III-1
BAB III
EKSTRAKSI INFORMASI MENGGUNAKAN
SUPPORT VECTOR MACHINE
3.1 Deskripsi Sistem Ekstraksi Informasi
Gambar III-1 Arsitektur sistem ekstraksi informasi
Sistem ekstraksi informasi secara umum terbagi menjadi 2 subsistem, yaitu subsistem pembelajaran model ekstraksi yang akan menghasilkan model ekstraksi, dan subsistem aplikasi model ekstraksi hasil pembelajaran untuk dapat menghasilkan informasi-informasi yang sesuai dengan struktur target yang telah ditentukan. Berikut ini adalah penjelasan detil mengenai masing-masing subsistem.
3.1.1 Pembelajaran Model Ekstraksi 3.1.1.1 Pemrosesan awal (preprocessing)
Sebelum dapat menjadi masukan bagi algoritma pembelajaran SVM, maka dataset yang akan dijadikan sebagai data pelatihan harus melalui pemrosesan awal terlebih dahulu (preprocessing). Pada pemrosesan awal tersebut, data pelatihan yang berupa kumpulan dokumen teks akan dipecah menjadi kumpulan token.
Sebuah token didefinisikan sebagai rangkaian karakter alfabetik atau numerik yang berurutan, sedangkan tanda baca dianggap sebagai sebuah token. Sebuah token dianggap sebagai satu instance yang dapat menjadi contoh positif atau contoh negatif untuk diekstrak bagi field di dalam struktur target. Agar dapat digunakan sebagai masukan untuk algoritma klasifikasi, maka token-token dari teks harus diubah ke dalam vektor fitur (feature vector).
Pengubahan token ke dalam vektor fitur pada ELIEL2 [FIN04a, FIN04b, FIN06] dan GATE-SVM [LI05a] secara umum hampir sama, yaitu menggunakan beberapa fitur
Natural Language Processing (NLP) seperti part-of speech (POS), gazetteer, dan
orthographic. Pada GATE-SVM [LI05a] dijelaskan bahwa proses pengubahan ke dalam vektor fitur tersebut menggunakan perangkat lunak open source yang disebut ANNIE (A Nearly New Information Extraction System), yang merupakan bagian dari GATE (General Architecture for Text Engineering). Sedangkan pada ELIEL2 [FIN04a, FIN04b, FIN06] tidak dijelaskan mengenai perangkat bantu yang digunakan untuk mengubah token ke dalam vektor fitur. Oleh karena itu, proses pengubahan token ke dalam vektor fitur akan menggunakan ANNIE dan menggunakan GATE-SVM [LI05a] sebagai acuan.
Fitur-fitur NLP yang dapat digunakan antara lain:
1. Orthography atau Case, yaitu penggunaan huruf besar dan huruf kecil oleh token. 2. Tokenkind, yaitu jenis token: kata, angka, simbol, atau tanda baca.
3. Lemma, yaitu bentuk dasar dari token, merupakan hasil dari analisis morfologikal. 4. Part of Speech (POS), yaitu tata bahasa dari token, apakah merupakan kata benda,
5. Lookup atau gazetteer, yaitu daftar kata dan istilah untuk berbagai kategori, misalnya untuk kategori negara yang berisi daftar seluruh negara yang ada di dunia.
6. Entity, yaitu fitur named entity recognition yang dimiliki oleh ANNIE, bekerja berdasarkan aturan ekstraksi yang sudah terdefinisi (rule-based).
Dari fitur-fitur NLP tersebut, POS merupakan satu-satunya fitur yang language dependent, yaitu bergantung pada bahasa yang digunakan. Sedangkan fitur-fitur lainnya tidak bergantung pada domain maupun bahasa.
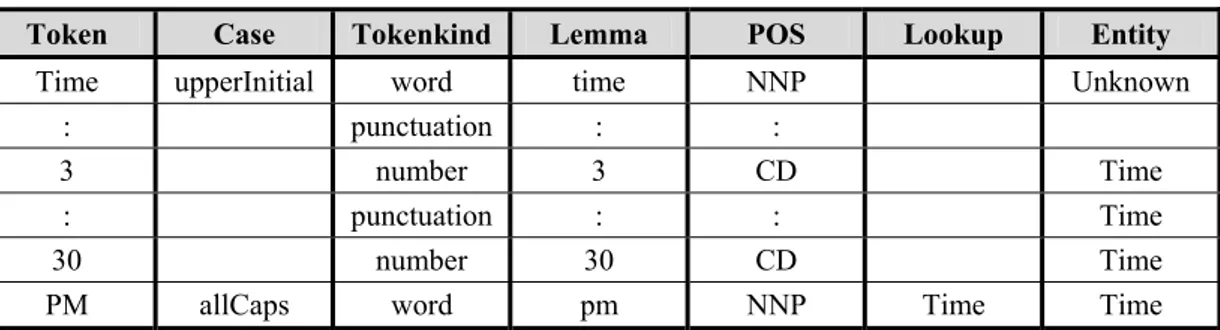
Pada Tabel III-1 dapat dilihat contoh teks “Time: 3:30 PM” dan fitur-fitur NLP yang bersesuaian. Sebagai catatan, tidak semua token memiliki fitur yang bersesuaian, sebagai contoh untuk token “Time” yang tidak memiliki fitur Lookup karena tidak terdapat di dalam daftar gazetteer yang dimiliki ANNIE.
Tabel III-1 Fitur NLP untuk contoh teks "Time: 3:30 PM"
Token Case Tokenkind Lemma POS Lookup Entity
Time upperInitial word time NNP Unknown
: punctuation : :
3 number 3 CD Time
: punctuation : : Time
30 number 30 CD Time
PM allCaps word pm NNP Time Time Kemudian, vektor fitur dari setiap token diturunkan dari fitur NLP dari setiap token dengan cara:
1. Setiap kemungkinan kemunculan fitur dari data pelatihan dikumpulkan dan diindeks dengan id yang unik, dan setiap dimensi dari vektor fitur berkorespondensi dengan sebuah fitur NLP.
2. Untuk setiap token, setiap komponen dari vektor fitur yang berkorespondensi dengan nilai dari fitur NLP yang bersesuaian akan diberi bobot 1, sedangkan komponen lainnya akan diberi bobot 0 dan tidak akan dimasukan sebagai masukan bagi algoritma klasifikasi. Untuk setiap token, vektor fitur merupakan himpunan fitur yang ditulis dengan format:
Pada ekstraksi informasi, konteks lingkungan tempat sebuah kata berada sama pentingnya dengan kata itu sendiri. Oleh karena itu, vektor fitur masukan bagi algoritma klasifikasi harus memperhitungkan kata yang mendahului dan kata-kata yang mengikuti token yang bersangkutan. Konteks lingkungan ini disebut sebagai window konteks.
Pada eksperimen yang dilakukan oleh [LI05a], jumlah kata yang mendahului dan mengikuti adalah sama. Jumlah kata ini disebut sebagai window size. Oleh karena itu, jika window size-nya adalah 3, maka vektor fitur yang menjadi masukan bagi algoritma klasifikasi diturunkan dari 7 buah token, yaitu:
- 3 buah token yang mendahului,
- token yang akan diklasifikasi (current token), dan - 3 buah token yang mengikuti.
Strategi representasi konteks yang sama juga digunakan oleh ELIEL2 [FIN04a, FIN04b, FIN06].
Sebagai vektor fitur masukan bagi algoritma klasifikasi, token-token yang berada di dalam window konteks dapat diberi bobot yang berbeda, bergantung pada letak token relatif terhadap token yang sedang diamati (current token). Terdapat dua skema pembobotan yang dapat digunakan.
1. Equal weighting, yaitu memberi bobot 1 pada semua komponen vektor fitur yang bersesuaian dengan fitur NLP yang dimiliki oleh setiap token di dalam window
konteks. Hal ini berarti bahwa semua token tetangga dianggap sama pentingnya, tidak bergantung pada letak token tetangga tersebut relatif terhadap current token. 2. Reciprocal weighting, yaitu memberi bobot berdasarkan letak token relatif
terhadap current token. Semakin dekat token tetangga dengan current token, maka bobotnya menjadi lebih tinggi. Sebaliknya, jika semakin jauh maka bobotnya pun menjadi lebih rendah. Nilai bobot dihitung dengan menggunakan rumus 1/j, dengan j adalah posisi token relatif terhadap current token.
3.1.1.2 Pembelajaran SVM
Terdapat beberapa algoritma klasifikasi yang dapat digunakan untuk menghasilkan model ekstraksi, salah satunya adalah Support Vector Machine (SVM). SVM telah mencapai performansi state-of-the-art untuk berbagai persoalan klasifikasi, termasuk untuk persoalan named entity recognition [LI05a]. Oleh karena itu, akan digunakan SVM sebagai algoritma klasifikasi.
Strategi yang akan digunakan yaitu strategi Begin/End (BE) tagging yang telah dijelaskan pada bagian 2.1.2.3. Strategi ini dipilih selain karena ELIE [FIN04a, FIN04b, FIN06] dan GATE-SVM [LI05a] menggunakan strategi ini, juga karena strategi ini menggunakan jumlah kelas yang paling sedikit yaitu n+1 kelas untuk sebuah classifer, dengan n adalah jumlah slot pada template, walaupun untuk strategi ini dibutuhkan dua buah classifier.
Akan tetapi, pada GATE-SVM [LI05a], strategi Begin/End tagging dimodifikasi. Untuk menyederhanakan implementasi, jumlah classifier yang digunakan hanya satu, yaitu untuk mengklasifikasikan token ke dalam n kelas B-type + n kelas E-type. Token lain-lain (O atau Others) tidak dianggap sebagai kelas. Dengan demikian, jumlah kelas yang digunakan oleh classifier adalah sebanyak 2n, dengan n adalah jumlah tipe slot pada template.
Karena mengklasifikasikan token ke dalam banyak kelas, maka classifier merupakan
multi class SVM. Secara umum, multi class SVM diimplementasikan dengan cara mengkombinasikan beberapa SVM biner. Penjelasan mengenai multi class SVM
dapat dilihat pada bagian 2.2.1. Di dalam tugas akhir ini, teknik kombinasi yang akan diujikan dan dibandingkan performansinya hanya teknik one-against-all (disebut juga
one-vs-others) dan one-against-one (disebut juga one-vs-another). Pemilihan teknik kombinasi ini didasarkan pada keterbatasan perangkat bantu, yaitu GATE 4.0, yang hanya mengimplementasikan multi class SVM dengan kedua teknik tersebut.
Pembelajaran SVM membutuhkan parameter pembelajaran, antara lain: - SVM kernel yang digunakan: linear, polynomial, RBF, atau sigmoid. - Parameter uneven margin: 0<τ <1
3.1.1.3 Model Ekstraksi
Pada akhir proses pembelajaran SVM akan dihasilkan model ekstraksi, yaitu berupa kumpulan hipotesis yang dapat memisahkan data ke dalam 2n kelas. Adapun bentuk hasil pembelajaran berupa model yang dihasilkan oleh SVM dapat dilihat pada Lampiran L.
3.1.2 Aplikasi Model Ekstraksi
3.1.2.1 Pemrosesan awal(preprocessing)
Sebelum dapat mengaplikasikan model ekstraksi, dokumen teks yang akan diekstrak informasi yang terkandung di dalamnya juga harus melalui pemrosesan awal terlebih dahulu (preprocessing). Sama seperti pada proses pembelajaran model ekstraksi, pada pemrosesan awal tersebut, data pelatihan yang berupa kumpulan dokumen teks dipecah menjadi kumpulan token dan diubah ke dalam vektor fitur sesuai dengan yang telah dijelaskan pada bagian 3.1.1.1.
3.1.2.2 Klasifikasi SVM
Proses klasifikasi dilakukan menggunakan model ekstraksi yang dihasilkan dari proses pembelajaran SVM. Model ekstraksi tersebut diaplikasikan pada vektor fitur setiap token, sehingga diperoleh label-label kelas untuk setiap token di dalam dokumen teks.
Tidak menutup kemungkinan bahwa satu token memiliki lebih dari satu label kelas (misalnya sebagai B-area sekaligus sebagai B-language), atau diklasifikasikan baik sebagai B-type maupun E-type. Pada kasus yang kedua, artinya token tersebut menjadi pengisi tunggal untuk suatu field tipe tertentu.
3.1.2.3 Pemrosesan Akhir (postprocessing)
Mengacu pada [LI05a], setelah diperoleh label kelas untuk setiap token, diperlukan adanya pemrosesan akhir (postprocessing), yang terdiri dari 3 tahap, yaitu:
1. Meyakinkan adanya konsistensi hasil, yaitu menghilangkan tag awal yang tidak memiliki tag akhir, dan sebaliknya.
2. Menyaring entitas kandidat yang dihasilkan dari tahap pertama, berdasarkan panjangnya. Tag dari entitas kandidat akan dihilangkan jika panjangnya (yaitu
jumlah kata/token) tidak sama dengan entitas manapun dengan tipe yang sama di dalam data pelatihan. Pada saat proses pelatihan, statistik jumlah token untuk setiap entitas untuk setiap tipe slot disimpan.
3. Mengumpulkan semua tag yang mungkin untuk sebuah token, kemudian dibandingkan probabilitasnya.
- Pertama-tama, keluaran dari SVM untuk setiap token, misalkan nilainya adalah x, diubah ke dalam probabilitas dengan menggunakan rumus
( )
x(
(
x)
)
s =1/1+exp −β , dimana β =2.0.
- Batas probabilitas sebuah label kelas dapat di-assign pada token disebut dengan thresholdProbabilityBoundary.
- Jika s
( )
x >thresholdProbabilityBoundary maka label kelas tersebut akan menjadi kandidat label, jika tidak maka diabaikan.- Kemudian, tag atau tipe slot untuk setiap entitas1 dihitung probabilitasnya dengan menggunakan rumus s
( ) ( )
xs ×s xe , dimana s( )
xs adalah probabilitas label kelas begin suatu tipe slot dan s( )
xe adalah probabilitas label kelas endtipe slot yang sama.
- Batas probabilitas sebuah tag dapat di-assign pada entitas disebut dengan thresholdProbabilityEntity.
- Jika
(
s( ) ( )
xs ×s xe)
>thresholdProbabilityEntity maka tag tersebut akan menjadi kandidat tag untuk sebuah entitas, jika tidak maka diabaikan.- Tag dengan probabilitas terbesar lah yang akan di-assign pada entitas tersebut.
3.2 Dataset untuk Ekstraksi Informasi
Terdapat dua dataset yang digunakan di dalam tahap eksperimen sistem ekstraksi informasi di dalam tugas akhir ini. Yang pertama adalah dataset job postings corpus
yang merupakan dataset standar untuk evaluasi performansi sebuah sistem ekstraksi informasi. Dataset yang kedua adalah dataset yang dibuat sendiri.
Dataset job postings corpus digunakan untuk memvalidasi apakah implementasi sistem ekstraksi informasi yang direplikasi dari [LI05a] sudah benar atau belum.
1 Yang dimaksud dengan entitas adalah kata atau frase, jadi bisa berupa sebuah token atau gabungan
Kemudian sistem ekstraksi informasi diaplikasikan pada dataset yang kedua, untuk kemudian dianalisis performansinya. Berikut ini penjelasan mengenai masing-masing dataset.
3.2.1 Job Postings Corpus
Terdapat beberapa dataset standar yang dapat digunakan untuk ekstraksi informasi. Dataset atau corpus tersebut dapat ditemukan pada RISE Repository yang dapat diakses pada URL: http://www.isi.edu/info-agents/RISE/repository.html. Salah satu dataset yang banyak digunakan adalah Job Postings Corpus, yang dikoleksi oleh Mary E. Califf [CAL98]. Dataset ini terdiri dari 300 pesan newsgroup yang memberikan detil mengenai lowongan pekerjaan di Austin. Format dokumen ini dapat dikatakan semi-terstruktur, karena bagian header di-generate oleh program mailing, sedangkan bagian isi pesan dibuat oleh manusia dalam natural language. Pada Gambar III-2 dapat dilihat contoh dokumen di dalam job postings corpus yang sudah diberi anotasi. Representasi pemberian anotasi yang digunakan adalah dengan memberikan tag awal dan akhir seperti dalam contoh Gambar II-4.
Gambar III-2 Contoh Job Postings Corpus [FIN06]
From: "Brian Baccam" <[email protected]> Newsgroups: austin.jobs
Subject: <language>VISUAL BASIC</language> in <city>San Antonio</city> Date: <post_date>30 Aug 1997<post_date> 21:56:47 GMT
Organization: Devon Tax Group Lines: 16
Message-ID: <<id>[email protected]</id>> NNTP-Posting-Host: pc22.devontax.com
X-Newsreader: Microsoft Internet News 4.70.1162 Xref: cs.utexas.edu austin.jobs:120377
<language>Visual Basic</language><title>progammer</title> needed in <city>San Antonio</city>. Will be working with a small
team to develop a tax management program. Minimum Qualifications:
* 2-4 yrs. of <language>Visual Basic</language> application development experience * strong working knowldge of <application>Access</application> and/or <application>SQL Server</application> a plus.
Location: <city>San Antonio</city> Position: Contractual
Duration: Minumum 3 months
Please send resume in text format only to: [email protected]
or fax to: (210) 829-7330
Dataset job postings corpus mendefinisikan 17 slot/field menyangkut informasi yang akan diekstrak dari sebuah iklan lowongan pekerjaan. Daftar field dan jumlah kemunculannya di dalam dataset beserta contoh nilainya dapat dilihat pada Tabel III-2.
Tabel III-2 Daftar field pada Job Postings Corpus [FIN06]
Field / Slot Kemunculan Contoh
id 299 NEWTNews.872347949.11738.consults@ws-n
title 466 ALC Application Programmer, Visual Basic Developers company 291 Alliance, CPS, Charter Professional Services Inc salary 143 $50k to $70k, to $60k
recruiter 325 Resource Spectrum state 462 TX, Texas, Miami, Georgia, MI city 639 Austin, Battle Creek, San Antonio country 363 US, USA, England, UK
language 867 RPG, COBOL, CICS, Java, c, c++, SQL, PowerBuilder platform 705 AS400, Windows 95, windows, portable systems, PC application 605 DB2, Oracle, DB2 server, sysbase
Area 980 Failure analysis, multimedia, TCP/IP, internet required years experience 173 2, 2+, two, 5, 4
desired years experience 45 5, 4, 10
required degree 80 BS, B.S., Bachelor, Bachelor’s, BSCS desired degree 21 Phd, BS, BSCS, Masters, MSCS post date 288 30 Aug 1997, 11 Sep 1997
Berikut ini adalah penjelasan mengenai setiap field pada template Job Postings Corpus.
- id, merupakan header yang ter-attach pada setiap pesan newsgroup
- title, judul pekerjaan yang diiklankan
- company, perusahaan tempat lowongan pekerjaan berada - salary, jumlah gaji yang ditawarkan
- recruiter, agensi yang mengiklankan lowongan pekerjaan - state, city, dan country, dimana lowongan pekerjaan terdapat - language, bahasa pemrograman yang harus dikuasai
- application, aplikasi komputer yang harus dikuasai - area, kategori umum dari pekerjaan di bidang komputer
- required years experience, lama pengalaman kerja yang dibutuhkan
- desired years experience, lama pengalaman kerja yang diinginkan (lebih memberikan nilai tambah)
- required degree, tingkat pendidikan terakhir yang dibutuhkan
- desired degree, tingkat pendidikan terakhir yang diinginkan (lebih memberikan nilai tambah)
- post date, tanggal pesan di-posting
Pada dataset ini language, platform, application, dan area adalah field yang memiliki beberapa nilai (multi-valued fields), sedangkan yang lainnya merupakan field bernilai tunggal (single-valued fields).
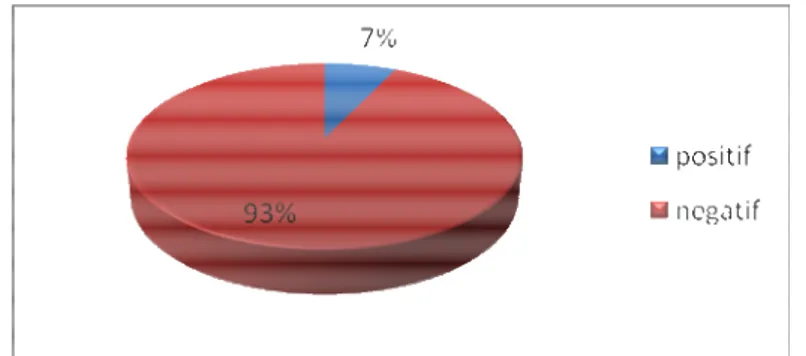
Jumlah instance, atau dengan kata lain jumlah token di dalam dataset ini adalah sebanyak 135.286 token. 125.713 token di antaranya merupakan contoh negatif, yaitu tidak memiliki tag tipe slot apapun. Sedangkan sisanya merupakan contoh positif. Dari Gambar III-3 dapat terlihat bahwa job postings corpus merupakan imbalanced dataset.
Gambar III-3 Rasio data positif dan negatif pada job postings corpus
3.2.2 Dataset Lowongan Pekerjaan
Dataset ini dibuat dengan mengumpulkan halaman-halaman web yang mengandung informasi lowongan pekerjaan. Total dokumen di dalam dataset adalah sebanyak 180 halaman web. Adapun bahasa yang digunakan sebagian Bahasa Inggris dan sebagian lagi Bahasa Indonesia dengan perbandingan 1 : 1, yaitu 90 dokumen Bahasa Inggris dan 90 dokumen Bahasa Indonesia. Adapun dokumen Bahasa Indonesia kebanyakan
merupakan dokumen multi-bahasa Indonesia-Inggris. Deskripsi lengkap mengenai dataset yang dikumpulkan termasuk sumber dataset dapat dilihat pada Lampiran D.
Proses anotasi dilakukan secara manual, dengan menggunakan editor anotasi yag disediakan oleh GATE 4.0. Adapun penjelasan mengenai pemberian anotasi terhadap dokumen teks dengan menggunakan GATE 4.0 GUI dapat dilihat pada Lampiran A.
Didefinisikan 14 slot/field menyangkut informasi yang akan diekstrak dari sebuah iklan lowongan pekerjaan, yaitu:
- industry, industri yang digeluti perusahaan, co: IT, Telecom - company_name, nama perusahaan
- job_category, kategori dari pekerjaan yang ditawarkan - job_title, nama pekerjaan
- location, lokasi pekerjaan (negara, propinsi, kota) - education_level, pendidikan minimum (S1, D3) - foreign_language, bahasa asing
- description, deskripsi pekerjaan yang akan dilakukan - salary, gaji yang ditawarkan
- contact, alamat email
- deadline, batas pengiriman lamaran kerja - posting_date, tanggal lowongan kerja di-post
- needed_experience, pengalaman kerja yang dibutuhkan
- experience_duration, lama pengalaman kerja yang dibutuhkan
Pendefinisian 14 slot ini didasarkan pada field yang berhubungan dengan sebuah lowongan pekerjaan, di dalam basis data Jomar, Sistem Cerdas untuk Perangkat Lunak Layanan Bursa Kerja [WID07].
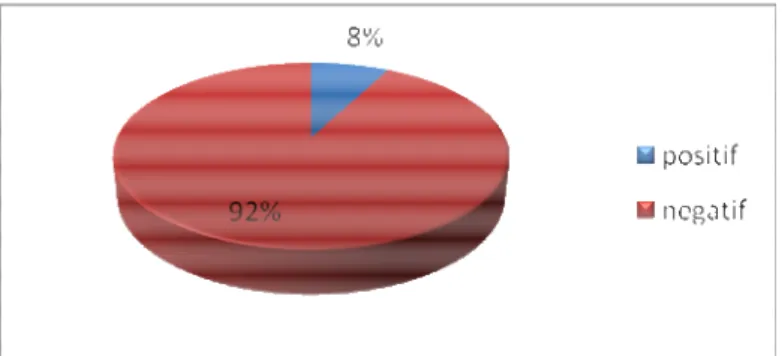
Jumlah instance, atau dengan kata lain jumlah token di dalam dataset ini adalah sebanyak 44.834 token. 41.377 token di antaranya merupakan contoh negatif, yaitu tidak memiliki tag tipe slot apapun. Sedangkan sisanya merupakan contoh positif. Dari Gambar III-4 dapat terlihat bahwa dataset lowongan pekerjaan merupakan
Gambar III-4 Rasio data positif dan negatif pada dataset lowongan pekerjaan
3.3 Perangkat Bantu Eksperimen
Perangkat bantu eksperimen yang diimplementasikan adalah perangkat lunak yang menggunakan library GATE 4.0 (http://gate.ac.uk) dan diimplentasikan dalam bahasa Java, menggunakan Netbeans IDE 6.0. Tujuan pembuatan perangkat bantu eksperimen adalah untuk mempermudah proses evaluasi performansi sistem ekstraksi informasi yang telah dibangun. Adapun implementasi perangkat lunak mengacu kepada paper mengenai GATE-SVM [LI05a]. Hal ini dilakukan untuk mempermudah pembuatan perangkat lunak, karena library yang disediakan oleh GATE 4.0 sudah sangat lengkap.
GATE 4.0 (General Architecture for Text Engineering) merupakan aplikasi open source yang ditujukan untuk pengembangan aplikasi natural language processing, salah satunya adalah untuk ekstraksi informasi. GATE 4.0 menyediakan modul pemrosesan teks untuk menghasilkan fitur-fitur NLP yang terdapat di dalam suatu dokumen teks. Modul tersebut adalah ANNIE (A Nearly New IE system). ANNIE juga digunakan oleh [LI05a] untuk menghasilkan fitur-fitur NLP yang akan diubah menjadi vektor fitur masukan algoritma pembelajaran.
GATE 4.0 juga menyediakan API untuk pembelajaran mesin, yaitu pada modul Batch Learning Processing Resource (PR). Implementasi dari Batch Learning PR ini mencakup 3 tipe pembelajaran NLP, yaitu:
- chunk recognition (named entity recognition)
- text classification
Chunk recognition atau named entity recognition merupakan nama lain dari ekstraksi informasi. Dengan kata lain, modul Batch Learning PR dapat digunakan untuk mengimplementasikan ekstraksi informasi. Adapun algoritma pembelajaran utama yang diimplementasikan di dalam Batch Learning PR ini adalah SVM, dengan menggunakan versi Java dari LibSVM. Selain SVM, Batch Learning PR juga mendukung beberapa algoritma pembelajaran di dalam Weka, yaitu Naïve Bayes, KNN, dan C4.5.
Penjelasan mengenai penggunaan ANNIE untuk memecah dokumen teks menjadi sekumpulan token dan menghasilkan fitur-fitur NLP untuk setiap token, dapat dilihat pada Lampiran B. Sedangkan penjelasan mengenai penggunaan Batch Learning PR
sebagai modul pembelajaran dapat dilihat pada Lampiran C. Perangkat bantu eksperimen sistem ekstraksi informasi yang diimplementasikan akan menggunakan ANNIE dan Batch Learning PR sebagai komponen utama. Perubahan yang dilakukan pada library GATE 4.0 untuk mengimplementasikan perangkat bantu eksperimen tersebut dapat dilihat pada Lampiran K.
Fungsionalitas yang dimiliki oleh perangkat bantu eksperimen antara lain:
1. Melakukan pemrosesan awal, yaitu menghasilkan fitur-fitur NLP dari sebuah dokumen teks, dengan menggunakan ANNIE – GATE 4.0. Dokumen yang sudah melalui pemrosesan awal dapat disimpan dalam format file XML.
2. Menyediakan antarmuka yang dapat digunakan untuk mengatur parameter pembelajaran, yang disimpan di dalam file configuration.xml, untuk kemudian digunakan oleh Batch Learning PR. Parameter yang dapat dikonfigurasi antara lain:
- thresholdProbabilityEntity dan thresholdProbabilityBoundary, yang diperlukan pada tahap pemrosesan akhir (postprocessing)
- Penggunaan metode filtering (tidak digunakan di dalam tugas akhir ini) - Algoritma klasifikasi yang digunakan: SVM, Naïve Bayes, atau KNN - Jika menggunakan algoritma SVM:
- parameter pembelajaran SVM, seperti fungsi kernel yang digunakan dan parameter uneven margin.
- Fitur-fitur NLP yang akan dijadikan sebagai atribut - Ukuran window konteks (window size)
3. Melakukan proses pembelajaran, menggunakan Batch Learning PR – GATE 4.0. Terdapat 4 buah mode pembelajaran, antara lain: Produce feature files only,
Training, Application, dan Evaluation. Penjelasan mengenai masing-masing mode pembelajaran dapat dilihat pada Lampiran C.
4. Menampilkan status proses pembelajaran pada panel Log Message.
5. Menampilkan hasil evaluasi (jika digunakan mode Evaluation pada pembelajaran) pada panel Evaluation Result. Hasil evaluasi juga dapat disimpan ke dalam file dengan format Excel (.xls).
6. Menampilkan perbedaan anotasi antara anotasi Label hasil ekstraksi informasi dengan anotasi Label yang terdapat pada dokumen teks, per tipe pengisi slot. Perbedaan anotasi ini dapat digunakan untuk menghitung jumlah correct, partial correct, spurious, dan missing.
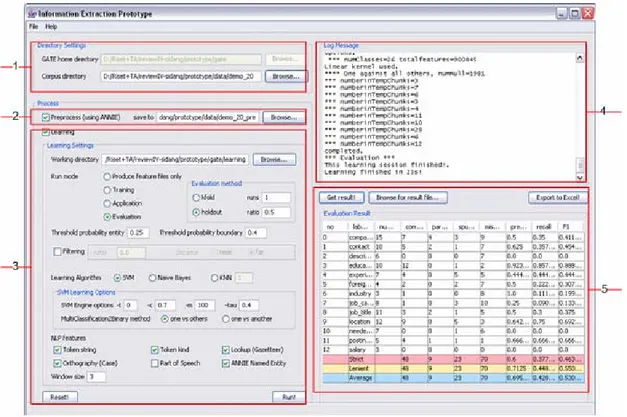
Pada Gambar III-5 dapat dilihat antarmuka perangkat bantu eksperimen yang diimplementasikan.
Keterangan:
1. Panel pengaturan direktori, digunakan untuk:
- mengatur direktori tempat GATE 4.0 berada (GATE home directory) - mengatur direktori yang berisi data yang akan diproses (Corpus directory). 2. Panel pengaturan pemrosesan awal (preprocessing) menggunakan ANNIE,
digunakan untuk mengatur direktori tempat menyimpan hasil pemrosesan awal. Jika tidak diisi maka hasil pemrosesan awal tidak akan disimpan.
3. Panel pengaturan proses pembelajaran, digunakan untuk:
- mengatur direktori tempat menyimpan file konfigurasi, file vektor fitur, dan model hasil pembelajaran (Working directory)
- mengatur parameter pembelajaran
- memulai proses pembelajaran, dengan mengklik tombol Run
4. Panel status proses pembelajaran, menampilkan log message proses pembelajaran. 5. Panel hasil evaluasi, menampilkan hasil evaluasi jika digunakan mode
pembelajaran Evaluation. Berisi metrik evaluasi untuk setiap tipe pengisi slot. Jika diklik ganda maka muncul jendela perbedaan anotasi antara anotasi Label yang sebenarnya dengan anotasi Label hasil ekstraksi, untuk tipe pengisi slot yang diklik. Pada Gambar III-6 dapat dilihat perbedaan anotasi untuk tipe pengisi slot company_name.
Gambar III-6 Jendela perbedaan anotasi untuk tipe pengisi slot company_name
- Baris yang tidak berwarna menandakan hasil ekstraksi yang benar (correct). - Baris berwarna biru menandakan hasil ekstraksi benar sebagian (partial
correct)
- Baris berwarna kuning menandakan hasil ekstraksi yang salah (spurious) - Baris berwarna merah menandakan entitas yang tidak terdeteksi (missing)

![Tabel III-2 Daftar field pada Job Postings Corpus [FIN06]](https://thumb-ap.123doks.com/thumbv2/123dok/1957418.2129531/9.892.134.765.326.822/tabel-iii-daftar-field-pada-job-postings-corpus.webp)