i
Diana Chalil
Riantri Barus
Analisis
Data
Kualitatif
USU Press
Art Design, Publishing & Printing
Gedung F, Pusat Sistem Informasi (PSI) Kampus USU Jl. Universitas No. 9
Medan 20155, Indonesia
Telp. 061-8213737; Fax 061-8213737
usupress.usu.ac.id
© USU Press 2014
Hak cipta dilindungi oleh undang-undang; dilarang memperbanyak menyalin, merekam sebagian atau seluruh bagian buku ini dalam bahasa atau bentuk apapun tanpa izin tertulis dari penerbit.
ISBN 979 458 732 X
Analisis Data Kualitatif : Teori dan Aplikasi dalam Analisis SWOT, Model Logit, dan Structural Equation Modeling (Dilengkapi dengan Manual SPSS dan Amos) / Diana Chalil; Riantri Barus– Medan: USU Press. 2014.
vi, 205 p. : ilus. ; 16,5 cm
ISBN : 979-458-732-X
1. Analisis SWOT 2. Model Logit 3. Structural Equation Modeling I. Judul
PRAKATA
Penelitian sosial dan ekonomi banyak menggunakan data kualitatif. Berbeda dengan data kuantitatif, walaupun dapat diobservasi dan diamati tetapi data kualitatif tidak dapat diukur dalam angka. Dengan demikian diperlukan pengukuran dan analisis khusus untuk data kualitatif. Pada Bab 1 buku ini dijelaskan pengertian mengenai data kualitatif tersebut, perbedaannya dengan data kuantitatif dan jenis-jenis data tersebut. Selanjutnya pada Bab 2 dibahas mengenai cara pengukurannya, mulai dari Skala Thurstone, Likert, Guttman, Semantic Differential atau Q-Sort. Pada Bab 3 diuraikan metode-metode yang dapat digunakan untuk mengumpulkan data tersebut. Pada Bab 4 metode tersebut dilanjutkan dengan penentuan besar dan penarikan sampel, baik untuk populasi besar maupun kecil, dengan Probability dan Non Probability Sampling. Selanjutnya, buku ini dilengkapi dengan Analisis Data Kualitatif melalui Metode Deskriptif dan Metode Inferensia pada Bab 5. Akhirnya buku ini ditutup dengan Bab 6 mengenai aplikasi seluruh teori tersebut dalam berbagai penelitian empiris yang menggunakan Analisis Deskriptif dengan Metode SWOT, dan Analisis Inferensia, dengan Model Binomial Logit, Multinomial Logit dan Structural Equation Modelling. Selamat membaca, semoga bermanfaat.
Medan, 13 April 2014
DAFTAR ISI
PRAKATA iii
DAFTAR ISI v
Bab 1. JENIS DATA 1
1.1. Data Nominal 2
1.2. Data Ordinal 4
1.3. Data Interval dan Data Rasio 5
Bab 2. SKALA DAN SKOR 7
2.1. Skala Thurstone 8
2.2. Skala Likert 11
2.3. Skala Guttman 13
2.4. Skala Semantic Differential 16
2.5. Skala Q-sort 19
Bab 3. PENGUMPULAN DATA 20
3.1. Metode Pengumpulan Data 20
3.1.1. Observasi 20
3.1.2. wawancara/Interview 21
3.1.3. Studi Pustaka/Literatur 22 3.1.4. Studi Materi Audiovisual 23
3.2. Panduan Wawancara 23
3.3. Kuesioner 24
3.3.1. Validitas 25
3.3.2. Reliabilitas 28
3.4. Parameter dan Indikator 32
Bab 4. SAMPEL 34 4.1. Metode Penentuan Besar Sampel 35 4.1.1. Metode Slovin/Yamane 37 4.1.2. Metode Krejcie dan Morgan 37
4.1.3. Metode Cochran 38
4.2. Metode Penarikan Sampel 39
4.2.1. Probability Sampling 40 4.2.2. Non Probability Sampling 43
Bab 5. ANALISIS DATA 46
5.1. Metode Deskriptif 47
5.1.1. Pengkodean 48
5.1.2. Skor 48
5.1.3. Bobot 49
5.2. Metode Inferensia 54
5.2.1. Model Logit 55
5.2.2. Structural Equation Modeling 74
Bab 6. CONTOH KASUS 95
6.1. Contoh Penggunaan Analisis SWOT 95 6.2. Contoh Penggunaan Analisis 120
Binomial Logit
6.3. Contoh Penggunaan Analisis 145 Multinomial Logit
6.4. Contoh Penggunaan Analisis SEM 174
DAFTAR PUSTAKA 185
LAMPIRAN 188
B a b 1
JENIS DATA
Data dapat dibedakan atas data kuantitatif dan data kualitatif. Data kuantitatif merupakan informasi numerikal berupa angka-angka, sedangkan data kualitatif merupakan informasi deskriptif berupa kata-kata atau kata-kata yang disimbolkan dalam angka-angka.
jawaban dengan skor yang sama tidak selalu menunjukkan waktu yang sama.
Data kuantitatif dapat berupa data diskrit dan kontinu, sedangkan data kualitatif hanya berupa data diskrit. Data diskrit adalah data dengan kemungkinan nilai yang terbatas, sedangkan data kontinu kemungkinannya tidak terbatas. Data diskrit dapat berupa data nominal atau ordinal, sedangkan data kontinu dapat berupa data interval atau rasio. Perbedaan masing-masing pengukuran tersebut terletak pada urutan dan nilainya.
1.1. Data Nominal
Data nominal tidak mempunyai urutan dan tidak mempunyai nilai pada pengukurannya dan hanya dibedakan berdasarkan pengelompokan. Kelompok yang dibuat harus mutually exclusive(jelas perbedaannya) dan dapat menjelaskan semua kejadian yang mungkin ada.
Angka-angka yang digunakan untuk menyatakan
kelompok-kelompok hanya merupakan label yang
(multidimensional). Contoh pertanyaan pada kuesioner untuk data nominal dengan kategori dengan 1 dimensi adalah sebagai berikut.
a. Contoh untuk kategori dengan 1 dimensi (unidimensional) Apa jenis kelamin Anda?
[] Pria [] Wanita
b. Bagaimana Anda menjaga stok dan daily turn over perusahaan?
[] Melalui jumlah produk pada setiap kategori [] Melalui catatan di toko terpusat
[] Melalui kebijakan departemen
[] Melalui gudang tunggal (Single Warehouse)
c. Berapa rata-rata omset harian konsumen Anda? [] Antara 100-200
[] Antara 200-300 [] Di atas 300
Sedangkan contoh form isian untuk data nominal dengan kategori dengan 2 dimensi adalah sebagai berikut.
Tabel 1.1. Contoh untuk kategori dengan 2 dimensi (multidimensional)
Omset harian
Kategori Produk
Kebijakan
Departemen Toko Pusat
Gudang Tunggal
100 – 200
200 – 300
1.2. Data Ordinal
Data ordinal mempunyai urutan tetapi tidak mempunyai nilai pada pengukurannya. Dalam data ordinal mencakup ciri-ciri data nominal ditambah suatu urutan, artinya angka-angka yang diberikan dalam data ordinal sudah menunjukkan suatu peringkat atau rangking. Data ordinal dapat digunakan jika postulat transitivitas, yang menyatakan bahwa jika a > b dan b > c, maka a > c, dipenuhi. Pemakaian data ordinal menggunakan pernyataan “lebih daripada" atau "kurang daripada" atau "pernyataan yang menunjukkan kesamaan" tanpa menyatakan berapa lebih besar atau lebih kecil. Jadi, perbedaan antara peringkat 1 dan 2 belum tentu sama dengan perbedaan antara peringkat 3 dan 4. Dengan demikian, di samping nilai modus, ukuran pemusatan lain yang dapat ditentukan dalam data ordinal adalah nilai median. Nilai median merupakan nilai yang tepat di tengah-tengah setelah data diurutkan dari yang terkecil sampai terbesar atau sebaliknya.
Urutkan atribut berikut (1-5) berdasarkan nilai pentingnya untuk pemasaran oven microwave.
[] Merek [] Fungsi [] Harga [] Kenyamanan [] Disain
Urutkan atribut berikut (1-5) berdasarkan nilai pentingnya ketika Anda memilih bedak talkum.
[] Kesegaran yang dihasilkan [] Wangi
[] Harga
[] Kehangatan yang dihasilkan [] Kemasannya
1.3. Data Interval dan Data Rasio
dibagi berdasarkan interval 33,3%. Tingkat adopsi lebih kecil dari 33,3% menunjukkan adopsi rendah, 33,3%-66,6% adopsi sedang, dan lebih besar dari 66,6% adopsi tinggi. Tingkat adopsi 0% menunjukkan tidak satupun komponen inovasi yang diteliti telah diadopsi responden.
B a b 2
SKALA DAN SKOR
Skala merupakan pengukuran terhadap berbagai jenis data mulai dari data nominal, ordinal, interval dan rasio (Dane, 1990 : 264). Terdapat berbagai jenis skala yang umum digunakan yaitu (1) Skala Thurstone, (2) Skala Likert, (3) Skala Guttman, (4) SkalaSemantic Differentialdan (5) Skala Q-Sort.
Pengukuran yang valid dan reliabel dari data kualitatif umumnya tidak diperoleh dari jawaban langsung responden, melainkan dari sikapnya terhadap beberapa pernyataan yang telah disusun. Misalnya untuk mengukur sikap seseorang terhadap masuknya imigran ke suatu negara bukan diberikan jawaban sangat tidak setuju sampai sangat setuju karena akan sangat susah untuk memastikan apakah seseorang mengerti perbedaan “sangat setuju” dengan “setuju” misalnya. Sebaiknya diberikan beberapa pernyataan yang menunjukkan urutan sikap tersebut. Misal, skala yang dipilih adalah 1 sampai 5. Pernyataan yang menunjukkan sikap yang semakin positif (setuju) adalah sebagai berikut:
a. Saya rasa sebaiknya negara mengizinkan lebih banyak imigran masuk.
b. Saya tidak merasa terganggu jika ada imigran dalam kecamatan yang sama dengan tempat tinggal saya.
c. Saya tidak merasa keberatan bertetangga dengan imigran. d. Saya tidak keberatan jika anak saya berteman dengan
imigran.
Tentu saja dalam kuesioner urutannya akan diacak, dan responden hanya menjawab setuju atau tidak setuju terhadap masing-masing pernyataan.
2.1. Skala Thurstone
Skala yang dikembangkan oleh Thurstone (1928) ini merupakan skala yang diaplikasikan pada pengukuran interval. Skala ini juga dikenal dengan nama equal-appearing interval. Langkah-langkah yang dilakukan dalam penyusunan skala Thurstone adalah:
a. Menetapkan faktor yang relevan dengan isu yang akan ditanggapi responden. Faktor tersebut tidak terbatas jumlahnya. Namun biasanya berkisar antara 100-200 faktor. Misal dalam kasus senjata api bagi satpam kampus, faktor-faktor tersebut diperoleh dari pendapat 24 mahasiswa. b. Dari 100-200 faktor yang diusulkan, berdasarkan pendapat
24 mahasiswa responden diperoleh 11 faktor yang dianggap paling relevan dengan isu altruism.
c. Selanjutnya masing-masing dari 24 mahasiswa tersebut mengurut 11 faktor tersebut mulai dari sangat setuju (ranking 1) sampai sangat tidak setuju (ranking 11). d. Nilai median dari pendapat 24 mahasiswa tersebut untuk
setiap faktor menjadi nilai skala (scale value) dari setiap faktor.
e. Terakhir, dihitung semi-interquartile untuk setiap faktor dengan menggunakan rumus:
− = % %...(2.1)
Misal dari hasil perhitungan nilai skala untuk setiap faktor tersebut, diperoleh urutan faktor dari skala terendah (urutan 1) sampai tertinggi (urutan 11) sebagai berikut.
Tabel 2.1. Hasil Urutan Faktor berdasarkan Nilai Skala Urutan
1 1,5 0,125 Saya tidak dapat memberikan kepercayaan pada satpam untuk menggunakan senjata api.
2 2,3 0,087 Jika dilengkapi dengan senjata, satpam dapat saja ceroboh dan menyebabkan masalah yang lebih besar lagi.
3 3,0 0,354 Dengan izin menggunakan senjata, satpam akan menjadi besar kepala.
4 4,3 0,469 Saya rasa satpam kurang kompeten jika dibandingkan dengan polisi.
5 5,4 0,390 Saya berharap tidak seorangpun akan membutuhkan senjata, tapi jika memang sudah diputuskan saya tidak dapat berbuat apa-apa.
6 6,0 0,000 Saya tidak perduli jika satpam dilengkapi dengan senjata.
7 7,0 0,113 Satpam juga sebaiknya dilengkapi dengan senjata karena tingkat kejahatan yang semakin meningkat. 8 8,1 0,359 Satpam akan lebih dihargai jika
dilengkapi dengan senjata
Urutan
10 9,9 0,131 Dengan membawa senjata satpam akan dapat menjamin keamanan terutama pada malam hari.
11 10,3 0,333 Satpam bertugas menjaga keamanan dan senjata api akan membantunya dalam menjalankan tugas tersebut. Sumber: Dane (1990 : 270)
skala 4,3, walaupun cukup besar tetapi masih dalam rentang yang diperbolehkan.
Urutan 1 sampai 11 dalam Skala Thurstone di atas tidak menunjukkan urutan sikap positif atau negatif responden. Pada prakteknya yang dicantumkan dalam kuesioner hanya faktor penentu tiap skala dan responden diminta untuk memilih salah satu faktor yang sesuai dengan pendapatnya. Faktor tersebut juga tidak dicantumkan secara berurutan untuk memastikan bahwa responden memberikan jawaban yang sebenarnya. Penelitilah yang nantinya akan menentukan sikap tiap resonden tersebut berdasarkan pilihan masing-masing. Walaupun dapat mengakomodir hampir seluruh perbedaan pendapat (karena mempunyai rentang skala yang cukup besar dari 1-11) namun Skala Thurstone tidak banyak digunakan dalam penelitian empiris karena membutuhkan waktu yang cukup lama dan melibatkan cukup banyak orang terutama dalam penentuan faktor. Sebagai alternatif, Likert (1932) memperkenalkan teknik skala yang lain yang dikenal dengan Skala Likert.
2.2. Skala Likert
komponen uji. Selanjutnya dari seluruh faktor yang valid dan reliabel dipilih 10-20 faktor yang mempunyai nilai korelasi ≥ 0,8. Faktor-faktor tersebut yang kemudian dicantumkan dalam kuesioner untuk menentukan skala penilaian/persepsi dari masing-masing responden.
Misalnya dalam penelitian mengenai pendapat responden mengenai altruism (sikap yang memperhatikan kesejahteraan orang lain tanpa memikirkan kebaikan diri sendiri), diperoleh 14 faktor sebagai berikut.
a. Hampir semua orang berusaha untuk mengaplikasikan Golden Rule walaupun dalam kondisi masyarakat yang semakin kompleks
b. Hampir semua orang tidak ragu-ragu untuk keluar dari kebiasaannya untuk menolong orang lain.
c. Hampir semua orang akan menjadi orang baik jika diberi kesempatan.
d. Perlakukan orang laina sebagaimana anda ingin orang lain memperlakukan kamu, merupakan moto hampir semua orang.
e. Orang biasa secara tulus memperhatikan persoalan orang lain.
f. Hampir semua orang yang rumahnya sudah rusak tetap akan menyilakan tetangganya untuk menumpang menginap pada saat ada serangan nuklir.
g. Hampir semua orang akan berhenti dan menolong orang yang sedang mogok mobilnya.
h. Rata-rata orang seebenarnya sombong.
i. Sangat jarang ada orang yang bersedia membahayakan keselamatan jiwanya untuk menolong orang lain.
j. Sangat menyedihkan melihat orang yang tidak memikirkan dirinya saat sekarang karena orang sekitarnya akan mengambil keuntungan dari sikapnya tersebut.
l. Hampir semua orang tidak suka menempatkan dirinya sebagai penolong rang lain.
m. Hampir semua orang melebih-lebihkan permasalahannya untuk mendapatkan simpati.
n. Umumnya orang melakukan hal-hal yang hanya mendatangkan kebaikan bagi dirinya.
Dalam Skala Likert, faktor yang dihasilkan merupakan pernyataan sikap yang berurutan (ordered item), sementara dalam Skala Thurstone tidak. Faktor 1-7 merupakan pernyataan positif faktor yang mendukung altruism, sebaliknya 8-14 merupakan pernyataan negatif yang tidak mendukung. Masing-masing faktor akan diskor untuk pilihan sangat tidak setuju sampai sangat setuju, misal dengan nilai minimum -3 dan maksimum +3. Dengan demikian, untuk kasus ini skor minimum untuk setiap responden adalah -42 dan maksimum +42, yang menunjukkan responden tidak percaya masyarakat yang altrurisme dan sebaliknya. Total skor dari seluruh responden yang pada akhirnya digunakan untuk penarikan kesimpulan mengenai pendapat responden, sehingga Skala Likert juga sering disebut sebagaisummative scale.
2.3. Skala Guttman
pasti setuju dengan faktor 1 sampai 5. Misal dari pooling faktor pengukur sikap warga Amerika terhadap pendatang, diperoleh pernyataan-pernyataan berikut (Research Methods Knowledge Base, 2006):
a. Saya akan mengizinkan anak saya untuk menikah dengan seorang imigran.
b. Saya rasa negara kita seharusnya mengizinkan lebih banyak imigran masuk.
c. Saya tetap merasa nyaman walaupun ada imigran baru pindah menjadi tetangga saya.
d. Saya tetap merasa nyaman walaupun ada imigran baru pindah ke negara saya.
e. Saya tetap merasa nyaman walaupun ada imigran pindah ke lingkungan saya.
f. Saya tetap merasa nyaman walaupun anak saya berkencan dengan imigran.
Setelah diperoleh pernyataan-pernyataan tersebut (biasanya pooling faktor yang baik mendapatkan 80-100 pernyataan), dilakukan penyusunan urutan jawaban responden dari mulai yang pernyataan dengan menanyakan pada responden. Misal hasil respon terhadap pernyataan-pernyataan tersebut adalah sebagai berikut.
Tabel 2.2.Hasil Jawaban Responden terhadap Pernyataan-Pernyataan
No.
Responden P 2 P4 P 5 P 3 P 6 P1
7 Y Y Y Y Y Y
15 Y Y Y - Y
-3 Y Y Y Y -
-29 Y Y Y Y -
-No.
Responden P 2 P4 P 5 P 3 P 6 P1
32 Y Y - Y -
-41 Y Y - - -
-6 Y Y - - -
-14 Y - - Y -
-33 - - -
-Berdasarkan urutan sikap terhadap pendatang keenam pernyataan tersebut dari paling rendah dukungannya sampai paling tinggi adalah pernyataan (2), (4), (5), (3), (6) dan (1). Namun Tabel 2.2 menunjukkan bahwa respon yang diberikan responden tidak sempurna. Seharusnya setiap responden yang setuju pernyataan (6) harus juga setuju dengan seluruh pernyataan lain sebelumnya. Kenyataannya responden 15 yang setuju dengan pernyataan (6) tidak setuju dengan pernyataan (3). Jika jawaban yang sama terjadi pada banyak responden maka pernyataan (3) akan dibuang. Untuk mengukur proporsi kesesuaian pada Skala Guttman ini dilakukan perhitungan coefficient of reproducibility(CR) dengan rumus:
= 1 − ...(2.2)
Nilai CR 0,90 menunjukkan bahwa proporsi kesesuaian yang baik.
Dari kasus ini urutan sikap terhadap imigran adalah sebagai berikut:
a. Saya rasa negara kita seharusnya mengizinkan lebih banyak imigran masuk.
c. Saya tetap merasa nyaman jika ada imigran pindah ke lingkungan tempat tinggal saya.
d. Saya tetap merasa nyaman jika ada imigran baru pindah menjadi tetangga saya.
e. Saya tetap merasa nyaman jika anak saya berkencan dengan imigran baru.
f. Saya akan mengizinkan anak saya untuk menikah dengan seorang imigran.
Namun dalam kuesioner yang akan diajukan kepada responden, urutan tersebut diacak. Kelemahan Skala Guttman adalah pada tahap seleksi pernyataan. Menghilangkan penyataan yang tidak sesuai satu per satu membutuhkan waktu yang lama dan mungkin memerlukan beberapa pengulangan. Nilai coefficient of reproducibility (CR) sebesar 0,90 juga mungkin sulit diperoleh jika dilakukan pada populasi yang heterogen. Peneliti mungkin harus mengidentifikasi dan menghilangkan sub kelompok tertentu untuk mendapatkan kelompok sampel yang cukup homogen. Konsekuensi pembatasan sampel yang demikian dapat mengurangi kemampuan generalisasi dari skala yang diperoleh.
2.4. SkalaSemantic Differential
atau nilai penting dari konsep tersebut (kuat-lemah, berat-ringan, keras-lunak, sederhana-kompleks, penurut-tegas, sukar-mudah). Aktivitas menunjukkan aksi atau kegiatan yang relevan dengan konsep tersebut (aktif-pasif, semangat-tenang, cepat-lambat, relaks-tegang, redup-cerah, tenang-ribut). Umumnya pengukuran tersebut dilakukan untuk mengetahui pendapat masyarakat mengenai suatu objek atau konsep. Skala ini banyak digunakan untuk survei pemasaran, personality, psikologi klinis atau komunikasi antar budaya.
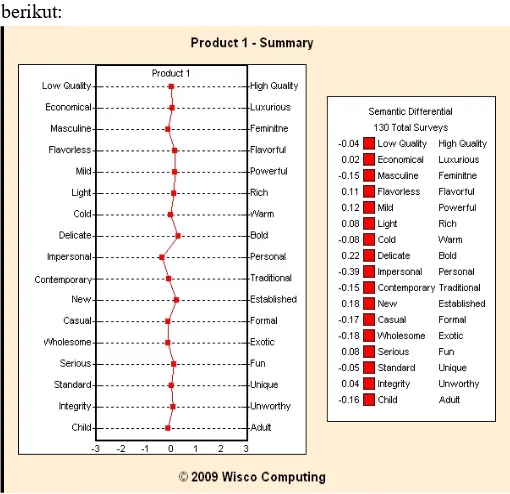
Langkah pertama yang dilakukan adalah menyusun pasangan kata sifat yang merefleksikan evaluasi, potensi atau aktivitas. Pemilihan kata sifat tersebut dapat dilakukan melalui “analisis faktor”. Misalnya survei dilakukan untuk mengetahui penilaian masyarakat mengenai kemasan baru suatu produk, yang dilihat dari 17 karakteristik produk. Masing-masing responden memilih 1 jawaban, dengan skor diantara -3 sampai 3 sebagai berikut.
Tabel 2.3.Penilaian Masyarakat Mengenai Kemasan Produk
Faktor -3 -2 -1 0 1 2 3 Faktor
1 Kualitas rendah Kualitas tinggi
2 Ekonomis Mewah
3 Maskulin Feminin
4 Sangat tidak
artistik Sangat artistik
5 Ringkih Kuat
6 Ringan Berat
7 Dingin Hangat
8 Tipis Tebal
9 Umum Pribadi
Faktor -3 -2 -1 0 1 2 3 Faktor
11 Baru Mapan
12 Kasual Formal
13 Umum Eksotis
14 Serius Menyenangkan
15 Umum Unik
16 Layak Tidak layak
17 Kekanakan Dewasa
Misalnya hasil survei tersebut disajikan dalam skalogram berikut:
Pada skalogram tersebut terlihat bahwa kebanyakan jawaban responden berada di sekitar angka 0. Dengan demikian dapat disimpulkan bahwa secara umum konsumen menganggap bahwa kemasan tersebut biasa-biasa saja.
2.5. Skala Q-sort
Skala Q-sort digunakan untuk studi perbandingan. Misalnya untuk menentukan posisi seseorang dalam satu kelompok atau mengurutkan posisi beberapa konsep yang berbeda. Berbeda dengan Skala Thurstone, pada Skala Q-sort yang diseleksi bukan pernyataannya tetapi responden/sorter nya. Metode ini sering digunakan dalam studi pemasaran.
B a b 3
PENGUMPULAN DATA
3.1. Metode Pengumpulan Data
Dalam pengumpulan data setidaknya terdapat 4 metode yang dapat dilakukan yaitu (1) observasi, (2) wawancara/ interview, (3) studi pustaka/literatur, dan (4) studi materi audiovisual. Masing-masing metode mempunyai kelebihan dan kelemahan (Creswell, 2003 : 186-187). Dengan demikian peneliti dapat mempertimbangkan metode yang akan digunakan sesuai dengan situasi dan kondisi yang dihadapi.
3.1.1. Observasi
Observasi dapat dilakukan dengan 4 cara dari murni sebagai partisipan sampai murni sebagai pengamat yaitu (1) peneliti langsung berbaur dan tidak diketahui perannya sebagai peneliti oleh lingkungan, (2) peneliti langsung berbaur tetapi diketahui perannya sebagai pengamat oleh lingkungan, (3) peneliti berperan sebagai pengamat, namun jika diperlukan akan mencoba langsung kegiatan yang sedang diamati dan (4) peneliti tidak terlibat dalam kegiatan yang sedang diteliti dan murni hanya mengamati kegiatan yang sedang diteliti.
fakta-fakta mengenai hal-hal yang kurang nyaman atau tidak dapat diungkapkan oleh partisipan/informan.
Kelemahan metode observasi adalah (1) dengan terlibat langsung peneliti dapat dianggap ikut campur atau mengganggu kegiatan responden (intrusive), (2) peneliti tidak dapat mengungkapkan hasil observasi yang dianggap pribadi (privacy) oleh responden, dan (3) informasi yang dapat ditangkap sangat tergantung oleh kemampuan peneliti. Biasanya peneliti yang berpengalaman dan kompeten lebih mampu membedakan fenomena-fenomena yang terkait atau yang tidak terkait dengan penelitian. Artinya, 2 peneliti yang berbeda kompetensi dapat menangkap informasi yang berbeda walaupun lokasi dan kegiatan yan diamati sama.
3.1.2. Wawancara/Interview
Wawancara/interview dapat dilakukan dengan 2 cara yaitu (i) tatap muka langsung dan (ii) melalui media (telefon dan teleconference). Tatap muka langsung dapat dilakukan secara individu maupun dalam kelompok kecil. Perlu diperhatikan bahwa wawancara kelompok dapat menghemat waktu, tetapi perlu diperhatikan seberapa besar responden dalam kelompok yang sama dapat saling mempengaruhi.
Kelebihan metode wawancara adalah (1) dapat mengumpulkan informasi yang tidak dapat langsung diamati, baik karena jarak lokasi maupun jarak waktu (data histori) dan (2) dapat mengumpulkan informasi yang terarah dan fokus melalui pertanyaan-pertanyaan yang tersusun dalam kuesioner.
mempengaruhi jawaban responden, dan (4) informasi yang diperoleh sangat tergantung pada kemampuan komunikasi responden.
3.1.3. Studi Pustaka/Literatur
Dokumen dalam studi pustaka/literatur dapat dibedakan atas dokumen pribadi dan dokumen publik. Dokumen pribadi misalnya berupa catatan usahatani responden atau koresponden melalui email dan surat, sedangkan dokumen publik dapat berupa dokumen yang dipublikasi atau tidak dipublikasi. Sumber informasi merupakan hal yang penting dalam menentukan kualitas dokumen. Misal, di Indonesia publikasi dari Badan Pusat Statistik merupakan salah satu sumber dokumen publik yang diakui dan dapat digunakan dalam referensi ilmiah.
Kelebihan studi pustaka/literatur adalah (1) memungkinkan peneliti mendapat informasi dari sumber dengan latar belakang bahasa yang berbeda, (2) dapat diakses oleh peneliti sesuai dengan ketersediaan waktu peneliti, (3) informasi yang diperoleh merupakan informasi yang relatif berbobot karena merupakan pemikiran yang mendalam dari penulisnya, dan (4) informasi yang diperoleh merupakan fakta yang sudah tertulis yang sudah tidak perlu diinterpretasikan lagi.
3.1.4. Studi Materi Audiovisual
Studi Materi Audiovisual agak berbeda dengan studi literatur karena umumnya materi audio visual merupakan data mentah yang sangat sedikit melibatkan analisis pihak ketiga. Sumber materi audiovisual dapat berupa foto, video, karya seni, software atau film.
Kelebihan studi materi audiovisual adalah (1) dapat memberikan gambaran langsung, dan (2) peneliti tidak perlu terlibat langsung dalam kondisi yang digambarkan dalam materi audiovisual.
Kelemahan materi audio visual adalah (1) interpretasi dari materi audiovisual tidak selalu mudah dilakukan. Peneliti mungkin tidak mempunyai pengalaman pada situasi yang sama, (2) tidak semua materi dapat diakses secara individu atau publik dan (3) pengambilan foto memerlukan izin objek foto dan kemungkinan mempengaruhi respon objek foto.
3.2. Panduan Wawancara
Salah satu metode pengumpulan data adalah dengan wawancara. Untuk mendapatkan informasi yang optimal dalam waktu yang tersedia, maka pewawancara sebaiknya telah menyusun pertanyaan-pertanyaan yang akan diajukan, dan telah menguasai pertanyaan-pertanyaan tersebut sehingga dapat menyampaikannya dengan jelas dan singkat. Sebelum mengajukan pertanyaan, pewawancara harus mampu menciptakan hubungan baik dengan responden. Kesan pertama dari penampilan dan kata-kata pewawancara sangat penting dalam menentukan suasana wawancara selanjutnya. Beberapa hal yang dapat perlu diperhatikan untuk memberikan kesan yang baik adalah:
b. Bersikap rendah hati
c. Bersikap hormat kepada responden
d. Ramah dalam sikap dan ucapan (tetapi jangan terlalu banyak berbicara tentang yang hal yang tidak penting yang tidak berkaitan dengan tujuan wawancara)
e. Bersikap netral dan penuh perhatian
f. Menunjukkan antusias dalam setiap jawaban yang diberikan responden
g. Bisa menjadi pendengar yang baik
h. Tidak memaksakan kehendak kepada responden
i. Dapat menyesuaikan dengan waktu luang yang dimiliki responden
Dengan demikian, sebelum turun ke lapangan dan melakukan wawancara yang sebenarnya, sebaiknya setiap pewawancara mendapatkan pelatihan (coaching). Pelatihan dilakukan untuk memberikan gambaran tentang:
a. Tujuan wawancara
b. Informasi-informasi penting apa yang diinginkan dari hasil wawancara
c. Siapa target responden yang akan dijumpai
d. Penjelasan tiap nomor pertanyaan dalam kuesioner, baik maksud maupun tujuan dari pertanyaan tersebut
e. Cara mencatat jawaban responden
f. Prosedur wawancara, mulai dari memperkenalkan diri sampai dengan meninggalkan responden
3.3. Kuesioner
memenuhi seluruh data yang dibutuhkan dalam metode penelitian. Jika penelitian menggunakan metode regresi misalnya, maka seluruh informasi yang dikumpulkan haruslah sesuai dengan variabel yang digunakan. Dengan demikian, pertanyaan yang diajukan dalam kuesioner juga harus dapat mengukur variabel yang akan digunakan.
Dalam penelitian, tidak semua variabel dapat diukur dengan mudah. Variabel yang tidak dapat secara langsung diobservasi, seperti sikap dan persepsi, dapat diukur dengan pendekatan (proxy). Pendekatan yang baik haruslah valid dan reliabel. Validitas menunjukkan sejauh mana pendekatan yang digunakan mampu mengukur variabel terkait yang tidak dapat diamati secara langsung, sementara reliabilitas menunjukkan sejauh mana pendekatan tersebut konsisten dan dapat dipercaya.
3.3.1. Validitas
Validitas dibagi menjadi 5 jenis yaitu Validitas Konsep (ConstructValidity), Validitas Isi (Content Validity), Validitas Prediktif (Predictive Validity), Validitas Internal dan Eksternal (Internal and External Validity), dan Validitas Rupa (Face Validity).
1. Validitas Konsep (Construct Validity)
Validitas konsep menunjukkan apakah indikator-indikator yang digunakan untuk mengukur suatu konsep sudah tepat atau tidak. Langkah-langkah yang dilakukan dalam pengujian validitas konsep adalah sebagai berikut:
langsung kepada calon responden. Dari definisi tersebut, maka peneliti dapat menyusun daftar pertanyaan dalam kuesioner.
b. Melakukan uji coba kuesioner tersebut pada sejumlah responden, minimal 30 orang. Jawaban untuk masing-masing pertanyaan diberi skor.
c. Melakukan tabulasi data
d. Menghitung nilai korelasi antara skor masing-masing pernyataan dengan total skor dengan menggunakan KorelasiPearson Product Moment, dengan rumus:
= (∑ ) (∑ ∑ )
[ ∑ (∑ ) ][ ∑ (∑ )
...(3.1)
dimana: N = jumlah responden (pengamatan); X = skor masing-masing pernyataan; Y = total skor
e. Jika koefisien korelasi yang diperoleh signifikan secara statistik, maka alat pengukur yang digunakan valid.
2. Validitas Isi (Content Validity)
3. Validitas Prediktif (Predictive Validity)
Alat pengukur juga sering digunakan untuk alat prediksi. Contoh alat ukur yang memiliki validitas prediktif adalah ujian seleksi masuk ke perguruan tinggi. Ujian tersebut adalah upaya untuk memprediksi kemampuan calon mahasiswa dalam mengikuti pelajaran di perguruan tinggi. Peserta yang lulus ujian diprediksikan dapat mengikuti pelajaran di perguruan tinggi dengan baik. Untuk menilai apakah soal ujian tersebut benar-benar memiliki validitas prediktif yang tinggi sangat tergantung pada apakah ada korelasi yang tinggi antara nilai ujian seleksi dengan prestasi belajar selama di perguruan tinggi. Bila ternyata ada korelasi yang tinggi, maka soal ujian tersebut memiliki validitas prediktif yang baik.
4. Validitas Internal dan Eksternal (Internal and External Validity)
signifikan dalam kasus di Kabupaten Serdang Bedagai. Namun ternyata di Deli Serdang, tidak ada lembaga sejenis yang melakukan program yang sejenis, sehingga variabel tersebut tidak signfikan. Sebagai alternatif, variabel yang dimasukkan hanya variabel umum saja seperti luasa lahan dan persepsi petani. Jika hasil estimasi regresi menunjukkan luas lahan dan rasio harga beras organik dan non organik secara nyata mempengaruhi keputusan petani untuk mengaplikasikan sistem pertanaman organik, maka dapat disimpulkan bahwa kasus tersebut mempunyai validitas internal yang tinggi. Jika model tersebut kemudian diaplikasikan pada petani di Kabupaten Deli Serdang misalnya, dan juga menunjukkan hasil yang signifikan maka penelitian di Kabupaten Serdang Bedagai tersebut juga mempunyai Validitas Eksternal yang tinggi.
5. Validitas Rupa (Face Validity)
Validitas Rupa menunjukkan validitas permukaan, yang dapat dengan mudah untuk diobservasi. Misal sebagai institusi pemerintahan, tugas utamanya adalah untuk melayani masyarakat. Dua hal yang dapat dengan mudah diobservasi adalah jumlah pengaduan masyarakat dan jumlah pemakaian seragam. Namun karena tugasnya adalah melayani masyarakat maka kepuasan masyarakatlah yang dianggap lebih tepat sebagai alat ukur kinerja bukan kedisiplinan stafnya menggunakan seragam. Dengan demikian, jumlah pengaduan masyarakat merupakan alat pengukur dengan Validitas Rupa yang baik, tetapi jumlah pemakaian seragam tidak.
3.3.2. Reliabilitas
dan hasil pengukuran yang diperoleh konsisten, maka alat pengukur tersebut reliabel.
Reliabilitas juga dilakukan untuk melihat apakah alat ukur yang digunakan bias/ambigu atau tidak. Alat ukur yang bias dapat berasal dari jawaban yang tidak konsisten dari 2 pertanyaan yang sejenis, atau dari jawaban yang tidak jelas dari 1 pertanyaan yang mengandung 2 informasi. Pertama, jika 2 pertanyaan yang berbeda namun sebenarnya menanyakan hal yang sama, maka kovarians keduanya akan sama dengan 0. Misal untuk mengetahui pendapat masyarakat mengenai fenomena pengobatan keluar negeri, alat ukur yang pertama yang digunakan adalah biaya pengobatan di luar negeri, sementara alat ukur yang kedua adalah biaya pengobatan di dalam negeri. Pilihan yang menyatakan biaya perobatan di luar negeri relatif murah sebenarnya merupakan pernyataan yang sama dengan biaya perobatan di dalam negeri yang relatif mahal. Sehingga jika tidak konsisten akan memberikan hasil yang bias dan sulit untuk diinterpretasikan.
Kedua, pertanyaan yang diajukan dapat ditafsirkan berbeda. Misal yang ditanyakan adalah apakah anda setuju Pemerintah meningkatkan anggaran belanja hankam untuk mencegah agresi komunis? Dalam hal ini terdapat ambigu jawaban yang diinginkan adalah pendapat mengenai peningkatan anggaran belanja hankam atau mengenai agresi komunis. Responden mungkin setuju untuk peningkatan anggaran hankam tetapi bukan untuk mencegah agresi komunis.
1. Teknik Pengukuran Ulang (Re-Test Method)
Dalam teknik ini, responden yang sama menjawab pertanyaan yang sama dalam waktu yang berbeda sebanyak dua kali. Selang waktu antara waktu menjawab yang pertama dengan yang kedua yang ideal adalah antara 15-30 hari. Selang waktu yang terlalu dekat ataupun terlalu jauh dapat mempengaruhi reliabilitas alat pengukur. Jawaban pertama dan jawaban kedua kemudian diuji dengan Korelasi Pearson Product Moment. Jika nilai korelasinya signifikan, maka dapat disimpulkan bahwa jawaban yang diberikan sudah stabil.
2. Teknik Belah Dua (Half-Split Method)
Teknik ini dapat digunakan jika pertanyaan yang diajukan dalam kuesioner cukup banyak, minimal 50-60 pertanyaan. Langkah-langkah yang dilakukan dalam Teknik Belah Dua adalah:
a. Peneliti mengajukan sejumlah pertanyaan responden, yang kemudian dihitung validitasnya. Pertanyaan yang tidak valid dikeluarkan
b. Selanjutnya, pertanyaan yang valid dibagi menjadi dua kelompok. Pembagian dapat dilakukan secara random ataupun dibagi berdasarkan nomor ganjil dan genap. Setiap jawaban diberi skor.
c. Total skor dari setiap kelompok diuji dengan Korelasi Pearson Product Moment.
d. Nilai koefisien korelasi dibandingkan dengan koefisien korelasi total jika alat pengukur tidak dibelah seperti pada teknik pengukuran ulang. Nilai koefisien korelasi teknik belah dua akan lebih kecil dari nilai koefisien korelasi total. Nilai koefisien korelasi total dapat dicari dengan rumus:
. = ( . )
dimana: r.tot : koefisien korelasi keseluruhan item r.tt : koefisien korelasi belahan pertama
dengan belahan kedua
Jika skor dari kedua jawaban tersebut berkorelasi signifikan, maka dapat disimpulkan bahwa jawaban yang diberikan sudah ekuivalen.
3. Teknik Bentuk Paralel/Uji Silang (Cross Check) Dalam teknik ini, responden diajukan dengan 2 pertanyaan yang berbeda namun sebenarnya mengukur aspek yang sama. Jika skor dari kedua jawaban tersebut berkorelasi signifikan, maka maka dapat disimpulkan bahwa jawaban yang diberikan sudah ekuivalen. Pertanyaan silang juga sering dicantumkan dalam kuesioner untuk memperoleh ukuran yang lebih lengkap dan tepat. Sebagai contoh kuesioner pada Lampiran 1. Jika kita ingin mengetahui pendapatan petani, maka kita akan menanyakan langsung berapa besar pendapatan petani tersebut seperti pada pertanyaan bagian I.A. nomor 9. Namun hasil tersebut harus dicross checkdengan menanyakan tingkat produksi dan harga jual petani yaitu pada pertanyaan bagian I.B. nomor 10. Demikian juga ketika kita ingin mengetahui kemana petani menjual TBSnya, maka ada beberapa pertanyaan yang harus kita ajukan sehingga kita dapat mengetahui konsistensi jawaban responden. Misal kita ingin mendapatkan informasi apakah responden selalu menjual hasil panennya ke pedagang yang sama. Maka kita dapat mengajukan 3 pertanyaan sebagai berikut:
a. Ke mana petani menjual TBS nya?
b. Apakah selalu pada pedagang yang sama? Ya / Tidak c. Apakah semua dijual pada 1 pedagang? Ya / Tidak
3.4. Parameter dan Indikator
Salah satu cara yang dapat digunakan untuk menjaga konsistensi jawaban responden adalah dengan menetapkan parameter dan indikator dari variabel yang diteliti. Indikator adalah sesuatu yang dapat memberikan (menjadi) petunjuk atau keterangan. Parameter adalah karakteristik yang dimiliki oleh populasi, ukuran seluruh populasi dalam penelitian yang harus diperkirakan dari yang terdapat di dalam percontohan. Misal untuk mengukur kinerja suatu organisasi dapat digunakan 3 indikator dengan masing-masing 3 parameter seperti pada Tabel 3.1.
Tabel 3.1.Indikator dan Paramater untuk Kinerja Organisasi
No Indikator Parameter
1 Lamanya mengurus surat
- Skor 1 = Tidak baik jika memerlukan waktu lebih dari 6 hari
- Skor 2 = Sedang jika memerlukan waktu antara 3 sampai 6 hari
- Skor 3 = Baik jika memerlukan waktu kurang dari 3 hari
2 Transparansi - Skor 1 = Tidak baik jika tidak ada informasi mengenai biaya pengurusan surat
- Skor 2 = Sedang jika informasi mengenai biaya pengurusan telah tersedia tetapi pada realisasinya ada biaya tambahan lainnya - Skor 3 = Baik jika seluruh informasi tersedia
dan realisasinya sama dengan informasi yang diberikan
3 Jumlah
petugas - Skor 1 = Tidak baik jika tidak jumlahpetugas untuk setiap shift < 5 orang - Skor 2 = Sedang jika jumlah petugas setiap
shift antara 5 sampai 8 orang
3.5. Pertimbangan Latar Belakang Responden
Latar belakang responden sangat menentukan pemilihan kata maupun penyusunan kalimat dalam kuesioner. Sebelum menyusun pertanyaan dalam kuesioner sebaiknya peneliti mempunyai sedikit gambaran mengenai calon responden. Misal, jika kuesioner ditujukan untuk petani sawit yang tidak mempunyai catatan usahatani, maka yang ditanyakan sebaiknya bukan pengeluaran untuk pupuk selama setahun misalnya, karena jawaban yang akan diberikan akan sangat tergantung pada ingatan petani pada saat pertanyaan diajukan. Sebaiknya pertanyaan dilakukan secara bertahap misalnya kapan petani melakukan pemupukan dan berapa banyak pupuk yang digunakan saat itu. Pertanyaan berikutnya berapa kali petani melakukan pemupukan selama setahun dan apakah jumlahnya selalu sama setiap kali. Kemudian berapa harga pembelian pada saat itu dan apakah itu merupakan harga rata-rata atau tidak.
B a b 4
SAMPEL
Unit sampel atau sampling unit/element menunjukkan satuan yang akan dipilih dalam penelitian. Jika penelitian mengenai analisis pendapatan rumahtangga petani, maka sampling unitnya adalah rumahtangga yang terdiri dari kepala keluarga (suami misalnya) dan anggota keluarga (isteri dan anak-anak misalnya). Jika penelitian mengenai usahatani kentang, maka sampling unitnya adalah setiap usahatani kentang yang dikelola oleh 1 manajemen (petani). Gabungan dari semua unit atau elemen yang dapat dimasukkan sebagai sampel penelitian disebut sebagai populasi.
Dalam penelitian dengan populasi yang besar, observasi pada setiap anggota kelompok akan membutuhkan waktu yang lama dan biaya yang besar. Observasi yang dilakukan pada setiap anggota populasi disebut sebagai metode sensus. Namun demikian sebagai upaya efisiensi umumnya dilakukan penarikan sampel yang diharapkan dapat mewakili gambaran populasi. Dengan demikian sampel yang dipilih haruslah representatif. Artinya, segala keragaman atau variasi yang dianggap penting dalam penelitian haruslah terwakili oleh sampel yang dipilih.
faktor lainnya. Anggota populasi yang homogen dapat diwakili oleh satu atau beberapa sampel saja. Berdasarkan homogenitas anggota populasi diperlukan beberapa metode penarikan sampel sebagai berikut.
4.1. Metode Penentuan Besar Sampel
Sebagaimana yang telah dijelaskan sebelumnya, sampel yang baik adalah sampel yang dapat mewakili populasi (representatif). Nilai rata-rata sampel yang representatif, misalnya, dapat digunakan sebagai estimasi dari nilai rata-rata populasi. Jika tidak, nilai rata-rata sampel yang dianggap sebagai nilai rata-rata populasi sebenarnya tidak sama dengan nilai rata-rata populasi. Ahli statistik membagi kesalahan tersebut atas 2 tipe yaitu kesalahan tipe 1 dan kesalahan tipe 2.
Kesalahan tipe 1 sering disebut sebagai false positive, dimana peneliti menyimpulkan bahwa suatu variabel berpengaruh nyata padahal sebenarnya tidak. Misalnya, peneliti ingin menguji pengaruh pemberian pupuk terhadap tingkat produksi. Peneliti melakukan pengambilan sampel secara acak sederhana. Koefisien regresi yang diuji adalah Ho; = 0, dengan tingkat kepercayaan 95% atau α = 0,051 dan signifikansi yang diperoleh peneliti lebih kecil dari 0,05. Dengan hasil tersebut peneliti menyimpulkan bahwa pupuk berpengaruh nyata terhadap tingkat produksi. Ternyata sampel petani yang diperoleh kebanyakan merupakan petani dengan luas lahan > 1 ha dan secara rutin menggunakan pupuk sesuai dengan rekomendasi. Padahal banyak petani dengan luas lahan < 1 ha tidak mempunyai cukup uang untuk melakukan
pemupukan secara rutin, dan masih banyak petani yang tidak mengikuti rekomendasi jumlah, jenis dan waktu pemupukan. Kemudian, ketika peneliti lain melakukan penelitian di daerah yang sama, dengan populasi yang sama tetapi dengan penarikan sampel secarastratified cluster sampling(stratifikasi berdasarkan luas lahan dan cluster berdasarkan frekuensi penggunaan pupuk), diperoleh hasil nilai signifikansi lebih besar dari 0,05. Penarikan sampel yang telah mengakomodir keragaman populasi denganstratified cluster samplingtersebut dapat dikatakan lebih representative dibandingkan dengan sampel yang ditarik secara simple random. Dengan demikian dapat dikatakan bahwa peneliti yang pertama telah melakukan kesalahan tipe I.
Kesalahan tipe 2 sering disebut sebagai false negative, dimana peneliti menyimpulkan bahwa suatu variabel tidak berpengaruh nyata padahal sebenarnya berpengaruh nyata. Secara empiris kesalahan tersebut jarang terjadi, sehingga jarang dipertimbangkan dalam penelitian.
Secara praktis, banyak penelitian empiris yang mengambil minimal 30 sampel dengan dasar Central Limit Theory2yang menyatakan bahwa dengan jumlah sampel ≥ 30, maka distribusinya akan mendekati distribusi normal. Hal tersebut telah dibuktikan dalam banyak buku teks3. Namun Chang (2006) membuktikan bahwa hal tersebut tidak selalu berlaku sama untuk semua kasus empiris. Misalnya, untuk kasus percobaan kegagalan sistem pembakaran/emisi dibutuhkan setidaknya 109 sampel dan bukan hanya 30 sampel untuk memastikan bahwa kemungkinan gagal telah terakomodir. Penentuan sampel sangat ditentukan oleh tingkat variasi populasi. Semakin heterogen suatu populasi maka akan
2Central Limit Theory menyatakan bahwa dengan besar sampel yang cukup
maka distribusi dari rata-rata sampel akan mendekati distribusi normal.
semakin banyak sampel yang dibutuhkan. Untuk memastikan semua heterogenitas tersebut dapat terwakili dalam sampel maka dilakukan pengelompokan atau stratifikasi seperti pada cluster sampling dan stratified sampling. Dengan demikian kesimpulan yang diperoleh dari data sampel tersebut dapat digunakan untuk melakukan kesimpulan terhadap populasi.
Terdapat beberapa metode yang dapat digunakan untuk menentukan jumlah sampel yang cukup untuk setiap kelompok sampling. Metode tersebut dapat dikelompokkan dalam metode sampling untuk populasi besar dan untuk populasi kecil. Metode Slovin (1967) lebih sering digunakan pada populasi besar, sedangkan Metode Krejcie dan Morgan (1970) dan Metode Cochran (1977) digunakan untuk menentukan besar sampel pada populasi kecil.
4.1.1. Metode Slovin/Yamane (1967)
Metode Slovin ditemukan Yamane pada tahun 1967. Metode ini mengasumsikan populasi besar, dan sampel ditarik secara acak (simple random sampling). Jika sampel berasal dari populasi yang heterogen, maka dilakukan pengelompokan atau stratifikasi terlebih dahulu. Selanjutnya ukuran sampel untuk setiap kelompok atau strata detentukan l berdasarkan formula berikut:
= (∝ )...(4.1)
dimana: = ukuran sampel, = ukuran populasi dan ∝ =
tingkat akurasi (level of precision; yang sering digunakan dalam penelitian empiris adalah pada tingkat 0,05 dan 0,01)
4.1.2. Metode Krejcie dan Morgan (1970)
= ( ) ( )( )...(4.2)
dimana: = ukuran sampel, = Nilai tabel chi-square untuk degree of freedom = 1, pada tingkat kepercayaan yang diinginkan 5% (3,841).
4.1.3. Metode Cochran (1977)
Cohran membedakan perhitungan besar sampel berdasarkan jenis data yaitu data yang kontinu dan kategorikal. Untuk data yang kontinu, formula yang digunakan adalah sebagai berikut
= ...(4.3)
dimana: = nilai t untuk tingkat α yang dipilih (jika α = 0,05 dengan dua arah atau 0,025 untuk tiap arah, maka nilai t nya 1.96), = nilai standar deviasi, =acceptable margin of error. Biasanya untuk data yang kontinu adalah sebesar 5%, sementara untuk data kategorikal 3%. Jika besar populasi sebesar 1.679 dan nilai α = 0,05, maka untuk data kontinu diperoleh besar sampel 118. Namun karena jumlahnya melebihi 5% dari jumlah populasi, maka Cochran (1977) menentukan formula koreksi untuk menghitung besar sampel final sebagai berikut:
= ...(4.4)
= ...(4.5)
dimana = proporsi sampel (dengan nilai 50% untuk data kategorikal) dan = p-1. Perbedaan formula untuk data kategorikal ini dengan formula data kontinu adalah pada perhitungan nilai variansnya. Untuk data kontinu maksimum proporsi distribusi sampelnya adalah 98%, sedangkan pada data kategorikal nilai proporsi maksimum adalah 0,5, sehingga nilai variansnya menjadi (0,5)(0,5) = 0,25. Dengan menggunakan = 0,5 dan = 0,5 dan perkiraan kuesioner yang dapat digunakan 65%, maka sampel perlu diambil adalah sebanyak 482. Hal tersebut menunjukkan bahwa besar sampel yang dibutuhkan pada data kategorikal jauh lebih besar dibandingkan pada data kontinu.
4.2. Metode Penarikan Sampel
Menurut Dane (1990 : 297-303) metode penarikan sampel dapat dibedakan atas MetodeProbability Samplingdan Metode Non Probability Sampling.Pada MetodeProbabilitySampling sampel ditentukan dengan teori kemungkinan. Sampel ditentukan secara acak sehingga setiap anggota populasi mempunyai peluang yang sama. Sebaliknya, pada MetodeNon Probability Sampling, sampel tidak ditentukan secara acak dan tidak mempunyai peluang sama untuk dipilih.
golongan berpendapatan rendah. Akibatnya, rata-rata pendapatan yang diperoleh dari hasil penelitian lebih rendah dibandingkan dengan nilai rata-rata populasi. Dalam Metode Probability Sampling, pengurangan kesalahan sampling dilakukan dengan Random Sampling, Stratified Sampling dan Cluster Sampling, sementara dalam Non Probability Sampling dengan Purposive Sampling, Quota Sampling dan Snowball Sampling.
4.2.1. Probability Sampling
Probability Sampling adalah teknik yang memastikan setiap elemen dalam sampling frame mempunyai kesempatan yang sama untuk ditarik sebagai sampel.Probability Sampling dapat dikelompokkan atas Random Sampling, Stratified SamplingdanCluster Sampling.
1. Random Sampling
Random Sampling ini digunakan jika populasi bersifat homogen. Metode ini dapat dibedakan atas metode Simple Random SamplingdanSystematic Random Sampling.
(1) Simple Random Sampling
Simple Random Sampling merupakan suatu metode penarikan sampel yang menarik sampel secara acak langsung dari seluruh populasi. Ada dua cara yang dapat digunakan untuk menentukan sampel dalam metode Simple Random Sampling, yaitu:
a. Undian
dalam sebuah kotak. Kertas-kertas yang diambil secara acak menunjukkan nomor yang akan menjadi sampel. Namun cara ini hampir tidak memungkinkan jika populasi besar.
b. Tabel angka acak (random)
Penggunaan tabel angka acak (random) lebih praktis dengan jumlah populasi yang besar. Penggunaan tabel dapat dilakukan dengan manual atau komputer. Jika dilakukan secara manual setelah angka pertama dipilih dari tabel, maka dalam pemilihan selanjutnya kita dapat bergeser ke atas atau ke bawah mengikuti kolom, ataupun ke kanan atau ke kiri mengikuti baris.
(2) Systematic Random Sampling
Systematic Random Sampling merupakan suatu metode penarikan sampel yang menarik sampel pertama secara acak, dan sampel selanjutnya ditentukan berdasarkan jarak tertentu dari sampel sebelumnya. Metode ini dapat digunakan jika sampling frame/populasi memiliki pola beraturan, seperti blok-blok. Sampel pertama ditentukan secara acak dengan rasio sampling yang merupakan proporsi populasi yang dipilih sebagai sampel. Misal jika jumlah populasi 100 dan sampel yang akan dipilih 20, maka rasio samplingnya = 20/100 = 1/5. Nilai acak dipilih dari angka 1 sampai 5. Interval sampel ditentukan dengan rasio anggota populasi/jumlah sampel = 100/20 = 5. Jika sampel awal yang terpilih adalah angka 4 maka selanjutnya yang dipilih adalah 9, 13, dan seterusnya.
2. Stratified Sampling
usahatani padi sawah. Tingkat efisiensi sangat tergantung pada skala usaha, dengan demikian, usahatani tersebut harus dibagi berdasarkan skala usaha yaitu luas lahan, misal luas lahan sempit (≤ 1 ha) dan luas (> 1 ha). Selanjutnya setelah dilakukan stratifikasi, penarikan sampel pada setiap strata dilakukan secara acak sederhana (simple random sampling) atau acak sistematis (systematic random sampling). Biasanya ukuran sampel pada tiap strata ditentukan secara proporsional, sehingga metode penarikan sampel tersebut disebut Stratified Proportional Sampling. Jika sampel yang akan ditarik sebanyak 30 dari 90 petani, maka besar sampel pada setiap stratanya dapat dilihat seperti pada Tabel 4.1.
Tabel 4.1.Contoh Penarikan Sampel dengan Metode Stratified Sampling
No. Luas (Ha) Populasi (KK) Sampel (KK)
1. ≤ 1 60 30= 20
2. > 1 30 30= 10
3. Cluster Sampling
maka yang dilakukan adalah Stratified Sampling, jika tidak sampel dari tiap kecamatan dipilih secara acak. Metode penarikan sampel yang dilakukan dengan 2 tahap demikian disebut juga sebagaiMultistage Sampling.
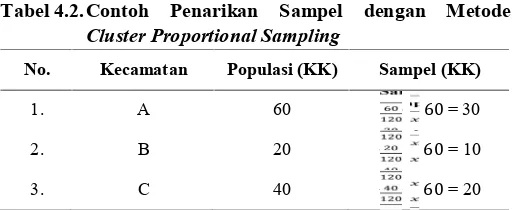
Jika besar sampel pada setiap cluster ditentukan secara proporsional, maka metode penarikan sampel tersebut disebut Cluster Proportional Sampling. Misal dalam kabupaten yang akan diteliti terdapat 3 kecamatan dan sampel yang akan ditarik sebanyak 60 dari 120 petani, maka besar sampel pada setiap kelompoknya dapat dilihat seperti pada Tabel 4.2.
Tabel 4.2.Contoh Penarikan Sampel dengan Metode Cluster Proportional Sampling
No. Kecamatan Populasi (KK) Sampel (KK)
1. A 60 60= 30
2. B 20 60= 10
3. C 40 60= 20
4.2.2. Non Probability Sampling
DalamNon Probability Sampling yang dipastikan bukan kesempatan yang sama pada setiap anggota populasi, namun setiap variasi yang relevan dengan topik penelitian dapat seluruhnya terakomodir. Non Probability sampling dapat dikelompokkan atas Convenience Sampling/Accidental Sampling,Purposive Sampling,Quota SamplingdanSnowball Sampling.
1. Convenience Sampling/Accidental Sampling
besar namun masih digunakan di beberapa penelitian, terutama jika terkait dengan izin atau kerelaan sampel. Misal untuk penelitian yang menggunakan perusahaan sebagai unit sampel. Namun dalam metode ini kesalahan sampling dapat dikurangi dengan menetapkan beberapa kriteria sampel sehingga yang terpilih merupakan sampel sukarela yang memenuhi kriteria (qualified voluntary sample).
2. Purposive Sampling
Purposive Sampling yaitu teknik sampling dengan menentukan sampel berdasarkan kriteria tertentu yang sesuai dengan tujuan penelitian. Sebagai contoh suatu penelitian dilakukan untuk mengetahui faktor-faktor yang mempengaruhi keputusan konsumen untuk mengkonsumsi beras organik. Peneliti akan datang ke lokasi penjualan beras dan menetapkan sampel dari konsumen yang membeli beras, baik yang organik maupun yang tidak organik. Dengan demikian dapat diestimasi faktor apa yang mempengaruhi seseorang untuk membeli atau tidak membeli beras organik.Purposive Samplinghampir sama dengan Convenience Sampling, namun biasanya pada Purposive Sampling ketersediaan sampelnya lebih banyak daripada besar sampel.
3. Quota Sampling
diperoleh sebanyak 40 orang, maka penelitian dilanjutkan untuk mencari sampel laki-laki. Jika yang dijumpai adalah perempuan, maka itu tidak termasuk ke dalam sampel, karena quota sampel perempuan sudah terpenuhi.
4. Snowball Sampling
B a b 5
ANALISIS DATA
Secara umum metode analisis penelitian dapat dikategorikan atas Metode Deskriptif dan Metode Inferensia. Analisis Deskriptif dapat diaplikasikan pada seluruh jenis pengukuran data, mulai dari data nominal, ordinal, interval maupun rasio. Penelitian yang dilakukan dapat merupakan penelitian awal (eksploratif) atau penelitian lanjutan. Analisis Inferensia hanya dapat diaplikasikan pada data interval dan rasio saja. Data yang digunakan pada variabel dependen dan independen dalam analisis inferensia dapat berupa data kuantitatif atau kualitatif. Hubungan antara kedua variabel tersebut dapat diestimasi dengan Model Regresi. Jika dalam hubungan tersebut variabel independen yang digunakan merupakan variabel kuantitatif maka model yang digunakan adalah Model Regresi Sederhana atau Berganda, sedangkan jika yang digunakan data kualitatif digunakan Model Regresi Logit. Jika data variabel kualitatif tidak dapat langsung diukur dan harus menggunakan beberapa variabel pendekatan, maka Model Structural Equation merupakan salah satu alternatif yang dapat digunakan.
petani di Desa Kampung Baru diperoleh gambaran bahwa rata-rata luas lahan petani kurang dari 1 ha. Gambaran tersebut hanya berlaku untuk petani di desa tersebut. Metode analisis inferensial biasanya digunakan untuk menentukan hubungan sebab akibat (cause effect)4. Misalnya untuk datacross section dari data 100 sampel petani jeruk di Kabupaten Karo yang ditarik secarastratified cluster samplingdiperoleh kesimpulan bahwa penggunaan pupuk subsidi mempengaruhi pendapatan petani. Hasil tersebut bukan hanya berlaku pada 100 petani sampel tersebut, tetapi juga digunakan untuk mengestimasi gambaran seluruh petani jeruk di Kabupaten Karo. Untuk data time series, misalnya dengan menggunakan data bulanan dari tahun 1998 sampai 2013 diperoleh kesimpulan bahwa nilai ekspor CPO Indonesia dipengaruhi oleh nilai tukar mata uang Indonesia dengan negara-negara importir. Jika hasil estimasi tersebut menunjukkan nilai tukar berpengaruh nyata, maka nilai ekspor CPO Indonesia di masa mendatang diperkirakan berdasarkan nilai koefisien regresi tersebut.
5.1. Metode Deskriptif
Dalam analisis deskriptif, metode statistik yang dapat digunakan antara lain adalah nilai rata-rata, kisaran data atau nilai persentil. Untuk data kualitatif, nilai tersebut dapat diperoleh jika telah dilakukan pengkodean. Analisis deskriptif juga dapat dilakukan dengan melakukan skoring dan pembobotan, seperti pada Analisis SWOT (Strength, Weakness, Opportunity dan Threat). Pada SWOT skoring menunjukkan kondisi eksisting dari faktor yang diteliti,
sedangkan bobot menunjukkan nilai penting dari masing-masing faktor.
5.1.1. Pengkodean
Pengkodean adalah proses pengubahan tanggapan verbal atau jawaban tertulis menjadi angka untuk memudahkan analisis, baik pada analisis deskripsi maupun inferensia. Pertanyaan yang diajukan dapat berupa pertanyaan terbuka atau pertanyaan tertutup. Pertanyaan terbuka dipilih untuk pengumpulan informasi awal jika tidak ada informasi terkait yang tersedia. Misal informasi mengenai mekanisme penawaran harga yang dilakukan petani, atau perlakuan petani terhadap limbah obat-obatan kimia. Pertanyaannya adalah "Apa yang Bapak/Ibu lakukan pada wadah bekas obat-obatan kimia?". Jawabannya beragam: dibuang di kebun, ditanam, dibakar, dijual dan dipakai lagi. Jawaban tersebut dapat langsung diberi kode 1 sampai 5 atau dikelompokkan lagi menjadi perlakuan "yang sesuai GAP, diberi kode 1" dan "yang tidak, diberi kode 0". Pertanyaan tertutup digunakan untuk pengumpulan informasi yang telah ada informasi awal. Misal informasi yang ingin diketahui adalah mengenai status lahan, dengan 3 pilihan: milik sendiri, sewa dan garap. Masing-masing diberi kode 1, 2 dan 3. Dengan kode tersebut maka analisis deskripsi seperti nilai rata-rata atau persentil akan mudah dilakukan. Informasi yang telah diubah dalam kode tersebut juga dapat dijadikan variabel untuk digunakan dalam estimasi persamaan.
5.1.2. Skor
dimasukkan dalam analisis adalah pencatatan kegiatan usahatani. Karena faktor tersebut dapat dikendalikan petani maka faktor tersebut menjadi faktor internal. Penilaian untuk tiap responden adalah mulai dari tidak ada pencatatan (skor 1) sampai sangat lengkap (skor 4). Catatan yang harus ada meliputi catatan mengenai biaya (yang mencakup penggunaan input), tingkat produksi, jumlah penjualan dan harga jual (termasuk kepada siapa hasil tersebut dijual). Jika total responden ada 100, maka nilai rata-rata aritmetik akan diperoleh dengan rumus
= ∑ ...(5.1)
dimana Xiadalah skor responden i untuk faktor X (dalam hal ini pencatatan usahatani) dan n adalah jumlah responden. Dengan demikian deskripsi dilakukan berdasarkan nilai rata-rata tersebut. Misal nilai rata-rata-rata-rata 2,1 menunjukkan bahwa secara umum petani sudah mulai punya catatan usahatani tetapi dalam cakupan yang sangat minim. Untuk mengetahui catatan apa saja yang paling banyak dilakukan dan tidak dilakukan, maka dapat dilengkapi dengan jumlah petani yang melakukan pencatatan untuk masing-masing dari keempat jenis catatan tersebut. Dengan demikian kesimpulan baik atau tidak baik, misalnya, dalam analisis deskripsi dapat lebih objektif dan konsisten.
5.1.3. Bobot
Salah satu teknik yang dapat digunakan adalah Teknik Komparasi Berpasangan (Pair Comparison) (Saaty, 1998 : 78), dengan membandingkan nilai penting setiap 2 faktor. Nilai penting tersebut bisa dari skala 1 sampai 3, sampai dengan skala 1 sampai 9. Hal tersebut sangat tergantung pada kemampuan responden untuk membedakan penilaian antar skala. Semakin rendah kemampuan responden untuk membedakan, maka akan semakin rendah skala yang digunakan. Kebanyakan petani hanya dapat membedakan dengan baik skala 1 sampai 3 sebagai berikut.
Tabel 5.1.Teknik Komparasi Berpasangan (Pair Comparison)
Skala Definisi Penjelasan
1 Kedua faktor sama pentingnya.
Dua faktor mempunyai pengaruh yang sama terhadap tujuan yang akan dicapai. 3 Satu faktor lebih
penting daripada faktor yang lainnya.
Pengalaman dan penilaian mempengaruhi satu faktor dibanding faktor lainnya. 2 Satu faktor sedikit
lebih penting daripada faktor yang lainnya.
Pengalaman dan penilaian sedikit mempengaruhi satu faktor dibanding faktor lainnya.
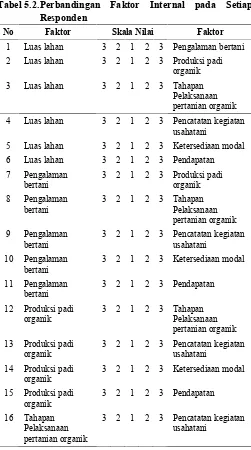
Tabel 5.2.Perbandingan Faktor Internal pada Setiap Responden
No Faktor Skala Nilai Faktor
1 Luas lahan 3 2 1 2 3 Pengalaman bertani 2 Luas lahan 3 2 1 2 3 Produksi padi
organik
3 Luas lahan 3 2 1 2 3 Tahapan
Pelaksanaan pertanian organik 4 Luas lahan 3 2 1 2 3 Pencatatan kegiatan
usahatani
5 Luas lahan 3 2 1 2 3 Ketersediaan modal
6 Luas lahan 3 2 1 2 3 Pendapatan
bertani 3 2 1 2 3 Pencatatan kegiatanusahatani 10 Pengalaman
bertani 3 2 1 2 3 Ketersediaan modal
11 Pengalaman
organik 3 2 1 2 3 Pencatatan kegiatanusahatani 14 Produksi padi
organik 3 2 1 2 3 Ketersediaan modal
15 Produksi padi
organik 3 2 1 2 3 Pendapatan
16 Tahapan Pelaksanaan pertanian organik
No Faktor Skala Nilai Faktor 17 Tahapan
Pelaksanaan pertanian organik
3 2 1 2 3 Ketersediaan modal
18 Tahapan Pelaksanaan pertanian organik
3 2 1 2 3 Pendapatan
19 Pencatatan kegiatan usahatani
3 2 1 2 3 Ketersediaan modal
20 Pencatatan kegiatan usahatani
3 2 1 2 3 Pendapatan
21 Ketersediaan modal
3 2 1 2 3 Pendapatan
Sumber: Safitri dan Chalil (2013)
Untuk no 4 misalnya, jika menurut responden 1 lahan misalnya lebih penting dibandingkan dengan pencatatan maka yang dipilih adalah angka 3 yang terletak di kolom ketiga, di sebelah lahan. Kebalikannya perbandingan pencatatan terhadap lahan akan menjadi 1/3. Hasil dari seluruh jawaban untuk responden 1 dapat dirangkum dalam Tabel 5.3.
Tabel 5.3. Rangkuman Seluruh Jawaban Responden
Lahan Pengalaman Produksi Tahapan Pencatatan Modal Pendapatan
Lahan 1 2 1 1 3 1 1/3
Pengalaman 1/2 1 1/3 1 3 1/3 1/3
Produksi 1 3 1 2 3 1 1
Tahapan 1 1 ½ 1 2 2 1/3
Pencatatan 1/3 1/3 1/3 ½ 1 1/3 1/3
Modal 1 3 1 ½ 3 1 1
Pendapatan 3 3 1 3 3 1 1
Jika terdapat 100 responden maka akan diperoleh rangkuman jawaban seperti matriks pada Tabel 5.3. Untuk mendapatkan nilai rata-rata dari setiap perbandingan, misal perbandingan lahan dengan pencatatan, maka dilakukan perhitungan dengan rumus berikut.
= , , , … , ... (5.2)
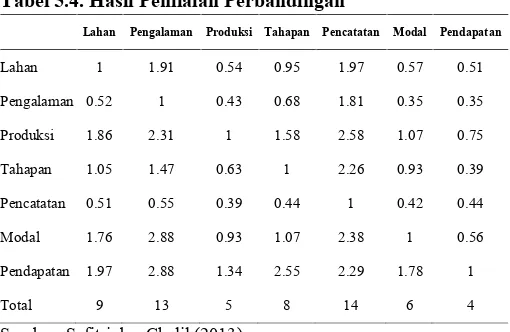
di mana seluruh X merupakan penilaian perbandingan lahan dengan pencatatan, X1 = nilai untuk responden 1, X2 = Nilai untuk responden 2, X3 = Nilai untuk responden 3 dan Xn = Nilai untuk responden n. Hasil untuk setiap perbandingan dapat dilihat pada Tabel 5.4.
Tabel 5.4. Hasil Penilaian Perbandingan
Lahan Pengalaman Produksi Tahapan Pencatatan Modal Pendapatan
Lahan 1 1.91 0.54 0.95 1.97 0.57 0.51
Pengalaman 0.52 1 0.43 0.68 1.81 0.35 0.35
Produksi 1.86 2.31 1 1.58 2.58 1.07 0.75
Tahapan 1.05 1.47 0.63 1 2.26 0.93 0.39
Pencatatan 0.51 0.55 0.39 0.44 1 0.42 0.44
Modal 1.76 2.88 0.93 1.07 2.38 1 0.56
Pendapatan 1.97 2.88 1.34 2.55 2.29 1.78 1
Total 9 13 5 8 14 6 4
Sumber: Safitri dan Chalil (2013)
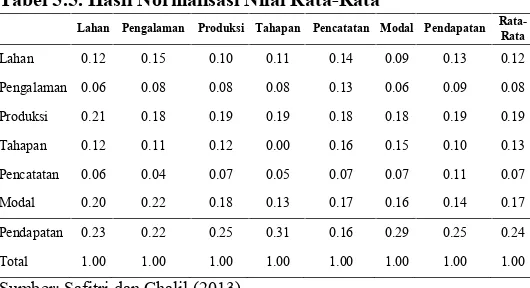
Tabel 5.5. Hasil Normalisasi Nilai Rata-Rata
Lahan Pengalaman Produksi Tahapan Pencatatan Modal Pendapatan
Rata-Rata
Lahan 0.12 0.15 0.10 0.11 0.14 0.09 0.13 0.12
Pengalaman 0.06 0.08 0.08 0.08 0.13 0.06 0.09 0.08
Produksi 0.21 0.18 0.19 0.19 0.18 0.18 0.19 0.19
Tahapan 0.12 0.11 0.12 0.00 0.16 0.15 0.10 0.13
Pencatatan 0.06 0.04 0.07 0.05 0.07 0.07 0.11 0.07
Modal 0.20 0.22 0.18 0.13 0.17 0.16 0.14 0.17
Pendapatan 0.23 0.22 0.25 0.31 0.16 0.29 0.25 0.24
Total 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00
Sumber: Safitri dan Chalil (2013)
Dengan pembobotan yang demikian, maka dapat diperoleh kesimpulan yang konsisten. Artinya, jika misalnya A > B, dan B > C, maka A > C.
5.2. Metode Inferensia
Multinomial Logit (dengan lebih dari 2 kategori). Jika data kualitatif tersebut berupa data laten maka salah satu metode alternatif yang dapat digunakan adalah dengan Structural Equation Model(SEM).
Data laten adalah data yang dapat diobservasi tetapi tidak dapat diukur secara langsung. Dengan demikian diperlukan data pembentuknya yang berupa data yang dapat diobservasi. Data laten tersebut dapat berupa variabel independen atau variabel dependen. Contohnya adalah kinerja. Kinerja tidak dapat diukur secara langsung, tetapi institusi misalnya dapat menilai kinerja pekerjanya berdasarkan beberapa parameter seperti penyelesaian pekerjaan dan waktu kerja. Penyelesaian perkerjaan yang diinginkan adalah yang tepat waktu dan sesuai dengan hasil yang baik. Misalnya waktu penyelesaian setiap surat sampai ke tangan pemohon yang baik adalah 1 hari, dan hasil yang baik adalah surat yang benar dari format yang ditentukan dan sesuai dengan yang dibutuhkan pemohon. Sementara, waktu kerja yang baik adalah masuk/keluar pada jam yang ditentukan.
5.2.1. Model Logit
estimasi expected value nilai Y dapat berkisar dari -∞ sampai ∞, sedangkan pada estimasi probabilita nilainya harus berkisar antara 0 dan 1. Logistic Regression Modelmerupakan sejenis generalized linear model yang mengkonversikan rentang nilai sebenarnya ke rentang 0-1.
Respon atau pilihan tersebut dapat terdiri dari 2 respon/pilihan atau lebih. Model dengan 2 respon/pilihan disebut dengan Binary Logit Model. Contohnya adalah keputusan petani untuk mengadopsi sistem organik, dengan 2 pilihan yaitu Y = 1 jika petani memutuskan untuk mengadopsi dan Y = 0 jika tidak. Contoh lain adalah pilihan pasar tujuan pada petani sawit, dengan 2 pilihan yaitu Y = 1 jika petani memutuskan untuk menjual di pasar ekspor dan Y = 0 jika di pasar lokal. Penentuan kondisi mana yang akan menjadi Y = 1 danY = 0 ditentukan oleh fokus penelitian. Pilihan Y = 1 bisa saja, misalnya untuk pilihan pasar lokal jika tujuan penelitian misalnya untuk melihat peluang Indonesia untuk mengembangkan pasar lokal sebagai substitusi ekspor CPO.
Beberapa faktor yang menyebabkan metode OLS tidak dapat digunakan dalam persamaan respon antara lain adalah (Gujarati, 1999 : 447-448):
a. Distribusi error term pada persamaan respon tidak mengikuti distribusi normal sebagaimana yang diasumsikan pada metode OLS, tetapi mengikuti distribusi binomial (probabilitistik).
b. Karena merupakan distribusi binomial (probabilistik) maka asumsi homogenitas juga tidak dapat terpenuhi, walaupun dalam masalah ini dapat diatasi dengan teknik transformasi. c. Dengan menggunakan OLS tidak ada jaminan bahwa nilai peluang yang menjadi variabel independen pada model respon akan berada diantara 0 dan 1.
1. Binomial Logit (1) Model Binomial Logit
Model dalam Binomial Logit adalah seperti pada Persamaan 5.3.
ln =β +βX ...(5.3)
Bagaimana mengubah nilai variabel independen menjadi nilai probabilitas variabel independen?
Y = f(x ) → p = f Y (x ) ...(5.4)
p = E(Y = 1|X ) = ...(5.5)
1 − p = ; Y =β ...(5.6)
= eβ β ...(5.7)
Mengapa fungsi logaritmik dapat memastikan nilai probabilita variabel independen berada diantara 0 dan 1?
p = E(Y = 1|X ) = β β ataup = ...(5.9) X = ∞→ Y = −∞→ e ∞= 0 → p =
∞= = 1...(5.10)
X = −∞→ Y =∞→ e∞=∞→ p =
∞= ∞= 0... (5.11)
(2) Uji-Uji dalam Model Binomial Logit Uji Kesesuaian Model
Analisis kesesuaian model logit dengan data yang akan diestimasi dilakukan dengan 2 cara yaitu (1) dengan membandingkan percentage correct predicted value untuk masing-masing nilai observasi dan (2) dengan membandingkan distribusi data dan distribusi Logit.
- UjiPercentage Correct/Change Accuracy