MISKONSEPSI TENTANG TARAF SIGNIFIKANSI PADA PENGUJIAN HIPOTESIS DI PENELITIAN PSIKOLOGI DAN PENDIDIKAN
Oleh Dali S. Naga
Abstract.
The translation of the word significance in statistical hypothesis testing into bermakna or berarti often leads to misconception about its true meaning. Statistically, significant does not imply that the hypothesis testing is meaningful or important. It is merely a technical term to denote the probability of erroneously rejecting H0. Hence it is
better to translate it literally into signifikan.
Keywords: Level of significance, Hypothesis testing.
Pendahuluan
Sejumlah penelitian psikologi dan pendidikan menggunakan statistika untuk pengujian hipotesis. Berbekal data statistik sampel, pengujian hipotesis tentang parameter populasi melibatkan level atau degree of significance yang sering dinyatakan melalui lambang . Pada sejumlah penelitian atau metodologi penelitian psikologi dan pendidikan, kata Inggris ini diterjemahkan menjadi bermakna atau kebermaknaan serta berarti atau keberartian. Masalah bermunculan pada orang yang kurang memahami arti sesungguhnya dari kata significance di dalam statistika.
Kalau kita bertanya apa yang bermakna atau berarti pada kebermaknaan atau keberartian itu, maka mulai muncul penjelasan yang menunjukkan miskonsepsi. Pada hipotesis korelasi, misalnya, miskonsepsi ini mengemuka ketika kebermaknaan atau keberartian itu diterjemahkan sebagai korelasi yang besar atau kuat atau penting. Pada hipotesis selisih dua rerata, misalnya, miskonsepsi ini tampak ketika kebermaknaan atau keberartian itu diterjemahkan sebagai selisih yang besar atau yang penting.
Demi kejelasan serta untuk mencegah timbulnya miskionsepsi, ada baiknya, kita mempelajari sejumlah bacaan tentang statistika. J. A. Capon (1988, h. 203), misalnya, jelas-jelas menyatakan bahwa ada perbedaan arti “significance” dalam pengertian umum dan artinya di dalam pengertian statistika. Th. Wonnacott dan J. Wonnacott (1990, h. 260) menyatakan bahwa ada masalah pada istilah “statistically significant.” Ini adalah kata teknis yang hanya mengertikan bahwa telah cukup banyak data yang terkumpul untuk memastikan bahwa perbedaan betul ada. Ini tidak berarti bahwa perbedaan itu harus penting.
itu. Kita melihat apa yang diartikan dengan kata significant ketika peneliti sampai kepada keputusan pada pengujian hipotesis.
Pengujian Hipotesis
Setelah peneliti menyusun hipotesis penelitian, maka mereka mencari data untuk menguji hipotesis penelitian mereka itu. Kalau data yang terkumpul bersifat probabilistik, maka biasanya, para peneliti menguji hipotesis mereka dengan bantuan statistika. Bersama itu, mereka tunduk kepada peraturan yang ditentukan di dalam statistika. Aturan pertama adalah penuangan hipotesis penelitian ke dalam hipotesis statistika. Di sini, para peneliti hanya memiliki kebebasan yang terbatas. Tidak boleh tidak, mereka harus memilih parameter statistika serta statistik statistika yang sudah tersedia untuk mengungkapkan hipotesis statistika mereka. Mereka hanya memiliki kebebasan untuk memilih di antara beberapa parameter seperti rerata, proporsi, koefisien korelasi, dan sejumlah parameter seperti itu.
Pada pengujian hipotesis statistika, peneliti perlu merumuskan hipotesis itu ke dalam bentuk H0 dan H1 atau notasi lain yang sama artinya. Pada dasarnya hanya boleh
ada dua pilihan H0 atau H1 dan tidak boleh ada pilihan ketiga atau pilihan tumpang tindih
di antara H0 dan H1. Dengan demikian, kalau sampai salah satu H ditolak maka tidak ada
lagi pilihan lain kecuali H lainnya harus diterima. Itulah sebabnya mengapa kalau H0
ditolak maka H1 harus diterima.
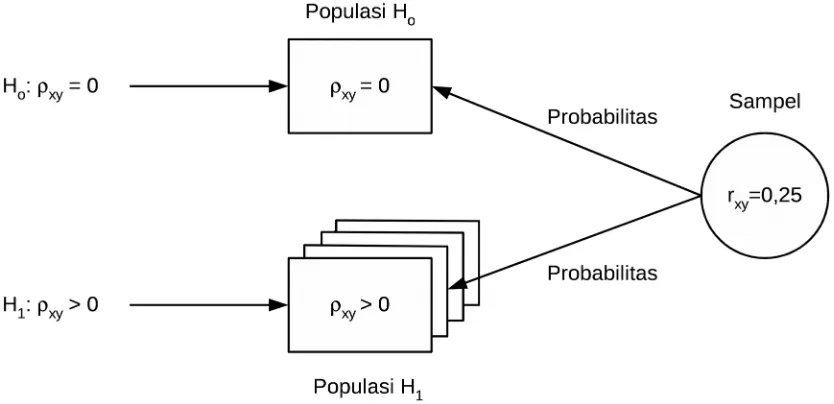
Untuk melihat bagaimana hipotesis statistika diuji, kita lihat Gambar 1. Pada H0
terdapat hubungan = sehingga hanya ada satu populasi H0. Dalam hal ini, hanya ada satu
populasi yang ditunjukkan oleh parameter ρXY = 0. Sebaliknya pada H1 terdapat hubungan
>, <, atau sehingga di sini terdapat banyak sekali populasi. Dalam hal ini, terdapat banyak sekali populasi yang ditunjukkan oleh ρXY > 0. Selanjutnya, pada Gambar 1
ditunjukkan pula sampel rXY = 2,25. Di sini, ρXY adalah parameter populasi koefisien
korelasi linier sedangkan rXY adalah statistik sampel koefisien korelasi linier.
Kita melihat tujuan dari pengujian hipotesis statistika ini. Dalam hal ini, peneliti hanya memiliki satu data sampel yakni statistik sampel rXY = 0,25 dan peneliti tidak
memiliki data populasi parameter ρXY. Dengan data atau statistik sampel itu, peneliti ingin
mengambil keputusan tentang parameter populasi. Caranya adalah peneliti akan memilih apakah sampel itu berasal dari populasi yang sama dengan populasi H0 atau berasal dari
populsi yang sama dengan populasi H1. Tampak pada Gambar 1 bahwa peneliti tidak
mungkin menyelidiki apakah sampel berasal dari populasi yang sama dengan populasi H1
karena terlalu banyak populasi H1. Jadi, peneliti hanya mungkin menyelediki apakah
sampel berasal dari populasi yang sama dengan populasi H0.
Pengambilan Keputusan
Peneliti hanya menyelidiki atau menguji apakah sampel rXY = 0,25 berasal dari
populasi yang sama dengan populasi H0 yakni ρXY = 0. Untuk itu peneliti menggunakan
probabilitas atau kemungkinan. Kalau peneliti menemukan bahwa ada probabilitas atau kemungkinan yang besar bahwa sampel berasal dari populasi yang sama dengan populasi H0, maka tanpa ragu-ragu lagi, peneliti berkeputusan untuk menerima hal itu yakni
menerima H0. Peneliti menerima bahwa sampel yang dimilikinya berasal dari populasi
yang sama dengan populasi H0. Akibatnya adalah hipotesis H1 ditolak.
Sebaliknya kalau peneliti menemukan bahwa hanya kecil yakni tidak lebih dari α (α itu kecil misalnya 0,01 atau 0,05) probabilitas atau kemungkinan bahwa sampel berasal dari populasi yang sama dengan populasi H0 maka peneliti menjadi ragu-ragu.
Kalau peneliti menerima H0 rasanya terlalu berbahaya karena probabilitas atau
kemungkinannya terlalu kecil. Tetapi kalau peneliti berani menolak H0 maka ada saja
risiko kelirunya karena ada probabilitas sebesar α (walau kecil) bahwa sampel berasal dari H0. Keputusannya adalah peneliti memilih menolak H0 dengan risiko probabilitas
keliru sebesar α. Risiko keliru dalam pengambilan keputusan menolak H0 inilah yang
dinamakan taraf signifikansi.
Kalau sampai H0 ditolak maka karena tidak ada pilihan ketiga atau pilihan
tumpang tindih, maka satu-satunya pilihan yang ada adalah menerima H1. Tampak di sini
bahwa dengan taraf signifikansi sebesar α tidak disebut-sebut risiko untuk menerima H0
tetapi ada risiko sebesar probabilitas α untuk keliru menolak H0. Tentang bagaimana
caranya mengetahui probabilitas atau kemungkinan itu, peneliti perlu mengetahui kedudukan sampel rXY = 0,25 di antara semua sampel yang dapat ditarik dari populasi H0
atau dengan kata lain kedudukan sampel rXY = 0,25 di dalam distribusi probabilitas
pensampelan dari sampel rXY. Hal itu tidak dibicarakan di sini.
Penjelasan Taraf Signifikansi
Setiap buku statistika menceriterakan taraf signifikansi α. Kita melihat beberapa di antaranya. Selain menjelaskan bahwa taraf signifikansi adalah probabilitas keliru di dalam pengambilan keputusan untuk menolak H0, mereka juga menambahkannya dengan
berbagai keterangan lainnya. D.H. Sanders, A.F. Murph, dan R.J. Eng (1980, h. 178) mengatakannya sebagai perbedaan signifikan di antara sampel dan H0 yang menjurus ke
terjadi karena kebetulan [menolak H0]. R.I. Levin dan D.S. Rubin (1998, h. 408)
mengatakan bahwa itu adalah perbedaan di antara statistik sampel dengan parameter populasi yang dihipotesiskan [H0]. J.L. Folks (1981, h. 168) mengatakannya sebagai
disjunksi logik yakni probabilitas statistik uji seekstrim seperti yang tampak sesungguhnya ketika hipotesis [H0] adalah benar. S.P. Gordon dan F.S. Gordon (1994, h.
385) mengatakannya sebagai terlalu tak boleh jadi untuk terjadi karena kebetulan menolak H0.
T.H. Wonnacott dan R.J. Wonnacott (1990, h. 260) mengatakan bahwa hal itu hanya mengatakan bahwa cukup banyak data sudah terkumpul untuk memastikan bahwa ada perbedaan [di antara sampel dan H0]. R.M. Yaremko, H. Harari, R.C. Harrison, dan E.
Lynn (1982, h. 184) mengatakannya sebagai nilai-p yakni probabilitas untuk memperoleh perbedaan [di antara sampel dan H0]. E.W. Minium (1978, h. 253 dan 270)
mengatakannya sebagai derajat kejarangan terjadi [bahwa sampel berasal dari H0]. J.
Welkowitz, R.B. Ewen, dan J. Cohen (1982, h. 129 dan 183) mengatakannya sebagai kurang dari α sebagai cukup tidak boleh jadi atau nyata beda [sampel] dari H0. J.D. Cryer
dan R.B. Miller (1994, h. 471) mengatakannya sebagai tidak boleh jadi untuk terjadi secara kebetulan murni [bahwa sampel berasal dari H0]. Dan R.J. Shavelson (1996, h.
263) mengatakannya sebagai tidak boleh jadi [sampel berasal dari H0]. Dan Mason dan
Bramble (1989, h. 210) menyatakan bahwa “dengan signifikansi statistika, kita hanya mengertikan bahwa hasilnya akan tidak boleh-jadi terjadi secara peluang jika hipotesis nol adalah benar. Itu tidak berarti bahwa hasilnya adalah penting atau berharga dalam arti lain.”
Penutup
Dengan penjelasan seperti ini, rasanya, terjemahan kata significant ke "bermakna" atau "berarti" mudah mendatangkan miskonsepsi. Barangkali kata "nyata" lebih memadai dalam arti "besarnya nyata berbeda" di antara sampel dan H0 atau "taraf kenyataan"
bahwa sampel bukan berasal dari populasi H0. Tetapi ini pun mudah mengundang
miskonspsi juga. Karena itu, sebaiknya kita menggunakan saja padanan berbentuk "taraf signifikansi."
Daftar Pustaka
Capon, J.A. (1988). Elementary statistics for the social sciences. Belmont, CA: Wadsworth Publishing Company.
Cryer, J.D. and R.B. Miller (1994). Statistics for business: data analysis and modeling. Belmont, CA: Wadsworth, Inc.
Folks, J.L. (1981). Ideas of statistics. New York: John Wiley & Sons.
Levin, R.I. and D.S. Rubin (1998). Statistics for management. Seventh edition. Upper-Saddle River, NJ: Prentice-Hall International Inc.
Mason, J.M. and W.J. Bramble (1989). Understanding and conducting research: applications in education and behavioral sciences. Second edition. New York: Mc-Graw-Hill Book Company.
Minium, E.W. (1978). Statistical reasoning in psychology and education. Second edition. New York: John Wiley & Sons.
Sanders, D.H., A.F. Murph, and R.J. Eng (1980). Statistics: a fresh approach. Second edition. New York: McGraw-Hill International Book Company.
Shavelson, R.I. (1996). Statistical reasoning for the behavioral sciences. Third edition. Boston: Allyn and Bacon.
Welkowitz, J., R.B. Ewen, and J. Cohen (1982). Introductory statistics for the behavioral sciences. Third edition. San Diego: Harcourt Brace Jovanovich.
Wonnacott, T.H. and R.J. Wonnacott (1990). Introductory statistics for business and economics. Third edition. New York: John Wiley & Sons.