1
Sistem informasi perpustakaan berbasis web pada perpustakaan
Humaniora dan Budaya UIN Maliki Malang menggunakan Algoritma
Wighted Directed Acyclic Graph
Angga Debby Frayudha
ʾ
Idhar Firmansyah
ʾ
Mohammad Nadzif Abdullah
ʾ
1)
Jurusan Teknik Informatika UIN, Malang 65144, email:
[email protected]
2)
Jurusan Teknik Informatika UIN, Malang 65144,email:
[email protected]
3)
Jurusan Teknik Informatika UIN, Malang 65144,email:
[email protected]
Abstrack – pada pengimplementasian algoritma wighted Directed Acyclic Graph pada sistem informasi perpustakaan untuk mencari jarak node terpanjang dapat memanfaatkan algoritma ini dikarenakan WDAG sebagai representasi utama dari metadata yang berguna untuk mengkalkulasi kemiripan melalui perhitungan berbasis taksonomi root concept maka sangat berguna jika digunakan sebagai smart search engine.kelebihan dari WDAG adalah:
1. mampu menampilkan bobot dari data yang ada sehingga hasil pencarian lebih akurat dan cepat 2. wdag sangat berguna pada smart search enggine
Pada proses pengimplementasian metode WDAG ini ditemui kendala dimana kemungkinan pencarian kurangbegitu akurat
Kata Kunci: WDAG, metadata, taksonomi, root concept, smart search engine
1. PENDAHULUAN
Weighted Directed Acyclic Graph merupakan sebuah graph berarah dan memiliki bobot pada arc, yang umumnya merupakan bentuk penyimpanan metadata dari sesuatu. Wdag sangat potensial untuk memunculkan penggabungan node yang identik pada non-leaf. In degree dari root node sebuah DAG adalah 0. Sebuah node disebut leaf jika out –degree adalah 0. Dengan demikian bahwa tree merupakan subset khusus dari DAG. Algoritma wdag similarity membandingkan dan menghitung kemiripan antara dua arc-labeled dan acr-weighted DAG. Dua masukan wDAG diserialkan pertama kali dan dibaca oleh algoritma wDAG, setelah algoritma
membandingkan dua wDAG, hasil yang diberikan adalah nilai kemiripan keduanya dan kemiripan akan diurutkan berdasarkan kemiripan tertinggi.
Pada bab ini memperkenalkan mengenai cara kerja WDAG pada smart search engine perpustakaan dan kemudian melihat tingkatan keberhasilan Algoritma tersebut, WDAG lebih sering digunakan
dalam optimasi pencarian dan untuk menemukan data yang dicari kita akan membahasnya di sini secara penuh untuk algoritma WDAG.
2. PEMBAHASAN
4.1 Tahapan Algoritma
Pada tahapan ini WDAG memiliki beberapa tahapan yang harus dilewati karena pada proses pencarian yang menggunakan metode ini sangat sensitive terhadap hasil pencarian membantu untuk hasil yang dicari tahapan yang harus dilalui adalah pelabelan dan pembobotan, urutan yang ada pada algoritma WDAG sebagai berikut
4.1.1 Input masukan WDAG
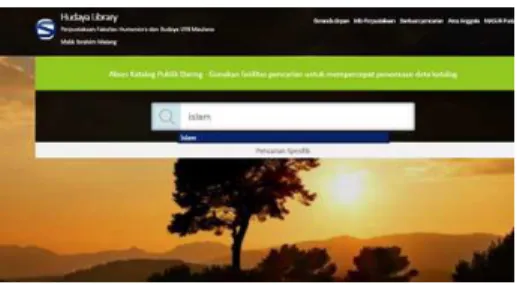
Disini inputan yang akan dicari berupa potongan kata yang akan muncul secara otomatis yang diambil dari database, inputan berupa kata atau kalimat yang akan dicari
2
Gambar 4.1 Inputan PencarianKata yang di inputkan akan diproses WDAG dan akan menghsilkan hasil pencarian terkait data yang di inputkan.
4.1.2 WDAG Similirity Algorithm
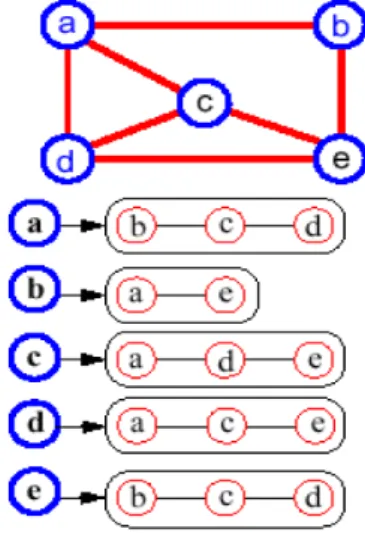
Ketika menghitung nilai kemiripan input WDAG, daftar asosiasi dibentuk untuk menyimpan kemiripan sub-WDAG saat pertama kali arc dihasilkan. Kemudian nilai kemiripan dapat digunakan kembali ketika algoritma kembali melewati sub-WDAG yang sama. Proses penentuan kemiripan dapat dilakukan melalui proses pemisahan kata menjadi individu kata yang kemudian dapat dibandingkan dengan dengan kumpulan kata yang sebelumnya telah dibuat aturan.
Gambar 4.2 WDAG
Jadi proses untuk mencari nilai kemiripan diambil dari berapa proses pemisahan kata menjadi beberapa kata yang per individu dan dibandingkan dengan kata yang ada.
4.1.3 Pelabelan
Pada proses similirty terjadi proses pelabelan, disini terdapat pencocokan kata dari inputan perkata yang akan disamakan ke dalam isi database. Perbandingan kata yang cocok akan mengeluarkan hasil berupa judul lanjutan atau nama pengarang. Pencocokan ini berdasarkan isi dari database, sehingga
jika kata yang dicari itu ada dalam database maka akan muncul kata selanjutnya
Gambar 4.3 Pelabelan
Prosesnya, ketika user menginputkan kata, maka proses awal adalah melakukan proses selecting melalui query like pada database. Hasil selecting akan berupa data dengan panjang data tertentu. Data ini akan dilakukan proses pemotongan/ split berdasarkan jumlah kosak kata, selanjutnya setiap kata hasil pemotongan dilakukan proses split berdasarkan huruf dan ditampung ke dalam array. Hal yang sama dilakukan pada kata yang diinputkan user, dilakukan proses split berdasarkan huruf dan tiap hurufnya disimpan dalam sebuah array dengan length tertentu. Dari array tersebut ditentukan nilai maksimal dan kemudian dibandingkan dengan array hasil query. Jika didapati memiliki length yang sama, maka proses selanjutnya adalah melakukan pengecekan similirity dari array huruf yang di-input-kan dan array huruf hasil query database. Lalu didapati output berdasarkan kata yang sama, kata ini yang selanjutnya ditampilkan ke user.
Gambar 4.4 Pelabelan kata
Jika kata yang dicari bukan merupakan node pada simpul simpul dan memiliki arc label yang berbeda, maka nilai kemiripan adalah 0. Sebaliknya jika arc label yang dimiliki adalah sama maka akan
3
dilakukan recursive transversal top-down melalui subWDAG yang dimiliki 4.1.4 Similirity Value
Nilai pada Similirity Berkaitan dengan besarnya nilai kesamaan, dan nilai ini yang menentukan output yang diharapkan. Jika inputan yang dicari bukan merupakan node dari bagian simpul maka nilai kemiripan 0. Akan tetapi jika inputan itu hilang dalam sub WDAG yang dilalui maka nilai kemiripan dari sub WDAG yang hilang adalah berupa nilai simplicity dikalikan 0.5 atau dapat dirumuskan
WDAG stm(inputan,null)= WDAG
plicity(inputan,null) * 0.5
Gambar 4.5 Similirity Value
Nilai kesamaan dengan bobot yang sama maka akan diurutkan berdasarkan abjad tetapi tetap proses WDAG bekerja hanya saja memperhitungkan bilamana terjadi hal tersebut.
4.1.5 Pembobotan
Pembobotan disini dimaksudkan untuk menentukan nilai ratting tertinggi dari peminjaman buku, peminjaman dengan intensitas tinggi maka akan berpengaruh pada nilai bobot dari nilai pembobotan tersebut. Sugestion dari kata yang di inputkan akan ditampilkan berdasarkan dari urutan bobot dari yang tertinggi hingga terendah sehingga dimasukan pengurutan hasil lebih optimal.
Gambar 4.6 wighted 4.1.5.1 Proses pemecahan kata
Pada bagian kata yang akan dicari, kata yang diinputkan user nanti akan dipecah menjadi beberapa bagian. Jika kata maka dipecah berdasarkan hurufnya, jika kata maka dipecah berasarkan kosak kata. Misalnya : kata diinputkan adalah “Pengantar” nanti kata ini akan dipecah sebanyak jumlah huruf yang ada. Hasil pecah menjadi “p”, “e”, “n”, “g”, “a”, “n”, “t”, ”a”, “r”. tiap huruf yang dipecah akan dicari kesamaannya dengan aturan indexing dalam system. Jika kalimat, misalnya “Pengatar Bahasa Arab” maka akan dipecah menjadi “Pengantar”, “Bahasa”, dan “Arab”. Selanjutnya setiap kata yang dipecah dengan aturan indexing dan akan dicari kesamaannya kedalam system dan dimunculkan dibawah kotak mesin pencari.
Gambar 4.7 pemecahan kata
4.1.5 Pseudocode Program
kita perlu untuk mewakili grafik kita sedemikian rupa sehingga jalan menemukan algoritma seperti
Input : word “q”;
$query select from database
FOR i =1 to n do
$a split(“q”,$query) // memanggil fungsi query dan keyword
ambil nilai maks.$a
IF $a > 1 then
$b split $a ; ambil data pada $a index ke - 1
IF $b > 1 then
split $b ; ambil nilai maks $b pada index ke – 0 ; ambil nilai $a pada index ke – 2
4
IF nilai maks $b > 2 then
ambil nilai maks $a pada index ke – 0 $h split “word”,nilai maks.$a then Bandingkan nilai maks.$a dengan split “word”
$h = hasil akhir
ELSE
$h Split $b berdasarkan nilai maks.$b pada index ke-0
Bandingkan nilai maks.$b dengan split “word”
Ambil nilai $h pada indeks – 0 $h pada indeks – 0 = hasil akhir
IF
Indeks - 0 = 0 maka break;
ELSE
Batasi data yang ditampilkan sebanyak 5. $counter = 0
$selectcounterT select from database
IF $selectcounterT > 0 then
eksekusi query.
$counterT nilai pada kolom counter $arrayWeight [index kata] = nilai $counter Set similirity $h = nilai $counter.
ELSE
$arrayWeight [index kata] = 0
ENDFOR
Contoh implementasi sederhana dari kelas ini adalah menyimpan koneksi untuk setiap node dan hanya akan kembali ke daftar. masing-masing sambungan akan memiliki simpul biaya dan akhir 4.1.6 Implementasi Program
Berikut potongan sourcecode :
$SQLTitle = mysql_query("SELECT biblio_id, title FROM `biblio` WHERE title LIKE '" . $Key . "%'");
$iT = 0; if (sizeof($SQLTitle) > 0) { while ($ResultT = mysql_fetch_array($SQLTitle)) { $iT+=1; $RTitle = $ResultT['title']; $XT = explode(" ", $RTitle); $XTFive = $XT[0]; $indexT = 1; for (; $indexT <= $getIndexing; $indexT++) { if ($indexT < sizeof($XT)) { $XTFive.= " " . $XT[$indexT]; } } $iT2 = 0; $iTCheck = 0; $SQLTitlex =
mysql_query("SELECT biblio_id, title FROM `biblio` WHERE title LIKE '" . $Key . "%'"); while ($ResultTChecker = mysql_fetch_array($SQLTitlex)) { $iT2 +=1; $RTitleChecker = $ResultTChecker['title']; if ($iT != $iT2) { $XTChecker = explode(" ", $RTitleChecker); $XTCheckerFive = $XTChecker[0]; for ($indexT = 1; $indexT <= $getIndexing; $indexT++) { if ($indexT < sizeof($XTChecker)) { $XTCheckerFive.= " " . $XTChecker[$indexT]; } } if ($XTFive == $XTCheckerFive) { $iTCheck = 1; break; } } else { break; } } $comunicatorWhileT = 0; if ($iTCheck == 0) { if ($indexT == sizeof($XT)) { break; } else { if ($indexingPath == 0) { $arrayWord[$indexingPath] = $XTFive; $counterT = 0; $selectCounterT = mysql_query("SELECT b.biblio_id, r.counter FROM biblio b, item i, rating r WHERE b.biblio_id=i.biblio_id AND r.item_code=i.item_code AND b.biblio_id='" . $ResultT['biblio_id'] . "'"); if (sizeof($selectCounterT > 0)) { while ($resultCounterT = mysql_fetch_array($selectCounterT)) {
5
$counterT = $resultCounterT['counter']; $arrayWeight[$indexingPath] = $counterT; } } else { $arrayWeight[$indexingPath] = 0; } $indexingPath +=1; } else { if ($arrayWord[$indexingPath] != $arrayWord[$indexingPath - 1]) { $arrayWord[$indexingPath] = $XTFive; $counterT = 0; $selectCounterT = mysql_query("SELECT b.biblio_id, r.counter FROM biblio b, item i, rating r WHEREb.biblio_id=i.biblio_id AND r.item_code=i.item_code AND b.biblio_id='" . $ResultT['biblio_id'] . "'"); if (sizeof($selectCounterT > 0)) { while ($resultCounterT = mysql_fetch_array($selectCounterT)) { $counterT = $resultCounterT['counter']; $arrayWeight[$indexingPath] = $counterT; } } else { $arrayWeight[$indexingPath] = 0; } $indexingPath +=1; } else { $comunicatorWhileT = 1; } } } } if ($comunicatorWhileT == 1) { break; } } } else { $GOD +=1; break; } 3. KESIMPULAN
Dari pemaparan isi paper diatas kita dapat mengetahui bagaimana cara mengimplementasikan WDAG pada sistem Informasi perpustakaan yang digunakan untuk mengoptimalkan smart search engine guna mengoptimalkan hasil pencarian yang tepat dan cepat
4. DAFTAR PUSTAKA
1. Jin Jing B.Eng, Similarity Of Wighted Directed Acyclic Graph, Zhejiang University, 2004
2. Bhavsar, V.C., Boley, H. and Yang, L., A Weighted-Tree Similarity Algorithm for Multi-Agent Systems in e-Business Environments, Computational Intelligence, 20(4), pp.584-602, 2004.
3. Bouquet, P., Serafini, L. and Zanobini, S., Semantic coordination: A new approach and an application. Proceedings of the International Semantic Web Conference (ISWC), pp. 130–145, 2003.