FAKTOR-FAKTOR YANG MEMPENGARUHI PROFITABILITAS
DAN KLASIFIKASI BERDASARKAN LABA ATAU RUGI
PERBANKAN DI INDONESIA MENGGUNAKAN
PENDEKATAN
NEURAL NETWORK
Dedi Setiawan (06211440000071)
Mahasiswa Departemen Statistika, FKMSD, ITS-Surabaya dedi1statistika@gmail.com
Abstrak. Industri perbankan saat ini masih menghadapi tantangan yang sangat bervariasi, mulai dari
profitabilitas yang rendah atau bahkan kerugian. Bank Indonesia (BI) selaku bank primer di Indonesia seharusnya dapat membuat kebijakan untuk dapat membantu meningkatakan industry perbankan kea rah yang lebih baik lagi. Dalam peraturan Bank Indonesia terdapat beberapa faktor yang digunakan untuk mengukur tingkat kesehatan bank, yaitu profil resiko (risk profile), Good Corporate Governance, rentabilitas (earnings), dan permodalan (capital). Untuk mengatasi masalah perbankan di Indonseia perlu dilakukan analisis untuk mengetahui faktor-faktor yang mempengarui tingkat profitabilitas. Selain, itu juga dilakukan pengklasifikasian bank di Indonesia yang rugi atau tidak. Unit observasi yang digunakan dalam penelitian ini sebnyak 84 bank yang ada di Indonesia, dengan menggunakan variabel sebanyak 7 variabel. Metode yang digunakan adalah regresi stepwise, regresi logistik dan juga neural network. Hasil yang diperoleh bahwa metode neural network lebih baik disbanding dengan metode regresi stepwise dan juga regresi logistik. Faktor-faktor yang berpengaruh terhadap profitabilitas perbakan di Indonesia adalah resiko kredit, efisiensi manajemen, permodalan, dan juga inflasi
Kata Kunci : Klasifikasi, Neural Network, Profitabilitas, Regresi, Rugi
I. PENDAHULUAN
Dewasa ini industri perbankan masih harus menghadapi berbagai tantangan yang terus berkembang. Oleh karena itu, perbankan bersama Bank Indonesia harus membuat kebijakan untuk memperbaiki posisi dan mengembangkan industri perbankan ke arah yang lebih baik dari tahun-tahun sebelumnya. Tantangan dan harapan inilah yang menjadi dasar tujuan bagi Bank Indonesia bersama perusahaan perbankan untuk menciptakan berbagai keputusan atau kebijakan. Kebijakan yang tepat dan didukung dengan pengawasan serta penilaian terhadap kinerja perbankan akan membantu perbankan untuk mencapai tujuan. Bank Indonesia selaku pembina dan pengawas bank di Indonesia menyatakan kebijakan yang berkaitan dengan masalah tingkat kesehatan bank umum. Dalam peraturan Bank Indonesia terdapat beberapa faktor yang digunakan untuk mengukur tingkat kesehatan bank, yaitu profil resiko (risk profile), Good Corporate Governance, rentabilitas (earnings), dan permodalan (capital). Untuk mengetahui penilaian kinerja perusahaan dapat dilakukan dengan menganalisis laba rugi yang di dalamnya terdapat profitabilitas atau laba yang dicapai perusahaan yang merupakan aspek penilaian rentabilitas (earnings). Penilaian terhadap profitabilitas bank dapat digunakan untuk menilai hasil kinerja bank dari tahun ke tahun serta dapat digunakan untuk menentukan strategi dan tujuan di masa yang akan datang.
didapat dari operating cost dan operating revenue, permodalan yang menggambarkan jumlah modal sendiri yang dimiliki bank untuk menutupi setiap rupiah aset yang mengalami penurunan nilai yang merupakan rasio dari equality capital dan total asset, efisiensi inflasi yang menggambarkan kenaikan harga barang secara umum yang terjadi secara berkelanjutan, untuk nilai efisiensi inflansi disini merupakan koefisien beta yang didapat dari nilai variabel inflansi, dan efisiensi Produk Domestik Bruto (PDB) yang menggambarkan nilai pasar dari seluruh barang dan jasa yang dihasilkan di indonesia, nilai efisiensi PDB disini merupakan koe fisien beta yang didapat dari nilai variabel PDB. Berdasarkan penjelasan di atas maka perlu dilakukan untuk menganalisis faktor-faktor yang mempengaruhi perbankan di Indonesia, salah satu metode yang dapat digunakan adalah regresi. Selain, itu juga dilakukan klasifikasai perbankan di Indonesia untuk mengetahui apkah bank tersebut termasuk bank yang merugi atau tidak. Metode yang digunakan adalah menggunakan pendekatan
Neural Network.
II. METODE DAN TINJAUAN PUSTAKA
Pada analisis ini, metode yang digunakan meliputi metode untuk pre-processing data dan metode analisis data. Metode preprocessing data yang digunakan adalah Attribute Transformation.
Sedangkan untuk metode analisis yang digunakan adalah analisis regresi stepwise, neural network, regresi logistik dan juga klasifikasi menggunakan algoritma neural network. Pada penelitian ini
software yang digunakan adalah Matlab R2010a dan R 3.4.2. Toolbox yang digunakan pada software
matlab adalah “nftool” dan “nprtool”. Sedangkan, untuk package R yang digunakan antara lain
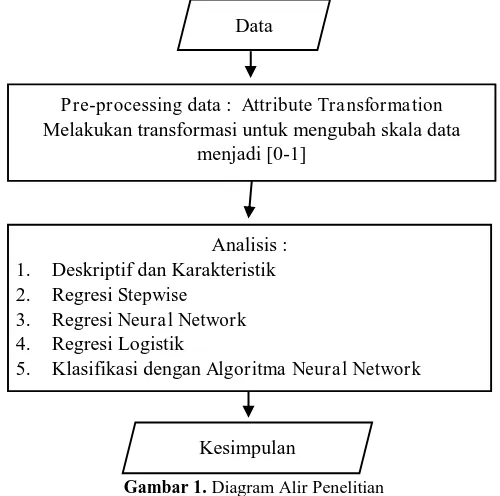
“GGally”, “nuralnet”, “tidyverse”, “ggplot2”, “tibble”, “dplyr”, “purrr”, “readr”, dan “stats”. Berikut tahapan analisis yang ditampilkan dalam bentuk diagram pada Gambar 1
Gambar 1. Diagram Alir Penelitian A. Tahap Pre-Processing
Tahap ini merupakan tahap untuk mempersiapkan data sebelum diolah menggunakan data mining dengan metode apapun. Secara umum, ada beberapa cara yang dapat digunakan pada tahap
pre-processing ini [1], yaitu :
1. Aggregation, yaitu mengombinasikan dua objek atau lebih guna mereduksi jumlah objek yang ingin diolah, dalam hal ini bisa observasi ataupun variabel.
Data
Pre-processing data : Attribute Transformation Melakukan transformasi untuk mengubah skala data
menjadi [0-1]
5. Klasifikasi dengan Algoritma Neural Network 6. Singular Value Decomposition (SVD)
2. Sampling, yaitu pemilihan sebagian dari keseluruhan data yang akan digunakan. Langkah ini hampir sama dengan langkah sebelumnya, yaitu bertujuan untuk mengurangi jumlah data, namun dengan tidak menghilangkan karakteristik populasi.
3. Dimensionality reduction, yaitu mereduksi dimensi, baik variabel maupun observasi demi memperkecil volume memori dan mempersingkat waktu pemrosesan. Biasanya digunakan
factor analysis, principal components analysis, multidimensional scaling, cluster analysis,
canonical correlation, dan lain sebagainya.
4. Feature selection digunakan untuk menghilangkan fitur-fitur atau variabel yang kurang relevan dan yang dapat menimbulkan kebingungan.
5. Feature creation, yaitu membuat artificial attribute sehingga dapat menangkap informasi penting dari data daripada hanya menggunakan attribute yang asli.
6. Discretization and binarization, yaitu transformasi data dari kontinyu ke diskret atau dari banyak nilai ke biner.
7. Attribute transformation, konversi yang dilakukan kepada attribute lama ke attribute baru menggunakan transformasi matematis tertentu sehingga dapat dilakukan pemrosesan data dengan lebih baik.
Pada analisis ini metode pre-processing data yang digunakan adalah Attribute Transformation
yaitu dengan merubah skala data menjadi [0-1], transformasi bertujuan untuk menyamakan skala dari data karena ada beberapa variabel yang memiliki skala yang sangat berbeda dengan variabel lain. Rumus yang digunakan untuk transformasi data ditampilkan pada persamaan 1.
� = ax � − i �� − i � (1)
B. Tahap Analisis
Pada penelitian ini metode yang digunakan adalah regresi dan dan klasifikasi menggunakan
algoritma neural network. Berikut merupakan penjelasan dari metode-metode yang digunakan dalam analisis.
1. Statistika Deskriptif
Statistika deskriptif adalah metode-metode yang berkaitan dengan pengumpulan dan penyajian suatu gugus data sehingga memberikan informasi yang berguna. Mean adalah salah satu ukuran untuk memberikan gambaran yang lebih jelas dan singkat tentang sekumpulan data. Mean juga merupakan wakil dari sekumpulan data atau dianggap suatu nilai yang paling dekat dengan hasil pengukuran yang sebenarnya. rumus yang digunakan untuk menghitung mean data adalah :
Nilai minimum adalah nilai terendah dari suatu data. Sedangkan nilai maksimum adalah nilai tertinggi dari suatu data. [2]
(3)
Regresi merupakan metode yang digunakan untuk mengatahui pola hubungan antara varaibel respon (y) dan variabel prediktor (x).secara sederhada peramaan regresi linier berganda dapat dituliskan dengan persamaan sebagai berikut ini
= � + � + � + ⋯ + � + � 4)
Ada beberapa macam jenis dan metode regresi ini, pada analisis ini metode regresi yang digunakan adalah regresi stepwise dan regresi neural network. Berikut penjelasan untuk regresi stepwise
i. Regresi Stepwise
Regresi Stepwise melibatkan dua jenis proses yaitu: forward selection dan backward elimination.
Teknik ini dilakukan melalui beberapa tahapan. Pada masing-masing tahapan,kita akan memutuskan variabel mana yang merupakan prediktor terbaik untuk dimasukkan ke dalam model. Variabel ditentukan berdasarkan uji-F, variabel ditambahkan ke dalam model selama nilai p-value nya kurang dari nilai kritik alpha (α). Kemudian variabel dengan nilai p-value lebih dari nilai kritik α akan
dihilangkan. Proses ini dilakukan terus menerus hingga tidak ada lagi variabel yang memenuhi kriteria untuk ditambahkan atau dihilangkan. [3]
ii. Koefisen Determinasi dan Sum Square Error
Kebaikan dari model regresi yang terbentuk dapat dilihat berdasarkan nilai dari koefisien deteriminasi (Rsq) dan atau nilai dari sum square error (SSE). Nilai koefisien determinasi merupakan
suatu ukuran yang menunjukan besar sumbangan dari variabel penjelasan terhadap respon [4]. Rumus untuk menghitung koefisien diterminasi di tampilkan pada persamaan 5 dibawah ini
��� = 1 − � 5)
keterangan,
SSE = Sum Square Error
SST = Sum Square Total
Sum square error adalah kesalah dari hasil prediksi model terhadap nilai sebenarnya, sehingga semakin kecil SSE maka model yang terbentuk semakin baik.
3. Klasifikasi
i. Regresi Logistik
Model regresi logistik digunakan untuk mencari hubungan antara variabel respon yang bersifat kategorik dengan variabel prediktor yang bersifat kontinu atau kategorik. Nilai dari variabel respon
Y yang bersifat biner atau dikotomus dibedakan atas dua kategori, misalnya Y = 0 dan Y = 1. Misalkan terdapat k variabel X’ = (X1, X2, …, Xk) yang berpasangan dengan variabel respon Y. Peluang Y = 1
dinotasikan dengan π(x). Fungsi regresi logistik π(x) adalah:
� = +��� �� � 6)
dimana, � = � + � + � + ⋯ + � [5]
Fungsi regresi di atas berbentuk curvilinear sehingga untuk membuatnya menjadi fungsi linear dilakukan transformasi logit sebagai berikut [6]:
log +� �� � = � 7)
Metode estimasi parameter menggunakan maximum likelihood estimation.
ii. Tingkat Akurasi
Akurasi klasifikasi pada dat imbalance dapat dihitung menggunakan Area Under ROC Curve
(AUC). Rumus untuk menghitung AUC adalah sebagai berikut ini [7]:
��� =�∑�= � 8)
Neural Networks (NN) dapat dipandang sebagai model regresi nonlinear dimana kompleksitas modelnya dapat diubah-ubah. Pada level kompleksitas yang paling rendah, NN hanya terdiri dari satu lapisan input dan satu lapisan output. NN memungkinkan untuk mengubah kompleksitas jaringan sehingga dapat mengakomodasi efek nonlinear, khususnya efek interaksi diantara variabel independen. Hornik dkk. (1987) telah menunjukkan bahwa NN dengan satu hidden layer mampu menghampiri sembarang fungsi pada himpunan kompak tanpa asumsi awal tentang fungsi yang dimodelkan.
Terdapat tiga jenis utama dari ANN yakni Multilayer Perceptron, Radial Basis Function, dan
Kohonen Network. Multilayer Perceptron merupakan model yang paling banyak digunakan untuk melakukan prediksi. Radial Basis Function merupakan model yang dapat melakukan hal yang dilakukan oleh Multilayer Perceptron. Kohonen Network baik digunakan pada permasalahan clustering [8]. Pada penelitian Ini digunakan model Multilayer Perceptron karena model ini umum digunakan pada permasalahan prediksi. merupakan model yang memetakan suatu set input data menjadi set output, dengan menggunakan Multilayer Perceptron fungsi aktivasi nonlinier. Pada Multilayer Perceptron variabel independen maupun dependen dapat memiliki tingkat pengukuran metrik maupun nonmetrik. Multilayer perceptron merupakan feedforward neural network dimana informasi bergerak hanya dalam satu arah, dari simpul input melalui simpul tersembunyi dan simpul
a) b)
Gambar 2. Gambar Arsitektur Artificial Neural Network a) Regresi dan b) Klasifikasi
C. Data dan Variabel Penelitian
Data yang digunakan dalam analisis ini adalah data mengenai profitablitas perbankan di Indonesia pada tahun 2010. Data yang digunakan memiliki 8 variabel, diantaranya adalah variabel profitabilitas (y), resiko kredit , resiko likuiditas (x2), efisiensi manajemen (x3), permodalan (x4), β
inflasi (x5), β PDB (x6), dan kode klasifikasi (bernilai 0 dan 1, 1 : rugi dan 0 : untung). Setelah
dilakukan transformasi untuk menyamakan skala data, selanjutnya akan dilakukan pembagian data untuk data training dan testing. Proporsi yang digunakan adalah [80, 20] persen.
III. HASIL DAN PEMBAHASAN
Hasil analisis mengenai profitabilitas perbankan dan klasifikasi perbankan di Indonesia pada thaun 2010 akan dibahas pada poin-poin dibawah ini.
A. Karakteristik Data
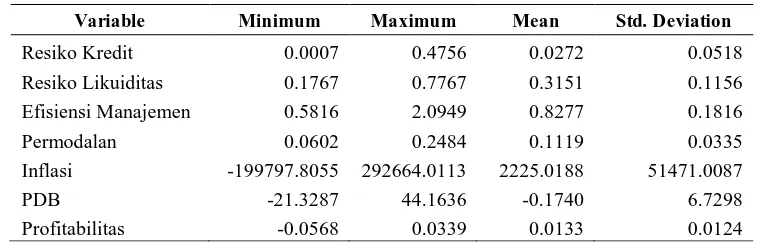
Karakteristik data perbankan di Indonesia pada tahun 2010 dapat dilihat pada Tabel 1 dibawah ini
Tabel 1. Karakteristik Data Perbankan di Indonesia Tahun 2010
Variable Minimum Maximum Mean Std. Deviation
Resiko Kredit 0.0007 0.4756 0.0272 0.0518
Resiko Likuiditas 0.1767 0.7767 0.3151 0.1156
Efisiensi Manajemen 0.5816 2.0949 0.8277 0.1816
Permodalan 0.0602 0.2484 0.1119 0.0335
Inflasi -199797.8055 292664.0113 2225.0188 51471.0087
PDB -21.3287 44.1636 -0.1740 6.7298
Profitabilitas -0.0568 0.0339 0.0133 0.0124
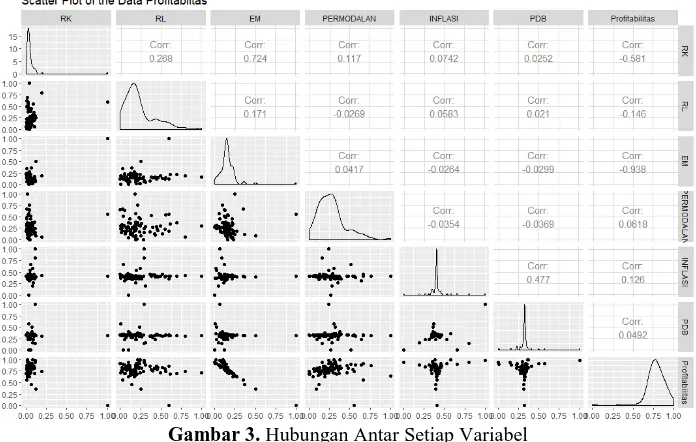
Gambar 3. Hubungan Antar Setiap Variabel
Berdasarkan plot pada Gambar 3 dapat diketahui tidak semua variabel memberikan pengaruh positif terhadap profitabilitas, variabel yang memeberikan pengaruh negatif adalah variabel Resiko Kredit, Resiko Likuiditas, dan Efisiensi Manajemen. Variabel efisiensi manajemen memberikan pengaruh yang sangat besar terhadap profitabilitas, sedangkan variabel PDB memberikan pengaruh sebaliknya. Dimana jika dilihat dari nilai korelasi urutan hubungan terbesar sampai terkecil secara
terurut adalah sebagai berikut efisiensi manajeman, risiko manajeman, risiko likuiditas, β inflasi, permodalan dan β PDB. Berikut merupakan pie chart untuk jumlah bank yang mengalami kerugian dan tidak.
Gambar 4. Pie Chart Klasifikasi Perbankan di Indonesia 2010
Berdasarkan Gambar 4 dari 84 bank yang di observasi, hanya 4 bank saja yang diklasifikasikan mengalami kerugian. Bank yang mengalami kerugian tersebuat diantaranya adalah Bank Central Asia Tbk (BBCA), Bank Mizuho Indonesia (BMZI), Bank Maybank Indonesia Tbk (BNII) dan Bank Tabungan Pensiunan Nasional,Tbk (BTPN). Sehingga, berdasarkan pie chart dapat disimpulkan bahwa data imbalance, cenderung masuk klasifikasi 0 (tidak merugi).
B. Regresi untuk Memprediksi Nilai Profitabilitas Bank
Selanjutnya akan dilakukan analisis regresi stepwise dan regresi neural network, berikut pembahasan mengenai hasil analisis
1. Regresi Stepwise
Variabel Estimate Std. Error T P-Value
(Intercept) 0.9028 0.02509 35.983 2E-16
RK 0.22367 0.06828 3.276 0.00173
EM -1.22501 0.06299 -19.448 2.00E-16 PERMODALAN 0.07546 0.03123 2.417 0.01862 INFLASI 0.09356 0.04982 1.878 0.06512
Berdasarkan Tabel 2 dengan menggunakan alpha sebesar 10% maka dapat diketahui bahwa variabel yang signifikan berpengaruh terhadap profitabilitas adalah resiko kredit, efisiensi manajemen, permodalan dan juga inflasi. Nilai Rsq untuk persmaan regresi diatas dengan data training didapatkan adalah sebesar 0,9173 dan nilai SSE sebesar 0,04359. Berikut plot residual yang digunakan untuk uji asumsi klasik residual
Gambar 4. Plot Residual
Berdasarkan Gambar 4 dapat diketahui bahwa residual tidak memenuhi asumsi klasik regresi. Dengan menggunakan persamaan yang diperoleh pada Tabel 2 diatas maka akan diprediksi untuk data testing
sejumlah 20% dari data dan didapatkan hasil nilai SSE sebesar 0,9572176, nilai SSE ini masih sangat tinggi bila dibandingkan dengan skala data profitabilitas yaitu (0-1).
2. Regresi Neural Network
Berikut ini analisis menggunakan regresi neural network dengan beberapa kombinasi hidden,
yang digunakan adalah [1,1], [8,1], [10,1] dan [20]. Dengan menggunakan data training dan testing
dan menggunakan kombinasi hidden yang digunakan maka didaptkan nilai SSE yang dapat ditampil pada tabel dibawh ini
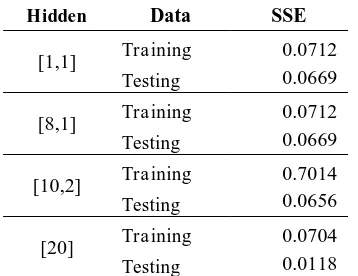
Tabel 3. Perbandingan Sum Square Error (SSE)
Berdasarkan Tabel 3 dapat disimpulkan bahwa model yang baik adalah saat hidden sebanyak 20 dan layer sebanyak satu, berikut gambar jaringan syaraf yang diperoleh
Hidden Data SSE
[1,1] Training 0.0712 Testing 0.0669 [8,1] Training 0.0712 Testing 0.0669 [10,2] Training 0.7014 Testing 0.0656 [20] Training 0.0704
Gambar 5. Jaringan Syaraf untuk [20]
3. Perbandingan Performansi Model
Berikut perbandingan nilai sum square error untuk masing-masing metode, dapat dilihat pada Gambar 6.
Gambar 6. Perbandingan Nilai Sum Square Error untuk Setiap Metode
Berdasarkan Gambar 6 dapat diketahui bahwa metode Neural Network untuk regresi lebih baik disbanding metode regresi linier berganda, hal ini dapat dilihat berdasarkan hasil nilai SSE dimana untuk metode NN cenderung memberikan nilai SSE yang kecil. Dari 4 kombinasi hidden layer yang digunakan hidden [20] merupakan yang paling optimum untuk kasus regresi profitabilitas perbankan di Indonesia pada tahun 2010 ini.
C. Klasifikasi Perbankan di Indonesia
Pengklasifikasian bank di Indonesia berdasarkan rugi tidaknya dapat menggunakan dua metode yaitu regresi logistik dan klasifikasi menggunkan algoritmaneural network, berikut hasil analis yang diperoleh
1. Regresi Logistik
Variabel B S.E. Wald df Sig. Exp(B)
RK 225.88387 332077.7 4.627E-07 1 0.9994573 1.259E+98 RL 5.2175073 27175.829 3.686E-08 1 0.9998468 184.47377 EM 64.62623 107832.79 3.592E-07 1 0.9995218 1.166E+28 Permodalan 3.0692944 35539.547 7.459E-09 1 0.9999311 21.526709 Inflasi -14.16733 183301.42 5.974E-09 1 0.9999383 7.034E-07 PDB -23.788734 285272.46 6.954E-09 1 0.9999335 4.663E-11 Constant -31.693887 52556.09 3.637E-07 1 0.9995188 1.72E-14
Berdarkan Tabel 5 dapat diketahui bahwa semua variabel tidak signifikan terhadpa kode, atau klasifikasi bank rugi tau tidak. Berikut hasil tabel klasifikasi untuk data training dan testing yang diperoleh
Tabel 5. Tabel Hasil Klasifikasi Data Training dan Testing Menggunkan Regresi Logistik
Sample Observed Predicted Percent Correct 0 1
Training
0 64 0 97%
1 2 0 0%
Overall
Percent 100% 0% 97%
Testing
0 16 0 89%
1 2 0 0%
Overall
Percent 100% 0% 89%
Berdasarkan Tabel 5 dapat diketahui bahwa tidak ada yang tepat diklasifikasikan ke kelompok satu, sehingga metode ini kurang baik digunakan saat data imbalance.
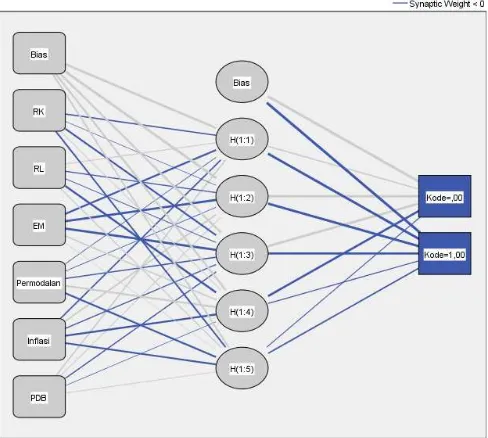
2. Klasifikasi dengan Neural Network
Berdasarkan hasil analisis klasifikasi dengan neural network menggunakan software SPSS didapatkan jumlah hidden layer optimum adalah sebanyak lima dengan jumlah layer sebanyak satu, berikut gambar arsitektur neural network yang terbentuk
Berdasarkan hasil neural network diatas maka dilakukan untuk data testing, sehingga didapatkan hasil prediksi untuk data testing yang dapat dilihat pada Tabel 6 dibawah ini
Tabel 6. Tabel Hasil Klasifikasi untuk Data Testing
Sample Observed Predicted Percent Correct
Berdasarkan Tabel 6 diatas dapat diketahui bahwa dengan menggunakan algoritma neural network, data testing dapat tepat 100% di klasifikasikan.
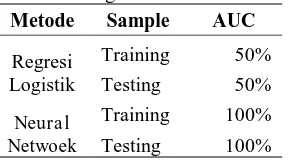
3. Perbandingan Akurasi
Data yang digunakan untuk setiap kelas klasifikasi tidak balance (imbalance) sehingga dalam perhitungan tingkat keakurasiian menggunkan metode AUC, berikut hasil AUC untuk setiap metode yang digunakan
Tabel 7. Perbandingan Nilai Akurasi Setiap Metode Metode Sample AUC
Berdasarkan Tabel 7 diatas dapat diketahui bahwa pengklasifikasian menggunakan neural network sangat baik, karena dapat memberikan nilai akurasi yang sempurna yaitu 100%.
IV. KESIMPULAN DAN SARAN
Pada tahun 2010 kondisi perbankan di Indonesia, terdapat 4 bank yang mengalami kerugian yaitu Bank Central Asia Tbk (BBCA), Bank Mizuho Indonesia (BMZI), Bank Maybank Indonesia Tbk (BNII) dan Bank Tabungan Pensiunan Nasional, Tbk (BTPN). Rata-rata profitabilitas perbakan di Indonesia pada tahun 2010 sebesar 1,33% dimana bank yang berada dibawah angka tersebut sebanyak 52,38% bank. Faktor-faktor yang berpengaruh terhadap profitabilitas perbakan di Indonesia adalah resiko kredit, efisiensi manajemen, permodalan, dan juga inflasi. Metode regresi dengan algoritma
neural network dengan hidden layer sebanyak 20 lebih baik dibandingkan dengan metode regresi
stepwise karena memberikan nilai SSE yang lebih rendah. Pengklasifikasian menggunakan NN sangat lebih baik dibandingkan dengan regresi logistik, saat jumlah hidden layer sebanyak 5 akurasi yang diperoleh sebesar 100%.
Perlu dilakukan pemodelan ulang dengan menggunakan kombinasi hidden layer dan jumlah layer yang lain. Untuk regresi performansi model tidak hanya di lihat dari SSE saja mungkin bisa menggunakan Rsq. Untuk pengklasifikasian seharusnya digunakan dengan data yang imbalance
sehingga untuk metode regresi logistiK bisa lebih akurat lagi. DAFTAR PUSTAKA
[1] Gorunescu, Florin. (2011). Data Mining : Concepts, Models, and Techniques. Berlin : Springer. [2] Hair, J. F. Jr. 1995. Multivariate Data Analysis with Readings, 4th edition. Madison : Pearson
[3] Suprihartiningsih, E. (2017). Analisis Regresi : Pemilihan Model Terbaik. Retrieved from http://ernasuprihartiningsih.blogspot.co.id
[4] Siagaan, D., Sugiarto. (2006). Metode Statistika Untuk Bisnis dan Ekonomi. PT Gramedia Pustaka Utama. Jakarta
[5] Hosmer, D.W. Lemeshow, S. (1989). Applied Logistic Regression. New York: John Wiley & Sons Ltd.
[6] Agresti, A. (1990). Categorical Data Analysis. New York: John Wiley and Sons, Inc.
[7] Bekkar, M., Djeemaa, H., & Alitouch, T. (2013). Evaluation Measures for Models Assesment over Imbalanced Data Sets, Vol 3. Journal of Information Engineering an Application, 27-38. [8] J. Hair & R. Anderson (1998). Multivariate Data Analysis. New York: Prentice Hall