SISTEM CLUSTERING DATA PENJUALAN MENGGUNAKAN
ALGORITMA FUZZY C-MEANS
SKRIPSI
DIAN PUSPITASARI SEBAYANG
101402083
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana Teknologi Informasi
DIAN PUSPITASARI SEBAYANG 101402083
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
2
PERSETUJUAN
Judul : SISTEM CLUSTERING DATA PENJUALAN
MENGGUNAKAN ALGORITMA FUZZY C-MEANS
Kategori : SKRIPSI
Nama : DIAN PUSPITASARI SEBAYANG
Nomor Induk Mahasiswa : 101402083
Program Studi : SARJANA (S1) TEKNOLOGI INFORMASI
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI UNIVERSITAS SUMATERA UTARA Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Dedy Arisandi, ST.,M.Kom Dr. Erna Budhiarti Nababan, M.IT NIP. 19790831200912 1 002 NIP. –
Diketahui/Disetujui oleh
Program Studi S1 Teknologi Informasi Ketua,
PERNYATAAN
SISTEM CLUSTERING DATA PENJUALAN MENGGUNAKAN ALGORITMA FUZZY C-MEANS
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 10 Februari 2015
4
UCAPAN TERIMA KASIH
Puji dan syukur penulis panjatkan kepada Allah SWT yang telah memberikan rahmat, karunia, taufik dan hidayah-Nya, serta segala sesuatu dalam hidup, sehingga penulis dapat menyelesaikan skripsi ini sebagai syarat untuk memperoleh gelar Sarjana Teknologi Informasi, Program Studi (S1)Teknologi Informasi, Fakultas Ilmu Komputer dan Teknologi Informasi.
Ucapan terima kasih penulis sampaikan kepada semua pihak yang telah membantu penulis dalam menyelesaikan skripsi ini baik secara langsung maupun tidak langsung. Pada kesempatan ini penulis ingin mengucapkan terima kasih yang sebesar-besarnya kepada:
1. Keluarga penulis, Ayahanda tercinta Alm. Drs. Abdul Alik Sebayang, Ibunda tercinta Tri Murti Br. Sembiring, Abang penulis M.Safrizal Sebayang. S.Pd, dan adik penulis Debi Ardillah Sebayang beserta keluarga besar yang selalu memberikan dukungan, perhatian serta doa kepada penulis sehingga dapat menyelesaikan skripsi ini.
2. Ibu Dr. Erna Budhiarti Nababan, M.IT. selaku Dosen Pembimbing I dan Bapak Dedy Arisandi, ST., M.Kom, selaku Dosen Pembimbing II yang telah banyak meluangkan waktunya serta memberikan bimbingan dan dukungan kepada penulis dalam penyusunan dan penulisan skripsi ini.
3. Bapak Muhammad Anggia Muchtar, ST., MM.IT. selaku Dosen Penguji I dan Ibu
Sarah Purnamawati, ST.,M.Sc selaku Dosen Penguji II yang telah memberikan kritik dan saran yang membangun dalam penyempurnaan skripsi ini.
4. Bapak Muhammad Anggia Muchtar, ST., MM.IT. selaku Ketua Program Studi S1 Teknologi Informasi dan Bapak Mohammad Fadly Syahputra, B.Sc., M.Sc.IT. selaku Sekretaris Program Studi S1 Teknologi Informasi.
6. Sahabat-sahabat penulis, Cassia Divina, Rafika Diaz, Indriyana Octavia, Ade Nur Fatimah, Yola Adhysta dan Sofiah Novitasari yang telah memberikan semangat, dukungan dan perhatian yang tak terungkapkan.
7. Teman-teman penulis di FOYA: Ovy, Desi, Handra, Muslim, Rozy, Dian Pomta, Edgar, Galih, Ekatama, Baim, Fezan, Joko, Khairul dan Heri yang telah memberikan dukungannya, selalu setia membantu penulis selama perkuliahan dan tidak hanya menjadi teman tapi keluarga bagi hidup penulis.
8. Teman-teman penulis di Teknologi Informasi USU angkatan 2010, terutama Sharfina Faza, Nurul Putri Ibrahim, Rini Jannati, Tri Annisa, Maslimona Harimita, Amelia dan Novi yang telah memberikan semangat dan menjadi teman diskusi penulis dalam menyelesaikan skripsi ini.
9. Seluruh staf TU (Tata Usaha) serta pegawai di Program Studi S1 Teknologi Informasi
10. Semua pihak yang terlibat langsung ataupun tidak langsung yang tidak dapat penulis ucapkan satu per satu yang telah membantu penyelesaian skripsi ini.
6
ABSTRAK
Perusahaan ritel meyimpan jumlah data yang besar setiap harinya karena memiliki jumlah transaksi yang sangat banyak. Data tersebut dapat diolah sehingga memperoleh informasi yang bermanfaat untuk strategi pemasaran. Salah satu informasi yang dapat diperoleh dan bermanfaat untuk strategi pemasaran adalah mengetahui pada saat kapan suatu produk banyak terjual. Untuk mengolah data tersebut digunakan teknik data mining yaitu metode clustering yang merupakan proses membagi data dalam suatu himpunan kedalam beberapa kelompok. Algoritma Fuzzy C-Means(FCM) adalah salah satu metode clusteringyang merupakan algoritma data supersived yang setiap datanya menjadi anggota dari suatu kluster dengan derajat didefinisikan dengan level keanggotaan. Dengan menggunakan algoritma FCM, data penjualan berupa jumlah barang terjual, jumlah invoice, jenis produk dari tahun 2011 hingga tahun 2013 menghasilkan tingkat penjualan tinggi untuk seluruh produk pada bulan Juli, Agustus dan Desember.
CLUSTERING SYSTEM FOR SALES DATA USING
FUZZY C-MEANS ALGORITHM
ABSTRACT
Retail companies stored enormous data from every transaction each day. That data can be processed to get useful information marketing purposes. One of information that can be obtained and become useful for marketing strategy is know when one specific product generated more sales. To process the data, clustering method, one of data mining technique, is used to cluster the data into groups. Fuzzy C-Means algorithm is one of clustering method that supervised data into member of a cluster with the degree defined by member level. With FCM algorithm, sales data in the form of amount of item sold, invoice total, and types of product from 2011 to 2013 generate high sales level for all products in July, August and December.
8
1.1 Latar Belakang 1
1.2 Rumusan Masalah 2
1.3 Batasan Masalah 3
1.4 Tujuan Penelitian 3
1.5 Manfaat Penelitian 3
1.6 Metodologi Penelitian 3
1.7 Sistematika Penulisan 4
BAB 2 LANDASAN TEORI 6
2.1 Pola Perilaku Konsumen 6
2.2 Penambangan Data (Data Mining) 7
2.2.1 Tahapan Data Mining 8
2.2.2 Pengelompokan Data Mining 10
2.3 Clustering 12
2.4 Fuzzy C-Means 15
2.5 Penelitian Terdahulu 18
BAB 3 ANALISIS DAN PERANCANGAN SISTEM 20
3.1 Data yang digunakan 21
3.2.1 Data Cleaning 23
3.2.2 Penentuan variabel 23
3.2.3 Pengelompokan kategori produk 23
3.3 Pemrosesan Data 25
3.3.1 Penentuan parameter FCM 25
3.3.2 Proses algoritma FCM 26
3.4. Analisis Komponen Sistem 37
3.4.1 Data Flow Diagram (DFD) 37
3.4.1.1 DFD level-0 37
3.4.1.2 DFD level-1 38
3.4.2 Flowchart 39
3.4.3 Sitemap aplikasi 41
3.5 Perancangan Sistem 41
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM 47
4.1 Implementasi Sistem 47
4.2 Implementasi Perancangan Antarmuka 47
4.2.1 Halaman login 48
4.2.2 Halaman home 48
4.2.3 Halaman manage 49
4.2.4 Halaman input data 49
4.2.5 Halaman data 50
4.2.6 Halaman kategori 51
4.2.7 Halaman periode 51
4.2.8 Halaman admin 52
4.3 Pengujian Sistem 52
4.3.1 Rencana pengujian sistem 52
4.3.2 Kasus dan hasil pengujian sistem 53
4.3.3 Pengujian sistem 55
BAB 5 KESIMPULAN DAN SARAN 62
5.1 Kesimpulan 62
5.2 Saran 62
10
DAFTAR TABEL
Hal
Tabel 2.1 Penelitian terdahulu 20
Tabel 3.1 Data cleaning 23
Tabel 3.2 Jumlah penjualan perhari 24
Tabel 3.3 Jumlah penjualan perbulan 25
Tabel 3.4 Nilai parameter awal 25
Tabel 3.5 Data penjualan kategori produk 26
Tabel 3.6 Pusat klaster ke-1 iterasi pertama 29
Tabel 3.7 Pusat klaster ke-2 iterasi pertama 30
Tabel 3.8 Pusat klaster ke-3 iterasi pertama 31
Tabel 3.9 Fungsi objektif iterasi pertama 32
Tabel 3.10 Perubahan matriks 33
Tabel 3.11 Nilai fungsi objektif 35
Tabel 3.12 Nilai derajat keanggotaan pada iterasi terakhir 36
Tabel 4.1 Rencana pengujian sistem 53
Tabel 4.2 Hasil pengujian 53
DAFTAR GAMBAR
Hal
Gambar 2.1 Bidang ilmu data mining 8
Gambar 2.2 Tahapan data mining 10
Gambar 3.1 Sampel laporan frekuensi data penjualan 22
Gambar 3.2 DFD level 0 38
Gambar 3.3 DFD level 1 39
Gambar 3.4 Flowchart algoritma Fuzzy C-Means 40
Gambar 3.5 Sitemap aplikasi 41
Gambar 3.6 Rancangan tampilan login 42
Gambar 3.7 Rancangan tampilan halaman home 42
Gambar 3.8 Rancangan tampilan halaman cluster 43 Gambar 3.9 Rancangan tampilan halaman input data 43 Gambar 3.10 Rancangan tampilan halaman daftar kategori produk 44 Gambar 3.11 Rancangan tampilan halaman daftar produk 45 Gambar 3.12 Rancangan tampilan halaman daftar periode 45 Gambar 3.13 Rancangan tampilan halaman admin 46
Gambar 4.1 Halaman login 48
Gambar 4.2 Halaman home 49
Gambar 4.3 Halaman manage 49
Gambar 4.4 Halaman input data 50
Gambar 4.5 Halaman data 50
Gambar 4.6 Halaman kategori 51
12
Gambar 4.8 Halaman admin 52
Gambar 4.9 Halaman hasil input data 56
Gambar 4.10 Proses clustering 56
ABSTRAK
Perusahaan ritel meyimpan jumlah data yang besar setiap harinya karena memiliki jumlah transaksi yang sangat banyak. Data tersebut dapat diolah sehingga memperoleh informasi yang bermanfaat untuk strategi pemasaran. Salah satu informasi yang dapat diperoleh dan bermanfaat untuk strategi pemasaran adalah mengetahui pada saat kapan suatu produk banyak terjual. Untuk mengolah data tersebut digunakan teknik data mining yaitu metode clustering yang merupakan proses membagi data dalam suatu himpunan kedalam beberapa kelompok. Algoritma Fuzzy C-Means(FCM) adalah salah satu metode clusteringyang merupakan algoritma data supersived yang setiap datanya menjadi anggota dari suatu kluster dengan derajat didefinisikan dengan level keanggotaan. Dengan menggunakan algoritma FCM, data penjualan berupa jumlah barang terjual, jumlah invoice, jenis produk dari tahun 2011 hingga tahun 2013 menghasilkan tingkat penjualan tinggi untuk seluruh produk pada bulan Juli, Agustus dan Desember.
7
CLUSTERING SYSTEM FOR SALES DATA USING
FUZZY C-MEANS ALGORITHM
ABSTRACT
Retail companies stored enormous data from every transaction each day. That data can be processed to get useful information marketing purposes. One of information that can be obtained and become useful for marketing strategy is know when one specific product generated more sales. To process the data, clustering method, one of data mining technique, is used to cluster the data into groups. Fuzzy C-Means algorithm is one of clustering method that supervised data into member of a cluster with the degree defined by member level. With FCM algorithm, sales data in the form of amount of item sold, invoice total, and types of product from 2011 to 2013 generate high sales level for all products in July, August and December.
PENDAHULUAN
1.1 Latar belakang
Kehadiran teknologi informasi terutama basis data dalam perusahaan sudah menjadi kebutuhan pokok. Banyak perusahaan yang mengumpulkan data dengan ukuran yang besar sehingga pertumbuhan jumlah data yang begitu cepat hanya membuat data tidak dimanfaaatkan dengan baik. Salah satu perusahaan yang memiliki penyimpanan jumlah data yang besar adalah perusahaan ritel. Perusahaan ritel setiap harinya memiliki jumlah transaksi yang sangat banyak. Hal ini berdampak pada pertumbuhan jumlah data yang sangat pesat dan menimbulkan jumlah data yang berskala besar dalam basis data. Data tersebut dapat diolah sehingga memperoleh informasi yang bermanfaat untuk strategi pemasaran. Salah satu cara memperoleh strategi pemasaran adalah dengan memperhatikan kapan suatu produk banyak dibeli konsumen, sehingga manajemen perusahaan mengetahui produk apa saja yang harus ditingkatkan penjualanannya.
2
ini adalah proses clustering lebih lambat dibandingkan k-meansdan metode yang digunakan tidakmenentukan jumlah klaster dari awal. Penelitian lainnya adalah implementasi data mining untuk mengetahui pola transaksi pada data penjualan menggunakan metode Deskripsi (Anisah, 2013) yang menghasilkan pola transaksi penjualan per periode dan informasi tingkat penjualan kategori produk yang laku dan jarang laku, pada penelitiannya memiliki kekurangan dalam segi metode yang digunakan, metode yang digunakan adalah metode deskripsi yang menggunakan jumlah transaksi penjualan sebagai variabel untuk menghasilkan nilai rata-rata, median dan modus untuk setiap produk.
Clustering merupakan proses membagi data dalam suatu himpunan kedalam beberapa kelompok yang kesamaan datanya dalam suatu kelompok lebih besar dari pada kesamaan data tersebut dengan data dalam kelompok lain. Salah satu algoritma yang termasuk dalam metode kluster adalah Fuzzy C-Means (FCM) yang merupakan algoritma clustering data supersived yang setiap datanya menjadi anggota dari suatu kluster dengan derajat didefinisikan dengan level keanggotaan (Kusrini, 2009).
Penelitian yang telah dilakukan menggunakan Algoritma FCM adalah penerapan data mining Penerapan Fuzzy C-Means dalam Pemilihan Peminatan Tugas Akhir. Hasil dari penelitian ini bahwa FCM sesuai untuk aplikasi pemilihan peminatan tugas akhir karena memiliki akurasi yang tinggi (Sumanto, 2011)
Oleh karena itu, penulis akan mengambil judul Sistem Clustering Data Penjualan Menggunakan Algoritma Fuzzy C-Means.
1.2 Rumusan masalah
1.3Batasan masalah
Untuk mencegah meluasnya pembahasan dan agar lebih terarah maka dibuat batasan masalah, yang meliputi :
1. Hanya digunakan pada perusahaan ritel
2. Hanya meneliti 3 (tiga) kategori produk secara umum, tidak berdasarkaan merk produk, hanya berdasarkan jenis dari produk tersebut.
1.4 Tujuan
Adapun tujuan dari penelitian ini adalah menentukan tingkat penjualan menggunakan Algoritma Fuzzy C-Means.
1.5 Manfaat
Adapun manfaat dari penelitian ini adalah sebagai berikut : 1. Mengetahui implementasi Algoritma Fuzzy C-Means
2. Dengan mengetahui tingkat penjualan produk, manajemen dapat membuat keputusan mengenai strategi pemasaran seperti menentukan program untuk meningkatkan penjualan item barang dengan promo dan periode waktu tertentu, dan manajemen dapat mengatur persediaan barang pada periode waktu tertentu. 3. Penulis berharap penelitian ini dapat menjadi referensi untuk pembaca.
1.6 Metodologi Penelitian
Metodologi penelitian yang digunakan pada tugas akhir ini adalah: 1. Studi literatur
Pada tahap ini dilakukan dengan membaca dan mempelajri dalam buku-buku dan referensi, jurnal atau sumber-sumber penelitian yang berkaitan dengan Data mining dan Algoritma Fuzzy C-Means (FCM).
2. Analisis masalah
Pada tahap ini akan dilakukan analisa data menggunakan data mining pada data transaksi penjualan
3. Pengumpulan data
4
4. Pra pengolah data dan Outliers
Mempersiapkan data yang akan diolah dan menemukan outliers dari data yang diolah.
5. Perancangan sistem
Pada tahap ini dilakukan perancangan antarmuka. Proses perancangan dilakukan berdasarkan hasil analisis studi literatur yang telah didapatkan.
6. Implementasi sistem
Pada tahap ini dilakukan proses implementasi pengkodean program dalam aplikasi komputer menggunakan bahasa pemrograman PHP dan MySQL.
7. Pengujian
Pada tahap ini dilkaukan proses pengujian dan percobaan terhadap sistem sesuai dengan kebutuhan yang ditentukan sebelumnya serta memastikan progrm yang dibuat berjalan seperti yang diharapkan.
8. Dokumentasi dan penyusunan laporan
Pada tahap ini dilakukan pembuatan dokumentasi sistem, lengkap dengan analisis yang diperoleh dan dokumentasi hasil analisis dan implementasi algoritma Fuzzy C-Means(FCM).
1.7. Sistematika Penulisan
Sistematika penulisan dari skripsi ini terdiri dari lima bagian utama sebagai berikut:
BAB 1: PENDAHULUAN
Bab ini akan menjelaskan tentang latar belakang, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metode penelitian, dan sistematika penulisan.
BAB 2: LANDASAN TEORI
BAB 3: ANALISIS DAN PERANCANGAN SISTEM
Bab ini berisi analisis terhadap fokus permasalahan penelitian dan perancangan sistem yang akan dibangun seperti menggambar flowchart atau diagram alur kerja system, analisis terhadap proses kerja algoritma Fuzzy C-Means pada pola transaksidan perancangan antarmuka atau interface.
BAB 4: IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini berisi pembahasan tentang implementasi algoritma yang disusun pada bab 3 dan pengujian terhadap sistem yang dibangun.
BAB 5: KESIMPULAN DAN SARAN
BAB 2
LANDASAN TEORI
Bab ini membahas tentang teori penunjang dan penelitian sebelumnya yang berhubungan dengan analisa datadan algoritma Fuzzy C-Means untuk mangetahui pola perilaku konsumen.
2.1. Pola Perilaku Konsumen
Perilaku konsumen adalah proses dan aktivitas ketika seseorang berhubungan dengan pencarian, pemilihan, pembelian, penggunaan, serta pengevaluasian produk dan jasa demi memenuhi kebutuhan dan keinginan (Duncan, 2005). Perilaku konsumen merupakan hal-hal yang mendasari konsumen untuk membuat keputusan pembelian. Untuk barang berharga jual rendah (low-involvement) proses pengambilan keputusan dilakukan dengan mudah, sedangkan untuk barang berharga jual tinggi (high-involvement) proses pengambilan keputusan dilakukan dengan pertimbangan yang matang (Kincaid, 2003).
memahami sikap konsumen dalam menghadapi sesuatu, seseorang dapat menyebarkan ide dengan lebih cepat dan efektif.
2.2. Penambangan Data (Data Mining)
Data mining merupakan pemilihan atau menggali pengetahuan dari jumlah data yang banyak (Han dan Kamber, 2001).Data mining disebut penemuan pengetahuan atau menemukan pola yang tersembunyi dalam data. Data mining adalah analisis otomatis dari data yang berjumlah besar atau kompleks dengan tujuan untuk menemukan pola atau kecenderungan yang penting yang biasanya tidak disadari keberadaanya (Pramudiono, 2006).
Data mining merupakan analisis dari peninjauan kumpulan data untuk menemukan hubungan yang tidak diduga dan meringkas data dengan cara yang berbeda dengan sebelumnya,yang dapat dipahami dan bermanfaat bagi pemilik data (Larose, 2006). Dengan kata lain, data mining adalah proses menganalisis data dalam jumlah besar dan membentuk suatu pola sehingga menjadi informasi yang berguna.
Berdasarkan definisi-definisi yang telah disampaikan, hal penting yang terkait dengan data mining adalah :
1.Data mining merupakan suatu proses otomatis terhadap data yang sudah ada. 2. Data yang akan diproses berupa data yang sangat besar.
3. Tujuan data mining adalah mendapatkan hubungan atau pola yang mungkin memberikan indikasi yang bermanfaat.
8
Gambar 2.1. Bidang Ilmu Data Mining
2.2.1. Tahapan Data Mining
Istilah data mining dan Knowledge Discovery in Database (KDD) seringkali digunakan secara bergantian untuk menjelaskan proses penggalian informasi yang tersembunyi dalam suatu basis data yang besar. Dalam implementasinya, data mining merupakan bagian dari proses KDD. Sebagai komponen dalam KDD, data mining berkaitan dengan ekstraksi dan penghitungan pola-pola dari data yang ditelaah dalam basis data. KDD mencakup keseluruhan proses pencarian pola/informasi dalam basis data yang dimulai dari pemilihan dan persiapan data sampai representasi pola yang ditentukan dalam bentuk yang mudah dimengerti oleh pihak berkepentingan. Proses KDD secara garis besar terdiri atas beberapa tahap (Fayyad, 1996).
1. Data Selection
2. Pre-processing/Cleaning
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi fokus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang tidak konsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (typo), juga dilakukan proses enrichment, yaitu proses “memperkaya” data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
3. Transformation
Coding adalah proses transformasi pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
4. Data mining
Data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode dan algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
5. Interpretation/Evalution
10
Gambar 2.2. Tahapan Data Mining
(Sumber : Fayyad, 1996)
2.2.2. Pengelompokan Data Mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapatdilakukan, yaitu (Larose, 2005):
1. Deskripsi
Terkadang penelitian analisis secara sederhana ingin mencoba mencari cara untuk menggambarkan pola dan kecenderungan yang terdapat dalam data. Sebagai contoh, petugas pengumpulan suara mungkin tidak dapat menemukan keterangan atau fakta bahwa siapa yang tidak cukup profesional akan sedikit didukung dalam pemilihan presiden. Deskripsi dari pola dan kecenderungan sering memberikan kemungkinan penjelasan untuk suatu pola atau kecenderungan.
2. Estimasi
menghasilkan model estimasi. Model estimasi yang dihasilkan dapat digunakan untuk kasus baru lainnya.
3. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada di masa datang. Contoh prediksi dalam bisnis dan penelitian adalah :
1. Prediksi harga beras dalam tiga bulan yang akan datang.
2. Prediksi presentase kenaikan kecelekaan lalu lintas tahun depan jika batas bawah kecepatan dinaikkan.
4. Klasifikasi
Dalam klasifikasi, terdapat target variabel kategori.Sebagai contoh, penggolongan pendapatan dapat dipisahkan dalam tiga kategori, yaitu pendapatan tinggi, pendapatan sedang, dan pendapatan rendah.
5. Pengklusteran
Pengklusteran merupakan pengelompokan record, pengamatan, atau memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan.Cluster adalah kumpulan record yang memiliki kemiripan satu dengan yang lainnya dan memiliki ketidakmiripan dengan record-record dalam cluster lain.
12
Contoh pengklusteran dalam bisnis dan penelitian adalah:
1. Melakukan pengklusteran terhadap ekspresi dari gen, untuk mendapatkan kemiripan perilaku dari gen dalam jumlah besar.
2. Mendapatkan kelompok-kelompok konsumen untuk target pemasaran dari suatu produk bagi perusahaan yang tidak memiliki dana pemasaran yang besar.
3. Untuk tujuan audit akuntansi, yaitu melakukan pemisahan terhadap perilakufinansial dalam baik dan mencurigakan.
6. Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam satu waktu.Dalam dunia bisnis lebih umum disebut analisis keranjang belanja. Contoh asosiasi dalam bisnis dan penelitian adalah :
1. Menemukan barang dalam supermarket yang dibeli secara bersamaan dan barang yang tidak pernah dibeli secara bersamaan.
2. Meneliti jumlah pelanggan dari perusahaan telekomunikasi seluler yang diharapkan untuk memberikan respons positif terhadap penawaran upgrade layanan yang diberikan.
2.3. Clustering
terlihat memiliki beberapa sifat yang melekat yang mengalami pengelompokan-pengelompokan natural (Hammouda & Karray, 2003).
Namun demikian, penemuan pengelompokan-pengelompokan ini atau upaya untuk mengkategorikan data adalah bukan sebuah tugas yang sederhana bagi manusia kecuali data memiliki dimensionalitas rendah (dua atau tiga dimensi paling banyak).Inilah sebabnya mengapa beberapa metode dalam soft computing telah dikemukakan untuk menyelesaikan jenis masalah ini.Metode ini disebut “Metode-Metode Pengelompokan Data” (Hammouda & Karray, 2003).
Algoritma-algoritma clustering digunakan secara ekstensif tidak hanya untuk mengorganisasikan dan mengkategorikan data, akan tetapi juga sangat bermanfaat untuk kompresi data dan konstruksi model. Melalui pencarian kesamaan dalam data, seseorang dapat merepresentasikan data yang sama dengan lebih sedikit simbol. Dan juga, jika kita dapat menemukan kelompok-kelompok data, kita dapat membangun sebuah model masalah berdasarkan pengelompokan-pengelompokan ini (Dubes & Jain, 1988).
Clustering menunjuk pada pengelompokan record, observasi-observasi, atau kasus-kasus ke dalam kelas-kelas objek yang sama. Cluster adalah sekumpulan record yang sama dengan satu sama lain dan tidak sama dengan record dalam cluster lain. Clustering berbeda dari klasifikasi dimana tidak ada variabel target untuk clustering. Tugas clustering mencoba untuk tidak mengklasifikasikan, mengestimasi, atau memprediksi nilai variabel target (Larose, 2005). Bahkan, algoritma clustering berusaha mensegmentasikan seluruh kumpulan data ke dalam subkelompok-subkelompok atau cluster-cluster homogen secara relatif. Dimana kesamaan record dalam cluster dimaksimalkan dan kesamaan dengan record diluar cluster ini diminimalkan.
14
Aktivitas clustering pola khusus meliputi langkah-langkah berikut (Dubes & Jain, 1988) :
1. Representasi pola (secara opsional termasuk ekstraksi dan/atau seleksi sifat. 2. Defenisi ukuran kedekatan pola yang tepat untuk domain data.
3. Clustering pengelompokan. 4. Penarikan data (jika dibutuhkan). 5. Pengkajian output (jika dibutuhkan).
Representasi pola merujuk pada jumlah kelas, jumlah pola-pola yang ada, dan jumlah, tipe dan skala fitur yang tersedia untuk algoritma clustering. Beberapa informasi ini dapat tidak bisa dikontrol oleh praktisioner. Seleksi sifat (fitur) adalah proses pengidentifikasian subset fitur original yang paling efektif untuk digunakan dalam clustering. Ekstraksi fitur adalah penggunaan satu atau lebih transformasi dari sifat-sifat input untuk menghasilkan sifat-sifat-sifat-sifat baru yang lebih baik.
Pertimbangkan data himpunan X (dataset) yang terdiri dari point-point data (atau secara sinonim, objek-objek, hal-hal, kasus-kasus, pola, tuple, transaksi) xi = (xi1, …,xid) A dalam ruang atribut A, dimana i = 1, N, dan setiap komponen adalah sebuah atribut A kategori numerik atau nominal. Sasaran akhir dari clustering adalah untuk menentukan point-point pada sebuah sistem terbatas dari subset k, cluster. Biasanya subset tidak berpotongan (asumsi ini terkadang dilanggar), dan kesatuan mereka sama dengan dataset penuh dengan pengecualian yang memungkinkan outlier. Ci adalah sekelompok point data dalam dataset X, dimana X = Ci ..Ck .. Coutliers, Cj1 .. Cj2 =0.
1. Partitioning Methdos
Metode yang membangun berbagai partisi dan kemudian mengevaluasi partisi tersebut dengan beberapa kriteria.Algoritma yang dipakai pada metode ini adalah Means, K-Medoid, PROCLUS, CLARA, CLARANS dan PAM.
2. Hierarchical Methods
Metode yang membuat suatu penguraian secara hierarchical dari himpunan data dengan menggunakan beberapa kriteria. Metode ini terdiri atas dua jenis, yaitu Agglomerative yang menggunakan strategi bottom-up dan Disisive yang menggunakan strategi top-down. Metode ini meliputi algoritma BIRCH, AGNES, DIANA, CURE dan CHAMELEON.
3. Density-Based Methods
Metode ini berdasarkan konektivitas dan fungsi densitas.Metode ini meliputi algoritma DBSCAN, OPTICS dan DENCLU.
4. Grid-Based Methods
Metode ini berdasarkan suatu struktur granularitas multi-level.Metode clustering ini meliputi algoritma STING, WaveCluster dan CLIQUE.
5. Model-Based Methods
Suatu model dihipotesakan untuk masing-masing cluster dan ide untuk mencari best fit dari model tersebut untuk masing-masing yang lain. Metode clustering ini meliputi pendekatan statistik, yaitu algoritma COBWEB dan jaringan syaraf tiruan SOM.
2.4. Fuzzy C-Means
16
Ada beberapa algoritma clustering data, salah satu diantaranya adalah Fuzzy C-Means (FCM). Fuzzy C-Means (FCM) adalah suatu teknik pengclusteran data yang mana keberadaan tiap-tiap titik data dalam suatu cluster ditentukan oleh derajat keanggotaan. Teknik ini pertama kali diperkenalkan oleh Jim Bezdek pada tahun 1981.
Konsep dari Fuzzy C-Means pertama kali adalah menentukan pusat cluster, yang akan menandai lokasi rata-rata untuk tiap-tiap cluster. Pada kondisi awal, pusat cluster ini masih belum akurat. Tiap-tiap titik data memiliki derajat keanggotaan untuk tiap-tiap cluster. Dengan cara memperbaiki pusat cluster dan derajat keanggotaan tiap-tiap titik data secara berulang, maka akan dapat dilihat bahwa pusatcluster akan bergerak menuju lokasi yang tepat. Perulangan ini didasarkan pada minimisasi fungsi objektif yang menggambarkan jarak dari titik data yang diberikan kepusat cluster yang terbobot oleh derajat keanggotaan titik data tersebut.
Output dari Fuzzy C-Means merupakan deretan pusat cluster dan beberapa derajat keanggotaan untuk tiap-tiap titik data. Informasi ini dapat digunakan untuk membangun suatu fuzzy inference system.
Algoritma Fuzzy C-Means
Langkah-langkah yang dilakukan di Algoritma Fuzzy C-Means Clustering meliputi (Kusuma, 2004) :
1. Input data yang akan di cluster X, berupa matriks berukuran n x m (n = jumlah sampel data ; m = atribut setiap data)
Xij data sampel ke-i ( i = 1, 2, .... , n), atribut ke-j ( 1, 2,... , m)
2. Menentukan jumlah dari • Cluster (c)
• Pangkat (w) -> w > 1, nilai w yang paling optimal dan sering dipakai adalah w = 2. (Klawonn, 1997).
• Maksimum Iterasi (MaxIter) • Kriteria penghentian ( )
3. Membangkitkan bilangan Random iki= 1,2,…n., k=1,2,…c sebagai elemenmatriks partisi awal U. Menghitung jumlah setiap kolom ( atribut ) dengan j = 1, 2, .. n dengan persamaan :
Qi = (2.1)
µik =
4. Menghitung pusat cluster ke-k : Vkj ,dengan k = 1,2,...,c; danj =1,2,...,m. dengan persamaan :
(2.2)
dengan :
= pusat cluster ke-k untuk atribut ke-j
= derajat keanggotaan untuk data sampel ke-i pada cluster ke-k = data ke-i, atribut ke-j
5. Menghitung fungsi obyektif pada iterasi ke- t, dengan persamaan :
= (2.3)
dengan:
= pusat cluster ke-k untuk atribut ke-j
18
= fungsi objektif pada iterasi ke-t
6. Menghitung perubahan matriks partisi dengan persamaan :
(2.4)
dengan: i = 1,2,...,n; dan k = 1,2,...,c. Dimana :
= pusat cluster ke-k untuk atribut ke-j
= derajat keanggotaan untuk data sampel ke-i pada cluster ke-k
= data ke-i, atribut ke-j
7. Memeriksa kondisi berhenti dengan aturan persamaan
8. Jika: ( |Pt – Pt-1| < ) atau (t >MaxIter) maka berhenti. Jika tidak maka t = t+1, Ulangi langkah ke-4.
2.5. Penelitian Terdahulu
Penelitian yang berhubungan dengan pengolahan data penjualan dan algoritma Fuzzy C-Means seperti pada tabel 2.1 adalah
1. Penerapan data mining pada penjualan menggunakan metode Agglomerative Hierarchical Clustering(Sutrisno, 2013) yang menghasilkan pola penjualan produk mana yang diminati oleh konsumen, kekurangan dalam penelitian ini adalah proses clustering lebih lambat dibandingkan k-means dan metode yang digunakan tidak menentukan jumlah klaster dari awal.
dalam segi metode yang digunakan, metode yang digunakan adalah metode deskripsi yang menggunakan jumlah transaksi penjualan sebagai variabel untuk menghasilkan nilai rata-rata, median dan modus untuk setiap produk.
3. Penerapan data mining pada penjualan produk minuman di PT. Pepsi Coca Cola Indobeverages menggunakan metode Clustering (Irdiansyah, 2013).Pada penelitian ini, metode yang digunakan adalah Agglomerative Hierarchical Clustering. Hasil dari penelitian adalah kelompok karakteristik umum dari grup-grup konsumen yang berbeda. Penelitian dilakukan dengan menggunakan parameter wilayah, jumlah penjualan dan rata-rata penjualan.
4. Penentuan jurusan sekolah menengah atas (Bahar, 2011). Pada penelitian ini algoritma FCM memiliki tingkat akurasi rata-rata 78.39%. Proses klastering dalam penelitian ini dilakukan dengan menentukan jumlahklaster yang terbentuk di awal proses sesuai dengan jumlah kelompok(Jurusan) yang diinginkan. sehingga, tidak dapat dipastikan berapasesungguhnya jumlah klaster ideal yang terbentuk dari data nilai siswa yangada, sehingga akurasi hasil pengelompokkan tidak dapat terukur.
5. Pemilihan peminatan tugas akhir mahasiswa (Sumanto, 2011).Kesimpulan dari penelitian iniadalah pemilihan peminatan tugas akhir mahasiswa sangat menentukan hasil tugas akhir mahasiswa. Tingkat akurasi penerapan FCM untuk pemilihan peminatan tugasakhir pada data yang digunakan pada eksperimen ini mencapai 80%.
Tabel 2.1 Penelitian Terdahulu
20
1 2013 Agglomerative Hierarchical Clustering
kekurangan dalam penelitian ini adalah proses clustering lebih lambat dibandingkan k-means dan metode yang digunakan tidak menentukan jumlah klaster dari awal.
2 2013 Metode Deskripsi Kekurangannya karena penelitian hanya menghasilkan nilai rata-rata, median dan modus untuk setiap produk.
3 2013 Agglomerative Hierarchical Clustering
Bab ini secara garis besar membahas tentang analisis datapenjualan menggunakan algoritma Fuzzy C-Means pada sistem dan tahap-tahap yang dilakukan dalam perancangan sistem yang akan dibangun.
3.1.Data yang digunakan
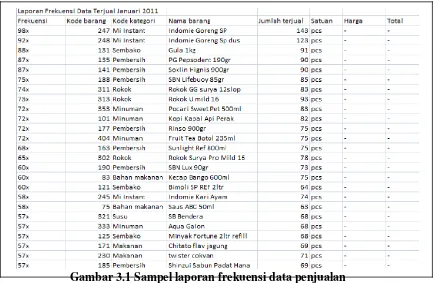
Data yang digunakan dalam penelitian ini adalah laporan frekuensi data penjualan produk yang bersumber dari salah satu swalayan di Kota Medan dari tahun 2011 hingga 2013 yang memberikan gambaran secara nyata bagaimana penjualanan suatu produk dari waktu ke waktu. Setelah data terkumpul dilakukan analisa data yang sesuai dengan kebutuhan sistem ini. Oleh karena itu, untuk menghasilkan kesimpulan pada analisis data, diperlukan data penjualan produk yang akan dianalisis berdasarkan metode clustering menggunakan algoritma Fuzzy C-Means.
22
Gambar 3.1 Sampel laporan frekuensi data penjualan
Sumber : Database Penjualan Swalayan Omi Ar Rasyid Medan
Pada swalayan terdapat banyak sekali nama-nama produk ataupun merk-merk produk yang tidak bisa disebutkan satu-satu. Mulai dari jenis produk sampai kegunaan produk tersebut. Oleh karena itu penulis akan membuat pengelompokkan produk berdasarkan kategori produknya. Kategori produk yang dipilih adalah sebagai berikut:.
1. Susu 2. Beras
3. Minyak goreng
Pemilihan kategori tersebut berdasarkan data dari kategori produk produk yang selalu dibeli konsumen setiap bulannya.
3.2. Praproses Data
Dalam mengolah data mining terdapat beberapa tahapan yang harus dilakukan sehingga data dapat digunakan secara maksimal. Tahapan tersebut merupakan bagian dari Knowledge Discovery in Database (KDD), yaitu:
Pada tahap ini dilakukan pembersihan data, yaitu menghapus data missing values. Data missing values tersebut merupakan data yang diperlukan untuk proses ini. Pada penelitian ini pembersihan dilakukan terhadap record yang memiliki jumlah frekuensi/invoice lebih besar dibandingkan jumlah terjual. Sampel data cleaning seperti pada tabel 3.1 :
Tabel 3.1. Data Cleaning
No Nama Barang Jumlah Terjual Jumlah Invoice
1 Aqua 1.5 ltr 50 63
2 Bear Brand 30 44
Pada Tabel 3.1, Jumlah barang yang terjual lebih sedikit dibandingkan dengan jumlah invoice, sehingga data tersebut tidak dapat digunakan.
3.2.2. Penentuan Variabel
Pada tahap ini akan dilakukan penentuan variabel yang akan menghasilkan analisa untuk mengolah data. Adapun variabelnyasebagai berikut :
a. Jenis produk yaitu jenis produkyang terjual
b. Periode yaitu rentang waktu penjualan produk
c. Jumlah produk yang Terjual yaitu nilai dari jumlah barang yang terjual adalah komponen terpenting dalam mengolah data penjualan. Dari jumlah barang yang terjual akan diketahui tingkat penjualanan suatu produk. Penelitian ini menggunakan jumlah barang berdasarkan kategorinya.
d. Jumlah invoice yaitu jumlah nota atau faktur yang mencatat penjualan suatu produk
3.2.3. Pengelompokan kategori produk
Pengelompokan kategori produk adalah mengubah nama produk untuk mempermudah penelitian, yakni:
1. Kategori produk susu terbagi atas :
24
b. Balita berubah menjadi produk A2
c. Anak 7-12 tahun berubah menjadi produk A3 d. Manula berubah menjadi produk A4
e. Ibu Hamil berubah menjadi produk A5 2. Kategori produk beras terbagi atas :
a. Harga < Rp. 10.000 berubah menjadi produk A6 b. Harga > Rp. 10.000 berubah menjadi produk A7 3. Kategori produk minyak goreng terbagi atas :
a. Minyak kelapa/kelapa sawit berubah menjadi produk A8 b. Minyak jagung berubah menjadi produk A9
c. Minyak zaitun berubah menjadi produk A10
Data yang akan digunakan adalah data penjualan dari 8 (delapan) kategori produk yang dibeli konsumen selama 3 tahun. Data memiliki 1080 record data penjualan berdasarkan hari seperti tabel 3.2.
Tabel 3.2. Jumlah penjualan perhari
No Periode
Tabel 3.3. Jumlah penjualan perbulan
Periode Jumlah barang terjual
Bulan Tahun A1 A2 A3 A4 A5 A6 A7 A8 A9 A10
1 Jan 2011 45 51 32 24 40 10 11 30 10 1
2 Feb 2011 46 55 41 14 48 11 11 35 8 0
3 Mar 2011 32 48 35 20 47 10 10 38 6 2
4 Apr 2011 28 60 30 9 50 12 10 25 5 1
5 Mei 2011 43 65 32 15 55 8 13 29 6 0
6 Jun 2011 48 48 28 10 54 9 15 30 6 0
7 Jul 2011 42 60 30 20 42 11 19 35 7 2
8 Agt 2011 35 75 31 24 45 13 18 43 10 0
9 Sept 2011 49 48 39 12 48 10 18 45 10 2
10 Okt 2011 44 50 33 14 50 10 14 32 5 0
11 Nov 2011 37 43 39 19 51 12 14 35 4 0
12 Des 2011 50 74 42 23 58 13 16 45 8 2
3.3.Pemrosesan Data
Terdapat beberapa tahapan dalam pengolahan data yang harus dilalui agar menghasilkan data yang diinginkan.
3.3.1. Penentuan Paramater Fuzzy C-Means
Untuk melakukan perhitungan dengan metode fuzzy c-means pada penelitian ini ditetapkan nilai parameter awal pada Tabel 3.4 berikut:
Tabel 3.4. Nilai Parameter Awal
Parameter Nilai
Cluster (c) 3
26
Maksimum Iterasi (MaxIter) 100 Kriteria Penghentian ( ) 10-5 Fungsi Objektif Awal(P0) 0
Iterasi Awal (t) 1
3.3.2. Proses Fuzzy C-Means
Tabel 3.5 merupakan data penjualan produk A1 pada tahun 2011, 2012 dan 2013 yang mewakili keseluruhan produk untuk dilakukan proses clustering.
Tabel 3.5. Data Penjualan Kategori Produk A1
21 September 2012 50
22 Oktober 2012 55
23 November 2012 48
24 Desember 2012 52
Tabel 3.5. Data Penjualan Kategori Produk A1 (lanjutan)
No Periode Jumlah barang
Setelah menetapkan nilai parameter awal dan data siap untuk diklaster, akan dilakukan proses clustering pertahun menggunakan langkah langkah dari Algoritma Fuzzy C-Means (FCM).
Langkah 1. Membangkitkan Bilangan Random
Membangkitkan bilangan random ik, i=1,2,...,n ; k=1,2,...c; sebagai elemen elemen matriks partisi awal (U).
28
Langkah 2. Menentukan Pusat Klaster (v)
Pada iterasi pertama, untuk menentukan pusat klaster dengan menggunakan persamaan 2.2, sebagai contoh perhitungan sebagai berikut.
Tahap perhitungan untuk mencari nilai pusat klaster ke-1 adalah 1. Nilai derajat keanggotaan klaster ke-1 pada data pertama
- ( i1) = 0.21845002136495 - ( i1)2 = ( i1,1) x ( i1,1)
= 0.96526143723138x 0.96526143723138 = 0.931729642206
- ( i1)2 x X1.1 = ( i1)2 x Nilai Jumlah barang terjual pada data pertama = 0.931729642206 x 45
= 41.92783389927
3. Kemudian, perkalian dari derajat keanggotaan yang telah dikuadratkan dengan masing masing nilai variabel dari data pertama hingga data terakhir dijumlahkan.
Hasil penjumlahan dari hasil perkalian tersebut pada variabel jumlah penjualan produk.
= ( i1)2x X1.1 + ... + ( i1)2x X1.36
= 41.92783389927 + ... + 49.21557855008 = 168.9835324312
4. Perhitungan hasil dari pusat klaster (Vkj) pada klaster ke-1
168.9835324312 3.913355933957
43.181232489917
Pusat Klaster ke-1 (Vkj) = 43.181232489917
Setelah diperoleh nilai pusat klaster ke-1(Vkj), tahap yang sama untuk menghitung nilai pusat klaster ke-2 dan pusat klaster ke-3.
Pusat Klaster ke-2 (Vkj) = 39.9037273399 Pusat Klaster ke-3 (Vkj) = 41.5870789438
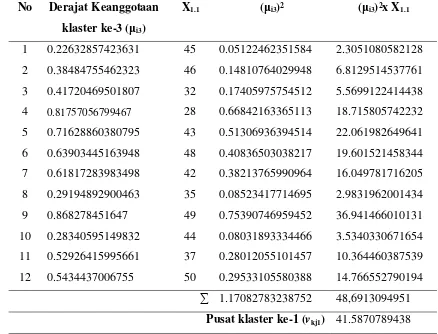
Hasil perhitungan pusat klaster pada iterasi pertama klaster ke-1 pada tabel 3.6, klaster ke-2 pada tabel 3.7 dan klaster ke-3 pada tabel 3.8
Tabel 3.6 Pusat Klaster ke-1 pada Iterasi Pertama
=
= Vkj=
hasil perkalian jumlah barang terjual
Jumlah derajat keanggotaan yang telah dikuadratkan ( i1)2 hasil perkalian jumlah
30
No Derajat Keanggotaan
klaster ke-1( i1)
X1.1 ( i1)2 ( i1)2x X1.1
1 0.96526143723138 45 0.9317296422061 41.92783389927 2 0.23158842863306 46 0.053633200276728 2.4671272127295 3 0.36663449996156 32 0.13442085656207 4.3014674099861 4 0.63792040354536 28 0.40694244125947 11.394388355265
5 0.5425824414747 43 0.29439570579664 12.659015349256
Tabel 3.6 Pusat Klaster ke-1 pada Iterasi Pertama (lanjutan)
No Derajat Keanggotaan
klaster ke-1( i1)
X1.1 ( i1)2 ( i1)2x X1.1
7 0.56055448102335 42 0.31422132619536 13.197295700205 8 0.073222192137453 35 0.0053614894214 0.18765212974949 9 0.34738428300868 49 0.1206758400814 5.9131161639913 10 0.30625440409682 44 0.093791760028698 4.1268374412627 11 0.59623081744602 37 0.35549118767235 13.153173943877 12 0.99212477592368 50 0.9843115710016 9.21557855008
3.913355933957 168.9835324312
Pusat klaster ke-1 (vkj1) 43.181232489917
Tabel 3.7 Pusat Klaster ke-2 pada Iterasi Pertama
No Derajat Keanggotaan
klaster ke-2 ( i2)
X1.1 ( i2)2 ( i2)2x X1.1
6 0.56457336016279 48 0.31874307900551 15.299667792264 7 0.45954918903236 42 0.21118545714031 8.8697891998928 8 0.71840481555564 35 0.51610547901353 18.063691765474 9 0.074715500871326 49 0.00558240607045 0.2735378974522 10 0.36732353479622 44 0.13492657921519 5.9367694854684 11 0.39104127319935 37 0.15291327734537 5.6577912617787 12 0.51137230169587 50 0.26150163094174 13.075081547087
3.09323916706 123.43177232
Pusat klaster ke-1 (vkj1) 39.903727339962
Tabel 3.8 Pusat Klaster ke-3 pada Iterasi Pertama
No Derajat Keanggotaan
klaster ke-3 ( i3)
X1.1 ( i3)2 ( i3)2x X1.1
1 0.22632857423631 45 0.05122462351584 2.3051080582128 2 0.38484755462323 46 0.14810764029948 6.8129514537761 3 0.41720469501807 32 0.17405975754512 5.5699122414438 4 0.81757056799467 28 0.66842163365113 18.715805742232 5 0.71628860380795 43 0.51306936394514 22.061982649641 6 0.63903445163948 48 0.40836503038217 19.601521458344 7 0.61817283983498 42 0.38213765990964 16.049781716205 8 0.29194892900463 35 0.08523417714695 2.9831962001434 9 0.868278451647 49 0.75390746959452 36.941466010131 10 0.28340595149832 44 0.08031893334466 3.5340330671654 11 0.52926415995661 37 0.28012055101457 10.364460387539 12 0.5434437006755 50 0.29533105580388 14.766552790194
1.17082783238752 48,6913094951
Pusat klaster ke-1 (vkj1) 41.5870789438
32
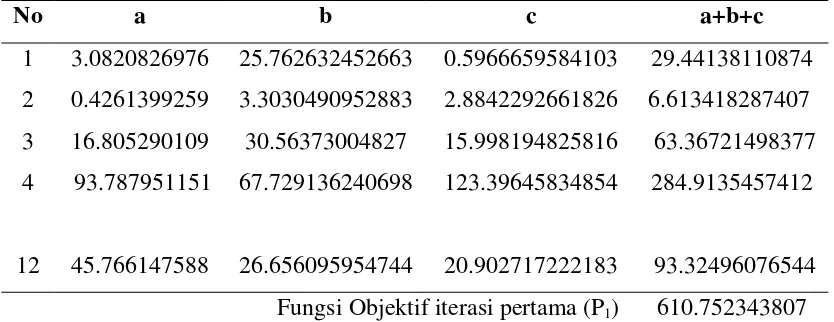
Langkah 3. Menghitung Fungsi Objektif (P)
Setelah terbentuk pusat klaster, selanjutnya menghitung fungsi objektif (P), Fungsi objektif digunakan sebagai syarat perulangan untuk mendapatkan pusat klaster yang tepat, sehingga diperoleh kecenderungan data untuk masuk ke klaster mana pada step akhir.
Perhitungan fungsi objektif Pt dimana nilai variabel Xij dikurang dengan pusat klaster Vkj kemudian hasil pengurangannya di kuadratkan lalu masing masing hasilkuadrat dijumlahkan untuk dikali dengan kuadrat dari derajat keanggotaan untuk tiap klaster, setelah itu jumlahkan semua nilai di semua klaster untuk mendapatkan fungsi objektif Pt. Fungsi objektif pada iterasi pertama (p1) dihitung dengan menggunakan persamaan (2.3).
=
= 610.752343807
Cara menghitungnya sebagai berikut : =
= (( X1j – V1j ) x (μi1)2 + ( X1j – V2j ) x (μi2)2+ ( X1j – V3j ) x (μi3)2 ) + ... +
(( X12j – V1j ) x (μi1)2 + ( X12j – V2j ) x (μi2)2+ ( X12j – V3j ) x (μi3)2 )
= 29.441381108746 + .... + 93.324960765445 = 610.752343807
Misalkan ( X1j – V1j ) x ( i1)2 adalah a, ( X1j – V2j ) x ( i2)2 adalah b dan ( X1j – V3j ) x ( i3)2 adalaj c. Untuk lebih rincinya dapat dilihat pada tabel 3.9.
No a b c a+b+c
1 3.0820826976 25.762632452663 0.5966659584103 29.44138110874 2 0.4261399259 3.3030490952883 2.8842292661826 6.613418287407 3 16.805290109 30.56373004827 15.998194825816 63.36721498377 4 93.787951151 67.729136240698 123.39645834854 284.9135457412
12 45.766147588 26.656095954744 20.902717222183 93.32496076544 Fungsi Objektif iterasi pertama (P1) 610.752343807
Langkah 4. Menghitung Perubahan Matriks Partisi (U)
Perhitungan perubahan matriks partisi (U) menggunakan persamaan 2.4. untuk menghasilkan derajat kenggotaan yang baru yang memiliki rentang antara 0 dan tidak lebih dari 1. Contoh menghitung perubahan matriks seperti tabel 3.10.
Tabel 3.10. Perubahan matriks
X1 Vkj (X1 – Vkj)2
45 43.181232489917 3.3079152557338 0.30230520514896 45 39.903727339962 25.971995025446 0.038503010608937 45 41.587078943843 11.648030135855 0.08585142623574
Untuk perhitungan perubahan matriks lebih rinci adalah sebagai berikut:
(X1 – Vkj)2 =
34
Setelah menghitung seluruh nilai perubahan matrik maka diperoleh Matriks partisi baru (U) untuk iterasi pertama
Langkah 5. Mengecek Kondisi Berhenti
Karena | P1– P0| = | 610.752343807– 0| = 610.752343807> (10-5), dan iterasi =
1 < MaxIter (=100), maka proses dilanjutkan ke iterasi kedua (t=2), iterasi berhenti jika nilai Pt lebih kecil dari nilai , iterasi berhenti di MaxIter yang telah ditentukan atau nilai Pt yang sebelumnya dan yang baru adalah sama.
41.33468753492 3
Fungsi objektif pada iterasi kedua (P2) juga dihitung seperti cara perhitungan fungsi objektif pada iterasi pertama. Hasilnya adalah:
=
= 137.99935387841
Hasil perbaikan matriks partisi untuk iterasi kedua (U2) :
Karena | P1– P0| = | 137.99935387841– 0| = 137.99935387841>> (10-5), dan iterasi = 1 < MaxIter (=100), maka proses dilanjutkan ke iterasi kedua (t=3).
Demikian seterusnya, hingga | | Pt– P0| < , atau t > MaxIter. Dalam penelitian ini, proses berhenti untuk kategori produk A1 pada tahun 2011 setelah iterasi ke-17. Urutan proses berhentinya iterasi dapat dilihat di tabel 3.11.
Tabel 3.11. Nilai fungsi objektif pada tiap iterasi
0.97953206926447 0.00278128016080 0.017686650574729 0.89001237349373 0.018896664766731 0.091090961739537 0.072055879808764 0.7985813098421 0.12936281034914
0.96149873423631 0.0036443344099176 0.034856931353771 0.024703053986294 0.9011960699356 0.024703053986294 0.644962223993 0.095912829858583 0.25912494614842
36
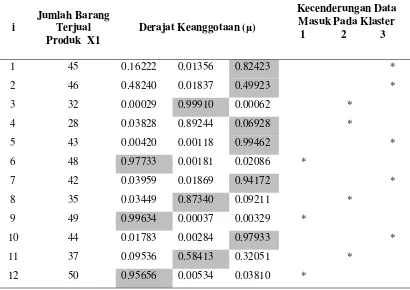
Pada iterasi terakhir, diperoleh pusat klaster:
V17 =
Dari hasil perbaikan matriks partisi baru pada iterasi terakhir inilah yang akan menentukan produk tersebut di setiap bulannya termasuk penjualan yang tinggi, sedang atau rendah, rincinya dapat dilihat pada tabel 3.12.
Tabel 3.12 Nilai derajat keanggotaan baru pada iterasi terakhir
i
1 45 0.16222 0.01356 0.82423 *
2 46 0.48240 0.01837 0.49923 *
3 32 0.00029 0.99910 0.00062 *
4 28 0.03828 0.89244 0.06928 *
5 43 0.00420 0.00118 0.99462 *
6 48 0.97733 0.00181 0.02086 *
7 42 0.03959 0.01869 0.94172 *
8 35 0.03449 0.87340 0.09211 *
9 49 0.99634 0.00037 0.00329 *
10 44 0.01783 0.00284 0.97933 *
11 37 0.09536 0.58413 0.32051 *
12 50 0.95656 0.00534 0.03810 *
Berdasarkan matriks iterasi terakhir, kelompok/klasterberdasarkan pusatklaster(centroid) terbentuk sebanyak 3 klaster yaitu:
- Pusat klaster pada klaster 0 adalah 48.6770 - Pusat klaster pada klaster 1 adalah 32.2828
- Pusat klaster pada klaster 2 adalah 43.3696
Dari ketiga pusat klaster tersebut dapat diperoleh informasi bahwa:
1. Kelompok pertama yang memiliki rata-rata jumlah penjualan sekitar 48.6770 cenderung masuk sebagai kelompok penjualan tinggi.
2. Kelompok kedua yang memiliki rata-rata jumlah penjualan sekitar 32.2828 cenderung masuk sebagai kelompok penjualan rendah.
38
3.4 . Analisis Komponen Sistem
3.4.1 Data flow diagram (DFD)
Diagram Alir Data (DAD) atau Data Flow Diagram adalah representasi grafik yangmenggambarkan informasi dan transformasi informasi yang diaplikasikan sebagai data yang mengalir dari masukan (input) dan keluaran (output).
DFD dapat digunakan untuk merepresenasikan sebuah sistem atau perangkatlunak pada beberapa level abstraksi. DFD dibagi menjadi beberapa level yang lebih detail untuk mrepresentasikan aliran informasi atau fungsi yang lebih detail. DFD menyediakan mekanisme untuk pemodelan fungsional ataupun pemodelan aliran informasi. Oleh karena itu, DFD lebih sesuai digunakan untuk memodelkan fungsiperangkat lunak yang akan diimplementasikan menggunakan pemrograman terstruktur karena pemrograman terstruktur membagi-bagi bagiannya dengan fungsi fungsi dan prosedur-prosedur (Shalahuddin, 2011).
3.4.1.1. DFD Level 0
DFD level 0 menggambarkan sistem yang akan dibuat sebagai suatu entitas tunggal yang berinteraksi dengan aktor maupun sistem lain. DFD level 0 digunakan untuk menggambarkan interaksi antara sistem yang akan dikembangkan dengan entitas luar. Gambar DFD level 0 yang akan dibangun dapat dilihat pada Gambar 3.2.
Gambar 3.2. DFD Level 0
(output), yaitu pesan login, menampilkan data, menampilkan klaster baru yang terbentuk, menampilkan hasil analisa data dan menampilkan kelompok klaster.
3.4.1.2. DFD Level 1
DFD level 1 digunakan untuk menggambarkan modul-modul yang dalam sistem yang akan dikembangkan. DFD level 1 merupakan hasil breakdown DFD level 0 yang sebelumnya dibuat. Gambar DFD level 1 dari sistem yang akan dibangun dapat dilihat pada Gambar 3.3:
40
3.4.2. Flowchart
Perancangan sistem dibangun menggunakan bahasa pemrograman PHP dengan database menggunakan mysql dan akan dianalisis dengan algoritma Fuzzy C-Means. Flowchart algoritma Fuzzy C-Means dapat dilihat pada Gambar 3.4.
3.4.3. Sitemap aplikasi
Sitemap aplikasi merupakan gambaran nyata bagaimana user dapat menjalankan aplikasi, menu-menu apa saja yang dapat diakses dan bagaimana caranya. Sitemap dapat dilihat pada Gambar 3.5.
Gambar 3.5 Sitemap Aplikasi
3.5. Perancangan Sistem
42
Gambar 3.6. Rancangan tampilan login
Keterangan :
A. Form untuk melakukan login agar pengguna dapat masuk kedalam sistem analisa penjualan dengan menginput username dan password. Pengguna akan masuk sebagai admin.
Tampilan awal pengguna sebagai Admin, terdapat tiga menu yaitu menu home, menu Manage Data, dan menu Admin. Rancangan tampilan awal dapat dilihat pada Gambar 3.7.
Gambar 3.7. Rancangan tampilan home
Keterangan :
A. Menu home, menu Manage Data dan menu Admin.
Rancangan tampilan halaman Home setelah memilih form kategori produk, produk dan tahun dapat dilihat pada Gambar 3.8
Gambar 3.8. Racangan tampilan Home setelah di clustering
Keterangan :
A. Menu Home setelah dicluster
B. Diagram jumlah barang yang terjual pertahun
C. Hasil clustering untuk melihat kelompok data yang telah diclustering.
Rancangan tampilan halaman input data penjualan dari sub-menu manage data dapat dilihat pada Gambar 3.9.
44
Keterangan :
A. Menu manage data dengan sub-menu input data penjualan, daftar kategori produk, dan daftar periode.
B. Form input data penjualan, dimana admin harus menginput data seperti Nama Kategori produk, Produk, Tahun, dan Data Perbulan dengan bagian:
B1. Jumlah Penjualan Produk B2. Jumlah Invoice Produk
Rancangan tampilan halaman daftar kategori produk dari sub-menu manage data dapat dilihat pada Gambar 3.10.
Gambar 3.10. Rancangan tampilan daftar kategori produk
Keterangan :
A. Menu manage data dengan sub-menu input data penjualan, daftar kategori produk, daftar produk dan daftar periode.
B. Tabel yang berisikan daftar kategori produk dengan kelola data seperti edit dan hapus.
Gambar 3.11. Rancangan tampilan daftar produk
Keterangan :
A. Menu manage data dengan sub-menu input data penjualan, daftar kategori produk, dan daftar periode.
B. Tabel yang berisikan daftar produk dengan kelola data seperti edit dan hapus. Rancangan tampilan halaman daftar periode dari sub-menu manage data dapat dilihat pada Gambar 3.12.
Gambar 3.12. Rancangan tampilan daftar periode
Keterangan :
C. Menu manage data dengan sub-menu input data penjualan, daftar kategori produk, dan daftar periode.
46
Rancangan tampilan halaman kelola pengguna dari sub-menu kelola dapat dilihat pada Gambar 3.13.
Gambar 3.13. Rancangan tampilan admin
Keterangan : A. Menu Admin
Pada bab ini akan dijelaskan tentang proses pengimplementasian metodeclustering pada data penjualan dengan algoritma Fuzzy C-Means pada sistem, sesuai dengan perancangan sistem yang telah dilakukan di Bab 3 serta melakukan pengujian sistem yang telah dibangun.
4.1. Implementasi Sistem
Tahap implementasi sistem merupakan proses pengubahan spesifikasi sistem menjadi sistem yang dapat dijalankan. Implementasi dan analisis dan perancangan sistem ini berbasis web dengan menggunakan bahasa pemrograman PHP.
Spesifikasi software dan hardware yang digunakan
Spesifikasi perangkat lunak (software) dan perangkat keras (hardware) yang digunakan dalam membangun sistemini adalah sebagai berikut.
1. Sistem operasi Windows 7 Ultimate 64-bit (6. 1, Build 7600).
2. Processor Intel(R) Core(TM) i5-2430M CPU @ 2.40GHz (4 CPUs), ~2.4GHz. 3. Memory 4096MB RAM Kapasitas hardisk 120 GB.
4. XAMPP versi 1.8.3-1 5. MySQL versi 5.6.16
4.2. Implementasi Perancangan Antarmuka
48
komputer (PC) atau laptop, kemudian copy folder program kedalam folder htdocs serta import databsenya (.sql), kemudian buka aplikasi pada browser.
4.2.1. Halaman login
Untuk bisa masuk kedalam sistem pola data penjualan, pengguna harus melakukan login terlebih dahulu. Halaman login merupakan halaman yang tampil pertama sekali saat sistem dijalankan. Halaman login dapat dilihat pada Gambar 4.1.
Gambar 4.1. Halaman Login
Pada halaman login, pengguna diwajibkan untuk mengisi username dan password dengan benar sesuai ketentuan sistem agar dapat masuk kedalam halaman utama. Pengguna login sebagai admin agar masuk kedalam sistem.
4.2.2. Halaman home
Gambar 4.2. Halaman Home
4.2.3. Halaman Manage
Halaman ini merupakan halaman untuk mengelola sistem ini. Terdapat sub-sub menu seperti input data, data penjualan, daftar kategori dan daftar periode. Halaman manage dapat dilihat pada Gambar 4.3.
Gambar 4.3 Halaman Manage
4.2.4. Halaman Input Data
50
Gambar 4.4. Halaman Input data
4.2.5. Halaman Data
Halaman ini merupakan sub menu dari halaman Manage. Pada halaman ini, admin dapat melihat, mengedit dan menghapus data penjualan. Halaman Data pada Gambar 4.5.
Gambar 4.5. Halaman data
4.2.6. Halaman kategori
Gambar 4.6. Halaman kategori
4.2.7. Halaman periode
Halaman ini merupakan sub menu dari halaman Manage. Pada halaman ini, admin dapat melihat, mengedit dan menghapus periode data penjualan. Halaman kategori pada Gambar 4.7.
52
4.2.8. Halaman admin
Halaman ini merupakan menu untuk kelola admin. Halaman admin pada Gambar 4.8.
.
Gambar 4.8. Halaman Admin
4.3. Pengujian Sistem
Pengujian sistem dilakukan untuk memeriksa kekompakkan atau kinerja antar komponen sistem yang diimplementasikan. Tujuan utama dari pengujian sistem adalah untuk memastikan bahwa elemen-elemen atau komponen-komponen dari sistem telah berfungsi sesuai dengan yang diharapkan. Metode pengujian yang digunakan adalah metode pengujian black box. Pengujian black box merupakan pengujian yang dilakukan pada interface sistem yang digunakan untuk mendemonstrasikan fungsi sistem yang dioperasikan(Gea, 2011).
4.3.1. Rencana pengujian sistem
Adapun rancangan pengujian sistem yang akan diuji dengan teknik pengujian Black Box dapat dilihat pada Tabel 4.1.
Tabel 4.1. Rencana Pengujian Sistem
No. Komponen sistem yang diuji Butir Uji
1 Login Tombol “Login”
Tabel 4.1. Rencana Pengujian Sistem(lanjutan)
No. Komponen sistem yang diuji Butir Uji
3 Halaman Home Data penjualan yang tersimpan
Halaman Manage Link input data
Link data penjualan
Link daftar kategori
Link daftar periode
4 Logout Link Logout
4.3.2. Kasus dan hasil pengujian sistem
Berikut adalah kasus untuk menguji sistem yang dibangun menggunakan metode Black Box berdasarkan rencana pengujian pada Tabel 4.1. Hasil pengujian dengan menggunakan metode Black Box dapat dilihat pada Tabel 4.2.
Tabel 4.2. Hasil Pengujian No. Komponen
sistem
yang diuji
Skenario uji Hasil yang diharapkan Hasil
Pengujian
1 Login Masukkan
username dan password yang benar.
Ketika data untuk login
dimasukkan dan tombol Login
diklik, maka akan dilakukan proses pengecekkan data untuk login. Apabila data login benar, maka akan langsung masuk ke halaman yang sesuai dengan status login.
Berhasil
Ketika menu ditekan, maka akan berpindah ke halaman yang dituju.
54
Tabel 4.2. Hasil Pengujian (lanjutan) No. Komponen
sistem
yang diuji
Skenario uji Hasil yang diharapkan Hasil
Pengujian
Ketika kategori produk, produk dan tahun telah dipilih, data tersebut akan dicluster dan menampilkan hasil cluster.
Berhasil kategori produk, tahun, dan jumlah penjualan, jumlah invoice untuk semua bulan. Tombol “simpan” untuk menyimpan data yang dimasukkan ke database.
Berhasil
Memilih submenu Data
Menampilkan data penjualan seluruh kategori produk, dan terdapat pilihan hanya untuk memilih kategori yang diinginkan. Terdapat link edit dan delete. Link “edit” akan mengarah kehalaman edit data penjualan dan link “hapus” dapat menghapus data dari sistem.
Tabel 4.2. Hasil Pengujian (lanjutan) No. Komponen
sistem
yang diuji
Skenario uji Hasil yang diharapkan Hasil
Pengujian
Memilih submenu Kategori
Kategori produk yang telah tersimpan dalam sistem dan terdapat link edit dan delete. Link “edit” akan mengarah kehalaman edit kategori dan link “hapus” dapat menghapus kategori dari sistem.
Berhasil
Memilih submenu Periode
Daftar periode yang telah tersimpan dalam sistem dan terdapat link edit dan delete. Link “edit” akan mengarah kehalaman edit kategori dan link “hapus” dapat menghapus kategori dari sistem.
Berhasil
6 Logout Klik Tombol
logout
Pada saat tombol logoutadmin akan keluar dari sistem
Berhasil
4.3.3. Pengujian sistem
Pengujian sistem dilakukan dengan menggunakan data penjualan sesuai kategori produk yang dipilih. Langkah-langkah pengujian sebagai berikut:
56
2. Saat admin telah masuk kedalam sistem, admin menginput data pada form input data. Tampilan setelah data diinput seperti Gambar 4.9.
Gambar 4.9. Hasil input data
3. Setelah data diinput, maka data penjualan akan tersimpan didalam sistem. Lalu, pada halaman home, Admin memilih kategori produk, produk dan tahun yang akan dicluster. Pada Gambar 4.10 admin memilih kategori produk susu,untuk produk Bayi < 5 tahun dan tahun 2011 untuk dicluster.
Gambar 4.10 Proses clustering
Gambar 4.11 Ouput clustering
Pada Gambar 4.12. Tampilan output dari sistem clustering, menampilkan diagram penjualan barang pertahun dan 3 (tiga) kelompok/cluster. Hasil dari pengelompokan tersebut didapatkan informasi bahwa:
1. Penjualan susu bayi < 5 tahun berada pada kelompok penjualan rendah tahun 2011 pada saat bulan Maret, April, Agustus dan November.
2. Penjualan susu bayi < 5 tahun berada pada kelompok penjualan sedang pada tahun 2011 pada saat bulan Januari, Februari, Mei, Juli dan Oktober.
3. Penjualan susu bayi < 5 tahun berada pada kelompok penjualan tinggi pada tahun 2011 pada saat bulan Juni, September dan Desember.
58
Tabel 4.3. Tingkat Penjualan Produk Kategor
Tabel 4.3. Tingkat Penjualan Produk (lanjutan)
Beras Harga < 10000 Rendah
60
Tabel 4.3. Tingkat Penjualan Produk (lanjutan) Kategor
Dari tabel 4.3 dapat dilihat pola penjualan seperti:
1. Kategori produk susu yang terdiri dari bayi kurang dari 5 tahun, balita, anak 7 hingga 12 tahun, manula dan ibu hamil memiliki tingkat penjualan yang tinggi di setiap akhir tahun.
3. Produk beras dengan harga lebih dari Rp. 10.000,- memiliki tingkat penjualan tinggi pada bulan Juli, Agustus dan Desember dan tingkat penjualan rendah disetiap awal bulan.
4. Produk Minyak kelapa/kelapa sawit memiliki tingkat penjualan tinggi pada bulan Juli, Agustus dan Desember dan tingkat penjualan rendah pada bulan April, Mei, Juni dan Oktober.
BAB 5
KESIMPULAN DAN SARAN
5.1. Kesimpulan
Kesimpulan yang dapat diambil dari hasil clustering pada data penjualan menggunakan algoritma fuzzy c-means antara lain :
1. Proses clustering pada data penjualan menggunakan algoritma Fuzzy C-Means pada penelitian ini dapat menentukan tingkat data penjualan.
2. Dari hasil penelitian pada data penjualan 2011 hingga 2013 diperoleh informasi bahwa seluruh kategori produk memiliki tingkat penjualan yang tinggi pada pada bulan Juli, Agustus dan Desember.
5.2. Saran
1. Penelitian selanjutnya dapat dikembangkan dengan menambah parameter lain. 2. Kekurangan dalam penelitian ini adalah data produk yang digunakan hanyalah
berupa general product atau berdasarkan jenisnya. Sehingga akan lebih baik jika menggunakan data produk berdasarkan merk.