JETri,
Volume 3, Nomor 2, Februari 2004, Halaman 17 - 32, ISSN 1412-0372Peranan Web Spider Dalam Internet Search Engine
Ferrianto Gozali & Mochamad Fajar Faezal*Dosen Jurusan Teknik Elektro-FTI, Universitas Trisakti
Abstract
Information is one of the basic necessities for human being. The complete and timely information is needed in almost every modern human activities. With internet as a global computer network, we can easily retrieve and find a comprehensive information we need from different places and experts from all over the world. With millions of web sites already on the Internet and thousands more being added daily, the chances of someone finding information they need are very easy and the capabilities of search engines to help users in information retrieval are very important.
Internet search engine is a software that responsible for spidering and indexing the information in the Internet and maintaining a database of those information. When a keyword is entered into a search engine, it looks for that keyword in its database and displays any relevant records, so it is not really search the global network Internet. The capability of Internet Search Engine in information retrieval not only depend on the input keyword provided by user but also depend on the capability of the engine to build and maintain the database due to a dynamic changes of information in the Internet.
This paper provides a brief overview about techniques used by internet search engine especially how it spidering the webs in the internet, indexing the information found in the web pages and building the database of the information. A model of web spider is developed and tested to show how web spider actually works and to investigate the relationship between the level of spidering with the capability of the search engine. The performance of the web spider is tested by spidering Trisakti University Web site www.trisakti.ac.id using various key words and level of pages.
Keywords: Internet Search Engine, web spider, web site, index, database.
1. PENDAHULUAN
Pemamfaatan jaringan komputer global atau internet sebagai suatu sarana untuk mendapatkan berbagai macam informasi berkembang dengan pesat. Tidak dapat dipungkiri lagi bahwa internet telah menjadi suatu perpustakaan elektronik terbesar dimana semua orang dapat mencari informasi yang dibutuhkannya ataupun meletakkan informasi yang dimilikinya agar dapat digunakan oleh orang lain yang membutuhkannya.
Namun demikian, untuk mencari suatu dokumen web yang sesuai dengan keinginan, dapat merupakan suatu pengalaman dan pekerjaan yang melelahkan. Tidak semua orang tahu dimana letak informasi yang
JETri,
Tahun Volume 3, Nomor 2, Februari 2004, Halaman 17 - 32, ISSN 1412-0372diinginkan dapat ditemukan, begitu pula tidak semua orang tahu bagaimana informasi yang disampaikan dapat dibaca oleh orang lain yang membutuhkan.
Salah satu cara yang umumnya dilakukan untuk menemukan informasi di World Wide Web atau disingkat www adalah dengan menggunakan suatu alat bantu berupa program aplikasi yang dapat membantu proses pencarian atau internet search engine seperti yahoo, lycos, altavista, excite, google, dan lain-lain. Berdasarkan hasil survey, hampir 80 persen pengguna internet menggunakan search engine untuk mencari informasi yang dibutuhkannya di Internet dan merupakan cara yang paling dikenal untuk mendapatkan berbagai macam informasi di Internet (Gultekin Ozsoyoglu & Abdullah Al-Hamdani, 2003, n.p.).
Bagaimanakah internet search engine dapat mengetahui tentang keberadaan suatu situs web dan dapat menampilkan informasi yang ada dalam situs tersebut? Semua itu dapat dilakukan dengan bantuan suatu progarm aplikasi yang dinamakan web spider atau web crawler atau kadang disebut search engine robots.
Dengan menggunakan web spider, search engine berusaha mengindeks seluruh halaman web yang dijumpainya berdasarkan content atau isi dari halaman web tersebut yaitu pada kata-kata yang ditemukan pada halaman web. Web spider yang berbeda seringkali menggunakan cara yang berbeda dalam proses penelusuran serta penyusunan indeks. Akibatnya database yang dihasilkan akan berbeda pula. Hal inilah yang menyebabkan adanya perbedaan hasil pencarian informasi yang sedikit berbeda bila menggunakan search engine yang berbeda atau menggunakan
search engine yang sama pada waktu yang berbeda walaupun dengan kata
kunci yang sama.
Penelitian terhadap penggunaan internet menunjukkan beberapa hal yang menarik antara lain, hampir 80 persen pengguna internet menggunakan search engine, lebih dari 52 persen pengguna internet menggunakan search engine yang sama setiap kali menggunakan search
engine, dan kurang dari 46 persen pengguna merasa selalu berhasil
mendapatkan apa yang dicarinya dengan menggunakan search engine tersebut (Gultekin Ozsoyoglu & Abdullah Al-Hamdani, 2003: n.p.). Hal ini menunjukkan pentingnya peranan internet search engine bagi user dalam proses pencarian informasi yang dibutuhkan.
Ferrianto Gozali & Mochamad Fajar Faezal, Peranan Web Spider Internet Search Engine
Pada tulisan ini akan dibahas tentang konsep dasar dari internet
search engine, bagaimana cara kerja web spider dari suatu search engine
dalam membangun database, faktor-faktor apakah yang digunakan web
spider dalam mengindeks suatu halaman web, serta bagaimana suatu search engine dapat mengikuti perubahan informasi yang terjadi dalam internet.
Uji coba, pengamatan dan pengukuran dilakukan dengan menggunakan suatu model web spider yang dikembangkan untuk membangun database yang digunakan dalam suatu search engine.
2. KONSEP DASAR INTERNET SEARCH ENGINE
Pada saat user menggunakan suatu search engine untuk mencari suatu informasi di Internet maka user tersebut sebenarnya tidak melakukan pencarian halaman web yang ada di jaringan global internet namun hanya melakukan pencarian pada database yang berisi informasi tentang halaman web yang berisi informasi yang dicari. Dengan meng “klik” hyperlink yang ditampilkan search engine barulah user berpindah dari komputer host
search engine tersebut ke halaman web yang sebenarnya di Internet.
Suatu search engine terdiri dari tiga bagian utama yaitu suatu web
spider atau web crawler, suatu indexer dan suatu query processor Ross
(Tyner & Walter Slany, 30 Juli 2004: 06.35 WIB: n.p.). Web spider merupakan perangkat lunak yang bertugas untuk menelusuri seluruh halaman web yang ada di internet, umumnya dengan mengikuti hyperlink yang terdapat pada halaman web yang disinggahinya.
Dengan kata lain, semakin banyak link yang dimiliki oleh suatu halaman web dari suatu situs web maka semakin sering pula halaman tersebut dikunjungi oleh web spider suatu search engine. Bagi halaman web yang terisolasi dan tidak memiliki link dengan situs web lain atau halaman web lainnya tidak akan disinggahi.
Proses penelusuran yang dilakukan oleh web spider suatu search
engine membutuhkan banyak pertimbangan seperti tingkat kelengkapan dan
kedalaman dalam penelusuran, waktu penelusuran yang dilakukan, serta kapan proses dilaksanakan. Hal ini akan membedakan informasi dalam database yang dimiliki suatu search engine.
JETri,
Tahun Volume 3, Nomor 2, Februari 2004, Halaman 17 - 32, ISSN 1412-0372Jika informasi tidak diletakkan pada halaman utama dari situs web yang dimiliki dan web spider dari search engine hanya melakukan penelusuran pada halaman utama dari situs web, maka informasi tersebut tidak akan diketahui pengguna internet pada saat menggunakan search engine tersebut. Hal inilah yang membedakan harga pemasangan iklan pada halaman utama atau bukan didalam suatu situs web.
Informasi yang diperoleh pada saat mengunjungi halaman web suatu situs web ini akan digunakan sebagai indeks yang dapat meningkatkan effisiensi penelusuran informasi.
Banyak cara yang digunakan dan untuk proses penentuan indeks pada suatu search engine. Umumnya search engine mengandalkan indeks yang dibuat secara otomatis oleh indexer yang dimiliki baik oleh search engine itu sendiri maupun dipadukan dengan teknologi lainnya seperti Lycos, Altavisa, Hotbot, Excite, Harvest, Infoseek, dll (Tyner & Walter Slany, 30 Juli 2004: 06.35 WIB: n.p.).
Dengan adanya web spider dan indexer inilah suatu search engine dapat memelihara database yang berisi informasi tentang jutaan halaman web yang ada di internet. Informasi pada database tersebut secara kontinyu di update sejalan dengan pertumbuhan situs web yang ada di Internet.
Query processor merupakan suatu perangkat lunak yang menyediakan fasilitas query bagi user dalam menggunakan search engine tersebut, memasukkan kata kunci yang ingin dicarinya serta mengeksekusi query tersebut.
Query processor juga bertanggung jawab untuk menganalisis input query, membandingkannya dengan indeks yang ada untuk mendapatkan item yang dicari. Hubungan antara ketiga bagian search engine tersebut dapat dilihat pada gambar.1. pada halaman berikut ini.
Dengan melihat fungsi serta proses yang terjadi maka persyaratan yang harus dimiliki oleh suatu search engine antara lain: mampu mencari lokasi serta ranking suatu halaman web secara efektif dan efisien, menampilkan hasil penelusuran yang mudah dimengerti oleh user, up-to-date dan konsisten serta mampu mengadaptasi query dari user.
Ferrianto Gozali & Mochamad Fajar Faezal, Peranan Web Spider Internet Search Engine
Gambar.1. Internet search engine
Search engine dapat dikelompokkan berdasarkan bagaimana proses
indeksing dilakukan. Secara umum dapat bedakan dalam tiga kelompok (Laura Gordon Murnane, 200:, n.p.) yaitu:
a. Search engine yang menggunakan web spider dan secara otomatis membangun tabel indeks dari seluruh situs web yang ditelusurinya seperti pada Google.
b. Search engine yang memelihara direktori secara manual seperti dijumpai pada Yahoo dimana informasi tentang situs web dikelompokkan secara manual.
c. Hybrid search engine yang membangun tabel indeks secara otomatis dan memelihara hubungan antar direktori secara manual. Bagaimana sebenarnya sebuah spider program memulai tugasnya berkelana di dalam web? Tergantung bagaimana sebuah spider itu di rancang. Umumnya web spider akan memulai tugasnya dengan membuka sebuah alamat situs web sebagai titik awal. Spider akan memulai dari sebuah situs, mengindeks informasi yang terdapat pada halaman web situs tersebut kemudian mengikuti semua link yang ada dalam halaman tersebut.
JETri,
Tahun Volume 3, Nomor 2, Februari 2004, Halaman 17 - 32, ISSN 1412-0372Dengan cara ini, suatu spider akan menyebar ke seluruh halaman pada situs
web dan mengumpulkan data secara cepat.
Meskipun semua search engine melakukan fungsi yang sama yaitu melakukan pencarian tetapi hasil yang diberikan oleh setiap search engine dapat saling berbeda antara satu dengan yang lainya. Hasil yang diperoleh setiap search engine tergantung banyak faktor. Faktor utama yang menyebabkan berbedanya hasil search yang dilakukan oleh search engine adalah bagaimana web spider yang digunakan oleh search engine tersebut melakukan spidering halaman web yang ada di internet. Hal ini akan berdampak pada kelengkapan database yang dimiliki oleh search engine tersebut.
Faktor lain yang ikut menentukan kemampuan dari search engine tersebut antara lain frekuensi peng-update-an database yang dilakukan oleh
search engine, algoritma search yang digunakan oleh search engine serta
kecepatannya mencari halaman yang dimaksud dengan interface yang tidak membingungkan user sebagai pengguna. Berikut akan dibahas berbagai pendekatan yang dilakukan dalam pengembangan web spider didalam suatu internet search engine.
3. WEB SPIDER PADA INTERNET SEARCH ENGINE
Salah satu cara yang digunakan search engine untuk mengideks secara cepat adalah mengumpulkan informasi tentang halaman web secara periodik dan otomatis dengan menggunakan program yang disebut web
spider. Beberapa istilah lain yang digunakan seperti ants, automatic indexer, crawler, bot, web robots, worms, merujuk pada hal yang sama.
Spider ini berkelana di web dan berfungsi untuk mengumpulkan
segala informasi tentang suatu halaman web dan mengindeksnya ke dalam suatu database. Informasi tentang halaman web tersebut didapat dari kata-kata yang terdapat di dalam halaman web tersebut. Kata-kata-kata tersebut kemudian di indeks menjadi sebuah daftar kata-kata yang biasanya dipakai sebagai kata kunci untuk menemukan halaman web. Proses pengumpulan informasi tentang halaman web dari situs web ini disebut web spidering.
Sebuah spider program harus membuka banyak sekali halaman web untuk membentuk dan menghasilkan kumpulan kata-kata sehingga menjadi sebuah database yang terkelola dengan baik. Urutan penelusuran halaman
Ferrianto Gozali & Mochamad Fajar Faezal, Peranan Web Spider Internet Search Engine
web pada suatu general search engine didasarkan pada dua konsep dasar yaitu breadth first spidering atau BFS dan depth first spidering atau DFS.
Breadth First Spidering
Ide dari bread first spidering adalah proses penelusuran halaman web dimana seluruh halaman web yang berada disekitar halaman utama akan ditelusuri terlebih dahulu sebelum dilanjutkan ke halaman web berikutnya yang letaknya lebih jauh dari halaman utama tersebut. Cara ini merupakan cara yang umum dilakukan oleh sebuah spider mengikuti link dalam suatu halaman. Breadth First spidering atau BFS dapat dilihat pada gambar 2 dimana halaman utama atau main page yang merupakan halaman web pada level-0 akan pertama di indeks.
Pada halaman utama terdapat link ke tiga buah halaman pada level-1 yaitu page-level-1, page-2 dan page-3 yang akan di indeks berikutnya. Setelah proses indeksing pada level-1 selesai barulah dilanjutkan pada level-2 dan selanjutnya.
JETri,
Tahun Volume 3, Nomor 2, Februari 2004, Halaman 17 - 32, ISSN 1412-0372Depth First Spidering
Alternatif lainnya adalah depth first spidering. Dalam hal ini. spider akan menelusuri halaman web dengan mengikuti link mulai dari link pertama pada halaman awal level 0 dilanjutkan pada link pertama pada level 1 dan begitu seterusnya sampai akhir dari link tersebut.
Selanjutnya proses secara iterative akan dilanjutkan dengan melakukan proses pengindeksan mulai dari link kedua yang berada pada halaman utama level 0 sampai seluruh link yang ada pada halaman utama level 0 tersebut selesai di indeks. Depth First spidering atau DFS dapat dilihat pada gambar 3 dibawah.
Ferrianto Gozali & Mochamad Fajar Faezal, Peranan Web Spider Internet Search Engine
Dalam mengikuti link pada sebuah alamat situs web yang dikunjungi, seberapa jauh kedalaman level yang diikuti spider tersebut diatur sendiri oleh pembuatnya. Ada spider yang mengindeks sebuah alamat situd web secara tuntas, ada yang mengikuti link tanpa menghiraukan letak dari halaman tersebut.
Beberapa search engine bahkan membatasi kedalaman spidering mereka untuk menghemat tempat penyimpanan yang dibutuhkan dan untuk menghindari loop yang terjadi pada sebuah situs web. Kecepatan dan banyaknya informasi yang diperoleh spider juga dipengaruhi oleh kedalaman ini.
Keberadaan internet khususnya web menimbulkan tantangan baru didalam teknologi penelusuran informasi atau information retrieval. Jumlah informasi yang ada di Web berkembang dengan sangat pesat, diperkirakan pada tahun 1998 terdapat lebih dari 350 juta halaman web dan bertambah hampir sejuta halaman setiap hari (Gultekin Ozsoyoglu & Abdullah Al-Hamdani, 2003: n.p.), bahkan dari hasil penelitian diperkirakan lebih dari 600 Giga byte data halaman web yang berubah setiap bulan nya (Gultekin Ozsoyoglu & Abdullah Al-Hamdani, 2003: n.p.). Kecepatan pertumbuhan informasi pada halaman web ini menyebabkan terbatasnya kemampuan dari
search engine yang menggunakan kedua cara spidering tersebut diatas.
Untuk mempercepat proses spidering serta memperbanyak informasi yang dimiliki pada database, beberapa situs bahkan memiliki lebih dari satu spider, misalnya, google.com memiliki beberapa spider yang bekerja sangat cepat dalam menumpulkan data tentang halaman situs web. Cara ini disebut multi-threaded spidering.
Setiap spider dapat membuka lebih dari 300 koneksi halaman web dalam waktu yang bersamaan. Pada performa terbaiknya, sebuah spider dapat membuka ratusan bahkan ribuan halaman web perdetik dan mengumpulkan sekitar 600 KByte data perdetik (K. Bharat & A. Broder, 1998: 52-56).
Cara lain yang dilakukan untuk mengatasi tersebut diatas adalah dengan melakukan spidering halaman web yang lebih menarik atau yang yang sesuai dengan suatu topik tertentu. Pendekatan ini disebut dengan istilah focused spidering atau directed spidering (Gultekin Ozsoyoglu &
JETri,
Tahun Volume 3, Nomor 2, Februari 2004, Halaman 17 - 32, ISSN 1412-0372Abdullah Al-Hamdani, 2003: n.p.), (Sergey Brin & Lawrence Page, 1998: n.p.). Pada focused spidering hanya sub set dari situs web yang akan di indeks yang sesuai dengan kriteria atau topik yang ditentukan.
Dalam melakukan indeksing suatu halaman web, spider harus dapat menentukan bagian-bagian dari dokumen yang dapat dijadikan untuk indeks. Salah satu hal yang penting adalah meta tags atau meta data, yaitu suatu keterangan dalam halaman web yang tak terlihat pada web browser. Meta data ini yang menjelaskan isi dari halaman web tersebut dan berguna untuk membantu automatic indeksing. World Wide Web (WWW) Consortium telah membuat daftar tentang information and standardization
proposals untuk metadata. Beberapa standard untuk metadata telah di
umumkan untuk public diantaranya adalah Dublin Core Metadata standard dan Warwick framework.
Dublin Core metadata terdiri dari 15-element yang ditujukan untuk memfasilitasi dan membantu mempercepat dan keakuratan otomatis indeks. Element-element itu adalah title; creator; subject; description; publisher; contributors; date; resource type; format; resource identier; source; language; relation; coverage; dan rights. Group ini juga telah membuat suatu cara untuk mempermudah penggabungan metadata ke dalam halaman
web. Jika ini dilakukan secara keseluruhan dalam internet, dapat dipastikan Information retrieval di web akan menjadi lebih akurat, tapi untuk dapat
mengadopsi hal ini secara international merupakan hal yang sulit diwujudkan karena tidak semua situs web menggunakan standard tersebut.
4. PENGEMBANGAN MODEL WEB SPIDER
Pengembangan model aplikasi web spider ini dilakukan untuk memperlihatkan bagaimana teknologi web spider yang digunakan dapat secara cepat membangun database dari suatu situs web sehingga user dapat melakukan pencarian dengan hasil yang baik.
Model spider ini hanya mengindeks file dan folder yang terhubung dan berada pada web-server tersebut dan tidak akan keluar dari root domain yang telah ditentukan. Sub domain tidak akan mengalami proses indeksing secara otomatis dan akan dibaca sebagai alamat situs web yang berbeda.
Pengembangan model dilakukan pada Windows 2000 dengan Web
Ferrianto Gozali & Mochamad Fajar Faezal, Peranan Web Spider Internet Search Engine
menggunakan MySQL database 3.23. Hal utama dalam melakukan
spidering adalah cara membaca sebuah file html dan mengumpulkan links
yang ada dalam file tersebut dengan mengikuti links tersebut seperti sebuah
web browser.
Sedangkan indexing mencakup proses membaca file html, mengambil isinya, mengubahnya kedalam text biasa, menyimpulkan isi yang terkandung dalam file tersebut.
Kemudian mngumpulkan keywords yang berhubungan dan menyimpannya sebagai bahan perbandingan query. Langkah-langkah utama dalam melakukan spidering dapat digambarkan sbb:
1. Menentukan file html sebagai starting point yaitu berupa file utama yang memiliki banyak links terhadap isi dari website yang akan di index, biasanya file root dari suatu situs web. Dalam mengikuti link, perlu di tentukan seberapa dalam kita akan mengikuti link, untuk mudahnya ini disebut level spidering.
2. Membaca file tersebut dalam text biasa, kemudian mengumpulkan links yang ada dalam file tersebut dan menyimpannya ke dalam database. Ini disebut level 0. HTML merupakan file teks yang memiliki struktur yang jelas yang dapat dibaca oleh browser. Links dalam HTML files berupa kode yang memiliki tags “<a href = >” dan beberapa kode script dalam vbscript seperti “windows.open” atau yang lainnya yang menunjukan
link terhadap halaman lain. Alamat link inilah yang disimpan kedalam database.
3. Membuka link berikutnya seperti web browser dan mengulang point 2 sampai link yang ada dalam level ini habis. Links yang di kumpulkan merupakan daftar link pada level berikutnya.
4. Lakukan point 2 dan 3 secara berulang sampai dicapai level yang diinginkan.
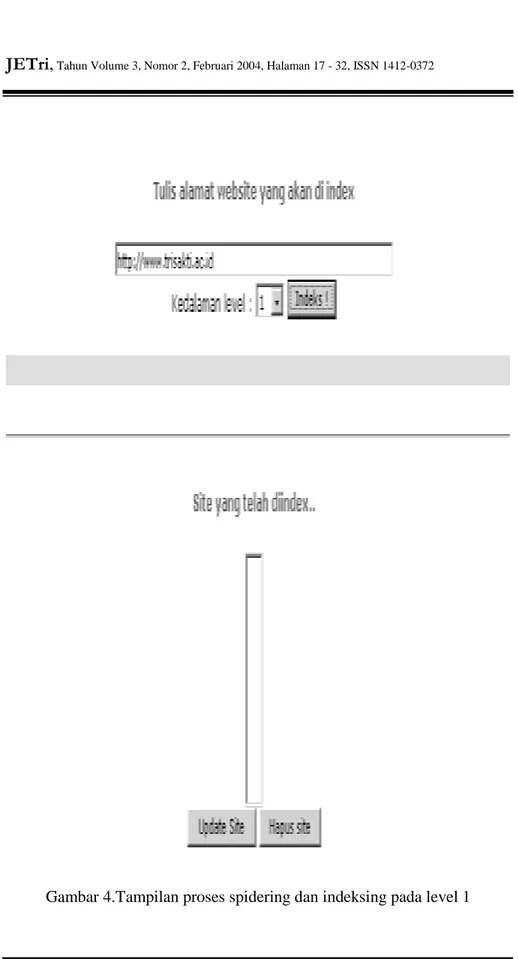
Untuk uji coba dilakukan pada situs web www.trisakti.ac.id seperti terlihat pada gambar 4 pada halaman berikut ini.
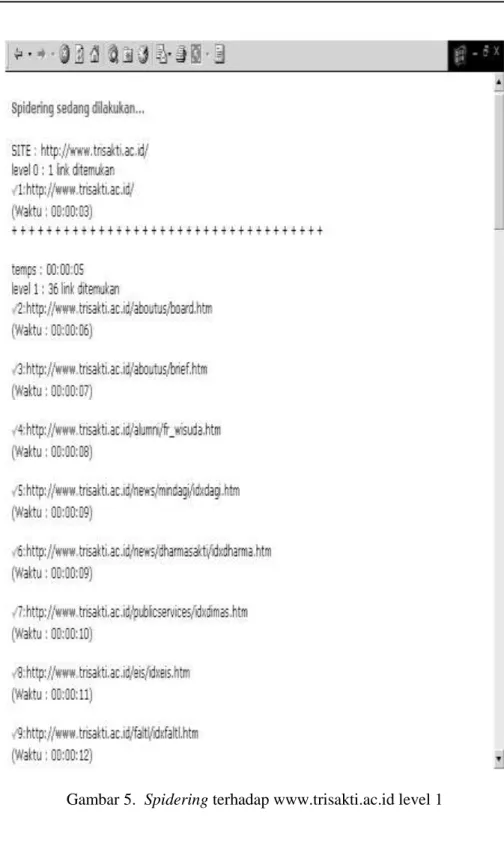
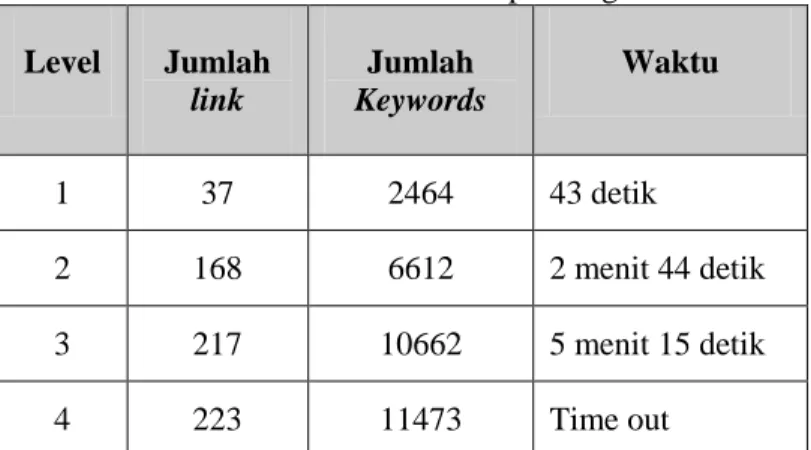
Spidering dilakukan sampai 5 level dan setiap level dilakukan 3 kali spidering untuk melihat kemampuan serta kecepatan web spider membentuk database hasil penelusuran. Tampilan layar proses spidering terlihat pada gambar 5 pada halaman berikunya lagi dan hasil rata-rata spidering tiap level dapat dilihat pada tabel 1. pada halaman berikut ini.
JETri,
Tahun Volume 3, Nomor 2, Februari 2004, Halaman 17 - 32, ISSN 1412-0372Ferrianto Gozali & Mochamad Fajar Faezal, Peranan Web Spider Internet Search Engine
JETri,
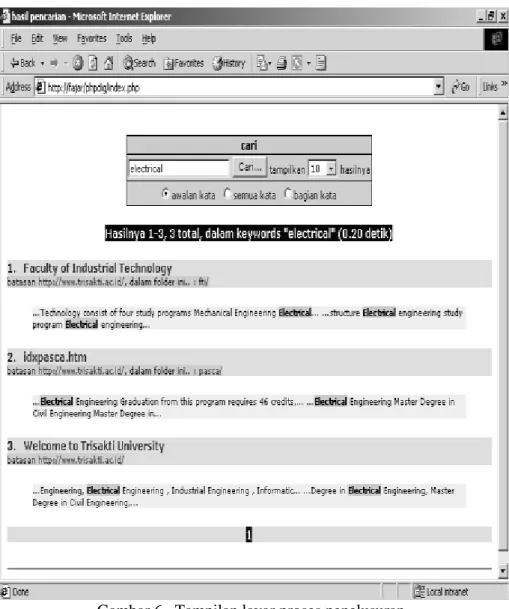
Tahun Volume 3, Nomor 2, Februari 2004, Halaman 17 - 32, ISSN 1412-0372Pemakaian hasil spidering untuk proses penelusuran dengan menggunakan awal kata, kata dan bagian kata dengan menggunakan query interface seperti pada gambar 6 dibawah menghasilkan jumlah halaman dimana kata tersebut ditemukan dan waktu rata-rata pencarian seperti pada tabel.2 dibawah.
Tabel 1. Hasil rata rata spidering
Level Jumlah link Jumlah Keywords Waktu 1 37 2464 43 detik 2 168 6612 2 menit 44 detik 3 217 10662 5 menit 15 detik 4 223 11473 Time out
Tabel.2. Hasil proses pencarian search engine
Level Jenis pencarian Waktu Jumlah Halaman
1 Awalan kata 0.20 detik 3 halaman
Kata 0.23 detik 3 halaman
Bagian kata 0.22 detik 3 halaman 2 Awalan kata 0.37 detik 11 halaman
Kata 0.37 detik 11 halaman
Bagian kata 0.40 detik 11 halaman 3 Awalan kata 0.38 detik 11 halaman
Ferrianto Gozali & Mochamad Fajar Faezal, Peranan Web Spider Internet Search Engine
Gambar 6. Tampilan layar proses penelusuran
5. KESIMPULAN
Web spider merupakan bagian yang sangat penting didalam suatu
search engine. Kemampuan web spider dalam mengikuti link dan aturan-aturan standard yang telah ditetapkan serta kemampuan spider tersebut dalam melakukan indeks terhadap halaman-halaman website yang ada sangat berpengaruh terhadap performance sebuah search engine.
JETri,
Tahun Volume 3, Nomor 2, Februari 2004, Halaman 17 - 32, ISSN 1412-0372Search engine mengindeks halaman di internet dengan berbagai cara. Salah satunya adalah secara otomatis dengan bantuan program web
spider. Kemampuan sebuah web spider dalam mengindeks halaman website
sangat mempengaruhi kemampuan search engine dalam mencari halaman yang diinginkan oleh user serta kedalaman sebuah web spider dalam mengindeks sebuah alamat website sangat mempengaruhi besar database yang dihasilkan.
DAFTAR PUSTAKA
1. Gultekin Ozsoyoglu and Abdullah Al-Hamdani, Web Information Resource Discovery: Past, Present, and Future, Dept of Electrical Engineering and Computer Science, Case Western Reserve University, Cleveland, Ohio 44106, 2003.
2. K. Bharat and A. Broder, A technique for measuring the relative size and overlap of public web search engines, in: Proc. of the 7th World-Wide Web Conference, 1998.
3. Laura Gordon Murnane, The Invisible Web: What Search Engines Can’t Find and Why, University of Maryland Libraries Digital Dateline Series, 2003.
4. Ross Tyner and Walter Slany, Sink or Swim Internet Search Tool & Techniques, Okanagan University College Library, University of
Calgary, United Kingdom, Online at
http://www.sci.ouc.bc.ca/libr/connct96/search.htm, diakses 30 Juli 2004: 06.35 WIB
5. Sergey Brin and Lawrence Page, The Anatomy of a Large-Scale Hypertextual Web Search Engine, Computer Science Department, Stanford University, Stanford, CA 94305, USA, 1998.