TUGAS TEORI INFORMASI & PENGKODEAN
“DIGITAL FORENSIC VOICE”
Proposal ini diajukan untuk memenuhi salah satu tugas mata kuliah Teori Informasi & Pengkodean
Disusun Oleh:
Irma Amelia Dewi
NIM: 23211310
Program Magister Teknik Komputer
SEKOLAH TEKNIK ELEKTRO DAN INFORMATIKA
INSTITUT TEKNOLOGI BANDUNG
Digital Forensic
Forensic adalah proses penggunaan pengetahuan ilmiah dan teknologi dalam
melakukan investigasi ,seperti mengumpulkan dan menganalisa sebuah objek dan kemudian menghasilkan fakta-fakta atau bukti-bukti untuk digunakan sebagai pemeliharaan, dokumentasi atau sebagai barang bukti ke pengadilan. Forensik erat hubungannya dengan analisa barang bukti laten/tiak terlihat. Barang bukti laten berbentuk dalam banyak format salah satunya seperti sidik jari, DNA dari noda darah dan juga file-file yang tersedia dalam media digital komputer.
Digital Forensic proses forensic yang dilakukan pada media yang berbentuk
digital yang dapat diambil dari perangkat komputer, PDA ,handphone smartphone dan jenis perangkat digital lainnya yang digunakan sebagai media penyimpanan (seperti flash disk, hard disk, atau CD-ROM), sebuah dokumen elektronik (misalnya sebuah pesan email atau gambar JPEG, rekaman suara, rekaman video), atau bahkan sederetan paket yang berpindah dalam jaringan komputer. Forensic dapat dilakukan meskipun data sengaja dihapus atau tidak sengaja dihapus.
Bagian spesifik dari digital forensic pada ruang lingkup perangkat seperti komputer disebut dengan Computer Forensic. Bentuk data digital pada Computer
Forensic dapat berupa file-file wordprocessor, spreadsheet, sourcode software,
database, image, sound, email, bookmark, cookies, registry dan lainnya. Computer
Forensic adalah aktifitas yang berhubungan dengan pemeliharaan, identifikasi,
pengambilan.penyaringan dan dokumentasi bukti komputer dalam kejahatan komputer (Cybercrime/Computercrime).
Audio forensik memiliki sejarah panjang dengan militer Amerika Serikat dan pemerintah. Dalam Perang Dunia II, teknologi ini digunakan untuk mengidentifikasi suara-suara musuh yang ditargetkan yang terdengar di atas radio dan telepon. Penggunaan sp
ektrograf suara, yang diplot pola frekuensi suara dan amplitudo, membantu analisis mengidentifikasi orang-orang yang menarik. Dalam beberapa tahun terakhir, forensik audio digunakan untuk menganalisis pesan yang dibuat oleh teroris untuk membantu menentukan lokasi mereka, waktu pembuatan audio dan faktor-faktor yang berasal lainnya.
Beberapa hal yang umumnya dievaluasi dalam klip audio untuk menentukan keasliannya adalah latar belakang suara, perubahan frekuensi suara, suara yang berasal
dari rekaman peralatan dan berhenti, mulai dan jeda. Setiap sinyal diskontinuitas di daerah ini akan dianalisa untuk membuktikan bahwa rekaman tersebut tidak otentik atau telah dikompromikan.
Salah satu teknik yang paling populer digunakan selama analisis adalah membandingkan satu suara yang tidak diketahui dengan suara yang dikenal untuk mengidentifikasi. Hal ini dapat dilakukan dalam kasus yang melibatkan suara, di mana satu pembicara telah diidentifikasi, tetapi yang lain tidak.
1. Teori Dasar Analisa Suara
Teori dasar untuk identifikasi suara bersandar pada premis bahwa setiap suara individual karakteristik cukup untuk membedakannya dari orang lain melalui analisis voiceprint. Ada dua faktor umum yang terlibat dalam proses suara manusia. Faktor pertama dalam menentukan keunikan suara terletak pada ukuran rongga vokal, seperti rongga tenggorokan, hidung dan mulut, dan bentuk, panjang dan ketegangan pita suara individu yang terletak di laring. Rongga vokal yang resonator, seperti pipa organ, yang memperkuat beberapa nada yang dihasilkan oleh pita suara, yang menghasilkan format atau batang voiceprint. Kemungkinan bahwa dua orang akan memiliki semua rongga vokal mereka ukuran yang sama dan konfigurasi dan digabungkan identik muncul sangat terpencil.
Faktor kedua dalam menentukan keunikan suara terletak pada cara yang artikulator-artikulator atau otot pidato dimanipulasi selama berbicara. Artikulator-artikulator termasuk bibir, gigi, lidah, langit-langit lunak dan otot-otot rahang yang saling dikendalikan menghasilkan pidato dimengerti. pidato dimengerti dikembangkan oleh proses pembelajaran acak meniru orang lain yang berkomunikasi.
Untuk memfasilitasi perbandingan visual dari suara, spektrograf bunyi digunakan untuk menganalisis bentuk gelombang pidato kompleks menjadi tampilan bergambar pada apa yang disebut sebagai sebuah spektrogram. spektrogram menampilkan sinyal suara dengan waktu sepanjang sumbu horisontal, frekuensi pada sumbu vertikal, dan amplitudo relatif yang ditunjukkan oleh tingkat naungan abu-abu pada layar. Resonansi suara pembicara ditampilkan dalam bentuk tayangan sinyal vertikal atau tanda untuk suara konsonan, dan bar horisontal atau forman untuk suara vokal. Konfigurasi yang ditampilkan terlihat karakteristik dari artikulasi terlibat untuk speaker menghasilkan kata dan frase. Spektrogram berfungsi sebagai catatan permanen
dari kata-kata lisan dan memfasilitasi perbandingan visual dari kata-kata serupa yang diucapkan oleh orang yang dikenal dengan suara pembicara yang belum diketahui identitasnya.
1.1 Teori Suara
Suara dihasilkan melalui proses Generation dan Filtering. Pada proses
Generation, suara pertama kali diproduksi melalui bergetarnya pita suara (vocal cord
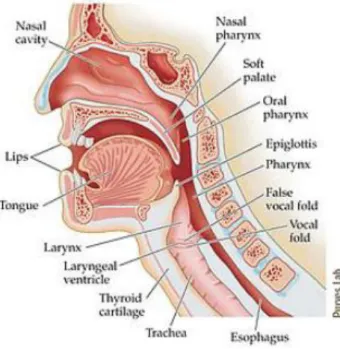
atau vocal fold) yang berada di larynx untuk menghasilkan bunyi periodik. Bunyi periodik yang bersifat konstan tersebut kemudian di-filterisasi melalui vocal tract (juga disebut dengan istilah resonator suara atau articulator) yang terdiri dari lidah (tongue), gigi (teeth), bibir (lips), langit-langit (palate) dan lain-lain sehingga bunyi tersebut dapat menjadi bunyi keluaran (output) berupa bunyi vokal (vowel) dan atau bunyi konsonan (consonant) yang membentuk kata-kata yang memiliki arti yang nantinya dapat dianalisa untuk voice recognition.
Gambar 1 Human vocal tract.
(sumber: http://www.dukemagazine.duke.edu/issues/050608/images/050608-lg-figure1purves.jpg)
Gambar 2 Suara Keluaran (output) setelah melalui filterisasi
vocal tract.
1.2 Komponen Suara
Suara terdiri dari beberapa komponen, yaitu pitch, formant dan spectrogram yang dapat digunakan untuk mengidentifikasi karakteristik suara seseorang untuk kepentingan voice recognition.
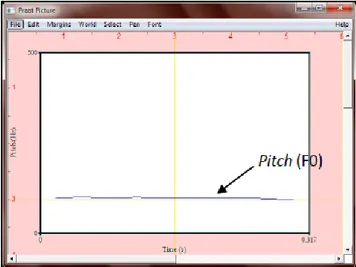
a. Pitch
Frekwensi getar dari pita suara yang juga disebut dengan istilah frekwensi fundamental (dasar) dengan notasi F0. Masing-masing orang memiliki pitch yang khas (habitual pitch) yang sangat dipengaruhi oleh aspek fisiologis larynx manusia. Pada kondisi pembicaraan normal, level habitual
pitch berkisar pada 50 s/d 250 Hz untuk laki-laki dan 120 s/d 500 Hz untuk
perempuan. Frekwensi F0 ini berubah secara konstan dan memberikan informasi linguistik seseorang seperti perbedaan intonasi dan emosi
Analisa pitch dapat digunakan untuk melakukan voice recognition terhadap suara seseorang, yaitu melalui analisa statistik terhadap minimum pitch, maximum pitch dan mean pitch
b. Formant
Formant adalah frekwensi-frekwensi resonansi dari filter, yaitu vocal tract (articulator) yang meneruskan dan memfilter bunyi periodik dari getarnya pita suara (vocal cord) menjadi bunyi keluaran (output) berupa kata-kata yang memiliki makna. Secara umum, frekwensi-frekwensi formant bersifat tidak terbatas, namun untuk identifikasi suara seseorang, paling tidak ada 3 (tiga) formant yang dianalisa, yaitu Formant 1 (F1), Formant 2 (F2) dan Formant 3 (F3).
Gambar 4 Diagram masing-masing Formant F1, F2, F3, F4 dan F5
c. Spectrogram
Spectrogram merupakan representasi spectral yang bervariasi terhadap waktu yang menunjukkan tingkat density (intensitas energi) spektral. Dengan kata lain spectrogram adalah bentuk visualisasi dari masing-masing nilai formant yang dilengkapi dengan level energi yang bervariasi terhadap waktu. Level energy ini dikenal dengan istilah formant bandwidth. Nantinya pada kasus-kasus yang bersifat pemalsuan suara dengan teknik pitch shift atau si subyek berusaha untuk menghilangkan karakter suara aslinya, maka formant bandiwidth dapat digunakan untuk memetakan atau
mengidentifikasi suara aslinya. Dikarenakan spectrogram memuat hal-hal yang bersifat detil, maka Spectrogram oleh beberapa ahli juga dikenal dengan istilah sidik jari suara (voice fingerprint).
Spectrogram membentuk pola umum yang khas dalam pengucapan kata dan pola khusus masing-masing formant dalam pengucapan suku kata, sehingga spectrogram juga digunakan untuk melakukan analisa identifkasi suara seseorang.
Jika durasi rekaman suara unknown lumayan panjang, maka analisa spectrogram juga dapat digunakan untuk mempercepat pemilihan pengucapan kata-kata yang akan dianalisa dalam rangka untuk mendapatkan jumlah minimal 20 kata untuk dapat menunjukkan ke-identik-an suara unknown dengan known (pembanding).
Gambar 5 Spectrogram representasi spektral dengan tingkatan energinya
D. source Filter Model
Terdapat dua sumber akustik dalam suatu ucapan yakni, suatu ucapan dengan suara dan ucapan tanpa suara. Ucapan bersuara dihasilkan oleh modulasi aliran udara dari paru-paru yang menyebabkan getaran pada vocal fold. Ucapan tanpa suara sumber suaranya bukan getaran biasa melainkan getaran yang disebabkan oleh aliran udara turbulen akibat penyempitan di saluran vokal.Ucapan tanpa suara ini disebut juga suara desah atau noise. Source filter model disini digunakan untuk penyaring frekuensi tertentu ataupun menguatkan serta melemahkan. Source filter model, terdiri dari komponen sumber yang berasal dari pita suara yang kemudian menuju filter
sehingga menghasilkan output ucapan yang telah disaring.
Gambar 6 Source filter model
2. Proses Pengolahan Sinyal Digital
Dibutuhkan pengolahan sinyal suara sehingga diperoleh koefisien karakteristik suara manusia untuk sistem ini yang terdiri dari Sampling, Frame Blocking, Windowing,
Discrette Fourier Transform (DFT), Filter Nonlinear Power Spectral Subtraction (SS), Mel Filter Bank dan Discrette Cosine Transform (DCT). Berikut adalah teori dasar dari proses
tersebut.
Sampling
Sinyal suara merupakan sinyal yang tidak terbatas dalam domain waktu (infinite time interval). Suara manusia akan menghasilkan sinyal analog yang terus kontinyu. Untuk melakukan ekstraksi koefisien karakteristik suara maka sinyal wicara harus dibentuk dalam potongan±potongan waktu yang terbatas (finite time interval). Karena itu sinyal yang ada dipotong±potong dalam slot interval waktu tertentu. Deret diskrit sampel x[n] diperoleh dari sinyal kontinu x(t) dengan hubungan sebagai berikut,
x[n]= x(nT )
Dimana T adalah periode sampling dan 1/T=Fs merupakan frekuensi sampling dalam satuan sampel/detik. Nilai n merupakan jumlah sampel. Berdasarkan pada teori sampling Nyquist, maka syarat dari frekuensi sampling adalah minimal dua kali frekuensi maksimal sinyal asli. Penentuan frekuensi sampling yang sesuai hukum Nyquist ini untuk mencegah adanya perubahan bentuk asli sinyal atau aliasing.
Frekuensi Sampling ≥ 2x Frekuensi Sinyal
Gambar 7 Sinyal sebelum sampling
Gambar 8 Sinyal setelah sampling
Frame Blocking
Frame Blocking merupakan pembagian suara menjadi beberapa frame
dan satu frame terdiri dari beberapa sampel. Proses ini diperlukan untuk membentuk sinyal suara yang non stasioner menjadi sinyal suara yang quasi-stasioner sehingga dapat diubah dari domain waktu ke dalam domain frekuensi dengan Transformasi Fourier. Hal ini karena sinyal suara manusia menunjukkan karakteristik quasi-stasioner pada saat pada rentang waktu 20-40 milidetik. Sehingga pada rentang tersebut transformasi Fourier dapat dilakukan karena Transformasi Fourier tidak dapat melakukan pemrosesan apabila sinyal suara manusia berada dalam keadaan non stasioner. Pengambilan jumlah sampel untuk tiap frame tergantung dari tiap berapa detik suara akan disampel dan berapa besar frekuensi samplingnya. Untuk mengakomodasi hilangnya data saat proses frame blocking digunakan
overlapping sinyal untuk tiap frame. Pada umumnya overlapping berada
pada rentang waktu 10-20 ms pada tiap frame.
Windowing
Sinyal suara yang dipotong-potong menjadi beberapa frame akan menyebabkan efek diskotinuitas pada awal dan akhir sinyal. Hal ini akan menyebabkan kesalahan data pada proses Transformasi Fourier.
Windowing diperlukan untuk mengurangi efek diskontinuitas dari
potongan ± potongan sinyal tersebut. Jika didefinisikan w(n) sebagai window dimana 0 ≤ n ≤ N-1, N adalah jumlah sampel dalam tiap frame maka hasil proses windowing seperti pada persamaan berikut:
w(n) x(n)W (n), 0≤ n≤ N1
Jenis windowing ada beberapa macam yaitu Hamming, Hanning, Bartlet, Rectanguler dan Blackman. Persamaan windowing sebagai berikut :
o Window Hamming
o Window hanning
o Window Barlet
o Window Blackman
Discretee Fourier Transform (DFT)
Transformasi Fourier adalah suatu metode yang sangat efisien untuk menyelesaikantransformasi fourier diskrit yang banyak dipakai untuk keperluan analisa sinyal seperti pemfilteran, analisa korelasi, dan analisa spektrum. Transformasi Fourier ini dilakukan untuk mentransformasikan sinyal dari domain waktu ke domain frekuensi. DFT adalah bentuk khusus dari persamaan integral fourier :
Dengan mengubah variable-variabel, waktu (t), frekuensi ( ) kedalam bentuk diskrit diperoleh transformasi Fourier diskrit (DFT) yang persamaannya adalah :
DFT dilakukan dengan membagi N buah titik pada transformasi fourier diskrit menjadi 2, masing-masing (N/2) titik transformasi. Proses memecah menjadi 2 bagian ini diteruskan dengan membagi (N/2) titik menjadi (N/4) dan seterusnya hingga diperoleh titik minimum. Pemakaian DFT ini karena untuk perhitungan komputasi yang lebih cepat dan mampu mereduksi jumlah perkalian dari N 2 menjadi NlogN iterasi.
Nonlinear Power Spectral Subtraction (SS)
Filter Nonlinear Power Spectral Subtraction (SS) merupakan proses pemfilteran noise sinyal dalam domain frekuensi. Filter ini terdiri atas dua tahap pemrosesan yaitu Voice Activity Detection (VAD) dan Spectral
Subtracting.
o Voice Activity Detection (VAD)
Tujuan dari tahapan proses VAD ini adalah untuk menentukan frame sinyal suara apakah berisi sinyal wicara (voiced), tidak ada sinyal bicara (unvoiced) atau tanpa suara/keadaan diam (silent). Frame voiced cenderung memiliki energi lebih besar dari pada frame unvoiced terlebih frame silent. Frame silent pada umumnya merupakan representasi dari noise latar belakang lingkungan suara. Proses VAD ini merupakan pondasi dasar dari algoritma
Nonlinear Power Spectral Subtraction karena keakurasian VAD
menentukan waktu kapan update noise dan besarnya filtering pada sinyal suara.
Estimasi noise pada filter ini menggunakan hasil pada VAD untuk menentukan kapan untuk melakukan komputasi ulang nilai noise yang dijadikan sebagai referensi filter.Inisialisasi noise referensi diasumsikan diambil dari sinyal suara dalam frame pertama yang hanya berisi noise. Nilai treshold dari VAD dihitung untuk
menentukan suatu frame merupakan sinyal suara manusia atau noise. Faktor komputasi ulang ( update) yaitu α N dan β N dapat diatur secara ³trial and error´. Namun berdasarkan penelitian sebelumnya [11] nilai optimal kedua factor tersebut adalah 0.95. Tahap pertama VAD adalah melakukan Transformasi Fourier (DFT atau FFT) untuk mengubah sinyal dalam frame dari domain waktu ke domain frekuensi.
Selanjutnya spektrum, mean dan standar deviasi dari noise pada frame pertama k=1 diinisialisasi sebagai noise
Jika VAD=0 maka spektrum, mean dan standar deviasi untuk semua frame noise diperbaharui.
Treshold selanjutnya diperbaharui jika frame tidak berisi sinyal suara berdasarkan mean dan standar deviasi dari estimasi noise. Pengaturan threshold dilakukan menggunakan perkalian gain α S dan α N yang dapat diatur secara eksperimental karena hingga saat ini tidak ada rumusan umum untuk menentukan kedua nilai tersebut.
Keputusan VAD dapat menggunakan treshold wicara dimana jika energy sinyal lebih dari dua kali standar deviasi di atas mean noise maka frame dikenali sebagai frame wicara. Jika energi sinyal kurang dari beberapa bagian dari standar deviasi maka
frame dikenali sebagai noise. Jika baik wicara maupun noise tidak dikenali keduanya maka frame dianggap sama dengan kondisi frame sebelumnya.
Spectral Subtracting
Ada beberapa metode/algoritma untuk melakukan filter Nonlinear
Power Spectral Subtraction ini. Namun pada penelitian ini
menggunakan algoritma berdasarkan faktor oversubtraction dan
spectral floor berdasarkan kalkulasi SNR posteriori. Persamaan umum
dari metode ini adalah sebagai berikut,
Dimana adalah faktor oversubtraction untuk melakukan overestimate spektrum noise dan adalah faktor spectral floor. Nilai dari factor merupakan fungsi dari estimasi posteriori signal-to-noise ratio (SNR) dan dirumuskan sebagai berikut,
Dimana SNR posteriori diperoleh malalui hubungan berikut,
Dengan α 0 merupakan nilai yang diinginkan dari pada saat sinyal dalam keadaan 0 dB SNR. Secara umum semakin besar nilai tereduksi secara signifikan. Namun apabila nilai maka noise sinyal akan yang terlalu besar akan merubah pola sinyal dengan nilai yang cukup besar. Sehingga nilai harus ditentukan secara tepat agar dapat mengurangi noise secara optimal namun tetap menjaga bentuk pola sinyal asli. Untuk power subtraction, range optimal dari α 0 adalah antara 3 sampai dengan 6. Sedangkan parameter spectral floor digunakan untuk mencegah adanya eliminasi terhadap sinyal suara di bawah batas terendah yaitu . Nilai parameter β paling optimal berada range 0.1
sampai dengan 0.001. Namun untuk level noise rendah dapat menggunakan nilai yang lebih kecil dari pada 0.01.
Mel Frequency Cepstrum Coefficient (MFCC)
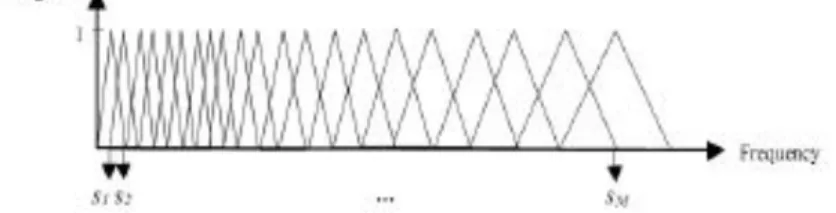
Informasi penting pada sinyal suara manusia berada pada frekuensi tinggi Informasi penting ini yang menentukan karakteristik suara manusia dan Mel scale digunakan untuk mengakomodasi karakteristik tersebut. Setiap nada suara manusia dengan frekuensi actual ω yang diukur dalam Hz nilai subjektif pitch dapat diukur dalam Mel Scale merupakan ukuran atau skala persepsi manusia dari frekuensi suatu suara. Hubungan antara Mel Scale dengan frekuensi tidak linear seluruhnya. Pada frekuensi dibawah 1 kHz hubungannya adalah linear tetapi untuk frekuensi lebih tinggi dari 1kHz hubungannya bersifat logaritmik. Hubungan ini berdasarkan berbagai penelitian tentang persepsi penangkapan suara oleh telinga manusia
Hubungan di atas menunjukkan hubungan antara frekuensi aktual dengan frekuensi pada Mel scale. Pada implementasinya skala ini menggunakan Filter Bank dimana setiap nilai magnitude frekuensi difilter oleh deret filter segitiga. Dengan nilai frekuensi tengah yaitu frekuensi Mel filter segitiga ini yang merepresentasikan proses Mel
scaling pada sinyal
Gambar 10 Konstruksi filter bank
Hasil dari DFT pada proses pengolahan sebelumnya akan lebih informatif jika ditunjukkan dalam tiap band. Berdasarkan penelitian sebelumnya, pendengaran manusia tidak sensitif untuk semua frekuensi band. Sensitifitas tersebut berkurang pada frekuensi rendah dan meningkat pada frekuensi di atas 1000 Hz. MFCC menggunakan landasan ini sebagai ekstraksi koefisien identitas suara. Koefisien ini telah memberikan hasil paling baik hingga saat ini khususnya dalam
aplikasi speaker recognition maupun speech recognition.
Mel Frequency Cepstral Coefficient MFCC didefinisikan sebagai Descretee Fourier Transform dari amplitude sinyal dalam mel frequency. Sehingga
untuk mendapatkan sinyal pada skala mel dilakukan filtering dengan frekuensi puncak adalah frekuensi mel.
Secara umum algoritma untuk menghitung MFCC adalah sebagai berikut,
1. Komputasi sinyal dalam domain frekuensi dengan DFT
2. Melewatkan magnitud dari spektrum sinyal X[k] melalui Mel Filter
Bank. Hasil dari filtering magnitude spektrum ini adalah kumpulan M
yang merupakan representasi dari energi tiap band dimana M merupakan jumlah filter pada filterbank.
3. Komputasi harga logaritmik dari energi dari tiap band output dari tiap filter. Proses logaritmik sinyal digunakan untuk mengadaptasikan sistem seperti telinga manusia,karena sinyal suara yang berada dibawah frekuensi 1 Khz (Low order) akan terdengar linear namun lebih dari 1 Khz (High Order) grafiknya akan menjadi logaritmis, untuk menyamakan persepsi itu maka digunakan proses logaritmis pada sinyal agar sinyal dapat di proses.
4. Mengubah logaritma dari energi ke MFCC dengan Discrette Cosine
Transform (DCT).
Gaussian Mixture Model (GMM)
Konsep dasar dari pemodelan dengan menggunakan Gaussian Mixture
Modeladalah Classifier, Klasifikasi Bayessian, Distribusi Gaussian Multivariate dan algoritma Expectation-Maximation (EM). Berikut
adalah penjelasan dari ketiga konsep dasar tersebut. o Classifier
Classifer adalah salah satu algoritma dengan menggunakan feature atau cirri sebagai input dan menerjemahkannya dengan
berdasarkan informasi yang diberikan pada algoritma sebagai parameternya. Keluaran dari algoritma ini biasanya berupa label/kategori atau dapat juga suatu nilai numerik.
Kemampuan klasifikasi dalam classifier untuk tiap kasus dapat dikembangkan dengan menggunakan jenis yang sesuai. Kemampuan ini juga membutuhkan model atau struktur yang tepat dalam sebuah classifier, misalnya pada jaringan syaraf tiruan yaitu berupa jumlah neuron dan lapisan. Untuk classifier Bayesian, model distribusi probabilitas harus disesuaikan dengan kasus yang akan diklasifikasi. Sebuah classifier dapat memiliki banyak parameter yang harus disesuaikan dengan nilai yang diharapkan. Proses penyesuaian ini biasa disebut dengan pembelajaran atau pelatihan. Kompleksitas dari sebuah classifier sangat mempengaruhi kemampuan dan fleksibilitas suatu proses identifikasi. Classifier yang sederhana memiliki nilai komputasional yang cukup kecil namun kemampuannya untuk mempelajari suatu data sangat rendah. Sedangkan classifier yang sangat kompleks akan dapat mempelajari suatu kasus dengan klasifikasi dengan akurasi yang tinggi bahkan sampai dengan 100%. Namun dengan akurasi yang sangat tinggi ini jika diberikan dengan kasus yang berbeda maka akan menghasilkan nilai dengan akurasi yang rendah. Karena itu data pengujian pada umumnya dibagi menjadi dua set yaitu data training dan data tes sehingga analisa performansi system akan lebih akurat.
Gambar 11 Hasil classifier dengan kompleksitas yang tinggi solid line) dapat melakukan klasifikasi dengan sedikit error a), Namun saat diberi
kasus yang berbeda akan memberikan hasil yang sebaliknya. b)
Sebuah classifier dapat menggunakan banyak parameter untuk penyesuaian system dengan tugas yang diberikan. Proses penyesuaian ini biasa disebut dengan pembelajaran atau pelatihan. Dalam pembelajaran terawasi, data untu pembelajaran sebelumnya telah diset dan ditentukan hasilnya atau biasa disebut dengan target pembelajaran. Sedangkan dalam pembelajaran tak terawasi, data pembelajaran tidak ditentukan targetnya tetapi pada waktu pelatihan ditujukan untuk mencari dan membentuk klasifikasi secara independen.
Klasifikasi Bayesian
Classifier Bayesian dalam menentukan keputusannya berdasarkan teori
probabilitas dan prinsip pemilihan nilai optimal. Jika diasumsikan sebuah klasifikasi membagi suatu vektor feature/ciri menjadi K kelas yang berbeda. Vektor ciri didefinisikan sebagai x=[ x1, x2 ...xd ] T dimana D adalah dimensi vektor. Probabilitas bahwa ciri x masuk pada kelas k adalah P(ωk|k) dan pada umunya digunakan sebagai referensi dari probabilitas posteriori. Probabilitas posteriori dapat dihitung berdasarkan Hukum Bayes denganpersamaan sebagai berikut,
dimana p( x | k ) adalah fungsi densitas peluang (pdf) dari kelas k
dalam suatu ciri x dan P( k) adalah priori probability yaitu probabilitas awal dari kelas sebelum melakukan pemrosesan terhadap ciri atau biasa disebut probabilitas inisialisasi. Apabila priori probability ini belum diketahui maka dapat diestimasi berdasarkan ukuran dari data pembelajaran. Dengan persamaan sebagai berikut,
Nilai ini digunakan sebagai faktor skala untuk menjamin bahwa jumlah dari probabilitas posteriori adalah sama dengan satu sesuai dengan hukum probabilitas. Permasalahan dalam klasifikasi Bayesian adalah
fungsi densitas peluang(pdf) dari p(x| k). Fungsi ini yang menentukan distribuasi ciri dalam suatu kelas atau dengan kata lain yang menentukan model kelas. Dalam aplikasi, pada umumnya tidak diketahui kecuali beberapa classifier tertentu.
Distribusi Normal Multivariate
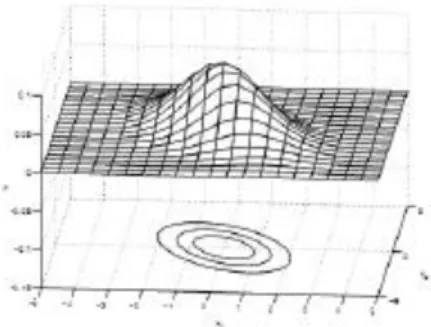
Fungsi densitas peluang (pdf) Gaussian adalah fungsi satu dimensi dengan bentuk menyerupai lonceng yang didefinisikan oleh dua parameter yaitu meanµ and varian atau kovarian . Dalam dimensi D dapat dirumuskan sebagai berikut
dimana µ adalah mean vektor dan adalah matriks kovarian. Pada gambar di bawah adalah salah satu contoh fungsi densitas peluang Gaussian dimensi 2.
Gambar 12 Contoh permukaan fungsi densitas peluang Gaussian d-2
Gaussian Mixture Model
Finite Mi ture Model dan metode estimasi parameternya dapat didekati
dengan menggunakan pdf apapun kecuali dengan menggunakan distribusi normal tunggal. Namun untuk implementasinya harus didefinisikan salah satu pdf yang paling sesuai untuk tiap kasus. Secara umum distribusi yang digunakan dapat distribusi apa saja tetapi distribusi normal multi ariate atau distribusi Gaussian merupakan salah satu distribusi yang paling terkenal dan banyak dipakai untuk berbagai aplikasi statistik. Misalnya untuk analisis multi ariate yang pada umumnya menggunakan asumsi memiliki distribusi normal, atau dalam
model linear dari vektor error yang sering diasumsikan memiliki distribusi normal. Selain itu distribusi normal dapat digunakan untuk melakukan perbandingan kompleks yaitu dalam analisis variabel random yang saling berkaitan. Sehingga jika suatu kasus tidak diketahui jenis distribusinya maka model yang paling umum dan fleksibel yang paling sesuai untuk digunakan dan distribusi Gaussian merupakan salah satu dari distribusi tersebut dengan kehandalan yang sangat tinggi.
Gambar 13 Contoh permukaan Gaussian mixture PDF dimensi-2 dengan 3 komponen
Gaussian mi ture model (GMM) adalah sebuah campuran (mi ing) dari
beberapa distribusi Gaussian atau jika dalam klasifikasi merupakan representasi dari adanya subkelas pada suatu kelas. Fungsi densitas peluangnya didefinisikan sebagaijumlah dari perkalian bobot dengan probabilitas gaussian.
Dimana αc merupakan bobot dari komponen campuran c dimana 0 < c < 1 untuk semua komponen dan angkan paramter distribusi,
merupakan definisi dari parameter Gaussian mixture probability density function. Estimasi parameter Gaussian Mixture untuk satu kelas dapat dicari melalui pembelajaran tak terawasi dimana data sampel tanpa adanya target klasifikasi. Pada umunya algoritma clustering digunakan untuk melakukan identifikasi komponen secara eksak khusunya dalam melakukan inisialisasi model.
Diasumsikan suatu set sampel feature X = {x1, . . . , xN} yang diambil dari distribusi tunggal yang didefinisikan oleh pdf p(x; ) dimana adalah parameter pdf. Maka fungsi likelihood dapat didefinisikan sebagai,
Dimana menunujukkan bahwa lekelihood dari data sampel feature X berdasarkan parameter distribusi . Untuk mendapatkan nilai Ö yang merupakan nilai maksimum likelihood
Pada umumnya nilai maksimum ini tidak digunakan secara langsung namun dengan mengkalkulasi nilai logaritmik likelihood nya.
Persamaan di atas biasa disebut sebagai fungsi log-likelihood dimana secara analisis lebih mudah dimengerti dari pada secara langsung karena nilainya yang cukup kecil. Berdasarkan p(x;θ) sangat dimungkinkan menemukan nilai maksimum secara analitik dengan mendefinisikan turunan fungsi log-likelihood sama dengan nol. Untuk Gaussian solusi analitik dapat dicari berdasarkan parameter mean dan varian. Dalam implementasinya, untuk mencari nilai maksimum tersebut menggunakan metode iterative misalnya algoritma Expectation-Maximation. Dalam proses maksimasi nilai loglikelihood ini seringkali menghasilkan hasil yang singular dan ini merupakan salah satu permasalahan dalam Gaussian Mixture Model.
Likehood Ratio
Metode estimasi likelihood ratio yang digunakan dalam Forensic Speaker Identification adalah membandingkan perbedaan antara sampel suara yang didapat dari hasil penyadapan telepon dengan hasil rekaman yang didapatkan secara langsung / wawancara. Likelihood ratio dinyatakan dalam persamaan :
Atau suatu probabilitas dimana Efsi adalah barang bukti berupa sampel, Hss adalah hipotesa bahwa sampel dari sampel suara yang didapat dari hasil penyadapan telepon dengan hasil rekaman yang didapatkan secara langsung / wawancara bersumber dari orang yang sama, Hds menyatakan hipotesa bahwa sampel dari sampel suara yang didapat dari hasil penyadapan telepon dengan hasil rekaman yang didapatkan secara langsung /wawancara bukan bersumber dari orang yang sama. Pada saat melakukan perhitungan Likelihood ratio perlu juga diketahui referensi,latar belakang disamping rekaman telepon dan rekaman pada saat wawancara secara langsung. Ini dikarenakan Likelihood ratio adalah ratio dari similarity sampai dengan typicality. Ini akan mengukur seberapa besar persamaan antara kedua sampel, kemudian mengevaluasi kesamaan sampai ciri khasnya. Seberapa kemungkinan akan melakukan pengambilan sampel secara acak pada pembicara yang berbeda dari suatu populasi yang tidak berkaitan Perlu juga mengumpulkan kata-kata yang bisa dibandingkan dengan suara di telepon yang akan diperiksa. Basis pembandingnya adalah kutipan kata yang sama. Misalnya, kata Halo tidak akan masuk data penelitian jika hanya terucap sekali. Namun, jika misalnya terucap 10 kali, kata itu menjadi calon untuk pembanding
3. Prosedur Audio Forensic
Untuk melakukan analisa suara seseorang dalam rangka mengidentifikasi suara yang berasal dari rekaman barang bukti dan memverifikasinya dengan suara pembanding, berikut adalah tahapan-tahapan yang digunakan
a. Acquisition
1) Catat spesifikasi teknis audio recorder seperti merk, model, ukuran dan serial number, dilanjutkan dengan foto bagian depan dan belakan recorder. Untuk pemotretan barang bukti, harus dilengkapi dengan label ‘Puslabfor’ dan skala ukur.
2) Sebelum melakukan langkah-langkah audio forensik lebih lanjut, pemeriksa harus terlebih dahulu mendapatkan fakta kasus yang berkaitan dengan
barang bukti rekaman suara dari penyidik dengan melakukan gelar perkara terhadap kasus tersebut.
3) Selain fakta kasus, pemeriksa juga harus sudah mendapatkan suara pembanding (control sample) terhadap suara yang ada di dalam audio recorder yang akan dianalisa dan dilengkapi dengan administrasi penyidikan yang lengkap. Pengambilan contoh suara pembanding ini dapat dilakukan oleh penyidik atau pemeriksa di dalam lingkungan yang bebas dari suara noise. Pengambilan contoh suara pembanding ini juga harus dilengkapi dengan Berita Acara Pengambilan Contoh Suara Pembanding yang disetujui dan ditandatangani oleh subyek yang contoh suaranya akan dianalisa.
4) Pengambilan contoh suara pembanding juga dapat dilakukan dari rekaman video asli yang menunjukkan subyek dalam berbicara. Rekaman video ini harus berasal dari sumber yang jelas dan resmi.
5) Untuk proses akuisisi audio recorder yang menghasilkan file dd image mengikuti langkah-langkah seperti yang dijelaskan pada point 3 s/d 11 SOP 1 tentang Akuisisi Harddisk, Flashdisk dan Memory Card.
6) Setelah mendapatkan file dd image yang IDENTIK dengan isi dari audio recorder, file dd image tersebut dilakukan proses logical mounting untuk melihat isi dari audio recorder tersebut.
7) Proses mounting bisa dilakukan di komputer analisis baik yang berbasis Ms. Windows maupun Linux Ubuntu. Sebelum proses mounting, harus dipastikan bahwa file dd image telah di-set read-only, dan dalam proses mounting itu sendiri, harus dalam lingkungan yang forensically-sound write protect. Untuk yang berbasis Ms. Windows dapat menggunakan aplikasi digital forensik yang telah teruji untuk lingkungan tersebut, sedangkan untuk yang berbasis Linux, dapat menggunakan perintah ‘mount –o ro,loop
File_Image.dd’.
8) Setelah di-mounting dalam lingkungan tersebut, pemeriksa dapat melakukan proses keyword searching, file content checking atau file recovery untuk dapat menemukan rekaman suara yang dicari.
9) File yang berisikan rekaman suara barang bukti kemudian di-ekspor dan diekstraksi metadata-nya untuk dianalisa lebih lanjut untuk mendapatkan histori teknis dari file rekaman tersebut termasuk keaslian file rekaman yang juga dapat diperiksa melalui spectrum analysis.
b. Audio Enhancement
1) Rekaman suara barang bukti diperdengarkan (playback) untuk melihat kualitas rekaman. Jika kualitasnya tidak bagus dikarenakan banyak suara noise, maka terhadap rekaman suara tersebut harus dilakukan proses enhancement untuk menaikkan kualitas rekaman sehingga pembicaraan yang ada di dalam rekaman suara tersebut dapat didengar dengan jelas. 2) Proses enhancement ini dapat dilakukan di komputer analisis berbasis Ms.
Windows dan Linux dengan didukung aplikasi-aplikasi audio yang dapat diandalkan untuk pemrosesan yang efisien dan efektif. Sebagian aplikasi ini bahkan dapat menghilangkan suara noise yang kuat sehingga memunculkan kembali suara pembicaraan yang ada.
3) Pelaksanaan proses enhancement ini mengikuti petunjuk (manual) dari aplikasi-aplikasi tersebut.
c. Decoding
1) Setelah suara pembicaraan yang berasal dari rekaman barang bukti jelas, dilanjutkan dengan pembuatan transkrip rekaman.
2) Pembuatan transkrip rekaman harus dilakukan oleh minimal 2 (dua) orang pemeriksa. Ini dimaksudkan untuk mendapatkan nilai akurasi yang lebih presisi terhadap hasil transkrip.
3) Transkrip rekaman harus mencantumkan label subyek (misalnya; subyek 1, subyek 2 dan seterusnya) dan waktu (dalam jam:menit:detik) yang sesuai dengan berjalannya rekaman. Interval penandaan waktu dapat disusun setiap 30 detik atau 1 menit.
4) Jika suara pembicaraan di dalam rekaman tersebut tidak jelas, maka ditulis ‘tidak jelas’. Artinya hasil transkrip hanya memperlihatkan suara pembicaraan yang jelas dan dapat dipahami pengucapan kata-katanya. d. Voice Recognition
1) Proses ini untuk memastikan apakah suara yang ada di dalam rekaman barang bukti adalah IDENTIK dengan contoh suara pembanding. Untuk itu proses ini mengambil kata-kata yang pengucapannya sama antara suara barang bukti dengan suara pembanding. Terhadap kata-kata tersebut dilakukan analisa audio forensik yang berbasiskan analisa terhadap pitch, formant, formant bandwidth dan spectrogram.
2) Disyaratkan minimal 20 (duapuluh) kata yang memiliki kesamaan antara suara barang bukti dan suara pembanding dari hasil analisa pitch, formant, bandwidth dan spectrogram, untuk menentukan apakah suara barang bukti IDENTIK dengan suara pembanding. Ini merujuk pada ‘Spectrographic Voice
Identification: A Forensic Survey’ yang disusun oleh Koenig, B.E. dari Federal
Bureau of Investigation.
3) Jika jumlah kata yang diucapkan dalam rekaman barang bukti tidak mencapai minimal 20 (duapuluh) kata, maka status rekaman suara barang bukti adalah TIDAK MEMENUHI SYARAT AUDIO FORENSIK. Selanjutnya tidak dapat dilakukan analisa voice recognition.
4) Analisa pitch didasarkan pada perhitungan statistik nilai pitch minimum, maksimum dan rata-rata (mean) serta standard deviation yang dilengkapi dengan grafiknya antara suara barang bukti dengan suara pembanding. 5) Analisa formant dan formant bandwidth didasarkan pada perhitungan
statistik One-Way Anova yang dilengkapi dengan bentuk graphical distribution untuk melihat penyebaran nilai antara suara barang bukti dengan suara pembanding. Analisa formant dan bandwidth ini meliputi formant 1, formant 2, formant 3, bandwidth 1, bandwidth 2 dan bandwidth 3.
6) Analisa spectrogram didasarkan pada pola umum dan pola khusus yang bersifat khas antara suara barang bukti dan suara pembanding. Pola-pola yang khas ini meliputi formant 1, formant 2 dan formant 3 yang disertai level energi (bandwidth) pada masing-masing formant. Dikarenakan spectrogram dapat mem-visualisasikan secara lengkap masing-masing formant dan bandwidth dari kata yang diucapkan secara konsisten, maka analisa spectrogram sangat penting dalam penentuan akhir analisa voice recognition.
4. Sampling Suara Pembanding
Untuk memastikan apakah suara yang ada pada rekaman suara barang bukti adalah IDENTIK atau TIDAK IDENTIK dengan suara orang lain atau subyek, maka perlu untuk dilakukan pengambilan (Sampling) contoh suara pembanding yang berasal dari suara si subyek.
5. Analisa Statistik Pitch
Analisa ini didasarkan pada kalkulasi statistik nilai pitch dari masing-masing suara unknown dan known. Karakteristik pitch dari masing-masing suara tersebut dibandingkan pada minimum pitch, maximum pitch dan mean pitch.
Jika karakteristik pitch dari masing-masing suara tersebut menunjukkan tingkat perbedaan yang besar, maka dapat disimpulkan bahwa pitch dari suara unknown dan
known adalah berbeda. Biasanya analisa ini juga didukung bentuk grafis pitch dari
masing-masing suara yang dianalisa
6. Analisa Statistik Formant dan Bandwidth Analisa Anova
Analisa ini didasarkan pada analisa One-way Anova (Analysis of Variances) yang mengkalkulasi secara statistik nilai-nilai Formant 1, Formant 2, Formant 3 dan Formant 4 dari suara unknown (SuaraBarangBukti) dan known (SuaraSubyek1). Anova akan menunjukkan tingkat perbedaaan antara 2 (dua) kelompok data pada masing-masing
formant dari suara unknown dan known, yang ditandai dengan perbandingan ratio F dan
Jika nilai ratio F lebih kecil dari F critical, dan nilai probability P lebih besar dari 0.5 maka dapat disimpulkan bahwa kedua kelompok data dari nilai formant yang dianalisa dari suara unknown dan known tidak memiliki perbedaan (accepted) yang signifikan pada level 0.05. Kesimpulan ini memiliki tingkat konfidensi sebesar 95%.
Analisa Likelihood Ratio (LR)
Penelaahan lebih detil terhadap analisa statistic terhadap formant dan bandwidth adalah dengan menggunakan Likelihood Ratio (LR) yang dalam contoh ini merupakan lanjutan dari Analisa Anova yang telah dijelaskan di atas. Formula LR adalah sebagai berikut :
LR = di mana :
p (E | Hp) adalah hipotesis tuntutan (prosecution), yaitu known dan unknown
samples berasal dari orang yang sama.
p (E | Hd) adalah hipotesis perlawanan (defense), yaitu known dan unknown
samples berasal dari orang yang berbeda.
p (E | Hp) berasal dari p-value Anova, sedangkan p (E | Hd) = 1 - p (E | Hp)
Jika LR > 1, maka hal ini mendukung p (E | Hp), sebaliknya jika LR < 1, maka p (E | Hd) yang didukung. Untuk itu, haruslah nilai p (E | Hp) > 0.5 untuk dapat menyimpulkan bahwa suara barang bukti (unknown) dan suara pembanding (known) berasal dari orang yang sama (IDENTIK).
7. Analisa Graphical Distribution
Analisa ditujukan untuk menggambarkan dalam bentuk grafis tingkat penyebaran (distribusi) masing-masing nilai formant untuk melihat level perbedaan distribusi nilai
formant dari suara unknown dan known. Biasanya analisa ini dibuat dalam bentuk
perbandingan F1 vs F2 dan F2 vs F3.
Jika terdapat nilai yang menyimpang pada formant yang dianalisa yang mana nilai menyimpang ini tidak terakomodasi dalam analisa statistik Anova, malah membuat kesimpulan yang keliru, maka analisa graphical distribution ini dapat mengkoreksi kesimpulan yang keliru tersebut.
Analisa graphical distribution F1 vs F2 dari masing-masing suara Test 1 (unknown) dan
Test 2 (known). Hasil dari analisa ini menunjukkan bahwa Formant 1 dan Formant 2
antara suara Test 1 dan Test 2 memiliki perbedaan pada tingkat penyebarannya.
Pada contoh SuaraBarangBukti dan SuaraSubyek1 yang telah didapat dan dijelaskan sebelumnya untuk Analisa Statistik Formant, tabulasi data untuk kedua jenis suara tersebut dapat digunakan untuk melanjutkan analisa ke analisa sebaran grafis (Graphical Distribution).
8. Analisa Spectrogram
Analisa ini menunjukkan pola umum yang khas pada kata yang diucapkan dan pola khusus yang khas pada masing-masing formant suku kata yang dianalisa. Pola-pola khas tersebut juga termasuk dalam analisa tingkatan energi dari masing-masing
formant seperti yang ditunjukkan pada Gambar 5 di atas.
Jika pola-pola khas tersebut untuk pengucapan kata-kata tertentu dari suara
unknown (suara barang bukti) dan known (suara pembanding) tidak menunjukkan
perbedaan yang signifikan, maka dapat disimpulkan bahwa kedua suara tersebut untuk pengucapan pada kata-kata tersebut adalah IDENTIK (memiliki kesamaan spectrogram).
Oleh karena spectrogram mampu menampilkan pola-pola yang khas formant dan
bandwidth pada pengucapan kata-kata yang mana pola-pola ini tidak terpengaruh
dengan tinggi rendahnya frekwensi resonansi tiap-tiap formant ketika pengucapan kata-kata dibuat, maka ada sebagian ahli menyatakan bahwa spectrogram merupakan sidik jari suara (voice fingerprint). Walaupun begitu ada juga sebagian ahli yang tidak sependapat dengan pernyataan tersebut. Mereka berargumentasi bahwa spectrogram untuk pengucapan kata yang sama namun berasal dari 2 (dua) orang yang berbeda akan memungkinkan menghasilkan pola khas spectrogram yang sama. Hal ini bisa
menyesatkan atau menghasilkan false positive. Artinya untuk voice recognition,
spectrogram bukanlah satu-satunya komponen suara yang dianalisa. Harus ada juga
analisa terhadap komponen suara yang lain seperti analisa statistic terhadap pitch dan