BAB 2
LANDASAN TEORI
2.1 Pengoptimalan, Optimisasi, Algoritma, dan Analisis Algoritma 2.1.1 Definisi Pengoptimalan
Dalam Kamus Besar Bahasa Indonesia, pengoptimalan diartikan sebagai proses, cara, perbuatan untuk menjadikan paling baik, paling tinggi, paling menguntungkan, dan sebagainya.
2.1.2 Definisi Optimisasi
Menurut Kamus Besar Bahasa Indonesia, optimisasi adalah prosedur yang digunakan untuk membuat sistem atau desain yang fungsional atau seefektif mungkin dengan menggunakan teknik aplikasi matematika.
2.1.3 Definisi Algoritma
Algoritma berasal dari kata Algoris dan Ritmis, yang pertama kali diungkapkan oleh Abu Ja’far Mohammad Ibn Musa Al Khowarizmi dalam buku Al-jabr wa’almuqabala (Horowittz, Ellis dan Sartaj Sahni, 1978, pl).
Ada beberapa definisi yang diberikan mengenai pengertian algoritma (Horowittz, Ellis dan Sartaj Sahni, 1978, pl), antara lain sebagai berikut:
1. Menurut Abu Ja’far Mohammad Ibn Musa Al Khowarizmi Algoritma adalah suatu metode khusus untuk menyelesaikan suatu permasalahan.
2. Menurut Goodman Hedetniemi Algoritma adalah urut-urutan terbatas dari operasi–operasi yang terdefinisi dengan baik, yang masing-masing
membutuhkan memori dan waktu yang terbatas untuk menyelesaikan suatu permasalahan.
3. Dalam ilmu komputer Algoritma adalah suatu metode yang terdiri dari serangkaian langkah–langkah yang terstruktur dan dituliskan secara sistematis yang akan dikerjakan untuk menyelesaikan masalah dengan bantuan komputer.
2.1.4 Definisi Analisis Algoritma
Algoritma tidak selalu memberikan hasil terbaik yang mungkin diperoleh, maka diharapkan adanya suatu evaluasi mutu hasil dari algoritma tersebut (Liu, C.L, 1995, p271). Sekali sebuah algoritma diberikan kepada sebuah permasalahan dan dijamin akan memberikan hasil yang diharapkan, maka langkah penting selanjutnya adalah menentukan besar biaya yang diperlukan algoritma tersebut untuk memperoleh hasil itu. Proses inilah yang disebut dengan analisis algoritma (Weiss, Mark Allen, 1996, p149).
Ukuran biaya eksekusi suatu algoritma yang paling sering digunakan adalah lamanya waktu diperlukan. Namun juga masih ada ukuran–ukuran lainnya, misalnya besarnya memori yang diperlukan untuk mengeksekusi algoritma tersebut (Liu, C.L, 1995, p272).
Maksud dilakukannya analisis algoritma (Horowitz, Elis dan Sartaj Sahni, 1978, p1) adalah untuk:
1. Memenuhi aktivitas intelektual.
2. Meramalkan suatu hal yang akan terjadi atau yang akan didapat dari algoritma tersebut.
3. Mengetahui efektifitas suatu algoritma dibanding dengan algoritma yang lain untuk persoalan yang sama.
2.2 Kompleksitas Waktu Algoritma dan Masalah
Salah satu ukuran biaya dalam pengeksekusian sebuah algoritma adalah lamanya waktu yang diperlukan. Pengukuran waktu yang diperlukan dalam mengeksekusi suatu algoritma dinamakan kompleksitas waktu (time complexity) algoritma tersebut (Liu, C.L, 1995, p272).
Besarnya waktu yang dibutuhkan algoritma untuk menyelesaikan sebuah permasalahan sebanding dengan jumlah inputan yang diberikan untuk permasalahan tersebut. Semakin besar data maka akan semakin besar waktu yang diperlukan. Sebagai contoh, diperlukan waktu yang lebih besar untuk mengurutkan 10.000 buah data dibanding dengan 10 buah data. Akan tetapi, pada keadaan sebenarnya, nilai dari suatu algoritma ditentukan dari banyak faktor, misalnya kecepatan komputer yang dipakai, kualitas compiler dan dalam beberapa kasus, kualitas program itu sendiri (Weiss, Mark Allen, 1996, p149).
Dua buah algoritma yang berbeda dapat digunakan memecahkan masalah yang sama dan mungkin saja mempunyai kompleksitas waktu (time complexity) yang sangat berbeda (Liu, C.L, 1995, p274). Kompleksitas waktu algoritma terbaik untuk memecahkan masalah tersebut dinamakan sebagai kompleksitas waktu suatu masalah (time complexcity of problem) (Liu, C.L, 1995, p277).
Berdasarkan pengertian problem (masalah) di atas, tidak semua masalah dapat dipecahkan, dengan kata lain mempunyai algoritma solusi.
Ada dua buah klasifikasi permasalahan, yaitu sebagai berikut:
1. Permasalahan yang dapat dipecahkan (decidable / solvable problem)
Permasalahan yang termasuk klasifikasi ini adalah semua jenis permasalahan yang mempunyai algoritma solusi, walaupun kadang kala tidak praktis. Dari segi
komputasi, permasalahan dalam klasifikasi ini dapat dibedakan menjadi tiga kategori, yaitu:
• Permasalahan Tractable (mudah dari segi komputasi)
Suatu masalah dikatakan tractable jika masalah tersebut dapat dipecahkan oleh suatu algoritma yang efisien. Contoh permasalahan tractable antara lain adalah masalah penentuan bilangan terbesar di antara n bilangan, pengurutan n bilangan, penentuan lintasan terpendek antara dua buah vertex di dalam sebuah graph dan lain sebagainya.
• Permasalahan Intractable (sukar dari segi komputasi)
Suatu masalah dikatakan intractable jika tidak ada algoritma yang efisien untuk memecahkan masalah tersebut.
• Permasalahan NP-Complete (NP singkatan dari Non-Deterministic Polinomial)
Suatu masalah dikatakan NP-Complete apabila masalah itu telah berhasil dibuktikan termasuk dalam masalah intractable. Contohnya adalah permasalahan pewarnaan graph.
2. Permasalahan yang tidak dapat dipecahkan (undecidable / unsolveable problem) Permasalahan yang termasuk dalam klasifikasi ini adalah semua permasalahan yang tidak mempunyai algoritma solusi, maksudnya adalah tidak dapat dilakukan perhitungan, atau tidak dapat diperoleh jawaban dalam waktu singkat. Contohnya permasalahan unbounded tiling.
Ada beberapa definisi yang diberikan pengukuran kompleksitas suatu masalah (Weiss, Mark Allen, 1996, p161), yaitu sebagai berikut:
1. Big-O Definisi:
T(n) = O(F(n)), jika ada konstanta positif c dan No di mana T(n) < cF(n),
ketika N > No
2. Big-Omega Definisi:
T(n) = Ω(F(n)), jika ada konstanta positif c dan No di mana T(n) > cF(n),
ketika N > No
3. Big-Theta Definisi:
T(n) = Θ(F(n)), jika dan hanya jika T(n) = O(F(n)) dan T(n) = Ω(F(n)) 4. Little-O
Definisi:
T(n) = o(F(n)), jika dan hanya jika T(n) = O(F(n)) dan T(n) ≠ Θ(F(n))
Dari keempat definisi yang diberikan di atas, definisi pertama yang sering digunakan dalam mengukur kompleksitas suatu permasalahan (Weiss, Mark Allen, 1996, p161)
Tabel 2.1 Fungsi kompleksitas suatu masalah dalam urutan ascending. Fungsi Nama
C Konstanta
Log N Logaritma
Log² N Logaritma Kuadrat N Linear N Log N N Logaritma N
N² Kuardatis
N3 Kubik
2n Eksponensial
2.3 Permasalahan NP-Hard dan NP-Complete
Waktu yang dibutuhkan algoritma terbaik untuk menghasilkan solusi dari banyak problem (permasalahan) dapat dibagi menjadi dua kelompok. Kelompok pertama terdiri dari problem di mana waktu yang dibutuhkan untuk menghasilkan solusinya terbatas pada waktu polynomial dalam tingkat kecil disebut juga Polynomial Problem (P), seperti permasalahan evaluasi polynomial dengan O(n), pengurutan (sorting) dengan O(n log n) dan string editing dengan O(mn). Kelompok kedua terdiri dari permasalahan dengan algoritma Non Polynomial (NP), seperti permasalahan traveling sales person dengan O(n22n) dan permasalahan Knapsack dengan O(2n/2). Dalam pencarian untuk
mengembangkan algoritma yang efisien, tidak satupun yang dapat mengembangkan algoritma dengan waktu polynomial untuk permasalahan kelompok kedua. Hal ini sangat penting karena algoritma yang waktu pencarian solusinya lebih besar dari polynomial
(biasanya waktu pencarian adalah eksponensial) membutuhkan waktu yang cukup lama untuk menjalankan problem skala menengah.
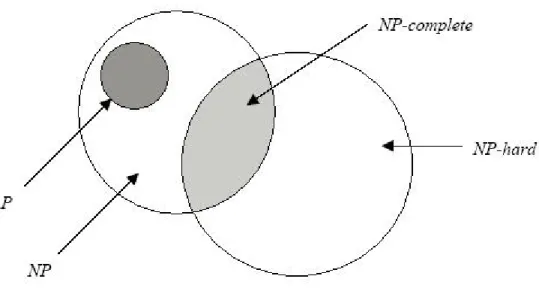
Algoritma Non Polynomial (NP) dibagi menjadi dua kelas yaitu NP-hard dan NP-complete. Suatu problem yang termasuk kedalam NP-complete memiliki sifat dapat dipecahkan dalam waktu polynomial jika dan hanya jika seluruh problem NP-complete juga dapat dipecahkan dalam waktu polynomial. Jika sebuah problem NP-hard dapat dipecahkan dalam waktu polynomial maka seluruh problem NP-complete dapat dipecahakan dalam waktu polynomial. Seluruh problem NP-complete merupakan problem NP-hard, tetapi sebagian problem NP-hard belum tentu menjadi problem NPcomplete. Hubungan antara P, NP, NP-compelete dan NP-hard dapat dilihat dengan jelas dengan gambar berikut.
2.4 Definisi Heuristic
Definisi Heuristic yang didapat dari berbagai sumber diterangkan pada penjelasan berikut ini:
1. Sebuah algoritma heuristic adalah suatu aturan untuk mengetahui bagaimana memecahkan permasalahan tertentu, tidak memberikan instruksi yang spesifik tetapi panduan umum untuk bermacam pendekatan yang mungkin dapat bekerja. (http://thesaurus.maths.org)
2. Istilah heuristic digunakan untuk algoritma di mana mencari solusi melalui semua kemungkinan yang ada, tetapi dalam pencariannya tidak bisa dijamin ditemukan solusi yang terbaik, oleh karena itu heuristic dapat dianggap algoritma perkiraan. Algoritma ini biasanya mencari solusi yang dekat dengan solusi terbaik dan proses pencariannya cepat dan mudah. Terkadang algortima ini dapat menjadi akurat dan menemukan solusi terbaik, tetapi algoritma ini tetap disebut heuristic hingga solusi terbaik itu terbukti untuk menjadi yang terbaik. (http://students.ceid.upatras.gr/)
2.5 Bin Packing
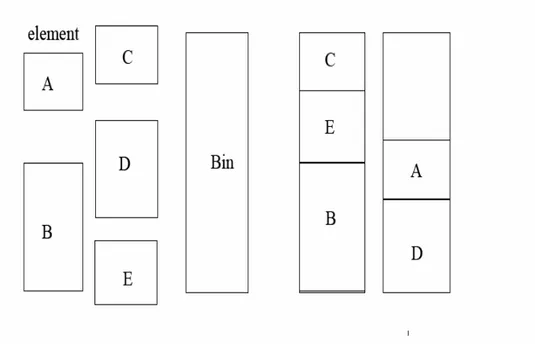
Dalam problem ini diberikan obyek sebanyak n (element) yang harus ditempatkan pada bin (tempat penyimpanan) dengan kapasitas L. Obyek i membutuhkan unit li dari kapasitas bin. Tujuan bin packing adalah untuk menentukan jumlah bin yang
dibutuhkan untuk menampung seluruh obyek n. tidak boleh ada obyek yang ditempatkan sebagian di dalam suatu bin dan sebagian lain di dalam bin lainnya. Untuk lebih jelasnya bisa dilihat gambar dibawah ini.
Gambar 2.2 one-dimensional bin packing
2.5.1 One Dimensional Bin Packing
One dimensional bin packing termasuk ke dalam permasalahan bin packing yang selama ini dianggap merupakan area di mana riset operasional bertemu dengan puzzle (matematika rekreasional) dan termasuk ke dalam persamalahan NP-hard.
Permasalahan optimalisasi bin packing termasuk ke dalam kelompok di mana tidak ada algoritma baku untuk menyelesaikannya, karena setiap kasus permasalahannya biasanya memiliki batasan-batasan unik tertentu (constraint). Karena itu algoritma yang digunakan dalam one dimensional bin packing tergolong ke dalam algoritma heuristic.
Untuk mengetahui optimal atau tidaknya suatu algoritma dalam one dimensional bin packing. Ronald Graham, seorang matematikawan amerika melakukan perhitungan dengan memisalkan :
• Suatu algoritma A
• Koefisien r
• Dan OPT adalah jumlah bin maksimum dari solusi yang paling optimal. Kemudian dari worst case yang terjadi dimasukkan ke dalam persamaan berikut.
A(L) ≤ r OPT(L)
Dalam permasalahan one dimensional bin packing alogoritma yang pertama kali dikembangkan adalah algoritma Next Fit. Algoritma ini mempunyai nilai optimalisasi sebesar
NF(L) ≥ 2 OPT(L) - 1
Algoritma ini bisa dikatakan sangat tidak optimal. Kemudian para ahli matematika mengembangkan algoritma ini dan didapat algoritma First Fit yang lebih optimal dengan nilai optimalisasi sebesar
FF(L) ≤ [ (17/10) OPT(L) ]
Dan perkembangan dari algoritma First Fit ini yaitu algoritma First Fit Decreasing memiliki nilai optimalisasi sebesar
FFD(L) ≤ (11/9) OPT(L) + 4
Algoritma ini juga memberikan hasil yang lebih stabil, sehingga penulis memutuskan untuk menggunakan algoritma ini di dalam penelitian ini, tentu saja dengan sedikit mengubah algoritma dasar yang ada sehingga sesuai dengan constraint yang ada dalam masalah pemotongan baja.
2.5.2 Algoritma First Fit Decreasing
Algoritma First Fit Decreasing adalah algoritma yang mengutamakan elemen berukuran besar untuk lebih dulu ditempatkan di dalam bin. Berbeda dengan algoritma First Fit biasa yang menempatkan elemen kedalam bin tanpa prioritas tertentu (algoritma first fit adalah algoritma yang menempatkan elemen pertama yang ditemui kedalam bin), sehingga kadang terjadi banyak elemen berukuran besar tertinggal di belakang. Berikut adalah contoh cara kerja dari algoritma First Fit Decreasing.
Misalkan kita memiliki elemen dengan ukuran dan jumlah tertentu seperti di bawah ini : - Ukuran 5 meter sebanyak 2.
- Ukuran 4 meter sebenyak 3. - Ukuran 3 meter sebanyak 2. - Ukuran 1 meter sebanyak 3. Dan bin berukuran 11 meter.
Maka berikut adalah langkah penempatan yang dilakukan oleh algoritma First Fit Decreasing :
Langkah 1 :
Bin 1 : 5 , sisa = 6
5 adalah elemen terbesar yang masih cukup untuk ditempatkan di dalam bin yang ada.
Langkah 2 :
Bin 1 : 5 , 5 , sisa = 1
5 masih elemen terbesar yang masih cukup untuk ditempatkan di dalam bin yang ada.
Langkah 3 :
Bin 1 : 5 , 5 , 1 , sisa = 0
Elemen berukuran 4 dan 3 tidak bisa ditempatkan di dalam bin karena ukurannya lebih besar daripada ukuran bin yang tersisa. Dan satu satunya elemen yang masih bisa ditempatkan dalam bin adalah elemen ukuran 1.
Langkah 4 :
Bin 1 : 5 , 5 , 1 , sisa =0 Bin 2 : 4 , sisa = 7
Diambil bin baru karena bin pertama sudah penuh dan tidak bisa diisi lagi, elemen berukuran 4 adalah elemen terbesar yang ada sekarang, sehingga elemen 4 di tempatkan di dalam bin.
Langkah 5 :
Bin 1 : 5 , 5 , 1 , sisa = 0 Bin 2 : 4 , 4 , sisa = 3
Diambil bin berukuran 4 karena itu merupakan elemen terbesar yang bisa ditempatkan dalam bin.
Langkah 6 :
Bin 1 : 5 , 5 , 1 , sisa = 0 Bin 2 : 4 , 4 , 3, sisa = 0
Diambil bin berukuran 3 karena itu merupakan elemen terbesar yang bisa ditempatkan dalam bin.
Langkah 7 :
Bin 1 : 5 , 5 , 1 , sisa = 0 Bin 2 : 4 , 4 , 3, sisa = 0
Bin 3 : 4 , sisa = 7
Diambil bin baru, bin 2 telah sepenuhnya terisi. Kemudian elemen berukuran 4 ditempatkan karena merupakan elemen terbesar yang bisa ditempatkan dalam bin.
Langkah 8 :
Bin 1 : 5 , 5 , 1 , sisa = 0 Bin 2 : 4 , 4 , 3, sisa = 0 Bin 3 : 4 , 3, sisa = 7
Diambil bin berukuran 3 karena itu merupakan elemen terbesar yang bisa ditempatkan dalam bin. (elemen yang tersisa hanya ukuran 1 dan 3)
Langkah 9 :
Bin 1 : 5 , 5 , 1 , sisa = 0 Bin 2 : 4 , 4 , 3, sisa = 0 Bin 3 : 4 , 3, 1 , sisa = 7
Elemen dengan ukuran 1 ditempatkan ke dalam bin. Langkah 10 :
Bin 1 : 5 , 5 , 1 , sisa = 0 Bin 2 : 4 , 4 , 3, sisa = 0 Bin 3 : 4 , 3 , 1 , 1 sisa = 2
Elemen terakhir yang tersisa , berukuran 1 ditempatkan ke dalam bin dan dengan ini semua elemen telah ditempatkan ke dalam bin sehingga algoritma telah selesai dijalankan.
Dari hasil algoritma First Fit Decreasing didapat hasil seperti pada langkah 10. Dengan menggunakan 3 buah bin dan waste (sisa) yang didapat adalah 2.
Dalam masalah pemotongan baja constraint yang dihadapi adalah data yang sangat beragam dan variannya yang tidak menentu. Terkadang elemen kecil berjumlah banyak, dan terkadang justru elemen dengan ukuran besar yang berjumlah banyak. Dan algoritma first fit decreasing ini bisa dikatakan lemah terhadap data yang memiliki sebaran tidak merata seperti itu (suatu elemen memiliki jumlah yang jauh lebih banyak daripada elemen-elemen lainnya). Constraint lain yang dihadapi adalah adanya waste dengan ukuran panjang tertentu yang masih bisa digunakan kembali (reuseable). Karena itu penulis menambahkan 2 algoritma untuk memberikan hasil yang lebih stabil dan lebih optimal., dan sebaran waste yang lebih reuseable.
2.5.3 Golden Section
Salah satu kekurangan pada algoritma First Fit Decreasing adalah ketika suatu elemen memiliki jumlah yang lebih banyak dari elemen-elemen lainnya. Terutama jika elemen dengan jumlah banyak itu berukuran relatif besar atau relative kecil. Karena itu penulis menambahkan dua algoritma kedalam algoritma First Fit Decreasing. Algoritma pertama yang ditambahkan adalah algoritma untuk mengatasi masalah elemen dengan ukuran relatif besar. Kedua algoritma ini juga ditambahkan untuk menghasilkan output yang lebih stabil dan optimal untuk jumlah data yang besar dan bervariasi (menekan pengaruh data nature terhadap algoritma heuristic).
Ketika algoritma First Fit Decreasing dipergunakan pada data dengan elemen relatif besar yang jumlahnya sangat banyak, maka algoritma tersebut akan terus memprioritaskan elemen dengan jumlah besar tersebut. Sehingga elemen-elemen lainnya dengan ukuran lebih kecil akan dikerjakan belakangan. Yang terjadi packing tidak akan menjadi optimal sebab tempat yang seharusnya bisa disisipkan elemen yang lebih kecil
telah diisi oleh elemen yang besar, dan terjadilah waste yang sebenarnya masih bisa dioptimalkan.
Misalkan, kita memiliki data seperti berikut : - Elemen berukuran 5 ada 2
- Elemen berukuran 3 ada 2 - Bin memiliki ukuran 11
Dengan algoritma First Fit Decreasing biasa hasil yang akan didapat adalah : - Bin 1 : 5 , 5 , sisa = 1
- Bin 2 : 3 , 3 , sisa = 5
Sedangkan untuk hasil yang optimal adalah : - Bin 1 : 5 , 3 , 3 , sisa = 0
- Bin 2 : 5 , sisa = 6
Karena itu penulis mengganggap perlu adanya suatu pembatas sehingga algoritma First Fit Decreasing tidak selalu mengambil potongan terbesar, potongan terbesar tetap diprioritaskan tetapi tidak selalu diambil, sehingga didapat hasil yang lebih optimal.
Penulis menggunakan pembatas sebesar 0,38. Pembatas ini didapat dari baris Fibonacci. Berikut adalah baris Fibonacci :
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946, 17711, …. dst.
Baris Fibonacci adalah baris dengan Un = U(n-1) + U(n-2).
Yang menarik dari barisan Fibonacci ini adalah hasil pembagian Un dengan U(n-1) adalah konstan (setelah suku ke 40). Bilangan hasil pembagian ini disebut Phi di dalam matematika. Nilai Phi sendiri adalah 1,618….
Bilangan Phi (1,618…..) ini adalah salah satu bilangan yang masih misterius dalam matematika, dan banyak diteliti karena banyaknya perbandingan Phi yang ditemui dalam kehidupan sehari-hari, seperti struktur tulang manusia, perbandingan tinggi tubuh, dan pada makhluk hidup lainnya.
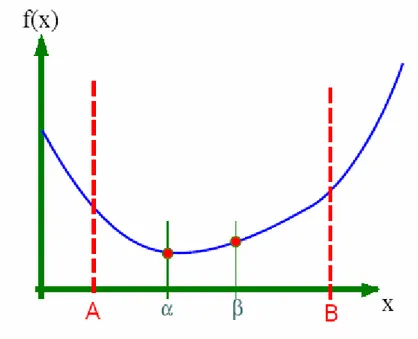
Salah satu metode untuk mencari nilai minimum fungsi juga menggunakan baris Fibonacci sebagai dasarnya, yaitu Golden Section Search.
.
Gambar 2.3 Golden Section Search. Sumber : www.wikipedia.com
Pada golden section search sebuah fungsi yang tidak diketahui gradiennya ingin dicari nilai minimumnya, maka dilakukan alpha – beta pruning dengan range pencarian yang terus berkurang sebanyak 0,38. (1 / Phi = 0,38). Dengan 10 kali iterasi saja daerah pencarian nilai minimum sudah lebih kecil dari 1 persen dari nilai daerah keseluruhan.
Penggunaan Golden Section (0,38) ini dalam algoritma First Fit Decreasing adalah dengan mempersempit pembatas yang ada sebesar 0,38 dari ukuran total bin
untuk setiap iterasinya. Sehingga untuk tiap iterasi nilai range pencarian yang dilakukan dapat dilihat dari tabel di bawah ini :
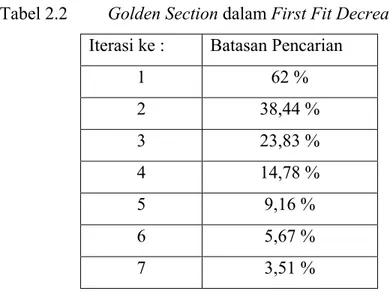
Tabel 2.2 Golden Section dalam First Fit Decreasing Iterasi ke : Batasan Pencarian
1 62 % 2 38,44 % 3 23,83 % 4 14,78 % 5 9,16 % 6 5,67 % 7 3,51 %
Dari Tabel 2.2 bisa dilihat dengan 7 iterasi saja nilai Golden Section bisa dibilang sudah cukup kecil, sehingga Golden Section ideal untuk digunakan sebagai pembatas karena tidak memerlukan banyak iterasi. Yang dilakukan Golden Section dalam algoritma First Fit Decreasing adalah sebagai pembatas, sehingga jika ada elemen dengan ukuran lebih kecil dan paling mendekati nilai Golden Search maka elemen itu akan diambil terlebih dahulu walaupun ada elemen dengan ukuran yang lebih besar dari elemen tersebut. Sehingga untuk permasalahan contoh di atas bisa didapat hasil yang optimal (Bin 1 = 5, 3 , 3 dan Bin 2 = 5).
2.5.4 Algoritma DynaCut
Algoritma DynaCut adalah algoritma yang digunakan penulis untuk mengatasi elemen dengan nilai kecil (di bawah rata-rata). Algoritma DynaCut adalah algoritma one dimensional bin packing yang membuat pattern/pola penempatan dengan nilai goal yield tertentu dengan melakukan pencarian menggunakan algoritma branch and bound.
Dalam penelitian ini penulis menggunakan algoritma DynaCut khusus untuk memanipulasi elemen bernilai kecil dengan jumlah yang besar.
Yang dilakukan algoritma DynaCut dalam penelitian adalah memeriksa iterasi elemen tersebut, apakah bisa mencapai goal yield tertentu. Elemen-elemen dengan ukuran yang sama dikelompokkan dan ditempatkan dalam sebuah bin yang sama dan dilihat apakah waste yang dihasilkan bisa lebih kecil daripada waste yang diharapkan. Dengan demikian proses algoritma First Fit Decreasing dapat berjalan dengan lebih baik karena tidak ada data yang abundance (melimpah). Dan juga hasil yang didapat bisa lebih optimal.
Dalam penelitian ini nilai goal yield yang dipakai adalah 0,00 sampai dengan 0,05. Hal ini dikarenakan sifat data sangat mempengaruhi hasil yang akan dicapai, sehingga nilai goal yield yang kecil tidak selalu menjamin mendapat hasil yang lebih optimal, karena itu variasi akibat data nature harus ditekan dengan membandingkan hasil yang didapat dengan menggunakan goal yield antara 0,00 sampai dengan 0,05.
2.6 Pemodelan Piranti Lunak
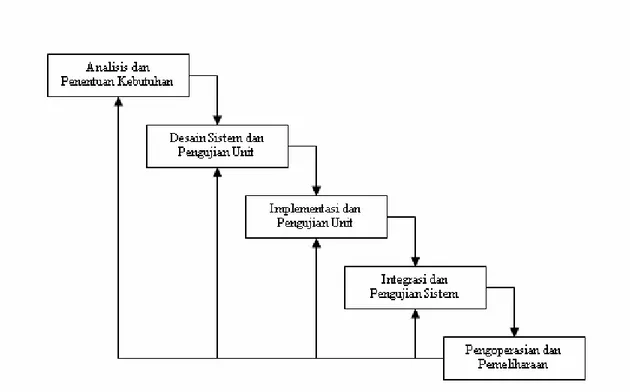
Pemodelan dalam suatu rekayasa piranti lunak merupakan suatu hal yang dilakukan ditahap awal. Pemodelan ini akan mempengaruhi pekerjaan-pekerjaan dalam rekayasa piranti lunak ini selanjutnya. Dalam mengembangkan program ini penulis menggunakan pemodelan waterfall. Tahapan-tahapan yang dilakukan dalam pemodelan waterfall adalah sebagai berikut :
Gambar 2.4 Perancangan Perangkat Lunak Model Waterfall. Sumber : Pressman, Roger S.
• Analisis dan penentuan kebutuhan
Tugas, kendala dan tujuan sistem ditentukan melalui konsultasi dengan pengguna sistem, kemudian ditentukan cara yang dapat dipahami baik oleh pengguna maupun staf pengembang.
• Desain sistem dan perangkat lunak
Proses desain sistem terbagi dalam kebutuhan perangkat keras dan perangkat lunak. Hal ini menentukan arsitektur perangkat lunak secara keseluruhan. Desain perangkat lunak mewakili fungsi sistem perangkat lunak dalam suatu bentuk yang dapat ditranformasikan ke dalam satu atau lebih program yang dapat dieksekusi.
• Implementasi dan pengujian unit
Dalam tahap ini, desain perangkat lunak direalisasikan dalam suatu himpunan program atau unit-unit program pengujian, mencakup kegiatan verifikasi terhadap setiap unit sehingga memenuhi syarat spesifikasinya.
• Integrasi dan pengujian sistem
Unit program secara individual diintegrasikan dan diuji sebagai satu sistem yang lengkap untuk memastikan bahwa kebutuhan perangkat lunak telah terpenuhi. Setelah pengujian, sistem perangkat lunak disampaikan kepada pengguna.
• Pengoperasian dan pemeliharaan
Secara normal, walaupun tidak perlu, tahap ini merupakan fase siklus hidup yang terpanjang. Sistem telah terpasang dan sedang dalam penggunaan. Pemeliharaan mencakup perbaikan kesalahan yang tidak ditemukan dalam tahap-tahap ini sebelumnya, meningkatkan implementasi unit-unit sistem dan mempertinggi pelayanan sistem sebagai kebutuhan baru yang ditemukan.