07-39
TEKNIK DATA MINING DAN DECISION SUPPORT SYSTEM UNTUK
KEUNGGULAN BERSAING (Study Kasus Perusahaan TV Kabel )
Ahlihi Masruro
1)1)
Teknik Informatika STMIK AMIKOM Yogyakarta
Jl. Ring Road Utara Condong Catur Depok Sleman Yogyakartaemail : [email protected])
Abstrak
Penggunaan TVCable di Indonesia diperkirakan akan meningkat seiring dengan tingkat kesadaran akan pentingnya hiburan dan informasi. Masalah yang timbul adalah bagaimana perusahaan bisa menawarkan paket chanel yang sesuai dengan yang diharapkan pelanggan berdasarkan data transaksi yang telah terjadi. Dengan teknik data mining, data akan digali serta dikelompokkan berdasarkan sejarah transaksi antara konsumen dan paket chanel. Data hasil pengelompokan tersebut akan di interasikan dengan masing-masing field sehingga terbentuk sebuah fakta baru. Dari data fakta baru ini kemudian diolah dengan sebuah methode system pendukung keputusan untuk dapat memberikan informasi yang dapat digunakan untuk pengambilan sebuah keputusan tentang penentuan paket TVCable.
Kata kunci :
Data Mining, Sistem Pendukung Keputusan, K-Mean Clustering, Simple Additive Weight
1. Pendahuluan
Tidak bisa dipungkiri bahwa trend masyarakat Indonesia saat ini untuk mendapatkan informasi dan hiburanlebih banyak menggunakan sarana televisi. Seiring dengan perkembangan tersebut memunculkan cara baru dalam menikmati siaran televisi yaitu dengan menggunakan TVCable. Hal ini memberikan kesempatan bagi perusahaan penyedia layanan TVCable untuk menawarkan paket-paket yang bisa dipilih oleh calon pelanggan. Oleh karena itu dibutuhkan sebuah sarana penyedia informasi yang akurat dan relevan untuk perusahaan dlam menentukan paket-paket layanaan yang sesuai dengan sekmen pasar yang dibidik, agar bisa memberiakan keunggulan bersaing. Dalam penelitian ini pengguna system akan diberiakan saran tentang paket program atau chanel yang kemungkinan akan banyak diminati calon pelanggan berdasarkan data transaksi yang telah dilakukan dalam kurun waktu tertentu. Data tersebut akan diolah dan dianalisis dengan sebuah method untuk melakukan mining data. Method mining yang digunakan adalah K-Means Clustering. Data hasil mining akan diolah kembali untuk menghasilkan sebuah
informasi yang akan membantu pengambil keputusan untuk menentukan langkah strategis yang akan diambil. Semisal dengan membuat paket pilihan chanel yang akan dipasarkan. Atau menentukan segmen pasar yang dibidik untuk penawaran produk baru. Adapun methode untuk SPK adalah SAW(Simple Additive Weight)
2. Tinjauan Pustaka
2.1. Sistem Pendukung Keputusan
Definisi awal sistem pendukung keputusan adalah sebuah sistem yang dimaksudkan untuk mendukung para pengambil keputusan manajerial dalam situasi keputusan semiterstruktur. Sistem pendukung keputusan dimaksudkan untuk menjadi alat bantu bagi para pengambil keputusan untuk memperluas kapabilitas mereka,namun tidak untuk menggantikan penilaian mereka. Moore dan Chang mendefinisikan sistem pendukung keputusan sebagai sistem yang dapat diperluas untuk mampu mendukung analisis data ad hoc dan pemodelan keputusan, berorientasi terhadap perencanaan masa depan, dan dapat digunakan pada interval yang tidak regular dan tidak terencana [1]
2.2. SAW
Sebuah metode data mining untuk menyelesaikan masalah dari berbagai macam atribut atau dikenal dengan MADM(Multi-Attribut Decision Making), metode ini juga dikenal sebagai metode penjumlahan terbobot. Konsep dasar dari SAW adalah mencari penjumlahan terbobot dari rating kerja pada setiap alternatif pada semua attribut. Rumus untuk metode SAW sebagai berikut
rij merupakan rating kinerja ternormalisasi dari
alternatif dan nilai kreteria.
07-40 Nilai Vi yang terbesar merupakan indikasi bahwa
alternatif tersebut adalah alternatif terpilih
2.3. Data Mining
Data mining dihubungkan dengan subarea statistik yang disebut exploratory data analysis, yang mempunyai tujuan yang sama dan berdasarkan pada ukuran statistik. Data mining juga berhubungan dekat dengan subarea kecerdasan buatan yang disebut knowledge discovery dan machine learning. Karakteristik penting yang membedakan data mining adalah volume data yang sangat besar meskipun ide dari area studi yang bersangkutan dapat diterapkan pada masalah data mining. Skalabilitas yang berhubungan dengan uraian data adalah kriteria baru yang penting. Sebuah algoritma scalable (dapat diskalakan) jika waktu prosesnya berkembang (misalnya, sejumlah memori utama dan kecepatan proses CPU). Algoritma lama harus disesuaikan atau algiritma baru dikembangkan untuk memastikan skalabilitas saat menemukan pola dari data. Data mining adalah suatu proses yang menggunakan teknik statistik, matematika, kecerdasan tiruan dan machine
learning untuk mengetraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar[1].
Sebagai suatu rangkaian proses, data mining dapat dibagi menjadi beberapa tahap. Tahap-tahap tersebut bersifat interaktif di mana pemakai terlibat langsung atau dengan perantaraan knowledge base[1].
a.Pembersihan data (untuk membuang data yang tidak konsisten dan noise)
b.Integrasi data (penggabungan data dari beberapa sumber)
c.Transformasi data (data diubah menjadi bentuk yang sesuai untuk di-mining)
d.Menentukan teknik data mining, yaitu teknik mencari pola dari hasil transformasi data.
e.Evaluasi pola yang ditemukan (untuk menemukan yang menarik/bernilai)
f.Presentasi pola yang ditemukan untuk
menghasilkan aksi
2.4. Metode K Means Clustering
Huruf ‘K’ pada algoritma K-Means mengacu pada fakta bahwa dalam K-Means clustering, jumlah cluster ditentukan sebelum proses dimulai. Kata ‘Means’ di K-Means mengacu pada fakta bahwa setiap cluster ditandai oleh rata-rata dari semua titik milik cluster. Dengan demikian, tujuan algoritma K-Means secara harfiah adalah mencari nilai rata-rata dari K kelompok data, sehingga memberikan kita cluster K yang kita cari. Secara khusus, berarti kita mencari manakah diantara
kelompok yang meminimalkan fungsi biaya, seperti digambarkan dalam gambar berikut:
Gambar. 1. Rumus K-Means Clustering
Sebagai langkah awal dalam K-Means Clustering adalah kita menentukan K yang berbeda "centroid" secara acak dari ruang di mana titik-titik data yang didapatkan. Dari sini, proses K-Means dapat dibagi menjadi dua tahap:
Tahap 1: Cluster Formulir. Centroid masing-masing terkait dengan cluster yang berbeda. Untuk membentuk kelompok ini, setiap titik dalam kumpulan data dievaluasi pada gilirannya. Ketika dievaluasi, titik ditugaskan untuk cluster sesuai dengan centroid terdekat.
Tahap 2: Sentroid Move. Setiap centroid kini dipindahkan ke posisi yang diperoleh dengan mengambil rata-rata dari masing-masing poin dalam cluster terkait dengan centroid tersebut.
Ke2 tahapan diats akan dikerjakan secara berulang-ulang sampai menunjukkan confergensi data.
3. Metode Penelitian
3.1 Pengumpilan Data
Data yang digunakan dalam penelitian ini adalah data yang didapat dari hasil transaksi-transaksi yang dilakukan oleh perusahaan penyedia layanan TV kabel dalam beberapa kurun waktu.
3.2 Proses Mining Data
Dalam proses mining data dilakukan dengan menggunakan methode K-Means Clustering. Methode ini dipilih karena aka membagi data transaksi kedalam beberapa pilihan kelompok baik berdasarkan kondisi dari pelanggan maupun dari paket-paket chanel pilihan yang ditawarkan oleh penyedia layanan TV Kabel. 3.3 Proses DSS
Dalam proses selanjutnya data baru yang didapat dari proses mining data akan digunakan atau diolah untuk menghasilkan sebuah Informasi melalui methode SAW pada proses pembuatan DSS
3.4 Informasi
Hasil akhir dari proses adalah sebuah informasi yang dapat digunakan oleh perusahaan TV Kabel untuk menentukan produk baru ataupun peningkatan layanan yang nantinya akan memberikan nilai tambah sebagai nilai keunggulan bersaing
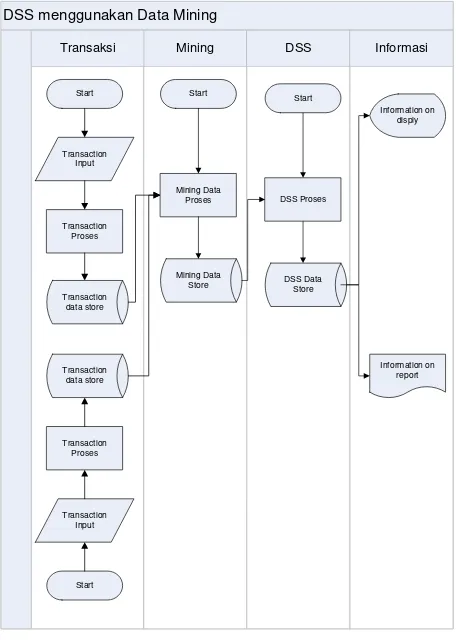
07-41 DSS menggunakan Data Mining
Mining DSS Informasi
Gambar. 2. Flowchart sistem
4. Hasil dan Pembahasan
Hasil dari penelitian ini menunjukkkan adanya keterkaitan antara transaksi yang terjadi dengan jenis paket layanan serta hubungan antara kondisi pengguna layanan dengan pilihan chanel dalam paket layanan TV Kabel, dalam hal ini adalah kelangsungan customer dalam menggunakan paket yang telah dipilih. Volume suatu paket dipilih oleh customer karena pilihan chanel yang ada dalam paket tersebut.
Pada data transaksi dapat dilihat mempunyai relasi tabel sebagai berikut
Gambar. 3. Relasi Transaksi
Dari relasi tabel tersebut beberapa data yang bisa ditampilkan untuk kita lakukan mining adalah
Tabel 1. Data transaksi
ID Paket Lama
(tahun)
3404071906760006 paket I 2
3404072906860106 paket II 1
3404075906800010 paket II 1
3404071906760035 paket I 2
3405071904750018 paket I 2
3405071010740026 paket I 2
3404070903650020 paket III 1
3405072011610015 paket I 2
3405072212640017 paket III 1
3405071306600022 paket III 1
Langkah selanjutnya adalah melakukan pengklusteran terhadap data yang dimiliki, dengan terlebih dulu mengkonversikan data yang kita miliki dalam sebuah matriks, dengan aturan:
Untuk tahun lahir yang didapat dari no ID diberi nilai 1 bila customer lahir antara tahun 1970 sampai 1980, 2 untuk customer yang lahir tahun 1969 kebawah, dan nilai 3 untuk customer yang lahir tahun 1981 keatas. Kemudian diberikan nilai yang sama terhadap pilihan paket 1 untuk paket I, 2 untuk paket II, dan 3 untuk paket III.
Kemudian diberikan nilai selanjutnya pada lama berlangganan dengan hanya ada 2 nilai yaitu 1 dan 2. Sehingga matriks yang kita dapatkan adalah
Gambar. 4. Matriks data
Matriks M memiliki nilai kolom pertama adalah nilai dari umur, kolom kedua menunjukkan pemilihan paket oleh customer. Kemudian baris ke 3 menunjukkan lama tidaknya pelanggan memperpanjang kontrak. Setelah dilakukan analisis didapatkan matriks
07-42 Gambar. 5. Matriks hasil cluster
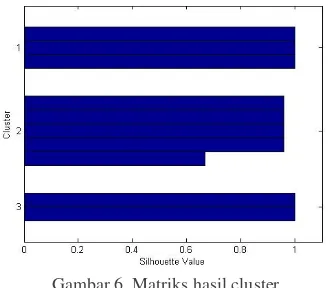
Dari hasil pengklusteran data tersebut terlihat bahwa data memiliki 3 kluster, bisa dilihat dari kolom terakhir dari matrik hasil kluster. Dalam gambar hasil k-means dari data yang ada adalah
Gambar.6. Matriks hasil cluster
Jelas sekali kluster yang terbentuk adalah 3, dengan cluster 1 dan 3 memiliki data yang kesesuaian tiap anggota data, sedangkan cluster no _2 ada salah satu data yang jauh dari pusat kluster
Langkah selanjutnya adalah melakukan pemetaan matrik data hasil kluster untuk dianalisa menggunakan methode SAW untuk mendapatkan informasi baru dari data yang dimiliki. Langkah dari SAW yang dilakukan adalah:
1. Menentukan alternatif pasar yang akan diberikan penawaran produk layanan. Pasar yang akan di ambil berdasarkan lokasinya L1 = Condong Catur
L2 = Catur Tunggal L3 = Wedomartani.
2. Dari alternatif lokasi tujuan pasar ditentukan kreteria setiap lokasi untuk acuan pengambilan keputusan. Yaitu:
3. Langkah selanjutnya adalah memberikan rating nilai untuk setiap kreteria yang memiliki kecocokan dengan kreteria kunci.
Tabel yang dihasilkan dari langkah diatas adalah
Tabel 2. Rating kecocokan
K1
K2
K3
L1
1
2
2
L2
2
1
2
L3
2
3
2
4. Langkah selanjutnya memberikan nilai
kepentingan pada setiap kreteria, dengan nilai 1 sampai 3 (rendah, cukup, tinggi)
5. Ditentukan bobot preferensi sebagai berikut W = (3, 3, 1)
Tabel 3. Matrik ternormalisasi
R =
6. Penghitungan DSS menggunakan SAW
memberikan nilai alternatif terbaik adalah pada alternatif ke 3 atau L3. Ditunjukkan dengan tabel
hasil berikut
Tabel 3. Matrik ternormalisasi
Rangking
V1
4.5
V2
5
V3
7
Dari hasil perhitungan tersebut dapat diambil kesimpulan bahwa untuk wilayah Babarsasi paket yang baik untuk ditawarkan adalah paket 2, karena mayoritas penduduknya lahir diatas tahun 1980 atau kurang dari 35tahun, dan kemungkinan terbesar akan memperpanjang berlangganan sampai minimal 2 tahun.
5. Kesimpulan dan Saran
5.1. Kesimpulan
Dari hasil penelitian ini dapat disimpulkan bahwa sebuah data transaksi dalam jumlah yang besar dapat memberikan informasi baru bagi pengambil keputusan pada sebuah perusahaan TV Kabel untuk menentukan strategi pemasaran ataupun strategi penentuan chanel dalam sebuah paket yang dapat digunakan sebagai sarana keunggunalan bersaing.
Algoritma data mining dan DSS yang digunakan merupakan sebagai alat pendukung dalam mendapatkan data yang digunakan untuk menyampaikan informasi yang diharapkan
1.2.Saran
07-43
Daftar Pustaka
1.Jahanshahloo, G.R., Hosseinzadeh L, F., Izadikhah, M.,
2006, Extension of the TOPSIS method for
decision-making problems with fuzzy data, Proceeding Applied
Mathematics and Computation, Arak-Iran.
2.Kusumadewi, Sri., 2006, Fuzzy Multi-Attribute Decision Making, Edisi Pertama, Graha Ilmu, Yogyakarta
3.Santosa, Budi., 2007, Data Mining Terapan dengan Matlab, Edisi Pertama, Graha Ilmu, Yogyakarta
Biodata Penulis
Nama Penulis, memperoleh gelar Sarjana Komputer