BAB 3
PROS EDUR DAN METODOLOGI 3.1. Analisis Masalah
3.1.1. Deskripsi Masalah
Pemenuhan keinginan atau permintaan pasar merupakan hal yang krusial bagi setiap perusahaan. Perusahaan yang siap berkompetisi harus dapat melakukan analisa terhadap keinginan pasar dan kemudian dengan cepat merespon permintaan tersebut. Hal ini berlaku pula pada PT. Kompas Gramedia merupakan perusahaan penerbitan buku terkemuka di Indonesia.
Berdasarkan pada hasil wawancara yang telah dilakukan, maka masalah yang dihadapi oleh PT. Kompas Gramedia dapat dirangkum sebagai berikut:
1. PT. Kompas Gramedia memiliki kesulitan untuk mengikuti kecepatan dalam merespon permintaan pelanggannya.
Proses produksi atau pencetakan dari suatu jenis buku memakan waktu yang tidak singkat, sehingga merupakan hal yang sulit apabila proses produksi barang dilakukan setelah permintaan muncul terlebih dulu. Jika keterlambatan dalam pemenuhan permintaan ini kerap kali terjadi, perusahaan dapat saja kehilangan kepercayaan dari masyarakat. 2. Adanya resiko pemumpukan barang pada gudang.
Apabila PT. Kompas Gramedia melakukan produksi tanpa menghiraukan permintaan masyarakat di masa yang akan datang, maka PT. Kompas Gramedia akan dihadapkan pada resiko terjadinya
kembali. Ini berarti waktu dan biaya yang telah dikeluarkan akan terbuang secara percuma.
3. Sistem prediksi yang digunakan PT. Kompas Gramedia saat ini memberikan hasil yang kurang akurat.
Saat ini, PT. Kompas Gramedia menggunakan cara prediksi sederhana yaitu dengan menghitung rata-rata penjualan masing-masing produk setiap bulannya dengan menggunakan deret ukur untuk menangani permintaan produk dalam kurun waktu tertentu.
Sayangnya cara yang digunakan tersebut sering kali memberikan angka prediksi yang kurang akurat. Jika sebenarnya pada data historis terdapat sebuah pola yang dapat membentuk sebuah alur tertentu, cara ini belum memanfaatkannya.
Namun, perlu disadari bahwa prediksi bukanlah hal yang dapat dilakukan dengan mudah. Prediksi yang dihasilkan oleh pendapat seorang ahli dengan ahli lainnya bisa saja berbeda dikarenakan adanya perbedaan dalam memahami pola permintaan suatu produk. Oleh karena itu, dibutuhkan suatu cara yang lebih pasti dalam melakukan prediksi.
3.1.2. Alternatif Pemecahan Masalah
Berdasarkan deskripsi masalah yang telah dijabarkan di atas, maka solusi yang dapat ditawarkan adalah suatu sistem yang dapat memberikan ketepatan prediksi yang lebih akurat dan dapat diandalkan.
Terdapat beberapa metode yang dapat digunakan dalam rangka melakukan prediksi data kontinu. Beberapa diantaranya menjanjikan
ketepatan yang cukup baik seperti metode regresi linier, Neural Network (NN), dan Support Vector Regression (SVR).
Setelah melakukan pengumpulan informasi, penulis memilih menggunakan metode Support Vector Regression. Sebelumnya Tay dan Cao (2001) telah melakukan sejumlah percobaan dan menyimpulkan bahwa Support Vector Machine untuk kasus regresi atau yang sering disebut dengan Support Vector Regression memiliki hasil yang menjanjikan dibandingkan dengan Back Propagation Neural Network dalam bidang prediksi data finansial time series.
3.2. Metodologi
Sebuah prediksi tidak dapat ditetapkan secara kebetulan semata, data merupakan hal yang paling utama untuk menentukan sebuah prediksi. Ketersediaan data akan membantu merepresentasikan kondisi yang ada. Pola dari data yang ada tersebut akan memperlihatkan sebuah alur, sehingga apabila dipelajari akan dapat membantu untuk memperkirakan alur selanjutnya. Alur dari data itu saling berkesinambungan sehingga dengan adanya kumpulan informasi data yang cukup, suatu model prediksi dapat dibuat.
Pada Support Vector Regression, data–data yang ada dibagi menjadi beberapa bagian dan diberikan pelatihan terlebih dahulu sehingga dapat menghasilkan sebuah model prediksi. Model prediksi yang ada kemudian divalidasi untuk memastikan keakuratan dari model prediksi yang dihasilkan.
1. Menentukan Set Data
Sebelum melakukan proses prediksi, data yang dipergunakan harus dipersiapkan terlebih dulu. Data yang disiapkan merupakan data yang memiliki kualitas yang baik. Kualitas baik yang dimaksudkan di sini adalah data harus relevan dengan kondisi saat ini. Hal ini akan mempermudah proses prediksi serta meningkatkan efisiensi waktu dan menghasilkan hasil prediksi yang baik.
Oleh karena itu, data yang ada sebelumnya sebaiknya telah mengalami proses data cleaning, artinya dari data mentah dilakukan proses pengeliminasian data–data yang dianggap mempunyai nilai yang akan mengganggu keakuratan prediksi seperti data yang memiliki informasi yang kurang lengkap hingga data yang bersifat tidak normal, seperti data penjualan pada waktu tertentu yang memiliki nilai jauh di atas rata-rata.
Kesatuan dari seluruh data yang telah dikumpulkan ini disebut dengan set data. Dalam kasus ini, set data yang digunakan adalah data satuan waktu bulan dari tahun 2008 sampai dengan 2010, dengan mengacu pada jumlah pembelian. Yang akan dicontohkan di dalam kasus ini adalah jumlah pembelian yang digunakan berdasarkan produk “CD Bebi Ayo Bergembira”.
Set data ini nantinya akan digunakan dalam perhitungan pada diagram prediksi yang berguna sebagai acuan dalam menentukan nilai prediksi sebenarnya.
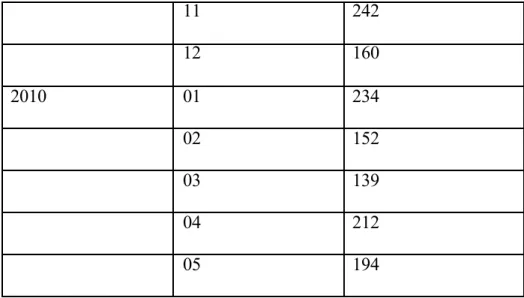
Tabel 3.1 Set Data Berdasarkan Produk “CD Bebi Ayo Bergembira”
Tahun Bulan Jumlah Penjualan
2008 02 291 03 112 04 132 05 91 06 139 07 181 08 196 09 161 10 90 11 222 12 140 2009 01 231 02 205 03 152 04 181 05 208 06 251 07 202 08 172 09 177 10 221
11 242 12 160 2010 01 234 02 152 03 139 04 212 05 194
Jumlah penjualan dari tabel set data tersebut didapatkan dari rata–rata jumlah penjualan per bulan. Hal ini dimaksudkan untuk mempermudah melihat alur atau pola dari pergerakan data per bulan. Berikut tampilan grafik yang dihasilkan dari tabel set data di atas dengan jumlah set data yang dimiliki sebanyak 28 buah data:
Gambar 3.2 Plot Set Data “CD Bebi Ayo Bergembira”
0 50 100 150 200 250 300 350 Fe b ‐08 Ma r‐ 08 Ap r‐ 08 Ma y ‐08 Ju n ‐08 Ju l‐ 08 Au g ‐08 Se p ‐08 Oc t‐ 08 No v‐ 08 De c‐ 08 Ja n‐ 09 Fe b ‐09 Ma r‐ 09 Ap r‐ 09 Ma y ‐09 Ju n ‐09 Ju l‐ 09 Au g ‐09 Se p ‐09 Oc t‐ 09 No v‐ 09 De c‐ 09 Ja n‐ 10 Fe b ‐10 Ma r‐ 10 Ap r‐ 10 Ma y ‐10 Ju m la h Pe nj ua la n Bulan
CD Bebi Ayo Bergembira
2. Membagi Set Data
Pada tahapan ini, set data akan dibagi menjadi dua buah bagian, yaitu set training dan set validasi:
a. Set Training
Merupakan pembagian dari set data yang fungsinya untuk digunakan sebagai data acuan dalam memprediksi. Set training ini memerlukan jumlah data yang cukup banyak, hal ini dimaksudkan untuk memperbesar keakurasian data yang nantinya akan dihasilkan. Semakin banyak set data training yang disediakan akan semakin baik dan semakin stabil data yang dihasilkan Pada kasus ini set training menggunakan variabel X untuk menunjukkan waktu dan variabel Y untuk jumlah penjualan.
Set training diambil sebanyak 70% dari total set data yang artinya 20 buah data dari total 28 set data. Dalam kasus ini, data set training yang dipakai adalah data mulai tahun 2008 bulan 2 sampai tahun 2009 bulan 9.
Tabel 3.2 Set Training Berdasarkan Produk “CD Bebi Ayo Bergembira”
Tahun Bulan Jumlah Penjualan
2008 02 291 03 112 04 132 05 91 06 139 07 181 08 196 09 161
10 90 11 222 12 140 2009 01 231 02 205 03 152 04 181 05 208 06 251 07 202 08 172 09 177 b. Set Validasi
Data validasi ini merupakan pembagian dari set data yang digunakan untuk menghitung keakurasian prediksi yang telah dilakukan pada saat menggunakan data training. Hasil data validasi prediksi akan di bandingkan dengan hasil yang sudah ada sebenarnya, untuk mengetahui apakah variabel–variabel yang sudah didapat menunjukkan hasil yang maksimal. Dengan membandingkan dengan data sebenarnya akan dapat dilihat kesalahan atau tingkat akurasi dari perhitungan prediksi yang dilakukan pada saat prediksi.
Set training diambil sebanyak 30% dari total data set yang artinya 8 buah data dari total 28 set data. Dalam kasus ini, data set training yang dipakai adalah data mulai tahun 2009 bulan 10 sampai tahun 2010 bulan 5.
Tabel 3.3 Set Validasi Berdasarkan Produk “CD Bebi Ayo Bergembira”
Tahun Bulan Jumlah Penjualan
2009 10 221 11 242 12 160 2010 1 234 2 152 3 139 4 212 5 194
Selain mempersiapkan kedua data tersebut, terdapat pula data set testing yaitu set data sejumlah n buah yang akan digunakan untuk prediksi dengan inputan berupa data X (satuan waktu). Sehingga setelah sukses membentuk variabel–variabel yang mempunyai akurasi yang bagus dan menghasilkan model prediksi yang baik barulah set testing ini dipergunakan untuk menghasilkan jawaban prediksi.
Dalam kasus ini akan diramalkan jumlah penjualan dari judul buku “CD Bebi Ayo Bergembira” untuk tahun 2010 bulan 6 hingga bulan 10. Dalam metode yang dipergunakan ini, disarankan untuk tidak melakukan prediksi terhadap kurun waktu yang terlalu jauh, karena data historis yang dipergunakan saat ini dapat saja kurang relevan lagi di masa yang akan datang sehingga kemungkinan tingkat kesalahan prediksi akan semakin besar. Oleh karena itu, kurun waktu prediksi dibatasi hingga 6 bulan ke depan untuk mengantisipasi kesalahan prediksi yang mungkin terjadi.
Tabel 3.4 Set Testing Berdasarkan Produk “CD Bebi Ayo Bergembira”
Tahun Bulan Jumlah Penjualan
2010 6 ???
7 ??? 8 ??? 9 ??? 10 ???
3. Pengaturan Parameter Input
Setelah menyiapkan data set training dan set validasi, tahap selanjutnya yaitu menentukan nilai–nilai awal untuk variabel atau feature seperti kernel, e, loss-function, C. Setiap parameter ini memiliki ciri khas yang sendiri–sendiri yang antara satu sama lain akan berkaitan dan saling mempengaruhi. Hal ini berguna untuk mendapatkan model prediksi terbaik. Perubahan pada nilai parameter-parameter ini akan mengubah model prediksi itu sendiri, oleh karena itu, jika pada tahap selanjutnya ternyata akurasi yang diperoleh masih rendah, pengaturan parameter dapat dilakukan kembali untuk menghasilkan model prediksi yang lebih baik.
a. Kernel
Terdapat beberapa tipe kernel yang sering dijumpai dan setiap tipe kernel tersebut akan menghasilkan nilai output yang berbeda.
Dalam kasus penjualan ini, kernel yang digunakan sebagian besar untuk percobaan adalah linear dan radial basis function (RBF). Hal yang perlu diperhatikan dalam memilih kernel yaitu:
Hal yang dimaksud di sini adalah penggunaan kernel harus disesuaikan dengan permasalahan yang dijumpai, karena setiap kernel mempunyai spesifikasi yang berbeda. Umumnya masalah dalam dunia nyata ini yang seringkali dijumpai adalah permasalahan non linear. Oleh kerena itu pada umumnya kernel RBF menjadi pilihan utama dalam proses pengkakulasian parameter.
• Besar kecilnya gamma atau sigma
Hal ini akan mempengaruhi hasil pada model prediksi, semakin kecilnya gamma maka noise akan dapat dihindari dan menghindari overfitting pada model prediksi.
b. Nilai e (insensitivity)
Besaran e akan mempengaruhi tingkat akurasi yang akan dihasilkan. Berikut hal yang perlu diperhatikan dalam menentukan nilai e:
• Inputan nilai e lebih besar dari nilai batas toleransi
Nilai batas toleransi menjadi besar sehingga akurasi model prediksi dapat saja meningkat.
• Inputan nilai e lebih kecil dari nilai batas toleransi
Nilai batas toleransi menjadi kecil, sehingga menyebabkan nilai akurasi model yang dihasilkan oleh prediksi dapat mengecil.
c. Loss–function
Pada umumnya loss-function yang banyak digunakan adalah tipe quadratical dan e-insensitive. Loss–function akan menentukan bentuk garis batas error yang besarnya sesuai dengan nilai e yang telah di input.
Perbedaan mendasar antara kedua loss-function itu terlentak pada bentuk yang dihasilkan. Untuk loss–function quadratical biasanya akan menghasilkan bentuk yang lebih fleksibel di bandingkan loss–function e-insensitive yang menghasilkan bentuk kaku (garis lurus).
d. Nilai C
Hal yang perlu diperhatikan dalam menentukan besarnya parameter C yaitu:
• Semakin besar nilai C
Tingkat akurasi akan semakin tinggi tetapi generalisasi data akan menurun.
• Semakin kecil nilai C
Data akan makin tergeneralisasi tetapi tingkat akurasi akan semakin menurun.
Pengkakulasian parameter ini akan menghasilkan jumlah support vector dan nilai bias. Seringkali pada pengkakulasian paramater terjadi kesalahan pada hasil output yang dihasilkan karena tidak sesuai dengan nilai output yang diinginkan. Hal ini sangat mungkin terjadi karena kesalahan pada data atau kesalahan sensor. Penyaringan data yang sebelumnya dilakukan belum tepat maka akan menimbulkan suatu gangguan atau noise. Hal ini dapat diantisipasi dengan memilih model yang memiliki besaran bias yang tinggi.
Proses pengkakulasian parameter ini merupakan tahapan yang memerlukan waktu yang cukup lama dilakukan untuk dapat menghasilkan hasil yang terbaik. Pada tahap ini diperlukan perhitungan secara berulang–
ulang dan apabila pada model prediksi tidak sesuai dengan hasil yang diinginkan, diperlukan revisi pada data yang ada dan perlu dilakukan pengkakulasian lagi.
4. Training
Pada tahapan training, data input berupa set training G = x , y , dimana x merupakan set training x (waktu dalam satuan bulan) dan y merupakan nilai penjualan aktual, akan diolah beserta dengan nilai parameter yang telah dimasukkan sebelumnya. Selanjutnya akan diadakan perhitungan dengan fungsi optimal dari regresi,
Φ w, ξ 1
2 w C ξ ξ
Nilai C diperoleh berdasarkan input pengguna, sedangkan ξ , ξ merupakan batas atas dan batas bawah dari hasil keluaran sistem. Selanjutnya berdasarkan jenis loss-function dan kernel yang dipilih pengguna, solusi perhitungan akan memperoleh Langrange multipliers yang kemudian dapat digunakan untuk menghitung nilai prediksi.
5. Validasi
Tingkat akurasi merupakan salah satu hal penting untuk mengetahui apakah suatu model prediksi layak digunakan atau tidak. Semakin tinggi tingkat akurasi yang dimiliki maka suatu model tersebut akan makin dipercaya untuk pengambilan keputusan.
Validasi merupakan tahapan untuk melakukan perbandingan antara data hasil prediksi yang dihasilkan oleh model prediksi dengan data actual yang terletak pada set validasi.
Kesalahan atau error yang muncul dapat disebabkan oleh beberapa hal sebagai berikut:
• Penyaringan data yang dilakukan
Penyaringan data merupakan bagian terpenting untuk menghindari kemungkinan–kemungkinan terjadinya error. Penyaringan ini dapat dilakukan dengan data cleaning dan menghilangkan data yang memiliki nilai yang tidak stabil dan hanya muncul sesekali.
• Penentuan parameter
Parameter–parameter seperti kernel, loss–function, penentuan besaran e dan C akan mempengaruhi besarnya tingkat error. Dengan pemilihan parameter yang sesuai dan tepat akan meminimalisasikan tingkat error yang terjadi.
• Perhitungan yang digunakan
Pemakaian metode perhitungan yang digunakan untuk menghitung tingkat kesalahan akan berpengaruh pada tingkat akurasi yang dihasilkan. Terdapat beberapa metode yang dapat digunakan untuk menghitung tingkat kesalahan. Pada kasus ini, penulis menggunakan Mean Absolute Percentage Error (MAPE) untuk menghitung besarnya tingkat kesalahan yang mudah terjadi. Tingkat akurasi ini didapat dari selisih absolut data testing dan data aktual yang dibandingkan dengan data aktual itu sendiri. Perhitungan tingkat akurasi ini dilakukan untuk mempermudah dalam mengetahui apakah feature dalam pembentukan model prediksi sudah tepat atau belum. Semakin kecil
nilai persentase kesalahan dari MAPE, maka model prediksi tersebut makin dapat lebih dipercaya dalam pengambilan keputusan.
6. Evaluasi model prediksi
Setelah memperoleh akurasi perhitungan dari model prediksi sementara, evaluasi model yang dihasilkan dengan berdasarkan pada tingkat akurasi yang dijanjikan, perlu dilakukan. Apabila hasil akurasi yang diinginkan telah tercapai, maka selanjutnya proses akan memasuki tahapan testing, sebaliknya jika evaluasi terhadap akurasi dinilai belum memuaskan, maka proses penemuan model dapat diulangi mulai dari tahap pengaturan nilai parameter. Hal ini dilakukan berulang kali hingga akurasi yang diinginkan dapat tercapai.
Model prediksi merupakan dasar dalam mengambil keputusan dalam prediksi oleh karena itu diperlukan pemilihan terhadap model prediksi yang terbaik dengan akurasi yang tinggi untuk pengambilan keputusan. Beberapa hal yang perlu diperhatikan pada sebuah model prediksi:
• Kualitas data yang digunakan
Model prediksi yang baik dimulai dari sekumpulan data yang berkualitas. Dengan menjaga kualitas data yang ada maka model prediksi akan menampilkan pergerakan data yang stabil dan meningkatkan kualitas prediksi.
• Parameter yang dipakai dalam model prediksi
Pemilihan dan penentuan parameter dalam sebuah model prediksi akan mempengaruhi bentuk hyperplane di mana semakin tipis hyperplane yang tercipta maka data yang dihasilkan makin akurat. Penggunaan parameter
seperti kernel, loss–function, penentuan besaran e dan C harus disesuaikan dengan permasalahan yang dihadapi sehingga dapat menghasilkan predective model terbaik.
• Akurasi yang dihasilkan
Semakin tinggi akurasi yang dihasilkan maka ketepatan prediksi semakin tinggi dan data yang dihasilkan makin terpercaya. Akan tetapi kadang dijumpai beberapa kasus di mana perbedaan kecil pada tingkat akurasi akan menghasilkan model prediksi yang benar – benar berbeda.
• Nilai output yang dihasilkan
Nilai yang dihasilkan pada suatu model prediksi perlu diperhatikan juga apakah sudah sesuai dengan keinginan. Dalam beberapa kasus, tingginya tingkat akurasi tidak menjamin keakuratan data yang dihasilkan.
7. Testing
Tahap terakhir yang perlu dilakukan adalah menentukan nilai prediksi yang sebenarnya. Tahapan ini dapat dilakukan jika kelima tahapan di atas telah dilalui dikarenakan pada tahapan ini, model yang sebelumnya telah diperoleh dan divalidasi akan digunakan kembali untuk memprediksikan sejumlah data penjualan pada masa depan.
8. Menampilkan hasil prediksi
Selanjutnya setelah melewati semua tahapan, hasil prediksi terhadap satuan waktu X akan diperoleh. Namun yang perlu diingat, setiap permasalahan yang ada memiliki model prediksi dan diagram prediksi yang berbeda. Oleh karena itu penerapan model yang sama pada kasus yang berbeda jelas dapat
menghasilkan hasil prediksi yang salah. Pada kasus dimana belum terdapat model prediksi, diperlukan data baru yang perlu diolah terlebih dahulu melalui tahapan-tahapan seperti yang telah dijabarkan. Besaran parameter yang tepat juga akan sangat bergantung pada data yang ada.
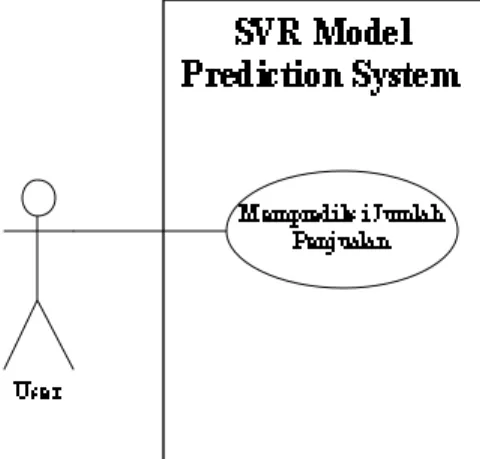
3.3. Perancangan Layar
Dalam membuat sebuah aplikasi, dibutuhkan analisis mengenai kebutuhan pengguna terhadap aplikasi tersebut. Pada sistem prediksi ini, yang lebih ditekankan adalah tingkat keakurasian dari hasil prediksi serta kemudahan dalam menggunakan aplikasi yang akan dibuat.
Gambar 3.4 menunjukkan proses pembuatan model prediksi. Pada aplikasi yang akan dibuat, terdapat beberapa fungsi sebagai berikut:
1. Fungsi Penginputan Data
Pengguna dapat memasukkan data dengan format *.xls atau *.xlsx (Microsoft Excel). Format yang digunakan dipilih dalam bentuk demikian karena format ini merupakan jenis sumber data yang cukup mudah digunakan.
2. Fungsi Modelling
Fungsi Modeling digunakan untuk menghasilkan sebuah model prediksi. Dari model yang dihasilkan, akurasi akan ditampilkan sehingga pengguna memiliki gambaran mengenai kurang lebih nilai keakuratan yang akan diperoleh dengan menggunakan model prediksi tersebut.
3. Fungsi Penginputan Jumlah Bulan
Penginputan jumlah bulan dibuat dengan dibatasi dari 1 hingga 6 bulan dengan dasar bahwa data yang disediakan oleh PT. Kompas Gramedia dalam satuan bulanan.
4. Fungsi Predict
Pada saat pengguna melakukan prediksi, maka hasil prediksi yang ditampilkan akan diikuti dengan total keseluruhan dari n bulan.
Antar muka dari suatu aplikasi merupakan fasilitas yang berfungsi agar pengguna dapat menjalankan suatu aplikasi dengan lebih mudah. Untuk itu, dibutuhkan rancangan antar muka yang baik sehingga pengguna dapat merasa nyaman namun tetap memperhatikan fungsionalitas dari aplikasi itu sendiri. Berikut perancangan layar untuk aplikasi prediksi:
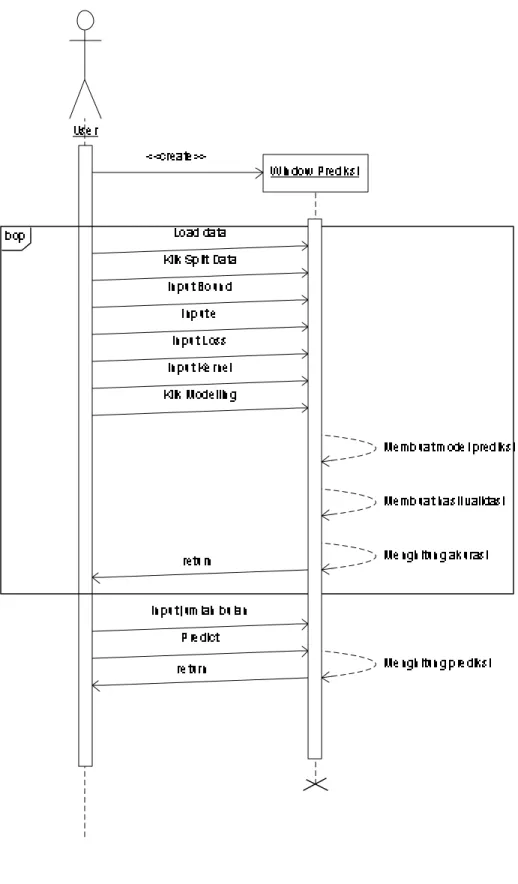
1. Rancangan Layar Awal
Rancangan layar ini diakses pertama kali ketika pengguna menjalankan program. Layar ini menampilkan panel Training yang terdiri dari fitur load data, split data, tampilan akurasi, tabel data dan modeling.
Gambar 3.5 Rancangan Layar Awal Judul Form
Panel Training Tombol Training
Gambar 3.6 Rancangan Layar Pada Panel Training 2. Rancangan Layar Ketika Melakukan Load
Ketika tombol Load diakses oleh pengguna, maka akan muncul sebuah pop up di mana pengguna dapat mencari data yang akan digunakan untuk prediksi. File yang dipilih tersebut akan muncul pada tampilan data load. Setelah melakukan load data ini maka tombol Split Data akan ditampilkan.
Judul Form
Tampilan Load Data Tombol
Load Tampilan
akurasi
Tabel data Modeling
Tombol Training
Gambar 3.7 Rancangan Layar Ketika Melakukan Load Data 3. Rancangan Layar Ketika Melakukan Split Data
Ketika pengguna telah menekan tombol Split Data yang berfungsi untuk membagi data yang telah di load dan menampilkan hasil pada tiga buah tabel yaitu Table Set yang berisikan keseluruhan set data, Table Train yang berisikan set training, dan Table Validate yang berisikan set validasi. Setelah split data dilakukan maka parameter yang dibutuhkan pada saat pembentukan model prediksi akan muncul.
Judul Form
Tampilan data load Tombol
load Tampilan
akurasi
Tabel data Modeling
Load Data
Gambar 3.8 Rancangan Layar Ketika Melakukan Split Data 4. Rancangan Layar Ketika Melakukan Modeling
Rancangan layar modeling ini digunakan untuk mengatur parameter yang digunakan untuk menghasilkan model prediksi. Parameter–parameter yang ditampilkan sebagai berikut. Setelah modeling ini dilakukan maka akan muncul hasil akurasi pada tampilan akurasi.
Bound e Loss Kernel Modeling Judul Form
Tampilan Load Data Tombol
Load Tampilan
akurasi
Tabel Data Modeling
Table Set Table Train Table Validate Tombol
Gambar 3.9 Rancangan Layar Ketika Melakukan Modeling Judul Form
Tampilan Load Data Tombol
Load Tampilan
akurasi
Tabel Data
Table Set Table Train Table Validate Tombol Training Bound e Loss Kernel Modeling Split Data
5. Rancangan Layar Ketika Akurasi Ditampilkan
Gambar 3.10 Rancangan Ketika Akurasi Ditampilkan
Rancangan layar akurasi ini untuk menampilkan hasil akurasi dari sebuah model prediksi yang dihasilkan. Setelah hasil akurasi dihasilkan maka akan muncul tombol Predicting yang berfungsi untuk beralih ke panel Predicting dan menampilkan hasil prediksi pada panel tersebut.
6. Rancangan Layar Panel Predicting
Panel Predicting ini terdiri dari tampilan data load yang berisikan nama file dari data yang sedang digunakan untuk melakukan prediksi saat ini, sebuah combo box untuk memilih banyaknya bulan untuk diprediksi, serta tampilan
Judul Form
Tampilan Load Data Tombol
Load Tampilan
akurasi
Tabel Data
Table Set Table Train Table Validate Tombol Training Bound e Loss Kernel Modeling Split Data Tombol Predicting
grafik dan tombol Predict. Batas maksimal bulan yang dapat dipilih adalah 6 bulan.
Gambar 3.11 Rancangan Layar Panel Predicting
7. Rancangan Layar S etelah Prediksi Telah Dilakukan
Tombol Predict ini digunakan untuk proses perhitungan nilai prediksi. Setelah tombol ini dipilih maka akan muncul tombol Result untuk menampilkan hasil prediksi dalam bentuk tabel dan tombol Graph untuk menampilkan grafik data.
a) Tampilan apabila tombol Result dipilih.
Apabila tombol Result dipilih maka, hasil prediksi per bulan dan total prediksi dari sejumlah bulan yang diprediksi akan ditampilkan.
Judul Form Tombol Training Tombol Training Tombol Predicting Tampilan Grafik
Tampilan Load Data Tampilan
akurasi
Gambar 3.12 Rancangan Layar Pada Bagian Result Result
Total result
Tampilan Load ata Tampilan
akurasi Judul Form Tombol Training Tombol Training Tombol Predicting Result Graph Month Result Total Result
b) Tampilan apabila tombol Graph dipilih.
Apabila tombol Graph dipilih, maka akan ditampilkan plot dari set data dan hasil prediksi yang telah dilakukan.
Gambar 3.13 Rancangan Layar Ketika Menampilkan Grafik
Tampilan Load ata Tampilan
akurasi Judul Form Tombol Training Tombol Training Tombol Predicting Result Graph Month Tampilan Grafik