Fakultas Ilmu Komputer
2243
Implementasi Algoritma K-Means untuk Klasterisasi Kinerja Akademik
Mahasiswa
Fajar Nur Rohmat Fauzan Jaya Aziz1, Budi Darma Setiawan2, Issa Arwani3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Seleksi penerimaan mahasiswa dalam sebuah perguruan tinggi menghasilkan data yang melimpah dan dapat dimanfaatkan untuk memperoleh informasi yang berguna bagi perguruan tinggi. Dalam penelitian ini, data mahasiswa yang diambil oleh penulis adalah nomor induk mahasiswa, jalur masuk perguruan tinggi, pendapatan orang tua dan indeks prestasi komulatif. Penggalian informasi pada sebuah data berukuran besar tidak dapat dilakukan dengan mudah dan hal ini bisa dilakukan dengan teknologi data mining. Data mining yang disebut juga dengan Knowledge Discovery in Database adalah sebuah proses secara otomatis atas pencarian data didalam sebuah memori yang amat besar dari data untuk mengetahui pola dengan menggunakan alat seperti klasifikasi hubungan (association) atau pengelompokan (clustering). Dengan menggunakan metode k-means clustering, peneliti mencoba untuk mengekstrak pengetahuan yang bisa menggambarkan kinerja prestasi akademik mahasiswa pada akhir semester dan hasil dari penelitian tersebut menunjukkan bahwa dari semua jumlah cluster yang dimasukkan, untuk cluster yang berjumlah 3 memiliki nilai silhouette coefficient yang paling mendekati nilai Si= 1, yaitu dengan nilai 0,108690751. Selain itu pendapatan orang tua tidak mempengaruhi tingkat kinerja akademik mahasiswa dan nilai akademis mahasiswa yang masuk melalui jalur reguler & jalur prestasi akademik mempunyai nilai IPK rata-rata tertinggi. Sehingga, pihak fakultas dapat mempertimbangkan untuk lebih memprioritaskan penerimaan mahasiswa baru melalui jalur reguler & prestasi akademik. Kata Kunci : data mahasiswa, data mining, k-means clustering, jalur penerimaan mahasiswa
Abstract
Selection of student acceptance in a college produces abundant data and can be utilized to obtain useful information for the college. In this study, student data taken by the authors are Student ID Number, University Entrance Path, Parent Revenue and Student Achievement Index. Excavation of information on a large data could not be done easily and this can be done with data mining technology. Data mining also known as Knowledge Discovery in Database is an automated process of searching data in a very large memory of data to know patterns by using tools such as association or clustering. By using k-means clustering method, the researcher tries to extract the knowledge which can depict the performance of student achievement at the end of semester and the result of the research indicates that of all cluster quantities inserted, for clusters amounting to 3 (three) has the value of silhouette coefficient closest to the value of 𝑆𝑖= 1, that is with the value of 0.108690751. In addition, parental income does not affect the level of academic performance of students and the academic value of students who enter through the regular path & achievement paths have the value of the highest average GPA. Thus, the faculty can consider to prioritize the acceptance of new students through regular channels & achievement contract.
Keywords : student data, data mining, k-means clustering, student admission path
1. PENDAHULUAN
Dalam berbagai bidang kehidupan saat ini, banyak sekali data yang dihasilkan oleh teknologi informasi yang semakin canggih,
mulai dari bidang industri, kesehatan, ekonomi, pendidikan, ilmu dan teknologi serta berbagai bidang kehidupan lainnya.
pada umumnya perguruan tinggi akan memberikan soal-soal test yang harus calon mahasiswa selesaikan, yang bertujuan untuk mengetahui kemampuan dan pengetahuan mereka. Setelah tahap seleksi selesai dan calon mahasiswa diterima dan mengalami proses belajar mengajar, maka akan diketahui prestasi mahasiswa disetiap akhir semester. Hal ini akan terjadi secara berulang pada sebuah perguruan tinggi setiap tahunnya, sehingga akan menghasilkan banyak sekali data mahasiswa yang apabila diolah akan dapat memberikan informasi yang bermanfaat bagi pihak perguruan tinggi.
Institusi pendidikan adalah bagian penting dalam masyarakat dan memainkan peranan yang penting dalam pertumbuhan dan pembangunan suatu bangsa. Selain itu institusi pendidikan juga berperan untuk mengontrol dan melakukan evaluasi serta prediksi prestasi akademik siswanya. Prestasi akademik siswa dapat didasarkan pada berbagai faktor seperti kepribadian, lingkungan sosial serta psikologi dari siswa tersebut. Educational data mining mengimplementasikan algoritma data mining untuk menemukan pengetahuan dari data yang berasal dari domain pendidikan. Hasil penelitian ini menyebutkan bahwa data mining dapat digunakan sebagai tool pengambilan suatu keputusan yang dapat menemukan suatu pengetahuan dari sejumlah besar data yang bisa digunakan dalam menilai prestasi siswa (Tiwari, M. Singh, R. Vimal, N. 2013). Dalam penelitian ini, data mahasiswa yang diambil oleh penulis adalah jenis kelamin, angkatan, asal sekolah (SMA / Sederajat), jalur masuk perguruan tinggi, pekerjaan orang tua, penghasilan orang tua, penghasilan tambhan orangtua, asal daerah, jumlah mata kuliah yang diulang, jumlah mata kuliah semester pendek yang diambil mahasiswa, indeks prestasi lulus dan beban per semster, jumlah SKS lulus dan beban per semester, jumlah mata kuliah lulus dan beban per semester, Indeks prestasi komulatif lulus dan beban per semester, jumlah SKS komulatif lulus dan beban per semester, jumlah mata kuliah komulatif lulus dan beban per semester, jumlah kehadiran mahasiswa per semester.
Penggalian informasi pada sebuah data berukuran besar tidak dapat dilakukan dengan mudah dan salah satu alat bantu yang dapat digunakan untuk menemukan pengetahuan / informasi yang tersembunyi dalam database adalah teknologi data mining. Data mining
merupakan proses pengekstrakan informasi dari jumlah kumpulan data yang besar dengan menggunakan algoritma dan teknik gambar statistic, mesin pembelajaran dan sistem manajemen database (HAN, J & Kamber, M. 2001).
Data mining yang disebut juga dengan Knowledge Discovery in Database (KDD) adalah sebuah proses secara otomatis atas pencarian data didalam sebuah memori yang amat besar dari data untuk mengetahui pola dengan menggunakan alat seperti klasifikasi hubungan (association) atau pengelompokan (clustering). Untuk itu data mining dapat digunakan untuk mengevaluasi kinerja siswa. Dengan menggunakan algoritma yang ada dalam data mining, dicoba untuk mengekstrak pengetahuan yang bisa menggambarkan kinerja siswa pada akhir semester. Hasil ekstraksi ini dapat digunakan untuk membantu dalam mengidentifikasi siswa yang mungkin akan putus sekolah dan membantu siswa yang membutuhkan perhatian khusus serta mengantisipasi keadaan tersebut dengan memberikan seorang profesor yang tepat untuk membantu menasehati dan membimbing para siswa (Chuchra, R. 2012).
Pada penelitian ini analisa data mining dilakukan dengan menggunakan metode k-means clustering. Adapun alasan penggunaan metode k-means clustering adalah karena metode k-means clustering mampu mengelompokkan data mahasiswa dengan kriteria yang bisa menjadi acuan untuk mengetahui bagaimana kinerja akademik mahasiswa tersebut. K-means clustering juga mampu mengelompokkan data dengan memaksimalkan kemiripan data antar cluster dan meminimalkan kemiripan data antar cluster, dimana ukuran kemiripan yang digunakan dalam cluster adalah fungsi jarak, sehingga pemaksimalan kemiripan data didapatkan berdasarkan jarak terpendek antara data terhadap titik pusat. Dengan menggunakan metode ini, data-data yang telah didapatkan dapat dikelompokkan kedalam beberapa cluster berdasarkan kemiripan dari data-data tersebut, sehingga data-data yang memiliki karakteristik yang sama akan dikelompokkan dalam satu cluster dan yang memiliki karakteristik yang berbeda akan dikelompokkan dalam cluster lain yang memiliki karakteristik yang sama (Ong, J O. 2013).
akademik mahasiswa berdasarkan latar belakang pendapatan orang tua dan jalur masuk perguruan tinggi.
2. LANDASAN KEPUSTAKAAN
2.1Kajian Pustaka
Berikut beberapa penelitian yang digunakan penulis sebagai bahan referensi dalam melakukan penelitian.
Penelitian O. J et al., (2010), Shovon & Haque, (2012) yang berjudul “Application of k-Means Clustering algorithm for prediction of Students’ Academic Performance” dan “Prediction of Student Academic Performance by an Application of K-Means Clustering Algorithm” menunjukkan bahwa clustering dapat digunakan untuk memonitor kinerja mahasiswa di suatu universitas. Metode ini juga dapat digunakan untuk memonitor kinerja per semester dalam meningkatkan prestasi akademik. Penelitian yang dilakukan O. J et al., (2010) menggunakan 79 data mahasiswa untuk uji coba clustering pada Universitas Nigeria, sedangkan penelitian Shovon & Haque, (2012) menggunakan 60 data mahasiswa untuk uji coba penelitiannya.
Penelitian Arora & Badal, (2013) yang berjudul “Evaluating Student’s Performance Using K-Means Clustering”, menggunakan algoritma k-means karena dinilai dapat dengan cepat dan efisien membantu memantau perkembangan kinerja mahasiswa di suatu instansi pendidikan. Jumlah data yang dianalisis adalah 118 data siswa untuk mendapatkan nilai rata-rata mahasiswa tiap semester. Metode ini dapat memainkan peran penting bagi analisis akademik untuk menentukan alasan penurunan kinerja mahasiswa selama semester tertentu sehingga dapat diambil tindakan untuk meningkatkan kinerja tersebut di semester berikutnya.
2.2 Mahasiswa
Mahasiswa adalah seseorang yang sedang dalam proses menimba ilmu ataupun belajar dan terdaftar sedang menjalani pendidikan pada salah satu bentuk perguruan tinggi yang terdiri dari akademik, politeknik, sekolah tinggi, institut dan universitas (Hartaji, D A. 2012).
Seorang mahasiswa bisa diartikan sebagai seorang individual yang sedang menimba ilmu pada tingkatan perguruan tinggi negeri maupun swasta ataupun lembaga yang lain yang setara
dengan perguruan tinggi. Seorang mahasiswa dinilai mempunyai kepandaian dalam berpikir, tingkat intelektualitas yang tinggi dan mempunyai persiapan yang matang dalam melakukan sesuatu. Setiap mahasiswa cenderung memiliki sifat berpikir secara kritis dan bertindak dengan cepat dan tepat, merupakan suatu prinsip yang saling melengkapi satu sama lain (Santoso, B. 2007).
Mahasiswa digolongkan dalam tingkatan perkembangan pada usia 18 sampai dengan 25 tahun. Tingkatan tersebut dikelompokkan pada masa remaja akhir sampai dengan masa dewasa awal serta dapat diamati dari segi perkembangan, pemantapan pendirian hidup merupakan tugas perkembangan pada usia mahasiswa (Yusuf, S. 2012).
Berdasarkan uraian tersebut penulis dapat menyimpulkan bahwa mahasiswa adalah seseorang yang sedang menimba ilmu dan masih berusia 18 sampai dengan 25 tahun serta terdaftar dan menjalani pendidikannnya di perguruan tinggi baik dari universitas, politeknik, akademik, institut dan sekolah tinggi. Sedangkan untuk subyek dalam penelitian ini adalah menggunakan mahasiswa yang masih aktif dan tercatat sebagai mahasiswa aktif dan berusia sekitar 23 tahun.
2.3 Pendapatan
Pendapatan adalah segala penerimaan setiap orang dalam bentuk apapun sebagai imbalan jasanya didalam suatu proses produksi. Imbalan jasa tersebut dapat berupa bunga, laba, upah serta hasil sewa sesuai dengan faktor produksi pada yang dilibatkan dalam suatu proses produksi (Yuliana, S. 2007).
Pendapatan merupakan sejumlah dana yang didapatkan melalui pemanfaatan faktor produksi yang dimiliki. Meliputi : (Suyanto. 2000)
1. Menyewakan sesuatu terhadap orang lain, seperti menyewakan alat transportasi, ruko, kebun, dsb.
2. Hasil gaji atau upah dari hasil bekerja terhadap orang lain atau bekerja sebagai pegawai negeri.
3. Hasil dari bunga dari hasil membeli saham atau mendapatkan bunga dari bank.
4. Hasil usaha sebagai wiraswasta dapat berupa menjadi pedagang, petani maupun pengusaha.
tunjangan, baik kesehatan maupun pensiunan yang diterima selama kurun waktu tertentu yang diperoleh dari imbalan jasa dari suatu perusahaan.
2.4 Clustering
Clustering pada suatu data pada dasarnya adalah suatu tahapan untuk menggolongkan suatu himpunan data yang atribut kelas belum dideskripsikan, berdasarkan kosepnya prinsip clustering adalah untuk memaksimalkan dan meminimalkan kemiripan intra kelas. Misalnya, ada suatu himpunan obyek, langkah pertama dapat di klasterisasi menjadi beberapa himpunan kelas kemudian menjadi sebuah himpunan beraturan sehingga dapat diturunkan berdasarkan klasifikasi tertentu.
Cluster dapat juga diartikan sebagai kelompok atau himpunan atau bagian atau golongan. Oleh hal itu analisa clustering pada dasarnya akan menghasilkan sejumlah cluster (kelompok / golongan / himpunan). Sebelum melakukan analisa perlu diterapkan pemahaman bahwa suatu himpunan data tertentu sebenarnya memiliki kemiripan di antara anggotanya tersebut. Oleh karena itu, setiap anggota-anggota yang memiliki kemiripan karasteristik dapat untuk dikelompokkan di dalam satu atau lebih dari suatu kelompok (Santoso, B. 2007).
Analisa clustering adalah salah satu dari teknik multivariat metode interdependensi (saling ketergantungan). Oleh sebab itu dalam analisa clustering antara variabel bebas (independent variable) dan variabel terikat (dependent variable) tidak ada pembedaan satu dengan yang lain (Nuningsih, S. 2010). Analisa clustering merupakan suatu proses yang digunakan sebagai metode penggabungan observasi ke dalam kelompok, sehingga : a. Setiap himpunan homogen akan memiliki
karakteristik tertentu. Dengan demikian observasi di dalam setiap kelompok sama dengan observasi lain di dalam satu kelompok yang sama.
b. Setiap himpunan seharusnya berbeda dari himpunan lain. Dengan demikian observasi dalam himpunan satu seharusnya berbeda dari observasi dalam himpunan lain. Data clustering merupakan bagian dari metode data mining yang mempunyai sifat tidak berarahan (unsupervised). Dalam pengelompokan data ada dua jenis metode yang sering digunakan yaitu hierarchical data
clustering dan non-hierarchical data clustering. Algoritma k-means merupakan bagian dari metode non-hierarchical data clustering.
2.5 Algoritma K-Means
Algoritma k-means adalah bagian dari metode non-hierarchical data clustering yang bertujuan untuk membagi-bagi data ke dalam bentuk satu atau lebih kelompok. Metode ini membagi-bagi data ke dalam kelompok dengan pemahaman setiap data yang mempunyai karakteristik yang sama dikelompokkan ke dalam satu kelompok yang sama dan begitu pula terhadap setiap data yang sifat karakteristiknya berbeda akan dikelompokkan ke dalam kelompok yang lain.
Data clustering yang menggunakan metode k-means ini secara umum dilakukan dengan algoritma dasar sebagai berikut:
1. Menentukan jumlah cluster. 2. Mengasumsikan pusat cluster.
3. Menghitung jarak objek pada centroid. 4. Mengalokasikan objek dengan patokan
jarak terkecil.
5. Menghitung titik pusat baru.
6. Menghitung kembali jarak objek pada centroid sampai objek tidak perpindah-pindah cluster.
2.5.1 Perkembangan Penerapan K-Means
Perkembangan metode k-means meliputi: 1. Metode distance space digunakan sebagai perhitungan jarak antara suatu data dengan centroid.
Metode distance space telah diimplementasikan dalam menghitung jarak (distance) antara suatu data dengan titik pusat. termasuk di antaranya L1 Norm (Manhattan distance), L2 Norm (Euclidean distance) dan Lp (Minkowski distance).
Penghitungan jarak di antara dua titik 𝑥1dan 𝑥2pada manhattan distance space adalah sebagai berikut:
𝐷𝑖1 (𝑥2, 𝑥1) = ||𝑥1− 𝑥2||1
= ∑ |𝑥2𝑗− 𝑥1𝑗| ⍴
𝑗=1 (1)
dimana:
| . | : nilai absolut
Sedangkan untuk perhitungan jarak di antara dua titik 𝑥1dan 𝑥2 pada L2 Euclidean distance space, adalah sebagai berikut:
𝐷𝑖1 (𝑥2, 𝑥1) = ||𝑥1− 𝑥2||1
= √∑ (𝑋2𝑗− 𝑋1𝑗)2 ⍴
𝑗=1 (2)
dimana:
𝐷𝑖1 : jarak data i pertama 𝑥1 : nilai data pertama 𝑥2 : nilai data kedua p : dimensi data | . | : nilai absolut
Dari beberapa jenis metode pengukuran jarak metode Euclidean sering dipergunakan karena dalam perhitungan pada metode tersebut jarak terpendek antara dua titik yang diperhitungkan, sedangkan untuk metode pengukuran jarak dengan menggunakan metode manhattan sering digunakan karena kemampuannya dalam mendeteksi keberadaan objek yang memiliki karakteristik yang unik dengan lebih baik.
2. Metode pengelomokan data kembali ke dalam setiap kelompok.
Pada dasarnya terdapat dua cara pengelompokan data kembali ke dalam masing-masing kelompok pada saat proses iterasi clustering. Cara tersebut adalah dengan menggunakan metode hard k-means dan fuzzy k-means. Perbedaan kedua metode ini adalah terletak pada asumsi yang
digunakan sebagai dasar
pendistribusiannya. Pengalokasian data dalam metode hard k-means didasarkan pada perbandingan jarak antar data dan titik pusat pada setiap kelompok yang ada. Data didistribusikan berulang-ulang secara tegas ke dalam kelompok yang memiliki titik pusat terdekat dengan data tersebut. Pengalokasian data pada setiap kelompok dapat dirumuskan menjadi:
𝑎𝑖𝑘 = {01d = min{D(𝑥𝑘 , V𝑖) (3) dimana:
𝑎𝑖𝑘 : Keanggotaan data ke-k ke kelompok ke-i
V𝑖 : Nilai titik pusat kelompok ke-i
2.6 Silhouette Coefficient
Metode silhouette coefficient berfungsi untuk menguji kualitas dari cluster yang dihasilkan serta sebagai metode untuk pengesahan suatu cluster yang menggabungkan antara metode cohesion dan metode separation. Untuk perhitungan nilai silhoutte coefisient dibutuhkan nilai jarak antar objek dengan menggunakan metode euclidean distance. Tahapan-tahapan dalam menentukan nilai silhoutte coeffisien adalah sebagai berikut : 1. Pada setiap objek 𝑖 dihitung nilai rata-rata
titik satu dengan semua objek yang berada dalam satu cluster. Maka akan diperoleh nilai rata-rata yang disebut dengan ai. 2. Pada setiap objek 𝑖 dihitung nilai minimal
jarak rata-rata dari titik satu ke titik yang lain yang berbeda cluster. Maka akan diperoleh nilai rata-rata minimum yang disebut dengan bi.
3. Kemudian setelah semua nilai diketahui maka nilai silhoutte coefisien dapat ditentukan dengan menggunakan rumus sebagai berikut:
Si=max {𝑎𝑖−𝑏𝑖}𝑏𝑖−𝑎𝑖 (4)
dimana :
Si : nilai silhoutte coefisien.
𝑎𝑖 : rata-rata jarak titik satu dengan semua data yang berada dalam satu cluster.
𝑏𝑖 : minimal jarak rata-rata dari titik satu ke titik yang lain yang berbeda cluster.
Hasil perhitungan nilai silhoutte coeffisien memiliki range antara -1 hingga 1. Hasil dapat dikatakan baik apabila bernilai positif, hal ini berarti titik sudah berada di dalam cluster yang tepat. Sedangkan jika nilainya negative ini menandakan terjadinya overlapping sehingga titik berada di antara dua cluster. Nilai silhoutte berdasarkan teori Kaufman dan Rousseeuw : 1. Strong Stucture
0,7 < 𝑆𝐶 ≤ 1 (5)
2. Medium Structure
0,5 < 𝑆𝐶 ≤ 0,7 (6)
3. Weak Structure
0,25 < 𝑆𝐶 ≤ 0,5 (7)
4. Nostructure
3. METODOLOGI
Metodologi penelitian ini membahas tentang metode dan alur penelitian yang diterapkan dan yang menjadi dasar pada tahapan implementasi dan pengujian sistem. Berikut dijelaskan mengenai uraian tentang penelitian dalam bentuk diagram alir seperti ditunjukkan pada Gambar 1.
Gambar 1. Diagram Alir Penelitian
3.1 Pengumpulan Data
Data yang dibutuhkan untuk penelitian yaitu data mahasiswa dan data dasar. Untuk data mahasiswa menggunakan data mahasiswa tahun masuk ajaran 2012 selama lima semester dengan jumlah data sebanyak 90.
Sembilan puluh data mahasiswa ini terdiri dari data dasar dan data akademik, dimana kedua jenis data ini akan menjadi fitur untuk proses pengklasifikasian kinerja akademik mahasiswa.
3.2 Praproses
Pada tahapan ini untuk mendapatkan suatu data yang baik maka dilakukan tahapan seleksi data. Seleksi data yang dilakukan yaitu merubah beberapa data yang bertujuan memudahkan pemahaman dengan mengacu pada kesetabilan data, data yang hilang dan pengulangan pada data. Sedangkan data nominal dirubah kedalam bentuk angka dengan beberapa tahapan supaya dapat diolah.
3.3 Clustering (Algoritma K-Means)
Berikut adalah alur tahapan dari metode Algoritma k-means dalam menentukan klasterisasi kinerja mahasiswa yang terbagi atas beberapa tahapan, yaitu :
a. Menentukan jumlah cluster. b. Mengasumsikan pusat cluster.
c. Menghitung jarak objek pada centroid.
d. Mengalokasikan objek dengan patokan jarak terkecil.
e. Menghitung titik pusat baru.
f. Menghitung kembali jarak objek pada centroid sampai objek tidak perpindah-pindah cluster.
3.4 Evaluasi
Tahap evaluasi ini menunjukkan ketepatan sebuah pengelompokkan, seberapa baik proses pengelompokkan dan kualitas kelompok yang terbentuk. Terdapat beberapa macam ukuran ketepatan untuk mengetahui kualitas suatu pengelompokkan. Salah satu ukuran ketepatan yang dapat digunakan dalam menentukan ketepatan pengelompokkan deret waktu adalah dengan metode silhouette coefficient.
4. IMPLEMENTASI
4.1 Spesifikasi Software & Hardware
Kriteria software atau perangkat lunak yang digunakan untuk mengimplementasikan algoritma k-means ditunjukkan pada Tabel 1.
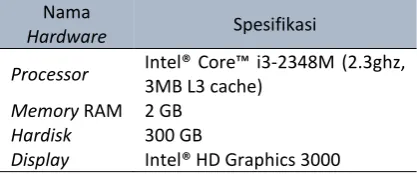
Tabel 1. Spesifikasi Software
Nama Software Spesifikasi
Sistem Operasi Windows 7 Professional 32-bit
Bahasa
Pemrograman Java
Tools NetBeans IDE 7.3.1
Server XAMPP 2.5
DBMS MySQL
Kriteria hardware atau perangkat keras yang digunakan untuk mengimplementasikan algoritma k-means ditunjukkan pada Tabel 2.
Tabel 2. Spesifikasi Hardware
Nama
Hardware Spesifikasi
Processor Intel® Core™ i3-2348M (2.3ghz,
3MB L3 cache)
Memory RAM 2 GB
Hardisk 300 GB
Display Intel® HD Graphics 3000
4.2 Implementasi Algoritma
Implementasi algoritma yang digunakan dalam penentuan klasterisasi kinerja akademik mahasiswa, yang meliputi hal berikut :
Mulai
Pengumpulan Data
Selesai Evaluasi
Praproses Cleaning data & Konversi Data
Clustering (Algoritma K-Means)
a. Implementasi Algoritma Proses Pengolahan Data
b. Implementasi Algoritma K-Means
c. Implementasi Algoritma Proses Clustering d. Implementasi Algoritma Proses Pengujian
4.3 Implementasi Antarmuka
Implementasi antarmuka sistem mengacu pada perancangan yang telah dilakukan pada bab sebelumnya. Tampilan antarmuka sistem yang diimplementasikan meliputi tampilan halaman home, halaman algoritma, halaman proses clustering, dan halaman proses pengujian.
4.3.1 Halaman Home
Antarmuka halaman home merupakan antar muka yang menampilkan data mahasiswa sekaligus pengolahan data terhadap data mahasiswa. Berikut adalah implementasi dari antarmuka halaman Home seperti yang ditunjukkan pada Gambar 2.
Gambar 2. Implementasi Halaman Home
4.3.2 Halaman Algoritma
Antarmuka halaman algoritma merupakan antar muka yang menampilkan diagram alir algoritma k-means. Berikut adalah implementasi dari antarmuka halaman algoritma seperti yang ditunjukkan pada Gambar 3.
Gambar 3. Implementasi Halaman Algoritma
4.3.3 Halaman Proses Clustering
Antarmuka halaman proses clustering merupakan halaman dimana pemprosesan
clustering dilakukan. Didalam halaman ini terdapat fitur form input jumlah cluster, fitur tabel yang menampilkan jumlah titik pusat beserta data titik pusat tersebut dan fitur tampilan hasil proses clustering. Pada halaman ini terdapat 2 tombol, yaitu tombol proses yang berfungsi sebagai tombol eksekusi perhitungan dan tombol clear yang berfungsi menghapus atau membersihkan field form input jumlah cluster. Berikut adalah implementasi dari antarmuka halaman Proses Clustering seperti yang ditunjukkan pada Gambar 4.
Gambar 4. Implementasi Halaman Proses Clustering
4.3.4 Halaman Proses Pengujian
Antarmuka halaman proses Pengujian merupakan halaman dimana pemprosesan Pengujian dilakukan. Didalam halaman ini terdapat fitur form input jumlah cluster dan fitur tabel hasil pengujian terhadap jumlah cluster dengan nilai silhouette. Berikut adalah implementasi dari antarmuka halaman Proses Pengujian seperti ditunjukkan pada Gambar 5.
Gambar 5. Implementasi Halaman Proses Pengujian
5 PENGUJIAN DAN ANALISIS
5.1 Pengujian
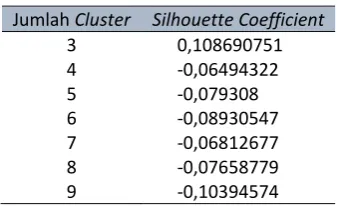
dengan memasukkan tujuh cluster yang berbeda seperti yang ditunjukkan pada Tabel 3.
Tabel 3. Hasil Pengujian
Jumlah Cluster Silhouette Coefficient
3 0,108690751 dapat dipetakan menjadi grafik hasil pengujian seperti ditunjukkan pada gambar 6.
Gambar 6. Grafik Hasil Pengujian
5.2 Analisis
Analisa yang dilakuan adalah dengan memilih salah satu dari ketujuh inputan yang dimasukkan tersebut dengan melihat nilai silhouette coefficien yang terbaik. Nilai silhoutte dapat dikatakan baik apabila bernilai positif, hal ini berarti titik sudah berada di dalam cluster yang tepat. Sedangkan jika nilainya negative ini menandakan terjadinya overlapping sehingga titik berada di antara dua cluster.
Pada pengujian diatas bisa dilihat dan diamati bahwa dari semua jumlah cluster yang dimasukkan untuk cluster yang berjumlah 3 (tiga) memiliki nilai silhouette coefficien yang paling mendekati nilai Si= 1, yaitu dengan nilai 0,108690751.
Pada saat cluster terbagi menjadi 3 titik pusat diketahui bahawa:
1. Pada hasil perhitungan di cluster 1, terlihat bahwa karakteristik mahasiswa pada cluster 1 didominasi oleh mahasiswa dengan jalur masuk perguruan tinggi melalui Minat dan Kemampuan.
Cluster 1 terdiri dari 21 mahasiswa, dengan deskripsi sebagai berikut :
a. Jalur masuk perguruan tinggi :
1) Minat dan kemampuan : 9 mahasiswa
2) UB IV : 7 mahasiswa
3) Jalur Prestasi Non Akademik : 5 mahasiswa
b. Pendapatan orang tua : 1) ≤1jt : 2 mhs
c. Dengan rata-rata nilai IPK : 2.731 2. Pada hasil perhitungan di cluster 2, terlihat
bahwa karakteristik mahasiswa pada cluster 2 tidak ada jalur masuk perguruan tinggi yang mendominasi.
Cluster 2 terdiri dari 7 mahasiswa, dengan deskripsi sebagai berikut :
a. Jalur masuk perguruan tinggi : 1) Kemitraan Instansi : 2 mhs 2) Kemitraan Daerah : 2 mhs 3) Alih Program : 2 mhs
4) Program Khusus Penyandang Disabilitas : 1 mhs
b. Dari pendapatan orang tua : 1) ≤1jt : 1 mhs
2) >1jt s/d ≤2jt : 1 mhs 3) >2jt s/d ≤3jt : 1 mhs 4) >3t s/d ≤4jt : 1 mhs 5) >10jt : 3 mhs
c. Dengan rata-rata nilai IPK : 2.8775 3. Pada hasil perhitungan di cluster 3, terlihat
bahwa karakteristik mahasiswa pada cluster 3 terdiri dari mahasiswa yang masuk melalui jalur Reguler dan Jalur Prestasi Akademik.
Cluster 3 terdiri dari 40 mahasiswa, dengan deskripsi sebagai berikut :
a. Jalur masuk perguruan tinggi : 1) Jalur Prestasi Akademik: 20 mhs 2) Reguler : 20 mhs
6) >5jt s/d ≤6jt : 1 mhs 7) >6jt s/d ≤7jt : 3 mhs 8) >7jt s/d ≤8jt : 3 mhs 9) >8jt s/d ≤9jt : 1 mhs 10)>9jt s/d ≤10jt : 2 mhs 11)>10jt : 3 mhs
c. Dengan rata-rata nilai IPK : 3.471
6 KESIMPULAN
Kesimpulan yang dapat diambil dari penelitian tentang implementasi algoritma k-means dalam menentukan klasterisasi kinerja akademik mahasiswa adalah sebagai berikut: 1. Dari hasil 7 kali pengujian terhadap jumlah
titik pusat dengan nilai 3, 4, 5, 6, 7, 8 dan 9 titik pusat, yang berjumlah 3 memiliki nilai silhouette coefficien yang paling mendekati nilai Si= 1, yaitu dengan nilai 0,108690751. 2. Setelah proses pengolahan data, hasil clustering menunjukkan bahwa pendapatan orang tua tidak mempengaruhi tingkat kinerja akademik mahasiswa.
3. Nilai akademis mahasiswa yang masuk perguruan tinggi melalui jalur reguler dan jalur prestasi akademik mempunyai nilai IPK rata-rata tertinggi
DAFTAR PUSTAKA
Chuchra, Rimmy. 2012, Use of Data Mining Techniques for The Evaluation of Student Performance : A Case Study, International Journal of Computer Science and Management Research, Vol 1.
Han, Jiawei; & Kamber, Micheline. 2001. Data Mining Concepts and Techniques Second Edition. San Francisco: Morgan Kauffman
Hartaji, Damar Adi. 2012. Motivasi Berprestasi Pada Mahasiswa yang Berkuliah Dengan Jurusan Pilihan Orang tua. Fakultas Psikologi Universitas Gunadarma. Nuningsih, S. 2010. K-Means Clustering (Studi
Kasus Pada Data Pengujian Kualitas Susu di Koperasi Peternakan Bandung Selatan. Skripsi FPMIPA UPI, Bandung. Ong, Johan Oscar. 2013. Implementasi Algoritma K-Means Clustering Untuk Menentukan Strategi Marketing President University(12):10-20.
Santoso, Budi. 2007. Data Mining: Teknik Pemanfaatan Data untuk Keperluan Bisnis. Graha Ilmu, Yogyakarta.
Suyanto. 2000. IPS Ekonomi I. Gelora Aksara Pratama. Jakarta.
Tiwari, M. Singh, R. Vimal, N. 2013. An Empirical Study of Data Mining Techniques for Predicting Student Performance in Higher Education, IJCSMC, Vol. 2, Issue 2.
Yuliana, Sudremi. 2007. Pengetahuan Sosial Ekonomi Kelas X. BumiAksara. Jakarta.