63
BAB III
METODOLOGI
3.1. Rangkaian
Metodologi Perancangan Prototype
Seperti yang telah diuraikan pada bab pendahuluan, sebagai bahan studi kasus penelitian adalah sebuah aplikasi DWS yang belum menerapkan MV di dalamnya. Telah dibahas juga bahwa teknik MV akan meningkatkan performansi dari query karena melakukan proses agregasi di awal dan menyimpannya dalam bentuk tabel. Dari fakta tersebut peneliti berhipotesis bahwa dengan menerapkan teknik MV secara tepat dalam aplikasi DWS maka performansi sistem baik itu waktu respon dan biaya processing akan lebih kecil dan efisien. Dalam melakukan implementasi MV dalam sebuah DWH sangatlah tidak mudah karena belum adanya alat bantu bagi para DBA dalam mengambil keputusan kandidat MV mana saja yang perlu diimplementasi dan tidak perlu diimplementasi. Oleh karena itu pada bab ini akan diuraikan rangkaian metodologi untuk merancang dan membangun prototipe untuk alat bantu proses seleksi MV.
Di dalam sebuah penelitian untuk merancang sebuah model dibutuhkan langkah – langkah yang tepat agar model yang dibangun sangat valid dan mampu merepresentasikan apa yang terjadi pada sistem yang berjalan. Sehingga ketika model diterapkan pada sistem yang sudah ada tidak memerlukan biaya atau usaha untuk merubah atau melakukan adaptasi. Di sini peneliti menggunakan referensi pendekatan tujuh langkah untuk membangun model yang baik (Law, 2009).
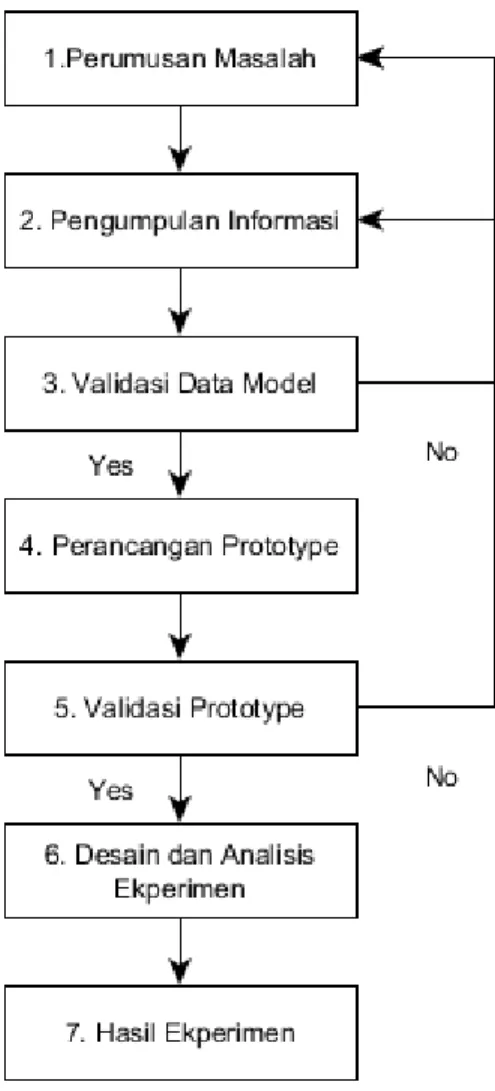
Berikut adalah kerangka pikir dari penelitian ini dalam alur diagram.
Gambar 3.1. Tujuh langkah membangun model
Penjelasan singkat langkah – langkah dalam rangkaian metodologi perancangan model seleksi MV adalah sebagai berikut :
1. Langkah pertama yaitu merumuskan masalah yang terjadi baik secara perspektif perusahaan atau teknologi.
2. Dilanjutkan dengan mengoleksi informasi data yang akan digunakan sebagai acuan dalam simulasi model termasuk di dalamnya
65
mengumpulkan studi literatur tentang proses seleksi MV untuk memilih
framework / metodeyang akan digunakan. Melakukan analisis dari sistem
yang berjalan sangat penting untuk membantu menentukan apakah metode yang akan digunakan sesuai dengan kondisi sistem.
3. Langkah selanjutnya adalah melakukan validasi terhadap data – data yang akan digunakan dalam simulasi model.
4. Melakukan perancangan prototipe dari model seleksi MV
5. Melakukan pengujian dan memvalidasi komponen - komponen didalam
prototype yang dibangun
6. Melakukan desain eksperimen dan analisis terhadap hasil ekperimen 7. Memaparkan hasil akhir secara keseluruhan
3.2. Perumusan
Masalah
3.2.1. Ruang Lingkup Masalah
Dalam penelitian ini diawal sudah didefinisikan tujuan yang ingin dicapai yaitu ingin mendapatkan respon query yang lebih cepat dengan melakukan implementasi MV. Mengapa dipilih teknik MV karena solusi ini sangat sesuai kondisi sistem yang berjalan dengan empat kriteria yang harus dipenuhi yaitu :
1. Tidak merubah arsitektur dari aplikasi DWS itu sendiri.
2. Tidak merubah konfigurasi dari aplikasi seperti security, sistem operasi maupun hardware.
3. Tidak merubah definisi SQL dari sebuah report query
4. Tidak merubah desain logik dari database aplikasi DWS dalam hal ini
Namun masalah yang timbul dan dihadapi adalah bagaimana cara menentukan MV yang tepat untuk kondisi saat ini karena belum adanya alat bantu bagi para DBA dalam memilih kandidat MV yang tepat. Sehingga penelitian ini akan berkontribusi untuk menjawab dua pertanyaan berikut :
1. Bagaimana cara melakukan seleksi MV dengan memperhitungkan beberapa
constraint seperti kapasitas storage, maintenance cost dan query frequency
berdasarkan informasi dari database
2. Seberapa besar rasio peningkatan performansi yang bisa didapatkan setelah mengimplementasikan MV hasil proses seleksi.
3.2.2. Ruang Lingkup Model
Model Seleksi MV
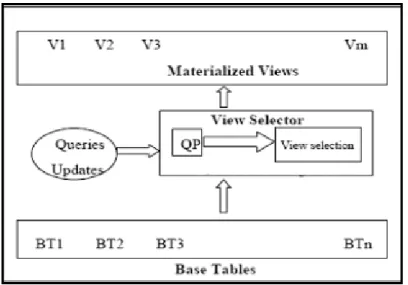
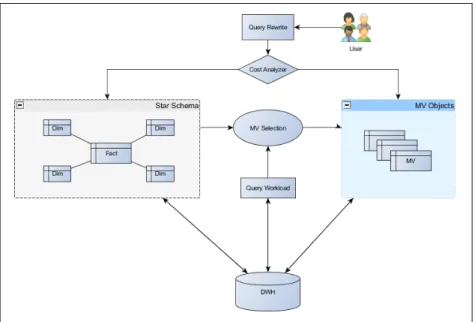
Model yang akan dibangun hanya terbatas pada proses seleksi MV pada database Oracle. Hasil output dari penelitian ini adalah sebuah prototype yang digunakan untuk membantu para DBA dalam memilih MV yang tepat berdasarkan parameter – parameter query. Setiap pengguna dalam hal ini user yang mengakses report melalui aplikasi akan tergerate sebuah query. Qyery tersebut akan diproses oleh fungsi query rewrite yang akan memilih apakah akan mengakses melalui MV atau melakukan aggregasi dari tabel aslinya berdasarkan biaya yang paling optimal. MV Selection adalah prototype yang akan dibangun untuk membantu melakukan proses seleksi MV. Secara umum model yang akan dibangun dapat digambarkan sebagai berikut :
67
Gambar 3.2. Model Seleksi MV
Pemilihan Framework Seleksi MV
Model yang akan dibangun akan menggunkan sebuah framework OVSP yang diadapatasi ke dalam database Oracle. Salah satu alasan framework OVSP diadaptasi dan digunakan karena model yang dibutuhkan untuk melakukan seleksi MV sesuai dengan kebutuhan untuk melakukan seleksi kandidat MV dengan memperhatikan nilai – nilai parameter input sebagai berikut :
1. Besarnya kapasitas penyimpanan yang diperlukan untuk menampung data MV (storage)
2. Frekuensi akses dari penggunaan query oleh pengguna 3. Frekuensi dari update base-relation
4. Biaya query processing 5. Biaya maintenanceview Parameter Ukuran Performansi
Prototype hanya akan menghasilkan rekomendasi MV mana yang tepat untuk dibuat. Selanjutkan MV tersebut harus secara manual untuk diimplementasi
ke dalam DWH. Di dalam pengujian ada dua kondisi yang akan dibandingkan yaitu kondisi sebelum dan sesudah melakukan implementasi MV hasil proses seleksi. Dari paramater input query workload yang sama maka akan didapatkan performansi query sebelum dan sesudah diimplementasi MV. Pengujian ini akan digunakan pendekatan empirical testing untuk melakukan estimasi perhitungan biaya query processing dan waktu respon dari sebuah query. Pengujian masing - masing akan diuji sebanyak minimal 4 kali untuk mendapatkan hasil yang lebih akurat.
Evaluasi performansi bertujuan untuk membandingkan antara hasil performansi pada sistem testing yang belum dan yang sudah mengimplementasi MV, sehingga didapatkan rasio peningkatan performansinya. Ada dua metrik performansi utama yang akan dianalisis berdasarkan apa yang telah diuji :
1. Total biaya query processing 2. Waktu respon workload query
Perhitungan model matematis yaitu mean atau rata – rata digunakan untuk menghitung percobaan yang dilakukan 4 kali. Karena eksperimen ini dilakukan pada model yang mempunyai skala lebih kecil daripada database produksi, maka hasil dari query plan bisa dijadikan acuan apakah proses query menjadi lebih baik atau tidak. Selanjutnya hasil pengujian akan dianalisis dan dievaluasi dengan menggunakan metode gap analysis untuk membandingkan manfaat antara sebelum dan setelah implementasi MV. Biaya yang dibutuhkan untuk implementasi dari MV ini juga dihitung. Pada akhirnya dengan menggunakan metode Cost Benefit Analysis akan dihasilkan rekomendasi apakah implementasi
69
MV ini layak dijadikan solusi berdasarkan perbandingan biaya dan manfaat dalam implementasi.
3.3. Pengumpulan Informasi dan Data
3.3.1. Parameter Input Model
Dalam membangun model seleksi MV dibutuhkan parameter input model untuk melakukan simulasi yang mendekati kondisi nyata agar hasil didapatkan akurat dan valid. Berikut ini adalah nilai – nilai parameter input model seleksi MV yang akan dibangun :
1. Frekuensi akses dari penggunaan query oleh pengguna. Pada umumnya parameter ini dibutuhkan untuk melakukan simulasi workload yang mirip dengan kondisi nyata.
2. Besarnya kapasitas penyimpanan yang diperlukan untuk menampung data
(storage). Parameter ini digunakan untuk melakukan simulasi besaran data
yang mirip dengan kondisi nyata. Satuan yang digunakan parameter ini adalah byte.
3. Nilai frekuensi dari update base-relation digunakan untuk mensimulasikan berapa jam sekali proses update pada DWH di kondisi nyata. Satuan yang digunakan adalah jam, misal jika update dilakukan 1 hari sekali maka nilai parameter ini adalah 24.
4. Biaya query processing dalam satuan block digunakan sebagai simulasi proses pembacaan data pada model agar menyerupai kondisi nyata. Parameter ini dipilih karena nilainya akan selalu tetap untuk ragam data yang sama dan tidak terpengaruh oleh besar kecilnya skala model. Misal untuk membaca 100
records data dibutuhkan 10 block query processing, maka apapun jenis
hardware yang digunakan selama konfigurasi model sama maka hasilnya juga
akan selalu sama.
5. Biaya maintenance view digunakan sebagai parameter untuk simulasi perhitungan biaya yang dibutuhkan jika terdapat data dari tabel sumber berubah. Satuan yang digunakan adalah block dan perhitunganya hampir sama dengan biaya query processing.
3.3.2. Studi Literatur
Studi literatur merupakan bagian yang sangat penting dalam melakukan penelitian. Dengan studi literatur maka semua teori pendukung dalam melakukan penelitian dapat memberi arahan bahwa experimen yang dilakukan berada pada jalur yang benar. Sumber – sumber literatur yang direferensi oleh peneliti :
9 Website internal perusahaan 9 Online library internal perusahaan 9 Jurnal – jurnal ilmiah
9 White paper tentang MV dan database Oracle 9 Artikel teknologi database dari internet
Materialized View (MV) adalah salah satu teknik yang digunakan untuk
meningkatkan respon query dengan cara melakukan perhitungan awal dan menyimpannya dalam sebuah tabel. Di dalam sebuah DWH tidak mungkin melakukan implementasi semua query ke dalam MV karena adanya batasan biaya
maintenance dan juga ukuran kapasitas penyimpanan. Oleh karena itu diperlukan
proses seleksi dari beberapa MV untuk diimplementasi berdasarkan total biaya yang paling rendah. Beberapa parameter yang digunakan untuk melakukan proses
71
seleksi MV : jumlah frekuensi akses terhadap query, total besar kapasitas penyimpanan, biaya maintenance view, biaya query processing dan frekuensi update tabel basis. Semua parameter tersebut digunakan dalam sebuah framework OVSP (Ashadevi et al, 2010) yang dijadikan referensi dalam penelitian ini.
3.3.3. Studi Sistem Berjalan
Sistem aplikasi DWS ini dipelihara dibawah departement IT Billing and
Charging. Aplikasi DWS melakukan proses koleksi data – data dari sistem
pra-bayar (prepaid) untuk disimpan dalam sebuah DWH. Data – data dalam DWH inilah nantinya yang akan ditampilkan dalam sebuah report untuk diakses dari berbagai divisi yaitu Revenue Assurance, Revenue Management, Finance dan
Marketing.
Pada bagian ini akan dilakukan studi database pada aplikasi DWS yang sedang berjalan yang nantinya akan dipakai dalam penelitian ini. Tujuan yang akan dicapai dari aktivitas ini adalah untuk memahami arsitektur dan logika bisnis aplikasi DWS terutama dalam kaitannya dengan desain dari DWH. Berikut ini adalah informasi internal yang bisa didapatkan dari dokumentasi internal :
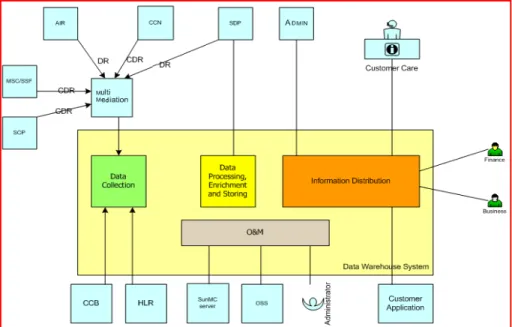
1. Arsitektur aplikasi DWS
Aplikasi DWS adalah solusi DWH untuk sistem prepaid untuk jaringan mobil di mana menyediakan report business-critical di dalam organisasi bisnis pelanggan. DWS digunakan untuk mengumpulkan dan menampilkan informasi seperti status pelanggan, informasi penggunaan dll.
Gambar 3.3. Arsitektur Aplikasi DWS (IT Billing and Charging Dept, 2009)
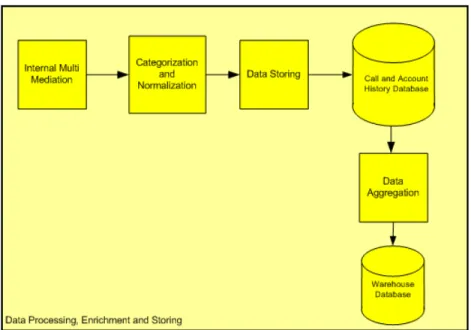
2. Aliran data DWH aplikasi DWS
Aplikasi DWS melakukan integrasi, korelasi dan pemrosesan data dari beberapa sistem dan menyimpannya dalam sebuah database Call and Account
History. Kemudian data selanjutnya diaggregasi dan disimpan dalam database
Warehouse. Setelah data tersebut diolah oleh DWS, maka data tersebut akan
berubah menjadi informasi yang dapat digunakan operator mobil untuk beberapa keperluan.
73
Gambar 3.4. Flow data DWS (IT Billing and Charging Dept, 2009)
Internal Multi Mediation (IMM) berfungsi sebagai gateway DWS dengan sistem front-end dalam hal ini adalah sistem pra-bayar. Di dalam IMM data CDR akan diterjemahkan sehingga dapat digunakan proses selanjutnya.
Categorization and Normalization bertugas untuk melakukan normalisasi dan kategorisasi dari tipe – tipe data sehingga ketika akan disimpan ke dalam database data tersebut memiliki standard yang sama.
Data Storing adalah sebuah interface untuk menyimpan data ke dalam database. Data Aggregation adalah proses melakukan aggregasi data ke dalam tingkat yang lebih tinggi seperti level harian, bulanan dan tahunan.
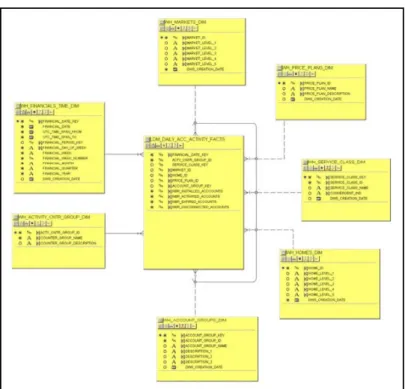
3. Model logikal dari aplikasi DWS
Model logikal yang digunakan dalam membangun DWH dari sistem DWS adalah star-schema (SS) yang telah dibahas pada bab 2.1.4. Pada desain SS
terdapat tabel fact yang berada ditengah dan berelasi dengan beberapa tabel
dimension. Contoh tabel fact dan dimension yang terdapat dalam DWH aplikasi
DWS :
Tabel 3.1. Tabel fact dan dimension (IT Billing and Charging Dept, 2009)
Pada aplikasi DWS ini terdiri dari beberapa relasi model SS yang merepresentasikan suatu fungsi dari kebutuhan bisnis. Model SS ini nantinya akan mewakili sebuah data mart, ada tiga data mart utama yang didesain dalam DWH sistem DWS ini yaitu :
1. Financial Data Mart (FDM)
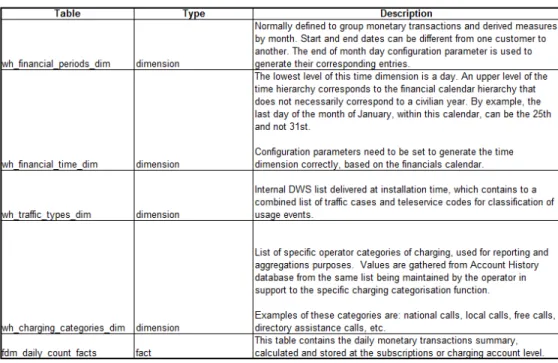
Tujuan dari data mart ini adalah untuk mendapatkan informasi tentang alur keuangan yang tersentral terhadap semua transaksi dari beberapa sumber. Tingkat aggregasi pada data mart ini adalah harian (daily) dan bulanan (monthly). Berikut adalah contoh sebuah model SS dalam data mart ini.
75
Gambar 3.5. Sebuah Model SS dari FDM (IT Billing and Charging Dept, 2009)
Pada data mart ini terdapat 2 tabel fact utama untuk menyimpan nilai
measurement yaitu daily summary facts yang digunakan untuk
agregasi transaksi nilai uang dan daily count facts yang digunakan untuk agreagasi level volume. Tabel dimension akan berelasi dengan tabel facts untuk melakukan drill-down diantaranya berdasarkan :
• Service class
• Account group, market, home dan price plans
• Voucher Group
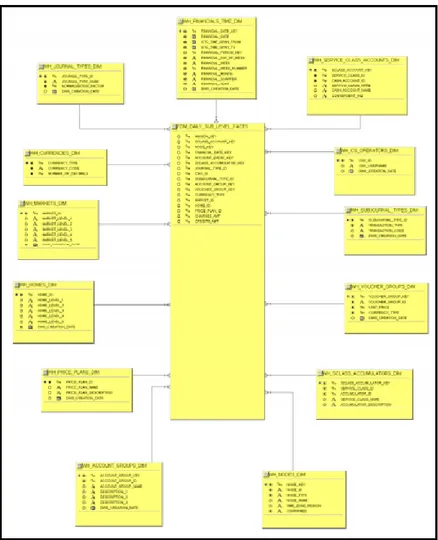
2. Service Usage Data Mart (SDM)
SDM ini digunakan untuk membantu analisis data dan laporan tentang informasi trafik pada level harian dan bulanan. Di dalamnya dapat dianalisis tentang jenis – jenis trafik yang ada seperti voice call, internet, SMS dll. Berikut ini adalah contoh salah satu model SS dalam SDM.
Gambar 3.6. Sebuah Model SS dari SDM (IT Billing and Charging Dept, 2009)
77
Pada data mart ini tabel fact menyimpan nilai measurement yang digunakan untuk agregasi total biaya, jumlah transaksi, durasi berbayar, durasi gratis dan jumlah volume. Tabel dimension akan berelasi dengan tabel facts untuk melakukan drill-down diantaranya berdasarkan :
• Charging Categories
• Account group, market, home dan price plans
• Traffic types
• Tariff types
• Roaming Categories
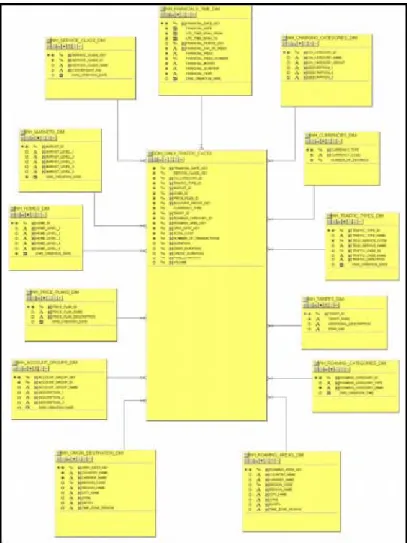
3. Account Life Cycle Data Mart (LDM)
Informasi tentang sebuah siklus daripada sebuah nomor pelanggan dapat dianalisis dalam LDM. Di dalamnya terdapat informasi tentang perubahan status dari nomor pelanggan seperti dari status install,
active, expired hingga disconnect. Pada gambar dibawah ditampilkan
Gambar 3.7. Sebuah Model SS dari LDM (IT Billing and Charging Dept, 2009)
Pada data mart ini hanya terdapat sebuah nilai measurement yang disimpan dalam tabel fact yaitu jumlah account. Tabel dimension akan berelasi dengan tabel facts untuk melakukan drill-down diantaranya berdasarkan :
• Account group, market, home dan price plans
• Service Class
Secara total terdapat 12 tabel fact dengan kegunaan seperti telah dijelaskan di atas. Semua data dalam data mart disebutkan diatas disimpan dengan retensi sampai 24 bulan kebelakang. Level aggregasi yang diimplementasi adalah daily
79
4. Model Fisik DWH
Secara desain fisik DWH, dalam aplikasi DWS ini tabel – tabel fact dan
dimension diimplementasikan dengan index dan partition. Tujuan utamanya
adalah karena jumlah data yang cukup besar sehingga akan memperbaiki performansi query ketika melakukan join dengan beberapa tabel. Berikut adalah contoh Data Definition Language (DDL) dari sebuah tabel dimension.
Contoh 3.1. DDL Tabel Dimension
Untuk tabel fact, karena jumlah datanya lebih besar daripada tabel dimension maka teknik partition digunakan untuk membagi besaran data berdasarkan informasi tanggal. Berikut ini adalah contoh dari DDL sebuah tabel fact.
Contoh 3.2. DDL Tabel Fact
3.3.4. Kebutuhan dan Spesifikasi Prototype
Dalam melakukan pengembangan sebuah prototype, perlu dilakukan analisis kebutuhan dan spesifikasi yang akan digunakan sebagai referensi dalam proses pengembangan. Berikut adalah kebutuhan dan spesifikasi dari prototipe.
Deskripsi Produk
Produk yang akan dihasilkan adalah prototipe untuk melakukan proses seleksi MV yang tepat untuk sebuah DWH. Prototipe ini harus bisa berjalan di atas database Oracle 10g tanpa melakukan perubahan apapun. Prototipe akan membutuhkan input dari query workload dan menghasilkan rekomendasi MV yang harus diimplementasi. Prototipe juga akan melakukan proses maintanance secara berkala terhadap MV yang sudah ada dan yang baru.
81
Prototipe yang akan dibangun harus memiliki beberapa fitur utama yaitu :
1. Mengolekasi data dari query workload baik dari database history ataupun dari file teks
2. Melakukan pemilihan query – query yang sering dipakai dan membutuhkan kapasitas kecil
3. Melakukan ekstraksi conditional clause dari kumpulan query
4. Melakukan pemilihan kandidat MV
5. Melakukan proses maintanance terhadap MV
Pengguna dari prototipe ini adalah para DBA yang mengerti dan paham dalam melakukan aktivitas tuning di dalam database. Karena hasil output dari prototipe adalah rekomendasi maka pengguna harus mengerti bagaimana cara menghasilkan dan mendapatkan query workload sebuah database. Selain itu pengguna juga harus mengerti bagaimana cara membuat dan membuang MV dari sebuah DWH.
Prototipe harus bisa berjalan di atas sistem operasi berbasis unix dan di atas database Oracle 10g. Namun prototipe juga diharapkan mampu untuk berjalan di atas sistem operasi dan database yang lain dengan perubahan yang minimal yaitu hanya merubah konfigurasi saja. Prototipe memiliki Graphical
User Interface (GUI) sebagai interaksi antar muka dengan pengguna. Prototipe
harus dapat diimplementasi secara plug and play dengan sistem yang berjalan tanpa mengganggu proses yang ada.
Dokumentasi dari produk dibutuhkan untuk mendukung kegiatan operasional harian. Dokumentasi meliputi cara penggunaan dan cara melakukan
troubleshoting. Di asumsikan database Oracle yang digunakan memiliki fitur –
fitur yang dibutuhkan dalam proses internal pada prototipe seleksi MV ini.
Fitur Sistem
Sistem yang akan dibangun secara umum diilustrasikan pada gambar di bawah ini :
Gambar 3.8. Rancangan Sistem Model
Berdasarkan gambar rancangan sistem di atas dapat dibagi menjadi lima komponen atau fungsi utama yaitu :
1. Fungsi input query workload yang bertujuan untuk mendapatkan data
83
database. Output yang diinginkan adalah obyek query workload yang telah disesuikan dengan kebutuhan pengguna.
2. Fungsi seleksi query. Proses yang akan dilakukan di dalam fungsi ini antara lain melakukan grouping dari teks query yang sama untuk didapatkan nilai frekuensinya, mengumpulkan informasi statistik dari
query di dalam database dan melakukan pembobotan untuk selanjutnya
dipilih.
3. Fungsi seleksi MV yang bertujuan untuk mendapatkan kandidat MV berdasarkan bobot dari data conditional clause yang terdapat pada setiap
query yang telah terpilih sebelumnya. Dari setiap query yang terpilih, akan
dilakukan proses ekstraksi data conditional clause (CC) untuk selajutnya diklasifikasikan berdasarkan data CC yang sama. Proses tersebut akan menghasilkan sebuah obyek data baru yaitu distinct conditional clause
(DCC) berserta informasi frekuensi kemunculan. Pada akhirnya akan
dihitung bobot masing – masing DCC berdasarkan nilai frekuensi dan kapasitas penyimpanan yang dibutuhkan. Dari DCC yang terpilih selanjutnya disebut sebagai kandidat MV.
4. Fungsi perhitungan biaya MV. Pada fungsi ini ada dua proses utama yaitu proses perhitungan biaya query processing dan biaya maintenance view dari kandidat MV yang terpilih. Selanjutnya keduanya dijumlahkan untuk kemudian dirangking berdasarkan nilai terkecil. Pada akhirnya user dalam hal ini para DBA mendapatkan rekomendasi MV mana yang layak untuk
diimplementasi yaitu MV yang memiliki total biaya paling rendah baik dalam hal query processing, maintanance view dan kebutuhan storage.
5. Fungsi manajemen MV yang bertujuan untuk melakukan maintenance MV yang sudah diimplementasi di dalam database. Dari MV yang sudah ada, maka secara periodik fungsi ini akan melakukan perhitungan bobot untuk mencari MV yang jarang diakses namun membutuhkan ukuran penyimpanan paling besar. Sehingga nantinya akan dibuang untuk diganti dengan MV yang lebih optimal dengan menggunakan proses seleksi yang dijelaskan sebelumnya.
Antar Muka Eksternal
Tampilan antar muka harus menggunakan GUI untuk mempermudah interaksi dengan pengguna. Untuk antar muka terhadap hardware dan software akan secara langsung ditangani oleh bahasa pemrograman yang dipakai. Sehingga komunikasinya secara transparan akan otomatis dimanajemen oleh operating
system dan kode pemrograman.
Sistem yang dibangun akan melakukan interaksi dengan database Oracle sebagai antar muka eksternal. Antar muka yang dipakai oleh sistem adalah menggunakan komunikasi SQL sebagai standard. Dalam sebuah pembangunan aplikasi dengan menggunakan bahasa pemrograman tertentu dibutuhkan satu layer tambahan sebagai jembatan antara SQL dengan layer kode pemrograman. Karena aplikasi akan dibangun menggunakan bahasa Java maka layer yang dibutuhkan adalah Java Database Connectivity (JDBC).
85
Kebutuhan Non-fungsional
Ada tiga kebutuhan non-fungsional yang harus dipenuhi agar sistem dapat berjalan dengan baik :
1. Aplikasi yang dibangun ketika menjalankan proses seleksi MV tidak mengganggu proses yang sedang berjalan. Penggunaan memori harus secara efisien dan proses dapat dikerjakan secara background.
2. Aplikasi tidak membutuhkan perubahaan security pada sistem yang sudah berjalan.
3. Aplikasi dapat dijalan di sistem operasi selain Unix dan dapat diintegrasikan dengan database selain Oracle dengan sedikit perubahan konfigurasi.
3.3.5. Data Testing
Dalam melakukan pengujian peneliti mempunyai kendala bahwa tidak bisa menggunakan database produksi sebagai media testing. Oleh karena itu perlu dipersiapkan model database testing yang digunakan untuk melakukan pengujian. Ada e langkah – langkah yang dilakukan dalam aktivitas ini :
1. Pemilihan Sampel Data Mart
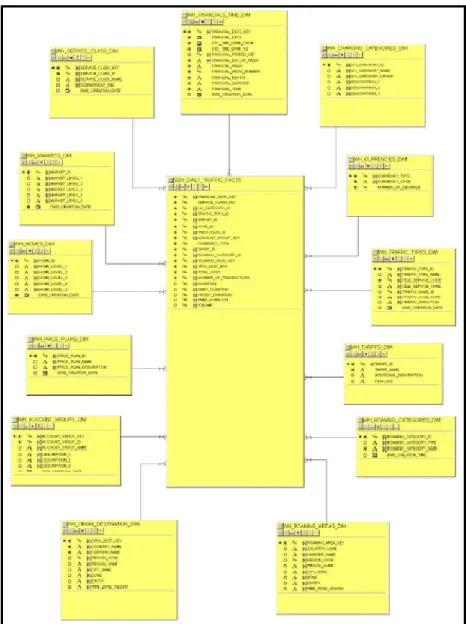
Sampling data mart dilakukan untuk mengambil sample dari sebuah data mart yang akan dipakai dalam pengujian. Data mart yang digunakan adalah SDM karena memiliki jumlah record yang besar dan degree yang tinggi. Dalam SDM dipilih sebuah fungsi aggregation yaitu daily traffic SDM yang terdiri dari sebuah
tabel fact dan 13 tabel dimension. Berikut ini adalah daftar dari tabel – tabel tersebut beserta diagram relasinya :
• WH_TRAFFIC_TYPES_DIM • WH_TARIFFS_DIM • WH_SERVICE_CLASS_DIM • WH_ROAMING_CATEGORIES_DIM • WH_ROAMING_AREAS_DIM • WH_PRICE_PLANS_DIM • WH_ORIGIN_DESTINATION_DIM • WH_MARKETS_DIM • WH_HOMES_DIM • WH_FINANCIALS_TIME_DIM • WH_CURRENCIES_DIM • WH_CHARGING_CATEGORIES_DIM • WH_ACCOUNT_GROUPS_DIM
87
Gambar 3.9. Sampel Testing (IT Billing and Charging Dept, 2009)
2. Sampling Ukuran Data
Menentukan besaran sampel data yang akan dipakai dalam pengujian. Sampel data untuk tabel dimension akan diambil semua record karena jumlah datanya tidak terlalu besar. Sedangkan untuk tabel fact karena datanya cukup besar dan menyimpan data hingga 2 tahun kebelakang maka perlu diambil sampel yang disesuikan dengan kemampuan sistem testing. Kemudian data tersebut akan
dipopulasi kedalam model database testing. Berdasarkan rekomendasi dari spesifikasi TPC-H (TPC, 2011) dan juga memperhitungkan kemampuan kapasitas media penyimpanan, maka besarnya sampel data dipilih sesuai dengan scale
factor (SF) yaitu 1 dan 10 (1 SF = 1 GB).
3. Export/Import dan Validasi
Aktivitas ini adalah melakukan export dari database live dan kemudian melakukan import kedalam database testing. Fitur Oracle Data pump akan digunakan untuk melakukan copy data baik metadata dan content. Berikut ini adalah contoh command untuk melakukan export dan import.
Contoh 3.3. Perintah export dan import
Validasi perlu dilakukan untuk memastikan data sampel yang diambil sesuai dengan data aslinya.
4. Sampel Query Workload
Melakukan sampel workload bertujuan untuk mendapatkan history dari query
– query yang digunakan dalam aplikasi DWS. Data ini digunakan sebagai
parameter input dari prototype untuk melakukan perhitungan dan seleksi terhadap MV. Di bawah ini adalah contoh query report yang digunakan dalam aplikasi
89
3.4. Validasi
Data
Model
Melakukan validasi hasil model database scale-down dibutuhkan agar model database testing memiliki perilaku yang sama dengan database produksi. Adapun cara – cara yang digunakan untuk validasi antara lain :
1. Selain itu Data Definition Language (DDL) dari masing – masing objek database haruslah sama. Berikut contoh hasil DDL dari sebuah tabel fact untuk model data :
2. Hasil data query dan query plan memiliki alur yang sama meski secara cost tidak harus sama karena secara hardware berbeda. Berikut contoh hasil dari
query plan yang dicocokan antara model dengan kondisi nyata :
Contoh 3.6. Query Plan
Jika kedua kriteria itu tidak dipenuhi maka perlu dilakukan aktivitas export /
import dari database produksi ke model sampai kedua kriteria tersebut dipenuhi.
3.5. Perancangan
Prototype
Metode yang akan digunakan untuk melakukan seleksi MV adalah dengan menggunakan framework OVSP yang diadaptasi dengan database Oracle. Selain karena metode ini memperhitungkan semua cost metric dalam seleksi MV, juga bisa diterapkan secara nyata dan sesuai dengan sistem yang sedang berjalan. Dalam implementasi ini beberapa informasi nilai dari parameter yang dibutuhkan dalam OVSP diperoleh langsung dari model database. Fitur – fitur yang digunakan adalah query workload, query plan, audit, statistic dan juga query
rewrite. Implementasi prototyipe OVSP akan menggunakan bahasa pemrograman
Java. Berikut ini adalah arsitektur dari rancangan prototyipe seleksi MV dan interaksinya dengan database Oracle.
91
Gambar 3.10. Rancangan Prototype
3.5.1. Input Query Set
Fungsi ini bertujuan untuk mendapatkan data query workload yang bersumber dari file teks ataupun dari informasi database. Output yang diinginkan adalah obyek query workload yang telah disesuikan dengan kebutuhan pengguna. Berikut ini adalah diagram alur dari fungsi ini :
Gambar 3.11. Input Query Set
Di dalam fungsi ini hanya dua jenis tipe query workload yang akan digunakan yaitu:
1. Tipe file teks digunakan jika DBA ingin secara manual melakukan export
query workload dari database untuk dimodifikasi berdasarkan kebutuhan.
Format yang digunakan adalah plain text di mana setiap baris diisi dengan sebuah query dan diakhir dengan carriage return. Berikut adalah contoh format file teks yang harus dipenuhi sebagai input.
<Query_text_1> <Query_text_2> <Query_text_3> . . . <Query_text_n>
93
2. Tipe database digunakan jika DBA ingin secara otomatis mengambil
query workload langsung dari database tentunya dengan disertai fungsi
filter yang sederhana. Pada tipe ini query workload didapatkan dengan mengumpulkan data history dari tabel view v$sqlarea atau obyek view lainnya. Berikut adalah perintah query yang dijalankan untuk mendapatkan query workload dari database :
select sql_text from <workload_view> where sql_text like '<simple_filter>’;
Hasil output dari fungsi ini akan digunakan sebagai data input pada fungsi selanjutnya yaitu fungsi query selection.
3.5.2. Query Selection
Hasil output dari fungsi input query set akan digunakan sebagai input di dalam fungsi query selection. Proses yang akan dilakukan di dalam fungsi ini antara lain melakukan grouping dari teks query yang sama untuk didapatkan nilai frekuensinya, mengumpulkan informasi statistik dari query di dalam database dan melakukan pembobotan untuk selanjutnya dipilih. Berikut ini adalah diagram alur dari fungsi query selection :
Gambar 3.12. Query Selection
Fungsi ini akan mengolah input dari dari data query workload yang dihasilkan fungsi input query set. Untuk setiap query yang terdapat didalamnya akan dilakukan proses perhitungan sebagai berikut :
1. Query Frequency (QF) adalah informasi berapa banyak query telah
dieksekusi oleh pengguna dengan cara dihitung berdasarkan jumlah kemunculan query yang sama di dalam data query workload.
2. Query Storage (QS) adalah kapasitas media penyimpanan (byte) yang
dibutuhkan untuk menampung data hasil query. Informasi ini bisa didapatkan dengan cara memanggil prosedur dari database yaitu
dbms_mview.estimate_mview_size untuk melakukan kalkulasi media
95
3. Query Weight (QW) dihitung berdasarkan jumlah kemunculan dan
kapasitas yang diperlukan sebuah query. Formula yang digunakan adalah
2log( QF) – log( QS).
4. Selanjutnya query akan dimasukan dalam obyek selected queries jika memenuhi salah satu kondisi yaitu bobot nilainya lebih kecil dari
threshold yang telah ditentukan atau bobot nilainya termasuk Top-N secara
terurut ascending.
Hasil output data berupa obyek selected queries akan digunakan oleh fungsi selanjutnya yaitu fungsi MV Selection.
3.5.3. MV Selection
Pada fungsi MV Selection bertujuan untuk mendapatkan kandidat MV berdasarkan bobot dari data conditional clause yang terdapat pada setiap query yang telah terpilih sebelumnya. Dari setiap query yang terpilih, akan dilakukan proses ekstraksi data conditional clause (CC) untuk selajutnya diklasifikasikan berdasarkan data CC yang sama. Proses tersebut akan menghasilkan sebuah obyek data baru yaitu distinct conditional clause (DCC) berserta informasi frekuensi kemunculan. Pada akhirnya akan dihitung bobot masing – masing DCC berdasarkan nilai frekuensi dan kapasitas penyimpanan yang dibutuhkan. Dari DCC yang terpilih selanjutnya disebut sebagai kandidat MV. Berikut adalah diagram alur dari fungsi ini :
Gambar 3.13. Ekstraksi CC
Sebagai input dari proses ekstraksi CC adalah obyek query yang telah terpilih sebelumnya. Berikut ini adalah rangkaian langkah – langkah dalam proses ekstraksi CC pada setiap query :
1. Melakukan ekstraksi CC yang terdapat pada setiap query. Pada setiap sintak query dibangun oleh empat komponen utama yaitu : projection,
where clause, aggregation/grouping dan sorting. CC yang dimaksud
dalam prototype ini adalah bagian where clause dari sebuah query. Berikut adalah contoh format sebuah query dan bagian CC di dalamnya :
Select <projection> from <database_object> where <conditional_clause> group by <aggregation_column> order by <sorting_column>
2. Menghitung nilai frekuensi dari masing – masing CC yang ada berdasarkan tingkat kemunculan DCC. Jika CC dari query adalah unik maka CC tersebut akan dijadikan sebagai DCC. Namun jika CC tidak unik maka akan ditambahkan kedalam DCC yang sudah ada. Berikut adalah representasi perhitungan antara CC dan DCC.
97
Gambar 2.14. Representasi format CC (Ashadevi, 2010)
3. Dari semua DCC yang ada disimpan kedalam obyek DCC sebagai output proses ini dan sebagai input proses memilih kandidat MV.
Setelah mendapatkan data DCC yang terdapat pada query yang terpilih, maka proses selanjutnya adalah memasangkan kembali DCC tersebut ke query asal untuk dihitung bobotnya berdasarkan nilai frekuensi dan kapasitas penyimpanan yang dibutuhkan. Proses ini dinamakan seleksi kandidat MV yang digambarkan diagram alur di bawah :
Pada flowchart seleksi kandidat MV di atas, terdapat beberapa langkah untuk melakukan perhitungan nilai bobot dari DCC yang ada. DCC yang memiliki bobot lebih kecil dari threshold atau termasuk Top-N DCC akan terpilih untuk dikonstruksi kembali menjadi query aslinya sehingga menjadi kandidat MV. Berikut ini adalah langkah – langkah dalam proses seleksi kandidat MV :
1. Menghitung DCC frequency ratio (DFR) dengan cara membagi dua buah nilai antara frequency sebuah DCC dengan total frequency keseluruhan DCC.
2. Menghitung DCC storage ratio (DSR) dengan cara membagi dua buah nilai antara storage sebuah DCC dengan total storage keseluruhan DCC. Nilai storage dari sebuah DCC dapat diperoleh dengan cara memanggil prosedur dari database dbms_mview.estimate_mview_size untuk
melakukan kalkulasi media penyimpanan terhadap sebuah query
3. Menghitung bobot dari DCC berdasarkan nilai frequency dan nilai storage dengan menggunakan formula log (DFR) + log (DSR). .Berikut ini adalah contoh simulasi perhitungan bobot dari DCC yang diolah.
99
4. DCC yang memiliki bobot dibawah threshold atau termasuk dalam Top-N, maka akan dikonstruksi ulang dengan sintak query asal untuk dijadikan kandidat MV.
Selanjutnya obyek kandidat MV ini akan diseleksi lebih lanjut untuk mendapatkan biaya yang dibutuhkan untuk membangun MV.
3.5.4. QP and MV Cost Calculation
Pada fungsi ini ada dua proses utama yaitu proses perhitungan biaya query
processing dan biaya maintenance view dari kandidat MV yang terpilih.
Selanjutnya keduanya dijumlahkan untuk kemudian dirangking berdasarkan nilai terkecil. Pada akhirnya user dalam hal ini para DBA mendapatkan rekomendasi MV mana yang layak untuk diimplementasi yaitu MV yang memiliki total biaya paling rendah baik dalam hal query processing, maintanance view dan kebutuhan
storage. Berikut adalah diagram alur dari fungsi ini :
Gambar 3.16. Perhitungan Biaya Kandidat MV
Berdasarkan diagram di atas terdapat tiga langkah perhitungan dari masing – masing kandidat MV yang terseleksi yaitu :
1. Menghitung biaya query processing (QP) dari setiap kandidat MV dengan cara memanggil prosedur query plan dari database. Prosedur query plan digunakan untuk melakukan estimasi perhitungan query processing cost berdasarkan hasil kalkulasi dari mesin database dalam satuan blok (8Kb). Berikut ini adalah contoh bagaimana memanggil prosedur query plan pada Oracle database menggunakan bahasa java beserta hasilnya :
Contoh 3.7. Implementasi Query Plan
2. Menghitung biaya maintancen view untuk mendapatkan estimasi biaya yang dibutuhkan jika terjadi perubahan data pada obyek – obyek tabel yang digunakan dalam MV. Berikut adalah perhitungan yang digunakan dalam proses ini :
101
Gambar 3.17. Biaya MV Maintanance (Ashadevi et al, 2010)
3. Menghitung total biaya yang diperlukan untuk membangun masing – masing kandidat MV dengan cara menjumlahkan biaya query processing (QP) dan biaya maintanance view (MV).
Hasil keluaran dari fungsi ini adalah obyek kandidat MV (Obyek MV Cost) yang dilengkapi dengan informasi total biaya tiap masing – masing kandidat MV.
3.5.5. Final Recommendation
Dalam fungsi ini, akan dihasilkan daftar MV yang direkomendasi untuk diimplementasi. Untuk melakukannya, setiap kandidat MV akan diurutkan secara
ascending berdasarkan total biaya yang dibutuhkan oleh kandidat MV.
Selanjutnya daftar MV tersebut akan diranking berdasarkan total biaya. Berikut adalah diagram alur dari fungsi ini :
Gambar 3.18. Final Recommendation
Hasil final recommendation adalah daftar MV yang siap untuk diimplementasi dilengkapi dengan sintak yang digunakan oleh Oracle database. Berikut ini adalah contoh output dari fungsi ini :
create materialized view <MV_Name> build immediate
refresh on commit
enable query rewrite as <MV_Query_Definition>
Contoh 3.8. Hasil Output Rekomendasi MV
Dalam implementasi MV terdapat fitur Oracle database yang harus digunakan yaitu query rewrite. Query Rewrite adalah sebuah fungsi dari database Oracle untuk melakukan update perintah query berdasarkan biaya query
processing yang paling minimal. Sehingga query otomatis akan mengakses MV
103
3.5.6. MV Maintenance
Fungsi ini bertujuan untuk melakukan maintenance MV yang sudah diimplementasi di dalam database. Dari MV yang sudah ada, maka secara periodik fungsi ini akan melakukan perhitungan bobot untuk mencari MV yang jarang diakses namun membutuhkan ukuran penyimpanan paling besar. Sehingga nantinya akan dibuang untuk diganti dengan MV yang lebih optimal dengan menggunakan proses seleksi yang dijelaskan sebelumnya. Berikut adalah diagram alur yang menjelaskan fungsi ini :
Gambar 3.19. MV Maintanance
Penjelasan dari diagram di atas adalah pada setiap MV yang sudah ada akan dilakukan perhitungan pembobotan dengan langkah – langkah sebagai berikut :
1. Menghitung nilai frekuensi penggunaan dari sebuah MV. Untuk menghitung nilai frekuensi tersebut, pada setiap implementasi MV harus diaktifkan fitur audit. Fitur audit digunakan untuk mendapatkan informasi tentang tingkat keseringan sebuah MV diakses. Dengan menerapkan audit
untuk operasi select, maka setiap sebuah MV digunakan dalam proses
query maka database akan langsung melakukan pencatatan. Berikut ini
adalah contoh bagaimana mengaktifkan audit pada sebuah MV
Contoh 3.9. Audit dalam DDL
2. Menghitung kapasitas storage (byte) yang dibutuhkan untuk menyimpan data MV. Untuk mendapatkan nilai tersebut diperlukan untuk mendapatkan informasi metadata sebuah MV dari database agar didapatkan informasi kapasitas storage. Informasi metadata tersebut berada dalam sistem tabel user_tables. Berikut contoh bagaimana mendapatkan informasi storage dari sebuah MV :
Select table_name, (avg_row_len * num_rows) table_size From user_tables
Where table_name = <MV_Name>
Contoh 3.10. Metadata Informasi Storage
3. Menghitung bobot berdasarkan informasi nilai frekuensi dan nilai storage dengan formula 2log (frekuensi) – log (storage).
Bobot dari MV tersebut diurutkan dari yang terkecil sehingga bisa memberikan rekomendasi MV mana yang harus dibuang atau dipertahankan.
105
3.6. Validasi Prototype
Validasi prototype penting dilakukan agar prototype yang dihasilkan mempunyai fungsi input dan output yang diharapkan. Dalam melakukan validasi
prototype ini, peneliti menggunakan metode unit testing. Setiap fungsi – fungsi
utama yang terdapat dalam prototype akan ditest secara programmatically dengan cara diberikan input data dan membandingkan hasil outputnya dengan hasil output yang diekspektasi. Sehingga semua fungsi – fungsi yang terdapat di dalam
prototype sudah benar secara logik.
Ada dua buah fungsi utama yang akan divalidasi menggunakan unit testing yaitu :
1. Fungsi ekstraksi query menjadi CC dan DCC. Untuk itu diperlukan test data untuk melakukannya sehingga bisa divalidasi kebenaran logiknya. Berikut adalah contoh sampel data query set beserta hasil ekspektasi yang digunakan untuk melakukan validasi fungsi :
select <c> from <t> where a=b and b=c and c=a
select <c> from <t> where a=b and c=d and b=c and e>c select <c> from <t> where c=d and e>c
select <c> from <t> where a2<e2 and c2=d2 and b2 like ‘%a’ select <c> from <t> where b1=d1 and d1=a1 and b1>c1 and e1 like ‘%use%’
select <c> from <t> where a=b and b=c and c>a select <c> from <t> where b1<d1 and d1=a1
Contoh 3.11. Sampel input dan ekspetasi output (Ashadevi et al, 2010) 2. Fungsi perhitungan pembobotan sangat penting untuk divalidasi agar nilai
perhitungan tidak salah. Untuk melakukan validasi, berikut adalah sampel data yang berisi informasi tentang nilai frekuensi, storage dan hasil perhitungan pembobotan. Hasil yang diharapkan harus sama persis dengan data input berikut :
107
Selain dua buah fungsi diatas, fungsi – fungsi lain seperti fungsi pengumpul data statistik dari database, informasi metadata, nilai query plan dan proses audit juga akan dilakukan unit testing.
3.7. Konfigurasi Pengujian Model
Konfigurasi pengujian model akan menggunakan sistem host-based yaitu server database dan klien database terdapat pada server yang sama. Dengan konfigurasi seperti ini bisa mengurangi ketidakakuratan perhitungan dikarenakan adanya waktu yang dipengaruhi oleh jaringan.
Gambar 3.20. Model host-based (TPC, 2011)
Sehingga pada sistem ini perhitungan performansi akan dihitung dari waktu pertama kali request masuk ke dalam SQL interface sampai respon data berhasil diterima di klien secara utuh. Gambar berikut bisa mengilustrasikan aliran request dan response sebuah query.
Gambar 3.21. Flow Request dan Respon (TPC, 2011)
Pada model ekperimen ini konfigurasi hardware menggunakan sistem yang lebih kecil daripada sistem yang ada. Dalam melakukan eksperimen terdapat beberapa alat bantu yang akan digunakan :
9 Oracle Database versi 10.2.0.3
Aplikasi DWS menggunakan database Oracle sebagai basis datanya 9 Java dan Netbeans IDE untuk membangun prototype.
Framework OVSP telah diuji oleh peneliti sebelumnya menggunakan
bahasa pemrograman Java (Ashadevi et al, 2010)
9 Junit untuk melakukan validasi dan testing fungsi – fungsi prototype Alat bantu ini dipilih karena paling umum digunakan dalam pemrograman bahasa Java
9 JSQLParser untuk melakukan ekstraksi SQL
Alat bantu ini dipilih karena open-source dan juga gratis 9 Ini4j untuk manajemen konfigurasi