APLIKASI EKSPLORATIF TREN DAN DISTRIBUSI HASHTAG PADA MEDIA SOSIAL TWITTER SECARA REAL-TIME
SKRIPSI
Ricko Rinaldy 11160940000031
PROGRAM STUDI MATEMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA
2021 M / 1442 H
APLIKASI EKSPLORATIF TREN DAN DISTRIBUSI HASHTAG DI MEDIA SOSIAL TWITTER SECARA REAL-TIME
Skripsi
Diajukan kepada
Universitas Islam Negeri Syarif Hidayatullah Jakarta Fakultas Sains dan Teknologi
Untuk Memenuhi Salah Satu Persyaratan dalam Memperoleh Gelar Sarjana Matematika (S.Mat)
Oleh:
Ricko Rinaldy 11160940000031
PROGRAM STUDI MATEMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA
2021 M / 1442 H
LEMBAR PENGESAHAN
Skripsi ini berjudul Aplikasi Eksploratif Tren dan Distribusi Hashtag di Media Sosial Twitter secara Real-Time yang ditulis oleh Ricko Rinaldy NIM 11160940000031 telah diuji dan dinyatakan lulus dalam sidang Munaqosah Fakultas Sains dan Teknologi Universitas Islam Negeri Syarif Hidayatullah Jakarta pada hari Rabu, 28 Oktober 2020. Skripsi ini telah diterima untuk memenuhi salah satu persyaratan dalam memperoleh gelar sarjana strata satu (S1) Program Studi Matematika.
Menyetujui,
Pembimbing I Pembimbing II
Taufik Edy Sutanto, M.Sc Tech, Ph.D Madona Yunita Wijaya, M.Sc NIP. 19790530 200604 1 002 NIP. 19850624 201903 2 007
Penguji I Penguji II
Dr. Nina Fitriyati, M.Kom Muhaza Liebenlito, M.Si NIP. 19760414 200604 2 001 NIDN. 2003098802
Mengetahui
Dekan Fakultas Sains dan Teknologi Ketua Program Studi Matematika
Prof. Dr. Lily Surraya E.P., M.Env.Stud Suma’inna, M.Si
NIP. 19690404 200501 2 005 NIP. 19791208 200701 2 015
MOTTO DAN PERSEMBAHAN
Skripsi ini saya persembahkan kepada mereka yang telah mendoakan, mendukung, serta membantu saya dalam penelitian maupun selama menjalani studi sehingga skripsi ini dapat diselesaikan:
• Kedua orang tua penulis, Bapak Herry Sri Waluyo dan Ibu Kalimah, serta kakak penulis, Ratna Jessica Karimah, yang sepenuh hati memberikan doa, semangat, dan dukungan moril maupun materil selama penelitian bahkan perkuliahan sehingga skripsi ini dapat diselesaikan.
• Mak Ani yang telah membantu, mendoakan, dan menemani penulis sampai skripsi ini terselesaikan.
• Reza, Rifqi, Nissa, Laras, Aul beserta keluarga HIMATIKA UIN Jakarta yang telah bersedia membantu, bekerja sama dan memberikan motivasi kepada penulis dalam perkuliahan juga pengerjaan skripsi.
• Teman-teman KKN JAWARA Zulfy, Sirajuddin, Thoriq, Fikri, Bang Jokel, Bang Firhan, Mahmoed, Naula, Devika, Nabila, Ayu, Yara, Bela, Wahyuni, Gaby, Rohmah, Mutia, Difa dan Suci yang telah bersama-sama menjalani KKN di Desa Cibitung Wetan.
“Maka barangsiapa mengerjakan kebaikan seberat zarrah, niscaya dia akan melihat (balasan)nya, dan barangsiapa mengerjakan kejahatan seberat zarrah,
niscaya dia akan melihat (balasan)nya” (Q.S. Al-Zalzalah [99] : 7-8)
Sebarkan kebaikan, hadirkan kebenaran,
meskipun manfaatnya tidak langsung dirasakan, itulah yang dilakukan oleh orang baik
-Ricko Rinaldy
ABSTRAK
Ricko Rinaldy, Aplikasi Eksploratif Tren dan Distribusi Hashtag di Media Sosial Twitter secara Real-Time, di bawah bimbingan Taufik Edy Sutanto, M.Sc Tech, Ph.D dan Madona Yunita Wijaya, M.Sc.
Penelitian ini mencoba mengembangkan aplikasi yang mengeksplorasi data Twitter secara real time dengan topik yang telah ditentukan. Upaya mengatasi masalah perolehan informasi yang saat ini sedang dibahas, ditangani dengan deteksi outlier. Metode yang berbeda digunakan untuk masing-masing tipe data univariat dan multivariat. Untuk mengetahui kesesuaian metode dengan data, dalam hal ini dilakukan perbandingan metode dengan pertimbangan akurasi dan waktu pengolahan. Hasilnya, dipilih metode standar deviasi untuk data univariat dengan waktu pemrosesan 0,26 detik dan 21 kesalahan prediksi (akurasi 99,99%). Untuk tipe data multivariate, Isolation Forest lebih unggul dengan rata-rata akurasi 99,873% dan waktu proses 0,327 detik dari 60 dataset yang dibangkitkan.
Berdasarkan informasi yang didapat dari hasil aplikasi, "#dirumahaja" dalam unggahan dengan kata kunci "virus corona" merupakan peringatan kepada masyarakat Indonesia untuk tidak melakukan aktivitas di luar rumah, semoga informasi ini dapat membantu pengguna merangkum topik di atas. tingkat urgensi mitigasi bencana.
Kata Kunci : Anomaly Detection, Exploratory Data Analysis, Real-time Processing, Trend Analysis.
ABSTRACT
Ricko Rinaldy, Hashtag Exploratory Application of Trend and Distribution on Social Media Twitter by Real-Time, with guidance of Taufik Edy Sutanto, M.Sc Tech, Ph.D and Madona Yunita Wijaya, M.Sc.
This research tries to develop an application that explores Twitter data in real time with a predetermined topic. Efforts to deal with the problem of obtaining information that are currently being discussed are handled by outlier detection.
Different methods are used for each of the univariate and multivariate data types to determine the suitability of the method with the data, in this case a comparison of the methods is carried out with consideration of accuracy and processing time. As a result, the standard deviation method was chosen for univariate data with a processing time of 0.26 seconds and 21 prediction errors (accuracy of 99.99%). For multivariate data types, the Isolation Forest is superior with an average accuracy of 99,873% and a processing time of 0.327 seconds from the 60 generated datasets.
Based on the information obtained from the results of application, "#dirumahaja"
in uploads with the keyword " virus corona" is a warning to the Indonesian people not to do activities outside the home, hopefully this information can help users summarize the above topics. the urgency level of disaster mitigation.
Keywords : Anomaly Detection, Exploratory Data Analysis, Real-time Processing, Trend Analysis.
KATA PENGANTAR
Alhamdulillah, puji syukur kehadirat Allah SWT atas segala rahmat, karunia, dan hidayah-Nya penulis dapat menyelesaikan skripsi ini dengan sebaik-baiknya.
Shalawat serta salam senantiasa tercurah kepada Nabi Muhammad SAW, para sahabat, keluarga, serta muslimin dan muslimat. Semoga kita mendapat syafa’at oleh Nabi Muhammad di akhirat kelak.
Skripsi yang berjudul “Aplikasi Eksploratif Tren dan Distribusi Hashtag di Media Sosial Twitter secara Real-Time” ini disusun sebagai salah satu syarat selesainya program S1 pada Program Studi Matematika di Universitas Islam Negeri Syarif Hidayatullah Jakarta.
Penyusunan skripsi ini dapat terselesaikan atas kerja sama dan bantuan dari berbagai pihak. Untuk itu penulis ingin menyampaikan terima kasih kepada:
1. Ibu Prof. Dr. Lily Surraya Eka Putri, M.Env.Stud., selaku Dekan Fakultas Sains dan Teknologi, Universitas Islam Negeri Syarif Hidayatullah Jakarta.
2. Ibu Suma’inna, M.Si., selaku Ketua Program Studi Matematika, dan Ibu Irma Fauziah, M.Sc., selaku Sekretaris Program Studi Matematika.
3. Bapak Taufik Edy Sutanto, M.Sc Tech, Ph.D., selaku Dosen Pembimbing I dan Ibu Madona Yunita Wijaya, M.Sc., selaku Pembimbing II yang telah menyediakan waktunya untuk memberikan arahan serta saran kepada penulis agar skripsi dapat diselesaikan dengan baik.
4. Ibu Dr. Nina Fitriyati, S.Si., M.Kom., dan Bapak Muhaza Liebenlito, M.Si., selaku penguji yang memberikan evaluasi kepada hasil pelaksanaan maupun penulisan skripsi ini agar dapat disempurnakan lagi.
5. Seluruh Ibu dan Bapak Dosen Program Studi Matematika yang rela membagikan ilmu, pengalaman, dan jendela wawasan yang sangat bermanfaat kepada penulis.
6. Pihak-pihak yang tidak dapat penulis sebutkan satu persatu tanpa mengurangi rasa hormat, yang telah memberikan dukungan dan bantuan sehingga skripsi ini terselesaikan.
Semoga skripsi ini dapat bermanfaat kepada pembaca. Penulis menerima berbagai saran dan kritik dari pembaca untuk pribadi yang lebih baik sebagai upaya menyempurnakan skripsi dan penelitian selanjutnya.
Tangerang, September 2020
Penulis
DAFTAR ISI
LEMBAR PENGESAHAN ... ii
PERNYATAAN KEASLIAN ... iii
PERNYATAAN PERSETUJUAN PUBLIKASI ... iv
MOTTO DAN PERSEMBAHAN ... v
ABSTRAK ... vi
ABSTRACT ... vii
KATA PENGANTAR ... viii
DAFTAR ISI ... x
DAFTAR GAMBAR ... xii
DAFTAR LAMPIRAN ... xiv
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Rumusan Masalah ... 5
1.3 Batasan Masalah ... 5
1.4 Tujuan Penelitian ... 5
1.5 Manfaat Penelitian ... 6
BAB II TINJAUAN PUSTAKA ... 7
2.1 Informasi Data ... 7
2.2 Big Data dan Real-time Analysis ... 8
2.3 Analisa Media Sosial ... 10
2.4 Exploratory Data Analysis ... 12
2.5 Pencilan ... 12
BAB III METODOLOGI PENELITIAN ... 15
3.1. Alur Penelitian ... 15
3.2. Metode Pengambilan Data ... 16
3.3. Metode Penyimpanan Data... 17
3.4. Perbandingan Metode Deteksi Pencilan ... 18
3.5. Metode Pengolahan Data ... 22
BAB IV HASIL DAN PEMBAHASAN ... 27
4.1 Hasil Perbandingan Metode Deteksi Pencilan ... 27
4.2 Penentuan Topik ... 30
4.2.1 Input User ... 30
4.2.2 Laman Utama ... 31
4.2.3 Memperbarui Isu ... 31
4.3 Detail Isu/Topik ... 32
4.4 Analisa Hashtag ... 34
BAB V PENUTUP ... 39
5.1 Kesimpulan ... 39
5.2 Saran ... 40
REFERENSI ... 41
LAMPIRAN ... 44
DAFTAR GAMBAR
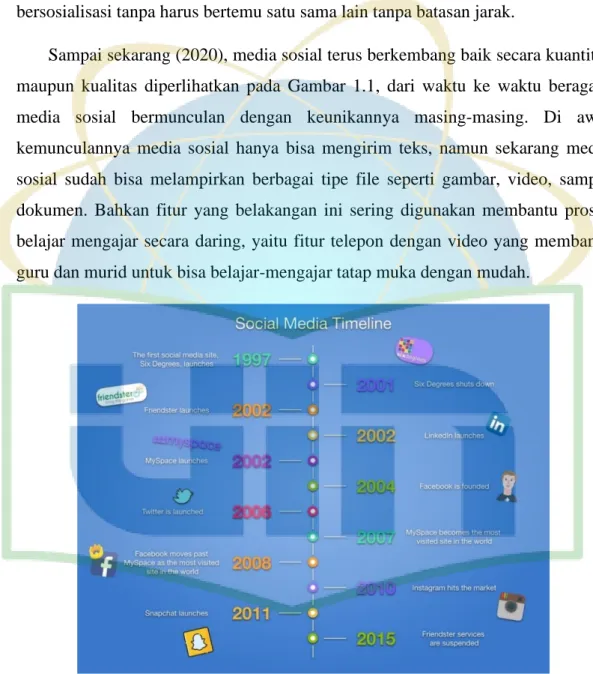
Gambar 1.1. Timeline Media Sosial ... 2
Gambar 1.2. Jumlah Pengguna Media Sosial Indonesia 10 Tahun Terakhir ... 3
Gambar 2.1. Tabel Penggunaan Ruang Pertemuan ... 8
Gambar 2.2. Ilustrasi Deteksi Pencilan dengan Boxplot ... 13
Gambar 2.3. Isolasi data (a) bukan pencilan 𝑥𝑖 (b) pencilan 𝑥0 ... 14
Gambar 2.4. Contoh Klasterisasi Data untuk Deteksi Pencilan pada Metode DBSCAN ... 14
Gambar 3.1. Diagram Alur Aplikasi ... 15
Gambar 3. 2 Contoh Data Tweet yang Diperoleh dari API Twitter ... 15
Gambar 3. 3 Tabel Data Atribut Tweet ... 16
Gambar 3.4. Ilustrasi Pengambilan Data Tweet... 17
Gambar 3.5. Diagram Hubungan antar Tabel ... 17
Gambar 3.6. Diagram Alur Deteksi Pencilan pada Data Univariat ... 19
Gambar 3.7. Diagram Alur Deteksi Pencilan Metode DBSCAN ... 20
Gambar 3.8. Diagram Alur Deteksi Pencilan Metode Isolation Forest ... 21
Gambar 3.9. Diagram Alur Ekspor Tweet ... 22
Gambar 3.10. Diagram Alur Pengolahan Atribut Lokasi ... 23
Gambar 3.11. Diagram Alur Pengolahan Atribut Lokasi ... 23
Gambar 3.12. Diagram Alur Pengolahan Data Jumlah Hashtag ... 24
Gambar 3.13. Diagram Alur Pengolahan Atribut Pengguna... 24
Gambar 3.14. Diagram Alur Pengolahan Atribut Waktu ... 25
Gambar 3.15. Diagram Alur Deteksi Pencilan... 25
Gambar 3.16. Diagram Alur Pengolahan Atribut Lokasi ... 25
Gambar 4.1. Contoh Dataset Multivariat 1 ... 27
Gambar 4.2. Contoh Dataset Multivariat 2 ... 27
Gambar 4.3. Salah Satu Hasil Klasterisasi Dataset 1 dengan Metode DBSCAN . 29 Gambar 4.4. Salah Satu Hasil Klasterisasi Dataset 1 dengan Metode Isolation Forest ... 29 Gambar 4.5. Salah Satu Hasil Klasterisasi Dataset 2 dengan Metode DBSCAN . 30
Gambar 4.6. Salah Satu Hasil Klasterisasi Dataset 2 dengan Metode Isolation
Forest ... 30
Gambar 4.7. Navigasi Akses Buat Isu ... 31
Gambar 4.8. Contoh Daftar Isu di Laman Utama ... 31
Gambar 4.9. Laman Manage Isu ... 32
Gambar 4.10. Sepuluh Peringkat Teratas Hashtag pada Isu “virus corona” ... 32
Gambar 4.11. Pengguna dengan Like Terbanyak pada Isu “virus corona” ... 33
Gambar 4.12. Pengguna dengan Retweet Terbanyak pada Isu “virus corona” .... 33
Gambar 4.13. Pengguna dengn Reply Terbanyak pada Isu “virus corona” ... 33
Gambar 4.14. Contoh Peringkat Hashtag yang Mengandung User Terdeteksi Pencilan ... 34
Gambar 4.15. Contoh Formulir Opsi Rentang Waktu ... 34
Gambar 4.16 Tren Tweet pada Isu “virus corona” ... 35
Gambar 4.17. Tren Tweet Mengandung “#dirumahaja” pada Isu “virus corona” 35 Gambar 4.18. Tren Perbandingan tweet dengan dan tanpa hashtag pada Isu “virus corona” ... 36
Gambar 4.19. Wordcloud dari Kumpulan Tweet berisi “#dirumahaja” pada Isu “virus corona” ... 36
Gambar 4.20. Jumlah Kemunculan Pengunggah dengan “#dirumahaja” pada Isu “virus corona” ... 37
Gambar 4.21. Tabel Ketersediaan Keterangan Lokasi Tweet... 37
Gambar 4.22. Geochart Kemunculan Pengunggah dengan “#dirumahaja” pada Isu “virus corona” ... 38
DAFTAR LAMPIRAN
LAMPIRAN I Laman Buat Isu ... 44
LAMPIRAN II Laman Buat Isu Offline ... 44
LAMPIRAN III Tampilan Laman Utama ... 45
LAMPIRAN IV Tampilan Laman Detail isu ... 45
LAMPIRAN V Tampilan Laman Analisa #dirumahaja ... 46
LAMPIRAN VI Laman Perbarui Isu ... 46
BAB I PENDAHULUAN
1.1 Latar Belakang Masalah
Manusia sebagai makhluk sosial saling membutuhkan satu dengan yang lainnya baik antara individu dengan individu maupun antara kelompok. Hal ini dalam rangka saling memberi dan mengambil manfaat, contohnya orang kaya yang membutuhkan orang miskin untuk bekerja mengurus rumahnya, dan sebaliknya orang miskin mendapatkan penghasilan dari perkerjaannya dengan orang kaya untuk dapat bertahan hidup dan mencukupkan keluarganya. Allah SWT berfirman:
“Apakah mereka yang membagi-bagi rahmat Rabbmu? Kami telah menentukan antara mereka penghidupan mereka dalam kehidupan dunia, dan Kami telah meninggikan sebagian mereka atas sebagian yang lain beberapa derajat, agar sebagian mereka dapat mempergunakan sebagian yang lain. Dan rahmat Rabbmu lebih baik dari apa yang mereka kumpulkan.” (Q.S. Az-Zukhruf [42] : 32)
Sosialisasi mencakup interaksi dan tingkah laku sosial. Menurut Sutaryo [1], sosialisasi merupakan suatu proses bagaimana memperkenalkan sistem pada seseorang serta bagaimana orang tersebut menentukan tanggapan serta reaksinya.
Salah satu bentuk sosialisasi adalah komunikasi, yaitu suatu proses ketika seseorang atau beberapa orang, kelompok, organisasi, dan masyarakat menciptakan, dan menggunakan informasi agar terhubung dengan lingkungan dan orang lain [2].
Cara manusia berkomunikasi dari waktu ke waktu terus berkembang, mulai dari munculnya kosa kata bahasa untuk menyampaikan informasi secara langsung
(tatap muka dengan jarak). Sampai di tahun 1997 hadir situs jejaring sosial pertama Sixdegrees, yang bisa diakses publik secara massal. Saat itulah awal mula kebiasaan baru masyarakat dalam berkomunikasi, situs jejaring sosial tersebut menjadi fasilitas untuk seseorang bisa menambah teman baru dengan berbincang-bincang melalui teks secara daring. Fasilitas ini mempermudah masyarakat untuk bisa bersosialisasi tanpa harus bertemu satu sama lain tanpa batasan jarak.
Sampai sekarang (2020), media sosial terus berkembang baik secara kuantitas maupun kualitas diperlihatkan pada Gambar 1.1, dari waktu ke waktu beragam media sosial bermunculan dengan keunikannya masing-masing. Di awal kemunculannya media sosial hanya bisa mengirim teks, namun sekarang media sosial sudah bisa melampirkan berbagai tipe file seperti gambar, video, sampai dokumen. Bahkan fitur yang belakangan ini sering digunakan membantu proses belajar mengajar secara daring, yaitu fitur telepon dengan video yang membantu guru dan murid untuk bisa belajar-mengajar tatap muka dengan mudah.
Gambar 1.1. Timeline Media Sosial1
1 https://www.broadbandsearch.net/blog/complete-history-social-media
Dengan berbagai fitur yang ditawarkan, masyarakat banyak mempergunakan media sosial untuk kepentingannya masing-masing. Fenomena ini menumbuhkan kebiasaan baru masyarakat, menurut perusahaan penyedia data internasional, Statista, rata-rata masyarakat Indonesia menghabiskan waktu menggunakan media sosial selama 3 jam 26 menit per harinya [3]. Statista juga menyatakan bahwa jumlah pengguna media sosial terus bertambah dari tahun ke tahun hingga tahun 2019 bertambah 3.484 juta pengguna yang ditampilkan pada Gambar 1.2.
Gambar 1.2. Jumlah Pengguna Media Sosial Indonesia 10 Tahun Terakhir2
Dilaporkan oleh Country Industry Head Twitter Indonesia, Dwi Ardiansah, pada kuartal ke-3 tahun 2019, pengguna aktif harian di media sosial Twitter dicatat meningkat 17 persen, ke angka 145 juta pengguna, Indonesia menjadi salah satu negara dengan pertumbuhan pengguna aktif harian paling besar [4]. Meningkatnya jumlah pengguna aktif seiring dengan informasi yang dikandung dalam data, semakin banyak dan beragam. Twitter memiliki cara tersendiri untuk mempermudah penggunanya untuk mendapatkan informasi tentang topik yang sedang mereka cari yaitu Hashtag.
Dalam hal penentuan hashtag dan pengunggah yang sedang menjadi pusat pembicaraan, frekuensi kemunculan menjadi faktor utamanya. Maka dari itu,
2 https://financesonline.com/number-of-social-media-users
dilakukan deteksi pencilan untuk mengetahui kapan frekuensi kemunculan tersebut melambung tinggi dibandingkan dengan sebelumnya. Metode yang dibutuhkan untuk deteksi pencilan adalah metode yang cepat dan akurat yang sesuai dengan tipe datanya, untuk tipe data univariat digunakan deteksi pencilan parametrik yang menggunakan parameter standar deviasi dan kuartil karena metodenya yang cepat, simpel, dan kompleksitasnya rendah dibandingkan dengan metode lainnya [5].
Sedangkan untuk tipe data multivariat digunakan metode pengelompokan dengan DBSCAN (Density-Based Spatial Clustering of Application with Noise) yang bisa mengelompokkan pengunggah dari atributnya (retweet dan like) lalu mengabaikan pengunggah tanpa kelompok sebagai pencilan, hal yang sama dilakukan oleh Isolation Forest dengan keunggulannya pada ukuran data yang besar [6].
Pentingnya ringkasan informasi dari suatu topik diperlukan pada topik yang membutuhkan penyebaran informasi yang lebih cepat. Salah satu contohnya pada topik bantuan bencana alam, informasi waktu yang aktual dan lokasi yang tepat untuk mendistribusikan bantuan. Seperti yang telah dilakukan oleh Laxmi Thapa di tahun 2016 pada jurnalnya yang berjudul "Spatial-temporal analysis of social media data related to nepal earthquake 2015", hasil penelitian tersebut menyatakan bahwa eksplorasi media sosial adalah cara yang paling mudah (dengan biaya yang sedikit) dan cepat untuk mendapatkan informasi tentang bencana yang sedang ataupun telah terjadi, sehingga manajemen mitigasi bencana dapat bergerak dengan efektif [7].
Untuk itu penulis termotivasi untuk membuat aplikasi yang mengambil data tweet secara real time pada topik yang ditentukan sebelumnya, dan menampilkan visualisasi waktu dan lokasi yang interaktif dari data untuk mempermudah meringkas informasi tentang tiap hashtag pada topik tersebut, ditambah dengan deteksi pencilan pada frekuensi kemunculan yang memberi informasi tentang hashtag yang sedang ramai dibicarakan. Untuk studi kasus (demonstrasi aplikasi) skripsi, akan disajikan analisa dari salah satu hashtag yang ada pada topik corona (covid-19) dari bulan Januari hingga Mei 2020. Dari pemaparan di atas skripsi ini
diberi judul “Aplikasi Eksploratif Tren dan Distribusi Hashtag di Media Sosial Twitter Secara Real-Time”.
1.2 Rumusan Masalah
Berdasarkan latar belakang yang telah dipaparkan, maka dirumuskan masalah tentang bagaimana membuat aplikasi interaktif untuk meringkas informasi secara real time dari suatu hashtag pada topik perbincangan tertentu di Twitter serta menentukan metode deteksi pencilan yang cocok untuk masing-masing data yang akan diaplikasikan.
1.3 Batasan Masalah
Dalam penelitian ini, agar pembahasan tidak meluas maka penulis membatasi objek kajian pada:
• Data Tweet yang digunakan berbahasa Indonesia sesuai yang telah dideteksi oleh komputer dari pengembang penyimpanan data Twitter.
• Visualisasi distribusi lokasi dibatasi untuk Negara Indonesia.
• Aplikasi berupa web-based, diperuntukkan untuk pengguna browser di komputer.
• Penentuan topik dilakukan oleh pengguna aplikasi menggunakan satu atau beberapa kata kunci.
• Aplikasi hanya bisa memperoleh data jika komputer pengguna terhubung dengan internet.
• Detail cakupan daerah sampai pada tingkat provinsi.
• Streaming data hanya dilakukan pada satu mesin.
1.4 Tujuan Penelitian
Tujuan yang ingin dicapai dalam penelitian ini, antara lain:
• Membuat sistem pengambilan data secara real time dari media sosial Twitter.
• Membuat sistem penyimpanan data dari atribut unggahan yang diperoleh dari media sosial Twitter.
• Membandingkan metode deteksi pencilan yang cocok untuk masing-masing tipe data pada studi kasus untuk digunakan pada aplikasi.
• Mengolah lalu menampilkan visualisasi data untuk mempermudah penyampaian informasi ringkasan suatu topik pembicaraan.
1.5 Manfaat Penelitian
Adapun manfaat dari penyusunan skripsi ini adalah sebagai berikut:
• Bagi pengguna aplikasi :
o Mendapatkan kemudahan untuk memperoleh ringkasan informasi terkait hashtag dan topik pembicaraan di Twitter.
o Membebaskan pengguna memilih topik pembicaraan di Twitter yang ingin dianalisis lebih lanjut.
o Mendapatkan informasi secara aktual tentang suatu topik pembicaraan di Twitter.
• Bagi penulis :
o Lebih memahami bahasa pemrograman Javascript dan framework Python untuk pengembangan aplikasi berbasis jaringan.
o Mengetahui terhadap atribut-atribut yang ada pada tweet.
o Dapat menjalankan dan membandingkan metode deteksi pencilan.
o Menambah pengetahuan tentang HTML dan CSS untuk menulis dan memperindah aplikasi berbasis jaringan (web-based).
• Bagi Universitas :
o Mengetahui ukuran kemampuan mahasiswa setelah belajar di bangku perkuliahan.
o Mengetahui tingkat kesiapan mahasiswa untuk terjun ke dalam dunia kerja.
o Mengetahui penerapan ilmu mahasiswa yang diperoleh saat kuliah.
BAB II
TINJAUAN PUSTAKA
2.1 Informasi Data
Data adalah karakteristik atau informasi, biasanya numerik, yang dikumpulkan melalui observasi [8]. Data biasanya berupa simbol atau angka yang menyatakan ukuran dari suatu objek. Data bisa menjadi informasi jika sudah diberikan interpretasi. Semakin beragam data, semakin beragam juga informasinya, namun setiap tipe data memiliki cara pengolahannya masing-masing. Sebelum mulai mengolah/mengambil informasi dan wawasan dari data, hendaknya sang peneliti mengetahui seluk beluk datanya terlebih dahulu agar bisa menentukan hal yang harus dipersiapkan pada data sehingga pengolahan data bisa berjalan dengan lancar.
Pengetahuan dasar data yang diperlukan adalah pengetahuan bidang datanya dan struktur datanya. Berdasarkan strukturnya, data terbagi menjadi dua yaitu data terstruktur dan tidak terstruktur:
• Data Terstruktur
Sesuai namanya, data terstruktur ialah data yang memiliki aturan/struktur yang telah ditetapkan. Umumnya data terstruktur dapat dilihat dalam bentuk tabel (baris dan kolom) yang terdiri dari satu atau lebih kolom dengan aturannya masing-masing. Contohnya seperti pada Gambar 2.1, data penggunaan ruangan pertemuan, terdiri dari kolom “nama”, “email”, “meeting time”. Masing-masing kolom tersebut memiliki aturan tertentu pada datanya, seperti kolom “nama” diisi hanya dengan huruf, “email” dapat diisi dengan angka maupun huruf namun harus diakhiri dengan domain email. Data terstruktur memiliki kemudahan untuk dibaca/dilihat dan diatur (manage) karena aturan yang dimiliki.
Gambar 2.1. Tabel Penggunaan Ruang Pertemuan3
• Data Tidak Terstruktur
Data tidak terstruktur merupakan data yang independen (tidak terikat aturan tertentu), tidak seperti data terstruktur yang berbentuk tabel data tak terstruktur memiliki banyak bentuk, beberapa contoh data tidak terstruktur adalah data gambar, teks, audio, dan lain-lain. Sayangnya pengolahan secara statistik menggunakan data tidak terstruktur tidak semudah pengolahan data terstruktur karena tidak teraturnya struktur/aturannya.
Hal lain yang harus diperhatikan sebelum mengolah data adalah proses pengambilan datanya. Data dapat diperoleh langsung melalui pengamatan/penelitian (observasi) yang disebut data primer atau diperoleh dari suatu sumber yaitu data sekunder. Untuk perolehan data primer harus memperhatikan signifikansi, contohnya jika data sampel dari suatu populasi maka sampel yang diambil harus bisa mewakili sifat/karakteristik dari populasi. Proses pengambilan data pun sebaiknya tidak melanggar hak/privasi seseorang ataupun suatu instansi.
2.2 Big Data dan Real-time Analysis
Big Data adalah bidang yang menangani cara menganalisis, mengekstrak informasi secara sistematis, atau menangani kumpulan data yang terlalu besar atau kompleks untuk ditangani oleh perangkat lunak aplikasi pemrosesan data tradisional. Data dengan banyak kasus (baris) menawarkan kekuatan statistik yang lebih besar, sementara data dengan kompleksitas yang lebih tinggi (lebih banyak
3 https://launchschool.com/books/sql/read/introduction
atribut atau kolom) dapat menyebabkan tingkat penemuan palsu yang lebih tinggi [9]. Istilah Big Data diperkenalkan oleh Doug Laney pada tahun 2001 sebagai kumpulan data yang memiliki tiga kelebihan yaitu volume (ukuran), velocity (kecepatan), variety (variasi) [10]. Setidaknya itulah salah satu definisi secara tidak langsung tentang Big Data yang pertama kali disinggung oleh ahli, namun banyak lagi definisi dari sumber lain seiring dengan pemanfaatan dan penelitian lebih dalam tentang Big Data itu sendiri.
Karena karakteristik yang dimilikinya, sebagian besar Big Data berupa data tidak terstruktur, data tidak terstruktur lebih fleksibel karena kebebasan strukturnya (tak harus dalam bentuk tabel). Keberagaman jenis data serta cepatnya data yang dihasilkan membuat ukuran data semakin besar. Dengan data yang melimpah dan beragam, tentunya terdapat informasi berharga yang bisa diambil di dalamnya.
Dengan tantangan ukuran dan keragaman data ini, Secara umum, pemrosesan big data dapat dikategorikan menjadi tiga jenis berbeda, yang terdiri dari batch processing, real-time processing, dan hybrid processing (batch dan real-time).
Batch processing adalah teknik pengolahan data dalam jumlah besar yang dilakukan dalam kurun waktu tertentu dengan tahapan input, pemrosesan, analisis, dan pelaporan. Di sisi lain, banyak aplikasi dan solusi big data memerlukan real- time processing. Real-time processing terdiri dari input, pemrosesan, dan analisis serta pelaporan data yang berkelanjutan. Bergantung dengan penggunaannya, batch processing biasanya digunakan untuk satu waktu analisa, sedangkan real-time processing digunakan untuk data kontinu yang memungkinkan analisa setiap waktu atau rentang waktu yang sedikit [11].
Seiring dengan berkembangnya berbagai aplikasi/fungsi internet, semakin banyak data yang dihasilkan penggunanya sehingga para ahli data dapat terus memanfaatkan data sebagai “sumber daya baru” [12]. Tetapi tak selalu harus digunakan metode yang kompleks untuk mengekstrak informasi dari data, metode yang simpel/mudah dengan informasi yang bermanfaat juga bisa dilakukan bahkan mudah dikembangkan lagi lebih lanjut [13]. Seperti salah satu fungsi/aplikasi media sosial sebagai sarana komunikasi dan berbagai informasi yang menghubungkan
setiap penggunanya berupa individu ataupun institusi, pemanfaatan data yang dihasilkan bisa menjadi penting dan menarik.
2.3 Analisa Media Sosial
Dengan terus meningkatnya ukuran data serta beragam jenis data yang masuk, media sosial menjadi ladang data dengan bermacam-macam informasi. Atribut- atribut unggahan media sosial saat ini sudah beragam jenis data seperti gambar, video, simbol/emoji, waktu/temporal, lokasi/spasial, dan lain-lain. Informasi tidak hanya berguna kepada pengguna, pengembang data pun mengatur pembatasan konten unggahan menggunakan teknik machine learning (based on data) seperti yang dilakukan oleh perusahaan besar Amazon pada pembatasan unggahan konten dewasa [14].
Adapun kegunaan lain dari media sosial adalah untuk kepopuleran. Dalam penelitian menyatakan bahwa, perusahaan yang berhasil pada kampanye/iklan/interaksi di media sosial dengan tingkat popularitas tinggi sebanding dengan meningkatnya angka konsumen yang loyal pada brand dari perusahaan tersebut. Loyalitas konsumen terhadap brand juga akan berpengaruh positif terhadap penjualan barang produksi. Dengan andilnya perusahaan ke dalam media sosial, konsumen juga dapat berkomunikasi langsung jika ada pengaduan, saran, ataupun kritik kepada perusahaan [15]. Selain itu peran influencer (pengguna yang sudah terkenal di media sosial) juga menarik perhatian warganet kepada perusahaan/brand yang bekerja sama dengannya, kegiatan media sosial oleh influencer mudah terlihat karena jaringannya yang luas [16].
Menganalisis data media sosial memberikan informasi seperti berita, tentang kejadian yang telah atau baru saja terjadi. Berita akan lebih informatif jika didapat secara aktual, dengan metode streaming data yaitu mengambil data secara langsung seketika suatu unggahan muncul di media sosial. Media sosial, karena penggunanya yang tersebar hampir di seluruh penjuru dunia, kemudahan dan kebebasan untuk mengunggah suatu konten tanpa terikat suatu aturan bisa menjadi lahan informasi
aktual yang bahkan melebihi penyedia warta. Dengan menelusuri unggahan tentang suatu topik kejadian/fenomena heboh yang terjadi, pengguna media sosial lalu berbagi informasi dengan rekannya sebagai topik pembicaraan obrolannya, akibatnya topik tersebut tersebar dan menjadi bahan perbincangan banyak orang, situasi seperti inilah yang disebut dengan istilah “viral” di media sosial.
Beberapa unggahan medial sosial teks mengandung hashtag yaitu susunan huruf tanpa spasi yang diawali dengan simbol pagar (#). Hashtag digunakan untuk menyatakan topik yang sedang dibicarakan pada unggahan. Sebelum melakukan analisa, kumpulan hashtag harus disaring terlebih dahulu agar informasi yang diperoleh juga sesuai (tidak terjadi disinformasi). Dengan hashtag yang lebih informatif, peringkasan topik atau pengambilan informasi akan menjadi lebih akurat dengan risiko berkurangnya kuantitas data. Tetapi tidak semua unggahan yang informatif selalu menggunakan hashtag, apalagi dalam situasi mendesak memungkinkan pengguna untuk tidak hashtag pada unggahannya. Ada empat cara untuk menentukan hashtag yang cocok dengan topik diantaranya menyingkirkan hashtag yang jarang muncul, mengidentifikasi dan menyingkirkan hashtag dari topik kejadian sebelum bencana, klasifikasi dengan machine learning, menyingkirkan hashtag dengan kata yang umum (bisa menimbulkan ambigu) [17].
Salah satu cara pengguna media sosial demi menarik perhatian orang banyak untuk popularitas serta memperluas jaringannya, dengan memanfaatkan keadaan atau fenomena unik yang terjadi sebagai konten unggahannya. Salah satunya adalah fenomena bencana, pengguna yang mengunggah konten tentang bencana mendapatkan perhatian karena konten tersebut dirasa informatif dan aktual oleh masyarakat. Menanggapi ini, berbagai peneliti mencoba untuk mengambil informasi keadaan terkini suatu bencana di media sosial yang bisa jadi lebih aktual dan realistis karena pengguna tersebut mengunggahnya secara spontan.
L. Thapa, menggunakan analisa spasial-temporal dari atribut tweet dengan topik bencana gempa bumi di Selandia Baru pada tahun 2015 [7]. Penelitian ini menyatakan bahwa media sosial bisa menjadi fasilitas untuk pemerintah/relawan mendapatkan informasi lokasi dan keadaan yang membantu proses penanggulangan
bencana tanpa mengeluarkan biaya dan usaha lebih, namun permasalahan yang dihadapi ada pada penyaringan tweet dengan informasi yang tepat sesuai topik yang ditentukan. Tentunya banyak lagi kelebihan fitur dan informasi/wawasan yang bisa diperoleh dari media sosial. Dengan masuknya era Big Data, para peneliti semakin giat melakukan eksplorasi dan pengembangan dalam pengolahan serta pemanfaatan data untuk kepentingan individu atau suatu kelompok maupun masyarakat.
2.4 Exploratory Data Analysis
Tukey mendefinisikan Exploratory Data Analysis (EDA) sebagai prosedur untuk menganalisis data, teknik untuk menafsirkan hasil prosedur tersebut, cara merencanakan pengumpulan data agar analisisnya lebih mudah, lebih tepat atau lebih akurat [18]. Exploratory Data Analysis merupakan penerapan dari statistika dasar yang sesuai dengan tipe datanya sehingga menghasilkan suatu informasi.
Beberapa tujuan EDA yaitu membentuk hipotesis tentang penyebab dari fenomena yang sedang diteliti, menilai asumsi yang akan menjadi dasar inferensi statistik, membantu memilih alat dan teknik statistika yang tepat, memberikan dasar untuk pengumpulan data lebih lanjut melalui survei atau eksperimen [19].
2.5 Pencilan
Dari kumpulan data dengan distribusi yang sama, outlier/pencilan, pada beberapa metode analisa menyebabkan kesalahan spesifikasi, estimasi parameter yang bias dan hasil yang salah, maka penting untuk sebelum analisa data melakukan identifikasi pencilan [20]. Hawkins [21] mendefinisikan pencilan sebagai pengamatan yang menyimpang begitu jauh dari pengamatan lain sehingga menimbulkan kecurigaan bahwa memang demikian dihasilkan oleh mekanisme yang berbeda. Bumi yang luas menyimpan data yang begitu masif dari setiap elemen/objek di dalamnya, akibatnya kemungkinan kemunculan pencilan juga besar. Contohnya dari kebanyakan pelanggan toko daring, ada pelanggan dengan
pengeluaran yang tinggi, jauh berbeda dengan mayoritas pelanggan lainnya, atau warna kulit hewan albino yang memiliki gen kulit berbeda dengan kebanyakan hewan sejenisnya.
Pencilan kadang kala muncul karena eror atau noise komputer maupun manusia, tetapi tak menutup kemungkinan untuk pencilan mengandung informasi tersendiri. Berbagai metode dikembangkan untuk mendeteksi pencilan, untuk data univariat, Tukey [18] memperkenalkan metode boxplot untuk mengindikasi pencilan seperti ilustrasi pada Gambar 2.2, batas rentang data pencilan dihitung dengan 1.5 kali jarak antara kuadran pertama dan ketiga, Davies dan Gather [22]
juga memiliki prinsip yang sama dalam mengidentifikasi pencilan, yaitu dengan menggunakan batas rentang jarak standar deviasi tertentu, juga menyatakan perbedaan penting antara deteksi pencilan dengan sekali proses atau terurut di setiap waktu tertentu [20].
Gambar 2.2. Ilustrasi Deteksi Pencilan dengan Boxplot4
Sedangkan untuk data multivariat, Isolation Forest membuat pohon tahapan isolasi seluruh data dengan membagi suatu variabel secara acak menjadi dua bagian terus menerus hingga data terisolasi, lalu menghitung skor pencilan melalui pohon- pohon keputusan yang terbentuk. Pembentukan pohon dalam tahapan mengisolasi suatu data diperlihatkan pada Gambar 2.3. data tanpa pencilan (𝑥𝑖) membuat pohon isolasi lebih tinggi atau membuat garis keputusan lebih banyak daripada data pencilan (𝑥0), sehingga penghitungan skor pencilan ditentukan berdasarkan tinggi pohon dari akar ke dahan terbawah [23].
4 https://salsabilabasalamah.medium.com/cara-mengidentifikasi-dan-penanganan-data-outlier- d2fe16c6d62c
Gambar 2.3. Isolasi data (a) bukan pencilan 𝑥𝑖 (b) pencilan 𝑥0
Selain Isolation Forest metode lain untuk mendeteksi pencilan pada data multivariat adalah DBSCAN (Density-Based Spatial Clustering of Application with Noise) [24], konsep utamanya menemukan wilayah lokasi koordinat data dengan kepadatan tinggi yang dipisahkan wilayah dengan kepadatan rendah, caranya dengan mengelompokkan data pada klaster dengan jarak (𝜖) dan jumlah minimum anggota tertentu pada lokasi koordinat sehingga terbentuklah satu atau lebih klaster yang mengeksekusi pencilan yang tidak memiliki klaster seperti pada Gambar 2.4 [25].
Gambar 2.4. Contoh Klasterisasi Data untuk Deteksi Pencilan pada Metode DBSCAN
Dengan keunggulannya masing-masing, metode pendeteksi pencilan terus berkembang dalam penyesuaian tipe dan bentuk data tertentu untuk menangani permasalahan dalam pengolahan data.
BAB III
METODOLOGI PENELITIAN
3.1. Alur Penelitian
Dari sudut pandang peneliti, alur penelitian seperti yang terlihat pada Gambar 3.1 diawali dengan menentukan kata kunci yang akan terkandung dalam tweet dari pengguna aplikasi, lalu menghubungkan API Twitter agar dapat memulai untuk mengunduh data tweet, data tweet yang diperoleh seperti pada Gambar 3.5 kemudian diekstrak beberapa atribut yang diperlukan (atribut yang diberikan berwarna latar kuning). Selanjutnya disimpan data sesuai kolom yang berpadanan dengan masing-masing atribut di basis data (database) terstruktur menjadi seperti tabel dalam Gambar 3.5. Proses pengolahan dilakukan pada data yang ada di basis data, pengolahannya meliputi exploratory data analysis dan pengemasan data untuk bisa diunduh oleh pengguna. Akhirnya pengguna bisa mengakses hasil pengolahan dan data yang berkaitan juga bisa diunduh di laman aplikasi.
Gambar 3.1. Diagram Alur Aplikasi
Gambar 3. 2 Contoh Data Tweet yang Diperoleh dari API Twitter
Gambar 3. 3 Tabel Data Atribut Tweet
Jika dari sudut pandang pengguna, pengguna membuat “isu”, yaitu topik berisi judul, deskripsi, dan kata kunci yang bersesuaian. Setelah topik ditentukan, streaming berjalan/mulai mengunduh tweet bahasa Indonesia yang mengandung kata kunci, pada saat itu juga isu yang dibuat muncul di laman utama dan bisa diakses kapan saja. Ketika diklik, laman isu menampilkan hashtag yang terkandung di setiap tweet beserta jumlahnya dan beberapa visualisasi atribut lainnya. Untuk bisa menganalisis salah satu hashtag lebih dalam lagi, pengguna dapat klik hashtag yang tertera lalu memunculkan laman analisa hashtag yang berisi grafik, peta, unduh data, dan hasil olahan exploratory data analysis lainnya.
3.2. Metode Pengambilan Data
Data berupa tweet yang diperoleh melalui pengunduhan data secara aktual dan otomatis. Dimulai dengan mengambil parameter dari pengguna berupa kata kunci yang akan terkandung dalam tweet, kata kunci terdiri dari satu atau lebih kata yang berhubungan dengan topik. Lalu tweet disaring berdasarkan kata kunci dan bahasa Indonesia melalui API yang terhubung langsung dengan server Twitter. Proses ini berulang hingga pengguna menghapus topiknya atau mesin diberhentikan oleh admin server. Ilustrasi pengambilan data seperti pada Gambar 3.4.
Data yang digunakan sebagai demonstrasi aplikasi pada penelitian ini yaitu kumpulan tweet yang dideteksi bahasa Indonesia oleh sistem Twitter dengan kata kunci “virus corona” selama 5 bulan sepanjang tanggal 1 Januari hingga 22 Mei 2020.
Gambar 3.4. Ilustrasi Pengambilan Data Tweet [26]
3.3. Metode Penyimpanan Data
Basis data yang dibentuk untuk aplikasi ini terdiri dari empat tabel yang saling terhubung (relational database), hubungan antar tabel dapat dilihat pada diagram di Gambar 3.5. Tabel-tabel tersebut diantaranya:
Gambar 3.5. Diagram Hubungan antar Tabel
• Tabel isutweet
Tabel isutweet merupakan tempat penyimpanan atribut topik yang ditentukan pengguna. Terdiri dari kolom id_ref (sebagai primary key / identitas baris), judul, deskripsi, tanggal_buat dan keyword
• Tabel tweetsmodel
Data tweet yang diunduh masih berupa data tidak terstruktur, beberapa atribut yang akan digunakan diekstrak bersamaan. Atribut yang diekstrak disimpan dalam tabel tweetsmodel dengan kolom id_tweet (primary key), user, user_id, teks, reply_count, retweet_count, like_count, waktu, id_isu (foreign key / kunci tamu dari tabel isutweet), lokasi, latitude, dan longitude.
Kolom lokasi tidak langsung didapatkan dari data mentah, melainkan melalui tahap penempatan titik dari latitude dan longitude yang diperoleh.
Tahap deteksi nama provinsi dengan latitude dan longitude dibantu dengan file “indonesia.geojson” hasil dari unggahan perusahaan Vizzuality di Github yang mengandung titik-titik sudut poligon batas wilayah provinsi [27], di mana penamaan provinsi diberikan jika titik lokasi tweet (latitude, longitude) berada di dalam poligon suatu provinsi yang terbentuk, jika lokasi yang tidak ada di poligon mana pun maka diisi null (none)
• Tabel tweetsmodel_tags
Tabel tweetsmodel_tags adalah tabel yang menghubungkan tabel tweetsmodel dengan tabel hashtag. Hashtag yang terkandung dalam tweet akan diarahkan ke tabel ini, lalu label hashtag dipadankan dengan yang ada di tabel hashtag. Jika hashtag belum ada di tabel, akan dibuat baris baru untuknya. Tabel ini digunakan untuk membantu proses penghitungan jumlah hashtag pada analisa.
• Tabel hashtag
Tabel hashtag adalah tabel yang mengandung seluruh hashtag yang tersedia beserta id nya dan jumlah kemunculan terakhir. Tabel ini berguna untuk mengoleksi hashtag yang belum tersedia sebelumnya serta menyimpan jumlah kemunculannya di 5 detik terakhir.
3.4. Perbandingan Metode Deteksi Pencilan
Untuk mendeteksi pencilan dengan baik, metode yang digunakan harus sesuai dengan data yang tersedia. Data dengan satu variabel (univariat) bisa ditangani oleh metode jarak standar deviasi dengan batas data pencilan dirumuskan dengan [20]:
𝜇 − 2𝜎 < 𝑥𝑖 < 𝜇 + 2𝜎 Keterangan:
𝜎 = standar deviasi dari keseluruhan data observasi 𝜇 = rata-rata dari keseluruhan data observasi 𝑥𝑖 = datum ke-𝑖
Salah satu metode lainnya untuk mendeteksi pencilan pada data dengan satu variabel, yaitu dengan boxplot, batas pencilan pada boxplot ditentukan dengan rumus [28]:
𝑄1− (3
2𝐼𝑄𝑅) < 𝑥𝑖 < 𝑄3+ (3 2𝐼𝑄𝑅) Keterangan:
𝑄𝑖 = Kuartil ke-𝑖
𝐼𝑄𝑅 = Selisih/Jarak antara kuartil ke-3 dan kuartil ke-1 𝑥𝑖 = Datum ke-𝑖
Kedua metode di atas memiliki alur pengerjaan yang sama, perbedaan hanya ada di penentuan batas data normal dan pencilan. Keseluruhan alur jalannya kedua metode ditampilkan pada Gambar 3.6.
Gambar 3.6. Diagram Alur Deteksi Pencilan pada Data Univariat
Agar dapat mengetahui metode mana yang lebih cocok untuk data observasi di penelitian ini, maka dilakukan perbandingan dengan sampel data .jumlah kemunculan hashtag di 29 detik periode pengambilan data. Hasil perbandingan data univariat akan diaplikasikan pada data kemunculan hashtag untuk 5 detik periode dan tren kemunculan hashtag per hari. Sedangkan untuk data multivariat, metode yang digunakan pada penelitian ini adalah DBSCAN dan Isolation Forest yang
diaplikasikan pada data retweet dan like dari tweet yang muncul di suatu periode pengambilan data. Namun sebelum diaplikasikan ke dalam sistem, terlebih dahulu metode dibandingkan dengan dua dataset yang dibangkitkan dengan acak masing- masing sebanyak 30 kali yang berisi 500 data normal dan 10 data pencilan.
DBSCAN mengelompokkan data observasi dan mengisolasi data yang tidak memiliki kelompok (pencilan). Metode ini memindai seluruh sampel dataset lalu memilih setiap data untuk menentukan ada atau tidaknya sejumlah minimal poin data dalam jarak tertentu. Jika tidak ditemukan sejumlah minimal data terdekat (minPts) untuk jangkauan jarak minimal (𝜖), maka data tersebut dinyatakan sebagai noise/pencilan. Gambaran alur kerja metode dapat dilihat pada Gambar 3.7.
Gambar 3.7. Diagram Alur Deteksi Pencilan Metode DBSCAN
Untuk menghitung jarak daerah pembentukan klaster, lingkaran dengan titik pusat klaster yang digunakan sebagai pusat lingkaran dibuat agar selanjutnya ditentukan bahwa anggota klaster dalam area lingkaran sudah cukup membentuk klaster atau belum. Lingkaran dibuat dengan panjang jari-jari jarak Euclidian sebesar 𝜖, yang dapat dituliskan dengan rumus [25]:
𝜖 = 𝑟 ≥ √(𝑥 − 𝑎)2+ (𝑦 − 𝑏)2 Keterangan :
𝑟 = Panjang jari-jari lingkaran
𝑥, 𝑦 = Titik-titik dalam daerah lingkaran 𝑎, 𝑏 = Titik pusat lingkaran
Sedangkan Isolation Forest, membuat hutan keputusan untuk mengisolasi data pencilan. Cara kerjanya dengan mengisolasi data dengan membagi data menjadi
dua bagian pada satu fitur yang dipilih secara acak, data di isolasi secara berulang dengan pohon keputusan acak yang membentuk hutan keputusan hingga dihitung skor anomalinya yang bergantung pada rata-rata ketinggian pohon. Untuk menyesuaikan data yang ada, beberapa parameter yang perlu dikalibrasi di antaranya banyaknya pohon keputusan, tinggi/kedalaman maksimal pohon, banyaknya sampel, dan batas skor anomali untuk penentuan data pencilan.
Mengenai cara kerja metode, lebih jelasnya dapat dilihat pada Gambar 3.8.
Gambar 3.8. Diagram Alur Deteksi Pencilan Metode Isolation Forest
Rumus untuk menghitung skor anomali suatu datum pada hutan keputusan metode Isolation Forest adalah [23]:
𝑠(𝑥, 𝑛) = 2−
𝐸(ℎ(𝑥)) 𝑐(𝑛)
Keterangan:
𝑠(𝑥, 𝑛) = Skor anomali datum 𝑥 pada kumpulan data 𝑛
𝐸(ℎ(𝑥)) = Rata-rata kedalaman pohon untuk datum x pada hutan keputusan 𝑐(𝑛) = Rata-rata kedalaman pohon keputusan dari kumpulan data 𝑛 pada
hutan keputusan
Skor anomali menggunakan kedalaman datum pada pohon untuk menentukan nilainya yang memiliki rentang dari 0 sampai 1. Semakin dalam data, maka data lebih memungkinkan untuk menjadi normal. Sebaliknya, semakin kecil kedalaman data (mendekati 0) maka skor anomali semakin besar (mendekati 1). Untuk menyamakan besaran skala kedalaman, besar rata-rata kedalaman pohon perlu dinormalisasi dengan rata-rata kedalaman untuk sekumpulan data tersebut. Dengan struktur pohon keputusan yang mirip dengan Binary Search Tree (BST), maka diambil rumus dari rata-rata BST [23]:
𝑐(𝑛) = 2𝐻(𝑛 − 1) − (2(𝑛 − 1)
𝑛 )
Keterangan:
𝐻(𝑛) = Angka harmonik dengan estimasi ln(𝑛) + 0.5772156649 (konstanta Euler)
Perbandingan metode untuk setiap tipe data dilakukan agar metode yang digunakan cocok untuk diimplementasikan pada aplikasi. Untuk data multivariat, kode tidak dibuat secara manual melainkan sudah tersedia pada modul sklearn. Hal- hal yang dibandingkan dari tiap metode adalah akurasi hasil deteksi dan biaya waktu yang dibutuhkan oleh metode untuk menjalankan metode tersebut.
3.5. Metode Pengolahan Data
Data yang tersimpan di basis data selanjutnya diolah untuk menampilkan gambaran umum dari semua data yang tersimpan dengan exploratory data analysis (EDA). Beberapa pengolahan yang dilakukan yaitu:
• Ekspor tweet
Tabel tweetsmodel disaring sesuai isu dan hashtag, lalu dibentuk dataframe untuk diekspor di laman aplikasi agar bisa diunduh dan dilihat langsung oleh pengguna. Gambar 3.9 merupakan diagram alur dari proses ekspor tweet.
Gambar 3.9. Diagram Alur Ekspor Tweet
• Tabel jumlah tweet dengan dan tanpa lokasi & Geochart
Tabel tweetsmodel disaring sesuai isu dan hashtag, lalu dihitung jumlahnya di tiap provinsi termasuk tweet yang tidak memiliki atribut lokasi
(None). Untuk mempermudah visualisasi, provinsi dengan jumlah tweet yang lebih banyak akan berwarna lebih merah sedangkan yang sedikit akan berwarna lebih nila pada peta, dibantu dengan titik-titik yang muncul di peta dibentuk oleh longitude dan latitude setiap tweet, Secara umum proses pengolahan diperlihatkan seperti pada diagram alur di Gambar 3.10
.
Gambar 3.10. Diagram Alur Pengolahan Atribut Lokasi
• Tabel jumlah kemunculan pengguna pada suatu hashtag
Tabel tweetsmodel disaring sesuai isu dan hashtag, lalu diambil id penggunanya (user_id) dan dihitung jumlahnya untuk masing-masing kemunculan dengan unggahannya menggunakan hashtag terkait seperti yang ditampilkan pada Gambar 3.11.
Gambar 3.11. Diagram Alur Pengolahan Atribut Lokasi
• Tabel kumpulan dan jumlah hashtag
Tabel tweetsmodel disaring sesuai isu dan diambil hashtag yang terkandung di dalamnya, kemudian dihitung jumlah kemunculan 5 detik terakhir dan akumulasi untuk masing-masing hashtag. Diagram alur proses di tampilkan pada Gambar 3.12
.
Gambar 3.12. Diagram Alur Pengolahan Data Jumlah Hashtag
• Tabel peringkat tweet dengan retweet, like, reply terbanyak
Tabel tweetsmodel disaring sesuai isu lalu diambil nama pengguna juga retweet, like dan reply pada unggahannya, dengan nilai yang paling tinggi ditampilkan paling atas lalu yang lebih kecil dan seterusnya. Secara umum, proses ditampilkan oleh diagram alur pada Gambar 3.13
.
Gambar 3.13. Diagram Alur Pengolahan Atribut Pengguna
• Tren jumlah tweet tiap waktu
Tabel tweetsmodel disaring sesuai isu dan hashtag, lalu dikelompokkan per hari. Tren menampilkan jumlah kelompok tweet dengan isu yang sama,
bersama kelompok tweet dengan isu dan hashtag yang sama. Secara umum, proses ditampilkan oleh diagram alur pada Gambar 3.14.
Gambar 3.14. Diagram Alur Pengolahan Atribut Waktu
• Deteksi Pencilan
Dari metode deteksi pencilan yang telah terpilih pada perbandingan metode, jumlah hashtag per 5 detik dan atribut pengguna (like, retweet, reply) pada laman detail isu dilakukan deteksi pencilan lalu dibedakan warna teks tampilannya. Sama halnya dengan Tren hashtag pada laman detail hashtag, dilakukan deteksi pencilan lalu ditandai dengan lambang bintang pada tren harian analisa hashtag. Secara umum gambaran diagram alur proses deteksi pencilan ditunjukkan seperti pada Gambar 3.15.
Gambar 3.15. Diagram Alur Deteksi Pencilan
• Wordcloud
Gambar 3.16. Diagram Alur Pengolahan Atribut Lokasi
Dari diagram alur pada Gambar 3.16, tabel tweetsmodel disaring dengan isu dan hashtag, lalu dikumpulkan semua teks unggahan dan
dilakukan eksekusi pada stopword (kata yang sering muncul dan kurang bermakna). Setelah itu kumpulan teks dipotong setiap kata kemudian dihitung masing-masing jumlahnya, maksimal 200 jumlah kata terbanyak akan ditampilkan, dengan tulisan yang lebih banyak memiliki ukuran yang lebih besar dalam bidang wordcloud. Bobot ukuran kata dihitung dengan rumus [29]:
𝑝𝑖 = ∑𝑚𝑗=01 max (𝑝) Keterangan :
𝑝 = Bobot seluruh kata unik 𝑝𝑖 = Bobot kata unik ke- 𝑖
𝑖 = Indeks kata unik dari seluruh dokumen 𝑗 = Indeks seluruh kata dari seluruh dokumen 𝑚 = Jumlah seluruh kata dari seluruh dokumen
BAB IV
HASIL DAN PEMBAHASAN
4.1 Hasil Perbandingan Metode Deteksi Pencilan
Data yang digunakan untuk membandingkan metode pada data univariat adalah sebagian daripada data yang telah diperoleh sebagai studi kasus, yang kemudian dibagi setiap 29 detik periode sehingga setiap periode menghasilkan rata-rata 1009 datum. Dari seluruh periode data yang terbentuk, 100 periode data ditentukan secara manual pencilan yang ada dalam data tersebut sebagai landasan kebenaran hasil pendeteksian metode. Sedangkan untuk multivariat, dibangkitkan dua dataset mendekati distribusi normal, masing-masing sebanyak 30 kali dengan 500 datum yang mana 10 di antaranya merupakan pencilan seperti yang ditunjukkan pada Gambar 4.1 dan Gambar 4.2 dengan titik sebaran data yang berwarna merah.
Gambar 4.1. Salah Satu Contoh Dataset Multivariat 1
Gambar 4.2. Salah Satu Contoh Dataset Multivariat 2
Dari dataset yang sudah ditentukan, masing-masing metode melakukan fitting dengan hyperparameter disetel secara manual (exhaustive search) yang menghasilkan prediksi terbaik, perbandingan dilakukan pada model dengan metode pada parameter terbaik tersebut.
Hasil perbandingan yang diperoleh pada metode untuk data univariat disajikan pada Tabel 4.1 memberikan informasi bahwa metode deteksi pencilan dengan standar deviasi lebih unggul baik dari segi waktu jalan maupun akurasi yang dihasilkan.
Tabel 4.1. Tabel Hasil Perbandingan Metode untuk Data Univariat
Metode Runtime Cost Akurasi (Kesalahan Prediksi) Standar Deviasi 0.260 detik 99.9934148635936% (21 Kesalahan)
Boxplot 0.289 detik 99.9921605518971% (25 Kesalahan) Pada data multivariat, perbandingan metode yang dilakukan untuk setiap dataset memberikan hasil dari 30 data yang dibangkitkan, diringkas oleh Tabel 4.2, diketahui bahwa DBSCAN lebih unggul dalam segi waktu jalan dengan rata-rata perbedaan waktu 0.322 detik, sedangkan akurasi yang dihasilkan lebih unggul pada metode Isolation Forest dengan rata-rata akurasi sebesar 99.873% dari rata-rata akurasi DBSCAN sebesar 99.36% dari kedua dataset.
Tabel 4.2. Tabel Hasil Perbandingan Metode untuk Data Multivariat
Dataset Metode Runtime Cost Akurasi (Kesalahan Prediksi)
Dataset 1 DBSCAN 0.005 detik 98.873 %
Isolation Forest 0.475 detik 99.826 %
Dataset 2 DBSCAN 0.005 detik 99.846 %
Isolation Forest 0.179 detik 99.92 %
Rata-rata DBSCAN 0.005 detik 99.36 %
Isolation Forest 0.327 detik 99.873 %
Deteksi pencilan yang dilakukan untuk setiap metode pada dataset 1 salah satunya ditampilkan oleh Gambar 4.3 dengan metode DBSCAN yang menandai
titik berwarna hitam sebagai pencilan dan Gambar 4.4 dengan metode Isolation Forest yang menandai titik berwarna hijau sebagai pencilan. Dari gambar diperoleh bahwa metode DBSCAN memiliki kesalahan deteksi pada 5 pencilan, dan tidak ada kesalahan untuk metode Isolation Forest.
Gambar 4.3. Salah Satu Hasil Klasterisasi Dataset 1 dengan Metode DBSCAN
Gambar 4.4. Salah Satu Hasil Klasterisasi Dataset 1 dengan Metode Isolation Forest
Gambar 4.5 dan Gambar 4.6 menunjukkan salah satu hasil deteksi pencilan pada dataset 2 untuk metode DBSCAN dan Isolation Forest. Berbeda dengan dataset 1, dataset 2 tidak memiliki jarak yang jauh satu sama lain seperti halnya data hasil normalisasi. Pada dataset 2 metode DBSCAN dapat mendeteksi semua pencilan tanpa ada kesalahan, sebaliknya untuk metode Isolation Forest menghasilkan satu kesalahan deteksi pencilan.
Gambar 4.5. Salah Satu Hasil Klasterisasi Dataset 2 dengan Metode DBSCAN
Gambar 4.6. Salah Satu Hasil Klasterisasi Dataset 2 dengan Metode Isolation Forest
4.2 Penentuan Topik 4.2.1 Input User
Laman untuk membuat isu atau topik yang ingin diteliti oleh pengguna berisi formulir untuk judul isu, deskripsi isu, dan kata kunci untuk streaming tweet, lebih lengkapnya dapat dilihat di LAMPIRAN I. Judul dan kata kunci, adalah kolom yang tidak boleh kosong. Untuk penelitian ini, dibuatkan laman khusus untuk impor data dari file (offline) yaitu laman “buat isu offline” seperti di LAMPIRAN II. Cara mengakses fitur ini bisa melalui navigasi utama di bagian atas aplikasi seperti di Gambar 4.7.
Gambar 4.7. Navigasi Akses Buat Isu
4.2.2 Laman Utama
Laman utama merupakan tempat awal bagi pengguna yang mengakses aplikasi. Laman utama berisi daftar isu yang dibuat oleh pengguna, daftar isu yang ditampilkan terdiri atas judul, kata kunci, tanggal buat, dan deskripsi seperti di Gambar 4.8. Untuk bisa mengakses salah satu isu, pengguna dapat mengeklik pada judul. Tampilan lebih lengkap laman utama seperti di LAMPIRAN III.
Gambar 4.8. Contoh Daftar Isu di Laman Utama
4.2.3 Memperbarui Isu
Isu yang sudah dibuat masih bisa diubah setiap saat. Untuk bisa mengubah atribut isu, pengguna bisa mengeklik “atur” di navigasi utama sampai muncul laman baru seperti di Gambar 4.9. Di laman tersebut ada dua tombol, “edit”
untuk memperbarui atribut isu dan “delete” untuk menghapus isu, tampilan lengkap laman perbarui isu seperti di LAMPIRAN VI.
Gambar 4.9. Laman Manage Isu
4.3 Detail Isu/Topik
Laman ini menampilkan tentang informasi dasar yang terkandung dalam topik.
Beberapa atribut diolah lalu ditampilkan sebagai informasi untuk pengguna, pengolahan dilakukan di latar belakang sistem. Informasi hasil olahan yang ditampilkan yaitu peringkat hashtag pada topik berdasarkan jumlahnya, peringkat lima pengguna dengan reply, like, dan retweet terbanyak, serta tweet dengan teks unggahan, pengguna, dan tanggal dibuatnya. Tampilan laman lebih lengkap tentang detail topik ini seperti pada LAMPIRAN IV. Topik “virus corona” menghasilkan peringkat jumlah hashtag seperti di Gambar 4.10, “#vivanews” di peringkat teratas dengan 203 kali kemunculan.
Gambar 4.10. Sepuluh Peringkat Teratas Hashtag pada Isu “virus corona”
Pada Gambar 4.11 like terbanyak oleh pengguna id “@ajizaan” dengan hashtag
“#MataNajwa” dan memperoleh 19.980 like pada unggahannya.
Gambar 4.11. Pengguna dengan Like Terbanyak pada Isu “virus corona”
Pada Gambar 4.12 retweet terbanyak oleh pengguna id “@ajizaan” dengan hashtag “#MataNajwa” dan memperoleh 10.649 retweet pada unggahannya.
Gambar 4.12. Pengguna dengan Retweet Terbanyak pada Isu “virus corona”
Gambar 4.13 menunjukkan id “@CalonbiniSehun_” dengan hashtag
“#LebaranBarengShopee” dengan reply terbanyak yaitu sebanyak 59.122.
Gambar 4.13. Pengguna dengn Reply Terbanyak pada Isu “virus corona”
Hasil peringkat pengguna berdasarkan like dan retweet pada gambar-gambar di atas sudah diterapkan deteksi pencilan, tidak ada pencilan yang terdeteksi oleh metode Isolation Forest. Adapun kasus jika ada pencilan, maka tulisan user yang merupakan pencilan menjadi berwarna hijau seperti yang ditunjukkan Gambar 4.14.
Gambar 4.14. Contoh Peringkat Hashtag yang Mengandung User Terdeteksi Pencilan
4.4 Analisa Hashtag
Laman ini menyediakan analisa lebih dalam untuk hashtag yang dipilih, analisa olahan untuk informasi spasial dan temporal terkait hashtag tersedia di laman ini, pengolahan dilakukan di latar belakang sistem. Data untuk diolah pada laman ini bisa disaring pada rentang bulan dan tahun tertentu sehingga menghasilkan hasil analisa berbeda. Visualisasi hasil pengolahan ditampilkan seperti pada LAMPIRAN V. Hashtag “#dirumahaja” dipilih berdasarkan keunikan dalam kemunculan 5 terbanyak yang muncul dalam konteks berbeda (bukan hasil dari platform berita) dan hubungannya dengan virus corona yang merupakan anjuran dari pemerintah untuk tetap berada di rumah agar terhindar dari virus corona.
Untuk menentukan rentang waktu untuk data yang diolah, disediakan formulir opsional untuk menyaring data sesuai rentang bulan pada tahun tertentu seperti pada Gambar 4.15. Hal ini untuk memberikan fleksibilitas analisa tweet suatu topik pada hashtag tertentu.
Gambar 4.15. Contoh Formulir Opsi Rentang Waktu
Dalam rentang waktu yang sudah ditentukan, EDA temporal analisa hashtag dibuat dalam bentuk tren kemunculannya dalam unggahan per hari. Tren pada Gambar 4.16 menunjukkan banyaknya kemunculan semua tweet pada topik, di Gambar 4.17 tren kemunculan hashtag, sedangkan di Gambar 4.18 perbandingan tren kemunculan hashtag dengan semua tweet pada topik. Untuk kemunculan tweet mengandung hashtag, grafik menunjukkan pelonjakan pada tanggal 29 Maret dan 14 April, sedangkan kemunculan tweet secara keseluruhan mengalami pelonjakan yang memuncak pada tanggal 05 Mei, dan penurunan drastis pada tanggal 14 Maret juga 26 Maret. Pelonjakan dan penurunan drastis pada grafik adalah hasil deteksi pencilan yang ditandai dengan simbol bintang berwarna merah di grafik.
Gambar 4.16 Tren Tweet pada Isu “virus corona”
Gambar 4.17. Tren Tweet Mengandung “#dirumahaja” pada Isu “virus corona”
Gambar 4.18. Tren Perbandingan tweet dengan dan tanpa hashtag pada Isu “virus corona”
Apa yang dibahas oleh hashtag “#dirumahaja” pada tren sebelumnya di ringkas dengan melihat frekuensi kata yang muncul. Kata-kata yang muncul dalam tweet dibuat dalam wordcloud (kumpulan kata unik yang muncul dalam teks), ukuran kata dalam wordcloud bergantung pada jumlah kemunculannya. Dilihat di Gambar 4.19, Beberapa kata yang sering muncul selain hashtag diantaranya “twitter”,
“covid”, “corona”, “mudik”, “jaga”, “jarak”, “rumah”, “isolasi” dan “mandiri”.
Gambar 4.19. Wordcloud dari Kumpulan Tweet berisi “#dirumahaja” pada Isu “virus corona”
Lalu siapa saja yang menggunakan hashtag “#dirumahaja” dapat dilihat melalui tabel pengguna yang diurutkan frekuensi kemunculannya. Tabel di Gambar 4.20, menunjukkan pengguna paling banyak menggunakan hashtag hanya dua kali yaitu pengunggah dengan id “@BPNPTRI”, “@KemenkesRI”,
“@NarasiNewsroom”, dan “@resacehtengah”.
Gambar 4.20. Jumlah Kemunculan Pengunggah dengan “#dirumahaja” pada Isu “virus corona”
Selanjutnya, agar mengetahui sebaran unggahan yang mengandung hashtag, aplikasi menyediakan peta dengan titik-titik lokasi kemunculan unggahan tersebut beserta tabel yang menunjukkan jumlah unggahan yang memiliki informasi lokasi dan jumlah unggahan yang tidak memiliki informasi lokasi. Pada Gambar 4.21, diperlihatkan bahwa 54 dari 118 tweet tidak memberikan informasi lokasi, sedangkan 64 sisanya mengandung informasi lokasi.
Kemudian pada Gambar 4.22, titik kemunculan unggahan ditampilkan dengan warna biru, jika titik-titik kemunculan berdekatan maka titik-titik tersebut menyatu lalu muncul dengan warna yang berbeda, keterangan jumlah titik-titik yang menyatu tertera pada angka di titik yang disatukan. Lokasi kemunculan unggahan tersebar di 15 provinsi berbeda, mayoritas kemunculan ada di Provinsi DKI Jakarta dan Provinsi Jawa Barat dan sekitarnya dengan 30 kemunculan.
Gambar 4.21. Tabel Ketersediaan Keterangan Lokasi Tweet
Gambar 4.22. Geochart Kemunculan Pengunggah dengan “#dirumahaja” pada Isu “virus corona”
BAB V PENUTUP
5.1 Kesimpulan
Penelitian ini membuat aplikasi yang membantu meneliti topik unggahan di Twitter secara aktual, termasuk memberikan informasi tentang hashtag yang digunakan para penggunanya. Informasi waktu dan spasial yang interaktif pada aplikasi akan lebih membantu untuk mendapatkan informasi suatu hashtag, ditambah pengaplikasian deteksi pencilan yang dapat mempermudah menemukan hashtag dan pengunggah yang sedang menjadi pusat perbincangan.
Perbandingan metode deteksi pencilan dilakukan untuk mendapatkan metode yang cepat dan akurat pada setiap tipe data, univariat dan multivariat. Pada tipe data univariat, dilakukan perbandingan antara metode parametrik standar deviasi dan boxplot pada data frekuensi kemunculan hashtag untuk rentang waktu pengolahan setiap 29 detik, hasilnya metode standar deviasi membutuhkan waktu pengolahan 0.26 detik untuk 99.9934148635936% akurasi (21 kesalahan) sedangkan metode boxplot membutuhkan 0.289 detik dengan 99.9921605518971% akurasi (25 kesalahan). Pada tipe data multivariat, dilakukan perbandingan dengan 2 dataset yang dibangkitkan masing-masing sebanyak 30 kali berjumlah 500 datum yang mana 10 di antaranya merupakan pencilan, rata-rata hasil dari kedua dataset menunjukkan DBSCAN dengan waktu pengolahan 0.005 detik mendapatkan 99.36% dibandingkan dengan Isolation Forest yang mendapatkan akurasi 99.873%
dalam waktu 0.327 detik.
Dari hasil perbandingan, metode standar deviasi dalam kasus data univariat lebih unggul karena waktu prosesnya yang lebih cepat dan akurasinya juga lebih besar. Sedangkan dalam kasus data multivariat, Isolation Forest unggul dalam akurasi walaupun waktu proses tidak lebih baik dari metode DBSCAN namun rata- rata waktu pengolahannya masih relatif kecil (kurang dari 1 detik) untuk waktu tunggu pengolahan pada aplikasi.






![Gambar 3.4. Ilustrasi Pengambilan Data Tweet [26]](https://thumb-ap.123doks.com/thumbv2/123dok/3817173.3947383/32.892.159.754.141.968/gambar-ilustrasi-pengambilan-data-tweet.webp)


