SKRIPSI
Oleh :
FAJAR BAYU ADINATA
0734010252
JURUSAN TEKNIK INFORMATIKA
FAKULTAS TEKNOLOGI INDUSTRI
UNIVERSITAS PEMBANGUNAN NASIONAL “VETERAN”
JAWA TIMUR
SKRIPSI
Diajukan Untuk Memenuhi Persyaratan Dalam Memperoleh Gelar Sarjana Komputer
Jurusan Teknik Informatika
Oleh :
FAJAR BAYU ADINATA
0734010252
JURUSAN TEKNIK INFORMATIKA
FAKULTAS TEKNOLOGI INDUSTRI
UNIVERSITAS PEMBANGUNAN NASIONAL “VETERAN”
JAWA TIMUR
Alhamdulillah, dengan mengucapkan puji dan syukur kehadirat Allah SWT atas rahmat dan hidayah-Nya sehingga penulis dapat menyelesaikan tugas akhir ini dengan judul “APLIKASI UTILITAS PENCARI NAMA FILE TERKOMPRESI
TANPA PROSES DEKOMPRESI” yang merupakan persyaratan dalam memperoleh gelar Sarjana Komputer di Universitas Pembangunan Nasional “VETERAN” Jatim.
Penulis mengucapkan terima kasih yang sebesar-besarnya kepada pihak-pihak yang telah membantu baik materi’il maupun dorongan spiritual untuk menyelesaikan penulisan kerja praktek ini, terutama kepada:
1. Bapak Prof. Dr. Ir. Teguh Soedarto, MP, selaku Rektor UPN “Veteran” Jatim.
2. Bapak Ir. Sutiyono, MT selaku DEKAN FTI UPN “VETERAN” Jatim.
3. Ibu Dr. Ir. Ni Ketut Sari, MT. Selaku Kepala Jur. Teknik Informatika, FTI
UPN “VETERAN” Jatim
4. Bapak Nur Cahyo Wibowo, S.Kom,.M.Kom dan Bapak Cristya Aji Putra,
S.Kom. selaku Dosen Pembimbing yang telah meluangkan waktu untuk memberikan bimbingan selama proses pelaksanaan Tugas Akhir penulis.
5. Bapak Bari Nuqoba, S.Si, M.Kom dan Bapak Firza Prima Aditiawan, S.Kom.
selaku Dosen Penguji yang telah meluangkan waktu untuk menguji Tugas Akhir Penulis.
6. Dosen-dosen Teknik Informatika, staff dan segenap akademika UPN
“VETERAN” Jatim.
9. Teman-teman seperjuangan Tugas Akhir,terutama kepada bro (fajar bayu)
yang selalu menyemangati penulis,pasutri om dan tante (aryo dan vivi) yang selalu bersama-sama dalam suka maupun duka di dalam perjalanan menyelesaikan Tugas Akhir ini, kemana-mana selalu bersama dan
kompak,semoga persahabatan kita langgeng selamanya meskipun sudah tidak bersama-sama lagi dalam naungan almamater UPN. Trims om kalau selalu
merepotkan dirimu,yang biasanya rumahmu jadi basecampku,seperti koz keduaku saja rumahmu,serta nado(thank you ke perpus ITS bareng-bareng). Tanpa kalian,mungkin aku belum bisa menyelesaikan Tugas Akhir ini.
10.Keluarga Besar KRIPOSOFT Community, ijah (dj sandro.s.kom), Leader
(ananta bayu,s.kom), Eddy Lee , Windy s.kom, Pablo (Anjar Ngebluz), Bebek
(Haniarta Bayu), Fery(AlenBig), Ahmad Nur, Fajar Bayu (FB) ,om dan tante (aryo dn vivi)terima kasih atas dukungannya, tanpa kalian semua penulis tidak dapat menikmati perkuliahan yang penuh dengan hangatnya persaudaraan,
susah senang bersama, touring dan rekreasi.
11.Teman-teman Teknik Informatika dan Sistem Infomasi angkatan
2007Universitas Pembangunan Nasional “Veteran” Jawa Timur, si rambut cewek (ahong), yusuf (makasih cup atas bantuan revisi lesanku), aris,cino, dion, farid, heru, indra,yurza, dan yang tidak bisa penulis sebutkan satu per
satu,terima kasih atas dukungannya baik materil maupun moril.
12.Kawan-kawan koz, mas viktor (john vicko),mbak pur (bayu,maaf panggilan u
13.Teman-teman SMA (ALUTA 07) yang masih kompak,meskipun diantara kalian sudah ada yang lulus duluan dan bekerja tapi masih menyempatkan waktu buat kumpul-kumpul di saat penulis pulang kampung. Makasih sudah
membuat penulis termotivasi untuk lulus.
14.Dan masih banyak orang-orang yang sangat berperan dalam mewujudkan
tugas akhir ini yang tidak bisa penulis sebutkan satu per satu.
Penulis menyadari sepenuhnya masih banyak terdapat kekurangan dalam
penulisan Tugas Akhir ini. Oleh sebab itu kritik serta saran yang membangun dari pembaca sangat membantu guna perbaikan dan pengembangan di masa yang akan
datang.
Akhirnya dengan ridho Allah penulis berharap semoga Tugas Akhir ini dapat memberikan manfaat bagi pembaca sekalian terutama mahasiswa di bidang komputer.
Surabaya, 25 Juni 2012
HALAMAN JUDUL LEMBAR PENGESAHAN
LEMBAR PENGESAHAN DAN PERSETUJUAN KETERANGAN REVISI
MOTTO
KATA PENGANTAR ...i
DAFTAR ISI ...iv
DAFTAR GAMBAR ...vii
ABSTRAKSI ...viii
BAB I PENDAHULUAN………...1
1.1. Latar Belakang……...………...1
1.2. Perumusan Masalah……...………….………....2
1.3. Batasan Masalah……….………2
1.4. Tujuan………....……….3
1.5. Manfaat………...3
1.6. Metode Penelitian………...3
1.7. Sistematika Penulisan……….4
BAB II TINJAUAN PUSTAKA………..………..6
2.1. Algoritma Dan Pemrograman..…..………6
2.1.1. Internal Subroutines.……....………...7
2.1.2. External Subroutines………..7
2.1.3. Pendekatan Top Down………...8
2.2. Kompresi Data………..10
2.3. Jenis-jenis Kompresi Data………12
2.4. Metode Kompresi Data………13
2.5. Teknik Kompresi Data……….14
2.6. Algorithma Zip……….16
2.7. Algorithma String Pattern Matching………17
2.10.3. Bentuk Data Flow Diagram………32
BAB III ANALISIS DAN PERANCANGAN SISTEM...………...33
3.1. Desain Penelitian………..33
3.2. Analisis Proses Kompresi……….35
3.3. DFD………..……35
3.4. Analisis Proses Pencarian……….40
3.5. Diagram Alir Sistem……….41
3.6. Pseudocode Proses Pencarian………...42
3.7. Pseudocode Pembuatan Tabel Pencarian String………..43
3.8. Perancangan Antar Muka……….44
BAB IV IMPLEMENTASI ………...……….45
4.1. Implementasi Prosedure Create Form……… ..45
4.2. Implementasi Prosedure ExceptionHandler……….45
4.3. Implementasi Prosedure Keluar………...46
4.4. Implementasi Prosedur Pencarian....………46
4.5. Implementasi Tabel String Pencarian………...47
4.6. Implementasi Tombol Cari………...48
4.7. Implementasi Antar Muka………50
BAB V PENGUJIAN SISTEM……….…...………...54
5.1. Pengujian Aplikasi………...54
5.1.1. Pengujian Aplikasi Dengan Nama File Dan Ekstensinya……54
5.1.2. Pengujian Aplikasi Dengan Nama File Tanpa Ekstensinya….59 5.1.3. Pengujian Aplikasi Dengan Nama File Berupa Bilangan……61
5.1.4. Pengujian Aplikasi Dengan Nama File Berupa Bilangan Yang Sebagian Saja / Tidak Lengkap Penulisannya…....……63
5.1.5. Pengujian Aplikasi Dengan Nama File Berupa Bilangan Tanpa Ekstensi……….………....65
5.1.9. Pengujian Aplikasi Dengan Nama File Berupa Bilangan
Disertai Dengan Kombinasi Huruf Dan Tanda Baca…...…..72
5.1.10. Pengujian Aplikasi Dengan Nama File Berupa Bilangan Disertai Dengan Kombinasi Huruf, Tanda Baca, Dan Spasi...74
5.1.11. Pengujian Aplikasi Dengan Nama File Berupa Huruf Besar...76
5.1.12. Pengujian Aplikasi Dengan Nama File Berupa Huruf Besar Dan Tanda Baca……….………..78
5.1.13. Pengujian Aplikasi Dengan Nama File Berupa Spasi...80
5.1.14. Pengujian Aplikasi Dengan Nama File Berupa Spasi Dan Tanda Baca………..…….82
5.1.15. Pengujian Aplikasi Dengan Nama File Berupa Tanda Baca…83 5.2. Perbandingan Aplikasi Dengan Menu Search Windows 7……….85
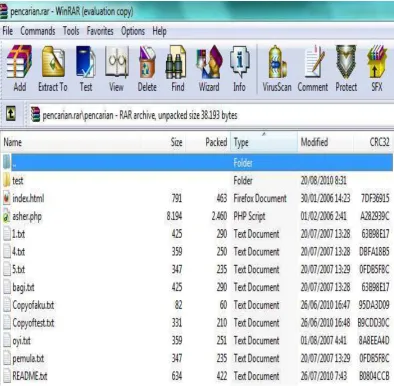
5.2.1. Perbandingan Dengan File Kompresi “.zip”………86
5.2.2. Perbandingan Dengan File Kompresi “.Rar”………...88
5.2.3. Pencarian File Kompresi “.Rar dan .Zip” Secara Bersama Dengan Menu Search Win 7………90
5.24. Pengujian Aplikasi Utilitas Pencarian Nama File Terkompresi………..91
BAB VI Penutup……….………...……….92
6.1. Kesimpulan………...……….………...92
Gambar 2.1. Struktur Header File Zip………...16
Gambar 2.2. Tampilan Embarcadero Delphi 2010………...24
Gambar 2.3. Entity………...………28
Gambar 2.4. Aliran Data………..28
Gambar 2.5. Proses………...28
Gambar 2.6. Storage…….………29
Gambar 3.1. Desain Penelitian……….34
Gambar 3.2. Decomposite Diagram……….35
Gambar 3.3. DFD Level 0………36
Gambar 3.4. DFD Level 1………37
Gambar 3.5. DFD Level 2 Dari Pilih Drive Dan Folder………..38
Gambar 3.6. DFD Level 2 Cari Nama File………..39
Gambar 3.7. Diagram Alir Sistem Pencarian ………..41
Gambar 3.8. Tabel Proses Pencarian String Di KMP…..………43
Gambar 3.9. Desain Form Pencari File………44
Gambar 4.1. Implementasi Form Pencari File……….………50
Gambar 4.2. Implementasi Komponen Penunjuk Folder……….51
Gambar 4.3. Implementasi Komponen Pencarian File……….52
Gambar 4.4. Implementasi Komponen Tombol Keluar………...52
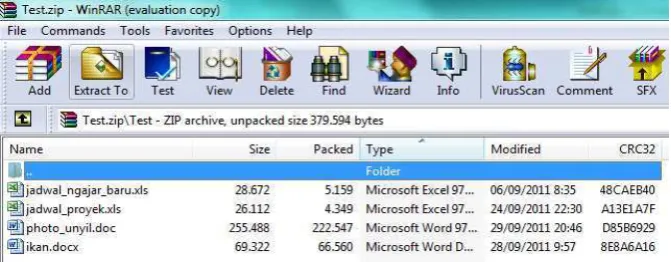
Gambar 5.1. Isi File TEST.ZIP………54
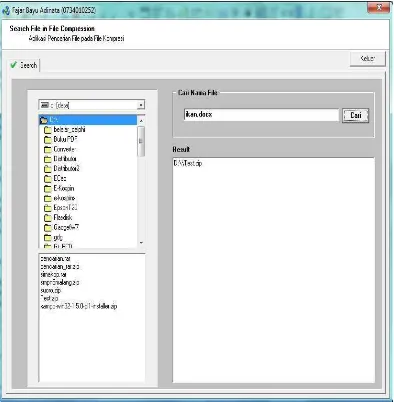
Gambar 5.2. Pengujian Untuk Mencari Ikan.docx………...55
Gambar 5.3. Isi File Pencarian.rar………56
Gambar 5.4. Pengujian Untuk Mencari File Pemula.txt………..57
Gambar 5.5. Pengujian Untuk Dengan Hasil Lebih Dari Satu……….58
Gambar 5.6. Pengujian Untuk Berdasarkan Nama File Tanpa Ekstensi………..59
Gambar 5.7. Isi File SIMAKOP.RAR………..60
Gambar 5.8. Pengujian Untuk Mencari Nama File Berupa Bilangan………...61
Gambar 5.9. Struktur File Di Xcode_magazine_19.zip………...62
Tanpa Ekstensi………..………66
Gambar 5.14. Struktur File Xcode_magazine_19.zip………..66
Gambar 5.15. Pengujian Untuk Mencari Nama File Berupa Bilangan Di Sertai Dengan Tanda Baca……….………..67
Gambar 5.16. Struktur File Xcode_magazine_19.zip………..68
Gambar 5.17. Pengujian Untuk Mencari Nama File Berupa Bilangan Di Sertai Dengan Spasi……….………69
Gambar 5.18 Struktur File Xcode_magazine_17.zip………...70
Gambar 5.19. Pengujian Untuk Mencari Nama File Berupa Bilangan Di Sertai Dengan Kombinasi Huruf…………..………71
Gambar 5.20. Struktur File O_Reilly_Google_Hacks_3Ed.rar………...71
Gambar 5.21. Pengujian Untuk Mencari Nama File Berupa Bilangan Di Sertai Dengan Kombinasi Huruf Dan Tanda Baca………...72
Gambar 5.22. Attachments_2011_09_17.zip………...73
Gambar 5.23. Pengujian Untuk Mencari Nama File Berupa Bilangan Di Sertai Dengan Kombinasi Huruf,Tanda Baca,Dan Spasi…...……..74
Gambar 5.24. Attachments_2011_09_17.zip………...75
Gambar 5.25. Pengujian Untuk Mencari Nama File Berupa Huruf Besar…………...76
Gambar 5.26. 4 Free E-Books (Nofia Fitri aka Bunga Mataharry).rar………76
Gambar 5.27. Pengujian Untuk Mencari Nama File Berupa Huruf Besar Dan Tanda Baca……….………...77
Gambar 5.28. 4 Free E-Books (Nofia Fitri aka Bunga Mataharry).rar………78
Gambar 5.29. Pengujian Untuk Mencari Nama File Berupa Spasi………..79
Gambar 5.30. O_Reilly_Google_Hacks_3Ed.rar……….80
Gambar 5.31. Pengujian Untuk Mencari Nama File Berupa Spasi Dan Tanda Baca………..………...81
Gambar 5.32. O_Reilly_Google_Hacks_3Ed.rar……….82
Gambar 5.33. Pengujian Untuk Mencari Nama File Berupa Tanda Baca…………...83
Penyusun : Fajar Bayu Adinata
ABSTRAK
Saat ini sering dilakukan pencarian data di dalam komputer. Data yang di cari pun terdiri dari berbagai macam ektensi misalnya : .doc ; .exe ; .txt ; .dpr dan
lain sebagainya. Dan yang umum dalam melakukan pencarian data dalam
komputer adalah data yang di cari terdapat dalam file yang tidak terkompresi.
Apabila dalam melakukan pencarian data, data yang dicari ada di dalam file terkompresi maka pencarian tidak dapat dilakukan langsung. Sebelum proses pencarian file terlebih dahulu dilakukan, proses dekompresi terlebih dahulu. Agar pencarian data yang di cari dapat ditemukan.
Dari cerita di atas, penulis mendapatkan inspirasi untuk menangani masalah tersebut. Maka dibuatlah suatu aplikasi utilitas yang bisa di manfaatkan untuk pencarian data dalam file yang terkompresi tanpa melakukan proses
dekompresi. Dengan menggunakan algoritma KMP sebagai algoritma pencarian
string nya. Dimana aplikasi ini mampu mencari file yang dibutuhkan dalam keadaan yang sudah terkompresi untuk mempermudah pengguna tanpa melakukan
proses dekompresi. Dengan adanya aplikasi ini pengguna akan dimudahkan dalam
mencari sebuah file dalam file terkompresi tanpa perlu melakukan proses
dekompresi terlebih dahulu.
Setelah aplikasi dibuat, barulah dilakukan ujicoba terhadap aplikasi ini dengan 10 kali percobaan. Dari 10 kali percobaan yang diacak untuk dites,
aplikasi dapat mengenali format kompresi bertipe .zip dan .rar dengan baik.
Aplikasi mampu mencari file berdasarkan nama file yang di masukkan user, baik
di masukkan secara lengkap dengan ekstensinya ataupun hanya sebagian dari
nama file nya saja. Dan juga aplikasi ini mampu menampilkan hasil kompresi
secara multiple file format apabila ditemukan kesamaan antara nama file yang
dicari dengan nama file yang terdapat dalam file terkompresinya.
1.1. Latar Belakang
Perkembangan penggunaan komputer yang semakin meningkat dalam
berbagai bidang berkontribusi pada semakin bervariasinya format data yang
disimpan oleh pengguna. Format data tersebut meliputi data teks, audio dan video
serta kombinasi diantara ketiganya yang lazim disebut data multimedia.
Dengan ditemukannya metode kompresi data, ukuran file atau data yang
besar dapat diperkecil. Secara spesifik, kompresi data atau file bertujuan untuk
mereduksi tempat (space) penyimpanan data atau file. Sejak era 1940-an, mulai
dipikirkannya suatu metode untuk memperkecil ukuran data atau kompresi. Hal
ini menunjukkan bahwa di masa lalu, para pakar juga telah memprediksi
pertumbuhan data yang akan semakin besar.
Terdapat banyak metode kompresi, tetapi secara umum mempunyai teknik
yang terbagi menjadi dua kategori yaitu lossy compression dan lossless
compression. Masing-masing teknik tersebut mempunyai kekhasan sendiri
terhadap data yang menjadi obyek kompresinya.
Pada teknik lossy compression, lebih tepat digunakan pada obyek data
audio, video dan citra digital, sedangkan teknik lossless compression lebih tepat
digunakan pada data dokumen yang banyak mengandung teks daripada data
multimedia karena mampu mempertahankan kebutuhan informasi yang dikandung
Salah satu proses yang sering dilakukan sebelum data yang sama dibuka
oleh aplikasi tertentu adalah pencarian data. Dalam hal ini, semakin banyak file
data yang dikompresi dan kurangnya pengaturan struktur penyimpanan folder
menyebabkan kendala dalam mencari file yang dibutuhkan, karena aplikasi file
pencari yang ada sekarang tidak mampu mencari file yang terletak dalam file yang
sudah terkompresi. Sehingga pengguna harus menjalankan program kompresinya
untuk melihat apakah terdapat file atau data yang dibutuhkan pada file
terkompresi tersebut. Hal ini tentunya memakan waktu yang cukup lama untuk
menemukan data tersebut.
Oleh karena itu, dalam tugas akhir ini, penulis mendapatkan ide untuk
membuat aplikasi yang mampu mencari file yang dibutuhkan dalam keadaan yang
sudah terkompresi untuk mempermudah pengguna tanpa melakukan proses
dekompresi terlebih dahulu.
1.2. Perumusan Masalah
Rumusan masalah yang digunakan dalam tugas akhir ini adalah :
Bagaimana membuat aplikasi pencari file dalam file yang sudah terkompresi tanpa
melakukan proses dekompresi terlebih dahulu ?
1.3. Batasan Masalah
Dalam tugas akhir ini batasan masalah yang dipergunakan yaitu :
a. Format file atau ekstensi file yang terkompresi adalah .zip dan .rar
b. File yang dicari dalam format atau ekstensi bebas, pencarian dilakukan
c. Hasil pencarian hanya pada satu folder saja.
d. Aplikasi ini dapat berjalan baik di microsoft windows 7
e. Aplikasi ini tidak dapat mencari di file kompresi yang terpassword
1.4. Tujuan
Tujuan yang ingin dicapai pada pengerjaan tugas akhir ini adalah:
Membangun aplikasi yang dapat mencari data dalam file terkompresi.
1.5. Manfaat
Adapun manfaat yang ingin diperoleh dari pengerjaan tugas akhir ini adalah dapat
membuat perangkat lunak untuk mempermudah pengguna dalam mencari file
dalam kumpulan file yang sudah terkompresi.
1.6. Metode Penelitian
Adapun metode penelitian yang dipergunakan dalam pengerjaan tugas akhir ini
adalah :
a. Studi Literatur
Mencari referensi dan bahan pustaka tentang teori-teori yang berhubungan
dengan permasalahan yang akan dikerjakan dalam tugas akhir ini.
b. Studi Kasus
Mencari contoh-contoh kasus serupa yang berhubungan dengan permasalahan
c. Analisis dan Perancangan
Membuat analisa berdasarkan data-data yang sudah dimiliki, membuat model
matematisnya dan merancang alur penyelesaian berdasarkan algoritma zip dan
rar. Perancangan aplikasi dimulai dengan perancangan antar muka aplikasi,
kemudian merancang detail algoritma pencarian file.
d. Implementasi Program
Mengimplementasikan teknik algoritma yang akan digunakan. Detail
mengenai implementasi program dilakukan sesuai hasil analisis dan
perancangan aplikasi pada tahapan sebelumnya.
e. Pengujian Aplikasi
Pengujian dilakukan pada aplikasi yang telah dibuat. Menguji validitas dan
efektifitas algoritma yang diterapkan pada aplikasi.
f. Evaluasi dan Penarikan kesimpulan
Evaluasi dilakukan untuk mengetahui kinerja aplikasi kompresi data teks
sesuai ukuran dan format data teksnua, selanjutnya dilakukan penarikan
kesimpulan.
1.7. Sistematika Penulisan
Sistematika penulisan tugas akhir ini disusun untuk memberikan gambaran
umum tentang penelitian yang dijalankan. Sistematika penulisan tugas akhir ini
BAB I PENDAHULUAN
Bab ini berisi latar belakang masalah, identifikasi masalah, maksud
dan tujuan yang ingin dicapai, batasan masalah, metodologi
penelitian yang diterapkan dalam memperoleh dan mengumpulkan
data, waktu dan tempat penelitian, serta sistematika penulisan.
BAB II TINJAUAN PUSTAKA
Membahas berbagai konsep dasar dan teori-teori yang berkaitan
dengan topik masalah yang diambil.
BAB III ANALISIS DAN PERANCANGAN
Menganalisis masalah dari model penelitian untuk memperlihatkan
keterkaitan antar proses yang diteliti serta model matematis untuk
analisisnya.
BAB IV IMPLEMENTASI SISTEM
Membahas mengenai pengimplementasian aplikasi yang telah
dibuat ke perangkat yang akan digunakan. serta melakukan
pengujian terhadap aplikasi yang telah diimplementasikan tersebut.
BAB V UJI COBA
Melakukan pengujian terhadap aplikasi yang telah
diimplementasikan tersebut untuk mengetahui apakah program
tersebut telah bekerja dengan benar.
BAB VI PENUTUP
Berisi kesimpulan dan saran yang sudah diperoleh dari hasil
2.1. Algorithma Dan Pemrograman
Pada era tahun 1950 – 1960, kecepatan komputer sangat rendah dan
disertai juga dengan keterbatasan dari media penyimpan, sehingga tentunya
berakibat juga dengan keterbatasan dalam penulisan program-program komputer.
Namun di era saat ini, dengan kecepatan komputer yang cukup handal demikian
juga ketersediaan dari media penyimpanan yang cukup handal dan besar, serta
didukung juga dengan perkembangan bahasa pemrograman yang ada sehingga
dapat dengan mudah membuat suatu program.
Permasalahan yang timbul dalam pembuatan program tersebut adalah
bagaimana memahaminya, sehingga apabila terdapat perubahan yang akan
dilakukan dapat memperbaikinya secara mudah. Hal ini tentu saja harus
diperhatikan terutama apabila dilihat dari biaya yang harus dikeluarkan dalam
pembuatan program tersebut. Istilah Pemrograman Terstruktur (Structured
Programming) mengacu dari suatu kumpulan tehnik yang dikemukan oleh Edsger
Dijkstra.
Dengan tehnik ini akan meningkatkan produktifitas programmer, dengan
mengurangi waktu yang dibutuhkan dalam penulisan (write), pengujian (test),
penelusuran kesalahan (debug) dan pemeliharan (maintenance) suatu program.
Pada pembahasan berikut ini akan melihat bagaimana tehnik ini yang pendekatan
yang dilakukan secara modular, dapat membantu dalam membangun suatu
Dalam pemrograman secara modular, suatu program akan dipilah kedalam
sejumlah modul, dimana setiap modul menjalankan fungsinya sendiri. Tentunya
fungsi yang dijalankan oleh setiap modul sangat terbatas sesuai dengan ruang
lingkup yang akan dikerjakan. Dengan adanya sejumlah modul program ini tentu
saja kesalahan yang timbul dapat dikurangi. Setiap program tentu akan memiliki
program utamanya, yang kemudian akan memanggil sejumlah modul-modul yang
ada.
Pemrograman secara modular ini dapat diimplementasikan dengan
penggunaan subroutine, suatu kelompok instruksi yang menjalankan suatu
pengolahan yang sifatnya terbatas seperti pencetakan, pembacaan untuk proses
input atau untuk proses penghitungan. Subroutine dapat dikelompokkan menjadi
internal subroutine dan external subroutine.
2.1.1. Internal Subroutines
Adalah bagian dari suatu program yang digunakan. Dideklarasikan cukup
sekali saja, untuk sejumlah proses yang sama akan dilakukan oleh program
tersebut. Program akan memanggil subroutines tersebut jika diperlukan dan
apabila telah selesai, kontrol selanjutnya dikembalikan ke instruksi berikutnya.
Instruksi yang mengendalikan kontrol transfer ke suatu subroutine umumnya
dikenal sebagai call dan return.
2.1.2. External Subroutines
Diletakkan secara terpisah dari program yang menggunakan subroutine
lain. Untuk menggunakannya tentu seorang programmer harus mengetahui
dimana ? , apa namanya ?, bagaimana pengiriman datanya ?, bagaimana jawaban
yang akan diperoleh ?. Subroutine ini biasanya digunakan untuk pemrosesan yang
komplek, yang dibutuhkan oleh banyak user.
2.1.3. Pendekatan Top Down
Pemrograman terstruktur mempergunakan Pendekatan Top-Down dalam perencanaan program. Merupakan pendekatan yang menggambarkan pemecahan
modul kompleks/besar menjadi modul-modul yang lebih sederhana/kecil
Berbentuk Struktur Hirarki. Di dalam pemrograman terstruktur, terdapat 3 bentuk
struktur perintah yang dipergunakan :
a. Sequence Structure
b. Loop Structure
c. Selection Structure
Struktur perintah yang instruksinya dieksekusi berdasarkan urutannya.
Dimulai dari bagian atas dan diakhiri di bagian bawahnya. Digambarkan dengan
bujur sangkar, sebagai simbol untuk : Input dan Output Operasi aritmatika.
Operasi pemindahan data dalam memori komputer. Menggambarkan perulangan
eksekusi dari satu atau lebih instruksi Menggambarkan struktur yang
Algoritma merupakan sekumpulan langkah-langkah untuk menyelesaikan
suatu tugas. Penamaan “Algoritma” diambil dari seorang ahli matematika
bernama Al-Khwarizmi. Sebuah algoritma harus:
a. Jelas, tepat dan tidak membingungkan
b. Memberikan penyelesaian yang tepat
c. Mempunyai akhir
Tujuh langkah dasar dalam pengembangan program :
a. Definisi Masalah
b. Outline Solusi
c. Pengembangan outline ke dalam algoritma
d. Melakukan test terhadap algoritma
e. Memindahkan algoritma ke dalam bahasa pemrograman
f. Menjalankan program pada komputer
g. Dokumentasi dan pemeliharaan program
h. Pada tahap ini memerlukan pemahaman terhadap permasalahan dengan
membaca berulang kali sampai dengan mengerti apa yang dibutuhkan.
Setelah permasalahan didefinisikan, permasalahan dapat di bagi kedalam
tugas tugas atau langkah langkah yang lebih kecil dan menghasilkan outline
solusi. Outline solusi pada langkah kedua dikembangakan menjadi algoritma
yaitu sebuah set langkah yang menggambarkan tugas yang akan dikerjakan dan
Tujuan utama dari melakukan test terhadap algoritma adalah adalah untuk
menemukan kesalahan utama logika sejak awal, sehingga akan lebih mudah
diperbaiki. Data test diperlukan untuk melakukan test terhadap algoritma ini.
Setelah ke-empat langkah sebelumnya dilakukan, maka pencodingan dapat
dimulai dengan menggunakan bahasa pemrograman yang dipilih. Setelah
pengcodingan, maka program dapat dijalankan pada komputer. Jika Program
sudah didesain dengan baik, maka akan mengurangi tingkat kesalahan dalam
melakukan testing program.
Langkah ini perlu dilakukan beberapa kali, sehingga program yang
dijalankan dapat berfungsi dengan benar. Dokumentasi melibatkan eksternal
dokumentasi (hierarchy chart, algoritmasolusi, dan hasil data test) dan internal
dokumentasi (coding program). Pemeliharaan program meliputi perubahan yang
dialami oleh program (perbaikan ataupun penambahan modul, dan lain-lain).
(Sumber : Pohan, Husni dan Kusna Sriyanto, Pengantar Perancangan Sistem,
KPC LPPM ITB, Bandung, 2002)
2.2. Kompresi Data
Pada akhir tahun 40-an dimana dimulainya tahun teori informasi, ide pengembangan metode coding yang efisien baru dimulai dan dikembangkan.
Dimulainya penjelajahan ide dari entropy, information content dan redudansi.
Salah satu ide yang popular adalah apabila probabilitas dari simbol dalam suatu
memakan tempat yang lebih kecil. Ide inilah yang menjadi cikal bakal dalam
terciptanya kompresi data.
Model pertama yang muncul untuk kompresi sinyal digital adalah
Shannon-Fano coding.Berdasarkan web arturo campos, Shannon dan fano terus
menerus mengembangkan algoritma ini yang menghasilkan codeord biner untuk
setiap symbol (unik) yang terdapat pada data file.
Berdasarkan web arturo campos ,Huffman coding memakai hampir semua
karakteristik dari Shannon-fano coding. Huffman coding dapat menghasilkan
kompresi data yang efektif dengan mengurangkan jumlah redudansi dalam
mengkodingkan simbol. Telah dapat dibuktikan, bahwa Huffman coding
merupakan metode fixed-length yang paling efisien.
Pada limabelas tahun terakhir, Huffman coding telah digantikan oleh
Arithmetic coding. Arithmetic coding melewatkan ide untuk menggantikan sebuah
simbol masukan dengan kode yang spesifik. Algoritma ini menggantikan sebuah
aliran simbol masukan dengan sebuah angka keluaran single floating-point. Lebih
banyak bit dibutuhkan dalam angka keluaran, maka semakin rumit pesan yang
diterima.
Algoritma dictionary-based compression menggunakan metode yang
sangat berbeda dalam mengkompres data. Algoritma ini menggantikan string
variable-length dari simbol menjadi sebuah token. Token merupakan sebuah indek
dalam susunan kata di kamus. Apabila token kecil dari susunan kata, maka token
akan menggantikan prase tersebut dan kompresi pun terjadi.
Kompresi data (pemampatan data) merupakan suatu teknik untuk
data umumnya diterapkan pada mesin komputer, hal ini dilakukan karena setiap
simbol yang muncul pada komputer memiliki nilai bit-bit yang berbeda. Misal
pada ASCII setiap simbol yang dimunculkan memiliki panjang 8 bit, misal kode A
pada ASCII mempunyai nilai decimal 65, jika dirubah dalam bilangan biner
menjadi 010000001. Pemampatan data digunakan untuk mengurangkan jumlah
bit-bit yang dihasilkan dari setiap simbol yang muncul. Dengan pemampatan ini
diharapkan dapat mengurangi (memperkecil ukuran data) dalam ruang
penyimpanan.
(Sumber: Campos, Arturo, LZ77, http://www.arturocampos.com/ac_lz77.html, 21
Oktober 2011, 20.30 WIB.)
2.3. Jenis-jenis Kompresi Data
Berdasarkan mode penerimaan data oleh manusia, kompresi data dapat
dibagi menjadi dua, yaitu :
a. Dialoque Mode
yaitu proses penerimaan data dimana pengirim dan penerima seakan
berdialog (real time), dimana kompresi data harus berada dalam batas penglihatan
dan pendengaran mausia. Contohnya pada video conference.
b. Retrieval Mode
yaitu proses penerimaan data tidak dilakukan secara real time. Jenis
kompresi ini dapat dilakukan random access terhadap data dan dapat bersifat
(Sumber : Kompresi Data, 2009. http://id.wikipedia.org/wiki/Kompresi_data, 15
Nopember 2011, 19.39 WIB.)
2.4. Metode Kompresi Data
Berdasarkan tipe peta kode yang digunakan untuk mengubah pesan awal
(isi file input) menjadi sekumpulan codeword, metode kompresi terbagi menjadi
dua kelompok, yaitu :
a. Metode Statik
Menggunakan peta kode yang selalu sama. Metode ini membutuhkan dua
fase (two-pass) : fase pertama untuk menghitung probabilitas kemunculan tiap
simbol/karakter dan menentukan peta kodenya dan fase kedua untuk mengubah
pesan menjadi kumpulan kode yang akan ditransmisikan. Contohnya pada
Huffman static, arithmetic coding
b. Metode Dinamik (adaptif)
Menggunakan peta kode yang dapat diubah dari waktu ke waktu. Metode
ini disebut adaptif karena peta kode mampu beradaptasi terhadap karakteristik isi
file selama proses kompresi berlangsung. metode ini bersifat onepass, karena isi
file selama dikompres hanya diperlakukan satu kali pembacaan terhadap isi file.
Berdasarkan teknik pengkodean atau pengubahan simbol yang digunakan, metode
kompresi dapat dibagi ke dalam tiga kategori, yaitu :
a. Metode simbolwise
Menghitung peluang kemunculan dari tiap simbol dalam file input, lalu
mengkodekan satu simbol dalam satu waktu, dimana simbol yang lebih sering
muncul diberi kode lebih pendek dibandinglan simbol yang lebih jarang muncul.
Contohnya pada Huffman coding, arithmetic coding.
b. Metode dictionary
Menggantikan karakter/fragmen dalam file input dengan indeks lokasi dari
karakter/fragmen tersebut dalam sebuah kamus (dictionary). Contohnya pada
algoritma LZW.
c. Metode predictive
Menggunakan model finite-context atau finite-state untuk memprediksi
distribusi probabilitas dari simbol-simbol selanjutnya. Contohnya pada algoritma
DMC
(Sumber : Kompresi Data, 2009. http://id.wikipedia.org/wiki/Kompresi_data, 15
Nopember 2011, 19.39 WIB.)
2.5. Teknik Kompresi Data
Teknik kompresi data dapat digolongkan menjadi dua kelompok utama
teknik kompresi data dengan menghilangkan ketelitian data utama guna
mendapatkan data sekecil mungkin (kompresi data sebesar mungkin). Teknik
kompresi data secara lossless yaitu teknik kompresi data dengan mengurangkan
jumlah data yang terjadi redudansi (memiliki symbol yang sama) sebelum terjadi
kompresi.
a. Lossy Compression
Merupakan teknik kompresi yang menghilangkan beberapa informasi data
yang dianggap tidak penting. Sehingga hasil data yang telah terkompresi tidak
sama dengan data yang sebelum dikompresi. Namun data yang telah terkompresi
tersebut sudah cukup untuk digunakan, walaupun datanya telah berubah.
Keunggulan dari teknik ini adalah file atau data yang telah terkompresi memiliki
ukuran yang lebih kecil dari ukuran data aslinya. Biasanya teknik kompresi ini
banyak diaplikasikan pada data gambar dan data audio.
b. Lossless Compression
Merupakan teknik kompresi yang mempertahankan kebutuhan informasi
yang dikandung oleh data, sehingga informasi yang terkandung pada file yang
telah terkompresi tetap terjaga meskipun ukurannya telah berubah dari ukuran
data aslinya. Keunggulan dari teknik ini adalah data yang telah terkompresi,
apabila didekompresi kembali akan menghasilkan data yang sama persis dengan
(Sumber : Kompresi Data, 2009. http://id.wikipedia.org/wiki/Kompresi_data, 15
Nopember 2011, 19.39 WIB.)
2.6. Algorithma Zip
Struktur Zip dapat dilihat pada Gambar 2.6. Setiap file terdiri atas
rangkaian dimana header memuat tentang informasi file, kompresi dan enkripsi.
Lalu semua file akan dirangkai dalam sebuah arbitrary dan sebuah informasi
mengenai keseluruhan Zip. Pada sebuah informasi, masing-masing memiliki
file-headers, yang menggandung kedua informasi tentang file dan informasi tentang
dimana Zip akan dimulai.
Untuk menguraikan kembali data yang sudah dikompresi sebelumnya,
dapat digunakan cara sebagai berikut :
a. Baca bit pertama dari string biner masukan.
b. Lakukan traversal pada pohon string mulai dari akar sesuai dengan bit yang
dibaca. Jika bit yang dibaca adalah 0 maka baca anak kiri, tetapi jika bit yang
dibaca adalah 1 maka baca anak kanan.
c. Jika anak dari pohon bukan daun (simpul tanpa anak) maka baca bit
berikutnya dari string biner masukan.
d. Hal ini diulang (traversal) hingga ditemukan daun.
e. Pada daun tersebut simbol ditemukan dan proses penguraian kode selesai.
f. Proses penguraian kode ini dilakukan hingga keseluruhan string biner
Berikut ini dapat dilihat struktur header file zip
. Gambar 2.1. Struktur Header File Zip.
Setelah mengetahui dan membaca file header, dilakukan proses pencarian
dengan mengakses data pada file entry untuk diperiksa apakah mengandung kata
string yang diinputkan. Jika menemukan file yang dicari, tampilkan file tersebut
beserta atribut lainnya.
(Sumber : zip, 2010. http://en.wikipedia.org/wiki/Zip, 25 Oktober 2011 jam 20.07
WIB).
2.7.
Algoritma Knuth-Morris-Pratt (KMP)
Pada algoritma brute force, setiap kali ditemukan ketidakcocokan pattern
Sedangkan pada algoritma KMP, kita memelihara informasi yang
digunakan untuk melakukan jumlah pergeseran. Algoritma menggunakan
informasi tersebut untuk membuat pergeseran yang lebih jauh, tidak hanya satu
karakter seperti pada algoritma brute force.
Dengan algoritma KMP ini, waktu pencarian dapat dikurangi secara
signifikan. Algoritma KMP dikembangkan oleh D. E. Knuth, bersama-sama
dengan J. H. Morris dan V. R. Pratt.
1 2 3 4 5 6 7 8 9…
Teks: bimbingan belajar atau bimbel
Pattern: bimbel
↑
j = 5
1 2 3 4 5 6 7 8 9…
Teks: bimbingan belajar atau bimbel
Pattern: bimbel
↑
j = 2
Misalkan A adalah alfabet dan x = x1x2…xk , k ∈ N, adalah string yang
panjangnya k yang dibentuk dari karakter-karakter di dalam alfabet A. Awalan
(prefix) dari x adalah upa-string (substring) u dengan u = x1x2…xk – 1 , k ∈ {1, 2,
…, k – 1} dengan kata lain, x diawali dengan u.Akhiran (suffix) dari x adalah
upa-string (substring) u dengan u = xk – bxk – b + 1 …xk , k ∈ {1, 2, …, k – 1} dengan
kata lain, x diakhiri dengan v.
Pinggiran (border) dari x adalah upa-string r sedemikian sehingga r =
x1x2…xk – 1 dan u = xk – bxk – b + 1 …xk , k ∈ {1, 2, …, k – 1},dengan kata lain,
pinggiran dari x adalah upa-string yang keduanya awalan dan juga akhiran
sebenarnya dari x. Contoh 10.5. Misalkan x = abacab. Awalan sebenarnya dari x
adalah , a, ab, aba, abac, abaca (ket: = string kosong).
Akhiran sebenarnya dari x adalah , b, ab, cab, acab, bacab. Pinggiran dari
x adalah , ab. Pinggiran mempunyai panjang 0, pinggiran ab mempunyai
panjang 2.
-Fungsi Pinggiran (Border Function)
Fungsi pinggiran b(j) didefinisikan sebagai ukuran awalan terpanjang dari
P yang merupakan akhiran dari P[1..j]. Sebagai contoh, tinjau patternP = ababaa.
Nilai F untuk setiap karakter di dalam P adalah sebagai berikut:
P
[
j
]
A
b
a
b
A
a
b
(
j
)
0
0
1
2
3
1
Algoritma menghitung fungsi pinggiran adalah sbb :
procedure HitungPinggiran(input m : integer, P : array[1..m] of char,
output b : array[1..m] of integer)
{ Menghitung nilai b[1..m] untuk pattern P[1..m] }
Deklarasi
k,q : integer
Algoritma:
b[1]←0
q←2
k←0
for q←2 to m do
while ((k > 0) and (P[q] ≠ P[k+1])) do
k←b[k]
endwhile
if P[q]=P[k+1] then
Contoh:
Teks: abcabcabd
Pattern: abcabd
Mula-mula kita hitung fungsi pinggiran untuk pattern tersebut:
J
1 2 3
4 5 6
P
[
j
]
A b C a b d
b
(
j
) 0 0 0
1 2 0
Teks: abcabcabd
Pat t ern
: abcabd
↑
j
= 3
endif
b[q]=k
Algoritma KMP selengkapnya adalah :
procedure KMPsearch(input m, n : integer, input P : array[1..m] of char,
input T : array[1..n] of char,
output idx : integer)
{ Mencari kecocokan pattern P di dalam teks T dengan algoritma Knuth-Morris-Pratt. Jika ditemukan P di dalam T, lokasi awal kecocokan disimpan di dalam peubah idx.
Masukan: pattern P yang panjangnya m dan teks T yang panjangnya n. Teks T direpresentasika sebagai string (array of character) Keluaran: posisi awal kecocokan (idx). Jika P tidak ditemukan, idx = -1. }
Deklarasi
i, j : integer
ketemu : boolean
b : array[1..m] of integer
procedure HitungPinggiran(input m : integer, P : array[1..m] of char, output b : array[1..m] of integer)
{ Menghitung nilai b[1..m] untuk pattern P[1..m] }
Algoritma:
HitungPinggiran(m, P, b)
j←0 i←1
ketemu←false
while (i ≤ n and not ketemu) do
while((j > 0) and (P[j+1]≠T[i])) do j←b[j]
endwhile
if P[j+1]=T[i] then j←j+1
endif
if j = m then ketemu←true else
i←i+1 endif endwhile
if ketemu then
idx←-1 endif
Kompleksitas Waktu Algoritma KMP :
Untuk menghitung fungsi pinggiran dibutuhkan waktu O(m), sedangkan
pencarian string membutuhkan waktu O(n), sehingga kompleksitas waktu
algoritma KMP adalah O(m+n).
( Sumber : Rinaldi Munir, 2012, Strategi Algoritmik,/IF2251/BahanKuliah ke-15 )
2.8. Embarcadero Delphi 2010
Delphi merupakan alat bantu pengembangan aplikasi yang berbasis visual.
Perangkat ini merupakan hasil pengembangan dari bahasa pemrograman pascal
yang diciptakan oleh Niklaus Wirth. Pada masa itu, Wirth bermaksud membuat
bahasa pemrograman tingkat tinggi sebagai alat bantu mengajar logika
pemrograman komputer kepada para mahasiswanya.
Bahasa pemrograman pascal ini kemudian dikembangkan oleh Borland
yang merupakan salah satu perusahaan software menjadi sebuah tools dengan
dibuatkan compiler dan dijual ke pasar dengan nama TURBO PASCAL.Seiring
dengan ditemukannya metode pemrograman berorientasi obyek, bahasa
pemrograman pascal berevolusi menjadi object pascal dan dikembangkan oleh
Borland dengan nama Borland Delphi.
Keberhasilan Borland dalam mengembangkan Delphi menjadikan salah
satu bahasa yang populer dan disukai oleh banyak programmer, disamping Visual
user friendly dari pada VB. Lingkungan pengembangan Delphi yang mudah,
intuitif dan memudahkan pemakai, berhasil melampaui popularitas rivalnya, yaitu
Visual Basic, sehingga pernah menyandang predikat “VB-Killer”.
Gambar 2.2. Tampilan Embarcadero Delphi 2010
Karena tuntutan perkembangan teknologi, Borland berganti nama menjadi
Code Gear, tetapi tetap mempergunakan nama Delphi untuk tools yang berbasis
object pascal ini. Tidak lama kemudian Code Gear diakuisisi oleh Embarcadero
dan namanya pun berubah menjadi Embarcadero RAD Studio dengan tetap
Beberapa kelebihan yang dimiliki oleh Embarcadero Delphi 2010 ini antara lain :
a. Delphi dibangun dengan menggunakan arsitektur native compiler, sehingga
proses kompilasi instruksi menjadi bahasa mesin menjadi lebih cepat.
b. Semua file yang disertakan saat proses kompilasi, digabungkan menjadi satu
sesuai dengan arsitektur native compiler, sehingga mengurangi
ketergantungan terhadap library ataupun file-file pendukung lainya, sesuai
dengan prinsip build once, runs everywhere
c. Delphi mempunyai kemampuan selective object linking, sehingga apabila
terdapat pemanggilan sebuah library dan ternyata tidak terdapat instruksi
dalam library tersebut yang dipergunakan dalam system, maka secara
otomatis, kompiler tidak akan menyertakan library tersebut dalam proses
kompilasinya. Hal ini berbeda dengan tools lain yang tidak mempunyai
kemampuan seperti itu. Dengan adanya kemampuan tersebut, maka file
eksekusi yang dihasilkan delphi menjadi lebih optimal.
d. Lingkungan pengembangan Delphi sangat intuitif karena semua komponen
yang menjadi alat utama desain visual telah ditampilkan saat pertama kali
langsung dapat diamati oleh user dan dapat digunakan secara langsung.
(Sumber : Embarcadero, 2012. http://id.wikipedia.org/wiki/, 15 Nopember 2011,
2.9. Flow Map
Flow Map adalah diagram yang menunjukan aliran data berupa
formulir-formulir ataupun keterangan berupa dokumentasi yang mengalir atau
beredar dalam suatu sistem. Notasi yang digunakan dalam suatu flow map
merupakan penggabungan notasi flow chart program. Hal-hal yang harus
diperhatikan dalam menggambarkan flow map adalah sebagai berikut:
a. Penggambaran flow map dimulai dari atas halaman ke bagian bawah,
kemudian dari kiri kebagian kanan
b. Penggambaran flow map dilakukan berdasarkan pembagian atau sub
sistem
c. Dalam flow map harus jelas dimana awal suatu status informasi,
kemudian dimana akhir siklus
d. Semua bagian siklus informasi harus jelas menggunakan kertas kerja
yang jelas sesuai dengan yang akan dilakukan dalam sistem
e. Semua sub sistem yang digambarkan, harus mengalami siklus informasi
f. Jika penggambaran suatu siklus informasi terpotong, maka gunakan
(Sumber : Flow Map, 2012. http://id.wikipedia.org/wiki/, 10 Nopember 2011,
19.39 WIB.)
2.10. DATA FLOW DIAGRAM
Data Flow Diagram (DFD) adalah alat pembuatan model yang
memungkinkan profesional sistem untuk menggambarkan system sebagai suatu
jaringan proses fungsional yang dihubungkan satu sama lain dengan alur data,
baik secara manual maupun komputerisasi.
DFD ini adalah salah satu alat pembuatan model yang sering digunakan,
khususnya bila fungsi-fungsi sistem merupakan bagian yang lebih penting dan
kompleks dari pada data yang dimanipulasi oleh sistem. Dengan kata lain, DFD
adalah alat pembuatan model yang memberikan penekanan hanya pada fungsi
sistem.
DFD ini merupakan alat perancangan sistem yang berorientasi pada alur
data dengan konsep dekomposisi dapat digunakan untuk penggambaran analisa
maupun rancangan sistem yang mudah dikomunikasikan oleh profesional sistem
kepada pemakai maupun pembuat program. Salah satu tool yang paling penting
bagi seorang analis sistem. Penggunaan DFD Sebagai Modeling Tool
dipopulerkan Oleh Demacro and Yordan dan Gane and Sarson dengan
menggunakan pendekatan Metode Analisis Sistem Terstruktur.
DFD (Data Flow Diagram) merupakan data yang tersimpan dan proses
dengan proses yang terhubung dengan data tersebut. DFD bukan termasuk
ataupun cabang tetapi dapat menggambarkan semua proses, meskipun proses
tersebut terjadi dalam waktu yang berbeda.
Ada beberapa peraturan-peraturan yang penting dalam membuatan DFD
tersebut.
a. Semua objek harus mempunyai nama
b. Aliran data harus di awal dan di akhiri oleh proses
c. Semua aliran data harus mempunyai tanda panah.
2.10.1. Symbol dalam DFD
Menurut Gene dan Serson didalam DFD terdapat simbol-simbol yang
banyak digunakan agar dapat membentuk atau membuat suatu DFD secara utuh,
berikut adalah macam-macam symbol yang umum digunakan.
a. Entity
Gambar 2.3. Entity
Entity dapat digambarkan dengan simbol bujur sangkar. Entity Merupakan
sumber atau tujuan dari aliran data. Bisa juga menggambarkan secara phisik,
yaitu seseorang atau seelompok orang atau system lain.Kadang-kadang diperlukan
untuk menduplikasinya agar dapat menghindari anak panah yang simpang siur.
Ditandai dengan garis diagonal disudut kanan bawah yang menyatakan kalau
b. Aliran Data
Gambar 2.4. Aliran data
Aliran Data menggambarkan aliran data dari suatu proses ke proses
lainnya. Merepresentasikan dengan menggunakan anak panah. Nama proses dapat
ditulis untuk menjelaskan arti dalam aliran tersebut dan ditulis untuk
mengidentifikasi aliran tersebut. Aliran data juga dapat menyebar atau menyatu.
c. Proses
Gambar 2.5. Proses
Proses merupakan fungsi yang mentransformasikan data secara umum
Karena proses adalah suatu kegiatan agar dapat menghasilkan output, maka untuk
memberi nama sebuah proses mulailah dengan kata kerja dan diikuti objek.
d. Storage atau Penyimpan
Storage atau Penyimpanan merupakan komponen yang berfungsi untuk
menyimpan data atau file yang dapat berfungsi untuk mentransformasikan data
secara umum.
2.10.2. Level-level DFD
Model ini menggambarkan sistem sebagai jaringan kerja antar fungsi yang
berhubungan satu dengan yang dengan aliran dan penyimpan data. Bisa terjadi
penurunan level dimana dalam penurunan level yang lebih rendah harus bisa
merepresentasikan proses tersebut kedalam spesifikasi proses yang jelas. Dalam
DFD level dimulai dari level 0 kemudian turun ke DFD level 1, 2 dan seterusnya
sesuai dengan kebutuhan tetapi penurunan tidak dilakukan pada semua bagian
sistem.
a. Diagram level Nol.
Pada diagram level nol ini merupakan diagram awal suatu program yang
digunakan agar dapat melanjutkan ke diagram level selanjutnya. Perlihatkan
data store yang digunakan
- Pada proses yang tidak dirinci lagi, tambahkan tanda * pada akhir penomoran
proses
b. Diagram level Satu
Keseimbangan data store yang digunakan diagram ini merupakan
dekomposisi dari diagram level zero. Dengan cara sebagai berikut :
- Keseimbangan aliran data antara diagram nol dan diagram rinci
- Pada proses yang tidak dirinci lagi, tambahkan tanda * pada akhir
penomoran proses
- Tentukan proses yg lebih kecil (sub-proses) dari proses utama yg ada di
level zero.
- Tentukan apa yg diberikan atau diterima masing-masing sub-proses pada
atau dari sistem dan perhatikan konsep keseimbangan.
- Apabila diperlukan, munculkan data store (transaksi) sebagai sumber
maupun tujuan alur data.
- Gambarkan DFD level Satu
- Hindari perpotongan arus data.
- Beri nomor pada masing-masing sub-proses yg menunjukkan dekomposisi
dari proses sebelumnya. Contoh : 1.1, 1.2, 2.1
c. DFD level dua, tiga.
Diagram ini merupakan dekomposisi dari level sebelumnya. Proses
dekomposisi dilakukan sampai dengan proses siap dituangkan ke dalam program.
2.10.3. Bentuk Data Flow Diagram
Menurut Jogiyanto, Terdapat dua bentuk DFD, yaitu Diagram Alur Data
Fisik, dan Diagram Alur data Logika. Diagram alur data fisik lebih menekankan
pada bagaimana proses dari sistem diterapkan, sedangkan Diagram alur data
logika lebih menekankan proses-proses apa yang terdapat di sistem.
a. Diagram Alur Data Fisik (DADF).
DADF lebih tepat digunakan untuk menggambarkan sistem yang ada
(sistem yang lama). Penekanan dari DADF adalah bagaimana proses-proses dari
sistem diterapkan (dengan cara apa, oleh siapa dan dimana), termasuk
proses-proses manual.
b. Diagram Alur Data Logika (DADL).
DADL lebih tepat digunakan untuk menggambarkan sistem yang akan
diusulkan (sistem yang baru). Untuk sistem komputerisasi, penggambaran DADL
hanya menunjukkan kebutuhan proses dari system yang diusulkan secara logika,
biasanya proses-proses yang digambarkan hanya merupakan proses-proses secara
komputer saja.
(Sumber : Nugroho, Adi, 2005, Pemodelan Berorientasi Obyek, Bandung,
3.1. Desain Penelitian
Desain penelitian adalah tahapan atau gambaran yang akan dilakukan
peneliti dalam melakukan penelitian. Desain penelitian dibuat untuk memudahkan
peneliti dalam melakukan tahap-tahap penelitian.
Tahapan-tahapan desain penelitian yang peneliti lakukan diantaranya
adalah :
a. Mengumpulkan data yang diperlukan berupa text book, paper dan karya
ilmiah lainnya yang membahas kompresi data dan teknik-teknik pencarian file
b. Setelah dikumpulkan data yang diperlukan, ditentukan data yang dipakai pada
penelitian ini, yaitu kompresi data format .zip dan string pattern matching.
c. Mempersiapkan alat dan bahan penelitian berupa komputer, bahasa
pemrograman dan aplikasi kompresi data.
d. Kemudian memulai proses pembangunan perangkat lunak dengan metode
rapid application development.
e. Hasil pembangunan perangkat lunak adalah aplikasi yang dapat mencari nama
file terkompresi format zip tanpa proses dekompresi.
f. Aplikasi tersebut kemudian diuji untuk mencari nama file terkompresi untuk
Gambar di bawah ini merupakan gambar desain penelitian dari
tahapan-tahapan penelitian yang dilakukan di atas :
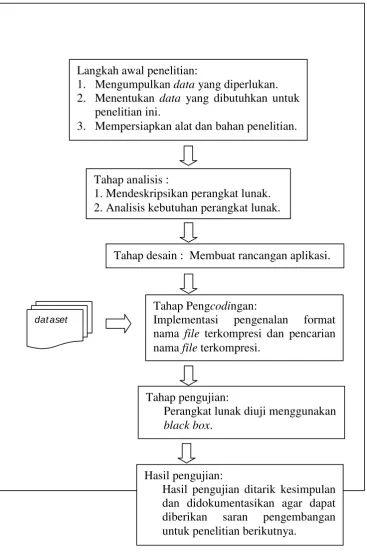
Gambar 3.1. Desain Penelitian Langkah awal penelitian:
1. Mengumpulkan data yang diperlukan. 2. Menentukan data yang dibutuhkan untuk
penelitian ini.
3. Mempersiapkan alat dan bahan penelitian.
Tahap analisis :
1. Mendeskripsikan perangkat lunak. 2. Analisis kebutuhan perangkat lunak.
Tahap desain : Membuat rancangan aplikasi.
Tahap Pengcodingan:
Implementasi pengenalan format nama file terkompresi dan pencarian nama file terkompresi.
Tahap pengujian:
Perangkat lunak diuji menggunakan
black box.
dat aset
Hasil pengujian:
3.2. Analisis Proses Kompresi
Berikut ini adalah analisis proses kompresi untuk format zip yang
dipergunakan dalam tugas akhir ini : Sistem akan mencari string yang mempunyai
tingkat duplikasi yang tinggi dari data yang diinputkan. String kedua (merupakan
string yang sama dari string pertama) akan digantikan oleh pointer yang
menunjuk string sebelumnya secara berpasangan (menurut jarak tertentu).
Jarak string dibatasi sebanyak 32 Kbytes dan panjangnya dibatasi sampai
256 bytes. Ketika sebuah string yang ditemukan tidak terdapat pada 32 Kbytes
sebelumnya, maka akan diperlakukan sebagai literal bytes. String dalam konteks
ini adalah urutan bytes dan tidak terbatas pada karakter alfabetik. Literal atau
string yang cocok dikompres dengan satu pohon huffman dan dan jarak yang sama
dikompres dengan pohon yang lain.
3.3. DFD
Decomposite Diagram
Sebelum dilakukan pembuatan DFD dibuat dulu Decomposite diagram
untuk mengetahui alur struktur program dari aplikasi utilitas pencari nama file
terkompresi tanpa proses dekompresi. Supaya kita bisa tahu alur program
selanjutnya.
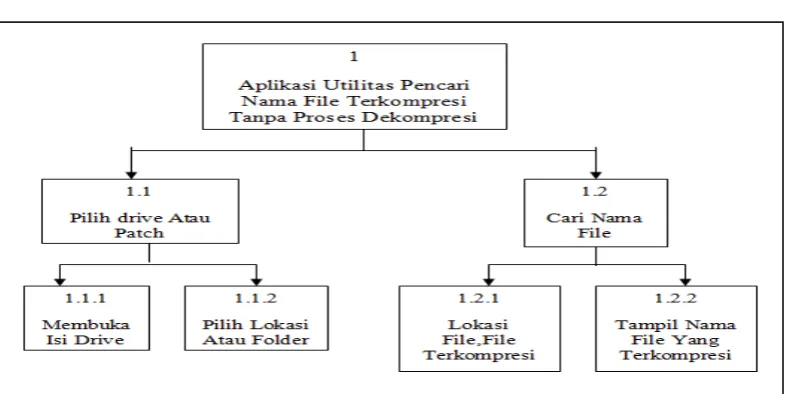
Yang pada decomposite diagram ini terdiri dari fungsi pilih drive atau
patch dan cari nama file.Fungsi “pilih drive atau patch” dipecah menjadi 2 sub
bagian yaitu membuka isi drive dan pilih lokasi atau folder.Fungsi “cari nama
file” dipecah menjadi 2 sub bagian yaitu lokasi file,file terkompresi dan tampil
nama file yang terkompresi
DFD Level 0
Pada DFD level 0 ini, membahas tentang sistem aplikasi utilities pencari
nama file terkompresi tanpa proses dekompresi dengan mengetahui drive dan
folder dari user untuk mengetahui alur pencarian nama file selanjutnya dari
program aplikasi pencari file ini.
DFD Level 1
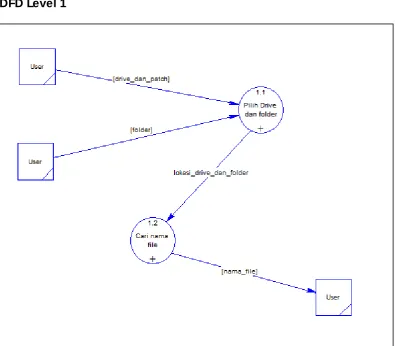
Gambar 3.4. DFD Level 1
Pada DFD level 1 ini dibahas,sistem dari aplikasi utilities pencari nama
file terkompresi tanpa proses dekompresi terdapat 2 fungsi yaitu “pilih drive dan
DFD Level 2
Gambar 3.5. DFD Level 2 Dari Pilih Drive Dan Folder
Pada DFD level 2 ini, terdapat 2 fungsi yaitu “tampil Isi drive dan folder”
fungsi “tampil lokasi folder” yang berfungsi menampilkan nama folder yang akan
di cari oleh user.
DFD Level 2
Gambar 3.6. DFD Level 2 Cari Nama File
dicari user untuk menemukan file yang terkompresi dan fungsi “tampil nama file
yang terkompresi” yang berfungsi untuk output nama file yang dicari.
3.4. Analisis Proses Pencarian
Sedangkan analisis proses pencarian nama file terkompresi dalam file
terkompresi dapat dijelaskan sebagai berikut :
Pertama user akan menginputkan string inputan ke dalam text box.
“Supaya sistem dapat mengenali file terkompresi maka sistem akan memeriksa
seluruh file yang terdapat pada folder tersebut. Apakah file tersebut mengandung
berekstensi .Zip atau .Rar. Jika ya, sistem akan membaca header pada file
kompresi tersebut. Apabila header pada file kompresi tersebut berhasil untuk
dikenali, maka sistem akan menciptakan tabel string pencarian. Tabel string
pencarian yaitu tabel yang berisi ekstraksi informasi dari header yang terdiri atas
daftar file yang terdapat dalam file terkompresi .Zip dan .Rar. Setelah tabel string
pencarian ini terbentuk, maka sistem akan membaca string yang terdapat pada
tabel string pencarian dan membandingkan dengan string yang akan diinputkan
oleh user di dalam text box tadi yang telah di inputkan oleh user, secara satu
persatu sesuai jumlah indeks yang terdapat pada tabel string pencarian tersebut.”
Apabila ditemukan ada yang cocok, maka akan ditampilkan hasilnya. Jika
tidak ditemukan yang cocok, maka sistem akan menutup file kompresi .Zip dan
.Rar yang aktif saat ini dan mencari dalam file kompresi .Zip dan .Rar yang lain
dengan urutan proses yang sama, sampai seluruh file kompresi .zip atau .rar yang
3.5. Diagram Alir Sistem
START
Nama file yang dicari
Baca file .zip dan verifikasi file tersebut
Hasilnya Benar ?
Baca header dan buat tabel string pencarian
For Loop = 1 to jumlah_indeks_tabel
Nama_file_dicari = indeks_tabel[loop] ?
Tampilkan Hasilnya
Break
Next Loop
END Y
T
T
3.6. Pseudocode Proses Pencarian
Sistem mengenali file terkompresi .zip,maka sistem akan memulai posisi
untuk membuat table string pencarian untuk file zip di dalam header.Ketika posisi
berada di nol atau sama maka di lakukan perbandingan antara inputan string
dengan nama file yang berada pada header file di file zip.Jika perbandigan sama
maka hasil string yang sama tadi di masukkan kedalam temp (temporary).
Kemudian lihat ke depan untuk membandingkan lagi.Perbandingan dilakukan
sampai jumlah file yang ada.Jika perbandingan antara inputan string dengan nama
yang ada pada header file zip sama maka hasil ditampilkan.
if FileZip is valid then begin
Posisi = BuatTable(FileZipHeader)
while posisi <> nil do begin
if CompareText(Look.FileName,FileZipHeader) = 0 then
begin
Result = FList.IndexOf(Look)
Exit
end
Look = Look.NextItem
end;
end
else begin
for I = 0 to FList.Count - 1 do
if CompareText(Items[I].FileName, FileZipHeader) = 0 then
begin
Result = I
Exit
end
end
3.7. Pseudocode Pembuatan Tabel Pencarian String
Dengan terlebih dahulu mengalokasikan ukuran tabel T, sesuai dengan
ukuran panjang string ditambah satu. Kemudian jika karakter indeks (i-1) pada
string W sama dengan panjang W(j), maka pada tabel T indeks i diisi dengan nilai
j + 1. Setelah itu nilai i dan j dinaikkan satu. Apabila nilai i sudah melebihi
panjang string W, maka pada tabel T indeks ke i diisi dengan nilai satu, nilai i
ditambah dengan satu dan nilai j diisi dengan satu.
SetLength( T, Length( W ) + 1 );
t[1] = 0; t[2] = 1;
while ( i <= Length( W ) ) do begin
if ( W[i - 1] = W[j] ) then begin
T[i] = j + 1; Inc( j ); Inc( i );
End else if ( j > 1 ) then begin
j = T[j]; end else begin
T[i] = 1; Inc( i ); j = 1; end;
end;
3.8. Perancangan Antar Muka
Perancangan antarmuka dibutuhkan untuk mewakili keadaan sebenarnya
dari aplikasi yang akan dibangun. Dan seperti developer visual lainnya,
Embarcadero RAD Studio sudah menyediakan berbagai macam komponen untuk
menghemat waktu pengembangan sesuai dengan kebutuhan developer. Berikut
akan disajikan perancangan antarmuka dari aplikasi yang akan dibangun :
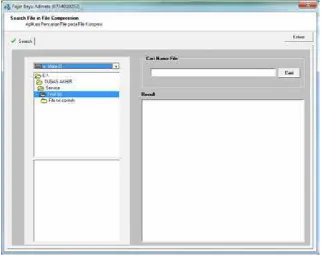
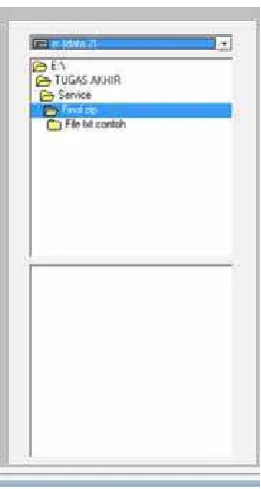
Gambar 3.9. Desain Form Pencari File
Tampak pada Gambar 3.9 terdapat komponen drive combo yang
digunakan untuk membaca seluruh drive yang aktif pada komputer, directory list
box yang digunakan untuk membaca dan menentukan folder yang aktif, file list
box yang digunakan untuk menampilkan seluruh file yang terdapat dalam
directory aktif saat ini, edit box yang dipergunakan untuk menginput nama file
yang dicari, list box hasil pencarian, tombol cari, edit box cari nama file dan kotak
4.1. Implementasi Prosedur Create Form
Berikut ini adalah implementasi prosedur Create Form yang dipergunakan dalam
tugas akhir ini :
Penjelasan source code di atas adalah sebagai berikut :
Pada prosedur form create ini dipergunakan untuk memberikan setting pada
sistem untuk penanganan kesalahan, pengaturan icon serta caption pada form.
4.2. Implementasi Prosedur ExceptionHandler
Berikut ini adalah implementasi prosedur penanganan kesalahan yang
dipergunakan dalam tugas akhir ini :
Penjelasan source code di atas adalah sebagai berikut :
Pada prosedur form ExceptionHandler ini dipergunakan untuk menangani
kesalahan pada form.
Application.OnException := ExceptionHandler;
Icon.Handle := Application.Icon.Handle; Caption := Application.Title;
4.3. Implementasi Prosedur Keluar
Berikut ini adalah implementasi prosedur keluar yang dipergunakan dalam tugas
akhir ini :
Penjelasan source code di atas adalah sebagai berikut :
Pada prosedur form Button1Click ini dipergunakan untuk keluar dari aplikasi
yang sedang berjalan pada form.
4.4. Implementasi Prosedur Pencarian
Berikut ini adalah implementasi prosedur pencarian yang dipergunakan dalam
tugas akhir ini :
i := 1;
m := 1;
while ( ( ( m + i ) <= Length( S ) ) and ( i <= Length(
W ) ) ) do begin
if ( S[m + i] = W[i] ) then begin
Inc( i );
end
else begin
m := m + ( i - T[i] );
if ( i > 1 ) then
i T[i]
i := T[i];
end;
end;
if m = Length( S ) then
Result := 0
Else Result := m;
Penjelasan source code di atas adalah sebagai berikut :
Variabel i dan m dipergunakan untuk mencatat panjang string yang akan
dilakukan oleh proses pencarian. Proses pencocokan pola string dimulai di awal
dan bergerak dari kiri ke kanan sampai mencapai akhir string. Apabila nilai m
sama dengan panjang string S, berarti string yang dicari ditemukan, selain itu jika
panjang m tidak sama dengan string S, berarti string yang dicari tidak ditemukan.
4.5. Implementasi Tabel String Pencarian
Penjelasan dari source code di atas adalah :
Variabel j dipergunakan untuk melakukan pembentukan kolom pada tabel,
j := 1;
SetLength( T, Length( W ) + 1 );
t[1] := 0;
t[2] := 1;
while ( i <= Length( W ) ) do begin
if ( W[i - 1] = W[j] ) then begin
T[i] := j + 1;
Inc( j );
Inc( i );
end
else if ( j > 1 ) then begin
j := T[j];
end else begin
T[i] := 1;
Inc( i );
j := 1;
end; end;
panjang string ditambah satu. Kemudian jika karakter indeks (i-1) pada string W
sama dengan panjang W(j), maka pada tabel T indeks i diisi dengan nilai j + 1.
Setelah itu nilai i dan j dinaikkan satu. Apabila nilai i sudah melebihi panjang
string W, maka pada tabel T indeks ke i diisi dengan nilai satu, nilai i ditambah
dengan satu dan nilai j diisi dengan satu.
4.6. Implementasi Tombol Cari
Edit1.Text:=LowerCase(Edit1.Text);
Memo2.Clear;
if FileListBox1.Count=0 then begin
ExceptionHandler(Self, Exception.Create('Tidak ada
file yang akan dicari.'));
exit;
end;
for i:=0 to FileListBox1.Count-1 do begin
AFileSrc :=
DirectoryListBox1.Directory+'\'+FileListBox1.Items[i];
FMain.Caption:=AFileSrc;
Application.ProcessMessages;
Memo1.Clear;
if pos('.zip',AFileSrc)>0 then begin
with CreateInArchive(CLSID_CFormatZip) do
begin
OpenFile(AFileSrc);
for ix:= 0 to NumberOfItems - 1 do
if not ItemIsFolder[ix] then
Penjelasan source code di atas adalah :
Input string dari user akan dirubah ke bentuk huruf kecil semua.
Kemudian jika pada listbox tidak terdapat file yang di cari maka akan tampil
pesan 'Tidak ada file yang akan dicari.', tetapi jika tidak kosong,
sistem akan mengenali terlebih dahulu ekstensi dari file tersebut apakah .Zip atau
.Rar. Jika ekstensi file tersebut adalah .zip, maka pembentukan proses penguraian
header disesuaikan dengan format .zip. Namun jika ekstensi file tersebut adalah
.Rar, maka pembentukan proses penguraian header disesuaikan dengan format
end;
if pos('.rar',AFileSrc)>0 then begin
with CreateInArchive(CLSID_CFormatRar) do
begin
OpenFile(AFileSrc);
for ix:= 0 to NumberOfItems - 1 do
if not ItemIsFolder[ix] then
Memo1.Lines.Add(ExtractFileName(ItemPath[ix]));
end; end;
Memo1.Text:=LowerCase(Memo1.Text);
str_to_search_for := Edit1.Text;
str_to_search_in := Memo1.Text;
if pos(Edit1.Text,Memo1.Text)>0 then
Memo2.Lines.Add(AFileSrc);
input dimulai dan ditampilkan hasilnya bila string yang ada di patttern sama
dengan string yang ada di teks.
4.7. Implementasi Antar Muka
Susunan antarmuka pada program yang dibuat dibentuk berdasarkan
sketsa rancangan antarmuka sebelumnya. Hasil implementasi seperti yang
ditunjukkan pada gambar di bawah ini.
Gambar 4.1. Implementasi Form Pencari File
Tampak pada Gambar 4.1 bahwa antarmuka pada program terbentuk dari
beberapa komponen. Komponen ini meliputi bagian lokasi penunjuk drive, bagian