BAB III
METODOLOGI PENELITIAN
3.1. Pendahuluan
Pada algoritma K-Means, penentuan jumlah cluster dan penentuan centroid (pusat) merupakan hal yang cukup sulit untuk dilakukan. Penentuan jumlah cluster dan penentuan centroid (pusat) mempengaruhi secara langsung kualitas dari proses
clustering.
Metode Hybrid Clustering yang dikenal sebagai GenClust yang menggabungkan pemakaian algoritma K-Means dengan Algoritma Genetika. Algoritma Genetika digunakan untuk menentukan jumlah cluster dan juga centroid dari tiap
cluster. Penggunaan metode GenClust dapat menghindarkan algoritma K-Means di dalam terjebak di dalam kondisi local optima.
Perlu dilakukan pengujian penentuan jumlah cluster dan juga penentuan
centroid menggunakan GenClust dan membandingkannya dengan K-Means klasik pada suatu dataset berukuran besar. Dataset yang ada menggunakan UCI Machine Learning Repository.
UCI Machine Learning Repository adalah sebuah koleksi database, domain teori, dan data generator yang digunakan oleh komunitas yang mempelajari mesin pembelajaran (machine learning), untuk keperluan analisis empiris dari algoritma
machine learning. Dataset yang tersedia pada UCI Machine Learning Repository
digunakan oleh pelajar, pendidik, dan peneliti diseluruh dunia sebagai sumber utama dari data set pada machine learning. Jumlah data set yang tersedia pada UCI Machine Learning Repository pada saat ini sudah berjumlah 320 data set yang dapat digunakan sesuai dengan kebutuhan pada pembelajaran machine learning.
Proses Algoritma GenClust:
a. Penentuan Jarak Objek ke
Centroid
Data yang digunakan merupakan data benchmark Iris Data Setyang diambil dari UCI Machine Learning Repository.
Iris Data set merupakan data set yang banyak digunakan di dalam permasalahan pengenalan pola. Atribut informasi yang ada pada Iris Data Set adalah terdiri-dari: Sepal Length, Sepal Width, Petal Length, dan Petal Width. Iris Data Set
memiliki 3 class yaitu: Iris Setosa, Iris Versicolour, dan Iris Virginica.
Pengukuran performance pada penelitian ini menggunakan metode Mean Square Error (MSE). Adapun persamaan untuk mengukur Mean Square Error (MSE) dapat dilihat pada Persamaan 3.1.
MSE = (3.1)
Dimana:
X = Nilai aktual atau sebenarnya Y = Nilai yang tercapai
3.3. Analisis Data
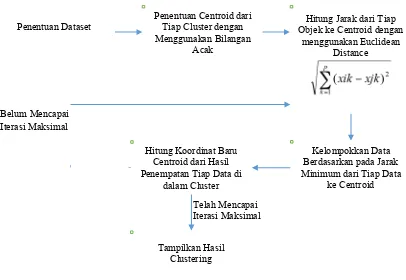
Adapun prosedur kerja yang dilakukan oleh penulis dari penelitian ini dapat dilihat secara keseluruhan pada Gambar 3.1:
Hitung Jarak dari Tiap
Adapun blok diagram dari Algoritma K-Means Klasik dapat dilihat pada Gambar 3.2.
Gambar 3.2. Tahapan ProsesAlgoritma K-Means
Pada Gambar 3.2. dapat dilihat bahwa pada algoritma K-Means klasik terdapat sejumlah tahapan sebagai berikut.
1. Penentuan Dataset
Dataset yang digunakan di dalam penelitian ini adalah Iris Dataset. Iris Dataset
memiliki 3 (tiga) class yaitu: Iris Setosa, Iris Versicolor, dan Iris Virginica dan memiliki 4(empat) atribut yaitu: Sepal Length, Sepal Width, Petal Length, dan
Petal Width.
2. Penentuan jumlah cluster dan centroid
Penentuan jumlah cluster dapat disesuaikan dengan permasalahan yang ada dan pada iris dataset yaitu sebanyak 3 cluster. Sedangkan penentuan centroid pada
K-Means dilakukan dengan cara membangkitkan bilangan random. 3. Hitung jarak dari tiap objek ke Centroid
Perkawinan Silang (Crossover) Mutasi Kromosom
Generasi Baru
Nilai Centroid pada K-Means
Setelah diperoleh jarak dari tiap objek ke pusat (centroid) maka langkah selanjutnya adalah dilakukan pengelompokan dari tiap objek berdasarkan jarak minimum yang diperoleh.
5. Hitung koordinat pusat yang baru dari hasil penempatan tiap objek ke dalam
cluster.
6. Jika sudah mencapai iterasi maksimal maka proses akan berhenti.
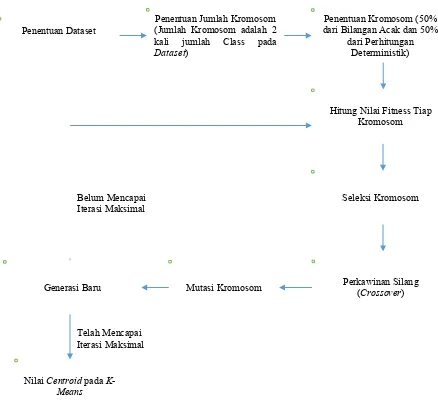
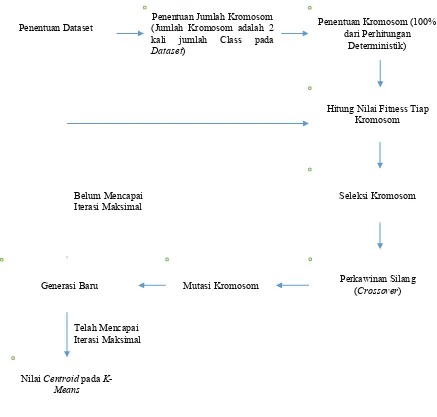
Adapun Blok Diagram dari penentuan centroid pada K-Means dengan menggunakan metode GenClust adalah dapat dilihat pada Gambar 3.3.
Penentuan Dataset
Penentuan Jumlah Kromosom (Jumlah Kromosom adalah 2 kali jumlah Class pada
Dataset)
Penentuan Kromosom (50% dari Bilangan Acak dan 50%
dari Perhitungan Deterministik)
Hitung Nilai Fitness Tiap Kromosom
Seleksi Kromosom Belum Mencapai
Iterasi Maksimal
Pada Gambar 3.3. dapat dilihat bahwa pada metode GenCust terdiri-dari sejumlah tahapan sebagai berikut.
1. Penentuan jumlah kromosom
Jumlah kromosom di dalam suatu populasi disesuaikan dengan jumlah class yang ada pada data set. Jumlah kromosom adalah 2 kali jumlah class di dalam suatu
dataset, dalam hal ini Iris Dataset memiliki 3 (tiga) class maka berarti jumlah kromosom untuk metode GenClust adalah sebanyak 6 kromosom.
2. Penentuan kromosom
Kromosom yang ditentukan adalah 50% dari pembangkitan bilangan acak sedangkan 50% dari perhitungan deterministik. Untuk keperluan penentuan kromosom melalui perhitungan deterministik maka dilakukan melalui sejumlah langkah sebagai berikut (Rahman dan Islam, 2014).
a. Jumlah gen yang dibangkitkan adalah sejumlah jumlah atribut yang ada pada
data set. Sebagai contoh, Iris Data set memili 4 (empat) atribut yaitu: Sepal Length, Sepal Width, Petal Length, dan Petal Width maka berarti jumlah gen yang dibangkitkan adalah sebesar 4 (empat) gen.
b. Tentukan nilai radius r
Nilai r menurut Rahman dan Islam (2014) adalah berkisar dari 0 sampai dengan 0.2. Nilai r tersebut kemudian akan dikalikan dengan nilai atribut terkecil dari
data set.
c. Hitung jarak dari tiap data set ke radius r
Hitung jarak dari tiap data pada data set dengan menggunakan persamaan 3.2. Misalkan terdapat dua record (Data) pada dataset yaitu Ra dan Rb
dist (Ra,Rb) = abs (Rai-Rbi) (3.2) Kemudian hitung nilai dari density dari tiap data set
Density (Ri) = |{Rj: dist (Ri, Rj) ≤ ��; ∀�}| (3.3) Kemudian cari nilai Ri yang memiliki Highest Density
Ri dengan Highest Density = Density (Ri) > Density (Rj);∀� (3.4)
Nilai Fitness Tiap kromosom dapat diperoleh dari nilai error yang diperoleh untuk tiap populasi dan digunakan untuk menentukan kromosom yang akan diseleksi. Nilai error tersebut dikaitkan dengan kesalahan penempatan data pada tiap class data set.
4. Seleksi Kromosom
Tahapan seleksi akan dilakukan dengan menggunakan Roulette Wheel Selection. 5. Perkawinan Silang (Crossover)
Metode crossover yang digunakan adalah arithmetic crossover. Nilai PC yang digunakan adalah ditentukan sebesar 0.25
6. Mutasi Kromosom
Jenis mutasi yang akan digunakan adalah mutasi dengan pengkodean biner. Nilai PM yang digunakan adalah ditentukan sebesar 0.25.
Berdasarkan pada uraian tahapan sebelumnya, maka proses penentuan centroid dengan menggunakan metode GenClust dapat diuraikan sebagai berikut (contoh kasus menggunakan Iris Data Set).
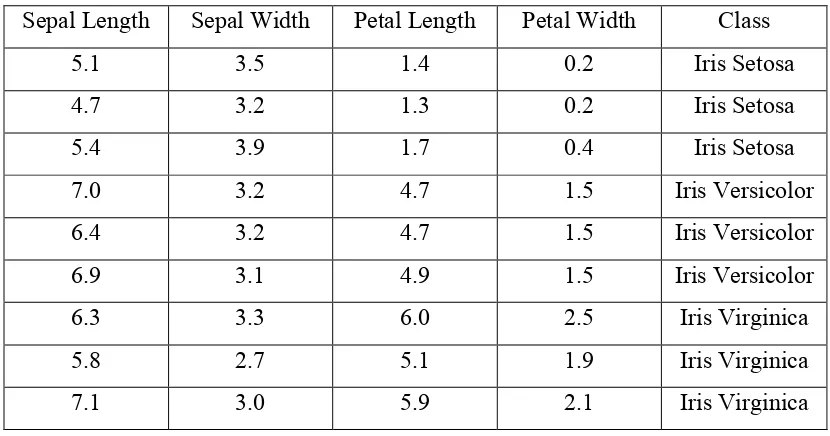
1. Untuk mempermudah pemahaman kita, maka kita misalkan data pada Iris Data set
adalah seperti dapat dilihat pada Tabel 3.1
Tabel 3.1. Contoh Data pada Iris Data Set
Sepal Length Sepal Width Petal Length Petal Width Class
5.1 3.5 1.4 0.2 Iris Setosa
4.7 3.2 1.3 0.2 Iris Setosa
5.4 3.9 1.7 0.4 Iris Setosa
7.0 3.2 4.7 1.5 Iris Versicolor
6.4 3.2 4.7 1.5 Iris Versicolor
6.9 3.1 4.9 1.5 Iris Versicolor
6.3 3.3 6.0 2.5 Iris Virginica
5.8 2.7 5.1 1.9 Iris Virginica
perhitungan deterministik. Jumlah gen untuk tiap kromosom yang dibangkitkan adalah sejumlah jumlah atribut yang ada pada data set. Sebagai contoh, Iris Data set memiliki 4 (empat) atribut yaitu: Sepal Length, Sepal Width, Petal Length, dan
Petal Width maka berarti jumlah gen yang dibangkitkan adalah sebesar 4 (empat) gen.
3. Penentuan Kromosom
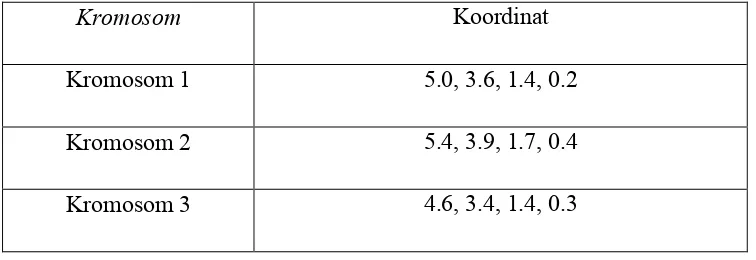
Penelitian mengenai Iris Data Set menggunakan 4 (empat) atribut yaitu: Sepal Length, Sepal Width, Petal Length, dan Petal Width. Berdasarkan data set yang terdapat di dalam Iris Dataset maka Sepal Length memiliki rentang nilai 4.3 sampai 7.9, Sepal Width memiliki rentang nilai 2 sampai 4.4, Petal Length memiliki rentang nilai 1 sampai 6.9, dan Petal Width memiliki rentang nilai 0.1 sampai 2.5. Maka bilangan acak yang dibangkitkan adalah sesuai dengan rentang dari tiap atribut yang ada. Tabel 3.2. menunujukkan kromosomyang dibangkitkan dengan bilangan acak.
Tabel 3.2. Kromosom yang Dibangkitkan dengan Bilangan Acak
Kromosom Koordinat
Kromosom 1 5.0, 3.6, 1.4, 0.2
Kromosom 2 5.4, 3.9, 1.7, 0.4
Kromosom 3 4.6, 3.4, 1.4, 0.3
Sedangkan penentuan kromosom lain yang dibangkitkan dengan menggunakan perhitungan deterministik dapat diuraikan sebagai berikut.
a. Jumlah gen untuk tiap kromosom yang dibangkitkan adalah sebanyak 4. b. Tentukan nilai radius r
Nilai radius r yang ditentukan adalah sebesar 0.2. Nilai radius r ini akan dikalikan dengan nilai atribut terkecil dari tiap atribut, sehingga:
Untuk Sepal Length (Lihat Tabel 3.1)
dist (R1,R2) = abs (R1-R2) = abs (5.1-4.7) = 0.4 dist (R2,R3) = abs (R2-R3) = abs (4.7-5.4) = 0.7 dist (R3,R4) = abs (R3-R4) = abs (5.4-7.0) = 1.6 dist (R4,R5) = abs (R4-R5) = abs (7.0-6.4) = 0.6 dist (R5,R6) = abs (R5-R6) = abs (6.4-6.9) = 0.5 dist (R6,R7) = abs (R6-R7) = abs (6.9-6.3) = 0.6 dist (R7,R8) = abs (R7-R8) = abs (6.3-5.8) = 0.5 dist (R8,R9) = abs (R8-R9) = abs (5.8-7.1) = 1.3
Karena r untuk sepal length = 0.86 maka berarti distance yang dapat diambil adalah distance yang memiliki nilai ≤ 0.86, dengan demikian berarti dist (R3, R4) dan dist (R8, R9) tidak termasuk.
density R1 = density (R1, R2) = 0.4
density R2 = density (R2, R3) = 0.7
density R4 = density (R4, R5) = 0.6
density R5 = density (R5, R6) = 0.5
density R6 = density (R6, R7) = 0.6
density R7 = density (R7, R8) = 0.5
Ambil nilai density tertinggi : 0.7, 0.6, dan 0.5. Maka nilai untuk sepal length
yang akan diambil adalah dari R2, R4, dan R5. Sehingga nilai sepal length
yang akan mengisi 3 (buah kromosom) adalah sebagai berikut.
Nilai sepal length untuk kromosom ke - 1 (dari R2 atau data ke-2 dari Tabel 3.1) = 4.7
Nilai sepal length untuk kromosom ke - 2 (dari R4 atau data ke-4 dari Tabel 3.1) = 7.0
Untuk Sepal Width (Lihat Tabel 3.1)
dist (R1,R2) = abs (R1-R2) = abs (3.5-3.2) = 0.3 dist (R2,R3) = abs (R2-R3) = abs (3.2-3.9) = 0.7 dist (R3,R4) = abs (R3-R4) = abs (3.9-3.2) = 0.7 dist (R4,R5) = abs (R4-R5) = abs (3.2-3.2) = 0 dist (R5,R6) = abs (R5-R6) = abs (3.2-3.1) = 0.1 dist (R6,R7) = abs (R6-R7) = abs (3.1-3.3) = 0.2 dist (R7,R8) = abs (R7-R8) = abs (3.3-2.7) = 0.6 dist (R8,R9) = abs (R8-R9) = abs (2.7-3.0) = 0.3
Karena r untuk sepal width = 0.4 maka berarti distance yang dapat diambil adalah distance yang memiliki nilai ≤ 0.4 dengan demikian berarti dist (R2, R3), dist (R3, R4), dan dist (R7, R8) tidak termasuk.
density R1 = density (R1, R2) = 0.3
density R4 = density (R4, R5) = 0
density R5 = density (R5, R6) = 0.1
density R6 = density (R6, R7) = 0.2
density R8 = density (R8, R9) = 0.3
Ambil nilai density tertinggi : 0.3, 0.2, dan 0.1. Maka nilai untuk sepal width
yang akan diambil adalah dari R1, R6, dan R5. Sehingga nilai sepal width
yang akan mengisi 3 (buah kromosom) adalah sebagai berikut.
Nilai sepal width untuk kromosom ke - 1 (dari R1 atau data ke-1 dari Tabel 3.1) = 3.5
Nilai sepal width untuk kromosom ke - 2 (dari R6 atau data ke-6 dari Tabel 3.1) = 3.1
Untuk petal length (Lihat Tabel 3.1)
dist (R1,R2) = abs (R1-R2) = abs (1.4-1.3) = 0.1 dist (R2,R3) = abs (R2-R3) = abs (1.3-1.7) = 0.4 dist (R3,R4) = abs (R3-R4) = abs (1.7-4.7) = 3 dist (R4,R5) = abs (R4-R5) = abs (4.7-4.7) = 0 dist (R5,R6) = abs (R5-R6) = abs (4.7-4.9) = 0.2 dist (R6,R7) = abs (R6-R7) = abs (4.9-6.0) = 1.1 dist (R7,R8) = abs (R7-R8) = abs (6.0-5.1) = 0.9 dist (R8,R9) = abs (R8-R9) = abs (5.1-5.9) = 0.8
Karena r untuk petal length = 0.2 maka berarti distance yang dapat diambil adalah distance yang memiliki nilai ≤ 0.2 dengan demikian berarti dist (R2, R3), dist (R3, R4), dist (R6, R7), dist (R7, R8) dan dist (R8, R9) tidak termasuk.
density R1 = density (R1, R2) = 0.1
density R4 = density (R4, R5) = 0
density R5 = density (R5, R6) = 0.2
Ambil nilai density tertinggi : 0.2, 0.1, dan 0. Maka nilai untuk petal length
yang akan diambil adalah dari R5, R1, dan R4. Sehingga nilai petal length
yang akan mengisi 3 (buah kromosom) adalah sebagai berikut.
Nilai petal length untuk kromosom ke - 1 (dari R5 atau data ke-5 dari Tabel 3.1) = 4.7
Nilai petal length untuk kromosom ke - 2 (dari R1 atau data ke-1 dari Tabel 3.1) = 1.4
Untuk petal width (Lihat Tabel 3.1)
dist (R1,R2) = abs (R1-R2) = abs (0.2-0.2) = 0 dist (R2,R3) = abs (R2-R3) = abs (0.2-0.4) = 0.2 dist (R3,R4) = abs (R3-R4) = abs (0.4-1.5) = 1.1 dist (R4,R5) = abs (R4-R5) = abs (1.5-1.5) = 0 dist (R5,R6) = abs (R5-R6) = abs (1.5-1.5) = 0 dist (R6,R7) = abs (R6-R7) = abs (1.5-2.5) = 1 dist (R7,R8) = abs (R7-R8) = abs (2.5-1.9) = 0.6 dist (R8,R9) = abs (R8-R9) = abs (1.9-2.1) = 0.2
Karena r untuk petal width = 0.01 maka berarti distance yang dapat diambil adalah distance yang memiliki nilai ≤ 0.01 dengan demikian berarti dist (R2, R3), dist (R3, R4), dist (R6, R7), dist (R7, R8) dan dist (R8, R9) tidak termasuk.
density R1 = density (R1, R2) = 0
density R4 = density (R4, R5) = 0
density R5 = density (R5, R6) = 0
Ambil nilai density tertinggi : 0. Maka nilai untuk petal width yang akan diambil adalah dari R1, R4, dan R5. Sehingga nilai petal width yang akan mengisi 3 (buah kromosom) adalah sebagai berikut.
Nilai petal width untuk kromosom ke - 1 (dari R1 atau data ke-1 dari Tabel 3.1) = 0.2
Nilai petal length untuk kromosom ke - 4 (dari R4 atau data ke-4 dari Tabel 3.1) = 1.5
Nilai petal length untuk kromosom ke - 5 (dari R5 atau data ke-5 dari Tabel 3.1) = 1.5
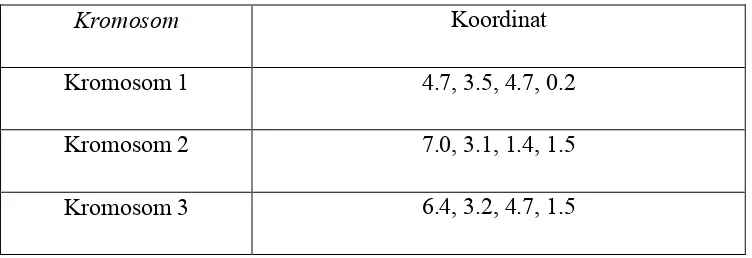
Tabel 3.3. Kromosom yang Diperoleh dari Perhitungan Deterministik
Kromosom Koordinat
Kromosom 1 4.7, 3.5, 4.7, 0.2
Kromosom 2 7.0, 3.1, 1.4, 1.5
Kromosom 3 6.4, 3.2, 4.7, 1.5
Berdasarkan pada Tabel 3.2 dan 3.3. maka kita memiliki suatu populasi yang terdiri dari 6 (enam) buah kromosom yaitu: 3 (tiga) diperoleh dari pembangkitan bilangan acak dan 3 (tiga) dari perhitungan deterministik. d. Hitung Nilai Fitness Tiap Kromosom
e. Lakukan proses seleksi
f. Perkawinan Silang (Crossover) g. Proses Mutasi
Perkawinan Silang (Crossover) Mutasi Kromosom
Generasi Baru
Nilai Centroid pada K-Means
Gambar 3.4. Penentuan Nilai Centroid K-Means dengan Algoritma GenClust yang Dimodifikasi
Pada Gambar 3.4. dapat dilihat bahwa proses penentuan centroid pada K-Means dengan menggunakan algoritma GenClust yang telah dimodifikasi pada dasarnya sama dengan penentuan centroid dengan menggunakan algoritma GenClust. Perbedaannya adalah penentuan kromosom seluruhnya diperoleh melalui perhitungan deterministik.
Penentuan Dataset
Penentuan Jumlah Kromosom (Jumlah Kromosom adalah 2 kali jumlah Class pada
Dataset)
Penentuan Kromosom (100% dari Perhitungan
Deterministik)
Hitung Nilai Fitness Tiap Kromosom
Seleksi Kromosom Belum Mencapai
Iterasi Maksimal
BAB 4
HASIL DAN PEMBAHASAN
4.1. Pendahuluan
Pada penelitian ini akan ditampilkan hasil penilaian performansi sehubungan dengan penentuan centroid pada algoritma K-Means. Penelitian ini akan membandingkan performansi antara penentuan centroid dengan menggunakan algoritma K-Means yang menggunakan penentuan centroid secara acak, penentuan centroid dengan menggunakan algoritma GenClust, dan penentuan centroid dengan menggunakan algoritma K-Means yang telah dimodifikasi. Pengukuran akurasi berdasarkan Mean Square Error. Nilai akurasi akan dinyatakan di dalam bentuk nilai Mean Square Error
yang merupakan nilai rata-rata untuk error berdasarkan pengujian dengan menggunakan jumlah iterasi yang bervariasi, yaitu: 50, 75, dan 100. Nilai MSEyang kecil menunjukkan bahwa hasil proses clustering dengan menggunakan K-Means Clustering telah berhasil mengenali pola yang ada, sebaliknya nilai MSE yang besar menunjukkan bahwa hasil clustering dengan menggunakan K-Means Clustering masih belum mencapai hasil yang diinginkan. Pengujian akan dilakukan dengan menggunakan
Iris dataset yang bersumber dari UCI Machine Learning Repository. Hasil pengujian yang dilakukan oleh peneliti akan disampaikan dalam bentuk tabel.
4.2. Hasil Pengujian dengan Menggunakan Algoritma K-Means Klasik
4.2.1. Pengujian dengan Jumlah Iterasi Sebanyak 50
Pengujian dilakukan sebanyak 10 kali dengan menggunakan 3 cluster dan jumlah iterasi sebesar 5 0untuk melihat nilai MSE dari masing-masing metode perhitungan distance
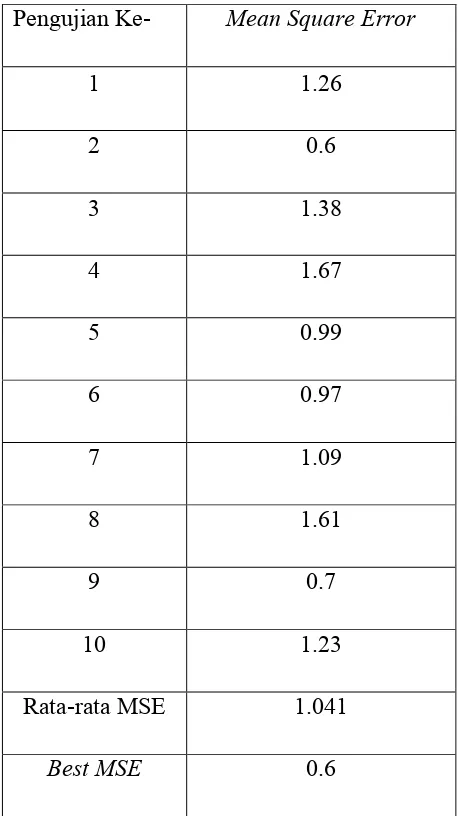
dengan mengambil nilai rata-rata error dengan menggunakan euclidean distance. Pengujian dilakukan sebanyak 10 kali dan hasil pengujian dapat dilihat pada Tabel 4.1.
Tabel 4.1. Pengujian dengan Menggunakan Algoritma K-Means Klasik dengan Jumlah Iterasi Sebesar 50
Pengujian Ke- Mean Square Error
1 1.26
2 0.6
3 1.38
4 1.67
5 0.99
6 0.97
7 1.09
8 1.61
9 0.7
10 1.23
Rata-rata MSE 1.041
Best MSE 0.6
nilai MSE yang terburuk adalah sebesar 1.67. Perbedaan nilai MSE yang cukup besar antara nilai MSE yang terbaik dengan nilai MSE yang terburuk menunjukkan kekurangan dari penentuan centroid dengan menggunakan bilangan acak pada algoritma K-Means klasik.
4.2.2. Pengujian dengan Jumlah Iterasi Sebanyak 75
Pengujian dilakukan sebanyak 10 kali dengan menggunakan 3 cluster dan jumlah iterasi sebesar 75 untuk melihat nilai MSE dari masing-masing metode perhitungan distance
dengan mengambil nilai rata-rata error pada masing-masing metode perhitungan
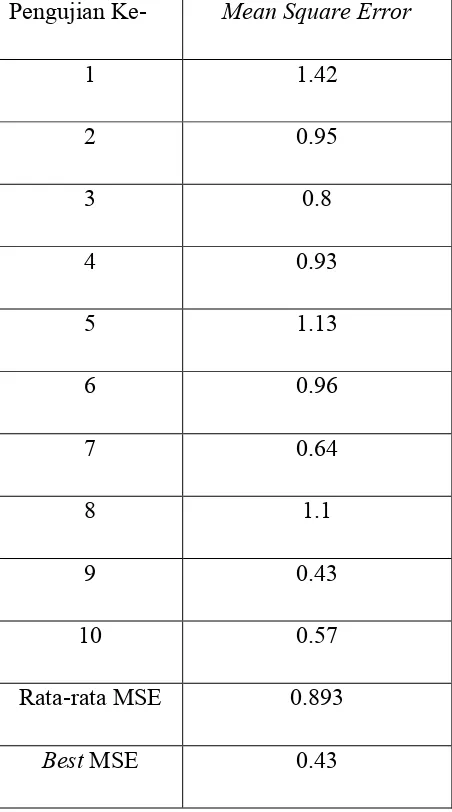
distance dengan metode perhitungan distance yang digunakan adalah Euclidean Distance. Pengujian dilakukan sebanyak 10 kali dan hasil pengujian dapat dilihat pada Tabel 4.2.
Tabel 4.2. Pengujian dengan Menggunakan Algoritma K-Means Klasik dengan Jumlah Iterasi Sebesar 75
Pengujian Ke- Mean Square Error
1 1.42
2 0.95
3 0.8
4 0.93
5 1.13
6 0.96
7 0.64
8 1.1
9 0.43
Dari Tabel 4.2. terlihat bahwa secara umum nilai MSE dapat bervariasi untuk tiap kali pengujian. Pengujian dilakukan sebanyak 10 kali dengan menggunakan 3 cluster dan jumlah iterasi sebesar 75. Hasil pengujian menunjukkan bahwa terdapat peningkatan
performance dibandingkan dengan proses K-Means dengan menggunakan jumlah iterasi sebesar 50 baik yang ditinjau dari sisi rata-rata MSE maupun nilai MSE terbaik yang diperoleh. Nilai MSE terbaik yang diperoleh adalah sebesar 0.43 dan rata-rata nilai MSE yang diperoleh juga lebih baik dibandingkan dengan menggunakan jumlah iterasi sebesar 50 yaitu sebesar 0.893. Nilai MSE terburuk yang diperoleh juga sedikit lebih baik yaitu sebesar 1.42.
4.2.3. Pengujian dengan Jumlah Iterasi Sebanyak 100
Pengujian dilakukan sebanyak 10 kali dengan menggunakan 3 cluster dan jumlah iterasi sebesar 100 untuk melihat nilai MSE dari masing-masing metode perhitungan distance
dengan mengambil nilai rata-rata error dengan metode perhitungan distance
menggunakan euclidean distance. Pengujian dilakukan sebanyak 10 kali dan hasil pengujian dapat dilihat pada Tabel 4.3.
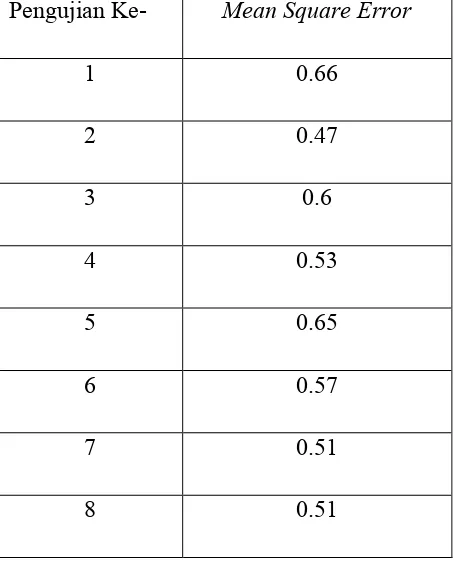
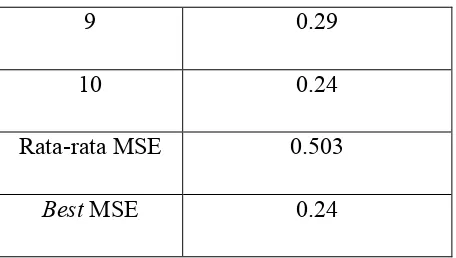
Tabel 4.3. Pengujian dengan Menggunakan Algoritma K-Means Klasik dengan Jumlah Iterasi Sebesar 100
Pengujian Ke- Mean Square Error
1 0.66
2 0.47
3 0.6
4 0.53
5 0.65
6 0.57
9 0.29
10 0.24
Rata-rata MSE 0.503
Best MSE 0.24
Dari Tabel 4.3. terlihat bahwa secara umum nilai MSE dapat bervariasi untuk tiap kali pengujian. Pengujian dilakukan sebanyak 10 kali dengan menggunakan 3 cluster dan jumlah iterasi sebesar 100. Pada pengujian ini juga memperoleh hasil dimana hasil pengujian dengan menggunakan jumlah iterasi sebesar 100 akan memberikan hasil yang lebih baik dibandingkan dengan menggunakan pengujian dengan menggunakan jumlah iterasi sebesar 75 iterasi. Perbaikan yang ada ditunjukkan di dalam nilai rata-rata MSE dan juga nilai MSE terbaik yang diperoleh. Nilai Rata-rata MSE yang diperoleh sudah cukup baik yaitu sebesar 0.503 dan nilai MSE terbaik yang diperoleh juga sudah lumayan bagus yaitu sebesar 0.24
Adapun hasil pengujian secara umum dengan menggunakan algoritma K-Means klasik dapat dilihat pada Tabel 4.4. dan Gambar 4.1.
Tabel 4.4. Hasil Pengujian dengan Menggunakan Algoritma K-Means Klasik
Jumlah Iterasi Average MSE Best MSE
50 1.041 0.6
75 0.893 0.43
100 0.503 0.24
Gambar 4.1. Hasil Pengujian dengan Menggunakan Algoritma K-Means Klasik
Pada Gambar 4.1 terlihat bahwa secara umum pada tiap tahap pengujian dapat memberikan nilai MSE yang berbeda. Perbedaan tersebut disebabkan oleh penentuan
centroid yang dilakukan secara acak, sehingga tidak bisa dipastikan nilai centroid yang akan diperoleh. Pada beberapa tahap pengujian nilai MSE dengan jumlah iterasi 50 dapat lebih baik dibandingkan dengan nilai MSE dengan jumlah iterasi sebesar 75 maupun 100. Sebagai contoh, pada pengujian ke-2 dengan jumlah iterasi sebesar 50 memberikan nilai MSE yang cukup baik yaitu sebesar 0.6. Namun, secara umum jumlah iterasi yang lebih banyak akan memberikan hasil MSE yang lebih baik. Hal ini disebabkan pada algoritma K-Means nilai centroid dapat disesuaikan berdasarkan pada data yang dimasukkan ke dalam suatu cluster. Hal yang menarik untuk dikaji adalah apakah performance yang diberikan akan lebih baik ketika penentuan centroid
dilakukan dengan menggunakan algoritma GenClust maupun dilakukan dengan menggunakan algoritma GenClust yang telah dimodifikasi. Pada tahap selanjutnya kita akan melakukan pengujian dengan menggunakan algoritma GenClust dan algoritma
GenClust yang telah dimodifikasi, dengan jumlah iterasi pada algoritma K-Means yang sama yaitu menggunakan jumlah iterasi sebesar 50, 75, dan 100.
1.26
4.3. Hasil Pengujian dengan Menggunakan Algoritma GenClust
Algoritma GenClust akan digunakan untuk penentuan centroid. Hasil penentuan
centroid dengan menggunakan Algoritma GenClust ini kemudian akan diuji pada algoritma K-Means di dalam mengklasifikasikan Iris Dataset. Perhitungan performance
dinyatakan dengan menggunakan nilai Mean Square Error (MSE). Nilai MSE yang semakin kecil berarti hasil klasifikasi yang diperoleh semakin baik, sebaliknya nilai MSE yang semakin besar berarti hasil klasifikasi yang diperoleh kurang baik. Jumlah iterasi yang digunakan di dalam algoritma K-Means juga sama yaitu menggunakan jumlah iterasi sebesar 50, 75, dan 100
4.3.1. Pengujian dengan Jumlah Iterasi Sebanyak 50
Pengujian dilakukan sebanyak 10 kali dengan menggunakan 6 cluster dan jumlah iterasi sebesar 50 untuk melihat nilai MSE dari masing-masing metode perhitungan distance
dengan mengambil nilai rata-rata error dengan menggunakan euclidean distance. Jumlah cluster sebesar 6 karena 3 cluster menggunakan 3 centroid yang berasal dari penentuan dengan menggunakan algoritma genetika dan 3 centroid yang berasal dari penentuan dengan menggunakan perhitungan deterministik. Pengujian dilakukan sebanyak 10 kali dan hasil pengujian dapat dilihat pada Tabel 4.5.
Tabel 4.5. Pengujian dengan Menggunakan Algoritma GenClust dengan menggunakan Jumlah Iterasi Sebesar 50
Pengujian Ke- Mean Square Error
1 0.47
2 1.087
3 1.39
4 1.14
8 1.12
9 1.01
10 0.87
Rata-rata MSE 0.9637
Best MSE 0.36
Dari Tabel 4.5. terlihat bahwa secara umum nilai MSE dapat bervariasi untuk tiap kali pengujian. Variasi tersebut disebabkan oleh terdapatnya pembangkitan bilangan acak pada algoritma genetika untuk penentuan kromosom dan juga proses yang terjadi pada tahap crossover dan mutasi. Pengujian dilakukan sebanyak 10 kali, hasil pengujian menunjukkan bahwa terdapat perbedaan MSE yang cukup besar antara MSE terbaik dengan MSE terburuk. MSE terbaik adalah sebesar 0.36 dan MSE terburuk adalah sebesar 1.39. Nilai Rata-rata MSE yang diperoleh adalah sebesar 0.9637.
4.3.2. Pengujian dengan Jumlah Iterasi Sebanyak 75
Pengujian dilakukan sebanyak 10 kali dengan menggunakan 6 cluster dan jumlah iterasi sebesar 75 untuk melihat nilai MSE. Jumlah cluster sebesar 6 karena 3 cluster
Tabel 4.6. Pengujian dengan Menggunakan Algoritma GenClust dengan menggunakan Jumlah Iterasi Sebesar 75
Pengujian Ke- Mean Square Error
1 0.45
2 0.65
3 1.12
4 1.12
5 0.4
6 0.85
7 0.93
8 1.05
9 1.16
10 0.45
Rata-rata MSE 0.818
Best MSE 0.4
4.3.3. Pengujian dengan Jumlah Iterasi Sebanyak 100
Pengujian dilakukan sebanyak 10 kali dengan menggunakan 6 cluster dan jumlah iterasi sebesar 100 untuk melihat nilai MSE. Jumlah cluster sebesar 6 karena 3 cluster
menggunakan 3 centroid yang berasal dari penentuan dengan menggunakan algoritma genetika dan 3 centroid yang berasal dari penentuan dengan menggunakan perhitungan deterministik. Pengujian dilakukan sebanyak 10 kali dan hasil pengujian dapat dilihat pada Tabel 4.7.
Tabel 4.7. Pengujian dengan Menggunakan Algoritma GenClust dengan menggunakan Jumlah Iterasi Sebesar 100
Pengujian Ke- Mean Square Error
1 0.42
2 0.45
3 0.37
4 0.48
5 0.39
6 0.48
7 0.36
8 0.96
9 0.36
10 0.79
Rata-rata MSE 0.506
pada algoritma genetika untuk penentuan kromosom dan juga proses yang terjadi pada tahap crossover dan mutasi. Pengujian dilakukan sebanyak 10 kali, hasil pengujian menunjukkan bahwa terdapat perbedaan MSE yang cukup besar antara MSE terbaik dengan MSE terburuk. MSE terbaik adalah sebesar 0.36 dan MSE terburuk adalah sebesar 0.96. Nilai Rata-rata MSE yang diperoleh adalah sebesar 0.506. Nilai rata-rata MSE lebih baik dibandingkan dengan pada pengujian dengan menggunakan jumlah iterasi sebesar 50 dan 75. Namun, nilai Best MSE sama dengan nilai Best MSE pada pengujian dengan 50 iterasi dan lebih baik dibandingkan dengan pengujian dengan menggunakan 70 iterasi.
Adapun hasil pengujian secara umum dengan menggunakan algoritma GenClust dapat dilihat pada Tabel 4.8. dan Gambar 4.2.
Tabel 4.8. Hasil Pengujian dengan Menggunakan Algoritma GenClust
Jumlah Iterasi Average MSE Best MSE
50 0.9637 0.36
75 0.818 0.4
100 0.506 0.36
Gambar 4.2. Hasil Pengujian dengan Menggunakan Algoritma GenClust
Pada Gambar 4.2 terlihat bahwa secara umum pada tiap tahap pengujian dapat memberikan nilai MSE yang berbeda. Variasi tersebut disebabkan oleh terdapatnya pembangkitan bilangan acak pada algoritma genetika untuk penentuan kromosom dan juga proses yang terjadi pada tahap crossover dan mutasi. Pada beberapa tahap pengujian nilai MSE dengan jumlah iterasi 50 dapat lebih baik dibandingkan dengan nilai MSE dengan jumlah iterasi sebesar 75 maupun 100. Sebagai contoh, pada pengujian ke-7 dengan jumlah iterasi sebesar 50 memberikan nilai MSE yang cukup baik yaitu sebesar 0.36. Namun, secara umum jumlah iterasi yang lebih banyak akan memberikan hasil MSE yang lebih baik. Hal ini disebabkan pada algoritma K-Means
nilai centroid yang telah ditentukan dengan menggunakan algoritma GenClust dapat disesuaikan berdasarkan pada data yang dimasukkan ke dalam suatu cluster. Hal yang menarik untuk dikaji adalah apakah performance yang diberikan akan lebih baik ketika penentuan centroid dilakukan dengan menggunakan algoritma yang telah dimodifikasi. Pada tahap selanjutnya kita akan melakukan pengujian dengan algoritma GenClust yang telah dimodifikasi, dengan jumlah iterasi yang sama yaitu menggunakan jumlah iterasi
0.47
4.4. Hasil Pengujian dengan Menggunakan Algoritma GenClust yang Telah
Dimodifikasi
Algoritma GenClust yang telah dimodifikasi akan digunakan untuk penentuan centroid. Hasil penentuan centroid dengan menggunakan Algoritma GenClust yang telah dimodifikasi ini kemudian akan diuji pada algoritma K-Means di dalam mengklasifikasikan Iris Dataset. Modifikasi algoritma GenClust ini dilakukan dengan menggunakan inisialisasi kromosom yang keseluruhan menggunakan perhitungan deterministik. Sehingga berbeda dengan algoritma GenClust sebelumunya. Pada algoritma GenClust jumlah kromosom yang digunakan sebanyak 6 kromosom, yaitu 3 kromosom menggunakan inisialisasi kromosom dari bilangan acak dan 3 kromosom menggunakan perhitungan deterministik. Pada algoritma GenClust yang telah dimodifikasi 6 buah kromosom yang digunakan berasal dari perhitungan deterministik. Kemudian centroid yang diperoleh dari algoritma GenClust yang telah dimodifikasi akan diuji untuk mengklasifikasikan data pada Iris Dataset. Perhitungan performance
dinyatakan dengan menggunakan nilai Mean Square Error (MSE). Nilai MSE yang semakin kecil berarti hasil klasifikasi yang diperoleh semakin baik, sebaliknya nilai MSE yang semakin besar berarti hasil klasifikasi yang diperoleh kurang baik. Jumlah iterasi yang digunakan di dalam algoritma GenClust yang telah dimodikasijuga sama yaitu menggunakan jumlah iterasi sebesar 50, 75, dan 100
4.4.1. Pengujian dengan Jumlah Iterasi Sebanyak 50
Tabel 4.9. Pengujian dengan Menggunakan Algoritma GenClust yang Telah Dimodifikasi Dengan Menggunakan Jumlah Iterasi Sebesar 50
Pengujian Ke- Mean Square Error
1 0.34
2 0.67
3 0.93
4 0.67
5 1
6 0.63
7 0.4
8 0.67
9 0.67
10 0.74
Rata-rata MSE 0.673
Best MSE 0.34
Dari Tabel 4.9. terlihat bahwa secara umum nilai MSE dapat bervariasi untuk tiap kali pengujian. Variasi tersebut disebabkan oleh terdapatnya pembangkitan bilangan acak pada algoritma genetika untuk tahap crossover dan mutasi. Pengujian dilakukan sebanyak 10 kali, hasil pengujian menunjukkan bahwa perbedaan MSE yang diperoleh tidak begitu besar, MSE terbaik adalah sebesar 0.34 dan MSE terburuk adalah sebesar 1. Nilai Rata-rata MSE yang diperoleh adalah sebesar 0.673.
diperoleh melalui perhitungan deterministik. Pengujian dilakukan sebanyak 10 kali dan hasil pengujian dapat dilihat pada Tabel 4.10.
Tabel 4.10. Pengujian dengan Menggunakan Algoritma GenClust yang Telah Dimodifikasi Dengan Menggunakan Jumlah Iterasi Sebesar 75
Pengujian Ke- Mean Square Error
1 0.35
2 0.39
3 0.63
4 0.67
5 0.63
6 0.67
7 0.47
8 0.93
9 0.93
10 0.39
Rata-rata MSE 0.606
Best MSE 0.35
pada pengujian dengan menggunakan jumlah iterasi sebesar 50. Namun, nilai Best MSE sedikit kurang baik dibandingkan dengan menggunakan jumlah iterasi sebesar 50.
4.4.3. Pengujian dengan Jumlah Iterasi Sebanyak 100
Pengujian dilakukan sebanyak 10 kali dengan menggunakan 6 cluster dan jumlah iterasi sebesar 75 untuk melihat nilai MSE. Perhitungan distance menggunakan Euclidean Distance. Jumlah cluster sebesar 6 karena menggunakan 6 buah kromosom yang diperoleh melalui perhitungan deterministik. Pengujian dilakukan sebanyak 10 kali dan hasil pengujian dapat dilihat pada Tabel 4.11.
Tabel 4.11. Pengujian dengan Menggunakan Algoritma GenClust yang Telah Dimodifikasi Dengan Menggunakan Jumlah Iterasi Sebesar 100
Pengujian Ke- Mean Square Error
1 0.11
2 0.67
3 0.63
4 0.4
5 0.63
6 0.45
7 0.44
8 0.67
9 0.35
10 0.33
Dari Tabel 4.11. terlihat bahwa secara umum nilai MSE dapat bervariasi untuk tiap kali pengujian. Variasi tersebut disebabkan oleh terdapatnya pembangkitan bilangan acak pada algoritma genetika untuk tahap crossover dan mutasi. Pengujian dilakukan sebanyak 10 kali, hasil pengujian menunjukkan bahwa tidak terdapat perbedaan MSE yang cukup besar antara MSE terbaik dengan MSE terburuk. MSE terbaik adalah sebesar 0.11 dan MSE terburuk adalah sebesar 0.67. Nilai Rata-rata MSE yang diperoleh adalah sebesar 0.468. Nilai rata-rata MSE lebih baik dibandingkan dengan pada pengujian dengan menggunakan jumlah iterasi sebesar 50 dan 75. Begitu juga nilai
Best MSE juga jauh lebih baik dibandingkan pengujian dengan menggunakan jumlah iterasi sebesar 50 dan 75.
Adapun hasil pengujian secara umum dengan menggunakan algoritma GenClust yang telah dimodifikasi dapat dilihat pada Tabel 4.12. dan Gambar 4.3.
Tabel 4.12. Hasil Pengujian dengan Menggunakan Algoritma GenClust yang Telah Dimodifikasi
Jumlah Iterasi Average MSE Best MSE
50 0.673 0.34
75 0.606 0.35
100 0.468 0.11
Adapun hasil pengujian dengan menggunakan Algoritma GenClust yang telah dimofikasi dengan menggunakan jumlah iterasi 50, 75, dan 100 dapat dilihat pada Gambar 4.3.
Gambar 4.3. Hasil Pengujian dengan Menggunakan Algoritma GenClust yang Telah Dimodifikasi
Pada Gambar 4.3 terlihat bahwa secara umum pada tiap tahap pengujian dapat memberikan nilai MSE yang berbeda. Variasi tersebut disebabkan oleh terdapatnya pembangkitan bilangan acak pada algoritma genetika untuk tahap crossover dan mutasi. Pada beberapa tahap pengujian nilai MSE dengan jumlah iterasi 50 dapat lebih baik dibandingkan dengan nilai MSE dengan jumlah iterasi sebesar 75 maupun 100. Sebagai contoh, pada pengujian ke-1 dengan jumlah iterasi sebesar 50 memberikan nilai MSE yang cukup baik yaitu sebesar 0.34. Namun, secara umum jumlah iterasi yang lebih banyak akan memberikan hasil MSE yang lebih baik. Hal ini disebabkan pada algoritma
K-Means nilai centroid yang telah ditentukan dengan menggunakan algoritma GenClust
dapat disesuaikan berdasarkan pada data yang dimasukkan ke dalam suatu cluster.
0.34
4.5. Pembahasan
Pada bagian sebelumnya telah dilakukan pengujian dengan menggunakan algoritma K-Means klasik, algoritma GenClust, dan Algoritma GenClust yang telah dimodifikasi. Kaitan antara penentuan centroid dengan performance dari algoritma K-Means menarik untuk diamati. Pada algoritma K-Means klasik penentuan centroid dilakukan dengan menggunakan bilangan acak. Pada algoritma GenClust penentuan centroid berdasarkan pada algoritma genetika, di mana digunakan 6 buah kromosom yaitu 3 buah kromosom diperoleh dengan menggunakan bilangan acak dan 3 buah kromosom diperoleh dengan menggunakan perhitungan deterministik, yang selanjutnya kromosom ini akan mengalami tahapan seleksi, crossover, dan mutasi sehingga dihasilkan kromosom terbaik yang nantinya akan digunakan sebagai centroid pada Algoritma K-Means.
Peneliti memodifikasi algoritma GenClust dimana peneliti menggunakan 6 buah kromosom, di mana semua kromosom tersebut diperoleh melalui perhitungan deterministik, yang kemudian kromosom tersebut akan mengalami proses di dalam algoritma gentika yang meliputi seleksi, crossover, dan mutasi sehingga menghasilkan
centroid yang nantinya akan digunakan sebagai centroid pada algoritma K-Means. Pengujian algoritma K-Means dilakukan dengan menggunakan jumlah iterasi yang beragam yaitu sebesar 50, 75, dan 100. Adapun hasil pengujian dapat dilihat pada Tabel 4.13.
Tabel 4.13. Hasil Pengujian dengan Menggunakan Algoritma K-Means Klasik, Algoritma GenClust, dan Algoritma GenClust yang Telah Dimodifikasi
50 Iterasi 75 Iterasi 100 Iterasi
Berdasarkan pada Tabel 4.13 dapat dilihat bahwa secara umum penentuan centroid
berpengaruh terhadap performance dari algoritma K-Means yang ditunjukkan di dalam nilai Mean Square Error (MSE) yang diperoleh berdasarkan pada hasil klasifikasi. Penentuan centroid berpengaruh terhadap performance dari algoritma genetika karena penempatan suatu data ke dalam suatu dataset berdasarkan pada kedekatan antara koordinat objek tersebut dengan koordinat centroid dimana perhitungan distance yang digunakan adalah Euclidean Distance.
Pada algoritma K-Means klasik penentuan centroid dilakukan dengan menggunakan bilangan acak. Pada algoritma GenClust penentuan centroid berdasarkan pada algoritma genetika, di mana digunakan 6 buah kromosom yaitu 3 buah kromosom diperoleh dengan menggunakan bilangan acak dan 3 buah kromosom diperoleh dengan menggunakan perhitungan deterministik, yang selanjutnya kromosom ini akan mengalami tahapan seleksi, crossover, dan mutasi sehingga dihasilkan kromosom terbaik yang nantinya akan digunakan sebagai centroid pada Algoritma K-Means.
Peneliti memodifikasi algoritma GenClust dimana peneliti menggunakan 6 buah kromosom, di mana semua kromosom tersebut diperoleh melalui perhitungan deterministik, yang kemudian kromosom tersebut akan mengalami proses di dalam algoritma gentika yang meliputi seleksi, crossover, dan mutasi sehingga menghasilkan
centroid yang nantinya akan digunakan sebagai centroid pada algoritma K-Means. Perhitungan deterministik memiliki keunggulan karena diukur berdasarkan
density dari tiap data untuk tiap atribut pada dataset. Pada penelitian sebelumnya yang telah dilakukan oleh Rahman dan Islam (2014), algoritma GenClust digunakan untuk penentuan centroid. Peneliti tertarik untuk menggunakan 6 buah kromosom yang seluruhnya diperoleh melalui perhitungan deterministik dan hasil pengujian sebagaimana yang dapat dilihat pada Tabel 4.13, performance yang diberikan oleh algoritma GenClust yang telah dimodifikasi lebih baik dibandingkan dengan menggunakan algoritma K-Means Klasik dan juga algoritma K-Means yang dikemukakan oleh Rahman dan Islam (2014).
BAB 5
KESIMPULAN DAN SARAN
5.1. Kesimpulan
Kesimpulan yang dapat diambil dari penelitian ini adalah sebagai berikut.
1. Kinerja yang ditunjukkan dalam bentuk nilai rata-rata MSE dan juga nilai Best
MSE menunjukkan bahwa penentuan centroid menentukan performance dari algoritma K-Means. Penentuan centroid dengan menggunakan algoritma K-Means yang telah dimodifikasi lebih baik dibandingkan dengan penentuan
centroid dengan menggunakan algoritma GenClust dan juga algoritma K-Means
Klasik.
2. Hasil penelitian menunjukkan bahwa Semakin besar jumlah iterasi juga akan memberikan hasil performance yang lebih baik pada algoritma K-Means. Hal ini terjadi karena pada tiap tahapan iterasi dari algoritma K-Means akan dilakukan proses penyesuaian terhadap nilai centroid berdasarkan item data yang ditempatkan di dalam suatu cluster.
5.2. Saran
Adapun saran yang dapat diberikan pada penelitian ini adaah sebagai berikut.
1. Penelitian ini dapat dikembangkan dengan menambahkan banyaknya cluster
yang digunakan di dalam penelitian sehingga dapat diperoleh perbandingan hasil yang lebih baik.