7
TINJAUAN PUSTAKA
2.1. Artificial Intelligence
Pada dasarnya, banyak pandangan serta pengertian mengenai AI, dan secara garis besar, Russell & Norvig (2010:2) membagi pengertian AI ke dalam empat kategori utama, diantaranya:
1. Thinking humanly
Pada kategori ini, AI dijelaskan sebagai suatu usaha baru untuk membuat komputer dapat berpikir, suatu mesin yang memiliki pikiran secara penuh dan memiliki rasa, atau dengan kata lain dapat juga disebut sebagai kegiatan yang mengadopsi cara manusia berpikir, seperti pengambilan keputusan, penyelesaian masalah, pembelajaran, dan sebagainya.
2. Thinking rationally
Pada kategori ini, AI dijelaskan sebagai suatu studi melalui pemodelan komputasi sehingga, studi AI ini dapat membuat segala sesuatu mungkin untuk dapat dipersepsikan dan memiliki alasan untuk dilakukan.
3. Acting humanly
Pada kategori ini, AI dijelaskan sebagai suatu seni untuk membuat mesin dapat menampilkan fungsi yang membutuhkan kecerdasan ketika digunakan oleh manusia.
4. Acting Rationally
Pada kategori ini, AI dijelaskan sebagai studi tentang perancangan agen-agen kecerdasan (intelligent agen-agents) dan AI difokuskan pada perilaku yang cerdas.
2.2. Algoritma
Cormen, Leiserson, Rivest dan Stein (2009 : 5) menyatakan bahwa algoritma merupakan langkah-langkah komputasi yang terdefinisi dengan baik yang mengambil beberapa nilai atau seperangkat nilai sebagai input dan menghasilkan beberapa nilai atau seperangkat nilai sebagai output. Langkah dalam algoritma adalah dengan mengubah input menjadi output. Algoritma dapat digunakan sebagai alat untuk memecahkan masalah komputasi.
Menurut Robert Setiadi (2008: 4), sebuah algoritma dikatakan benar jika algoritma tersebut berhasil mengeluarkan output yang benar untuk semua kemungkinan input. Sebuah algoritma dikatakan baik apabila seluruh proses di dalamnya efisien untuk menghasilkan solusi dalam waktu sesingkat mungkin dengan menggunakan resource seminimal mungkin.
2.3. Algoritma Pathfinding
Tujuan dari algoritma pathfinding adalah untuk menemukan jalur terbaik dari node awal ke node akhir. Secara umum, Russell & Norvig membagi algoritma pathfinding menjadi dua jenis (2010: 81,92), yaitu :
1. Algoritma Uniformed Search
Algoritma uninformed search adalah algoritma yang tidak memiliki keterangan tentang jarak atau biaya dari path dan tidak memiliki pertimbangan akan path mana yang lebih baik.
2. Algoritma Informed (Heuristic) Search
Algoritma informed search adalah algoritma yang memiliki keterangan tentang jarak atau biaya dari path dan memiliki pertimbangan akan path berdasarkan pengetahuan akan path mana yang lebih baik. Yang termasuk dalam algoritma ini adalah algoritma Greedy Best-first Search dan A*.
2.3.1. Algoritma Greedy Best-first Search
Menurut Russell dan Norvig (2010: 92), greedy merupakan nama lain dari Best First Search. Greedy dapat diartikan rakus atau serakah. Greedy memperluas node yang paling dekat dengan tujuan, dengan alasan bahwa hal ini mungkin menjadi solusi yang cepat dalam melakukan pencarian. Algoritma greedy mengevaluasi node dengan fungsi heuristic :
dimana merupakan estimasi biaya dari n ke tujuan
Algoritma greedy membangun langkah per langkah, dan selalu memilih langkah selanjutnya yang menawarkan solusi terbaik. Pada setiap langkah algoritma greedy mengambil pilihan terbaik yang dapat
diperoleh pada saat itu tanpa memperhatikan konsekuensi ke depannya, sebagaimana prinsip algoritma greedy (Dasgupta, Papadimitriou, & Vazirani, 2006: 139). Dengan demikian, secara umum algoritma greedy bekerja dengan cara melakukan pencarian himpunan kandidat dengan fungsi seleksi dan diverifikasi dengan fungsi kelayakan kemudian memilih solusi paling optimal dengan fungsi obyekif.
Langkah-Iangkah pencarian lintasan terpendek yang dilakukan
Greedy Best-First Search (Suyanto, 2014: 30) :
• Masukkan simpul awal ke dalam Open List.
• Open berisi simpul awal dan Closed List masih kosong.
• Masukkan simpul awal ke Closed List dari suksesornya pada Open List.
• Ulangi langkah berikut sampai simpul tujuan ditemukan dan tidak ada lagi simpul yang akan dikembangkan.
• Hitung nilai simpul-simpul yang ada pada Open List, ambil simpul terbaik ( paling kecil).
• Jika simpul tersebut sama dengan simpul tujuan, maka sukses.
• Jika tidak, masukkan simpul tersebut ke dalam Closed • Bangkitkan semua suksesor dan simpul tersebut • Untuk setiap suksesor kerjakan :
o Jika suksesor tersebut belum pernah dibangkitkan, evaluasi suksesor tersebut, tambahkan ke Open, dan catat parent-nya.
o Jika suksesor tersebut sudah pernah dibangkitkan, ubah parent-nya. Jika jalur melalui parent ini lebih baik daripada jalur melalui parent yang sebelumnya. Selanjutnya, perbaharui biaya untuk suksestor tersebut.
2.3.2. Algoritma A*
Menurur Russell & Norvig (2010 : 93), A* merupakan bentuk yang paling dikenal dari Best First Search. A* mengevaluasi node dengan menggabungkan , yaitu cost untuk mencapai node, dan , yaitu cost yang diperlukan dari node untuk mencapai tujuan, sehingga :
merupakan cost suatu path dari node awal ke node n, dan adalah perkiraan cost terendah dari node n ke tujuan. adalah perkiraan solusi dengan cost termurah melalui n.
Dengan demikian, untuk menemukan solusi termurah, hal yang pertama yang dicoba adalah node dengan nilai terendah. Strategi ini jelas lebih baik dengan disediakannya fungsi heuristik yang dapat memenuhi kondisi tertentu sehingga A* menjadi optimal.
Algoritma A* menggunakan dua buah list yaitu Open List dan
Closed List. Seperti halnya best-first search yang lain kedua list
mempunyai fungsi yang sama. Pada awalnya Open List hanya berisi satu simpul yaitu simpul awal dan Closed List masih kosong. Perlu diperhatikan setiap simpul akan menyimpan petunjuk parent-nya sehingga setelah pencarian berakhir, maka lintasan juga akan didapatkan. Berikut adalah langkah-langkah algoritma A* (Suyanto, 2014: 33-34) :
Masukkan simpul awal ke Open List.
Ulangi langkah berikut sampai pencarian berakhir.
• Cari node n dengan nilai paling rendah, dalam
Open List. Node ini akan menjadi current node.
• Keluarkan current node dari Open List dan masukkan ke Close List
• Untuk setiap suksesor dari current node lakukan langkah berikut :
i. Jika sudah terdapat dalam Closed List, abaikan, jika tidak lanjutkan.
ii. Jika belum ada pada Open List, masukkan ke Open
List. Simpan current node sebagai parent dari
suksesor-suksesor ini. Simpan cost masing-masing simpul.
iii. Jika sudah ada dalam Open List, periksa jika simpul suksesor ini mempunyai nilai lebih kecil dibanding suksesor sebelumya. Jika lebih kecil, jadikan sebagai
current node dan ganti parent node ini.
• Walaupun telah mencapai simpul tujuan, jika masih ada suksesor yang memiliki nilai yang lebih kecil, maka simpul tersebut akan terus dipilih sampai bobotnya jauh lebih besar atau mencapai simpul akhir dengan bobot yang lebih kecil dibanding dengan simpul sebelumnya yang telah mencapai simpul tujuan.
• Pada setiap pemilihan simpul berikutnya, nilai akan dievaluasi, dan jika terdapat nilai yang sama maka akan dipilih berdasarkan nilai terbesar.
2.4. Heuristik
Menurut Wichmann (2004: 7), heuristik merupakan aturan-aturan untuk memilih cabang-cabang yang memiliki kemungkinan mengarah pada pemecahan masalah. Karena heuristik menggunakan informasi yang terbatas maka heuristik mungkin gagal dalam memprediksikan prilaku secara tepat dalam suatu pencarian. Heuristik dapat membantu menunjukkan arah yang tepat bagi suatu algoritma, tetapi mungkin juga gagal dalam memberikan petunjuk kepada algoritma tersebut.
Menurut Suyanto (2014: 66), algoritma informed search tanpa fungsi heuristik yang baik akan memperlambat pencarian dan dapat menghasilkan lintasan yang tidak tepat. Untuk menghasilkan lintasan yang benar-benar
tepat, maka fungsi heuristiknya harus underestimate terhadap biaya dari suatu
node ke final node. Fungsi heuristik yang sempurna akan membuat algoritma informed search langsung menuju final node tanpa harus mencari ke
arah-arah lain. Sehingga, jika fungsi heuristiknya terlalu underestimate akan menyebabkan algoritma ini beranggapan bahwa ada lintasan yang lebih baik dari lintasan yang ada. Untuk fungsi heuristik yang underestimate, bila nilainya terlalu rendah akan menyebabkan algoritma ini seperti dijkstra yang mencari ke segala arah yang mungkin. Hal ini dikarenakan tidak cukupnya informasi mengenai masalah yang dihadapi, sehingga menyebabkan algoritma informed search melakukan pencarian dengan lebih banyak dan lebih lama. Jika algoritma ini diharapkan melakukan pencarian dengan lebih cepat tanpa memperoleh lintasan terpendek, maka fungsi heuristiknya suatu saat dapat overestimate.
2.4.1. Straight Line Distance
Menurut Patel (2006), straight line distance atau euclidean
distance digunakan ketika unit yang kita pakai dapat bergerak ke
segala arah. Fungsi heuristik dari straight line distance yaitu:
function heuristic(node) =
dx = abs(node.x - goal.x) dy = abs(node.y - goal.y)
return D * sqrt(dx * dx + dy * dy)
Suyanto (2014:66) menuliskan kembali fungsi straight line
distance yang dibuat oleh Patel (2006) ke dalam rumus matematika
sebagai berikut :
Dimana :
• adalah koodinat X dari node pertama pada grid • adalah koodinat X dari final node
• adalah koodinat Y dari node pertama pada grid • adalah koodinat Y dari final node
Straight line distance cocok digunakan dalam kasus pencarian
lintasan pada peta. Fungsi heuristik Straight line distance menjamin bahwa nilai heuristik yang dihasilkan pasti lebih kecil (underestimate) atau sama dengan jarak sebenarnya. Sehingga persamaan tersebut dapat digunakan untuk mencari nilai heuristik.
2.5. Analisis Algoritma
Menurut Allen (2013: 145), yang dimaksud dengan analisis algoritma adalah proses menganalisis, menentukan besarnya biaya yang diperlukan suatu algoritma untuk memecahkan suatu permasalahan.
Menurut Cormen (2013: 21), menganailsis algoritma dapat diartikan sebagai proses memprediksi sumber-sumber yang dibutuhkan oleh algoritma. Terkadang sumber-sumber seperti memori, communication bandwith, atau perangkat keras komputer menjadi hal-hal yang utama, tetapi sering kali waktu komputasi menjadi hal yang paling penting untuk dihitung dalam menganalisis algoritma.
2.6. Time Complexity
Menurut Setiadi (2008: 46) time complexity adalah lamanya waktu yang dibutuhkan komputer untuk menjalankan suatu algoritma. Beberapa algoritma dapat diselesaikan kurang dari 1 milidetik. Namun, tidak semua algoritma dapat selesai diproses dalam kurang dari satu milidetik. Algoritma yang kompleks dapat memerlukan waktu beberapa menit hingga berhari - hari untuk menyelesaikan proses nya. Hal ini berlaku bahkan dengan komputer tercanggih sekalipun. Perhitungan time complexity biasanya dipengaruhi oleh jumlah data yang harus di proses.
2.7. Shortest Path
Menurut Arannz, Llanos, Escribano (2014: 2), shortest path adalah pencarian lintasan atau path terpendek antar node yang ada pada graf. Biaya (cost) yang dihasilkan adalah yang paling minimum.
2.8. Flowchart
Menurut Robertson (2010:264), flowchart merupakan representasi grafis dari sebuah algoritma, dimana flowchart digambar menggunakan simbol-simbol khusus.
Tabel 2.1 Simbol Flowchart
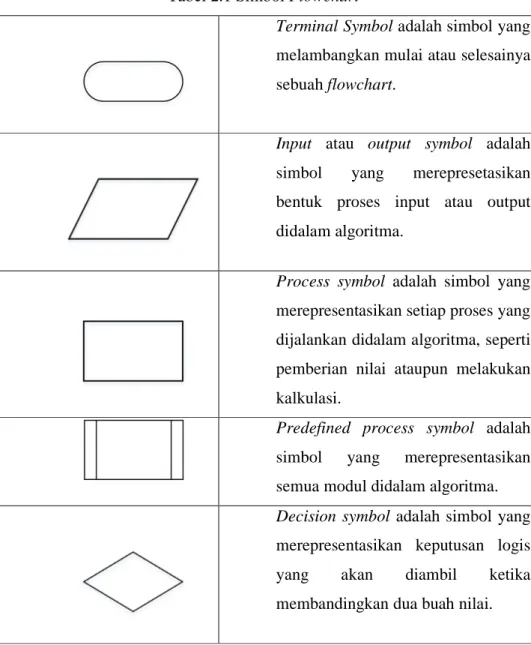
Terminal Symbol adalah simbol yang
melambangkan mulai atau selesainya sebuah flowchart.
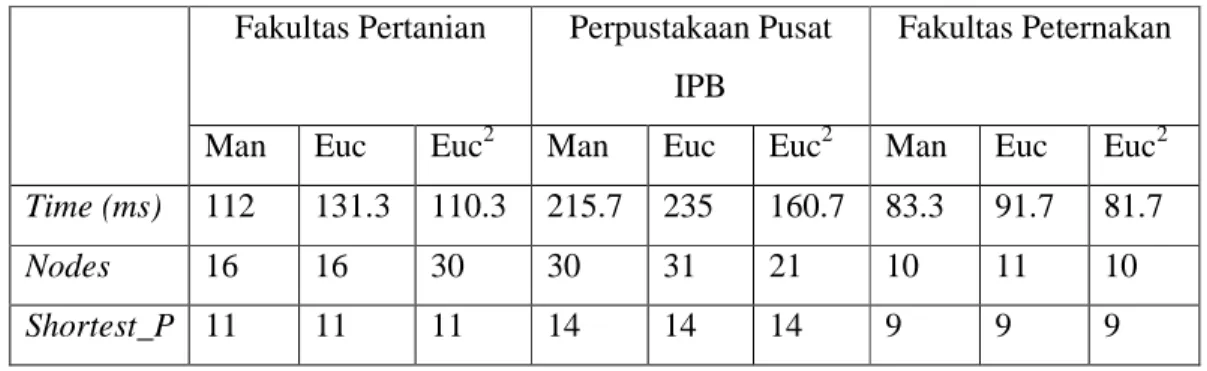
Input atau output symbol adalah
simbol yang merepresetasikan bentuk proses input atau output didalam algoritma.
Process symbol adalah simbol yang
merepresentasikan setiap proses yang dijalankan didalam algoritma, seperti pemberian nilai ataupun melakukan kalkulasi.
Predefined process symbol adalah
simbol yang merepresentasikan semua modul didalam algoritma.
Decision symbol adalah simbol yang
merepresentasikan keputusan logis yang akan diambil ketika membandingkan dua buah nilai.
Flowlines adalah garis yang menghubungkan simbol-simbol yang ada didalam sebuah flowchart.
2.9. Koordinat Peta
Menurut Natalia, Achmaliadi, Hanafi, Safitri, Kurniawa, Pramono (2005 : 1-7), koordinat peta adalah perpotongan antara garis bujur dengan garis lintang. Terdapat dua sistem yang biasa digunakan, yaitu sistem koordinat BUJUR-LINTANG dan sistem koordinat UTM (Universal
Transveres Method). Sistem koordinat BUJUR-LINTANG lebih cocok
digunakan di Indonesia karena Indonesia terletak pada garis khatulistiwa. Sistem koordinat BUJUR-LINTANG terdiri dari dua komponen yang menentukan yaitu :
1. Garis dari atas ke bawah (vertikal) yang menghubung- kan kutub utara dengan kutub selatan bumi, disebut juga garis lintang (Latitude).
2. Garis mendatar (horizontal) yang sejajar dengan garis khatulistiwa, disebut juga garis bujur (Longitude).
Karena bentuk dunia seperti bola, maka ketentuan yang mengatur koordinat bujur-lintang mirip dengan ketentuan matematika yang mengatur lingkaran. Dengan demikian, cara untuk menentukan koordinat bujur-lintang adalah sama dengan perhitungan lingkaran yaitu : derajat (° ) dan menit ('). 1° bujur atau lintang adalah 111,322 km. 1° adalah 60 menit, sehingga 1 menit adalah 1,885 km.
2.10. Related Works
2.10.1 Penentuan Rute Terpendek Menggunakan Variasi Fungsi Heuristik Algoritme A* Pada Mobile Devices
Ananda, Wahjuni, dan Giri (2010) melakukan penelitian tentang perbedaan tiga macam fungsi heuristik dalam menentukan rute terpendek dengan algoritma
Informed Search. Fungsi heuristik yang dibandingkan adalah Manhattan, Euclidian,
dan Euclidian Kuadrat. Dalam penelitian ini, algoritma Informed Search yang digunakan adalah A*(star) dan perangkat yang digunakan untuk penelitian adalah
mobile phone. Peta yang digunakan untuk penelitian adalah peta IPB yang
ditampilkan dalam bentuk grid.
Fungsi Manhattan memiliki rumus sebagai berikut :
Fungsi Euclidean memiliki rumus sebagai berikut :
Fungsi Euclidean Kuadrat memiliki rumus sebagai berikut :
Peta IPB direpresentasikan dalam bentuk matrik 15 x 12. Matrik tersebut terdiri dari dua bilangan, yaitu 0 dan 1. Bilangan 0 menandakan bahwa rute bisa dilewati, sedangkan bilangan 1 menandakan rute tidak bisa dilewati. Nilai 5, 6, 7, 8, 9, dan 10 adalah representasi dari properti yang dimiliki oleh peta, misalnya gedung rektorat dan fakultas - fakultas unversitas. Berikut merupakan bentuk matrik dari peta IPB : myMap =[[1,1,1,0,1,1,0,1,1,1,1,1], [1,1,1,0,7,1,0,1,1,1,1,1], [0,0,0,0,0,0,0,0,0,0,1,1], [0,1,1,1,1,0,1,0,1,0,1,1], [0,1,1,1,1,0,1,0,1,0,1,1], [0,1,1,1,1,0,0,0,1,0,0,0], [0,6,1,1,1,0,1,1,1,0,1,1], [0,1,10,10,1,0,1,1,6,0,1,1], [0,1,10,10,9,0,1,1,1,0,0,0], [0,1,10,10,1,0,1,1,1,0,1,0], [0,1,1,1,10,0,0,0,0,0,1,0], [0,1,1,5,1,1,1,1,1,0,8,0], [0,0,0,0,0,0,0,0,0,0,0,0], [1,1,1,1,1,0,1,1,1,1,1,1], [1,1,1,1,1,0,1,1,1,1,1,1]];
Dalam penelitian ini, unsur yang diuji adalah waktu eksekusi masing - masing fungsi heuristik (Time) , banyaknya node yang diperiksa untuk menemukan rute terpendek (Nodes), dan rute terpendek dari node awal ke node akhir
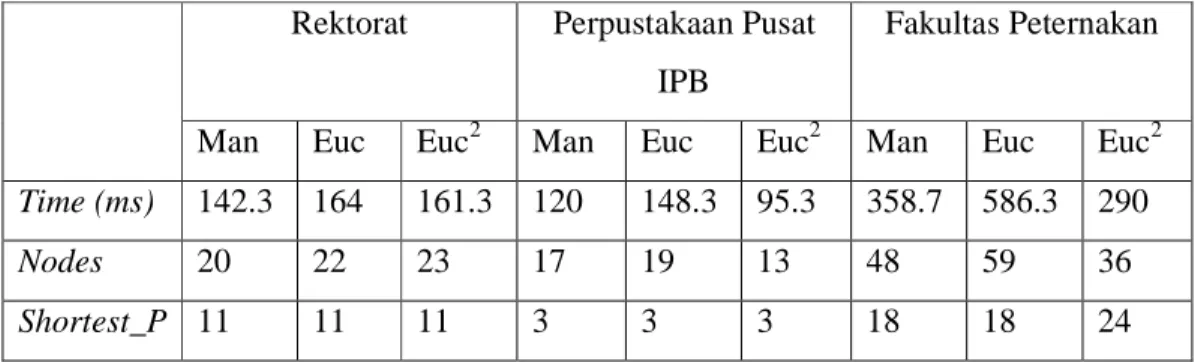
(Shortest_P). Pada pengujian pertama, rute dilakukan dari rektorat menuju fakultas
pertanian, perpustakaan IPB, dan fakultas peternakan. Hasil dari pengujian sebagai berikut :
Tabel 2.2 Hasil Pencarian Rute dengan Rute Awal Rektorat Fakultas Pertanian Perpustakaan Pusat
IPB
Fakultas Peternakan
Man Euc Euc2 Man Euc Euc2 Man Euc Euc2
Time (ms) 112 131.3 110.3 215.7 235 160.7 83.3 91.7 81.7
Nodes 16 16 30 30 31 21 10 11 10
Shortest_P 11 11 11 14 14 14 9 9 9
Dari hasil yang diperoleh pada tabel hasil pencarian rute dengan rute awal Rektorat, Shortest_P yang didapat oleh tiga fungsi heuristik yaitu 11 untuk rute rektorat-fakultas pertanian, 14 untuk rute rektorat-perpustakaan IPB, dan 9 untuk rute rektorat-fakultas peternakan. Jumlah node yang diperiksa dengan menggunakan fungsi heuristik Euclidian kuadrat lebih sedikit dibandingkan dengan fungsi heuristik yang lainnya yaitu 16 utnuk rute fakultas pertanian, 21 untuk rute rektorat-perpustakaan IPB, dan 10 untuk rute rektorat-fakultas peternakan. Fungsi heuristik Manhattan menghasilkan waktu pencarian rute yang lebih cepat dibandingkan dengan fungsi Euclidian, tetapi fungsi heuristik Euclidian kuadrat menghasilkan waktu pencarian yang lebih cepat dibandingkan fungsi heuristik lainnya yaitu 110.3 ms pada rute rektorat-fakultas pertanian, 160.7 ms pada rute rektoratperpustakaan pusat IPB, dan 81.7 ms pada rute rektoratfakultas peternakan.
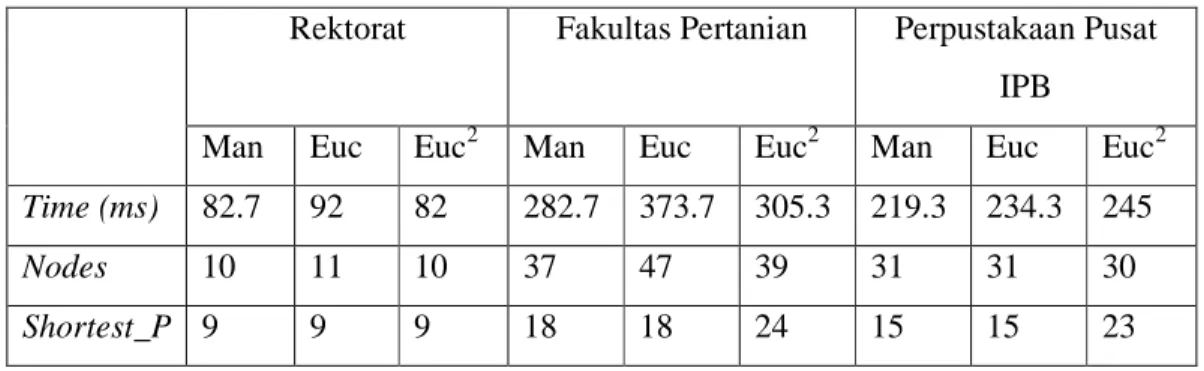
Pada pengujian kedua, rute dilakukan dari rektorat menuju fakultas pertanian, perpustakaan IPB, dan fakultas peternakan. Hasil dari pengujian sebagai berikut :
Rektorat Perpustakaan Pusat IPB
Fakultas Peternakan
Man Euc Euc2 Man Euc Euc2 Man Euc Euc2
Time (ms) 142.3 164 161.3 120 148.3 95.3 358.7 586.3 290
Nodes 20 22 23 17 19 13 48 59 36
Shortest_P 11 11 11 3 3 3 18 18 24
Dari hasil yang diperoleh pada tabel hasil pencarian rute dengan rute awal Fakultas Pertanian, Shortest_P yang didapat oleh tiga fungsi heuristik memiliki perbedaan yaitu 11 untuk rute fakultas pertanian-rektorat, 9 untuk rute fakultas pertanian-perpustakaan IPB, sedangkan rute fakultas pertanian-fakultas peternakan, besarnya Shortest_P pada fungsi heuristik Manhattan dan Euclidian adalah 18, tetapi fungsi heuristik Euclidian kuadrat menghasilkan nilai 24. Pada rute fakultas pertanian-rektorat, banyaknya node yang diperiksa menggunakan fungsi heuristik Euclidian kuadrat memiliki nilai paling besar yaitu 23, sedangkan pada rute yang lain, fungsi heuristik ini memiliki nilai yang paling kecil yaitu 13 untuk rute fakultas pertanian-perpustakaan IPB dan 36 untuk rute fakultas pertanian-fakultas peternakan. Fungsi heuristik Euclidian kuadrat memiliki waktu pencarian tercepat pada rute fakultas pertanian-perpustakaan IPB yaitu 95.7 ms dan 290 ms pada rute fakultas pertanian-fakultas peternakan, sedangkan pada rute fakultas pertanian-rektorat, fungsi heuristik Manhattan memiliki waktu pencarian tercepat yaitu 142.3 ms.
Pada pengujian ketiga, rute dilakukan dari rektorat menuju fakultas pertanian, perpustakaan IPB, dan fakultas peternakan. Hasil dari pengujian sebagai berikut :
Tabel 2.4 Hasil Pencarian Rute dengan Rute Awal Perpustakaan Pusat IPB Rektorat Fakultas Pertanian Fakultas Peternakan Man Euc Euc2 Man Euc Euc2 Man Euc Euc2
Time (ms) 174.7 199.3 149 123 135.7 131 191.7 236 168.3
Nodes 24 26 20 18 19 19 26 30 22
Shortest_P 14 14 14 9 9 9 15 15 15
Dari hasil yang diperoleh pada tabel hasil pencarian rute dengan rute awal Perpustakaan Pusat IPB, Shortest_P yang didapat oleh tiga fungsi heuristik yaitu 14
untuk rute perpustakaan pusat IPB-rektorat, 9 untuk rute perpustakaan IPB- fakultas pertanian, dan 15 untuk rute perpustakaan pusat IPB-fakultas peternakan. Pada rute perpustakaan pusat IPB-fakultas pertanian, banyaknya node yang diperiksa menggunakan fungsi heuristik Manhattan memiliki nilai paling kecil yaitu 18, sedangkan pada rute yang lain, fungsi heuristik Euclidian kuadrat memiliki nilai yang paling kecil yaitu 20 untuk rute perpustakaan IPB-rektorat dan 22 untuk rute perpustakaan pusat IPB-fakultas peternakan. Fungsi heuristik Euclidian memiliki waktu pencarian terlambat dibandingkan dengan fingsi heuristik lainnya yaitu 199.3 ms, 135.7 ms, dan 236 ms. Untuk rute perpustakaan pusat IPB-rektorat dan perpustakaan pusat IPB-fakultas peternakan, fungsi heuristik Euclidian kuadrat memiliki waktu pencarian tercepat yaitu 149 ms dan 168.3 ms. Sedangkan fungsi heuristik Manhattan memiliki waktu pencarian tercepat pada rute perpustakaan pusat IPB-fakultas pertanian yaitu sebesar 123 ms.
Pada pengujian keempat, rute dilakukan dari rektorat menuju fakultas pertanian, perpustakaan IPB, dan fakultas peternakan. Hasil dari pengujian sebagai berikut :
Tabel 2.5 Hasil Pencarian Rute dengan Rute Awal Fakultas Perternakan Rektorat Fakultas Pertanian Perpustakaan Pusat
IPB
Man Euc Euc2 Man Euc Euc2 Man Euc Euc2
Time (ms) 82.7 92 82 282.7 373.7 305.3 219.3 234.3 245
Nodes 10 11 10 37 47 39 31 31 30
Shortest_P 9 9 9 18 18 24 15 15 23
Dari hasil yang diperoleh pada tabel hasil pencarian rute dengan rute awal Fakultas Perternakan, Shortest_P yang didapat oleh tiga fungsi heuristik memiliki perbedaan yaitu 9 untuk rute fakultas peternakan-rektorat, 18 untuk rute fakultas peternakan-fakultas pertanian dengan menggunakan fungsi heuristik mahattan dan Euclidian, sedangkan untuk fungsi heuristik Euclidian kuadrat pada rute yang sama menghasilkan cost sebesar 24. Untuk rute fakultas peternakan-perpustakaan pusat IPB, Shortest_P pada fungsi heuristik Manhattan dan Euclidian adalah 15, tetapi fungsi heuristik Euclidian kuadrat menghasilkan nilai 23. Jumlah node yang diperiksa dengan menggunakan fungsi heuristik Euclidian lebih besar daripada
fungsi heuristik yang lain yaitu 11 untuk rute fakultas peternakan-rektorat, 47 untuk rute fakultas fakultas pertanian, dan 31 untuk rute fakultas peternakan-perpustakaan pusat IPB. Fungsi heuristik Manhattan memiliki waktu pencarian tercepat pada rute fakultas peternakan – fakultas pertanian dan rute fakultas peternakan-perpustakaan pusat IPB yaitu 219.3 ms dan 282.7 ms. Pada rute fakultas peternakanperpustakaan pusat IPB, fungsi heuristik Euclidian kuadrat memiliki waktu pencarian terlambat yaitu 245 ms.
Simpulan dari penelitian ini adalah penggunaan fungsi heuristik pada algoritma A* sangat mempengaruhi dalam pencarian rute terpendek dan waktu eksekusi dari algoritma A* dalam menentukan rute terpendek. Fungsi Euclidean membutuhkan waktu lebih banyak tetapi, selalu menemukan rute terpendek. Fungsi Euclidean Kuadrat memiliki waktu pencarian lebih cepat tetapi, belum tentu menghasilkan rute paling pendek. Fungsi Manhattan memberikan waktu lebih cepat daripada fungsi Euclidean dan selalu menemukan rute terpendek.
2.10.2 Experimental Comparison of Uninformed and Heuristic AI Algorithms for N Puzzle and 8 Queen Puzzle Solution
Mathew dan Tabbasum (2014) melakukan penelitian tentang perbandingan algoritma Uninformed dan Heuristic dalam menyelesaikan N-Puzzle dan 8 Queen
Puzzle. Dalam penelitian ini, akan dibandingkan algoritma Breadth First Search (BFS) dan Depth First Search (DFS) sebagai Uninformed Search, Greedy Best First Search, A* Search, dan Hill Climbing Search sebagai Heuristic Search. N-Puzzle
yang digunakan untuk pengujian berukuran 8 dalam matrik 3 x 3 dan untuk 8 Queen
Puzzle, digunakan matrik berukuran 8 x 8.
BFS bekerja dengan mengekspansi semua node ke dalam tree, kemudian
melakukan pencarian pada level yang sama terlebih dahulu sampai level tersebut selesai ditelusuri, selanjutnya level akan berpindah pada level selanjutnya. DFS melakukan pencarian hampir sama seperti BFS, hanya saja DFS melakukan pencarian terhadap satu branch sampai tidak ada branch lagi, kemudian dilanjutkan dengan branch alternatif lainnya.
A* bekerja dengan melakukan pencarian berdasarkan nilai path cost dan heuristic cost, sedangkan Greedy Best First Search hanya melihat nilai heuristik saja. Hill Climbing Search melakukan pencarian hampir sama seperti A* dengan melihat
path cost dan heuristic cost, tetapi Hill Climbing Search mencari nilai path cost
terbesar dan heuristic cost terkecil.
Hasil dari penelitian ini adalah :
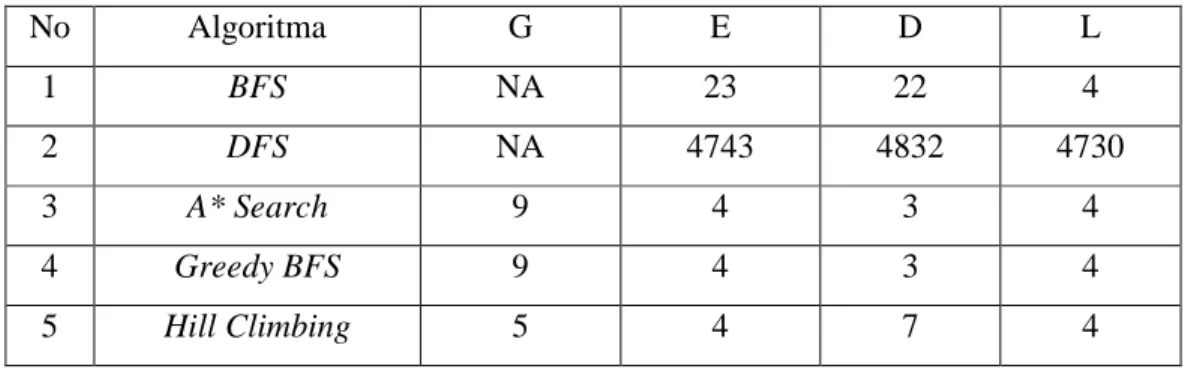
Tabel 2.6 Hasil Algoritma Pencarian pada N Puzzle
No Algoritma G E D L 1 BFS NA 23 22 4 2 DFS NA 4743 4832 4730 3 A* Search 9 4 3 4 4 Greedy BFS 9 4 3 4 5 Hill Climbing 5 4 7 4
G adalah node yang akan dihitung dalam pencarian, E adalah node yang akan diekspansi, D adalah node yang dihilangkan, L adalah panjang langkah yang dihasilkan dari pencarian
Berdasarkan tabel hasil algoritma pencarian pada N Puzzle, dapat disimpulkan bahwa BFS lebih baik dalam pencarian Uninformed dibandingkan DFS.
A* Search memiliki hasil yang sama dengan Greedy BFS, sedangkan Hill Climbing
menggunakan memori yang lebih sedikit dibandingkan A* Search dan Greedy BFS. Tabel 2.7 Hasil Perbandingan dari 8-Queen Puzzle
BFS DFS Greedy Hill Climbing A* Min Cost - - No of crashes of No of crashes of No of crashes of
placed queens placed queens placed queens Back-tracking
No Yes Yes No Yes
Complete Yes No No No Yes Time O(bd+1) O(bm) O(bm) O(∞) Exponential
with path length Space O(bd+1) O(bm) O(bm) O(b) Stores all
nodes
Optimal Yes No No No Yes
Berdasarkan tabel hasil perbandingan dari 8-Queen Puzzle, dapat disimpulkan bahwa algoritma A* adalah algoritma yang paling baik dalam menyelesaikan masalah 8-Queen Puzzle.
2.10.3 Pathfinding: A* or Dijkstra’s?
Goyal, Mogha, Luthra, dan Sangwan (2014) melakukan analisis perbandingan algoritma pathfinding pada peta. Tujuannya adalah mengetahui algoritma mana yang memiliki waktu berpikir lebih singkat dan jarak lintasan yang lebih pendek. Algoritma yang dianalisis pada penelitian ini adalah algoritma A* dengan Dijkstra's menggunakan greedy best-first search. Pengujian dilakukan dengan simulasi pada petak berukuran 40x40 dengan
agent berada petak start dan akan menuju petak finish yang telah ditentukan. Agent hanya bisa bergerak ke delapan arah yaitu atas, bawah, kanan, kiri dan
diagonal. Terdapat dua kali percobaan dengan obstacle yang berbeda. Berikut ini adalah hasil percobaan dari kedua algoritma :
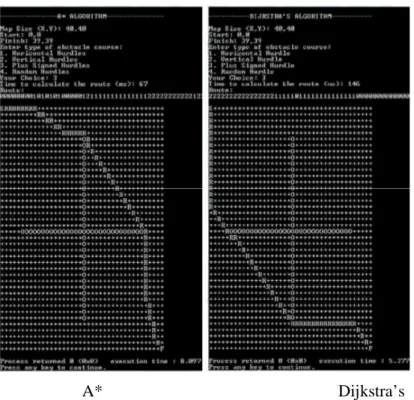
A* Dijkstra’s Gambar 2.1 Hasil Percobaan Pertama
(sumber : Goyal, Mogha, Luthra, dan Sangwan, 2014: 11)
A* Dijkstra’s Gambar 2.2 Hasil Percobaan Kedua
Simbol S menunjukan node awal dan simbol F menunjukan
node akhir. Simbol R merupakan rute yang dipilih oleh algoritma,
sedangkan simbol O adalah penghalang atau obstacle pada peta yang tidak bisa dilalui sebagai rute. Berikut merupakan tabel hasil perbandingan algoritma dari dua pengujian yang telah dilakukan :
Tabel 2.8 A* vs Dijkstra's
Comparison in Time (ms) Comparion in Lenght (nodes)
A* Dijkstra's A* Dijkstra's
Case 1 67 146 55 55
Case 2 102 129 55 55
Berdasarkan hasil yang diperoleh, jarak yang dihasilkan oleh algoritma A* dan Dijkstra's pada kedua percobaan adalah sama yaitu 55 nodes. Waktu yang dibutuhkan oleh algoritma A* untuk menentukan lintasan yang dilalui pada case pertama dan kedua adalah 67 dan 102 ms, sedangkan waktu yang dibutuhkan oleh algoritma Dijkstra's pada case pertama dan kedua adalah 146 dan 129. Dapat disimpulkan bahwa algoritma A* memiliki waktu berpikir yang lebih singkat dari algoritma Dijkstra's.
Berikut ini merupakan tabel perbandingan antara tiga penelitian terdahulu :
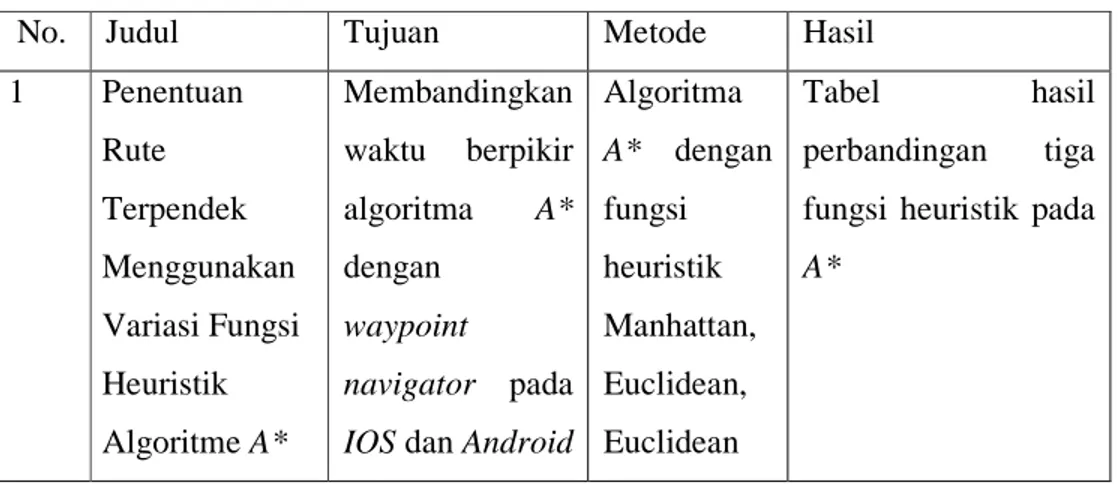
Tabel 2.9 Perbandingan Penelitian Terdahulu
No. Judul Tujuan Metode Hasil
1 Penentuan Rute Terpendek Menggunakan Variasi Fungsi Heuristik Algoritme A* Membandingkan waktu berpikir algoritma A* dengan waypoint navigator pada IOS dan Android
Algoritma A* dengan fungsi heuristik Manhattan, Euclidean, Euclidean Tabel hasil perbandingan tiga fungsi heuristik pada
Pada Mobile Devices Kuadrat 2 Experimental Comparison of Uninformed and Heuristic AI Algorithms for N Puzzle and 8 Queen Puzzle Solution Menganalisa perbandingan algoritma Uninformed search dengan Informed search Algoritma BFS, DFS, Greedy best-first search, A* Search, Hill Climbing Search Tabel hasil perbandingan pada N-Puzzle dan 8-Queen Puzzle 3 Pathfinding: A* or Dijkstra’s? Membandingkan algoritma pathfinding pada petak berukuran 40x40 Algoritma A* dengan dijkstra Tabel perbandingan waktu berpikir dan banyak petak yang dilalui algoritma yang diuji