TUGAS AKHIR
Diajukan Untuk Memenuhi Salah Satu Syarat Kelulusan Sarjana Strata 1
Oleh
Rochmah Hidayati 10201486
TEKNIK INFORMATIKA
SEKOLAH TINGGI MANAJEMEN INFORMATIKA DAN KOMPUTER ASIA
MALANG
v
BERDASARKAN USIA & DATA AKADEMIK MENGGUNAKAN METODE K-MEANS Teknik Informatika, Sekolah Tinggi Manajemen Informatika dan Komputer ASIA Malang, 2014
Kata kunci: Clustering, usia, data akademik, K-Means (xv + 112 + lampiran)
Masalah ketidakseimbangan antara jumlah mahasiswa baru dan mahasiswa yang menyelesaikan studi tepat waktu merupakan permasalahan yang penting untuk diperhatikan. Karena salah satu factor yang menentukan kualitas perguruan tinggi adalah presentase kemampuan mahasiswa untuk menyelesaikan studi tepat waktu. Ketidakseimbangan tersebut bisa jadi karena mahasiswa menempuh studi tidak tepat waktu, memiliki status non-aktif atau bahkan dropout.
Pada penelitian ini penulis mencoba membangun sistem untuk mengelompokkan mahasiswa menjadi dua cluster yaitu cluster pertama (rawan dropout) dan cluster kedua (tidak dropout), dengan mengambil dataset mahasiswa STMIK ASIA jurusan teknik informatika angkatan 2006-2008 pada tahun ajaran 2012/2013. Total record dataset dari angkatan 2006-2008 adalah 576 record. Data tersebut dibagi menjadi 2 berdasarkan angkatan , yaitu untuk angkatan 2006-2007 adalah 315 record sebagai data training dan angkatan 2008 adalah 261 record sebagai data testing. Dalam penelitian ini menggunakan teknik clustering dengan metode K-Means untuk pengelompokan data. Tahap pertama pengujian terhadap data training dengan mengambil centroid awal secara random, pengujian ini bertujuan untuk mencari centroid awal yang tepat untuk disimpan dan digunakan pada saat pengujian data testing. Pemilihan pusat cluster yang tepat pada pengujian data training akan memberikan hasil dengan tingkat kebenaran pengelompokan yang lebih tinggi saat pengujian data testing.
Hasil pengujian terhadap data testing dengan 261 record data dan setelah tahap preprocessing menjadi 174 record, menggunakan centroid awal C1= 42, 8, 0.59 dan C2= 24, 4, 2.56 menghasilkan 10 iterasi dengan hasil akhir cluster 1 (rawan dropout) sebanyak 40 anggota atau sebesar 23% dan Cluster 2 (tidak dropout) sebanyak 134 anggota atau sebesar 77%. Dengan tingkat kebenaran/ketepatan pengelompokan berkisar antara 70% sampai dengan 73.13%.
vi
KATA PENGANTAR
Dengan memanjatkan rasa syukur kehadirat Tuhan YME atas segala rahmad dan hidayah-Nya yang diberikan kepada penulis sehingga laporan Tugas Akhir dengan judul “APLIKASI CLUSTERING UNTUK PENGELOMPOKAN MAHASISWA STMIK ASIA BERDASARKAN USIA
& DATA AKADEMIK MENGGUNAKAN METODE K-MEANS” dapat
terselesaikan dengan baik.
Laporan Tugas Akhir ini merupakan salah satu persyaratan kelulusan Program Strata Satu di STMIK ASIA Malang yang harus dipenuhi oleh setiap mahasiswa.
Dalam penyusunan ini tidak terlepas dari bantuan, dorongan dan do’a restu dari berbagai pihak, untuk itu penulis menyampaikan rasa
terima kasih dengan tulus kepada:
1. Bapak Ir. Teguh Widodo, MM., selaku Ketua STMIK Asia Malang 2. Bapak Sunu Jatmika, M.Kom., selaku Pembantu Ketua I STMIK Asia 3. Ibu Rina Dewi Indah Sari, M.Kom., selaku Ketua Jurusan Teknik
Informatika
4. Bapak Budi Santoso, B.Eng., selaku Dosen Wali
5. Bapak Tria Aprilianto, S.Kom., selaku Dosen Pembimbing.
Terimakasih atas bimbingan, saran, waktu dan kesabaran yang diberikan kepada penulis dalam proses bimbingan.
vii
Terimakasih atas pengarahan, saran dan bimbingan yang telah diberikan kepada penulis, sehingga tugas akhir ini dapat terselesaikan dengan baik.
8. BAAK yang telah bersedia memberikan data sampel untuk penelitian. 9. Kedua orang tua tercinta, yang telah memberikan dorongan semangat
serta bantuan moral, doa dan materi kepada penulis dalam penyelesaian tugas akhir ini.
10. Teman - teman yang selalu memberikan dukungan kepada penulis terutama pihak yang telah banyak membantu dan memotivasi penulis, dan seluruh pihak yang tidak dapat penulis sebutkan satu persatu.
Penulis menyadari sebagai manusia yang penuh dengan keterbatasan, mengakui bahwa masih banyak terdapat kesalahan dan kekurangan pada laporan tugas akhir ini. Oleh karena itu diharapkan kritik dan saran yang bersifat membangun. Akhir kata, semoga laporan ini dapat memberikan manfaat.
Malang, 28 Maret 2014
ix
2.4.2 Permasalahan yang Terkait Dengan K-Means ... 24
2.4.3 K-Means sebagai Metode Semi-Supervised Classification ... 27
x
2.11 PHP ... 64
2.12 Pengantar MySQL ... 65
BAB III ANALISA DAN PERANCANGAN 3.1 Deskripsi Sistem ... 67
BAB IV IMPLEMENTASI DAN PENGUJIAN 4.1 Spesifikasi ... 98
xi
4.2.2.2 Seleksi Cleaning ... 101
4.2.2.3 Data yang ter-eliminasi ... 101
4.2.2.4 Mining Data ... 102
4.2.3 Menu Data Testing ... 103
4.2.3.1 Mining Data Testing ... 104
4.3 Pengujian ... 105
4.3.1 Tujuan Pengujian ... 105
4.3.2 Pengujian Data Training ... 105
4.3.3 Pengujian Data Training ... 107
4.4 Hasil Pengujian ... 108
BAB V PENUTUP 5.1 Kesimpulan ... 110
5.2 Saran ... 111
DAFTAR PUSTAKA
LAMPIRAN
xii
DAFTAR GAMBAR
Gambar 2.1 Tahapan Proses KDD ... 8
Gambar 2.2 Posisi Data Mining dalam Bisnis Cerdas (Bussiness Intelligent) ... 14
Gambar 2.10 Gerak Maju Model-Model dari Logika ke Fisika ... 52
Gambar 2.11 Diagram Arus Data Logika ... 53
Gambar 2.12 Diagram Arus Data Fisik ... 54
Gambar 2.13 Diagram Konteks (Context Diagram) ... 55
Gambar 2.14 Diagram Level Zero (Overview Diagram) ... 56
Gambar 2.15 Lefel dalam DFD ... 57
Gambar 2.16 Contoh Database Management Sistem ... 61
Gambar 3.1 Diagram Blok Data Mining ... 68
Gambar 3.2 Tahap-tahap Preprocessing ... 69
Gambar 3.3 Context Diagram Sistem ... 72
Gambar 3.4 Diagram Level Nol Sistem ... 73
Gambar 3.5 Diagram Rinci Proses Input Data Training Mahasiswa 74 Gambar 3.6 Diagram Rinci Proses Menampilkan Data Training ... 74
Gambar 3.7 Diagram Rinci Proses Mengolah Data Training ... 75
Gambar 3.8 Diagram Rinci Proses Import Data Testing ... 76
Gambar 3.9 Diagram Rinci Proses Menampilkan Data Testing .... 76
Gambar 3.10 Diagram Rinci Proses Mengolah Data Testing ... 77
Gambar 3.11 Relasi antar tabel biodata, status dan IPK ... 78
xiii
Gambar 3.16 Struktur Menu Program ... 95
Gambar 3.17 Desain Tampilan Menu ... 95
Gambar 3.18 Desain Tampilan Data Training ... 96
Gambar 3.19 Desain Tampilan Data Testing ... 96
Gambar 4.1 Tampilan Login ... 99
Gambar 4.2 Tampilan Menu Utama ... 99
Gambar 4.3 Tampilan Menu Data Training ... 100
Gambar 4.4 Tampilan Atribut ... 100
Gambar 4.5 Tampilan Tab Seleksi Cleaning ... 101
Gambar 4.6 Tampilan Data yang ter-eliminasi ... 102
Gambar 4.7 Tampilan Tab Mining Data ... 102
Gambar 4.8 Tampilan Post Processing ... 103
Gambar 4.9 Tampilan Menu Data Testing ... 104
Gambar 4.10 Tampilan Centroid Awal Mining Data Testing ... 104
xiv
DAFTAR TABEL
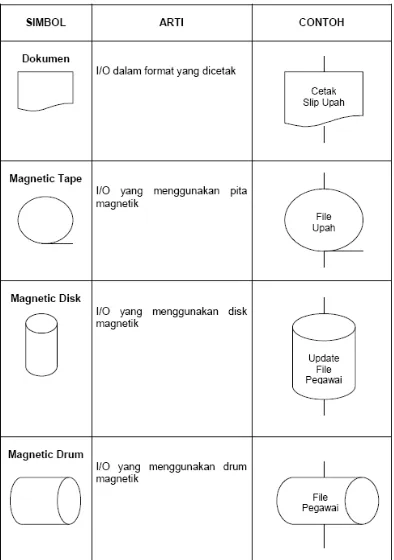
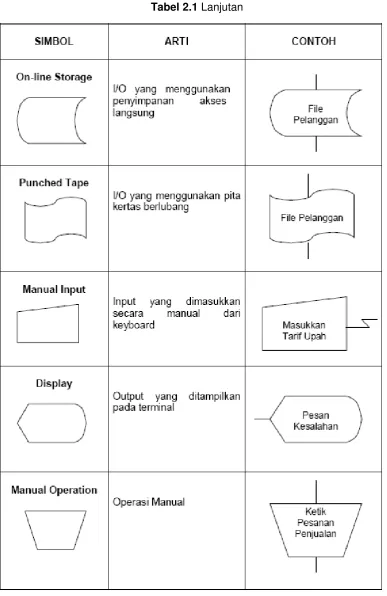
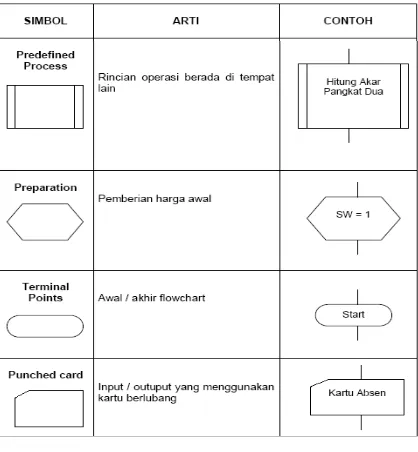
Tabel 2.1 Simbol Flowchart Standart ... 35
Tabel 3.1 Dataset ... 80
Tabel 3.2 Atribut ... 80
Tabel 3.3 Seleksi Cleaning Data ... 82
Tabel 3.4 Struktur Tabel Data Training ... 85
Tabel 3.5 Struktur Tabel Data Centroid ... 85
Tabel 3.6 Proses Mining Iterasi 1 ... 88
Tabel 3.7 Iterasi 2 ... 90
Tabel 3.8 Iterasi 3 ... 91
Tabel 3.9 Iterasi 4 ... 92
Tabel 3.10 Anggota Cluster 1 ... 93
Tabel 3.11 Anggota Cluster 2 ... 93
Tabel 4.1 Tabel Pengujian Pada Data Training ... 106
Tabel 4.2 Tabel Pengujian Pada Data Testing ... 107
xv
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Perguruan Tinggi ASIA Malang merupakan salah satu perguruan tinggi yang cukup menarik banyak mahasiswa. Tetapi ada beberapa hal yang tidak seimbang antara masuk dan keluarnya mahasiswa yang telah menyelesaikan studinya. Mahasiswa yang masuk dalam jumlah besar, tetapi mahasiswa yang lulus tepat waktu sesuai dengan ketentuan jauh sangat kecil dibandingkan masuknya. Artinya terdapat mahasiswa yang tidak diketahui statusnya. Ketidakjelasan status tersebut bisa jadi karena mahasiswa menempuh studi tidak tepat waktu, memiliki status non-aktif atau bahkan drop out.
Beberapa penyebab kegagalan studi mahasiswa diantaranya adalah rendahnya kemampuan akademik, faktor pembiayaan, domisili saat menempuh studi dan faktor lainnya. Tingginya presentasi mahasiswa yang memiliki status non aktif juga menyebabkan tingginya mahasiswa lulus tidak tepat waktu. Hal tersebut menjadi sangat penting bagi manajemen perguruan tinggi mengingat presentase mahasiswa lulus tepat waktu adalah salah satu elemen penilaian akreditasi yang ditetapkan oleh Badan Akreditasi.
data akademik, administrasi dan biodata mahasiswa. Data tersebut apabila digali dengan tepat maka diketahui pola atau pengetahuan untuk mengambil keputusan. Serangkaian proses mendapatkan pengetahuan atau pola dari kumpulan data disebut dengan data mining. Data mining memecahkan masalah dengan menganalisis data yang telah ada dalam database. Clustering merupakan salah satu metode data mining yang bersifat tanpa arahan (unsupervised). KMeans merupakan salah satu metode clustering non hirarki yang berusaha mempartisi data kedalam bentuk satu/lebih cluster/kelompok. Metode ini mempartisi data ke dalam cluster sehingga karakteristik yang sama dikelompokkan kedalam satu cluster yang sama.
Berdasaran latar belakang tersebut dibuatlah aplikasi untuk mendapatkan informasi presentase pengelompokkan mahasiswa STMIK ASIA dengan judul “Aplikasi Clustering Untuk Pengelompokan Mahasiswa STMIK ASIA berdasarkan Usia & Data Akademik
Menggunakan Metode K-Means”.
1.2 Rumusan Masalah
3
1.3 Batasan Masalah
1. Data yang digunakan adalah biodata dan data akademik mahasiswa STMIK ASIA angkatan 2006 sampai dengan angkatan 2008 jurusan teknik informatika pada tahun ajaran 2012/2013
2. Atribut yang digunakan untuk mengelompokan data adalah usia mahasiswa, lama masa studi minimal (tahun), dan IPK terakhir
3. Pembagian cluster terdiri dari 2 kelompok, yaitu cluster rawan dropout dan cluster tidak dropout
4. Teknik yang digunakan adalah clustering menggunakan metode K-Means
5. Sistem hanya mencakup data mining dengan analisis pengelompokan mahasiswa rawan dropout dan tidak dropout
6. Hasil clustering berupa presentase jumlah dari cluster rawan dropout dan cluster tidak dropout, anggota dari cluster rawan dropout dan cluster tidak dropout dan presentase kebenaran pengelompokan
7. Bahasa pemrograman yang digunakan adalah css dan php 8. Database yang digunakan adalah MySQL
1.4 Tujuan dan Manfaat
1.4.1 Tujuan
Adapun tujuan utama dari penelitian ini adalah :
2. Bagi instansi sebagai program alternatif untuk pengelompokkan mahasiswa yang mengelompokkan mahasiswa STMIK ASIA menjadi kelompok rawan dropout dan kelompok tidak dropout berdasarkan usia dan data akademik dengan teknik clustering menggunakan metode K-Means.
1.4.2 Manfaat
Adapun manfaat penelitian ini adalah: 1. Bagi penulis
Dapat Menambah pengetahuan dan merupakan salah satu kesempatan untuk menerapkan ilmu pengetahuan yang didapatkan dalam perkuliahan
2. Bagi peneliti selanjutnya
Dapat memberikan tambahan referensi terutama penelitian yang berkaitan dengan analisa data mining menggunakan metode lain yang dapat mempermudah penyelesaian masalah dengan tepat. 3. Bagi instansi
Agar dapat memberikan gambaran sekiranya perancangan program seperti apa yang tepat untuk pengelompokkan mahasiswa.
1.5 Metodologi Penelitian
5
a. Literature, yaitu dengan cara mempelajari teori-teori literatur dan buku-buku dan melakukan kajian secara online di internet yang berhubungan dengan objek kajian sebagai dasar dalam penelitian ini, dengan tujuan memperoleh dasar teoritis gambaran dari apa yang dilakukan. Teori yang dipelajari yaitu: data mining, clustering, metode K-Means, pemrograman web menggunakan php dan css, mysql dan sebagainya. b. Sampling, yaitu teknik pengumpulan data yang dilakukan dengan
cara melakukan pengambilan data arsip/formulir/catatan yang berkaitan dengan obyek penelitian. Dalam penelitian ini data sampling yang diambil adalah biodata dan data akademik mahasiswa STMIK ASIA jurusan teknik informatika angkatan 2006–2008 tahun ajaran 2012/2013.
1.6 Sistematika Penulisan
Secara garis besar laporan tugas akhir ini terbagi menjadi beberapa bab yang tersusun sebagai berikut:
BAB I PENDAHULUAN
BAB II LANDASAN TEORI
Bab ini menguraikan tentang teori-teori dari sumber pustaka dan referensi yang bersangkutan dengan penelitian tugas akhir diantaranya adalah konsep dan proses data mining, teknik clustering, metode K-means, flowchart, konsep dasar sistem, konsep dasar informasi, konsep dasar sistem informasi, DFD, konsep dasar database management system , PHP, dan MYSQL.
BAB III ANALISA DAN PERANCANGAN
Bab ini menjelaskan tentang analisa dan perancangan dalam penelitian atau studi kasus pada data mahasiswa STMIK ASIA angkatan 2006 – angkatan 2008 dan tahap penyelesaian masalah menggunakan teknik clustering dengan menerapkan metode K-Means. Pembahasan terdiri dari deskripsi sistem, arsitektur sistem, analisa kebutuhan input,proses dan output, desain sistem, desain database,tahap-tahap mengolah data, desain menu dan desain user interface.
BAB IV IMPLEMENTASI DAN PENGUJIAN
Bab ini menjelaskan implementasi serta pengujian dari aplikasi clustering untuk pengelompokan mahasiswa STMIK ASIA berdasarkan usia & data akademik menggunakan metode K-Means.
BAB V PENUTUP
7
BAB II
LANDASAN TEORI
2.1 Knowledge Discovery in Database (KDD)
KDD terdiri dari serangkaian langkah perubahan, termasuk data preprocessing dan juga post processing. Data preprocessing merupakan langkah untuk mengubah data mentah menjadi format yang sesuai untuk tahap analisis berikutnya. Selain itu data preprocessing juga digunakan untuk membantu dalam pengenalan atribut dan data segmen yang relevan dengan task data mining. Data preprocessing kemungkinan akan membutuhkan waktu yang sangat lama, hal ini dikarenakan data yang mentah kemungkinan disimpan dengan format dan database yang berbeda. Post processing meliputi semua operasi yang harus dilakukan agar hasil dari data mining dapat diakses dan lebih mudah untuk diinterpretasikan oleh para analis. Teknik visualisasi juga dapat digunakan untuk mempermudah para analis untuk menggali dan memahami kegunaan dari data mining. Kumpulan proses dalam KDD meliputi :
1. Pembersihan data (data cleaning) 2. Integrasi data (data integration) 3. Pemilihan data (data selection)
4. Transformasi data (data transformation) 5. Penambangan data (data mining) 6. Evaluasi pola (pattern evaluation)
Berdasarkan definisi ini terlihat bahwa data mining hanya merupakan salah satu proses dari keseluruhan proses yang ada pada KDD, tetapi merupakan proses yang sangat penting dalam usaha menemukan pola-pola yang berguna dari sejumlah data yang besar (data tersebut bisa disimpan dalam basis data, data warehouse, atau media penyimpanan informasi lainnya).
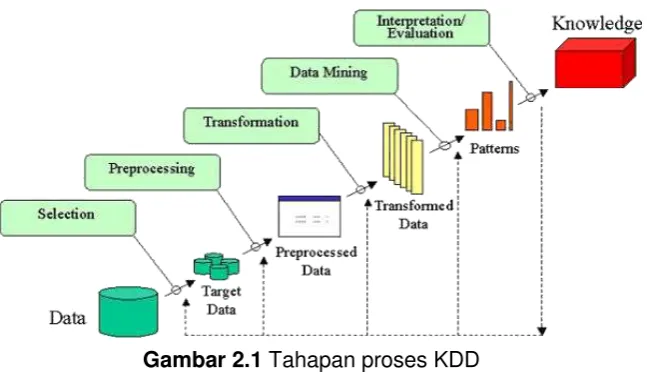
Menurut Jiawei Han Secara garis besar proses KDD dapat direpresentasikan dengan gambar sebagai berikut :
2.1.1 Data Selection
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan dalam suatu berkas, terpisah dari basis data operasional.
2.1.2 Preprocessing
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses awal pada data yang menjadi fokus KDD untuk meyakinkan
9
kualitas dari data yang telah dipilih pada tahapan sebelumnya. A. Alasan pentingnya preprocessing
1. Jika data tidak berkualitas, maka hasil Mining juga tidak berkualitas a. Kualitas keputusan harus didasarkan kepada kualitas data (misal,
duplikasi data atau data hilang bisa menyebabkan ketidak-benaran atau bahkan statistik yang menyesatkan.
b. Data warehouse memerlukan kualitas integrasi data yang konsisten
2. Ekstraksi data, pembersihan dan transformasi merupakan kerja utama dari pembuatan suatu data warehouse
3. Data preprocessing membantu didalam memperbaiki presisi dan kinerja data Mining dan mencegah kesalahan didalam data Mining B. Data yang harus dikoreksi
1. Data Incomplete
Berisi nilai yang salah yang disebabkan karena : a. Tidak tercatat (not recorded)
b. Tidak tersedia (not available)
c. Sengaja dihapus karena dianggap salah atau tidak penting 2. Data Noisy
Berisi data salah yang tidak wajar (Anomalies/outliers) karena : a. Instrumen pengumpulan data yang digunakan mungkin salah b. Kesalahan manusia atau komputer yang terjadi pada saat entri
c. Kesalahan dalam transmisi data. 3. Data Inconsistent
Berisi data yang tidak konsisten dan berbeda dari sewajarnya disebabkan oleh : Perubahan kode di sistem yang menjadikan data tidak konsisten
C. Alasan data kotor dan harus dikoreksi
Ketidak-lengkapan data dari :
a. Nilai data tidak tersedia saat dikumpulkan
b. Perbedaan pertimbangan waktu antara saat data dikumpulkan dan saat data dianalisa
c. Masalah manusia, hardware dan software Noisy data datang dari proses data :
a. Pengumpulan b. Pemasukan (entry) c. Transmisi
Ketidak-konsistenan data datang dari : a. Sumber data yang berbeda
b. Pelanggaran kebergantungan fungsional D. Tugas utama preprocessing
a. Pembersihan data (data yang kotor) b. Integrasi data (data heterogen) c. Transformasi data (data detail)
11
e. Diskritisasi data (kesinambungan atribut) E. Cara Koreksi Data Incomplete
1. Elimination : membuang semua data yang mempunyai satu atau
lebih atribut hilang. Risiko dan tantangan :
a. Tidak efektif ketika nilai-nilai yang hilang tidak teratur. b. Kerugian dalam kehilangan informasi.
2. Inspection : memeriksa setiap nilai – nilai yang hilang yang dilakukan ahli IT pada sistem aplikasi
Risiko dan tantangan :
a. Subyektifitas dan dominasi kewenangan
b. Membutuhkan waktu untuk data set yang besar
c. Tindakan korektif yang paling akurat bila menguasai data
3. Identification : tidak membuang data, tetapi menggunakan nilai-nilai konvensional yang wajar
Risiko dan tantangan :
a) Nilai atribut konvensional berbeda dari yang diasumsikan
4. Substitution : mengganti data yang hilang dengan data yang
diprediksi
Risiko dan tantangan :
a) Data estimasi memakan waktu dan cukup rumit
F.
Data Integrationa. Penggabungan Schema perlu adanya standarisasi Problem : Penamaan atribut ataupun field yang berbeda G. Data Transformation
Data ditransformasikan menjadi bentuk yang sesuai untuk proses Data Mining
Metode :
a. Smoothing : binning, clustering, dan regresi b. Agregasi : summary data pada konstruksi kubus
c. Generalisasi : nilai data mentah digeneralisasi pada kelompok data yang general seperti Usia : muda, setengah baya dan senior
d. Normalisasi : data atribut diperkecil sehingga jatuh dalam kisaran tertentu. Seperti 0.0 – 1.0
2.1.3 Data mining
Data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode dan algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
2.1.4 Interpretation/Evalution
13
informasi yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya.
2.2 Data Mining
2.2.1 Pengertian Data Mining
Tan (2006) mendefinisikan data Mining sebagai proses untuk mendapatkan informasi yang berguna dari gudang basis data yang besar. Data Mining juga dapat diartikan sebagai pengekstrakan informasi baru yang diambil dari bongkahan data besar yang membantu dalam pengambilan keputusan. Istilah data Mining kadang disebut juga knowledge discovery.
Salah satu teknik yang dibuat dalam data Mining adalah bagaimana menelusuri data yang ada untuk membangun sebuah model, kemudian menggunakan model tersebut agar dapat mengenali pola data yang lain yang tidak berada dalam basis data yang tersimpan. Kebutuhan untuk prediksi juga dapat memanfaatkan teknik ini. Dalam data Mining, pengelompokan data juga bisa dilakukan. Tujuannya adalah agar kita dapat mengetahui pola universal data-data yang ada. Anomali data transaksi juga perlu dideteksi untuk dapat mengetahui tindak lanjut berikutnya yang dapat diambil. Semua hal tersebut bertujuan mendukung kegiatan operasional perusahaan sehingga tujuan akhir perusahaan diharapkan dapat tercapai.
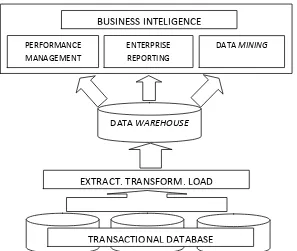
Dari gambar tersebut, dapat dilihat bahwa data Mining adalah bidang yang sepenuhnya menggunakan apa yang dihasilkan oleh data warehouse, bersama dengan bidang yang menangani masalah pelaporan dan manajemen data. Sementara, data warehouse sendiri bertugas untuk menarik/meng-query data dari basis data mentah untuk memberikan hasil data yang nantinya digunakan oleh bidang yang menangani manajemen, pelaporan, dan data Mining. Dengan data Mining inilah, penggalian informasi baru dapat dilakukan dengan bekal data mentah yang diberikan oleh data warehouse. Hasil yang diberikan oleh ketiga bidang tersebut berguna untuk mendukung aktivitas bisnis cerdas (business intelligence). (Prasetyo, 2012:2)
2.2.2 Pekerjaan Dalam Data Mining
Pekerjaan yang berkaitan dengan data mining dapat dibagi
Gambar 2.2 Posisi data Mining dalam bisnis cerdas (business intelligent)
TRANSACTIONAL DATABASE EXTRACT, TRANSFORM, LOAD
DATA WAREHOUSE
PERFORMANCE MANAGEMENT
ENTERPRISE REPORTING
15
menjadi empat kelompok, yaitu model prediksi (prediction modeling), analisis kelompok (cluster analysis), analisis asosiasi (association analysis), dan deteksi anomaly (anomaly detection).
1. Model prediksi
Model prediksi berkaitan dengan pembuatan sebuah model yang dapat melakukan pemetaan dari setiap himpunan variabel ke setiap targetnya, kemudian menggunakan model tersebut untuk memberikan nilai target pada himpunan baru yang didapat. Ada dua jenis model prediksi, yaitu klasifikasi dan regresi. Klasifikasi digunakan untuk variabel target diskret, sedangkan regresi untuk variabel target kontinu. 2. Analisis kelompok
Analisis kelompok melakukan pengelompokan data-data ke dalam sejumlah kelompok (cluster) berdasarkan kesamaan karakteristik masing-masing data pada kelompok-kelompok yang ada. Data-data yang masuk dalam batas kesamaan dengan kelompoknya akan bergabung dalam kelompok tersebut, dan akan terpisah dalam kelompok yang berbeda jika keluar dari batas kesamaan dengan kelompok tersebut.
3. Analisis asosiasi
menarik dengan cara yang efisien. 4. Deteksi anomali
Pekerjaan deteksi anomali (anomaly detection) berkaitan dengan pengamatan sebuah data dari sejumlah data yang secara signifikan mempunyai karakteristik yang berbeda dari sisa data yang lain. Data-data yang karakteristiknya menyimpang (berbeda) dari Data-data yang lain disebut outlier. Algoritma deteksi anomali yang baik harus mempunyai laju deteksi yang tinggi dan laju eror yang rendah.
(Prasetyo, 2012:5)
2.3 Clustering
Salah satu metode yang diterapkan dalam KDD adalah clustering. Clustering adalah membagi data ke dalam grup-grup yang mempunyai obyek yang karakteristiknya sama. Garcia-Molina et al menyatakan clustering adalah mengelompokkan item data ke dalam sejumlah kecil grup sedemikian sehingga masing-masing grup mempunyai sesuatu persamaan yang esensial.
17
Tan, dkk membagi clustering dalam dua kelompok, yaitu hierarchical and partitional clustering. Partitional Clustering disebutkan sebagai pembagian obyek-obyek data ke dalam kelompok yang tidak saling overlap sehingga setiap data berada tepat di satu cluster. Hierarchical clustering adalah sekelompok cluster yang bersarang seperti sebuah pohon berjenjang (hirarki).
William membagi algoritma clustering ke dalam kelompok besar seperti berikut:
1. Partitioning algorithms: algoritma dalam kelompok ini membentuk bermacam partisi dan kemudian mengevaluasinya dengan berdasarkan beberapa criteria.
2. Hierarchy algorithms: pembentukan dekomposisi hirarki dari sekumpulan data menggunakan beberapa criteria.
3. Density-based: pembentukan cluster berdasarkan pada koneksi dan fungsi densitas.
4. Grid-based: pembentukan cluster berdasarkan pada struktur multiple-level granularity
5. Model-based: sebuah model dianggap sebagai hipotesa untuk masing-masing cluster dan model yang baik dipilih diantara model hipotesa tersebut.
2.4 K-Means
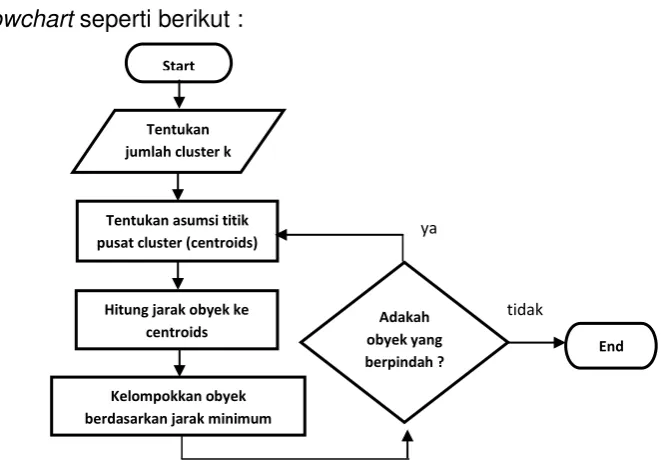
Algoritma K-Means adalah algoritma clustering yang paling popular dan banyak digunakan dalam dunia industry. Algoritma ini disusun atas dasar ide yang sederhana. Ada awalnya ditentukan berapa cluster yang akan dibentuk. Sebarang obyek atau elemen pertama dalam cluster dapat dipilih untuk dijadikan sebagai titik tengah (centroid point) cluster. Algoritma K-Means selanjutnya akan melakukan pengulangan langkah-langkah berikut sampai terjadi kestabilan (tidak ada obyekyang dapat dipindahkan):
1. Menentukan koordinat titik tengah setiap cluster
2. Menentukan jarak setiap obyek terhadap koordinat titik tengah
3. Mengelompokkan obyek-obyek tersebut berdasarkan pada jarak minimumnya.
(Andayani, 2007)
Secara sederhana algoritma K-Means dapat digambarkan dalam Flowchart seperti berikut :
Gambar 2.3Flowchart Algoritma K-means
19
2.4.1 Perkembangan Penerapan K-Means
Beberapa alternatif penerapan K-Means dengan beberapa pengembangan teori-teori penghitungan terkait telah diusulkan. Hal ini termasuk pemilihan :
1. Distance space untuk menghitung jarak di antara suatu data dan centroid
2. Metode pengalokasian data kembali ke dalam setiap cluster 3. Objective function yang digunakan
A. Distance Space Untuk Menghitung Jarak Antara Data dan
Centroid
Beberapa distance space telah diimplementasikan dalam menghitung jarak (distance) antara data dan centroid termasuk di antaranya L1 (Manhattan/City Block) distance space, L2 (Euclidean) distance space, dan Lp (Minkowski) distance space, Jarak antara dua titik x1 dan x2 pada Manhattan/City Block distance space dihitung dengan menggunakan rumus sebagai berikut :
Dimana :
p : dimensi data | . | : Nilai absolute
sedangkan untuk L2(Euclidean) distance space, jarak antara dua titik
𝑫
𝑳𝟏𝒙
𝟐,
𝒙
𝟏=
𝒙
𝟐− 𝒙
𝟏 𝟏=
𝒙
𝟐𝒋− 𝒙
𝟏𝒋𝒑
𝒋=𝒍
dihitung menggunakan rumus sebagai berikut :
Dimana :
p : Dimensi data
Lp (Minkowski) distance space yang merupakan generalisasi dari beberapa distance space yang ada seperti L1 (Manhattan/City Block) dan L2 (Euclidean), juga telah diimplementasikan. Tetapi secara umum distance space yang sering digunakan adalah Manhattan dan Euclidean. Euclidean sering digunakan karena penghitungan jarak dalam distance space ini merupakan jarak terpendek yang bisa didapatkan antara dua titik yang diperhitungkan, sedangkan Manhattan sering digunakan karena kemampuannya dalam mendeteksi keadaan khusus seperti keberadaaan outliers dengan lebih baik.
B. Metode Pengalokasian Ulang Data ke Dalam Masing-Masing
Cluster
Secara mendasar, ada dua cara pengalokasian data kembali ke dalam masing-masing cluster pada saat proses iterasi clustering. Kedua cara tersebut adalah pengalokasian dengan cara tegas (hard), dimana data item secara tegas dinyatakan sebagai anggota
𝑫
𝑳𝟐𝒙
𝟐,
𝒙
𝟏=
𝒙
𝟐,
𝒙
𝟏=
𝒙𝟐𝒋
−
𝒙
𝟏𝒋𝒑
𝒋=𝒍
𝟐
21
cluster yang satu dan tidak menjadi anggota cluster lainnya, dan dengan cara fuzzy, dimana masing-masing data item diberikan nilai kemungkinan untuk bisa bergabung ke setiap cluster yang ada. Kedua cara pengalokasian tersebut diakomodasikan pada dua metode Hard K-Means dan Fuzzy K-Means. Perbedaan di antara kedua metode ini terletak pada asumsi yang dipakai sebagai dasar pengalokasian.
a. Hard K-Means
Pengalokasian kembali data ke dalam masing-masing cluster dalam metode Hard K-Means didasarkan pada perbandingan jarak antara data dengan centroid setiap cluster yang ada. Data dialokasikan ulang secara tegas ke cluster yang mempunyai centroid terdekat dengan data tersebut. Pengalokasian ini dapat dirumuskan sebagai berikut :
Dimana :
aik : keanggotaan data ke-k cluster ke-i vi : nilai centroid cluster ke-i
b. Fuzzy K-Means
Metode Fuzzy K-Means (atau lebih sering disebut sebagai Fuzzy C-Means) mengalokasikan kembali data ke dalam masing-masing cluster dengan memanfaatkan teori Fuzzy. Teori ini mengeneralisasikan metode pengalokasian yang bersifat tegas
(hard) seperti yang digunakan pada metode Hard K-Means. Dalam metode Fuzzy K-Means dipergunakan variabel membership function, uik , yang merujuk pada seberapa besar kemungkinan suatu data bisa menjadi anggota ke dalam suatu cluster. Pada Fuzzy K-Means yang diusulkan oleh Bezdek, diperkenalkan juga suatu variabel m yang merupakan weighting exponent dari membership function. Variabel ini dapat mengubah besaran pengaruh dari membership function, uik, dalam proses clustering menggunakan metode Fuzzy K-Means. m mempunyai wilayah nilai m>1. Sampai sekarang ini tidak ada ketentuan yang jelas berapa besar nilai m yang optimal dalam melakukan proses optimasi suatu permasalahan clustering. Nilai m yang umumnya digunakan adalah 2.
Membership function untuk suatu data ke suatu cluster tertentu dihitung menggunakan rumus sebagai berikut :
23
tinggi ke suatu kelompok akan mempunyai nilai membership function ke kelompok tersebut yang mendekati angka 1 dan ke kelompok yang lain mendekati angka 0.
C. Objective Function Yang Digunakan
Objective function yang digunakan khususnya untuk Hard K-Means dan Fuzzy K-Means ditentukan berdasarkan pada pendekatan yang digunakan dalam poin 2.4.1. dan poin 2.4.2. Untuk metode Hard K-Means, objective function yang digunakan adalah sebagai berikut :
Dimana :
N : jumlah data C : jumlah cluster
aik : keanggotaan data ke-k ke cluster ke-i vi : nilai centroid cluster ke-i
aik mempunyai nilai 0 atau 1. Apabila suatu data merupakan
dimana :
N : jumlah data C : jumlah cluster M : weighting exponent
Uik : membership function data ke-k ke cluster ke-i Vi : nilai centroid cluster ke-i
Di sini Uik bisa mengambil nilai mulai dari 0 sampai 1. (Agusta, 2007)
2.4.2 Permasalahan yang Terkait Dengan K-Means
Beberapa permasalahan yang sering muncul pada saat menggunakan metode K-Means untuk melakukan pengelompokan data adalah :
1. Ditemukannya beberapa model clustering yang berbeda 2. Pemilihan jumlah cluster yang paling tepat
3. Kegagalan untuk converge 4. Pendeteksian outliers
5. Bentuk masing-masing cluster 6. Masalah overlapping
25
kecenderungan untuk memberikan hasil yang lebih baik dan independent, walaupun dari segi kecepatan untuk converge lebih lambat.
Permasalahan 2 merupakan masalah laten dalam metode K-Means. Beberapa pendekatan telah digunakan dalam menentukan jumlah cluster yang paling tepat untuk suatu dataset yang dianalisa termasuk di antaranya Partition Entropy (PE) dan GAP Statistics. Satu hal yang patut diperhatikan mengenai metode-metode ini adalah pendekatan yang digunakan dalam mengembangkan metode-metode tersebut tidak sama dengan pendekatan yang digunakan oleh K-Means dalam mempartisi data items ke masing-masing cluster.
setiap data diperlengkapi dengan membership function (Fuzzy K-Means) untuk menjadi anggota cluster yang ditemukan.
Permasalahan keempat merupakan permasalahan umum yang terjadi hampir di setiap metode yang melakukan pemodelan terhadap data. Khusus untuk metode K-Means hal ini memang menjadi permasalahan yang cukup menentukan. Beberapa hal yang perlu diperhatikan dalam melakukan pendeteksian outliers dalam proses pengelompokan data termasuk bagaimana menentukan apakah suatu data item merupakan outliers dari suatu cluster tertentu dan apakah data dalam jumlah kecil yang membentuk suatu cluster tersendiri dapat dianggap sebagai outliers. Proses ini memerlukan suatu pendekatan khusus yang berbeda dengan proses pendeteksian outliers di dalam suatu dataset yang hanya terdiri dari satu populasi yang homogen.
Permasalahan kelima adalah menyangkut bentuk cluster yang ditemukan. Tidak seperti metode data clustering lainnya termasuk Mixture Modelling, K-Means umumnya tidak mengindahkan bentuk dari masing-masing cluster yang mendasari model yang terbentuk, walaupun secara natural masing-masing cluster umumnya berbentuk bundar. Untuk dataset yang diperkirakan mempunyai bentuk yang tidak biasa, beberapa pendekatan perlu untuk diterapkan.
27
secara teori, metode ini tidak diperlengkapi feature untuk mendeteksi apakah di dalam suatu cluster ada cluster lain yang kemungkinan tersembunyi.
(Agusta, 2007)
2.4.3 K-Means sebagai Metode Semi-Supervised Classification
K-Means merupakan metode data clustering yang digolongkan sebagai metode pengklasifikasian yang bersifat unsupervised (tanpa arahan). Pengkategorian metode-metode pengklasifikasian data antara supervised dan unsupervised classification didasarkan pada adanya dataset yang data itemnya sudah sejak awal mempunyai label kelas dan dataset yang data itemnya tidak mempunyai label kelas. Untuk data yang sudah mempunyai label kelas, metode pengklasifikasian yang digunakan merupakan metode supervised classification dan untuk data yang belum mempunyai label kelas, metode pengklasifikasian yang digunakan adalah metode unsupervised classification.
secara teori metode penentuan jumlah cluster ini tidak sama dengan metode pengelompokan yang dilakukan oleh K-Means, kevalidan jumlah cluster yang dihasilkan umumnya masih dipertanyakan.
Melihat keadaan dimana pengguna umumnya sering menentukan jumlah cluster sendiri secara terpisah, baik itu dengan menggunakan metode tertentu atau berdasarkan pengalaman, di sini, kedua metode K-Means ini dapat disebut sebagai metode semi-supervised classification, karena metode ini mengalokasikan data items ke masing-masing cluster secara unsupervised dan menentukan jumlah cluster yang paling sesuai dengan data yang dianalisa secara supervised.
(Agusta, 2007)
2.4.4 Algoritma K-Means
1. Hard K-Means
Metode Hard K-Means melakukan proses clustering dengan mengikuti algoritma sebagai berikut :
a. Tentukan jumlah cluster
b. Alokasikan data sesuai dengan jumlah cluster yang ditentukan c. Hitung nilai centroid masing-masing cluster
d. Alokasikan masing-masing data ke centroid terdekat
29
threshold yang ditentukan.
Untuk menghitung centroid cluster ke-i, vi , digunakan rumus sebagai berikut:
Dimana :
𝑁𝑖 : jumlah data yang menjadi anggota cluster ke-i
Untuk perhitungan membership function digunakan rumus pada persamaan (3).
2. Fuzzy K-Means
Metode Fuzzy K-Means melakukan proses clustering dengan mengikuti algoritma sebagai berikut :
a. Tentukan jumlah cluster
b. Alokasikan data sesuai dengan jumlah cluster yang ditentukan c. Hitung nilai centroid dari masing-masing cluster
d. Hitung nilai membership function masing data ke masing-masing cluster
e. Kembali ke Step c. apabila perubahan nilai membership function
masih di atas nilai threshold yang ditentukan, atau apabila perubahan pada nilai centroid masih di atas nilai threshold yang
ditentukan, atau apabila perubahan pada nilai objective function masih di atas nilai threshold yang ditentukan.
Untuk menghitung centroid cluster ke-i, vi , digunakan rumus
𝒗
𝒊𝒋=
𝒙
𝒌𝒋 𝑵𝒊 𝒌=𝟏𝑵
𝒊sebagai berikut :
Dimana :
𝑁 : Jumlah data
𝑚 : Weighting exponent
𝑢𝑖𝑘 : Membership function data ke-k ke cluster ke-i
Sedangkan untuk menghitung membership function data ke-k ke cluster ke-i digunakan rumus pada persamaan (4).
(Agusta, 2007)
2.4.5 Kelebihan dan Kekurangan K-Means
a) Kelebihan K-Means :
1. Selalu konvergen atau mampu melakukan klusterisasi
2. Tidak membutuhkan operasi matemais yang rumit, bisa dibilang operasinya sederhana
3. Beban komputasi relatif lebih ringan sehingga klusterisasi bisa dilakukan dengan cepat walaupun relatif tergantung ppada banyak jumlah data dan jumlah kluster yang ingin dicapai
b) Kekurangan K-Means :
1. Jumlah kluster harus ditentukan
31
3. Solusi kluster yang dihasilkan hanya bersifat local optima sehingga kita tidak tahu apakah itu sudah merupakan konfigurasi optimal atau belum
4. Tergantung pada mean (rerata)
5. Operasi matematis nya sangat sederhana
2.5 Flowchart
Flowchart adalah penggambaran secara grafik dari langkah-langkah dan urut-urutan prosedur dari suatu program. Flowchart menolong analis dan programmer untuk memecahkan masalah kedalam segmen-segmen yang lebih kecil dan menolong dalam menganalisis alternatif-alternatif lain dalam pengoperasian.
Flowchart biasanya mempermudah penyelesaian suatu masalah khususnya masalah yang perlu dipelajari dan dievaluasi lebih lanjut.
2.5.1 Pedoman-pedoman dalam membuat Flowchart
Bila seorang analis dan programmer akan membuat Flowchart, ada beberapa petunjuk yang harus diperhatikan, seperti :
1. Flowchart digambarkan dari halaman atas ke bawah dan dari kiri ke kanan.
2. Aktivitas yang digambarkan harus didefinisikan secara hati-hati dan definisi ini harus dapat dimengerti oleh pembacanya.
3. Kapan aktivitas dimulai dan berakhir harus ditentukan secara jelas. 4. Setiap langkah dari aktivitas harus diuraikan dengan menggunakan
5. Setiap langkah dari aktivitas harus berada pada urutan yang benar. 6. Lingkup dan range dari aktifitas yang sedang digambarkan harus
ditelusuri dengan hati-hati. Percabangan-percabangan yang memotong aktivitas yang sedang digambarkan tidak perlu digambarkan pada Flowchart yang sama. Simbol konektor harus digunakan dan percabangannya diletakan pada halaman yang terpisah atau hilangkan seluruhnya bila percabangannya tidak berkaitan dengan sistem.
7. Gunakan simbol-simbol Flowchart yang standar. 2.5.2 Jenis-jens Flowchart
Flowchart terbagi atas lima jenis, yaitu : 1. Flowchart Sistem (System Flowchart).
Flowchart Sistem merupakan bagan yang menunjukkan alur kerja atau apa yang sedang dikerjakan di dalam sistem secara keseluruhan dan menjelaskan urutan dari prosedur-prosedur yang ada di dalam sistem. Dengan kata lain, Flowchart ini merupakan deskripsi secara grafik dari urutan prosedur-prosedur yang terkombinasi yang membentuk suatu sistem.
33
Flowchart Paperwork menelusuri alur dari data yang ditulis melalui sistem. Flowchart Paperwork sering disebut juga dengan Flowchart Dokumen.
Kegunaan utamanya adalah untuk menelusuri alur form dan laporan sistem dari satu bagian ke bagian lain baik bagaimana alur form dan laporan diproses, dicatat dan disimpan.
3. Flowchart Skematik (Schematic Flowchart).
Flowchart Skematik mirip dengan Flowchart Sistem yang menggambarkan suatu sistem atau prosedur. Flowchart Skematik ini bukan hanya menggunakan simbol-simbol Flowchart standar, tetapi juga menggunakan gambar-gambar komputer, peripheral, form-form atau peralatan lain yang digunakan dalam sistem.
Flowchart Skematik digunakan sebagai alat komunikasi antara analis sistem dengan seseorang yang tidak familiar dengan simbol-simbol Flowchart yang konvensional. Pemakaian gambar sebagai ganti dari simbol-simbol Flowchart akan menghemat waktu yang dibutuhkan oleh seseorang untuk mempelajari simbol abstrak sebelum dapat mengerti Flowchart.
4. Flowchart Program (Program Flowchart).
Flowchart ini menunjukkan setiap langkah program atau prosedur dalam urutan yang tepat saat terjadi.
Programmer menggunakan Flowchart program untuk menggambarkan urutan instruksi dari program komputer.
Analis Sistem menggunakan Flowchart program untuk menggambarkan urutan tugas-tugas pekerjaan dalam suatu prosedur atau operasi.
5. Flowchart Proses (Process Flowchart).
Flowchart Proses merupakan teknik penggambaran rekayasa industrial yang memecah dan menganalisis langkah-langkah selanjutnya dalam suatu prosedur atau sistem.
Flowchart Proses digunakan oleh perekayasa industrial dalam mempelajari dan mengembangkan proses-proses manufacturing. Dalam analisis sistem, Flowchart ini digunakan secara efektif untuk menelusuri alur suatu laporan atau form.
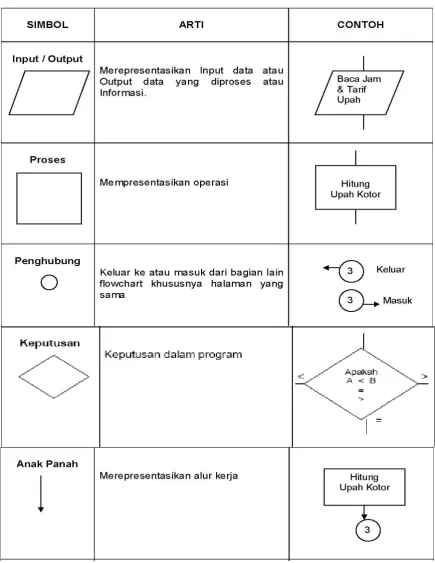
2.5.3 Simbol-simbol Flowchart
Simbol-simbol Flowchart yang biasanya dipakai adalah simbol-simbol Flowchart standar yang dikeluarkan oleh ANSI dan ISO.
35
37
39
2.6 Konsep Dasar Sistem
2.6.1 Pengertian Sistem
Sistem dilihat dari segi etimologinya berasal dari bahasa inggris yaitu sistem yang berarti susunan, cara, jaringan (Echols dan Shadily, 2000:575). Menurut Hartono (1999:683), sistem adalah suatu kesatuan yang terdiri dua atau lebih komponen atau subsistem yang berinteraksi untuk mencapai suatu tujuan.
Pengertian sistem dalam kamus besar bahasa Indonesia berarti Perangkat unsur yang secara teratur saling berkaitan sehingga membentuk suatu totalitas.
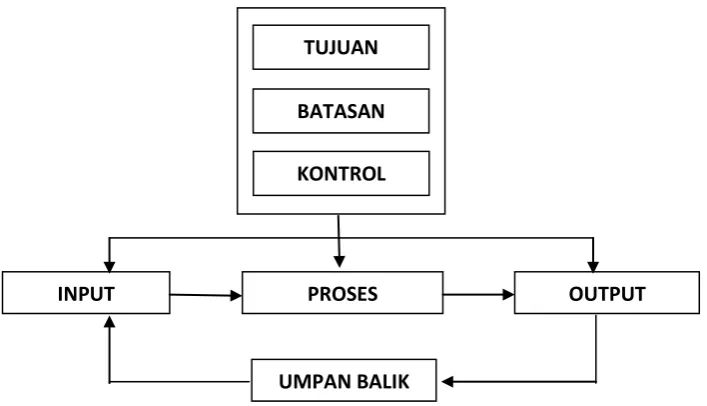
2.6.2 Elemen Sistem
Elemen yang terdapat dalam sistem meliputi: tujuan sistem, batasan sistem, control, input, proses, output dan umpan balik. Hubungan antar elemen dalam sistem dapat dilihat pada gambar dibawah ini (Kristianto, 2003:2):
INPUT PROSES OUTPUT
UMPAN BALIK KONTROL
TUJUAN
BATASAN
Dari gambar di atas bisa dijelaskan sebagai berikut : tujuan, batasan, dan kontrol sistem akan berpengaruh pada input, proses, dan output. Input dalam sistem akan diproses dan diolah sehingga menghasilkan output, dimana output tersebut akan dianalisis dan akan menjadi umpan balik bagi si penerima. Kemudian dari umpan balik ini akan muncul segala macam pertimbangan untuk input selanjutnya. Selanjutnya siklus ini akan berlanjut dan berkembang sesuai dengan permasalahan yang ada (Kristanto, 2003:2).
1. Tujuan Sistem
Tujuan sistem dapat berupa tujuan organisasi, kebutuhan organisasi, permasalahan yang ada dalam suatu organisasi maupun urutan prosedur untuk mencapai tujuan organisasi. Jadi, dapat dikatakan bahwa tujuan sistem adalah tujuan yang akan dicapai dari pembuatan suatu sistem.
2. Batasan Sistem
Batasan sistem adalah sesuatu yang membatasi sistem dalam pencapaian tujuan. Batasan sistem dapat berupa peraturan yang ada dalam organisasi, sarana dan prasarana, maupun batasan yang lain. 3. Kontrol Sistem
41
4. Input
Merupakan suatu elemen dari sistem yang bertugas untuk menerima seluruh masukan data yang dapat berupa jenis data, frekuensi pemasukan data, dan lainnya.
5. Proses
Merupakan elemen dari sistem yang bertugas untuk mengolah atau memproses seluruh masukan data menjadi suatu informasi yang lebih berguna.
6. Output
Merupakan hasil dari input yang telah diproses oleh bagian pengolah dan merupakan tujuan akhir dari sistem.
7. Umpan Balik
Umpan balik merupakan elemen dalam sistem yang bertugas mengevaluasi bagian dari output yang dikeluarkan, dimana elemen ini sangat penting demi kemajuan sebuah sistem. Umpan balik in dapat berupa perbaikan sistem, pemeliharaan sistem, dan sebagainya (Kristanto, 2003:3-4).
2.7 Konsep Dasar Informasi
2.7.1 Pengertian Informasi
Menurut Kristanto (2003:6), Informasi merupakan kumpulan data yang diolah menjadi bentuk yang lebih berguna dan lebih berarti bagi yang menerimanya.
yang telah diproses, atau data yang memiliki arti. 2.7.2 Siklus Informasi
Siklus informasi dimulai dari data mentah yang diolah melalui suatu model menjadi informasi (output), kemudian informasi diterima oleh penerima, sebagai dasar untuk membuat keputusan dan melakukan tindakan, yang berarti akan membuat data kembali. Kemudian data tersebut akan ditangkap sebagai input dan selanjutnya membentuk siklus.
2.7.3 Kualitas Informasi
Kualitas dari suatu informasi tergantung dari tiga hal berikut : 1. Akurat
Informasi harus bebas dari kesalahan dan tidak bias atau menyesatkan. Akurat juga berarti informasi harus jelas mencerminkan maksudnya, informasi harus akurat karena dari sumber informasi sampai ke penerima informasi kemungkinan banyak terjadi gangguan (noise) yang dapat merubah atau merusak informasi tersebut.
2. Tepat pada Waktunya
43
3. Relevan
Relevan dalam hal ini adalah dimana informasi tersebut memiliki manfaat dan keterkaitan dalam pemakaiannya. Relevansi informasi untuk tiap satu individu dengan individu lainnya memiliki perbedaan (Kristanto, 2003:6)
2.8 Konsep Dasar Sistem Informasi
2.8.1 Pengertian Sistem Informasi
Sistem informasi adalah suatu sistem di dalam suatu organisasi yang merupakan kombinasi dari orang-orang, fasilitas, teknologi, media, prosedur, dan pengendalian yang ditujukan untuk mendapatkan jalur komunikasi penting, memproses tipe transaksi rutin tertentu, memberi sinyal kepada manajemen dan yang lainnya terhadap kejadian internal dan eksternal yang penting dan menyediakan suatu dasar informasi untuk pengambilan keputusan yang baik (Hartono, 1999:697)
Sedangkan menurut Kristanto (2003:11), sistem informasi didefinisikan sebagai berikut :
1. Suatu sistem yang dibuat oleh manusia yang terdiri dari komponen dalam organisasi untuk mencapai suatu tujuan yaitu menyajikan informasi.
2.8.2 Komponen Sistem Informasi
Untuk mendukung lancarnya suatu sistem informasi dibutuhkan beberapa komponen yang fungsinya sangat vital di dalam sistem informasi, yaitu antara lain :
1. Blok Masukan
Input mewakili data yang masuk ke dalam sistem informasi. Input dalam hal ini termasuk metode dan media untuk menangkap data yang akan dimasukkan yang dapat berupa dokumen dasar.
2. Blok Model
Blok ini terdiri dari kombinasi prosedur, logika, dan model matematik yang akan memanipulasi data input dan data yang tersimpan pada basis data dengan cara yang sudah tertentu untuk menghasilkan keluaran yang diinginkan.
3. Blok Keluaran
Produk dari sistem informasi adalah keluaran yang merupakan informasi yang berkualitas dan dokumentasi yang berguna untuk semua tingkatan manajemen serta semua pamakai sistem.
4. Blok Teknologi
45
Basis data merupakan kumpulan dari data yang saling berhubungan satu dengan yang lainnya, tersimpan di perangkat keras komputer, dan dipergunakan perangkat lunak untuk memanipulasinya.
6. Blok Kendali
Beberapa pengendalian perlu dirancang dan diterapkan untuk meyakinkan bahwa hal-hal yang dapat merusak sistem dapat dicegah ataupun bila terlanjur terjadi kesalahan dapat langsung dengan cepat (Kristanto, 2003 : 12-13).
2.9 Alat dan Teknik dalam Pengembangan Sistem
Untuk dapat melakukan langkah-langkah sesuai dengan yang diberikan oleh metodologi pengembangan sistem yang terstruktur, maka dibutuhkan alat untuk melaksanakannya. Alat-alat yang digunakan dalam suatu metodologi umumnya berupa suatu gambar atau diagram atau grafik. Penggunaan diagram atau gambar ini dipandang lebih mengena dan lebih mudah dimengerti. Selain berbentuk gambar, alat-alat yang digunakan juga ada yang tidak berupa gambar atau grafik (nongraphical tools). Seperti misalnya data dictionary, structured English, pseudocode serta formulir-formulir untuk mencatat dan menyajikan data.
Alat-alat pengembangan sistem yang berbentuk grafik diantaranya adalah sebagai berikut ini.
a. HIPO diagram, digunakan di metodologi HIPO dan di metodologi yang lainnya.
analysis and design
c. SADT diagram, digunakan di metodologi SADT
d. Warnier/Orr diagram, digunakan di metodologi Warnier/Orr
e. Jaksin’s diagram, digunakan di metodologi Jakson System
Development
Disamping alat-alat berbentuk grafik yang digunakan pada suatu metodologi tertentu, masih terdapat beberapa alat berbentuk grafik yang sifatnya umum, yaitu data digunakan di semua metodologi yang ada. Alat-alat ini berupa suatu bagan. Bagan dapat diklasifikasikan sebagai berikut ini.
1. Bagan untuk menggambarkan aktifitas (activity charting). a. Bagan alir sistem (systems Flowchart)
b. Bagan alir program (program Flowchart) yang dapat berupa: 1) Bagan alir logika program (program logic Flowchart)
2) Bagan alir program komputer terinci (detailed computer program flowchart)
c. Bagan alir kertas kerja (paperwork flowchart) atau disebut juga dengan bagan alir formulir (form flowchart)
d. Bagan alir hubungan database (database relationship flowchart) e. Bagan alir proses (process flowchart)
f. Gantt chart
2. Bagan untuk menggambarkan tataletak (layout charting)
47
relationship charting)
a. Bagan distribusi kerja (working distribution chart) b. Bagan organisasi (organization chart)
(Jogiyanto, 1990)
2.9.1 Diagram Arus Data
Ide dari suatu bagan untuk mewakili arus data dalam suatu sistem bukanlah hal yang baru. Penggunaan notasi dalam diagram arus data sangat membantu sekali untuk memahami suatu sistem pada semua tingkat kompleksitasnya seperti yang diungkapkan oleh Chris Gane dan Trish Sarson. Pada tahap analisis, penggunaan notasi ini sangat membantu sekali di dalam komunikasi dengan pemakai sistem untuk memahami sistem secara logika. Diagram yang menggunakan notasi-notasi ini untuk menggambarkan arus dari data sistem sekarang dikenal dengan nama diagram arus data (data flow diagram atau DFD).
merupakan dokmentasi dari sistem yang baik. (Jogiyanto, 2005:699) 2.9.1.1 Simbol yang Digunakan DFD
Beberapa symbol digunakan di DFD untuk maksud mewakili:
A. External entity (Kesatuan Luar) atau Boundary (Batas Sistem)
Setiap sistem pasti mempunyai batas sistem (boundary) yang memisahkan suatu sistem dengan lingkungan luarnya. Kesatuan luar (external entity) merupakan kesatuan (entity) di lingkungan luar sistem yang dapat berupa orang, organisasi atau sistem lainnya yang berada di lingkungan luarnya yang akan memberikan input atau menerima output dari sistem.
Suatu kesatuan luar dapat disimbolkan dengan suatu notasi kotak atau suatu kotak dengan sisi kiri dan atasnya berbentuk garis tebal sebagai berikut :
B. Data Flow (Arus Data)
Arus data (data flow) di DFD diberi symbol suatu panah. Arus data ini mengalir diantara proses (process), simpanan data (data store) dan kesatuan luar (external entity). Arus data ini menunjukkan arus dari data yang dapat berupa masukan untuk sistem atau hasil dari proses sistem.
49
Arus data sebaiknya diberi nama yang jelas dan mempunyai arti. Nama dari arus data dituliskan disamping garis panahnya.
C. Process (Proses)
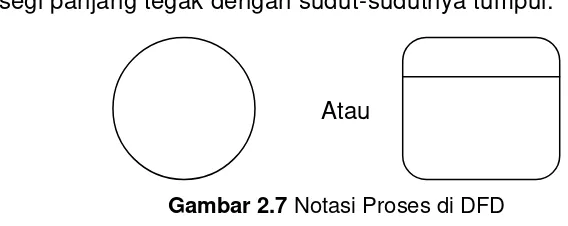
Suatu proses adalah kegiatan atau kerja yang dilakukan oleh orang, mesin atau komputer dari hasil suatu arus data yang masuk ke dalam proses untuk dihasilkan arus data yang akan keluar dari proses. Untuk physical data flow diagram (PDFD), proses dapat dilakukan oleh orang, mesin, atau komputer, sedang untuk logical data flow diagram (LDFD), suatu proses hanya menunjukkan proses dari komputer. Suatu proses dapat ditunjukkan dengan symbol lingkaran atau dengan symbol empat persegi panjang tegak dengan sudut-sudutnya tumpul.
Atau
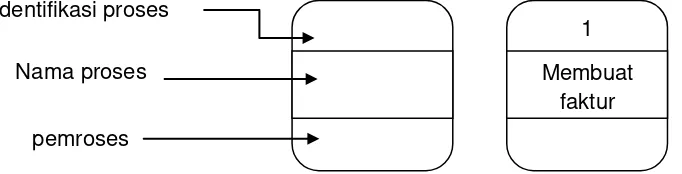
Setiap proses harus diberi penjelasan yang lengkap meliputi berikut ini:
1. Identifikasi proses
Identifikasi ini umumnya berupa suatu angka yang menunjukkan nomor acuan dari proses dan ditulis pada bagian atas di symbol proses.
Gambar 2.7 Notasi Proses di DFD Order langganan
2. Nama proses
Nama proses menunjukkan apa yang dikerjakan oelh proses tersebut. Nama dari proses biasanya berbentuk suatu kalimat diawali dengan kata kerja (misalnya menghitung, membuat, membandingkan, memverifikasi, mempersiapkan, merekam dan lain sebagainya).
3. Pemroses
Untuk PDFD yang menunjukkan proses tidak hanya proses dari komputer,tetapi juga proses manual, seperti proses yang dilakukan oleh orang, mesin dan lain sebagainya, maka pemroses harus ditunjukkan. Pemroses ini menunjukkan siapa atau dimana suatu proses dilakukan. Untuk LDFD yang prosesnya hanya menunjukkan proses komputer saja, maka pemroses dapat tidak disebutkan. Keterangan pemroses ini di symbol proses dapat dituliskan dibawah nama proses sebagai berikut ini:
D. Data Store (Simpanan Data)
Simpanan data (data store) merupakan tempat penyimpanan untuk data yang memungkinkan penambahan dan perolehan data.
Identifikasi proses
51
Penyimpanan data menandakan penyimpanan manual, seperti lemari file, atau sebuah file atau basisdata terkomputerisasi.
Simpanan data di DFD dapat disimbolkan dengan sepasang garis horizontal pararel yang tertutup di salah satu ujungnya.
Nama dari data store menunjukkan nama dari filenya, misalnya file langganan, file hutang, file arsip faktur dan lain sebagainya. (Jogiyanto, 2005:707)
2.9.1.2 Diagram Arus Data Logika dan Fisik
Diagram arus data dikategorikan baik sebagai logika maupun fisik. Diagram arus logika hanya memfokuskan pada kebutuhan-kebutuhan sistem, yaitu proses-proses apa secara logika yang dibutuhkan oleh sistem, tidak berhubungan dengan bagaimana sistem diterapkan. Sebaliknya diagram arus data fisik menunjukkan bagaimana sistem tersebut akan diimplementasikan, termasuk perangkat keras, perangkat lunak, file-file dan orang-orang yang terlibat dalam sistem.
Idealnya, sistem yang dikembangkan dengan cara menganalisis sistem yang ada (DAD logika yang ada) dan kemudian menambahkan fitur-fitur dimana sistem yang baru harus dimasukkan (DAD logika yang
Gambar 2.9 Simbol dari simpanan data di DFD Nama data store
diajukan). Terakhir metode terbaik untuk mengimplementasikan sistem yang baru harus dikembangkan (DAD fisik).
Mengembangkan diagram arus data logika untuk sistem yang ada memberi pemahaman yang lebih baik mengenai bagaimana sistem yang ada beroperasi serta menjadi titik awal yang baik untuk mengembangkan model logika dari sistem yang ada. Langkah yang menghabiskan banyak waktu ini seringnya diabaikan sehingga bertolakbelakang dengan DAD logika yang diajukan.
Salah satu argument yang biasanya diambil waktu untuk membangun diagram arus data logika dari sistem yang ada ialah yag bisa digunakan untuk menciptakan diagram arus data logika dari sistem baru. Proses-proses yang akan diperlukan dalam sistem yang baru bisa
Mendapatkan diagram arus data logika untuk sistem yang ada dengan cara mengamati diagram arus data fisik dan memisahkan kegiatan tertentu
Menciptakan diagram arus data logika untuk sistem yang baru dengan menambahkan maskan, keluaran, dan proses-proses yang diperlukan dalam sistem yang baru terhadap diagram arus data logika untuk sistem yang ada
Diagram arus
Mendapatkan diagram arus data fisik dengan cara mengamati proses-proses ada diagram logika baru. Menentukan dimana antarmuka pengguna harus berada, sifat proses, dan penyimpanan data yang diperlukan
53
digunakan, dan fitur-fitur baru, kegiatan, masukan, dan data-data yang disimpan bisa ditambahkan. Pendekatan ini menampilkan suatu cara memastikan bahwa fitur-fitur terpenting dari sistem lama tetap terpakai dalam sistem yang baru. Selain itu, dengan menggunakan model logika untuk sistem yang ada sebagai dasar untuk sistem yang diajukan dimaksudkan untuk transisi bertahap untuk perancangan sistem yang baru. Setelah model logika untuk sistem yang baru dikembangkan, maka bisa digunakan untuk menciptakan sebuah diagram arus data fisik untuk sistem yang baru. Gerak maju dari model-model ini digambarkan dalam gambar 2.10.
Gambar 2.11 menunjukkan suatu diagram arus data logika dan suatu diagram aliran data fisik untuk sebuah kasir took grosir. KONSUMEN membawa ITEM ke register; HARGA untuk semua ITEM silihat dan kemudian ditotal; berikutnya, PEMBAYARAN diberikan ke kasir; terakhir, KONSUMEN diberi NOTA. Diagram arus data logika menggambarkan proses-proses yang terlibat tanpa terlalu mendetail
dalam hal implementasi fisik kegiatan-kegiatan tersebut.
Diagram aliran data fisik menunjukkan bahwa sebuah bar code-kode produk universal (UPC/universal product code) BAR CODE yang ditemukan dihampir sebagian besar item-item toko grosir-digunakan. Selain itu, diagram arus data fisik yang menyebutkan proses-proses manual seperti scanning, menjelaskan bahwa sebuah file sementara digunakan untuk menjaga subtotal item, dan menunjukkan bahwa PEMBAYARAN bisa dibuat melalui KAS, CEK, atau KARTU DEBIT. Terakhir, disebutkan nota berdasarkan namanya, NOTA REGISTER KAS.
2.9.1.3 Langkah Membuat/menggambar DFD
Tidak ada aturan baku untuk menggambarkan DFD. Tapi dari beberapa referensi yang ada, secara garis besar langkah untuk membuat DFD adalah:
55
1. Identifikasi entitas luar, Input dan Output
Identifikasi terlebih dahulu semua entitas luar, input dan output yang terlibat di sistem.
2. Buat Diagram Konteks (Context Diagram)
Diagram ini adalah diagram level tertinggi dari DFD yang mengggambarkan hubungan sistem dengan lingkungannya.
Caranya:
a. Tentukan nama asistennya b. Tentukan batasan sistemnya
c. Tentukan terminator apa saja yang ada dalam sistem
d. Tentukan apa yang diterima/diberikan external entity dari/ke sistem e. Gambarkan diagram konteks
3. Buat Diagram Level Zero (Overview Diagram)
Diagram ini adalah dekomposisi dari diagram konteks. Caranya:
a. Tentukan proses utama yang ada pada sistem
b. Tentukan apa yang diberikan diterima masing-masing proses ke/dari didtem sambil memperhatikan konsep keseimbangan (alur data yang keluar/masuk dari suatu level harus sama dengan alur data yang masuk/keluar pada level berikutnya).
c. Apabila diperlukan, munculkan data store (master) sebagai sumber maupun tujuan alur data
d. Hindari perpotongan arus data
e. Beri nomor pada proses utama (nomor tidak menunjukkan urutan proses)
57
4. Buat Diagram Level satu
Diagram ini merupakan dekomposisi dari diagram level zero. Caranya :
a. Tentukan proses yang lebih kecil (sub-proses) dari proses utama yang ada di level zero
b. Tentukan apa yang diberikan/diterima masing-masing sub-proses ke/dari sistem dan perhatikan konsep keseimbangan
c. Apabila diperlukan, munculkan data store (transaksi) sebagai sumber maupun tujuan alur data
d. Hindari perpotongan arus data
e. Beri nomor pada masing-masing sub-proses yang menunjukkan dekomposisi dari proses sebelumnya
2.10 Konsep Database Management System
Satu Database Management System (DBMS) berisi satu koleksi data yang saling berelasi dan satu set program untuk mengakses data tersebut. Jadi DBMS terdiri dari Database dan Set Program Pengelola untuk menambah data, menghapus data, mengambil dan membaca data.
Dalam satu file terdapat record-record yang sejenis, sama besar, sama bentuk, merupakan satu kumpulan entity yang seragam. Satu record terdiri dari field-field yang saling berhubungan untuk menunjukkan bahwa field tersebut dalam satu pengertian yang lengkap dan direkam dalam satu record. Untuk menyebut isi dari field maka digunakan atribut atau merupakan judul dari satu kelompok entity tertentu, misalnya atribut Alamat menunjukkan entity alamat dari siswa. Entiti adalah suatu objek yang nyata yang akan direkam.
Set program pengelola merupakan satu paket program yang dibuat agar memudahkan dan mengefisienkan pemasukkan atau perekaman informasi dan pengambilan atau pembacaan informasi ke dalam database.
2.10.1 Definisi
1. Entity
59
entity adalah siswa, buku, pembayaran, nilai test. Pada bidang kesehatan, entity adalah pasien, dokter, obat, kamar, diet (Kadir,1998:46).
2. Atribut
Setiap entity mempunyai atribut atau sebutan untuk mewakili suatu entity. Seorang siswa dapat dilihat dari atributnya, misalnya nama, nomor siswa, alamat, nama orang tua, hobi. Atribut juga disebut sebagai data elemen, data field, data item(Kadir, 1998:46).
3. Data Value (Nilai atau Isi Data)
Data value adalah data actual atau informasi yang disimpan pada tiap data elemen atau atribut. Atribut nama karyawan menunjukkan tempat dimana informasi nama karyawan disimpan, sedang data value adalah Icha Fitriyanti, Adam Pratama, merupakan isi data nama karyawan tersebut.
4. Record/Tuple
Kumpulan elemen-elemen yang salin berkaitan menginformasikan tentang suatu entity secara lengkap. Satu record mewakili satu data atau informasi tentang seseorang misalnya, nomor karyawan, nama karyawan, alamat, kota, tanggal masuk.
5. File