1
Penerapan Metode Extreme Learning Machine untuk Peramalan
Permintaan
Irwin Dwi Agustina, Wiwik Anggraeni, S.Si, M.Kom, Ahmad Mukhlason, S.Kom, M.Sc Jurusan Sistem Informasi, Institut Teknologi Sepuluh Nopember, Surabaya, Indonesia Abstrak
Permintaann konsumen yang selalu berubah-ubah menuntut pelaku industri untuk dapat melakukan perencanaan produksi yang tepat. Kegiatan perencanaan produksi meliputi penentuan jumlah barang yang akan diproduksi, bahan baku yang dibutuhkan, dan harga barang jadi. Dengan perencanaan produksi yang tepat, diharapkan perusahaan dapat memiliki tingkat inventory rendah dan mampu merespon permintaann konsumen lebih cepat.
Perencanaan yang efektif dan efisien harus didukung oleh sistem peramalan yang akurat. Oleh karena itu, pada tugas akhir ini penulis akan membuat sistem peramalan permintaann dengan menerapkan metode extreme learning machine (ELM). Metode ini merupakan salah satu metode pembelajaran baru dari jaringan syaraf tiruan.
Hasil uji coba dalam tugas akhir ini menunjukkan bahwa metode ELM memiliki tingkat akurasi yang lebih baik dibandingkan dengan metode konvensional seperti Moving Average dan Exponential Smoothing. Dengan implementasi metode ELM untuk peramalan permintaan ini diharapkan mampu membantu para pelaku industri dalam menentukan jumlah permintaann secara lebih akurat dan efektif .
Kata Kunci : Permintaan konsumen, Peramalan, Jaringan Syaraf Tiruan, Extreme Learning Machine
1. PENDAHULUAN
ermintaan konsumen terhadap barang maupun jasa selalu berubah dari waktu ke waktu. Perubahan ini dipengaruhi oleh banyak faktor baik internal maupun eksternal, sehingga memperkirakan permintaan konsumen di masa datang selalu menjadi tantangan bagi pelaku usaha dan industri. Terutama untuk perusahaan-perusahaan make to stock, peramalan memiliki peranan penting.
Peramalan yang akurat dan efektif dapat membantu pengambil keputusan dalam perusahaan menentukan jumlah barang yang akan diproduksi, bahan baku yang dibutuhkan serta menentukan harga terhadap barang jadi sehingga perusahaan memiliki tingkat inventory rendah, serta mampu merespon permintaan konsumen lebih cepat. Peramalan permintaan yang akurat juga akan membawa dampak positif bagi pihak-pihak lain dalam satu rantai pasok.
Banyak metode telah dikemukakan untuk mendapatkan hasil ramalan yang akurat. Salah satunya adalah metode jaringan syaraf tiruan (JST) yang mengadopsi sistem pembelajaran pada otak manusia. JST banyak diaplikasikan secara intensif pada peramalan khususnya sales forecasting, karena kelebihannya pada kontrol area, prediksi dan pengenalan pola. Banyak penelitian menyimpulkan bahwa metode JST lebih baik daripada metode-metode peramalan konvensional (Sun et al, 2008).
Pada tugas akhir ini akan diaplikasikan suatu metode baru dari JST yaitu Extreme Learning Machine (ELM). ELM merupakan jaringan syaraf tiruan feedforward dengan satu hidden layer atau lebih dikenal dengan istilah single hidden layer feedforward neural network (SLFNs). Metode ELM mempunyai kelebihan dalam learning speed, serta mempunyai tingkat akurasi yang lebih baik dibandingkan dengan metode konvensional seperti Moving Average dan Exponential Smoothing sehingga dengan menerapkan ELM pada
demand forecasting diharapkan mampu menghasilkan ramalan yang lebih efektif.
2. METODE EXTREME LEARNING MACHINE
Extreme Learning Machine merupakan metode pembelajaran baru dari jaringan syaraf tiruan. Metode ini pertama kali diperkenalkan oleh Huang (2004). ELM merupakan jaringan syaraf tiruan feedforward dengan single hidden layer atau biasa disebut dengan Single Hiddel Layer Feedforward neural Networks (SLFNs) (Sun et al, 2008).
Metode pembelajaran ELM dibuat untuk mengatasi kelemahan-kelemahan dari jaringan syaraf tiruan feedforward terutama dalam hal learning speed. Huang et al mengemukaan dua alasan mengapa JST feedforward mempunya leraning speed rendah, yaitu :
1. menggunakan slow gradient based learning algorithm untuk melakukan training.
2. semua parameter pada jaringan ditentukan secara iterative dengan menggunakan metode pembelajaran tersebut.
Pada pembelajaran dengan menggunakan Conventional gradient based learning algorithm seperti backpropagration (BP) dan variaanya Lavenberg Marquadt (LM) semua parameter pada
JST feedforward harus ditentukan secara manual (Zhu,2005).
Parameter yang dimaksud adalah input weight dan hidden bias. Parameter-parameter tersebut juga saling berhubungan antara layer yang satu dengan yang lain, sehingga membutuhkan learning speed yang lama dan sering terjebak pada local minima (Huang et al, 2005).
Sedangkan pada ELM parameter-parameter seperti input weight dan hidden bias dipilih secara random, sehingga ELM memiliki learning speed yang cepat dan mampu menghasilkan good generalization performance. Gambar 1 merupakan struktur dari ELM.
Gambar 1 Struktur ELM
Metode ELM mempunyai model matematis yang berbeda dari jaringan syaraf tiruan feedforward. Model matematis dari ELM lebih sederhana dan efektif. Berikut model matrematis dari ELM. Untuk N jumlah sample yang berbeda (Xi,ti) n T n R Xi Xi Xi Xi = [ 1, 2,...., ] ∈ (1) m T n
R
Xt
Xt
Xt
Xt
=
[
1,
2,....,
]
∈
(2) Standart SLFNs dengan jumlah hidden nodes sebanyak N dan activation function g(x) dapat digambarkan secara matematis sebagai berikut :j i j N i i N i o b X W ig xj igi =
∑
• + =∑
= = ) . ( ) ( 1 1 β β (3) Dimana : N J =1,2,..., T in i i iw
w
w
w
=
(
1,
2,...,
)
= merupakan vektor dari
weight yang menghubungkan
i
thhidden nodes dan input nodes. T im i i i
(
β
1,
β
2,...,
β
)
β
=
merupakan weight vectoryang menghubungkan
i
th hidden dan output nodes.i
b
threshold darii
th hidden nodes.j i
x
w
merupakan inner produk dariw
i danx
jSLFNs dengan
N
hidden nodes dan activation function )(x
g diasumsikan dapat meng-approximate dengan tingkat error 0 atau dapat dinotasikan sebagai berikut :
o
t
o
N j j j=
∑
=1 − sehinggao
j=
t
j (3) j i j N i i X b t W ig • + =∑
= ) . ( 1β
(4)Persamaan [4] dapat dituliskan secara sederhana sebagai T H
β
= (5))
,....,
,
,...,
,
,...,
(
w
iw
Nb
ib
Nx
ix
NH
=
(2.13))
(
)
(
)
(
)
(
1 1 1 1 1 1 N N N N N Nb
x
w
g
b
x
w
g
b
x
w
g
b
x
w
g
+
+
+
+
=
• • • •K
M
M
M
K
(6) T N Tβ
β
β
=
M
1 (7) T N Tt
t
T
M
1=
(8)H pada persamaan [6] di atas adalah hidden layer output matrix.
g
(
w
1•x
1+
b
1)
menunjukkan output dari hidden neuron yang berhubungan dengan inputi
x
.β
merupakan matrix dari output weight dan T matrix dari target atau output .Pada ELM input weight dan hidden bias ditentukan secara acak, maka output weight yang berhubungan dengan hidden layer dapat ditentukan dari persamaan [5].
T
H
Τ=
β
(9)3. METODOLOGI
Pada bab ini dibahas mengenai penjelasan dari setiap tahapan penyelesaian dari permasalahan yang diangkat pada Tugas Akhir ini.
1. Pengumpulan Data
Data yang digunakan adalah data penjualan harian selama dua tahun yaitu tahun 2008-2009 dari bulan Januari-Desember milik “ Cak Cuk Shop” Surabaya. Peramalan dibatasi pada dua produk yaitu kaos dan pin. Antara kedua produk tidak ada hubungan saling mempengaruhi sehingga setiap produk dianggap sebagai produk dipenden dimana jumlah permintaan untuk setiap produk tidak dipengaruhi oleh jumlah permintaan dari produk lainnya. Gambar 2 dan 3 berikut merupakan plot data penjualan kaos dan pin selama periode Januari 2008- Desember 2009.
2. Peramalan dengan Metode ELM
Ada beberapa tahap yang harus dilalui pada peramalan dengan metode ELM. Secara garis besar langkah ELM dibagi menjadi tiga tahap yaitu preprocessing data, training, kemudian testing. Langkah-langkah peramalan metode ELM secara rinci ditunjukkan pada gambar 4.
3
Gambar 2 Plot data penjualan kaos
Gambar 3 Plot data penjualan pin
Dari gambar 3.3 langkah-langkah ELM dapat dirinci sebagai berikut :
1. Pembagian data training dan testing. 2. Training ELM.
3. Testing ELM.
4. Analisa hasil peramalan.
Berikut penjelasan dari masing-masing langkah peramalan dengan metode ELM.
3. Pembagian data menjadi data training dan testing Proses training dan testing mutlak diperlukan pada proses peramalan dengan ELM. Proses training untuk mengembangkan model dari ELM, sedangkan testing digunakan untuk mengevaluasi kemampuan ELM sebagai forecasting tool. Oleh karena itu data dibagi menjadi dua yaitu data training dan testing.
Menurut Zhang (1997) beberapa peneliti membagi data training dan testing dengan komposisi sebagai berikut :
- Data training sebanyak 80% dari total data. - Data testing 20% dari total data.
4. Pelatihan ELM
Sebelum digunakan sebagai tool peramalan, ELM harus melalui proses pelatihan terlebih dahulu. Tujuan dari proses ini adalah untuk mendapatkan input weight , bias dan output weight dengan tingkat kesalahan yang
rendah. Langkah- langkah pada training ELM ditunjukkan pada gambar 5..
Gambar 4 Flowchart peramalan dengan metode ELM
rendah. Langkah-langkah dari proses training ELM ditunjukkan pada gambar 5.
Gambar 5 Flowchart pelatihan ELM
5. Normalisasi Data Training
Data yang akan diinputkan pada ELM sebaiknya dinormalisasi sehingga mempunyai nilai dengan range tertentu. Hal ini diperlukan karena fungsi aktivasi yang digunakan akan menghasilkan output dengan range data [0,1] atau [-1,1]. Pada tugas akhir ini data training dinormalisasi sehingga mempunyai range nilai [-1,1]. Berikut Rumus yang digunakan pada proses normalisasi.
1 }) min{ } /(max{ }) min{ ( 2× − − = Xp− Xp Xp Xp X (1) Dimana :
X = nilai hasil normalisasi yang berkisar antara [-1,1]. p
X
= nilai data asli yang belum dinormalisasi. )min(Xp = nilai minimum pada data set.
)
max(
X
p = nilai maksimum pada data set.6. Menentukan fungsi aktivasi dan jumlah hidden neuron Pada proses training jumlah hidden neuron dan fungsi aktivasi dari ELM harus ditentukan terlebih dahulu. Pada tugas akhir ini dilakukan uji coba dengan menggunakan fungsi aktivasi log sigmoid dan tan sigmoid karena kedua fungsi tersebut yang paling sering digunakan pada permasalahan forecasting, serta fungsi transfer purelin karena data yang diramalkan bersifat stasioner. Hal ini mengacu pada tulisan Zhang (1997) bahwa fungsi transfer linier memiliki kelemahan pada pola data yang memiliki trend.
Untuk jumlah hidden neuron menurut Sun et al(2008) ELM menghasilkan output peramalan yang stabil dengan jumlah hidden neuron 0-30. Namun jika output yang didapatkan dari ELM kurang optimal, maka akan digunakan alternative fungsi transfer yang lain atau merubah jumlah hidden neuron.
7. Menghitung input weight, bias of hidden neuron dan output weight
Output dari proses pelatihan ELM adalah input dan output weight serta bias dari hidden neuron dengan tingkat kesalahan rendah yang diukur dengan MSE dan MAPE. Input weight ditentukan secara random, sedangkan output weight merupakan invers dari matrix hidden layer dan output. Secara matematis dapat ditulis sebagai berikut : T HΤ = β (2) ) ,...., , ,..., , ,..., (wi w N bi bN xi xN H =
)
(
)
(
)
(
)
(
1 1 1 1 1 1 N N N N N Nb
x
w
g
b
x
w
g
b
x
w
g
b
x
w
g
+
+
+
+
=
• • • •K
M
M
M
K
(3) T N T β β β = M1 (4) T N T t t T M 1 = (5) 8. Denormalisasi OutputOutput yang dihasilkan dari proses pelatihan didenormalisasi, sehingga didapatkan predicted sales dari data training. Berikut rumus denormaliasi yang digunakan } min{ }) min{ } (max{ ) 1 ( 5 . 0 Xp Xp Xp Xp X= × + × − + (6) Dimana :
X
= nilai data setelah denormalisasi. pX = data output sebelum denormalisasi.
)
min(
X
p = data minimum pada data set sebelum normalisasi.)
max(
X
p = data maksimun pada data set sebelum normalisasi.9. Testing ELM
Berdasarkan input weight dan output weight yang didapatkan dari proses training, maka tahap selanjutnya adalah melakukan peramalan dengan ELM. Data yang digunakan adalah data testing sebanyak 20% dari data. Pada tahap ini data input dinormalisasi terlebih dahulu dengan range dan rumus normalisasi yang sama dengan data training. Secara otomatis output dari proses ini juga harus didenormalisasi.
10. Analisa Hasil Peramalan
Setelah melalui berbagai tahap seperti yang telah dijabarkan di atas, maka didapatkan nilai peramalan penjualan yi . Hasil yang didapatkan tersebut kemudian dianalisa apakah memiliki tingkat kesalahan (MSE dan MAPE) yang kecil. Jika tingkat kesalahan yang dihasilkan masih relatif besar, maka dievaluasi kembali langkah-langkah yang telah dilakukan. Mulai dari proses training,testing maupun predicting hingga hasil yang didapatkan optimal. Berikut rumus matematis dari Mean Square Error (MSE) dan Mean Absolut Precentage Error (MAPE).
∑
= − = N i i i t y N mse 1 2 ) ( 1 (7)Dimana :
N
=
jumlah data
y
i=
data ouput (predicted sales)t
i=
data penjualan actual∑
= ⎟⎟⎠ ⎞ ⎜⎜ ⎝ ⎛ − = N i i i i y t y N mape 1 ) 100 ( 1 (8)Dimana :
N
=
jumlah data
y
i=
data ouput (predicted sales)t
i=
data penjualan actual11. Membandingkan Hasil Peramalan ELM dengan hasil peramalan MA dan ES.
Setelah analisis terhadap hasil ramalan metode ELM dilakukan, maka akan diketahui nilai MSE danMAPE. Langkah selanjutnya adalah membandingkan nilai MSE dan MAPE tersebut dengan dua metode peramalan konvensional yaitu Moving Average dan Exponential Smoothing. Metode MA yang digunakan adalah Single
5 Moving Average dua periode. Sedangkan untuk metode ES menggunakan metode Single Exponential Smoothing.
Selain nilai MSE dan MAPE, plot data hasil ramalan dari masing-masing metode juga diperbandingkan. Hal ini dilakukan untuk mengetahui perbandingan tingkat akurasi metode ELM dengan metode konvensional serta performa dari ELM.
4. IMPLEMENTASI DAN HASIL
Pada tahap implementasi dilakukan uji coba dengan menggunakan fungsi aktivasi sigmoid, tansig dan purelin dengan jumlah hidden (1,3,5 dan 7). Fungsi sigmoid dan tansig digunakan karena kedua fungsi aktivasi tersebut merupakan fungsi aktivasi yangs sering digunakan terutama untuk masalah peramalan. Sedangkan fungsi aktivasi purelin digunakan karena data yang ada bersifat stasioner.
Metode ELM pada tugas akhir ini diimplementasikan pada dua produk yaitu kaos dan pin. Pada produk kaos hasil uji coba dengan fungsi aktivasi dan jumlah hidden neuron yang berbeda kedua produk menghasilkan bobot dan bias yang paling optimal pada jumlah hidden neuron 5 pada aktivasi purelin. Sedangkan pada produk pin hasil palng optimal pada fungsi aktivasi purelin dengan jumlah hidden neuron 3.
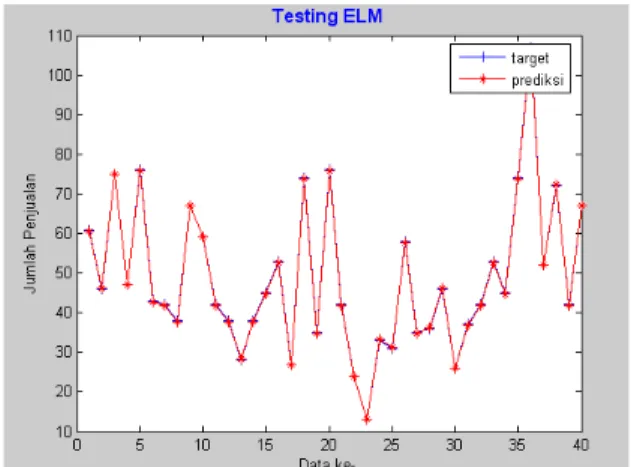
Gambar 6 Grafik perbandingan data histori dan
testing ELM pada data kaos
Gambar 7 Grafik perbandingan data histori dan data
testing ELM
Bobot dan bias yang didapatkan pada proses training akan digunakan sebagai parameter pada proses testing. Hasil dari proses testing pada produk kaos ditunjukkan pada gambar 6 pada produk kaos dan 7 pada produk pin.
Gambar 8 Grafik perbandingan data histori, hasil peramalan MA, ES dan ELM untuk data kaos.
Gambar 9 Grafik perbandingan data histori, hasil peramalan MA, ES dan ELM untuk data pin.
Tabel 1 Perbandingan nilai MSE dan MAPE antara metode MA, ES dan ELM untuk data kaos
MA ES ELM
MSE 116.74 502.19 0.0481 MAPE 19.19 32.93 0.0042
Tabel 2 Perbandingan nilai MSE dan MAPE antara metode MA, ES dan ELM untuk data pin
MA ES ELM
MSE 13.78 55.45 0.0023
Hasil perbandingan testing ELM pada data kaos dan data pin dengan hasil peramalan dengan metode Moving Average dan Exponential Smoothing ditunjukkan pada gambar 8 dan 9. Dari gambar tersebut dapat diketahui bahwa ELM menghasilkan ramalan yang jauh lebih baik dari metode konvensional yaitu Moving Average dan Exponential Smoothing. Hal ini juga diperkuat dengan perbandingan MSE dan MAPE dari metode ELM, ES dan MA yang ditunjukkan pada tabel 1 dan 2.
5. KESIMPULAN
Kesimpulan yang dapat diambil dari tugas akhir ini adalah sebagai berikut :
y Berdasarkan hasil uji coba terhadap ELM dengan fungsi aktivasi dan jumlah hidden neuron yang berbeda, maka pada tugas akhir ini ELM menghasilkan output optimal pada fungsi aktivasi purelin dengan jumlah hidden neuron lima untuk data kaos, dan jumlah hidden neuron tiga untuk data pin.
y ELM menghasilkan output peramalan dengan tingkat kesalahan yang rendah yaitu MAPE 0.0042 % pada produk kaos dan 0.0095% pada produk pin. Metode peramalan Moving Average mempunyai tingkat kesalahan 19.19% pada produk kaos dan 55.43% pada produk pin. Sedangkan pada Exponential Smoothing mempunyai tingkat kesalahan 32.93% pada produk kaos dan 111.39% pada produk pin.
y Training time atau learning speed yang dibutuhkan oleh ELM sangat singkat, yaitu rata- rata 0.0059 detik.
y Output dari ELM ditentukan oleh penentuan parameter seperti fungsi aktivasi atau fungsi transfer dan jumlah hidden neuron.
6. DAFTAR PUSTAKA
[1] Abraham, A. 2004. Meta-Learning Evolutionary Artificial Neural Networks. Elsevier science : Neurocomputing Journal 56 c (2004). 1-38. [2] Barron, A.R. 1994. A comment on”Neural
network: A review form statistical perspective”.
Statistical Science 9 (1), 33-35.
[3] Brockwell, P.J., dan Davis, R.A. 2002.
Introduction to Time Series and Forecasting. Springer : New York.
[4] Demuth, H.,dan Beale, M. 2000. Neural Network Toolbox For Use with MATLAB. Massachusetts: The MathWork Inc.
[5] Huang, G.B., Zhu, Q.Y., dan Siew, C.K. 2004. Extreme Learning Machine : A New Learning Scheme of Feddforward neural Networks.
Proceeding of International Joint Conference on Neural Networks. Hungary, 25-29 Juli.
[6] Huang, G.B., Zhu, Q.Y., dan Siew, C.K. 2005. Extreme Learning Machine : Theory and applications. Elsevier science : Neurocomputing
70 (2006) 489-501.
[7] Makridakis, S., Wheelwright,S.C., dan McGee, V.E. 1999. Metode dan Aplikasi Peramalan.
Jakarta : Erlangga.
[8] Mitchel, T.M. 1997. Machine learning. Singapura: McGraw-Hill.
[9] Sun, Z.L., Choi, T.M., Au, K.F., dan Yu, Y. 2008. Sales Forecasting using Extreme Learning Machine with Application in Fashion Retailing.
Elsevier Decision Support Systems 46 (2008) 411-419.
[10] Zhang, G., Pattuwo, B.E., dan Hu, M.Y. 1997. Forecasting with Artificial Neural Networks : The State of the Art. Elsevier International Journal of Forecasting 14 (1998) 35-62.