BAB III. Metode Penelitian. Yang menjadi objek penelitian ini adalah Jumlah Cadangan Devisa di
Teks penuh
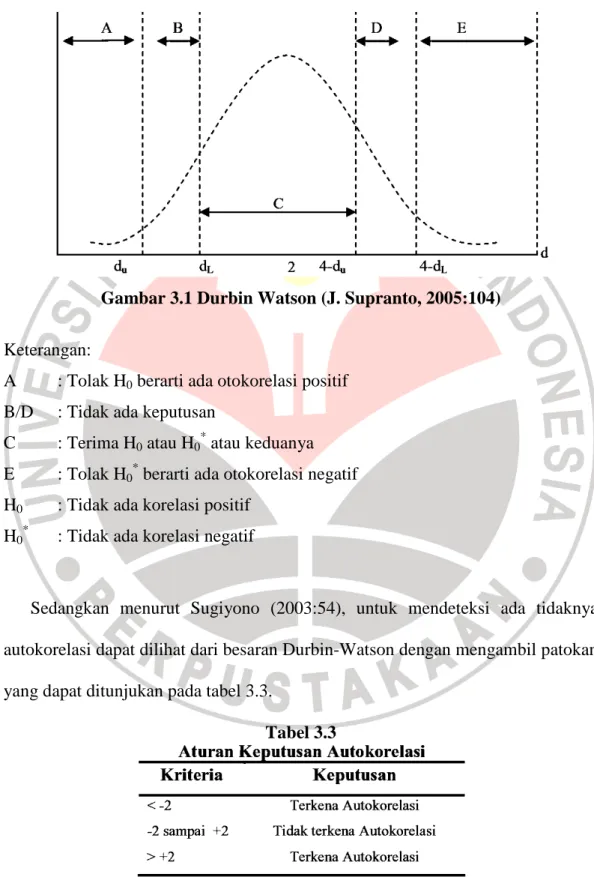
Gambar
Dokumen terkait
Penelitian ini menemukan bahwa cadangan devisa Indonesia dipengaruhi secara bersama oleh variabel kurs rupiah, suku bunga, dan nilai ekspor netto non migas sebesar 90,12%.. Perubahan
data Jumlah Uang Beredar M1, Suku Bunga Bank Indonesia (BI rate) dan Inflasi 41... yang ada di Indonesia untuk
Dalam hal ini untuk mengetahui pengaruh tingkat inflasi, tingkat suku bunga SBI dan kurs rupiah terhadap harga saham, pada perusahaan perbankan Bank Mandiri dengan
Semakin tinggi tingkat suku bunga suatu Negara akan menarik aliran modal masuk sehingga menambah persediaan valuta asing dalam negeri atau cadangan devisa,
Berdasarkan pengertian tersebut, maka hasil dari penelitian ini akan diketahui apakah ada pengaruh yang signifikan dari inflasi, suku bunga dan nilai tukar
Hasil penelitian ini adalah variabel inflasi, suku bunga SBI, nilai tukar rupiah terhadap dollar, dan cadangan devisa secara bersamaan berpengaruh signifikan terhadap Penanaman Modal
Menambah pengetahuan dan wawasan penulis dalam meneliti penelitian mengenai pengaruh inflasi, suku bunga SBI (Sertifikat Bank Indonesia), dan kurs valuta asing
Dalam penelitian ini penulis mengambil judul “ANALISIS PENGARUH TINGKAT INFLASI, NILAI TUKAR RUPIAH, SUKU BUNGA SBI DAN CADANGAN DEVISA TERHADAP PELARIAN MODAL DI INDONESIA (1997.I
