Fakultas Ilmu Komputer
2381
Implementasi Metode Fuzzy K-Nearest Neighbor Untuk Klasifikasi
Penyakit Tanaman Kedelai Pada Citra Daun
Yerry Anggoro1, Budi Darma Setiawan2, Putra Pandu Adikara3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Kebutuhan protein sangatlah penting bagi tubuh manusia, salah satunya adalah kedelai yang merupakan sumber protein nabati. Selain jagung dan beras, kedelai merupakan komoditi pangan utama di Indonesia. Akan tetapi produksi kedelai dalam negeri belum memenuhi permintaan secara baik. Produksi kedelai di tingkat petani sebenarnya masih bisa ditingkatkan melalui inovasi teknologi, salah satunya yaitu mendeteksi penyakit tanaman kedelai pada daun dengan metode Fuzzy K-Nearest
Neighbor dan segmentasi menggunakan metode Otsu. Citra diproses dengan metode Otsu untuk
memisahkan bagian yang berpenyakit dengan bagian yang tidak berpenyakit lalu melakukan pengklasifikasian dengan metode Fuzzy K-Nearest Neighbor untuk menentukan penyakit karat daun,
Downy Mildew, dan pustul bakteri. Terdapat empat pengujian yaitu pengujian perbandingan data latih
dan data uji dengan akurasi tertingi pada perbandingan 90:10 dengan jumlah 54 data latih dan 6 data uji sebesar 100%, pengujian terhadap nilai Threshold dengan T=10 menghasilkan akurasi 83,33%, pengujian terhadap nilai k=5 menghasilkan akurasi 83,33%, dan pengujian terhadap nilai m=2 dengan akurasi 83,33%.
Kata kunci: Otsu, Fuzzy K-Nearest Neighbor, kedelai.
Abstract
Protein is one of essential thing to the human body, there are many source of protein and one of it is a soy which is nabati protein source. besides corn and rice, soy is the main food commodities in Indonesia. However, domestic production of soybean has not been enough to fulfil the necessity. Soybean production at the level of actual farmers could still be enhanced through technological innovation, one of that is to detect plant disease of soybeans on the leaves by the method of Fuzzy K-Nearest Neighbor and the segmentation using the method of Otsu. The image processed with the method of Otsu to separate parts that are diseased with parts that are not diseased and then do a classification by the method of Fuzzy K-Nearest Neighbor to determine leaf rust disease, Downy Mildew, and bacterial pustule. There are four tests such as test comparison data training and test data with the highest accuracy in comparison with a total of 90:10 54 training data and test data of 6 100%, testing against the values of Threshold with T = 10 generates 83,33% accuracy, testing against the values of k = 5 generates 83,33%, accuracy and testing against the values m = 2 with accuracy of 83,33%.
Keywords: Otsu, Fuzzy K-Nearest Neighbor, soybean.
1. PENDAHULUAN
Kedelai (Glycine max L. Merril) merupakan salah satu dari tiga komoditas tanaman pangan setelah padi dan jagung di Indonesia. Kedelai sebagai sumber protein nabati penting yang harganya relatif murah, sehingga dapat dijangkau oleh seluruh lapisan masyarakat (Putri Setya Rahmita, Syamsuddin Djauhari, 2015).
mana rata–rata kebutuhan kedelai setiap tahunnya sebanyak ± 2,2 juta ton biji kering. Hal ini mengakibatkan kerugian bagi Indonesia antara lain, mengurangi kesempatan kerja dan meningkatnya ketergantungan jangka panjang, hilangnya devisa negara yang cukup besar sehingga mempengaruhi sistem ketahanan pangan nasional (Kementerian Pertanian, 2015). Rendahnya kualitas hasil kedelai di Indonesia merupakan masalah utama petani Indonesia, selain pengolahan kedelai, pembudidayaan dan proses tanam kedelai juga merupakan tantangan. Usaha peningkatan produktivitas kedelai tidak terlepas dari berbagai kendala, antara lain adanya gangguan hama dan penyakit pada proses penanaman dan pembudidayaan kedelai. Serangan hama adalah salah satu ancaman dalam meningkatkan produksi kedelai. Ada 266 jenis serangga yang berasosiasi dengan tanaman kedelai di Indonesia, yang terdiri 61 jenis serangga predator, 41 jenis serangga parasit, 111 jenis hama dan 53 jenis serangga (Okada et al. 1988 dalam Marwoto, 2008). Dari 111 jenis serangga hama, 50 jenis tergolong hama perusak daun, namun yang berstatus hama penting hanya 9 jenis (Arifin dan Sunihardi 1997 dalam Marwoto, 2008). Berdasarkan hasil identifikasi terhadap 9 jenis serangga hama pemakan daun, ulat grayak (Spodoptera litura) merupakan salah satu jenis hama pemakan daun yang sangat penting. Beberapa penyakit tanaman kedelai dapat dideteksi melalui gejala yang ditampakkan pada daun seperti penyakit karat daun, pustul bakteri, Downy Mildew, dan beberapa penyakit daun lainnya.
Cara untuk mengidentifikasi penyakit pada tanaman kedelai, sebagian besar dilakukan oleh petani kedelai hanya dengan mengamati pada tampilan luar tanaman. Oleh karena pengamatan dilakukan dengan mata telanjang, maka penyakit tanaman kedelai sering kali tidak teridentifikasi dengan akurat sehingga menyebabkan penyakit yang lebih serius pada tanaman. Identifikasi yang benar perlu dilakukan untuk tindakan pencegahan dan pengobatan pada penyakit. Dengan menerapkan teknologi informasi dan komunikasi di bidang pertanian, seharusnya masalah seperti ini dapat ditangani.
Salah satu penerapan teknologi informasi dan komunikasi di bidang pertanian yaitu dapat digunakan sebagai alat bantu klasifikasi penyakit tanaman kedelai. Klasifikasi merupakan suatu proses penggabungan atau
pengelompokan dua atau lebih data sesuai dengan kesamaan suatu kriteria tertentu. Metode klasifikasi Data Mining yang biasa digunakan antara lain metode C4.5, K-Nearest
Neighbor (KNN), ID3, Naïve Bayes dan metode
lainnya. K-Nearest Neighbor (KNN) merupakan metode klasifikasi termasuk kelompok Instance–Based Learning. Algoritme ini juga merupakan salah satu teknik Lazy
Learning, yaitu metode belajar dimana
generalisasi di luar data pelatihan tertunda sampai permintaan dibuat untuk sistem. KNN dilakukan dengan mencari kelompok k objek dalam data latih yang paling dekat (mirip) dengan objek pada data baru atau data uji (Ndaumanu & Arief, 2014). Algoritme
K-Nearest Neighbor (K-NN atau KNN) dilakukan
dengan melakukan klasifikasi terhadap objek berdasarkan data pembelajaran yang jaraknya paling dekat dengan objek tersebut. Salah satu penerapan penelitian yang menggunakan metode K-Nearest Neighbor untuk pengklasifikasian penyakit tanaman jeruk keprok dengan citra daun. Dalam penelitian ini, metode K-Nearest Neighbor (KNN) dipakai untuk klasifikasi data uji yaitu daun jeruk sebagai objeknya dan hasil dari penelitian tersebut adalah identifikasi penyakit tanaman jeruk dengan akurasi mencapai 96,67% (Priambodo, 2015).
Oleh karena itu, pada skripsi ini penulis mencoba mengimplementasikan algoritme
Fuzzy K-Nearest Neighbor (FK-NN) untuk
klasifikasi penyakit tanaman kedelai. Dengan penerapan metode ini diharapkan akan menghasilkan akurasi yang lebih tinggi daripada penelitian yang sudah ada. Berdasarkan latar belakang yang telah dijelaskan di atas, maka penulis mengambil judul untuk skripsi ini adalah “Implementasi Metode Fuzzy K-Nearest Neighbor untuk Klasifikasi Penyakit Tanaman Kedelai pada Citra Daun”
2. DASAR TEORI
2.1 Metode Otsu
(foreground) dan latar belakang (background). Formulasi dari metode Otsu adalah dengan melibatkan nilai ambang yang akan dicari dari suatu citra graylevel dinyatakan dengan k. Nilai k berkisar antara 0 sampai dengan L, dengan nilai L = 255. Probabilitas setiap pixel pada level ke i dapat dinyatakan pada persamaan 1.
Pi = ni/N (1)
Yang mana:
Pi adalah probabilitas pixel ke-i, ni menyatakan jumlah piksel pada level ke i, N menyatakan total jumlah piksel pada citra. Nilai Zeroth cumulative moment, First cumulative
moment dan total nilai rata-rata berturut-turut
dapat dinyatakan dengan rumus berikut.
𝜔(𝑘) = ∑𝑘 𝑃𝑖
𝜔(𝑘) adalah Momen Kumulatif ke-0
𝜇(𝑘) adalah Momen Kumulatif ke-1
𝜇𝑡 adalah nilai rata-rata
Nilai ambang k dapat diperoleh dengan pertama dilakukan adalah yaitu mencari tingkat keabuan ke-i yaitu y1 dan y2 yang difungsikan di persamaan
y1=2G-R-B (6)
y2=2R-G-B (7)
2.2 Fuzzy K-Nearest Neighbor
Metode Fuzzy K-Nearest Neighbor (FK-NN) diperkenalkan oleh Keller et all (1985) dengan mengembangkan K-NN yang digabungkan dengan teori Fuzzy dalam menyampaikan definisi pemberian label kelas pada data uji yang diprediksi.
Seperti halnya pada teori Fuzzy, sebuah data mempunyai nilai keanggotaan pada setiap kelas yang artinya sebuah data bisa dimiliki oleh kelas yang berbeda dengan nilai derajat keanggotaan dalam interval [0,1].
Rumus yang digunakan adalah :
u(x, 𝑐𝑖)= pertama dilakukan adalah mencari tingkat keabuan ke-i yaitu y1 dan y2 yang difungsikan di Persamaan 6 dan Persamaan 7.
Dari nilai y1 dan y2 yang diterapkan pada metode Otsu, maka didapatkan dua nilai
Threshold (T1 dan T2). Dengan tujuan untuk
meminimalkan noise yang terdapat pada citra, maka proses segmentasi juga perlu dimodifikasi dengan fungsi sebagai berikut:
𝑃𝑟= {
Dari sebuah gambar, akan diketahui nilai red, green, blue dari citra tersebut, dari nilai tersebut maka dilakukan proses untuk memperbaiki citra yaitu dengan thresholding dengan menggunakan metode Otsu. Pada gambar diketahui piksel pertama memiliki nilai red 157, green 188, dan blue 144. Perhitungan ini berlaku untuk keseluruhan piksel citra. Apabila sebuaj citra terdiri dari 36 piksel, maka terdapat 36 nilai red, green, dan blue yang diketahui. Langkah pertama yaitu intuk mencari nilai y1 dan y2 sesuai persamaan 6. y1= 2G – R – B
= 2*188 – 157 – 144 = 75
Tabel 1 Nilai y1
75 73 70 70 68 69 72 73
72 65 58 55 53 61 65 72
64 59 47 35 39 48 61 69
42 47 32 22 26 39 56 69
56 45 28 21 24 39 58 73
49 45 36 31 36 47 65 75
52 49 45 48 51 60 72 78
52 52 53 58 60 71 79 84
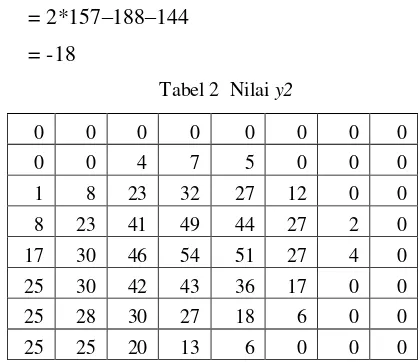
Tabel 1 merupakan hasil dari normalisasi perhitungan y1, untuk y1 yang bernilai lebih kecil daripada 0, maka dibulatkan menjadi 0, dan untuk y1 yang bernilai lebih besar dari pada 255 maka dibulatkan menjadi 255. Normalisasi ini juga berlaku untuk perhitungan y2. Untuk mencari nilai y2 menggunakan persamaan 7. y2= 2R – G – B
= 2*157–188–144 = -18
Tabel 2 Nilai y2
0 0 0 0 0 0 0 0
0 0 4 7 5 0 0 0
1 8 23 32 27 12 0 0
8 23 41 49 44 27 2 0
17 30 46 54 51 27 4 0
25 30 42 43 36 17 0 0
25 28 30 27 18 6 0 0
25 25 20 13 6 0 0 0
Untuk mencari nilai ni1 (histogram1) yaitu dengan menghitung frekuensi piksel yang digunakan oleh perhitungan y1 Untuk hasil perhitungan ni1 (histogram1) ditunjukkan pada tabel 3.
Tabel 3 Nilai ni1
0 1 ….. 21 22 ... ... ... ... 255
0 0 ….. 1 1 ... ... ... ... 0
Untuk menghitung nilai ni2 (histogram2) yaitu dengan menghitung jumlah frekuensi piksel yang digunakan di perhitungan y2 untuk perhitungan ni2 (histogram2) ditunjukkan pada tabel 4.
Tabel 4 Nilai ni2
0 1 2 3 4 5 ... ... ... 255 24 1 1 0 2 1 ... ... ... 0
Langkah berikutnya adalah mencari nilai total rata-rata dengan menggunakan persamaan 4, nilai Momen Kumulatif ke-0 dengan persamaan 2, nilai Momen Kumulatif ke-1 dengan persamaan 3. Setelah semua diketahui, maka barulah nilai threshold1 (t1) dan
threshold2 (t2) dapat dihitung.
Perhitungan pertama adalah menghitung nilai total rata-rata dan , cara perhitungan nilai rata-rata berdasarkan contoh dibawah ini.
𝜇𝑡 = ∑ 𝑖. 𝑃𝑖𝐿
𝑖=1
= ∑2560. (640
𝑖=1 )
=0
Kemudian menghitung Momen Kumulatif ke-1 cara perhitungan Momen Kumulatif ke-1 berdasarkan contoh dibawah ini.
𝜇(𝑘) = ∑ 𝑖. 𝑃𝑖𝐾
𝑖=1
𝜇(1) = ∑ 0. (1 640
𝑖=1 )
= 0
Maka, saat warna ke-0 dari perhitungan ni1 mengasilkan nilai total dan nilai kumulatif ke-1 yang sama yaitu 0. Untuk keseluruhan perhitungan nilai total rata-rata dan Nilai Momen Kumulatif ke-1 berdasarkan hasil perhitungan ni1 ditunjukkan pada tabel 5.
Tabel 5.Nilai momen kumuliatif ke-1
berdasarkan ni1
0 1 ….. 21 22 ….. ... ... 255
0 0 ….. 0,3 0,7 …... ... ... 55,0
perhitungan ni2 adalah 55,0. Langkah berikutnya adalah menghitung nilai Momen Kumulatif ke-0 berdasarkan hasil perhitungan ni1. Sebagai contoh perhitungan ditunjukkan dibawah ini.
𝜔(𝑘) = ∑ 𝑃𝑖𝑘
𝑖=1
𝜔(21) = ∑ (1 641
𝑖=1 ) = 0,02
Tabel 6 Nilai Momen Kumulatif ke-0
berdasarkan ni1
0 1 ….. 21 2 .... .... 255
0 0 ….. 0,02 0,03 .... .... 1
Tabel 6 adalah hasil perhitungan Nilai Momen Kumulatif ke-0 berdasarkan ni1. Dengan persamaan dan perhitungan juga dapat diketahui Nilai Momen Kumulatif ke-0 berdasarkan ni2. Setelah mendapatkan nilai total rata-rata, nilai Momen Kumulatif ke-0, dan nilai Momen Kumulatif ke-1, maka perhitungan varian, maksimum varian, dan nilai
threshold dapat dilakukan. Berikut contoh
perhitungan varian saat warna ke-0 dari hasil nilai total rata-rata, nilai Momen Kumulatif ke-1.
Dan berikut contoh perhitungan varian saat warna ke-0 dari hasil nilai total rata-rata, nilai Momen Kumulatif ke-0.
Hasil keseluruhan dari perhitungan dari keduanya akan dibuat tabel yang nantinya dicari nilai varian terbesar yang akan menjadi t1 dan t2. T1 berada pada piksel ke-53 dan t2 berada pada piksel ke-17. Setelah nilai t1 dan t2 didapatkan, maka nilai t1 dan t2 ditambahkan dan dikurangkan dengan nilai peubah Threshold yang pada perhitungan ini menggunakan nilai 10 dan didapat dilai t1 baru 63 dan t2 baru 7.
Kemudian akan dibandingkan dengan nilai y1 dan nilai y2. Nilai Red, Green, Blue piksel pertama akan akan bernilai tetap jika t1 lebih besar dari y1, dan nilai t2 lebih kecil daripada y2 pada piksel pertama. jika kondisi tersebut tidak terpenuhi maka nilai Red, Green, Blue akan diubah menjadi 0.
Dari citra yang telah dibuat menjadi bentuk Otsu, maka citra tersebut diekstraksi nilai red,
green, dan blue dengan membagi nilai warna
dengan jumlah piksel.
Rata-rata R=
(158+161+165+148+184+168+167+162+155+146+165+167+142+140+134+154+179+ +147+96+101+93+140+183+159+128+141+118+146+166+173+186+167)
32
=151
Rata-rata G=
(175+174+173+157+193+185+175+167+160+153+174+175+139+134+132+159+190+148+87+ 90+89+147+198+163+122+132+118+157+178+177+190+177)
32
=155
Rata-rata B=
(133+131+132+114+150+143+136+127+120+111+131+136+104+100+94+119+148+ 114+56+58+54+106+155+128+90+99+82+117+142+142+155+140
32
=117
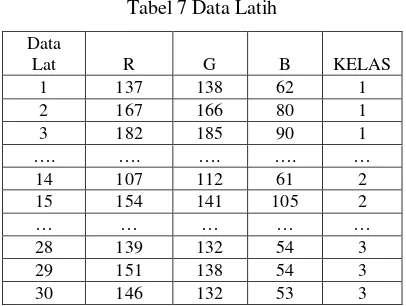
Dengan cara yang sama, gunakan beberapa data dan ambil nilai fitur, red, green, dan blue seperti pada Tabel 7.
Tabel 7 Data Latih
Data
Lat R G B KELAS
1 137 138 62 1
2 167 166 80 1
3 182 185 90 1
…. …. …. …. …
14 107 112 61 2
15 154 141 105 2
… … … … …
28 139 132 54 3
29 151 138 54 3
30 146 132 53 3
Masuk ke kelas apakah data dengan fitur R= 151, G= 155, B=117. Untuk langkah pertama adalah mencari jarak euclidean dengan persamaan berikut:
D(x,y)=√∑𝑛𝑘=1(𝑥𝑖− 𝑦𝑖)2
=√(151 − 137)2(155 − 138)2(117 − 62)2 = 𝟔𝟎, 𝟗𝟎
Sehingga didapat nilai euclidean sepeti di tabel
𝜎𝐵2(k) = [55,0∗0,02−0,3]
2
0,02[1−0,02]
= 18
𝜎𝐵2(k) = [15,0∗0,4−0]
2
0,4[1−0,4]
= 134,44
Tabel 8 Jarak terhadap data latih
Data
Latih jarak
rank min
distance kelas
1 59.24525 15 1
2 41.78516 7 1
3 50.89204 10 1
… … … …
14 83.19255 29 2
15 18.68154 1 2
… … … …
28 68.13222 21 3
29 65.25335 18 3
30 68.19091 22 3
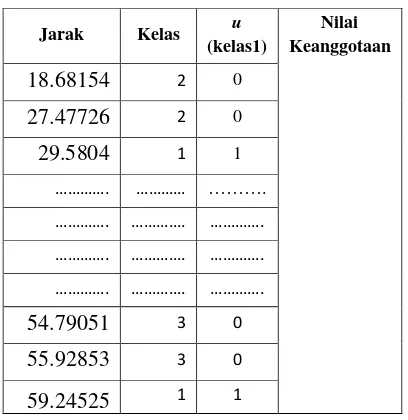
Kemudian hasil tersebut diurutkan berdasarkan rank min distance terendah. Kemudian dihitung nilai derajat keanggotaan berdasarkan K yang telah ditentukan, semisal nilak k adalah 15.
Tabel 9 Nilai keanggotaan kelas 1
Jarak Kelas u (kelas1)
Nilai Keanggotaan
18.68154 2 0
27.47726 2 0
29.5804 1 1
…………. ………… ……….
…………. …………. ………….
…………. …………. ………….
…………. …………. ………….
54.79051 3 0
55.92853 3 0
59.24525 1 1
Pada tabel 9 diatas nilai u adalah nilai keanggotaan data kedalam kelas, nilainya 1 jika jarak milik kelas 1 dan 0 jika jarak milik kelas 2 atau 3 selanjutnya menghitung nilai keanggotaan data terhadap kelas 1 menggunakan persamaan 8.
u(x, 𝑐1)=
0∗18,6815(2−1)−2 + 0∗27,4773(2−1)−2 +1∗29,5804(2−1)−2 +⋯+
+1∗59,2453(2−1)−2
18,6815(2−1)−2 + 27,4773(2−1)−2 +29,5804(2−1)−2 +⋯+
+59,2453(2−1)−2
= 0,34
Tabel 10 Nilai keanggotaan kelas 2
Jarak Kelas u(kelas1) Nilai Keanggotaan
18.68154 2 1
27.47726 2 1
.... .... ....
.... .... ....
.... .... ....
.... .... 0,57
.... .... ....
55.92853 3 0
59.24525 1 0
Pada tabel 10 diatas nilai u adalah nilai keanggotaan data kedalam kelas, nilainya 1 jika jarak milik kelas 2 dan 0 jika jarak milik kelas 1 atau 3. Selanjutnya menghitung nilai keanggotaan data terhadap kelas 3.
u(x, 𝑐2)=
1∗18,6815(2−1)−2 + 1∗27,4773(2−1)−2 +0∗29,5804(2−1)−2 +⋯+
+0∗59,2453(2−1)−2
18,6815(2−1)−2 + 27,4773(2−1)−2 +29,5804(2−1)−2 +⋯+ +59,2453(2−1)−2
= 0,57
Tabel 11 Nilai keanggotaan kelas 3
Jarak Kelas u(kelas1) Nilai Keanggotaan
18.68154 2 0
27.47726 2 0
.... .... ....
.... .... ....
.... .... ....
.... .... 0,03
.... .... ....
55.92853 3 1
59.24525 1 0
u(x, 𝑐3)=
0∗18,6815(2−1)−2 + 0∗27,4773(2−1)−2 +0∗29,5804(2−1)−2 +⋯+
+0∗59,2453(2−1)−2
18,6815(2−1)−2 + 27,4773(2−1)−2 +29,5804(2−1)−2 +⋯+
+59,2453(2−1)−2
= 0,03
Untuk data uji diperoleh nilai keanggotaan pada kelas 1 sebesar 0.34, nilai keanggotaan pada kelas 2 sebesar 0.57 dan nilai keanggotaan pada kelas 3 sebesar 0.03. Nilai keanggotaan terbesar dipilih sebagai kelas target yaitu kelas 2 atau penyakit karat daun, sehingga data uji masuk kedalam kelas target.
4. PENGUJIAN DAN ANALISIS
4.1 Skenario Pengujian
Pengujian sistem meliputi beberapa skenario yaitu :
1. Pengujian terhadap perbandingan data latih dan data uji.
Pengujian ini bertujuan untuk mengetahui perbandingan data latih dan data uji yang optimal dari data.
2. Pengujian terhadap nilai peubah threshold. Peubah threshold (T) adalah variabel yang digunakan pada preprocessing citra dengan metode Otsu. Pengujian ini bertujuan untuk mencari nilai peubah threshold (T) yang paling optimal untuk proses
preprocessing sehingga menghasilkan
akurasi terbaik.
3. Pengujian terhadap nilai k.
Pengujian ini bertujuan untuk mencari nilai k yang paling optimal untuk proses klasifikasi citra sehingga klasifikasi yang dihasilkan memiliki akurasi yang tinggi. 4. Pengujian terhadap nilai m.
Pengujian ini bertujuan untuk mencari nilai m yang paling optimal untuk proses klasifikasi citra sehinggan klasifikasi yang dihasilkan memiliki akurasi yang tinggi.
4.2 Hasil Pengujian
Hasil pengujian dilakukan berdasarkan pada skenario pengujian yang telah dibuat kemudian dianalisis.
Gambar 3 Pengujian terhadap perbandingan data latih dan data uji
Pada Gambar 3 terlihat grafik garis semakin menurun yang menghubungkan semua skenario perbandingan data latih dan data uji. Perbandingan pertama yaitu 90:10 yaitu dengan komposisi 54 data latih dan 6 data uji menghasilkan rata-rata akurasi sebesar 93,33%, perbandingan kedua dengan komposisi 48 data latih dan 12 data uji menghasilkan akurasi rata-rata sebesar 89,89%, perbandingan ketiga dengan komposisi 42 data latih dan 18 data uji menghasilkan akurasi rata-rata sebesar 83,33%, perbandingan keempat dengan komposisi 36 data latih dan 24 data uji menghasilkan akurasi rata-rata sebesar 82,49% dan perbandingan skenario pengujian terkahir dengan jumlah komposisi data latih dan data uji masing-masing 50 menghasilkan rata-rata akurasi sebesar 64,66%. Berdasarkan gambar didapatkan kesimpulan bahwa akurasi tertinggi didapatkan saat pengujian pertama dan kedua yaitu dengan perbandingan 90:10.
Berdasarkan Gambar 3, perbedaan akurasi yang dihasilkan dipengaruhi oleh perbandingan data latih dan data uji, semakin banyak data latih dan semakin sedikit data uji, maka akurasi yang dihasilkan semakin tinggi. Sebaliknya, semakin sedikit data latih dan semakin banyak data uji maka akurasi yang dihasilkan semakin rendah.
Hal ini disebabkan karena proses pelatihan menggunakan banyak data sehingga variasi hasil latih yang didapatkan lebih beragam sehingga memudahkan pada proses pengujian yang menggunakan data lebih sedikit dalam memutuskan klasifikasi data citra sehingga akurasi yang dihasilkan tinggi.
93,332 89,894 83,33 82,496 64,664
0 50 100
90:10 80:20 70:30 60:40 50:50
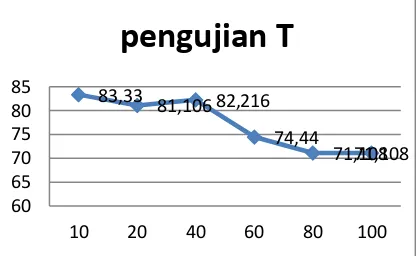
Gambar 4 Pengujian terhadap nila threshold (T)
Gambar 4 menunjukkan garis semakin menurun pada tiap pengujian. Skenario pengujian pertama mendapatkan 83,33% sebagai rata-rata akurasi, skenario pengujian kedua medapatkan rata-rata akurasi sebesar 81,1%, skenario pengujian ketiga memiliki rata-rata akurasi yang sama dengan skenario kedua yaitu 82,21%, kemudian skenario berikutnya dengan nilai T=60 mendapatkan rata-rata akurasi sebesar 74,44%, untuk skenario pengujian dengan nilai T=80 mempunyai rata-rata akurasi sebesar 71,1% dan skenario pengujian terakhir dengan nilai T=100 mendapatkan rata-rata akurasi terendah yaitu 71,1%.
Dari Gambar 4 dapat disimpulkan bahwa semakin besar T, maka akurasi yang dihasilkan semakin rendah. Hal ini disebabkan semakin besar T, maka nilai pembanding histogram akan semakinbesar yang menyebabkan terbentuknya banyak noise sehingga banyak bagian citra tidak terdeteksi atau terdeteksi salah.
Gambar 5 Pengujian terhadap nilai k
Gambar 5 menunjukkan grafik naik pada nilai k 3 dengan akurasi 77,77% dan k 5 dan 7 dengan akurasi 83,33%, kemudian k 10 dengan akurasi 81,1% dan grafik menurun pada k selanjutanya yaitu 15, 20, dan 25 dengan nilai akurasi 78,88%, 76,66% dan 77,77%. Hasil pengujian yang didapatkan pada pengujian terhadap nilai k terhadap tingkat akurasi yaitu semakin bertambahnya nilai k, maka akurasi
yang didapatkan semakin menurun dan stabil pada nilai k tertentu. Hal ini disebabkan rentang kelas pada k yang semakin banyak memberikan pengaruh besar pada penentuan prediksi klasifikasi dan nilai keanggotaan yang digunakan untuk penentuan kelas target pada penelitian kemudian akurasi yang dihasilkan oleh nilai k yang berdekatan cenderung stagnan, hal ini disebabkan persebaran nilai fitur pada data, untuk data yang berdekatan lebih sering memiliki kelas yang sama sehingga mempengaruhi nilai derajat keanggotaan.
Gambar 6 Pengujian terhadap nilai m
Pada Gambar 6 diketahui bahwa m=1 mempunyai akurasi 82,21%, lalu dengan m 3,4,6,8,10 dengan akurasi 82,21% dan yang tertinggi adalah m=2dengan akurasi 83,33%. Pada pengujian terhadap nilai m, nilai m pada proses pengklasifikasian menggunakan metode
Fuzzy K-Nearest Neighbor tidak berpengaruh
langsung terhadap nilai akurasi, namun berpengaruh pada nilai derajat keanggotaan tiap-tiap data uji terhadap masing-masing kelas. Variabel m merupakan bobot pangkat yang digunakan untuk mengetahui seberapa besar jarak antar tetangga ketika menghitung pengaruh tetangga pada nilai keanggotaan. Nilai m yang semakin besar akan membuat nilai keanggotaan semakin rendah, sehingga berpengaruh pada penentuan hasil kelas klasifikasi penyakit kedelai berdasarkan citra daun dimana hasil klasifikasi tersebut yang mempengaruhi hasil klasifikasi.
5. KESIMPULAN
Dari hasil uji dan analisis yang telah dilakukan terhadap klasifikasi penyakit tanaman kedelai menggunakan metode Fuzzy K-Nearest
Neighbor, dapat diambil kesimpulan
1. Algoritme Fuzzy K-Nearest Neighbor (FK-NN) dapat diterapkan pada data yang berupa citra daun kedelai. Terdapat dua proses utama yang dilakukan dalam penentuan klasifikasi tanaman kedelai berdasarkan daun, yaitu preprocessing citra dan proses klasifikasi. Proses preprocessing bertujuan untuk memperbaiki kualitas citra sehingga akurasi yang dihasilkan pada proses klasifikasi bisa optimal. Selanjutnya proses klasifikasi melibatkan beberapa tahapan yaitu menentukan k sebagai tetangga terdekat yang kemudian dicari jarak antar data uji dan data latih, kemudian dicari nilai keanggotaan tiap-tiap kelas sehingga didapat kelas terdekat yang merupakan kelas target dari data uji yang baru.
2. Tingkat akurasi pada Fuzzy K-Nearest
Neighbor (FK-NN) dipengaruhi oleh beberapa
faktor antara lain perbandingan antara jumlah data latih dan data uji, nilai threshold, nilai k, dan nilai m. Pada perbandingan data latih dan data uji, akurasi yang dihasilkan mencapai 100% dengan jumlah komposisi data latih lebih banyak dari pada data uji. Untuk pengujian terhadap nilai threshold, dari beberapa percobaan yang dilakukan didapat akurasi tertinggi pada nilai threshold 10 dengan akurasi mencapai 83,3%. Pada pengujian lain menggunakan nilai k, k terbaik adalah pada nilai 5 dengan akurasi yang dihasilkan adalah 83,3% dan pengujian terakhir adalah nilai pangkat m yang menghasilkan akurasi tertinggi pada m=2 yaitu mencapai 83,3%.
6. DAFTAR PUSTAKA
Hasan, O. (n.d.). A Fuzzy K-NN Approach for Cancer Diagnosis with Microarray Gene
Expression Data.
Irwan, A. W. 2006. Budidaya Tanaman Kedelai (Glycine max (L.) Merill). Jurusan Budidaya Pertanian Fakultas Pertanian
Universitas Padjadjaran, 1–43.
Kementerian Pertanian. 2015. Pengelolaan Produksi Kedelai dan Bantuan Pemerintah
Tahun Anggaran 2016. Jakarta: Kementrian
Pertanian.
Kementrian Pertanian. 2013. Hama, Penyakit,
dan Masalah Hara pada Tanaman Kedelai.
Jakarta: Kementrian Pertanian.
Marwoto. 2008. Strategi dan Komponen Teknologi Pengendalian Ulat Grayak
(Spodoptera Litura). Jurnal Litbang
Pertanian, 27(4), 131–136.
Narendro, D. 2016. Klasifikasi Penyakit pada
Citra Daun Apel Menggunakan Metode
Fuzzy K-Nearest Neighbor.
Ndaumanu, R. I., & Arief, M. R. 2014. Analisis Prediksi Tingkat Pengunduran Diri Mahasiswa dengan Metode K-Nearest Neighbor, 1(1).
Nugraha, R. R. 2012. Penerapan Logika Fuzzy untuk Menghitung Uang Saku Perhari, (13511014).
Prasetyo, E., Informatika, J. T., Industri, F. T., Pembangunan, U., Veteran, N., Timur, J., & Neighbor, K. 2012. Fuzzy K-Nearest
Neighbor in Every Class untuk Klasifikasi
Data, (Santika), 57–60.
Priambodo, A. 2015. Implementasi Metode
K-Nearest Neighbor untuk Identifikasi
Penyakit Tanaman Jeruk Keprok Berdasarkan Citra Daun.
Putra, D. 2010. Pengolahan Citra Digital. Yogyakarta: Andi.
Putri Setya Rahmita, Syamsuddin Djauhari, B. T. R. 2015. Efektivitas Daun Sirih (Piperb Bitle), Daun Salam (Syzygium polyanthum WIGH WALP), Buah Pinang (Areca catechu) dan Kulit Kayu Manis (Cinnamomum verum) Terhadap Perkembangan Penyakit Rebah Semai (Sclerotium olfsii SACC.) Pada Tanaman Kedelai (GLYCINE MAX), 3.
Sutoyo, S. T. et al., 2009. Teori Pengolahan
Citra Digital. 1st penyunt. Yogyakarta:
Andi.
Umam, M. S. 2015. Implementasi Metode Learning Vector Quantization (LVQ) untuk Identifikasi Penyakit Pada Citra Daun Tanaman Kedelai.
Yao, Q. et al., 2009. Application of Support
Vector Machine for Detecting Rice
Diseases Using Shape and Color Texture
Features. China: International Conference