OPTIMASI TEKNIK KOMPRESI MENGGUNAKAN ALGORITMA KOMBINATORIAL PADA
DOKUMEN BERBAHASA INDONESIA
Elfitrin Syahrul Angkatan tahun 2012
(tahun ke-1)
Ringkasan
Kompresi data bukanlah suatu hal yang baru. Metode ini telah digunakan sejak
satu abad sebelum masehi yaitu stenography atau pemendekan penulisan. Dan sampai saat ini teknik atau metoda kompresi terus dikembangkan karena teknik kompresi yang
paling optimal tersebut tidak ada. Beberapa penelitian menambahkan beberapa proses
dan mengoptimalkan setiap tahapan untuk meningkatkan performansi atau memperkecil
ukuran data/filesekecil mungkin.
Salah satu metoda kompresi yang kompetitif dengan menambahkan proses
pemodelan menggunakan algoritma kombinatorial adalah Algoritma Kompresi
Burrows-Wheeler (Burrows-Burrows-Wheeler Compression Algorithm-BWCA). BWCA menggunakan
transformasi Burrows-Wheeler (Burrows-Wheeler Transformastion – BWT) yang
merupakan transformasi kombinatorial. Teknik ini mentransformasikan input data
menggunakan teknik pernyortiran karakter, sehingga karakter yang sama saling
berdekatan, sehingga tahapan pengkodean dapat memanpatkan data lebih efektif.
Transformasi ini bersifat reversibel sehingga data original dapat dihasilkan kembali pada
proses dekoding.
Beberapa metoda kompresi yang telah dikembangkan khususnya teknik kompresi
teks, pada umumnya peningkatan performansi kompresi ditekankan hanya pada teknik
kompresi. Beberapa penelitian telah menunjukkan pengaruh morfologi/struktur data
memperngahruhi performansi kompresi. Beberapa penelitian kompresi teks yang telah
dilakukan menggunakan objek bahasa seperti Inggris, Ibrani, Arab, Turki, Jerman, dan
Turki. Pada saat ini penelitian kompresi terhadap Bahasa Indonesia yang melihat secara
mendalam morfologi/struktur bahasa Indonesia masih sangat jarang, terutama untuk
metode kompresi yang kompetitif seperti BWCA.
STUDI PUSTAKA Kompresi Data
Kompresi berarti membuat sesuatu yang lebih kecil. Kompresi data berarti mengurangi jumlah bit yang diperlukan untuk mewakili bagian tertentu dari data. Kompresi teks berarti mengurangi jumlah bit atau byte yang diperlukan untuk menyimpan informasi tekstual. Hal ini sangat diperlukan karena bentuk teks terkompresi dapat didekompresi untuk menyusun kembali menjadi teks awal. Inilah yang membedakan kompresi teks dari banyak jenis reduksi data, meliputi pengkodean suara atau gambar, di mana beberapa degradasi sinyal dapat ditoleransi jika kompresi dicapai bernilai penurunan kualitas. [Bell, Cleary & Witten, 1990].
Tolok ukur berubah terhadap pengukuran data kompresi adalah "rasio kompresi", atau rasio ukuran file dikompresi ke file terkompresi asli. Misalnya, file data memakan 100 kilobyte (KB) dengan menggunakan perangkat lunak kompresi data ukuran file dapat dikurangi ukurannya dengan, katakanlah, 50 KB, sehingga lebih mudah untuk menyimpan pada disk dan lebih cepat untuk mengirimkan melalui koneksi jaringan. Dalam kasus tertentu, perangkat lunak kompresi data mengurangi ukuran data file dengan faktor dua, atau hasil dalam "rasio kompresi" 2:1.
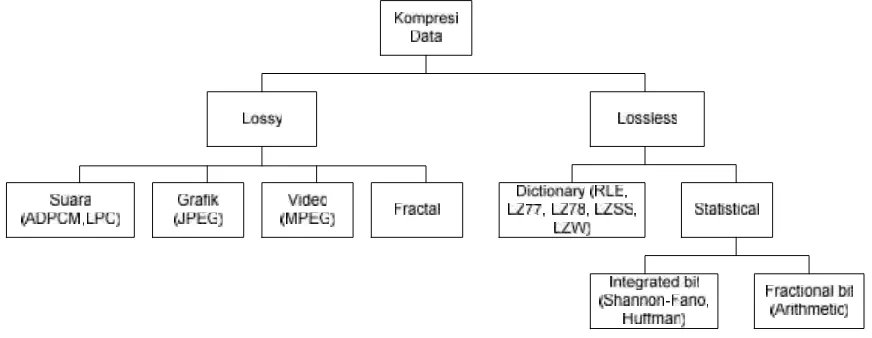
Gambar 1. Teknik Kompresi Data
Pada umumnya bentuk kompresi dapat di bagi menjadi dua seperti yang terlihat pada Gambar 1 yaitu "lossless" dan "lossy". Kompresi Lossless digunakan saat data harus terkompresi persis seperti sebelum kompresi. Kompresi data lossless biasanya diterapkan untuk file teks, karena kehilangan satu karakter dalam kasus terburuk dapat membuat teks menjadi tidak berarti. Rasio kompresi lossless umumnya dalam kisaran 2:01-8:01
Algoritma Kompresi Lossless Teks
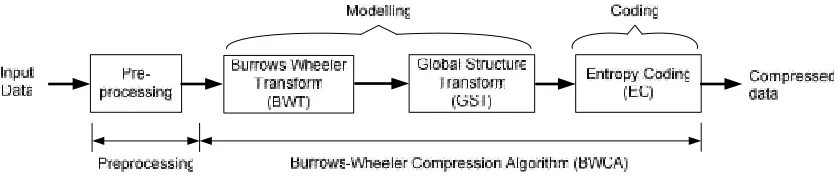
Gambar 2. Model Dasar Kompresi Lossless.
Coding atau pengkodean merupakan tahapan mengkompresi data dengan memanfaatkan frekuensi data input atau lebih dikenal dengan pengkodean statistik (Statistical Coding). Data input yang sering muncul akan di representasikan dengan bit yang paling sedikit. Beberapa contoh teknik pengkodean adalah pengkodean Huffman,
Arithmetic, Shannon-Fano, dan Run Length Encoding (RLE). Shannon merilis teknik pengkodean yang pertama sekali pada tahun 1948. Pada penelitiannya yang berjudul
Information Theorydibuktikan bahwa performansi kompresi menggunakan pengkodean statistic tidak akan dapat melebihi nilai entropinya [Shannon, 1949; Cover 1991]. Oleh karena itu beberapa penelitian menambahkan tahapan pre-processing yang disebut denganmodelingatau pemodelan.
Pemodelan tidak mengkompresi data. Tahap ini mentransformasi data sedemikian rupa sehingga data semakin homogen. Algoritma pemodelan di sesuaikan dengan aplikasi data yang akan di kompresi.
Beberapa proses pemodelan menggunakan algoritma kombinatorial seperti Transformasi Burrows-Wheeler atau Burrows-Wheeler Transformation (BWT) dan Move-To-Front (MTF). Algoritma kompresi Burrows-Wheeler atau Burrows-Wheeler Compression Algorithm (BWCA) merupakan metoda kompresi yang menggunakan BWT sebagai salah satu algoritmanya.
Wirth dan Moffat [Wirth dan Moffat, 2001] menyatakan bahwa BWCA merupakan teknik kompresi yang sangat kompetitif. Peneliti juga telah membuktikan efektifitas metoda ini menggunakan aplikasi yang berbeda yaitu kompresi citra medik [Sitis, Taru, thèse].
Algoritma Kompresi Burrows-Wheeler (BWCA)
Burrows dan Wheeler merilis sebuah laporan penelitian pada tahun 1994 berjudul "A Block Sorting Lossless Data Compression Algorithm" menyajikan algoritma kompresi data berdasarkan algoritma penyortiran. Algoritma ini menggunakan blok data dan memprosesnya menggunakan skema penyortiran. BWCA merupakan teknik kompresi reversible atau lossless, sehingga proses dekoding akan dapat mengembalikan data aslinya.
Gambar 3. Algoritma kompresi Burrows-Wheeler (BWCA)
Pada dasarnya BWCA dapat di bagi menjadi 3 (tiga) tahapan yaitu:
1. Transformasi Burrows-Wheeler (Burrows-Wheeler Transformation-BWT), transformasi ini merubah sedemikian rupa letak simbol input data sehingga simbol yang sama saling berdekatan,
2. Global Structure Transform(GST) yang mentransformasi redundansi lokal menjadi global menggunakan List of Updated Table (LUT), sehingga menghasilkan sederatan simbol nol,
3. Pengkodean (Entropy Coding– EC) merupakan tahap terakhir dari teknik kompresi untuk memampatkan data.
Gambar 4. Memperlihatkan contoh BWCA untuk input data
“abracadabraabracadabra”.
Gambar 4. TransformasiData Untuk Input “Abracadabra Abracadabra” Untuk Setiap Tahapan Dari BWCA.
BWT adalah salah satu transformasi data kompresi. Transformasi ini tidak mengkompresi data, akan tetapi mentransformasikan input data sehingga keluaran BWT cenderung mengelompokkan simbol-simbol yang sama. Seperti yang terlihat pada Gambar 3 (c), input BWT hanya ada dua simbol sama bersebelahan yaitu "a" atau dalam heksadesimal "61". Keluaran BWT cenderung mengelompokkan simbol yang sama bersebelahan seperti yang terlihat pada Gambar 4 (c).
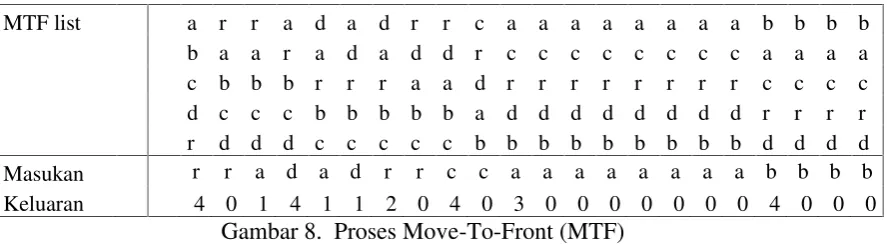
Tahapan kedua dari BWCA adalah GST. Transformasi ini merubah simbol kedua yang sama menjadi sederatan simbol yang sama. Gambar 4(d) mengilustrasikan proses GST. Salah satu algoritma kombinatorial dari GST adalah Move-To-Front (MTF). Tahapan ini menghasilkan simbol “0”.
pengkodean yaituRun length coding (RLC) dan pengkodean Huffman atau pengkodean
Arithmeticyang lebih kompleks akan tetapi performansi lebih tinggi.
Transformasi Burrows-Wheeler (BWT)
BWT yang merupakan transformasi utama dari teknik kompresi BWCA yang tidak mengurangi ukuran data atau mengkompresi data. BWT adalah algoritma kombinatorial yang merubah urutan input simbol data sehingga simbol yang sama cenderung terkumpul seperti yang terlihat pada Gambar 4 (c). Sub bab ini akan membahas rekonstruksi proses BWT dan pembalikannya untuk input data yang sama dengan Gambar4 yaitu “abracadabraabracadabra”.
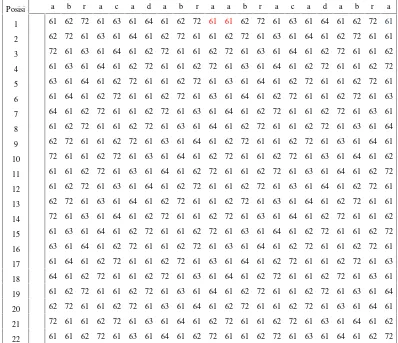
Proses BWT di ilustrasikan oleh Gambar 5 dan 6. Input data BWT yang terletak di baris pertama Gambar 5 (posisi) dan baris kedua dari matriks tersebut yang merepresentasi input “abracadabraabracadabra” dalam heksadesimal.
Posisi a b r a c a d a b r a a b r a c a d a b r a
Gambar 6 Rotasi matrik Gambar 5 yang telah di sortir.
Proses selanjutnya dari BWT adalah sorting matrik secara alfabetik seperti yang di ilustrasikan oleh Gambar 6. Keluaran dari BWT terletak di kolom terakhir (L atau
Last) dari dan indeks untuk pengembalikan BWT. Indeks BWT pada input data ini adalah 4 karena data asli terletak pada baris ke-4 (lihat Gambar 6). Keluaran BWT yang terletak di kolom terakhir dari matrik diatas adalah 72 72 64 61 61 64 72 72 63 63 61 61 61 61 61 61 61 61 62 62 62 62, dimana terlihat konsekutif data yang sama sehingga data ini lebih efektif sebagai masukan proses pengkodean yang akan mengkompresi data.
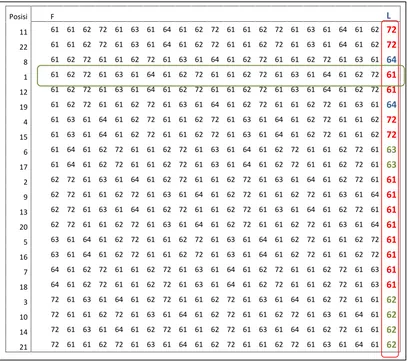
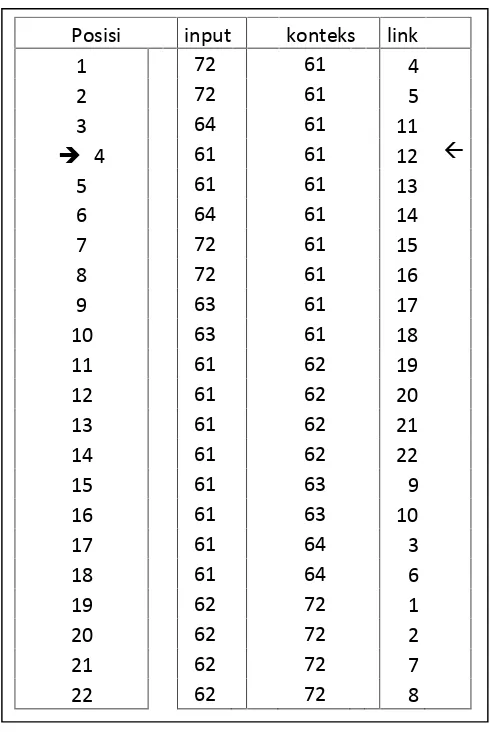
Proses pembalikan dari BWT di ilustrasikan oleh Gambar 7. Prinsip dasar kerja pembalikan BWT adalah permutasi. Keluaran BWT merupakan masukan dari pembalikan BWT yang terlihat di kolom 2 dari Gambar 7 dan kolom pertama merupakan posisi dari input pembalik BWT, kemudian di tentukan konteks yang merupakan sorting dari masukan pembalik BWT (input) dan link merupakan posisi simbol konteks di input. Proses pembalikan BWT memerlukan informasi indeks keluaran BWT, dimana pada contoh diatas indeks BWT adalah 4.
Gambar 2.7
Gambar 7 Transformasi Balik BWT
Proses diawali dari informasi indeks, dimana pada contoh diatas adalah 4. Informasi original pertama adalah kontek yang terletak di posisi ke-4, yaitu simbol “61”, dan pada baris ini mengacu ke link 12. Informasi link 12 merupakan acuan ke data kedua di kolom kontek yang terletak di posisi ke-12 yaitu simbol “62”. Pada posisi 12 mengacu ke link 20 yang mengacu ke posisi 20 untuk mendapatkan data ketiga yaitu “72”. Tahapan permutasi ini di lakukan sampai data/simbol original terakhir di peroleh.
Global Structure Transform(GST)
GST merupakan algoritma kombinatorial yang di implementasi pada beberapa teknik kompresi. Burrows dan Wheeler menyarankan menggunakan GST setelah transformasi BWT. Burrows dan Wheeler menggunakan Move-To-Front (MTF) pada tahapan GST. Transformasi ini merubah simbol kedua yang sama menjadi nol seperti yang terlihat pada gambar 8, sehingga keluaran GST menjadi lebih homogen.
MTF list a r r a d a d r r c a a a a a a a a b b b b
Sejak di rilis pada tahun 1994, BWCA mengalami peninngkatan, termasuk tahap GST. Beberapa algoritma di rilis untuk meningkatkan kinerja BWCA. Peneliti mengklasifikasikan 2 metoda GST; MTF dan variannya serta Frequency Counting Methods. Pada penelitian seblumnya peneliti telah menguji coba kinerja BWCA untuk beberapa varian GST untuk aplikasi citra medik [Syahrul, 2011]. Pada penelitian ini peneliti akan menggunakan metode yang sama untuk aplikasi yang berbeda yaitu dokumen teks berbahasa Indonesia. Beberapa GST yang digunakan berdasarkan dua kategori diatas:
1. Move-To-Front(MTF) dan varian nya yang terdiri dari: a. Move-To-Front(MTF)
b. Move One From Front(M1FF) c. Move One From FrontTwo (M1FF2) d. Time Stamp(TS)
EC merupakan tahapan terakhir dari proses kompresi. Burrows dan Wheeler menggunakan Run Length Encoding (RLE) dan Huffman. Mereka menyarankan menggantikan pengkodean Huffman dengan pengkodean Arithmetic yang mempunyai rasio kompresi lebih baik akan tetapi prosesnya lebih kompleks. Penelitian ini akan menganalisa dampak RLE dan pengkodean Arithmetic untuk meningkatkan rasio kompresi.
Aplikasi Algoritma Kompresi Burrows-Wheeler
BZIP2
BZIP2 adalah perangkat lunak kompresi yang tidak di pantenkan. kompresor data ini berkualitas tinggi dan proses kompresi yang dua kali lebih cepat dari kompresi data pada umumnya, serta enam kali lebih cepat pada tahapan dekompresi.
Metoda Wiseman
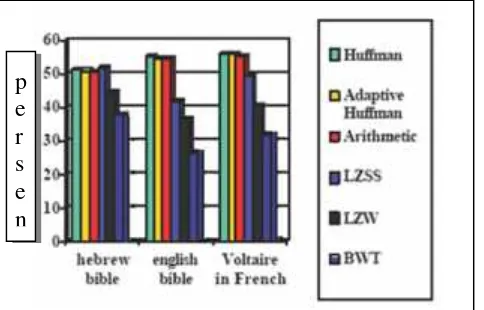
Wiseman melakukan beberapa penelitian menggunakan BWCA baik untuk aplikasi citra dan dokumen teks, khususnya untuk bahasa Ibrani. Gambar 9 menunjukkan perbandingan hasil kompresi dari pengkodean Huffman, adaptif Hufffman, Arithmetic, LZSS, LZW dan BWT terhadap tiga dokumen berbahasa Ibrani, Inggris dan Perancis.
Perbandingan presentasi untuk beberapa teknik kompresi terhadap bahasa Inggris, Hebrew dan Perancis menggunakan teknik kompresi yang berbeda, yaitu Huffman, Adaptive Huffman, Arithmetic, LZSS, LZW dan BWT.
Gambar 9. Perbandingan Persentasi Ukuran File Terkompresi.
Morfologi Kelas Kata Dalam Bahasa Indonesia
Bahasa Indonesia mengenal pengelompokan kosa dalam bentuk kelas kata. Tata bahasa Indonesia banyak pendapat para mengenai jumlah dan jenis kelas kata. Kelas kata terdiri dari seperangkat kategori morfologis yang tersusun dalam kerangka sistem tertentu yang berbeda dan sistem kategori morfologis kelas kata lain. Kategori morfologis adalah sederetan kata yang memiliki bentuk gramatikal dan makna gramatikal yang sama. Setiap kategori morfologis itu terbentuk oleh prosede morfologis tertentu. Prosede morfologis adalah pembentukan kata secara sinkronis. Prosede morfologis itu ada dua macam yaitu derivasi dan intleksi. Derivasi adalah prosede morfologis yang menghasilkan kata-kata yang makna leksikalnya berbeda dari kata pangkal pembentuknya. Sebaliknya, infleksi menghasilkan kata-kata yang bentuk gramatikalnya berbeda-beda, tetapi leksemnya tetap seperti pada kata pangkalnya.
Produktivitas Proses Morfemis
Dalam proses morfemis ini adalah dapat tidaknya proses pembentukan kata itu, terutama afiksasi, reduplikasi, dan komposisi, digunakan berulang-ulang yang secara relatif tak terbatas; artinya, adanya kemungkinan menambah bentuk kata dengan proses
yang identitas leksikalnya tidak sama dengan bentuk dasarnya, tidak dapat dikatakan dengan proses yang produktif. Proses inflektif bersifat tertutup. Misalnya, kata Inggris
street hanya mempunyai dua alteman, yaitu street dan jamaknya yaitu streets. Bentuk lain tidak ada, dan tidak bisa diada-adakan. Begitu juga kata bahasa Latin amare
’mencintai’ mempunyai paradigmayang panjang sekali, dengan semua kala (tense), modus, diatesis, persona, jumlah, jenis, dan sebagainya; semuanya sampai seratus lebih. Namun, bentuk baru tidak dapat ditambahkan. Jadi, daftarnya adalah daftar tertutup.
Proses derivasi bersifat terbuka. Artinya, penutur suatu bahasa dapat membuat kata-kata baru dengan proses tersebut. Umpamanya, bagi mereka yang belum pernah mendengar atau membaca katakegramatikalan ataukemenarikan akan segera mengerti kedua kata baru itu karena mereka sudah tahu akan katagramatikal atau menarikserta tahu juga fungsi penominalan konfiks ke-l-an dalam bahasa Indonesia. Begitu juga mereka akan segera mengerti kata-kata lain sebagai hasil proses konfiksasi dengan ke-l-anini. Seperti dalamketidakikutsertaandankekeraskepalaan. Proses derivasi produktif; sedangkan proses infleksi tidak produktif. Keproduktifan proses derivasi ini, dan penambahan alteman-alteman baru pada daftar derivasional, dibatasi oleh kaidah-kaidah yang sudah ada. Misalnya, pembentukan kata baru dengan prefiks memper -terbatas pada dasar numeral; dan tidak dapat pada dasar verbal. Kita bisa membuat
memperbanyak, memperburuk, memperketat, memperdua,danmemperlima;tetapi tidak dapat *memperbaca, *memperlihat, *mempertulis, dan *mempertunjuk, sebab dasar
baca, lihat, tulis,dantunjukbukan ajektif, melainkan verba.
Selain itu perlu juga diperhatikan, meskipun kaidah mengizinkan untuk terbentuknya suatu kata, namun kenyataan dalam berbahasa bentuk-bentuk tersebut tidak terdapat. Umpamanya, dalam bahasa Indonesia ada bentuk memperbaiki, tetapi tidak ada *memperbetuli; ada bentuk kekasih, tetapi tidak ada *kesayang; ada bentuk
kedatangan, tetapi tidak ada bentuk*ketibaan. Dalam bahasa Inggris ada bentuk recital
danrecitation; namun meskipun adaarrivaltetapi tidak ada*arrivation; juga meskipun adaderivation tetapi*derivaltidak ada.
Tidak adanya sebuah bentuk yang seharusnya ada (karena menurut kaidah dibenarkan) disebut bloking (Aronoff 1976;43. Bauer 1983:87). Fenomena ini terjadi karena adanya bentuk lain yang menyebabkan tidak adanya bentuk yang dianggap seharusnya ada. Dalam bahasa Inggris, misalnya, ada kata bad dan small, yang menyebabkan tidak adanya kata*ungooddan *unbig. Dalam bahasa Inggris juga tidak ada kata *stealer karena adanya kata thief. Padahal kata *stealer itu seharusnya ada, sejajar dengan katawriter, reader, dan painter.
Kita lihat kata memisau dan mengobeng tidak ada karena ada kata kerja
memotong atau mengiris yang membloking kehadiran kata memisau itu; dan ada kata
memutarataumembukayang membloking kehadiran katamengobengitu.
Dalam bahasa Indonesia kasus bloking tampaknya tidak sejalan dengan dalam bahasa Inggris. Maka, meskipun bahasa Indonesia punya kata buruk dan kecil, tetapi bentuk tidak bagus dan tidak besar juga ada. Begitu juga, meskipun ada kata maling
sekategori ada) tidak pernah muncul, karena kalah bersaing dengan konstruksi
membuat jadi cantikataubikin cantik.
Bentuk-bentuk yang menurut kaidah gramatikal dimungkinkan keberadaannya, tetapi ternyata tidak pernah ada, seperti*mencantikkan dan *memisau di atas, disebut bentuk yang potensial, yang pada suatu saat kelak mungkin dapat muncul. Sedangkan pada bentuk-bentuk yang nyata ada, seperti pada bentuk menjelekkan dan bersepeda
disebut bentuk-bentukaktual.
MORFOFONEMIK
Morfofonemik, disebut juga morfonemik, morfofonologi, atau morfonologi, atau peristiwa berubahnya wujud morfemis dalam suatu proses morfologis, baik afiksasi, reduplikasi, maupun komposisi. Umpamanya dalam proses afiksasi bahasa Indonesia dalam prefiksme-akan terlihat bahwa prefiksme-itu akan berubah menjadimem-, men-, meny-men-, meng-men-,atau tetap me-, menurut aturan-aturan fonologis tertentu. Kalau bentuk dasarnya mulai dengan konsonan /b/ dan /p/ maka prefiks me- itu akan menjadi mem-, seperti pada kata membeli dan memotong (bentuk dasarnya beli dan potong); kalau bentuk dasarnya mulai dengan konsonan /d/ dan /t/, maka prefikme- itu akan menjadi
men-,seperti pada katamendengardanmenolong(bentuk dasarnyadengardantolong); kalau bentuk dasarnya mulai dengan konsonan /s/, maka prefiks me- itu akan menjadi
meny-, seperti pada kata menyikat dan menyusul (bentuk dasarnya sikat dan susul); kalau bentuk dasarnya mulai dengan konsonan/g/dan/k/, atau juga fonem vokal, maka prefiks me- itu akan menjadi meng-, seperti pada kata menghitung, mengirim dan
mengobral (bentuk dasarnya adalah hitung, kirim, dan obral); kalau bentuk dasarnya hanya terdiri dari satu suku, maka prefiksme-itu akan berubah menjadimenge-,seperti tampak pada katamengetik, mengelas,danmengecat(bentuk dasarnya tik, las,dancat); dan kalau bentuk dasarnya mulai dengan konsonan/l/dan/r/,maka prefiksme-itu tidak mengalami perubahan, seperti pada kata melatih dan merawat (bentuk dasarnya latih
danrawat).
Perubahan fonem dalam proses morfofonemik ini dapat berwujud: (1) pemunculan fonem, (2) pelepasan fonem, (3) peluluhan fonem, (4) perubahan fonem, dan (5) pergeseran fonem. Pemunculan fonem dapat kita lihat dalam proses pengimbuhan prefiks me- dengan bentuk dasar baca yang menjadi membaca; dimana terlihat muncul konsonan sengau /m/. Juga dalam proses pengimbuhan sufiks -an
dengan bentuk dasarhari yang menjadi /hariyan/ dimana terlihat muncul konsonan /y/
yang semula tidak ada. Pelepasan fonem dapat kita lihat dalam proses pengimbuhan akhiranwan pada kata sejarahdimana fonem/h/pada kata sejarahitu menjadi hilang; juga dalam proses penggabungan kata anak dan artikel –nda dimana fonem /k/ pada kataanak menjadi hilang; dan juga dalam pengimbuhan dengan prefiks ber- pada kata
renangdimana fonem/r/dari prefiks itu dihilangkan. Perhatikan! anak + -nda => ananda
Penelitian ini di rangkai dari beberapa kegiatan seperti yang terlihat pada Gambar 3.1.
Metode penelitian secara umum dibagi dua tahap yaitu, pengumpulan data sebagai input data dan
pengembangan teknik kompresi menggunakan algoritma kombinatorial.
Gambar 3.1. Metode penelitian optimalisasi proses kompresi dan dekompresi teks
Algoritma kombinatorial utama yang digunakan pada penelitian ini adalah Transformasi
Burrows-Wheeler (BWT). Algoritma ini memiliki kompleksitas yang cukup tinggi. Untuk dapat
melakukan penelitian dengan baik diperlukan peralatan yang dapat menunjang proses atau
tahapan metode penelitian pada Gambar 3.1. Sub bab dibawah ini akan menguraikan mengenai
peralatan yang dibutuhkan dan Sub bab 3.2 sampai dengan sub bab 3.6. menjelaskan secara lebih
detil tahapan penelitian yang akan di laksanakan.
Processor : Pentium IV 2,3 GHz
Memory : 4 GB
VGA Card : Intel 82852/82855 GM/GME Graphics Controller
Modem Standar : 56 Kbps atau Ethernet : 100 Mbps
- Sistem operasi yang digunakan dalam penelitian ini adalah Windows XP
- Perangkat lunak yang dibutuhkan untuk pengolahan data dan pembuatan program adalah
software C/C++
- Jaringan telepon atau jaringan LAN-ethernet untuk koneksi internet, serta terdaftar pada suatu
ISP (Internet Service Provider). Koneksi internet ini dibutuhkan dalam penelusuran pustaka,
perolehan data penelitian, serta korespondensi dengan pakar yang memahami topik penelitian
ini.
3.2 Analisa Kebutuhan
Pada kegiatan analisa kebutuhan dilakukan tahapan pengumpulan informasi, spesifikasi
dan validasi. Tahap pengumpulan informasi diawali dengan penelusuran pustaka yang relevan.
Studi pustaka diawali dengan membandingkan struktur beberapa bahasa (Inggris, Perancis, Arab,
Hebrew dan Indonesia) dan dampaknya terhadap teknik kompresi yang telah ada.
Penelusuran pustaka dilakukan dengan dua cara, pertama mencari pustaka dalam bentuk buku
teks dan hasil penelitian di beberapa perpustakaan sedangkan cara kedua, penelusuran pustaka
elektronik berbentuk jurnal ilmiah dan prosiding hasil seminar ilmiah, melalui internet.
3.3 Pengumpulan Data
Untuk mengevaluasi metode yang akan di teliti, menggunakan beberapa corpus. Pertama
adalah Corpus Calgary yang umum di gunakan oleh peneliti untuk membandingkan studi empirik
dari beberapa teknik kompresi yang di teliti. Corpus Calgary merupakan kumpulan file yang
awalnya digunakan oleh Bell, Witten dan Cleary pada tahun 1989 untuk mengevaluasi kinerja
praktis dari skema kompresi teks yang beragam. Metode ini juga diterapkan pada tiga file html.
1 Bib 111.261
references.
2 book1 768.771unformatted ASCII text - Thomas Hardy: Far from the
Madding Crowd.
3 book2 610.856ASCII text in UNIX "troff" format - Witten: Principles of
Computer Speech.
4 Geo 10240032 bit numbers in IBM floating point format - seismic data.
5 news 377.109ASCII text - USENET batch file on a variety of topics.
6 obj1 21.504VAX executable program - compilation of PROGP.
7 obj2 246.814Macintosh executable program - "Knowledge Support
System".
8 paper1 53.161UNIX "troff" format - Witten, Neal, Cleary: Arithmetic
Coding for Data Compression.
9 paper2 82.199UNIX "troff" format - Witten: Computer (in)security.
10 paper3 46.5261728 x 2376 bitmap image (MSB first): text in French and
line diagrams.
11 paper4 13.286text files in UNIX "troff" format
12 paper5 11.954text files in UNIX "troff" format
13 paper6 38.105text files in UNIX "troff" format
14 pic 513.216text files in UNIX "troff" format
15 progc 39.611Source code in C - UNIX compress v4.0.
16 progl 71.646Source code in Lisp - system software.
17 progp 49.379Source code in Pascal - program to evaluate PPM
compression.
18 trans 93.695ASCII and control characters - transcript of a terminal
session.
Corpus kedua adalah pengumpulan dokumen berbahasa Indonesia yang merupakan objek
utama penelitian ini. Pada tahap awal penelitian beberapa dokumen yang digunakan adalah:
- Dokumen akademik
- Dokumen teknik (Technical document) - Buku elektronik
- Media cetak online.
Tipe dokumen yang dikumpulkan merupakan plain text dalam bentuk .txt, .doc, .odt, .xls, dan
pada Gambar 3.2. Sebagaimana telah disebutkan pada sub bab 2…., struktur data sangat
mempengaruhi performansi kompresi.
3.3 Pengembangan Algoritma
Tahap penelitian ini secara umum dapat di gambarkan pada gambar 3.3 dibawah ini. Tiga
tahapan di perlukan untuk mengoptimalkan algoritma kompresi yang akan di terapkan yaitu,
yang sesuai untuk struktur sintetis dari suatu bahasa. Tahapan ini akan menganalisis masukan
yang paling sesuai untuk suatu bahasa berdasarkan struktur sintesisnya
[DvorskyxxTextCompression] :
- berdasarkan Karakter
- suku kata
- kata
- n-gram
- kalimat
Tahapan ini akan menggunakan skema original BWT oleh Burrows dan Wheeler.
3.3.2 Tahapan Pemodelan
Proses pemodelan merupakan tahapan optimalisasi algoritma kombinatorial. Tahapan ini
menggunakan dua transformasi kombinatorial. Transformasi utama menggunakan Transformasi
Burrows-Wheeler (BWT) dan yang kedua Global Structure Transform (GST) seperti yang telah di jelaskan pada studi pustaka.
Burrows-Wheeler Transform (BWT)
Transformasi BWT mempunyai komplesitas yang cukup tinggi, karena proses sorting dalam permutasi data. Sejak dipublikasikan pada tahun 1994, perkembangan algoritma ini cukup pesat,
dimulai dengan menerapkan suffix tree atausuffix array untuk menekan kompleksitas algoritma tersebut. Penelitian ini akan fokus pada analisa kompleksitas penerapan berbagai metode
algoritma BWT. Dan beberapa peneliti telah mempublikasikan varian dari BWT seperti algoritma
Ferragina-manzani (FM algorithm). Penelitian dilanjutkan dengan analisis dua varian BWT yaitu gBWT dan algoritma FM dari Ferragina dan Manzani.
Global Structure Transform (GST)
mengoptimalkan output dari BWT sehingga lebih efektif di kompresi oleh proses pengkodean
(Entropy Coding). Berdasarkan studi pustaka, GST dapat di klasifikasikan 2 kategori, yaitu:
1. Move-To-Front(MTF) dan varian nya yang terdiri dari:
a. Move-To-Front(MTF)
b. Move One From Front(M1FF)
c. Move One From FrontTwo (M1FF2) d. Time Stamp(TS)
e. Best x of 2x-1
2. MetodeFrequency Counting a. Inversion Frequency(IF)
b. Distance Coding(DC)
c. Weighted Frequency Count(WFC)
d. Advanced Weighted Frequency Count(AWFC)
e. Incremental frequency Count(IFC)
3.3.2 Tahapan Pengkodean
Tahapan terakhir dari algoritma kompresi Burrows-Wheeler merupakan dua pengkodean
yaitu Run Length Encoding zero (RLE0) dan Coding (seperti Huffman Coding dan Arithmetic Coding). Burrows dan Wheeler menyarankan menggunakan Arihtmetic Coding dari pada
Huffman Coding untuk mendapatkan hasil kompresi yang lebih optimal.
Pada studi pustaka, beberapa peneliti menyarankan beberapa algoritma untuk tahapan ini
yang dibuktikan lebih optimal untuk keluaran BWT dan GST. Tahap ini akan menguji coba dua
algoritma coding yaitu Huffman dan Arithmetic Coding.
3.4 Rekayasa Perangkat Lunak
Kegiatan membangun metode dan merekayasa perangkat lunak dilakukan selama dua
tahun. Kegiatan penelitian pada tahun pertama adalah uji coba metoda original dari Burrows dan
Wheeler yang menciptakan algoritma tersebut. Burrows dan Wheeler menggunakan Transformasi
Optimalisasi metode di lakukan dengan analisa studi empirik setiap implementasi setiap
transformasi.
3.6. Masa Pelaksanaan Penelitian
Penelitian akan dilakukan lama dua tahun, mulai tahun 2013 sampai dengan tahun 2014.
Jadual penelitian yang direncanakan akan dilakukan sebagaimana tertera pada tabel berikut ini.
1 2 3 4 5 6 7 8 9 10 11 12
Pengujian
Verifikasi
Laporan
dan
Publikasi
BWT stages, 2003.
[Abel, 2007] J. Abel. Incremental Frequency Count—a post BWT–stage for the Burrows-Wheeler compression algorithm.Softw. Pract. Exper., 37(3):247–265, 2007.
[Abel, 2010] J. Abel. Post BWT stages of the Burrows-Wheeler compression algorithm.
Softw.Pract. Exper., 40:751–777, August 2010.
[Aronoff 1976;43] Aronoff, M, Word Formation in Generative Grammar. Linguistic Inquiry Monograph 1. Cambridge (Mass.): MIT Press,1976.
[Bauer 1983:87] L. Bauer, English Word Formation. Cambridge: Cambridge University Press, 1983.
[Bell, Cleary & Witten, 1990] Bell, T.C., J.G. Cleary, and I.H. Witten,Text compression.
Prentice Hall, Englewood Cliffs, NJ, 1990.
[Bookstein dan Klein, 1993] Bookstein, A. and Klein, S.T. "Is Huffman Coding Dead?"
Computing, vol. 50, p. 279-296, 1993.
[Burrows, 1994] M. Burrows and D. J. Wheeler. A block-sorting lossless data compression algorithm. Technical report, System Research Center (SRC) California, May 10, 1994.
[Changsong dkk., 1998] X. Changsong, R. Matzner: A New Compression Scheme for Syntactically Structured Messages (Programs) and its Application to Java and the Internet. Data Compression Conference, 1998.
[Cover, 1991] T. Cover and J. Thomas.Elements of Information Theory. Wiley and Sons, 1991.
[Diri, 2001] B. Diri, Content Based Compression of Turkish Documents. Journal of Applied Sciences, 1: 446-451,2001.
[Fauzia, 2001] F. S. Awan, N. Zhang, N. Motgi, R. T. Iqbal, A. Mukherjee, LIPT: A Reversible Lossless Text Transform to Improve Compression Performance. Data Compression Conference 2001.
[Fenwick, 2007] P. M. Fenwick. Burrows–Wheeler compression: Principles and reflections.Theor. Comput. Sci., 387(3):200–219, 2007.
[Isal, 2001] R. Y. K. Isal and A. Moffat, Word-based block-sorting text compression. In
Proceedings of the 24th Australasian conference on Computer science (ACSC '01). IEEE Computer Society, Washington, DC, USA, 92-99, 2001.
[Moffat, 1990] A. Moffat, Linear time adaptive arithmetic coding, IEEE Transactions on Information Theory 36(2): 401-406, 1990.
[Rubin, 1979] A. Moffat, Linear time adaptive arithmetic coding. IEEE Transactions on Information Theory 36(2): 401-406, 1990.
[Seward, 2000] J. Seward. BZIP2. (invited midday presentation), Data Compression Conference, 2000.
[Shannon, 1948] C. E. Shannon. A mathematical theory of communication. The Bell System Technical Journal, 27:379–423,623–656, July, October 1948.
[Shannon, 1949] C. E. Shannon and W. Weaver. The Mathematical Theory of Communication. University of Illinois Press, Urbana, Illinois, 1949.
[Shuai, 2008] D. D. Shuai. Parallel lossless data compression: A particle dynamic approach. In Proceedings of the 4th international conference on Intelligent Computing: Advanced Intelligent Computing Theories and Applications - with Aspects of Theoretical and Methodological Issues, ICIC ’08, pages 266–274, 2008.
[Syahrul, 2008] E. Syahrul, J. Dubois, V. Vajnovszki, T. Saidani, M. Atri,"Lossless Image Compression Using Burrows Wheeler Transform (Methods and Techniques)", Proceedings of IEEE International Conference on Signal-Image Technology & Internet-Based Systems (SITIS'08), Bali , Indonesia, December 2008.
[Syahrul, 2010] E. Syahrul, J. Dubois, V. Vajnovszki, "Burrows Wheeler Compression Algorithm (BWCA) in Lossless image Compression", Elfitrin SYAHRUL, Julien DUBOIS, Vincent VAJNOVSZKI, International Conference on Soft Computing, Intelligent System and Information Technology (2nd ICSIIT), Bali, Indonesia, July 2010
[Syahrul, 2010] E. Syahrul, J. Dubois, A. Juarna, V. Vajnovszki, "Lossless Compression Based on Combinatorial Transform : Application to Medical Images", International Congress on Computer Applications and Computational Science (CACS), Singapore, December 2010
[Wirth dan Moffat, 2001] A. I. Wirth, A. Moffat, Can We Do without Ranks in Burrows Wheeler Transform Compression? Data Compression Conference, p: 419-428, 2001.
[Weinberger, 2000] M. J. Weinberger, G. Seroussi, and G. Sapiro. The LOCO-I Lossless Image Compression Algorithm: Principles and Standardization into JPEG-LS.
IEEE TRANSACTIONS ON IMAGE PROCESSING, 9(8):1309–1324, 2000.
[Wiseman , 2007] Y. Wiseman. Burrows-Wheeler based JPEG.Data Science Journal, 6:19–27, 2007.
[Wiseman , 2007b] Y. Wiseman and I. Gefner,. Conjugation-based compression for Hebrew texts. 6, 1, Article 4 (April 2007).
[Witten, 1987] Witten, I.H., Neal, R., and Cleary, J.G, "Arithmetic coding for data compression," Comm. A.C.M., 30(6), pp. 520-540, June 1987.
[Wirth dan Moffat, 2001] A. I. Wirth, A. Moffat, Can We Do without Ranks in Burrows Wheeler Transform Compression? Data Compression Conference, 419-428, 2001.
[Ziv dan Lempel, 1977] J. Ziv, A. Lempel, A Universal Algorithm for Sequential Data Compression. IEEE Transactions on Information Theory 23(3): 337-343, 1977.