SISTEM KLASIFIKASI KELUHAN PELANGGAN DI UPT TIK UNS
MENGGUNAKAN ALGORITMA
NAIVE BAYESIAN CLASSIFIER
1Ristu Saptono, 2Wiranto, 3Wachid Daga Suryono
Program Studi Informatika, Fakultas Matematika dan Ilmu Pengtahuan Alam, Universitas Sebelas Maret Jl. Ir. Sutami 36A Kentingan, Jebres, Surakarta
Telp. (0271) 663451
E-mail: 1[email protected], 2[email protected], 3[email protected]
ABSTRAK
Keluhan merupakan sinyal ketidakpuasan konsumen terhadap perusahaan. UPT. TIK UNS menghimpun keluhan tersebut, akan tetapi karena keluhan berupa teks yang tidak terstruktur sehingga menyulitkan operator yang bertugas untuk menyalurkan keluhan ke masing-masing bidang. Oleh karena itulah dibangun sebuah sistem untuk mengklasifikasikan keluhan tersebut. Sistem tersebut dibangun menggunakan algoritma Naive Bayes Classifier berdasarkan supervise learning. Peningkatan akurasi untuk Algoritma Naive Bayes Classifier dilakukan dengan menggunakan teknik Laplacian Smoothing. Proses dilakukan dengan menghitung prior dan likelihood untuk mendapatkan posterior tertinggi dari setiap keluhan. Dari posterior tersebut, keluhan akan diklasifikasikan ke dalam empat klasifikasi keluhan yaitu keluhan berupa jaringan komputer dan internet yang akan ditangani oleh admin bagian Network Operation Center UPT. TIK UNS, keluhan terkait perangkat lunak dan sistem serta aplikasi web dan maintenance yang akan ditangani oleh admin bagian software development UPT. TIK UNS, keluhan berupa hal-hal terkait administrasi dan permasalahan secara umum akan ditangani oleh admin bagian Front Office UPT. TIK UNS, dan klasifikasi keluhan yang keempat adalah untuk keluhan yang tidak termasuk keluhan yang ditangani oleh bagian Network Operation Center, bagian Software Development maupun bagian Front Office dari UPT. TIK UNS. Hasilnya adalah sistem melakukan supervised-learning menggunakan algoritma Naive Bayesian Classifier dengan tingkat akurasi hingga 87%, sedangkan ketika proses testing tingkat akurasi yang terendah yang dicapai adalah 60% dan akurasi testing paling tinggi berada di angka 87%.
Kata Kunci: Klasifikasi, Keluhan, Naive Bayes Classifier, Laplacian Smoothing
ABSTRACT
Complaint is signal of unsatisfied customer to the institution. UPT. TIK UNS collecting that complaint, but because complaint is unstructured text so it is make a problem for the operator that classifying complaint to every department. Because of that, UPT. TIK UNS build the system to classify complaint. The system build using Naive Bayesian Classifier algorithm. Accuraccy improvement for Naive Bayesian Classifier using Laplacian Smoothing. The proccess is to count prior and likelihood to gain the maximum posterior for every complaint. From posterior, complaint will be direct to four classification i.e. comlaint about computer network and internet will be handled by Network Operation Center division of UPT. TIK UNS. Complaint about software and system also web application will be handled by Software Development division of UPT. TIK UNS. complaint about administration and general problem will be handled by Front Office division of UPT. TIK UNS. and the fourth classification are for complaint that not classify into the Network Operation Center division, Software Development division, and Front Office division. The result is supervised learning using Naive Bayesian Classifier with highest accuracy on 87%, whereas for the testing has a lowest accuracy on 60% and highest accuracy on 87%.
Keyword : Classification, Complaint, Naive Bayesian Classifier, Laplacian Smoothing
1. PENDAHULUAN
Keluhan merupakan salah satu sinyal ketidakpuasan yang diberikan konsumen terhadap sebuah perusahaan. Ketidakpuasan tersebut dapat dialamatkan kepada produk dari perusahaan maupun pelayanan atau jasa yang diberikan oleh perusahaan. Menurut Andreassen dalam (Wijaya, 2008) ketidakpuasan yang diakibatkan adanya perbedaan antara harapan dan kemampuan sesungguhnya dari sebuah produk atau jasa yang diterima oleh konsumen, akan menimbulkan negative effect yang
diyakini akan berpengaruh terhadap loyalitas konsumen. Liu et al (2000) mengatakan bahwa kegagalan dalam penyediaan layanan dapat menjadi hal yang sangat buruk karena dapat mengarahkan kepada word-of-mouth yang negatif (Alfansi & Atmaja, 2008).
Menurut Sumarni (2008) dalam (Chandra, 2013) negative word of mouth adalah suatu fenomena yang paling ditakutkan perusahaan atau pengusaha karena seorang konsumen yang tingkat kepuasan, terutama emosionalnya negatif, akan berbicara, bukan hanya
ke orang-orang dekatnya saja. Menurut Harasi (2006) dalam (Chandra, 2013) Word of mouth yang negatif mempunyai kekuatan pengaruh yang lebih tinggi dibandingkan word of mouth yang positif, konsumen cenderung untuk mempercayai word of mouth yang negatif karena sifat alaminya yang menghindari resiko. Oleh sebab itu, penanganan terhadap keluhan konsumen pun menjadi hal yang mutlak dilaksanakan oleh perusahaan.
Perusahaan menggunakan berbagai macam cara agar konsumen dapat menyampaikan keluhannya dengan baik, misalnya via telepon (call center), website resmi perusahaan, dan lain-lain. Saat ini, cara lain yang mulai dilirik oleh perusahaan agar konsumen dapat menyampaikan keluhannya adalah melalui sosial media. Data menunjukkan bahwa sebanyak 63 juta masyarakat Indonesia menggunakan internet, sebanyak 95% pengunaannya adalah untuk sosial media yakni Facebook dan Twitter (Pitakasari, 2013).
UPT. TIK UNS sebagai sebuah unit pelaksana teknis dibidang pelayanan memiliki cara untuk menghimpun keluhan dari konsumen, salah satunya adalah melalui Twitter yang dapat diakses di
http://www.twitter.com/UPTPuskomUNS.
Konsumen dapat menyampaikan keluhan terhadap UPT. Puskom UNS dengan melakukan mentions terhadap akun Twitter tersebut. (Mahardika, 2015). Selain itu, UPT. TIK UNS juga menghimpun keluhan secara konvensional. Keluhan tersebut dihimpun pada sebuah buku keluhan. Buku keluhan tersebut berada di Front Office UPT. TIK UNS.
Salah satu kelemahan penyampaian keluhan melalui Twitter adalah mentions berbentuk teks digital tidak terstruktur. Selain itu, tidak semua mentions yang diberikan kepada UPT. Puskom UNS adalah berupa keluhan. Hal tersebut menyulitkan administrator Twitter, karena administrator harus memilih terlebih dahulu mentions mana yang dianggap sebagai keluhan, dan selanjutnya menjawab keluhan dari konsumen secara manual. Selain itu, mentions yang tidak terbaca ataupun adanya mentions berisi keluhan yang sama dari dua atau lebih user berbeda menyebabkan administrator tidak dapat menjawab keluhan secara maksimal. (Mahardika, 2015)
Sama seperti sebuah keluhan yang disampaikan secara tekstual. Keluhan tekstual tersebut berbentuk teks biasa. Kemudian diubah menjadi teks digital yang tidak terstruktur. Dari permasalahan di atas dapat disimpulkan bahwa administrator mengalami kesulitan dalm melakukan pemilahan terhadap keluhan. Sehingga dibutuhkan sebuah sistem yang dapat memudahkan administrator untuk mengelola keluhan pelanggan dengan memilah tweet berupa keluhan dan bukan keluhan. Salah satu cara yang dapat digunakan adalah dengan metode analisis text mining. Analisis text mining diperlukan dalam menangani masalah teks digital tidak terstruktur. Salah satu cara yang dapat digunakan adalah dengan
metode analisis text mining. Analisis text mining diperlukan dalam menangani masalah teks digital tidak terstruktur. Salah satu kegiatan penting dalam text mining adalah klasifikasi atau kategorisasi teks. Kategorisasi teks sendiri saat ini memiliki berbagai cara pendekatan antara lain pendekatan probabilistik, support vector machine (SVM), dan artificial neural network, atau decision tree classification. Penelitian ini menggunakan metode Naïve Bayes Classifier. Metode Naïve Bayes Classifier telah digunakan secara luas karena kemudahannya, baik dalam proses pelatihan maupun klasifikasi (Chakrabarti, et al., 2003). Naïve Bayes Classifier bisa menjadi sangat efisien jika dilakukan berdasarkan supervised learning (Aribowo, 2010).
Pada penelitian kali ini akan menggunakan teorema Bayes. Teorema Bayes adalah teorema yang digunakan dalam statistika untuk menghitung peluang untuk suatu hipotesis (Shadiq, 2009). Metode Naive Bayes Classifier dipilih karena merupakan metode yang baik di dalam mesin pembelajaran berdasarkan data training, dengan menggunakan probabilitas bersyarat sebagai dasarnya (Basuki, 2006). Selain itu Naive Bayes Classifier juga memiliki kecepatan yang sangat cepat, ketepatan yang baik untuk semua data dan transparansi yang tanpa aturan (Putra, 2009). Naïve Bayes adalah metode Bayesian Learning yang paling cepat dan sederhana. Hal ini berasal dari teorema Bayes dan hipotesis kebebasan, menghasilkan klasifikasi statistik berdasarkan peluang (Mardiani, 2009)
Perhitungan dilakukan menggunakan metode Naïve Bayes Classifier yang di dalamnya sering ditemukan adanya perhitungan yang mengandung nilai peluang sama dengan 0, menyebabkan hasil perhitungan menjadi kurang akurat. Untuk menghindari munculnya peluang bernilai 0 pada metode ini, digunakan teknik Laplacian Smoothing pada metode Naïve Bayes Classifier.
Jadi, ketika ada keluhan ke UPT. TIK UNS, maka secara otomatis keluhan tersebut dapat diklasifikasikan sesuai dengan kategori.
1.1 Sistem
Pressman (2007) menyatakan bahwa, Sistem atau Aplikasi Perangkat Lunak adalah program yang memecahkan masalah sesuai dengan spesifikasi atas apa yang diperlukan. Aplikasi pada bahasan kali ini adalah adalah sebuah proses bisnis atau data teknis yang memfasilitasi operasi bisnis atau manajemen/membuat keputusan teknis. Sebagai tambahan untuk aplikasi pemrosesan data secara konvensional, aplikasi perangkat lunak harus mengontrol fungsi bisnisnya secara real time.
1.2 Klasifikasi
Agus Mulyanto (2009) mendefinisikan klasifikasi adalah fungsi yang menjelaskan atau
membedakan konsep atau kelas data, dengan tujuan untuk dapat memperkirakan kelas dari suatu obyek.
1.3 Keluhan
Keluhan secara definisi diartikan sebagai satu pernyataan atau ungkapan rasa kurang puas terhadap satu produk atau layanan jasa, baik secara lisan maupun tertulis, dari penyampai keluhan baik internal maupun eksternal. Atau sebuah ungkapan ketidakpuasan antara harapan dengan fakta terhadap apa yang diterima dalam bentuk produk maupun layanan jasa (Estrada, 2011).
1.4 Text Mining
Menurut Feldman dan Sanger (2007) Text mining merupakan variasi dari data mining yang digunakan untuk menemukan pola tertentu dari sekumpulan besar data tekstual.
Langkah yang dilakukan dalam text mining adalah sebagai proses text preprocessing. Tindakan yang dilakukan pada tahap text preprocessing adalah toLowerCase, yaitu mengubah semua karakter huruf menjadi huruf kecil serta tokenizing, yaitu proses pemecahan kalimat menjadi token berupa kata atau term, dimana setiap term dipisahkan oleh delimiter. Tanda titik (.), koma (,), spasi ( ) dan karakter angka yang ada pada kalimat dapat dianggap sebagai delimiter (Weiss, 2005).
1.5 Naive Bayes Classifier
Naive Bayes Classifier merupakan klasifikasi yang berdasarkan pada teorema Bayes. Naive Bayesian Classifier mengasumsikan bahwa setiap atribut dalam sebuah kelas merupakan atribut independen yang tidak terkait dengan atribut lain. Asumsi ini disebut class conditional independence. Naive Bayesian classifier memiliki tingkat akurasi dan kecepatan yang tinggi ketika diaplikasikan kepada data berjumlah besar.
Persamaan di bawah ini merupakan persamaan Naïve Bayes untuk klasifikasi dokumen.
d n k kc
t
P
c
P
d
c
P
1)
|
(
)
(
)
|
(
(1) dimana:P(c|d) = posterior, yakni probabilitas dokumen d berada di kelas c,
P(c) = prior, yaitu probabilitas kelas c sebelum masuknya dokumen d,
P(tk|c) = likelihood, yaitu probabilitas kemunculan
token tk dalam kelas c,
nd = jumlah token dalam dokumen d.
Dalam Naïve Bayes Classifier, dokumen d akan masuk ke dalam kelas c yang memiliki maximum a posterior
(MAP) atau kelas cmap, dihitung dengan persamaan
sebagai berikut:
d n k k C c mapP
c
P
t
c
c
1)
|
(
)
(
max
arg
(2)dimana c adalah variabel kelas yang tergabung dalam himpunan kelas C
1.6 Laplacian Smoothing
Teknik Laplacian Smoothing digunakan untuk mengatasi nilai probabilitas kondisional pada Naïve Bayes Classifier yang dapat bernilai 0. Cara yang digunakan pada teknik ini adalah dengan menambahkan angka 1 pada perhitungan Likelihood. Persamaan di bawah ini menunjukkan perhitungan nilai Likelihood untuk algoritma Naïve Bayes Classifier
)
(
|
|
)
,
(
1
)
|
(
C
n
W
C
F
n
C
F
P
i i
(3) dimana:n(Fi,C) = jumlah term Fi yang ditemukan di seluruh
data pelatihan dengan kategori C
n(C) = jumlah term di seluruh data pelatihan dengan kategori C
|W| = jumlah seluruh term dari seluruh data pelatihan
2. PEMBAHASAN
Langkah-langkah yang dilakukan dalam penelitian ini adalah sebagai berikut:
2.1. Studi Literatur
Pada tahap ini, dilakukan studi literatur untuk mempelajari text mining dan algoritma Naïve Bayes Classifier.
2.2. Pengumpulan Data
Data diambil dari buku keluhan UPT. TIK UNS yang berjumlah 180 keluhan.
2.3. Text Mining
Tahap text mining yang dilakukan pada penelitian ini adalah text preprocessing. Pada tahap ini, keluhan yang berupa string diubah dalam bentuk abjad kecil melalui fungsi ToLowerCase(). Selanjutnya keluhan yang berupa string diubah menjadi bentuk token/term, yang dipisahkan oleh delimiter berupa spasi ( ).
2.4. Klasifikasi dengan Naïve Bayes Classifier
Data yang ada diklasifikasikan sebagai keluhan akan diklasifikasikan ke dalam empat klasifikasi keluhan yaitu keluhan berupa jaringan komputer dan internet yang akan ditangani oleh admin bagian Network Operation Center UPT. TIK UNS, keluhan terkait perangkat lunak dan sistem serta aplikasi web dan maintenance yang akan ditangani oleh admin bagian software development UPT. TIK UNS, keluhan berupa hal-hal terkait administrasi dan permasalahan secara umum akan ditangani oleh admin bagian Front Office UPT. TIK UNS, dan klasifikasi keluhan yang keempat adalah untuk keluhan yang tidak termasuk keluhan yang ditangani
oleh bagian Network Operation Center, bagian Software Development maupun bagian Front Office dari UPT. TIK UNS menggunakan algoritma Naïve Bayes Classifier.
Algoritma Naïve Bayes Classifier dilakukan berdasarkan proses supervised learning. Proses supervised learning pertama dilakukan terhadap 140 keluhan awal. Kemudian keluhan ke 141 sampai 150 dijadikan sebagai test atau data pengujian. Selanjutnya ditambahkan 10 keluhan untuk digunakan dalam proses supervised learning berikutnya hingga 170 data keluhan digunakan sebagai dokumen pelatihan. Begitu pula dengan pengujiannya, dilakukan 10 data keluhan berikutnya setiap proses supervised-learning.
Tabel 1. Proses Learning dan Testing
No Nama Training Testing
1 Proses 1 = 140 = 10 2 Proses 2 = = 10 3 Proses 3 = = 10 4 Proses 4 = = 10
Langkah-langkah yang dilakukan dalam supervised learning menggunakan algoritma Naïve Bayes Classifier adalah sebagai berikut:
1. Menghitung nilai prior setiap kategori 2. Menghitung frekuensi setiap term pada
keluhan untuk setiap kategori
3. Menghitung nilai likelihood setiap term pada keluhan untuk setiap kategori
4. Menghitung nilai posterior setiap keluhan untuk setiap kategori
5. Menentukan klasifikasi keluhan berdasarkan nilai posterior tertinggi
2.5. Analisa Hasil
Pada tahap ini akan dilakukan evaluasi terhadap hasil learning maupun testing.
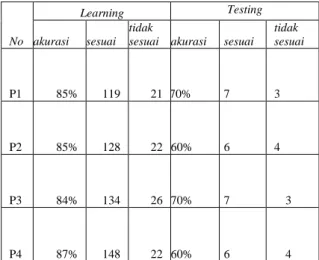
Pada proses pertama, dilakukan learning terhadap 140 keluhan pertama yang awalnya sudah diklasifikasikan secara manual. 140 keluhan yang sudah diklasifikasi ini diberikan kepada sistem untuk keperluan supervise learning. Hasil yang di dapat adalah dari 140 keluhan tersebut 119 keluhan diantaranya sesuai dengan keluhan manual dan 21 tidak sesuai. Selanjutnya, dilakukan pengujian untuk 10 keluhan berikutnya. Hasil yang didapat adalah 7 keluhan sesuai dengan klasifikasi keluhan manual dan 3 keluhan tidak sesuai dengan keluhan manual.
Pada proses kedua, 140 data keluhan ditambah dengan 10 data berikutnya yang juga berupa testing pada proses pertama menjadi menjadi data keluhan untuk supervised learning. jadi pada proses kedua terdapat 150 data keluhan untuk supervised learning. Hasilnya adalah 128 keluhan sesuai dengan keluhan manual dan 22 keluhan tidak sesuai dengan keluhan manual.
Proses ini dilakukan berulang seterusnya hingga proses ke delapan yang memuat data keluhan sebanyak 170 data keluhan untuk dilakukan supervised learning. dan 10 data keluhan berikutnya untuk data testing.
Akurasi learning tertinggi terjadi pada proses keempat, dimana akurasi mencapai 85%. Sedangkan untuk akurasi testing tertinggi berada pada proses ke delapan dimana akurasi testing / pengujian mencapai 87%.
Tabel 2. Hasil Akurasi Learning dan Testing Sistem
No
Learning Testing
akurasi sesuai tidak
sesuai akurasi sesuai tidak sesuai P1 85% 119 21 70% 7 3 P2 85% 128 22 60% 6 4 P3 84% 134 26 70% 7 3 P4 87% 148 22 60% 6 4 Dimana :
P1 = Proses pertama (Learning 140 data. Testing 141-150)
P2 = Proses kedua (Learning 150 data. Testing 151-160)
P3 = Proses ketiga (Learning 160 data. Testing 161-170)
P4 = Proses keempat (Learning 170 data. Testing 171-180)
3. KESIMPULAN
Hasil dari penelitian ini menunjukkan bahwa pada proses testing, sistem melakukan supervised-learning menggunakan algoritma Naive Bayesian Classifier dengan tingkat akurasi hingga 88%, sedangkan ketika proses testing yang hanya melibatkan beberapa sampel menunjukkan tingkat akurasi yang rendah yakni sejumlah 60% pada beberapa testing awal. Akan tetapi menunjukkan perbedaan yang signifikan ketika pada proses testing akhir yang berhasil menunjukkan akurasi testing hingga 87%.
PUSTAKA
Agus Mulyanto. 2009. Sistem Informasi Konsep dan Aplikasi. Pustaka Pelajar. Yogyakarta
Alfansi, L. and Atmaja, F.T. 2008. Konseptualisasi dan Pemodelan Antesenden Kesetiaan Pelanggan Industri Jasa di Indonesia, dalam Proceeding of National Conference on
Management Research, PPM School of Management and Graduate School of Management, University of Hasanudin, Makasar, Indonesia.
Aribowo, T., 2010. Aplikasi Inferensi Bayes pada Data Mining terutama Pattern Recognition. Bandung: Program Studi Sistem dan Teknologi Informasi, Sekolah Teknik Elektro dan Informatika.
Sulistyo Basuki. 2006. Metode Penelitian. Jakarta: Wedatama Widya Sastra dan Fakultas Ilmu Pengetahuan Budaya Universitas Indonesia. Chakrabarti, Roy & Soundalgekar, 2003. Fast and
Accurate Text Classification Via Multiple Linear Discriminant Projection. The International Journal on Very Large Data Bases, pp. 170-185. Chandra, B. A., 2013. Faktor-Faktor yang
Mempengaruhi Perilaku Komplain Konsumen (Studi Pada Mahasiswa Atma Jaya Fakultas Ekonomi Pengguna Rumah Makan di Yogyakarta), Yogyakarta: Fakultas Ekonomi, Universitas Atma Jaya.
Feldman, R. & Sanger, J., 2007. The Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data. New York: Cambridge University Press.
Hamzah, A., 2012. Meningkatkan Kinerja Naive Bayes Classifier (NBC) Untuk Klasifikasi Teks dengan menggunakan CLustering untuk Pemilihan Feature Kata. Yogyakarta, Prosiding Seminar Nasional Teknoin.
Liu, B.S.C., Sudharshan, D. & Hamer, L.O., 2000. After-service Response in Service Quality Assessment: A Real-Time Updating Model Approach. Journal of Services Marketing, 14(2), pp.160-77.
Mahardika, A. A., 2015. Sistem Klasifikasi Feedback Pelanggan Dan Rekomendasi Solusi Atas Keluhan Di Upt Puskom Uns Dengan Metode Naïve Bayes Classifier Dan Vector Space Model. Skripsi tidak diterbitkan. Surakarta: Informatika FMIPA UNS.
Mardiani, Tinaliah & Ebranda, 2009. Penerapan Metode Naive Bayes untuk SIstem Klasifikasi SMS pada Smartphone Android, Skripsi tidak diterbitkan . Palembang: Teknik Informatika STMIK MDP.
Pressman, R. S., 2010. Software Testing Techniques. Boston: McGraw Hill.
Putra, M. T., 2009. Perbandingan Klasifikasi KNN dan Naive Bayesian serta Perbandingan Clustering Simple K-Means yang Menggunakan Distance Function Manhattan Distance dan Euclidan Distance pada Dataset "Dresses_Attribute_Sales", Laporan penelitian tidak diterbitkan. Banda Aceh: Informatika FMIPA Universitas Syiah Kuala Aceh.
Shadiq, M. A., 2009. Keoptimalan Naive Bayes dalam Klasifikasi, Bandung: Ilmu Komputer Universitas Pendidikan Indonesia.
Pitakasari, A.R., 30 Maret 2013. Penggunaan Internet di Indonesia 95 Persen untuk Sosmed Republika Online, (Online), (http://www.republika.co.id/berita/trendtek/inter net/13/10/30/mvh7rmpenggunaan-internet-di-indonesia-95-persen-untuk-sosmed, diakses 7 Mei 2014).
Weiss, S.M., Indurkhya, Zhang, T. & Damerau, F.J., 2005. Text Mining: Predictive Methods for Analyzing Unstructured Information. New York: Springer.
Wijaya, T., 2008. Pengaruh Kepuasan Pada Penanganan Keluhan dan Citra Perusahaan Terhadap Loyalitas Konsumen Natasha Skin Care. Jurnal Ekonomi dan Bisnis Vol. XIV No. 1: 55-69.