SENTIMENT ANALYSIS UNTUK MENILAI KEPUASAN
MASYARAKAT TERHADAP KINERJA PEMERINTAH
DAERAH MENGGUNAKAN NAIVE BAYES
CLASSIFIER (STUDI KASUS: WALIKOTA
BANDUNG PERIODE 2013 – 2018)
1Agus Soepriadi, 2Meta Permata
Jurusan Teknik Informatika, STMIK Bandung, Bandung, Indonesia [email protected], metapermatasari8@gmail
Abstrak
Diketahui dari berbagai sentimen masyarakat yang disampaikan melalui media sosial terhadap pelayanan publik yang dilakukan oleh aparatur pemerintah nyatanya saat ini belum memenuhi harapan masyarakat, sehingga dapat menimbulkan citra yang kurang baik. Mengingat fungsi utama pemerintah adalah melayani masyarakat maka pemerintah perlu terus berupaya meningkatkan kualitas pelayanan. Dengan menganalisis sentimen masyarakatnya dimaksudkan sebagai acuan bagi unit pelayanan instansi pemerintah untuk mengetahui tingkat kepuasan masyarakat terhadap kinerja pemerintah sebagai gambaran tentang kondisi kinerja penyelenggaraan pelayanan publik yang kemudian dapat dijadikan bahan penilaian. Penerapan metode Naive Bayes Classifier ini dapat membantu walikota sebagai bahan pertimbangan menentukan kebijakan dari hasil pengklasifikasian sentimen berdasarkan bidang yang diuji. Adapun perancangan sistem menggunakan PHP programming dan database PHPMyAdmin.
Kata kunci : Sentiment Analysis, Sentimen, Naive Bayes, Tahap Pembelajaran/ Preprocessing, Klasifikasi.
1. PENDAHULUAN
Analisis sentimen dilakukan untuk melihat pendapat atau kecenderungan opini terhadap sebuah masalah, apakah cenderung berpandangan negatif atau positif. Salah satu contoh penggunaan analisis sentimen dalam dunia nyata adalah identifikasi opini publik terhadap kinerja pemerintah daerah. Pelayanan publik yang dilakukan oleh aparatur pemerintah saat ini belum memenuhi harapan masyarakat. Hal ini dapat diketahui dari berbagai sentimen masyarakat yang disampaikan melalui media masa dan jejaring sosial, sehingga dapat menimbulkan citra yang kurang baik terhadap aparatur pemerintah. Mengingat fungsi utama pemerintah adalah melayani masyarakat maka pemerintah perlu terus berupaya meningkatkan kualitas pelayanan.
Dengan menganalisis sentimen masyarakatnya dimaksudkan sebagai acuan bagi unit pelayanan instansi pemerintah untuk mengetahui tingkat kepuasan masyarakat terhadap kinerja pemerintah sebagai gambaran tentang kondisi kinerja penyelenggaraan pelayanan publik yang kemudian dapat dijadikan bahan penilaian terhadap unsur pelayanan yang masih perlu perbaikan dan menjadi pendorong setiap unit penyelenggara pelayanan untuk meningkatkan kinerja pelayanannya serta menjadi bahan evaluasi kinerja untuk pengambilan keputusan dalam menetapkan suatu kebijakan selanjutnya yang efisien dan efektif. Aplikasi sentimen analisis menjanjikan cara yang lebih praktis dan ekonomis dibandingkan dengan metode klasik menggunakan pendekatan kuesioner. Adapun tujuan dari penelitian adalah merancang dan
membangun aplikasi yang diharapkan mampu :
1. Mengetahui tingkat kepuasan masyarakat terhadap kinerja pemerintah daerah. 2. Mengetahui bagaimana hasil kinerja
pemerintah daerah dari sentimen masyarakat.
3. Menguji bagaimana penerapan sentiment analysis dalam contoh kasus penilaian kinerja pemerintah daerah menggunakan metode Naive Bayes.
2. LANDASAN TEORI
2.1 Kinerja
Kinerja menurut Mahsun (2006: 25) : “Kinerja adalah gambaran mengenai tingkat pencapaian pelaksanaan suatu kegiatan/program/kebijakan dalam mewujudkan sasaran, tujuan, misi dan visi organisasi yang tertuang dalam strategic planning suatu organisasi”.
Kinerja Aparatur instansi pemerintah adalah : “Gambaran mengenai tingkat pencapaian sasaran atau tujuan instansi pemerintah sebagai penjabaran dari visi, misi dan strateji instansi pemerintah yang mengindikasikan tingkat keberhasilan / kegagalan pelaksanaan kegiatan- kegiatan sesuai dengan program, kebijakan yang ditetapkan” (Dokumen Budaya kerja Disdukcapil).
2.2 Pengukuran Kinerja
Pengukuran kinerja merupakan suatu langkah yang harus dilakukan dalam upaya meningkatkan kinerja organisasi. Young mendefinisikan pengukuran kinerja sebagai berikut :
“Pengukuran kinerja adalah tindakan pengukuran yang dilakukan terhadap berbagai aktivitas dalam rantai nilai yang ada pada perusahan. Hasil pengukuran tersebut digunakan sebagai umpan balik yang memberikan informasi tentang prestasi, pelaksanaan suatu rencana dan apa yang diperlukan perusahaan dalam penyesuaian-penyesuaian dan pengendalian” (Dalam Mangkunegara, 2009:42).
2.3 Kepuasan Masyarakat
Secara umum, kepuasan adalah perasaan senang atau kecewa seseorang yang muncul setelah membandingkan antara kinerja produk dengan hasil yang diinginkan (Kotler, 2005). Jika kinerja memenuhi harapan, maka pelanggan akan puas. Jika kinerja melebihi harapan, maka pelanggan akan merasa amat puas. Kepuasan masyarakat adalah pendapat masyarakat dalam memperoleh pelayanan dari aparatur penyelenggara pelayanan publik dengan membandingkan antara harapan dan kebutuhannya (Kepmen PAN nomor 25 tahun 2004).
2.4 Data Mining
Menurut Hermawati (2013:2) : “Data mining adalah analisis otomatis dari data yang berjumlah besar atau kompleks dengan tujuan untuk menemukan pola atau kecenderungan yang penting yang biasanya tidak disadari keberadaannya”.
Pada aplikasinya, sebenarnya data mining merupakan bagian dari proses KDD. Sebagai komponen dalam KDD, data mining terutama berkaitan dengan ekstrasi dan perhitungan pola-pola dari data yang ditelaah (Han, et al 2012:7).
Gambar 1: Proses KDD Secara garis besar, langkah-langkah utama dalam proses KDD adalah : 1. Data Selection
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan dalam suatu berkas, terpisah dari basis data operasional.
2. Preprocessing
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi fokus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten dan memperbaiki kesalahan pada data, seperti kesalahan cetak. Juga dilakukan proses enrichment, yaitu proses memperkaya data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
3. Transformation
Coding adalah proses transformasi pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
4. Data Mining
Data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode atau algoritma dalam data mining sangat bervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
5. Evaluation
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dari proses KDD yang disebut interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya. 2.5 Text Mining
Text Mining adalah proses ekstraksi pola (informasi dan pengetahuan yang berguna) dari sejumlah besar sumber data tak terstruktur. Penambangan teks memiliki tujuan dan menggunakan proses yang sama dengan penambangan data, namun memiliki masukan yang berbeda. Masukan untuk penambangan teks adalah data yang tidak (atau kurang) terstruktur, seperti dokumen Word, PDF, kutipan teks, dll., sedangkan
masukan untuk penambangan data adalah data yang terstruktur (Ronen Feldman, 2007). 2.6 Sentiment Analysis
Sentiment Analysis atau opinion mining merupakan proses memahami, mengekstrak dan mengolah data tekstual secara otomatis untuk mendapatkan informasi sentiment yang terkandung dalam suatu kalimat opini. Sentiment Analysis dilakukan untuk melihat pendapat atau kecenderungan opini terhadap sebuah masalah atau objek oleh seseorang, apakah cenderung berpandangan atau beropini negatif atau positif (Bo Pang, 2002).
2.7 Preprocessing
Tahap preprocessing diperlukan untuk membersihkan data dari yang tidak diperlukan, dengan tujuan pada tahap masuk ke dalam metode Naive Bayes Classiffier lebih optimal dalam perhitungannya. Pada tahap ini melibatkan rekognisi dari isi dan struktur teksnya. Adapun tahapan- tahapan dari preprocessing.
1. Cleansing
Clenasing merupakan proses membersihkan kata-kata yang tidak diperlukan untuk mengurangi noise. Kata yang dihilangkan adalah URL, hashtag (#), username (@username), dan email. Selain itu juga tanda baca seperti titik(.), koma(,), dan tanda baca yang lainnya akan dihilangkan.
2. Case Folding
Case folding merupakan tahapan merubah bentuk kata-kata menjadi sama bentuknya, baik semuanya menjadi lower case ataupun menjadi upper case.
3. Tokenizing
Tokenizing bekerja untuk mengidentifikasi kata- kata dalam teks menjadi beberapa urutan yang terpotong oleh spasi atau karakter spesial.
4. Filtering
Filtering berperan untuk membuang kata-kata yang sering muncul dan bersifat umum, kurang menunjukan relevansinya dengan teks. Kata-kata yang akan dibuang tersebut didefinisikan dalam stopword list. 5. Stemming
Stemming adalah tahapan untuk membuat kata yang berimbuhan kembali ke bentuk
asalnya. Contohnya kata “memberikan” setelah melewati tahap ini maka akan menjadi “beri”.
3. METODE PENELITIAN
3.1 Metode Naive Bayes Classifier
Naïve Bayes Classifier merupakan salah satu metode machine learning yang menggunakan perhitungan probabilitas. Ciri utama dari Naïve Bayes Classifier ini adalah asumsi yang sangat kuat (naif) akan independensi dari masing-masing variabel. Dengan kata lain, Naïve Bayes Classifier mengasumsikan bahwa keberadaan sebuah atribut (variabel) tidak ada kaitannya dengan keberadaan atribut (variabel) yang lain.
Algoritma Naïve Bayes Classifier terdiri dari dua tahap. Tahap pertama adalah pelatihan terhadap himpunan dokumen contoh (data latih) dan tahap kedua adalah proses klasifikasi dokumen yang belum diketahui kategorinya (kelas).
Gambar 2 Tahapan Naive Bayes Classifier
Berikut adalah model matematis untuk Naive Bayes Classifier:
𝑃(𝑤𝑘|𝑣𝑗) = |𝑛𝑘 + 1| n + |kosakata| Dimana :
P(wk|vj) : Probabilitas kemunculan kata wk pada suatu dokumen dengan kategori class vj
Nk
: Frekuensi munculnya kata
wk dalam dokumen yang
berkategori Vj.
N
: Banyaknya seluruh kata
dalam dokumen berkategori
Vj.
kosakata : Banyaknya kata pada
dokumen test
4. HASIL & PEMBAHASAN
4.1 Data Masukan
Data masukan yang digunakan adalah data tweet dari akun twitter resmi dinas terkait. Untuk bidang pendidikan tweet akan diambil langsung dari akun twitter resmi dinas
pendidikan kota Bandung
(@disdik_bandung). Untuk bidang transportasi tweet akan diambil langsung dari akun twitter resmi dinas transportasi kota Bandung (@dishub_kotabdg). Dan untuk bidang lingkungan tweet akan diambil langsung dari akun twitter resmi dinas lingkungan kota Bandung (@dbmpkotabdg). Jadi data tweet akan diklasifikasikan menjadi eman kelas yaitu positif pendidikan, negatif pendidikan, positif transportasi, negatif transportasi, positif lingkungan dan negatif lingkungan. Data tweet tersebut didapat dengan memanfaatkan fitur API (Application Interface). Berikut contoh data yang digunakan.
Gambar 3 Contoh tweet
4.2 Implementasi Preprocessing
Sebelum masuk ke proses utama yaitu pengklasifikasian tweet menggunakan metode Naive Bayes Classifier, data akan diolah terlebih dahulu pada tahap preprocessing agar pada tahap klasifikasi hasilnya bisa jauh optimal.
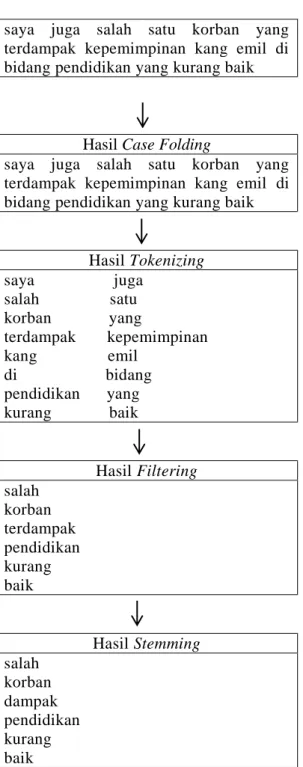
Kondisi awal :
@ridwankamil @dionmufty saya juga
salah satu korban yang terdampak kepemimpinan kang emil di bidang pendidikan yang kurang baik
saya juga salah satu korban yang terdampak kepemimpinan kang emil di bidang pendidikan yang kurang baik
Hasil Case Folding
saya juga salah satu korban yang terdampak kepemimpinan kang emil di bidang pendidikan yang kurang baik
Hasil Tokenizing saya juga salah satu korban yang terdampak kepemimpinan kang emil di bidang pendidikan yang kurang baik Hasil Filtering salah korban terdampak pendidikan kurang baik Hasil Stemming salah korban dampak pendidikan kurang baik
4.3 Implementasi Naive Bayes Classifier Tahap ini merupakan tahap yang paling esensial dari tahap yang lainnya. Pada tahap ini proses pengklasifikasian berdasarkan sentimen yang ada di dalam dokumen dimulai. Tahap ini mempunyai beberapa proses, berikut prosesnya:
1. Data Pelatihan : Tweet yang akan dijadikan sebagai data pelatihan untuk data testing contoh dari kumpulan training data yang
sudah melalui tahapan preprocessing text dari masing-masing kategori.
2. Bentuk Vocabulary : Kumpulan semua kata yang unik dari tweet pada tabel training data, yaitu term contoh : kurang, jangan, salah, baik, maju, hebat.
3. Hitung P(Vj) : Total kelas ada enam yaitu positif pendidikan, negatif pendidikan, positif transportasi, negatif transportasi, positif lingkungan dan sarana umum dan negatif lingkungan dan sarana umum dengan setiap kelas memiliki jumlah kata sebanyak 34 kata term maka kemungkinannya adalah :
Tabel 1 Nilai P(Vj) Untuk Setiap Kategori
Kategori P(Vj) Negatif Pendidikan 1 34 Positif Pendidikan 1 34 Negatif Transportasi 1 34 Positif Transportasi 1 34 Negatif Lingkungan 1 34 Positif Lingkungan 1 34
4. Bentuk Teksj : untuk kelas positif pendidikan contoh kata uniknya yaitu “cerdas”, “maju”, “hebat”. Untuk kelas negatif pendidikan contoh yaitu “tolak”, “palsu”, “salah”. Untuk kelas netral yaitu misal kata “pendidikan” dan “disdik” ada dalam kelas positif dan negatif untuk bidang pendidikan.
5. Setelah dilakukan pembuangan kata yang tidak relevan pada setiap karakter, maka proses selanjutnya pembelajaran data latih akan dimasukkan ke dalam model probabilitas Naive Bayes (learning).
Tabel 2 Model Probabilitas Untuk Kategori Pendidikan Kelas Dokumen 𝑃(𝑤𝑘|𝑣𝑗) = |𝑛𝑘 + 1| n + |kosakata| baik ku-rang pen- didi-kan dam-pak kor-ban sa-lah
Negatif Pendidi-kan 1 34 2 34 2 34 2 34 1 34 1 34 Positif Pendidi-kan 1 34 1 34 2 34 1 34 1 34 1 34
Tabel 3 Model Probabilitas Untuk Kategori Transportasi Kelas Dokumen 𝑃(𝑤𝑘|𝑣𝑗) = |𝑛𝑘 + 1| n + |kosakata| baik ku-rang pen- didi-kan dam-pak kor-ban sa-lah Negatif Transpor-tasi 1 34 1 34 1 34 1 34 1 34 1 34 Positif Transpor-tasi 1 34 1 34 1 34 1 34 1 34 1 34
Tabel 3 Model Probabilitas Untuk Kategori Transportasi Kelas Dokumen 𝑃(𝑤𝑘|𝑣𝑗) = |𝑛𝑘 + 1| n + |kosakata| baik ku-rang pen- didi-kan dam-pak kor-ban sa-lah Negatif Lingkungan 1 34 1 34 1 34 1 34 1 34 1 34 Positif Lingkungan 1 34 1 34 1 34 1 34 1 34 1 34
6. Klasifikasi Naive Bayes Untuk Data Uji Selanjutnya, setelah didapatkan data latih, maka tahapan dilanjutkan ke dalam proses pengklasifikasian untuk menguji model yang telah dibangun kepada data uji untuk mengukur ketepatan atau performa model probabilitas dari data latih dalam mengklasifikasikan data uji untuk dicari Vmap.
Vmap adalah perhitungan yang digunakan Naive Bayes Classifier untuk menentukan probabilitas data uji dari masing-masing kelas berdasarkan dari proses learning. Nilai probabilitas yang terbesar akan dipilih. Berikut perhitungannya:
Vmap = argmax p(ci) П p(wk | c) x p(c)
Berdasarkan dari hasil training, berikut hasil perhitungannya:
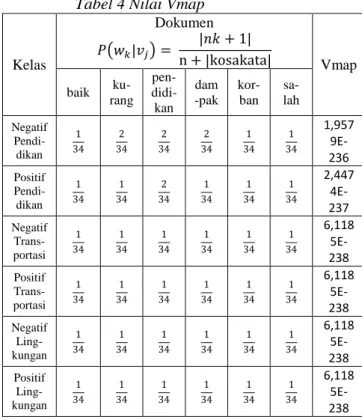
Tabel 4 Nilai Vmap
Kelas Dokumen 𝑃(𝑤𝑘|𝑣𝑗) = |𝑛𝑘 + 1| n + |kosakata| Vmap baik ku- rang pen- didi-kan dam -pak kor- ban sa- lah Negatif Pendi-dikan 1 34 2 34 2 34 2 34 1 34 1 34 1,957 9E-236 Positif Pendi-dikan 1 34 1 34 2 34 1 34 1 34 1 34 2,447 4E-237 Negatif Trans-portasi 1 34 1 34 1 34 1 34 1 34 1 34 6,118 5E-238 Positif Trans-portasi 1 34 1 34 1 34 1 34 1 34 1 34 6,118 5E-238 Negatif Ling-kungan 1 34 1 34 1 34 1 34 1 34 1 34 6,118 5E-238 Positif Ling-kungan 1 34 1 34 1 34 1 34 1 34 1 34 6,118 5E-238
Peluang kemunculan kata yang besar akan menghasilkan Vmap yang tinggi, sehingga dokumen data uji akan terklasifikasi ke dalam karakter dengan Vmap yang paling tinggi.
Pada kasus data uji diatas, dapat disimpulkan bahwa dokumen
terklasifikaasi ke dalam kategori negatif pendidikan. Untuk lebih detailnya dijelaskan dalam lampiran perhitungan Naive Bayes.
5. KESIMPULAN DAN SARAN
5.1 Kesimpulan
Dari berbagai penjelasan yang telah diuraikan dalam laporan ini, maka dapat disimpulkan beberapa hal sebagai berikut :
a. Dengan adanya aplikasi ini dapat diketahui tingkat kepuasan masyarakat terhadap kinerja pemerintah daerah sehingga bisa dijadikan bahan evaluasi.
b. Dengan adanya aplikasi ini dapat diketahui bagaimana hasil kinerja
pemerintah daerah menurut sentimen masyarakat.
c. Aplikasi yang mengimplementasi metode Naïve Bayer dapat mengklasifikasikan sentimen yang menghasilkan kategori sentimen positif dan negatif.
5.2 Saran
Berikut saran pengembangan sistem di masa akan datang :
a. Untuk penelitian selanjutnya, diharapkan ada penelitian dengan menggunakan algoritma lain untuk membandingkan tingkat akurasinya. b. Untuk pengembangan selanjutnya,
menambahkan lebih banyak term untuk mendukung hasil yang akurat. c. Berdasarkan hasil pengujian yang
telah dilakukan proses generate data sentimen bisa dilakukan dengan data yang tak terbatas (sesuai data yang ada).
6. DAFTAR PUSTAKA
[1] A.A.Anwar Prabu Mangkunegara. 2011. Manajemen Sumber Daya Manusia Perusahaan. PT.Remaja Rosda Karya, Bandung.
[2] Feldman, R & Sanger, J. 2007. The Text Mining Handbook : Advanced Approaches in Analyzing Unstructured Data. Cambridge University Press : New York.
[3] Han, J., Kamber, M., & Pei, J. (2012). Data Mining: Concepts and Techniques Third Edition. Waltham: Morgan Kaufmann.
[4] Hermawati, F. A., 2013. Data Mining. Yogyakarta: Andi
[5] Hidayatullah, Ahmad F. 2014. Analisis Sentimen Dan Klasifikasi Kategori Terhadap Tokoh Publik Pada Twitter. Seminar Nasional Informatika 2014 (semnasIF 2014) ISSN: 1979-2328 UPN ”Veteran” Yogyakarta, 12 Agustus 2014. [6] Kepmen PAN No. 25/M.PAN/2/2004 tentang Pedoman Umum Penyusunan Indeks Kepuasan Masyarakat Unit Pelayanan Instansi Pemerintah.
[7] Kotler, Philip. 2005. Manajamen Pemasaran, Jilid 1 dan 2. Jakarta: PT. Indeks Kelompok Gramedia.
[8] Mahsun, M., (2006), Pengukuran Kinerja Sektor Publik, BPFE Yogyakarta, Yogyakarta.
[9] Muhammad, Gelar. 2015. Sentimen Analisis Mengenai Berita Menggunakan Twitter Studi Kasus Detik.com dan Kompas.com. Perpustakaan Widyatama : Bandung.
[10]Muhamad, Iwan R. 2014. Analisis Sentimen Pada Posting Official Akun Twitter Telkom Speedy Menggunakan Naive Bayes Classifier. Perpustakaan UNIKOM : Bandung.
[11]Pang,B. , Lee, L. and Vaithyanathan, S.,2002, Thumbs up? Sentiment Classification Using Machine Learning Techniques, in Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing (EMNLP’02), USA, 2002, pp. 79 – 86. [12]Saraswati, N.W.S. 2011. Text Mining
dengan Metode Naïve Bayes Classifier dan Support Vector Machine untuk Sentimen Analysis. Thesis Program Studi Teknik Elektro. Program pasca Sarjana Universitas Udayana. Bali. [13]Sentiaji, Aditia R. Analisis Sentimen
Terhadap Acara Televisi Berdasarkan Opini Publik. Universitas Komputer Indonesia. Bandung.
[14]Shelke,N.M, Deshpande,S. and Thakre, 2012,Survey of Techniques for Opinion Mining, International Journal of Computer Applications (0975 – 8887) Volume 57– No.13, November 2012 [15]Zaqisyah. 2014. Optimasi Akurasi
Analisis Sentimen Pada Posting Twitter Menggunakan Metode Naive Bayes dan Stemming. Perpustakaan UNIKOM : Bandung.