MEMILIH METODE ANALISIS KUANTITATIF
UNTUK PENELITIAN ARSITEKTUR
Hanson Endra Kusuma
Kelompok Keahlian Perancangan Arsitektur
Sekolah Arsitektur, Perencanaan dan Pengembangan Kebijakan Institut Teknologi Bandung
Email: [email protected] ABSTRAK
Penelitian diawali dengan konteks permasalahan dan penentuan tujuan. Berdasarkan tujuan tersebut, direncanakan metode pengumpulan data dan analisis data. Tujuan menentukan metode pengumpulan data dan analisis data. Tetapi, sebaliknya metode pengumpulan data dan analisis data yang akan digunakan juga membatasi tujuan yang bisa ditentukan, karena jenis data yang dikumpulkan dan jenis analisis yang dipilih akan membatasi kemungkinan temuan penelitian. Dengan demikian, pemahaman terhadap metode pengumpulan data dan kemampuan beragam jenis analisis data, serta kemungkinan temuan analisis, merupakan pengetahuan esensial yang perlu dimiliki sebelum memulai penelitian. Paper ini mencoba membahas secara konseptual, garis besar metode analisis kuantitatif (statistik) yang sering digunakan pada penelitian arsitektur, terutama untuk tesis dan disertasi. Analisis yang dibahas dalam paper ini : analisis distribusi, analisis koresponden, anova, analisis korelasi, analisis komponen prinsip/analisis faktor, analisis klaster, analisis regresi dan Structural Equation Modeling (SEM). Masing-masing fungsi dan cara penggunaan analisis dijelaskan secara konseptual disertai dengan contoh, agar mudah dipahami terutama oleh mahasiswa pasca-sarjana yang akan memulai merancang penelitian.
Kata-kunci : penelitian arsitektur, penelitian kuantitatif, jenis data, metode analisis kuantitatif
POSISI ANALISIS KUANTITATIF
Jika dibagi ke dalam dua perspektif yang saling berlawanan, penelitian dapat dikelompokkan ke dalam dua kategori metodologi : kualitatif dan kuantitatif. Penelitian kualitatif didasari oleh sudut pandang/perspektif/paradigma social constructivism, yang beranggapan setiap fenomena merupakan suatu keutuhan yang tidak dapat dijelaskan hanya dengan beberapa faktor saja. Penelitian kuantitatif didasari oleh perspektif post-positivism, yang beranggapan fenomena dapat dijelaskan dengan menggunakan sekumpulan faktor yang mewakili fenomena (reduksionis) dan faktor sebab menentukan/mempengaruhi faktor akibat dari fenomena tersebut (deterministik). Selain dua perspektif tersebut di atas, John W. Creswell (2003) menambahkan dua perspektif yang pengkategoriannya bukan berdasarkan pada pandangan terhadap keutuhan fenomena seperti dua perspektif tersebut di atas, yaitu : pragmatism dan advocacy/participatory. Pragmatism beranggapan yang paling penting adalah pemahaman terhadap permasalahan atau mengetahui solusi permasalahan, dan metode apa saja dapat digunakan sesuai dengan permasalahan yang dihadapi. Perspektif ini mendasari penelitian pragmatis atau gabungan yang disebut mixed methods (Creswell, 2003, hal 11-13) atau combined-strategies (Linda Groat & David Wang, 2002, hal 369-370). Perspektif advocacy/participatory, - seperti arti kata dari namanya -, mengutamakan keadilan sosial, perubahan atau manfaat yang dirasakan oleh partisipan atau siapa saja yang terlibat penelitian, termasuk kelompok-kelompok minoritas atau yang tidak diperhatikan. Perspektif ini sangat memberikan perhatian pada agenda perubahan atau misi politik dalam pelaksanaannya. Dari empat kategori metodologi penelitian yang didasari empat perspektif di atas, kategori penelitian yang mengumpulkan data kuantitatif dan membutuhkan analisis kuantitatif adalah penelitian kuantitatif (sesuai dengan namanya). Pada konteks fenomena tertentu, penelitian gabungan juga mungkin mengumpulkan data kuantitatif, jika juga menggunakan metode
pengumpulan data kuantitatif. Dari deskripsi di atas, jelas bahwa analisis data kuantitatif (lazim disebut statistik) merupakan bagian dari metode penelitian kuantitatif, baik penelitian kuantitatif dalam kelompok penelitian korelasional (tanpa intervensi) maupun eksperimential/quasi-eksperimental (dengan intervensi). Penggunaan analisis kuantitatif pada penelitian kualitatif hanya sebatas analisis distribusi frekuensi yang merupakan ujung dari content analysis.
TEMUAN PENELITIAN DAN ANALISIS
Ciri khas dari penelitian kuantitatif : penggunaan beberapa faktor yang dianggap mewakili atau menjelaskan fenomena (reduksionis) dan pencarian hubungan non kausal atau kausal antar faktor tersebut (deterministik). Karena itu, pada penelitian kuantitatif pengumpulan data hanya dilaksanakan pada/tentang faktor yang dianggap mewakili atau menjelaskan fenomena, dan sebagai konsekuensinya data yang dikumpulkan tersebut akan membatasi kemungkinan temuan analisis. Dengan kata lain, lingkup temuan analisis dibatasi oleh data yang dikumpulkan, tetapi temuan penelitian itu sendiri tergantung pada jenis analisis yang digunakan. Jadi, penelitian kuantitatif tidak mungkin direncanakan tanpa perencanaan pengumpulan lingkup dan jenis data, serta jenis analisis kuantitatif yang akan digunakan.
JENIS DATA
Jenis data yang dikumpulkan akan menentukan jenis analisis yang dapat digunakan. Dalam analisis kuantitatif, jenis data dikelompokkan menjadi 3 : nominal, ordinal dan continuous. Data nominal merupakan data kategori, seperti jenis pekerjaan, kota tempat tinggal, pendidikan, bidang keahlian dll. Data kategori dapat berupa angka numerik coding dari kategori atau teks (kata-kata) yang menjadi indikator dari kategori. Data ordinal merupakan data urutan atau data yang memiliki rangking. Data continuous merupakan data interval dan rasio. Data interval adalah data yang memiliki peringkat, misalnya jika angka semakin besar semakin baik, semakin tinggi dst. Contoh data interval, data yang diperoleh dari kuesioner yang menggunakan jawaban skala likert atau semantic differential method (menggunakan kata sifat yang saling berlawanan, dan umumnya berskala 1 sampai dengan 4, 5, 6 atau 7). Data rasio merupakan data yang memiliki nilai kuantitatif yang sebanding dengan besaran angkanya, misalnya data berat badan, 10 kg dua kali lebih berat daripada 5 kg. Yang lain misalnya jumlah uang, jumlah orang, luas ruang, lebar jalan dll.
ANALISIS DATA
Melihat dari jumlah variabel yang digunakan dalam analisis, analisis dikelompokkan menjadi analisis univariat, bivariat dan multivariat. Analisis univariat menggunakan hanya satu variabel, misalnya analisis distribusi. Analisis bivariat menggunakan dua variabel, misalnya analisis koresponden, anova, analisis korelasi dan analisis regresi bivariat. Analisis multivariat menggunakan banyak variabel, misalnya analisis komponen prinsip, analisis faktor, analisis klaster, analisis regresi multivariat dan structural equation modeling (SEM). Analisis bivariat dapat menggunakan data nominal, ordinal atau continuous. Analisis multivariat hanya menggunakan data continuous. Di bawah ini penjelasan konseptual masing-masing analisis yang disebutkan di atas.
Analisis Distribusi
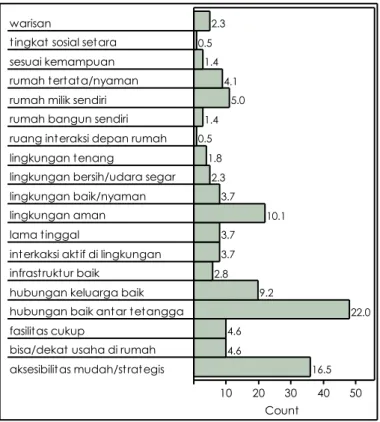
Analisis distribusi digunakan untuk mengetahui ragam kategori di dalam data dan penyebaran/frekuensi dari masing-masing kategori tersebut. Jenis data yang digunakan umumnya data kategori (nominal) meskipun data bukan nominal seperti data ordinal atau continuous juga dapat diperlakukan sebagai data nominal dan dianalisis dengan analisis distribusi. Luaran analisis distribusi paling populer ditampilkan dalam bentuk diagram batang (histogram) atau diagram lingkaran/kue (pie-chart). Dari diagram distribusi secara visual akan bisa diketahui dengan mudah, misalnya persentase dan frekuensi (termasuk frekuensi paling tinggi dan rendah) pendapatan dalam suatu permukiman (diagram 1), jumlah penghuni yang tinggal di bawah satu atap (diagram 2), luas hunian per orang (diagram 3), atau alasan merasa betah paling dominan tinggal di suatu permukiman tertentu (diagram 4).
Diagram 1 (kiri atas). Distribusi pendapatan per bulan kepala keluarga (PBK), data 108 responden. Angka di bawah diagram batang menunjukkan frekuensi setiap kategori. Angka di ujung diagram batang probabilitas/persentase setiap kategori.
Diagram 2 (tengah atas). Distribusi jumlah total penghuni dalam satu rumah, data 108 responden. Diagram 3 (kanan atas). Distribusi luas rumah per penghuni dalam satuan m2, data 104 responden.
Diagram 4. Alasan betah tinggal di permukiman kampung kota di Bandung, yang disurvei tahun 2005. Angka di bawah diagram batang menunjukkan frekuensi setiap kata kunci. Angka di ujung diagram batang probabilitas/ persentase setiap kata kunci. Kata kunci berasal dari deskripsi 108 responden yang berisi alasan betah tinggal di permukimannya. Deskripsi yang berupa data teks dianalisis dengan content
analysis dengan langkah-langkah sbb : 1. Ekstraksi kata kunci dari data teks.
2. Pengkategorian kata kunci : mengelompok- kan kata kunci yang memiliki arti sama atau mirip, dan selajutnya memberikan nama yang dapat mewakili sekelompok kata kunci tersebut.
3. Konversi data teks menjadi data numerik 0-1 (langkah ini optional, untuk mempermudah langkah berikutnya).
4. Analisis distribusi kata kunci yang telah dikategorikan dan dikonversi menjadi data 0-1. Keluaran akhir langkah ini berupa diagram batang seperti ditampilkan di sebelah kanan.
Analisis Koresponden
Analisis koresponden digunakan untuk mengetahui kedekatan hubungan antar kategori dari dua variabel nominal. Variabel yang digunakan selalu nominal, baik numerik ataupun karakter/teks. Analisis koresponden tidak menghasilkan koefisien, seperti analisis korelasi atau regresi, tetapi menghasilkan correspondence analysis plot (cap), dengan axis yang memiliki skor yang menunjukkan kedekatan hubungan antar kategori. Setiap axis memiliki cumulative inertia portion yang menjadi indikator porsi kemampuan axis tersebut menjelaskan data. Kedekatan hubungan antar kategori dapat diketahui langsung secara visual dengan melihat kedekatan posisi antar kategori tersebut pada bidang cap, misalnya titik kategori pendidikan SD paling dekat dengan titik kategori pendapatan PBK ≤ 400rb, dan agak jauh dari titik 400rb < PBK≤ 800rb; jadi jika pendidikan SD kemungkinan besar pendapatan kurang dari 400rb per bulan, bukan lebih dari 400rb (diagram 5). Selanjutnya jika pendapatan kurang dari 400rb per bulan (PBK ≤ 400rb, lihat diagram 6), maka kemungkinan besar akan tinggal di rumah dengan luas lantai per orang kurang dari 9 m2 (luas < 9 m2, lihat diagram 6). Kedekatan pada analisis koresponden menunjukkan kemungkinan co-incidence atau co-occurence antar kategori dari variabel nominal.
A. PBK ≤ 400rb B. 400rb < PBK ≤ 800rb C. 800rb < PBK ≤ 1200rb D. 1200rb < PBK ≤ 1600rb E. 1600rb < PBK 14.2 32.1 26.4 15.1 12.3 5 15 25 35 Count PENGHASILAN PER BULAN
A. 1-4 B. 5-8 C. 9-12 D. lebih dari 13 25.0 54.6 12.0 8.3 10 30 50 Count JUMLAH PENGHUNI A. luas < 9m2 B. 9m2 ≤ luas < 18m2 C. 18m2 ≤ luas < 27m2 D. 27m2 ≤ luas < 36m2 E. 36m2 ≤ luas 35.6 33.7 12.5 7.7 10.6 5 15 25 35 Count LUAS RUMAH PER PENGHUNI
Distributions
aksesibilitas mudah/strategis bisa/dekat usaha di rumah fasilitas cukup
hubungan baik antar tetangga hubungan keluarga baik infrastruktur baik
interkaksi aktif di lingkungan lama tinggal
lingkungan aman lingkungan baik/nyaman lingkungan bersih/udara segar lingkungan tenang
ruang interaksi depan rumah rumah bangun sendiri rumah milik sendiri rumah tertata/nyaman sesuai kemampuan tingkat sosial setara warisan 16.5 4.6 4.6 22.0 9.2 2.8 3.7 3.7 10.1 3.7 2.3 1.8 0.5 1.4 5.0 4.1 1.4 0.5 2.3 10 20 30 40 50 Count
Diagram 5 (kiri atas). Koresponden antara pendidikan dan penghasilan per bulan kepala keluarga (PBK). Analisis menggunakan 98 dari 108 sampel (91%), tidak menyertakan kategori pendidikan Tidak Sekolah, D2, D3 dan S2 yang memiliki jumlah total hanya 10 orang (9% dari jumlah total sampel). Cumulative inertia
portion 96% : mampu menjelaskan 96% kecenderungan data.
Diagram 6 (kanan atas). Koresponden antara luas rumah per penghuni dan penghasilan per bulan kepala keluarga (PBK). Analisis menggunakan 102 dari 108 sampel (94%), data 6 sampel tidak ada (missing-value).
Cumulative inertia portion 94% : mampu menjelaskan 94% kecenderungan data.
Anova
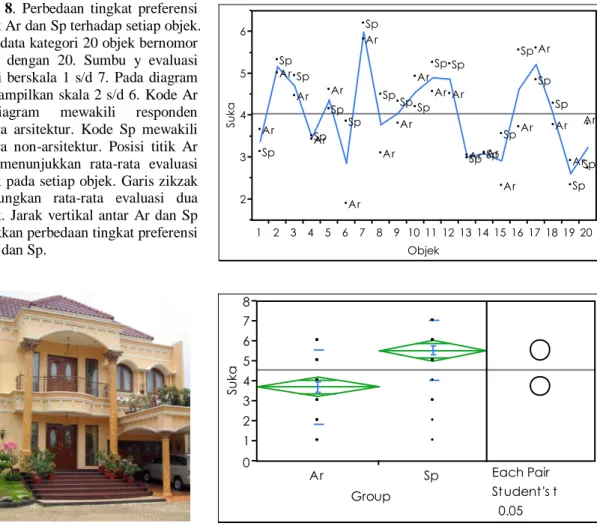
Anova (analysis of variance) digunakan untuk mengetahui perbedaan parameter (indikator numerik yang digunakan untuk memberikan ukuran, selalu data continuous) antar data nominal dengan melihat nilai rata-rata parameter dari setiap kategori dalam data nominal tersebut. Anova paling mudah dipahami jika ditampilkan dalam bentuk diagram dua dimensi. Diagram dua dimensi tersebut selalu menggunakan data nominal sebagai sumbu x dan data continuous pada sumbu y. Misalnya, pada diagram 7, sumbu x adalah data 20 rumah tinggal dan sumbu y adalah evaluasi preferensi 99 responden terhadap setiap rumah. Dari diagram dapat diketahui perbedaan tingkat preferensi dari setiap rumah. Rumah dengan tingkat preferensi paling tinggi no 7, 2 dan 17.
Anova juga dapat digunakan untuk melihat perbedaan parameter antar kelompok dari setiap kategori data nominal, seperti yang diperlihatkan pada diagram 8. Dari diagram dapat diketahui perbedaan preferensi antar kelompok terhadap setiap rumah, misalnya perbedaan preferensi Ar dan Sp terhadap rumah no 6 dan 16 lebih besar dibanding rumah lain. Perbedaan preferensi antara kelompok Ar dan Sp terhadap rumah no 16 signifikan, dapat dibuktikan dari pemisahan mean comparison pada diagram 9.
Diagram 7. Perbedaan tingkat preferensi antar objek. Sumbu x data kategori 20 rumah tinggal nomor 1 s/d 20. Sumbu y data interval evaluasi suka-tidak suka, menggunakan metode semantic differential method, berskala 1 (sangat
tidak suka) sampai dengan 7 (sangat suka). Garis tengah setiap mean diamond merupakan rata-rata evaluasi setiap objek. Garis zikzak menghubungkan rata-rata evaluasi semua objek. Titik-titik pada bidang diagram merupakan skor evaluasi dari setiap objek yang saling tumpang-tindih. 1 2 3 4 5 6 7 Su ka 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Objek -0.4 -0.3 -0.2 -0.1 0 0.1 0.2 0.3 0.4 0.5 0.6 c2 A. luas < 9m2 B. 9m2 ≤ luas < 18m2 C. 18m2 ≤ luas < 27m2 D. 27m2 ≤ luas < 36m2 E. 36m2 ≤ luas A. PBK ≤ 400rb B. 400rb < PBK ≤ 800rb C. 800rb < PBK ≤ 1200rb D. 1200rb < PBK ≤ 1600rbE. 1600rb < PBK -0.4 -0.2 0 0.2 0.4 0.6 0.8 c1 Bivariate Fit of c2 By c1 -0.75 -0.5 -0.25 0 0.25 0.5 0.75 c1 S1 SD SLTA SLTP A. PBK ≤ 400rb B. 400rb < PBK ≤ 800rb C. 800rb < PBK ≤ 1200rb D. 1200rb < PBK ≤ 1600rb E. 1600rb < PBK -0.2 -0.1 0 0.1 0.2 0.3 0.4 0.5 0.6 c2 Bivariate Fit of c1 By c2
Diagram 8. Perbedaan tingkat preferensi kelompok Ar dan Sp terhadap setiap objek. Sumbu x data kategori 20 objek bernomor 1 sampai dengan 20. Sumbu y evaluasi preferensi berskala 1 s/d 7. Pada diagram hanya ditampilkan skala 2 s/d 6. Kode Ar pada diagram mewakili responden mahasiswa arsitektur. Kode Sp mewakili mahasiswa non-arsitektur. Posisi titik Ar atau Sp menunjukkan rata-rata evaluasi kelompok pada setiap objek. Garis zikzak menghubungkan rata-rata evaluasi dua kelompok. Jarak vertikal antar Ar dan Sp menunjukkan perbedaan tingkat preferensi antara Ar dan Sp.
Foto 1 (kiri atas). Objek no 16. Rumah tinggal dengan tingkat preferensi antara Ar dan Sp berbeda signifikan. Diagram 9 (kanan atas). Perbedaan tingkat preferensi antara kelompok Ar dan Sp pada objek no 16. Sumbu x, data nominal kategori Ar dan Sp, sumbu y evaluasi tidak suka-suka berskala 1 s/d 7. Garis tengah mean
diamond menunjukkan rata-rata evaluasi kelompok bersangkutan. Ujung atas dan bawah merupakan batas
interval 95%. Mean comparison pada bagian kanan ditampilkan dengan dua lingkaran yang masing-masing mewakili kelompok Ar dan Sp. Titik pusat lingkaran segaris-lurus dengan garis tengah mean diamond. Diameter lingkaran mewakili interval 95%, segaris dengan titik teratas dan terbawah mean diamond. Dua lingkaran terpisah menandakan perbedaan evaluasi antara kelompok signifikan.
Analisis Korelasi Bivariat
Analisis koreleasi bivariat digunakan untuk mengetahui kedekatan hubungan dua variabel continuous (interval atau rasio). Kedekatan hubungan antara dua variabel ditunjukkan dengan koefisien korelasi (r) yang umumnya dipahami sbb :
0 < r ≤ 0.2 korelasi sangat rendah 0.2 < r ≤ 0.4 korelasi rendah 0.4 < r ≤ 0.6 korelasi sedang 0.6 < r ≤ 0.8 korelasi tinggi 0.8 < r < 1 korelasi sangat tinggi
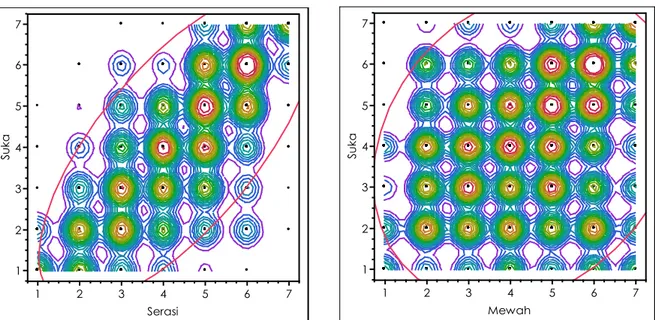
Koefisien korelasi positif menunjukkan hubungan searah dan korelasi negatif hubungan berlawanan arah. Secara visual, besar-kecil koefisien korelasi dapat diketahui dari penyebaran data pada scatter-plot yang disusun dari sumbu x dan y dua variabel yang dikorelasikan. Jika density ellips yang melingkupi penyebaran data semakin ramping dan diagonal maka koefisien korelasi akan semakin besar (diagram 10), sebaliknya jika density ellips semakin gemuk/bulat maka koefisien korelasi akan semakin kecil (diagram 11). Pada diagram 10, koefisien korelasi 0.7 (tinggi), berarti jika bangunan semakin serasi maka cenderung semakin disukai. Pada diagram 11, koefisien korelasi 0.22 (rendah), berarti jika bangunan semakin mewah belum tentu semakin disukai atau semakin tidak disukai. Hubungan antara kemewahan dan preferensi rendah.
2 3 4 5 6 Su ka Ar Sp Ar Sp Ar Sp Ar Sp Ar Sp Ar Sp Ar Sp Ar Sp Ar Sp Ar Sp Ar Sp Ar Sp Ar Sp ArSp Ar SpAr Sp Ar Sp Ar Sp Ar Sp Ar Sp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Objek 0 1 2 3 4 5 6 7 8 Su ka Ar Sp Group Each Pair Student's t 0.05
Diagram 10 (kiri atas). Korelasi antara keserasian dan preferensi. Sumbu x, data continuous/interval berskala 1 sangat tidak serasi s/d 7 sangat serasi. Sumbu y, data continuous/interval berskala 1 sangat tidak suka s/d 7 sangat suka. Titik pada diagram merupakan skor evaluasi yang saling tumpang-tindih. Density contour akan semakin padat jika tumpang-tindih skor pada satu titik semakin banyak. Ellips pada diagram melingkupi 90% penyebaran data. Koefisien korelasi 0.7, significant value kurang dari 0.01%, tingkat kepercayaan lebih dari 99.99%. Kesepakatan umum yang sering digunakan, sig. value lebih kecil dari 0.05.
Diagram 11 (kanan atas). Korelasi antara kemewahan dan preferensi. Sumbu x, data continuous/interval berskala 1 sangat sederhana s/d 7 sangat mewah. Sumbu y, data continuous/interval berskala 1 sangat tidak suka s/d 7 sangat suka. Koefisien korelasi 0.22, significant value kurang dari 0.01%.
Analisis Korelasi Multivariat
Disebut korelasi multivariat karena melibatkan lebih dari dua variabel. Jika sejumlah variabel dikorelasikan satu sama lain, maka akan diperoleh sejumlah koefisien korelasi, yang disusun dalam matriks koefisien korelasi seperti pada tabel 1. Matriks tersebut dapat dimanfaatkan untuk dengan cepat membandingkan besaran koefisien korelasi antar variabel dan mengidentifikasi variabel-variabel yang memiliki korelasi sangat tinggi, tinggi, sedang, rendah dan sangat rendah. Gambaran tinggi-rendah koefisien korelasi antar variabel tersebut juga merupakan gambaran hubungan antar faktor yang menyusun fenomena yang diambil datanya. Meskipun belum definitif, gambaran hubungan antar faktor tersebut dapat digunakan untuk mereka-reka pola temuan analisis yang akan diperoleh jika data dianalisis lebih lanjut dengan analisis multivariat yang lain.
Tabel 1. Matriks koefisien korelasi 13 variabel evaluasi rumah tinggal.
Analisis Regresi Bivariat
Analisis regresi bivariat digunakan untuk mengetahui hubungan kausal antara dua variabel continuous, berupa kekuatan pengaruh (besar kecil), bentuk pengaruh (linier atau polinomial). Karena itu, pada analisis regresi digunakan istilah variabel yang mempengaruhi (disebut juga
1 2 3 4 5 6 7 Su ka 1 2 3 4 5 6 7 Serasi 1 2 3 4 5 6 7 Su ka 1 2 3 4 5 6 7 Mewah
Bagus Fungsional Kompleks ProporsionalTeratur Unik ModernNyaman Mewah Baru Serasi Suka Rumit
Bagus 1.00 0.37 0.14 0.45 0.34 0.45 0.39 0.61 0.35 0.43 0.59 0.78 0.15 Fungsional 0.37 1.00 -0.10 0.42 0.35 0.06 0.06 0.46 -0.04 0.07 0.40 0.42 -0.13 Kompleks 0.14 -0.10 1.00 -0.10 -0.20 0.46 0.24 -0.03 0.59 0.35 -0.06 0.02 0.70 Proporsional 0.45 0.42 -0.10 1.00 0.46 0.13 0.11 0.49 0.07 0.16 0.55 0.51 -0.07 Teratur 0.34 0.35 -0.20 0.46 1.00 0.01 0.08 0.41 0.03 0.13 0.47 0.40 -0.21 Unik 0.45 0.06 0.46 0.13 0.01 1.00 0.31 0.24 0.50 0.41 0.24 0.40 0.46 Modern 0.39 0.06 0.24 0.11 0.08 0.31 1.00 0.13 0.47 0.67 0.22 0.30 0.23 Nyaman 0.61 0.46 -0.03 0.49 0.41 0.24 0.13 1.00 0.09 0.18 0.57 0.68 -0.01 Mewah 0.35 -0.04 0.59 0.07 0.03 0.50 0.47 0.09 1.00 0.61 0.16 0.22 0.56 Baru 0.43 0.07 0.35 0.16 0.13 0.41 0.67 0.18 0.61 1.00 0.28 0.34 0.33 Serasi 0.59 0.40 -0.06 0.55 0.47 0.24 0.22 0.57 0.16 0.28 1.00 0.70 -0.05 Suka 0.78 0.42 0.02 0.51 0.40 0.40 0.30 0.68 0.22 0.34 0.70 1.00 0.05 Rumit 0.15 -0.13 0.70 -0.07 -0.21 0.46 0.23 -0.01 0.56 0.33 -0.05 0.05 1.00
variabel bebas, sebab atau independent variable) dan variabel yang dipengaruhi (disebut juga variabel terikat, akibat atau dependent variable). Variabel apa yang menjadi variabel mempengaruhi atau dipengaruhi sepenuhnya ditentukan oleh peneliti/penganalisis, bukan oleh formula statistik atau software analisis data. Penentuan variabel bebas dan terikat tersebut dalam penelitian kuantitatif merupakan bagian dari hipotesis yang disusun oleh peneliti.
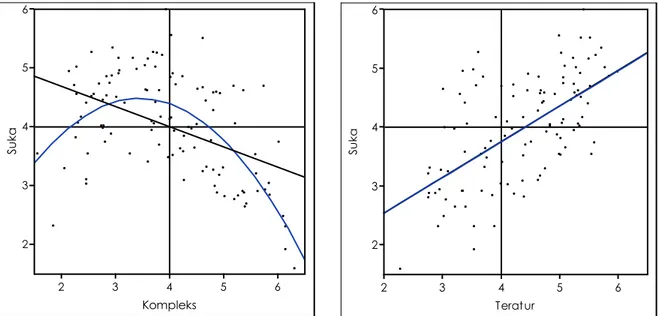
Contoh luaran analisis regresi bivariat dapat dilihat pada diagram 12 dan 13. Pada diagram 12, Rsquare regresi polinomial lebih besar daripada regresi linier, dan RMSE regresi polinomial lebih kecil daripada regresi linier, karena itu interpretasi bentuk hubungan antara kompleksitas dan preferensi lebih tepat menggunakan regresi polinomial : kurva lengkung. Kompleksitas tinggi ataupun rendah preferensi akan selalu rendah. Preferensi paling tinggi jika kompleksitas sedang. Rsquare dan RMSE regresi polinomial ataupun linier pada diagram 13 hampir tidak berbeda, karena itu hubungan kausal antara keteraturan dan preferensi dapat disimpulkan linier.
Diagram 12 (kiri atas). Regresi linier dan polinomial antara kompleksitas dan preferensi. Sumbu x, data
continuous/interval berskala 1 sangat sederhana s/d 7 sangat kompleks. Sumbu y, data continuous/interval
berskala 1 sangat tidak suka s/d 7 sangat suka. Satu titik mewakili satu objek rumah tinggal yang dievaluasi. Jumlah total titik/objek 110. 6 dari 116 data (5%) dianggap sebagai outlier dan tidak disertakan dalam analisis. Data dikumpulkan dari tahun 2005 sampai tahun 2009. Regresi linier (garis lurus): Rsquare 0.200,
RMSE 0.790, significant value <0.01%. Regresi polinomial pangkat dua (garis lengkung): Rsquare 0.410, RMSE 0.682, significant value <0.01%. Rsquare: proporsi varians yang dijelaskan oleh model, semakin
mendekati 1 semakin besar ’porsi dari fenomena’ yang dijelaskan oleh model. RMSE (Root Mean Square
Error): diskrepansi antara predicted value dan actual value, semakin kecil semakin baik.
Diagram 13 (kanan atas). Regresi linier dan polinomial antara keteraturan dan preferensi. Sumbu x, data
continuous/interval berskala 1 sangat tidak teratur s/d 7 sangat teratur. Sumbu y, data continuous/interval
berskala 1 sangat tidak suka s/d 7 sangat suka. Jumlah total titik/objek 109. 7 dari 116 data (6%) dianggap sebagai outlier dan tidak disertakan dalam analisis. Data dikumpulkan dari tahun 2005 sampai tahun 2009. Regresi linier (garis lurus): Rsquare 0.370, RMSE 0.717, significant value <0.01%. Regresi polinomial pangkat dua (garis lengkung): Rsquare 0.370, RMSE 0.721, significant value <0.01%.
Analisis Regresi Multivariat
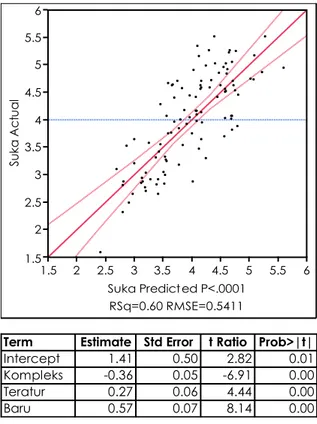
Analisis regresi multivariat melibatkan lebih dari satu variabel sebab, dan digunakan untuk membandingkan kekuatan pengaruh antara beberapa variabel sebab terhadap variabel akibat. Dengan demikian akan diketahui variabel sebab yang dominan, kurang dominan atau tidak dominan mempengaruhi variabel akibat. Semakin besar koefisien regresi (umumnya disebut bobot regresi – regression weight) semakin besar pengaruh terhadap variabel akibat, misalnya dari tabel 2 dapat dilihat bahwa dari tiga variabel sebab, variabel kebaruan paling besar mempengaruhi variabel preferensi (bobot regresi 0.57).
2 3 4 5 6 Su ka 2 3 4 5 6 Kompleks 2 3 4 5 6 Su ka 2 3 4 5 6 Teratur
Diagram 14 (kanan). Scatter-plot predicted value dan actual value variabel akibat, dengan variabel akibat preferensi (tdk suka-suka) dan variabel sebab kompleksitas (simpel-kompleks), keteraturan (tdk teratur-teratur), dan kebaruan (lama-baru). 11 dari 116 data (9.5%) dianggap sebagai outlier dan tidak disertakan dalam analisis. Pada diagram, jika titik menyebar semakin mendekati garis diagonal, maka
Rsquare akan semakin besar/semakin mendekati
angka 1, dan RMSE (root mean square error) semakin kecil/semakin mendekati angka 0. Rsquare besar dan RMSE kecil menunjukkan prediksi semakin tepat (perbedaan antara predicted value dan
actual value semakin kecil). Rsquare disebut juga coefficient of determination. Rsquare 0.6 dapat
diinterpretasikan kemungkinan 60% dari fenomena dapat dijelaskan dengan model regresi yang dibuat, kemungkinan 40% tidak dapat dijelaskan.
Tabel 2 (kanan). Bobot regresi dan significant value regresi multivariat. Bobot regresi masing-masing variabel sebab tertulis di kolom estimate. Significant
value untuk semua variabel sebab kurang dari 0.00
(lihat kolom paling kanan Prob>ItI).
Analisis Komponen Prinsip dan Analisis Faktor
Analisis komponen prinsip (principal component analysis) digunakan untuk menemukan komponen prinsip (variabel pengganti/variabel laten) yang dapat mewakili variabel terukur dengan cara mengumpulkan sebanyak mungkin variabilitas (≈porsi fenomena yang dijelaskan) dari semua variabel terukur pada beberapa komponen prinsip yang utama. Sebagai contoh, tabel 4 memperlihatkan eigenvalue dari 13 komponen prinsip hasil analisis 13 variabel terukur. Dapat dilihat bahwa 3 komponen prinsip pertama memiliki eigenvalue lebih dari 1 : memiliki porsi varians/variabilitas melebihi variabel terukur, karena itu digunakan untuk mewakili/menggantikan variabel terukur. 4 komponen prinsip pertama, memiliki cumulative percent 73.12%. Jadi 4 komponen prinsip tersebut dapat merepresentasikan 73.12% porsi kemampuan menjelaskan fenomena dari 13 variabel terukur. Sehingga, untuk menjelaskan 73.12% fenomena, cukup menggunakan 4 komponen prinsip (4 variabel laten), tidak perlu menggunakan 13 variabel terukur. Factor loading masing-masing variabel terukur terhadap komponen prinsip diperlihatkan pada tabel 3. Dapat dilihat hampir semua variabel terukur memberikan kontribusi besar terhadap komponen prinsip pertama. Hal ini mempermudah analisis seperti preference mapping yang tidak membutuhkan nama komponen prinsip. Tetapi, jika dalam interpretasi analisis dibutuhkan nama variabel maka selanjutnya dilakukan analisis faktor dengan cara merotasi komponen prinsip secara ortogonal sehingga antar komponen tidak berkorelasi dan sebanyak mungkin factor loading dari setiap variabel terukur ke setiap komponen prinsip dibuat mendekati 0 (varimax rotation, tabel 5). Tabel 3. Empat komponen prinsip
utama hasil analisis komponen prinsip yang tidak dirotasi. Empat komponen tersebut memiliki jumlah total persentase eigenvalue sebesar 73,12% (lihat cum. percent pada tabel 1), dengan proporsi eigenvalue terbesar pada komponen pertama (4.67). Jumlah total eigenvalue selalu sama dengan jumlah total variabel yang dianalisis. Komponen dengan eigenvalue 4.67, dapat diartikan bahwa komponen tersebut mewakili 4.67 komponen lain. 1.5 2 2.5 3 3.5 4 4.5 5 5.5 6 Su ka A ct ua l 1.5 2 2.5 3 3.5 4 4.5 5 5.5 6 Suka Predicted P<.0001 RSq=0.60 RMSE=0.5411
Term Estimate Std Error t Ratio Prob>|t|
Intercept 1.41 0.50 2.82 0.01
Kompleks -0.36 0.05 -6.91 0.00
Teratur 0.27 0.06 4.44 0.00
Baru 0.57 0.07 8.14 0.00
VARIABEL KOMP. PRINSIP 1 KOMP. PRINSIP 2 KOMP. PRINSIP 3 KOMP. PRINSIP 4
Bagus 0.85 -0.07 0.05 -0.26 Suka 0.84 -0.25 0.10 -0.27 Serasi 0.74 -0.36 0.00 -0.05 Nyaman 0.70 -0.37 0.24 -0.13 Baru 0.62 0.45 -0.48 0.03 Proporsional 0.60 -0.42 0.07 0.31 Unik 0.57 0.45 0.28 -0.24 Kompleks 0.26 0.76 0.32 0.22 Rumit 0.27 0.75 0.36 0.18 Mewah 0.52 0.66 -0.09 0.21 Fungsional 0.47 -0.44 0.15 0.24 Teratur 0.48 -0.48 -0.16 0.48 Modern 0.52 0.38 -0.62 -0.08
Tabel 4 (kiri bawah). Nilai eigenvalue analisis komponen prinsip. Tabel 5 (kanan bawah). Faktor/variabel laten hasil faktor analisis. Factor loading masing-masing variabel terukur terhadap faktor/variabel laten, hasil rotasi varimax 4 komponen prinsip. Komponen prinsip pada analisis komponen prinsip = faktor/variabel laten pada analisis faktor.
Analisis Klaster
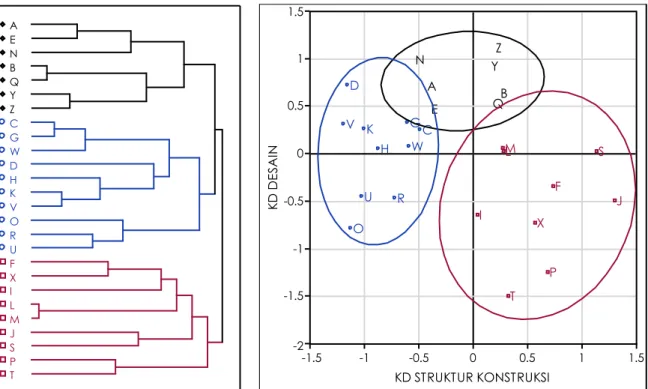
Analisis klaster digunakan untuk mengelompokkan kategori berdasarkan kemiripan skor dari setiap kategori, misalnya seperti yang diperlihatkan pada diagram 15 dan 16, dosen pembimbing dikelompokkan berdasarkan kontribusi pengetahuan pada struktur konstruksi dan pada desain. Posisi dosen pembimbing yang memberikan kontribusi yang hampir sama akan berdekatan.
Diagram 15 (kiri). Dendrogram klaster dosen studio berdasarkan dua variabel KD struktur konstruksi dan KD desain. KD struktur konstruksi : kontribusi dosen pada pengetahuan struktur konstruksi mahasiswa. KD desain : kontribusi dosen pada pengetahuan desain mahasiswa.Huruf kapital A, B, C dst merupakan kode inisial dosen pembimbing studio. Cabang dendrogram menunjukkan pengelompokan dosen yang dievaluasi cenderung mirip oleh mahasiswa. Cabang semakin pendek dan dekat menunjukkan kemiripan evaluasi dari dosen yang bersangkutan semakin tinggi.
Diagram 16 (kanan). Scatter-plot klaster dosen studio berdasarkan variabel KD struktur konstruksi dan KD desain. Sumbu x, angka semakin besar/semakin ke kanan kontribusi dosen pada pengetahuan struktur konstruksi mahasiswa semakin besar. Sumbu y, angka semakin besar/semakin ke atas kontribusi dosen pada pengetauhan desain mahasiswa semakin besar. Jumlah data yang dianalisis 320, dikumpulkan dengan kuesioner yang dibagikan ke mahasiswa peserta studio tingkat dua, tiga dan empat semester 1 tahun ajaran 2007/2008. Angka/sumbu 0 merupakan nilai rata-rata.
Method = Ward A B C D E F G H I J K L M N O P Q R S T U V W X Y Z Dendrogram Hierarchical Clustering -2 -1.5 -1 -0.5 0 0.5 1 1.5 KD D ESA IN A B C D E F G H I J K LM N O P Q R S T U V W X Y Z -1.5 -1 -0.5 0 0.5 1 1.5 KD STRUKTUR KONSTRUKSI
Number Eigenvalue Percent Cum Percent
1 4.67 35.90 35.90 2 3.05 23.43 59.34 3 1.06 8.14 67.47 4 0.73 5.64 73.12 5 0.67 5.12 78.24 6 0.52 3.99 82.23 7 0.47 3.65 85.88 8 0.40 3.10 88.98 9 0.35 2.70 91.69 10 0.32 2.50 94.19 11 0.29 2.25 96.43 12 0.28 2.14 98.57 13 0.19 1.43 100.00
VARIABEL PREFERENSI KOMPLEKSITAS KETERATURAN KEBARUAN
Suka 0.85 0.03 0.30 0.19 Bagus 0.79 0.15 0.23 0.30 Nyaman 0.74 0.01 0.40 -0.04 Serasi 0.65 -0.06 0.47 0.18 Kompleks -0.03 0.89 -0.08 0.13 Rumit 0.01 0.88 -0.10 0.09 Mewah 0.08 0.68 0.08 0.53 Unik 0.53 0.58 -0.14 0.19 Teratur 0.13 -0.15 0.81 0.14 Proporsional 0.37 -0.01 0.71 0.04 Fungsional 0.35 -0.04 0.60 -0.10 Modern 0.16 0.11 0.00 0.88 Baru 0.19 0.30 0.09 0.82
Structural Equation Modeling (SEM)
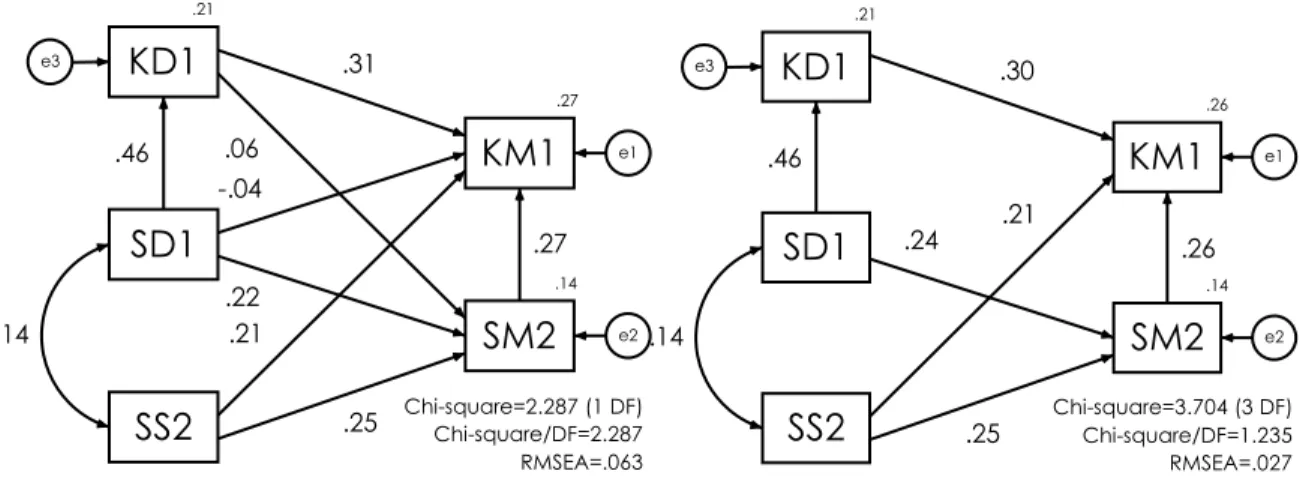
SEM digunakan untuk mengetahui hubungan kausal (regresi) dan hubungan langsung-tidak langsung (path analysis) antar variabel continuous. SEM juga dapat digunakan untuk membandingkan dan memilih model yang lebih sesuai fenomena (sesuai dengan data) dengan melihat indikator goodness of fit index, misalnya dengan membandingkan besaran angka Chi-square/DF dan RMSEA dua model pada diagram 17 dan 18, dapat ditentukan bahwa model SEM diagram 18 lebih baik, dan dapat digunakan untuk menyimpulkan fenomena yang diteliti.
Diagram 17 (kiri) dan Diagram 18 (kanan). Model SEM variabel laten endogenous (dependent) dan
exogenous (independent) evaluasi studio tingkat dua, tiga dan empat semester 1 tahun ajaran 2007/2008.
Variabel endogenous : KM1 (pengetahuan dan ketrampilan desain dan programming mahasiswa), SM2 (motivasi dan antusiasme mahasiswa mengerjakan tugas) dan KD1 (kontribusi dosen pada pengetahuan desain, rancang tapak dan programming). Variabel exogenuous : SD1 (kemudahan komunikasi, penjelasan solusi, tingkat motivasi yang diberikan oleh dosen ke mahasiswa) dan SS2 (daya tarik tugas dan waktu yang dipergunakan). Angka di samping vektor (garis dengan satu panah) merupakan bobot regresi. Angka di samping garis dengan dua panah saling berlawanan koefisien korelasi. Angka di atas variabel multiple
correlation coefficient, yang merupakan indikator besaran total pengaruh variabel exogenous terhadap
variabel endogenous. Chi-square/DF atau RMSEA digunakan untuk mengetahui derajat goodness of fit antara
model dengan data. Chi-square/DF mendekati 1 dan RMSEA mendekati 0 model semakin baik. KESIMPULAN
Penelitian kuantitatif dilaksanakan untuk memahami fenomena lebih terstruktur dengan memanfaatkan temuan-temuan baru yang diperoleh dari analisis data. Setiap jenis analisis data memiliki kemampuan mengungkap temuan berbeda yang tersembunyi di dalam data. Karena itu, pemahaman akan ciri khas temuan dari setiap jenis analisis data merupakan pra-syarat dalam merencanakan penelitian dan sebelum memulai penelitian. Pemahaman akan beragam jenis analisis data mempermudah penyusunan strategi pengumpulan data, penentuan tujuan penelitian dan bahkan perumusan permasalahan dan topik penelitian.
REFERENSI
1. Barbara M. Byrne (2001). Structural Equation Modeling With Amos. Basic Concepts, Applications, and Programming. London : Lawrence Erlbaum Associates.
2. Grim, L.G. & Yarnold, P.R. (2001). Reading And Understanding Multivariate Statistics. Washington : American Psychological Association.
3. Grim, L.G. & Yarnold, P.R. (2002). Reading And Understanding More Multivariate Statistics. Washington : American Psychological Association.
4. John W. Creswell (2003). Research Design: Qualitative, Quantitative, and Mixed Method Approaches. London : Sage Publications.
5. Linda Groat & David Wang (2002). Architectural Research Methods. New York : John Wiley & Sons. Inc.
.21