian 4.2 yakni dengan menggunakan arsitektur 1 hidden layer, 1 hidden layer dengan variasi 1, 1 hidden layer dengan variasi 2 serta arsitektur dengan menggunakan 2 hidden layer. Menghasilkan nilai akurasi yang bervariasi seperti yang terlihat pada gambar grafik 4.4.1
Gambar 4.4.1 : Grafik perbandingan seluruh hasil akurasi JST
dengan 1 dan 2 hidden layer beserta variasi dari 1 hidden layer
Dari grafik tersebut terlihat bahwa klasifikasi dengan metode jaringan syaraf tiruan menghasilkan nilai akurasi tertinggi ketika menggunakan arsitektur 2 hidden layer. Akurasi yang didapatkan ketika menggunakan arsitektur dengan 2 hidden layer yang optimal adalah sebesar 71,52% untuk jumlah neuron sebanyak
15 pada setiap hidden layernya. Hal ini disebabkan karena semakin banyak hidden layer yang digunakan maka akan bertambah pula tingkat kompleksitas perhitungan
Berdasarkan gambar 4.2.4, Variasi atribut bobot dan bias pada arsitektur jaringan syaraf tiruan tidak terlalu berpengaruh dalam meningkatkan akurasi hasil klasifikasi ciri suara. Dengan divariasikannya nilai bobot dan bias pada arsitektur jaringan syaraf tiruan hanya dapat meningkatkan akurasi sebesar 0,31%.
69 BAB V PENUTUP
5.1.Kesimpulan
Dari hasil penelitian ini dapat disimpulkan sebagai berikut :
1. Hasil beberapa percobaan klasifikasi perintah suara dengan metode Jaringan Syaraf Tiruan dan menggunakan feature mean, median, standar deviasi dan standar deviasi by mean adalah sebagai berikut :
➢ Sistem mendapatkan akurasi 63,49% dengan menggunakan 1 hidden layer dimana didalamnya terdapat 25 neuron.
➢ Sistem mendapatkan akurasi 63,80% dengan menggunakan 1 hidden layer yang berisikan 25 neuron dan menggunakan variasi
bobot dengan rentang nilai dari -1 hingga 1 dan bias dengan rentang nilai dari -1,5 hingga 1,5
➢ Sistem mendapatkan akurasi 71,52% dengan menggunakan 2 hidden layer dimana terdapat sebanyak 15 neuron untuk setiap
layer.
2. Identifikasi kata dalam proses pemotongan kalimat suara menggunakan Energy dan Zero-Crossing mampu dilakukan dengan akurasi sebesar 90,41% untuk data suara yang diambil dari depan dan akurasi sebesar 92,37% untuk data suara yang diambil dari samping.
5.2.Saran
Dari hasil penelitian ini, ada beberapa saran untuk penulis dalam penelitian dengan topik yang sama :
1. Gunakan kombinasi kata yang sedikit mungkin untuk 1 file kalimat suara. Contohnya dengan 2 kata dalam 1 file suara, karena semakin banyak kata yang diucapkan dalam satu kalimat, seseorang akan cenderung untuk mengucapkannya dengan jeda yang sangat singkat dan suara yang dihasilkan semakin kurang jelas.
2. Perbanyak ciri data suara untuk setiap sumber suara karena aksen / logat dari daerah individu sumber data sangat mempengaruhi variasi kata yang ia diucapkan.
71
DAFTAR PUSTAKA
Amrutha S, Aravind S, Ansu Mathew, Swathy Sugathan, Rajasree R, Priyalakshmi S. (2015) Voice Controlled Smart Home. International Journal of Emerging Technology and Advanced Engineering, Volume 5, Issue 1, [272-276]. Available from: https://www.researchgate.net/publication/282270177_Voice_Contr
olled_Smart_Home [ akses 30 Oktober 2017].
CH.Venkateswara Rao, Anirvan Sen, Debasish Tahbildar, Klanidhi Kumar. (2016) Smart Home Equipped with Voice Recognition. International Journal of Industrial Electronics and Electrical Engineering, Volume 4, Issue 4, [115-117]. Available from:
http://pep.ijieee.org.in/journal_pdf/11-247-1462944702115-117.pdf [ akses 30 Oktober 2017].
Ignatius Nathanael Andika, Bayu Kanigoro. (2014) Aplikasi Pengenalan Suara untuk Rumah Pintar Menggunakan Algoritma Fast Fourier Transform Berbasiskan Android. Jakarta : Binus University.
Available from:
http://library.binus.ac.id/Collections/ethesis_detail/2014-2-00638-IF [ akses 30 Oktober 2017 ]
Anastasia Rita Widiarti, Phalita Nari Wastu. (2009) Javanese Character Recognition Using Hidden Markov Model. World Academy of Science, Engineering and Technology, International Journal of Computer and Information Engineering Vol 3. [2201 - 2204].
Available from :
https://www.researchgate.net/publication/266998615_Javanese_Ch
aracter_Recognition_Using_Hidden_Markov_Model [akses 2 November 2017]
Campbell Jr, J.P.. (1997), Speaker recognition: A tutorial. Proceedings of the IEEE. 85. 1437 - 1462. 10.1109/5.628714. Available from : https://scholar.google.com/citations?user=NUJqUkUAAAAJ&hl=
en [ akses 8 Januari 2018 ]
Fauzan Masykur, Fiqiana Prasetiowati (2016), Aplikasi Rumah Pintar (Smart Home) Pengendali Peralatan Elektronik Rumah Tangga Berbasis WEB. Jurmal Teknologi Informasi dan Ilmu Komputer Vol
3. [51-58]. Available from :
jtiik.ub.ac.id/index.php/jtiik/article/download/156/pdf [ akses 8 januari 2018 ]
Transmisi, [82-86]. Available from : https://www.researchgate.net/publication/277998882_Aplikasi_Pe
ngenalan_Ucapan_dengan_Ekstraksi_Mel-Frequency_Cepstrum_Coefficients_MFCC_Melalui_Jaringan_Sya
raf_Tiruan_JST_Learning_Vector_Quantization_LVQ_untuk_Men
goperasikan_Kursor_Komputer [ akses 8 januari 2018 ].
Ali Mustofa (2007). Sistem Pengenalan Penutur dengan Metode Mel-Frequency Wrapping. Malang: Universitas Brawijaya. Available
from :
http://jurnalelektro.petra.ac.id/index.php/elk/article/view/16704 [ akses 8 januari 2018 ]
Diana L & Shidik (2014). Analisis Data Transaksi Penjualan Untuk Klasifikasi Jenis Barang dan Relasi Daya Beli Relatif Masyarakat Menggunakan Algoritma K-Means Serta Asosiasi Apriori. Jurnal Teknologi Informasi. [212-219]. Available from :
https://anzdoc.com/jurnal-teknologi-informasi-volume-10-nomor-2-oktober-2014-is.html [ akses 8 januari 2018]
T. Ginnakopoulos (2015). An Open Source Phyton Library for Audio Signal Analisys. Italy : University of Pavia. Available from : https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0
A. Astri (2016). Rancangan Bangun Open/Close Pintu Ruangan Otomatis Menggunakan Voice Recognition Berbasis Raspberry PI. Sumatera Selatan : Politeknik Negeri Sriwijaya. Available from : http://eprints.polsri.ac.id/2964/ [ akses 15 desember 2018 ]
Jang, J-S. R. (2005). ASR (Automatic Speech Recognition) Toolbox. Available from : http://mirlab.org/jang/matlab/toolbox/asr/ [ akses 15 desember 2018 ]
Jang, J-S. R. (2015). Audio Signal Processing and Recognition. Available from : http://mirlab.org/jang/book/audiosignalprocessing/ [akses 15 desember 2018 ]
Mittal & Zhang (2001). Artificial Neural Network for The Prediction of Temperature, Moisture and Fat Contents in Meatballs During Deep-Fat Frying. International Journal of Food Science and Technology
[489-497] Available from :
https://www.researchgate.net/publication/230452945_Artificial_ne
ural_network_for_the_prediction_of_temperature_moisture_and_f
at_contents_in_meatballs_during_deep-fat_frying [ akses 15 desember 2018 ]
Hermawan A. (2006). Jaringan Syaraf Tiruan : Teori dan Aplikasi.
Available from :
https://openlibrary.telkomuniversity.ac.id/pustaka/103410/jaringan
Siang JJ. (2005). Jaringan Syaraf Tiruan dan Pemrogramannya Menggunakan Matlab. Yogyakarta : Andi Offets.
Anam, Khoirul (2013) Pengenalan Suara Manusia Dengan Menggunakan Metode Linear Predictive Coding. Available from : https://etheses.uin-malang.ac.id/7376/1/06550095.pdf [akses 15
Desember 2018]
76
A. Lampiran Program
1. Source Code GUI newGUI
Berikut merupakan source code tampilan muka Main Sistem function varargout = newGUI(varargin)
% Begin initialization code - DO NOT EDIT gui_Singleton = 1; if nargin && ischar(varargin{1})
gui_State.gui_Callback = str2func(varargin{1}); end
if nargout
[varargout{1:nargout}] = gui_mainfcn(gui_State, varargin{:});
else
% End initialization code - DO NOT EDIT
% --- Executes just before newGUI is made visible.
function newGUI_OpeningFcn(hObject, eventdata, handles, varargin)
% This function has no output args, see OutputFcn. % hObject handle to figure
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% varargin command line arguments to newGUI (see VARARGIN)
% Choose default command line output for newGUI handles.output = hObject;
% Update handles structure guidata(hObject, handles);
% uiwait(handles.figure1);
% --- Outputs from this function are returned to the command line.
function varargout = newGUI_OutputFcn(hObject, eventdata, handles)
% varargout cell array for returning output args (see VARARGOUT);
% hObject handle to figure
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% Get default command line output from handles structure varargout{1} = handles.output;
% --- Executes on button press in pushbutton1.
[filenames pathname] = uigetfile({'*.wav'},'File Selector','MultiSelect','on');
set(handles.text2, 'String', pathname); set(handles.listbox1,'string',filenames); handles.pathname = pathname;
handles.filenames = filenames; guidata(hObject,handles);
% hObject handle to pushbutton1 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% --- Executes on selection change in listbox1.
function listbox1_Callback(hObject, eventdata, handles) % hObject handle to listbox1 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% Hints: contents = cellstr(get(hObject,'String')) returns listbox1 contents as cell array
% contents{get(hObject,'Value')} returns selected item from listbox1
% --- Executes during object creation, after setting all properties. function listbox1_CreateFcn(hObject, eventdata, handles) % hObject handle to listbox1 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles empty - handles not created until after all CreateFcns called
% Hint: listbox controls usually have a white background on Windows.
% See ISPC and COMPUTER.
if ispc && isequal(get(hObject,'BackgroundColor'), get(0,'defaultUicontrolBackgroundColor'))