Perbaikan Struktur Weighted Tree
dengan Metode Partisi Fuzzy
dalam Pembangkitan Frequent Itemset
Oleh:
Budi Dwi S (5106201001) Pembimbing
Daniel O. Siahaan.S.Kom. M.Sc, PD.Eng Akhmad Saikhu, S.Si, M.Kom
PROGRAM STUDI PASCA SARJANA
JURUSAN TEKNIK INFORMATIKA FAKULTAS TEKNOLOGI INFORMASI INSTITUT TEKNOLOGI SEPULUH NOVEMBER
SURABAYA 2010
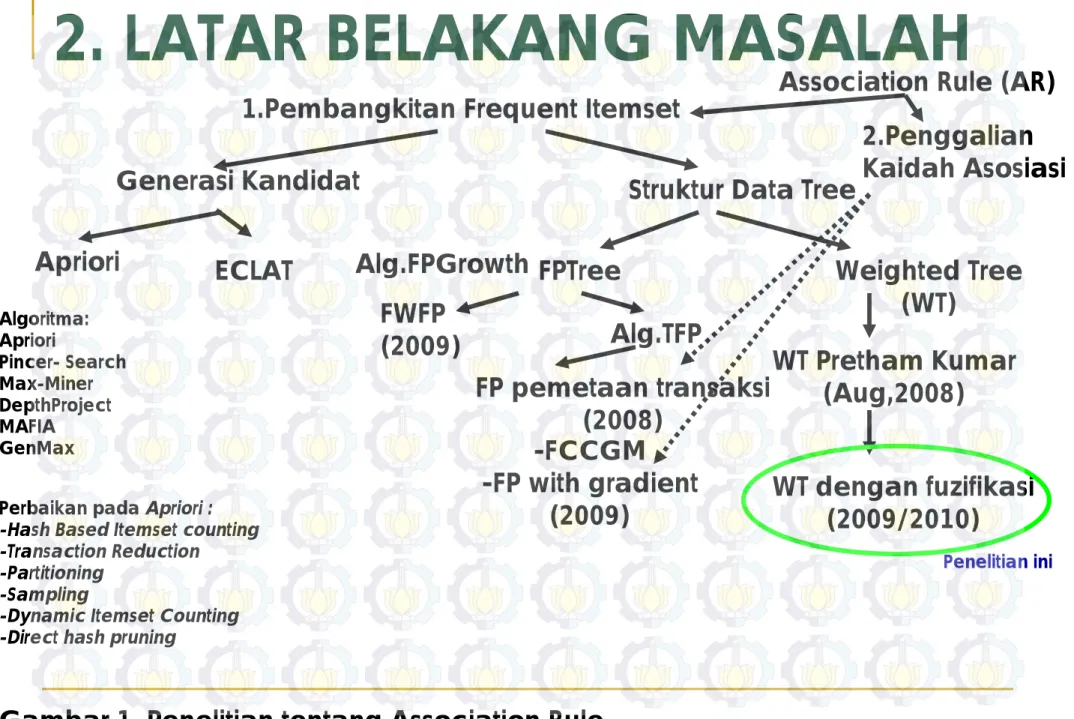
2. LATAR BELAKANG MASALAH
1.Pembangkitan Frequent Itemset
Apriori
FPTree
Weighted Tree
(WT)
Generasi Kandidat
Struktur Data Tree
WT Pretham Kumar
(Aug,2008)
WT dengan fuzifikasi
(2009/2010)
Alg.FPGrowth
FWFP
(2009)
-FCCGM
-FP with gradient
(2009)
ECLAT
FP pemetaan transaksi
(2008)
Algoritma: Apriori Pincer- Search Max-Miner DepthProject MAFIA GenMaxPerbaikan pada Apriori :
-Hash Based Itemset counting -Transaction Reduction
-Partitioning -Sampling
-Dynamic Itemset Counting -Direct hash pruning
Alg.TFP
Penelitian ini
Gambar 1. Penelitian tentang Association Rule
Association Rule (AR)
2.Penggalian
Kaidah Asosiasi
Penelitian Pembangkitan Frequent itemset
dilakukan oleh Pretham Kumar (Kumar, 2008)
dengan tujuan menurunkan jumlah node yang
digunakan FP Tree
Permasalahan yang muncul pada penelitian
tersebut adalah apabila variasi quantity terlalu
tinggi, maka jumlah node meningkat.
Untuk mengatasi kelemahan tersebut, penelitian
ini menambahkan Metode Partisi Fuzzy pada
weighted tree
Hasilnya adalah apabila variasi quantity
meningkat, jumlah node yang digunakan tetap
minimal.
Kata kunci : Association rule, Weighted tree, Metode Partisi Fuzzy
2. PERUMUSAN MASALAH
Bagaimana cara mengurangi jumlah
transaksi yang akan diolah
Bagaimana cara mendapatkan
penurunan jumlah node
Bagaimana cara membangkitkan
frequent itemset
Batasan masalah adalah :
Data ujicoba yang digunakan SPECTF
Heart Data
3. TUJUAN PENELITIAN
Tujuan penelitian adalah memperbaiki
Struktur data Weighted Tree dengan
harapan mendapatkan penurunan
jumlah node yang lebih baik saat
pembangkitan frequent itemset
Kontribusi utama penelitian adalah
penurunan jumlah node dan Kontribusi
pendukung mendapatkan balancing
4. KAJIAN PUSTAKA & DASAR
TEORI
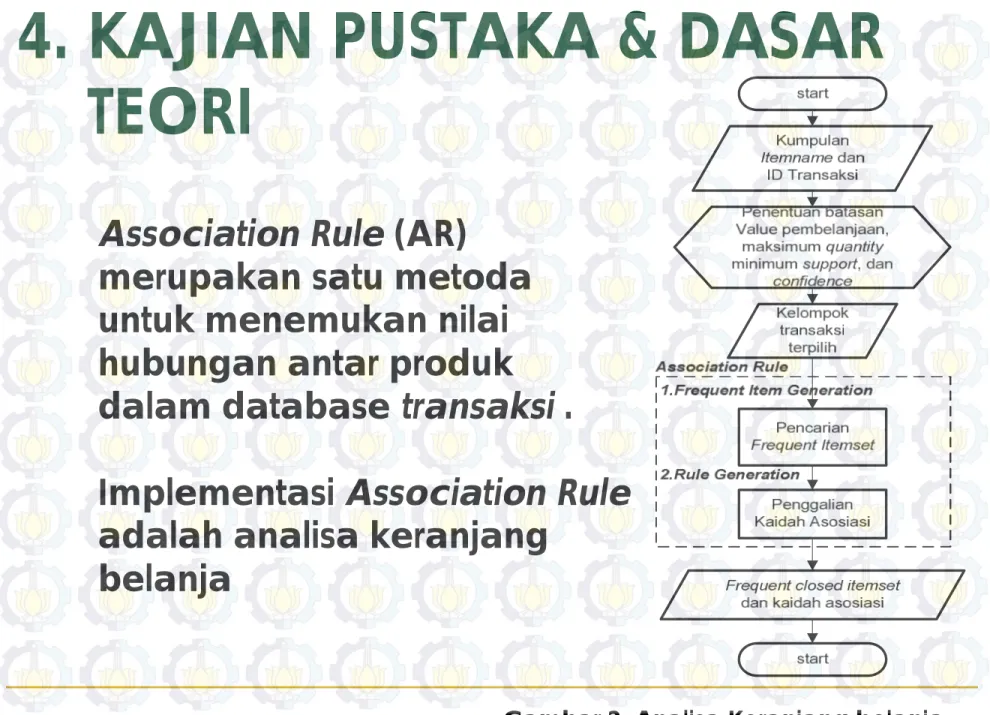
Association Rule (AR)
merupakan satu metoda
untuk menemukan nilai
hubungan antar produk
dalam database transaksi .
Implementasi Association Rule
adalah analisa keranjang
belanja
4. KAJIAN PUSTAKA & DASAR
TEORI
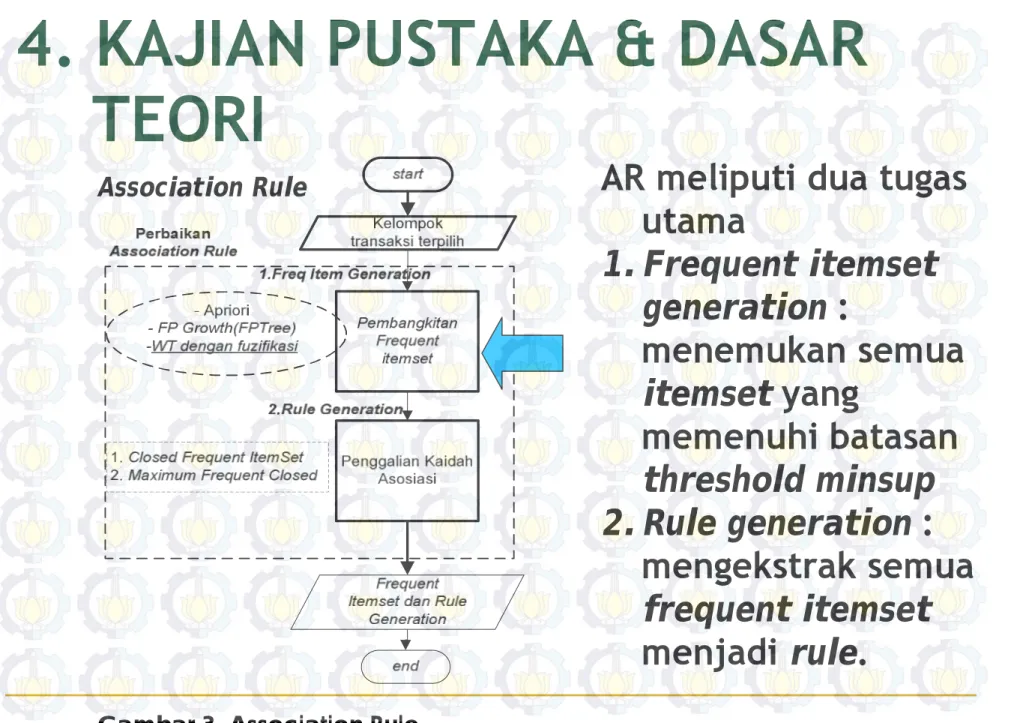
AR meliputi dua tugas
utama
1. Frequent itemset
generation :
menemukan semua
itemset yang
memenuhi batasan
threshold minsup
2. Rule generation :
mengekstrak semua
frequent itemset
menjadi rule.
Association Rule
4. KAJIAN PUSTAKA & DASAR
TEORI
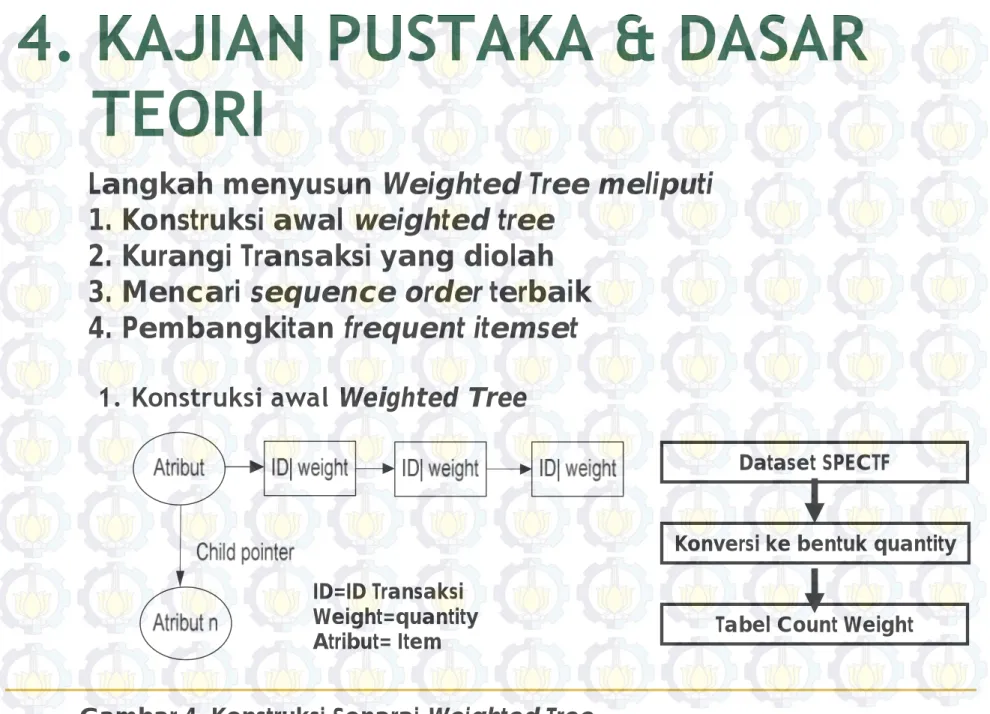
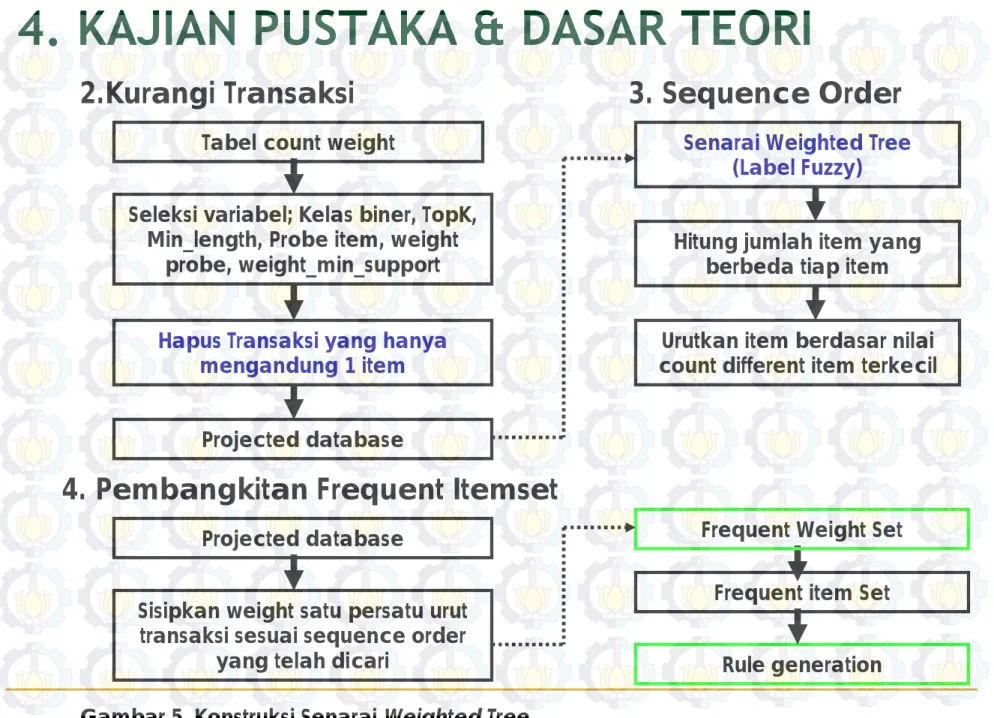
Langkah menyusun Weighted Tree meliputi
1. Konstruksi awal weighted tree
2. Kurangi Transaksi yang diolah
3. Mencari sequence order terbaik
4. Pembangkitan frequent itemset
Gambar 4. Konstruksi Senarai Weighted Tree
1. Konstruksi awal Weighted Tree
Dataset SPECTF
Konversi ke bentuk quantity Tabel Count Weight ID=ID Transaksi
Weight=quantity Atribut= Item
4. KAJIAN PUSTAKA & DASAR TEORI
2.Kurangi Transaksi
Gambar 5. Konstruksi Senarai Weighted Tree
3. Sequence Order
4. Pembangkitan Frequent Itemset
Tabel count weight
Seleksi variabel; Kelas biner, TopK, Min_length, Probe item, weight
probe, weight_min_support
Projected database
Senarai Weighted Tree (Label Fuzzy)
Hitung jumlah item yang berbeda tiap item Urutkan item berdasar nilai count different item terkecil
Hapus Transaksi yang hanya mengandung 1 item
Sisipkan weight satu persatu urut transaksi sesuai sequence order
yang telah dicari Projected database
Frequent item Set Frequent Weight Set
4. KAJIAN PUSTAKA & DASAR
TEORI
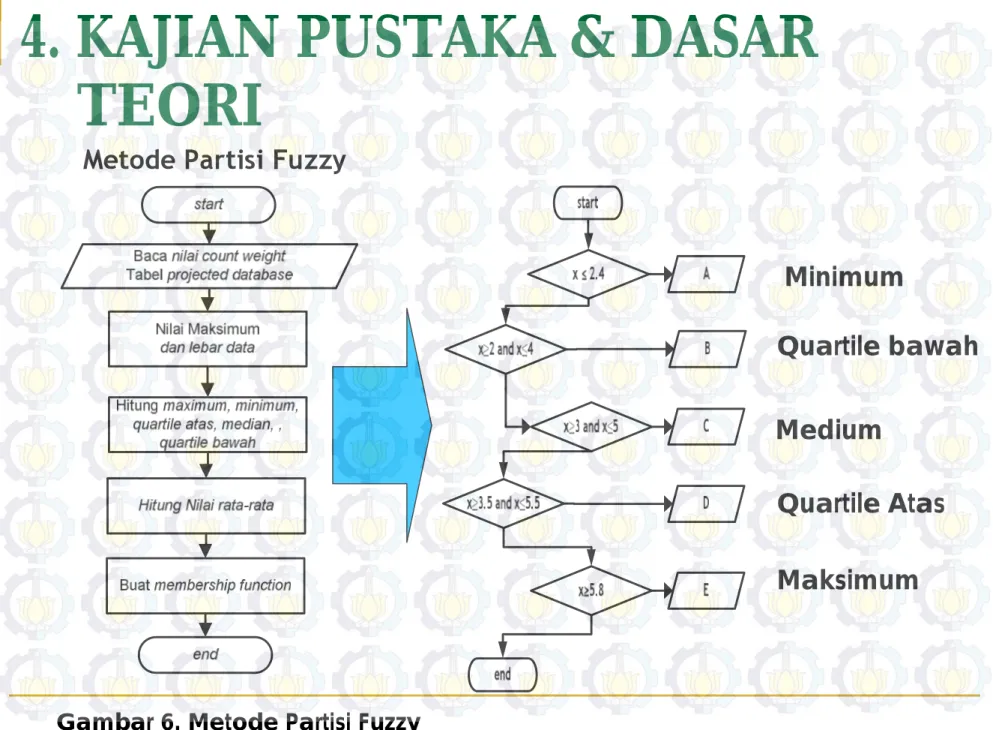
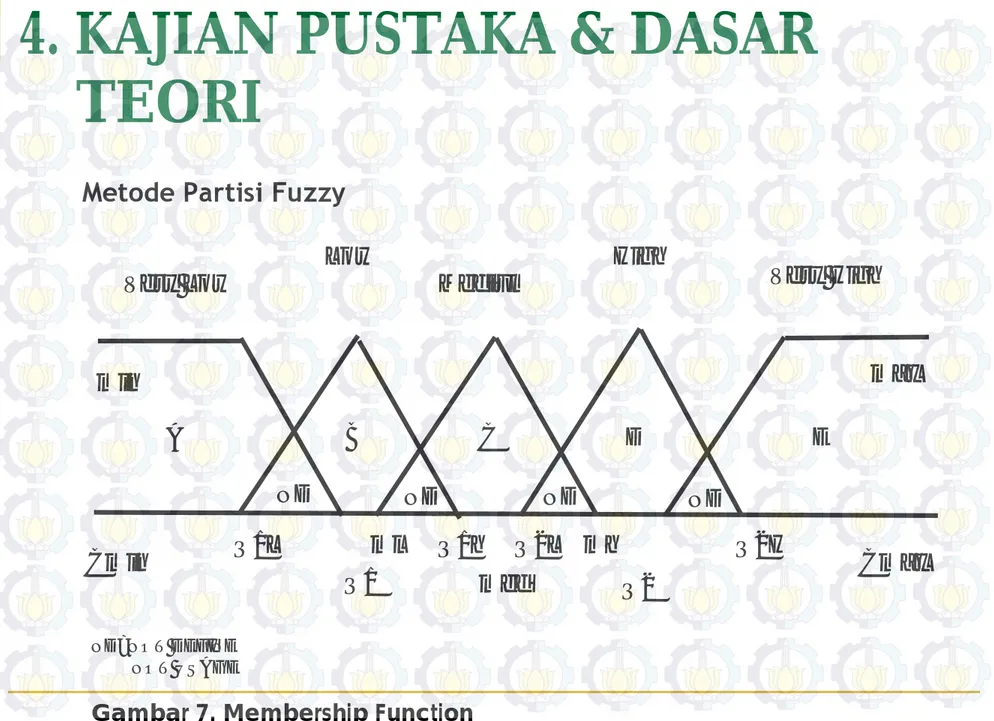
Metode Partisi Fuzzy
Minimum
Quartile bawah
Medium
Quartile Atas
Maksimum
Very Low
Low
Medium
High
Very High
A
B
C
D
E
med
Q2
Q1
Cmax
Cmin
min
max
ND
ND
ND
ND
ND=NOT DEFINE NOT USAGEml
Q1h
mh
Q1L
Q2L
Q2H
4. KAJIAN PUSTAKA & DASAR
TEORI
Metode Partisi Fuzzy
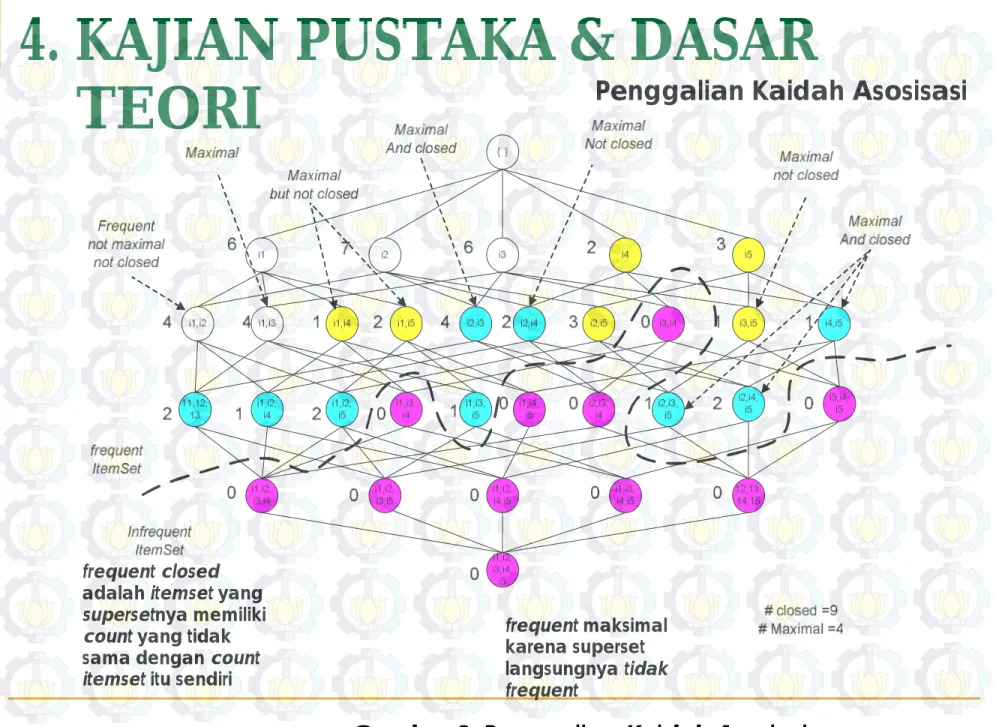
Penggalian Kaidah Asosisasi
frequent closed
adalah itemset yang
supersetnya memiliki count yang tidak
sama dengan count
itemset itu sendiri
frequent maksimal
karena superset langsungnya tidak
frequent
Gambar 8. Penggalian Kaidah Asosiasi
4. KAJIAN PUSTAKA & DASAR
TEORI
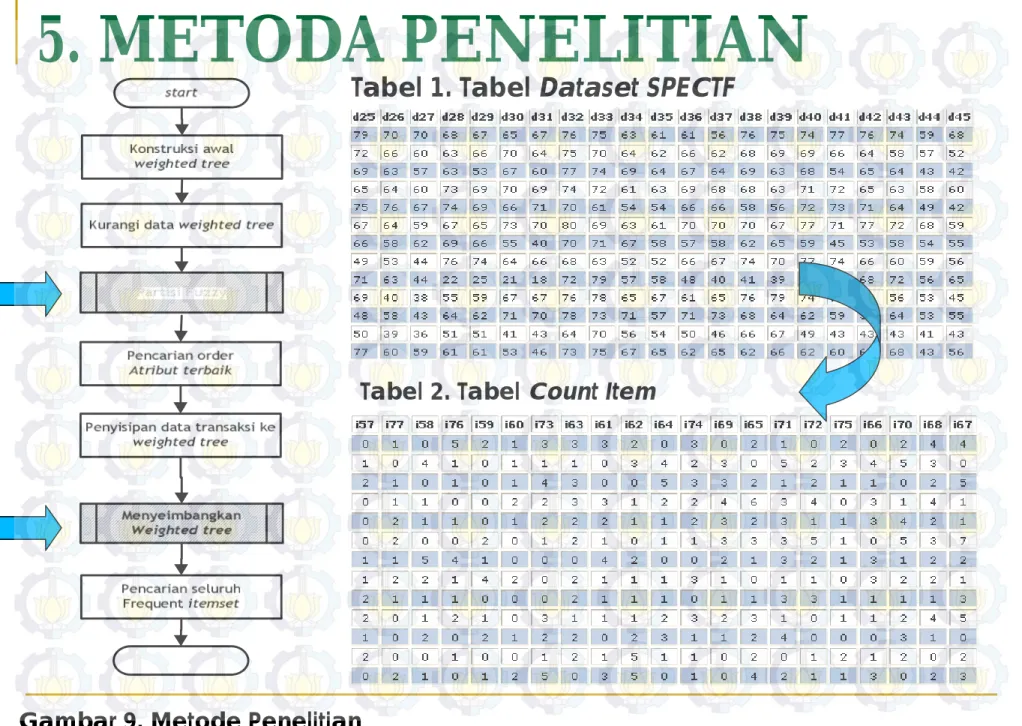
5. METODA PENELITIAN
Tabel 1. Tabel Dataset SPECTF
Tabel 2. Tabel Count Item
5. METODOLOGI PENELITIAN
Tabel 3. Projected Database
Jika weight item <
weight minimum
support, maka
hapus quantity
item
Jika ada1 transaksi
hanya mengandung1
item saja, maka
5. METODOLOGI PENELITIAN
Serial Node Weighted Tree Pretham Kumar
Serial Node Weighted Tree penelitian ini
Rute terpendek
Gambar 10. Rute pendek
Gambar 6. Senarai Weighted Tree
item
Weight quantity
Label Fuzzy
Senarai Weighted Tree (Label Fuzzy)
Hitung jumlah LABEL item yang berbeda tiap item
Urutkan item berdasar nilai count different item terkecil
5. METODOLOGI PENELITIAN
Penelitian Pretham Kumar
Penelitian ini
Waktu proses
5. METODOLOGI PENELITIAN
6. UJICOBA
Karakteristik dataset SPECTF Heart Data
Skenario pertama adalah Skenario ujicoba weighted tree. 1. Ujicoba Weighted Tree dengan K=4
2. Ujicoba Weighted Tree dengan K=8 3. Ujicoba Weighted Tree dengan K=10 4. Ujicoba Weighted Tree dengan K=14
Skenario kedua Analisa Perbandingan dengan hasil penelitian sebelumnya.
1. Prosentase Penurunan jumlah node partisi fuzzy terhadap jumlah node pretham kumar
2. Prosentase Penurunan jumlah node partisi fuzzy terhadap jumlah node FP Tree 3. Pengaruh K terhadap jumlah serial node.
4. Pengaruh K terhadap Jumlah Saving Node.
5. Pengaruh Minimum Length terhadap jumlah node setelah partisi fuzzy. 6. Pengaruh jumlah node saat nilai K maksimum.
7. Pengaruh K terhadap perbandingan waktu proses. Skenario ketiga Analisa Hasil Ujicoba dataset
1. Pengaruh K terhadap jumlah transaksi yang memenuhi syarat. 2. Pengaruh K terhadap jumlah serial node.
3. Pengaruh K terhadap waktu proses.
4. Pengaruh Weight Minimum support terhadap jumlah transaksi yang memenuhi syarat.
5. Pengaruh Weight Minimum support terhadap jumlah serial node. 6. Pengaruh Weight Minimum support terhadap waktu proses
7. ANALISA HASIL UJICOBA
Penurunan rata rata 30.7%
Terhadap jumlah node
Penelitian Pretham Kumar
Penurunan rata rata 35.78%
Terhadap FP Tree
7. ANALISA HASIL UJICOBA
1.Pengaruh K terhadap jumlah transaksi yang memenuhi syarat
2.Pengaruh K terhadap jumlah serial node
3.Pengaruh K terhadap waktu proses
4.Pengaruh weight minimum support terhadap jumlah transaksi yang memenuhi syarat
7. ANALISA HASIL UJICOBA
1.Pengaruh K terhadap jumlah node dan prosentase penurunan dari penelitian sebelumnya
2.Pengaruh minimum length terhadap jumlah transaksi yang memenuhi syarat
3. Perbandingan jumlah node penelitian
4. Perbandingan waktu proses penelitian
7. ANALISA HASIL UJICOBA
Nilai penurunan jumlah node
pada penelitian ini yaitu 4855
terhadap jumlah node
FPTree 7729, sehingga
didapatkan penurunan
jumlah node pada penelitian
ini (saat K maksimum) =
(1-(4855 /7729))%= 37.18%
Nilai penurunan jumlah node
merupakan perbandingan
jumlah node setelah
dilakukan partisi fuzzy dan
penelitian Pretham Kumar.
Hasil penelitian ini dapat
menaikkan prosentase
penurunan jumlah node
penelitian Pretham Kumar
dari 13.9% menjadi 37.18%
yang artinya meningkatkan
efisiensi komputasi sebesar
1-(13.9/37.18) = 63%.
1.Penelitian ini memberikan kontribusi berupa penurunan jumlah node
karena adanya penambahan metode partisi fuzzy pada struktur data
weighted tree. Adapun besarnya angka penurunan jumlah node
rata-rata mencapai 30.7% terhadap penelitian Pretham kumar dan 35.78%
terhadap FPTree.
2.Dengan menurunkan jumlah node pada proses pembangkitan
frequent itemset akan didapatkan nilai big operation yang lebih baik
pada proses pembacaan dari segi perhitungan waktu dan space
yang digunakan.
3.Dari hasil ujicoba dataset, didapatkan bahwa nilai weight minimum
support berbanding terbalik dengan jumlah transaksi, jumlah node
dan waktu proses. Artinya jika nilai weight minimum support rendah
maka jumlah transaksi, jumlah node dan waktu proses meningkat.
Pemilihan nilai weight minimum support yang tepat sangat diperlukan
untuk mendapatkan hasil yang diinginkan pengguna.
4.Hasil uji coba adalah frequent itemset yang dibangkitkan
berdasarkan nilai weight berupa quantity item pada struktur weighted
tree dengan pertimbangan batasan nilai support dan confidence.
9. DAFTAR PUSTAKA
1. Anbalagan E, Mohan E, dan Puttamadappa C. (2009), “Building E-shop using Incremental Association Rule Mining and transaction clustering”, International
journal of Computational Inteligent Research, ISSN 0973-1873, Vol. 5, No. 1, hal.
11-23.
2. Kumar P dan Ananthanarayana. (2008), “Discovery of frequent itemsets using weighted tree approach”, IJCSNS International Journal of Computer Science and
Network Security, Vol. 8 No.8, hal. 195-200.
3. Lin, R.H., Chuang, C.L., Liou, J.H, dan Wu, G.D. (2008), “An integrated method for finding customers in CRM”. Expert Systems with Applications, Entry from
http://www.sciencedirect.com/science).
4. Jian, W dan Ming, L.X (2008), “An Effective Mining Algorithm for weighted
Association Rules in Communication Network”, Journal of Computers, Vol. 3, No. 10, hal. 20-27.
5. Wang, C.H dan Pang, C.T (2009), “Finding Fuzzy Association Rules using FWFP Growth with Linguistic Supports and Confidences”, World Academy of Science,
Engineering and Technology No. 53, hal. 1139-1147.
6. Rahman, A.M, Ashkan Z, Masoud R, dan Mostafa, H.C (2006), “Complete Discovery of Weighted Frequent Subtrees in Tree-StructuredDatasets”, IJCSNS International
Journal of Computer Science and Network Security, Vol. 6 No. 8A, hal. 188-196.
7. Absari, Dhiani Tresna (2008), “Penggalian Top-K Frequent Closed Constrained
Gradient itemsets pada basis data retail”, Entry from
TERIMA KASIH
*
4. KAJIAN PUSTAKA & DASAR
TEORI
1. Probe item merupakan item acuan untuk mengetahui tingkat
asosiasi item lain, item ini adalah item terpilih karena memiliki
nilai count tertinggi dan dipilih yang memiliki acuan weight
quantity sama dalam tiap transaksinya.
2. Top-K item merupakan Urutan item berdasar nilai count
tertinggi dan hampir selalu muncul dalam tiap transaksi.
3. Top-K Frequent item merupakan Urutan frequent item dengan
nilai count tertinggi yang dihasilkan weighted tree
4. Projected database merupakan kumpulan id transaksi, nama
item dan quantity yang akan dicari nilai asosiasinya. Itemnya
adalah item total dikurangi probe item.
5. Minimum length merupakan batas minimum jumlah item
dalam 1 transaksi yang akan dipantau tingkat asosiasinya.
6. Weight minimum support adalah batas maximum
6. UJICOBA
2. Senarai Weighted Tree
Transaksi yang harus dihapus adalah TrID = 9, TrID = 19, TrID = 43, TrID = 53, TrID = 76, TrID = 154, i68|E->D->D->D->D->E->E->E->E->E->E->D->D->E->E->D->C->E->E->D->
i70|C->E->E->E->E->E->C->D->D->E->D->B->D->D->B->E->C->C->D->E->D->E-> i66|D->D->D->D->E->D->C->D->D->D->C->D->D->D->D->E->D->D->D->
i75|C->E->E->D->D->E->E->E->E->D->E->D->E->E->
1. Kode Biner = 1 Top K item = 04 Min length = 10 Probe Item = i67 W_MinSupp = 1
3. Rute Terpendek
4. Rule Generation
6. UJICOBA
1, Nilai TopK=08, Min_length=10, Probeitem=i67,Weight_min_sup=1
3. Rute terpendek
2. Senarai Weighted tree
4. Rule generation A:1 C:6 D:7 E:10 B:2 D:7 C:8 D:48 {root} i69 i72,i74,i61 I68,i66,i75, i71, i65, i70 C:4 D:9 E:10 E:42 D:9 Gambar 18. WT dengan K=8
6. UJICOBA
i68|E->D->D->D->D->E->E->E->E->E->E->D->D->E->E->D->C->E->E->D-> i70|C->E->E->E->D->E->E->C->D->D->D->E->D->B->D->D->B->E->C->E->C->D->E->D->E-i66|D->D->D->D->E->D->D->C->D->D->D->C->D->D->D->D->E->D->D->D-> i75|C->E->E->D->D->E->E->E->E->D->E->D->E->E-> i72|D->E->E->E->D->D->E->D->D->D->E->E->E->E->D->E->E-> i71|D->E->D->C->D->D->E->E->D->D->E->E->D->C->E->D->C->E->E->E->D->E-> i65|D->D->E->D->E->D->D->D->D->E->E->D->E->E->D->E->C->E->D->D->E->E-> i69|D->C->E->C->E->D->E->C->A->C->D->E->D->E->E->D->E->D->C->E->C->E->D-> i74|E->E->E->E->E->D->E->E->D->E->D->D->D->E->E->E-> i64|E->E->D->E->D->C->D->E->D->D->E->E->E->D->D->D->E->D->D->1. Kode Biner = 1 Top K item =10 Min length = 10 Probe Item = i67 W_MinSupp = 1
2. Senarai Weighted Tree
3. Rule Generation
6. UJICOBA
i68,1=>Di68,8=>Ei68,11=>NoLf, Bi70,2=>Ci70,4=>Di70,9=>Ei70,10 Ci66,2=>Di66,16=>Ei66,2=>NoLf, Ci75,1=>Di75,4=>Ei75,9=>NoLf, Di72,7=>Ei72,11=>NoLf,=>NoLf, Ci71,3=>Di71,9=>Ei71,10=>NoLf, Ci65,1=>Di65,11=>Ei65,10=>NoLf, Ai69,1=>Ci69,6=>Di69,7=>Ei69,9 Di74,5=>Ei74,11=>NoLf,=>NoLf, Ci64,1=>Di64,10=>Ei64,8=>NoLf, Ci62,1=>Di62,8=>Ei62,4=>NoLf, Di61,8=>Ei61,11=>NoLf,=>NoLf, Ci63,2=>Di63,3=>Ei63,12=>NoLf, Ci73,4=>Di73,9=>Ei73,5=>NoLf,1. Kode Biner = 1 Top K item =14 Min length = 10 Probe Item = i67 W_MinSupp = 1
2. Senarai Weighted Tree dengan Count Item
3. Rule Generation CDE Frequent Maximal DE Frequent Closed
Gambar 21. Penggalian Weight Frequent set
Perbandingan waktu
Gambar 22. Perbandingan waktu
Perbandingan cost
Gambar 23. Perbandingan cost (descendant)
E
D
C
A
B
A:1 C:6 B:2 C:4 C:9 D:58 D:12 E:21 E:50 {root} I68,i66,i75,i71,i65,i64 i72, i74 D:9 E:10 D:7 E:9 i69 i70 {root} 4x1 4x2 3x3 2x4 29/13=2.23 1x1 1x2 1x3 14/5=2.8Lampiran 3
Perbandingan cost
Lampiran 4
K=20, Wmin_supp=1, Min_length=10
Perbandingan jumlah transaksi terhadap waktu
Perbandingan waktu terhadap K
Lampiran 5
start Kumpulan Itemname dan ID Transaksi Pencarian Frequent ItemSet Analisa Korelasi (Causality Analysis) Penggalian Kaidah Asosiasi (Closed) Apriori Dan FP Tree end Metode: yang ada
Closet Closet+ TF2P Top-K Mining DCI Closed Transaction Clustering Metode: 1. Ancor Node Descendant sum
2. Close node count Array
Majeed ,2008 Absari,2008 Anbalagan,2009 Perbaikan Association Rule Candidate generation Penelusuran Istilah Market Basket Analysis Merupakan penerapan AR pada database transaksi
Kumar,2008 Lin, 2008
Han ,2005 Absari, 2008
1.Freq Item Gen
2.Rule Generation
Interisting Measure
1. Freq Closed Itemset - Urutan Top Down - Urutan Bottom Up 2. Pemangkasan daerah pencarian
-Item Merging -Prefix itemset skipping 3. pemeriksaan ItemSet Closed Improving Apriori :
-Hash Based Itemset counting -Transaction Reduction -Partitioning -Sampling
Dynamic Itemset Counting Type KDD 1. AR 2. Classification 3. Squential Pattern 4. Pattern with Time Series 5. Categorization&Segmentation Function KDD 1. Prediction 2. Identification Pattern 3. Classification Partition 4. Optimization
1. Count Support of candidate 2. Prunning Leaf Node 3. Kriteria node, pemangkasan 4. Subset generation Meliputi: 1. Header Table 2. Conditional pattern base 3. Conditional weighted tree Tanpa Batasan
minimum Support (Wang 2006)
Alg TFP
Close node count saat penyisipan Descendant sum saat terbentuk ditambah formulasi query untuk gradient
FCCGM (Wang,2006)
AR : 1. Freq Item gen Generate All support >=minsupp Ex:closed, brute force 2. Rule generation From freq itemset, each rule is binary partition of freq itemset
Penggalian Itemset Frequent 1. BFS : Apriori 2. DFS : Eclat Output: 1. Frequent Closed 2. frequent Maximal Freq itemset <> AR If freq itemset=x B=X-A
A->B menjadi AR jika 1. conf(A B) >=minconf 2. supp(A B)= supp(AUB)=supp(X) 3. conf(A B)=supp(AUB)/supp(A) Sifat Basis Data :
Sparse Database / Basis Data jarang
1.Urut Count 2.Urut Gradient
Kontribusi umum:
1. Meningkatkan efisiensi penelusuran dg weighted tree
2. validasi konsistensi dengan korelasi 3. Prunning dataset yang diolah Kontribusi pribadi: 1. Menggabungkan metode 2. Menggunakan dataset real 3. korelasi beda hari Konsep penggalian TFP:
1. Inisialisasi Awal 2. Penentuan min_l dan k 3. Penyusunan Tabel Global Header 4. Pembentukan Fptree membangkitkan close count node dan descendant sum 5. Penggalian Top K Frequent Closed dengan
Mine Cond FPTree secara bottomup dan rekursif Kelompok Transaksi Transaksi Beda Hari Frequent Closed And Rule Generation Frequent Closed And Rule Generation Frequent Closed And Rule Generation Penentuan batasan
Minimum Support, confidence dan gradient
(Fuzzy Set)