i
Halaman Judul
SEGMENTASI CITRA DOKUMEN
TEKS TULISAN TANGAN AKSARA JAWA
MENGGUNAKAN ALGORITMA SEGLINES
(STUDI KASUS PADA DOKUMEN “SERAT PERTANDA”)SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh :
Albertus Dio Padmadharma
075314057
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
2011
ii
Halaman Judul
IMAGE SEGMENTATION OF
JAVANESE SCRIPT HANDWRITING TEXT DOCUMENT
USING SEGLINES ALGORITHM
(“SERAT PERTANDA”)
A Thesis
Presented as a Partial Fulfillment of the Requierments
To Obtain Sarjana Komputer Degree
In Informatics Engineering
By :
Albertus Dio Padmadharma
075314057
INFORMATICS ENGINEERING STUDY PROGRAM
INFORMATICS ENGINEERING DEPARTMENT
FACULTY OF SCIENECE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
2011
iii
Lembar Persetujuan
iv
Lembar Pengesahan
v
PERNYATAAN KEASLIAN KARYA
vi Abstrak
Penelitian ini berfokus pada proses segmentasi citra dokumen teks tulisan
tangan Aksara Jawa menggunakan algoritma Seglines dan dokumen yang
digunakan adalah dokumen Serat Pertanda. Tujuan dilakukannya penelitian ini
adalah untuk memahami konsep dasar algoritma Seglines pada citra dokumen
tulisan tangan aksara Jawa dan menguji unjuk kerjanya.
Algoritma Seglines menghasilkan prosentase akurasi segmentasi sampai
96.45% - 99.79%. Prosentase itu didapat dari hasil segmentasi pada skrip yang
digunakan secara luas di India, misalnya Gurmukhi. Algoritma ini dipilih karena
dapat melakukan segmentasi terhadap baris yang bersentuhan secara horizontal
dan menyatukan komponen dari baris yang over segmented.
Penelitian dilakukan dengan melakukan proses segmentasi pada citra
dokumen yang telah mengalamai proses normalisasi kemiringan, binerisasi dan
reduksi noise. Penelitian kemudian dilanjutkan dengan menganalisa citra
dokumen dan citra baris yang dihasikan dari proses segmentasi dengan
menggunakan algoritma Seglines.
Hasil pengujian yang dilakukan terhadap citra dokumen
serat_pertanda2.jpg dengan menggunakan algoritma Seglines diketahui bahwa
waktu yang diperlukan untuk memproses citra tersebut adalah 0,57486 detik.
Prosentase akurasi yang didapatkan adalah 43,33 % untuk segmentasi citra
dokumen tulisan tangan aksara Jawa dengan algoritma Seglines. Untuk hasil
segmentasi setelah ditambahkan saran berupa fungsi penelusuran potongan aksara
dengan garis potong segmentasi dan fungsi pencarian headlines (45% dari
headlines) untuk segmentasi aksara didapatkan hasil 88,68% memenuhi syarat
segmentasi. Prosentase hasil segmentasi dengan tolak ukur penulisan aksara Jawa
didapatkan nilai sebesar 59,10% Kecilnya nilai prosentase disebabkan aksara yang
sudah ditemukan ada beberapa bagiannya yang terpotong. Berdasarkan tinjauan di
atas, maka dapat disimpulkan bahwa algoritma Seglines relatif baik untuk
melakukan segmentasi citra dokumen teks tulisan tangan.
vii Abstract
This study focuses on the process of image segmentation of text
documents using “Aksara Jawa” handwriting. “Serat Pertanda” document used by
Seglines algorithms as input. The purpose of this study was to understand the
basic concepts of Seglines algorithms on handwritten document image using
“Aksara Jawa” handwriting and test its performance.
Research carried out by performing the document image segmentation
process which has been processed using skew detection, binerization and noise
reduction. The study was followed by analyzing the document image and the
result.
The results of tests performed on the document image
“serat_pertanda2.jpg” using the algorithm Seglines known that it takes 0.57486
seconds. The line image of the handwritten document image use segmentation
algorithm Seglines obtained 17 lines correspond to the number of lines from the
document image serat_pertanda2.jpg. This shows that the algorithm Seglines good
if used for segmentation lines. Percentage of accuracy obtained is 43.33% for
handwritten document image segmentation use algorithm Seglines base on
Javanese script.
For the segmentation results after adding pieces of advice in the form of
alphabet search function by secant segmentation and search functions headlines
(45% of the headlines) for syllable segmentation results obtained 88.68%. This
percentage value indicates that the system can find the main characters in each
line. Percentage of segmentation results with a benchmark or writing the script of
Java semantics obtained a value of 59.10% The low value is caused porsentase
characters that have been found there are some parts that are cut off. Based on the
review above, it can be concluded that the relatively good Seglines algorithm to
segment the image of handwritten text documents.
viii
KATA PENGANTAR
ix
x
PERNYATAAN KEASLIAN KARYA ... v
Abstrak ... vi
Abstract ... vii
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI ... viii
KATA PENGANTAR ... ix
1. 5. Metode Penelitian ... 5
1. 6. Sistematika Penulisan ... 7
BAB II ... 8
2. 1. Pengertian Citra ... 8
2. 1. 1. Citra biner (monokrom) ... 9
2. 1. 2. Citra grayscale (skala keabuan) ... 9
2. 1. 3. Citra warna (true color) ... 10
2. 2. Citra Dokumen Teks ... 11
2. 3. Grayscaling ... 11
2. 4. Binerisasi ... 11
2. 5. Histogram ... 12
2. 6. Strip... 12
xi
2. 9. 2. Huruf pasangan (Aksara pasangan) ... 23
2. 10. Matlab ... 24
BAB III ... 25
3.1 Desain Input ... 25
3. 1. 1. Input Gambar ... 25
3. 2. Gambaran sistem secara umum ... 28
3. 2. 1. Diagram Arus Data Level 0 / Diagram Konteks ... 28
3. 2. 2. Diagram Arus Data Level 1 ... 29
3. 3. Perancangan Tampilan ... 31
3.4 Implementasi Proses : ... 33
3. 4. 1. Proyeksi Horizontal ... 33
3. 4. 2. Buat Strip ... 33
3. 4. 3. Pencarian Headlines ... 34
3. 4. 4. Identifikasi Average Line Height ... 34
3. 4. 5. Pemeriksaan Headlines ... 34
3. 4. 6. Proses Pembentukan Baris ... 35
3. 4. 7. Proyeksi Vertikal ... 36
3. 4. 8. Identifikasi Index Kolom ... 37
3. 4. 9. Potong Karakter ... 37
3. 5. Perancangan cara pengujian ... 38
BAB IV ... 40
4. Implementasi ... 40
4.1 Implementasi Proses : ... 40
4. 1. 1. Proyeksi Horizontal ... 40
4. 1. 2. Buat Strip ... 40
xii
4. 1. 3. Pencarian Headlines ... 41
4. 1. 4. Identifikasi Average Line Height ... 42
4. 1. 5. Pemeriksaan Headlines ... 42
4. 1. 6. Proses Pembentukan Baris ... 42
4. 1. 7. Proyeksi Vertikal ... 44
4. 1. 8. Identifikasi Index Kolom ... 44
4. 1. 9. Potong Karakter ... 45
4. 2. Implementasi Tampilan ... 46
4. 2. 1. Tampilan halaman utama... 46
4. 2. 2. Tampilan pilih file gambar ... 46
4. 2. 3. Tampilan simpan file gambar ... 47
4. 2. 4. Tampilan pesan proses simpan ... 47
4. 2. 5. Tampilan halaman utama... 47
4. 2. 6. Tampilan lihat gambar ... 48
4. 2. 7. Tampilan lihat Tabel Char Map ... 49
BAB V ... 50
5. 1. Data Masukan ... 50
5. 2. Perangkat Keras dan Perangkat Lunak ... 50
xiii
DAFTAR GAMBAR
Gambar 1. Metode Iterasi ... 6
Gambar 2. (a) Citra Biner; (b) Representasi Citra Biner dalam data digital ... 9
Gambar 3. (a) Citra Skala Keabuan; (b) Representasi Citra Skala Keabuan dalam data digital ... 10
Gambar 4. (a) Citra Warna; ... 10
Gambar 5. (a) Citra biner; ... 12
Gambar 6. Strip Gurmukhi ... 13
Gambar 7. Tulisan kata Gurmukhi: (a) upperzone dari garis nomor 1 sampai 2, (b) midlle zone dari garis no 3 sampai 4, (c) lowerzone dari garis nomor 4 sampai 5. ... 13
Gambar 8. Tulisan kata gujarati: (a) upper zone dari garis nomor 1 sampai 2, (b) middle zone dari garis 2 sampai 3, (c) lower zone dari garis 3 sampai 4 ... 13
Gambar 9. Batas-batas strip hasil segmentasi proyeksi profil pada citra teks Gurmukhi cetak ... 15
Gambar 10. Strip 1 dari dokumen Gurmukhi cetak ... 17
Gambar 11. Hasil segmentasi dengan Algoritma 1 ... 19
Gambar 12. Citra Dokumen Hasil Segmentasi Algoritma Seglines ... 21
Gambar 13. Huruf Dasar ... 23
Gambar 14. Huruf Pasangan ... 24
Gambar 15. Citra Serat_Pertanda2.JPG sebelum Pre-Processing ... 26
Gambar 16. Citra Serat_Pertanda2.JPG setelah Pre-Processing ... 27
Gambar 17. Diagram Konteks ... 28
Gambar 18. Diagram Arus Data ... 29
Gambar 19. Rancangan Tampilan Halaman Utama ... 31
Gambar 20. Rancangan Tampilan Tabel Char Map ... 32
Gambar 21. Rancangan Tampilan Halaman Lihat Gambar ... 32
Gambar 22. Tampilan Halaman Utama ... 46
Gambar 23. Tampilan Pilih Gambar ... 46
Gambar 24. Tampilan Simpan Gambar ... 47
xiv
Gambar 25. Pesan Proses Simpan Gambar Berhasil ... 47
Gambar 26. Tampilan Halaman Utama ... 48
Gambar 27. Tampilan Lihat Gambar ... 48
Gambar 28. Tampilan Lihat Gambar ... 48
Gambar 29. Tampilan Lihat Tabel ... 49
Gambar 30. Histogram Citra Dokumen Serat_Pertanda2 ... 51
Gambar 31. Histogram Strip ... 51
Gambar 32. Citra Dokumen Dalam Strip ... 53
Gambar 33. Kekeliruan Dalam Deteksi Headlines ... 55
Gambar 34. Headlines ... 57
Gambar 35. Baris Pertama Citra Dokumen Serat_Pertanda2... 58
Gambar 36. Histogram Vertikal Baris Pertama Citra Dokumen Serat_Pertanda2 58 Gambar 37. Baris pertama citra dokumen Serat_Pertanda2 dalam segmen hasil proyeksi vertikal ... 59
Gambar 38. Citra dokumen Serat_Pertanda2 yang telah tersegmen ... 60
Gambar 39. baris yang tersegmentasi kurang baik ... 62
Gambar 40. Aksara Yang Tidak Lengkap Bagian Uppernya ... 62
Gambar 41. Baris Ke Enam Citra Dokumen yang telah diperbarui ... 64
Gambar 42. Salah Satu Aksara Dari Baris Ke Enam yang telah diperbarui ... 64
Gambar 43. Segmentasi pada baris Ke Enam ... 64
Gambar 44. Baris dengan histogram lebih dari 45% x maks histogram ... 65
Gambar 45. Histogram bernilai lebih besar dari 45% maks histogram ... 66
Gambar 46. Gambar baris keenam setelah dikenai fungsi verProjOverLine ... 67
xv
DAFTAR TABEL
Tabel 1. Nilai P1 dan P2 untuk setiap tulisan... 22
Tabel 2. Indek Strip ... 52
Tabel 3. Indek Headlines... 54
Tabel 4. Indek Headlines... 56
Tabel 5. Indek baris baru ... 57
Tabel 6. Indek segmen baris pertama citra dokumen serat_pertanda2 ... 59
Tabel 7. Analisis Output Segmentasi Citra Dokumen Serat_Pertanda2 ... 61
Tabel 8. Koordinat x dan y dari perpotongan bagian aksara dengan garis(crossPikselUpper) ... 64
Tabel 9. Indeks histogram bernilai lebih 45% x maks histogram ... 65
BAB I
PENDAHULUAN
1. 1. Latar Belakang
Yogyakarta adalah kota yang terkenal sebagai kota pendidikan dan kaya akan
sejarah budayanya. Salah satu kekayaan sejarah kebudayaan adalah
naskah-naskah kuno aksara Jawa. Banyaknya peninggalan berbentuk naskah-naskah
membuktikan adanya tradisi tulis dalam masyarakat Jawa untuk diwariskan ke
generasi selanjutnya. Naskah-naskah Jawa dapat kita jumpai di Keraton
Kesultanan Yogyakarta dan Pura Pakualaman (Suryakusuma, 2003). Pura
Pakualaman sendiri sebagai salah satu kerajaan di Jawa mencatat sejarah yang
dituangkan dalam naskah kuno (Kusuma W., 2011).
Naskah-naskah kuno, di Keraton Kesultanan Yogyakarta dan Pura
Pakualaman, telah bertahun-tahun ada dan perlu diremajakan untuk menjaga
kelestariannya. Salah satu cara untuk melestarikan naskah kuno adalah proses
pengubahan naskah kuno tersebut ke dalam format digital. Naskah dalam format
digital memiliki manfaat yang besar terutama bagi dunia pendidikan. Para peneliti
dapat menggunakan naskah tersebut untuk proses penelitian ilmiah, seperti alih
aksara dari aksara Jawa ke latin dan melakukan penerjemahan.
Seiring dengan semakin luasnya pengaplikasian teknologi pengolahan citra
dalam kehidupan sehari-hari, contohnya pengolahan citra dalam dunia perfilman,
fotografi, pengenalan pola, keamanan data dan proteksi hak cipta, maka
aplikasinya dalam mengolah citra aksara Jawa sangat dimungkinkan. Pengolahan
citra digital sendiri adalah sebuah disiplin ilmu yang mempelajari hal-hal yang
berkaitan dengan perbaikan kualitas gambar, transformasi gambar, melakukan
melakukan proses penarikan informasi atau deskripsi obyek yang terkandung
pada citra, melakukan kompresi atau reduksi data untuk tujuan penyimpanan data,
transmisi data, dan waktu proses data (Edy dkk , 2009). Input dari pengolahan
citra ini adalah citra, sedangkan hasilnya adalah citra baru hasil pengolahan.
Segmentasi adalah salah satu tahapan dari pengolahan citra dengan tujuan
membagi wilayah-wilayah yang homogen. Segmentasi membagi citra ke dalam
daerah intensitasnya masing-masing sehingga dapat membedakan antara obyek
dengan latar belakangnya. Segmentasi sendiri juga membantu proses pengambilan
setiap citra karakter yang terdapat dalam citra dokumen.
Penelitian mengenai segmentasi citra pada naskah atau dokumen telah banyak
dilakukan. Segmentasi citra dokumen teks satra Jawa Modern dengan
mempergunakan Profil Proyeksi (Widiarti, 2007) yang memperlihatkan hasil
segmentasi yang baik, pada dokumen sastra Jawa modern Menak Sorangan I dan
Panji Sekar halaman 3 dan 4. Rata-rata prosentase keberhasilannya sebesar
86.797%.
Penelitian mengenai segmentasi citra yang kedua adalah segmentasi citra
dokumen sastra Jawa dengan menggunakan algoritma Watershed (Pinaryanto,
2009). Penelitian ini menunjukan hasil yang baik untuk segmentasi obyek
terhadap citra dokumen teks sastra Jawa. Hasil pengujian terhadap 10 citra
dokumen teks sastra Jawa, diperoleh hasil 97,123% untuk prosentase kebenaran
dan 84,932% untuk prosentase akurasi.
Penelitian mengenai segmentasi citra yang ketiga adalah segmentasi citra
dokumen teks sastra Jawa modern (Vitri, 2007). Prosentase keberhasilan pada
penelitian ini adalah 94,62%. Nilai prosentase ini menunjukan bahwa kombinasi
metode segmentasi yang digunakan yaitu profil proyeksi dan Chain Code relatif
baik untuk proses segmentasi pada citra dokumen teks sastra Jawa Modern. Proses
segmentasi dilakukan dengan menggunakan algoritma profil proyeksi untuk
mendapatkan citra aksara kemudian dilanjutkan dengan menggunakan algoritma
Perbedaan penelitian kali ini dengan penelitian-penelitian sebelumnya adalah
citra dokumen dan algoritma yang digunakan. Dokumen aksara Jawa yang
digunakan adalah citra dokumen teks tulisan tangan aksara Jawa. Citra dokumen
diambil dari dokumen Serat Pertanda yang ditulis tangan. Dalam penelitian kali
ini dilakukan proses segmentasi pada citra dokumen tulisan tangan aksara Jawa
dengan mempergunakan algoritma Seglines.
Algoritma Seglines adalah algoritma dikembangkan berdasarkan ide proyeksi
horizontal dan proyeksi vertikal yang kontinu dari algoritma Profil Proyeksi
(Jindal dkk, 2007). Algoritma ini dikembangkan oleh M.K. Jindal dkk untuk
memecahkan permasalahan segmentasi baris tulisan India yang saling bersentuhan
antara baris satu dengan baris lainnya dan beberapa baris horizontal yang saling
bertumpang tindih (Jindal dkk. 2000). Pada awalnya algoritma digunakan untuk
segmentasi baris horizontal pada 54 dokumen menghasilkan prosentase akurasi
sebesar 95%. Aplikasi algoritma ini juga terbatas pada tulisan yang dicetak oleh
mesin. M.K. Jindal dkk kemudian mengembangkan lagi menjadi algoritma
Seglines dan mengujinya terhadap delapan jenis skrip yang dicetak di India.
Delapan jenis skrip yang digunakan secara luas di India adalah Gurmukhi,
Devanagari, Bangla, Gujarati, Kannada, Tamil, Telugu dan Malayalam. Algoritma
Seglines menghasilkan prosentase akurasi segmentasi sebesar 96.45% - 99.79%
tergantung jenis skrip. Algoritma ini digunakan untuk mengatasi permasalahan
segmentasi terutama segmentasi baris. Metode ini dipilih karena dapat melakukan
segmentasi terhadap baris yang bersentuhan secara horizontal dan menyatukan
komponen dari baris yang over segmented. Karena dari analisa data awal
diperoleh fakta bahwa citra dokumen tulisan tangan memiliki baris yang saling
bersentuhan satu sama lainnya, peneliti tertarik untuk melihat apakah Seglines
1. 2. Rumusan Masalah
Berdasarkan latar belakang yang disampaikan, maka permasalahan
yang ingin diselesaikan, yaitu :
1. Bagaimana cara kerja dan implementasi algoritma Seglines pada
segmentasi citra dokumen tulisan tangan aksara Jawa?
2. Bagaimana cara menguji unjuk kerja algoritma Seglines pada
segmentasi citra dokumen tulisan tangan aksara Jawa?
1. 3. Batasan Masalah
Dalam penulisan laporan tugas akhir ini penulis memberikan
batasan-batasan masalah :
1. Pembuatan program yang mengimplementasikan segmentasi citra
dokumen tulisan tangan aksara Jawa dengan menggunakan algoritma
Seglines.
2. Data sumber citra yang digunakan adalah citra dokumen tulisan tangan
aksara Jawa yang telah mengalami proses pre-processing untuk
menghilangkan noise, normalisasi kemiringan dan binerisasi.
3. Citra yang dapat diproses adalah citra dokumen tulisan tangan aksara
Jawa dengan ekstensi *.jpg.
4. Menggunakan sistem operasi Windows 7.
1. 4. Tujuan
Dalam penulisan laporan tugas akhir ini penulis memiliki tujuan dan
berharap ada manfaat yang dapat diperoleh.
Tujuan penelitian dalam penulisan laporan tugas akhir ini adalah :
1. Memahami konsep dasar algoritma Seglines pada citra
dokumen tulisan tangan aksara Jawa.
2. Menguji unjuk kerja algoritma Seglines pada segmentasi citra
dokumen tulisan tangan aksara Jawa.
1. 5. Metode Penelitian
Metode penelitian yang ditempuh oleh penulis adalah :
1. Studi pustaka tentang segmentasi citra menggunakan algoritma
Seglines melalui buku-buku, jurnal-jurnal, browsing di internet dan
materi kuliah citra.
2. Studi data tentang strip dan citra dokumen aksara Jawa.
3. Mengembangkan aplikasi segmentasi sebagai alat bantu pengujian
dengan menggunakan metode “Incremental” menurut (Pressman,
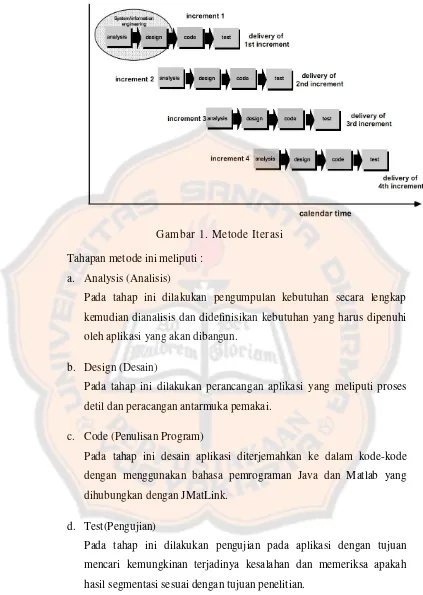
Gambar 1. Metode Iterasi
Tahapan metode ini meliputi :
a. Analysis (Analisis)
Pada tahap ini dilakukan pengumpulan kebutuhan secara lengkap
kemudian dianalisis dan didefinisikan kebutuhan yang harus dipenuhi
oleh aplikasi yang akan dibangun.
b. Design (Desain)
Pada tahap ini dilakukan perancangan aplikasi yang meliputi proses
detil dan peracangan antarmuka pemakai.
c. Code (Penulisan Program)
Pada tahap ini desain aplikasi diterjemahkan ke dalam kode-kode
dengan menggunakan bahasa pemrograman Java dan Matlab yang
dihubungkan dengan JMatLink.
d. Test(Pengujian)
Pada tahap ini dilakukan pengujian pada aplikasi dengan tujuan
mencari kemungkinan terjadinya kesalahan dan memeriksa apakah
4. Analisa hasil pengujian sistem untuk mendapatkan kesimpulan apakah
algoritma ini baik jika digunakan untuk proses segmentasi citra
dokumen tulisan tangan aksara Jawa
1. 6. Sistematika Penulisan
Secara umum dalam penelitian ini, sistematika penulisan yang akan
digunakan adalah sebagai berikut :
1. BAB I : PENDAHULUAN
Bab ini membahas latar belakang masalah, rumusan masalah, tujuan
penelitian, batasan masalah, metodologi penelitian, dan sistematika
penulisan.
2. BAB II : LANDASAN TEORI
Bab ini membahas teori-teori mengenai pengertian citra, pengertian
dan tujuan segmentasi, algoritma segmentasi, dan metode yang akan
digunakan dalam pengembangan aplikasi.
3. BAB III : ANALISA DAN PERANCANGAN SISTEM
Bab ini membahas analisa dan perancangan sistem secara umum,
rancangan proses serta rancangan antar muka yang akan digunakan.
4. BAB IV : IMPLEMENTASI SISTEM
Bab ini membahas implementasi dalam bentuk aplikasi berdasarkan
analisa dan perancangan yang telah dilakukan.
5. BAB V : HASIL DAN PENGUJIAN
Bab ini membahas analisa hasil implementasi segmentasi citra aksara
Jawa menggunakan algoritma Seglines.
6. BAB VI : PENUTUP
Bab ini membahas kesimpulan dan saran dari hasil analisa sistem,
BAB II
LANDASAN TEORI
Bab ini membahas teori-teori mengenai pengertian citra, pengertian dan tujuan
segmentasi, algoritma segmentasi, dan metode yang akan digunakan dalam
pengembangan aplikasi.
1.Teori
2. 1. Pengertian Citra
Citra adalah suatu representasi (gambaran), kemiripan, atau imitasi dari suatu
obyek (Edy dkk, 2009). Citra sebagai keluaran suatu sistem perekaman data dapat
bersifat optik berupa foto, bersifat analog berupa sinyal-sinyal video seperti
gambar pada monitor televisi, atau bersifat digital.
Citra digital adalah citra yang dapat diolah komputer (Edy dkk, 2009). Citra
digital ini disimpan dalam format digital atau dalam bentuk file sehingga dapat
diolah komputer. Citra digital memiliki ukuran dalam piksel (elemen terkecil
dalam citra). Citra digital yang disimpan dalam memori komputer hanya berupa
angka-angka yang menunjukkan besar intensitas pada masing-masing piksel
tersebut. Monitorlah yang nantinya akan menampilkan gambaran dari citra digital
tersebut setelah diproses, contohnya gambar sebuah kotak kecil. Sebuah citra
digital memiliki ukuran sebesar M x N piksel, dimana M merupakan lebar dari
citra digital dan N merupakan tinggi dari citra digital.
Beberapa jenis citra digital yang sering digunakan adalah citra biner, citra
2. 1. 1. Citra biner (monokrom)
Citra biner memiliki dua warna, yaitu hitam dan putih. Piksel pada citra
yang berwarna putih bernilai 1 dan piksel yang berwarna hitam bernilai 0.
Citra biner membutuhkan satu bit di memori untuk menyimpan kedua
warna ini.
Pada citra biner (gambar 2) yang terdiri atas piksel 3x3 dan
disampingnya merupakan representasi citra tersebut jika disimpan dalam
memori.
(a) (b)
Gambar 2. (a) Citra Biner; (b) Representasi Citra Biner dalam data digital
2. 1. 2. Citra grayscale (skala keabuan)
Banyaknya warna pada citra graysclae tergantung pada jumlah bit yang
disediakan memori untuk menampung kebutuhan warna ini. Warna yang
ada adalah hitam dan putih dengan tingkat gradasi tertentu. Banyaknya
kemungkinan nilai dan gradasi bergantung pada jumlah bit yang
digunakan. Untuk skala keabuan 8 bit, jumlah kemungkinan nilainya
adalah 28 = 256, dengan range nilai 0 – 255. Warna hitam sebagai warna
minimal dengan piksel bernilai 0 dan warna putih sebagai warna maksimal
dengan piksel bernilai 255, sedangkan warna abu-abu berada di antara
kedua warna tersebut.
Pada citra grayscale (gambar 3) yang terdiri atas piksel 3x3 dan
disampingnya merupakan representasi citra tersebut jika disimpan dalam
(a) (b)
Gambar 3. (a) Citra Skala Keabuan; (b) Representasi Citra Skala Keabuan dalam data digital
2. 1. 3. Citra warna (true color)
Setiap piksel pada citra warna mewakili warna yang merupakan
kombinasi dari tiga warna dasar (RGB = Red Green Blue). Setiap warna
dasar menggunakan penyimpanan 8 bit=1 byte, yang berarti setiap warna
mempunyai gradasi sebanyak 255 warna.
Satu piksel citra warna (true color) diwakili oleh 3 byte, dimana
masing-masing byte mempresentasikan warna merah, hijau, dan biru. Pada
citra biner (gambar 4) yang terdiri atas piksel 3x3 dan disampingnya
merupakan representasi citra tersebut jika disimpan dalam memori.
(a) (b)
Gambar 4. (a) Citra Warna;
2. 2. Citra Dokumen Teks
Dokumen teks merupakan sebuah tulisan yang berisi informasi (Anonim,
2010). Dokumen ini ditulis dengan tangan atau dicetak di atas kertas, dan
informasinya ditulis menggunakan tinta baik itu menggunakan tangan (tulis
tangan) ataupun media elektronik (komputer).
Citra dokumen teks merupakan citra yang berisi kumpulan teks atau tulisan
dalam format digital. Untuk inputan sistem ini, citra dokumen yang digunakan
berupa citra biner. Jika citra masukan berupa citra warna maka akan diubah
dahulu menjadi citra biner dengan proses binerisasi.
2. 3. Grayscaling
Grayscaling adalah proses penyederhanaan citra berwarna menjadi citra
grayscale (Basuki, Achmad dkk. 2005). Satu piksel citra warna (true color)
diwakili oleh 3 byte, dimana masing-masing byte mempresentasikan warna
merah, hijau, dan biru. Proses grayscaling akan menjadikan 3 nilai tadi menjadi 1
nilai. Proses grayscaling dilakukan dengan mengambil nilai rata-rata dari nilai
R,G, dan B yang akan menghasilkan nilai keabuan sebesar S, dirumuskan
(Basuki, Achmad dkk. 2005) :
2. 4. Binerisasi
Citra biner (hitam-putih) merupakan citra sederhana yang sering digunakan
dalam proses pengenalan angka atau pengenalan huruf (Basuki, Achmad dkk.
2005). Untuk mengubah suatu citra grayscale menjadi citra biner, dengan
menggunakan nilai tengah citra dengan derajat keabuan 256, yaitu 128 sehingga
dapat dirumuskan untuk sebuah piksel x dengan suatu derajat keabuan :
Jika x < 128 maka x=0, selain itu maka x = 1.
Misalnya nilai piksel x=123 maka akan diubah menjadi 0 (piksel berwarna hitam) S = R + G + B
3
(2-1)
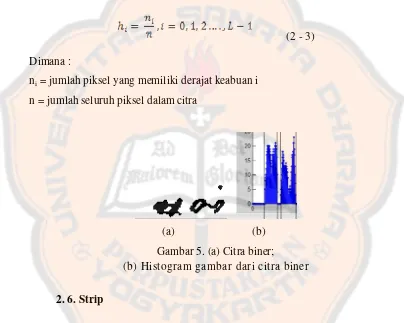
2. 5. Histogram
Histogram merupakan salah satu alat bantu yang paling sederhana dan
sangat berguna dalam pengolahan citra (Achmad, Bazal & Firdausy, Kartika. 2005).
Histogram citra adalah grafik yang menggambarkan penyebaran nilai-nilai
intensitas piksel dari suatu citra.
Misalkan citra digital memiliki L derajat keabuan, yaitu dari 0 sampai L-1 (pada
citra dengan kuantitas derajat keabuan 8 bit, nilai derajat keabuan dari 0 sampai
255). Secara matematis histogram citra dihitung dengan rumus (Munir, 2004) :
(2 - 3)
Dimana :
ni = jumlah piksel yang memiliki derajat keabuan i
n = jumlah seluruh piksel dalam citra
(a) (b)
Gambar 5. (a) Citra biner;
(b) Histogram gambar dari citra biner
2. 6. Strip
Strip adalah kumpuan baris horisontal yang memiliki minimal satu piksel
(Jindal, M. K. dkk. 2000). Strip juga dapat didefinisikan sebagai kumpulan baris
Gambar 6. Strip Gurmukhi
(Jindal, M. K. dkk. 2000)
2. 7. Tulisan India
Jindal, M.K dkk menggunakan tulisan India sebagai bahan uji (Jindal, M.
K. dkk. 2007). Tulisan menjadi input dari proses segmentasi dengan algoritma
Seglines. Pada tulisan India diterapkan konsep tiga zona horisontal (three
horizontal zones), yaitu upper zone, middle zone, dan lower zone kecuali pada
tulisan Urdu.
Gambar 7. Tulisan kata Gurmukhi: (a) upperzone dari garis nomor 1 sampai 2, (b) midlle zone dari garis no 3 sampai 4, (c) lower zone dari
garis nomor 4 sampai 5.
(Jindal, M. K. dkk. 2007)
Gambar 7(a), 7(b), 7(c) memperlihatkan isi dari three zones, yaitu upper, middle,
dan lowerzone yang diimplementasikan pada tulisan Gurmukhi (headline based
script). Headline adalah daerah dari garis nomor 2 sampai 3.
Gambar 8. Tulisan kata gujarati: (a) upper zone dari garis nomor 1 sampai 2, (b) middle zone dari garis 2 sampai 3, (c) lower zone dari garis
3 sampai 4
Gambar 8(a), 8(b), 8 (c) memperlihatkan isi dari three zones, yaitu
upper, middle, dan lower zone yang diimplementasikan pada
tulisan Gujarati (nonheadline based script).
Jika dibandingkan dengan aksara Jawa maka terlihat aksara Jawa
juga dapat dibagi menjadi tiga zona.
Dalam dokumen Gurmukhi cetak, penggunaan algoritma proyeksi
horizontal untuk proses segmentasi baris dokumen ke dalam baris
per baris kalimat menghasilkan hasil kurang baik. Berikut adalah
contoh strip hasil segmentasi algoritma proyeksi horizontal dalam
dokumen Gurmukhi cetak :
1. Strip berisi dua atau lebih baris yang mengalami
“horizontally overlapping lines” (strip nomor 1 pada
gambar 9)
2. Strip berisi hanya berisi karakter pada daerah lower zone
(strip nomor 2 pada gambar 9)
3. Strip berisi hanya berisi karakter pada daerah upper zone
(strip nomor 3 pada gambar 9)
4. Strip berisi hanya berisi karakter pada daerah middle zone
(strip nomor 4 pada gambar 9)
5. Strip berisi Upper, middle, dan lower zone atau lengkap
satu baris karakter (strip nomor 5 pada gambar 9)
6. Strip berisi hanya berisi karakter pada daerah upper dan
middle zone (strip nomor 6 dan 8 pada gambar 9)
7. Strip berisi bagian karakter lower zone yang menyentuh
bagian upper zone baris berikutnya (strip nomor 7 pada
Gambar 9. Batas-batas strip hasil segmentasi proyeksi profil pada citra teks Gurmukhi cetak
(Jindal, M. K. dkk. 2000)
2. 8. Segmentasi
Segmentasi adalah salah satu tahapan dari pengolahan citra dengan tujuan
membagi wilayah-wilayah yang homogen. Segmentasi adalah proses membagi
citra ke dalam daerah intensitasnya masing-masing sehingga dapat dibedakan
antara obyek dengan latarnya (Mulyanto, Edy dkk . 2009). Segmentasi sendiri
juga membantu proses pengambilan setiap citra karakter yang terdapat dalam citra
dokumen.
2. 8. 1. Profil Proyeksi
Metode profil proyeksi dibagi menjadi dua yaitu profil proyeksi
horizontal dan profil proyeksi vertikal.
1. Definisi Profil Proyeksi Horizontal (Jindal, M. K. dkk. 2000) :
Untuk citra dengan ukuran LxM dimana L adalah tinggi citra dan M
adalah lebar citra, maka proyeksi horizontal didefinisikan sebagai:
HP(i), i = 1,2,3, …., L (2 - 4)
Dimana HP(i) adalah banyaknya piksel hitam dalam i baris horizontal.
2. Definisi Profil Proyeksi Vertikal (Jindal, M. K. dkk. 2000) :
Untuk citra dengan ukuran LxM dimana L adalah tinggi citra dan M
adalah lebar citra, maka proyeksi vertikal didefinisikan sebagai:
VP(j), j = 1,2,3, …., M (2 - 5)
Dimana VP(i) adalah banyaknya piksel hitam dalam j kolom vertikal.
2. 8. 2. Seglines
Algoritma Seglines adalah algoritma yang dikembangkan
berdasarkan ide proyeksi horizontal dan proyeksi vertikal yang kontinu
dari algoritma Profil Proyeksi (Jindal dkk, 2007). Algoritma ini
dikembangkan oleh M.K. Jindal dkk untuk memecahkan permasalahan
segmentasi baris horizontal tulisan India yang saling bersentuhan
antara baris satu dengan baris lainnya dan beberapa baris horizontal
yang saling bertumpang tindih (Jindal dkk, 2000). Algoritma tersebut
mengalami perkembangan sehingga dapat dilakukan segmentasi
terhadap garis yang tumpang tindih secara horizontal (horizontally
overlapping lines) dan menyatukan bagian dari baris yang terpotong
atau over segmented. Input algoritma Seglines adalah sebuah kolom
artikel berita dari delapan jenis skrip yang digunakan di India dan
Pada langkah satu algoritma 1 dan Seglines menggunakan metode
proyeksi horizontal untuk mendapatkan strip. Misalnya, strip satu
ditunjukan oleh gambar 10.
Gambar 10. Strip 1 dari dokumen Gurmukhi cetak
(Jindal, M. K. dkk. 2000)
Berikut adalah algoritma 1 yang digunakan untuk proses segmentasi dokumen Gurmukhi cetak.
Gambar 11 adalah citra dokumen Gurmukhi cetak yang telah
melalui proses segmentasi dengan algoritma 1.
Gambar 11. Hasil segmentasi dengan Algoritma 1
(Jindal, M. K. dkk. 2000)
Algoritma 1 kemudian dinamakan algoritma Seglines dan terus
dikembangkan untuk segmentasi horizontally overlapping lines dan
menggabungkan komponen baris yang over segmented.
Algotima Seglines adalah algoritma yang dibuat untuk proses
segmentasi pada citra dokumen tulisan India.
1. Algoritma Seglines BEGIN
document from eight scripts are shown in Figs. 3, 5, 7, 9, 11, 13, 15 and 17.
Step 2: if input document is from any headline based script, go to step 3 else go to step 4.
Step 3: identify the position of headlines using horizontal projections. Denote the ending position of the headlines as H1, H2, H3, …, Hn. Also denote the lines to be identified as L1, L2, L3, …, Ln.
//number of headlines is same as number of actual //lines Go to step 5.
Step 4: identify the position of meanlines, using first order differences of horizontal projections. Denote the position of the meanlines as H1, H2, H3, …, Hn. //number of meanlines are same as number of actual //lines.
Step 5: define
Step 6: set LINE_NO = 1 and first row of line LINE_NO as first row of first strip, i.e. FR(LLINE_NO)= FR(S1). Step 7: for i = 1 to m, perform the following operations:
Step 7.1: if H(Si) < P1 * AVG_LINE_HEIGHT, Si is of type 1.
//contains only upperzone Repeat step 7.
//ignore current strip and go for next strip.
Step 7.2: if H(Si) > 0.50 * AVG_LINE_ HEIGHT, Si will be of type 2, 3, 4, 5, 6, 8, 9 or 10 and will contain at least one headline/meanline and one baseline. Step 7.3: identify the position of baseline. Mark it as BASELINE_NO. Also set height of the middlezone as HGT_MID = BASELINE_NO – HLINE_NO.
Step 7.4: set last row of line LINE_NO as
LR(LLINE_NO) = BASELINE_NO + P2 *(HGT_MID). //This will solve the segmentation problem of strip //type 2, 3, 4, 5, 6, 8 and 9.
Step 7.5: if LR(Si) > LR(LLINE_NO)
//strip type 10 containing horizontally overlapping //lines
increment LINE_NO. Also set FR(LLINE_NO) = LR(LLINE_NO-1) + 1 and go to step 7.1.
//for same strip.
Step 7.6: if LR(Si+1) <= LR(LLINE_NO), increment i. //strip type 7 containing only lowerzone
Repeat step 7.6.
//for multiple lowerzones.
Step 7.7: increment LINE_NO. Set FR(LLINE_NO) = LR(LLINE_NO-1) + 1. Go to step 7.
//for next strip.
Step 8: for j = 1 to LINE_NO
Display FR(Lj) to LR(Lj) as line boundaries. END.
Gambar 12. Citra Dokumen Hasil Segmentasi Algoritma Seglines
(Jindal, M. K. dkk. 2000)
Gambar 12 adalah hasil segmentasi dengan menggunakan
algoritma Seglines pada suatu citra teks dokumen India. Pada gambar
terlihat algoritma Seglines dapat membagi baris menjadi 9 baris sesuai
dengan kenyataannya.
Pada algoritma Seglines terlihat ada variabel P1 dan P2. Keduanya
adalah variable yang telah ditentukan oleh Jindal, M.K dkk. P1 adalah
(AVG_LINE_HEIGHT) dan P2 adalah ratio tinggi dari bagian lower
dengan pertimbangan bagian middlezone.
TABEL 1. NILAI P1 DAN P2 UNTUK SETIAP TULISAN
Tabel 1 menunjukan nilai P1 dan P2 yang ditentukan oleh Jindal,
M.K dkk untuk melakukan penghitungan pada identifikasi baris
(Jindal, M. K. dkk. 2007). Nilai P1 dipakai pada bagian baris “P1 *
AVG_LINE_HEIGHT” sedangkan nilai P2 dipakai pada bagian baris
LR(LLINE_NO) = BASELINE_NO + P2 *(HGT_MID).
2. 9. Aksara Jawa
Hanacaraka atau dikenal dengan nama carakan atau cacarakan (bahasa Sunda)
adalah aksara turunan aksara Brahmi yang digunakan atau pernah digunakan
untuk penulisan naskah-naskah berbahasa Jawa, bahasa Madura, bahasa Melayu,
bahasa Sunda, bahasa Bali, dan bahasa Sasak. (Anonim, 2011).
Bentuk hanacaraka yang sekarang dipakai (modern) sudah tetap sejak masa
Kesultanan Mataram (abad ke-17) tetapi bentuk cetaknya baru muncul pada abad
ke-19. Aksara ini adalah modifikasi dari aksara Kawi dan merupakan abugida.
Hal ini bisa dilihat dengan struktur masing-masing huruf yang paling tidak
mewakili dua buah huruf (aksara) dalam huruf latin. Sebagai contoh aksara Ha
yang mewakili dua huruf yakni H dan A, dan merupakan satu suku kata yang utuh
bila dibandingkan dengan kata "hari". Aksara Na yang mewakili dua huruf, yakni
N dan A, dan merupakan satu suku kata yang utuh bila dibandingkan dengan kata
"nabi". Dengan demikian, terdapat penyingkatan cacah huruf dalam suatu
Aksara hanacaraka Jawa memiliki 20 huruf dasar, 20 huruf pasangan yang
berfungsi menutup bunyi vokal, 8 huruf "utama" (aksara murda, ada yang tidak
berpasangan), 8 pasangan huruf utama, lima aksara swara (huruf vokal depan),
lima aksara rekan dan lima pasangannya, beberapa sandhangan sebagai pengatur
vokal, beberapa huruf khusus, beberapa tanda baca, dan beberapa tanda pengatur
tata penulisan (pada).
2. 9. 1. Huruf dasar (aksara nglegena)
Pada aksara Jawa hanacaraka baku terdapat 20 huruf dasar (aksara
nglegena), yang biasa diurutkan menjadi suatu "cerita pendek":
Gambar 13. Huruf Dasar
(Hanacaraka, 2011)
2. 9. 2. Huruf pasangan (Aksara pasangan)
Pasangan dipakai untuk menekan vokal konsonan di depannya.
Sebagai contoh, untuk menuliskan mangan sega (makan nasi) akan
diperlukan pasangan untuk "se" agar "n" pada mangan tidak bersuara.
Gambar 14. Huruf Pasangan
(Hanacaraka, 2011)
2. 10. Matlab
Nama Matlab merupakan singkatan dari “matrix laboratory”. Matlab adalah
sebuah bahasa pemrograman yang dengan unjuk kerja tinggi untuk komputasi
teknis, yang mengintegrasikan komputasi, visualisasi dan pemrograman di dalam
lingkungan yang mudah penggunaannya dalam memcahkan persoalan dengan
solusinya yang dinyatakn dalam notasi matematik. Penggunaan Matlab :
a. Matematika dan komputasi
b. Pengembangan algoritma
c. Pemodelan, simulasi, dan pembuatan “prototipe”
d. Analisis data, eksplorasi, dan visualisasi
e. Grafik untuk sains dan teknik
f. Pengembangan aplikasi, termasuk pembuatan antarmuka grafis untuk
BAB III
ANALISA DAN PERANCANGAN SISTEM
Bab ini membahas analisa dan perancangan sistem secara umum,
rancangan proses serta rancangan antar muka yang akan digunakan.
3.1 Desain Input
Untuk melakukan percobaan dan menganalisa unjuk kerja algoritma
segmentasi baris atau seglines, maka diperlukan suatu inputan. Format file citra
yang diuji adalah citra yang berekstension *.jpg. File citra yang digunakan sudah
dikenai proses pre-processing sebelum masuk sebagai input sistem, yaitu proses
normalisasi kemiringan, binerisasi, dan reduksi noise. Penjelasan tentang input
citra dokumen yang digunakan adalah :
3. 1. 1. Input Gambar
Nama dokumen yang diambil citranya adalah dokumen serat
pertanda dan dokumen tersebut ditulis dengan tulisan tangan. Dokumen
serat pertanda ini didapat dari Perpustakaan Artati Universitas Sanata
Dharma Yogyakarta. Citra asli dari citra dokumen ditunjukan oleh gambar
15. Citra dokumen diambil dengan menggunakan kamera dan disimpan
Gambar 15. Citra Serat_Pertanda2.JPG sebelum Pre-Processing
Langkah pre-processing yang dilakukan sebelum citra tersebut dijadikan inputan
sistem adalah :
1. Proses Normalisasi Kemiringan
Proses normalisasi kemiringan dilakukan secara manual dengan
menggunakan aplikasi Adobe Photoshop, yaitu fungsi
edit>>tranformasi>>skew. Untuk mengurangi kemiringan atau
“kecondongan” dari hasil pemotretan dengan kamera, bukan
2. Proses Binerisasi
Proses Binerisasi citra dokumen dilakukan dengan menggunakan
fungsi im2bw yang telah disediakan oleh matlab. Dilakukan dengan
mencari graythresh atau nilai ambang dari citra, nilai ambang
digunakan untuk mengubah suatu intensitas piksel dalam citra menjadi
piksel hitam atau putih.
3. Proses Reduksi Noise
Proses reduksi noise dilakukan dengan menggunakan fungsi median
filter dari matlab lalu diteliti secara manual. Fungsi MEDFILT2(A)
akan melakukan operasi median filtering dengan inputan suatu matrik,
misalnya matrik A dengan menggunakan matrik ketetanggaan 3x3.
3. 2. Gambaran sistem secara umum
Sistem yang akan dibangun adalah sistem yang digunakan untuk melakukan
proses segmentasi citra dokumen dalam format *.jpg. Algoritma yang digunakan
untuk proses segmentasi adalah algoritma Seglines. Citra dokumen yang
dimasukan adalah citra dokumen aksara Jawa. Pada citra dokumen yang
dimasukan telah melewati proses binerisasi, reduksi noise, dan normalisasi
kemiringan. Ketiga proses tersebut dilakukan supaya algoritma segmentasi dapat
berjalan dengan maksimal. Secara umum gambaran sistem ditunjukan gambar
3. 2. 1. Diagram Arus Data Level 0 / Diagram Konteks
Gambar 17. Diagram Konteks
Pada gambar 17 terdapat proses sistem segmentasi. User
memasukan inputan berupa citra dokumen ke dalam sistem segmentasi.
Keluaran dari hasil proses yang dilakukan oleh sistem segmentasi adalah
3. 2. 2. Diagram Arus Data Level 1
Gambar 18. Diagram Arus Data
Pada gambar terdapat proses “1. Proyeksi horizontal”, “2. Buat
strip”, “3. Pencarian headlines”,”4. Identifikasi average line height”, “5.
Pemeriksaan headlines“, ”6. Proses Pembentukan Baris” , “7. Proyeksi
Citra dokumen yang dimasukan oleh user akan diterima oleh
proses “1. Proyeksi horizontal” , untuk mencari histogram dari tiap
barisnya dan menghasilkan output berupa histogram horizontal dari citra
dokumen.
Histogram horizontal hasil output dari proses proyeksi horizontal
lalu digunakan sebagai inputan oleh proses “2. Buat strip” menjadi strip
dan index strip.
Dari histogram horizontal lalu digunakan sebagai inputan untuk
proses “3. Pencarian Headlines” untuk dicari histogram maksimumnya.
Histogram maksimum ini kemudian digunakan untuk mencari
histogram-histogram headlines. Histogram headlines adalah histogram yang bernilai
70% dari histogram maksimum dari citra dokumen.
Berlanjut ke proses ”4. Identifikasi Average Line Height” dari
headlines-headlines yang ada dicari jarak rata-rata antar headlines-nya.
Proses “5. Pemeriksaan headlines” adalah proses pemeriksaan pada
headlines-headlines untuk menghilangkan salah deteksi headlines berupa
terdeteksinya dua headlines dalam satu baris. Proses ini memerlukan input
berupa data headlines dan average line height.
Kemudian “6. Proses Pembentukan Baris” adalah proses untuk
menentukan baris dari citra dokumen dengan menggunakan data indek
strip, average line height, dan headlines yang nantinya akan ditampilkan
ke user.
Setelah baris ditemukan maka data untuk proses proyeksi vertikal
sudah didapat, yaitu indek baris. Proses “7. Proyeksi vertikal” memproses
masukan berupa citra baris dan menghasilkan histogram vertikalnya.
Proses “8. Identifikasi index kolom” kemudian memproses
histogram vertikal untuk mendapatkan index kolom berupa histogram
vertikal yang bernilai lebih besar dari 0 kemudian disimpan. Index kolom
dan baris yang disimpan tadi lalu diakses oleh proses potong karakter
untuk diubah menjadi citra-citra karakter yang kemudian ditampilkan ke
3. 3. Perancangan Tampilan
Dalam perancangan sistem ini akan dibuat tampilan berupa :
a.Tampilan Halaman Utama
Halaman utama adalah halaman yang akan dijumpai pertama kali. Dalam
halaman ini terdapat tombol start untuk melakukan proses segmentasi,
tombol Char Map untuk menampilkan tabel berisi indek segmen, tombol
input untuk menampilkan gambar yang kita inputkan, tombol hor.proj untuk
menampilkan gambar citra dokumen yang telah dibagi dalam strip-strip,
tombol headlines untuk menampilkan gambar citra dokumen bersama
dengan headlines-headlinesnya, tombol output untuk menampilkkan citra
dokumen hasil segmentasi. Tombol Reset untuk memulai proses segmentasi
baru lagi.
Gambar 19. Rancangan Tampilan Halaman Utama
Jika user menekan tombol “Char Map” maka akan memunculkan
tampilan seperti gambar 20 yang berisi koordinat x y aksara atau
Gambar 20. Rancangan Tampilan Tabel Char Map
Halaman Lihat Gambar seperti pada gambar 21 adalah halaman yang
digunakan untuk menampilkan gambar citra dokumen. Gambar yang
ditampilkan tergantung dari tombol yang kita tekan, misalnya tombol
hor.proj maka halaman image akan menampilkan gambar citra
dokumen bersama dengan headline-headline dalam citra dokumen
tersebut.
3.4 Implementasi Proses :
3. 4. 1. Proyeksi HorizontalProyeksi horizontal adalah fungsi yang digunakan untuk
membuat histogram. Dalam kode program fungsi ini diberi nama
HorProj . Cara kerja proyeksi horizontal adalah dengan menghitung
jumlah piksel hitam di setiap baris pikselnya. Pseudocode untuk
melakukan proses proyeksi horizontal adalah sebagai berikut:
Proyeksi horizontal
1. Hitung jumlah piksel hitam di setiap barisnya
2. Simpan nilai histogram hasil penghitungan piksel hitam
(HP)
3. 4. 2. Buat Strip
Buat Strip digunakan untuk mencari baris histogram dari
histogram horizontal dengan nilai lebih dari 0 yang diperkirakan
sebagai baris tulisan / strip. Dalam kode program fungsi ini dengan
nama FindIndexOfRow. Kemudian dari baris histogram tersebut dicari
indek baris yang menjadi awal baris dan akhir baris tulisan / strip. Baris
histogram bernilai 0 merupakan jeda antar baris tulisan / strip.
Pseudocode untuk melakukan proses FindIndexOfRow adalah sebagai
berikut:
1. Dari histogram hasil proyeksi horizontal (HP) cari baris
pertama ditemukannya nilai HP > 0, catat indek HP
sebagai awal strip
2. Lakukan perulangan sampai kondisi HP > 0 bernilai salah,
catat indek HP-1 sebagai akhir strip
3. 4. 3. Pencarian Headlines
Pencarian Headlines digunakan untuk mencari headlines. Dalam
kode program fungsi ini diberi nama FindHeadlines. Headlines dicari
dari histogram horizontal yang ada, yaitu dengan cara mencari
histogram maksimum terlebih dahulu baru kemudian mencari
baris-baris histogram yang nilainya lebih besar dari 70% histogram
maksimum. Histogram yang nilainya lebih besar dari 70% maksimum
histogram disebut sebagai histogram headlines atau headlines.
Pseudocode untuk melakukan proses FindHeadlines adalah sebagai
berikut:
1. Cari max histogram (max)
2. Jika HP > 70%*max
3. Simpan index HP sebagai (headlines)
4. Ulangi langkah 2 dan 3 sampai akhir headlines
3. 4. 4. Identifikasi Average Line Height
Identifikasi Average Line Height digunakan untuk mencari
rata-rata jarak antar headlines yang disebut ALH. Dalam kode program
fungsi ini diimplementasi dengan nama AverageLineHeight.
Pseudocode untuk melakukan proses AverageLineHeight adalah
sebagai berikut:
1. Cari jumlah keseluruhan dari selisih antara suatu headlines
dengan headlines dibawahnya
2. Ulangi langkah 1 sampai headlines terakhir
3. Jumlah selisih headlines dibagi dengan jumlah headlines -1
3. 4. 5. Pemeriksaan Headlines
Pemeriksaan Headlines digunakan untuk melakukan proses
diberi nama FixIndexHeadlines2. Pseudocode untuk melakukan proses
FixIndexHeadlines2 adalah sebagai berikut:
1. Hitung selisih antara suatu headlines dengan headlines
dibawahnya, selisih tersebut misalnya kita sebut diff
(misalnya : headlines n dengan headlines n + 1)
2. Cari simpangan baku (standard deviasi) dari semua diff
headlines dengan headlines dibawahnya
3. Jika diff bernilai kurang dari ALH-0.5 x standard deviasi,
maka hapus headlines berikutnya
( misalnya untuk diff i maka hapus headlines i+1 )
3. 4. 6. Proses Pembentukan Baris
Proses pembentukan baris adalah proses pencarian first row dan
last row yang baru dengan menggunakan data yang sudah
dikumpulkan, yaitu berupa strip yang sudah ada, headlines, dan
average line height. Pseudocode untuk melakukan proses
AverageLineHeight adalah sebagai berikut:
Baca strip ii (ket: mulai dari ii = 1 sampai ii strip)
1. Cek tinggi strip (H(ii)) < 0.3 x ALH, jika iya lakukan
langkah 3, jika tidak langsung ke langkah 4.
2. Lanjut ke strip selanjutnya, hitung kembali tinggi strip,
kembali ke langkah 1.
3. Cek tinggi strip > 0.5 x ALH, jika iya lanjut ke langkah 5,
jika tidak langsung ke langkah 14.
4. Jika baris baru (LINE_NO) <= jumlah headlines, cari
baseline, hitung tinggi baris baru dan akhir baris baru.
5. Jika tinggi baris baru > 0.5*stdev+ALH, set akhir baris
(LR_NEW(LINE_NO) =
FR_NEW(LINE_NO)+round(0.5*stdev+ALH)).
6. Jika akhir baris baru > tinggi gambar, set akhir baris baru =
tinggi gambar dan hanya lakukan langkah ini sekali saja.
7. Jika akhir baris strip (LR(ii)) > akhir baris baru
(LR_NEW(LINE_NO)) dan baris baru < jumlah headlines,
jika iya lanjut ke langkah 9, jika tidak, langsung ke langkah
10.
8. Jika akhir baris baru < tinggi gambar, tinggi strip = tinggi
baris baru sehingga
H(ii)=H(ii)-(LR_NEW(LINE_NO)-FR_NEW(LINE_NO)), lanjut ke baris baru (LINE_NO)
selanjutnya, awal baris baru = akhir baris baru sebelumnya
+1, selain itu break
9. Jika akhir baris baru < tinggi gambar dan baris baru <
jumlah headlines, lanjut ke langkah 11, selain itu break
10.Selama akhir strip < akhir baris baru, lanjutkan ke strip
berikutnya, selain itu break
11.Lanjut ke baris baru selanjutnya, awal baris baru = akhir
baris baru sebelumnya +1, lanjut ke strip selanjutnya,
langkah 1
12.Jika tinggi strip > 0.3 x ALH dan tinggi strip juga < 0.5 x
ALH, lanjut ke strip selanjutnya, perbaharui tinggi strip,
kembali ke langkah 1.
13.Cek tinggi strip H(ii), jika H(ii) berada di antara P1*ALH
dan P2*ALH maka ubah nilai H(ii)=LR(ii)-FR(ii-1)
3. 4. 7. Proyeksi Vertikal
Proyeksi vertikal digunakan untuk menghitung jumlah piksel
hitam di setiap kolom pada suatu baris. Dalam kode program fungsi ini
diberi nama VerProj. Pseudocode untuk melakukan proses proyeksi
Proyeksi vertikal
1. Hitung jumlah piksel hitam di setiap kolomnya dari suatu
baris
2. Simpan nilai histogram hasil penghitungan piksel hitam
(VP)
3. 4. 8. Identifikasi Index Kolom
Indektifikasi Index Kolom adalah proses mencari baris
histogram vertikal dengan nilai lebih dari 0 yang diperkirakan sebagai
aksara. Fungsi yang digunakan sama dengan fungsi yang digunakan
untuk mencari baris strip, perbedaannya adalah jika masukannya adalah
histogram hasil proyeksi vertikal (VP) maka outputnya adalah indek
kolom awal dan indek kolom akhir. Pseudocode untuk melakukan
proses FindIndexOfRow adalah sebagai berikut:
1. Dari histogram hasil proyeksi vertikal (VP) cari baris
pertama ditemukannya nilai VP > 0, catat indek VP
sebagai awal kolom
2. Lakukan perulangan sampai kondisi VP > 0 bernilai salah,
catat indek VP-1 sebagai akhir strip
3. Ulangi langkah 1 dan 2 sampai akhir VP
3. 4. 9. Potong Karakter
Potong karakter adalah proses memotong baris menjadi
aksara-aksara dengan mengunakan inputan indek kolom dan citra baris. Dalam
kode program fungsi ini diberi nama cutChar. Fungsi cutChar
digunakan untuk memotong karakter menurut indek awal kolom dan
akhir kolom yang didapat dari FindIndexOfRow. Pseudocode untuk
1. Masukan gambar baris yang akan disegmen, masukan indek
kolom awal dan akhir karakter akan disegmen dari hasil
proyeksi vertikal.
2. Crop baris dari titik pojok kiri atas sepanjang tinggi
karakter dan sepanjang lebar gambar baris.
3. 5. Perancangan cara pengujian
Sebuah pengujian diperlukan untuk mengetahui performa algoritma Seglines
pada proses segmentasi citra dokumen aksara Jawa. Oleh karena itu perancangan
pengujian perlu dibuat dan dilakukan dengan cara :
a. Memasukan 10 citra asli dokumen aksara Jawa
b. Menghitung jumlah obyek dan jumlah karakter:
1. Citra asli (secara manual)
2. Hasil segmentasi citra(dari program)
3. Hasil segmentasi citra secara utuh (secara manual)
4. Menghitung persentase kebenaran segmentasi obyek dan
segmentasi karakter citra:
% kebenaran = H x 100 % (3-1)
N
Menghitung persentase akurasi segmentasi obyek citra:
%akurasi = H-I x 100 % (3-2)
N
Keterangan:
H = jumlah obyek atau jumlah karakter hasil segmentasi citra yang
utuh (perhitungan secara manual)
I = jumlah bukan obyek
N = jumlah obyek atau jumlah karakter citra asli (perhitungan
Untuk perancangan proses pengujian ada dua :
1. Pengujian pertama memakai tolok ukur uji dari sisi algoritma.
% kebenaran = AS x 100 % (3-3)
N
Keterangan :
AS = jumlah aksara jawa pada bagian utama dari suatu
baris yang tersegmentasi benar menurut algoritma Seglines
N = jumlah total hasil segmentasi dalam suatu baris
2. Pengujian kedua memakai tolok ukur dari sisi pengguna dalam bentuk penulisan Aksara Jawa yang benar.
% kebenaran = AJ x 100 % (3-4)
N
Keterangan :
AS = jumlah aksara jawa pada bagian utama dari suatu
baris yang tersegmentasi benar menurut cara penulisan
Aksara Jawa
BAB IV
Implementasi
Dalam bab ini disajikan implementasi dari proses pembuatan algoritma
pada tahap coding berdasarkan analisa dan perancangan yang telah dibuat.
4. Implementasi
Berikut adalah implementasi proses-proses dan tampilan yang dilakukan dalam
program.
4.1 Implementasi Proses :
4. 1. 1. Proyeksi Horizontal
Proyeksi horizontal adalah fungsi yang digunakan untuk
membuat histogram. Dalam kode program fungsi ini diberi nama
HorProj . Cara kerja proyeksi horizontal adalah dengan menghitung
jumlah piksel hitam di setiap baris pikselnya. Potongan fungsi untuk
melakukan proses proyeksi horizontal adalah sebagai berikut:
for a = 1:width,
Buat Strip digunakan untuk mencari baris histogram dari
histogram horizontal dengan nilai lebih dari 0 yang diperkirakan
sebagai baris tulisan / strip. Dalam kode program fungsi ini dengan
Kemudian dari baris histogram tersebut dicari indek baris yang
menjadi awal baris dan akhir baris tulisan / strip. Baris histogram
bernilai 0 merupakan jeda antar baris tulisan / strip. Potongan fungsi
untuk melakukan proses FindIndexOfRow adalah sebagai berikut:
if(hisver(i)>0)
4. 1. 3. Pencarian Headlines
Pencarian Headlines digunakan untuk mencari headlines. Dalam
kode program fungsi ini diberi nama FindHeadlines. Headlines dicari
dari histogram horizontal yang ada, yaitu dengan cara mencari
histogram maksimum terlebih dahulu baru kemudian mencari
baris-baris histogram yang nilainya lebih besar dari 70% histogram
maksimum. Histogram yang nilainya lebih besar dari 70% maksimum
histogram disebut sebagai histogram headlines atau headlines.
Pseudocode untuk melakukan proses FindHeadlines adalah sebagai
4. 1. 4. Identifikasi Average Line Height
Identifikasi Average Line Height digunakan untuk mencari
rata-rata jarak antar headlines yang disebut ALH. Dalam kode program
fungsi ini diimplementasi dengan nama AverageLineHeight.
Pseudocode untuk melakukan proses AverageLineHeight adalah
sebagai berikut:
for i=2:length
diff=sqrt((listH(i)-listH(i-1))^2); matDiff(i-1)=diff;
sum = sum + diff;
end
avg = 1/(length-1)*sum ;
4. 1. 5. Pemeriksaan Headlines
Pemeriksaan Headlines digunakan untuk melakukan proses
“clean” atau pembersihan headlines. Dalam kode program, fungsi ini
diberi nama FixIndexHeadlines2. Pseudocode untuk melakukan proses
FixIndexHeadlines2 adalah sebagai berikut:
for i=2:length
diff2=listH(i)-listH(i-1); matDiff(i-1)=diff2;
4. 1. 6. Proses Pembentukan Baris
Proses pembentukan baris adalah proses pencarian first row dan
last row yang baru dengan menggunakan data yang sudah
dikumpulkan, yaitu berupa strip yang sudah ada, headlines, dan
average line height. Pseudocode untuk melakukan proses
AverageLineHeight adalah sebagai berikut:
if H(ii)<P1*ALH
%do nothing
%lanjut ke strip selanjutnya
ii=ii+1;
FR_NEW(LINE_NO)=LR_NEW(LINE_NO-1)+1;
Proyeksi vertikal digunakan untuk menghitung jumlah piksel
hitam di setiap kolom pada suatu baris. Dalam kode program fungsi ini
diberi nama VerProj. Pseudocode untuk melakukan proses proyeksi
vertikal adalah sebagai berikut:
for a = 1:length,
4. 1. 8. Identifikasi Index Kolom
Indektifikasi Index Kolom adalah proses mencari baris
histogram vertikal dengan nilai lebih dari 0 yang diperkirakan sebagai
aksara. Fungsi yang digunakan sama dengan fungsi yang digunakan
untuk mencari baris strip, perbedaannya adalah jika masukannya adalah
histogram hasil proyeksi vertikal (VP) maka outputnya adalah indek
kolom awal dan indek kolom akhir. Pseudocode untuk melakukan
if(hisver(i)>0)
indek(j,1)=i; FR(j)=i;
while hisver(i)>0 && i<t, i=i+1;
end
indek(j,2)=i-1; LR(j)=i-1;
H(j)=LR(j)-FR(j); indek(j,3)=H(j); j=j+1;
end
4. 1. 9. Potong Karakter
Potong karakter adalah proses memotong baris menjadi
aksara-aksara dengan mengunakan inputan indek kolom dan citra baris. Dalam
kode program fungsi ini diberi nama cutChar. Fungsi cutChar
digunakan untuk memotong karakter menurut indek awal kolom dan
akhir kolom yang didapat dari FindIndexOfRow. Pseudocode untuk
melakukan proses cutChar adalah sebagai berikut:
4. 2. Implementasi Tampilan
4. 2. 1. Tampilan halaman utama
Implementasi tampilan halaman utama adalah sebagai berikut :
Gambar 22. Tampilan Halaman Utama
4. 2. 2. Tampilan pilih file gambar
Implementasi tampilan pilih file gambar adalah sebagai berikut :
4. 2. 3. Tampilan simpan file gambar
Implementasi tampilan simpan file gambar adalah sebagai berikut :
Gambar 24. Tampilan Simpan Gambar
4. 2. 4. Tampilan pesan proses simpan
Implementasi Tampilan pesan proses file gambar adalah sebagai berikut :
Gambar 25. Pesan Proses Simpan Gambar Berhasil
4. 2. 5. Tampilan halaman utama
Gambar 26. Tampilan Halaman Utama
4. 2. 6. Tampilan lihat gambar
Implementasi Tampilan lihat gambar adalah sebagai berikut :
GAMBAR 27. Tampilan Lihat
Gambar
4. 2. 7. Tampilan lihat Tabel Char Map
Implementasi Tampilan lihat Tabel Char Map adalah sebagai berikut :
BAB V
Hasil dan Pembahasan
Bab ini menyajikan hasil penelitian yang dilakukan yaitu berupa hasil
percobaan. Bab ini juga membahas analisa hasil penelitian tersebut sesuai dengan
syarat dan tujuannya
5. 1. Data Masukan
Format file citra yang diuji adalah citra yang berekstension
*.jpg. File citra yang digunakan sudah dikenai proses pre-processing,
yaitu proses binerisasi, normalisasi kemiringan, dan reduksi noise. File
citra dimasukan ke dalam sistem dengan proses pilih file citra dari
matlab.
Nama Ukuran panjang dan lebar citra
Ukuran file
Serat_Pertanda2.jpg 1153x1230 318 KB
5. 2. Perangkat Keras dan Perangkat Lunak
Spesifikasi perangkat keras (Hardware) dan perangkat lunak
(Software) yang digunakan dalam proses pengujian sistem Segmentasi
Citra Dokumen Teks Tulisan Tangan Aksara Jawa Menggunakan
Algoritma Seglines Studi Kasus Pada Dokumen "Serat Pertanda" ini :
1. Processor : Intel Core2Duo 2 Ghz
2. Memory : 2 GB
3 .Hardisk : 250 GB
4. Sistem Operasi : Windows 7
5. 3. Eksekusi Modul
Proses segmentasi dimulai dengan melakukan proyeksi
horizontal. Hasil proses proyeksi horizontal dengan citra
Serat_Pertanda2.jpg adalah histogram baris. Dari histogram baris ini
kemudian dicari indek-indek yang menjadi batas awal dan batas akhir
strip.
Contoh histogram baris dari dokumen Serat_pertanda2 :
Gambar 30. Histogram Citra Dokumen Serat_Pertanda2
Dari histogram hasil proyeksi horizontal kemudian dicari awal
strip dan akhir stripnya. Pada gambar 31 terlihat dari histogram
ditemukan 3 strip, indek awal baris dan akhir dari tiap strip kemudian
dicatat.
Dari hasil pengujian proses buat strip dengan input berupa
histogram hasil proyeksi horizontal untuk citra serat_pertanda2.jpg
diperoleh strip S dan indeks strip berupa :
1. Awal baris (FR)
2. Akhir baris (LR)
3. Tinggi strip (H)
Gambar 31 menggambarkan pembagian daerah masing-masing
strip dalam bentuk histogram. Strip 1 berawal dari baris piksel 23
kemudian berakhir pada baris piksel 53 dan memiliki tinggi baris 30
piksel. Untuk Strip 1 didapatkan data awal baris (FR) = 23, akhir baris
(LR) = 53, dan tinggi strip (H) = 30 piksel. Tabel 2 menunjukan data
awal baris, akhir baris dan tinggi strip dari strip-strip yang ditemukan.
Tabel 2. Indek Strip
No FR LR H
dalam bentuk histogram maka gambar 32 menunjukan pembagian strip
dalam bentuk citra dokumennya.
Terlihat pada gambar 32, strip satu hanya terdiri atas pasangan
aksara berupa sandhangan dari baris 1. Strip 2 terdiri atas baris 1
sampai 7 yang menjadi satu strip karena dari hasil proyeksi horizontal
tidak ditemukannya jeda antar baris. Selain tidak adanya jeda, juga ada
aksara dari baris 1 sampai 7 yang menyentuh aksara baris di bawahnya.
Strip 3 terdiri atas baris 8 sampai 17 yang kembali menjadi satu strip
karena tidak adanya jeda antar baris. Walaupun tidak didapatkan strip
hasil segmentasi yang terlihat telah tersegmentasi dengan baik,
Gambar 32. Citra Dokumen Dalam Strip
Pada proses selanjutnya, data histogram dikenai proses lagi
untuk mendapatkan informasi lain yaitu proses pencarian headlines.
Pada proses pencarian headlines, pertama-tama dilakukan proses
pencarian histogram maksimum. Maksimum histogram dari citra
dokumen Serat_pertanda2 adalah 664.
Langkah kedua dari proses pencarian Headlines adalah mencari
histogram yang bernilai 70% dari maksimum histogram yang telah
ditemukan. Hitsogram yang ditemukan lalu disimpan indeknya dan
disebut sebagai headlines. Dari masing-masing headlines akan