OPTIMASI MULTI-OBJECTIVE MENGGUNAKAN NSGA-II DALAM PENJADWALAN MESIN PRODUKSI FLOW SHOP
TESIS
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Magister Teknik Informatika
FIFIN SONATA 137038026
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN
2015
PERSETUJUAN
Judul : Optimasi Multi-objective Menggunakan NSGA-II Dalam Penjadwalan Mesin Produksi Flow Shop
Kategori : Tesis
Nama : Fifin Sonata
Nomor Induk Mahasiswa : 137038026
Program Studi : Teknik Informatika
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI UNIVERSITAS SUMATERA UTARA
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Prof. Dr. Tulus, Vor.Dipl.Math., M.Si Prof. Dr. Muhammad Zarlis
Diketahui/disetujui oleh
Program Studi S2 Teknik Informatika Ketua,
Prof. Dr. Muhammad Zarlis
NIP: 195707011986011003
PERNYATAAN
OPTIMASI MULTI-OBJECTIVE MENGGUNAKAN NSGA-II DALAM PENJADWALAN MESIN PRODUKSI FLOW SHOP
TESIS
Saya mengakui bahwa tesis ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, Juli 2015
Fifin Sonata
137038026
PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Sebagai sivitas akademika Universitas Sumatera Utara, saya yang bertanda tangan di bawah ini:
Nama : Fifin Sonata
NIM : 137038026
Program Studi : Teknik Informatika Jenis Karya Ilmiah : Tesis
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Sumatera Utara Hak Bebas Royalti Non-Eksklusif (Non-Exclusive Royalty Free Right) atas tesis saya yang berjudul:
OPTIMASI MULTI-OBJECTIVE MENGGUNAKAN NSGA-II DALAM PENJADWALAN MESIN PRODUKSI FLOW SHOP
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Non- Eksklusif ini, Universitas Sumatera Utara berhak menyimpan, mengalih media, memformat, mengelola dalam bentuk database, merawat dan mempublikasikan tesis saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagai penulis dan sebagai pemegang dan/atau sebagai pemilik hak cipta.
Demikian penyataan ini dibuat dengan sebenarnya.
Medan, Juli 2015
Fifin Sonata
137038026
Telah diuji pada
Tanggal : 3 Juli 2015
PANITIA PENGUJI TESIS
Ketua : Prof. Dr. Muhammad Zarlis
Anggota : 1. Prof. Dr. Tulus, Vor.Dipl.Math., M.Si 2. Prof. Herman Mawengkang
3. Dr. Syahril Efendi, S.Si., M.IT
RIWAYAT HIDUP
DATA PRIBADI
Nama Lengkap (berikut gelar) : Fifin Sonata, S.Kom
Tempat dan Tanggal Lahir : Banyuwangi, 24 Desember 1982
Alamat Rumah : Jl. Sejati Pasar V Marendal I – Deli Serdang
Telepon/Fax/HP : 085649796958
E-mail : [email protected]
Instansi Tempat Bekerja : AMIKOM Medan
Alamat Kantor : Jl. Iskandar Muda No.43-49 Medan DATA PENDIDIKAN
SD : SDN BENCULUK V - Cluring - Banyuwangi TAMAT : tahun 1994 SLTP : SMPN 1 Cluring - Banyuwangi TAMAT : tahun 1997 SLTA : SMUN 2 Genteng - Banyuwangi TAMAT : tahun 2000 S1 : Institut Teknologi Adhi Tama Surabaya TAMAT : tahun 2006
S2 : Teknik Informatika USU TAMAT : tahun 2015
UCAPAN TERIMA KASIH
Alhamdulillahirabbil‟alamiin penulis panjatkan kepada Allah SWT atas hidayah dan petunjuk-NYA, sehingga penulis dapat menyelesaikan laporan tesis dengan judul
“OPTIMASI MULTI-OBJECTIVE MENGGUNAKAN NSGA-II DALAM PENJADWALAN MESIN PRODUKSI FLOW SHOP ”, yang merupakan salah satu syarat memperoleh gelar Magister Teknik Informatika pada Program Studi Teknik Informatika, Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.
Penulis mendapatkan banyak sekali bantuan dari berbagai pihak dalam menyelesaikan laporan tesis ini. Atas berbagai bantuan itu penulis mengucapkan terima kasih yang sebesar-besarnya kepada:
Ayahanda Supriyanto dan Ibunda Hariani yang telah memberikan bimbingan hidup sejak lahir hingga kini dan telah banyak berkorban serta berdo‟a demi kebahagiaan penulis.
Suamiku tercinta Ahmad Khaidir, S.Kom, MT dan anakku tersayang Ahmad Albaihaqie yang telah mendampingi dan memberi semangat pada penulis.
Adikku Anggun Jati Diri yang terus memberikan dukungan moril kepada penulis.
Bapak Prof. Dr. Muhammad Zarlis selaku pembimbing I tesis yang telah bersedia meluangkan waktu untuk membimbing dan membagi ilmunya kepada penulis.
Bapak Prof. Dr. Tulus, Vor.Dipl.Math., M.Si selaku pembimbing II tesis yang telah bersedia meluangkan waktu untuk membimbing dan membagi ilmunya kepada penulis.
Bapak Muhammad Andri Budiman, ST., M.Com.Sc, MEM selaku dosen wali dan seluruh dosen serta staf di Program Studi Teknik Informatika Fakultas Ilmu Komputer dan Teknologi Informasi USU yang telah memberikan banyak sekali bantuan selama penulis berkuliah.
Seluruh teman KomB-2013 terima kasih atas dukungan dan persahabatan yang
telah diberikan. Semoga tali silaturrahmi kita tidak terputus.
Dan berbagai pihak yang tidak dapat penulis sebutkan satu per satu di sini yang telah ikut membantu baik secara langsung maupun tidak langsung selama penulisan tugas akhir ini. Semoga Allah SWT membalas semua kebaikan yang telah dilakukan.
Penulis menyadari masih banyak kekurangan yang terdapat pada penyusunan tesis ini. Oleh karena itu penulis menerima setiap masukan dan kritik yang diberikan demi penyempurnaan tesis ini dan berharap semoga tesis ini dapat bermanfaat untuk kita semua.
Medan, Juli 2015
Penulis
ABSTRAK
Penjadwalan merupakan suatu kegiatan pengalokasian sumber daya yang terbatas untuk mengerjakan sejumlah pekerjaan. Proses penjadwalan timbul jika terdapat keterbatasan sumber daya yang dimiliki, sehingga diperlukan adanya pengaturan sumber-sumber daya yang ada secara efisien. Adapun tujuan dari penjadwalan produksi umumnya ialah untuk mengoptimalkan dimensi atau objek tertentu.
Penjadwalan flow shop adalah salah satu jenis penjadwalan produksi dimana setiap job akan melalui setiap mesin dengan urutan yang seragam. Optimasi penjadwalan mesin produksi flow shop berkaitan dengan penyusunan penjadwalan mesin yang mempertimbangkan 2 objek yaitu makespan dan total tardiness. Optimasi kedua permasalahan tersebut diatas merupakan optimasi yang bertolak belakang sehingga diperlukan model yang mengintegrasikan permasalahan tersebut dengan optimasi multi-objective A Fast Elitist Non-Dominated Sorting Genetic Algorithm for Multi- Objective Optimazitaion : NSGA-II. Penyelesaian penjadwalan mesin produksi flow shop dengan algoritma NSGA-II untuk membangun jadwal dengan meminimalkan makespan dan total tardiness. Model yang dikembangkan akan memberikan solusi penjadwalan mesin produksi flow shop yang efisien berupa solusi pareto optimal yang dapat memberikan sekumpulan solusi alternatif bagi pengambil keputusan dalam membuat penjadwalan mesin produksi yang diharapkan. Agar dapat terlihat nilai solusinya maka dilakukan perbandingan dominasi solusi Aggregat Of Function (AOF) dengan solusi NSGA-II. Solusi pareto optimal yang dihasilkan merupakan solusi optimasi multi-objective yang optimal dengan trade-off terhadap seluruh objek, sehingga seluruh solusi pareto optimal sama baiknya.
Kata kunci : Makespan, Multi-objective, NSGA-II, Penjadwalan Mesin Produksi
Flow Shop, Total tardiness
MULTI-OBJECTIVE OPTIMIZATION USING NSGA-II IN FLOW SHOP PRODUCTION MACHINE SCHEDULING
ABSTRACT
Scheduling is an activity to allocate limited resources to finish the jobs. Scheduling process arise if there are limitations on available resources that requiring utilization the available resources efficiently. Generally, the purpose of production scheduling is to optimize specific dimensions or objects. Flow shop scheduling is a type of production scheduling where each job will go through each machine with an uniform sequence. Optimization of the flow shop production machine scheduling related to determine machine scheduling that considers two objects i.e makespan and total tardiness. Both above optimization problem is a contradictory optimization that require a model which integrates these problems with multi-objective optimization A Fast elitist Non-dominated Sorting Genetic Algorithm for Multi-Objective Optimization: NSGA-II. The main purpose of completion the flow shop production machine scheduling with NSGA-II algorithm is to determine schedules that minimizing makespan and total tardiness. The developed model will generate efficient solutions of flow shop production machine scheduling in the form of pareto optimal solutions which provide a set of alternative solutions for decision makers in making expected production machine scheduling. In order to analyze the value of the solution that generated, the dominance comparisons made between Aggregate of Function (AOF) solutions and NSGA-II solutions. Pareto optimal solutions that generated are optimal multi-objective optimization solutions with trade-off for all objects, thereby all pareto optimal solutions are just as good.
Keywords : Flow Shop Production Scheduling Engine, Makespan, Multi-
objective, NSGA-II, Total tardiness
DAFTAR ISI
Hal.
RIWAYAT HIDUP ... vi
UCAPAN TERIMA KASIH ... vii
ABSTRAK ... ix
ABSTRACT ... x
DAFTAR ISI ... xi
DAFTAR TABEL ... xiii
DAFTAR GAMBAR ... xiv
BAB 1 PENDAHULUAN ... 1
1.1. Latar Belakang ... 1
1.2. Rumusan Masalah ... 2
1.3. Batasan Masalah ... 2
1.4. Tujuan Penelitian ... 3
1.5. Manfaat Penelitian ... 3
1.6. Metodologi Penelitian ... 3
BAB 2 LANDASAN TEORI ... 4
2.1. Penjadwalan dan Penjadwalan Flow shop ... 4
2.2. Multi-objective Optimization (MO) ... 6
BAB 3 METODE PENELITIAN ... 15
3.1. Pengumpulan Data ... 16
3.2. Pemodelan Sistem ... 16
3.3. Tahapan NSGA-II ... 16
3.4. Pengukuran dan Perbandingan Optimasi Menggunakan NSGA-II 18 BAB 4 HASIL PENELITIAN DAN PEMBAHASAN ... 19
4.1. Model Matematis ... 19
4.2. Implementasi Tahapan NSGA-II ... 20
4.3 Hasil Penelitian ... 22
4.4. Perbandingan AOF dan NSGA-II ... 33
BAB 5 KESIMPULAN DAN SARAN ... 36
5.1. Kesimpulan ... 36
5.2. Saran ... 36
DAFTAR PUSTAKA ... 38
LAMPIRAN 1 ... 41
LAMPIRAN 2 ... 44
DAFTAR TABEL
Hal
Tabel 3.1 Tabel Data Penjadwalan Mesin Produksi ... 16
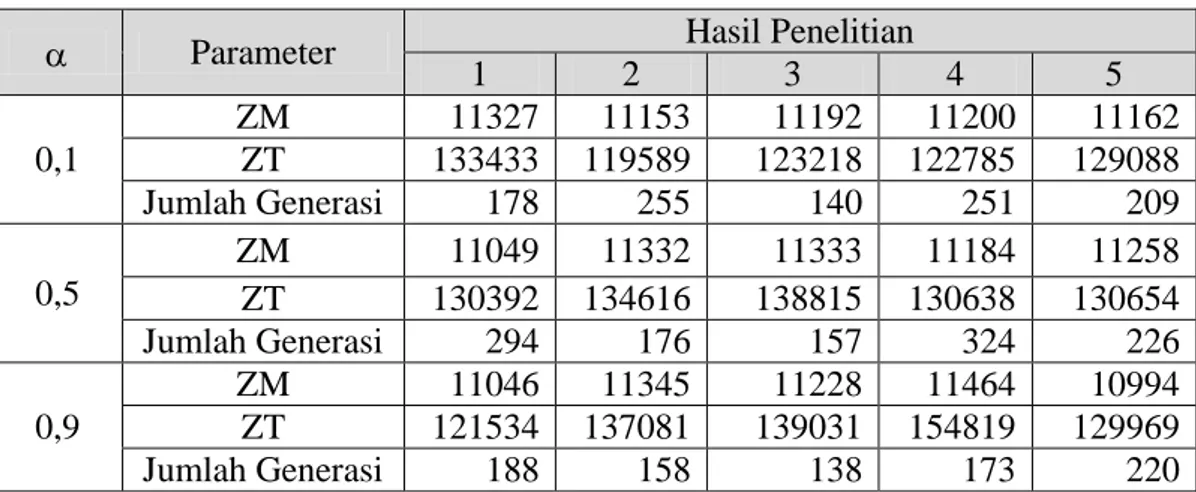
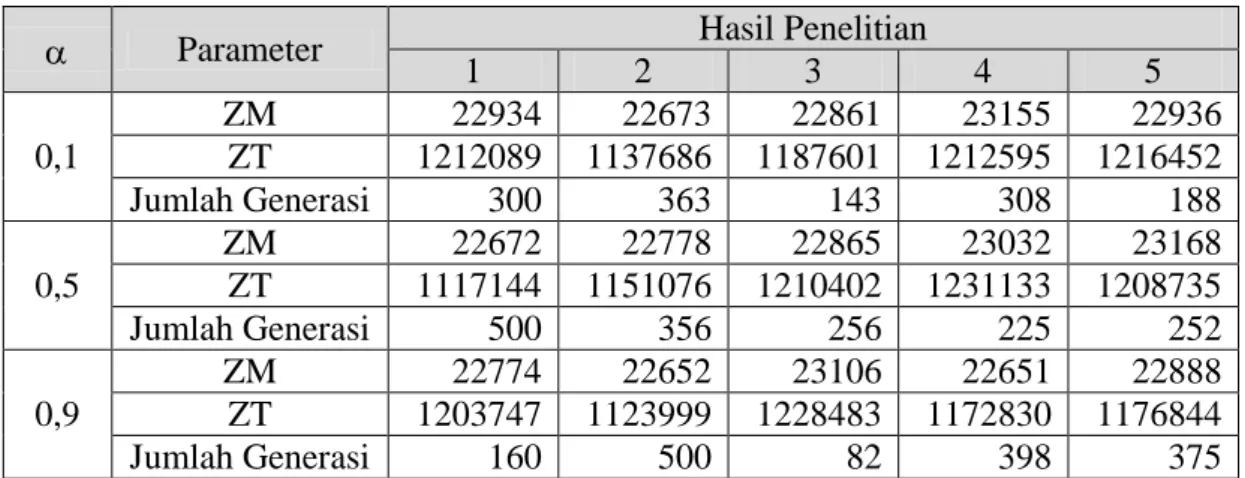
Tabel 4.1 Hasil Penelitian AOF Instance I_150_30... 23
Tabel 4.2 Hasil Penelitian AOF Instance I_250_50... 23
Tabel 4.3 Hasil Penelitian AOF Instance I_350_30... 24
Tabel 4.4 Hasil Penelitian AOF Instance I_350_50... 24
Tabel 4.5 Hasil Penelitian AOF Instance I_50_50... 24
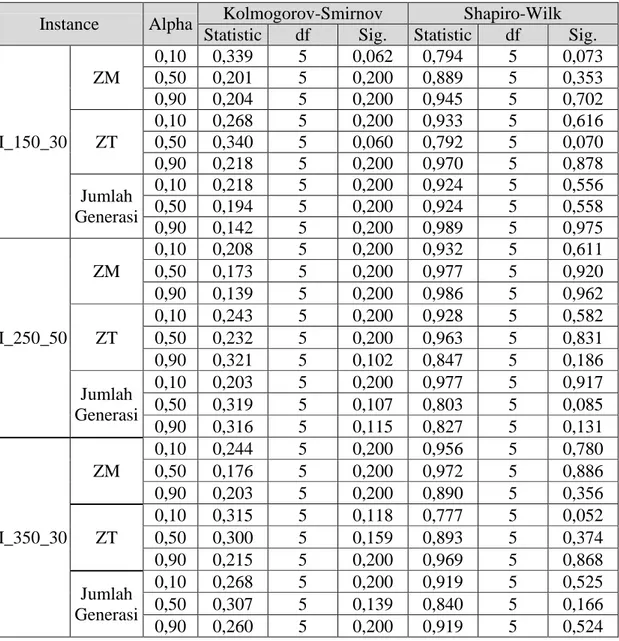
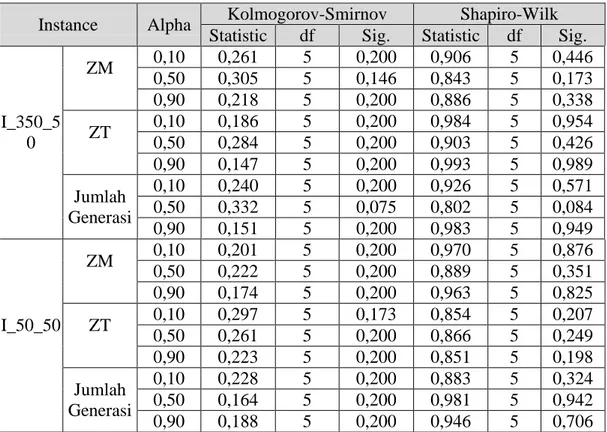
Tabel 4.6 Hasil Uji Normalitas AOF ... 25
Tabel 4.7 Hasil Uji Homogenitas AOF ... 26
Tabel 4.8 Hasil Uji ANOVA AOF ... 27
Tabel 4.9 Parameter Algoritma Genetika untuk AOF ... 29
Tabel 4.10 Hasil Penelitian Estimasi Hypervolume NSGA-II... 31
Tabel 4.11 Hasil Uji Normalitas Estimasi Hypervolume NSGA-II ... 31
Tabel 4.12 Parameter NSGA-II ... 32
Tabel 4.13 Populasi NSGA-II pada generasi ke-1000 ... 33
Tabel 4.14 Perbandingan dominasi Solusi AOF dengan Solusi NSGA-II untuk Instance I_150_30 ... 34
Tabel 4.15 Perbandingan dominasi Solusi AOF dengan Solusi NSGA-II untuk Instance I_250_50 ... 34
Tabel 4.16 Perbandingan dominasi Solusi AOF dengan Solusi NSGA-II untuk Instance I_350_30 ... 34
Tabel 4.17 Perbandingan dominasi Solusi AOF dengan Solusi NSGA-II untuk Instance I_350_50 ... 35
Tabel 4.18 Perbandingan dominasi Solusi AOF dengan Solusi NSGA-II untuk
Instance I_50_50 ... 35
DAFTAR GAMBAR
Hal
Gambar 2.1 Populasi yang dihasilkan pada setiap Generasi EO (Deb, 2011) ... 8
Gambar 2.2 Skema prosedur Multi-objective Optimization (Deb, 2011) ... 10
Gambar 2.3 Perhitungan Crowding-Distance (Deb,2011) ... 12
Gambar 2.4 Prosedur NSGA-II (Deb,2011) ... 14
Gambar 3.1 Diagram Alir Rancangan Penelitian ... 15
Gambar 3.2 Diagram Alir Umum NSGA-II ... 17
Gambar 4.1 Populasi pada Algoritma Genetika untuk Makespan dan Total Tardiness ... 30
Gambar 4.2 Populasi pada NSGA-II untuk Makespan dan Total Tardiness ... 32
ABSTRAK
Penjadwalan merupakan suatu kegiatan pengalokasian sumber daya yang terbatas untuk mengerjakan sejumlah pekerjaan. Proses penjadwalan timbul jika terdapat keterbatasan sumber daya yang dimiliki, sehingga diperlukan adanya pengaturan sumber-sumber daya yang ada secara efisien. Adapun tujuan dari penjadwalan produksi umumnya ialah untuk mengoptimalkan dimensi atau objek tertentu.
Penjadwalan flow shop adalah salah satu jenis penjadwalan produksi dimana setiap job akan melalui setiap mesin dengan urutan yang seragam. Optimasi penjadwalan mesin produksi flow shop berkaitan dengan penyusunan penjadwalan mesin yang mempertimbangkan 2 objek yaitu makespan dan total tardiness. Optimasi kedua permasalahan tersebut diatas merupakan optimasi yang bertolak belakang sehingga diperlukan model yang mengintegrasikan permasalahan tersebut dengan optimasi multi-objective A Fast Elitist Non-Dominated Sorting Genetic Algorithm for Multi- Objective Optimazitaion : NSGA-II. Penyelesaian penjadwalan mesin produksi flow shop dengan algoritma NSGA-II untuk membangun jadwal dengan meminimalkan makespan dan total tardiness. Model yang dikembangkan akan memberikan solusi penjadwalan mesin produksi flow shop yang efisien berupa solusi pareto optimal yang dapat memberikan sekumpulan solusi alternatif bagi pengambil keputusan dalam membuat penjadwalan mesin produksi yang diharapkan. Agar dapat terlihat nilai solusinya maka dilakukan perbandingan dominasi solusi Aggregat Of Function (AOF) dengan solusi NSGA-II. Solusi pareto optimal yang dihasilkan merupakan solusi optimasi multi-objective yang optimal dengan trade-off terhadap seluruh objek, sehingga seluruh solusi pareto optimal sama baiknya.
Kata kunci : Makespan, Multi-objective, NSGA-II, Penjadwalan Mesin Produksi
Flow Shop, Total tardiness
MULTI-OBJECTIVE OPTIMIZATION USING NSGA-II IN FLOW SHOP PRODUCTION MACHINE SCHEDULING
ABSTRACT
Scheduling is an activity to allocate limited resources to finish the jobs. Scheduling process arise if there are limitations on available resources that requiring utilization the available resources efficiently. Generally, the purpose of production scheduling is to optimize specific dimensions or objects. Flow shop scheduling is a type of production scheduling where each job will go through each machine with an uniform sequence. Optimization of the flow shop production machine scheduling related to determine machine scheduling that considers two objects i.e makespan and total tardiness. Both above optimization problem is a contradictory optimization that require a model which integrates these problems with multi-objective optimization A Fast elitist Non-dominated Sorting Genetic Algorithm for Multi-Objective Optimization: NSGA-II. The main purpose of completion the flow shop production machine scheduling with NSGA-II algorithm is to determine schedules that minimizing makespan and total tardiness. The developed model will generate efficient solutions of flow shop production machine scheduling in the form of pareto optimal solutions which provide a set of alternative solutions for decision makers in making expected production machine scheduling. In order to analyze the value of the solution that generated, the dominance comparisons made between Aggregate of Function (AOF) solutions and NSGA-II solutions. Pareto optimal solutions that generated are optimal multi-objective optimization solutions with trade-off for all objects, thereby all pareto optimal solutions are just as good.
Keywords : Flow Shop Production Scheduling Engine, Makespan, Multi-
objective, NSGA-II, Total tardiness
BAB 1 PENDAHULUAN
1.1. Latar Belakang
Penjadwalan mesin produksi merupakan salah satu hal penting dalam proses manufaktur dan produksi. Permasalahan penjadwalan mesin produksi biasanya terletak pada penyusunan dan pengaturan job-job yang akan di proses pada serangkaian mesin. Masalah penjadwalan flowshop adalah menjadwalkan proses produksi dari masing-masing n job yang mempunyai urutan proses produksi dan melalui m mesin yang sama (Soetanto, 1999) . Salah satu kesulitan dalam melakukan penyusunan dan pengaturan job terhadap mesin yang tersedia adalah sulitnya mencari teknik-teknik yang tepat untuk membuat model penjadwalan mesin produksi yang optimal dan memenuhi segala kriteria-kriteria penjadwalan yang telah ditetapkan.
Penjadwalan flow shop berkembang dari single-objective (optimasi dengan satu fungsi) menjadi multi-objective (optimasi dengan beberapa fungsi objektif).
Dalam kasus multi-objective, akan dihasilkan sekumpulan solusi optimal yang dikenal dengan pareto-optimal solutions (solusi pareto-optimal) (Deb, 2008).
Beberapa penelitian telah mengembangkan model yang berkaitan dengan
penjadwalan mesin produksi flow shop, baik yang menggunakan optimasi single-
objective ataupun multi-objective. Penelitian penjadwalan mesin produksi dengan satu
fungsi objektif yang mengoptimalkan nilai makespan telah dilakukan oleh
Chakraborty et al (2007) dan Choudhury et al (2007). Penelitian penjadwalan mesin
produksi yang telah dilakukan oleh Lemesre et al (2005) dan Rahimi et al (2006)
berkaitan dengan penjadwalan flow shop dengan 2 fungsi objektif yaitu completion
time dan tardiness, namun mempunyai waktu komputasi yang cukup lama. Gajpal et
al (2014) dan T‟kindt et al (2001) meneliti penjadwalan mesin produksi dengan 2
fungsi objektif yaitu total weighted completion time dan makespan. Balasundaram et
al (2014), Rajendran et al (2004); dan Yagmahan dan Yenise(2010) meneliti 2 fungsi
objektif yaitu makespan dan total flow time. Minella et al (2007) meneliti penjadwalan mesin produksi dengan 2 fungsi objektif yaitu makespan dan total tardiness. Secara umum, semua penelitian diatas memiliki kinerja komputasi yang baik, mampu memformulasikan secara matematis fungsi objektif dalam penjadwalan flow shop.
Tetapi sebagian besar metode yang digunakan hanya mampu menyelesaikan permasalahan secara dependent yaitu hanya dapat digunakan pada permasalahan tertentu bergantung pada jenis permasalahan (heuristic).
Dalam kasus optimasi multi-objective, algoritma Non-Dominated Sorting Genetic Algorithm for Multi-objective Optimization : NSGA-II yang merupakan kelompok Algoritma Metaheuristic yang telah diuji kehandalannya dibandingkan dengan optimasi multi-objective lainnya. NSGA-II merupakan metode pengembangan dari Genetik Algoritma (GA) dan NSGA. Dibandingkan dengan GA dan NSGA, NSGA-II dibedakan pada penggunaan operator crowding distance agar menghasilkan solusi pareto optimal yang lebih baik. Penelitian menggunakan NSGA-II telah dilakukan oleh Josezefowiez et al (2008) yang meneliti tentang multi-objective untuk vehicle routing problems, Mishra et al (2009) melakukan penelitian kasus optimasi multi-objective pada kasus managemen portofolio dan Deb et al (2008) membuat penelitian yang mampu menciptakan metode baru bernama omni optimizer yang di adopsi dari NSGA-II untuk kasus optimasi baik single maupun multi-objective.
Berdasarkan permasalahan di atas, maka perlu dilakukan penelitian untuk menganalisis algoritma multi-objective NSGA-II dalam penjadwalan mesin produksi flow shop untuk mengoptimalkan 2 fungsi objektif yaitu makespan dan total tardiness sehingga memberikan sekumpulan solusi alternatif bagi pengambil keputusan.
1.2. Rumusan Masalah
Permasalahan yang ingin diselesaikan adalah menganalisis algoritma multi-objective NSGA-II dalam penjadwalan mesin produksi flow shop untuk mengoptimalkan 2 fungsi objektif yaitu makespan dan total tardines .
1.3. Batasan Masalah
Batasan yang digunakan dalam penelitian ini adalah sebagai berikut :
1. Pola kedatangan job bersifat statis.
2. Fungsi objektif yang digunakan adalah makespan dan total tardiness.
3. Tidak terjadi kerusakan mesin / breakdown karena aktifitas perawatan selama waktu penjadwalan.
4. Mesin selalu available untuk langsung memproses job.
5. Tidak membahas masalah pekerja/ sumber daya manusia.
6. Tidak ada pembatalan proses. Setiap job harus diproses sampai selesai.
1.4. Tujuan Penelitian
Penelitian ini bertujuan untuk menganalisis algoritma multi-objective NSGA-II dalam permasalahan penjadwalan mesin produksi flow shop yang optimal baik dari makespan dan total tardiness.
1.5. Manfaat Penelitian
Penelitian ini diharapkan dapat memberikan kontribusi dalam bidang keilmuan optimasi, yaitu dengan penerapan algoritma multi-objective NSGA-II untuk menyelesaikan permasalahan penjadwalan mesin produksi flow shop dan dapat memberikan sekumpulan solusi alternatif bagi pengambil keputusan dalam membuat penjadwalan mesin produksi yang diharapkan.
1.6. Metodologi Penelitian
Dalam penelitian ini, metode penelitian yang digunakan adalah sebagai berikut : 1. Kajian pustaka atau Literature review, membaca riset-riset yang telah
dilakukan sehubungan dengan teknik yang akan dipergunakan dalam menyelesaikan masalah ini dan riset-riset yang membahas tentang masalah yang berhubungan dengan riset yang akan dilakukan oleh Penulis.
2. Pengumpulan data atau Collecting Data, mengumpulkan data yang berkaitan dan diperlukan dalam mengatasi masalah ini.
3. Analisis, menganalisis teknik yang akan dipergunakan dengan mempergunakan data yang tersedia sehingga membentuk suatu sistem.
4. Pengujian atau testing, menguji sistem yang telah dibentuk untuk memastikan
apakah sistem tersebut bekerja sesuai dengan yang diharapkan.
BAB 2
LANDASAN TEORI
2.1. Penjadwalan dan Penjadwalan Flow shop
Menurut Kumar (2011), jadwal merupakan rencana sistematis yang umumnya menceritakan hal-hal yang akan dikerjakan. Menurut Pinedo (2005), Penjadwalan diartikan sebagai proses pengambilan keputusan yang dilakukan secara teratur di bidang manufaktur dan jasa. Menurut Gajpal (2014), penjadwalan adalah proses alokasi sumber daya yang terbatas.
Menurut Ruiz (2007), permasalahan flow shop didefinisikan sebagai sekumpulan job N=1,2,...,n yang diproses oleh satu set mesin M=1,2,...n. Menurut Balasundaram (2014), penjadwalan flow shop adalah pengklasifikasian sebuah optimasi kombinatorial yang terdiri dari n-job, m mesin, diasumsikan bahwa job-job melewati semua mesin yang sama. Penjadwalan flow shop didefinisikan sebagai sebuah permasalahan produksi dimana terdapat satu set n job yang di proses pada aliran semua mesin yang identik, Tyagi (2014), Menurut Budi Santosa (2014), permasalahan dalam penjadwalan berfokus pada bagaimana mengalokasikan sumber daya produksi yang terbatas, seperti mesin, alat material handling, operator, dan peralatan lainnya untuk melakukan proses pada serangkaian aktivitas operasi (job) dalam periode waktu tertentu dengan optimalisasi pada fungsi objektif tertentu.
2.1.1. Tujuan penjadwalan
Menurut Ginting (2009), ada beberapa tujuan dari aktivitas penjadwalan adalah sebagai berikut :
1. Meningkatkan penggunaan sumberdaya atau mengurangi waktu tunggunya,
sehingga total waktu proses dapat berkurang dan produktivitas dapat
meningkat.
2. Mengurangi persediaan barang setengah jadi atau mengurangi sejumlah job yang menunggu dalam antrian ketika sumber daya yang ada masih mengerjakan tugas lain.
3. Mengurang beberapa keterlambatan pada job yang mempunyai batas waktu penyelesaian .
4. Membantu pengambilan keputusan mengenai perencanaan kapasitas pabrik dan jenis kapasitas yang dibutuhkan.
2.1.2. Definisi dalam penjadwalan
Menurut Ginting (2009), ada beberapa istilah dalam penjadwalan yaitu : 1. Processing time (t
i)
Adalah waktu yang dibutuhkan untuk mengerjakan suatu job. Dalam waktu proses ini sudah termasuk waktu yang dibutuhkan untuk persiapan dan pengaturan (set-up) selama proses berlangsung.
2. Due-date (d
i)
Adalah batas waktu di mana operasi terakhir dari suatu job harus selesai.
3. Slack time (SL
i)
Adalah waktu tersisa yang muncul akibat dari waktu prosesnya lebih kecil dari due-date-nya.
4. Flow time (F
i)
Adalah rentang waktu antara satu titik di mana tugas tersedia untuk diproses dengan suatu titik ketika tugas tersebut selesai.
5. Completion Time (C
i)
Adalah waktu yang dibutuhkan untuk menyelesaikan job mulai dari saat tersedianya job (t= 0) sampai pada job tersebut selesai dikerjakan.
6. Lateness (L
i)
Adalah selisih antara Completion time (C
i) dengan due-date-nya (d
i). Suatu
job memiliki lateness yang bernilai positif apabila pckerjaan tersebut
criseresaikan setelah due date-nya, job tersebut akan memiliki keterlambatan
yang negatif. sebaliknya jika job diselesaikan setelah batas waktunya, job
tersebut memiliki keterlambatan yang positif.
7. Tardiness (Ti)
Adalah ukuran waktu terlambat yang bernilai positif jika suatu job dapat diselesaikan lebih cepat dari due-date-nya, job tersebut akan memiliki keterlambatan yang negatif. Sebaliknya jika job diselesaikan setelah batas waktunya, job tersebut memiliki keterlambatan yang positif
8. Makespan (M
i)
Adalah total waktu penyelesaian pekeriaan-pekeriaan mulai dari urutan pertama yang dikerjakan pada mesin work center pertama sampai kepada urutan job terakhir pada mesin atau work center terakhir
2.2. Multi-objective Optimization (MO)
Multi-objective Optimization (MO) merupakan sebuah proses yang dilakukan secara simultan untuk optimalisasi dua atau lebih tujuan (objektif). Proses akan semakin rumit jika optimasi dilakukan pada fungsi objektif yang saling bertentangan, dimana solusi optimal untuk sebuah fungsi objektif akan berbeda untuk fungsi objektif lainnya.
Menurut Deb (2002), MO akan menghasilkan sekumpulan solusi optimal yang dikenal dengan pareto-optimal solutions (solusi pareto-optimal) bukan single-optimal solutions.
Secara umum permasalahan MO diformulasikan oleh Deb (2011) ke dalam bentuk persamaan matematika sebagai berikut :
Minimize/Maximize f
m(x), m = 1,2,…,M;
Subject to g
j(x) 0, j = 1,2,…,J;
h
k(x) = 0, k = 1,2,…,K;
x
i(L) x
i x
i(U)i = 1,2,…,n.
Solusi x R
nadalah vektor dengan n variabel keputusan : x = (x
1,x
2,…,x
n)
T.
Ada banyak optimasi yang tersedia untuk menyelesaikan permasalahan MO, beberapa diantaranya akan dijelaskan pada sub-bab dibawah ini.
2.2.1. Single Aggregat Objective Function (AOF)
Ide dasar dari optimasi ini adalah menggabungkan beberapa fungsi objektif menjadi satu bentuk fungsi objektif. Salah satunya adalah weighted linear sum of objective, yaitu fungsi-fungsi objektif yang akan dioptimasi diberi bobot dan dijumlahkan secara
(2.1)
linear menjadi sebuah fungsi yang dapat diselesaikan dengan Single-objective Optimization (SO).
Secara umum, persamaan matematika untuk AOF diformulasikan oleh Srinivas (1994) sebagai berikut :
Minimize/Maximize Z =
Subject to x X dimana X adalah himpunan solusi;
0 w
i 1
Dengan menggunakan optimasi ini solusi yang dihasilkan akan sangat bergantung pada nilai bobot (w) yang diberikan. Nilai setiap bobot merupakan nilai desimal antara 0 sampai 1, yang jika semua bobot dijumlahkan akan bernilai 1.
2.2.2. Evolutionary Algorithm (EA)
Menurut Deb (2011), pendekatan yang digunakan dalam Algoritma Evolutionary Optimization (EO) adalah tahapan iterasi (pengulangan) terhadap populasi solusi (sekumpulan solusi) yang mengembangkan populasi solusi baru untuk iterasi berikutnya. EO sangat terkenal dan banyak digunakan dalam permasalahan MO karena : (1) EO tidak membutuhkan informasi tambahan seperti bobot pada optimasi AOF, (2) Relatif sederhana untuk diimplementasikan dan (3) Fleksibel dan dapat diterapkan pada banyak permasalahan.
Penerapan EO yang memakai populasi solusi untuk Single-objective Optimization (SO) akan terlihat sia-sia karena hanya mencari satu solusi optimal saja.
Namun untuk MO, penerapan EO ini adalah pilihan yang tepat sebab EO akan menghasilkan populasi solusi pareto-optimal, yang seluruh populasi tersebut diproses lebih lanjut agar mendapatkan sebuah solusi.
2.2.2.1. Evolutionary Optimization (EO) untuk Single-Objective Optimization
Tahapan pencarian solusi EO untuk SO dijelaskan oleh Deb (2011) dimulai dengan inisialiasi populasi solusi yang dihasilkan secara acak. Selanjutnya dilakukan tahapan iterasi dimana setiap iterasi akan menghasilkan populasi baru dengan menggunakan 4 operator utama yaitu seleksi, crossover (penyilangan), mutasi dan elite-preservation.
Iterasi akan berhenti ketika satu atau lebih kriteria berhenti telah terpenuhi.
(2.2)
Inisialiasi populasi dilakukan dengan menghasilkan populasi solusi secara acak, namun jika beberapa solusi telah diketahui sebelumnya, maka inisialisasi populasi akan lebih cepat dengan menggunakan solusi tersebut. Seleksi diterapkan untuk memilih beberapa solusi dan ditempatkan pada penyimpanan (pool) sementara.
Crossover diterapkan dengan menyilangkan dua solusi (parent) secara acak dari pool dan menghasilkan satu atau lebih solusi (children). Parameter utama crossover adalah probabilitas crossover (p
c [0,1]) yang menunjukkan bagian populasi yang diikutsertakan pada crossover. Sementara itu, parameter utama mutasi adalah probabilitas p
myang biasanya bernilai 1/ ( adalah jumlah variabel). Elitism akan menggabungkan populasi lama dengan yang baru (children) dan mempertahankan solusi yang lebih baik untuk populasi berikutnya, untuk memastikan algoritma mempunyai peningkatan kinerja secara monoton. Untuk menentukan kriteria berhenti, biasanya digunakan angka yang menunjukkan batas jumlah generasi populasi.
Dibawah ini dilampirkan gambar yang menjelaskan populasi solusi yang dihasilkan pada setiap generasi EO.
(i) Inisialiasasi Populasi (ii) Populasi Generasi ke-5
(iii) Populasi Generasi ke-40 (iv) Populasi Generasi ke-100
Gambar 2.1 Populasi yang dihasilkan pada setiap Generasi EO (Deb, 2011)
Pada gambar diatas, terlihat bahwa inisialiasi awal populasi yang acak, akan berada dalam solusi feasible (himpunan solusi yang mungkin) pada generasi ke-5, dan akan makin konvergen menuju sebuah solusi untuk generasi berikutnya.
2.2.2.2. Evolutionary Multi-objective Optimization (EMO)
Definisi dan skema prosedur untuk mencari solusi pareto-optimal EMO dijelaskan oleh Deb (2011) sebagai berikut dibawah ini.
Solusi optimal pada MO dapat didefinisikan dengan konsep matematika partial ordering yang dikenal dengan istilah Dominasi pada MO. Definisi Dominasi dari dua buah solusi adalah sebagai berikut :
Sebuah solusi x
(1)dikatakan mendominasi solusi yang lain x
(2), jika kedua kondisi berikut terpenuhi (benar) yaitu :
1. Solusi x
(1)tidak lebih buruk dari x
(2)untuk semua objektif, Dengan demikian, solusi-solusi tersebut dibandingkan berdasarkan nilai fungsi objektif-nya (atau lokasi dari titik (z
(1)dan z
(2)) pada ruang solusi).
2. Solusi x
(1)lebih baik dari x
(2)minimal pada satu objektif.
Tujuan ideal (utama) dalam MO adalah :
1. Mencari sekumpulan solusi yang terdapat pada pareto-optimal front.
2. Mencari sekumpulan bermacam-macam yang merepresentasikan jangkauan pareto-optimal front.
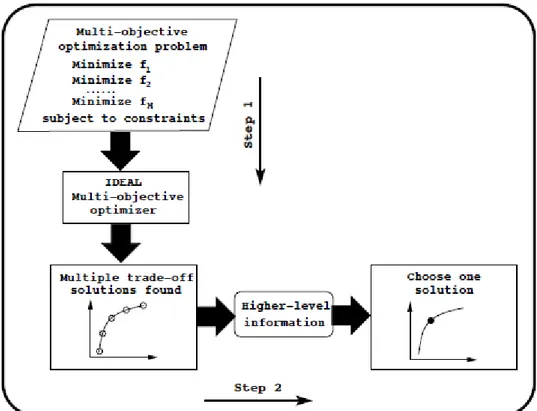
Meskipun perbedaan utama antara SO dan MO terdapat pada kardinalitas solusi yang optimal, namun dari sisi penerapan tetap yang dibutuhkan hanya satu solusi. Pemilihan satu solusi dari sekumpulan solusi yang optimal melibatkan informasi tingkat tinggi yang biasanya non teknis, kualitatif dan pengalaman.
Langkah-langkah dasar pada prosedur EMO adalah :
Langkah 1 : Mencari beberapa titik non-dominated yang paling dekat dengan pareto-optimal front.
Langkah 2 : Memilih satu dari titik yang dihasilkan pada langkah 1 berdasarkan informasi tingkat tinggi.
Gambar 2.2 dibawah ini menjelaskan skema dari langkah-langkah prosedur EMO
diatas.
Prosedur Elitist Non-dominated Sorting Genetic Algorithm (NSGA-II) adalah salah satu prosedur EMO yang terkenal, karena NSGA-II mempunyai 3 keutamaan, yaitu :
1. Prinsip elitist.
2. Mekanisme diversity preserving (melestarikan keragaman).
3. Mengutamakan solusi non-dominated.
Beberapa prosedur yang membedakan NSGA-II dengan algoritma EMO lainnya adalah fast-non-dominated-sort, crowding-distance-assignment dan Crowded Comparison Operator.
Gambar 2.2 Skema prosedur Multi-objective Optimization (Deb, 2011)
Prosedur fast-non-dominated-sort digunakan untuk mengidentifikasi dan mengurutkan solusi kedalam beberapa tingkatan front non-dominated yang berbeda.
Sebagai permulaan, semua solusi dihitung entitas : (1) jumlah dominasi n
p, yaitu
jumlah solusi yang mendominasi solusi p, (2) S
p, yaitu himpunan solusi yang
didominasi solusi p. Penghitungan entitas ini membutuhkan kompleksitas komputasi
sebesar O(MN
2).
Semua solusi di front non-dominated pertama akan mempunyai jumlah dominasi bernilai nol. Selanjutnya untuk setiap solusi dengan n
p=0 akan ditelusuri semua solusi q yang terdapat pada S
pdan mengurangi jumlah dominasi q (n
q) dengan satu. Jika n
qada yang bernilai nol, maka q dipisahkan ke himpunan Q. Solusi q yang terdapat pada himpunan Q akan menjadi front non-dominated berikutnya. Proses ini dilanjutkan sampai semua front berhasil diidentifikasikan.
Algoritma untuk fast-non-dominated-sort yang lebih rinci disajikan oleh Deb (2002) sebagai berikut :
fast-non-dominated-sort(P) for each p P
S
p= n
p= 0
for each q P
if (p ≺ q) then jika p mendominasi q
S
p= S
p {q} tambahkan q ke himpunan solusi yg didominasi p
else if (q ≺ p) then
n
p= n
p+ 1 increment jumlah dominasi p
if n
p= 0 then
p termasuk front pertamap
rank= 1 Ƒ
1= Ƒ
1 {p}
i = 1 inisialisasi jumlah front
while Ƒ
i≠
Q = untuk menyimpan anggota front berikutnya
for each p Ƒ
ifor each q S
pn
q= n
q– 1
if n
q= 0 then
q termasuk front berikutnyaq
rank= i + 1 Q = Q {q}
i = i + 1 Ƒ
i= Q
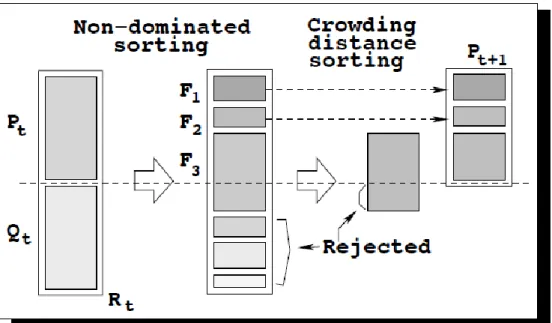
Selain menghasilkan solusi yang konvergen terhadap himpunan pareto- optimal, NSGA-II juga menjaga agar solusi yang dihasilkan menggambarkan keragaman dari himpunan pareto-optimal. Untuk itu didefinisikan metric perkiraan kepadatan (Density Estimation Metric) dan operator perbandingan keramaian (Crowded-Comparison Operator).
Untuk perkiraan kepadatan solusi di sekeliling sebuah solusi i, dilakukan perhitungan jarak rata-rata antara dua solusi di kedua sisi solusi i untuk setiap objektif.
Nilai yang dihasilkan i
distanceadalah perkiraan keliling cuboid yang dibentuk oleh
solusi terdekat i sebagaimana disajikan dalam gambar dibawah ini.
Gambar 2.3 Perhitungan Crowding-Distance (Deb,2011)
Perhitungan Crowding-Distance memerlukan pengurutan solusi dalam urutan membesar sesuai dengan fungsi objektif-nya. Solusi dengan nilai fungsi terkecil dan terbesar selanjutnya diberi nilai distance tak terhingga, sementara solusi lainnya diberi nilai berdasarkan perhitungan nilai absolut dari selisih nilai objektif solusi terdekat yang telah dinormalisasi. Nilai total Crowding Distance dihitung dari jumlah distance untuk setiap fungsi objektif. Algoritma rincinya telah disusun oleh Deb (2002) sebagai berikut :
Crowding-distance-assignment (χ)
l = |χ| jumlah solusi di χ
for each i, set χ[i]
distance= 0 inisialisasi jarak
for each objective m
χ = sort(χ,m) pengurutan menggunakan nilai objektif
χ[1]
distance= χ[l]
distance= agar titik batas selalu terpilih
for i = 2 to (l-1) untuk semua titik lain
χ[i]
distance= χ[i]
distance+ (χ[i+1].m - χ[i-1].m) / ( )
Setelah distance metric terbentuk, selanjutnya dapat dibandingkan kedekatan sebuah solusi dengan solusi lainnya. Solusi dengan nilai distance yang kecil berarti lebih ramai daripada solusi yang lain. Untuk itu digunakan Crowded-Comparison Operator sebagai panduan proses seleksi untuk mendapatkan pareto-optimal front yang tersebar merata.
Asumsikan setiap individu i pada populasi mempunyai 2 atribut, yaitu Nondomination rank (i
rank) dan Crowding Distance (i
distance). Maka Deb (2002) mendefinisikan partial order ≺
nsebagai berikut :
i ≺
nj jika (i
rank< j
rank)
atau ((i
rank= j
rank) dan (i
distance> j
distance))
Definisi diatas mempunyai arti jika dua buah solusi berbeda Nondomination rank, maka akan dipilih solusi yang mempunyai rank lebih kecil. Jika solusi mempunyai rank yang sama (berasal dari front yang sama), maka akan dipilih solusi dari daerah yang kurang ramai (distance besar).
Prosedur utama dari algoritma NSGA-II terdiri dari tahapan inisialisasi populasi parent P
osecara acak, kemudian diurutkan berdasarkan tingkatan nondomination (rank/fitness). Awalnya operator binary tournament selection, recombination, dan mutasi akan digunakan untuk menghasilkan populasi offspring (child) Q
o. Tahapan inisialisasi diatas hanya dilakukan sekali, untuk generasi berikutnya akan dilakukan langkah-langkah yang berbeda.
Pertama, populasi R
tdibentuk dari penggabungan populasi P
tdan Q
t. populasi R
tberjumlah 2N. Populasi R
tkemudian diurutkan menurut nilai nondomination sehingga dihasilkan solusi pada front Ƒ
1merupakan solusi terbaik. Jika ukuran Ƒ
1lebih kecil dari N, maka seluruh solusi pada Ƒ
1dimasukkan pada populasi baru P
t+1. Sisa jumlah populasi P
t+1diisikan Ƒ
2,Ƒ
3dan seterusnya. Untuk memenuhi jumlah populasi baru tepat sebanyak N solusi, maka solusi pada front terakhir diurutkan menggunakan operator ≺
n.Algoritma pengulangan utama dari NSGA-II, dirincikan oleh Deb (2002) sebagai berikut :
R
t= P
t Q
tmenggabungkan parent dan offspring
Ƒ = fast-non-dominated-sort(R
t)
Ƒ = (Ƒ1, Ƒ2, …) semua front non-dominated RtP
t+1= and i = 1
until |P
t+1| + | Ƒ
i| N sampai populasi parent terisi
crowding-distance-assignment(Ƒ
i) hitung crowding-distance di Ƒ
iP
t+1= P
t+1 Ƒ
imasukkan front non-dominated ke-i ke populasi parent
i = i + 1 periksa front berikutnya untuk disertakan
Sort(Ƒ
i, ≺
n) urutkan mengecil menggunakan ≺
nP
t+1= P
t+1 Ƒ
i[1:(N - |P
t+1|)] pilih elemen pertama Ƒ
isebanyak (N-|P
t+1|)
Q
t+1= make-new-pop(P
t+1) gunakan seleksi, crossover dan mutasi untuk menghasilkan populasi baru Q
t+1t = t + 1 increment jumlah generasi
Prosedur NSGA-II diatas dapat digambarkan sebagai berikut :
Gambar 2.4 Prosedur NSGA-II (Deb,2011)
BAB 3
METODE PENELITIAN
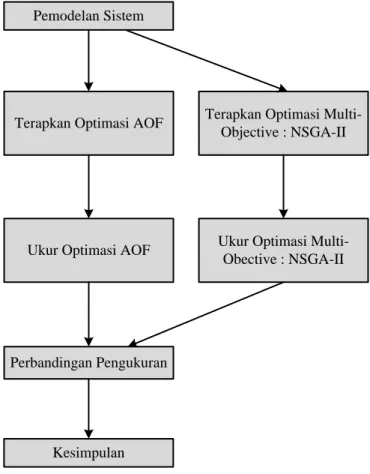
Dalam optimasi penjadwalan flow shop mesin produksi akan di bandingkan nilai makespan dan total tardiness sebelum dan sesudah diterapkannya optimasi multi- objective NSGA-II. Secara umum, diagram alir rancangan penelitiannya dapat digambarkan pada Gambar 3.1 dibawah ini.
Pemodelan Sistem
Terapkan Optimasi AOF
Ukur Optimasi AOF
Perbandingan Pengukuran
Kesimpulan
Terapkan Optimasi Multi- Objective : NSGA-II
Ukur Optimasi Multi- Obective : NSGA-II
Gambar 3.1 Diagram Alir Rancangan Penelitian
3.1. Pengumpulan Data
Untuk menguji sistem, data yang diujikan berupa data sekunder yang diperoleh dari http://www.upv.es/gio/rruiz yang terdiri dari 110 instance kasus data yang akan diujikan.
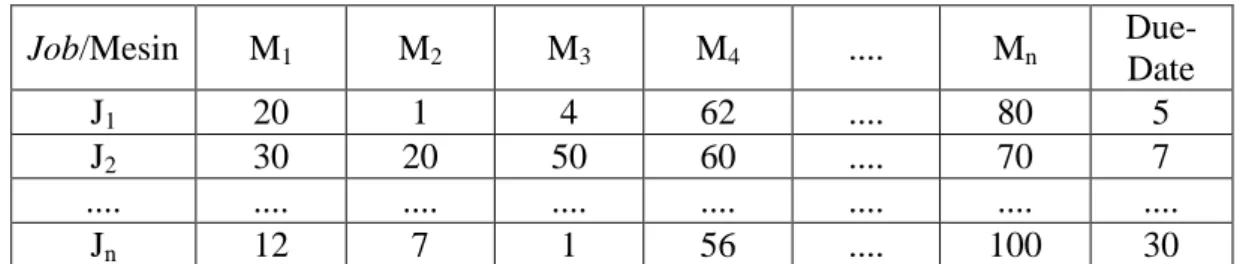
Tabel 3.1 Tabel Data Penjadwalan Mesin Produksi
Job/Mesin M
1M
2M
3M
4.... M
nDue-
Date
J
120 1 4 62 .... 80 5
J
230 20 50 60 .... 70 7
.... .... .... .... .... .... .... ....
J
n12 7 1 56 .... 100 30
Data-data tersebut diselanjutnya akan digunakan untuk memodelkan sistem dan diproses dengan menggunakan algoritma Multi-objective : NSGA-II.
3.2. Pemodelan Sistem
Untuk mendapatkan solusi yang optimal dengan algoritma multi-objective NSGA-II, maka permasalahan penjadwalan mesin produksi flow shop akan dimodelkan secara matematis dalam bentuk persamaan multi-objective yang terdiri beberapa fungsi objektif dan pembatas.
Persamaan multi-objective terdiri dari dua buah fungsi objektif yaitu fungsi yang memformulasikan nilai makespan, serta fungsi yang memformulasikan total tardiness.
Selain itu perlu untuk mendefinisikan variabel solusi yang ingin dihasilkan, sebab optimasi NSGA-II dimulai dengan inisialisasi populasi secara acak sesuai dengan definisi variabel solusi.
3.3. Tahapan NSGA-II
Optimasi Multi-objective : NSGA-II yang digunakan untuk mencari solusi pareto- optimal dari model matematis multi-objective dapat dibagi menjadi tahapan-tahapan sebagai berikut :
1. Inisialisasi Populasi
2. Non-Dominated Sort
3. Crowding Distance 4. Seleksi
5. Operator Genetika a. crossover b. mutasi 6. Rekombinasi
dimana pada beberapa tahapan diatas, akan ditentukan prosedur yang lebih rinci untuk penerapan NSGA-II pada permasalahan penjadwalan mesin produksi flow shop.
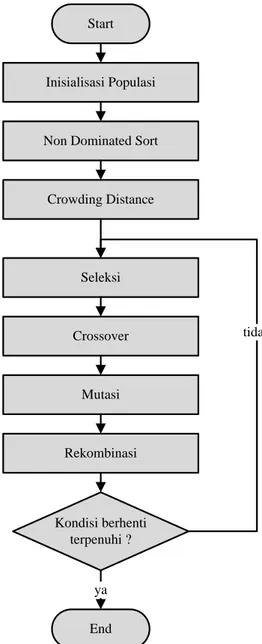
Diagram alir secara umum dari NSGA-II ditampilkan dalam Gambar 3.2 dibawah ini.
Start
End Inisialisasi Populasi
Non Dominated Sort
Crowding Distance
Seleksi
Crossover
Mutasi
Rekombinasi
Kondisi berhenti terpenuhi ?
ya
tidak