Selected Readings on
Database Technologies
and Applications
Terry Halpin
Neumont University, USA
Hershey • New York
Director of Editorial Content: Kristin Klinger Managing Development Editor: Kristin M. Roth Senior Managing Editor: Jennifer Neidig Managing Editor: Jamie Snavely Assistant Managing Editor: Carole Coulson Typesetter: Carole Coulson Cover Design: Lisa Tosheff Printed at: Yurchak Printing Inc. Published in the United States of America by
Information Science Reference (an imprint of IGI Global) 701 E. Chocolate Avenue, Suite 200
Hershey PA 17033 Tel: 717-533-8845 Fax: 717-533-8661 E-mail: [email protected] Web site: http://www.igi-global.com and in the United Kingdom by
Information Science Reference (an imprint of IGI Global) 3 Henrietta Street
Covent Garden London WC2E 8LU Tel: 44 20 7240 0856 Fax: 44 20 7379 0609
Web site: http://www.eurospanbookstore.com
Copyright © 2009 by IGI Global. All rights reserved. No part of this publication may be reproduced, stored or distributed in any form or by any means, electronic or mechanical, including photocopying, without written permission from the publisher.
Product or company names used in this set are for identification purposes only. Inclusion of the names of the products or companies does
not indicate a claim of ownership by IGI Global of the trademark or registered trademark.
Library of Congress Cataloging-in-Publication Data
Selected readings on database technologies and applications / Terry Halpin, editor. p. cm.
Summary: "This book offers research articles focused on key issues concerning the development, design, and analysis of databases"--Provided by publisher.
Includes bibliographical references and index.
ISBN 978-1-60566-098-1 (hbk.) -- ISBN 978-1-60566-099-8 (ebook) 1. Databases. 2. Database design. I. Halpin, T. A.
QA76.9.D32S45 2009 005.74--dc22
2008020494 British Cataloguing in Publication Data
A Cataloguing in Publication record for this book is available from the British Library.
All work contributed to this book set is original material. The views expressed in this book are those of the authors, but not necessarily of the publisher.
Table of Contents
Prologue ... xviii
About the Editor ... xxvii
Section I
Fundamental Concepts and Theories
Chapter I
Conceptual Modeling Solutions for the Data Warehouse ... 1
Stefano Rizzi, DEIS - University of Bologna, Italy
Chapter II
Databases Modeling of Engineering Information ... 21
Z. M. Ma, Northeastern University, China
Chapter III
An Overview of Learning Object Repositories ... 44
Argiris Tzikopoulos, Agricultural University of Athens, Greece Nikos Manouselis, Agricultural University of Athens, Greece Riina Vuorikari, European Schoolnet, Belgium
Chapter IV
Discovering Quality Knowledge from Relational Databases ... 65
Section II
Development and Design Methodologies
Chapter V
Business Data Warehouse: The Case of Wal-Mart ... 85 Indranil Bose, The University of Hong Kong, Hong Kong
Lam Albert Kar Chun, The University of Hong Kong, Hong Kong Leung Vivien Wai Yue, The University of Hong Kong, Hong Kong Li Hoi Wan Ines, The University of Hong Kong, Hong Kong Wong Oi Ling Helen, The University of Hong Kong, Hong Kong Chapter VI
A Database Project in a Small Company (or How the Real World Doesn’t Always
Follow the Book) ... 95 Efrem Mallach, University of Massachusetts Dartmouth, USA
Chapter VII
Conceptual Modeling for XML: A Myth or a Reality ...112 Sriram Mohan, Indiana University, USA
Arijit Sengupta, Wright State University, USA Chapter VIII
Designing Secure Data Warehouses... 134 Rodolfo Villarroel, Universidad Católica del Maule, Chile
Eduardo Fernández-Medina, Universidad de Castilla-La Mancha, Spain Juan Trujillo, Universidad de Alicante, Spain
Mario Piattini, Universidad de Castilla-La Mancha, Spain Chapter IX
Web Data Warehousing Convergence: From Schematic to Systematic ... 148 D. Xuan Le, La Trobe University, Australia
J. Wenny Rahayu, La Trobe University, Australia David Taniar, Monash University, Australia
Section III Tools and Technologies
Chapter X
Visual Query Languages, Representation Techniques, and Data Models ... 174 Maria Chiara Caschera, IRPPS-CNR, Italy
Chapter XI
Application of Decision Tree as a Data Mining Tool in a Manufacturing System ... 190 S. A. Oke, University of Lagos, Nigeria
Chapter XII
A Scalable Middleware for Web Databases ... 206 Athman Bouguettaya, Virginia Tech, USA
Zaki Malik, Virginia Tech, USA
Abdelmounaam Rezgui, Virginia Tech, USA Lori Korff, Virginia Tech, USA
Chapter XIII
A Formal Verification and Validation Approach for Real-Time Databases ... 234 Pedro Fernandes Ribeiro Neto, Universidade do Estado–do Rio Grande do Norte, Brazil Maria Lígia Barbosa Perkusich, Universidade Católica de Pernambuco, Brazil
Hyggo Oliveira de Almeida, Federal University of Campina Grande, Brazil Angelo Perkusich, Federal University of Campina Grande, Brazil
Chapter XIV
A Generalized Comparison of Open Source and Commercial Database Management Systems ... 252 Theodoros Evdoridis, University of the Aegean, Greece
Theodoros Tzouramanis, University of the Aegean, Greece
Section IV
Application and Utilization
Chapter XV
An Approach to Mining Crime Patterns ... 268 Sikha Bagui, The University of West Florida, USA
Chapter XVI
Bioinformatics Web Portals ... 296 Mario Cannataro, Università “Magna Græcia” di Catanzaro, Italy
Pierangelo Veltri, Università “Magna Græcia” di Catanzaro, Italy Chapter XVII
An XML-Based Database for Knowledge Discovery: Definition and Implementation ... 305 Rosa Meo, Università di Torino, Italy
Giuseppe Psaila, Università di Bergamo, Italy Chapter XVIII
Enhancing UML Models: A Domain Analysis Approach ... 330 Iris Reinhartz-Berger, University of Haifa, Israel
Chapter XIX
Seismological Data Warehousing and Mining: A Survey ... 352 Gerasimos Marketos,University of Piraeus, Greece
Yannis Theodoridis, University of Piraeus, Greece
Ioannis S. Kalogeras, National Observatory of Athens, Greece
Section V Critical Issues
Chapter XX
Business Information Integration from XML and Relational Databases Sources ... 369
Ana María Fermoso Garcia, Pontifical University of Salamanca, Spain Roberto Berjón Gallinas, Pontifical University of Salamanca, Spain
Chapter XXI
Security Threats in Web-Powered Databases and Web Portals ... 395 Theodoros Evdoridis, University of the Aegean, Greece
Theodoros Tzouramanis, University of the Aegean, Greece Chapter XXII
Empowering the OLAP Technology to Support Complex Dimension Hierarchies... 403 Svetlana Mansmann, University of Konstanz, Germany
Marc H. Scholl, University of Konstanz, Germany Chapter XXIII
NetCube: Fast, Approximate Database Queries Using Bayesian Networks ... 424 Dimitris Margaritis, Iowa State University, USA
Christos Faloutsos, Carnegie Mellon University, USA Sebastian Thrun, Stanford University, USA
Chapter XXIV
Node Partitioned Data Warehouses: Experimental Evidence and Improvements ... 450 Pedro Furtado, University of Coimbra, Portugal
Section VI Emerging Trends
Chapter XXV
Chapter XXVI
Action Research with Internet Database Tools ... 490 Bruce L. Mann, Memorial University, Canada
Chapter XXVII
Database High Availability: An Extended Survey ... 499 Moh’d A. Radaideh, Abu Dhab Police – Ministry of Interior, United Arab Emirates
Hayder Al-Ameed, United Arab Emirates University, United Arab Emirates
Detailed Table of Contents
Prologue ... xviii
About the Editor ... xxvii
Section I
Fundamental Concepts and Theories
Chapter I
Conceptual Modeling Solutions for the Data Warehouse ... 1
Stefano Rizzi, DEIS - University of Bologna, Italy
This opening chapter provides an overview of the fundamental role that conceptual modeling plays in data
warehouse design. Specifically, research focuses on a conceptual model called the DFM (Dimensional Fact Model), which suits the variety of modeling situations that may be encountered in real projects
of small to large complexity. The aim of the chapter is to propose a comprehensive set of solutions for
conceptual modeling according to the DFM and to give the designer a practical guide for applying them
in the context of a design methodology. Other issues discussed include descriptive and cross-dimension
attributes; convergences; shared, incomplete, recursive, and dynamic hierarchies; multiple and optional arcs; and additivity.
Chapter II
Databases Modeling of Engineering Information ... 21
Z. M. Ma, Northeastern University, China
As information systems have become the nerve center of current computer-based engineering, the need for engineering information modeling has become imminent. Databases are designed to support data storage, processing, and retrieval activities related to data management, and database systems are the key to implementing engineering information modeling. It should be noted that, however, the current mainstream databases are mainly used for business applications. Some new engineering requirements challenge today’s database technologies and promote their evolution. Database modeling can be clas
Chapter III
An Overview of Learning Object Repositories ... 44 Argiris Tzikopoulos, Agricultural University of Athens, Greece
Nikos Manouselis, Agricultural University of Athens, Greece Riina Vuorikari, European Schoolnet, Belgium
Learning objects are systematically organized and classified in online databases, which are termed learn -ing object repositories (LORs). Currently, a rich variety of LORs is operat-ing online, offer-ing access to wide collections of learning objects. These LORs cover various educational levels and topics, store learning objects and/or their associated metadata descriptions, and offer a range of services that may vary from advanced search and retrieval of learning objects to intellectual property rights (IPR) manage-ment. Until now, there has not been a comprehensive study of existing LORs that will give an outline of their overall characteristics. For this purpose, this chapter presents the initial results from a survey of 59 well-known repositories with learning resources. The most important characteristics of surveyed LORs are examined and useful conclusions about their current status of development are made.
Chapter IV
Discovering Quality Knowledge from Relational Databases ... 65 M. Mehdi Owrang O., American University, USA
Current database technology involves processing a large volume of data in order to discover new knowl-edge. However, knowledge discovery on just the most detailed and recent data does not reveal the long-term trends. Relational databases create new types of problems for knowledge discovery since they are normalized to avoid redundancies and update anomalies, which make them unsuitable for knowledge discovery. A key issue in any discovery system is to ensure the consistency, accuracy, and completeness of the discovered knowledge. This selection describes the aforementioned problems associated with the quality of the discovered knowledge and provides solutions to avoid them.
Section II
Development and Design Methodologies
Chapter V
Business Data Warehouse: The Case of Wal-Mart ... 85 Indranil Bose, The University of Hong Kong, Hong Kong
Lam Albert Kar Chun, The University of Hong Kong, Hong Kong Leung Vivien Wai Yue, The University of Hong Kong, Hong Kong Li Hoi Wan Ines, The University of Hong Kong, Hong Kong Wong Oi Ling Helen, The University of Hong Kong, Hong Kong
process of the data warehouse. The implications of the recent advances in technologies such as RFID, which is likely to play an important role in the Wal-Mart data warehouse in future, are also detailed in this chapter.
Chapter VI
A Database Project in a Small Company (or How the Real World Doesn’t Always
Follow the Book) ... 95 Efrem Mallach, University of Massachusetts Dartmouth, USA
The selection presents a small consulting company’s experience in the design and implementation of a database and associated information retrieval system. The company’s choices are explained within the
context of the firm’s needs and constraints. Issues associated with development methods are discussed,
along with problems that arose from not following proper development disciplines. Ultimately, the author asserts that while the system provided real value to its users, the use of proper development disciplines could have reduced some problems while not reducing that value.
Chapter VII
Conceptual Modeling for XML: A Myth or a Reality ...112 Sriram Mohan, Indiana University, USA
Arijit Sengupta, Wright State University, USA
Conceptual design is independent of the final platform and the medium of implementation, and is usu -ally in a form that is understandable to managers and other personnel who may not be familiar with the
low-level implementation details, but have a major influence in the development process. Although a
strong design phase is involved in most current application development processes, conceptual design
for XML has not been explored significantly in literature or in practice. In this chapter, the reader is
introduced to existing methodologies for modeling XML. A discussion is then presented comparing and
contrasting their capabilities and deficiencies, and delineating the future trend in conceptual design for
XML applications.
Chapter VIII
Designing Secure Data Warehouses... 134 Rodolfo Villarroel, Universidad Católica del Maule, Chile
Eduardo Fernández-Medina, Universidad de Castilla-La Mancha, Spain Juan Trujillo, Universidad de Alicante, Spain
Mario Piattini, Universidad de Castilla-La Mancha, Spain
As an organization’s reliance on information systems governed by databases and data warehouses (DWs) increases, so does the need for quality and security within these systems. Since organizations generally
deal with sensitive information such as patient diagnoses or even personal beliefs, a final DW solution should restrict the users that can have access to certain specific information. This chapter presents a
Chapter IX
Web Data Warehousing Convergence: From Schematic to Systematic ... 148 D. Xuan Le, La Trobe University, Australia
J. Wenny Rahayu, La Trobe University, Australia David Taniar, Monash University, Australia
This chapter proposes a data warehouse integration technique that combines data and documents from
different underlying documents and database design approaches. Well-defined and structured data,
semi-structured data, and unstructured data are integrated into a Web data warehouse system and user
specified requirements and data sources are combined to assist with the definitions of the hierarchical structures. A conceptual integrated data warehouse model is specified based on a combination of user
requirements and data source structure, which necessitates the creation of a logical integrated data ware-house model. A case study is then developed into a prototype in a Web-based environment that enables the evaluation. The evaluation of the proposed integration Web data warehouse methodology includes
the verification of correctness of the integrated data, and the overall benefits of utilizing this proposed
integration technique.
Section III Tools and Technologies
Chapter X
Visual Query Languages, Representation Techniques, and Data Models ... 174 Maria Chiara Caschera, IRPPS-CNR, Italy
Arianna D’Ulizia, IRPPS-CNR, Italy Leonardo Tininini, IASI-CNR, Italy
An easy, efficient, and effective way to retrieve stored data is obviously one of the key issues of any information system. In the last few years, considerable effort has been devoted to the definition of more
intuitive, visual-based querying paradigms, attempting to offer a good trade-off between expressive-ness and intuitiveexpressive-ness. In this chapter, the authors analyze the main characteristics of visual languages
specifically designed for querying information systems, concentrating on conventional relational data -bases, but also considering information systems with a less rigid structure such as Web resources storing XML documents. Two fundamental aspects of visual query languages are considered: the adopted visual
representation technique and the underlying data model, possibly specialized to specific application
contexts.
Chapter XI
Application of Decision Tree as a Data Mining Tool in a Manufacturing System ... 190 S. A. Oke, University of Lagos, Nigeria
This selection demonstrates the application of decision tree, a data mining tool, in the manufacturing
for decision making, which could be properly revealed with the application of appropriate data mining techniques. Decision trees are employed for identifying valuable information in manufacturing databases. Practically, industrial managers would be able to make better use of manufacturing data at little or no extra investment in data manipulation cost. The work shows that it is valuable for managers to mine data for better and more effective decision making.
Chapter XII
A Scalable Middleware for Web Databases ... 206 Athman Bouguettaya, Virginia Tech, USA
Zaki Malik, Virginia Tech, USA
Abdelmounaam Rezgui, Virginia Tech, USA Lori Korff, Virginia Tech, USA
The emergence of Web databases has introduced new challenges related to their organization, access, integration, and interoperability. New approaches and techniques are needed to provide across-the-board transparency for accessing and manipulating Web databases irrespective of their data models, platforms, locations, or systems. In meeting these needs, it is necessary to build a middleware infrastructure to
sup-port flexible tools for information space organization communication facilities, information discovery,
content description, and assembly of data from heterogeneous sources. This chapter describes a scalable
middleware for efficient data and application access built using available technologies. The resulting
system, WebFINDIT, is a scalable and uniform infrastructure for locating and accessing heterogeneous and autonomous databases and applications.
Chapter XIII
A Formal Verification and Validation Approach for Real-Time Databases ... 234 Pedro Fernandes Ribeiro Neto, Universidade do Estado–do Rio Grande do Norte, Brazil Maria Lígia Barbosa Perkusich, Universidade Católica de Pernambuco, Brazil
Hyggo Oliveira de Almeida, Federal University of Campina Grande, Brazil Angelo Perkusich, Federal University of Campina Grande, Brazil
Real-time database-management systems provide efficient support for applications with data and trans -actions that have temporal constraints, such as industrial automation, aviation, and sensor networks, among others. Many issues in real-time databases have brought interest to research in this area, such as: concurrence control mechanisms, scheduling policy, and quality of services management. However, considering the complexity of these applications, it is of fundamental importance to conceive formal
verification and validation techniques for real-time database systems. This chapter presents a formal verification and validation method for real-time databases. Such a method can be applied to database
systems developed for computer integrated manufacturing, stock exchange, network-management, and command-and-control applications and multimedia systems.
Chapter XIV
A Generalized Comparison of Open Source and Commercial Database Management Systems ... 252 Theodoros Evdoridis, University of the Aegean, Greece
This chapter attempts to bring to light the field of one of the less popular branches of the open source
software family, which is the open source database management systems branch. In view of the
objec-tive, the background of these systems is first briefly described followed by presentation of a fair generic
database model. Subsequently and in order to present these systems under all their possible features, the main system representatives of both open source and commercial origins will be compared in relation to this model, and evaluated appropriately. By adopting such an approach, the chapter’s initial concern is to ensure that the nature of database management systems in general can be apprehended. The overall orientation leads to an understanding that the gap between open and closed source database management
systems has been significantly narrowed, thus demystifying the respective commercial products.
Section IV
Application and Utilization
Chapter XV
An Approach to Mining Crime Patterns ... 268 Sikha Bagui, The University of West Florida, USA
This selection presents a knowledge discovery effort to retrieve meaningful information about crime from a U.S. state database. The raw data were preprocessed, and data cubes were created using Structured Query Language (SQL). The data cubes then were used in deriving quantitative generalizations and for further analysis of the data. An entropy-based attribute relevance study was undertaken to determine the relevant attributes. A machine learning software called WEKA was used for mining association rules, developing a decision tree, and clustering. SOM was used to view multidimensional clusters on a regular two-dimensional grid.
Chapter XVI
Bioinformatics Web Portals ... 296 Mario Cannataro, Università “Magna Græcia” di Catanzaro, Italy
Pierangelo Veltri, Università “Magna Græcia” di Catanzaro, Italy
Bioinformatics involves the design and development of advanced algorithms and computational platforms to solve problems in biomedicine (Jones & Pevzner, 2004). It also deals with methods for acquiring, storing, retrieving and analysing biological data obtained by querying biological databases or provided by experiments. Bioinformatics applications involve different datasets as well as different software tools and algorithms. Such applications need semantic models for basic software components and need
advanced scientific portal services able to aggregate such different components and to hide their details and complexity from the final user. For instance, proteomics applications involve datasets, either pro -duced by experiments or available as public databases, as well as a huge number of different software tools and algorithms. To use such applications, it is required to know both biological issues related to data generation and results interpretation and informatics requirements related to data analysis.
Chapter XVII
An XML-Based Database for Knowledge Discovery: Definition and Implementation ... 305 Rosa Meo, Università di Torino, Italy
Inductive databases have been proposed as general purpose databases to support the KDD process. Unfortunately, the heterogeneity of the discovered patterns and of the different conceptual tools used
to extract them from source data make integration in a unique framework difficult. In this chapter, us -ing XML as the unify-ing framework for inductive databases is explored, and a new model, XML for data mining (XDM), is proposed. The basic features of the model are presented, based on the concepts of data item (source data and patterns) and statement (used to manage data and derive patterns). This model uses XML namespaces (to allow the effective coexistence and extensibility of data mining opera-tors) and XML schema, by means of which the schema, state and integrity constraints of an inductive
database are defined.
Chapter XVIII
Enhancing UML Models: A Domain Analysis Approach ... 330 Iris Reinhartz-Berger, University of Haifa, Israel
Arnon Sturm, Ben-Gurion University of the Negev, Israel
UML has been largely adopted as a standard modeling language. The emergence of UML from different modeling languages has caused a wide variety of completeness and correctness problems in UML mod-els. Several methods have been proposed for dealing with correctness issues, mainly providing internal consistency rules, but ignoring correctness and completeness with respect to the system requirements and the domain constraints. This chapter proposes the adoption of a domain analysis approach called application-based domain modeling (ADOM) to address the completeness and correction problems of UML models. Experimental results from a study which checks the quality of application models when utilizing ADOM on UML suggest that the proposed domain helps in creating more complete models without compromising comprehension.
Chapter XIX
Seismological Data Warehousing and Mining: A Survey ... 352 Gerasimos Marketos,University of Piraeus, Greece
Yannis Theodoridis, University of Piraeus, Greece
Ioannis S. Kalogeras, National Observatory of Athens, Greece
Earthquake data is comprised of an ever increasing collection of earth science information for
post-processing analysis. Earth scientists, as well as local and national administration officers, use these data collections for scientific and planning purposes. In this chapter, the authors discuss the architecture of a
seismic data management and mining system (SDMMS) for quick and easy data collection, processing,
and visualization. The SDMMS architecture includes a seismological database for efficient and effective
Section V Critical Issues
Chapter XX
Business Information Integration from XML and Relational Databases Sources ... 369
Ana María Fermoso Garcia, Pontifical University of Salamanca, Spain Roberto Berjón Gallinas, Pontifical University of Salamanca, Spain Roberto Berjón Gallinas, Pontifical University of Salamanca, Spain
This chapter introduces different alternatives to store and manage jointly relational and eXtensible Markup Language (XML) data sources. Nowadays, businesses are transformed into e-business and have to manage large data volumes and from heterogeneous sources. To manage large amounts of in-formation, Database Management Systems (DBMS) continue to be one of the most used tools, and the most extended model is the relational one. On the other side, XML has reached the de facto standard to present and exchange information between businesses on the Web. Therefore, it could be necessary to use tools as mediators to integrate these two different data to a common format like XML, since it is the
main data format on the Web. First, a classification of the main tools and systems where this problem
is handled is made, with their advantages and disadvantages. The objective will be to propose a new system to solve the integration business information problem.
Chapter XXI
Security Threats in Web-Powered Databases and Web Portals ... 395 Theodoros Evdoridis, University of the Aegean, Greece
Theodoros Tzouramanis, University of the Aegean, Greece
It is a strongly held view that the scientific branch of computer security that deals with Web-powered databases (Rahayu & Taniar, 2002) that can be accessed through Web portals (Tatnall, 2005) is both complex and challenging. This is mainly due to the fact that there are numerous avenues available for
a potential intruder to follow in order to break into the Web portal and compromise its assets and functionality. This is of vital importance when the assets that might be jeopardized belong to a legally sensitive Web database such as that of an enterprise or government portal, containing sensitive and
confidential information. It is obvious that the aim of not only protecting against, but mostly preventing
from potential malicious or accidental activity that could set a Web portal’s asset in danger, requires an attentive examination of all possible threats that may endanger the Web-based system.
Chapter XXII
Empowering the OLAP Technology to Support Complex Dimension Hierarchies... 403 Svetlana Mansmann, University of Konstanz, Germany
Marc H. Scholl, University of Konstanz, Germany
and modeling complex multidimensional data, with the major effort at the conceptual level of transforming irregular hierarchies to make them navigable in a uniform manner. The properties of various hierarchy types are formalized and a two-phase normalization approach is proposed: heterogeneous dimensions are reshaped into a set of well-behaved homogeneous subdimensions, followed by the enforcement of
summarizability in each dimension’s data hierarchy. The power of the current approach is exemplified
using a real-world study from the domain of academic administration.
Chapter XXIII
NetCube: Fast, Approximate Database Queries Using Bayesian Networks ... 424 Dimitris Margaritis, Iowa State University, USA
Christos Faloutsos, Carnegie Mellon University, USA Sebastian Thrun, Stanford University, USA
This chapter presents a novel method for answering count queries from a large database approximately and quickly. This method implements an approximate DataCube of the application domain, which can be used to answer any conjunctive count query that can be formed by the user. The DataCube is a conceptual device that in principle stores the number of matching records for all possible such queries. However, because its size and generation time are inherently exponential, the current approach uses one or more Bayesian networks to implement it approximately. By means of such a network, the proposed method, called NetCube, exploits correlations and independencies among attributes to answer a count query quickly without accessing the database. Experimental results show that NetCubes have fast generation and use, achieve excellent compression and have low reconstruction error while also naturally allowing for visualization and data mining.
Chapter XXIV
Node Partitioned Data Warehouses: Experimental Evidence and Improvements ... 450 Pedro Furtado, University of Coimbra, Portugal
Data Warehouses (DWs) with large quantities of data present major performance and scalability chal-lenges, and parallelism can be used for major performance improvement in such context. However, instead of costly specialized parallel hardware and interconnections, the authors of this selection focus on low-cost standard computing nodes, possibly in a non-dedicated local network. In this environment, special care must be taken with partitioning and processing. Experimental evidence is used to analyze the shortcomings of a basic horizontal partitioning strategy designed for that environment, and then
im-provements to allow efficient placement for the low-cost Node Partitioned Data Warehouse are proposed
Section VI Emerging Trends
Chapter XXV
Rule Discovery from Textual Data ... 471 Shigeaki Sakurai, Toshiba Corporation, Japan
This chapter introduces knowledge discovery methods based on a fuzzy decision tree from textual data. The author argues that the methods extract features of the textual data based on a key concept dictionary, which is a hierarchical thesaurus, and a key phrase pattern dictionary, which stores characteristic rows of both words and parts of speech, and generate knowledge in the format of a fuzzy decision tree. The author also discusses two application tasks. One is an analysis system for daily business reports and the other is an e-mail analysis system. The author hopes that the methods will provide new knowledge for researchers engaged in text mining studies, facilitating their understanding of the importance of the fuzzy decision tree in processing textual data.
Chapter XXVI
Action Research with Internet Database Tools ... 490 Bruce L. Mann, Memorial University, Canada
This chapter discusses and presents examples of Internet database tools, typical instructional methods used with these tools, and implications for Internet-supported action research as a progressively deeper
examination of teaching and learning. First, the author defines and critically explains the use of arti -facts in an educational setting and then differentiates between the different types of arti-facts created by
both students and teachers. Learning objects and learning resources are also defined and, as the chapter
concludes, three different types of instructional devices – equipment, physical conditions, and social mechanisms or arrangements – are analyzed and an exercise is offered for both differentiating between and understanding differences in instruction and learning.
Chapter XXVII
Database High Availability: An Extended Survey ... 499 Moh’d A. Radaideh, Abu Dhab Police – Ministry of Interior, United Arab Emirates
Hayder Al-Ameed, United Arab Emirates University, United Arab Emirates
With the advancement of computer technologies and the World Wide Web, there has been an
explo-sion in the amount of available e-services, most of which represent database processing. Efficient and
effective database performance tuning and high availability techniques should be employed to ensure that all e-services remain reliable and available all times. To avoid the impacts of database downtime, many corporations have taken interest in database availability. The goal for some is to have continuous availability such that a database server never fails. Other companies require their content to be highly available. In such cases, short and planned downtimes would be allowed for maintenance purposes. This
chapter is meant to present the definition, the background, and the typical measurement factors of high
xviii
Prologue
HISTORICAL OVERVIEW OF DATABASE TECHNOLOGY
This prologue provides a brief historical perspective of developments in database technology, and then reviews and contrasts three current approaches to elevate the initial design of database systems to a conceptual level.
Beginning in the late 1970s, the old network and hierarchic database management systems (DBMSs)
began to be replaced by relational DBMSs, and by the late 1980s relational systems performed sufficiently well that the recognized benefits of their simple bag-oriented data structure and query language (SQL)
made relational DBMSs the obvious choice for new database applications. In particular, the simplicity of Codd’s relational model of data where all facts are stored in relations (sets of ordered n-tupes) facilitated data access and optimization for a wide range of application domains (Codd, 1970). Although Codd’s data model was purely set-oriented, industrial relational DBMSs and SQL itself are bag-oriented, since SQL allows keyless tables, and SQL queries queries may return multisets (Melton & Simon, 2002).
Unlike relational databases, network and hierarchic databases store facts in not only record types but also navigation paths between record types. For example, in a hierarchic database the fact that employee 101 works for the Sales department would be stored as a parent-child link from a department record (an instance of the Department record type where the deptName attribute has the value ‘Sales’) to an em-ployee record (an instance of the Emem-ployee record type where the empNr attribute has the value 101).
Although relational systems do support foreign key “relationships” between relations, these relation-ships are not navigation paths; instead they simply encode constraints (e.g. each deptName in an Employee table must also occur in the primary key of the Department table) rather than ground facts. For example, the ground fact that employee 101 works for the Sales department is stored by entering the values 101, ‘Sales’ in the empNr and deptName columns on the same row of the Employee table.
In 1989, a group of researchers published “The Object-Oriented Database System Manifesto” in which they argued that object-oriented databases should replace relational databases (Atkinson et al. 1989).
Influenced by object-oriented programming languages, they felt that databases should support not only
core databases features such as persistence, concurrency, recovery, and an ad hoc query facility, but also object-oriented features such as complex objects, object identity, encapsulation of behavior with data, types or classes, inheritance (subtyping), overriding and late binding, computational completeness, and extensibility. Databases conforming to this approach are called object-oriented databases (OODBs) or simply object databases (ODBs).
Partly in response to the OODB manifesto, one year later a group of academic and industrial
re-searchers proposed an alternative “3rd generation DBMS manifesto” (Stonebraker et al., 1990). They
considered network and hierarchic databases to be first generation, and relational databases to be second
xix
While other kinds of databases (e.g. deductive, temporal, and spatial) were also developed to address
specific needs, none of these has gained a wide following in industry. Deductive databases typically
provide a declarative query language such as a logic programming language (e.g. Prolog), giving them powerful rule enforcement mechanisms with built-in backtracking and strong support for recursive rules (e.g. computing the transitive closure of an ancestor relation).
Spatial databases provide efficient management of spatial data, such as maps (e.g. for geographi -cal applications), 2-D visualizations (e.g. for circuit designs), and 3-D visualizations (e.g. for medi-cal imaging). Built-in support for spatial data types (e.g. points, lines, polygons) and spatial operators (e.g. intersect, overlap, contains) facilitates queries of a spatial nature (e.g. how many residences lie within 3 miles of the proposed shopping center?).
Temporal databases provide built-in support for temporal data types (e.g. instant, duration, period) and temporal operators (e.g. before, after, during, contains, overlaps, precedes, starts, minus), facilitating queries of a temporal nature (e.g. which conferences overlap in time?).
A more recent proposal for database technology employs XML (eXtensible Markup Language). XML databases store data in XML (eXtensible Markup Language), with their structure conforming either to
the old DTD (Document Type Definition) or the newer XSD (XML Schema Definition) format. Like
the old hierarchic databases, XML is hierarchic in nature. However XML is presented as readable text, using tags to provide the structure. For example, the facts that employees 101 and 102 work for the Sales department could be stored (along with their names and birth dates) in XML as follows.
<department name = “Sales”> <employee empNr = “101”> <name>Fred Smith</name> <birthdate>1946-02-15</birthdate> </employee>
<employee empNr = “102”> <name>Sue Jones</name> <birthdate>1980-06-30</birthdate> </employee>
</department>
Just as SQL is used for querying and manipulating relational data, the XQuery language is now the standard language for querying and manipulating XML data, (Melton & Buxton, 2006).
One very recent proposal for a new kind of database technology is the so-called “ontology database”, which is proposed to help achieve the vision of the semantic web (Berners-Lee et al., 2001). The basic idea is that documents spread over the Internet may include tags to embed enough semantic detail to enable understanding of their content by automated agents. Built on Unicode text, URIrefs (Uniform
Resource Identifiers) to identify resources, XML and XSD datatypes, facts are encoded in RDF (Resource
Description Framework) triples (subject, predicate, object) representing binary relationships from a node (resource or literal) to another node. RDF Schema (RDFS) builds on RDF by providing inbuilt support for classes and subclassing. The Web Ontology Language (OWL) builds on these underlying layers to provide what is now the most popular language for developing ontologies (schemas and their database instances) for the semantic web.
OWL includes three versions. OWL Lite provides a decidable, efficient mechanism for simple on
-tologies composed mainly of classification hierarchies and relationships with simple constraints. OWL
DL (the “DL” refers to Description Logic) is based on a stronger SHOIN(D) description logic that is
still decidable. OWL Full is more expressive but is undecidable, and even goes beyond even first order
xx
All of the above database technologies are still in use, to varying degrees. While some legacy systems still use the old network and hierarchic DBMSs, new database applications are not built on these obso-lete technologies. Object databases, deductive databases, and temporal databases provide advantages for niche markets. However the industrial database world is still dominated by relational and object-relational DBMSs. In practice, ORDBs have become the dominant DBMS, since virtually all the major industrial relational DBMSs (e.g. Oracle, IBM DB2, and Microsoft SQL Server) extended their systems with object-oriented features, and also expanded their support for data types including XML. The SQL standard now includes support for collection types (e.g. arrays, row types and multisets, recursive queries and XML). Some ORDBMSs (e.g. Oracle) include support for RDF. While SQL is still often used for data exchange, XML is being increasingly used for exchanging data between applications.
In practice, most applications use an object model for transient (in-memory) storage, while using an RDB or ORDB for persistent storage. This has led to extensive efforts to facilitate transformation between these differently structured data stores (known as Object-Relational mapping). One interesting initiative in this regard is Microsoft’s Language Integrated Query (LINQ) technology, which allows users to interact with relational data by using an SQL-like syntax in their object-oriented program code.
Recently there has been a growing recognition that the best way to develop database systems is by
transformation from a high level, conceptual schema that specifies the structure of the data in a way
that can be easily understood and hence validated by the (often nontechnical) subject matter experts,
who are the only ones who can reliably determine whether the proposed models accurately reflect their
business domains.
While this notion of model driven development was forcefully and clearly proposed over a quarter century ago in an ISO standard (van Griethuysen, 1982), only in the last decade has it begun to be widely accepted by major commercial interests. Though called differently by different bodies (e.g. the Object management Group calls it “Model Driven Architecture” and Microsoft promotes model driven
development based on Domain Specific Languages) the basic idea is to clearly specify the business
domain model at a conceptual level, and then transform it as automatically as possible to application code, thereby minimizing the need for human programming. In the next section we review and contrast three of the most popular approaches to specifying high level data models for subsequent transformation into database schemas.
CONCEPTUAL DATABASE MODELING APPROACHES
In industry, most database designers either use a variant of Entity Relationship (ER) modeling or simply
design directly at the relational level. The basic ER approach was first proposed by Chen (1976), and
structures facts in terms of entities (e.g. Person, Car) that have attributes (e.g. gender, birthdate) and participate in relationships (e.g. Person drives Car). The most popular industrial versions of ER are the Barker ER notation (Barker, 1990), Information Engineering (IE) (Finkelstein, 1998), and IDEF1X (IEEE, 1999). IDEF1X is actually a hybrid of ER and relational, explicitly using relational concepts such as foreign keys. Barker ER is currently the best and most expressive of the industrial ER notations, so we focus our ER discussion on it.
The Unified Modeling Language (UML) was adopted by the Object Management Group (OMG) in 1997 as a language for object-oriented (OO) analysis and design. After several minor revisions, a major
overhaul resulted in UML version 2.0 (OMG, 2003), and the language is still being refined. Although
xxi
Language (OCL) is too technical for most business people to understand (Warmer & Kleppe, 2003). For such reasons, although UML is widely used for documenting object-oriented programming applications, it is far less popular than ER for database design.
Despite their strengths, both ER and UML are fairly weak at capturing the kinds of business rules found in data-intensive applications, and their graphical language does not lend itself readily to verbal-ization and multiple instantiation for validating data models with domain experts.
These problems can be remedied by using a fact-oriented approach for information analysis, where
communication takes place in simple sentences, each sentence type can easily be populated with multiple instances, attributes are avoided in the base model, and far more business rules can be captured graphi-cally. At design time, a fact-oriented model can be used to derive an ER model, a UML class model, or a logical database model.
Object Role Modeling (ORM), the main exemplar of the fact-oriented approach, originated in Eu-rope in the mid-1970s (Falkenberg, 1976), and been extensively revised and extended since, along with commercial tool support (e.g. Halpin, Evans, Hallock & MacLean, 2003). Recently, a major upgrade to the methodology resulted in ORM 2, a second generation ORM (Halpin 2005; Halpin & Morgan 2008). Neumont ORM Architect (NORMA), an open source tool accessible online at www.ORMFoundation. org, is under development to provide deep support for ORM 2 (Curland & Halpin, 2007).
ORM pictures the world simply in terms of objects (entities or values) that play roles (parts in rela-tionships). For example, you are now playing the role of reading, and this prologue is playing the role
of being read. Wherever ER or UML uses an attribute, ORM uses a relationship. For example, the Person.
birthdate attribute is modeled in ORM as the fact type Person was born on Date, where the role played by date in this relationship may be given the rolename “birthdate”.
ORM is less popular than either ER or UML, and its diagrams typically consume more space because of their attribute-free nature. However, ORM arguably offers many advantages for conceptual analysis, as illustrated by the following example, which presents the same data model using the three different notations.
In terms of expressibility for data modeling, ORM supports relationships of any arity (unary, binary,
ternary or longer), identification schemes of arbitrary complexity, asserted, derived, and semiderived facts and types, objectified associations, mandatory and uniqueness constraints that go well beyond ER
and UML in dealing with n-ary relationships, inclusive-or constraints, set comparison (subset, equality, exclusion) constraints of arbitrary complexity, join path constraints, frequency constraints, object and role cardinality constraints, value and value comparison constraints, subtyping (asserted, derived and semiderived), ring constraints (e.g. asymmetry, acyclicity), and two rule modalities (alethic and deontic (Halpin, 2007a)). For some comparisons between ORM 1 and ER and UML see Halpin (2002, 2004).
As well as its rich notation, ORM includes detailed procedures for constructing ORM models and transforming them to other kinds of models (ER, UML, Relational, XSD etc.) on the way to implementa-tion. For a general discussion of such procedures, see Halpin & Morgan (2008). For a detailed discussion of using ORM to develop the data model example discussed below, see Halpin (2007b).
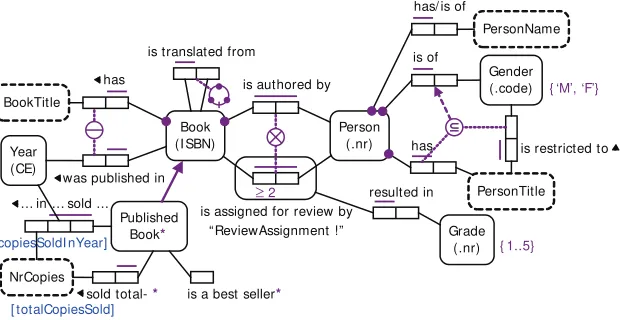
Figure 1 shows an ORM schema for a fragment of a book publisher application. Entity types appear
as named, soft rectangles, with simple identification schemes parenthesized (e.g. Books are identified by
xxii
A bar over a sequence of one or more roles depicts a uniqueness constraint (e.g. each book has at most one booktitle, but a book may be authored by many persons and vice versa). The external
unique-ness constraint (circled bar) reflects the publisher’s policy of publishing at most one book of any given
title in any given year. A dot on a role connector indicates that role is mandatory (e.g. each book has a booktitle).
Subtyping is depicted by an arrow from subtype to supertype. In this case, the PublishedBook subtype is derived (indicated by an asterisk), so a derivation rule for it is supplied. Value constraints are placed in braces (e.g. the possible codes for Gender are ‘M’ and ‘F’).
The ring constraint on the book translation fact type indicates that relationship is acyclic. The ex-clusion constraint (circled X) ensures that no person may review a book that he or she authors. The
frequency constraint (≥ 2) ensures that any book assigned for review has at least two reviewers. The
subset constraint (circled ⊆) ensures that if a person has a title that is restricted to a specific gender (e.g. ‘Mrs’ is restricted to females), then that person must be of that gender—an example of a constraint on a
conceptual join path. The textual declarations provide a subtype definition and two derivation rules, one
in attribute style (using role names) and one in relational style. ORM schemas can also be automatically verbalized in natural languages sentences, enabling validation by domain experts without requiring them to understand the notation (Curland & Halpin, 2007).
Figure 2 depicts the same model in Barker ER notation, supplemented by textual rules (6 numbered constraints, plus 3 derivations) that cannot be captured in this notation.
Barker ER depicts entity types as named, soft rectangles. Mandatory attributes are preceded by an asterisk and optional attributes by “o”. An attribute that is part of the primary identifier is preceded by “#”, and a role that is part of an identifier has a stroke “|” through it.
All relationships must be binary, with each half of a relationship line depicting a role. A crowsfoot indicates a maximum cardinality of many. A line end with no crowsfoot indicates a maximum cardinal-ity of one. A solid line end indicates the role is mandatory, and a dashed line end indicates the role is optional. Subtyping is depicted by Euler diagrams with the subtype inside the supertype. Unlike ORM and UML, Barker ER supports only single inheritance, and requires that the subtyping always forms a partition.
Figure 1. Book publisher schema in ORM
Book (I SBN)
is authored by
Person (.nr)
is assigned for review by “ReviewAssignment !”
PersonName has/ is of
Gender (.code) is of
{ ‘M’, ‘F’}
has
PersonTitle is restricted to
resulted in
Grade (.nr) { 1..5} BookTitle
has
Year (CE)
was published in
Published Book*
is translated from
… in … sold ...
NrCopies
sold total- * is a best seller*
Each PublishedBook is a Book that was published in some Year.
* For each PublishedBook, totalCopiesSold= sum(copiesSoldI nYear).
* PublishedBook is a best seller iff PublishedBook sold total NrCopies > = 10000.
[ copiesSoldI nYear]
[ totalCopiesSold]
xxiii
Figure 3 shows the same model as a class diagram in UML, supplemented by several textual rules captured either as informal notes (e.g. acyclic) or as formal constraints in OCL (e.g. yearPublished ->
notEmpty()) or as nonstandard notations in braces (e.g., the {P} for preferred identifier and {Un} for
uniqueness are not standard UML). Derived attributes are preceded by a slash. Attribute multiplicities
are assumed to be 1 (i.e. exactly one) unless otherwise specified (e.g. restrictedGender has a multiplicity
of [0..1], i.e. at most one). A “*” for maximum multiplicity indicates “many”. Figure 3. Book publisher schema in UML, supplemented by extra rules Figure 2. Book publisher schema in Barker ER, supplemented by extra rules
BOOK * copies sold in year
Derivation Rules:
Published_Book.totalCopiesSold = sum(Book_Sales_Figure.copies_sold_in_year) . Published_Book.is_a_best seller = totalCopiesSold > = 10000.
Subtype Definition:
Each Published_Book is a Book where year_published is not null.
PERSON
REVI EW ASSI GNMENT
o grade
1 (book title, year published) is unique. 2 The translation relationship is acyclic. 3 Review Assignment is disjoint with authorship. 4 Possible values of gender are ‘M’, ‘F’.
5 Each person with a person title restricted to a gender has that gender.
6 Possible values of grade are 1..5. 2
yearPublished -> notEmpty().
totalCopiesSold = sum(salesFigure.copiesSoldI nYear). isaBestSeller = (totalCopiesSold > = 10000).
author
restrictedGender [ 0..1] : GenderCode Title
*
1 translation
title.restrictedGender = self.gender or
title.restrictedGender -> isEmpty()
xxiv
Part of the problem with the UML and ER models is that in these approaches personTitle and gender would normally be treated as attributes, but for this application we need to talk about them to capture a relevant business rule. The ORM model arguably provides a more natural representation of the business domain, while also formally capturing much more semantics with its built-in constructs, facilitating transformation to executable code. This result is typical for industrial business domains.
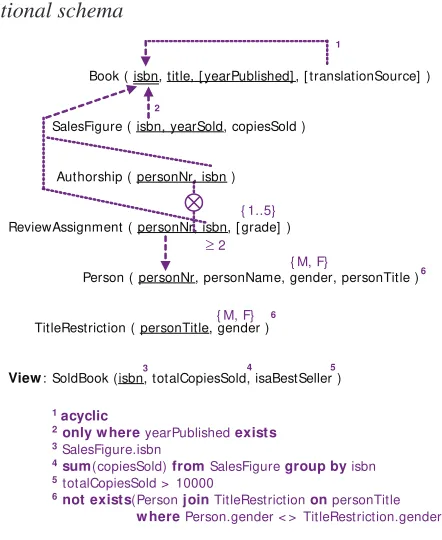
Figure 4 shows the relational database schema obtained by mapping these data schemas via ORM’s Rmap algorithm (Halpin & Morgan, 2008), using absorption as the default mapping for subtyping. Here square brackets indicate optional, dotted arrows indicate subset constraints, and a circled “X” depicts an exclusion constraint. Additional constraints are depicted as numbered textual rules in a high level relational notation. For implementation, these rules are transformed further into SQL code (e.g. check clauses, triggers, stored procedures, views).
CONCLUSION
While many kinds of database technology exist, RDBs and ORDBs currently dominate the market, with XML being increasingly used for data exchange. While ER is still the main conceptual modeling approach for designing databases, UML is gaining a following for this task, and is already widely used for object
oriented code design. Though less popular than ER or UML, the fact-oriented approach exemplified by
ORM has many advantages for conceptual data analysis, providing richer coverage of business rules, easier validation by business domain experts, and semantic stability (ORM models and queries are un-impacted by changes that require one to talk about an attribute). Because ORM models may be used to generate ER and UML models, it may also be used in conjunction with these if desired.
Figure 4. Book publisher relational schema
Book ( isbn, title, [ yearPublished] , [ translationSource] )
SalesFigure ( isbn, yearSold, copiesSold )
Authorship ( personNr, isbn )
ReviewAssignment ( personNr, isbn, [ grade] )
Person ( personNr, personName, gender, personTitle )
TitleRestriction ( personTitle, gender )
View: SoldBook (isbn, totalCopiesSold, isaBestSeller )
1
1 acyclic
2only w here yearPublished exists 3SalesFigure.isbn
4sum(copiesSold) from SalesFigure group by isbn 5 totalCopiesSold > 10000
6not exists(Person join TitleRestriction on personTitle w here Person.gender < > TitleRestriction.gender).
≥ 2
{ M, F}
{ M, F} { 1..5}
2
3 4 5
6
xxv
With a view to providing better support at the conceptual level, the OMG recently adopted the
Se-mantics of Business Vocabulary and Business Rules (SBVR) specification (OMG, 2007). Like ORM, the
SBVR approach is fact oriented instead of attribute-based, and includes deontic as well as alethic rules. Many companies are now looking to model-driven development as a way to dramatically increase the productivity, reliability, and adaptability of software engineering approaches. It seems likely that both object-oriented and fact-oriented approaches will be increasingly utilized in the future to increase the proportion of application code that can be generated from higher level models.
REFERENCES
Atkinson, M., Bancilhon, F., DeWitt, D., Dittrick, K., Maier, D. & Zdonik, S. (1989). The
Object-Ori-ented Database System Manifesto. In W. Kim, J-M. Nicolas & S. Nishio (Eds), Proc. DOOD-89: First
Int. Conf. on Deductive and Object-Oriented Databases (pp. 40–57). Elsevier.
Barker, R. (1990). CASE*Method: Entity Relationship Modelling, Addison-Wesley, Wokingham.
Berners-Lee, T., Hendler, J. & Lassila, O. (2001). ‘The Semantic Web’, Scientific American, May 2001.
Bloesch, A. & Halpin, T. (1997). Conceptual queries using ConQuer-II. In D. Embley & R. Goldstein
(Eds.), Proc. 16th Int. Conf. on Conceptual Modeling ER’97 (pp. 113-126). Berlin: Springer.
Booch, G., Rumbaugh, J. & Jacobson, I. (1999). The Unified Modeling Language User Guide. Reading:
Addison-Wesley.
Chen, P. (1976). ‘The Entity-Relationship Model—Toward a Unified View of Data’, ACM Transactions on Database Systems, vol. 1, no. 1, pp. 9−36.
Codd, E. (1970). A Relational Model of Data for Large Shared Data Banks. CACM, vol. 13, no. 6, pp.
377−87.
Curland, M. & Halpin, T. (2007). Model Driven Development with NORMA. In: Proc. HICSS-40,
CD-ROM, IEEE Computer Society.
Falkenberg, E. (1976). Concepts for modelling information. In G. Nijssen (Ed.), Modelling in Data Base
Management Systems (pp. 95-109). Amsterdam: North-Holland.
Finkelstein, C. (1998). ‘Information Engineering Methodology’, Handbook on Architectures of Information
Systems, eds. P. Bernus, K. Mertins & G. Schmidt, Springer-Verlag, Berlin, Germany, pp. 405–27.
Halpin, T. (2002). Information Analysis in UML and ORM: a Comparison. Advanced Topics in Database
Research, vol. 1, K. Siau (Ed.), Hershey PA: Idea Publishing Group, Ch. XVI (pp. 307-323).
Halpin, T. (2004). Comparing Metamodels for ER, ORM and UML Data Models. In: Siau K (ed)
Ad-vanced Topics in Database Research, vol. 3, Idea Pub. Group, Hershey, pp. 23–44.
Halpin, T. (2005). ORM 2. In: Meersman R et al. (eds) On the Move to Meaningful Internet Systems
2005: OTM 2005 Workshops, LNCS vol 3762. Springer, Berlin Heidelberg New York, pp. 676–687.
Halpin, T. (2006). Object-Role Modeling (ORM/NIAM). In: Handbook on Architectures of Information
xxvi
Halpin, T. (2007a). Modality of Business Rules. In: Research Issues in Systems Analysis and Design,
Databases and Software Development, ed. K. Siau, IGI Publishing, Hershey, pp. 206-226.
Halpin, T. (2007b). Fact-Oriented Modeling: Past, Present and Future. In: Krogstie J, Opdahl A,
Brinkkem-per S (eds) Conceptual Modelling in Information Systems Engineering. Springer, Berlin, pp. 19-38.
Halpin, T. & Bloesch, A. (1999). Data modeling in UML and ORM: a comparison. Journal of Database
Management, 10(4), 4-13.
Halpin, T., Evans, K, Hallock, P. & MacLean, W. (2003). Database Modeling with Microsoft® Visio for
Enterprise Architects, San Francisco: Morgan Kaufmann.
Halpin, T. & Morgan, T. (2008). Information Modeling and Relational Databases. 2nd Edn. San Fran-cisco: Morgan Kaufmann.
IEEE (1999). IEEE standard for conceptual modeling language syntax and semantics for IDEF1X97
(IDEFobject), IEEE Std 1320.2–1998, IEEE, New York.
ter Hofstede, A., Proper, H. & van der Weide, T. (1993). Formal definition of a conceptual language for
the description and manipulation of information models. Information Systems 18(7), 489-523.
Jacobson, I., Booch, G. & Rumbaugh, J. (1999). The Unified Software Development Process. Reading:
Addison-Wesley.
Melton, J. & Simon, A. 2002, SQL:1999Understanding Relational Language Components, Morgan
Kaufmann.
Melton, J. & Buxton, S. 2006, Querying XML: XQuery, XPath, and SQL/XML in Context, Morgan Kaufmann.
OMG (2003). OMG Unified Modeling Language Specification, version 2.0 [Online] Available: http://
www.uml.org/.
OMG (2007). Semantics of Business Vocabulary and Business Rules (SBVR). URL: http://www.omg. org/cgi-bin/doc?dtc/2006-08-05.
Rumbaugh, J., Jacobson, I. & Booch, G. (1999). The Unified Modeling Language Reference Manual.
Reading: Addison-Wesley.
Stonebraker, M., Rowe, L., Lindsay, B., Gray, J., Carey, M., Brodie, M., Bernstein, P. & Beech, D. (1990).
‘Third Generation Database System Manifesto’, ACM SIGMOD Record, vol. 19, no. 3.
van Griethuysen, J. (ed.) (1982). Concepts and Terminology for the Conceptual Schema and the
Infor-mation Base, ISO TC97/SC5/WG3, Eindhoven.
Warmer, J. & Kleppe, A. (2003). The Object Constraint Language: Getting Your Models Ready for MDA,
xxvii
About the Editor
Terry Halpin, BSc, DipEd, BA, MLitStud, PhD, is distinguished professor and vice president (Conceptual
Modeling) at Neumont University. His industry experience includes several years in data modeling technology at Asymetrix Corporation, InfoModelers Inc., Visio Corporation, and Microsoft Corporation. His doctoral thesis formalized Object-Role Modeling (ORM/NIAM), and his current research focuses on conceptual modeling and
Section I
1
Chapter I
Conceptual Modeling Solutions
for the Data Warehouse
Stefano Rizzi
DEIS - University of Bologna, Italy
ABSTRACT
In the context of data warehouse design, a basic role is played by conceptual modeling, that pro-vides a higher level of abstraction in describing the warehousing process and architecture in all its aspects, aimed at achieving independence of implementation issues. This chapter focuses on a conceptual model called the DFM that suits the variety of modeling situations that may be encountered in real projects of small to large complexity. The aim of the chapter is to propose a comprehensive set of solutions for conceptual modeling according to the DFM and to give the designer a practical guide for applying them in
the context of a design methodology. Besides the basic concepts of multidimensional modeling, the other issues discussed are descriptive and cross-dimension attributes; convergences; shared, incomplete, recursive, and dynamic hierarchies; multiple and optional arcs; and additivity.
INTRODUCTION
2
Conceptual Modeling Solutions for the Data Warehouse
support; the workload they support has com-pletely different characteristics, and is widely known as OLAP (online analytical processing). Traditionally, OLAP applications are based on multidimensional modeling that intuitively rep-resents data under the metaphor of a cube whose cells correspond to events that occurred in the business domain (Figure 1). Each event is
quanti-fied by a set of measures; each edge of the cube
corresponds to a relevant dimension for analysis, typically associated to a hierarchy of attributes that further describe it. The multidimensional
model has a twofold benefit. On the one hand,
it is close to the way of thinking of data analyz-ers, who are used to the spreadsheet metaphor; therefore it helps users understand data. On the other hand, it supports performance improvement as its simple structure allows designers to predict the user intentions.
Multidimensional modeling and OLAP work-loads require specialized design techniques. In the context of design, a basic role is played by conceptual modeling that provides a higher level of abstraction in describing the warehousing pro-cess and architecture in all its aspects, aimed at achieving independence of implementation issues.
Conceptual modeling is widely recognized to be the necessary foundation for building a database
that is well-documented and fully satisfies the
user requirements; usually, it relies on a graphical notation that facilitates writing, understanding, and managing conceptual schemata by both de-signers and users.
Unfortunately, in the field of data warehousing
there still is no consensus about a formalism for conceptual modeling (Sen & Sinha, 2005). The entity/relationship (E/R) model is widespread in the enterprises as a conceptual formalism to provide standard documentation for relational information systems, and a great deal of effort has been made to use E/R schemata as the input for designing nonrelational databases as well (Fahrner & Vossen, 1995); nevertheless, as E/R is oriented to support queries that navigate associations be-tween data rather than synthesize them, it is not well suited for data warehousing (Kimball, 1996). Actually, the E/R model has enough expressivity to represent most concepts necessary for modeling a DW; on the other hand, in its basic form, it is not able to properly emphasize the key aspects of the multidimensional model, so that its usage for DWs is expensive from the point of view of the
Conceptual Modeling Solutions for the Data Warehouse
graphical notation and not intuitive (Golfarelli, Maio, & Rizzi, 1998).
Some designers claim to use star schemata for conceptual modeling. A star schema is the standard implementation of the multidimensional model on relational platforms; it is just a
(denor-malized) relational schema, so it merely defines
a set of relations and integrity constraints. Using the star schema for conceptual modeling is like starting to build a complex software by writing the code, without the support of and static, func-tional, or dynamic model, which typically leads to very poor results from the points of view of adherence to user requirements, of maintenance, and of reuse.
For all these reasons, in the last few years the research literature has proposed several original approaches for modeling a DW, some based on extensions of E/R, some on extensions of UML. This chapter focuses on an ad hoc conceptual
model, the dimensional fact model (DFM), that
was first proposed in Golfarelli et al. (1998) and continuously enriched and refined during the fol -lowing years in order to optimally suit the variety of modeling situations that may be encountered in real projects of small to large complexity. The aim of the chapter is to propose a comprehensive set of solutions for conceptual modeling according to the DFM and to give a practical guide for apply-ing them in the context of a design methodology. Besides the basic concepts of multidimensional modeling, namely facts, dimensions, measures, and hierarchies, the other issues discussed are
descriptive and cross-dimension attributes; con-vergences; shared, incomplete, recursive, and dynamic hierarchies; multiple and optional arcs; and additivity.
After reviewing the related literature in the next section, in the third and fourth sections, we introduce the constructs of DFM for basic and advanced modeling, respectively. Then, in
the fifth section we briefly discuss the different
methodological approaches to conceptual design. Finally, in the sixth section we outline the open issues in conceptual modeling, and in the last section we draw the conclusions.
RELATED LITERATURE
In the context of data warehousing, the literature proposed several approaches to multidimensional modeling. Some of them have no graphical support and are aimed at establishing a formal foundation for representing cubes and hierarchies as well as an algebra for querying them (Agrawal, Gupta, & Sarawagi, 1995; Cabibbo & Torlone, 1998; Datta & Thomas, 1997; Franconi & Kamble, 2004a; Gyssens & Lakshmanan, 1997; Li & Wang, 1996; Pedersen & Jensen, 1999; Vassiliadis, 1998); since we believe that a distinguishing feature of conceptual models is that of providing a graphical support to be easily understood by both designers and users when discussing and validating require-ments, we will not discuss them.
Table 1. Approaches to conceptual modeling
E/R extension object-oriented ad hoc
no method
Franconi and Kamble (2004b); Sapia et al. (1998); Tryfona et al. (1999)
Abelló et al. (2002); Nguyen, Tjoa, and Wagner
(2000)
Tsois et al. (2001)
4
Conceptual Modeling Solutions for the Data Warehouse
The approaches to “strict” conceptual model-ing for DWs devised so far are summarized in Table 1. For each model, the table shows if it is associated to some method for conceptual design and if it is based on E/R, is object-oriented, or is an ad hoc model.
The discussion about whether E/R-based, object-oriented, or ad hoc models are preferable is controversial. Some claim that E/R extensions should be adopted since (1) E/R has been tested for years; (2) designers are familiar with E/R; (3) E/R
has proven flexible and powerful enough to adapt
to a variety of application domains; and (4) several important research results were obtained for the
E/R (Sapia, Blaschka, Hofling, & Dinter, 1998;
Tryfona, Busborg, & Borch Christiansen, 1999). On the other hand, advocates of object-oriented models argue that (1) they are more expressive and better represent static and dynamic properties of information systems; (2) they provide powerful mechanisms for expressing requirements and constraints; (3) object-orientation is currently the dominant trend in data modeling; and (4) UML, in particular, is a standard and is naturally extensible (Abelló, Samos, & Saltor, 2002; Luján-Mora, Trujillo, & Song, 2002). Finally, we believe that ad hoc models compensate for the lack of familiarity from designers with the fact that (1) they achieve better notational economy; (2) they give proper emphasis to the peculiarities of the