LANDASAN TEORI
Dalam bab ini diuraikan beberapa landasan teori yang terkait, mencakup konsep neuro-fuzzy dan soft computing, teori himpunan fuzzy meliputi himpunan fuzzy, aturan fuzzy dan penalaran fuzzy, serta sistem inferensi fuzzy (fuzzy inference systems, FIS) , metode regresi penduga kuadrat terkecil (least squares estimator, LSE) dan metode optimisasi penurunan tercuram (steepest descent, SD), jaringan syaraf adaptif, Adaptive Neuro-Fuzzy Inference Systems (ANFIS), serta fuzzy clustering yang mencakup fuzzy C- means (FCM) dan substractive clustering.
2.1. Neuro-Fuzzy dan Soft Computing
2.1.1. Pengertian Neuro-Fuzzy dan Soft Computing
Neuro-fuzzy dan soft computing (SC) adalah integrasi dua pendekatan komplementer: jaringan syaraf (neural networks, NN) yang mengenali pola dan beradaptasi untuk menanggulangi lingkungan yang berubah-ubah; sistem inferensi fuzzy (fuzzy inference systems, FIS) yang menggabungkan pengetahuan manusia serta melakukan inferensi dan pembuatan keputusan. Sinergi ini memungkinkan SC menggabungkan pengetahuan manusia secara efektif, menghadapi ketidaktepatan dan ketidakpastian, dan belajar beradaptasi dengan lingkungan yang tidak diketahui atau berubah-ubah untuk performa yang lebih baik.
2.1.2. Karakteristik Neuro-Fuzzy dan Soft Computing a) Kepakaran manusia
SC menggunakan kepakaran manusia dalam bentuk aturan if-then fuzzy, sama baiknya seperti dalam representasi pengetahuan konvensional, untuk memecahkan masalah-masalah praktis.
b) Model-model komputasi biologically inspired
Diinspirasi oleh NN biologis, NN tiruan digunakan secara ekstensif dalam SC untuk menghadapi persepsi, pengenalan pola, dan regresi nonlinier serta masalah- masalah klasifikasi.
c) Teknik-teknik optimisasi baru
SC mengaplikasikan metode-metode optimisasi inovatif yang timbul dari berbagai sumber.
d) Komputasi numeris
Tidak seperti kecerdasan artifisial (artificial intelligence, AI) yang simbolik, SC terutama bergantung pada komputasi numeris.
e) Domain-domain aplikasi baru
Karena komputasi numerisnya, SC telah menemukan sejumlah domain aplikasi baru disamping domain-domain dengan pendekatan AI. Domain-domain aplikasi ini membutuhkan komputasi yang intensif.
f) Pembelajaran bebas model
NN dan FIS adaptif mempunyai kemampuan untuk membangun model menggunakan hanya data contoh sistem target. Pengetahuan detil dalam sistem target menolong men-set struktur model inisial, tetapi bukan keharusan.
g) Komputasi intensif
Tanpa asumsi banyak pengetahuan background masalah yang sedang diselesaikan, neuro-fuzzy dan SC sangat bergantung pada komputasi mengerkah angka kecepatan tinggi untuk menemukan aturan-aturan atau keberaturan dalam himpunan data.
h) Toleransi kesalahan
Penghapusan sebuah neuron dalam suatu NN atau sebuah aturan dalam suatu FIS, tidak menghancurkan sistem. Sistem tetap bekerja karena arsitektur paralel dan redundannya meskipun kualitas performa berangsur memburuk.
i) Karakeristik goal driven
Neuro-fuzzy dan SC adalah goal driven; jalan yang memimpin state kini ke solusi tidak terlalu penting selama bergerak menuju tujuan dalam long run. Pengetahuan domain spesifik menolong mengurangi waktu komputasi dan pencarian tetapi bukan suatu kebutuhan.
j) Aplikasi-aplikasi dunia riil
Semua masalah dunia riil mengandung ketidakpastian built-in yang tidak dapat dielakkan, sehingga terlalu cepat menggunakan pendekatan konvensional yang memerlukan deskripsi detil masalah yang sedang dipecahkan. SC adalah pendekatan terintegrasi yang seringkali dapat menggunakan teknik-teknik spesifik dalam subtugas- subtugas untuk membangun solusi umum yang memuaskan untuk masalah dunia riil.
2.2. Teori Himpunan Fuzzy 2.2.1. Himpunan Fuzzy
Himpunan fuzzy (kabur) adalah generalisasi konsep himpunan biasa (ordiner).
Untuk semesta wacana X, himpunan fuzzy ditentukan oleh fungsi keanggotaan yang
memetakan anggota x ke rentang keanggotaan dalam interval [0, 1]. Sedangkan untuk himpunan biasa fungsi keanggotaan bernilai diskrit 0 dan 1.
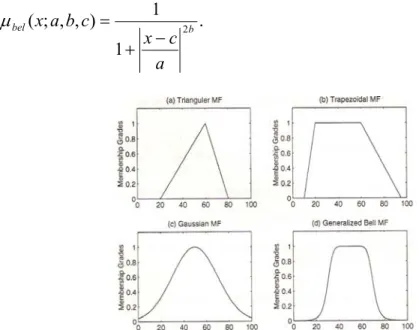
Berikut didefinisikan beberapa kelas MF terparameter satu dimensi, yaitu MF dengan sebuah input tunggal.
MF segitiga dispesifikasikan oleh tiga parameter {a, b, c} seperti berikut:
Parameter {a, b, c} (dengan a < b < c) menentukan koordinat x dari ketiga corner yang mendasari MF segitiga.
MF trapesium dispesifikasikan oleh empat parameter {a, b, c, d} sebagai berikut:
Parameter {a, b, c, d} (dengan a < b ≤ c < d) menentukan koordinat x dari keempat
corner yang mendasari MF trapesium.
MF Gauss dispesifikasikan oleh dua parameter {c, σ}:
, )
,
; (
2
2
1 ⎟
⎠
⎜ ⎞
⎝
− ⎛ −
= σ
σ μ
c x
gauss x c e
dimana c merepresentasikan pusat MF dan σ mendefinisikan lebar MF.
MF bel umum (atau MF bel) dispesifikasikan oleh tiga parameter {a, b, c}:
( )
⎪⎪
⎪
⎩
⎪⎪
⎪
⎨
⎧
−
−−
−
=
, 0
, , , 0
b c
x c a b
a x
segitiga x μ
( )
⎪⎪
⎪
⎩
⎪⎪
⎪
⎨
⎧
−
−
−
−
=
, 0
, , 1
, , 0
, , ,
;
c d
x d
a b
a x d c b a
trapesium x μ
. x d ≤
. d x c≤ ≤
. c x b≤ ≤
. b x a≤ ≤
. a x≤ .
a x≤
. b x a≤ ≤
. c x b≤ ≤
. x c≤
. 1
) 1 , ,
;
( 2b
bel
a c c x
b a
x + −
μ =
Gambar 2.1. Contoh empat kelas MF terparameter: (a) µsegitiga(x;20,60,80); (b) µtrapesium(x;10,20,60,95); (c) µgauss(x;50,20); (d) µbel(x;20,4,50).
Sumber: Neuro-Fuzzy and Soft Computing (1997,p26)
Gambar 2.2 menunjukkan arti fisik dari setiap parameter dalam suatu MF bel.
Gambar 2.2. Arti fisik dari parameter-parameter dalam suatu MF bel umum.
Sumber: Neuro-Fuzzy and Soft Computing (1997,p28)
MF S berbentuk huruf S (Gambar 2.3) dispesifikasikan oleh parameter {a, b}:
Titik persilangan terjadi pada (a + b) / 2.
⎪⎪
⎩
⎪⎪
⎨
⎧
−
−
−
−
= −
, 1
, )]
/(
) [(
2 1
, )]
/(
) [(
2
, 0 )
,
;
( 2
2
a b x b
a b a b x
a
S x μ
. a x≤
. 2 / ) (a b x
a≤ ≤ +
. 2
/ )
(a+b ≤ x≤b .
b x≥
Gambar 2.3. Grafik fungsi MF S.
Sumber: Analisis & Desain Sistem Fuzzy Menggunakan Tool Box Matlab (2002,p54)
MF Z dispesifikasikan oleh dua parameter {a, b} (Gambar 2.4):
Gambar 2.4. Grafik fungsi MF Z.
Sumber: Analisis & Desain Sistem Fuzzy Menggunakan Tool Box Matlab (2002,p55)
MF pi dispesifikasikan oleh empat parameter {a, b, c, d}: (Gambar 2.5):
Parameter c menentukan titik tengah dan parameter b menetukan lebar bidang pada titik persilangan. Titik persilangan terdapat pada: u = c± b / 2.
Gambar 2.5. Grafik fungsi MF pi.
Sumber: Analisis & Desain Sistem Fuzzy Menggunakan Tool Box Matlab (2002,p53)
) ,
; (
* ) ,
; ( ) , , ,
;
(x a b c d S x a b Z x c d
pi μ μ
μ =
⎪⎪
⎩
⎪⎪
⎨
⎧
−
−
−
−
= −
, 0
, )]
/(
) [(
2
, )]
/(
) [(
2 1
, 1 )
,
;
( 2
2
a b x b
a b a b x
a
Z x μ
. a x≤
. 2 / ) (a b x
a≤ ≤ +
. 2
/ )
(a+b ≤x≤b .
b x≥
MF sigmoid didefinisikan oleh
)], ( exp[
1 ) 1 ,
;
(x a c a x c
sigmoid = + − −
μ
dimana a mengontrol slope pada titik persilangan x = c.
Gambar 2.6. Grafik fungsi MF sigmoid: (a) Dua fungsi sigmoid y1 dan y2; (b) sebuah close MF didapatkan dari | y1- y2| ; (c) dua fungsi sigmoid y1 dan y3; (d) sebuah close MF didapatkan dari y1y3.
Sumber: Neuro-Fuzzy and Soft Computing (1997,p29)
2.2.2. Aturan Fuzzy dan Penalaran Fuzzy a) Aturan If-Then Fuzzy
Suatu aturan if-then fuzzy atau aturan fuzzy mengasumsikan bentuk if x is A then y is B,
dimana A dan B nilai linguistik yang didefinisikan himpunan fuzzy pada semesta X dan Y. “x is A” disebut anteseden, sedangkan “y is B” disebut konsekuen.
Dua fungsi implikasi yang banyak digunakan adalah min (Mamdani) karena kemudahannya dalam interpretasi grafis dan prod (Larsen):
1. Min (minimum). Fungsi ini akan memotong output himpunan fuzzy. Gambar 2.7 menunjukkan salah satu contoh penggunaan fungsi min.
Gambar 2.7. Fungsi implikasi min.
Sumber: Analisis & Desain Sistem Fuzzy Menggunakan Tool Box Matlab (2002,p90)
2. Dot (product). Fungsi ini akan menskala output himpunan fuzzy. Gambar 2.8 menunjukkan salah satu contoh penggunaan fungsi dot.
Gambar 2.8. Fungsi implikasi dot.
Sumber: Analisis & Desain Sistem Fuzzy Menggunakan Tool Box Matlab (2002,p90)
b) Penalaran Fuzzy
Aturan dasar inferensi dalam two-valued logic tradisional adalah modus ponens:
menarik kebenaran proposisi B dari kebenaran A dan implikasi A→B.
Dalam penalaran manusia, modus ponens banyak digunakan dalam cara pendekatan (approximate). Ini dituliskan sebagai
premis 1 (fakta): x is A',
premis 2 (aturan): if x is A then y is B, konsekuensi (konklusi): y is B'.
dimana A' dekat dengan A dan B' dekat dengan B. Prosedur inferensi di atas disebut approximate reasoning atau penalaran fuzzy; juga disebut generalized modus ponens (GMP) karena mengandung modus ponens dalam kasus spesial.
A, A', dan B adalah himpunan fuzzy pada X, X, dan Y. Implikasi fuzzy A→B diekspresikan sebagai relasi fuzzy R pada X×Y. Maka himpunan fuzzy B yang ditarik dari “x is A'” dan aturan fuzzy “if x is A then y is B” didefinisikan oleh
μB’( y) = maxx min[μA’( x), μR(x, y)]
= ٧x [μA’( x) ٨ μR(x, y)], atau ekuivalen dengan
B' = A' о R = A' о (A→B).
Ada 3 metode yang digunakan dalam melakukan komposisi aturan-aturan fuzzy untuk inferensi, yaitu: max, sum, dan probor. µsf(xi) = nilai keanggotaan solusi fuzzy sampai aturan ke-i; µkf(xi) = nilai keanggotaan konsekuen fuzzy aturan ke-i.
1. Metode Max (Maximum).
Solusi himpunan fuzzy diperoleh dengan mengambil nilai maksimum aturan, menggunakannya untuk memodifikasi daerah fuzzy, dan mengaplikasikannya ke output dengan menggunakan operator OR (union).
µsf(xi) ← max(µsf(xi), µkf(xi)) 2. Metode Additive (Sum)
Solusi himpunan fuzzy diperoleh dengan melakukan penjumlahan terbatas terhadap semua output daerah fuzzy.
µsf(xi) ← min(1, 1 - µsf(xi) + µkf(xi))
3. Metode Probabilistic OR (probor)
Solusi himpunan fuzzy diperoleh dengan melakukan produk terhadap semua output daerah fuzzy. Secara umum dituliskan:
µsf(xi) ← (µsf(xi) + µkf(xi)) - (µsf(xi) * µkf(xi))
Jadi, proses penalaran fuzzy dapat dibagi ke dalam empat langkah:
a) Derajat kesepadanan / memasukkan input fuzzy
Bandingkan fakta yang diketahui dengan anteseden dari aturan fuzzy untuk menemukan derajat kesepadanan dengan memperhatikan setiap anteseden MF.
b) Kuat penyulutan / mengaplikasikan operator fuzzy
Gabungkan derajat-derajat kesepadanan dengan memperhatikan anteseden MF-MF dalam suatu aturan menggunakan operator fuzzy AND atau OR untuk membentuk kuat penyulutan yang mengindikasikan tingkat bagian anteseden dari aturan dipenuhi.
c) MF konsekuen yang qualified (terinduksi) / mengaplikasikan metode implikasi Gunakan kuat penyulutan ke MF konsekuen dari suatu aturan untuk menemukan suatu MF konsekuen qualified.
d) Output keseluruhan MF / komposisi semua output
Agregasikan semua MF konsekuen qualified untuk mendapatkan suatu MF output keseluruhan.
2.2.3. Sistem Inferensi Fuzzy
Sistem inferensi fuzzy (FIS) adalah sebuah framework komputasi populer berdasarkan pada konsep teori himpunan fuzzy, aturan if-then fuzzy, dan penalaran fuzzy.
Tiga komponen konsep FIS yaitu: basis aturan, mengandung seleksi dari aturan- aturan fuzzy; basis data, mendefinisikan MF-MF yang digunakan dalam aturan fuzzy;
dan mekanisme penalaran, melakukan prosedur inferensi pada aturan-aturan dan fakta- fakta yang diberikan untuk menarik output atau konklusi yang reasonable.
FIS dapat mengambil input fuzzy maupun input tegas (sebagai fuzzy singleton), tapi output yang dihasilkan hampir selalu himpunan fuzzy. Kadang kala output tegas dibutuhkan, sehingga dibutuhkan metode defuzifikasi untuk mengekstrak nilai tegas yang paling baik merepresentasikan himpunan fuzzy.
Gambar 2.9. Diagram blok untuk suatu sistem inferensi fuzzy.
Sumber: Neuro-Fuzzy and Soft Computing (1997,p74)
Model Fuzzy Sugeno
Model fuzzy Sugeno (model fuzzy TSK) diajukan oleh Takagi, Sugeno, dan Kang (Takagi dan Sugeno, 1985, p116-132; Sugeno dan Kang, 1988, p15-33) dalam upaya untuk membangun pendekatan sistematis untuk membangkitkan aturan-aturan fuzzy dari himpunan data input-output yang diberikan. Suatu aturan fuzzy khas dalam model fuzzy Sugeno berbentuk
if x is A and y is B then z = f(x, y),
dimana A dan B himpunan fuzzy dalam anteseden dan z = f(x, y) fungsi tegas dalam konsekuen. Jika f(x, y) polinomial orde satu, FIS yang dihasilkan disebut model fuzzy Sugeno orde satu. Jika f konstan, dihasilkan model fuzzy Sugeno orde nol.
Gambar 2.10 menunjukkan prosedur penalaran model fuzzy Sugeno orde satu.
Output keseluruhan diperoleh melalui rataan terbobot. Dalam praktek, rataan terbobot dapat digantikan dengan jumlah terbobot (z = w1z1 + w2z2) untuk mengurangi komputasi, khususnya dalam proses pelatihan. Penyederhanaan ini dapat menyebabkan hilangnya arti linguistik MF kecuali jumlah kuat penyulutan (
∑
iw ) dekat dengan 1. iGambar 2.10. Model fuzzy Sugeno.
Sumber: Neuro-Fuzzy and Soft Computing (1997,p81)
2.3. Metode Kuadrat Terkecil untuk Identifikasi Sistem 2.3.1. Identifikasi Sistem
Menentukan suatu model matematika untuk suatu sistem yang tidak diketahui (sistem target) dengan mengobservasi pasangan data input-output secara umum merupakan identifikasi sistem.
Identifikasi sistem secara umum meliputi dua langkah top-down:
a) Identifikasi struktur. Perlu menggunakan pengetahuan a priori sistem target untuk menentukan kelas model yang di dalamnya pencarian model yang paling cocok
dilakukan. Seringkali kelas model dinotasikan oleh fungsi terparameter y = f(u; θ), dimana y adalah output model, u adalah vektor input, dan θ adalah vektor parameter.
b) Identifikasi parameter. Setelah struktur model diketahui, digunakan teknik- teknik optimisasi untuk menentukan vektor parameter θ = θˆ sehingga model yang dihasilkan yˆ = f(u;θˆ) dapat mendeskripsikan sistem secara tepat.
Gambar 2.11. Diagram blok untuk identifikasi parameter.
Sumber: Neuro-Fuzzy and Soft Computing (1997,p96)
Seringkali struktur sistem diketahui sehingga masalah identifikasi sistem hanya pada identifikasi parameter. Gambar 2.11 mengilustrasikan skema identifikasi parameter, dimana input ui diaplikasikan ke model, dan beda antara output sistem target yi dan output model yˆ digunakan dengan cara yang sesuai untuk meng-update vektor i parameter θ untuk mengurangi beda ini. Himpunan data yang terdiri dari m pasangan input-output yang diinginkan (ui; yi), i = 1,…,m, sering disebut himpunan data pelatihan atau himpunan data contoh.
Secara umum, identifikasi sistem melakukan identifikasi struktur maupun parameter berulang kali sampai model yang memuaskan ditemukan, sebagai berikut:
a) Spesifikasi dan parameterisasi sebuah kelas dari model-model matematika yang merepresentasikan sistem yang diidentifikasi.
b) Lakukan identifikasi parameter untuk memilih parameter-parameter yang paling baik mem-fit himpunan data pelatihan.
c) Adakan tes-tes validasi untuk melihat apakah model yang diidentifikasi merespon secara benar kepada suatu himpunan data yang tidak terlihat.
(Himpunan data ini disjoint dari himpunan data pelatihan dan disebut himpunan data tes, validasi, atau cek.)
d) Terminasi prosedur ketika hasil-hasil tes validasi memuaskan. Selainnya, kelas lain dari model-model dipilih dan langkah b) sampai d) diulangi.
2.3.2. Penduga Kuadrat Terkecil
Dalam masalah kuadrat terkecil umum, output suatu model linier y diberikan oleh ekspresi terparameter linier
y = θ1 f1(u) + θ2 f2(u) +…+ θn fn(u),
dimana u = [u1,…, up]T adalah vektor input model, f1,…, fn adalah fungsi dari u yang diketahui, dan θ1,…, θn adalah parameter yang tidak diketahui yang akan diestimasi.
Mensubstitusi setiap pasangan data ke persamaan sebelumnya menghasilkan m persamaan linier:
. , ,
) ( )
( )
(
) ( )
( )
(
) ( )
( )
(
2 1
2 2
1 1
2 2
2 2 1 2 1
1 2
1 2 1 1 1
m n
m n m
m
n n
n n
y y y
f f
f
f f
f
f f
f
M M L
M L L
=
=
=
⎪⎪
⎩
⎪⎪
⎨
⎧
+ + +
+ + +
+ + +
θ θ
θ
θ θ
θ
θ θ
θ
u u
u
u u
u
u u
u
Menggunakan notasi matrik, persamaan sebelumnya dapat ditulis:
Aθ = y, (1)
dimana A adalah matrik m×n:
⎥⎥
⎥
⎦
⎤
⎢⎢
⎢
⎣
⎡
=
) ( )
(
) ( )
(
1
1 1
1
m n m
n
f f
f f
u u
u u
A
L M M M
L
,
θ adalah vektor parameter tidak diketahui n×1:
θ
⎥⎥
⎥
⎦
⎤
⎢⎢
⎢
⎣
⎡
= θn
θ M
1
,
dan y adalah vektor output m×1:
⎥⎥
⎥
⎦
⎤
⎢⎢
⎢
⎣
⎡
= ym
y M
1
y .
Baris ke-i dari matrik data gabungan
[
AMy]
, dinotasikan oleh[
i]
T i M y
a , berelasi dengan pasangan data input-output (ui; yi) melalui
[
1( i), , n( i)]
T
i f u f u
a = L .
Seringkali m lebih besar daripada n, sehingga solusi eksak yang memenuhi semua m persamaan tidak selalu mungkin karena data dapat dikontaminasi oleh derau, atau model mungkin tidak sesuai sistem target. Maka persamaan (1) dimodifikasi dengan memasukkan vektor galat e untuk menghitung derau acak atau galat pemodelan:
Aθ + e = y.
Dicari θ = θˆ yang meminimkan jumlah kuadrat galat yang didefinisikan oleh ),
( ) (
) (
) (
1
2
θ θ
θ
e e y A y Aa = = − −
−
=
∑
=
T m T
i
T i
yi
θ E
dimana e = y – Aθ adalah vektor galat yang diproduksi oleh sebuah pemilihan spesifik θ. E(θ) adalah dalam bentuk kuadratik dan minimum pada θ = θˆ, disebut penduga kuadrat terkecil (least squares estimator, LSE), yang memenuhi persamaan normal
AT A θˆ = AT y.
Jika AT A nonsingular, θˆ unik dan diberikan oleh
θˆ = (AT A)-1 AT y. (2)
tetapi jika AT A singular, maka LSE tidak unik dan harus menggunakan generalized inverse untuk menemukan θˆ.
2.3.3. Penduga Kuadrat Terkecil Rekursif LSE dapat diekspresikan sebagai
θk = (AT A)-1 AT y,
dimana tanda topi (^) dihilangkan agar sederhana. Diasumsikan dimensi baris A dan y adalah k; maka subscript k ditambahkan untuk menotasikan banyak pasangan data yang digunakan untuk menduga θ. Jika sebuah pasangan data baru (aT; y) tersedia sebagai entri ke-(k+1), maka disamping menggunakan seluruh k+1 pasangan data yang tersedia untuk mengkalkulasi ulang LSE θk+1, dapat digunakan θk untuk menemukan θk+1.
θk+1 dapat diekspresikan sebagai
θk+1 ⎥
⎦
⎢ ⎤
⎣
⎥ ⎡
⎦
⎢ ⎤
⎣
⎡
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
⎥⎦
⎢ ⎤
⎣
⎥ ⎡
⎦
⎢ ⎤
⎣
= ⎡
−
y
T T T
T T
y a
A a
A a
A
1
.
Untuk menyederhanakannya, digunakan dua matrik n×n Pk dan Pk+1
Pk = (AT A)-1
1 1
−
+ ⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
⎥⎦
⎢ ⎤
⎣
⎥ ⎡
⎦
⎢ ⎤
⎣
= ⎡ T
T k T
a A a
P A
[ ]
⎟⎟−1⎠
⎞
⎜⎜⎝
⎛ ⎥
⎦
⎢ ⎤
⎣
= T ⎡ T
a a A A
= (AT A + aaT)-1.
Dua matrik ini terhubung oleh
T k
k P aa
P−1 = −+11− . (3)
Menggunakan Pk dan Pk+1, maka
⎩⎨
⎧
+
=
=
+
+ ( ).
,
1
1 k T y
k
T k k
a y A P
y A P θ
θ (4)
Untuk mengekspresikan θk+1 dalam θk, ATy dalam persamaan (4) harus dieliminasi. Dari persamaan pertama dalam persamaan (4),
AT y =Pk−1θk.
Dengan memasukkan ekspresi ini ke persamaan kedua dan menggunakan persamaan (3) θk+1 = Pk+1(Pk−1θk +ay)
] )
[( 11
1 k T k y
k P aa a
P − +
= + −+ θ
= θk + Pk+1a (y - aT θk).
Maka θk+1 dapat diekspresikan sebagai suatu fungsi dari penduga lama θk dan pasangan data baru (aT; y). Penduga baru θk+1 sama dengan penduga lama θk plus term pengkoreksi berdasarkan data baru; term pengkoreksi ini sama dengan suatu vektor adaptasi Pk+1a dikalikan galat prediksi yang dihasilkan penduga lama yaitu y - aT θk. Mengkalkulasi Pk+1 melibatkan inverse matrik n×n. Ini computationally expensive dan membutuhkan formula inkremental untuk Pk+1. Dari persamaan (3)
1 1
1 ( − )−
+ = k + T
k P aa
P .
Jika A dan I + CA-1B adalah matrik-matrik bujur sangkar nonsingular, maka:
(A + BC)-1 = A-1 – A-1B (I + CA-1B)-1CA-1.
Menggunakan formula inverse matrik dengan A = Pk−1, B = a, dan C = aT, diperoleh formula inkremental berikut untuk Pk+1:
k T k T k
k
k P P a I a P a a P
P +1 = − ( + )−1
1 a P a. P aa P P
k T
k T k
k − +
=
Singkatnya, penduga kuadrat terkecil rekursif untuk Aθ = y, dimana baris ke-k (1 ≤ k ≤ m) dari [AMy], dinotasikan oleh [aTk Myk], dikalkulasi secara sekuensial:
⎪⎩
⎪⎨
⎧
− +
=
− +
=
+ + + + +
+ +
+ + +
), (
1 ,
1 1 1 1 1
1 1
1 1 1
k T k k k k k k
k k T k
k T k k k k k
y θ
θ
θ P a a
a P a
P a a P P
P (5)
dimana k berkisar antara 0 sampai m-1 dan seluruh LSE θˆ sama dengan θm, penduga dengan menggunakan semua m pasangan data.
Untuk memulai algoritma tersebut, perlu dipilih nilai-nilai inisial untuk θ0 dan P0. Kondisi inisial untuk bootstrap persamaan (5) adalah θ0 = 0 dan P0 = γI, dimana γ adalah suatu angka positif besar dan I adalah matrik identitas berdimensi M×M.
2.4. Optimisasi Berbasis Derivatif
Teknik optimisasi berbasis gradien dapat menentukan arah pencarian berdasarkan informasi derivatif fungsi obyektif. Tujuannya meminimalkan fungsi obyektif bernilai riil E pada ruang input n-dimensi θ = [θ1, θ2, …, θn]T, dengan menemukan titik minimum (mungkin lokal) θ = θ* yang meminimalkan E(θ).
2.4.1. Metode Penurunan (Descent)
Fungsi obyektif E dapat berbentuk nonlinier terhadap parameter θ. Dalam metode penurunan iteratif, titik berikut θnext ditentukan oleh langkah turun dari titik kini θnow
dalam vektor arah d:
θnext = θnow + ηd,
dimana η adalah ukuran langkah (tingkat pembelajaran) positif pencocok sepanjang apa untuk diproses dalam arah tersebut.
Metode penurunan iteratif menghitung langkah ke-k ηkdk melalui dua prosedur:
pertama menentukan arah d, dan kemudian mengkalkulasi ukuran langkah η. Titik berikut θnext harus memenuhi pertidaksamaan berikut:
E(θnext) = E(θnow + ηd) < E(θnow).
Perbedaan diantara berbagai algoritma penurunan berada pada prosedur pertama untuk menentukan arah. Lalu semua algoritma bergerak ke sebuah titik minimum (lokal) dengan ukuran langkah optimum yang dapat ditentukan oleh minimisasi garis.
Metode Berbasis Gradien
Metode penurunan berbasis gradien jika arah turun d ditentukan dengan dasar gradien (g) dari fungsi obyektif E.
Gradien dari fungsi terdiferensialkan E : Rn → R pada θ adalah vektor derivatif pertama dari E, dinotasikan g. Yaitu,
) . , ( ), , ( ) )) (
( ( ) (
2 1
T
n
def E E E
E
g ⎥
⎦
⎢ ⎤
⎣
⎡
∂
∂
∂
∂
∂
= ∂
∇
= θ
θ θ
θ θ
θ θ
θ L
Secara umum, berdasarkan gradien, arah turun mengikuti kondisi untuk arah penurunan yang layak:
, 0 )) ( ) cos(
) ( 0 (
0
<
= + =
′ =
=
now T
now T
d
dE ξ θ
η η φ θ
η
d g d d g
dimana ξ menandakan sudut antara g dan d, dan ξ(θnow) menotasikan sudut antara gnow
dan d pada titik kini θnow. Arah gradien selalu tegak lurus ke kurva bentuk.
Gambar 2.12. Arah-arah penurunan yang layak. Arah-arah dari titik awal θnow dalam area bayang adalah kandidat-kandidat vektor penurunan yang mungkin. Ketika d = -g, d adalah arah penurunan tercuram pada
titik lokal θnow.
Sumber: Neuro-Fuzzy and Soft Computing (1997,p131)
Bentuk fundamental motode ini, dimana arah penurunan layak ditentukan dengan membelokkan gradien melalui perkalian dengan G (deflected gradient):
θnext = θnow - ηGg, (6)
dengan ukuran langkah positif η dan matrik positif definite G.
Secara ideal, ingin ditemukan suatu nilai θnext yang memenuhi:
. ) 0
) (
( =
∂
=∂
= next
E
next
θ
θ θ
θ θ g
Dalam praktek, sulit memecahkan persamaan tersebut secara analitis. Untuk meminimalkan fungsi obyektif, prosedur penurunan diulangi sampai satu dari kriteria berhenti berikut terpenuhi:
1. Nilai fungsi obyektif cukup kecil;
2. Panjang vektor gradien g lebih kecil dari pada nilai tertentu; atau 3. Waktu komputasi tertentu telah lewat.
2.4.2. Metode Penurunan Tercuram (Steepest Descent)
Ketika G = I (matrik identitas), persamaan (6) menjadi formula penurunan tercuram (steepest descent, SD) :
θnext = θnow - ηg.
Jika 1cosξ =− yaitu d menunjuk arah yang sama dengan arah gradien negatif (-g), fungsi obyektif E dapat dikurangi secara lokal oleh jumlah terbanyak pada titik kini θnow. Akibatnya arah gradien negatif (-g) menunjuk arah locally steepest downhill.
Jika metode penurunan tercuram menggunakan minimisasi garis yaitu titik minimum η* pada arah d ditemukan pada setiap iterasi maka
η η η θ
φ d
dE( now now) )
( − g
′ =
∇T
= E(θnow - η gnow) gnow
= gTnextgnow
= 0,
dimana gnext adalah vektor gradien pada titik berikut. Persamaan ini mengindikasikan bahwa vektor gradien berikut gnext selalu ortogonal terhadap vektor gradien kini gnow.
2.4.3. Analisis untuk Kasus Kuadratik
Menganalisis fungsi obyekif kuadratik adalah penting, karena fungsi general dapat didekati dengan baik oleh fungsi kuadratik di sekitar suatu minimum (lokal), karena konsekuensi dari teori Taylor.
Misalkan fungsi obyektif E memiliki bentuk kuadratik:
2 . ) 1
( c
E θ = θTAθ +bTθ +
Gradien dari E(θ) dapat diekspresikan sebagai g(θ) = Aθ + b.
Metode Penurunan Tercuram tanpa Minimisasi Garis
Dalam persamaan sebelumnya, digunakan ukuran langkah tetap kecil η (SD sederhana):
θnext = θnow - ηg. (7)
Versi lain dengan menormalisasi gradien (SD versi ternormalisasi):
g , κ g θ
θnext = now − (8)
dimana κ adalah ukuran langkah riil, mengindikasikan jarak Euclidean transisi dari θnow
ke θnext:
now .
next θ θ
κ = −
Besar langkah ηg dalam persamaan (7) dengan η tetap secara otomatis berubah pada setiap iterasi berdasarkan gradien berbeda g. Jika titik minimum berada pada plateau landscape, maka g menjadi sangat kecil dan penurunan tercuram sederhana mempunyai konvergensi pelan. Versi ternormalisasi dalam persamaan (8) dengan suatu κ tetap selalu membuat langkah yang sama, berapapun kecuraman dari slope.
Bagaimana Meng-update κ
Ukuran langkah κ dapat di-update berdasarkan dua aturan heuristik berikut (Jang, 1993, p665-685):
1. Jika fungsi obyektif melalui m reduksi berturut, naikkan κ dengan p%.
2. Jika fungsi obyektif melalui n kombinasi satu naik dan satu turun berturut, turunkan κ dengan q%.
2.5. Jaringan Syaraf Adaptif
Suatu jaringan adaptif (Gambar 2.13) adalah struktur jaringan yang semua atau sebagian node bersifat adaptif, artinya output-output dari node bergantung pada parameter-parameter modifiable yang bersinggungan dengan node ini. Suatu jaringan adaptif digunakan untuk identifikasi sistem, dan tugas kita adalah menemukan arsitektur jaringan yang sesuai dan himpunan dari parameter-parameter yang dapat memodelkan terbaik suatu sistem target yang tidak diketahui yang digambarkan oleh himpunan pasangan data input-output.
2.5.1. Arsitektur
Gambar 2.13. Suatu jaringan adaptif feedforward dalam representasi lapis.
Sumber: Neuro-Fuzzy and Soft Computing (1997,p200)
Konfigurasi dari jaringan adaptif terdiri atas himpunan node yang dihubungkan oleh link-link berarah, dimana setiap node melakukan fungsi node statis pada sinyal- sinyal inputnya untuk membangkitkan output node tunggal dan setiap link menspesifikasikan arah aliran sinyal dari satu node ke lainnya.
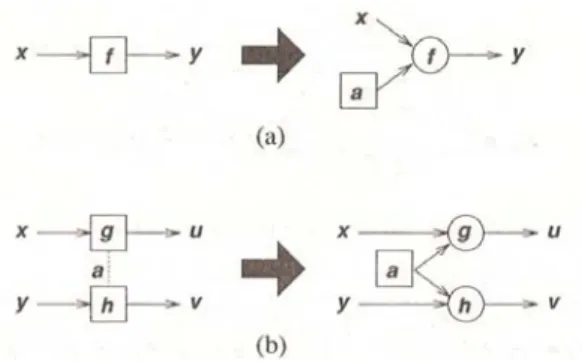
Parameter-parameter pada jaringan adaptif didistibusikan ke dalam node-nodenya, sehingga setiap node mempunyai suatu himpunan parameter lokal. Jika himpunan parameter node tidak kosong, maka fungsi nodenya bergantung pada nilai-nilai parameter; digunakan kotak untuk merepresentasikan jenis node adaptif ini. Di lain
pihak, jika himpunan parameter node kosong, maka fungsinya tetap; digunakan lingkaran untuk menotasikan tipe node tetap ini.
Gambar 2.14. Dekompisisi dari node-node adaptif: (a) sebuah node tunggal; (b) masalah sharing parameter.
Sumber: Neuro-Fuzzy and Soft Computing (1997,p201)
Setiap node adaptif dapat didekomposisi ke dalam sebuah node tetap plus satu atau lebih node parameter, seperti diilustrasikan dalam contoh berikut. Gambar 2.14(a) menunjukkan jaringan adaptif dengan satu node, yang dapat direpresentasikan oleh y = f(x, a), dimana x dan y adalah input dan output, dan a adalah parameter dari node.
Representasi ekuivalennya adalah dengan memindahkan parameter keluar dari node dan menaruhnya ke dalam suatu node parameter, seperti ditunjukkan dalam Gambar 2.14(a). Node parameter berguna dalam memecahkan beberapa masalah representasi, seperti masalah sharing parameter dalam Gambar 2.14(b), dimana dua node adaptif u
= g(x, a) dan v = h(y, a) berbagi parameter a yang sama, seperti dinotasikan oleh garis titik-titik yang menghubungkan dua node ini. Dengan mengeluarkan parameter dan menaruhnya kedalam sebuah node parameter, dapat dimasukkan kebutuhan sharing parameter ke dalam arsitektur. Ini menyederhanakan representasi jaringan dan juga implementasi perangkat lunak.
Jaringan adaptif secara umum diklasifikasikan ke dalam dua kategori berdasarkan tipe koneksi yang dimiliki: feedforward dan recurrent. Jaringan adaptif yang
ditunjukkan dalam Gambar 2.13 feedforward, karena output dari tiap node merambat dari sisi input (kiri) ke sisi output (kanan) unanimously. Jika terdapat sebuah link balik yang membentuk sebuah jalur sirkular dalam suatu jaringan, maka jaringan recurrent;
Gambar 2.15 adalah sebuah contoh.
Gambar 2.15. Suatu jaringan adaptif recurrent.
Sumber: Neuro-Fuzzy and Soft Computing (1997,p202)
Dalam representasi lapis dari jaringan adaptif feedforward pada Gambar 2.13, tidak terdapat link antar node-node dalam lapis yang sama, dan output dari node-node dalam suatu lapis spesifik selalu terhubung dengan node-node pada lapis berikutnya.
Representasi ini seringkali diminati karena modularitasnya, yaitu node-node dalam lapis yang sama mempunyai fungsionalitas yang sama atau membangkitkan level abstraksi yang sama untuk vektor-vektor input.
Secara konseptual, jaringan adaptif feedforward sesungguhnya merupakan pemetaan statis antara ruang input dan outputnya. Tujuannya adalah membangun suatu jaringan untuk mencapai suatu pemetaan nonlinier yang diinginkan yang diatur oleh sebuah himpunan data yang mengandung pasangan-pasangan input-output yang diinginkan dari sistem target. Himpunan data ini seringkali disebut himpunan data pelatihan, dan prosedur-prosedur untuk mengatur paramater-parameter untuk meningkatkan performa jaringan sering disebut aturan pelatihan atau algoritma adaptasi. Seringkali performa suatu jaringan diukur sebagai ketidakcocokan antara output yang diinginkan dan output jaringan dalam kondisi input yang sama.
Ketidakcocokan ini disebut ukuran galat.
2.5.2. Perambatan Balik untuk Jaringan Feedforward
Perambatan balik adalah aturan pelatihan dasar untuk jaringan adaptif yang pada esensinya metode SD sederhana. Bagian inti adalah bagaimana secara rekursif memperoleh suatu vektor gradien dimana tiap elemen didefinisikan sebagai derivatif ukuran galat terhadap suatu parameter.
Misalkan sebuah jaringan adaptif feedforward yang diberikan mempunyai L lapis dan lapis l (l = 0, 1, …, L; l = 0 merepresentasikan lapis input) mempunyai N(l) node.
Maka output dan fungsi node i [i = 1, …, N(l)] dalam lapis l dapat direpresentasikan sebagai xl,i dan fl,i, seperti ditunjukkan pada Gambar 2.16. Karena output suatu node bergantung pada siyal-sinyal yang masuk dan himpunan parameter dari node, maka ekspresi umum untuk fungsi node fl,i sebagai berikut:
xl,i = fl,i (xl-1,1,…xl-1,N(l-1), α, β, γ, …),
dimana α, β, γ, dan seterusnya adalah parameter-parameter dari node ini.
Gambar 2.16. Konvensi notasional: representasi lapis.
Sumber: Neuro-Fuzzy and Soft Computing (1997,p206)
Mengasumsikan bahwa himpunan data pelatihan yang diberikan mempunyai P entri, dapat didefinisikan suatu ukuran galat untuk entri data pelatihan ke-p (1 ≤ p ≤ P) sebagai jumlah kuadrat galat:
, ) (
) (
1
2
∑
,=
−
=N L
k
k L k
p d x
E
dimana dk adalah komponen ke-k dari vektor output yang diinginkan ke-p dan xL,k adalah komponen ke-k dari vektor output aktual yang dihasilkan dengan menggunakan vektor input ke-p ke jaringan. Karena untuk ANFIS hanya terdapat satu node output maka:
Ep = (d – xL)2.
Maka ingin diminimkan suatu ukuran galat keseluruhan untuk seluruh P pasangan input- output pelatihan, yang didefinisikan sebagai E=
∑
Pp=1Ep.Sebelum mengkalkulasi vektor gradien, observasi hubungan kausal berikut:
Dengan kata lain, perubahan kecil pada parameter α akan mempengaruhi output node yang mengandung α; selanjutnya akan mempengaruhi output lapis akhir dan karenanya ukuran galat. Karena itu, konsep dasar dalam menghitung vektor gradien adalah dengan melewatkan sebuah bentuk informasi derivatif dimulai dari lapis output dan berjalan mundur lapis demi lapis sampai lapis input dicapai.
Sinyal galat єl,i didefinisikan sebagai derivatif ukuran galat Ep terhadap output node i dalam lapis l, mengambil jalur baik langsung dan tak langsung.
i l
p i
l x
E
,
, ∂
= ∂
∈
+
.
Ekspresi ini disebut derivatif beruntun oleh Werbos (1974), yang mempertimbangkan baik jalur langsung maupun tak langsung yang membawa pada hubungan kausal.
Sinyal galat output node ke-i (pada lapis L) dapat dikalkulasi secara langsung:
i L
p i
L p i
L x
E x
E
, ,
, ∂
= ∂
∂
= ∂
∈
+
.
Ini sama dengan єL,i = -2(di – xL,i). Untuk node internal pada posisi ke-i dari lapis l, sinyal galat didapatkan dengan aturan berantai:
∑
∑
+=
+ + + +
=
+ + + +
∂
∈ ∂
∂ =
∂
∂
= ∂
∂
= ∂
∈ ( 1)
1 ,
, 1 , 1 ,
, ) 1
1 (
1
1 , 1 ,
,
l N
m li
m l m l i
l m l l
N m
l layer padaeror sinyal
m l
p
l layer padaeror sinyal
i l
p i
l x
f x
f x
E x
E
3 2 1 3
2 1
,
dimana 0 ≤ l ≤ L-1.
Vektor gradien didefinisikan sebagai derivatif ukuran galat terhadap masing- masing parameter. Jika α adalah suatu parameter dari node ke-i pada lapis l, maka
α α
α ∂
=∈ ∂
∂
∂
∂
= ∂
∂
∂+ + li
i l i l i l
P p f f
x
E E ,
, , ,
.
Jika parameter α diijinkan untuk di-share diantara node-node berbeda, maka persamaan di atas diubah ke bentuk yang lebih umum:
∑
∈ ∗ + +∗ ∂
∂
∂
= ∂
∂
∂
S x
P p f
x E E
α α
*
,
dimana S adalah himpunan node yang mengandung α sebagai suatu parameter; dan x* dan f* adalah output dan fungsi dari suatu node generik dalam S.
Derivatif dari ukuran galat keseluruhan E terhadap α adalah
∑
= + +∂
= ∂
∂
∂ P
p
Ep
E
1 α
α .
Karena itu, untuk penurunan tercuram sederhana tanpa minimisasi garis, formula update untuk parameter generik α (misalnya parameter premis a, b, atau c) adalah
η α
α ∂
− ∂
=
Δ +E
, (9)
dimana η adalah tingkat pelatihan, yang dapat diekspresikan sebagai
∑
⎜⎝⎛∂∂ ⎟⎠⎞=
α α
η κ
E 2
,
dimana κ adalah ukuran langkah, panjang setiap transisi sepanjang arah gradien dalam ruang parameter.
2.5.3. Aturan Pelatihan Hibrid: Mengkombinasikan SD dan LSE
Meski dapat menggunakan perambatan balik untuk mengidentifikasi parameter jaringan adaptif, namun seringkali memakan waktu panjang sebelum konvergen. Output jaringan adaptif linier dalam beberapa parameter jaringannya; sehingga dapat diidentifikasi dengan metode kuadrat terkecil (MKT) linier. Pendekatan ini menghasilkan aturan pelatihan hibrid (Jang, 1991, p762-767; Jang, 1993, p665-685) yang mengkombinasikan SD dan LSE untuk identifikasi cepat parameter.
Pelatihan Off-Line (Pelatihan Batch)
Diasumsikan jaringan adaptif hanya mempunyai satu output yang direpresentasikan oleh
o = F(i, S), (10)
dimana i adalah vektor variabel-variabel input, S adalah himpunan parameter, dan F adalah fungsi keseluruhan yang diimplementasi oleh jaringan adaptif. Jika terdapat sebuah fungsi H sehingga fungsi komposit H о F linier dalam beberapa elemen S, maka elemen-elemen ini dapat diidentifikasi oleh MKT. Secara lebih formal, jika himpunan parameter S dapat dibagi ke dalam dua himpunan
2
1 S
S
S = ⊕ ,
(dimana ⊕ merepresentasikan jumlah langsung) sehingga H о F linier dalam elemen- elemen S2, maka dengan mengaplikasikan H ke persamaan (10), diperoleh
H(o) = H о F(i, S), (11)
yang linier dalam elemen S2. Jika diberikan nilai elemen-elemen S1, dapat dimasukkan P data pelatihan ke dalam persamaan (11) dan memperoleh persamaan matrik:
Aθ = y (12)
dimana θ adalah vektor yang tidak diketahui yang elemennya adalah parameter- parameter dalam S2. Solusi terbaik untuk θ yang meminimkan Aθ −y 2 adalah penduga kuadrat terkecil (LSE) θ*.
Sekarang dapat dikombinasikan SD dan LSE untuk meng-update parameter jaringan adaptif. Untuk pelatihan hibrid yang diaplikasikan ke dalam mode batch, setiap epoch (periode pelatihan) tersusun atas forward pass dan backward pass. Dalam forward pass, setelah vektor input dihadirkan, dikalkulasi output node lapis demi lapis sampai baris dalam matrik A dan y dalam persamaan (12) diperoleh. Lalu parameter- parameter dalam S2 diidentifikasi baik dengan formula LSE pseudoinverse dalam persamaan (2) atau formula LSE rekursif dalam persamaan (5). Kemudian dapat dihitung ukuran galat untuk setiap pasangan data pelatihan. Dalam backward pass, sinyal galat merambat dari akhir output menuju akhir input; vektor gradien diakumulasi untuk setiap entri data pelatihan. Pada akhir backward pass untuk semua data pelatihan, parameter- parameter dalam S1 di-update oleh SD dengan persamaan (9).
Untuk nilai parameter tetap dalam S1 yang diberikan, parameter dalam S2 yang ditemukan dijamin titik optimum global dalam ruang parameter S2 karena pemilihan ukuran kuadrat galat. Bukan hanya aturan pelatihan hibrid ini mengurangi dimensi ruang
pencarian metode SD, tetapi secara substansial juga mengurangi waktu yang dibutuhkan untuk mencapai konvergensi.
2.6. ANFIS: Adaptive Neuro-Fuzzy Inference Systems
Arsitektur suatu kelas dari jaringan adaptif yang secara fungsional ekuivalen dengan FIS disebut sebagai ANFIS, yang kepanjangannya adaptive neuro-fuzzy inference system.
2.6.1. Arsitektur ANFIS
Diasumsikan FIS mempunyai dua input x dan y dan satu output z. Untuk model fuzzy Sugeno orde satu (Sugeno dan Kang, 1988, p15-33; Takagi dan Sugeno, 1983, p55-60;
Takagi dan Sugeno, 1985, p116-132), himpunan aturan yang umum dengan dua aturan if-then fuzzy adalah sebagai berikut:
Aturan 1: If x is A1 and y is B1, then f1 = p1x + q1y + r1, Aturan 2: If x is A2 and y is B2, then f2 = p2x + q2y + r2.
Gambar 2.17. (a) Suatu model fuzzy Sugeno tingkat pertama dua input dengan dua aturan; (b) arsitektur ANFIS yang ekuivalen.
Sumber: Neuro-Fuzzy and Soft Computing (1997,p336)
Gambar 2.17(a) mengilustrasikan mekanisme penalaran model Sugeno ini; arsitektur ANFIS yang ekuivalen ditunjukkan pada Gambar 2.17(b), dimana node dalam lapis yang sama mempunyai fungsi yang serupa. (Dinotasikan output node ke-i dalam lapis l sebagai Ol,i.)
a) Lapis 1 Setiap node i dalam lapis ini adalah node adaptif dengan fungsi node ),
, (
1 x
O i =μAi untuk i = 1, 2, atau ),
2(
,
1 y
O i =μBi− untuk i = 3, 4,
dimana x (atau y) adalah input ke node i dan Ai (atau Bi-2) adalah label linguistik (seperti
“kecil” atau “luas”) yang berhubungan dengan node ini. Dengan kata lain, O1,i adalah derajat keanggotaan himpunan fuzzy A ( = A1, A2, B1, atau B2) dan menspesifikasikan derajat dimana input x (atau y) yang diberikan memenuhi kuantifier A. Parameter dalam lapis ini disebut sebagai parameter premis.
b) Lapis 2 Setiap node dalam lapis ini adalah node tetap berlabel П, yang outputnya adalah produk dari semua sinyal yang masuk:
), ( )
, (
2 w x y
O i = i =μAi μBi i = 1, 2.
Setiap output node merepresentasikan kuat penyulutan dari sebuah aturan.
c) Lapis 3 Setiap node dalam lapis ini adalah node tetap berlabel N. Node ke-i mengkalkulasi rasio kuat penyulutan aturan ke-i dan jumlah kuat penyulutan semua aturan:
2 1 ,
3 w w
w w
O i i i
= +
= , i = 1, 2.
Output dari lapis ini disebut kuat penyulutan ternormalisasi.
d) Lapis 4 Setiap node i dalam lapis ini adalah node adaptif dengan fungsi node )
, (
4i wifi wi pix qiy ri
O = = + + ,
dimana w adalah kuat penyulutan ternormalisasi dan {pi i, qi, ri} adalah himpunan parameter node ini. Parameter dalam lapis ini disebut sebagai parameter konsekuen.
e) Lapis 5 Node tunggal dalam lapis ini adalah node tetap berlabel Σ, yang menghitung output keseluruhan sebagai penjumlahan dari semua sinyal yang masuk:
output keseluruhan = 5,1 .
∑ ∑
∑
==
i i
i i i
i i i
w f f w
w O
2.6.2. Algoritma Pelatihan hibrid
Dari arsitektur ANFIS yang ditunjukkan dalan Gambar 2.17(b), terlihat bahwa ketika nilai parameter-parameter premis tetap, output keseluruhan dapat diekspresikan sebagai kombinasi linier dari parameter-parameter konsekuen. Secara simbolik, output f dalam Gambar 2.17(b) dapat ditulis ulang sebagai
2 2 1
2 1
2 1
1 f
w w f w w w f w
+ +
= +
=w1(p1x+q1y+r1)+w2(p2x+q2y+r2)
=(w1x)p1 +(w1y)q1 +(w1)r1 +(w2x)p2 +(w2y)q2 +(w2)r2,
yang linier dalam parameter konsekuen p1, q1, r1, p2, q2, dan r2. Dari observasi dipunyai S = himpunan parameter-parameter total,
S1 = himpunan parameter-parameter premis (nonlinier), S2 = himpunan parameter-parameter konsekuen (linier)
dalam persamaan (4); dan H(·) dan F(·,·) adalah fungsi identitas dan fungsi dari sistem inferensi fuzzy dalam persamaan (11). Sehingga algoritma pelatihan hibrid dapat diaplikasikan secara langsung. Dalam forward pass, output-output node bergerak maju sampai lapis 4 dan parameter konsekuen diidentifikasi dengan MKT. Dalam backward pass, sinyal-sinyal galat bergerak mundur dan parameter premis di-update dengan penurunan gradien. Tabel 2.1 merangkum aktivitas dalam setiap pass.
Tabel 2.1. Dua pass dalam prosedur pelatihan hibrid untuk ANFIS.
Sumber: Neuro-Fuzzy and Soft Computing (1997,p340)
2.7. Fuzzy Clustering
Clustering mempartisi suatu himpunan data ke dalam beberapa kelompok sehingga kemiripan di dalam kelompok lebih besar daripada antar kelompok. Karena itu diperlukan matrik kemiripan yang mengambil dua vektor input dan mengembalikan nilai kemiripannya. Karena matrik kemiripan sensitif terhadap rentang elemen-elemen dalam vektor input, maka setiap variabel input harus dinormalisasi, misalnya kedalam interval [0, 1]. Teknik-teknik clustering digunakan bersamaan dengan pemodelan fuzzy terutama untuk menentukan aturan-aturan if-then fuzzy inisial.
2.7.1. Fuzzy C-Means Clustering (FCM)
Fuzzy C-means clustering (FCM) adalah suatu algoritma clustering data dimana setiap titik data termasuk dalam suatu cluster pada tingkat yang dispesifikasikan oleh sebuah derajat keanggotaan. Algoritma ini diajukan oleh Bezdek (1973).