PENERAPAN FUNGSI
ASSOCIATION RULE
PADA
DATA MINING
UNTUK MENGOPTIMALKAN TATA LETAK BARANG DI TOSERBA
MENGGUNAKAN
ALGORITMA FREQUENT PATTERN GROWTH
(Studi kasus : Toserba BORMA Cipadung Bandung)
Riki Irfan Hidayat#1, Edi Mulyana*2, Jumadi*3
Jurusan Teknik Informatika, Universitas Islam Negeri Sunan Gunung Djati Bandung Jalan A.H. Nasution Nomor 105 Cibiru, Bandung
1[email protected], 2[email protected], 3[email protected]
Abstrak
Terus bertambahnya data transaksi yang dialami oleh Toserba BORMA Cipadung menyebabkan semakin menumpuknya data tersebut, namun pemanfaatannya belum maksimal, hanya digunakan sebagai laporan penjualan saja.
Dengan menggunakan Data mining data tersebut dapat lebih dimaksimalkan pemanfaatannya yaitu
dengan mencari informasi yang tersembunyi dalam data tersebut, yaitu pola beli konsumen dalam berbelanja berupa kebiasaan suatu produk dibeli bersama dengan produk apa. Informasi ini dapat dijadikan salah satu referensi bagi manajer dalam menentukan tata letak barang yang optimal sebagai salah satu upaya untuk meningkatkan keunggulan dalam persaingan bisnis retail.
Teknik Data Mining yang digunakan adalah Association Rule yang mempunyai 2 parameter yaitu
support dan confident dengan menerapkan Algoritma Frequent Pattern Growth. Hasil pencarian informasi dalam data transaksi BORMA dari tanggal 8 sampai dengan 9 April 2013 sebanyak 3.242 transaksi diperoleh informasi
yaitu jika konsumen membeli Asesoris Komputer, maka akan membeli ATK dengan nilai support4 % dan
confident tertinggi yaitu 93%, dan jika konsumen membeli Mie Instant, maka akan membeli Susu Dalam Kemasan dengan nilai support tertinggi yaitu 30% dan nilai confident33%.
Kata kunci :assosiation rule, confident, data mining, frequent pattern growth, support.
1. Pendahuluan
Perkembangan teknologi komputer saat ini sudah semakin pesat, yang mengakibatkan hampir seluruh aktivitas kehidupan manusia menggunakan bantuan komputer, hal ini berdampak pada peningkatan data komputer secara signifikan, jumlah data komputer pada tahun 2008 mencapai 487 milyar Giga Byte (Gantz, 2009 : 1). Jumlah ini terus bertambah hingga sekarang sehingga
menimbulkan fenomena data explosion atau
ledakan jumlah data.
Fenomena ini juga dialami oleh PT. Harja Gautama Lestari – Toserba Borma, Cipadung – Bandung. Sebagai sebuah perusahaan retail yang berdiri sejak tahun 2000, data transaksi Borma mengalami peningkatan secara signifikan, jumlah data dari tanggal 8 s.d. 9 April 2013 sebanyak 3.242 transaksi, diperkirakan jumlah seluruhnya mencapai ± 7,5 juta transaksi.
Namun pemanfaatan data tersebut belum optimal, karena selama ini hanya digunakan sebagai laporan penjualan saja sehingga dikenal dengan
istilah “rich of data but poor of information”
(Pramudiono, 2003 : 1).
Dengan menggunakan Data Mining data
tersebut dapat lebih dioptimalkan pemanfaatannya yaitu dengan mencari informasi yang tersembunyi dan jarang diketahui. Informasi tersebut dapat digunakan untuk meningkatkan keunggulan dalam persaingan bisnis retail.
Salah satu fungsi Data Mining adalah
Association Rule, yaitu fungsi untuk mencari
informasi berupa asosiasi atau hubungan antar item
dalam suatu data transaksi dan menampilkannya dalam bentuk pola yang menjelaskan tentang pola beli konsumen dalam berbelanja. Pengetahuan mengenai pola inilah yang nantinya bisa menjadi pedoman untuk meningkatkan keunggulan dalam persaingan bisnis retail dengan cara mengoptimalkan tata letak barang yang sesuai dengan pola beli konsumen sehingga dapat meningkatkan kenyamanan konsumen dalam berbelanja. Suatu pola ditentukan oleh dua
parameter, yaitu Support dan Confidence. Support
(nilai penunjang) adalah persentase kombinasi item
tersebut dalam database, sedangkan Confidence
Algortima yang digunakan pada penelitian ini
adalah Frequent Pattern Growth atau FP-Growth,
algortima ini mengadopsi teknik Divide and
Conguer, langkah pertama, algortima ini
memadatkan database yang mewakili frequent
itemset (data yang paling sering muncul) kedalam
Frequent Pattern Tree atau FP-Tree yang
menyimpan informasi hubungan antar tiap itemset.
Kemudian membagi database yang telah dipadatkan
kedalam sekumpulan conditional database,
masing-masing conditional database terhubung dengan satu
frequent item dan pencarian informasi dilakukan
secara terpisah (Han, 2006 : 243). Metode Divide
and Conguer digunakan untuk memecahkan masalah menjadi submasalah yang lebih kecil sehingga mempermudah menemukan pola (Chandrawati dalam Suprasetyo, 2012:2).
2. Data Mining
Data mining merupakan ekstraksi informasi
yang tersirat dalam sekumpulan data. Data mining
juga dapat diartikan sebagai pengekstrakan informasi baru yang diambil dari bongkahan data besar yang membantu dalam pengambilan keputusan (Prasetyo, 2012:2).
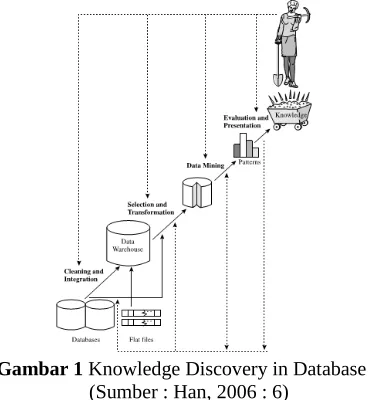
Data mining merupakan salah satu tahap dalam proses pencarian pengetahuan atau KDD
(Knowledge Discovery in Database), dapat dilihat pada Gambar 1
Gambar 1 Knowledge Discovery in Database (Sumber : Han, 2006 : 6)
Secara umum proses Knowledge Discoery in
Database dapat dijelaskan sebagai berikut :
A. Data cleaning
Sebelum proses data mining dapat
dilaksanakan, perlu dilakukan proses cleaning atau
pembersihan pada data yang menjadi fokus KDD.
Proses cleaning meliputi antara lain memeriksa data
yang tidak lengkap atau missing value dan
mengurangi kerancuan / noisy.
B. Data integration
Menggabungkan berbagai sumber data yang
dibutuhkan atau integration, kualitas data yang
dimiliki akan sangat menentukan kualitas dari hasil
data mining.
C. Data selection
Pemilihan atau seleksi data yang diperlukan dari sekumpulan sumber data sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi inilah yang akan digunakan untuk
proses data mining. Disimpan dalam suatu berkas
terpisah dari sumber data.
D. Transformation
Data-data yang telah melalui proses cleaning,
integration, dan selection tidak bisa langsung digunakan, tahap ini merupakan proses kreatif untuk merubah bentuk data kedalam bentuk yang dapat dieksekusi oleh program. Bentuk yang dibuat sangat tergantung dari informasi apa yang akan dicari dalam data tersebut.
E. Data mining
Data mining adalah proses mencari pola atau informasi menarik dalam data dengan menggunakan teknik atau metode tertentu. Teknik,
metode, atau algoritma dalam data mining sangat
bervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
F. Interpretaion atau Evaluation
Pola-pola yang diidentifikasi oleh program kemudian diterjemahkan atau diinterpretasikan kedalam bentuk yang bisa dimengerti manusia untuk membantu dalam perencanaan strategi bisnis.
3. Association Rule
Aturan asosiasi (Association rules) atau
analisis afinitas (afinity analysis) berkenaan dengan
studi tentang ‘apa bersama apa’. Ini bisa berupa studi transaksi di supermarket, misalnya seseorang yang membeli shampoo juga membeli sabun mandi. Disini berarti shampoo bersama dengan sabun mandi. Karena awalya berasal dari studi tentang database transaksi pelanggan untuk menentukan kebiasaan suatu produk dibeli bersama produk apa, maka aturan asosiasi juga sering dinamakan market basket analysis (Santoso, 2007:225).
Strategi umum yang diadopsi oleh banyak algoritma penggalian aturan asosiasi adalah memecah masalah kedalam dua pekerjaan utama (Prasetyo 2012 : 5), yaitu :
A. Frequent itemset generation
Tujuannya adalah mencari semua itemset yang
memenuhi ambang batas atau minimum support.
Itemset ini disebut frequent itemset (itemset yang
sering muncul). Nilai support ini diperoleh dengan
rumus dapat dilihat pada Rumus 1
Support
(
A
)=
Jumla h Transaksi Mengandung A
TotalTransaksi
(Sumber : Kusrini, 2009 : 150)
Rumus 1 menjelaskan bahwa nilai support
diperoleh dengan cara membagi jumlah transaksi yang mengandung item A dengan jumlah seluruh transaksi.
B. Rule generation
Tujuannya adalah mencari aturan atau pola
dengan confidence tinggi dari frequentitemset yang
ditemukan dalam langkah itemset generation.
Aturan ini kemudian disebut aturan yang kuat
(strong rule).
Rumus untuk menghitung confidence dapat
dilihat pada Rumus 2
Confidence
=(
A → B
)=
Jumla h Transaksi Mengandung A dan B
Jumla h Transaksi Mengandung A
Rumus 2 Rumus mencari nilai confidence
(Sumber : Kusrini, 2009 : 151) Rumus 2 menjelaskan bahwa untuk mencari nilai confidence itemset A,B yaitu dengan membagi jumlah transaksi yang mengandung item A dan B dengan seluruh transaksi yang mengandung item A.
4. Analisis dan Perancangan Sistem 4.1 Analisis Sistem yang Sedang Berjalan A. Deskripsi Masalah
Berdasarkan analisa dan penelitian yang dilakukan di Toserba Borma, Cipadung – Bandung, setiap hari terjadi transaksi jual beli yang datanya tersimpan dalam database penjualan. Jumlah transaksi selama 2 hari saja yaitu pada bulan April tanggal 8 s.d. 9 tahun 2013 mencapai 3.242 transaksi, ini merupakan angka yang besar apabila kita mengingat awal mula berdiri Toserba Borma Cipadung yaitu pada tahun 2000, tentu data yang terkumpul akan sangat besar sekali. Namun selama ini data transaksi tersebut hanya digunakan sebagai laporan penjualan saja kepada pihak atasan tanpa ada suatu proses untuk mendapatkan manfaat lebih dari adanya data tersebut.
B. Pemecahan Masalah
Aplikasi data mining yang akan dibangun ini
akan memberikan solusi yaitu dengan menggali atau mengekstrak informasi yang tersembunyi dalam data transaksi, guna mendapatkan manfaat lebih dari adanya data tersebut.
Informasi yang dicari yaitu pola beli konsumen berupa kebiasaan suatu produk dibeli bersamaan dengan produk apa, informasi ini bermanfaat untuk menata layout toko yang ideal, misalnya konsumen biasanya membeli roti dengan susu. Maka dalam layout toko posisi roti idealnya berdekatan dengan susu.
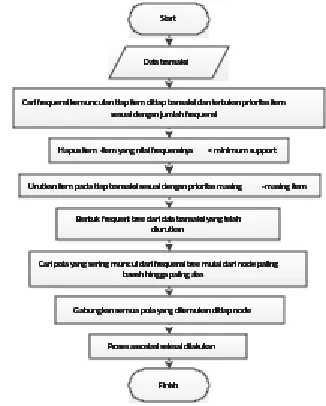
4.2 Analisis Pencarian Pola
Proses pencarian pola adalah serangkaian proses yang harus dijalani secara bertahap dalam mencari pola yang tersembunyi dalam sebuah database. Dimulai dari proses pengumpulan data,
preprocessing (data cleaning, integration, selection, transformation), data mining dan pattern evaluation.
Secara umum flowchart proses pencarian pola
dapat dilihat pada Gambar 2
Gambar 2 Flowchart proses pencarian pola
Tahap Data mining merupakan tahap yang
paling utama, pada tahap ini algoritma Frequent
Pattern Growth digunakan untuk mencari pola-pola
yang tersembunyi dalam data. Flowchart cara kerja
algoritma Frequent Pattern Growth secara umum
dapat dilihat pada Gambar 3
Gambar 3Flowchart cara kerja FP-Growth A. Pengumpulan Data
Sumber data yang digunakan dalam penelitian ini berasal dari data transaksi di Toserba Borma, Cipadung – Bandung.
B. Data preprocessing
terlebih dahulu (preprocessing) tujuannya selain untuk meningkatkan kualitas data, konsistensi dan
hasil mining, juga untuk meningkatkan efisiensi dan
mempermudah proses data mining (Han, 2006, 47).
Pada tahap ini dilakukan proses Data
cleaning, Data integration, Data selection, dan
Data transformation.
1. Data cleaning
Pada tahap ini data yang digunakan kita coba
untuk lengkapi kekurangannya (missing values),
menghilangkan kerancuan (noisy) dan memperbaiki
data yang tidak konsisten.
1.1 Missing values
Pada data transaksi penjualan selama 2 hari tidak terdapat atribut kategori pada data tersebut, sedangkan dalam penelitian ini justru yang akan digunakan adalah kategori barang bukan nama barang, data transaksi tersebut dapat dilihat pada Tabel 1
Tabel 1 Tabel data BORMA 8-9 April 2013
Tanggal Mid Notrx Code Description Harga D J 08/04/201
600ML/24 1650 0 1650 08/04/201
MANIS 397 7800 0 3120 0
Keterangan : selengkapnya dapat dilihat pada file
lampiran 1 - tbl_transaksi_borma.xls dalam CD laporan
Kita tambahkan atribut kategori pada setiap barang yang dibeli, dengan cara mengambil 3 digit angka pertama pada kolom code kemudian kita tentukan kategori barangnya. Misalnya code 251.3401 untuk barang DAIA DET BUNGA 900G/12 dan code 251.1205 untuk barang RINSO AN 700GR/12 maka kita dapat menentukan code barang 251 termasuk kategori DETERJEN, hasil tahap ini dapat dilihat pada Tabel 2
Tabel 2 Tabel data transaksi setelah tahap
Missing values
Tanggal Mid Notrx Code Kategori Description H 08/04/201
3 7:38:42 POS01 114297 002.1013 BUAH
3 8:07:27 POS01 114299 024 TELUR AYAM TELUR AYAM 13400 08/04/201
3 8:07:27 POS01 114299 024 TELUR AYAM TELUR AYAM 12815 08/04/201
3 8:07:27 POS01 114299 202.2101 SUSU
Keterangan : selengkapnya dapat dilihat pada file
lampiran 2 - tbl_transaksi_borma_1_missing_ values.xls dalam CD laporan.
1.2 Noisy
Setelah atribut kategori ditambahkan, maka langkah selanjutnya adalah menghilangkan
kerancuan (noisy) dalam data tersebut teknik yang
digunakan adalah binding untuk mengurutkan data berdasarkan notrx agar data mudah dibaca. Data transaksi setelah diurutkan dapat dilihat pada Tabel 3
Tabel 3 Tabel data transaksi setelah tahap noisy
Tanggal Mid Notrx Code Kategori Description H 08/04/201
8 82.353 501.1868 ASESORIS KOMPUTER MOUSE VOTER USB 15600 08/04/201
8 82.355 192.2121 KALKULATOR
CITIZEN
SDC-Keterangan : selengkapnya dapat dilihat pada file
lampiran 3 - tbl_transaksi_borma_2_noisy.xls
dalam CD laporan.
2. Data integration
Pada tahap ini berbagai sumber data yang
menunjang digabungkan (integration), namun
karena sumber data yang digunakan hanya satu, maka tahap ini tidak dilakukan.
3. Data selection
Atribut pada data transaksi yang sesuai dengan
kebutuhan untuk mencari pola kita pilih (selection).
Langkah pertama adalah menggabungkan beberapa kategori yang sama yang terdapat dalam satu transaksi menjadi satu kategori, misalnya pada notrx 82.353 terdapat 3 kategori yaitu ASESORIS KOMPUTER maka kita anggap dalam transaksi itu hanya satu kategori saja. Data transaksi setelah dilakukan penggabungan kategori dapat dilihat pada Tabel 4
Tabel 4 Tabel data transaksi setelah penggabungan kategori
Tanggal Mid Notrx Code Kategori Description H 08/04/201
3 13:38:39 POS18 82.358 501.1403 ASESORIS KOMPUTER FLASH
Keterangan : selengkapnya dapat dilihat pada file
Langkah selanjutnya adalah dengan memilih top 25 kategori yang paling sering dibeli oleh konsumen, pada penelitian ini hanya digunakan 25 kategori terbanyak sebagai sampel, terdapat 122 kategori yang dibeli oleh konsumen dapat dilihat pada Tabel 5
Tabel 5 Tabel kategori yang dibeli oleh konsumen
Kode Kategori Jumlah Dalam Transaksi 291 SUSU DALAM KEMASAN 436 292 MINUMAN DALAM BOTOL 426 211 MIE INSTANT 416 402 SHAMPOO 357 213 BISKUIT KEMASAN 355 251 DETERJEN 293 214 MAKANAN RINGAN 272
Keterangan : lanjut pada lampiran 5 (kategori yang dibeli oleh konsumen) pada laporan bagian lampiran
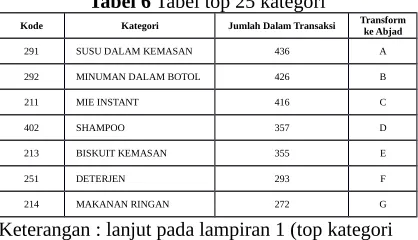
Transaksi yang mengandung kategori yang tidak termasuk dalam top 25 maka akan dihapus. Pada tabel top 25 kategori kita tambahkan abjad dari A sampai Y, dapat dilihat pada Tabel 6.
Tabel 6 Tabel top 25 kategori
Kode Kategori Jumlah Dalam Transaksi Transformke Abjad 291 SUSU DALAM KEMASAN 436 A 292 MINUMAN DALAM BOTOL 426 B 211 MIE INSTANT 416 C 402 SHAMPOO 357 D 213 BISKUIT KEMASAN 355 E 251 DETERJEN 293 F 214 MAKANAN RINGAN 272 G
Keterangan : lanjut pada lampiran 1 (top kategori yang dibeli oleh konsumen) .
Data transaksi setelah dilakukan pemilihan top 25 terbanyak dapat dilihat pada Tabel 7
Tabel 7 Tabel data transaksi top 25 kategori
Tanggal Mid Notrx Code Kategori Description H 08/04/201
3 12:09:31 POS18 82.353 501.1526
ASESORIS
3 13:32:20 POS18 82.354 031.1461 ATK ISI BOLPEN PARKER 17300 08/04/201
3 13:38:39 POS18 82.358 501.1403
ASESORIS
3 13:50:39 POS18 82.362 501.5784
ASESORIS
4 031 ATK ATK/BUKU 1500 08/04/201
3 13:57:20 POS18 82.365 031 ATK ATK/BUKU 1600
Keterangan : selengkapnya dapat dilihat pada file
lampiran 6 - tbl_transaksi_borma_3_data_ selection_r1.xls dalam CD laporan.
4. Data transformation
Pada tahap ini kita pilih atribut yang akan digunakan yaitu hanya notrx dan kategori dan menghapus atribut yang lain , namun kategori yang digunakan harus sudah berupa abjad seperti yang telah ditentukan pada tabel 6, data transaksi setelah dipilih atributnya dapat dilihat pada Tabel 8
Tabel 8 Tabel data transaksi pemilihan atribut
Notrx Transform ke Abjad 82.353 Y
Keterangan : selengkapnya dapat dilihat pada file
lampiran 7 - tbl_transaksi_borma_3_data_ selection_r2.xls dalam CD laporan.
Karena kita akan mencari pola hubungan tiap kategori dalam sebuah transaksi maka minimal ada 2 kategori dalam sebuah transaksi, transaksi yang hanya terdapat satu kategori kita hapus dapat dilihat pada Tabel 9.
Tabel 9 Tabel data transaksi minimal 2 kategori tiap transaksi
Notrx Transform ke Abjad 82.359 Y
Keterangan : selengkapnya dapat dilihat pada file
lampiran 8 - tbl_transaksi_borma_3_data_ selection_r3.xls dalam CD laporan
.
Kemudian tabel 9 diatas kita rubah dalam bentuk matrik biner dimana baris menyatakan notrx dan kolom menyatakan barang yang dibeli. Data transaksi dalam bentuk matrik biner dapat dilihat pada Tabel 10
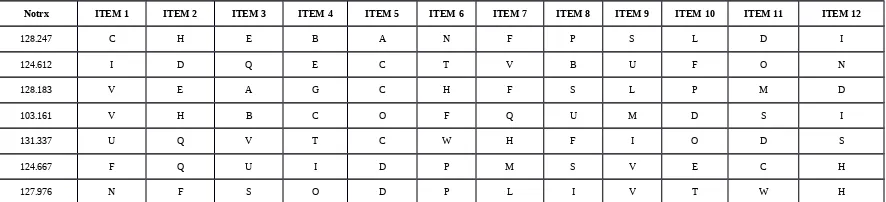
Notrx ITEM 1 ITEM 2 ITEM 3 ITEM 4 ITEM 5 ITEM 6 ITEM 7 ITEM 8 ITEM 9 ITEM 10 ITEM 11 ITEM 12 128.247 C H E B A N F P S L D I 124.612 I D Q E C T V B U F O N 128.183 V E A G C H F S L P M D 103.161 V H B C O F Q U M D S I 131.337 U Q V T C W H F I O D S 124.667 F Q U I D P M S V E C H 127.976 N F S O D P L I V T W H
Keterangan : selengkapnya dapat dilihat pada file lampiran 9 - tbl_transaksi_borma_3_data_selection_r4.xls
dalam CD laporan.
Pada tahap ini data preprocessing sudah selesai
dan data transaksi sudah siap untuk di mining.
C. Data Mining
Pada tahap ini FP-Tree dibangkitkan yang akan
digunakan oleh algoritma FP Growth untuk
menentukan frequent itemsest. Pada penelitian ini
akan diambil contoh data sebanyak 10 transaksi
dapat dilihat pada Tabel 11. Batasan minimum
support yang diberikan 20% yaitu 2 atau
2
10
yaitu 0,2 (rumus untuk menghitung support dapat
dilihat pada Rumus 1) dan batasan confidence yaitu
75%, dalam pembentukan FP-Tree diperlukan 2 kali
penelurusan database.
Tabel 11 Tabel contoh data transaksi setelah tahap transformation
notrx Item 1 Item 2 Item 3 Item 4 Item 5
127.624 X R A T C 103.173 C G A H
131.326 N H G A 128.214 A C H
124.547 R D A 114.550 G C P 124.650 X J I 127.623 T E L 131.324 G Q K 131.024 O U D
Penelusuran database pertama digunakan untuk
menghitung nilai support masing-masing item dan
menghapus item yang nilai support nya kurang dari
minimum support yang telah ditentukan. Hasil dari penelusuran pertama ini adalah diketahuinya jumlah
frequensi kemunculan setiap item pada data
transaksi dan digunakan untuk mengurutkan item
berdasarkan frequensi kemunculan yang paling tinggi dapat dilihat pada Tabel 12
Tabel 12 Tabel frequensi setiap item
Item Frequensi Support
A 5 5/10 = 0,5 atau 50% C 4 4/10 = 0,4 atau 40%
Lanjutan Tabel 12 Tabel frequensi setiap item
Item Frequensi Support
G 4 4/10 = 0,4 atau 40% H 3 3/10 = 0,3 atau 30% X 2 2/10 = 0,2 atau 20% R 2 2/10 = 0,2 atau 20% T 2 2/10 = 0,2 atau 20% D 2 2/10 = 0,2 atau 20% N 1 1/10 = 0,1 atau 10% P 1 1/10 = 0,1 atau 10% J 1 1/10 = 0,1 atau 10% I 1 1/10 = 0,1 atau 10% E 1 1/10 = 0,1 atau 10% L 1 1/10 = 0,1 atau 10% Q 1 1/10 = 0,1 atau 10% K 1 1/10 = 0,1 atau 10% O 1 1/10 = 0,1 atau 10% U 1 1/10 = 0,1 atau 10%
Dari hasil tersebut diperoleh item yang
memiliki frekuensi di atas minimum support > 2 yaitu A,C,G,H,X,R,T, dan D yang kemudian diberi
nama Frequent List dapat dilihat pada Tabel 13.
Frequent List inilah yang akan berpengaruh pada
pembangkitan FP-Tree, sedangkan item yang nilai
support nya < 2 akan dihapus yaitu item N,P,J,I,E,L,Q,K,O, dan U.
Tabel 13 Tabel Frequent List
Item Frequensi Support
A 5 5/10 = 0,5 atau 50% C 4 4/10 = 0,4 atau 40% G 4 4/10 = 0,4 atau 40% H 3 3/10 = 0,3 atau 30% X 2 2/10 = 0,2 atau 20% R 2 2/10 = 0,2 atau 20% T 2 2/10 = 0,2 atau 20% D 2 2/10 = 0,2 atau 20%
Setelah diperoleh Frequent List, urutkan item pada
data transaksi berdasarkan frequensi paling tinggi dapat dilihat pada tabel 14.
berdasarkan frequent list
notrx Item 1 Item 2 Item 3 Item 4 Item 5
127.624 A C R T X 103.173 A C G H
131.326 A G H 128.214 A C H 124.547 A R D 114.550 C G
124.650 X 127.623 T 131.324 G 131.024 D
Setelah item dalam data transaksi disusun ulang
berdasarkan frequent list, penelurusan database yang
kedua dilakukan untuk membangkitkan FP-Tree
yang dimulai dari membaca notrx 127.624 yang akan menghasilkan simpul A,C,R,T, dan X sehingga
terbentuk lintasan {NULL} → A → C → R → T →
X dengan nilai support awal 1, dapat dilihat pada Gambar 4
Gambar 4 Pembangkitan FP-Tree pada pembacaan notrx 127.624
Setelah pembacaan notrx 127.624, maka selanjutnya adalah membaca transaksi selanjutnya yaitu notrx 103.173 sehingga menghasilkan lintasan
{NULL} → A → C → G → H.
Karena node A dan C sudah terbentuk pada pembacaan pertama, maka kita padatkan node tersebut dengan menambahkan nilai supportnya yaitu 2 menandakan bahwa node A dan C telah dilewati 2 kali, sedangkan node G dan H kita beri nilai support 1, dapat dilihat pada Gambar 5
Gambar 5 Pembangkitan FP-Tree pada pembacaan notrx 103.173
Selanjutnya adalah pembacaan notrx 131.326
sehingga menghasilkan lintasan {NULL} → A → G
→ H. Karena node A sudah terbentuk maka kita
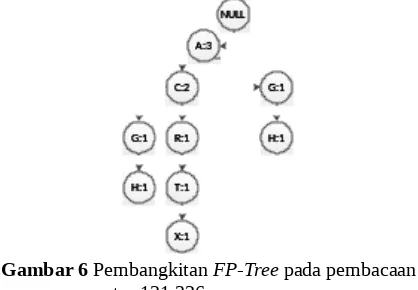
padatkan kembali dengan menambah nilai support A menjadi 3 sedangkan node G dan H kita beri nilai support 1, dapat dilihat pada Gambar 6.
Gambar 6 Pembangkitan FP-Tree pada pembacaan notrx 131.326
Selanjutnya adalah pembacaan notrx 128.214
sehingga menghasilkan lintasan {NULL} → A → C
→ H. Karena node A dan C sudah terbentuk maka
kita padatkan dengan menambah nilai support A menjadi 4 dan C menjadi 3 sedangkan node H kita beri nilai awal 1, dapat dilihat pada Gambar 7.
Gambar 7 Pembangkitan FP-Tree pada pembacaan notrx 128.214
Selanjutnya adalah pembacaan notrx 124.547
sehingga menghasilkan lintasan {NULL} → A → R
→ D. Karena node A telah terbentuk maka kita
padatkan kembali sehingga nilai supportnya menjadi 5 dan node R dan D kita beri nilai 1, dapat dilihat pada Gambar 8.
notrx 124.547
Selanjutnya adalah pembacaan notrx 114.550
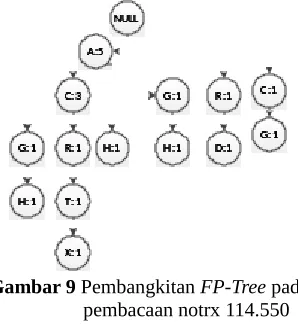
sehingga menghasilkan lintasan {NULL} → C → G.
Karena node C dan G belum terbentuk maka kita beri nilai support 1, dapat dilihat pada Gambar 9.
Gambar 9 Pembangkitan FP-Tree pada pembacaan notrx 114.550
Selanjutnya adalah pembacaan notrx 124.650
sehingga menghasilkan lintasan {NULL} → X.
Karena node X belum terbentuk maka kita beri nilai support 1, dapat dilihat pada Gambar 10.
Gambar 10 Pembangkitan FP-Tree pada pembacaan notrx 124.650 Selanjutnya adalah pembacaan notrx 127.623
sehingga menghasilkan lintasan {NULL} → T.
Karena node T belum terbentuk maka kita beri nilai support 1. Dapat dilihat pada Gambar 11.
Gambar 11 Pembangkitan FP-Tree pada pembacaan notrx 127.623
Selanjutnya adalah pembacaan notrx 131.324
sehingga menghasilkan lintasan {NULL} → G.
Karena node G belum terbentuk maka kita beri nilai support 1, dapat dilihat pada Gambar 12.
Gambar 12 Pembangkitan FP-Tree pada pembacaan notrx 131.324 Selanjutnya adalah pembacaan transaksi terakhir yaitu notrx 131.024 yang menghasilkan
lintasan {NULL} → D. Karena node D belum
terbentuk maka kita beri nilai support 1. dapat dilihat pada Gambar 13.
Gambar 13 Pembangkitan FP-Tree pada pembacaan notrx 131.024
Setelah FP-Tree selesai dibangkitkan, maka
langkah selanjutnya adalah mencari frequent itemset
dengan menerapkan metode Divide and Conguer
sesuai urutan pada Frequent List (Tabel 13) dimulai
dari yang paling kecil hingga paling besar frequensinya.
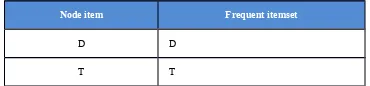
1. Kondisi FP-Tree untuk item D
Langkah pertama, cari semua lintasan yang berakhiran D. Setiap node yang berada pada lintasan D diberi nilai support awal 0, ini dilakukan untuk mengetahui informasi berapa kali item dibeli bersamaan dengan item D dan frequent itemset mana
yang memenuhi minimum support. Hali ini dapat
Gambar 14 Kondisi FP-Tree pada item D Kemudian, naikkan satu persatu node yang melewati lintasan ke D dan masukan nilai support yang dimiliki D kesetiap node yang melewati hingga
ke node NULL. Item A dan R nilai kemunculan
bersama dengan D hanya 1 kali sehingga item A dan
R dibuang. Karena item D hanya berdiri sendiri
maka frequent itemset yang memenuhi minimum
support adalah item D itu sendiri.
2. Kondisi FP-Tree untuk item T
Langkah pertama, cari semua lintasan yang berakhiran T. Setiap node yang berada pada lintasan T diberi nilai support awal 0, ini dilakukan untuk mengetahui informasi berapa kali item dibeli bersamaan dengan item T dan frequent itemset mana
yang memenuhi minimum support. Hali ini dapat
dilihat pada Gambar 15.
Gambar 15 Kondisi FP-Tree pada item T Kemudian, naikkan satu persatu node yang melewati lintasan ke T dan masukan nilai support yang dimiliki T kesetiap node yang melewati hingga
ke node NULL. Item A,C, dan R nilai kemunculan
bersama dengan T hanya 1 kali sehingga item A,C
dan R dibuang. Karena item T hanya berdiri sendiri
maka frequent itemset yang memenuhi minimum
support adalah item T itu sendiri.
3. Kondisi FP-Tree untuk item R
Langkah pertama, cari semua lintasan yang berakhiran R. Setiap node yang berada pada lintasan R diberi nilai support awal 0, ini dilakukan untuk mengetahui informasi berapa kali item dibeli bersamaan dengan item R dan frequent itemset mana
yang memenuhi minimum support. Hali ini dapat
dilihat pada Gambar 16.
Gambar 16 Kondisi FP-Tree pada item R Kemudian, naikkan satu persatu node yang melewati lintasan ke R dan masukan nilai support yang dimiliki R kesetiap node yang melewati hingga
ke node NULL. Item A nilai kemunculan bersama
dengan R sebanyak 2 kali sedangkan item C hanya 1
kali sehingga item C dibuang. Maka frequent itemset
yang memenuhi minimum support adalah item A
bersama R dan R itu sendiri.
4. Kondisi FP-Tree untuk item X
Langkah pertama, cari semua lintasan yang berakhiran X. Setiap node yang berada pada lintasan X diberi nilai support awal 0, ini dilakukan untuk mengetahui informasi berapa kali item dibeli bersamaan dengan item X dan frequent itemset mana
yang memenuhi minimum support. Hali ini dapat
dilihat pada Gambar 17.
Gambar 17 Kondisi FP-Tree pada item X Kemudian, naikkan satu persatu node yang melewati lintasan ke X dan masukan nilai support yang dimiliki X kesetiap node yang melewati hingga
ke node NULL. Item A,C,R, dan T nilai kemunculan
bersama dengan X hanya 1 kali sehingga item
A,C,R, dan T dibuang. Karena item X hanya berdiri
sendiri maka frequent itemset yang memenuhi
minimum support adalah item X itu sendiri.
5. Kondisi FP-Tree untuk item H
Langkah pertama, cari semua lintasan yang berakhiran H. Setiap node yang berada pada lintasan H diberi nilai support awal 0, ini dilakukan untuk mengetahui informasi berapa kali item dibeli bersamaan dengan item H dan frequent itemset mana
yang memenuhi minimum support. Hali ini dapat
Gambar 18 Kondisi FP-Tree pada item H Kemudian, naikkan satu persatu node yang melewati lintasan ke H dan masukan nilai support yang dimiliki H kesetiap node yang melewati hingga
ke node NULL. Item A nilai kemunculan bersama
dengan H sebanyak 3 kali sedangkan item C nilai
kemunculan bersama dengan H sebanyak 2 kali dan
item G nilai kemunculan bersama dengan H
sebanyak 2 kali. Maka frequent itemset yang
memenuhi minimum support adalah item A bersama
H, C bersama H, G bersama H, dan H itu sendiri.
6. Kondisi FP-Tree untuk item G
Langkah pertama, cari semua lintasan yang berakhiran G. Setiap node yang berada pada lintasan G diberi nilai support awal 0, ini dilakukan untuk mengetahui informasi berapa kali item dibeli bersamaan dengan item G dan frequent itemset mana
yang memenuhi minimum support. Hali ini dapat
dilihat pada Gambar 19.
Gambar 19 Kondisi FP-Tree pada item G Kemudian, naikkan satu persatu node yang melewati lintasan ke G dan masukan nilai support yang dimiliki G kesetiap node yang melewati hingga
ke node NULL. Item A nilai kemunculan bersama
dengan G sebanyak 2 kali sedangkan item C nilai
kemunculan bersama dengan G sebanyak 2 kali.
Maka frequent itemset yang memenuhi minimum
support adalah item A bersama G, C bersama G, dan G itu sendiri.
7. Kondisi FP-Tree untuk item C
Langkah pertama, cari semua lintasan yang berakhiran C. Setiap node yang berada pada lintasan C diberi nilai support awal 0, ini dilakukan untuk mengetahui informasi berapa kali item dibeli bersamaan dengan item C dan frequent itemset mana
yang memenuhi minimum support. Hali ini dapat
dilihat pada Gambar 20.
Gambar 20 Kondisi FP-Tree pada item C Kemudian, naikkan satu persatu node yang melewati lintasan ke C dan masukan nilai support yang dimiliki C kesetiap node yang melewati hingga
ke node NULL. Item A nilai kemunculan bersama
dengan C sebanyak 3 kali. Maka frequent itemset
yang memenuhi minimum support adalah item A
bersama C, dan C itu sendiri.
8. Kondisi FP-Tree untuk item A
Langkah pertama, cari semua lintasan yang berakhiran A. Setiap node yang berada pada lintasan A diberi nilai support awal 0, ini dilakukan untuk mengetahui informasi berapa kali item dibeli bersamaan dengan item A dan frequent itemset mana
yang memenuhi minimum support. Hali ini dapat
dilihat pada Gambar 21.
Gambar 21 Kondisi FP-Tree pada item A Kemudian, naikkan satu persatu node yang melewati lintasan ke A dan masukan nilai support yang dimiliki A kesetiap node yang melewati hingga
ke node NULL. Karena item A langsung terhubung
ke node NULL maka tidak ada lagi node yang
melewati item A, frequent itemset yang memenuhi
minimum support adalah item A itu sendiri.
Setelah memeriksa semua node yang ada pada
FP-Tree ditemukan 15 frequent itemset dapat dilihat pada Tabel 15
Tabel 15 Tabel frequent itemset dalam FP-Tree
Node item Frequent itemset
D D
R R, AR
ditemukan kita hitung confidence-nya sebab dalam
association rule minimal harus terdapat 2 item
dalam frequent itemset maka yang akan kita hitung
hanya frequent itemset AR, GH, CH, AH, CG, AG,
dan AC.
Selanjutnya adalah pembuatan rule dengan
cara menghitung confidence setiap frequent itemset,
hanya rule yang mempunyai nilai confidence ≥ 75%
atau 0,75 yang akan kita ambil sebagai strong rule
atau aturan yang kuat. Rumus untuk menghitung
dilihat pada Tabel 16.
Tabel 16 Tabel frequent itemset dalam FP-Tree
No. Jik
Pada tahap ini rule yang telah ditemukan dan
memenuhi confidence pada tahap Data Mining
kemudian diterjemahkan kedalam bahasa yang dapat dimengerti oleh manusia. Hasil dari tahap ini dan merupakan akhir dari serangkaian proses pencarian pola yang tersembunyi adalah :
1. R → A ( jika konsumen membeli susu
Keterangan : Penterjemahan pola pada contoh data ini bersumber dari tabel kategori dapat dilihat pada lampiran 2.
4.3 Perancangan
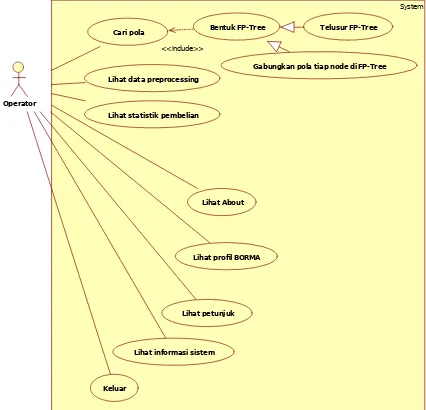
1. Use Case Diagram Aplikasi Data Mining Use case diagram menggambarkan
fungsionalitas yang dimiliki oleh aplikasi. Use case
untuk aplikasi data mining ini dapat dilihat pada Gambar 22
System
Operator
Cari pola Bentuk FP-Tree Telusur FP-Tree
Gabungkan pola tiap node di FP-Tree Lihat data preprocessing
Gambar 22 Use casediagram aplikasi data mining 2. Class Diagram Aplikasi Data Mining
Class diagram menggambarkan struktur dan
deskripsi class, packed, dan objek beserta hubungan
satu sama lain. Class diagram untuk aplikasi data
penggaliData
+load data() +cari frequent item() +hapus item < minsupport()
+urutkan transaksi berdasarkan frequensi item() +bentuk FP-Tree()
+cari pola setiap node() +gabungkan setiap pola() +tampilkan pola()
transaksi
+notrx = integer +item = string
+tambah(notrx, item) +*
+1
pola
+itemset = string +support = integer +confident = integer
+tambah(itemset, support, confident) +*
+1
+* +*
Gambar 23 Classdiagram aplikasi data mining
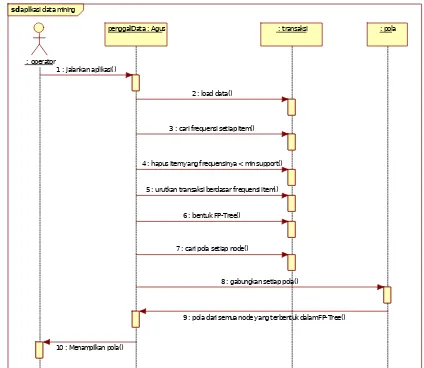
3. Sequence Diagram Aplikasi Data Mining Sequence diagram menggambarkan interaksi antar objek didalam sistem yang disusun dalam
suatu urutan waktu. Sequence diagram pada aplikasi
data mining ini dapat dilihat pada Gambar 24 aplikasi data mining
sd
penggaliData : Agus
: operator
: transaksi : pola
1 : jalankan aplikasi()
2 : load data()
3 : cari frequensi setiap item()
4 : hapus item yang frequensinya < min support()
5 : urutkan transaksi berdasar frequensi item()
6 : bentuk FP-Tree()
7 : cari pola setiap node()
8 : gabungkan setiap pola()
9 : pola dari semua node yang terbentuk dalam FP-Tree()
10 : Menampilkan pola()
Gambar 24 Sequencediagram aplikasi data mining
4. Navigasi
Struktur rancangan navigasi/menu yang dibuat untuk aplikasi datamining dapat dilihat pada Gambar 25
Gambar 25 Struktur rancangan navigasi
5. Implementasi
Hasil pengujian pencarian pola terhadap 1.275 data transaksi Borma tanggal 8 sampai dengan 9 April 2013 yang telah melewati tahap preprocesssing dapat dilihat pada Gambar 26.
Gambar 26 Pengujian sistem dengan data transaksi Borma
Pada Gambar 5.23 terlihat pada tabel data transaksi terdapat 1.275 data transaksi yang telah diurutkan sesuai dengan frequensi tiap barang pada
tabel Frequent Item dengan nilai support 1%, hal ini
akan sangat sulit dilakukan apabila menggunakan perhitungan manual karena data sangat banyak.
Kemudian Frequent Pattern Tree dibangkitkan
untuk melihat pola-pola pembelian konsumen yang hasilnya dapat dilihat pada tabel association rule. Pola-pola yang ditemukan yang memenuhi minimum confidence yaitu sebesar 20% dapat dilihat pada Tabel 17
Tabel 17 Pola beli konsumen dengan minimum support 1% dan confidence 20%
Pola Beli Konsumen Support (%) Confidence (%) Jika membeli ASESORIS KOMPUTER, maka
akan membeli ATK 4 93 Jika membeli ATK, maka akan membeli
ASESORIS KOMPUTER 5 64 Jika membeli SABUN MANDI, maka akan
membeli SHAMPOO 18 53 Jika membeli PASTA GIGI, maka akan membeli
SHAMPOO 18 50 Jika membeli PELEMBUT PAKAIAN, maka akan
membeli DETERJEN 17 50 Jika membeli SABUN CUCI PIRING, maka akan
membeli SHAMPOO 15 50 Jika membeli PEMBERSIH WAJAH, maka akan
membeli SHAMPOO 17 48 Jika membeli TELUR AYAM, maka akan membeli
MIE INSTANT 16 47 Jika membeli SABUN MANDI, maka akan
membeli PASTA GIGI 18 47 Jika membeli PASTA GIGI, maka akan membeli
SABUN MANDI 18 47
Keterangan : selengkapnya dapat dilihat pada file
lampiran 10 - pola beli konsumen dengan minimum support 1% dan confidence 20%.xls dalam CD laporan.
6. Kesimpulan
Data transaksi yang tersimpan dapat lebih
dimanfaatkan dengan menggunakan Aplikasi Data
Mining Algoritma Frequent Pattern Growth yang dapat mencari informasi yang tersembunyi dalam data transaksi yaitu pola beli konsumen. Informasi ini dapat dijadikan salah satu referensi bagi manajer dalam menentukan tata letak barang yang optimal sebagai salah satu upaya untuk meningkatkan keunggulan dalam persaingan bisnis retail.
Cipadung, dengan batasan minimum support 1% dan
confident sebesar 20%, ditemukan pola beli
konsumen tertinggi yaitu jika membeli Asesoris
Komputer, maka akan membeli ATK dengan nilai
support4% dan nilai confident tertinggi yaitu 93%,
dan jika konsumen membeli Mie Instant, maka
akan membeli Susu Dalam Kemasan dengan nilai
support tertinggi yaitu 30% dan confident33%.
7. Saran
Setelah mengevaluasi terhadap proses dan hasil dari aplikasi data mining ini, penulis memiliki beberapa saran untuk pengembangan aplikasi selanjutnya yang berhubungan dengan data mining ini, yaitu :
1. Untuk pencarian pola selanjutnya diharapkan
untuk meneliti kembali algoritma yang lebih baik yang bisa diterapkan selain algoritma
Frequent Pattern Growth.
2. Informasi yang dicari lebih bervariasi, karena
wilayah kajian data mining ini sangat luas.
3. Untuk tampilan aplikasi, dapat lebih
disempurnakan dengan menggunakan diagram pada pola yang ditemukan agar pengguna lebih mudah memahaminya.
8. Daftar Pustaka
Gantz, John., David Reinsel, 2009, As the Economy
Contracts, the Digital Universe Expands, USA : IDC GMS.
Pramudiono, Iko. 2003, Pengantar Data Mining :
Menambang Permata Pengetahuan di Gunung Data, Ilmu Komputer (diakses 23 Juni 2013).
Kusrini, Emha Taufiq L. 2009. Algoritma Data
Mining, Yogakarta : Penerbit ANDI.
Han, Jiawei., Micheline Kamber, 2006, Data Mining
Concepts and Techniques Second Edition, San Fransisco : Morgan Kaufmann Publisher.
Suprasetyo, Achmad Fendi. 2012, Market Basket
Analisis Menggunakan Algoritma Frequent Pattern Growth pada Data Transaksi Penjualan Barang Harian di Swalayan XYZ, Gorontalo : Fak. Teknik UNG.
Prasetyo, Eko. 2012, Data Mining Konsep dan
Aplikasi Menggunakan MATLAB, Yogyakarta : Penerbit ANDI.
Santosa, Budi. 2007, Data Mining Teknik
Pemanfaatan Data untuk Keperluan Bisnis,
Yogyakarta : Graha Ilmu.
9. Lampiran
Lampiran 1 (top kategori yang dibeli oleh konsumen)
Kode Kategori Jumlah Dalam Transaksi Transform keAbjad 291 SUSU DALAM KEMASAN 436 A 292 MINUMAN DALAM BOTOL 426 B 211 MIE INSTANT 416 C 402 SHAMPOO 357 D 213 BISKUIT KEMASAN 355 E 251 DETERJEN 293 F 214 MAKANAN RINGAN 272 G 232 BUMBU DAPUR 262 H 404 PEMBERSIH WAJAH 248 I 031 ATK 245 J 012 PERABOT RUMAH TANGGA 244 K 403 PASTA GIGI 241 L 401 SABUN MANDI 236 M 024 TELUR AYAM 236 N 255 PELEMBUT PAKAIAN 229 O
Lanjutan lampiran 1 (top kategori yang dibeli oleh konsumen)
Kode Kategori Jumlah Dalam Transaksi Transform keAbjad 406 HANDBODY LOTION 221 P 301 TISSUE 219 Q 036 PERALATAN KANTOR 204 R 253 SABUN CUCI PIRING 201 S 002 BUAH DAN SAYURAN 199 T 303 PEMBALUT 194 U 226 MINYAK GORENG 192 V 228 KOPI SACHET 191 W 019 LISTRIK ELEKTRONIK 173 X 501 ASESORIS KOMPUTER 168 Y
Lampiran 2 kategori untuk penterjemahan pola pada contoh data transaksi
Item Nama kategori