STATISTIKA INFERENSIAL
Materi:
Analisis Regresi Linier Dengan Software Aplikasi SPSS:
1. Uji Asumsi Dasar Regresi (Asumsi Klasik),
2. Pemodelan dan Analisis Regresi Linier,
3.
Simulasi Kasus: Pengaruh Informasi Akuntansi terhadap Return Saham.
Ir. GINANJAR SYAMSUAR, ME.
SEKOLAH TINGGI ILMU EKONOMI INDONESIA
(STEI)
–
JAKARTA
DAFTAR ISI
Halaman
DAFTAR ISI
... 1
I.
TEORI DASAR
... 2
A.
PENGANTAR ... 2
B.
ANALISIS
REGRESI
LINIER: ... 2
1.1.
.Tahap-1: Uji Asumsi Dasar Regresi Linier ... 3
(1) Uji Normalitas Residu: ... 3
(2) Uji Multikolinieritas: ... 4
(3) Uji Autokorelasi: ... 5
(4) Uji Heteroskedastisitas: ... 6
(5) Cara Memperbaiki (Mengobati) adanya Penyimpangan Asumsi ... 7
1.2.
Tahap-2: Pemodelan Regresi Linier (Konstruksi model) ... 8
(1) Pemilihan Metode Analisis Regresi Linier dalam SPSS: ... 8
(2) Analisis secara simultan: ... 9
Signifikansi model: ... 9
Korelasi ganda dan Koefisien determinasi: ... 10
(3) Analisis secara parsial: ... 11
Signifikansi koefisien variabel bebas: ... 11
Penentuan variabel bebas dominan dan kontribusi terhadap variabel terikat: ... 11
II.
MATERI SIMULASI KASUS
... 13
PENGARUH
INFORMASI
AKUNTANSI
TERHADAP
RETURN
SAHAM ... 13
Pustaka:
...32
Page | 1
I.
TEORI DASAR
ANALISIS REGRESI LINIER DAN KORELASI
A.
PENGANTAR
Dalam mengkaji hubungan antara dua variabel atau lebih, penting dipahami skala
pengukuran dari setiap data variabelnya, sehingga teknik analisis yang akan digunakan untuk
menjelaskan hubungan atau kaitan diantara variabel tersebut dapat dipilih yang paling sesuai.
Apabila hal ini diabaikan, maka dapat menghasilkan interpretasi hasil yang kurang tepat
(misleading). Dalam hal ini, analisis regresi mensyaratkan bahwa variabel yang digunakan
paling tidak diukur secara interval, sehingga kalau ada salah satu variabel yang diukur secara
nominal atau ordinal maka hasil yang diperoleh tidak dapat ditafsirkan secara tepat, oleh karena
asumsi dalam penggunaan teknik ini yang tidak dapat dilanggar adalah bahwa variabel yang
digunakan mengikuti distribusi normal.
Pada materi ini teknik yang dibahas merupakan teknik analisis statistik inferensial kajian
analisis regresi linier, yaitu teknik yang mendasarkan pada pemanfaatan data yang diperoleh
dari suatu sampel acak, sehingga hasilnya merupakan gambaran keadaan populasi dari mana
sampel acak tersebut diambil. Teknik statistik semacam ini memberikan jaminan bahwa
kesimpulan dan penafsiran dibuat dengan tingkat kesalahan yang rendah,1 biasanya dipakai
0,05 (5 %) atau 0.1 (10%).
Teknik analisis statistik yang dibahas dalam materi ini bersumber pada SPSS (Statistical Package for the Social Sciences) yang difokuskan hanya pada teknik yang dapat menjelaskan
hubungan atau kaitan antara beberapa variabel, baik hubungan antara dua variabel (bivariate)
maupun banyak variabel (multivariate). Pembahasan diutamakan pada cara membaca dan
menafsirkan arti dari parameter yang diperoleh dari hasil pengolahan data yang terdapat pada
output SPSS. Teknik analisis statistik yang dibahas adalah Analisis Regresi Linier dan Korelasi.
B.
ANALISIS REGRESI LINIER:
Analisis regresi merupakan alat yang dapat memberikan penjelasan hubungan antara dua
jenis variabel yaitu hubungan antara variabel dependen atau variabel kriteria dengan variabel
independen atau variabel prediktor. Analisis hubungan antara dua variabel disebut sebagai
1
Page | 2
analisis regresi sederhana jika hanya melibatkan satu variabel independen (variablebebas/prediktor). Analisis disebut sebagai analisis regresi berganda jika melibatkan lebih dari
satu variabel independen.
Hubungan antara variabel dependen (Y) dengan variabel independen (X) dituliskan dalam
model linier umum:
̂ = �̂ + �̂
+ ⋯ + �̂
� �+ �, �~� , � ,
� � � = − ̂
di mana
ˆ
i, i = 1,2,...p adalah koefisien regresi yang berarti besarnya perubahan pada Yˆ,jika Xi bertambah satu satuan dan variabel yang lain konstan,
ˆ
0adalah intercept. Residual�
mengikuti distribusi normal dengan rata-rata 0 dan varians konstan sebesar σ2.
Dengan teknik estimasi metode Ordinary Least Square (OLS) atau metode Kuadrat Terkecil,
model regresi linier yang dihasilkan harus memenuhi asumsi metode tersebut yaitu (i) setiap Y
merupakan kombinasi linier atas X dan mengikuti distribusi normal, (ii) ε tersebar secara acak
dan tidak berpola mengikuti besarnya nilai X, (iii) tidak terdapat hubungan (korelasi) yang tinggi
antar variabel X.
Oleh karena itu, untuk melakukan analisis regresi linier demi mendapatkan hasil yang masuk
akal yang dapat anda percaya, data yang anda gunakan harus memenuhi persyaratan asumsi
dasar. Jika tidak, output yang anda dapatkan dari menjalankan analisis regresi kemungkinan
tidak benar (Julie Pallant dalam Dr. J. Hanson, 2008). Dengan demikian dalam membuat
pemodelan regresi linier yang harus dilakukan pertama kali adalah pemeriksaan data untuk
pemenuhan asumsi dasar model regresi, selanjutnya apabila syarat asumsi sudah dipenuhi
dilanjutkan dengan tahap pemodelan (konstruksi model).
1.1. Tahap-1: Uji Asumsi Dasar Regresi Linier
Untuk mendapatkan model yang secara empirik signifikan atau [Pr>F]<0,05
merupakan model yang tepat (fit). Dalam hal ini uji kecocokan model (Gooodness of Fit
test) yang secara umum ditunjukkan oleh besarnya koefisien determinasi (R2) terlebih
dulu terhadap data pembentuk modelnya harus dilakukan serangkaian pengujian syarat
asumsi dasar yaitu diantaranya:
(1) Uji Normalitas Residu:
Normalitas adalah residu yang seharusnya terdistribusi normal seputar skor-skor
variabel terikat. Residu adalah sisa atau perbedaan hasil antara nilai data pengamatan
Page | 3
normal atau tidak, dapat dilakukan dengan cara berikut:1. Melihat grafik Normal P-P Plot, dan
2. Uji Kolmogorov-Smirnov
Pada grafik Normal P-P Plot, residu yang normal adalah data memencar mengikuti
fungsi distribusi normal yaitu menyebar seiring garis z diagonal (cara ini tidak dianjurkan,
bisa digunakan hanya sebagai penegas visual bagi uji Kolmogorov-Smirnov).
Cara deteksi hasil uji Kolmogorov-Smirnov adalah apabila nilai signifikansi
Kolmogorov-Smirnov (Asymp. Sig.) lebih besar dari 0.05 (Sig.>0.05) maka residu model
telah terdistribusi normal. Pada Output SPSS hasil uji Kolmogorov-Smirnov nilai signifikansi
tersebut ditunjukan pada baris akhir table One-Sample Kolmogorov-Smirnov seperti
berikut:
One-Sample Kolmogorov-Smirnov Test
Unstandardized Residual
N 32
Normal Parametersa Mean .0000000 Std. Deviation .33713584 Most Extreme Differences Absolute .101 Positive .096 Negative -.101 Kolmogorov-Smirnov Z .573 Asymp. Sig. (2-tailed) .897 a. Test distribution is Normal.
Apabila diperoleh indikasi bahwa syarat asumsi normalitas ini tidak dipenuhi yaitu jika Signifikansi Kolmogorov-Smirnov < 0.05, maka data harus diperbaiki terlebih dulu sebelum dilakukan analisis regresi.
(2) Uji Multikolinieritas:
Uji Regresi mengasumsikan variabel-variabel bebas tidak memiliki hubungan linier
satu sama lain. Sebab, jika terjadi hubungan linier antar variabel bebas akan membuat
prediksi atas variabel terikat menjadi bias karena terjadi masalah hubungan di antara para
variabel bebasnya.
Dalam Regresi Berganda dengan SPSS, masalah Multikolinieritas ini ditunjukkan
lewat tabel Coefficients, yaitu pada kolom Tolerance dan kolom VIF (Variance Inflated
Factors). Tolerance adalah indikator seberapa banyak variabilitas sebuah variabel bebas
Page | 4
untuk setiap variabel bebas. Jika nilai Tolerance sangat kecil (< 0,10), maka itumenandakan korelasi berganda satu variabel bebas sangat tinggi dengan variabel bebas
lainnya dan mengindikasikan Multikolinieritas. Nilai VIF merupakan invers dari nilai
Tolerance (1 dibagi Tolerance). Jika nilai VIF > 10, maka itu mengindikasikan terjadinya
Multikolinieritas.
Hipotesis untuk Multikolinieritas ini adalah:
Ho: Tolerance < 1 dan VIF < 10 Tidak terjadi Multikolonieritas antar variabel bebas
H1: Tolerance > 1 dan VIF > 10 Terjadi Multikolinieritas antar variabel bebas
Output SPSS untuk uji Multikolinieritas terdapat pada tabel Coefficients seperti berikut:
Coefficientsa
Model
Unstandardized Coefficients
Standardized Coefficients
t Sig.
Collinearity Statistics B Std. Error Beta Tolerance VIF 1 (Constant) .683 .097 7.006 .000
X1 1.404 .359 .703 3.917 .001 .669 1.495 X2 .025 .052 .075 .479 .636 .886 1.129 X3 -.024 .077 -.052 -.307 .761 .750 1.333 X4 -1.223 .460 -.441 -2.660 .013 .783 1.278 a. Dependent Variable: Y
(3) Uji Autokorelasi:
Autokorelasi juga disebut sebagai Independent Errors. Regresi Berganda
mengasumsikan residu observasi seharusnya tidak berkorelasi (atau bebas). Asumsi ini
bisa diuji dengan teknik statistik Durbin-Watson, yang menyelidiki korelasi berlanjut antar
error (kesalahan). Durbin-Watson menguji apakah residual yang berdekatan saling
berkorelasi. Statistik pengujian bervariasi antara 0 hingga 4.
Cara melakukan uji Durbin-Watson adalah, nilai Durbin-Watson hitung (d) yang
dihasilkan oleh SPSS (output SPSS pada tabel Model summary) harus lebih besar dari
batas atas Durbin-Watson tabel (du) dan lebih kecil dari 4 dikurang oleh batas atas
Durbin-Watson tabel (du) atau (du < d < 4-du) yang berarti terbebas dari pengaruh
Page | 5
Interval Keputusan Statistik Durbin-Watson (d)
Autokorelasi
Untuk mendapatkan nilai du dan dl dilihat dari tabel Durbin-Watson yaitu dengan cara
mengidentifikasi nilai yang dimaksud pada jumlah variabel bebas (k) dengan jumlah data
yang sedang diolah (n). a. Predictors: (Constant), X4, X3, X2, X1
b. Dependent Variable: Y
(4) Uji Heteroskedastisitas:
Uji Regresi bisa dilakukan jika data bersifat Homoskedastisitas bukan
Heteroskedastisitas. Homoskedastisitas adalah kondisi dimana varians dari data adalah
sama pada seluruh pengamatan. Terdapat sejumlah uji guna mendeteksi gejala
heteroskedastisitas misalnya uji Goldfeld-Quandt, uji Park, uji Glejser, dan uji korelasi rank
Spearman antara absolut residu dengan variabel bebasnya. Bisa juga secara plot grafik
(Scatterplot) yaitu persilangan antara ZPred (X-axis) dengan SResid (Y-axis),
keputusannya adalah jika plot data tersebut tidak membentuk pola maka
homoskedastisitas (cara ini tidak dianjurkan, bisa digunakan hanya sebagai penegas visual
Page | 6
Pengambilan keputusan pada metode uji korelasi rank Spearman antara absolutresidu (sisaan) dengan variabel bebas regresi adalah dilihat dari nilai signifikansi
korelasinya, dimana apabila nilai signifikansinya lebih besar dari 0.05 (Sig.>0.05) berarti
terbebas dari pengaruh Heteroskadastisitas (Homoskedastisitas).
Metode uji korelasi rank Spearman hampir mirip dengan metode uji Glejser yaitu
dalam hal mengabsolutkan nilai residu, hanya kalau dalam uji ini meregresikan absout
residu sebagai variabel terikat terhadap variabel bebas yang ada. Keputusannya adalah
dengan cara deteksi apabila variabel bebasnya signifikan mempengaruhi variabel
terikatnya (Sig. < 0.05) berarti Heteroskedastisitas.
Output SPSS untuk uji Heteroskedastisitas metode korelasi rank Spearman adalah
seperti berikut: **. Correlation is significant at the 0.01 level (2-tailed).
(5) Cara Memperbaiki (Mengobati) adanya Penyimpangan Asumsi
Apabila berdasarkan hasil serangkaian pengujian terhadap asumsi dasar regresi linier
dan ditemukan adanya asumsi yang dilanggar, maka cara memperbaiki atau
mengobatinya adalah:
1. Lakukan Transformasi data variabelnya.
Page | 7
Hal ini harus dilakukan sampai terbebas dari pengaruh adanya asumsi yangdilanggar agar hasil analisis regresi bisa dipertangungjawabkan dan bisa digeneralisasi
bagi sampel lainnya untuk penelitian lain yang serupa.
1.2. Tahap-2: Pemodelan Regresi Linier (Konstruksi model)
Model regresi linier ganda (Multivariate Linear Regression) yang secara umum
modelnya seperti dituliskan diatas. Selain berguna untuk dapat menjelaskan hubungan p
variabel X secara bersama terhadap variabel Y, dengan analisis regresi ganda juga dapat
diperoleh suatu penjelasan tentang peranan atau kontribusi relatif setiap variabel X
terhadap variabel Y. Secara empirik walaupun misalnya model regresinya signifikan, yang
berarti bahwa secara bersama (simultan) p variabel X dapat menjelaskan variabel Y, tidak
berarti bahwa setiap variabel mempunyai pengaruh yang signifikan pada variabel Y. Suatu
kajian tersendiri perlu dilakukan untuk kemudian dapat memilah variabel X yang
berpengaruh secara parsial pada variabel Y.
(1) Pemilihan Metode Analisis Regresi Linier dalam SPSS:
Pada saat membuat analisis regresi pada SPSS sebelumnya sangat perlu dan penting
untuk diperhatikan terhadap tujuan akhir bentuk model regresi yang ingin dihasilkan, yaitu
apakah model yang diinginkan adalah merupakan model lengkap dimana semua variabel
bebas ditampilkan tanpa memandang apakah variabel tersebut berpengaruh besar atau
kecil pada variabel terikatnya (dependent). Pilihan metode analisis regresi pada SPSS
terdiri atas option metode seperti berikut berikut:
a. Metode Enter
Adalah metode analisis biasa dimana semua variabel bebas dimasukkan sebagai variabel prediktor, tidak memandang pengaruh apakah variabel tersebut berpengaruh besar atau kecil pada variabel terikat (dependent).
b. Metode Stepwise
Digunakan untuk analisis regresi secara bertahap dengan tujuan pokok untuk mencari variabel yang paling dominan.
c. Metode Remove
Digunakan untuk mencari prediktor yang dominan dan bila variabel prediktor tidak berpengaruh, akan dibuang (di-remove).
d. Metode Backward
Page | 8
e. Metode ForwardMenganalisis variabel dari depan, maksudnya semua variabel pertamanya dianggap tidak berpengaruh semua, kemudian variabel yang berpengaruh dimasuk-masukkan
.
(2) Analisis secara simultan:
Signifikansi model:
Model persamaan regresi ganda umum diatas, secara simultan bentuk hipotesis yang
harus diujinya diformulasikan sebagai berikut:
H0: 1 = 2 = ...= p = 0
dengan alternatif
H1: i 0, (i = 1,2,...,p), sedikitnya ada satu buah koefisien variabel bebas tidak sama
dengan nol,
yang dari ouput SPSS dapat dilihat pada output tabel ANOVA, sebagai contoh tabel Anova
berikut adalah regresi ganda dengan dua variabel bebas (p=2):
ANOVAb
Model Sum of Squares df Mean Square F Sig. 1 Regression 11101.959 2 5550.980 684.793 .000a
Residual 843.031 104 8.106 Total 11944.991 106
a. Predictors: (Constant), X2, X1 b. Dependent Variable: Y
Dengan ���. = �̂ = 0.00 mengindikasikan bahwa regresi Y pada X1 dan X2 signifikan,
karena lebih kecil dari 0.05 (=5%).
Adapun bentuk model regresi linier yang diuji berdasarkan hipotesis dengan uji
signifikansi tabel Anova diatas dapat diformulasikan berdasarkan dari informasi tabel
Coefficients pada Output SPSS seperti berikut:
Coefficientsa
Model
Unstandardized Coefficients
Standardized Coefficients
t Sig. B Std. Error Beta
Page | 9
Konstruksi model regresi bergandanya adalah dibentuk oleh nilai pada kolom Bsebagai koefisien variabel bebas X, sehingga modelnya diperoleh seperti berikut:
=
.
− .
− .
Korelasi ganda dan Koefisien determinasi:
Korelasi ganda (multiple correlation coefficient) R adalah korelasi antara nilai
pengamatan �� dengan nilai prediksi �� (�̂�) dan menunjukkan seberapa baik model
memprediksi data yang diamati. Kisaran nilai korelasi ganda R adalah 0 hingga 1. Semakin
nilai R mendekati angka 1, maka semakin kuat variabel-variabel bebas memprediksikan
variabel terikat. Dan apabila nilai R dikuadratkan maka nilai R kuadrat (R Square) ini
fungsinya untuk menjelaskan apakah sampel penelitian mampu memperoleh jawaban
yang dibutuhkan dari populasinya (atau untuk melihat apakah model regresi yang
diperoleh sudah memadai/cocok, dikenal sebagai uji Goodness of Fit), akan tetapi karena
estimasi R2 cenderung terlalu tinggi (overestimate) selanjutnya nilai ini disempurnakan
dengan Adjusted R Square sebagai koreksi atas nilai R, yang dihitung dengan cara:
�
=
−
� − −
−
dengan p adalah banyaknya variabel bebas (independent) X pada persamaan model
regresi ganda. Secara matematis R2 dan R2a dapat dirumuskan dengan
= −
� �
�
�
�
�
= −
� �
�
�
�
⁄
� −
⁄
� − −
Pedoman interpretasi atas nilai Adjusted R Square ( �) (dalam Andy Field, 2009)
adalah sebagai berikut:
< 0.10 Ketepatannya Buruk
0.11 – 0.30 Ketepatannya Rendah
0.31 – 0.50 Ketepatannya Cukup
Page | 10
Kalikan Adjusted R2 dengan 100% maka akan diperoleh berapa % varians tiapsampel pada variabel terikat bisa diprediksi oleh variabel-variabel bebas secara
bersama-sama (simultan), nilai ini disebut sebagai Koefisien determinasi.
Pada output SPSS nilainya ditampilkan pada tabel Model Summary seperti berikut:
Model Summaryb a. Predictors: (Constant), X4, X3, X2, X1
b. Dependent Variable: Y
Dengan menggunakan R2a = 0,332 maka variasi dari Y yang dapat dijelaskan oleh
model adalah sebesar 33.2 persen, sedangkan sisanya sebesar 66.8 persen dijelaskan
oleh variabel bebas lain yang tidak diikutkan pada penelitian ini, hal ini merupakan
interpretasi dari Koefisien determinasi.
(3) Analisis secara parsial:
Signifikansi koefisien variabel bebas:
Secara umum model regresi dengan Y pada X1 dan X2 dapat digunakan lebih
lanjut, namun demikian untuk mengetahui apakah X1 dan X2 secara parsial berpengaruh
terhadap Y dapat diuji dengan melihat output SPSS tabel Coefficients seperti berikut:
Coefficientsa
Dapat disimpulkan bahwa X1 dan X2 secara parsial berpengaruh signifikan terhadap
Y dengan tingkat signifikansi (p-value) masing-masing 0.013 dan 0.000, dimana kedua
nilai ini lebih kecil dari taraf signifikansi penelitian 5% (0.05).
Penentuan variabel bebas dominan dan kontribusi terhadap variabel terikat:
Walaupun model regresi linier ganda signifikan, mungkin tidak semua variabel
bebas X mempunyai pengaruh nyata pada variabel terikat Y, apalagi jika lebih banyak
Page | 11
melakukan analisis. Untuk menganalisis dan mendeteksi adanya pengaruh variabelbebas yang dominan terhadap variabel terikatnya serta kemudian besaran kontribusinya
bisa dihitung, untuk hal ini ada beberapa cara analisis yaitu diantaranya:
Metode korelasi parsial sederhana, yaitu dengan menghitung nilai korelasi masing-masing variabel bebas terhadap variabel terikatnya, lalu untuk nilai besaran
kontribusinya ditentukan dengan cara mengkuadratkan nilai korelasi parsialnya, atau Metode regresi stepwise (bertatar) yang pada dasarnya tolok ukur metodenya
adalah sama didasarkan atas nilai korelasi sederhana antara variabel bebas dengan
variabel terikatnya, namun caranya bertahap dengan cara membuat model pola
hubungan antar variabel dimana terlebih dulu dimulai dari nilai korelasi sederhana
antar variabel yang tertinggi, kemudian dengan prosedur yang sama dilanjutkan ke
level terbawahnya. Dalam output SPSS bisa diidentifikasi pada tabel Model summary
dimana sekaligus nilai besaran kontribusinya bisa dilihat dari kolom Adjusted R
Square Change.
Pada metode korelasi parsial sederhana, untuk mengetahui variabel bebas dominan
yang selanjutnya dihitung nilai besaran kontribusinya dilihat pada output SPSS tabel
Coefficient, seperti berikut:
Pada tabel Coefficients perhatikan nilai korelasi pada kolom Zero-order, kemudian hitung
nilai kuadratnya untuk setiap variabel bebas yang bersesuain, maka diperoleh sebagai
berikut:
Variabel Korelasi ( r ) r2 Kontribusi terhadap variabel terikat Y (%)
Ranking
X1 0.757 0.5731 57.31% Dominan (1)
X2 0.529 0.2798 27.98% Dominan (2)
Page | 12
II.
MATERI SIMULASI KASUS
PENGARUH INFORMASI AKUNTANSI TERHADAP RETURN SAHAM
(Studi Empirik Terhadap 32 Perusahaan Consumer Goods yang Terdaftar di Bursa Efek Indonesia Tahun 2013)SIMULASI SOFTWARE APLIKASI STATISTIK SPSS KAJIAN ANALISIS REGRESI LINIER
Oleh:
Ir. Ginanjar Syamsuar, ME.
Page | 14
Operasionalisasi VariabelNo Variabel Indikator Rumus Hitung Perubahan Skala Sumber
Data*)
Page | 15
FORMULASI DAN SOLUSI MASALAH
FORMULASI:
Pemodelan Regresi Linier
Model regresi linier estimasi yang dihipotesiskan pada kasus ini adalah:
̂ = � + �
+ �
+ �
+ �
dimana: Y Variabel terikat (dependent): Return Saham perusahaan consumer goods X1 Variabel bebas (independent): Laba Kotor
X2 Variabel bebas (independent): Arus Kas Infestasi X3 Variabel bebas (independent): Arus Kas Operasi X4 Variabel bebas (independent): Ukuran Perusahaan
�
Konstanta regresi Return Saham perusahaan consumer goods� , � , � , �
Koefisien variabel bebasHipotesis:
Hipotesis bagi model regresi linier tersebut diformulasikan sebagai berikut:
Regresi:
Ho: Diduga perubahan laba kotor, arus kas investasi, arus kas operasi, dan ukuran perusahaan tidak berpengaruh signifikan terhadap perubahan return saham perusahaan.
H1: Diduga perubahan laba kotor, arus kas investasi, arus kas operasi, dan ukuran perusahaan berpengaruh signifikan terhadap perubahan return saham perusahaan.
Korelasi:
Ho: Diduga tidak terdapat korelasi yang siginifkan diantara perubahan laba kotor, perubahan arus kas investasi, perubahan arus kas operasi, perubahan ukuran perusahaan, dengan perubahan return saham perusahaan.
H1: Diduga terdapat korelasi yang siginifkan diantara perubahan laba kotor, perubahan arus kas investasi, perubahan arus kas operasi, perubahan ukuran perusahaan, dengan perubahan return saham perusahaan.
SOLUSI
:Data prosesing dengan SPSS:
1. Install program SPSS-16 ke dalam komputer (notebook) anda. 2. Lanjutkan pengisian data variabel (entry data) diatas ke SPSS.
3. Lakukan pengujian uji asumsi klasik terhadap data penelitian (amati dan pastikan data anda bebas dari asumsi klasik!),
Page | 16
Analisis dan pembahasan:
5. Dengan menggunakan alpha 5%, lakukan analisis lalu tentukan keputusan terhadap hipótesis (H0 dan H1) mengenai hipotesis model regresi linier berganda yang telah ditetapkan diatas, (apakah Ho diterima atau ditolak.?), analisis secara simultan dan parsial, jelaskan interpretasinya. 6. Dengan menggunakan alpha 5%, lakukan analisis lalu tentukan keputusan terhadap hipótesis
Page | 17
ENTRI DATA KE SPSS
(Data terlampir pada Lampiran-1)
Entry data ke program SPSS sesuai format yang terlihat pada Lampiran-1. Data inipun boleh/bisa
dilengkapi terlebih dahulu di Excel kemudian dipanggil (Open) di program SPSS atau di-entry langsung
pada SPSS.
1. Apabila Data diambil dari file yang sudah tersimpan di Excel, maka instruksinya sebagai berikut:
Instruksi SPSS
Untuk entry data dari file excel yang sudah ada, pilih menu
File
>
Open
>
Data,
Tentukan Directory tempat file yang akan di-entry-kan, Kemudian pilih type file
Excel(*.xls, *.xlsx, *.xlsm) pada
File of Type
:, tekan
OPEN,
lalu
Continue
2. Apabila Data langsung di-entry-kan ke program SPSS, maka instruksinya sebagai berikut:
Instruksi SPSS
Page | 18
ANALISIS DAN PEMBAHASAN
I.
Pengujian Asumsi Klasik yang Melandasi Analisis Regresi Linier
a)
Uji Normalitas
Uji normalitas dimaksudkan untuk mengetahui apakah residual model regresi yang diteliti
berdistribusi normal atau tidak. Metode yang digunakan untuk menguji normalitas adalah
dengan menggunakan uji Kolmogorov-Smirnov. Jika nilai signifikansi dari hasil uji Kolmogorov-Smirnov > 0,05, maka asumsi normalitas terpenuhi.
Instruksi SPSS
Untuk menguji asumsi normalitas, pilih menu
Analyze
>
Nonparametric
Tests
>
1-sample K-S
Kemudian masukkan
Test Variable List
: Res_1, tekan
OK
1.
Output Uji Normaltas (NPar Tests):
Hasil uji Normalitas ditunjukkan pada tabel berikut:
One-Sample Kolmogorov-Smirnov Test
Unstandardized Residual
N 32
Normal Parametersa Mean .0000000 Std. Deviation .33713584 Most Extreme Differences Absolute .101 Positive .096 Negative -.101 Kolmogorov-Smirnov Z .573 Asymp. Sig. (2-tailed) .897 a. Test distribution is Normal.
2.
Pembahasan Hasil Output Uji Normalitas:
Page | 19
b)
Uji Multikolinieritas
Artinya adanya korelasi linier yang tinggi (mendekati sempurna) diantara dua atau lebih
variabel bebas. Multikolinieritas diuji dengan menghitung nilai VIF (Variance Inflating Factor).
Bila nilai VIF lebih kecil dari 5 maka tidak terjadi multikolinieritas atau non multikolinieritas.
Instruksi SPSS:
Untuk menguji asumsi multikolinieritas, pilih menu
Analyze
>
Regression
>
Linear
Kemudian masukkan Dependent Variable:
Y
, Independent Variable:
X1
sampai
X4
,
klik
Statistics
lalu pilih
Collinearity Diagnostics
, tekan
OK
1.
Output Uji Multikolinieritas:
Hasil uji Multikolinieritas ditunjukkan pada kolom akhir tabel berikut:
Coefficientsa
Model
Unstandardized Coefficients
Standardized Coefficients
t Sig.
Collinearity Statistics B Std. Error Beta Tolerance VIF 1 (Constant) .683 .097 7.006 .000
X1 1.404 .359 .703 3.917 .001 .669 1.495 X2 .025 .052 .075 .479 .636 .886 1.129 X3 -.024 .077 -.052 -.307 .761 .750 1.333 X4 -1.223 .460 -.441 -2.660 .013 .783 1.278 a. Dependent Variable: Y
2.
Pembahasan Hasil Output Uji Multikoliniertias:
Dari output SPSS tersebut diperoleh kesimpulan bahwa semua variabel bebas bersifat
non-multikolinieritas karena nilai VIF < 5.
c)
Uji Autokorelasi
Autokorelasi adalah suatu keadaan di mana terdapat suatu korelasi (hubungan) antara residual
tiap seri. Pemeriksaan autokorelasi menggunakan metode Durbin-Watson, di mana jika nilai d
(Durbin-Watson) dekat dengan 2, maka asumsi tidak terjadi autokorelasi terpenuhi.
Instruksi SPSS:
Untuk menguji asumsi autokorelasi, pilih menu
Analyze
>
Regression
>
Linear
Kemudian masukkan
Dependent Variable
:
Y
,
Independent Variable
:
X1
sampai
Page | 20
1.
Output Uji Autokorelasi:
Hasil uji Autokorelasi ditunjukkan pada kolom akhir (Durbin-Watson) tabel berikut:
Model Summaryb
Model R R Square
Adjusted R Square
Std. Error of the
Estimate Durbin-Watson 1 .646a .418 .332 .3612467 1.773 a. Predictors: (Constant), X4, X3, X2, X1
b. Dependent Variable: Y
2.
Pembahasan Hasil Output Uji Autokorelasi:
Untuk mendapatkan kesimpulan model terbebas dari Autokorelasi adalah dengan melihat
tabel statistik Durbin Watson. Dimana dicari berapa nilai du dan dl dengan melihat tabel
Durbin-Watson untuk k=4 (Jumlah variable bebas) pada n=32 (jumlah data), maka
diperoleh nilai dl=1.18 dan du= 1.73, selanjutnya petakan pada interval keputusan statistik
Durbin-Watson berikut.
Interval Keputusan Statistik Durbin-Watson (d)
Autokorelasi Negatif
Autokorelasi Tidak Ada
Autokorelasi Positif
0 dl du 4-du 4-dl 4
Interval: Keputusan:
d < dldan d > 4- dl Artinya ada autokorelasi pada model
du < d < 4- du Tidak ada autokorelasi pada model
dl≤ d ≤ dudan 4- du≤ d ≤ 4- dl
Tidak diketahui ada atau tidaknya autokorelasi pada model
Bedasarkan rumus diatas, maka hasil 4 – du = 2,27, sedangkan 4 – dl = 2.82. Sehingga
interval keputusan untuk bebas autokorelasi adalah 1.73 < d < 2.27, dengn demikian
karena dari hasil pengujian autokorelasi yaitu pada output SPSS diperoleh nilai statistic
Durbin-Watson 1.773 yang dalam hal ini dapat ditarik kesimpulan model terbebas dari
Page | 21
d)
Uji Heteroskedastisitas
Heteroskedastisitas adalah suatu keadaan dimana masing-masing kesalahan pengganggu
mempunyai varian yang berlainan. Heteroskedastisitas diuji dengan menggunakan uji koefisien
korelasi Rank Spearman yaitu mengkorelasikan antara absolut residual hasil regresi dengan
semua variabel bebas. Bila signifikansi hasil korelasi lebih kecil dari 0,05 (5%) maka
persamaan regresi tersebut mengandung heteroskedastisitas dan sebaliknya berarti non
heteroskedastisitas atau homoskedastisitas.
Instruksi SPSS-1:
Untuk menguji asumsi
Heteroskedastisitas
, pilih menu
Analyze > Regression >
Linear
Kemudian masukkan Dependent Variable:
Y
, Independent Variable:
X1
sampai
X4
,
klik
Save lalu
pilih
Unstandardized Residuals
, kemudian akhiri dengan tekan
OK
Maka pada worksheet data akan terbentuk varibel yang ditampilkan sebagai variabel res_1
Instruksi SPSS-2:
Untuk mendapatkan nilai absolut residual, klik
Transform > Compute
, Target
Variable:
Abs_Res
,
Numeric Expression:
Abs(Res_1)
Lihat pada worksheet muncul variabel Abs_Res, yaitu variabel absolut residual.
Instruksi SPSS-3:
Kemudian lakukan korelasi, pilih menu
Analyze > Correlate > Bivariate
Page | 22
1.
Output Korelasi Spearman untuk Uji Heteroskedastisitas:
Hasil uji heteroskedastisitas koefisien Rank Spearman ditunjukkan pada tabel berikut:
Correlations
X1 X2 X3 X4 ABS_RES Spearma
n's rho
X1 Correlation Coefficient 1.000 -.092 .836** .276 .105 Sig. (2-tailed) . .616 .000 .126 .567 N 32 32 32 32 32 X2 Correlation Coefficient -.092 1.000 -.241 .336 -.180 Sig. (2-tailed) .616 . .184 .060 .325 N 32 32 32 32 32 X3 Correlation Coefficient .836** -.241 1.000 .169 .034 Sig. (2-tailed) .000 .184 . .355 .855 N 32 32 32 32 32 X4 Correlation Coefficient .276 .336 .169 1.000 -.217 Sig. (2-tailed) .126 .060 .355 . .233 N 32 32 32 32 32 ABS_RES Correlation Coefficient .105 -.180 .034 -.217 1.000 Sig. (2-tailed) .567 .325 .855 .233 . N 32 32 32 32 32 **. Correlation is significant at the 0.01 level (2-tailed).
2.
Pembahasan Output Korelasi Spearman untuk Uji
Heteroskedastisitas:
Hasil Output SPPS tersebut diperoleh:
Variabel bebas
r
Sig
Kesimpulan
Laba kotor (X1) 0.105 0.567 Homoskedastisitas
Arus kas infestasi (X2) -0.180 0.325 Homoskedastisitas Arus kas operasi (X3) 0.034 0.855 Homoskedastisitas Ukuran perusahaan (X4) -0.217 0.233 Homoskedastisitas
Dari tabel di atas ditunjukkan bahwa nilai signifikansi korelasi spearman semuanya lebih
besar dari taraf signifikan pengujian yaitu 0.05 (5%), sehingga keputusannya adalah
bahwa keempat variabel tersebut bebas dari pengaruh asumsi heteroskedastisitas atau
dengan kata lain bersifat homoskedastisitas. Artinya tidak ada korelasi antara besarnya
data dengan residual sehingga bila data diperbesar tidak menyebabkan residual
Page | 23
II.
Analisis Regresi Linier dan Korelasi
A.
Analisis Regresi Linier
Instruksi SPSS:
Untuk menguji regresi, pilih menu
Analyze
>
Regression
>
Linear
Kemudian masukkan
Dependent Variable:
Y
,
Independent Variable:
X1
sampai
X4
,
klik
Statistics
lalu pilih
Descriptive
dan
Part and Partial Correlation
, tekan
Continue
lalu
OK
1.
Output Analisis Regresi Linier:
Descriptive Statistics
Mean Std. Deviation N Y .447755 .4418817 32 X1 -.056805 .2212217 32 X2 .507055 1.3330549 32 X3 .091799 .9750549 32 X4 .135524 .1595617 32
Correlations
Y X1 X2 X3 X4 Pearson Correlation Y 1.000 .514 -.051 .236 -.164
Page | 24
a. All requested variables entered.b. Dependent Variable: Y a. Predictors: (Constant), X4, X3, X2, X1
ANOVAb
Model Sum of Squares df Mean Square F Sig. 1 Regression 2.530 4 .632 4.846 .004a
Residual 3.523 27 .130 Total 6.053 31
Page | 25
2.
Pembahasan Hasil Output SPSS Regresi Linier:
a)
Uji Simultan:
Hipotesis Regresi
Ho: Diduga perubahan laba kotor (gross profit), arus kas investasi, arus kas operasi, dan ukuran perusahaan tidak berpengaruh signifikan terhadap perubahan return saham perusahaan.
H1: Diduga perubahan laba kotor (gross profit), arus kas investasi, arus kas operasi, dan ukuran perusahaan berpengaruh signifikan terhadap perubahan return saham perusahaan.
Atau secara statistik ditulis sebagai:
Ho: 1=2=3=4=0 koefisien regresi
H1: paling sedikit ada satu buah nilai 1 atau 2 atau 3 atau 4 0
Dari hasil output SPSS yang ditunjukan oleh tabel ANOVA yaitu:
ANOVAb
Model Sum of Squares df Mean Square F Sig. 1 Regression 2.530 4 .632 4.846 .004a
Residual 3.523 27 .130 Total 6.053 31
a. Predictors: (Constant), X4, X3, X2, X1 b. Dependent Variable: Y
Diperoleh bahwa nilai signifikansi F= 0,004. Jadi Sig F < 5% (0,000<0,05). Yang memberikan informasi bahwa secara bersama-sama variabel bebas yang terdiri dari variabel Laba kotor (X1), Arus kas infestasi (X2), Arus kas operasi (X3), dan Ukuran perusahaan (X4) berpengaruh signifikan terhadap variabel Return saham perusahaan (Y), dalam hal ini hipotesis Ho ditolak pada taraf signifikan 5%.
Dengan besaran pengaruh secara simultannya ditunjukan pada tabel Model Summary hasil output SPSS yaitu ditunjukan pada nilai Adjusted R Square sebesar 0,332 atau 33,20%, sebgai berikut:
Model Summary
Model R R Square
Adjusted R Square
Page | 26
Yang memberikan informasi bahwa variabel Y (Return Saham) dipengaruhi sebesar 33,2% secara simultan oleh Laba kotor (X1), Arus kas infestasi (X2), Arus kas operasi (X3), dan Ukuran perusahaan (X4) sedangkan sisanya 66,8% dipengaruhi oleh variabel lain yang tidak diikutkan dalam analisis penelitian ini. Atau variasi variabel independen yang digunakan dalam model (X1, X2, X3 dan X4) secra simultan mampu menjelaskan sebesar 33.2% variasi variabel dependen Y (Return Saham). Sedangkan sisanya sebesar 22,8% dijelaskan oleh variabel lain yang tidak dimasukkan dalam model penelitian ini.Sedangkan Model persamaan regresi linier berganda Return saham-nya dapat disusun sesuai hasil output SPSS tabel Coefficient sebagai berikut:
Coefficientsa
Sehingga Model Regresi Return Saham pengaruh informasi akuntasi yang dianalisis adalah:
= .
+ .
+ .
− .
− .
Intepretasi koefisien model regresi:
1. Return saham akan bertambah sebesar 1.404 satuan jika Laba kotor (X1) berubah satu satuan
2. Return saham akan bertambah sebesar 0.025 satuan jika Arus kas infestasi (X2) berubah satu satuan
3. Return saham akan berkurang sebesar 0.025 satuan jika Arus kas operasi (X3) berubah satu satuan, dan
4. Return saham akan berkurang sebesar 1.223 satuan jika Ukuran perusahaan (X4) dalam hal ini asset total perusahaan berubah satu satuan.
b)
Uji Parsial:
Hipotesis
H
o:
i
= 0
i
adalah koefisien regresi variable bebas ke-
i
dimana
i
= 1,2,3,4
Page | 27
Untuk menguji hipotesis secara parsial analisisnya bisa dilihat dari output SPSS tabel Coefficients, dimana pengujiannya dilihat dari nilai uji t atau nilai Significant pada table tersebut yang dibandingkan dengan nilai t-tabel atau taraf significansi 5%.Hasil analisis output uji parsial dijelaskan sebagai berikut:
a. Uji t terhadap variabel Laba kotor (X1) didapatkan signifikansi t sebesar 0,001. Karena signifikansi t lebih kecil dari 5% (0,001<0,05), maka secara parsial variabel Laba kotor (X1) berpengaruh signifikan terhadap variable Return saham (Y)
b. Uji t terhadap variabel Arus kas infestasi (X2) didapatkan signifikansi t sebesar 0,636. signifikansi t lebih besar dari 5% (0,0.636>0,05), maka secara parsial variabel Arus kas infestasi (X2) tidak berpengaruh signifikan terhadap variabel Return saham (Y)
c. Uji t terhadap variabel Arus kas operasi (X3) didapatkan signifikansi t sebesar 0,761. Karena signifikansi t lebih besar dari 5% (0,761>0,05), maka secara parsial variabel Arus kas operasi (X3) tidak berpengaruh signifikan terhadap variabel Return saham (Y)
d. Uji t terhadap variabel Ukuran perusahaan (X4) didapatkan signifikansi t sebesar 0,013. Karena signifikansi t lebih kecil dari 5% (0,013<0,05), maka secara parsial variabel Ukuran perusahaan (X4) berpengaruh signifikan terhadap variabel Return saham (Y).
B.
Analisis Korelasi
a)
Korelasi Ganda (Simultan)
Hipotesis Korelasi
Ho: Diduga tidak terdapat korelasi yang siginifkan diantara perubahan laba kotor, perubahan arus kas investasi, perubahan arus kas operasi, perubahan ukuran perusahaan, dengan perubahan return saham perusahaan.
H1: Diduga terdapat korelasi yang siginifkan diantara perubahan laba kotor, perubahan arus kas investasi, perubahan arus kas operasi, perubahan ukuran perusahaan, dengan perubahan return saham perusahaan.
Untuk menentukan keputusan apakah Ho ditolak atau diterima maka dianalisis melalui output SPSS tabel Model summary sebagai berikut:
Instruksi SPSS:
Untuk menguji korelasi ganda (simultan), pilih menu
Analyze
>
Regression
>
Linear
Kemudian masukkan Dependent Variable:
Y
,
Independent Variable:
X1
sampai
X4
, klik
Statistics
lalu pilih (centang)
Estimate
,
Page | 28
a. Predictors: (Constant), X4, X3, X2, X1b. Dependent Variable: Y
2.
Pembahasan Hasil Output SPSS Korelasi ganda:
Dari tabel tersebut pada kolom R dengan nilai 0.646 adalah merupakan koefisien
korelasi ganda (multiple correlation coefficient) dimana menjelaskan seberapa baik
variabel-variabel bebas memprediksikan hasil, adapun kisaran nilai R ini adalah mulai 0
hingga 1, semakin nilai R mendekati angka 1 maka semakin kuat variable-variabel
bebas memprediksikan variable terikat (Return saham). Apabila dengan hanya
membandingkan dan mempetakan nilai R=0.646 terhadap kisaran nilai R maka hal ini
dapat diindikasikan bahwa korelasi ganda signifikan dengan kata lain berpotensi
hipotesis Ho ditolak.
Akan tetapi secara teori bahwa untuk mengambil keputusan uji hipotesis adalah diuji
dengan statistik uji-F atau nilai significant yang dibandingkan dengan taraf-signifikan
5% yang digunakan dalam penelitian ini. Dari tabel diatas diperoleh bahwa nilai Sig.F
lebih kecil dari 0.05 (0.004 < 0.05) dimana hal ini memberikan informasi bahwa benar
hipotesis Ho ditolak, dengan kata lain dapat disimpulkan bahwa terdapat korelasi
secara simultan yang signifikan diantara perubahan Laba kotor, perubahan Arus kas
infestasi, perubahan Arus kas operasi, perubahan Ukuran perusahaan dengan Return
Saham (Model regresi yang diperoleh memadai).
b)
Korelasi Parsial:
Untuk menentukan atau menghitung korelasi parsial atau korelasi antara variabel-variabel bebas dengan variabel terikatnya, maka dianalisis melalui output SPSS tabel Coefficients.
Instruksi SPSS:
Untuk menghitung korelasi parsial, pilih menu
Analyze
>
Regression
>
Linear
Page | 29
1.
Output SPSS untuk Analisis Korelasi parsial:
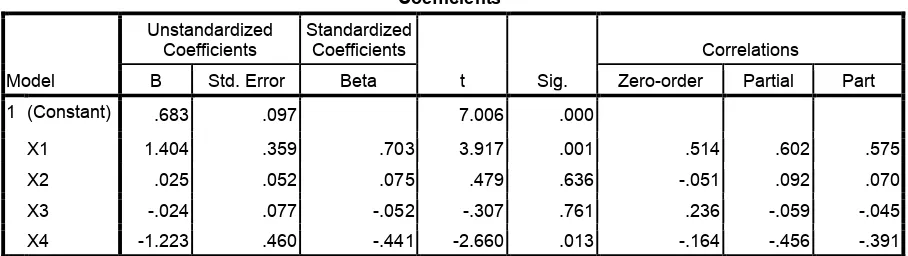
Coefficientsa
Model
Unstandardized Coefficients
Standardized Coefficients
t Sig.
Correlations
B Std. Error Beta Zero-order Partial Part 1 (Constant) .683 .097 7.006 .000
X1 1.404 .359 .703 3.917 .001 .514 .602 .575 X2 .025 .052 .075 .479 .636 -.051 .092 .070 X3 -.024 .077 -.052 -.307 .761 .236 -.059 -.045 X4 -1.223 .460 -.441 -2.660 .013 -.164 -.456 -.391 a. Dependent Variable: Y
2.
Pembahasan Hasil Output SPSS Korelasi parsial:
Untuk mengetahui nilai korelasi yang digunakan adalah dilihat dari besaran nilai
korelasi zero-order pada tabel coefficient output SPSS.
Dari tabel hasil diatas pada kolom zero-order, dapat kita ketahui bahwa korelasi parsial
diantara masing-masing variabel bebasnya dengan variabel terikat adalah:
Return saham (Y) dengan Perubahan Laba kotor (X1), memiliki korelasi sebesar 0.514 dimana ukuran keeratan antar variabelnya digolongkan sedang.
Return saham (Y) dengan Perubahan Arus kas infestasi (X2), memiliki korelasi negatif sebesar 0.051 dimana ukuran keeratan antar variabelnya tergolong lemah. Return saham (Y) dengan Perubahan Arus kas operasi (X3), memiliki korelasi
sebesar 0.236 dimana ukuran keeratan antar variabelnya tergolong lemah.
Return saham (Y) dengan Perubahan Ukuran perusahaan (X4), memiliki korelasi negatif sebesar 0.164 dimana ukuran keeratan antar variabelnya tergolong lemah.
Menentukan Variabel Dominan:
Untuk menguji variabel dominan, terlebih dahulu diketahui kontribusi masing-masing
variabel bebas yang diuji terhadap variabel terikat. Kontribusi masing-masing variabel
diketahui dari koefisien determinasi regresi sederhana terhadap variabel terikat atau
diketahui dari kuadrat korelasi sederhana (Zero-Order) variabel bebas dan terikat. Dari
tabel di bawah diketahui bahwa variabel yang paling dominan pengaruhnya adalah
Page | 30
Variabel
r
r
2Kontribusi (%)
Laba kotor (X1) .514 0.2642 26.42%
Arus kas infestasi (X2) -.051 0.0026 0.26%
Arus kas operasi (X3) .236 0.0557 5.57%
Ukuran perusahaan (X4) -.164 0.0269 2.69%
Ranking Dominansi pengaruh:
Sehingga urutan rangking dominansi pengaruh variabel bebas terhadap variabel
terikatnya adalah:
Page | 31
Pustaka:
1. Institute for Economic and Financial Research. (2013). Indonesian Capital Markets Directory (ICMD) 2013:Consumer Goods Industry.
2. Andy Field. (2009). Discovering Statistics Using SPSS (Introducing Statistical Method), 3nd ed. SAGE Publications Ltd. London.
3. Robert Ho, 2006, Handbook of Univariate and Multivariate Data Analysis and Interpretation with SPSS, Chapman & Hall/CRC; 1 edition. ISBN: 1584886021.
4. Cohen, J., Cohen, P., West, S. G., & Aiken, L. S. (2003). Applied multiple regression/correlation analysis for the behavioral sciences, 3rd Ed. Mahwah, NJ: Lawrence Erlbaum Associates.
5. Kathleen Martin, D.P.E., Carmen Acuna, Ph.D., 2002, SPSS for Institutional Researchers, Bucknell University.