i
KETERKAITAN ANTARA KINERJA DOSEN, KONTRIBUSI
MAHASISWA, DAN KEPUASAN MAHASISWA
Skripsi
Dikerjakan Untuk Memenuhi Salah Satu Syarat Memperoleh
Gelar Sarjana Teknik Jurusan Informatika
Disusun Oleh:
EDELTRUDIS DE’E BHIA
NIM. 06 5314 077
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
ASSOCIATION BETWEEN LECTURERS’ PERFORMANCE,
STUDENTS’ CONTRIBUTION, AND STUDENTS’
SATISFICATION
A Thesis
Presented as Partial Fulfillment of the Requirements
To Obtain the Sarjana Teknik Degree
In Informatics Engineering
By
EDELTRUDIS DE’E BHIA
Student Number : 06 5314 077
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
vi
yang penting atau menarik dari sejumlah data yang sangat besar. Salah satu metode yang dikenal dalam penambangan data adalah analisis asosiasi yang menghasilkan aturan asosiasi (association rule). Analisis asosiasi adalah teknik penambangan data yang bertugas untuk menemukan aturan asosiasi antara suatu kombinasi item.
vii
large amount of data. One of method in data mining is association analysis that yielding association rules. Association analysis is a technique of data mining to find the association rule between combination of items.
In this final project one of algorithm to find association rules that is Apriori algorithm was implemented. This algorithm implementation was used to find out the association of several data that are used in the learning evaluation which is conducted by Pusat Pengembangan dan Penjaminan Mutu Pembelajaran (P3MP) Sanata Dharma University, Yogyakarta. The data consist of lectures’ performance, students’ contribution and students’ satisfication. The result of that algorithm implementation is a strong and meaningful association rule which shows association between lectures’ performance, students’ contribution, dan students’ satisfication. The rule is [P1=1, P2=1] ==> [P3=1] (confidence= 0.93)
ix
Puji dan syukur penulis haturkan ke hadirat Tuhan Yang Maha Esa karena atas berkat dan rahmatNya sehingga penulisan tugas akhir ini dapat terselesaikan dengan baik. Tugas akhir ini disusun sebagai salah satu syarat untuk memperoleh gelar Sarjana Teknik pada program studi Teknik Informatika di Fakultas Sains dan Teknologi Universitas Sanata Dharma, Yogyakarta.
Tugas akhir ini dapat terselesaikan berkat bimbingan, dukungan, bantuan, serta dorongan dari beberapa pihak. Oleh karena itu pada kesempatan ini penulis mengucapkan terimakasih kepada :
1. Ibu Paulina Heruningsih Prima Rosa,S.Si.,M.Sc, selaku dosen pembimbing yang telah banyak memberikan bimbingan dalam penyusunan tugas akhir ini. 2. Bapak Eko Hari Parmadi, S.Si.,M.Kom dan Bapak Alb. Agung Hadhiatma
S.T., M.T, selaku panitia penguji yang telah memberikan banyak kritik dan saran guna penyempurnaan tugas akhir ini.
3. Pusat Pengembangan dan Penjaminan Mutu Pembelajaran (P3MP) Universitas Sanata Dharma Yogyakarta yang telah mengijinkan penulis mengambil data evaluasi pembelajaran untuk menjawab kebutuhan data pada tugas akhir ini.
x
memberikan banyak nasihat hidup, doa, semangat, dan perhatian sehingga penulis dapat menyelesaikan tugas akhir ini.
6. Semua teman – teman TI’ 06 dan anak – anak kost GITA Paingan 3 serta teman – teman HKF. Terimakasih untuk nasihat, canda tawa, semangat, doa, perhatian dan kebersamaan selama ini, serta
7. Semua pihak yang telah membantu penulisan baik secara langsung maupun tidak langsung, yang tidak dapat penulis sebutkan satu per satu.
Dengan rendah hati penulis menyadari bahwa tugas akhir ini masih jauh dari sempurna. Oleh karena itu penulis mengharapkan kritik dan saran untuk penyempurnaan tugas akhir ini. Besar harapan penulis agar tugas akhir ini bermanfaat dan dapat menjadi inspirasi bagi pembaca khususnya mahasiswa dikalangan Teknik Informatika untuk melakukan pengembangan lebih lanjut.
Yogyakarta, September 2010
xi
HALAMAN JUDUL... i
HALAMAN JUDUL INGGRIS ... ii
HALAMAN PERSETUJUAN... iii
HALAMAN PENGESAHAN... iv
PERNYATAAN KEASLIAN KARYA... v
ABSTRAKSI... vi
ABSTRACT... vii
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS ... viii
KATA PENGANTAR... ix
DAFTAR ISI... xi
DAFTAR TABEL... xiv
DAFTAR GAMBAR... xv
Bab I. PENDAHULUAN...1
I.1. Latar Belakang ... 1
I.2. Rumusan Masalah ... 3
I.3. Tujuan ... 4
I.4. Batasan Masalah ... 4
I.5. Metodologi ... 4
I.6. Sistematika Penulisan ... 5
xii
II.3. Metode Analisis Asosiasi ... 9
II.4. Algoritma Apriori ... 12
II.5. Contoh Penerapan Algoritma Apriori ... 15
Bab III. ANALISI DAN PERANCANGAN PENAMBANGAN DATA... 20
III.1. Identifikasi Masalah ... 20
III.2. Analisa Sistem ... 21
III.2.1. Input Sistem ... 21
III.2.2. Proses Sistem ... 25
III.2.3. Output Sistem ... 27
III.3. Perancangan Sistem ... 28
III.3.1. Diagram Konteks ... 28
III.3.2. Diagram Use Case ... 28
III.3.3. Diagram Aktivitas ... 34
III.3.4. Diagram Kelas ... 36
III.3.5. Detail Algoritma Tiap Method Pada Tiap Kelas.... 36
III.3.6. Diagram Sequence ... 45
III.3.7. Desain Antar Muka ... 46
Bab IV. IMPLEMENTASI PENAMBANGAN DATA... 48
IV.1. Implementasi Antar Muka ... 48
IV.I.1. Form Utama ... 48
xiii
IV.2. Program Sistem Pencarian Aturan Asosiasi Data Evaluasi
Pembelajaran ... 56
IV.2.1. Membaca Data dari File Excel ... 56
IV.2.2. Pemrosesan Awal Data Kategori Penilaian ... 57
IV.2.3. Pencarian Candidate 1-Itemset ... 59
IV.2.4. Pencarian Frequent 1-Itemset ... 60
IV.2.5. Pencarian Frequent k-Itemset ... 61
IV.2.6. Pencarian Subset dari Semua Frequent k-Itemset .. 66
IV.2.7. Penentuan Aturan Asosiasi yang Kuat ... 67
IV.2.8. Penyimpanan Data Hasil Apriori ... 68
Bab V. ANALISIS HASIL DAN PEMBAHASAN... 69
Bab VI. KESIMPULAN DAN SARAN... 94
VI.1. Kesimpulan ... 94
VI.2. Saran ... 94
DAFTAR PUSTAKA ... 96
LAMPIRAN ... 97
Lampiran 1 Contoh bentuk kuesioner evaluasi pembelajaran P3MP ... 97
xiv
Tabel 2.1 Contoh Tabel Transaksi D ... 11
Tabel 2.2 Tabel Transaksi ... 15
Tabel 2.3 Frequent itemset dengan minimum support = 60 % ... 16
Tabel 3.1 Contoh Data Kategori Penilaian ... 22
Tabel 3.2 Kriteria kategori penilaian ... 24
Tabel 3.3 Partisi atribut kategori penilaian ... 24
Tabel 3.4 Data kategori penilaian setelah partisi ... 25
Tabel 3.5 Detail algoritma pada method di kelas Itemset ... 36
Tabel 3.6 Detail algoritma pada method di kelas Candidate ... 38
Tabel 3.7 Detail algoritma pada method di kelas LargeItemset ... 39
Tabel 3.8 Detail algoritma pada method di kelas Ls ... 40
Tabel 3.9 Detail algoritma pada method di kelas ProsesApriori ... 40
Tabel 5.1 Aturan Asosiasi Yang Kuat dan Bermakna Dari Percobaan Jenis I .. ... 89
xv
Gambar 2.1 Tahap – tahap Data Mining ... 8
Gambar 2.2 Data mining dan teknologi basisdata lainnya ... 9
Gambar 2.3 Pencarian candidate itemset dan frequent itemset dengan minimum support = 60% ... 16
Gambar 3.1 Diagram Konteks ... 28
Gambar 3.2 Diagram Use Case ... 28
Gambar 3.3 Diagram Aktivitas Pilih Data Dalam File Excel ... 34
Gambar 3.4 Diagram Aktivitas Cari Frequent Itemset dan Aturan Asosiasi Yang Kuat ... 35
Gambar 3.5 Diagram Kelas ... 36
Gambar 3.6 Diagram Sequence Pilih Data Dalam File Excel ... 45
Gambar 3.7 Diagram Sequence Cari Frequent Itemset dan Aturan Asosiasi Yang Kuat ... 45
Gambar 3.8 Desain Antar Muka Form Utama ... 46
Gambar 3.9 Desain Antar Muka Form Proses Apriori ... 47
Gambar 4.1 Form Utama ... ... 48
Gambar 4.2 Form Proses Apriori ... ... 49
Gambar 4.3 Hasil Pilih File ... 50
Gambar 4.4 Hasil Pemrosesan Awal ... 51
Gambar 4.5 Hasil proses Apriori (1) ... ... 52
xvi
Gambar 4.9 Pesan Kesalahan (1) ... 54
Gambar 4.10 Pesan Kesalahan (2) ... 54
Gambar 4.11 Pesan Kesalahan (3) ... 55
1
I.1. Latar Belakang
Perkembangan teknologi dan penemuan terbaru dalam pengumpulan dan penyimpanan data telah memungkinkan berbagai organisasi untuk mengumpulkan berbagai data misalnya data nasabah, data transaksi, data akademik dan sebagainya. Jumlah data ini selalu bertambah setiap tahunnya sehingga menyebabkan terjadinya data explosion. Namun pertumbuhan akumulasi data yang pesat telah menciptakan kondisi yang sering disebut sebagai rich of data but poor of information. Hal ini dikarenakan data yang terkumpul itu tidak dapat digunakan untuk aplikasi yang berguna. Di dalam tumpukan data tersebut mungkin terdapat informasi – informasi yang sangat penting atau menjadi penting pada saat dibutuhkan. Namun karena ukuran data yang sangat besar, akan sangat sulit untuk menganalisanya secara manual. Oleh sebab itu diperlukan suatu cara yang dapat secara otomatis menganalisa data dan kemudian membuat kesimpulan untuk diperiksa lebih lanjut (Pramudiono, 2005)
yang sangat besar berupa pengetahuan yang selama ini tidak diketahui secara manual. (Han, 2001 )
Salah satu organisasi yang memiliki data dalam ukuran besar yaitu Pusat Pengembangan dan Penjaminan Mutu Pembelajaran (P3MP) yang menangani tentang evaluasi pembelajaran di Universitas Sanata Dharma, Yogyakarta yang dilakukan setiap tengah semester. Evaluasi pembelajaran tersebut ditujukan untuk memberikan penilaian bagi para dosen dengan memperhatikan beberapa kategori penilaian yang meliputi kinerja dosen, kontribusi mahasiswa, dan kepuasan mahasiswa. Data evaluasi pembelajaran tersebut didapat melalui kuesioner yang dibagikan kepada mahasiswa. Dari kategori penilaian yang ada dapat dicari keterkaitan antara kategori tersebut, yang pada akhirnya dapat digunakan untuk mengetahui apakah ada hubungan pengaruh antara kinerja dosen, kontribusi mahasiswa, dan kepuasan mahasiswa.
aturan asosiasi tersebut sangat sulit jika dilakukan secara manual dengan menggunakan himpunan data (dataset) yang banyak.
Banyak algoritma yang dapat digunakan untuk menyelesaikan persoalan pada penambangan data. Pada kasus tersebut diatas metode yang sesuai adalah metode analisis asosiasi (association analysis) dengan algoritma apriori. Alasan penggunaan metode analisis asosiasi karena metode tersebut dapat digunakan untuk menemukan aturan asosiasi (association rule) antar item dalam suatu dataset, yaitu dengan membuat korelasi antar item yang dikelompokkan ke dalam transaksi kemudian mengambil kesimpulan berdasarkan hubungan yang terbentuk dari beberapa item data tersebut. Hal ini sesuai dengan masalah yang akan dipecahkan yaitu apakah ada hubungan pengaruh antara kinerja dosen, kontribusi mahasiswa, dan kepuasan mahasiswa. Sedangkan penggunaan algoritma apriori pada kasus ini karena algoritma apriori merupakan algoritma yang dinilai paling sederhana (Negandhi, 2007).
I.2. Rumusan Masalah
I.3. Tujuan
Dapat menemukan aturan asosiasi pada basisdata evaluasi pembelajaran P3MP Universitas Sanata Dharma guna menentukan keterkaitan antara kinerja dosen, kontribusi mahasiswa, dan kepuasan mahasiswa.
I.4. Batasan Masalah
1. Algoritma yang digunakan adalah algoritma apriori.
2. Data – data yang diambil adalah data kategori penilaian evaluasi pembelajaran P3MP Universitas Sanata Dharma, Yogyakarta yang terdiri dari data kinerja dosen, kontribusi mahasiswa, dan kepuasan mahasiswa sejak semester genap 2007 / 2008 sampai dengan semester genap 2008 / 2009.
I.5. Metodologi
Berikut ini merupakan metodologi yang digunakan untuk menyelesaikan masalah pada tugas akhir ini :
1. Pembersihan data. Hal ini bertujuan untuk membuang data yang tidak konsisten dan noise seperti data – data yang hilang atau data yang tidak valid.
2. Integrasi data yaitu penggabungan data dari beberapa sumber. 3. Transformasi data. Pada tahap ini data diubah menjadi format
4. Aplikasi teknik penambangan data dengan menggunakan algoritma apriori.
5. Presentasi Pola. Pada tahap ini pola direpresentasikan kepada pengguna akhir dalam bentuk yang dapat dipahami.
I.6. SISTEMATIKA PENULISAN
Bab I. Pendahuluan
Bab ini membahas mengenai latar belakang, rumusan masalah, batasan masalah, tujuan, metodologi, dan sistematika penulisan.
Bab II. Landasan Teori
Bab ini membahas mengenai pengetahuan yang menjadi dasar teori untuk mengimplementasikan penambangan data dengan menggunakan metode analisis asosiasi dengan algoritma apriori guna menemukan aturan asosiasi pada basisdata evaluasi pembelajaran P3MP Universitas Sanata Dharma.
Bab III. Analisis dan Perancangan Penambangan Data
Dalam bab ini akan diidentifikasikan masalah yang akan diselesaikan serta tahap tahap penyelesaian masalah tersebut dengan menggunakan algoritma apriori. Dalam bab ini pula akan dijelaskan perancangan program implementasi penambangan data dengan algoritma apriori.
Bab IV. Implementasi Penambangan Data
Bab V. Analisa Hasil dan Pembahasan
Bab ini berisi analisa hasil program dan pembahasan masalah berdasarkan hasil yang telah didapat secara keseluruhan.
Bab VI. Kesimpulan dan Saran
7
LANDASAN TEORI
II.1. Pengertian Penambangan Data
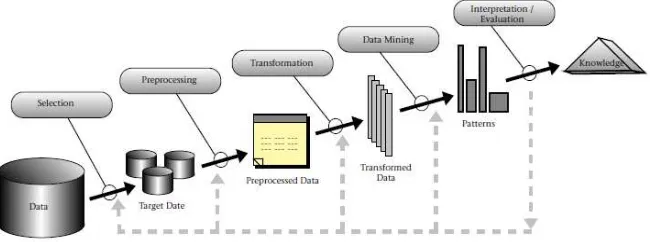
Menurut Han dan Kamber (2001) penambangan data (data mining) adalah serangkaian proses untuk mengekstrak pola yang penting atau menarik dari sejumlah data yang sangat besar berupa pengetahuan yang selama ini tidak diketahui secara manual. Penambangan data merupakan bagian dari knowledge discovery in databases (KDD), dimana penambangan data berfungsi sebagai proses untuk mengekstrak data menjadi informasi yang berguna.
II.2. Proses Penambangan Data
Penambangan data merupakan suatu rangkaian proses yang terdiri dari beberapa tahap, yaitu :
1. Pembersihan Data. Hal ini bertujuan untuk membuang data yang tidak konsisten dan noise seperti data – data yang hilang atau data yang tidak valid.
2. Integrasi data yaitu penggabungan data dari berbagai sumber. 3. Transformasi data. Pada tahap ini data diubah menjadi format data
4. Aplikasi teknik penambangan data yaitu mengaplikasikan algoritma untuk mengekstrak pola yang menarik.
5. Presentasi pola. Pada tahap ini pola direpresentasikan kepada pengguna akhir dalam bentuk yang dapat dipahami.
Tahap – tahap tersebut diilustrasikan pada gambar di bawah ini :
Gambar 2.1 Tahap – Tahap Data Mining
Sumber : Fayyad, et.al. (1996)
Suatu sistem atau query penambangan data mungkin saja menghasilkan ribuan pola, namun tidak semua pola tersebut adalah pola yang menarik atau penting. Ukuran suatu pola yang menarik atau penting adalah jika pola tersebut mudah dimengerti oleh manusia, bermanfaat, valid / benar pada data baru atau data tes dan membenarkan beberapa hipotesis.
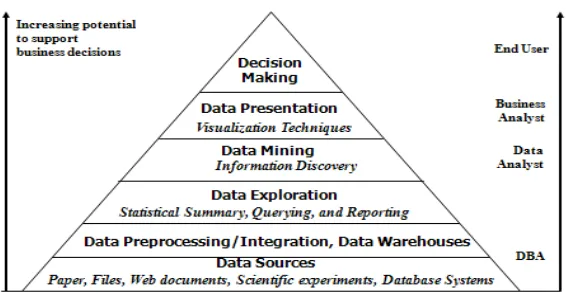
keputusan (decision making). Teknologi yang ada di gudang data dan OLAP dimanfaatkan penuh untuk melakukan penambangan data. Gambar di bawah ini menunjukkan posisi masing – masing teknologi basisdata tersebut :
Gambar 2.2 Data mining dan teknologi basisdata lainnya
Sumber : Jiawei Han and Micheline Kamber
www.cs.uiuc.edu/~hanj
II.3. Metode Analisis Asosiasi
Salah satu metode dalam penambangan data adalah metode analisis asosiasi (association analysis). Metode analisis asosiasi merupakan metode yang bertujuan untuk menemukan aturan asosiasi (association rule) antar item dalam suatu himpunan data (dataset), yaitu dengan membuat korelasi antar item yang dikelompokkan ke dalam transaksi kemudian mengambil kesimpulan berdasarkan hubungan yang terbentuk dari sekumpulan item data tersebut. Kumpulan item data ini sering disebut itemset.
kombinasi item dalam basisdata sedangkan confidence adalah kuatnya hubungan antar item dalam aturan asosiasi (Pramudiono, 2003). Pencarian aturan asosiasi dengan menggunakan analisis asosiasi bertujuan untuk menemukan semua aturan yang terdapat pada basisdata dengan minsup (minimum support) dan minconf (minimum confidence) yang melebihi batas tertentu. Suatu aturan asosiasi dirasa valid apabila mempunyai nilai confidence / nilai kepastian ≥ 50 % (López-Cózar, 2000).
Support dari aturan adalah rasio dari record yang mengandung dengan total record dalam basisdata. Untuk mendapatkan nilai support dapat menggunakan rumus :
...(2.1)
Sedangkan Minsup (minimum support) menandakan ambang batas (threshold) yang menentukan apakah sebuah itemset akan digunakan pada perhitungan selanjutnya untuk pencarian aturan asosiasi.
Confidence dari aturan asosiasi adalah rasio dari record yang mengandung dengan total record yang mengandung . Untuk mendapatkan nilai confidence dapat menggunakan rumus :
.......(2.2)
Atau dapat ditulis sebagai berikut:
Sedangkan Minconf (minimum confidence) menandakan ambang batas (threshold) dari sebuah aturan asosiasi untuk menentukan aturan asosiasi yang kuat (strong association rule).
Misalnya terdapat himpunan data transaksi D sebagai berikut:
Tabel 2.1 Contoh Tabel Transaksi D
TID Itemset
1 Bread, Milk
2 Bread,Diaper,Beer,Eggs
3 Milk,Diaper,Beer,Coke
4 Bread,Milk,Diaper,Beer
5 Bread,Milk,Diaper,Coke
Misalkan akan dihasilkan rule: {Milk,Diaper}→Beer Maka support menjadi
Confidence menjadi
Secara umum yang dilakukan dalam proses pencarian aturan asosiasi ini dapat dibagi menjadi 2 tahapan, yang terdiri dari :
o Pencarian frequent itemset
Yaitu proses pencarian semua itemset yang memiliki nilai support minsup. Itemset ini disebut frequent itemset atau large itemset ( l-itemset). Dalam tugas akhir ini proses pencarian frequent itemset menggunakan algoritma apriori.
Yaitu proses mendapatkan aturan asosiasi yang kuat (strong association rule) dari kombinasi frequent itemset yang membentuk aturan asosiasi yang memiliki nilai confidence minconf. Aturan asosiasi dapat ditemukan dari setiap frequent itemset.
II.4. Algoritma Apriori
Algoritma apriori merupakan algoritma untuk mencari frequent itemset yang berdasarkan prinsip apriori, yaitu jika suatu itemset merupakan frequent itemset maka semua subset-nya akan berupa frequent itemset (Tan, et.al. 2006). Pembentukan frequent itemset dilakukan dengan mencari semua kombinasi item – item yang memiliki support lebih besar atau sama dengan minsup yang telah ditentukan.
Pseudocode untuk pencarian frequent itemset menggunakan algoritma apriori adalah sebagai berikut (Gunawan, 2003) :
= candidate itemset untuk ukuran k
= frequent itemset / large itemset untuk ukuran k = {candidate 1-itemset}
= {large 1-itemset}
for ( ) do begin
// new candidate
for all transaction do begin
//candidate contained in
end
end
Answer =
Algoritma diatas dapat dijelaskan sebagai berikut :
a. Pada iterasi pertama dihitung jumlah kemunculan setiap item dalam transaksi untuk menentukan large 1-itemset. Pada iterasi selanjutnya akan dihasilkan candidate k-itemset ( ) menggunakan frequent(k-1)-itemset yang ditemukan pada iterasi sebelumnya. Candidate generation diimplementasikan menggunakan sebuah fungsi yang disebut apriori-gen. Apriori-gen digunakan untuk menghasilkan candidate itemset, yang menyebabkan tidak seluruh itemset diolah pada proses selanjutnya, hanya yang memenuhi persyaratan saja yaitu sesuai dengan support yang telah ditentukan. Hal ini mempersingkat waktu proses pencarian seluruh aturan asosiasi.
c. Selanjutnya nilai support dari semua candidate k-itemset dalam dinaikkan. Penelusuran dilanjutkan pada transaksi berikutnya sampai
semua transaksi dalam basisdata ditelusuri. Lalu akan dilakukan eliminasi candidate itemset yang memiliki nilai support lebih kecil dari minsup. Sedangkan semua candidate k-itemset yang memenuhi minsup disimpan dalam yang akan digunakan untuk membentuk large (k+1)-itemset. Algoritma berakhir ketika tidak ada large itemset baru yang dihasilkan.
Pencarian frequent itemset menggunakan algoritma apriori memiliki 2 karakteristik penting. Pertama, apriori merupakan algoritma level-wise dimana proses pada algoritma ini membangkitkan frequent itemset per level, dimulai dari level 1-itemset sampai ke itemset terpanjang dan candidate level yang baru, dibentuk dari frequent itemset yang ditemukan di level sebelumnya lalu menentukan nilai supportnya. Kedua, algoritma ini menggunakan strategi generate and test untuk menemukan frequent itemset. Pada tiap iterasi, candidate itemset yang baru, dihasilkan dari frequent itemset yang ditemukan pada iterasi sebelumnya. Nilai support tiap candidate dihitung dan di bandingkan kembali dengan ambang batas
minsupnya. Jumlah iterasi yang dibutuhkan algoritma ini adalah , dimana merupakan ukuran maksimum dari frequent itemset.
Strategi yang digunakan adalah breadth-first search dimana proses pencarian dilakukan per level dan untuk tiap level-nya ditentukan nilai support-nya untuk menemukan frequent itemset pada level tersebut. Sedangkan strategi perhitungan nilai support dilakukan dengan horizontal counting, dengan cara membaca transaksi satu persatu, jika ditemukan itemset yang dicari pada transaksi tersebut maka counter bertambah satu, begitu selanjutnya.
II.5. Contoh Penerapan Algoritma Apriori
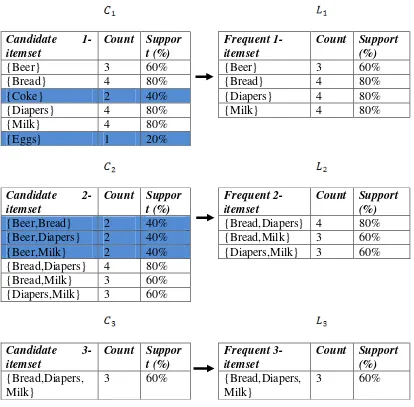
Berikut akan ditunjukkan cara kerja algoritma apriori untuk menemukan frequent itemset dan pembangkitan aturan asosiasi menggunakan data dari tabel transaksi yang diambil dari (Tan,et.al. (2006)). Minsup dan minconf yang ditentukan berturut – turut 60% dan 70%.
Tabel 2.2 Tabel Transaksi
TID Itemset
1 {Bread,Milk,Diapers}
2 {Bread,Diapers,Beer,Eggs}
3 {Milk,Beer,Coke}
4 {Bread,Milk,Diapers,Beer}
5 {Bread,Milk,Diapers,Coke}
Candidate
1-Gambar 2.3 Pencarian candidate itemset dan frequent itemset dengan
minimum support = 60%
Berdasarkan pencarian frequent itemset diatas maka dapat dibuat tabel frequent itemset sebagai berikut :
Tabel 2.3 Frequent itemset dengan minimum support = 60%
Frequent itemset Count Support(%)
Dari contoh diatas dapat dilihat bahwa bila nilai minsup diturunkan maka akan banyak candidate itemset yang terbentuk dan kardinalitas itemset yang lebih besar lagi, sehingga menyebabkan banyak pengulangan. Tetapi nilai minsup yang besar akan menyebabkan sedikit ditemukan frequent itemset sehingga menjadikan algoritma ini efisien, karena sedikit sekali melakukan proses pembacaan basisdata dan perhitungan nilai support.
Sehingga dengan frequent itemset yang ditemukan diatas dapat diproses sebagai berikut :
Subset dari frequent itemset : {Bread} ,{Diapers}, {Milk}, {Bread,Diapers}, {Bread,Milk}, {Diapers,Milk}, {Bread,Diapers,Milk}. Dari subset yang ada dapat dibentuk aturan asosiasi sebagai berikut :
a. Bread ⇒ Diapers
c (Bread⇒Diapers)= s(Bread,Diapers)/s Bread
= 80/80
=100%
b. Diapers ⇒ Bread
c (Diapers⇒Bread)=s (Bread,Diapers)/s Diapers
=80/80
=100%
c. Bread ⇒ Milk
=60/80
=75%
d. Milk ⇒ Bread
c (Milk⇒Bread) =s (Bread,Milk)/s Milk
=60/80
=75%
e. Diapers ⇒Milk
c (Diapers⇒Milk) =s (Diapers,Milk)/s Diapers
=60/80
=75%
f. Milk ⇒Diapers
c (Milk⇒Diapers) =s (Diapers,Milk)/s Milk
=60/80
=75%
g. Bread ⇒ Diapers & Milk
c (Bread⇒Diapers & Milk )= s (Bread,Diapers,Milk)/s Bread
=60/80
=75%
h. Diapers & Milk⇒ Bread
c (Diapers&Milk ⇒Bread)=s(Bread,Diapers,Milk)/s Diapers&Milk
=60/60
i. Diapers ⇒ Bread & Milk
c (Diapers⇒Bread & Milk )= s (Bread,Diapers,Milk)/s Diapers
=60/80
=75%
j. Bread & Milk ⇒ Diapers
c (Bread& Milk⇒Diapers)= s (Bread,Diapers,Milk)/s Bread&Milk
=60/60
=100%
k. Milk ⇒ Bread & Diapers
c (Milk⇒Bread&Diapers )= s (Bread,Diapers,Milk)/s Milk
=60/80
=75%
l. Bread &Diapers ⇒ Milk
=60/80 =75%
Semua aturan asosiasi yang ada ternyata mempunyai nilai confidence
≥ 70% sehingga semua aturan asosiasi yang terbentuk diatas merupakan
aturan asosiasi yang kuat (strong association rule).
20
ANALISIS DAN PERANCANGAN PENAMBANGAN DATA
III.1. Identifikasi Masalah
Pada tugas akhir ini akan dicari aturan asosiasi antara kategori - kategori penilaian yang digunakan pada evaluasi pembelajaran. Data kategori penilaian tersebut diambil dari basisdata evaluasi pembelajaran sejak semester genap 2007 / 2008 sampai dengan semester genap 2008 / 2009, yang diperoleh dari P3MP Universitas Sanata Dharma, Yogyakarta.
III.2. Analisis Sistem
III.2.1. Input Sistem
Data diperoleh dari Pusat Pengembangan dan Penjaminan Mutu Pembelajaran (P3MP) Universitas Sanata Dharma, Yogyakarta. Data diperoleh dalam bentuk Microsoft Excel yang berisi daftar nilai P3MP selama 3 semester yang dimulai dari semester genap 2007 / 2008 sampai dengan semester genap 2008 / 2009 karena baru selama tiga semester ini digunakan bentuk kuesioner baru yang melibatkan tiga kategori penilaian yaitu kinerja dosen, kontribusi mahasiswa, dan kepuasan mahasiswa.
Dalam kuesioner tersebut terdapat 18 pertanyaan yang dapat dibagi menjadi tiga bagian kategori penilaiagn dengan rincian sebagai berikut:
o Pertanyaan nomor 1 – 10 digunakan untuk menentukan indeks kinerja
dosen,
o Pertanyaan nomor 11 – 17 digunakan untuk menentukan kontribusi
mahasiswa, dan
o Pertanyaan nomor 18 digunakan untuk menentukan kepuasan mahasiswa
Selain itu tiap soal memiliki rentang nilai dari 1 sampai 7. Contoh bentuk kuesionernya dapat dilihat pada lampiran 1.
Nilai kategori penilaian yang digunakan pada penelitian ini berupa nilai rata – rata, yang merupakan hasil perhitungan jumlah rata – rata nilai tiap soal dibagi jumlah soal yang ada pada masing – masing kategori. Jumlah data untuk penelitian ini adalah 1225 record yang terdiri atas atribut – atribut sebagai berikut :
o Mtk : Nama matakuliah
o P1 : Nilai rata - rata untuk pertanyaan nomor 1 – 10 (nilai indeks kinerja
dosen)
o P2 : Nilai rata - rata untuk pertanyaan nomor 11 – 17 (nilai kontribusi
mahasiswa)
o P3 : Nilai rata - rata untuk pertanyaan nomor 18 (nilai kepuasan
mahasiswa).
Tabel 3.1 Contoh Data Kategori Penilaian
No Mtk P1(1-10) P2(11-17) P3(18)
1 Teori Kepribadian 5,28 5,01 5,11
2 Filsafat Moral CF 5,28 5,03 5,22
3 Manajemen BK I AB 5,60 4,97 4,76
4 PPL I F 6,27 6,06 6,24
5 Spritualitas Kristiani 5,17 5,16 5,06
6 Teologi Moral 5,79 4,87 4,32
7 Bahasa Inggris II 5,91 5,15 5,03
8 Structure II B 5,97 5,16 5,52
9 Sociolinguistics C 5,52 4,43 4,64
Nilai kategori penilaian ini biasa disebut sebagai atribut kuantitatif. Masalah pencarian aturan asosiasi pada atribut kuantitatif seperti ini disebut Quantitative Association Rule Problem, dimana untuk atribut kuantitatif baik yang dipartisi atau tidak ke dalam interval – interval, nilainya dipetakan ke bilangan bulat berurutan. Ada 5 langkah untuk menemukan aturan asosiasi kuantitatif (Ernawati, 2007) yaitu :
1) Tentukan jumlah partisi untuk setiap atribut kuantitatif
2) Untuk atribut kuantitatif baik yang dipartisi atau tidak ke dalam interval
– interval, nilai – nilai dipetakan ke bilangan bulat berurutan, sehingga algoritma hanya melihat nilai – nilai (atau range nilai) untuk atribut kuantitatif.
3) Tentukan support untuk setiap nilai untuk atribut kuantitatif. Untuk atribut kuantitatif, nilai – nilai yang berdekatan dikombinasikan sepanjang supportnya lebih kecil dari max_support (suatu nilai yang ditentukan pengguna). Kemudian tentukan semua himpunan item yang supportnya lebih besar daripada min_support. Himpunan ini merupakan frequent itemset.
4) Gunakan frequent itemset untuk membangkitkan aturan asosiasi. Ide umumnya jika ABCD dan AB adalah frequent itemset, maka dapat
5) Tentukan aturan yang menarik dari aturan – aturan yang dihasilkan. Sesuai dengan langkah pengolahan data menggunakan algoritma apriori untuk masalah pencarian aturan asosiasi kuantitatif seperti yang telah dijelaskan diatas, maka langkah awal yang harus dilakukan adalah membuat partisi untuk setiap atribut kuantitatif. Karena pihak P3MP sudah memiliki kriteria penilaian untuk tiap kategori penilaian, maka pembagian partisi atribut ini didasarkan pada ketentuan yang dapat dilihat pada Tabel 3.2 dibawah ini :
Tabel 3.2 Kriteria kategori penilaian
No Rentang Nilai % terhadap skor
maksimal 7
Kriteria
1 5,60 – 7,00 80% - 100% Sangat Tinggi
2 4,90 – 5,59 70% - 79 % Tinggi
3 3,92 – 4,89 56% - 69% Cukup
4 3,22 – 3,91 46% - 55% Rendah
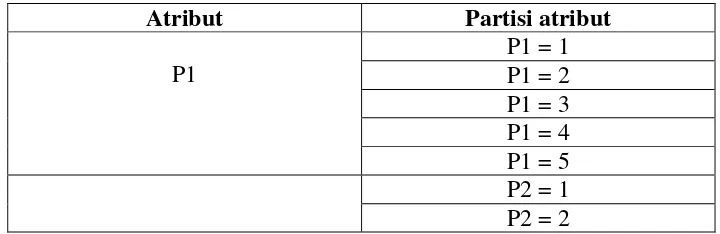
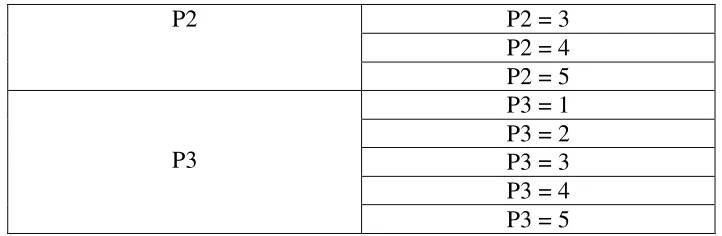
5 ...,< 3,22 ...,< 46% Sangat Rendah Berdasarkan ketentuan diatas maka pada kasus ini, tiap atribut kategori penilaian (P1, P2, dan P3) akan dipartisi menjadi 5 interval sesuai dengan rentang nilai yang ada pada Tabel 3.2, dimana masing – masing interval dinyatakan dalam bilangan bulat 1, 2, 3, 4, dan 5 seperti yang digambarkan pada Tabel 3.3 berikut ini :
Tabel 3.3 Partisi atribut kategori penilaian
Atribut Partisi atribut
P1
P2 P2 = 3 P2 = 4 P2 = 5
P3
P3 = 1 P3 = 2 P3 = 3 P3 = 4 P3 = 5
Dengan membuat partisi seperti ini maka algoritma apriori hanya akan melihat nilai atau range nilai untuk atribut kuantitatif. Contoh data kategori penilaian setelah dilakukan proses partisi untuk data pada Tabel 3.1 dapat dilihat pada Tabel 3.4. Untuk langkah selanjutnya sama seperti langkah kerja algoritma apriori secara umum.
Tabel 3.4 Data kategori penilaian setelah dipartisi
No Mtk P1(1-10) P2(11-17) P3(18)
1 Teori Kepribadian P1=2 P2=2 P3=2
2 Filsafat Moral CF P1=2 P2=2 P3=2
3 Manajemen BK I AB P1=1 P2=2 P3=3
4 PPL I F P1=1 P2=1 P3=1
5 Spritualitas Kristiani P1=2 P2=2 P3=2
6 Teologi Moral P1=1 P2=3 P3=3
7 Bahasa Inggris II P1=1 P2=2 P3=2
8 Structure II B P1=1 P2=2 P3=2
9 Sociolinguistics C P1=2 P2=3 P3=3
10 Bahasa Jurnalistik A P1=1 P2=2 P3=1 dst
III.2.2. Proses Sistem
b. Melakukan pemrosesan awal (preprocessing) dengan membuat partisi data berdasarkan kriteria kategori penilaian pada Tabel 3.2. Hasil pemrosesan awal akan ditampilkan pada tabel view.
c. Membaca nilai minimum support dan minimum confidence yang dimasukkan pengguna.
d. Membaca data yang ditampilkan pada tabel view. Data yang dibaca adalah data yang telah dipartisi. Mencari semua candidate 1-itemset beserta count dan support untuk masing – masing candidate. Hasil perhitungan supportnya akan digunakan untuk penentuan frequent 1-itemset yakni dengan membandingkan nilai support candidate dengan minimum support yang telah dimasukkan pengguna. Candidate 1-itemset yang memiliki nilai support lebih besar atau sama dengan minimum support akan menjadi frequent 1-itemset. e. Mencari frequent k-itemset dengan membuat kombinasi frequent
1-itemset yang telah ada hingga membentuk candidate 2-itemset untuk mendapatkan frequent 2-itemset dan seterusnya hingga tidak ada lagi frequent itemset yang dapat dibentuk.
masing – masing aturan dengan cara mengambil nilai support masing – masing subset dan dihitung dengan menggunakan persamaan 2.3. Nilai confidence tiap aturan akan dibandingkan dengan minimum confidence yang telah dimasukkan oleh pengguna. Jika nilai confidencenya lebih besar atau sama dengan minimum confidence maka aturan tersebut adalah aturan asosiasi yang kuat. g. Menampilkan semua hasil apriori berupa semua frequent itemset
dan aturan asosiasi yang kuat sebagai output. Hasil apriori yang diperoleh dapat disimpan dalam file .txt atau .doc
III.2.3. Output Sistem
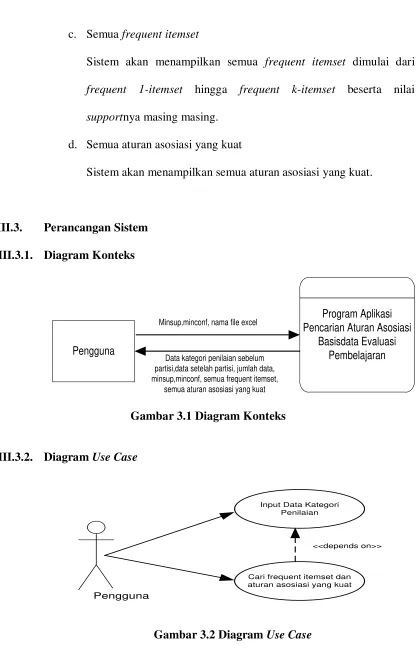
Sistem yang dibuat akan menghasilkan keluaran (output) sebagai berikut:
a. Data dan jumlah data
Sistem akan menampilkan data kategori penilaian yang dibaca dari file excel yang belum dipartisi, data kategori penilaian setelah dilakukan pemrosesan awal beserta jumlah dari masing – masing data tersebut.
b. Minimum support dan minimum confidence
c. Semua frequent itemset
Sistem akan menampilkan semua frequent itemset dimulai dari frequent 1-itemset hingga frequent k-itemset beserta nilai supportnya masing masing.
d. Semua aturan asosiasi yang kuat
Sistem akan menampilkan semua aturan asosiasi yang kuat.
III.3. Perancangan Sistem
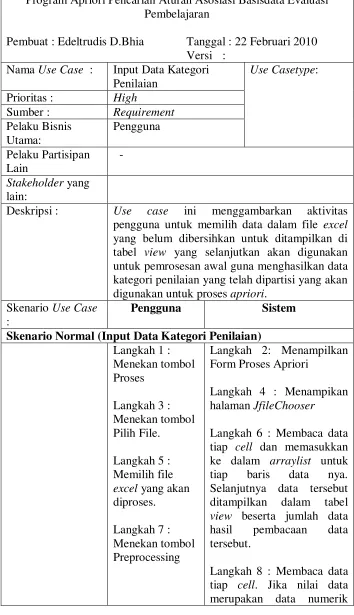
III.3.1. Diagram Konteks
Pengguna
Program Aplikasi Pencarian Aturan Asosiasi
Basisdata Evaluasi Pembelajaran
Data kategori penilaian sebelum partisi,data setelah partisi, jumlah data, minsup,minconf, semua frequent itemset,
semua aturan asosiasi yang kuat Minsup,minconf, nama file excel
Gambar 3.1 Diagram Konteks
III.3.2. Diagram Use Case
Input Data Kategori Penilaian
Cari frequent itemset dan aturan asosiasi yang kuat
<<depends on>>
Pengguna
Program Apriori Pencarian Aturan Asosiasi Basisdata Evaluasi Pembelajaran
Pembuat : Edeltrudis D.Bhia Tanggal : 22 Februari 2010 Versi :
Deskripsi : Use case ini menggambarkan aktivitas pengguna untuk memilih data dalam file excel yang belum dibersihkan untuk ditampilkan di tabel view yang selanjutkan akan digunakan untuk pemrosesan awal guna menghasilkan data kategori penilaian yang telah dipartisi yang akan digunakan untuk proses apriori.
Skenario Use Case :
Pengguna Sistem
Skenario Normal (Input Data Kategori Penilaian)
Langkah 1 :
Langkah 2: Menampilkan Form Proses Apriori Selanjutnya data tersebut ditampilkan dalam tabel view beserta jumlah data hasil pembacaan data tersebut.
dari kategori penilaian maka akan dilakukan proses partisi data berdasarkan kriteria kategori penilain yang ada. Selanjutnya data yang telah dipartisi akan ditampilkan dalam tabel view beserta jumlah data tersebut.
Program Apriori Pencarian Aturan Asosiasi Basisdata Evaluasi Pembelajaran
Pembuat : Edeltrudis D.Bhia Tanggal : 22 Februari 2010 Versi :
Dilakukan proses prunning yang dihasilkan pada langkah 6. Mencari subset frequent itemset yang menjadi anteseden dan ada frequent itemset yang menjadi konsekuen.
Langkah 11 : Menekan tombol Simpan
adalah aturan asosiasi yang kuat.
Langkah 10: Menampilkan output berupa jumlah data, minsup, minconf, semua frequent itemset dan aturan asosiasi yang kuat ke dalam JTextArea.
III.3.3. Diagram Aktivitas
a. Diagram Aktivitas Input Data Kategori Penilaian
Pengguna Sistem
Menekan tombol Proses Menampilkan Form Proses Apriori
Menekan tombol Pilih File Menampilkan halaman JFileChooser
Memilih file excel yang akan diproses
Membaca data excel tiap cell dan memasukkan dalam arraylist
Menampilkan data di tabel view
Menekan tombol
Preprocessing Membaca data excel tiap cell
cellType.Number
Masih ada cell yang akan
diperiksa
Memasukkan data tiap cell ke dalam arraylist Tidak ada cell lagi yang akan diperiksa
Menampilkan data yang telah dipartisi ke dalam tabel view
b. Diagram Aktivitas Cari Frequent Itemset dan Aturan Asosiasi Yang Kuat
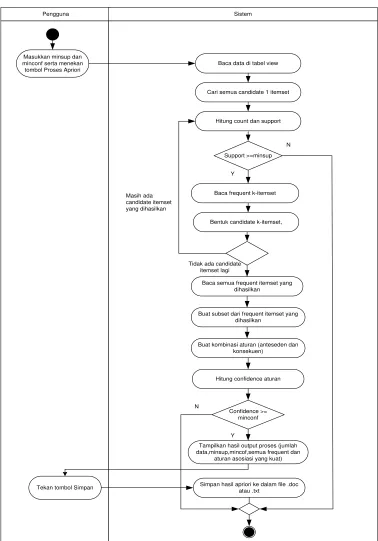
Pengguna Sistem
Masukkan minsup dan minconf serta menekan tombol Proses Apriori
Baca data di tabel view
Support >=minsup
Baca semua frequent itemset yang dihasilkan
Tidak ada candidate itemset lagi
Buat subset dari frequent itemset yang dihasilkan
Buat kombinasi aturan (anteseden dan konsekuen)
Hitung confidence aturan
Confidence >= minconf
Y
Tampilkan hasil output proses (jumlah data,minsup,mincof,semua frequent dan
aturan asosiasi yang kuat) N
Tekan tombol Simpan Simpan hasil apriori ke dalam file .doc atau .txt
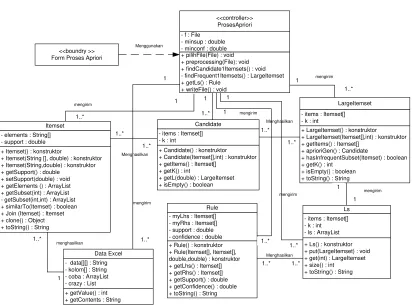
III.3.4. Diagram Kelas
+ Itemset(String [], double) : konstruktor + Itemset(String,double) : konstruktor
III.3.5. Detail Algoritma Tiap Method Pada Tiap Kelas
a. Detail algoritma pada method di kelas Itemset
Tabel 3.5 Detail algoritma pada method di kelas Itemset
Nama method Fungsi method Algoritma method
getElements() Membaca element data dari dataset yang ada dan memasukkannya ke dalam ArrayList.
Inisialisasi i=0. Selama i < elements.length, masukkan elements[i] ke dalam ArrayList result. getSubset(int,int) Untuk membuat
Lakukan langkah ini apakah itemset pertama sama dengan itemset kedua, jika tidak sama maka kedua itemset tersebut akan dijoinkan untuk menghasilkan kedua elements tersebut menjadi satu elements baru.
clone() Untuk menyalin itemset yang ada dalam suatu ArrayList baru.
Inisialisasi i =0. Selama i < elements.length ada itemset dari dataset inputan.
elements data selama i < elements.length.
b. Detail algoritma pada method di kelas Candidate
Tabel 3.6 Detail algoritma pada method di kelas Candidate
Nama method Fungsi method Algoritma method
getL(double) Melakukan proses
yang dimasukkan pengguna. Jika supportcandidate itemset >= minimum support maka masukkan candidate itemset tersebut dalam ArrayList itemArraylist.
c. Detail algoritma pada method di kelas LargeItemset
Tabel 3.7 Detail algoritma pada method di kelas LargeItemset
Nama method Fungsi method Algoritma method
aprioriGen() Membuat kombinasi
candidate k- itemset
1. Inisialisasi nilai i=0 dan j=i+1. Baca frequent k-itemset pada iterasi sebelumnya.
itemset yang baru. 2. Selama j < panjang data subset maka lakukan langkah 3.
3. Selama l < panjang data itemset pada tingkat k maka bandingkanlah apakah itemset tersebut
mengandung subset dari parameter Itemset. Jika benar kembalikan nilai flag = true.
d. Detail algoritma pada method di kelas Ls
Tabel 3.8 Detail algoritma pada method di kelas Ls
Nama method Fungsi method Algoritma method
put(LargeItemset) Menampung semua
e. Detail algoritma pada method di kelas ProsesApriori
Tabel 3.9 Detail algoritma pada method di kelas ProsesApriori
Nama method Fungsi method Algoritma method
ke dalam tabel view.
2. Selama i < banyakBaris dan j < banyakKolom maka getCell(j,i) dari sheet pertama.
3. Masukan data ke dalam ArrayList Data.
1. Inisialisasi nilai i =0, j=0, banyakBaris, dan yang telah ada. Ganti nilai cell dengan nilai kualitatif partisi data. dalam ArrayList Data. findCandidate1Itemsets() Menemukan
1. Inisialisasi nilai i=1 dan j=1, jumlahKolom, dan jumlahBaris pada tabel view.
3. Jika ArrayList Data 1. Inisialisasi nilai x=0, dan vv=0. Selama ukuran ArrayList data1 > x maka lakukan langkah 2.
2. Selama jumlahBaris >= j dan jumlahKolom >= i lakukan langkah 3.
3. Jika data1.get(x) = nilai data(j,i) maka vv di-increment (ditambah 1) 4. Masukkan nilai vv dalam ArrayList temp. Untuk hitung support candidate 1-itemset : 1. Inisialisasi nilai htng = 0, Selama ukuran
ArrayList temp > x, ambil temp.get(x) dibagi
jumlahBaris.
2. Jika sup1 >= minsup, ambil itemset dari data1.get(x). Lalu masukkan itemset dan sup1 ke dalam ArrayList semua frequent k-itemset : 1. Mulai k=2 dan selama dan support untuk itemset tersebut.
3. Panggil method
getL(minsup) untuk proses prunning.
4. Simpan frequent k-itemset dalam ArrayList dengan memanggil method put(LargeItemset).
Untuk mencari semua aturan asosiasi yang kuat : 1. Inisialisasi nilai b=0, dan selama b < ukuran tingkat frequent itemset (ls.size), ambil frequent (b), lalu cari subset dari frequent (b).
memenuhi ukuran subset frequent (b) lakukan perbandingan berikut : Jika frequent itemset fx mengandung subset dari frequent (b) maka ambil subset frequent itemset fx, lalu hapus list remain yang mengandung anteseden, konsekuen, dan nilai confidence ke dalam ArrayList isiRule.
JTextArea dan ukuran teks dalam byte
III.3.6. Diagram Sequence
a. Diagram Sequence Input Data Kategori Penilaian
Pengguna << boundry>>
Gambar 3.6 Diagram Sequence Input Data Kategori Penilaian
b. Diagram Sequence Cari Frequent Itemset dan Aturan Asosiasi Yang
Kuat
III.3.7. Desain Antar Muka
a. Form Utama
Pada Gambar 3.8 berikut digambarkan Form Utama yang menampilkan judul program dan dilengkapi dengan 3 tombol yaitu tombol Proses, Bantuan dan Keluar. Tombol Proses berfungi untuk memanggil Form Proses Apriori, tombol Bantuan untuk memanggil Form Bantuan, dan tombol Keluar untuk menutup form ini dan keluar dari program.
PROGRAM APRIORI
Pencarian Aturan Asosiasi Basisdata Evaluasi Pembelajaran Universitas Sanata Dharma Yogyakarta
Proses
Bantuan
Keluar
Gambar 3.8 Desain Antar Muka Form Utama
b. Form Proses Apriori
Pilih File Proses Apriori
Minsup Minconf
Jumlah Data Proses Apriori
Preprocessing
Simpan
48
IV.1. Implementasi Antar Muka
Antar muka merupakan tampilan yang nantinya akan berinteraksi langsung dengan pengguna.
IV.I.1. Form Utama
Pada saat program pertama kali dijalankan maka akan ditampilkan form seperti pada gambar di bawah ini :
Gambar 4.1 Form Utama
berfungsi untuk keluar dari program ini. Jika pengguna menekan tombol Proses, maka program ini akan menampilkan form Proses Apriori seperti yang tampak pada Gambar 4.2.
IV.I.2. Form Proses Apriori
Gambar 4.2 Form Proses Apriori
Gambar 4.3 Hasil Pilih File
Gambar 4.4 Hasil Pemrosesan Awal
Selanjutnya pengguna harus memasukkan nilai minimum support dan minimum confidence ke dalam textfield yang telah disediakan, dimana nilai – nilai tersebut akan digunakan sebagai pembanding dalam proses apriori.
Gambar 4.5 Hasil proses Apriori (1)
Gambar 4.6 Hasil Proses Apriori (2)
Selanjutnya pengguna dapat menekan tombol Simpan jika ingin menyimpan data hasil apriori yang telah ditampilkan pada JTextArea. Ketika tombol Simpan ditekan, maka akan ditampilkan save dialog seperti yang tampak pada Gambar 4.7. Pengguna diminta untuk menyimpan file dengan nama tertentu di direktori tertentu dan menggunakan extention .doc atau .txt.
Gambar 4.7 Tampilan Save Dialog
Selanjutnya jika pengguna telah menekan tombol Save pada save dialog maka program akan menampilkan pesan seperti yang tampak pada Gambar 4.8 yang menandakan bahwa data telah berhasil disimpan di direktori yang telah dipilih pengguna.
IV.I.3. Pengecekan Masukan
Jika belum ada file excel yang dimasukkan ke dalam sistem dan pengguna langsung menekan tombol Preprocessing maka program akan menampilkan pesan kesalahan seperti di bawah ini :
Gambar 4.9 Pesan Kesalahan (1)
Adapun listing program yang menangani proses ini adalah sebagai berikut :
if(nama_tabel.getText().equalsIgnoreCase("")){
JOptionPane.showMessageDialog(this,"File Belum Dipilih"); }else{
preprocessing(f); }
Jika ada field masukan yang belum terisi dan pengguna langsung menekan tombol Proses Apriori maka program akan menampilkan pesan kesalahan seperti di bawah ini :
Gambar 4.10 Pesan Kesalahan (2)
Adapun listing program yang menangani proses pengecekan masukan ini adalah sebagai berikut :
String sup = inminsup.getText(); String conf = inminconf.getText(); String fil = nama_tabel.getText(); if(sup.equalsIgnoreCase("")||
JOptionPane.showMessageDialog(this,"Ada Data Yang Belum Terisi"); }else{
File f = null;
DefaultTableModel tableModel = null; String[][] data; String[] kolom; hasil.setText("");
temp = new ArrayList(); temp1 = new ArrayList(); temp2 = new ArrayList(); temp3 = new ArrayList(); ak = new ArrayList();
newElements = new ArrayList(); aku = new LargeItemset(); ada = new ArrayList(); tampung = new ArrayList(); isirule = new ArrayList(); subset = new ArrayList(); remain =new ArrayList(); coba = new ArrayList();
supportssubset = new ArrayList(); findCandidate1Itemsets(); cetak();
getLs(); }
Jika belum ada hasil apriori yang dihasilkan dan ditampilkan pada JTextArea namun pengguna telah menekan tombol Simpan maka akan ditampilkan pesan kesalahan sebagai berikut :
Gambar 4.11 Pesan Kesalahan (3)
Adapun listing program yang menangani proses ini adalah sebagai berikut : FileOutputStream fos ;
if(hasil.getText().equalsIgnoreCase("")){
JOptionPane.showMessageDialog(this,"Hasil Apriori Kosong"); }else{
IV.I.4. Form Bantuan
Jika pengguna mengalami kesulitan dalam penggunaan program ini, maka pengguna dapat menekan tombol Bantuan yang ada pada Form Utama yang akan menampilkan Form Bantuan seperti yang tampak pada gambar berikut.
Gambar 4.12 Form Bantuan
IV.2. Program Sistem Pencarian Aturan Asosiasi Data Evaluasi Pembelajaran
IV.2.1. Membaca Data dari File Excel
//method ambil data file excel public void pilihFile(File f){ try{
Workbook workbook = Workbook.getWorkbook(f); //baca sheet pertama
Sheet sheet1 = workbook.getSheet(0); //mendapatkan jumlah baris dan kolom int banyakKolom = sheet1.getColumns(); int banyakBaris = sheet1.getRows(); //deklarasi header tabel
data = new String[banyakBaris][banyakKolom]; kolom = new String[banyakKolom];
ArrayList coba = new ArrayList(); crazy = new LinkedList(); /* ambil data */
for (int j = 0; j < banyakKolom; j++) {
Input sistem adalah data dalam file excel yang telah dipilih pengguna. Data yang dibaca akan dimasukkan ke dalam array string data[][] lalu disimpan dalam arraylist coba, yang selanjutnya akan dimasukkan dalam list crazy sehingga data yang terbaca dan tersimpan merupakan data per record yang akan mempermudah program dalam pencarian count dan support candidate k-itemset dan frequent k-itemset.
IV.2.2. Pemrosesan Awal Data Kategori Penilaian
//method untuk preprocessing public void preprocessing(File f){ try{
jumlah++; } kriteria kategori penilaian yang telah ditentukan P3MP menjadi nilai kualitatif. Data kualitatif tersebut akan disimpan dalam array string data[][]. Data[][] akan dimasukkan dalam arraylist coba yang selanjutnya akan dimasukkan ke dalam list crazy seperti yang dilakukan pada proses pembacaan data dari file excel pada langkah sebelumnya.
IV.2.3. Pencarian Candidate 1-Itemset
public void findCandidate1Itemsets(){ //mengambil jumlah kolom dari tabel jtabel1
jumlahkolm = this.getTableModel().getColumnCount()-1; System.out.println("jumlah kolom: "+jumlahkolm); //mengambil jumlahbaris dari tabel jtabel1
String value = (String) this.getTableModel().getValueAt(j,i);
Dilakukan pembacaan data excel yang telah ditampilkan di tabel view guna mendapatkan candidate 1-itemset. Dilakukan perulangan while untuk mendapatkan distinct data P1=1, P2=2, dan seterusnya sebagai candidate 1-itemset yang selanjutnya akan dimasukkan dalam arraylist data1. Berdasarkan panjang data1 akan dilakukan proses perhitungan count dan support candidate 1-itemset.
Itemset[] theItems = new Itemset[temp2.size()]; for (int i = 0; i < temp2.size(); i++) { theItems[i] = (Itemset) temp2.get(i); }
Untuk mendapatkan frequent 1-itemset dilakukan perulangan while sepanjang jumlah candidate 1-itemset dengan membandingkan nilai support candidate 1-itemset dengan nilai minimum support yang dimasukkan pengguna. Jika supportnya lebih besar dari minimum support maka candidate 1-itemset tersebut menjadi frequent 1-itemset. Frequent 1-itemset dan supportnya akan dimasukkan ke dalam kostruktor Itemset(String,double) yang selanjutnya akan dimasukkan dalam arraylist temp2.
remain.clear();
public void put(LargeItemset l) { ls.add(l.getK() - 1, l); }
Selanjutnya dilakukan proses pencarian candidate k-itemset dengan memanggil method aprioriGen di kelas LargeItemset yang bertipe Candidate dimana di dalam method ini dilakukan proses pencarian subset dan join antar frequent itemset dengan memanggil method join(Itemset) dan getSubset(int,int) yang ada di kelas Itemset.
theCItems[i] = (Itemset) cItems.get(i); }return new Candidate(theCItems, k + 1); }
}
//method similarTo (untuk membandingkan apakah itemset pertama sama dengan itemset kedua, jika tidak sama maka kedua itemset tersebut akan dijoinkan untuk menghasilkan candidate itemset yang baru)
public boolean similarTo(Itemset item) { if (elements.length == 1) {
return !elements[elements.length - 1].equals(item.elements[elements.length - 1]); }
//method join (untuk menggabungkan kedua itemset jika keduanya merupakan itemset yang berbeda)
public Itemset join(Itemset item) {
String[] joinedElements = new String[elements.length + 1]; for (int i = 0; i < elements.length; i++) {
joinedElements[i] = new String(elements[i]); }
joinedElements[elements.length] = new String(item.elements[elements.length - 1]); return new Itemset(joinedElements, 0d);
}
//method hasInfrequentSubset ( untuk meninjau apakah itemset yang telah dijoinkan merupakan subset dari frequent itemset sebelumnya)
return false; }
// method getSubset (membuat kombinasi subset dari itemset yang telah dijoinkan) public ArrayList getSubSet(int k) {
return getSubSet(k, elements.length); }
private ArrayList getSubSet(int k, int size) { ArrayList subSet = new ArrayList();
Selanjutnya dilakukan proses perhitungan count dan support dari candidate k-itemset yang telah ditemukan dengan melakukan perulangan for, guna membaca data dari list crazy dan diakhiri dengan proses prunning untuk menghasilkan frequent k –itemset dengan memanggil method getL(double) yang ada di kelas Candidate.
//pencarian count dan support dari kombinasi candidate k-itemset for(int i =0;i < items.length;i++){
}
//method getL untuk prunning candidate k-itemset guna mendapatkan frequent k-itemset public LargeItemset getL(double minimumSupport) {
ArrayList itemArrayList = new ArrayList();
Itemset[] itemArray = new Itemset[itemArrayList.size()]; for (int i = 0; i < itemArrayList.size(); i++) {
IV.2.6. Pencarian Subset dari Semua Frequent k-Itemset
// mendapatkan semua subset dari semua frequent k-itemset yang telah dihasilkan for(aaa =0; aaa < ada.size(); aaa++){
mengandung subset yang dibandingkan maka frequent itemset tersebut akan digunakan untuk pencarian aturan asosiasi.
IV.2.7. Penentuan Aturan Asosiasi yang Kuat
Proses ini diawali dengan penentuan frequent itemset yang akan menjadi anteseden dan konsekuen, menentukan support untuk keduanya lalu menghitung nilai confidence dari aturan yang terbentuk. Aturan yang memiliki nilai confidence lebih besar atau sama dengan nilai minimum confidence yang dimasukan pengguna akan menjadi aturan asosiasi yang kuat. //ambil itemset untuk menjadi anteseden (subset) dan konsekuen (remain)
IV.2.8. Penyimpanan Data Hasil Apriori
public void writeFile(){
JFileChooser fileChooser = new JFileChooser(new File("..")); int returnValue = fileChooser.showSaveDialog(this); if (returnValue == JFileChooser.APPROVE_OPTION) { String filename = fileChooser.getSelectedFile().getPath(); File ff = new File(filename);
//buat file output stream try{
fos = new FileOutputStream(ff); }catch(FileNotFoundException fe){ fe.printStackTrace();
return; } try{
//ambil teks dari JTeksarea String strwrite = hasil.getText(); //ukuran teks dalam byte int fsize = strwrite.length(); //buat buffer
byte bufOut[] = strwrite.getBytes(); //tulis data ke dalam file stream fos.write(bufOut,0,fsize); //tutup stream
fos.close();
}catch(IOException ie){
JOptionPane.showMessageDialog(this,"Gagal Menyimpan Data"); }
JOptionPane.showMessageDialog(this,"Data Berhasil Disimpan di "+filename); }}
69
Pada tahap ini akan dilakukan uji percobaan dengan menggunakan data training yaitu data evaluasi pembelajaran selama 3 semester sejak semester genap 2007 / 2008 sampai dengan semester genap 2008 / 2009 sebanyak 1225 record. Dilakukan 2 jenis percobaan guna mendapatkan aturan asosiasi yang kuat dan bermakna. Pemaknaan aturan asosiasi ini didasarkan pada asumsi awal P3MP yang menyatakan bahwa tujuan akhir dari evaluasi pembelajaran adalah kepuasan mahasiswa, dimana kinerja dosen dapat mempengaruhi kontribusi mahasiswa dan selanjutnya akan mempengaruhi kepuasan mahasiswa dalam mengikuti matakuliah tertentu.
1. Percobaan Jenis I
a. Minimum support 10 %
12. Support: 0.16{P2=3, P3=3}. Frequent 3-Itemsets:
1. [P1=2] ==> [P2=3] (confidence= 0.52)
Frequent 2-Itemsets:
1. Support: 0.19{P1=1, P2=2, P3=2}, 2. Support: 0.19{P1=1, P2=1, P3=1}.
11. [P2=2] ==> [P3=2] (confidence= 0.57)
4. [P3=2] ==> [P1=1] (confidence= 0.63) 5. [P1=1] ==> [P3=1] (confidence= 0.54) 6. [P3=1] ==> [P1=1] (confidence= 0.96) 7. [P2=2] ==> [P3=2] (confidence= 0.57) 8. [P3=2] ==> [P2=2] (confidence= 0.77) End
Aturan asosiasi yang menarik atau bermakna dari percobaan ini yaitu :
1. [P1=1] ==> [P2=2] (confidence= 0.59) 5. [P1=1] ==> [P3=1] (confidence= 0.54) 7. [P2=2] ==> [P3=2] (confidence= 0.57) d. Minimum support 25 %
Dengan menggunakan nilai minimum support 25 % dan minimum confidence 50 % maka akan menghasilkan frequent 1-itemset sebanyak 6 itemset, frequent 2-itemset sebanyak 3 itemset . Pada percobaan ini iterasi berhenti pada frequent 2-itemset kemudian dari frequent itemset tersebut terbentuk 6 aturan asosiasi yang kuat.
========== ========== Hasil Apriori ========== ========== Jumlah Data : 1225
Minimum Support: 25.0 Minimum Confidence: 50.0 Generated sets of large itemset: Frequent 1 -Itemset : 6 Frequent 2 -Itemset : 3 Frequent 1-Itemsets:
1. Support: 0.31 {P1=2}, 2. Support: 0.59 {P1=1}, 3. Support: 0.51 {P2=2}, 4. Support: 0.26 {P2=3}, 5. Support: 0.38 {P3=2}, 6. Support: 0.33 {P3=1}. Frequent 2-Itemsets:
2. Support: 0.32{P1=1, P3=1}, 3. Support: 0.29{P2=2, P3=2}. == Best Rule ==
1. [P1=1] ==> [P2=2] (confidence= 0.59) 2. [P2=2] ==> [P1=1] (confidence= 0.69) 3. [P1=1] ==> [P3=1] (confidence= 0.54) 4. [P3=1] ==> [P1=1] (confidence= 0.96) 5. [P2=2] ==> [P3=2] (confidence= 0.57) 6. [P3=2] ==> [P2=2] (confidence= 0.77) End
Aturan asosiasi yang menarik atau bermakna dari percobaan ini yaitu :
1. [P1=1] ==> [P2=2] (confidence= 0.59) 3. [P1=1] ==> [P3=1] (confidence= 0.54) 5. [P2=2] ==> [P3=2] (confidence= 0.57) e. Minimum support 30 %
Dengan menggunakan nilai minimum support 30 % dan minimum confidence 50 % maka akan menghasilkan frequent 1-itemset sebanyak 5 itemset, frequent 2-itemset sebanyak 2 itemset . Pada percobaan ini iterasi berhenti pada frequent 2-itemset kemudian dari frequent itemset tersebut terbentuk 4 aturan asosiasi yang kuat.
========== ========== Hasil Apriori ========== ========== Jumlah Data : 1225
Minimum Support: 30.0 Minimum Confidence: 50.0 Generated sets of large itemset: Frequent 1 -Itemset : 5 Frequent 2 -Itemset : 2 Frequent 1-Itemsets:
5. Support: 0.33 {P3=1}. Frequent 2-Itemsets:
1. Support: 0.35{P1=1, P2=2}, 2. Support: 0.32{P1=1, P3=1}. == Best Rule ==
1. [P1=1] ==> [P2=2] (confidence= 0.59) 2. [P2=2] ==> [P1=1] (confidence= 0.69) 3. [P1=1] ==> [P3=1] (confidence= 0.54) 4. [P3=1] ==> [P1=1] (confidence= 0.96) End
Aturan asosiasi yang menarik atau bermakna dari percobaan ini yaitu :
1. [P1=1] ==> [P2=2] (confidence= 0.59) 3. [P1=1] ==> [P3=1] (confidence= 0.54) f. Minimum support 35 %
Dengan menggunakan nilai minimum support 35 % dan minimum confidence 50 % maka akan menghasilkan frequent 1-itemset sebanyak 3 itemset, frequent 2-itemset sebanyak 1 itemset . Pada percobaan ini iterasi berhenti pada frequent 2-itemset kemudian dari frequent itemset tersebut terbentuk 2 aturan asosiasi yang kuat.
========== ========== Hasil Apriori ========== ========== Jumlah Data : 1225
Minimum Support: 35.0 Minimum Confidence: 50.0 Generated sets of large itemset: Frequent 1 -Itemset : 3 Frequent 2 -Itemset : 1 Frequent 1-Itemsets:
Frequent 2-Itemsets:
1. Support: 0.35{P1=1, P2=2}.
== Best Rule ==
1. [P1=1] ==> [P2=2] (confidence= 0.59) 2. [P2=2] ==> [P1=1] (confidence= 0.69) End
Aturan asosiasi yang menarik atau bermakna dari percobaan ini yaitu :
1. [P1=1] ==> [P2=2] (confidence= 0.59) g. Minimum support 40 %
Dengan menggunakan nilai minimum support 40 % dan minimum confidence 50 % maka akan menghasilkan frequent 1-itemset sebanyak 2 itemset. Pada percobaan ini iterasi berhenti pada frequent 1-itemset dan dari frequent 1-itemset tersebut tidak terbentuk frequent 2-itemset sehingga tidak akan terbentuk aturan asosiasi yang kuat karena sebuah aturan asosiasi terbentuk dari paling sedikit 2 itemset.
========== ========== Hasil Apriori ========== ========== Jumlah Data : 1225
Minimum Support: 40.0 Minimum Confidence: 50.0 Generated sets of large itemset: Frequent 1 -Itemset : 2 Frequent 1-Itemsets:
1. Support: 0.59 {P1=1}, 2. Support: 0.51 {P2=2}.
== Best Rule == EMPTY!