PRODI EKONOMIKA TERAPAN
SEKOLAH VOKASI
BUKU III : MODUL BAHAN AJAR
PRAKTIKUM
STATISTIKA TERAPAN (SPSS DAN EVIEWS)
SEMESTER III/2 SKS/ PRK 465
Oleh :
1. Anisa Nurpita, SE
2. Adi Irawan, SE
Didanai dengan dana BOPTN P3-UGM
Tahun Anggaran 2012
DAFTAR ISI
Judul ……….. 0
Daftar Isi ……….. i
Tinjauan Bahan Ajar ……….. ii
BAB I Penggunaan Eviews dan SPSS ……….. 1
BAB II Entry Data dan Database dengan SPSS ……….. 10
BAB III Entry Data dan Database dengan Eviews ……….. 17
BAB IV Descriptive Statistic Data dengan SPSS ……….. 23
BAB V Descriptive Statistic Data dengan Eviews ……….. 27
BAB VI Interpretasi Descriptive Statistic Data dari SPSS ……….. 32
BAB VII Interpretasi Descriptive Statistic Data dari Eviews ……….. 45
BAB VIII Pengenalan Pembuatan Model Penelitian dan Hipotesis ……….. 48
BAB IX Olah Data : OLS dengan SPSS ……….. 53
BAB X Olah Data : OLS dengan Eviews ……….. 66
BAB XI Uji Hipotesis ……….. 74
BAB XII Interpretasi Hasil Olah Data ……….. 80
TINJAUAN MATA KULIAH Statistika Terapan (SPSS dan Eviews)
Mata Kuliah Statistika Terapan (SPSS dan Eviews) ini adalah matakuliah wajib yang harus diambil mahasiswa. Mata kuliah ini merupakan matakuliah aplikasi dari teori Statistika dengan menggunakan SPSS dan Eviews berisi tentang praktik penggunaan SPSS dan Eviews dimana SPSS dan Eviews adalah salah dua alat yang dapat digunakan sebagai alat mempermudah mengaplikasikan statistika dalam proses pengolahan data. Selain itu dalam praktikum ini juga berisi tentang bagiamana cara mengentry data kke SPS maupun Eviews kemudian membuat basis data, membuat
descriptive statistic dari data kemudian menginterpretasikan hasil deskripsi
statistiknya, membuat model dan membuat uji hipotesis penenlitian, mengolah data dengan meregresi Ordinary Least Square (OLS), membuat uji signifikansi dan menginterpretasikan hasil dari regresi tersebut.
Matakuliah ini sangat berguna bagi mahasiswa terutama untuk menjadi bekal kemampuan softskill olah data yang nanti akan sangat diperlukan mahasiswa di dunia kerja. Sebagian besar pekerjaan membutuhkan ketrampilan mengolah data terutama sebagai alat untuk mengestimasi apa yang terjadi di masa depan.
TUJUAN PEMBELAJARAN MATAKULIAH INI ADALAH AGAR MAHASISWA:
1. Memiliki pemahaman tentang SPSS dan Eviews
2. Memiliki kemampuan mengentry data dan membuat data base 3. Memilik kemampuan membuat descriptive statistic data.
4. Memiliki kemampuan menginterpretasikan descriptive statistive data. 5. Memiliki kemampuan membuat model dan membuat uji hipotesisinya. 6. Memiliki kemampuan mengolah data sesuai dengan model.
7. Memiliki kemampuan menginterpretasikan hasil olah data. 8. Memiliki kemampuan menyimpulkan hasil olah data.
CAPAIN PEMBELAJARAN (LEARNING OUTCOME/LO) MATAKULIAH INI ADALAH MAHASISWA:
1 Mampu mengaplikasikan SPSS dan Eviews untuk statistika.
2 Mampu mengentry data dan membuat data base dengan SPSS.
3 Mampu mengentry data dan membuat data base dengan Eviews.
4 Mampu membuat descriptive statistic data dengan SPSS.
5 Mampu membuat descriptive statistic data dengan Eviews.
6 Mampu membuat interpretasi dari hasil descriptive statistic data SPSS.
7 Mampu membuat interpretasi dari hasil descriptive statistic data Eviews.
8 Mampu membuat model dan membuat uji hipotesis
9 Mampu mengolah data sesuai model menggunakan OLS di SPSS
10 Mampu mengolah data sesuai model menggunakan OLS di Eviews.
11 Mampu menguji Hipotesis
12 Mampu menginterpretasikan hasil olah data baik SPSS maupun Eviews
13 Mampu membuat kesimpulan dari data yang diolah.yang sesuai dengan hipotesisnya
Materi Pembelajaran atau Pokok Bahan Kajian 1. Penggunaan Eviews dan SPSS
2. Entry Data dan Data Base dengan SPSS 3. Entry Data dan Data Base dengan Eviews
4. Descriptive statistic Descriptive Data dengan SPSS 5. Descriptive statistic dengan Eviews
6. Interpretasi descriptive statistic Data dari SPSS 7. Interpretasi descriptive statistic Data dari Eviews 8. Pengenalan Pembuatan Model Penelitian dan Hipotesis 9. Olah Data : OLS dengan SPSS
13. Kesimpulan dari Hasil Olah Data
PETUNJUK PENGGUNAAN BAHAN AJAR
Bahan ajar ini digunakan sebagai lanjutan dari teori Statistika. Instruktur Praktikum hendaknya mengikuti tahap-tahap yang ada dalam penyajian setiap bab dalam modul bahan ajar ini. Setelah penyampaian tahap-tahap latihan diarahkan dan pembimbingan dilaksanakan maka mahasiswa diharuskan mengerjakan tugas yang telah ada disetiap bab dalam modul bahan ajar ini. Tugas wajib dikumpulkan kepada instruktur sebagai bahan evaluasi dan penilaian setiap materi praktikum.
DAFTAR PUSTAKA
Douglas, AL, et.al. 2005. Statistical Technique in Business and Economics. Mc.Graw-Hill Companies,
Gujarati, Damodar N. 2003.Basic Econometrics 4th edition.Singapore: Mc Graw Hill,
Maddala, G.S. 2001. Introduction to Econometrics. Third Edition. Chichester: John Wiley&Sons ltd,
Priyatno, Dwi. 2009. 5 Jam Belajar Olah Data Dengan SPSS 17. Edisi satu.Yogyakarta: Penerbit Andi,
Santoso. S. 2010. Mastering SPSS 18. Jakarta. PT.Elex Media Komputindo. Santoso. S. 2010. Mastering SPSS 18. Jakarta. PT.Elex Media Komputindo.
Wahana Komputer. 2010. Mudah Belajar Statistik dengan SPSS 18. Edisi satu.Yogyakarta: Penerbit Andi
Wahyu, Winarno Wing.2007. Analisis Ekonometrika dan Statistika dengan Eviews, Yogyakarta.UPP STIM YKPN
BAB I
PENGENALAN SPSS DAN EVIEWS
PENDAHULUAN
SPSS dan Eviews adalah software yang digunakan untuk aplikasi statistik terutama dalam hal mengolah data. Pembelajaran statistik akan terasa tidak sah jika tidak mengenal dan mempraktekkan cara-cara pemrosesan dan pengolahan data secara nyata. Kedua software ini harus diketahui setiap mahasiswa agar dapat mempermudah cara pengaplikasian ilmu statistik.
Manfaat
Bab ini bermanfaat untuk menjabarkan pentingnya aplikasi SPSS dan Eviews dalam statistika. SPSS dan Eviews hanyalah media yang dapat digunakan untuk menyelesaikan beberapa masalah statistika terutama terkait olah data.
Relevansi
SPSS for Windows merupakan sebuah program aplikasi yang dirilis pada tahun 1992 dengan
kemampuan analisis statistik cukup tinggi serta sistem manajemen data pada lingkungan grafis dengan menggunakan menu-menu deskriptif dan kotak-kotak dialog yang sederhana sehingga mudah untuk dipahami cara pengoperasianya.
SPSS yang pertama kali dirilis adalah SPSS/PC+ berbasis teks pada tahun 1984. Aplikasi ini dapat menggunakan program atau kode eksternal, artinya membutuhkan software bantu lain berupa editor.
SPSS (Stastistical Package for the Social Science) pada awalnya merupakan program, computer sosial yang dibuat pertama kali oleh mahasiswa Stanford University yaitu Norman H. Nie, C Handlai Hull dan Dale H Bent pada tahun 1968 yang dijalankan dengan computer
mainframe. Setelah penerbit terkenal Mc Graw-Hill menerbitkan user manual SPSS, program
tersebut menjadi sangat terkenal.
Seiring dengan perkembangan jenis user untuk proses produksi, riset sains dan lainya maka SPSS telah berkembang tidak hanya Statistical Package for the Social Science tetapi menjadi
Statistical Product and Service Solution.
SPSS aplikasi berbasis Windows dimulai dari SPPSS 6.0 sampai saat ini SPSS 19. Untuk memantapkan posisinya sebagai salah satu market leader dalam business intelligence, SPSS juga menjalin aliasi strategis dengan software house terkemuka dunia lainya seperti Oracle
Setelah merilis versi SPSS 17 pada akhir tahun 2009 SPSS secara resmi diakuisisi oleh IBM dan nama pun berubah menjadi IBM SPSS. Sekarang SPSS menjadi bagian dari Business
Analytics and Process Optimization dari IBM. Bersamaan dengan itu, dirilis versi terbaru dari
SPSS menjadi PAWS Statistic 18. PAWS adalah kependekan dari Predictive Analytics
Software, yang menunjukan konsistensi dari IBM untuk mempertahankan kekuatan SPSS
sebagai alat predictive analytics software.
Sedangkan Eviews merupakan program lain selain SPSS yang sering juga digunakan untuk olah data secara statistic. Program olah data ini merupakan program olah data yang menyediakan atau memberikan alat untuk melakukan regresi (regression) dan peramalan (forecasting). Dengan program olah data E-Views dapat dikembangkan suatu hubungan statistik dari suatu data yang dimiliki dan menggunakan hubungan dari data yang sedang diamati tersebut untuk melakukan peramalan terhadap nilai data yang dimaksudkan, terutama dalam konteks data runtun waktu (time series).
Kegunaan e-views adalah sebagai berikut: 1. Untuk melakukan peramalan
2. Untuk melakukan analisis biaya dan selanjutnya melakukan peramalan 3. Untuk melakukan analisis keuangan
4. Untuk melakukan permalan dalam ekonomi makro 5. Untuk melakukan simulasi
6. Untuk melakukan analisis data ilmu pengetahuan dan melakukan evaluasi. Learning Outcome
Learning Outcome dari Bab ini adalah mahasiswa mampu mengaplikasikan SPSS dan
Eviews untuk statistika.
PENYAJIAN A. SPSS
1. Cara Kerja SPSS
Untuk memahami carakerja software SPSS, berikut dikemukakan kaitan antara sara kerja computer dengan SPSS dalam mengolah data.
Komputer
Pada dasarnya computer berfungsi mengolah data menjadi informasi yang berarti. Data yang akan diolah dimasukan sebagai input, kemudian dengan prosess pengolahan data oleh computer dihasilkan output yang berupa informasi untuk kegunaan lebih lanjut.
Statistik
Statistik juga mempunyai fungsi mirip dengan computer, yaitu mengolah data dengan perhitungan statistic tertentu, menjadi informasi yang berarti.
Statistic merupakan ilmu yang berkaitan dengan kegiatan pengoleksian, pengorganisasian, presentasi, analisis, dan interprestasi data numeric untuk membantu pembuatan keputusan lebih efektif (Dougglas 2005)
SPSS
Proses pengolahan data pada SPSS juga mirip dengan kedua proses diatas hanya disini ada variasi dalam penyajian input dan output data.
Penjelasan Proses Statistik dengan SPSS
a. Data yang akan diproses dimasukan lewat menu DATA EDITOR yang otomatis muncul di layar SPSS ketika dijalankan.
b. Data yang telah diinput kemudian diproses, juga lewat menu DATA EDITOR.
c. hasil pengolahan data muncul dilayar (window) yang lain dari SPSS yaitu VIEWER. Output SPSS bisa berupa teks/tulisan, tabel, atau grafik.
Dengan demikian, dalam SPSS ada berbagai macam Window yang tampil PROSES KOMPUTER INPUT DATA OUTPUT DATA PROSES STATISTIK INPUT OUTPUT PROSES DENGAN DATA EDIT OUTPUT DATA INPUT DATA dengan DATA
harus digunakan DATA EDITOR sebagai bagian input dan proses data, serta VIEWER yang merupakan tempat output pengolahan data.
2.
Mengaktifkan Program SPSS 17Untuk mengaktifkan program SPSS 17, Langkah-langkahnya sebagai berikut Lakukan double klik pada ikon SPSS 17 pada desktop atau ikon pada Start menu
Klik Cancel untuk memulai membuat variable dan data baru, kotak dialok dibawah ini memandu penguna untuk memilih proses yang akan dilakukan. Namun untuk praktisnya , tutup kotak dialog tersebut dengan klik ikon cancel. untuk lebih praktinya dianjurkan untuk mengakifkan kotak dialok dibawah ini dengan memklik Don’t show this dialog in the future.
3.
Mengenal Halaman SPSS 17 MenubarFile
Menu ini digunakan untuk keperluan yang berhubungan dengan file data, seperti membuka data baru, output baru, membuka dan menutup file, menyimpan, print dan sebagainya.
Edit
Menu ini digunakan untuk perbaikan dan pengubahandata misalnya untuk mencopy data, memotong atau cut, menambahkan variable, menambahkan kasus, mencari variabel atau kasus akan diganti atau diubah, menghapus data mencari data dan sebagainya.
View, Menu ini digunakan untuk mengatur penampakan layar atau toolbar pada halaman SPSS seperti bentuk tulisan atau font, tampak atau tidaknya garis pada windows, value label, status bar dan menu editor. Pengerjaan pada menu ini tidak mengubah isi variable atau data dan juga tidak berpengaruh pada perhitungan statistic yang dilakukan.
B. Eviews
Eviews adalah program yang banyak digunakan dalam pendidikan, pemerintah dan industri. EViews, yang merupakan singkatan Views Ekonometrik, adalah versi baru dari paket statistik untuk memanipulasi data time series. Meskipun sebagian besar EViews dirumuskan oleh ekonom, program itu sendiri juga dapat digunakan dalam bidang-bidang studi, seperti sosiologi, statistik, keuangan, dll. EViews memanfaatkan lingkungan windows user-friendly, sebagian besar perusahaan operasi dapat dilakukan dengan menu drop-down
Kegunaan EVIEWS antara lain adalah analisis data dan evaluasinya, analisis financial, peramalan ekonomi makro, simulasi, peramalan penjualan dan analisis biaya. Versi terakhir (Januari 2011) adalah versi 7.2.
1. Mengaktifkan Eviews Klik Program Eviews dua kali
Jika program EVIEWS sudah terbuka, maka tampilan awalnya adalah seperti ini :
2. Mengenal halaman awal Eviews
a. Menu Utama Eviews adalah File, Edit, Window and Help mengikuti standard Windows-conventions.Objects, View, Procs, Quick and Options tergabung pada special Eviews-features.
Eviews Help memuat Bantuan-sistem yang sangat lengkap meliputi hampir seluruh panduan pengguna software ini. Jadi jika belajar EVIEWS dapat juga melalui menu help ini
PENUTUP Latihan
a. Kerjakan instruksi berikut: 1. Bukalah SPSS
2. Bukalah Eviews
b. Deskripsikan apa manfaat SPSS dan Eviews dalam ilmu statistika? c. Serahkan tugas pada instruktur!
Daftar Pustaka
Douglas, AL, et.al. 2005. Statistical Technique in Business and Economics. Mc.Graw-Hill Companies.
Priyatno, Duwi. 2009. 5 Jam Belajar Olah Data Dengan SPSS 17. Edisi satu. Yogyakarta: Penerbit Andi
Santoso. S. 2010. Mastering SPSS 18. Jakarta : PT.Elex Media Komputindo
Wahana Komputer. 2010. Mudah Belajar Statistik dengan SPSS 18. Edisi satu. Yogyakarta: Penerbit Andi
Wahyu, Winarno Wing.2007. Analisis Ekonometrika dan Statistika dengan Eviews, Yogyakarta: UPP STIM YKPN
BAB II
ENTRY DATA DAN PEMBUATAN DATABASE DENGAN SPSS
PENDAHULUAN
Entry data merupakan salah satu tahap yang penting dalam mengolah data. Ketepatan,
ketelitian dalam memasukkan data adalah kunci pokok membuat data yang baik. Manfaat
Manfaat entry data dan database adalah memudahkan seseorang dalam mencari data yang kemudian dapat diolah sesuai kebutuhan.
Relevansi
Entry data dan Pembuatan database merupakan salah satu tahap awal dalam pengolahan
data. Dari sinilah olah data yang baik dapat dihasilkan jika entry datanya benar. Ketelitian dan ketepatan sangat dibutuhkan sehingga dapat membentuk database yang baik.
Learning Outcome
Setiap mahasiswa mampu mengentry data dan membuat database dengan SPSS.
PENYAJIAN
A. Halaman Kerja SPSS
1) Name, kolom ini digunakan untuk memberikan nama pada variable.
2) Type, kolom ini digunakan untuk menentukan tipe data apa yang akan kita
input.
3) Width, digunakan untuk menentukan berapa digit huruf atau angka (lebar
kolom)
4) Decimals, kolom ini digunakan untuk menentukan berapakah angka yang ada
di belakang tanda koma.
5) Label, digunakan untuk memberikan nama variable atau keterangan penjelasan
suatu variable.
6) Values, digunakan untuk menentukan nilai untuk data ordinal maupun
nominal (misalnya 1=Akuntansi, 2= Manajemen, dan 3 = Ekonomi Terapan) 7) Missing, kolom Mising digunakan untuk menentukan data yang hilang.
8) Columns, digunakan untuk menentukan berapa digit lebar kolom yang akan
digunakan.
9) Align, digunakan untuk menentukan rata kanan, kiri atau tengah.
10) Measure, digunakan untuk menentukan tipe atau ukuran data, yaitu nominal, ordinal atau skala.
b) Data View
Halaman Data View digunakan untuk memasukan data pada kolom variable yang telah dibuat.
B. Cara menyusun Variable pada Variable View
a) Klik tab Variabel View. Kemudian tempatkan kursor atau pointer pada kolom Name, lalu kemudian berikan nama misalnya Jurusan, Nilai Statistik atau jenis kelamin.
b) Kemudian Klik kursor pada Type, kemudian klik kotak kecil yang telah tersedia yaitu :
1) Numeric yaitu tipe data berbentuk angka
2) Comma, digunakan untuk data yang menggunakan koma. 3) Dot, yaitu tipe data menggunakan titik.
4) Scientific notation, yaitu tipe data berbentuk angka yang menggunakan notasi bilangan.
5) Date, yaitu tipe data berbentuk tanggal
6) Dollar, yaitu data yang menggunakan satuan dolar. 7) Custom Currency, yaitu data angka nilai mata uang.
8) String, yaitu data yang berupa kalimat atau angka yang tidak dapat diperhitungkan nilainya.
c) Pilih salah satu tipe data yang sesuai kemudian klik OK
d) Kemudian Klik Width untuk menentukan berapa digit lebar baris yang akan digunakan untuk input data.
e) Pada Desimal, tentukan berapa jumlah angka dibelakang koma yang akan digunakan.
f) Pada Label, berikan nama sebagai penjelasan dari Kolom Name jika kolom Name sekiranya belum jelas.
g) Pada values, jika data adalah data ordinal atau kategori (nominal) dan ingin menyederhanakan dalam bentuk angka misalnya 1= Akuntansi, 2= Manajemen dan 3= Ek.Terapan makaklik kotak kecil . Selanjutnya, pada kotak dialog Value Label isilah kotak Value dengan angka 1, sedangkan kotak Value Label diisikan dengan Akuntansi kemudian klik tombol Add. dan ulangi sampai semua value terisi.
h) Kolom Missing Value digunakan jika ada data yang hilang atau yang tidak digunakan. Jika tidak ada, abaikan kolom ini.
i) Pada Column tentukan berapa digit lebar kolom yang akan digunakan.
j) Pada Align dapat ditentukan apakah rata kanan, tengah atau kiri yang akan kita gunakan.
k) Measure, pilihlah sesuai jenis data yang anda gunakan yaitu:
1) Scale : data interval atau rasio yang bukan merupakan data hasil kategorisasi misalnya nilai statistika, nilai mate-matika dan sebagainya. 2) Ordinal, yaitu data hasil kategorisasi yang tidak setara misalnya 1=
C. Menyimpan data
Untuk Menyipan data yang telah diinput maka klik File > Save As/ Save selanjutnya pada dialog Save Data As yang terbuka, silahkan pilih salah satudirektori untuk menyimpan file. kemudian berikan nama file dan klik save.
PENUTUP Tugas
a. Entrylah data berikut dan buatlah database.
Data Produksi Sektor Manufaktur di Greek, 1961-1987 Tahun Output (miliar) Labor (ribuan) Capital (miliar) 1961 35,858 637 59,6 1962 37,504 643,2 64,2 1963 40,378 651 68,8 1964 46,147 685,7 75,5 1965 51,047 710,7 84,4 1966 53,871 724,3 91,8 1967 56,834 735,2 99,9 1968 65,439 760,3 109,1 1969 74,939 777,6 120,7 1970 80,976 780,8 132 1971 90,802 825,8 146,6 1972 101,955 864,1 162,7 1973 114,367 894,2 180,6 1974 101,823 891,2 197,1 1975 107,572 887,5 209,6 1976 117,6 892,3 221,9 1977 123,224 930,1 232,5 1978 130,971 969,9 243,5 1979 138,842 1006,9 257,7 1980 135,486 1020,9 274,4 1981 133,441 1017,1 289,5 1982 130,388 1016,1 301,9 1983 130,615 1008,1 314,9 1984 132,244 985,1 327,7 1985 137,318 977,1 339,4
b. Serahkan pada Instruktur!
DAFTAR PUSTAKA
Douglas, AL, et.al. 2005. Statistical Technique in Business and Economics. Mc.Graw-Hill Companies.
Priyatno, Duwi. 2009. 5 Jam Belajar Olah Data Dengan SPSS 17. Edisi satu. Yogyakarta: Penerbit Andi
Santoso. S. 2010. Mastering SPSS 18. Jakarta : PT.Elex Media Komputindo
Wahana Komputer. 2010. Mudah Belajar Statistik dengan SPSS 18. Edisi satu.Yogyakarta: Penerbit Andi
BAB III
ENTRY DATA DAN PEMBUATAN DATABASE DENGAN EVIEWS
PENDAHULUAN
Entry data merupakan salah satu tahap yang penting dalam mengolah data. Ketepatan, ketelitian
dalam memasukkan data adalah kunci pokok membuat data yang baik.
Manfaat
Manfaat entry data dan database adalah memudahkan seseorang dalam mencari data yang
kemudian dapat diolah sesuai kebutuhan.
Relevansi
Entry data dan Pembuatan database merupakan salah satu tahap awal dalam pengolahan data.
Dari sinilah olah data yang baik dapat dihasilkan jika entry datanya benar. Ketelitian dan
ketepatan sangat dibutuhkan sehingga dapat membentuk database yang baik.
Learning Outcome
Setiap mahasiswa mampu mengentry data dan membuat database dengan Eviews.
PENYAJIAN
A. Memasukkan Data dalam Program E-views
Klik item menu utama: FILEÆ NEWÆWORKFILEÆKlik satu kali. Setelah
WORKFILE di-klik maka selanjutnya akan muncul tampilan WORKFILE RANGE.
Dalam kota workfile range terdapat workfile frequency data yang menunjukkan jenis data
(tahunan, semesteran, kuartalan, bulanan, mingguan, harian).
Pilihlah salah satu pilihan jenis data. Selanjutnya, isi kotak START DATE dan END
DATE jika data adalah tahunan/kuartalan/semeseran.
Jika data adalah cross section atau data sewaktu maka
Isilah jumlah observasi yang akan Saudara teliti, missal 100.
Apabila proses di atas telah selesai, langkah selanjutnya adalah memasukkan data.
Cara: meng-klik Item menu utama: QUICÆ EMPTY GROUP (EDIT SERIES).
Cara ini merupakan cara yang paling praktis dan efisien. Langkah pertama yang harus
dilakukan dalam memasukkan data adalah dengan mengklik MENU UTAMA:
QUICK kemudian EMPTY GROUP (EDIT SERIES).
Untuk dapat memberikan nama adalah dengan cara mengklik kotak sejajar dengan tulis
OBS kemudian tuliskan nama variabel yang akan dimasukkan datanya dalam program
olah data e-views, lalu kemudian tekan tombol ENTER.
B. Mengimpor Data dari Microsoft Excel
Untuk mengimpor dari MS Excel ke program olah data e-views, maka langkah-langkah
yang perlu dilakukan adalah sebagai berikut:
1. Buka program MS Excel
2. Setelah program MS Excel terbuka, kemudian bukalah data yang akan diekspor ke
dalam program olah data e-views
3. Lakukan pem-blok-an terhadap data yang akan diekspor ke dalam program olah
data e-views, termasuk nama variabel dan data, kemudian klik kanan COPY.
4. Pastikan jenis data yang akan diekspor: tahunan, semesteran, kuartalan, dll
Setelah proses peng-copy-an data telah dilakukan, selanjutnya masuklah dalam program
olah data e-views (Catatan: MS Excel tetapi dalam posisi terbuka atau OPEN---- jangan
ditutup) dan dalam program e-views buatlah Workfile data dengan cara: FILEÆ
NEWÆWORKFILE. Dalam kotak dialog workfile range
PENUTUP
a. Masukkan data berikut ini ke dalam Workfile dan buatlah database. Dimana Y adalah
pendapatan dan C adalah jumlah pengeluaran konsumsi.
obs
Y
(dalam
ratusan))
C
(dalam
ratusan)
1
19583
3346
2
20263
3114
3
20325
3554
4
26800
4642
5
29470
4669
6
26610
4888
7
30678
5710
8
27170
5536
9
25853
4168
10
24500
3547
11
24274
3159
12
27170
3621
13
30168
3782
14
26525
4247
15
27360
3982
16
21690
3568
17
21974
3155
18
20816
3059
19
18095
2967
20
20939
3285
21
22644
3914
22
24624
4517
23
27186
4349
24
33990
5020
25
23382
3594
26
20627
2821
27
22795
3366
28
21570
2920
29
22080
2980
30
22250
3731
b. Serahkan pekerjaan Saudara kepada Instruktur!
DAFTAR PUSTAKA
Douglas, AL, et.al. 2005. Statistical Technique in Business and Economics. Mc.Graw-Hill
Companies.
Wahyu, Winarno Wing.2007. Analisis Ekonometrika dan Statistika dengan Eviews, Yogyakarta:
UPP STIM YKPN.
BAB IV
PEMBUATAN DESCRIPTIVE STATISTIC DATA DENGAN SPSS
PENDAHULUAN
Kegiatan statistik berkaitan dengan angka, data berupa angka diolah menjadi output yang relevan dan sering disajikan dalam bentuk tabel dan grafik namun kegiatan statistic tidak hanya membuat tabel dan grafik saja, banyak hal lain yang bisa diperoleh dari data angka yang telah diinput. Salah satunya menyajikan sebuah ringkasan data atau biasa diartikan dengan upaya mendeskripsikan data lewat beragam ukuran statistik.
Descriptiptive statisitic penting dibuat untuk dapat melihat statistik suatu data atau
sekumpulan data. Dari Hasil descriptive statistic ini, dapat diinterpretasikan dan dianalisis. Manfaat
Dalam SPSS, Descriptive statistic dapat tersajikan dengan sekelompok data sehingga memudahkan seseorang untuk melihat komponen-komponen descriptive statistic, seperti:
1. Mean 2. Median 3. Maximum 4. Minimum 5. Standard Deviasi 6. Skewness 7. Kurtosis 8. dll
Kemudahan dalam melihat descriptive statistic ini nantinya dapat digunakan untuk interpretasi descriptive statisticnya.
Relevansi
Materi ini relevan dengan praktikum Statistik dalam tahap pengolahan data awal yaitu menyajikan descriptive statistic data.
Learning Outcomes
Dapat membuat descriptive statistic data dengan SPSS.
PENYAJIAN
a. Descriptive Statistic
SPSS menyediakan dua menu yang berhubungan dengan statistic deskriptif yakni menu REPORT dan DESCRIPTIVE STATISTICS.
bertipe kategorikal (nominal atau ordinal), yang mempunyai kaitan dengan variable scale (interval atau rasio). Pada menu ini juga ada fasilitas untuk meringkas satu kelompok data.
a) OLAP Cubes, digunakan untuk pembuatan tabel yang menghubungkan sejumlah variable sebagai baris dan sejumlah variabel lain sebagi isian kolom.
b) Case Summaries, digunakan untuk melihat lebih jauh isi statistic deskriptif yang meliputi subgroup dari sebuah kasus.
2.
DESCRIPTIVE STATISTICSMenu ini mengulas lebih dalam penggunaan berbagai ukuran descriptif data, seperti Skewness, Kurtosis dan sebagainya. Menu ini mempunyai beberapa submenu:
a)
Frequencies, submenu ini membahas beberapa ukuran statistic dasar, sepertiMean, Median, Kuartil, Persentil, Standar Deviasi, dan lainya.
b)
Descriptive, lebih kompleks dari menu Frequencies; menu ini dapatmenyajikan ukuran statistic beberapa variable dalam satu tabel, serta untuk mengetahui skor z dari suatu distribusi data. Skor z biasadigunakan untuk pengujian kenormalan distribusi data.
c)
Explore, menuh ini lebih lengkap dari menu sebelumnya, berfungsi untukmemeriksa lebih teliti sekelompok data, antara lain data screening, uji asumsi kenormalan data dan kesamaan varians, serta penggunaan data per kasus.
d)
Crosstabs, digunakan untuk menyajikan deskripsi data dalam bentuk tabelsilang, yang terdiri atas baris dan kolom. Selain itu, menu ini juga dilengkapi dengan analisis hubungan diantara baris dan kolom, seperti independensi diantara mereka,besar hubungannya dan lainya.
e)
Ratio, menu ini menyediakan ringkasan statistic untuk data hasilperbandingan dua data tertentu. Berbeda dengan menu lainya, menu ini hanya menangani perbandingan dua data, bukan satu data yang berdiri sendiri.
f)
P-P Plots dan Q-Q Plots, menu ini menampilkan grafik pengujian distribusidata.
PENUTUP Tugas
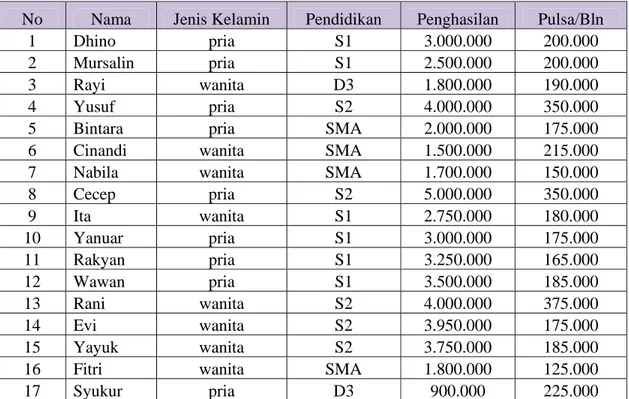
a. Buatlah statistik deskriptif dari data di bawah ini!
Tabel Data Jenis Kelamin, Pendidikan, Penghasilan dan Pemakaian Pulsa
No Nama Jenis Kelamin Pendidikan Penghasilan Pulsa/Bln
1 Dhino pria S1 3.000.000 200.000
2 Mursalin pria S1 2.500.000 200.000
3 Rayi wanita D3 1.800.000 190.000
4 Yusuf pria S2 4.000.000 350.000
5 Bintara pria SMA 2.000.000 175.000
6 Cinandi wanita SMA 1.500.000 215.000
7 Nabila wanita SMA 1.700.000 150.000
8 Cecep pria S2 5.000.000 350.000 9 Ita wanita S1 2.750.000 180.000 10 Yanuar pria S1 3.000.000 175.000 11 Rakyan pria S1 3.250.000 165.000 12 Wawan pria S1 3.500.000 185.000 13 Rani wanita S2 4.000.000 375.000 14 Evi wanita S2 3.950.000 175.000 15 Yayuk wanita S2 3.750.000 185.000
16 Fitri wanita SMA 1.800.000 125.000
20 Retno wanita S1 2.750.000 200.000
b. Serahkan kepada Instruktur!
DAFTAR PUSTAKA
Priyatno, Duwi. 2009. 5 Jam Belajar Olah Data Dengan SPSS 17. Edisi satu. Yogyakarta: Penerbit Andi
Santoso. S. 2010. Mastering SPSS 18. Jakarta : PT.Elex Media Komputindo
Wahana Komputer. 2010. Mudah Belajar Statistik dengan SPSS 18. Edisi satu. Yogyakarta: Penerbit Andi
BAB V
PEMBUATAN DESCRIPTIVE STATISTIC DATA DENGAN EVIEWS
PENDAHULUAN
Kegiatan statistik berkaitan dengan angka, data berupa angka diolah menjadi output yang relevan dan sering disajikan dalam bentuk tabel dan grafik namun kegiatan statistic tidak hanya membuat tabel dan grafik saja, banyak hal lain yang bisa diperoleh dari data angka yang telah diinput. Salah satunya menyajikan sebuah ringkasan data atau biasa diartikan dengan upaya mendeskripsikan data lewat beragam ukuran statistik.
Descriptiptive statisitic penting dibuat untuk dapat melihat statistik suatu data atau
sekumpulan data. Dari Hasil descriptive statistic ini, dapat diinterpretasikan dan dianalisis. Manfaat
Dalam Eviews, Descriptive statistic dapat tersajikan dengan sekelompok data sehingga memudahkan seseorang untuk melihat komponen-komponen descriptive statistic, seperti:
1. Mean 2. Median 3. Maximum 4. Minimum 5. Standard Deviasi 6. Skewness 7. Kurtosis 8. dll
Kemudahan dalam melihat descriptive statistic ini nantinya dapat digunakan untuk interpretasi descriptive statisticnya.
Relevansi
Materi ini relevan dengan praktikum Statistik dalam tahap pengolahan data awal yaitu menyajikan descriptive statistic data.
Learning Outcomes
Dapat membuat descriptive statistic data dengan Eviews.
PENYAJIAN
Analisis deskripsi merupakan analisis yang paling mendasar untuk menggambarkan keadaan data secara umum. Analisis deskripsi ini meliputi beberapa hal sub menu deskriptive
statistic seperti frekuensi, deskriptif, eksplorasi data, tabulasi silang dan analisis rasio.
tenaga kerja (L).
2. Setelah database terbuka maka tahap selanjutnya adalah klik view Æ descriptive
3. Maka akan keluar penyajian descriptive statistic data sebagai berikut:
4. Dari hasil descriptive statistic di atas kita dapat interpretasikan hasil descriptive
a. Buatlah descriptive statistic data dari data berikut: Dimana:
CM : Child Mortality (Angka Kematian Bayi)
PGNP : Gross National Product/ Pendapatan Nasional Bruto Per Kapita FLR : Female Literacy Rate (Tingkat Melek Huruf Perempuan)
Data Observasi Negara X
OBS CM FLR PGNP 1 128 37 1870 2 204 22 130 3 202 16 310 4 197 65 570 5 96 76 2050 6 209 26 200 7 170 45 670 8 240 29 300 9 241 11 120 10 55 55 290 11 75 87 1180 12 129 55 900 13 24 93 1730 14 165 31 1150 15 94 77 1160 16 96 80 1270 17 148 30 580 18 98 69 660 19 161 43 420 20 118 47 1080 21 269 17 290 22 189 35 270 23 126 58 560 24 12 81 4240 25 167 29 240 26 135 65 430 27 107 87 3020 28 72 63 1420 29 128 49 420 30 27 63 19830
DAFTAR PUSTAKA
Maddala, G.S. 2001. Introduction to Econometrics. Third Edition. Chichester: John Wiley&Sons ltd.
Wahyu, Winarno Wing.2007. Analisis Ekonometrika dan Statistika dengan Eviews, Yogyakarta: UPP STIM YKPN.
DENGAN SPSS
PENDAHULUAN
Penyajian dan interpretasi statistic deskriptif data adalah tahap setelah hasil statistic deskriptif didapatkan. Sebelum data itu diolah /diestimasi, data tersebut harus di deskripsikan terdahulu untuk memudahkan dalam membaca data yang diolah. Maka penyajian dan interpretasi data ini menjadi penting dalam tahap pemrosesan data.
Manfaat
Memudahkan seseorang dalam melihat data apa yang digunakan dalam olah data tersebut sehingga tidak terjadi ekspektasi tinggi atau ekspektasi lebih rendah sari sebuah data atau sekumpulan data.
Relevansi
Materi ini berhubungan erat dari materi sebelumnya, relevansinya adalah setelah menemukan haisl statistic deskriptifnya dengan SPSS maka tahap selanjutnya adalah menyajikan maupun menginterpretasikan hasil statistic deskriptif .
Learning Outcome
Dapat membuat interpretasi dari hasil descriptive statistic data SPSS.
PENYAJIAN
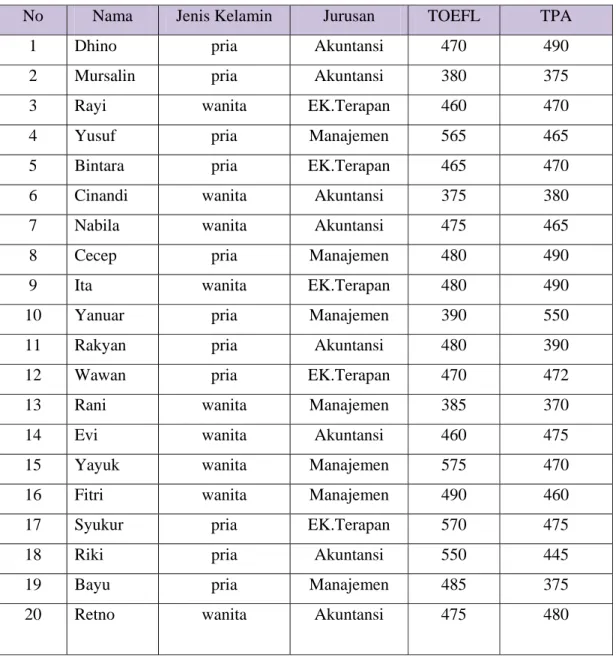
Dalam satu kelas yang sama terdapat 1000 mahasiswa yang berasal dari tiga jurusan yang berbeda, diambil sampel sebanyak 20 mahasiswa yang mengikuti dua tes yang sama yaitu TOEFL dan Tes Potensi Akademik. Saudara diminta untuk menganalisis data dibawah ini menggunakan Deskriptif Statistik (Frequencies, Descriptives, Esplore, Crosstab) dan menyimpulkan informasi apa sajakah yang saudara peroleh dari data yang berada pada tabel dibawah ini
Tabel Nilai TOEFL dan TPA Mahasiswa Diloma Ekonomi SV UGM
No Nama Jenis Kelamin Jurusan TOEFL TPA
1 Dhino pria Akuntansi 470 490
2 Mursalin pria Akuntansi 380 375
3 Rayi wanita EK.Terapan 460 470
4 Yusuf pria Manajemen 565 465
5 Bintara pria EK.Terapan 465 470
6 Cinandi wanita Akuntansi 375 380
7 Nabila wanita Akuntansi 475 465
8 Cecep pria Manajemen 480 490
9 Ita wanita EK.Terapan 480 490
10 Yanuar pria Manajemen 390 550
11 Rakyan pria Akuntansi 480 390
12 Wawan pria EK.Terapan 470 472
13 Rani wanita Manajemen 385 370
14 Evi wanita Akuntansi 460 475
15 Yayuk wanita Manajemen 575 470
16 Fitri wanita Manajemen 490 460
17 Syukur pria EK.Terapan 570 475
18 Riki pria Akuntansi 550 445
19 Bayu pria Manajemen 485 375
20 Retno wanita Akuntansi 475 480
1. Langkah pertama, saudara diminta untuk mengentry data tabel diatas kedalam program SPSS sesuai dengan petunjuk modul !
2. Frequencies
a) Menggunakan data yang sudah ada Pilih menu Analyze >> Descriptive Statistic >> Frequenscies !
Statistics. Langkah ini akan menampilkan kotak dialog seperti gambar
d) Berikan tanda centang pada pilihan Central Tendency, Dispersion dan Distribution.
e) Kemudian, klik Continue, maka anda akan kembali ke kotak dialog Frequencies
f) Klik tab Chart sehingga tampil kotak dialog sebagai berikut
g) Pilih Histograms. Beri centang pada With normal curve. Kemudian, klik Continue. Selanjutnya anda akan kembali ke kotak dialog sebelumnya.
h) Klik OK hasil outputnya sebagai berikut dan simpanlah dalam server yang telah disedialkan dengan nama file NIM_Frequencies.spo
Pembacaan hasil analisis Output Statistics
• N adalah jumlah data; dalam kasus ini jumlah data yang valid ada 20 data dan tidak ada data yang hilang.
• Mean adalah rata-rata nilai TOEFL dari dua puluh mahasiswa yaitu besarnya 474.00
• Standard error of mean, yaitu standar kesalahan untuk populasi yang diperkirakan dari sampel dengan menggunakan ukuran rata-rata. Nilainya sebesar 13.385.
• Median adalah titik tengah, yaitu semua data diurutkan dan dibagi menjadi dua sama besar, dari data yang ada diketahu besarnya median adalah 475.00
jumlah data sama yang paling banyak. Dalam hal ini besarnya mode yaitu 480.00
• Standard Deviation, yaitu ukuran penyebaran data dari rata-ratanya nilainya sebesar 59.859
• Variance, yaitu varian data yang didapat dari kelipatan standar deviasi, nilainya sebesar 3583.158
• Skweness, yaitu ukuran distribusi data. Untuk mengetahui apakah data terdistribusi normal atau tidak maka dihitung rasio skweness dengan standard error of skewness atau 0.002/0.512 =0.003906. Karena besarnya nilai rasio ini berada diantara -2 sampai 2, maka data berdistribusi normal. • Kurtosis, sama halnya dengan skewness, kurtosis juga digunakan untuk
mengetahui data terdistribusi dengan normal atau tidak, maka dihitung rasio kurtosis dengan standard error of kurtosis. Data dapat dikatakan berdistribusi normal jika berada di antara -2 sampai 2.
• Range adalah selisih atau jarak data, yaitu data tertinggi dikurangi dengan data terendah. Nilai range sebesar 200.
• Minimum adalah nilai terendah, dalam hal ini adalah 375 • Maximum adalah nilai tertinggi, dalam hal ini adalah 575 Output Nilai TOEFL
• Dari tabel nilai TOEFL bisa dilihat frequency dari setiap nilai berapakah besarnya persentasenya serta juga dapat dilihat cumulative persentase dari tiap data.
Output Histogram
• Dari hasil analisis data nilai TOEFL diatas dapat dilihat bahwa kurva histogram membentuk seperti lonceng yang tegak tidak condong ke kanan maupun ke kiri, sehingga dpat dikatakan data terdistribusi dengan normal.
3.Descriptive
a) Menggunakan data yang sudah ada Klik Analyze >> Descriptive Statistics >> Descriptives
c) Masukan variable Nilai TOEFL dan Nilai TPA ke kotak Variable(s). Kemudian klik tab Option sehingga akan menampilkan kotak dialog sebagai berikut
d) Klik tab Continue. Langkah ini akan mengembalikan ke kotak dialog sebelumnya.
e) Klik tab OK sehingga akan keluar out put hasil analisa kemudian jelaskan makna output data kemudian simpan dengan nama file NIM_Descriptive.spo
a) Menggunakan data yang sudah ada Klik Analyze >> Descriptive Statistics >> Explore.
b) Setelah itu aka melihat tampilan kotak dialog sebagai berikut.
c) Masukan variable nilai TOFL dan Nilai TPA ke kotak Dependent List. Dan jurusan kedalam factor list
d) Kemudian, klik tab Plots. Langkah ini akan memunculkan kotak dialog sebagai berikut.
e) Karena akan dilakukan uji normalitas data, maka berilah tanda centang pada Normality plots with test. Kemudian klik tab Continue maka akan kembali ke dialog sebelumnya.
f) Klik tab OK dan analisislah tabel yang muncul kemudian simpanlah dengan nama File NIM_Explore.spo
g) Untuk melakukan analisis statistic lebih lanjut seperti idependent sample t test, korelasi bivariate, regresi dan analisis lain yang akan dibahas dibab lebih lanjut maka syaratnya data harus terdistribusi secara normal. Tes normalitas dilakukan dengan menggunakan uji Kolmogrorov-Smirnov dengan criteria pengujian sebagai berikut:
Signifikansi > 0.05, maka data terdistribusi normal.
Begitu juga nilai TOEFL untuk jurusan Manajemen mempunyai signifikansi sebesar lebih besar dari 0.05 (0.200>0.05) maka data juga dapat dikatakan terdistribusi normal sedangkan untuk Nilai TOEFL jurusan EK.Terapan nilainya lebih kecil dari 0.05 (0.019<0.05) maka bisa dikatakan data tidak terdistribusi dengan normal.
5. Crosstab
a) Menggunakan data yang sudah ada Klik Analyze >> Descriptive Statistics >> Crostabs setelah itu anda akan melihat tampilan kotak dialog sebagai berikut
-b) Masukan variable Jenis kelamin ke kotak Row(s), sedangkan variabel jurusan ke kotak Column(s). Kemudian Klik tab Statistics. Langkah ini menampilkan kotak sebagai berikut.
c) Sebagai latihandasar maka kosongkanlah semua kotak dialog dan tab Continue untuk kembali ke kotak dialog awal.
d) Klik lah OK analisislah hasil output dan simpan dengan nama file NIM_CROSTAB.Spo
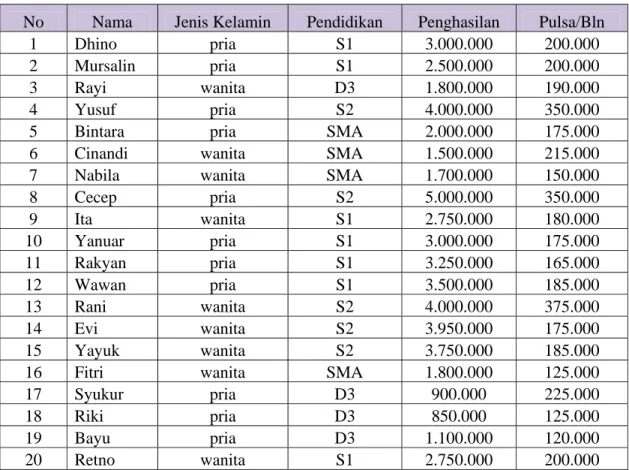
a. Buatlah penyajian dan interpretasi descriptive statistic dari data berikut: Tabel Data Jenis Kelamin, Pendidikan, Penghasilan dan Pemakaian Pulsa
No Nama Jenis Kelamin Pendidikan Penghasilan Pulsa/Bln
1 Dhino pria S1 3.000.000 200.000
2 Mursalin pria S1 2.500.000 200.000
3 Rayi wanita D3 1.800.000 190.000
4 Yusuf pria S2 4.000.000 350.000
5 Bintara pria SMA 2.000.000 175.000
6 Cinandi wanita SMA 1.500.000 215.000
7 Nabila wanita SMA 1.700.000 150.000
8 Cecep pria S2 5.000.000 350.000 9 Ita wanita S1 2.750.000 180.000 10 Yanuar pria S1 3.000.000 175.000 11 Rakyan pria S1 3.250.000 165.000 12 Wawan pria S1 3.500.000 185.000 13 Rani wanita S2 4.000.000 375.000 14 Evi wanita S2 3.950.000 175.000 15 Yayuk wanita S2 3.750.000 185.000
16 Fitri wanita SMA 1.800.000 125.000
17 Syukur pria D3 900.000 225.000
18 Riki pria D3 850.000 125.000
19 Bayu pria D3 1.100.000 120.000
20 Retno wanita S1 2.750.000 200.000
b. Serahkan pekerjaan kepada instruktur!
DAFTAR PUSTAKA
Douglas, AL, et.al. 2005. Statistical Technique in Business and Economics. Mc.Graw-Hill Companies.
Priyatno, Duwi. 2009. 5 Jam Belajar Olah Data Dengan SPSS 17. Edisi satu. Yogyakarta: Penerbit Andi
Santoso. S. 2010. Mastering SPSS 18. Jakarta : PT.Elex Media Komputindo
Wahana Komputer. 2010. Mudah Belajar Statistik dengan SPSS 18. Edisi satu.Yogyakarta: Penerbit Andi
BAB VII
PENYAJIAN DAN INTERPRETASI DESCRIPTIVE STATISTIC DATA DENGAN EVIEWS
PENDAHULUAN
Penyajian dan interpretasi statistic deskriptif data adalah tahap setelah hasil statistic deskriptif didapatkan. Sebelum data itu diolah /diestimasi, data tersebut harus di deskripsikan terdahulu untuk memudahkan dalam membaca data yang diolah. Maka penyajian dan interpretasi data ini menjadi penting dalam tahap pemrosesan data.
Manfaat
Memudahkan seseorang dalam melihat data apa yang digunakan dalam olah data tersebut sehingga tidak terjadi ekspektasi tinggi atau ekspektasi lebih rendah sari sebuah data atau sekumpulan data.
Relevansi
Materi ini berhubungan erat dari materi sebelumnya, relevansinya adalah setelah menemukan haisl statistik deskriptifnya dengan Eviews maka tahap selanjutnya adalah menyajikan maupun menginterpretasikan hasil statistic deskriptif .
Learning Outcome
PENYAJIAN
Penyajian Descriptive Statistic ini penting untuk memudahkan seseorang menginterpretasikan hasil descriptive statistic. Langkah-langkah yang dapat digunakan adalah sebagai berikut:
1. Buka hasil Descriptive Statistic dari hasil sebelumnya
2. Dari hasil yang sudah ada dapat ditarik beberapa poin yaitu mean, median, maksimum, minimum, standar deviasi, dll untuk masing-masing variabel. Dari poin tersebut seseorang mampu menginterpretasikan hasil descriptive statistic per masing-masing data.
3. Contoh :
Rata-rata produksi yang dihasilkan oleh Perusahaan X adalah sebesar 97,80 Milyar. Rata-rata Modal per tahun yang digunakan untuk berproduksi Perusahaan X adalah 196,80 Milyar.
Dari tahun 1961 hingga 1987 maksimum jumlah produksi yang mampu dihasilkan Perusahaan X adalah sebesar 138,84 Milyar.
Dari tahun 1961 hingga tahun 1987 minimum produksi yang pernah dialami Perusahaan X adalah 35,85 Milyar.
PENUTUP Tugas
a. Interpretasikan hasil Descriptive Statistic data berikut ini, Diketahui Y adalah Pendapatan dan C0N adalah jumlah konsumsi yang dikeluarkan. Di mana Besarnya konsumsi dipengaruhi oleh pendapatan.
b. Serahkan pekerjaan Saudara kepada Instruktur!
DAFTAR PUSTAKA
Maddala, G.S. 2001. Introduction to Econometrics. Third Edition. Chichester: John Wiley&Sons ltd.
Wahyu, Winarno Wing.2007. Analisis Ekonometrika dan Statistika dengan Eviews, Yogyakarta: UPP STIM YKPN.
BAB VIII
PENGENALAN PEMBUATAN MODEL PENELITIAN DAN HIPOTESIS
PENDAHULUAN
Pembuatan model penelitian sangat penting dalam tahap awal olah data. Data tidak dapat diolah
jika model penelitiannya belum ditentukan. Setelah model ditentukan maka tahap selanjutnya
adalah membuat hipotesis penelitian. Hipotesis penelitian ini dibuat harus mengacu pada model
penelitian, keduanya saling berkaitan dan tak terpisahkan.
Manfaat
Manfaat materi ini adalah memudahkan penentuan data mana yang harus diolah dan apa yang
harus dilakukan setelah olah data.
Relevansi
Materi ini merupakan tahap awal sebelum proses pengolahan data secara statistik. Di mana
penentuan model dan hipotesis adalah acuan kita untuk mengolah data. Data tidak dapat diolah
jika model dan hipotesis belum dibuat.
Learning Outcome
Mahasiswa mampu membuat model penelitian dan hipotesis.
PENYAJIAN
A. Pembuatan Model Penelitian
Fungsi model konseptual menurut Jan Jonker, dkk (2011) antara lain :
1. Fungsi pertama dari model Konseptual sangat erat hubungannya dengan teori
referensi/litelatur yang digunakan. Dengan bantuan model konseptual, peneliti
dapat menunjukkan bagaimana melihat fenomena yang diketengahkan dalam
penelitiannya. Konsep-konsep teoritis yang digunakan untuk membangun model
konseptual memberikan persfektif atau sebuah cara untuk melihat fenomena
empiris.
2. Fungsi kedua adalah pembangunan model dapat membantu dalam penataan
masalah, mengidentifikasi faktor-faktor relevan, dan kemudian memberikan
koneksi yang membuatnya lebih mudah untuk memetakan bingkai masalahnya.
Jika dipetakan dengan benar, maka model konseptual dapat menjadi representasi
yang benar dari fenomena yang sedang dipelajari. Selanjutnya model tersebut
akan membantu menyederhanakan masalah dengan mengurangi jumalh properti
yang harus disertakan, sehingga lebih mudah berfokus untuk hal-hal yang hakiki.
3. Fungsi ketiga adalah menghubungkannya ke dalam sistem teori.
Karakteristik Model Konseptual menurut Jan Jonker, dkk (2011) antara lain :
1. Model Konseptual merupakan konstruksi verbal atau visual yang membantu
untuk membedakan antara apa yang penting dan apa yang tidak
2. Sebuah model menawarkan kerangka kerja yang menggambarkan (secara logis)
hubungan kausal antara faktor-faktor yang berkaitan. Model konseptual dapat
mempromosikan hal yang masuk akal atau makna dalam situasi tertentu
3. Model konseptual menciptakan realitas dalam aarti pemahaman kolektif. Karena
model konseptual didasarkan pada bahasa yang berasal dari pengertian teoritis
Model konseptual dibangun berdasarkan teori atau setidaknya pengertian teoritis. Tanpa
masukan teoritis, maka mustahil untuk membuat konstruksi yang berfokus dari sebuah
realitas yang terjadi. Teori memberitahu kepada kita dimana harus mencari, apa yang
harus dicari, dan bagaimana melihat suatu masalah.
Latihan:
Suatu kecamatan ingin melihat pengaruh pendapatan setiap keluarga terhadap besaran
konsumsi yang dikeluarkan setiap keluarga per bulan.
Maka buatlah model berdasarkan ilustrasi di atas. Catatan : model yang dibentuk harus
berdasarkan teori yang ada.
Jawab:
Berdasarkan teori konsumsi bahwa pengeluaran konsumsi dipengarhi oleh pendapatan
seseorang. Maka model yang dibentuk adalah:
Y
C =
α
+β
Dimana:
C : konsumsi setiap keluarga/bulan
Y : pendapatan setiap keluarga/bulan
B. Pembuatan Hipotesis
“yakinlah secara logis dengan kerangka teoritis ilmiah dan buktikan secara empiris
dengan pengumpulan data yang relevan : Jujun S. Suriasumantri, 2003)
Hipotesis merupakan dugaan atau jawaban sementara terhadap permasalahan yang
diajukan. Seperti diketahui, pada umumnya metode ilmiah yang disimpulkan dalam dua
langkah utama yaitu, pertama mengajukan hipotesis yang merupakan kerangka teoritis
yang secara deduktif dijalin dari pengetahuan yang dapat diandalkan, dan kedua,
pengumpulan data empiris untuk menguji apakah kenyataan yang sebenarnya mendukung
atau menolak hipotesis (Jujun, S, Suriasumantri, 2003)
Cara merumuskan hipotesa ialah dengan tahapan sebagai berikut: rumuskan hipotesa
penelitian, hipotesa operasional, dan hipotesa statistik.
a. Hipotesa penelitian ialah hipotesa yang kita buat dan dinyatakan dalam
bentuk kalimat.
Contoh:
- Ada hubungan antara gaya kepempininan dengan kinerja pegawai
- Ada hubungan antara promosi dan volume penjualaan
b. Hipotesa operasional ialah mendefinisikan hipotesa secara operasional
variable-variabel yang ada didalamnya agar dapat dioperasionalisasikan.
Misalnya “gaya kepemimpinan” dioperasionalisasikan sebagai cara
memberikan instruksi terhadap bawahan. Kinerja pegawai
dioperasionalisasikan sebagai tinggi rendahnya pemasukan perusahaan.
Hipotesa operasional dijadikan menjadi dua, yaitu hipotesa 0 yang bersifat
netral dan hipotesa 1 yang bersifat tidak netral. Maka bunyi hipotesanya:
H0: Tidak ada hubungan antara cara memberikan instruksi terhadap
bawahan dengan tinggi – rendahnya pemasukan perusahaan
H1: Ada hubungan antara cara memberikan instruksi terhadap bawahan
dengan tinggi – rendahnya pemasukan perusahaan
c. Hipotesa statistik ialah hipotesa operasional yang diterjemahkan kedalam
bentuk angka-angka statistik sesuai dengan alat ukur yang dipilih oleh
peneliti. Dalam contoh ini asumsi kenaikan pemasukan sebesar 30%,
maka hipotesanya berbunyi sebagai berikut:
H0: P = 0,3
H1: P tidak sama dengan 0,3
Uji Hipotesa
Hipotesa yang sudah dirumuskan kemudian harus diuji. Pengujian ini akan
membuktikan H0 atau H1 yang akan diterima. Jika H1 diterima maka H0
ditolak, artinya ada hubungan antara cara memberikan instruksi terhadap
bawahan dengan tinggi – rendahnya pemasukan perusahaan.
Latihan
Berdasarkan teori konsumsi bahwa pengeluaran konsumsi dipengarhi oleh pendapatan
seseorang. Maka model yang dibentuk adalah:
Y
C =
α
+β
Dimana:
C : konsumsi setiap keluarga/bulan
Y : pendapatan setiap keluarga/bulan
Maka untuk membuat hipotesis untuk variabel pendapatan adalah:
Ho = Pendapatan tidak berpengaruh terhadap konsumsi
H1 = Pendapatan berpengaruh terhadap konsumsi
PENUTUP
Tugas
Jumlah barang X yang diminta dipengaruhi oleh harga barang X, harga barang Y, Pendapatan
seseorang. Jika harga barang X adalah Px, harga barang Y adalah Py, dan pendapatan seseorang
adalah I maka,
a. Teori apakah yang dapat diacu untuk membuat model
b. Buatlah model sesuai dengan teori
c. Buatlah hipotesis dari model ini
d. Serahkan pekerjaan Saudara kepada instruktur!
DAFTAR PUSTAKA
Douglas, AL, et.al. 2005. Statistical Technique in Business and Economics. Mc.Graw-Hill
Companies,
Gujarati, Damodar N. 2003.Basic Econometrics 4th edition.Singapore: Mc Graw Hill.
Jan Jonker, Bartjan J.W. Pennink, Sari Wahyuni. 2011. Metodologi Penelitian. Panduan Untuk
Master Ph.D di bidang Manajemen. Jakarta : Salemba Empat
Jujun S. Suriasumantri. 2003. Filsafat Ilmu. Sebuah Pengantar Populer. Jakarta : Pustaka Sinar
Harapan
Maddala, G.S. 2001. Introduction to Econometrics. Third Edition. Chichester: John Wiley&Sons
ltd,
BAB IX
OLAH DATA: ORDINARY LEAST SQUARES (OLS) DENGAN SPSS
PENDAHULUAN
Olah data dengan analisis regresi adalah salah satu analisis yang paling populer dan luas pemakaiannya terutama dengan metode Ordinary Least Squares (OLS). OLS ini sering digunakan untuk mengolah data secara statistik.
Manfaat
Olah data OLS dengan SPSS digunakan untuk pengolahan data secara sederhana. Hampir seluruh ilmu memerlukan dan menggunakan olah data OLS ini terutama dalam memecahkan masalah-masalah penelitian sederhana.
Relevansi
Materi ini relevan dan menjadi aplikasi pokok dalam statistik terutama kaitannya dengan olah data sederhana.
Learning Outcome
Dapat mengolah data sesuai model menggunakan OLS di SPSS
PENYAJIAN
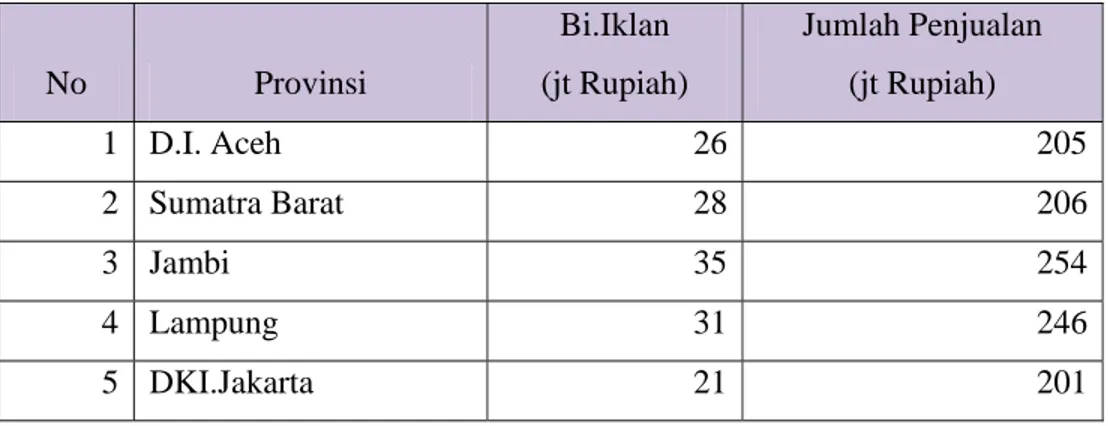
Sebuah perusahaan Otomotif dalam negri beberapa bulan ini gencar mempromosikan produk barunya yaitu motor roda tiga dengan bak angkut Sebagai sampel untuk meneliti populasi pengaruh biaya iklan terhadap besarnya penjualan di seluruh Propinsi di Indonesia diambil sampel dari 20 Propinsi dengan data sebagai berikut:
Tabel Jumlah Biaya Iklan dan Jumlah Penjualan
No Provinsi Bi.Iklan (jt Rupiah) Jumlah Penjualan (jt Rupiah) 1 D.I. Aceh 26 205 2 Sumatra Barat 28 206 3 Jambi 35 254 4 Lampung 31 246 5 DKI.Jakarta 21 201
8 DIY 30 209 9 Jawa Timur 24 204 10 Bali 31 216 11 NTB 32 245 12 NTT 47 286 13 Kalimantan Selatan 54 312 14 Kalimantan Timur 40 265 15 Kalimantan Tengah 42 322 16 Kalimantan Barat 48 298 17 Sulawesi Tenggara 47 295 18 Sulawesi Utara 48 350 19 Sulawesi Selatan 50 365 20 Papua Barat 52 375
1. Langkah pertama, saudara diminta untuk mengentry data tabel diatas kedalam program SPSS sesuai dengan petunjuk modul !
2. Regression Linier
a) Menggunakan data yang sudah ada Pilih menu Analyze >> Regression >> Liniear !
c) Dependent atau variable tergantung. Karena variable yang akan diprediksi adalah variable Penjualan, maka masukan variable penjualan pada kotak DEPENDENT.
d) Independent(s) atau variable bebas, dalam hal ini variable bebas adalah bi.iklan. Maka masukan variable Bi.Iklan ke kotak Independent.
e) Case Labels atau keterangan pada kasus. Karena kasus didasarkan pada Provinsi, maka masukan variabel Provinsi ke kotak Case Labels.
f) Method pilih enter, yaitu prosedur pemilihan variable dimana semua variable dalam blok dimasukan dalam perhitungan ‘sigle step’
standar angka probabilitas sebesar 5%. Karena itu angka entry 0.05 atau 5%
• Include Constant in equation biarkan tetap aktif • Klik continue
h) Pilih Kolom Statistics dengan klik mouse
Pilihan ini berkenaan dengan perhitungan statistik regresi yang akan digunakan. Pengisian:
• Regression Coefisient atau perlakukan koefisien regresi, tetap aktifkan pilihan estimate
• Klik Descriptive pada kolom sebelah kanan, serta tetap aktifkan model fit
• Residual, klik Casewise diagnostics dan pilih all cases untuk melihat pengaruh regresi terhadap semua provinsi.
• Klik Continue
i) Pilih Plot, fasilitas ini berguna untuk menguji asumsi-asumsi pada regresi, seperti normalitas, linieritas, kesamaan varians dan juga dapat digunakan untuk mendeteksi ada tidaknya data yang tidak normal.
j) Direncanakan ada tiga plot sehubungan dengan pengujian asumsi pada analisis regresi:
1. klik mouse pada pilihan SDRESID dan masukan ke pilihan Y, lalu klik lagi pada pilihan ZPRED dan masukan ke X kemudian klik Next untuk plot kedua.
2. klik ZPRED masukan ke pilihan Y, lalu klik lagi DEPENDNT dan
masukan ke pilihan X kemudian klik Next. Plot pertama dan kedua digunakan untuk menguji linieritas dan kesamaan varians
3. untuk plot ketiga, pada pilihan Standardized Residual Plots, klik mouse pada Normal Probability Plot klik Continue lalu tekan OK. Plot ketiga digunakan untuk menguji normalitas
Analisis
• Rata-rata penjualan dari 20 Provinsi adalah 268.95 jt dengan standard deviasi 56.127 jt
• Rata-rata biaya iklan adalah sebesar 38.25 jt dengan standard deviasi sebesar 10.508 Jt
• Besar hubungan antarvariabel penjualan dengan bi. iklan yang dihitung dengan koefisien korelasi adalah 0.910. Hal ini menunjukan bahwa bi.iklan dan penjualan memiliki hubungan yang sangat erat dengan hubungan positif yang artinya semakin besar bi.iklan maka semakin besar pula penjualan yang didapat. • Tingkat signifikansi koefisien korelasi satu sisi dari output
menghasilkan angka 0.000, karena probabilitasnya lebih kecil dari 0.05 maka korelasi antara bi.iklan dengan penjualan sangat nyata.
• Tabel pertama menunjukan variable yang dimasukan adalah bi.iklan dan tidak ada variable yang dikeluarkan. Hal ini disebabkan metode yang dipakai adalah sigle step (enter) dan bukan stepwise.
• Angka R square adalah 0.829 adalah pengkuadratan dari koefisien korelasi. R square bisa disebut koefisien determinasi , yang dalam hal ini berarti 82.9% dari penjualan perusahaan bisa dijelaskan oleh variable bi.iklan. dan sisanya dijelaskan sebab lain. Semakin kecil R Square, semakin lemah hubungan kedua variable.
• Standard Error of Estimate adalah 23.848 jt, pada analisis sebelumnya standard deviasi penjualan nilainya 56.127jt karena lebih kecil dari standard deviasi penjualan, maka model regresi lebih bagus sebagai predictor atau peramal penjualan daripada menggunakan rata-rata.
dengan tingkat signifikansi 0.000.Karena probabilitas 0.000 lebih kecil dari 0.05, maka bisa dikatakan model regresi dapat
digunakan sebagai alat prediksi penjualan.
• Tabel selanjutnya menggambarkan persamaan rgresi Y= 82.924 + 4.863X
Y= Penjualan X= Bi.iklan
Konstanta sebesar 82.924 menyatakan bahwa jika tidak ada biaya promosi, maka penjualan adalah sebesar 82.924 jt
Koefisien regresi sebesar 4.863 menyatakan bahwa setiap penambahan biaya iklan 1jt maka penjualan akan meningkat sebesar 4.863jt demikian sebaliknya
• Uji t untuk menguji signifikansi konstanta dan variable dependen Dalam contoh ini kita akan menguji koefisien regresi dari variable Bi.iklan.
Hipotesis kasus ini:
Ho = Koefisien regresi tidak significant Hi = Koefisien regresi signifikan Pengambilan keputusan Berdasarkan Probabilitas
• Jika probabilitas > 0.025 (karena menggunakan uji 2sisi), Maka Ho diterima
• jika probabilitas < 0.025, Maka Ho ditolak Keputusan:
Terlihat bahwa pada kolom Sig/significance adalah 0.000 atau dibawah <0.025 maka Ho ditolak atau koefisien regresi signifikan atau Bi.iklan benar-benar berpengaruh secara signifikan terhadap penjualan
4. Output ketujuh
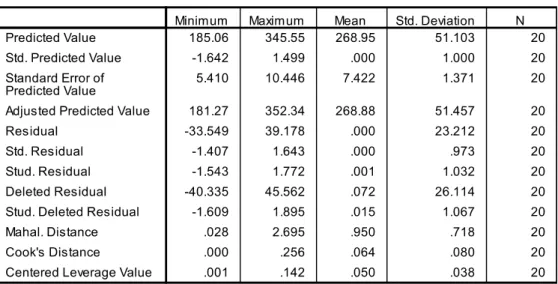
Pada tabel output ke tujuh ini berjudul Casewise Diagnostics
Dari tabel ini kita dapat melihat antara selisih nilai penjualan yang diramalkan dengan nilai penjualan aslinya misanya:
Diprovinsi Aceh penjualan yang diramalkan menggunakan persamaan regresi nilainya sebesar 209.37jt sedangkan nilai aslinya yaitu 205 jt sehingga selisihnya 4.373jt.
Semakin kecil Std.Residual maka semakin baik persamaan regresi dalam memprediksi data.
Pada tabel ini berjudul Residual Statistics, tabel ini memuat ringkasan yang berisi nilai minimum, maksimum, mean dan standar deviasi dari nilai yang prediksi.
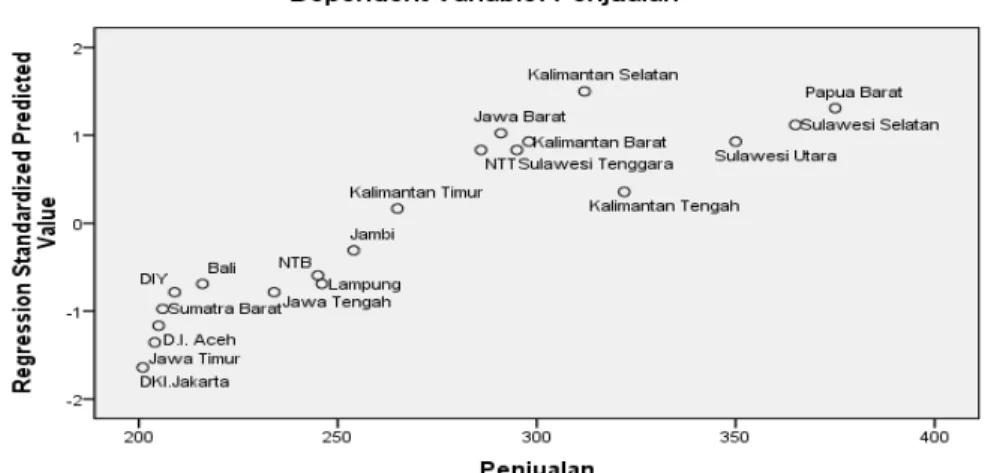
6. Output Bagian Gambar
• Persyaratan NORMALITAS
Jika data berasal dari distribusi normal maka nilai-nilai sebaran data terletak disekitar garis lurus dan dari gambar diatas terlihat bahwa sebaran sebagian besar berada di garis lurus. Maka bisa dikatakan bahwa persyaratan Normalitas bisa terpenuhi.
• Persyaratan Kelayakan Model Regresi (Model Fit)
Jika model regresi layak untuk dipakai untuk prediksi (fit), maka data akan berpencar disekitar angka nol (0 dalam sumbu Y) dan tidak membentuk pola atau garis tertentu. Dari chart diatas terlihat sebaran data ada disekitar 0 serta tidak tampak adanya suatu pola tertentu dari sebaran. Maka bisa dikatakan model regresi memenuhi syarat untuk memprediksi penjualan.
• Persyaratan Model Fit tiap data
Jika model memenuhi syarat, maka sebaran data akan berada mulai dari kiri bawah lurus kearah kanan atas. Terlihat sebaran data dibawah ini membentuk arah seperti yang disyaratkan. Oleh karena itu dapat dikatakan model regresi sudah layak digunakan.
PENUTUP Tugas
a. Dari Seluruh Provinsi yang ada di Indonesia diambil 20 Sampel untuk meneliti seberapa besar pengaruh Pendapatan Pajak Reklame terhadap Jumlah Pendapatan Daerah, hasil penelitian ii nantinya akan digunakan oleh Pemerintah Daerah sebagai dasar penentuan strategi yang tepat guna meningkatkan pendapatan daerah. Oleh karena itu olah data di bawah ini dengan menggunakan Ordanary Least Square (OLS).
Tabel Pajak Reklame Serta Jumlah Pendapatan Daerah
No Provinsi Retribusi jt (Rupiah) Jumlah Pendapatan Daerah (jt Rupiah) 1 D.I. Aceh 2700 20600 2 Sumatra Barat 2600 20400 3 Jambi 3600 25500 4 Lampung 3150 24650 5 DKI.Jakarta 2250 22000 6 Jawa Barat 4950 29200 7 Jawa Tengah 3550 24500 8 DIY 3000 20900 9 Jawa Timur 2400 20400 10 Bali 3100 21600 11 NTB 3200 24500 12 NTT 4700 28600 13 Kalimantan Selatan 5400 31200
14 Kalimantan Timur 4000 26500 15 Kalimantan Tengah 4200 32200 16 Kalimantan Barat 4850 29900 17 Sulawesi Tenggara 4750 29000 18 Sulawesi Utara 4800 35000 19 Sulawesi Selatan 5500 37500 20 Papua Barat 5200 37500
b. Serahkan pekerjaan Saudara kepada Instruktur!
DAFTAR PUSTAKA
Dajan, Anto. 1974. Pengantar Metode Statistik. Jilid I. Jakarta: LP3ES
Priyatno, Duwi. 2009. 5 Jam Belajar Olah Data Dengan SPSS 17. Edisi satu. Yogyakarta: Penerbit Andi
Santoso. S. 2010. Mastering SPSS 18. Jakarta : PT.Elex Media Komputindo
Subagyo.P dan Ps.Djarwanto. 2005. Statistik Induktif. Edisi Lima. Yogyakarta: BPFE
Wahana Komputer. 2010. Mudah Belajar Statistik dengan SPSS 18. Edisi satu. Yogyakarta: Penerbit Andi