Fakultas Ilmu Komputer
Universitas Brawijaya
3237
Peramalan Debit Inflow Waduk Gajah Mungkur menggunakan Metode Extreme Learning Machine
Yudha Irwan Syahputra1, Indriati2, Achmad Ridok3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Waduk Gajah Mungkur merupakan salah satu waduk terbesar di Jawa yang dikategorikan waduk multiguna. Dengan berbagai manfaat perlu dilakukan peramalan debit inflow untuk menghindari kelebihan atau kekurangan air pada tampungan waduk serta kekeliruan dalam pembuangan air.
Kesalahan yang biasa terjadi adalah pelepasan air yang dapat mengakibatkan banjir pada wilayah yang lebih rendah dari waduk. Peramalan debit juga dapat digunakan untuk merencanakan alokasi air seperti pembangkit listrik dan juga irigasi. Perubahan debit inflow yang terjadi selalu fluktuatif, sehingga dari permasalahan tersebut peramalan debit inflow diperlukan untuk mengatasi banyaknya jumlah debit air yang keluar. Data yang digunakan adalah debit inflow dari Januari 2009 sampai Desember 2019 dan metode yang digunakan adalah Extreme Learning Machine (ELM) yang dikarenakan memiliki learning speed cepat serta generalisasi yang baik. Hasil pengujian yang didapatkan yaitu jumlah fitur optimal sebanyak 7, jumlah hidden neuron optimal sebanyak 9, dengan persentase data latih 80% dan 20% data uji menghasilkan RMSE 28,7303, MAD 21,8002 dengan runtime 0,0272s. Dengan nilai RMSE yang jauh dari nol maka tingkat kesalahan (error) yang diperoleh termasuk tinggi dan jelek. Dan juga dengan runtime yang dalam hitungan detik atau kurang dari detik maka penelitian ini juga mempertegas bahwa ELM memiliki kelebihan pada learning speed yang cepat.
Kata kunci: debit, peramalan, Extreme Learning Machine, Neural Network, RMSE, MAD Abstract
The Gajah Mungkur Reservoir is one in all the most largest dams or reservoirs in Java which is categorized as a multipurpose reservoir. With various benefits, it is necessary to forecast the inflow discharge to avoid excess or shortage of water in the reservoir as well as errors in water disposal. A common mistake is the release of water which can cause flooding in areas lower than the reservoir.
Discharge forecasting can also be used to plan water allocations such as power generation and irrigation. Changes in inflow discharge that occur are always fluctuating, so from these problems forecasting inflow discharge is needed to overcome the large amount of water discharge that comes out.
The data used is inflow discharge from January 2009 to December 2019 and the method used is Extreme Learning Machine (ELM) because it has fast learning speed and good generalization. The test results obtained are the optimal number of features as many as 7, the optimal number of hidden neurons as many as 9, with the percentage of training data 80% and 20% of the test data producing RMSE 28.7303, MAD 21.8002 with a runtime of 0.0272s. With an RMSE value that is far from zero, the error rate obtained is high and bad. And also with a runtime that is in seconds or less than seconds, this research also confirms that ELM has advantages in fast learning speed.
Keywords: discharge, forecasting, Extreme Learning Machine, Neural Network, RMSE, MAD
1. PENDAHULUAN
Waduk atau bendungan merupakan salah satu bangunan infrastruktur di bidang sumber daya air yang berfungsi sebagai penampung air sediaan. Salah satu waduk yang terkenal di Jawa
adalah Waduk Gajah Mungkur (WGM) atau Bendungan Wonogiri. WGM berlokasi 7 km di sebelah selatan Kota Wonogiri tepat di hilir persimpangan Sungai Keduang. WGM mempunyai fungsi sebagai pemasok listrik daerah Wonogiri yang berkapasitas maksimal
12,4 mW dan sebagai penyediaan air irigasi kurang lebih untuk lahan seluas 23.600 ha di daerah Kabupaten Karanganyar, Klaten, Sragen, dan Sukoharjo. Fungsi lain dari waduk ini juga sebagai pengendalian banjir (flood control), obyek pariwisata, dan budidaya perikanan air tawar (Suprihati, 2014). Oleh karena itu dapat dikatakan bahwa waduk juga memiliki andil dalam bidang perekonomian, energi dan juga pangan (Hakim, et al., 2019).
Waduk Gajah Mungkur telah dijelaskan memiliki banyak fungsi bagi masyarakat sekitar, sehingga waduk tersebut dapat dikategorikan sebagai waduk serbaguna (Anggraheni, et al., 2017). Dengan berbagai macam fungsi tersebut diperlukan peramalan debit air yang masuk (inflow) untuk menghindari kelebihan atau kekurangan air pada tampungan waduk serta kekeliruan dalam pembuangan air (Sari &
Yusuf, 2016). Kesalahan yang biasa terjadi adalah pelepasan air yang dapat mengakibatkan banjir pada wilayah bagian hilir Sungai Bengawan Solo (Harton, 2021). Selain itu data debit inflow juga sangat berguna bagi sektor pembangkit listrik. Jika peramalan debit dapat dilakukan, maka pada pembangkit listrik dapat diketahui kapasitas energi listrik yang akan dihasilkan (Samosir, et al., 2015). Oleh karena itu, peramalan debit inflow diperlukan untuk mengatasi banyaknya debit air yang keluar (outflow) (Anggraheni, et al., 2017). Metode konvensional yang sering dilakukan untuk peramalan debit pada operasional bangunan hidrolik adalah peramalan sederhana, yang dimana beranggapan bahwa debit aliran sungai pada masa mendatang akan sama dengan debit yang terekam saat ini (Hatmoko & Amirwandi, 2001).
Penelitian dengan studi kasus peramalan atau prediksi telah banyak dilakukan. Beberapa peramalan dengan objek debit air pernah dilakukan menggunakan metode Backpropagation (Hakim, et al., 2019), ARIMA (Hanggara, et al., 2015), Neural Network Autoregressive Exogenous (Sari & Yusuf, 2016), dan juga Extreme Learning Machine (Paudi, et al., 2020). Hal tersebut menandakan bahwa kasus peramalan dapat dilakukan dengan menggunakan berbagai macam metode.
Penelitian tenang peramalan atau prediksi juga dilakukan oleh Inas Hakimah Kurniasih, Muhammad Tanzil Furqon, dan Sigit Adinugroho. Penelitian yang berjudul “Prediksi Pertumbuhan Penduduk di Kota Malang menggunakan Metode Extreme Learning
Machine (ELM)” dilakukan pada tahun 2020.
Penelitian tersebut menghitung nilai akurasi dengan MAPE dan menghitung runtime.
Penelitian tersebut mendapatkan dua hasil evaluasi, pertama menghasilkan nilai MAPE 0,498% dengan runtime 1,166 detik, kemudian yang kedua menghasilkan nilai MAPE 0,117%
dengan runtime 1,278 detik (Kurniasih, et al., 2020).
Selain itu terdapat penelitian tentang perbandingan algoritma backpropagation dan ELM. Penelitian perbandingan dilakukan oleh Heny Pratiwi dan Kusno Harianto. Penelitian yang berjudul “Perbandingan Algoritma ELM Dan Backpropagation Terhadap Prestasi Akademik Mahasiswa” dilakukan pada tahun 2020. Dari penelitian tersebut didapatkan bahwa algoritma ELM lebih baik dibandingkan dengan backpropagation. Penelitian tersebut menghasilkan bahwa algoritma ELM mempunyai tingkat kesalahan 14,84%, sedangkan backpropagation sebesar 28,20%.
Dikarenakan hasil akurasi ELM lebih tinggi dibanding backpropagation, maka dapat dikatakan model paling baik adalah dengan menggunakan ELM (Pratiwi & Harianto, 2019).
Oleh karena itu, metode yang diusulkan pada penelitian ini adalah metode Extreme Learning Machine (ELM).
Huang adalah orang yang pertama kali mempresentasikan ELM. ELM adalah metode pembelajaran jaringan saraf tiruan baru yang didasarkan pada gagasan Single-hidden Layer Feedforward neural Networks (SLFNs). ELM diperkenalkan guna meminimalisir kelemahan pada metode jaringan syaraf tiruan feedforward, terutama pada proses learning speed. Dengan memilih acak input weight dan hidden bias, ini memungkinkan learning speed ELM lebih cepat . ELM juga sederhana untuk diterapkan pada persoalan yang kompleks dan nyata (Huang, et al., 2006). Selain itu, bentuk matematis ELM tidak persis sama dengan jaringan saraf tiruan feedforward. Bentuk matematis ELM lebih mudah dan efisien (Huang, et al., 2004) (Huang, et al., 2006). Dengan menerapkan metode ELM diharapkan mampu menghasilkan tingkat kesalahan (error) yang rendah.
Oleh karena itu, berdasarkan deskripsi tersebut dapat dilakukan penelitian mengenai
“Peramalan Debit Inflow Waduk Gajah Mungkur Menggunakan Metode Extreme Learning Machine”. Debit inflow Waduk Gajah Mungkur merupakan objek penelitian ini. Data debit inflow kemudian dijadikan beberapa fitur
dan target supaya bisa dilakukan peramalan menggunakan metode ELM. Kemudian dilakukan perhitungan evaluasi dengan menghitung nilai Root Mean Square Error (RMSE) dan Mean Absolute Deviation (MAD).
Diharapakan penelitian ini dapat menghasilkan ramalan dengan tingkat kesalahan (error) yang rendah dan dapat mempertegas kelebihan metode Extreme Learning Machine yaitu memiliki learning speed yang cepat.
2. LANDASAN KEPUSTAKAAN 2.1. Debit
Menurut Asdak (1995) debit adalah kecepatan aliran air melalui penampang sungai dalam satu satuan waktu. Satuan untuk debit umumnya adalah volume per satuan waktu.
Satuan debit dalam Sistem Satuan Internasional adalah m3/s (meter kubik per seconds). Sehingga debit juga dapat dikatakan sebagai satuan besaran air yang masuk kedalam sebuah waduk atau bendungan. Rumus menghitung debit air dapat ditunjukkan pada Persamaan 1.
𝑄 = 𝐴 × 𝑉 (1)
Keterangan:
Q : Debit
A : Luas penampang V : Kecepatan aliran
2.2. Extreme Learning Machine (ELM) Jaringan Saraf Tiruan (JST) dengan pembelajaran baru yang diperkenalkan pertama kali oleh Huang (2004) adalah Extreme Learning Machine (ELM). JST pada ELM mempunyai konsep single-hidden layer, yang sering dikenal dengan Single-hidden Layer Feedforward neural Networks (SLFNs). ELM dirancang guna mempercepat learning speed dari jaringan saraf tiruan feedforward. JST feedforward lain dapat menghasilkan learning speed rendah dikarenakan mengadaptasi slow gradient based learning algorithm dalam proses pelatihan.
Selain itu, parameter pada JST feedforward lain umumnya ditentukan secara iterative dengan menggunakan metode pembelajaran itu sendiri (Huang, et al., 2004). Pada metode ELM pendekatan yang digunakan adalah least square based yang merupakan generalisasi dari single- hidden layer feedforward networks dalam melakukan pembelajaran (Ikhsan, et al., 2019).
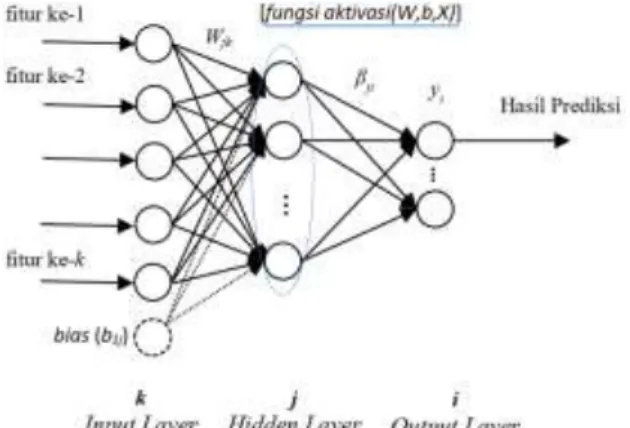
Gambaran model matematis dari ELM adalah sebagai berikut:
Gambar 1. Arsitektur ELM Sumber: (Cholissodin, et al., 2017) Tahapan-tahapan proses training ELM adalah (Cholissodin, et al., 2017):
1. Menginisialisasi bobot (W) dan bias (b) secara random.
2. Menghitung 𝐻𝑖𝑛𝑖𝑡, 𝐻𝑖𝑛𝑖𝑡 = 𝑋. 𝑊𝑇+ 𝑏 3. Menghtiung output hidden layer 𝐻 = 1/
(1 + 𝑒𝑥𝑝(−𝐻𝑖𝑛𝑖𝑡)
4. Menghitung Moore-Penrose pseudo inverse 𝐻+= (𝐻𝑇× 𝐻)−1× 𝐻𝑇
5. Menghitung output weight 𝛽 = 𝐻𝑇× 𝑌 Tahapan-tahapan proses testing ELM adalah:
1. Diketahui bobot (W), bias (b) dan output weight (β).
2. Menghitung 𝐻𝑖𝑛𝑖𝑡, 𝐻𝑖𝑛𝑖𝑡 = 𝑋. 𝑊𝑇+ 𝑏 3. Menghitung output hidden layer 𝐻 = 1/
(1 + 𝑒𝑥𝑝(−𝐻𝑖𝑛𝑖𝑡)
4. Menghitung output layer 𝑌′ = 𝐻 × 𝛽 5. Menghitung nilai evaluasi, Root Mean
Square Error (RMSE) dan Mean Absolute Deviation (MAD).
2.3. Akurasi Peramalan
Root Mean Square Error (RMSE) didapatkan dengan cara melakukan akar pangkat dua pada nilai Mean Square Error (MSE). Untuk nilai MSE, didapatkan dengan cara memangkatkan hasil pengurangan antara data ramalan dengan data aktual yang kemudian dibagi dengan jumlah data (Setialaksana, et al., 2020). Untuk lebih jelas, rumus perhitungan RMSE ditunjukkan pada Persamaan 2.
𝑅𝑀𝑆𝐸 = √1
𝑁∑𝑁𝑖=1(𝐴𝑘𝑡𝑢𝑎𝑙 − 𝑃𝑒𝑟𝑎𝑚𝑎𝑙𝑎𝑛)2 (2)
Selanjutnya untuk MAD merupakan perhitungan rerata kesalahan ramalan dengan melakukan perhitungan selisih antara nilai
ramalan dengan nilai aktual pada sejumlah data.
Rumus perhitungan MAD ditunjukkan pada Persamaan 2.11 (Heizer & Render, 2011).
𝑀𝐴𝐷 = ∑ |𝐴𝑘𝑡𝑢𝑎𝑙−𝑃𝑒𝑟𝑎𝑚𝑎𝑙𝑎𝑛
𝑁 |
𝑁𝑖=1 (3)
Keterangan:
N : Jumlah data i : Indeks data 2.4. Cross Validation
Cross Validation merupakan metode yang umum digunakan untuk melakukan validasi kemampuan suatu model (Fonseca-Delgado &
Gomez-Gil, 2013). Cross Validation juga lebih menarik daripada metode lain, karena dapat memberikan estimasi statistik dari kemampuan prediksi yang diharapkan (Fonseca-Delgado &
Gomez-Gil, 2013). Jenis Cross Validation yang sering digunakan adalah k-Fold Cross Validation (Pratama, et al., 2018). Data dalam k- Fold akan dipisahkan menjadi sejumlah k yang berukuran kira-kira sama besar. Gambaran mengenai k-Fold Cross Validation untuk data time series ditunjukkan pada Gambar 2.
Gambar 2. Cross Validation pada Time Series
3. DATASET
Data pada penelitian merupakan data yang telah dikembangkan atau dikumpulkan oleh orang lain dan dapat digunakan dalam penelitian.
Data yang seperti ini disebut data sekunder. Data sekunder yang digunakan adalah data debit inflow Waduk Gajah Mungkur dari tahun 2009 sampai 2019 yang didapatkan dari PT. Perum Jasa Tirta I. Data penelitian secara keseluruhan berjumlah 132 data dan memilki pola data time series bulanan
.
4. METODOLOGI
Metode yang digunakan untuk peramalan debit inflow Waduk Gajah Mungkur adalah Extreme Learning Machine (ELM). Dalam peramalan debit inflow ELM memiliki beberapa tahapan. Pertama adalah melakukan input datasets debit inflow dang menginisialisasi parameter awal seperti jumlah fitur, hidden neuron, bobot dan juga bias. Setelah datasets ter- input selanjutnya dilakukan pembagian data latih dan data uji serta dilakukan normalisasi data.
Data latih digunakan untuk proses training dan data uji digunakan untuk proses testing. Setelah data dinormalisasi selanjutnya adalah proses training. Proses training akan menghasilkan output weight yang nanti akan digunakan pada proses testing. Pada proses training terdapat beberapa proses antara lain perhitungan 𝐻𝑖𝑛𝑖𝑡, perhitungan output hidden layer (H), perhitungan Moore-Penrose pseudo inverse (H+), dan perhitungan output weight. Output weight kemudian digunakan pada proses testing sebagai parameter awal bersama dengan bobot dan bias. Proses testing memiliki beberapa tahapan antara lain perhitungan 𝐻𝑖𝑛𝑖𝑡, perhitungan output hidden layer (H), dan perhitungan output layer yang merupakan hasil ramalan. Namun pada output layer belum merupakan nilai yang sebenarnya.
Denormalisasi data merupakan proses untuk mengubah output layer menjadi nilai yang sebenarnya. Setelah dilakukan denormalisasi maka selanjutnya dapat dilakukan perhitungan nilai evaluasi yaitu Root Mean Square Error (RMSE) dan Mean Absolute Deviation (MAD).
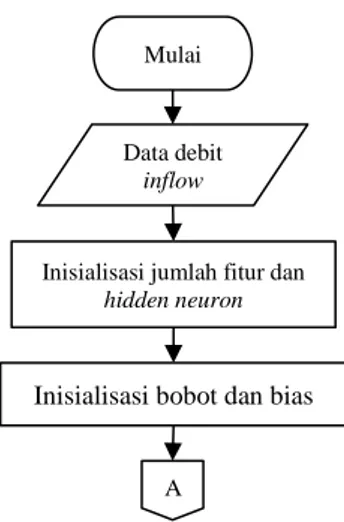
Untuk lebih jelas, proses-proses tersebut dapat dilihat pada Gambar 3.
Gambar 3 Flowchart peramalan debit inflow
Mulai
Data debit inflow
Inisialisasi jumlah fitur dan hidden neuron
A
Inisialisasi bobot dan bias
Gambar 3. Flowchart peramalan debit inflow (lanjutan)
5. HASIL DAN PEMBAHASAN
Bagian ini akan menjelaskan mengenai hasil dan analisis dari berbagai macam skenario pengujian. Skenario pengujian yang dilakukan pada penelitian ini ada 5 antara lain pengujian jumlah fitur, pengujian jumlah hidden neuron, pengujian perbandingan data latih dan data uji, pengujian cross validation dan pengujian parameter terbaik. Pada setiap masing-masing pengujian akan menghasilkan parameter optimal yang memiliki rata-rata nilai RMSE terendah.
Selain RMSE juga dihitung rata-rata MAD dan juga runtime sistem.
5.1. Pengujian Jumlah Fitur
Pengujian ini bertujuan guna mengetahui apakah jumlah fitur dapat mempengaruhi nilai RMSE, MAD serta runtime sistem. Pengujian ini juga bertujuan untuk mendapatkan jumlah fitur yang paling optimal. Jumlah fitur yang diuji adalah 1 sampai 10 fitur. Masing-masing jumlah fitur dilakukan percobaan sebanyak 5 kali.
Setelah dilakukan 5 kali percobaan selanjutnya dihitung rata-rata dari RMSE, MAD dan runtime yang telah didapatkan selama perobaan.
Parameter lain yang digunakan bersifat tetap antara lain rentang bobot[-1,1], rentang bias[0,1], 80% data training, 20% data testing serta hidden neuron sebanyak 5. Grafik RMSE dan MAD dari pengujian ini ditunjukkan pada Gambar 4.
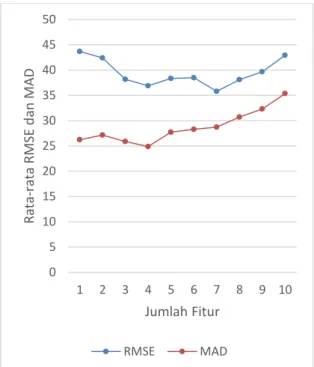
Gambar 4. Grafik RMSE dan MAD Pengujian Jumlah Fitur
Grafik pada Gambar 4 menunjukkan jumlah fitur dengan RMSE terendah adalah 7 fitur dengan rata-rata RMSE 35,81, sedangkan jumlah fitur dengan MAD terendah adalah 4 fitur dengan rata-rata MAD 24,89. Secara keseluruhan nilai RMSE dari masing-masing jumlah fitur adalah fluktuatif, terjadi penurunan dan kenaikan. Penurunan terjadi dari jumlah fitur 1 sampai 7 dari RMSE 43,70 hingga 35,81, sedangkan kenaikan terjadi dari jumlah fitur 7 sampai 10 dari RMSE 35,81 hingga 42,94.
Selanjutnya untuk nilai MAD dari secara keseluruhan cenderung naik, namun pada jumlah fitur 3 dan 4 mengalami penurunan. Mengacu pada nilai RMSE, semakin banyak jumlah fitur belum tentu menghasilkan nilai RMSE yang rendah. Dapat dilihat bahwa pada jumlah fitur 1 dan 10 memiliki rata-rata RMSE 2 tertinggi.
Jumlah fitur 1 menghasilkan RMSE tinggi karena pola data yang digunakan kurang sehingga pengenalan pada data kurang maksimal. Begitupun pada jumlah fitur 10, jika terlalu banyak pola data, maka dapat terjadi overfitting. Overfitting adalah terlalu mengenali data sehingga jika ada data baru akan menghasilkan hasil ramalan yang kurang maksimal. Dari analisa tersebut dapat disimpulkan bahwa jumlah fitur berpengaruh terhadap nilai RMSE. Namun terlepas dari jumlah fitur, nilai random dari input bobot dan bias juga berpengaruh terhadap nilai RMSE.
0 5 10 15 20 25 30 35 40 45 50
1 2 3 4 5 6 7 8 9 10
Rata-rataRMSE dan MAD
Jumlah Fitur
RMSE MAD
Pembagian data
Training
Testing
Denormalisasi
Perhitungan evaluasi RMSE dan MAD
Selesai A
Normaliasi
Gambar 5. Grafik Runtime Pengujian Jumlah Fitur
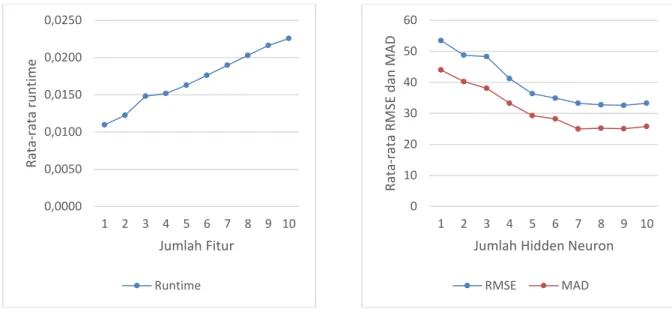
Grafik pada Gambar 5 menunjukkan runtime pada pangujian ini. Runtime yang dihasilkan pada pengujian ini cenderung naik sehingga semakin banyak fitur, maka waktu eksekusi program akan semakin meningkat. Hal itu menunjukkan bahwa jumlah fitur dapat mempengaruhi runtime sistem. Namun untuk metode Extreme Learning Machine (ELM) rata- rata runtime secara keseluruhan adalah 0,0171.
Dari rata-rata tersebut dapat dikatakan bahwa ELM memiliki learning speed yang cepat.
5.2. Pengujian Jumlah Hidden Neuron
Pengujian jumlah hidden neuron bertujuan guna mengetahui apakah jumlah hidden neuron dapat mempengaruhi nilai RMSE, MAD serta runtime sistem. Pengujian ini juga bertujuan untuk mendapatkan jumlah hidden neuron yang paling optimal. Jumlah hidden neuron yang diuji berkisar dari 1 hingga 10. Masing-masing parameter dilakukan percobaan sebanyak 5 kali.
Setelah dilakukan 5 kali percobaan selanjutnya dihitung rata-rata dari RMSE, MAD dan runtime yang telah didapatkan selama perobaan.
Parameter lain yang digunakan bersifat tetap antara lain rentang bobot[-1,1], rentang bias[0,1], 80% data training dan 20% data testing.
Sedangkan jumlah fitur yang digunakan adalah 7 fitur, yang merupakan jumlah optimal pada pengujian jumlah fitur dengan menghasilkan nilai RMSE terendah. Grafik RMSE dan MAD dari pengujian ini ditunjukkan pada Gambar 6.
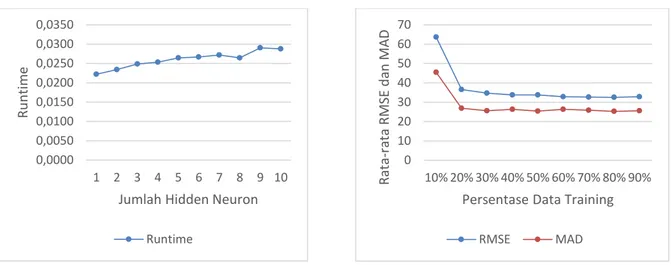
Gambar 6. Grafik RMSE dan MAD Pengujian Jumlah Hidden Neuron
Grafik pada Gambar 6 menunjukkan bahwa pada jumlah hidden neuron 9 menghasilkan nilai RMSE dan MAD terendah yaitu RMSE 32,60 dan MAD 25,05. Sedangkan untuk nilai RMSE dan MAD tertinggi terdapat pada jumlah hidden neuron 1 yaitu RMSE 53,49 dan MAD 43,99.
Secara keseluruhan nilai RMSE dan MAD dari 1 hidden neuron sampai 10 mengalami penurunan.
Jadi dapat disimpulkan bahwa semakin banyak hidden neuron maka nilai RMSE dan MAD semakin baik. Namun tidak selalu jika jumlah hidden neuron banyak akan memiliki RMSE dan MAD rendah. Hal itu dapat dilihat dari jumlah hidden neuron 10. RMSE dan MAD pada 10 hidden neuron lebih besar dari 9 hidden neuron.
Hal ini mengindikasikan bahwa jika jumlah hidden neuron semakin banyak dapat juga menghasilkan RMSE dan MAD yang lebih tinggi. Kemudian nilai RMSE dan MAD tertinggi terdapat pada jumlah hidden neuron 1 dengan rata-rata RMSE 53,49 dan MAD 43,99.
RMSE dan MAD tinggi pada jumlah hidden neuron yang sedikit dapat terjadi karena adanya underfitting. Underfitting merupakan ketidakmampuan model dalam menangkap pola pembelajaran dengan baik. Hal ini dikarenakan input atau dalam hal ini hidden neuron memiliki jumlah yang sedikit, sehingga model yang dihasilkan ketika dilakukan pengujian memiliki tingkat kesalahan (error) yang tinggi. Dari analisis tersebut dapat disimpulkan bahwa jumlah hidden neuron berpengaruh terhadap nilai RMSE dan MAD. Semakin banyak hidden neuron maka RMSE dan MAD akan semakin rendah.
0,0000 0,0050 0,0100 0,0150 0,0200 0,0250
1 2 3 4 5 6 7 8 9 10
Rata-rata runtime
Jumlah Fitur Runtime
0 10 20 30 40 50 60
1 2 3 4 5 6 7 8 9 10
Rata-rataRMSE dan MAD
Jumlah Hidden Neuron
RMSE MAD
Gambar 7. Grafik Runtime Pengujian Jumlah Hidden Neuron
Grafik pada Gambar 7 menunjukkan bahwa runtime yang dihasilkan cenderung naik. namun dalam beberapa kondisi mengalami penurunan yaitu pada jumlah hidden neuron 8 dan 10.
Penurunan yang terjadi tidak terlalu signifikan yaitu 0,0007s dari 7 hiden neuron ke 8, dan 0,0002s dari 9 hidden neuron ke 10. Sehingga dapat disimpulkan runtime pada metode Extreme Learning Machine (ELM) untuk pengujian jumlah hidden neuron memiliki learning speed yang cepat.
5.3. Pengujian Perbandingan Data Training dan Data Testing
Pengujian ini berencana guna memutuskan apakah korelasi perbandingan antara data training dan testing dapat mempengaruhi nilai RMSE, MAD serta runtime sistem. Selain itu, mendapatkan persentase optimal dari data training juga merupakan tujuan pengujian ini.
Persentase data training yang diujikan merupakan kelipatan 10 mulai dari 10% hingga 90%. Masing-masing pengujian dilakukan percobaan sebanyak 5 kali. Setelah dilakukan 5 kali percobaan, selanjutnya dihitung rata-rata dari RMSE, MAD dan runtime yang telah didapatkan selama perobaan dilakukan.
Parameter lain yang digunakan bersifat tetap antara lain rentang bobot[-1,1], rentang bias[0,1].
Jumlah fitur dan jumlah hidden neuron ditetapkan menggunakan jumlah optimal yang didapatkan dari pengujian jumlah fitur dan jumlah hidden neuron yang menghasilkan nilai RMSE terendah. Jumlah optimal untuk jumlah fitur adalah 7 fitur, dan jumlah optimal untuk jumlah hidden neuron sebanyak 9. Grafik RMSE dan MAD dari pengujian ini ditunjukkan pada Gambar 8.
Gambar 8. Grafik RMS dan MAD Pengujian Perbandingan Data
Grafik pada Gambar 8 menunjukkan bahwa persentase data training yang optimal adalah 80% data training dengan 10% data testing.
Dengan menggunakan parameter optimal tersebut menghasilkan RMSE sebesar 32,52 dan MAD sebesar 25,27. Secara keseluruhan nilai RMSE dan MAD cenderun menurun seiring banyaknya persentase data training. Sehingga dapat disimpulkan bahwa perbandingan data training terhadap data testing dapat mempengaruhi RMSE dan MAD. Semakin banyak data training maka semakin baik nilai RMSE dan MAD.
Gambar 9. Grafik Runtime Pengujian Perbandingan Data
Grafik pada Gambar 9 menunjukkan bahwa runtime pada pengujian ini cenderung naik sehingga didapatkan semakin banyak data training maka runtime akan semakin meningkat.
Namun pada metode ELM runtime dari keseluruhan dari pengujian ini memiliki rata-rata 0,01776 s. Sehingga dapat disimpulkan bahwa metode ELM dengan pengujian perbandingan data training terhadap data testing memiliki learning speed yang cepat.
0,0000 0,0050 0,0100 0,0150 0,0200 0,0250 0,0300 0,0350
1 2 3 4 5 6 7 8 9 10
Runtime
Jumlah Hidden Neuron Runtime
0 10 20 30 40 50 60 70
10% 20% 30% 40% 50% 60% 70% 80% 90%
Rata-rataRMSE dan MAD
Persentase Data Training
RMSE MAD
0,0000 0,0050 0,0100 0,0150 0,0200 0,0250
10% 20% 30% 40% 50% 60% 70% 80% 90%
Runtime
Persentase Data Training Runtime
5.4. Pengujian Cross Validation
Pengujian cross validation bertujuan guna mengevaluasi performa dari suatu model pembelajaran. Cross validation yang digunakan adalah k-Fold Cross Validation dengan nilai k=10 sehingga dilakukan sebanyak 10 pengujian.
Contoh pengujian yang dilakukan adalah fold 1 sebagai data latih dan fold 2 sebagai data test.
Selanjutnya fold 1 dan 2 sebagai data latih, fold 3 sebagai data test, dan seterusnya sampai terakhir yaitu fold 1 sampai 10 sebagai data train dan fold 11 sebagai data test. Kemudian dari keseluruhan fold dihitung rata-rata dari RMSE. Parameter lain yang digunakan bersifat tetap antara lain rentang bobot[-1,1], rentang bias[0,1]. Jumlah fitur dan jumlah hidden neuron ditetapkan menggunakan jumlah optimal yang didapatkan dari pengujian jumlah fitur dan jumlah hidden neuron yang menghasilkan nilai RMSE terendah. Jumlah optimal untuk jumlah fitur adalah 7 fitur, dan jumlah optimal untuk jumlah hidden neuron adalah 9 hidden neuron. Hasil pengujian dapat dilihat pada Tabel 1.
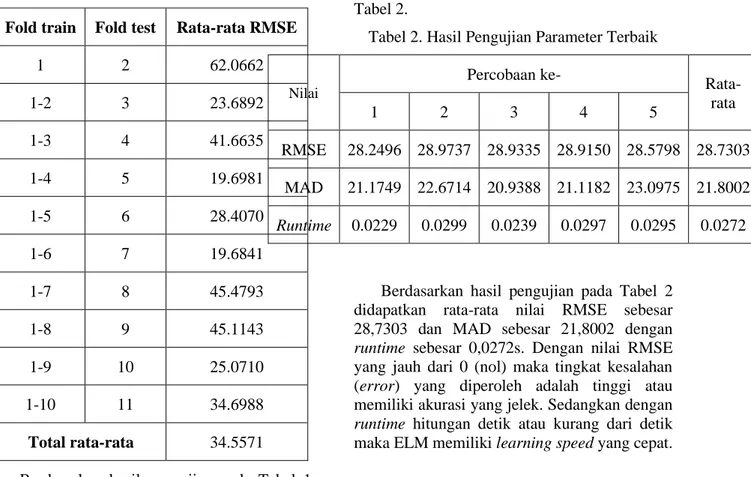
Tabel 1. Hasil Pengujian Cross validation Fold train Fold test Rata-rata RMSE
1 2 62.0662
1-2 3 23.6892
1-3 4 41.6635
1-4 5 19.6981
1-5 6 28.4070
1-6 7 19.6841
1-7 8 45.4793
1-8 9 45.1143
1-9 10 25.0710
1-10 11 34.6988
Total rata-rata 34.5571 Berdasarkan hasil pengujian pada Tabel 1 menunjukan bahwa performa model ELM yang telah dibuat memiliki tanda-tanda adanya underfitting dan overfitting. Underfitting dan overfitting ditandai dengan nilai RMSE yang
tinggi. Hal ini dapat dipengaruhi oleh jumlah data yang digunakan, pola data yang terlalu fluktuatif dan bervariasi serta juga dapat dipengaruhi oleh bobot dan bias pada ELM itu sendiri yang masih diinisialisasikan secara acak.
Rata-rata RMSE dari cross validation ini adalah sebesar 34,5571.
5.5. Pengujian Parameter Terbaik
Pada pengujian ini dilakukan untuk menguji parameter-parameter terbaik yang telah didapatkan pada pengujian sebelumnya.
Pengujian ini bertujuan hanya untuk mendapatkan rata-rata RMSE dan MAD menggunakan parameter terbaik. Parameter terbaik yang didapatkan dari masing-masing pengujian adalah jumlah fitur sebanyak 7 dan jumlah hidden neuron sebanyak 9 dengan perbandingan data optimal 80% data latih dan 20% data uji. Parameter lain adalah rentang bobot[-1,1] dan rentang bias[0,1]. Pada pengujian ini percobaan yang dilakukan sebanyak 5 kali dan dilanjutkan dengan menghitung rerata dari RMSE, MAD serta runtime. Hasil pengujian ini dapat dilihat pada Tabel 2.
Tabel 2. Hasil Pengujian Parameter Terbaik
Nilai
Percobaan ke-
Rata- rata
1 2 3 4 5
RMSE 28.2496 28.9737 28.9335 28.9150 28.5798 28.7303 MAD 21.1749 22.6714 20.9388 21.1182 23.0975 21.8002 Runtime 0.0229 0.0299 0.0239 0.0297 0.0295 0.0272
Berdasarkan hasil pengujian pada Tabel 2 didapatkan rata-rata nilai RMSE sebesar 28,7303 dan MAD sebesar 21,8002 dengan runtime sebesar 0,0272s. Dengan nilai RMSE yang jauh dari 0 (nol) maka tingkat kesalahan (error) yang diperoleh adalah tinggi atau memiliki akurasi yang jelek. Sedangkan dengan runtime hitungan detik atau kurang dari detik maka ELM memiliki learning speed yang cepat.
6. PENUTUP
Kesimpulan yang didapatkan dari penelitian ini adalah parameter terbaik atau optimal untuk melakukan peramalan debit inflow
Waduk Gajah Mungkur menggunakan metode Extreme Learning Machine antara lain jumlah fitur sebanyak 7 dan jumlah hidden neuron sebanyak 9. Jumlah fitur 7 menghasilkan rata- rata RMSE 35,8106, MAD 28,7264, dan runtime 0,0190s dan untuk jumlah hidden neuron 9 menghasilkan rata-rata RMSE 32,5972, MAD 25,0540, dan runtime 0,0291s.
Parameter perbandingan data yang optimal didapatkan pada 80% data training dan 20% data testing yang menghasilkan rata-rata RMSE 32,5190 dan MAD 25,2691 dengan runtime 0,0213s.
Pengujian parameter terbaik ELM dengan menggunakan jumlah fitur sebanyak 7, hidden neuron sebanyak 9, 80% data
training dan 20% data testing menghasilkanrata-rata RMSE sebesar 28,7303 dan MAD sebesar 21,8002 dengan runtime 0,0272s.
Dengan nilai RMSE yang jauh dari 0 (nol) maka tingkat kesalahan (error) yang diperoleh termasuk tinggi dan jelek. Dan juga dengan runtime yang dalam hitungan detik atau kurang dari detik maka penelitian ini juga mempertegas bahwa ELM memiliki kelebihan pada learning speed yang cepat.
Selanjutnya untuk saran penelitian selanjutnya yang dapat dilakukan yaitu pertama dilakukan
penambahan faktor pada peramalan debit inflow Waduk Gajah Mungkur. Faktor yang dimaksudkan tidak hanya debit inflow bulan sebelumnya saja melainkan faktor lain yang dapat mempengaruhi seperti curah hujan.
Kedua, dengan mengoptimalkan bobot dan bias pada metode Extreme Learning Machine yang masih menggunakan nilai
random.Pengoptimalan dapat menggunakan algoritma genetika atau algoritma Particle
Swarm Optimization(PSO) untuk menghasilkan random bobot dan bias yang optimal sehingga menghasilkan ramalan dengan error yang rendah.
7. DAFTAR PUSTAKA
Anggraheni, D., Jayadi, R. & Istiarto, 2017.
Evaluasi Kinerja Pola operasi Waduk (POW) Wonogiri 2014. Jurnal Teknisia, XXII(1), pp. 294-306.
Cholissodin, I. et al., 2017. Optimasi Kandungan Gizi Susu Kambing Peranakan Etawa (PE) menggunakan ELM-PSO di UPT Pembibitan Ternak dan Hijauan Makanan Ternak Singosari-Malang. Jurnal Teknologi Informasi dan Ilmu Komputer (JTIIK), IV(1), pp. 31-36.
Fonseca-Delgado, R. & Gomez-Gil, P., 2013.
An Assessment of Ten-Fold and Monte Carlo Cross Validation for Time Series Forecasting. 2013 10th International Conference on Electrical Engineering, Computing Science and Automatic Control (CCE), pp. 215-220.
Hakim, B. D., I. & Supianto, A. A., 2019.
Peramalan Debit Bendungan Dengan Menggunakan Metode Backpropagation dan Algoritma Genetika. Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, Januari, III(1), pp. 51-58.
Hanggara, I., Montarcih, L. & Sisinggih, D., 2015. Analisa Peramalan Debit Sungai Menggunakan Metode ARIMA (Auto Regressive Integrated Moving Avarage) di Sungai Brantas Hulu. Jurnal Teknik Pengairan, VI(2), pp. 197-205.
Harton, R., 2021. Permukiman Tergenang Air Akibat Spillway Waduk Gajah Mungkur Wonogiri Dibuka, Warga: Sudah Biasa!.
[Online]
Available at:
https://www.solopos.com/permukiman- tergenang-air-akibat-spillway-waduk- gajah-mungkur-wonogiri-dibuka-warga- sudah-biasa-1107160
[Diakses 4 March 2021].
Hatmoko, W. & Amirwandi, S., 2001.
Penerapan Metode Thomas-Fiering untuk Peramalan Debit Aliran Sungai Cimanuk di Bendung Rentang. Prosiding PIT XVIII HATHI.
Heizer, J. & Render, B., 2011. Manajemen Operasi. 9th penyunt. Jakarta: Salemba Empat.
Huang, G.-B., Zhu, Q.-Y. & Siew, C.-K., 2004.
Extreme Learning Machine: A New Learning Scheme of Feedforward Neural Networks. Proceedings of International Joint Conference on Neural Networks (IJCNN2004), pp. 985-990.
Huang, G.-B., Zhu, Q.-Y. & Siew, C.-K., 2006.
Extreme Learning Machine: Theory and Applications. Neurocomputing, Volume 70, pp. 489-501.
Ikhsan, F., Setiawan, B. D. & Tibyani, 2019.
Prediksi Penjualan Seblak Menggunakan Algoritme Extreme Learning Machine di Sebalk Malabar. Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, III(11), pp. 10630-10637.
Kurniasih, I. H., Furqon, M. T. & Adinugroho, S., 2020. Prediksi Pertumbuhan Penduduk di Kota Malang menggunakan Metode Extreme Learning Machine (ELM).
Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, IV(2), pp.
509-516.
Luhung, I. A., 2021. Pintu Air Waduk Gajah Mungkur Dibuka: Warga Diminta Siaga.
[Online]
Available at:
https://radarsolo.jawapos.com/read/2021/
02/11/241000/pintu-air-waduk-gajah- mungkur-dibuka-warga-diminta-siaga [Diakses 4 March 2021].
Paudi, P. I. U., Furqon, T. M. & S., 2020.
Implementasi metode Extreme Learning Machine (ELM) untuk Memprediksi Jumlah Debit Air yang Layak Didistribusi (Studi Kasu: PDAM Kabupaten Gowa Makasar). Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, IV(3), pp. 733-739.
Pratama, M. I., Adikara, P. P. & Adinugroho, S., 2018. Peramalan Harga Saham Menggunakan Metode Extreme Learning Machine (ELM) Studi Kasus Saham Bank Mandiri. Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, II(11), pp.
5009-5014.
Pratiwi, H. & Harianto, K., 2019. Perbandingan Algoritma ELM Dan Backpropagation Terhadap Prestasi Mahasiswa. Jurnal Sains Komputer & Informatika (J-SAKTI), 3(2), pp. 282-294.
Samosir, C. S., Soetopo, W. & Yuliani, E., 2015.
Optimasi Pola Operasi Waduk Untuk Memenuhi Kebutuhan Pembangkit Listrik Tenaga Air (Studi Kasus Waduk Wonogiri). Jurnal Teknik Pengairan, VI(1), pp. 108-115.
Sari, V. & Yusuf, A. N. A., 2016. Neural
Network Autoregressive Exogenus (NNARX) untuk Meramalkan Inflow Debit Air di Waduk Gajah Mungkur Kabupaten Wonogiri. Jurnal Pengabdian dan Pemberdayaan Masyarakat, I(1), pp.
241-249.
Setialaksana, W. et al., 2020. Model Jaringan Syaraf Tiruan dalam Peramalan Kasus Positif Covid-19 di Indonesia. Jurnal Media Pendidikan Teknik Informatika dan Komputer, II(2), pp. 53-56.
Suprihati, 2014. Peran Waduk Gajah Mungkur Terhadap Pertumbuhan Sektor Pertanian di Kabupaten Sragen. Jurnal Akuntansi dan pajak, XIV(2), pp. 20-38.