Informasi Dokumen
- Penulis:
- Nida Amalia
- Pengajar:
- Dr.Eng. Chastine Fatichah, S.Kom., M.Kom.
- Dini Adni Navastara, S.Kom., M.Sc.
- Sekolah: Institut Teknologi Sepuluh Nopember
- Mata Pelajaran: Informatika
- Topik: Aplikasi Pengenalan Ucapan Huruf Hijaiyah Berbasis Android untuk Refreshable Braille Display Menggunakan Mel-Frequency Cepstrum Coefficients dan Neural Network
- Tipe: Tugas Akhir
- Tahun: 2017
- Kota: Surabaya
Ringkasan Dokumen
I. Einleitung: Pädagogischer Kontext und didaktische Relevanz
Die vorliegende Masterarbeit "Aplikasi Pengenalan Ucapan Huruf Hijaiyah Berbasis Android untuk Refreshable Braille Display Menggunakan Mel-Frequency Cepstrum Coefficients dan Neural Network - ITS Repository" adressiert ein relevantes Problem im Bereich der inklusiven Bildung für sehbehinderte und blinde Lernende. Sie präsentiert eine Android-basierte Anwendung zur Spracherkennung arabischer Buchstaben (Huruf Hijaiyah), die mit einem Refresh-Braille-Display gekoppelt ist. Die Arbeit untersucht somit den Einsatz von Spracherkennungstechnologien und deren didaktische Potenziale im Kontext des arabischen Alphabets und der Braille-Schrift. Dies ist besonders wertvoll, da der Zugang zu Lernmaterialien für blinde und sehbehinderte Menschen in vielen Bereichen, insbesondere im religiösen Unterricht, oft limitiert ist. Die Arbeit trägt damit zu einer verbesserten Teilhabe und Chancengleichheit im Bildungssystem bei.
1.1 Bildungsziele und Lerninhalte
Die Arbeit leistet einen wichtigen Beitrag zur Erreichung verschiedener Bildungsziele. Sie fördert die Selbstständigkeit blinder und sehbehinderter Lernender beim Erlernen des arabischen Alphabets und der korrekten Aussprache der Huruf Hijaiyah. Die Anwendung unterstützt individuelles und selbstgesteuertes Lernen, indem sie unmittelbares Feedback zur Aussprache gibt und die Buchstaben gleichzeitig in Braille-Schrift darstellt. Der Fokus auf die korrekte Aussprache ist entscheidend, da die Bedeutung arabischer Wörter stark von der korrekten Betonung und Artikulation abhängt. Die didaktische Konzeption der Anwendung zielt darauf ab, den Lernprozess zu vereinfachen und zu beschleunigen, indem sie moderne Technologien nutzt, um traditionelle Lernmethoden zu ergänzen.
1.2 Theoretische Grundlagen und methodische Ansätze
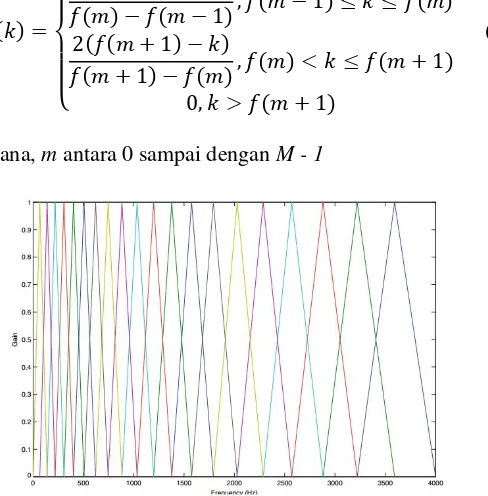
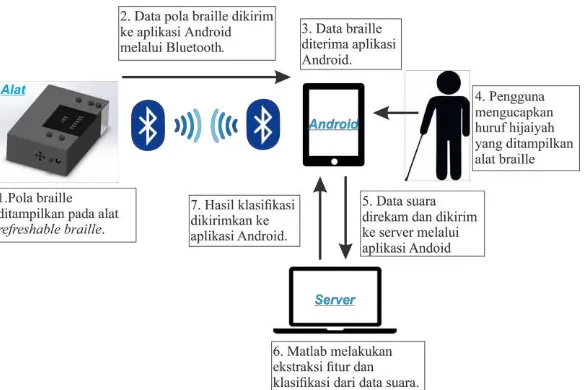
Die Arbeit stützt sich auf fundierte theoretische Grundlagen der Spracherkennung, der Signalverarbeitung und des maschinellen Lernens. Die Anwendung der Mel-Frequency Cepstrum Coefficients (MFCC) zur Merkmalsextraktion und des Backpropagation-Algorithmus für die neuronale Netze repräsentiert einen aktuellen Stand der Forschung in diesem Bereich. Die Wahl dieser Methoden wird im Kontext der Arbeit begründet und ihre Eignung für die Spracherkennung von arabischen Buchstaben diskutiert. Die Integration von Voice Activity Detection (VAD) verbessert die Robustheit des Systems gegenüber Hintergrundgeräuschen, ein wichtiger Aspekt für die praktische Anwendung im Alltag. Der Einsatz des Arduino und der Bluetooth-Kommunikation demonstriert die Integration verschiedener technologischer Komponenten zu einem funktionierenden Lernsystem.
1.3 Pädagogische Implikationen und Anwendungspotential
Die Ergebnisse der Arbeit haben weitreichende pädagogische Implikationen. Die entwickelte Anwendung kann nicht nur im individuellen Lernprozess eingesetzt werden, sondern auch als Ergänzung zum traditionellen Unterricht in Schulen und religiösen Einrichtungen. Die Möglichkeit der selbstständigen Lernkontrolle und des unmittelbaren Feedbacks trägt zu einer effektiveren und motivierenderen Lernumgebung bei. Darüber hinaus bietet die Arbeit ein Beispiel für den erfolgreichen Einsatz von Technologie zur Förderung von Inklusion und zur Überwindung von Barrieren für Menschen mit Behinderungen. Die Arbeit eröffnet Perspektiven für zukünftige Forschung im Bereich der Entwicklung adaptiver und personalisierter Lernsysteme für sehbehinderte und blinde Lernende, die auf Spracherkennung und anderen Technologien beruhen.
II. Methoden und Ergebnisse: Eine akademische Bewertung
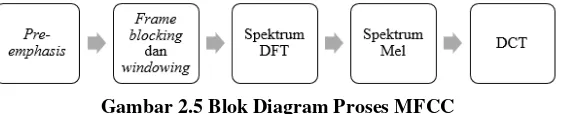
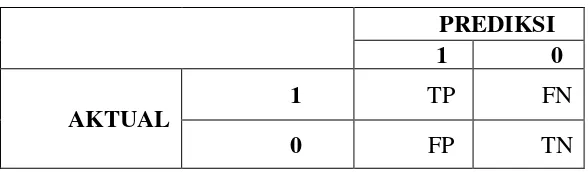
Der methodische Ansatz der Arbeit ist solide und basiert auf etablierten Verfahren der Spracherkennung und des maschinellen Lernens. Die detaillierte Beschreibung der Datengewinnung, der Vorverarbeitungsschritte (VAD), der Merkmalsextraktion (MFCC) und der Klassifizierung (neuronales Netz) erlaubt eine Nachvollziehbarkeit und Bewertung der Ergebnisse. Die quantitative Auswertung der Ergebnisse mittels der Confusion Matrix und der Berechnung von Genauigkeit, Sensitivität und Spezifität bietet eine valide Grundlage für die Beurteilung der Performance des Systems. Die Diskussion der verschiedenen Parameter (z.B. Frame-Länge, Overlap, Anzahl der Neuronen) und deren Einfluss auf die Klassifikationsgenauigkeit zeugt von einem wissenschaftlich fundierten Vorgehen.
2.1 Datenanalyse und statistische Validität
Die Arbeit präsentiert eine detaillierte Analyse der verwendeten Daten, einschließlich der Beschreibung des Datensatzes, der Aufteilung in Trainings- und Testdaten und der statistischen Auswertung der Ergebnisse. Die Größe des Datensatzes und die Methode der Datenerhebung sollten kritisch betrachtet werden, um die Generalisierbarkeit der Ergebnisse zu beurteilen. Die statistische Signifikanz der Ergebnisse sollte ebenfalls explizit diskutiert werden. Eine detailliertere Analyse der Fehlerquellen und der Limitationen des Systems wäre wünschenswert.
2.2 Vergleich mit bestehenden Ansätzen
Die Arbeit sollte die Ergebnisse im Vergleich zu anderen, etablierten Ansätzen zur Spracherkennung und insbesondere zur Erkennung arabischer Sprache einordnen. Ein Vergleich mit existierenden Anwendungen im Bereich der inklusiven Bildung wäre ebenfalls relevant, um den Beitrag der Arbeit im Kontext des Forschungsstandes zu positionieren. Die Diskussion der Stärken und Schwächen des Systems im Vergleich zu alternativen Methoden trägt zur wissenschaftlichen Qualität der Arbeit bei.
2.3 Ausblick und zukünftige Forschungsfragen
Die Arbeit schließt mit einem Ausblick auf zukünftige Forschungsfragen. Die Erweiterung des Systems um weitere Funktionen (z.B. die Erkennung von Wörtern oder Sätzen, die Integration weiterer arabischer Dialekte) wäre ein interessantes Forschungsfeld. Die Verbesserung der Robustheit des Systems gegenüber unterschiedlichen Sprechern, Akzenten und Umgebungsgeräuschen bietet ebenfalls Potenzial für zukünftige Arbeiten. Die Integration der Anwendung in bestehende digitale Lernplattformen und die Evaluation im realen Unterricht würde die praktische Relevanz und den Nutzen der Anwendung weiter unterstreichen.

![Tabel 2.1 Daftar Huruf Hijaiyah dan Pengucapannya [9]](https://thumb-ap.123doks.com/thumbv2/123dok/1810711.2099792/33.420.72.365.308.530/tabel-daftar-huruf-hijaiyah-dan-pengucapannya.webp)
![Gambar 2.1 Penomoran Sel Braille [9]](https://thumb-ap.123doks.com/thumbv2/123dok/1810711.2099792/34.420.134.280.210.368/gambar-penomoran-sel-braille.webp)
![Gambar 2.2 Huruf Hijaiyah dalam Braille [10]](https://thumb-ap.123doks.com/thumbv2/123dok/1810711.2099792/35.420.74.360.71.263/gambar-huruf-hijaiyah-dalam-braille.webp)

![Gambar 2.4 Arduino Nano [14]](https://thumb-ap.123doks.com/thumbv2/123dok/1810711.2099792/37.420.70.359.149.277/gambar-arduino-nano.webp)