CLUSTERING PENGGUNAAN ENERGI LISTRIK PELANGGAN PLN MENGGUNAKAN ALGORITMA FUZZY C-MEANS
Briant Saputro1, Marji2, Nurul Hidayat3
Program Studi Ilmu Komputer, Program Teknologi Informasi dan Ilmu Komputer Universitas Brawijaya, Jl. Veteran Malang, 65145, Indonesia
E-mail: [email protected]1, [email protected]2, nt [email protected]3
ABSTRAK
Pelayanan pelanggan pada suatu perusahaan merupakan hal yang paling penting untuk membuat suatu perusahaan itu berkembang. Untuk mnjamin kepuasaan pelanggan dan kesetiaan pelanggan, menjamin pertumbuhan perusahaan yang berkesinambungan merupakan visi dan misi suatu perusahaan dalam mengembangkan perusahaan tersebut.
PLN merupakan sebuah perusahaan listrik Negara yang berorientasi kepada pelanggan. Manajemen PLN sendiri telah mengembangkan system pengelolaan pelanggan. Namun, pelayanan dari sistem tersebut masih bersifat teknik, belum melakukan analisa terhadap penggunaan energi listrik oleh pelanggan.
Costumer Relationship Management (CRM) adalah salah satu cara untuk menyelesaikan permasalaahan analisa terhadap perilaku pelanggan berdasarkan data historis. Salah satu metode riset dalam CRM adalah melakukan clustering pelanggan. Pengelompokkan pelanggan bias menolong perusahaan dalam menemukan karakteristik dan perilaku pelanggan yang berbeda dalam setiap kelompok[2].
Fuzzy c-means merupakan salah satu dari sekian banyak algoritma clustering. Fuzzy c-means adalah suatu teknik pengelompokkan data dimana keberadaan tiap titik data cluster ditentukan oleh derajat keanggotaan[6].
Dalam skripsi ini dilakukan penelitian mengenai penerapan algoritma FCM terhadap permasalahan clustering pelanggan PLN. Tingkat validasi data hasil pengelompokkan berdasar jumlah cluster, serta tingkat validasi data hasil pengelompokkan berdasar banyak iterasi dan nilai minimum error.
Hasil dari penelitian ini, yaitu algoritma fuzzy c-means dapat terapkan dalam clustering pelanggan PLN. Penggunaan data nominal asli dalam clustering menghasilkan pusat cluster lebih baik daripada penggunaan data kategorisasi. Hasil penelitan memperlihatkan, clustering pelanggan lebih akurat jika dikelompokkan ke dalam 3 cluster pada data yang berdaya besar(industri dan bisnis). Dalam percobaan tingkat validasi data hasil pengelompokan berdasar jumlah cluster mencapai nilai optimum dengan jumlah cluster 3. sedangkan penggunaan nilai iterasi dan minimum error yang sarankan adalah 100 dan 0.00001.
Kata Kunci:Abstrak, Fuzzy c-mean, CRM, clusteringpelanggan, PLN
Listrik merupakan sumber daya yang sangat dibutuhkan oleh manusia saat ini. Penggunaan listrik oleh manusia meningkat setiap tahunnya, bahkan setiap bulan baik digunakan untuk rumah tangga, bisnis maupun industri. Terkait kebutuhan listrik tersebut, pemerintah Indonesia menyediakan kebutuhan listrik melalui perusahaan listrik Negara (PLN).
Visi dan misi PLN dalam pelayanan antara lain menjadikan pelanggan sebagai mitra sejajar, menjamin kepuasan dan kesetiaan pelanggan, menjamin
pertumbuhan perusahaan yang
berkesinambungan dan menciptakan pelayanan berbasis sistem teknologi informasi. Sebagai perusahaan yang berorientasi pada pelanggan, manajemen PLN telah mengembangkan sistem pengolahan pelanggan. Sebagai perusahaan yang berorientasi pada pelanggan, manajemen PLN telah mengembangkan sistem pengelolaan pelanggan yang bernama costumer information system
(CIS). Namun pelayanan yang dilakukan masih bersifat teknik, belum melakukan pengelolaan pelanggan terhadap analisa
pengelolaan pelanggan dalam
menggunakan energi listrik
Manajemen hubungan pelanggan (CRM) adalah sebuah strategi yang berfokus pada perilaku konsumen dan cara berkomunikasi dengan mereka. Berdasarkan sudut pandang teknologi, CRM adalah dasar untuk melakukan analisis perilaku konsumen berdasarkan data historis pelanggan. CRM dapat digunakan untuk meningkatkan pelayanan kepada pelanggan dengan tujuan member kepuasan kepada pelanggan.
PLN menyimpan data penggunaan listrik dari pelanggannya secara berkala. Sehubungan dengan komitmen PLN sebagai perusahaan yang berorientasi pada pelanggan, akan dilakukan analisa terhadap salah satu bagian CRM yaitu segmentasi pelanggan.Identifikasi pelanggan sangat penting dilakukan dalam
membangun manajemen hubungan
pelanggan terutama dalam rangka memetakan interaksi hubungan apa yang harus dilakukan perusahaan [1].
Pengelompokkan pelanggan bisa menolong pelaku pemasaran dalam menemukan karakteristik dan perilaku pelanggan yang berbeda dalam setiap kelompok [2]. Adanya gambaran nyata
tentang pelanggan memudahkan
perusahaan menentukan strategi alokasi dan penggunaan sumber daya yang ada dan memberikan pelayanan terbaik bagi pelanggannya. Dengan demikian, energi perusahaan dapat lebih dihemat dan manajemen dapat memfokuskan pelayanan pada konsumen.
Salah satu algoritma yang dapat digunakan untuk melakukan segmentasi pelanggan adalah algoritma Fuzzy C-Means. Algoritma Fuzzy C-Means
merupakan salah satu algoritma clustering.
Fuzzy c-means adalah suatu teknik
clustering data dimana keberadaan tiap titik data cluster ditentukan oleh derajat keanggotaan [3].
Algoritma FCM sudah cukup luas digunakan dalam segmentasi pelanggan , diantaranya Simha dan Iyengar (2005) dan Zumstein (2007). Selain itu fuzzy c-means
juga dapat menyelesaikan permasalahan pada karakterisasi pelanggan PLN. Dalam penelitian tersebut, algoritma FCM memberikan informasi yang sangat dibutuhkan dalam karakterisasi pelanggan dan dapat memberikan informasi tersembunyi, terutama informasi yang ada dalam kondisi transisi fuzzy .
2. TINJAUAN PUSTAKA 2.1 Data Clustering
pengukuran kesamaan tersedia, maka terdapat sejumlah teknik untuk membentuk cluster.
Analisis cluster dapat diterapkan pada bidang apa saja. Namun pemakaian teknik ini lebih familiar pada bidang pemasaran karena memang salah satu kegiatan yang dilakukan dalam pemasaran adalah pengelompokan, yang disebut segmentasi pasar. Tujuan analisis cluster
di dalam pemasaran adalah sebagai berikut:
1. Membuat segmen pasar
(segmenting the market)
Pelanggan atau pembeli sering diklasterkan berdasarkan manfaat atau keuntungan yang diperoleh dari pembelian barang. Setiap cluster
akan terdiri dari pelanggan/pembeli yang relatif homogen, dinyatakan dalam manfaat yang dicari.
2. Memahami perilaku pembeli
Analisis cluster digunakan untuk mengenali atau mengidentifikasi kelompok pembeli yang homogen. Kemudian perilaku dalam untuk setiap kelompok perlu dikaji secara terpisah. Responden (pembeli) dikelompokkan didasarkan pada self-reported importance yang terkait pada setiap faktor pilihan yang digunakan untuk memilih pasar atau
mall di mana para pembeli membeli barang yang dibutuhkan.
3. Mengenali peluang produk baru
Dengan mengklasterkan merek dan produk, competitive set di dalam pasar bisa ditentukan. Merek di dalam cluster yang sama bersaing sengit satu sama lain, daripada merek dari clusterlain.
4. Mereduksi data
Analisis cluster digunakan sebagai suatu alat mereduksi data secara umum, untuk mengembangkan
cluster atau subgroupdari data yang mudah dikelola dari kumpulan data asli, secara individual.
2.2 Fuzzy c-means
Fuzzy c-means pertamakali
dikemukakan oleh Dunn dan
dikembangkan oleh Bezdek yang banyak digunakan dalam pattern recognition. Metode ini merupakan pengembangan dari metode nonhierarkhi K-Means Cluster, karena pada awalnya ditentukan dulu jumlah kelompok atau cluster yang akan di bentuk. Kemudian dilakukan iterasi sampai mendapatkan keanggotaan kelompok tersebut. Pemilihan metode ini didasarkan pada beberapa jurnal dan
penelitian sebelumnya yang
mengindikasikan bahwa metode fuzzy cluster merupakan metode yang paling robust, karena pusat cluster dan hasil pengelompokkan tidak berubah jika ada data baru yang ekstrim [5].
Metode ini juga memberikan hasil yang smooth (halus) karena pembobotan yang digunakan berdasarkan himpunan
fuzzy [4]. Kehalusan disini berarti objek pengamatan tidak mutlak untuk menjadi anggota satu kelompok saja, tapi juga mungkin menjadi anggota kelompok yang lain dengan ukuran tingkat keanggotaan yang berbeda-beda. Objek akan cenderung menjadi anggota kelompok tertentu dimana tingkat keanggotaan objek dalam kelompok itu paling besar dibandingkan dengan kelompok lainnya.
Gambar 2.1 gambar sebaran objek
Salah satu penerapan logika fuzzy
adalah dalam clustering atau
pengelompokan. Fuzzy clustering adalah bagian dari pattern recognition atau pengenalan pola. Fuzzy clustering
memainkan peran yang paling penting dalam pencarian struktur dalam data.
Fuzzy clustering adalah salah satu teknik untuk menentukan cluster optimal dalam suatu ruang vektor yang didasarkan pada bentuk normal Euclidian untuk jarak antar vektor [6].
Ada dua metode dasar dalam fuzzy clustering. Metode pertama disebut dengan fuzzy c-means. Metode ini dinamakan demikian karena dengan
clustering ini akan dibentuk sebanyak
c-cluster yang sudah ditentukan sebelumnya. Metode yang kedua adalah metode yang banyaknya cluster tidak ditentukan sebelumnya. Metode ini dinamakan dengan fuzzy subtractive clustering [6]. Metode clustering yang akan digunakan dalam penelitian ini adalah fuzzy c-means. Metode ini pertama kali dikenalkan oleh Jim Bezdek pada tahun 1981. Fuzzy c-means adalah salah satu teknik pengklusteran data yang mana keberadaan tiap titik data dalam suatu cluster
ditentukan oleh derajat keanggotan. Algoritma dari fuzzy c-means adalah sebagai berikut.
FCM merupakan algoritma yang bersifat iteratif. Tujuan dari FCM adalah untuk menemukan pusat cluster (centroid)
yang meminimalkan fungsi
pertidaksamaan. Berikut langkah-langkah dari FCM [6]:
1. Input data yang akan dicluster X, berupa matrix berukuran n x m (n = jumlah sampel data, m = atribut setiap data).
Xij data sampel ke-i (i = 1,2,…n), atribut ke-j (j = 1,2,..m)
2. Menentukan jumlah cluster (c), pangkat (w), maksimum iterasi (MaxIter), error terkecil yang
diharapkan ( ξ ),
fungsi objektif awal (Po = 0), dan iterasi awal (t = 1).
3. Membangkitkan bilangan random ηik,
i= 1,2,…n., k=1,2,…c sebagai elemen matriks partisi awal U.
Menghitung jumlah setiap kolom (atribut) Dengan j = 1,2..n dengan
5. Menghitung fungsi obyektif pada iterasi ke-t, dengan persamaan.
6. Menghitung perubahan matriks partisi dengan persamaan.
7. Memeriksa kondisi berhenti dengan aturan persamaan.
1. Data Kategorikal
Tabel 4.1Uji Rasio Validasi Terhadap Jumlah ClusterData Kategorisasi
Cluster Data Kategorikal
Pada percobaan terhadap data kategorikal diperoleh hasil bahwa pengelompokkan terbaik dicapai pada jumlah cluster 3. Karena pada percobaan yang menggunakan nilai cluster tersebut menghasilkan nilai rasio yang paling kecil. Hasil tersebut berlaku untuk semua kombinasi varibel data. Hasil validasi rasio kerapatan data dalam clusterdengan keterpisahan data antar cluster pada data kategorisasi dapat dilihat pada tabel 4.1.
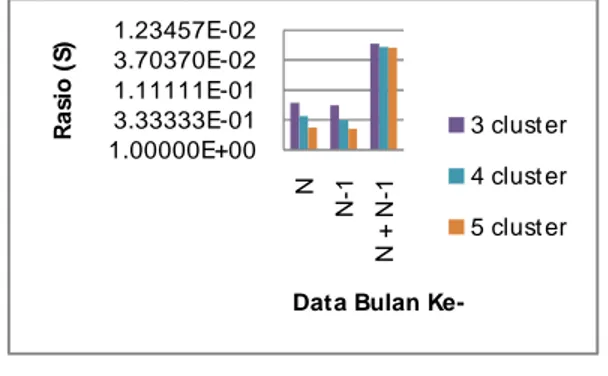
Gambar 4.1Hasil validasi pengelompokkan pada data kategorisasi pelanggan PLN dengan 3 klaster, 4 klaster
dan 5 klaster.
2. Data Asli
Tabel 4.4Uji Rasio Validasi Terhadap Jumlah ClusterData Asli
Clust diperoleh hasil bahwa pengelompokkan terbaik dicapai pada jumlah cluster 3. Hasil pengelompokan terbaik merupakan hasil dengan rasio validasi paling kecil. Hasil tersebut berlaku untuk semua
kombinasi varibel data. Untuk lebih jelasnya, hasil validasi rasio kerapatan data dalam cluster dengan keterpisahan data antar cluster pada data kategorisasi dapat dilihat pada tabel 4.2.
Gambar 4.2Hasil validasi
pengelompokkan pada data asli pelanggan PLN dengan 3 klaster, 4 klaster dan 5
klaster.
Pengujian ini dilakukan untuk mengetahui pengaruh nilai eror dan iterasi terhadap pengelompokkan yang dilakukan. Tabel 4.3 merupakan hasil pengujian dari beberapa nilai minimum eror dan iterasi.
Tabel 4.2Uji Rasio Validitas Terhadap Iterasi dan Minimum eror (dengan
pengujian cluster= 3)
Minimum
0.00001 5 3.1340E-02
10 3.5518E -02
50 3.6456E-02
100 3.6456E-02
1000 3.6456E-02
0.0000001 5 3.50990E-02
10 2.9310E-02
50 3.6455E-02
100 3.6455E-02
1000 3.6455E-02
Namun hal ini juga tergantung pada penggunaan iterasi maksimal yang digunakan. Sebab nilai eror hanya merupakan salah satu parameter untuk menghentikan iterasi komputasi pada proses clustering selain menggunakan iterasi maksimal pada algoritma fuzzy c-means.
Pada percobaan ini diperlihatkan bahwa penggunaan nilai eror 0.00001 sudah memperlihatkan hasil validasi rasio kerapatan data dalam cluster dengan keterpisahan antar cluster yang konvergen. Sementara itu, nilai percobaan menggunakan nilai iterasi maksimal 50,100, dan 1000 pada proses pengelompokkan sudah cukup akurat. Sebab nilai rasio validasi antara kepadatan data dalam cluster dengan keterpisahan antar cluster yang konvergen. Walaupun tidak ada jaminan bahwa proses clustering
akan sangat akurat pada iterasi 100, namun dalam penelitian ini akan digunakan nilai eror 0.0001 dan iterasi maksimal 100 sebagai parameter pembatas dalam proses iterasi pengelompokkan. Alasannya, pada nilai tersebut proses clustering tidak membutuhkan waktu komputasi yang terlalu besar namun mampu menghasilkan nilai uji validasi yang cukup baik.
5. KESIMPULAN
Karakterisasi pelanggan PLN dapat dilakukan dengan menganalisa data tersebut sebagai salah satu parameter input yang kemudian akan diproses untuk mendapatkan nilai derajat keanggotaan tiap data. Hasil daripada karakterisasi adalah berupa nilai pusat cluster dan matriks partisi(yang berisi nilai derajat keanggotaan) setiap data pada setiap
cluster.
Karakteristik pelanggan didapatkan dengan membandingkan nilai setiap cluster
pada setiap data dari hasil clustering
(matriks partisi) dimana nilai terbesar dari perbandiangan digunakan sebagai acuan untuk menetukan kecenderungan cluster
tiap data.
Dalam percobaan tingkat validasi data hasil pengelompokan berdasar jumlah
cluster mencapai nilai optimum dengan nilai jumlah cluster 3. Penggunaan nilai iterasi dan minimum error yang disarankan adalah 100 dan 0.00001.
DAFTAR PUSTAKA
[1] Kertajaya, Hermawan. 2007. Boosting Loyalty Marketing Performance Menggunakan Teknik Penjualan, Customer Relationship Management dan Servis untuk Mendongkrak Laba. Jakarta. Mark Plus Inc.
[2] Han Jiawei dan Kamber Micheline. 2001. Data Mining : Concepts and Techniques. San Francisco. Morgan Kaufmann Publisher.
[3] Kusuma, Dewi. 2002. Anilisis dan
Desain Sistem fuzzy Menggunakan
Toolbox Matlab. Graha Ilmu.
Yogyakarta.
[4] Shihab, A. 2000. fuzzy Clsutering Algorithm And Their Application To Medical Image Analysis. Disertation,University of London. London.
[5] Klawon, F. . 2001. What Is About fuzzy Clustering? Undersatnding And Improving The Concept Of The Fuzzier. Science Journal.