1
KLASIFIKASI ANALISIS SENTIMEN TERHADAP BIPOLAR
DISORDER PADA MEDIA SOSIAL TWITTER DENGAN
MENGGUNAKAN METODE SUPPORT VECTOR MACHINE (SVM)
Corinna Abigail Madeline
1, Sutresna Wati
21
Jurusan Sistem Informasi Fakultas Ilmu Komputer dan Teknologi Informasi
2Teknik Komputer, Direktorat Teknologi Informasi
Universitas Gunadarma,
Jl. Margonda Raya No. 100, Depok 16424, Jawa Barat
[email protected]
Abstrak
Skripsi ini membahas tentang klasifikasi analisis sentimen pada media sosial Twitter mengenai gangguan bipolar dengan metode Support Vector Machine pada dua kelas sentimen, yaitu sentimen positif dan sentimen negatif. Data yang digunakan merupakan data hasil klasifikasi pada penelitian sebelumnya dengan lexicon based oleh Penulis pada Penelitian Ilmiah tahun 2019, dimana tweets sebanyak 1000 data yang diambil kemudian dibersihkan dan diberi label sentimen dengan lexicon based menggunakan kamus kata positif dan kamus kata negatif, sehingga pada penelitian ini data yang digunakan sudah memiliki label kelas sentimen. Dari sebanyak 1000 data menghasilkan 415 data bersih, kemudian dibagi ke dalam data latih dan data uji dengan perbandingan 90:10 dan dihitung bobot kata pada dokumen dengan TF-IDF. Data latih kemudian dilatih dengan menggunakan SVM untuk menghasilkan model klasikasi, kemudian diujikan pada data uji. Hasil penelitian ini diimplementasikan pada aplikasi website kerangka Flask dengan menggunakan HTML, CSS, dan JavaScript. Hasil penelitian menunjukkan bahwa tingkat akurasi algoritma SVM yang dihasilkan sebesar 90,5%.
Kata Kunci: analisis sentimen, bipolar disorder, tweets, twitter, support vector machine
Abstract
This thesis discusses the classification of sentiment analysis on Twitter social media about bipolar disorder using the Support Vector Machine method in two classes of sentiment, namely positive sentiment and negative sentiment. The data used is the classification result data in previous research with lexicons based on the author of the 2019 Scientific Research, where 1000 tweets were taken and then cleaned and labeled sentiment with lexicons based on using a positive word dictionary and a negative word dictionary, so that in this study the data which is used already has a sentiment class label. From 1000 data, it produces 415 clean data, then divided into training data and test data with a ratio of 90:10 and the word weight is calculated in the document with TF-IDF. The training data was then developed using SVM to produce a classification model, then tested it on the test data. The results of this study were implemented in the Flask website framework application using HTML, CSS, and JavaScript. The results showed that the accuracy of the resulting SVM accuracy was 90.5%.
2
PENDAHULUANPerkembangan teknologi informasi khususnya internet di Indonesia terbilang sangat pesat. Menurut laman datareportal, terdapat 175,4 juta pengguna internet di Indonesia pada Januari 2020 [5]. Jumlah pengguna internet di Indonesia meningkat 25 juta atau dapat dipersentasekan sebanyak 17% antara tahun 2019 dan 2020. Media sosial memiliki beberapa fungsi, diantaranya penyebaran informasi yang efisien, memberi hiburan kepada audiense, mendidik, dan juga memudahkan komunikator untuk memersuasi. Setiap pengguna media sosial bebas mengungkapkan opini dalam menanggapi permasalahan yang berlangsung. Oleh karena itu, terjadi pergerakan arus informasi yang sangat besar. Salah satunya media sosial pemicu hal tersebut adalah Twitter. Twitter adalah layanan jejaring sosial dan mikroblog daring yang memungkinkan penggunanya untuk mengirim dan membaca pesan berbasis teks hingga 280 karakter. Twitter memungkinkan informasi dapat disebarkan dengan cepat dan menjangkau orang-orang di berbagai negara. Menurut informasi yang didapat dari laman websindo, pengguna aktif Twitter mencapai 52% pada Januari 2019 [6]. Di dunia, pengguna aktif Twitter mencapai 340 miliar, pada 25 Januari 2020 oleh laman wearesocial [4].
Banyak sekali variasi topik yang dihasilkan para pengguna Twitter. Topik tersebut bisa merupakan tanggapan dari suatu kejadian, produk, tokoh, kampanye politik, dan lainnya. Dengan tingginya pergerakan arus informasi yang sangat besar, hal ini merupakan ladang emas yang sangat berharga jika dapat diolah dengan baik. Salah satu cara mengolah Twitter yaitu dengan melihat sentimen dari apa yang pengguna Twitter ungkapkan. Sehingga diketahui sentimen dari suatu topik yang sedang dibicarakan oleh para pengguna Twitter. Jika topik tersebut memiliki sentimen yang negatif, para pengguna Twitter cenderung tidak setuju, menolak, atau tidak menyukai topik tersebut. Sebaliknya, jika topik tersebut memiliki sentimen yang positif, maka para pengguna Twitter cenderung setuju, mendukung, atau menyukai topik tersebut. Pemilihan media sosial Twitter dalam penelitian ini karena Twitter merupakan salah satu media sosial yang sangat digemari oleh masyarakat luas sampai saat ini, terutama oleh kawula muda. Karena penggunanya yang terus meningkat, masyarakat terbiasa menyampaikan pendapatnya akan suatu peristiwa yang terjadi melalui media sosial Twitter. Twitter merupakan salah satu media sosial yang efektif untuk menampung berbagai opini dari masyarakat, dibandingkan dengan media sosial lain. Opini dalam Twitter dapat menjadi trending topic atau topik yang sedang ramai dibicarakan. Menurut Agung Yudha, yang menjabat sebagai Pemimpin Kebijakan Publik di Twitter Indonesia mengatakan bahwa Twitter merupakan platform yang paling banyak dipakai oleh pemimpin dunia untuk berbagai informasi dan juga untuk berkomunikasi. Berdasarkan data dari Twiplomacy 2018 yang dimuat dalam cnbcindonesia.com, Twitter merupakan platform yang
3
dengan jumlah akun pemimpin dunia terbanyak dengan total sebanyak 951 akun, lebih banyak 274 akun dibandingkan Facebook [3].
Salah satu topik yang sampai saat ini masih menjadi perbincangan masyarakat yaitu mengenai gangguan bipolar. Gangguan bipolar, atau yang biasa disebut dengan bipolar disorder, merupakan masalah kesehatan jiwa yang menyebabkan perubahan ekstrem pada mood, energi, aktivitas, dan kemampuan seseorang untuk melakukan kegiatan sehari-hari. Menurut data WHO pada tahun 2016 yang dimuat dalam [2], terdapat sekitar 35 juta orang terkena depresi, 60 juta orang terkena bipolar, 21 juta terkena skizofrenia, serta 47,5 juta terkena demensia. Menurut Ketua Bipolar Care Indonesia (BCI) simpul Bandung, Andri Suratmat (2018), sejumlah dua persen setara dengan 72.860 orang yang mengidap gangguan bipolar. Jumlah tersebut terbilang lebih kecil dibandingkan dengan negara-negara maju lainnya, seperti di Australia, jumlah orang yang mengidap gangguan bipolar mencapai 45 persen. Seseorang yang terkena gangguan bipolar bisa terjadi karena kehidupan sehari-hari yang cenderung individualis. Dengan begitu, mereka tidak memiliki tempat untuk mencurahkan keluh kesah dan cenderung dipendam sendiri.
Terdapat dua metode yang digunakan untuk menganalisis suatu sentimen dalam penelitian ini, yaitu metode lexicon based dan metode Support Vector Machine (SVM). Metode lexicon based termasuk teknik unsupervised, menggunakan kamus kata-kata yang telah disediakan, kemudian akan digunakan untuk menghitung nilai untuk sentimen dokumen. Metode SVM termasuk teknik pembelajaran mesin supervised. Metode ini pertama kali diperkenalkan oleh Vapnik, pada tahun 1992 bersama rekannya Bernhard Boser dan Isabelle Guyon. SVM merupakan algoritma yang bekerja menggunakan pemetaan non-linier untuk mengubah data pelatihan asli ke dimensi yang lebih tinggi [1]. Dalam hal ini dimensi baru akan mencari hyperplane untuk memisahkan secara linier dan dengan pemetaan non-linier yang tepat ke dimensi yang lebih tinggi.
Dalam penggunaannya, SVM membutuhkan data latih untuk dapat melatih sistem agar dapat menentukan klasifikasi tweets termasuk ke dalam sentimen positif atau sentimen negatif, dan juga data uji untuk proses pengujian menggunakan metode SVM. Namun dengan jumlah data yang banyak, tentunya pemberian label secara manual akan memakan banyak waktu. Untuk itu, Penulis menggunakan lexicon based pada penelitian sebelumnya dan Support Vector Machine dalam penelitian ini. Lexicon based digunakan untuk menentukan nilai sentimen, kemudian hasil dari metode lexicon based tersebut akan digunakan sebagai data latih dan data uji pada metode SVM, sehingga pemberian label pada data tidak perlu dilakukan secara manual. Analisis yang demikian disebut dengan analisis sentimen. Dengan analisis sentimen, maka dapat diketahui pandangan masyarakat bahwa terhadap pernyataan seseorang mengenai gangguan bipolar. Maka dari itu penulisan akan diberi judul “Klasifikasi Analisis Sentimen Terhadap Bipolar Disorder
4
pada Media Sosial Twitter dengan Menggunakan Metode Support Vector Machine (SVM)”. Dalam penelitian ini, penggunaan metode lexicon based tidak akan dibahas karena Penulis hanya melanjutkan dari penelitian sebelumnya [16]. Hasil dari penelitian ini diharapkan dapat memberikan pemahaman kepada masyarakat mengenai masalah kesehatan jiwa ini dan masyarakat dapat memberi dukungan kepada siapapun yang memiliki gangguan bipolar untuk dapat menunjang kesembuhan.
Tujuan penelitian ini adalah mengetahui sentimen pengguna Twitter terhadap gangguan bipolar yang memiliki kecenderungan positif atau negatif dengan menggunakan klasifikasi SVM, kemudian memvisualisasikan hasil analisis sentimen ke dalam aplikasi website menggunakan bahasa pemrograman Python dan kerangka Flask. Aplikasi website ini diharapkan dapat membantu masyarakat yang ingin mengetahui sentimen mengenai gangguan bipolar.
METODE PENELITIAN
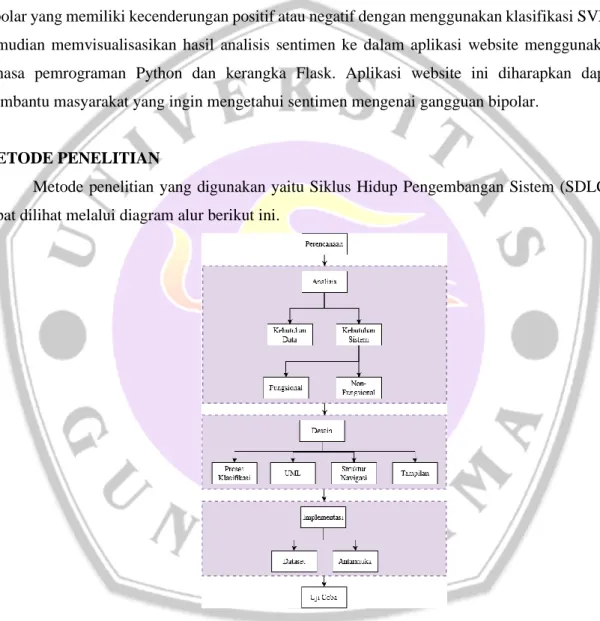
Metode penelitian yang digunakan yaitu Siklus Hidup Pengembangan Sistem (SDLC), dapat dilihat melalui diagram alur berikut ini.
Gambar 1. Tahapan Penelitian
Adapun metode penelitian yang digunakan dijabarkan sebagai berikut: 1. Perencanaan
Dalam tahap ini Penulis memasukkan dataset yang telah diolah sebelumnya pada Penelitian Ilmiah yang bejudul “Pendapat Pengguna Twitter Terhadap Bipolar Disorder Dengan Metode Lexicon Based” dengan format .csv ke dalam bahasa pemrograman
5
Python. Pada data tersebut telah dilakukan pembersihan dan pengelompokkan data sehingga data yang akan dipakai merupakan data yang benar. Pada tahap pemrograman, pengolahan data tweets selanjutnya dilakukan dengan bahasa pemrograman Python, yaitu Jupyter Notebook versi 3.7, dan beberapa library yang disediakan oleh Python yaitu Tweepy, NumPy, Pandas, dan Matplotlib.
2. Analisis
Dalam tahap ini dilakukan analisis yang meliputi analisis kebutuhan data dan analisis kebutuhan sistem.
3. Desain
Dalam tahap ini dilakukan perancangan pada proses klasifikasi, perancangan UML, perancangan struktur navigasi, dan perancangan tampilan.
4. Implementasi
Dalam tahap ini berisi implementasi penelitian pada aplikasi website dengan menggunakan bahasa pemrograman Python dan kerangka Flask.
5. Pengujian
Dalam tahap ini akan dilakukan pengujian pada fungsi aplikasi website dengan Pengujian Black-Box.
HASIL DAN PEMBAHASAN
A. Tampilan Halaman Aplikasi 1. Tampilan Tab Home
Pada tampilan tab Home, terdapat menu tab yang juga menampilkan menu lainnya. Pada tab Home berisi pesan selamat datang dan pengenalan mengenai keseluruhan isi website. Tampilan Home dapat dilihat pada gambar 2.
6
2. Tampilan Tab Teori Singkat
Pada tampilan tab Teori Singkat, berisi teori-teori singkat yang digunakan pada proses penelitian. Tampilan tab Teori Singkat dapat dilihat pada gambar 3.
Gambar 3. Tampilan Tab Teori Singkat
3. Tampilan Tab Data Tweets
Tampilan tab Data Tweets berisikan tabel dataset yang akan diproses pada tahapan selanjutnya. Tabel dataset tersebut berisi sebanyak 415 data yang sudah dibersihkan pada penelitian sebelumnya dan diberikan label dengan metode lexicon based yang terdiri dari 58 data positif dan 357 data negatif. Tampilan tab Data Tweets dapat dilihat pada gambar 4.
7
4. Tampilan Tab Data Latih
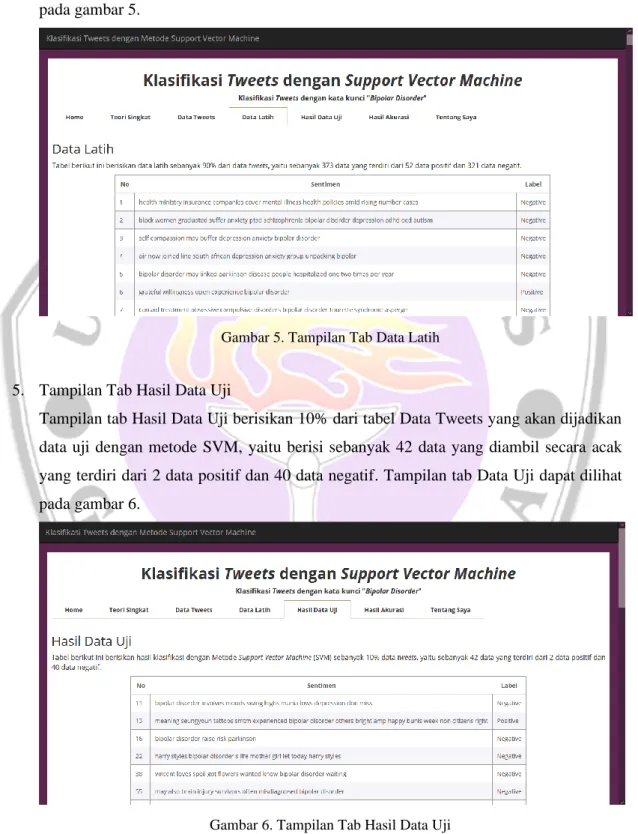
Tampilan tab Data Latih berisikan 90% dari tabel Data Tweets yang akan dijadikan data latih pada proses selanjutnya, yaitu berisi sebanyak 373 data yang diambil secara acak yang terdiri dari 52 data positif dan 321 data negatif. Tampilan tab Data Latih dapat dilihat pada gambar 5.
Gambar 5. Tampilan Tab Data Latih
5. Tampilan Tab Hasil Data Uji
Tampilan tab Hasil Data Uji berisikan 10% dari tabel Data Tweets yang akan dijadikan data uji dengan metode SVM, yaitu berisi sebanyak 42 data yang diambil secara acak yang terdiri dari 2 data positif dan 40 data negatif. Tampilan tab Data Uji dapat dilihat pada gambar 6.
8
6. Tampilan Tab Hasil Akurasi
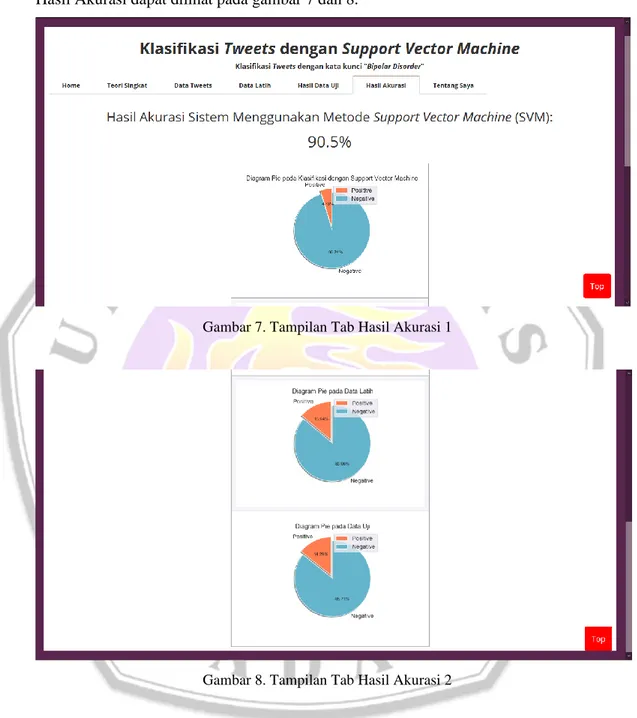
Tampilan tab Hasil Akurasi berisikan hasil persentase akurasi dari penelitian ini dan tampilan diagram lingkaran pada hasil klasifikasi, data latih, dan data uji. Tampilan tab Hasil Akurasi dapat dilihat pada gambar 7 dan 8.
Gambar 7. Tampilan Tab Hasil Akurasi 1
Gambar 8. Tampilan Tab Hasil Akurasi 2
7. Tampilan Tab Tentang Saya
Tampilan tab Tentang Saya berisikan biodata Penulis. Tampilan tab Tentang Saya dapat dilihat pada gambar 9.
9
Gambar 9. Tampilan Tab Tentang Saya
B. Uji Coba Data
Pengujian keakurasian data dilakukan dengan menghitung keberhasilan dari hasil akurasi metode SVM dengan data pertama yang menggunakan lexicon based dari penelitian sebelumnya dengan menggunakan persamaan berikut:
𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦 = 𝐽𝑢𝑚𝑙𝑎ℎ 𝑘𝑙𝑎𝑠𝑖𝑓𝑖𝑘𝑎𝑠𝑖 𝑏𝑒𝑛𝑎𝑟
𝐽𝑢𝑚𝑙𝑎ℎ 𝑘𝑒𝑠𝑒𝑙𝑢𝑟𝑢ℎ𝑎𝑛 𝑑𝑎𝑡𝑎 𝑢𝑗𝑖 𝑥 100% (1)
Akurasi adalah jumlah data yang diklasifikasikan dengan benar dibagi dengan total data pada data uji. Data yang digunakan sebagai data uji sebanyak 42 data dan diperoleh jumlah klasifikasi benar yaitu sebanyak 38 data. Maka diperoleh perhitungan akurasi sebagai berikut:
𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦 = 38
42 𝑥 100% = 90.5% Maka hasil persentase akurasi yang diperoleh yaitu 90.5%.
KESIMPULAN DAN SARAN
A. Kesimpulan
Aplikasi website analisis sentimen masyarakat terhadap gangguan bipolar pada media sosial Twitter dengan metode SVM telah berhasil dibuat dengan menggunakan kerangka Flask. Penelitian ini merupakan penelitian lanjutan dari Penelitian Ilmiah oleh Penulis pada tahun 2019 dengan judul “Pendapat Pengguna Twitter terhadap Bipolar
Disorder dengan Metode Lexicon-based” yang dilakukan dengan bahasa pemrograman
R, dimana sentimen yang sudah diambil kemudian diberi label dengan metode lexicon
based, yaitu menggunakan kamus kata negatif dan kamus kata positif. Sebanyak 1000
data yang diambil, dilakukan klasifikasi dengan metode lexicon based dan dihasilkan data sebanyak 415 dengan data positif sebanyak 58 data dan data negatif sebanyak 357 data.
10
Kemudian pada penelitian ini, dilanjutkan dengan melakukan klasifikasi SVM untuk melihat persentase akurasi pada datanya dengan menggunakan bahasa pemrograman Python.
Berdasarkan uji coba data menggunakan data latih dan data uji dengan perbandingan 90:10 dengan jumlah data latih sebanyak 373 data dan jumlah data uji sebesar 42 data, menunjukkan bahwa nilai akurasi yang didapatkan berdasarkan perbandingan hasil klasifikasi antara algoritma SVM dengan klasifikasi lexicon based yaitu sebesar 90.5%. Selain itu diperoleh juga nilai presisi sebesar 100%, recall sebesar 33.3%, dan 𝑓1-score sebesar 50%. Berdasarkan pengujian sistem yang dilakukan dengan pengujian Black-Box, menunjukkan bahwa semua fungsi yang terdapat pada aplikasi website ini berjalan dengan baik dan sesuai dengan yang diharapkan. Oleh karena data yang dihasilkan memiliki kecenderungan negatif, diharapkan dengan adanya penelitian ini masyarakat dapat lebih sadar bahwa penderita gangguan bipolar membutuhkan dukungan agar dapat sembuh dan juga lebih peduli dengan masalah kesehatan jiwa ini, terutama bila mempunyai kerabat yang memiliki gangguan bipolar.
B. Saran
Adapun saran yang diberikan pada penelitian ini untuk pengembangan yang lebih lanjut, yaitu dapat mengambil data tweets dengan jumlah yang lebih besar dan dapat menggunakan kernel SVM yang lain selain kernel linear agar dapat melihat perbedaan hasil akurasi yang didapatkan.
DAFTAR PUSTAKA
[1] Ben-Hur, A. dan Weston, J., A User’s Guide to Support Vector Machines, Colorado State University, 2010.
[2] Madeline, Corinna A., “Pendapat Pengguna Twitter Terhadap Bipolar Disorder Dengan Metode Lexicon Based”, Penelitian Ilmiah, Universitas Gunadarma, Depok, 2019. [3] Sebayang, Rehia, “Ini Platform Medsos Terbanyak yang Digunakan Pemimpin Dunia”,
www.cnbcindonesia.com/tech/20180712183744-37-23307/ini-platform-medsos-terbanyak-yang-digunakan-pemimpin-dunia, 2018.
[4] Kemp, Simon, “Digital 2020: 3.8 Billion People Use Social Media”, https://wearesocial.com/blog/2020/01/digital-2020-3-8-billion-people-use-social-media, 2020.
[5] Kemp, Simon, “Digital 2020: Indonesia”, https://datareportal.com/reports/digital-2020-indonesia, 2020.
[6] Wibisono, G. dan Susanto, W., “Perancangan Website Sebagai Media Informasi Dan Promosi Batik Khas Kabupaten Kulonprogo”, AMIK BSI Yogyakarta, Vol. 3, No. 2, 2015.