2010 Mathematics Subject Classification: 62H30, 62H86, 62P25. 61
PERBANDINGAN METODE FUZZY C-MEANS CLUSTERING DAN FUZZY
C-SHELL CLUSTERING
(STUDI KASUS: KABUPATEN/KOTA DI PULAU JAWA BERDASARKAN
VARIABEL PEMBENTUK INDEKS PEMBANGUNAN MANUSIA)
Agus Widodo1, Purhadi2
1Mahasiswa Pascasarjana Jurusan Statistika, FMIPA, ITS 2Jurusan Statistika, FMIPA, ITS
Kampus ITS Sukolilo, Surabaya, 60111
E-mail: [email protected], [email protected]
Abstract
Cluster analysis is a multivariate analysis technique with the main purpose is to classify objects into groups based on the characteristics observation. Clustering methods currently being developed is the method of grouping based on the fuzzy sets, also called as fuzzy clustering analysis. There are various methods of fuzzy clustering analysis, such as Fuzzy C-Means Cluster (FCM) and Fuzzy C-Shell Cluster (FCS). FCM is developed based on c-means using fuzzy weighting, while the FCS applying geometric partition, in particular using the circle and ellipse shapes. The optimum number of groups is obtained by the criteria of validity measure, mentioned as Xie and Beni index, while for the right method is used the ratio of standard deviation within the group against the standard deviation between groups. FCM and FCS will be applied to the grouping of districts/cities by using the variable forming the Human Development Index (HDI) in 2008 for the districts/cities on the island of Jawa. HDI forming variables, consisting of the life expectancy; literacy rates, mean years school, and the purchasing power parity . The obtained results show that FCM is the best method for this case with an optimum number of groups is six groups.
Keywords : Fuzzy C-Means cluster, Fuzzy C-shell Cluster, Xie and Beni Index, Human Development Index (HDI)
Abstrak
Analsis kelompok merupakan salah satu teknik dalam analisis multivariat yang mempunyai tujuan utama untuk mengelompokkan objek-objek pengamatan menjadi beberapa kelompok berdasarkan karakteristik yang dimilikinya. Metode pengelompokan yang saat ini sedang berkembang adalah metode pengelompokan yang berdasarkan himpunan fuzzy atau yang disebut sebagai fuzzy clustering analysis. Berbagai metode dalam fuzzy clustering analysis, diantaranya adalah Fuzzy C-Means Cluster (FCM) dan Fuzzy C-Shell Cluster (FCS). FCM adalah pengembangan dari K-mean dengan menggunakan pembobotan fuzzy, sedangkan FCS menggunakan pengelompokan yang bersifat geometris, khususnya menggunakan bentuk lingkaran dan ellips. Untuk jumlah kelompok yang optimum didapatkan dengan menggunakan kriteria ukuran validitas, yaitu Indeks Xie dan Beni, sedangkan untuk metode yang
tepat digunakan rasio simpangan baku di dalam kelompok terhadap simpangan baku antar kelompok. FCM dan FCS diterapkan pada pengelompokan kabupaten/kota dengan menggunakan variabel pembentuk Indeks Pembangunan Manusia (IPM) tahun 2008 untuk kabupaten/kota di pulau Jawa. Variabel-variabel pembentuk IPM, terdiri dari angka harapan hidup, angka melek huruf, rata-rata lamanya sekolah, dan
Purchasing Power Parity (paritas daya beli). Dengan pembandingan berdasarkan fungsi objektif, indeks validitas dan waktu komputasinya, didapatkan bahwa metode FCM merupakan metode terbaik untuk digunakan dengan jumlah kelompok yang optimum adalah enam kelompok.
Kata kunci: Fuzzy C-Means cluster, Fuzzy C-shell Cluster, Indeks Xie dan Beni, Indeks Pembangunan Manusia
1. Pendahuluan
Pada proses pengelompokan berhierarki atau tak berhierarki, pembentukan kelompok dilakukan dengan sedemikian rupa sehingga setiap objek berada tepat pada satu kelompok. Namun, pada suatu saat, hal itu tidak dapat dilakukan untuk menempatkan suatu objek tepat pada suatu kelompok, karena sebenarnya objek tersebut terletak diantara dua atau lebih kelompok yang lain. Sehingga perlu dilakukan penggelompokkan dengan menggunakan fuzzy clustering yang memperhitungkan tingkat keanggotaan himpunan fuzzy sebagai dasar pembobotan [1]. Pengelompokan dengan logika fuzzy terus berkembang karena pada umumnya data tidak bisa dipisahkan secara tegas ke dalam kelompok, tetapi memiliki kecenderungan yang dinyatakan sebagai derajat keanggotaan, yang bernilai diantara 0 dan 1, terhadap kelompoknya [2].
Pengelompokan dengan menggunakan algoritma fuzzy c-means (FCM) merupakan salah satu teknik yang merupakan perkembangan metode pengelompokan tak berhierarki ( c-means) dengan menggunakan logika fuzzy. FCM pertama kali diperkenalkan oleh Dunn pada tahun 1973 [3] yang kemudian dikembangkan oleh Bezdek [4] yang digunakan dalam bidang pengenalan pola (pattern recognition). Metode FCM sering digunakan dalam pengelompokan, karena metode ini memberikan hasil yang halus dan cukup efektif untuk meningkatkan homogenitas tiap kelompok yang dihasilkan [5]. Dalam penelitian ini digunakan metode fuzzy c-shell cluster sebagai pembanding dari fuzzy c-means cluster untuk melihat seberapa efisien metode fuzzy c-mean clsuter digunakan dalam fuzzy clustering karena metode FCS jarang digunakan. Dave ([6]) menjelaskan teknik pendekatan yang dipakai dalam FCS menggunakan pengelompokan bersifat geomteris, khususnya menggunakan bentuk lingkaran dan ellips. Bentuk dasar kelompok adalah p-dimensi hyper-spherical shell yang dikarakteristikkan dengan pusat dan radius. Dalam penelitiannya diaplikasikan sebagai pengenalan pola (pattern recognition) dalam bidang analisis citra.
Salah satu indikator keberhasilan pembangunan adalah Indeks Pembangunan Manusia (IPM), dimana IPM sebagai indikator modal manusia dalam mencapai kualitas hidup yang lebih baik tergambar melalui komponen pendidikan, ekonomi, dan kesehatan. Modal manusia di suatu daerah untuk bersaing dengan daerah lain ini tidak hanya bersumber dari jumlah penduduk, melainkan juga dari keterampilan yang dimiliki penduduk dan kesehatan penduduknya. Penghitungan IPM didasarkan 4 variabel yang memiliki satuan pengukuran yang berbeda, terdiri dari: peluang hidup (diukur dengan variabel Angka Harapan Hidup dalam tahun), pendidikan
(diukur dengan variabel Angka Melek Huruf dalam persen dan Angka Rata-rata Lama Sekolah dalam tahun), dan hidup layak (diukur dengan variabel paritas daya beli perbulan dalam rupiah). Tinggi rendahnya IPM Kabupaten/Kota di pulau Jawa hanya ditunjukkan oleh Indeks Komposit tetapi tidak ditunjukkan variabel mana yang dominan terhadap tinggi/rendahnya peringkat IPM. Provinsi-provinsi di pulau Jawa pada tahun 2008, memiliki peringkat IPM di atas 20 besar, kecuali provinsi Banten yang memiliki peringkat ke-23. Provinsi DKI Jakarta sebagai peringkat pertama, kemudian propinsi Daerah Istimewa Yogyakarta dengan peringkat 4. Pada provinsi Jawa Tengah, memiliki peringkat ke-14, sedangkan propinsi Jawa Barat pada peringkat ke-15, serta propinsi Jawa Timur memiliki peringkat ke-19 dari seluruh propinsi yang ada di Indonesia. Pengelompokan wilayah bertujuan untuk membagi wilayah-wilayah dalam beberapa kelompok dengan karakteristik yang memiliki tingkat keserupaan yang tinggi di dalam setiap kelompok dan memiliki perbedaan antar kelompok. Pada kasus pengelompokan kabupaten/kota di pulau Jawa berdasarkan Indikator Pembangunan Manusia ini ingin didapatkan metode pengelompokan yang tepat untuk data komponen pembentuk IPM. Pengelompokan dengan kedua metode ini memerlukan indeks validitas yang digunakan untuk mengetahui banyak kelompok yang optimum yang terbentuk. Indeks validitas yang digunakan adalah Indeks Xie dan Beni [7]. Dalam penelitiannya, indeks ini memiliki ketepatan dan keandalan yang tinggi dalam memberikan banyak kelompok optimum. Jumlah kelompok optimum yang digunakan dari kedua metode tersebut berdasarkan nilai uji homogenitas covarian matriksnya. Adapun tujuan penelitian ini adalah membandingkan pengelompokan antara metode fuzzy c-shell cluster
dan fuzzy c-means cluster dengan menggunakan indeks validitas cluster dalam kasus pengelompokan kabupaten/kota di Pulau Jawa berdasarkan variabel pembentuk IPM.
2. Metode
Teori Himpunan Fuzzy
Konsep dari himpunan fuzzy sejalan dengan himpunan tegas, hanya saja derajat atau tingkat keanggotaan dari himpunan fuzzy tersebut bersifat kontinu dimana nilainya dalam interval [0,1]. Dimisalkan didefinisikan suatu himpunan
Z
yang anggotanya dapat dilambangkan denganz
. Suatu himpunan fuzzy A dalamZ
yang didefinisikan dengan{( ,
( ) |
}
A
z uA z
z
Z
,uA z
( )
adalah fungsi keanggotaan untuk himpunan fuzzy A. Dimanafungsi keanggotaan akan memetakan setiap elemen dari
Z
ke derajat keanggotaan antara 0 dan 1. Semakin nilai fungsi keanggotaan mendekati satu, maka semakin tinggi derajat atau tingkat keanggotaan z dalam A. Himpunan fuzzy dalam pengelompokan berperan dalam pembentukan fungsi dan tingkat keanggotaan dari setiap objek dalam kelompok.Fuzzy C-means Cluster
Metode FCM merupakan pengembangan dari metode tak berhierarki c-means cluster
yang mengalokasikan data ke dalam masing-masing kelompok dengan memanfaatkan teori himpunan fuzzy. Dalam metode FCM digunakan variabel fungsi keanggotaan, uik, yang merujuk pada seberapa besar kemungkinan suatu data bisa menjadi anggota ke dalam suatu kelompok. Kemudian [4] memperkenalkan suatu variabel m yang merupakan weigthing exponent dari
membership function. Nilai m mempunyai nilai di atas satu (1 < m < ). Pada saat ini belum ada ketentuan yang jelas mengenai besaran nilai m yang optimal dalam proses tersebut. Nilai
yang paling sering digunakan oleh para peneliti untuk variabel m adalah 2 [10]. Fungsi keanggotaan untuk suatu data ke dalam suatu kelompok tertentu dihitung dengan menggunakan rumus sebagai berikut:
1 1 2 1 2 1
.
m c ik ik j jk d u d
(1)Fungsi keanggotaan tersebut di atas, merujuk pada seberapa besar kemungkinan suatu objek bisa menjadi anggota ke dalam suatu kelompok, atau derajat keanggotaan objek ke-k ke kelompok
ke-i, yang mempunyai nilai 0uik 1, dan 1 1 c ik i u
. Nilai 2 ( k, i) ik d x v merupakan formulasi jarak yang digunakan, yang dirumuskan sebagai berikut:2 2
( , ) ( ) (T )
ik k i k i k i k i
d x v x v x v x v (2)
dimana
v
i adalah nilai pusat kelompok ke-i, danv
jadalah nilai pusat kelompok ke-j yang dihitung dengan menggunakan persamaan di bawah ini :1 1
.
n m ik k k i n m ik k u x v u
(3)Dalam FCM, pusat awal kelompok masih belum akurat. Setiap data memiliki derajat keanggotaan untuk setiap kelompok, dengan melakukan perulangan akan memperbaiki pusat kelompok dan derajat keanggotaan, sehingga pusat kelompok akan bergerak menuju lokasi yang tepat. Perulangan ini berdasarkan pada minimalisasi fungsi objektif. Fungsi objektif didasarkan pada pendekatan jarak antara data dengan setiap pusat kelompok. Fungsi objektif yang digunakan pada FCM adalah sebagai berikut:
2 1 1 ( ) ( ) ( , )
.
c n m FCM ik ik k i i k J u d x v
X, U, V (4)Algoritma FCM adalah sebagai berikut:
1. Menentukan jumlah kelompok yang akan dibentuk (2 c n).
2. Menginisialisasi matriks fungsi keanggotaan awal U0, biasanya dipilih secara acak. 3. Menghitung nilai pusat kelompok ke-k dengan menggunakan persamaan (3).
4. Menghitung matriks derajat keanggotaan yang baru
U
t1 dengan persamaan (1). Menbandingkan nilai keanggotaan dalam matriksU
, jika Ut1Ut
maka sudah konvergen dan iterasi dihentikan, dimana
merupakan nilai threshold yang ditentukan. Jika Ut1Ut
, maka kembali ke langkah 4. Nilai threshold adalah suatu bilangan positif yang kecil sekali mendekati nol, 0.00001 (10-5).Fuzzy C-shell Cluster
Algoritma pada fuzzy c-shell cluster, bentuk dasar dari kelompok adalah p-dimensi
hyper-spherical shell, yang dapat dikarakteristikkan oleh pusat dan jari-jari. Dimisalkan
adalah himpunan riil, dan
padalah himpunan dari p-tuples. Misalkan
1, 2, ,
p n
x x x
X menjadi suatu himpunan data yang infinte sedimikian
x
k
X
adalah vektor ke-k. MisalkanU
M
fcadalah keanggotaan dari X; dan misalkan V adalah c-tuple
v v1, 2, ,vc
, dimanap i
v
, dan dimisalkan R adalah c-tuple
r r1, ,2 ,rc
,ri. Untuk FCS, fungsi objektifnya adalah sebagai berikut:2 1 1 ( , )
,
n c m FCS ik ik k i J uD
U, V, R X (5)dengan nilai m
1,
, serta jarakD x v
ik( , )
k i merupakan formulasi jarak yang dirumuskan sebagai berikut:
2 2 ( , ) . ik k i k i i D x v x v r (6)Fungsi keanggotaannya dirumuskan sebagai berikut :
1 1 2 1 2 1 ( , ) ( , ) m n ik k i ik j jk k j d x v u d x v
(7)Algoritma FCS [6] adalah sebagai berikut:
1. Menentukan jumlah kelompok yang akan dibentuk (2 c n).
2. Menginisialisasi matriks fungsi keanggotaan awal U0, biasanya dipilih secara acak. 3. Menghitung pusat kelompok
v
i dan jari-jari kelompokr
i dengan mengunakan persamaan3 dan 10, di bawah ini:
1 1
.
n m ik k i k i n m ik k u x v r u
(8)4. Menghitung jarak,
D
ik2 menggunakan persamaan (6).5. Menghitung matriks derajat keanggotaan yang baru
U
t1 dengan persamaan (7).6. Membandingkan nilai keanggotaan dalam matriks
U
, jika Ut1Ut
maka sudah konvergen dan iterasi dihentikan, dimana
merupakan nilai threshold yang ditentukan. Jika Ut1Ut
, maka kembali ke langkah 4. Nilai threshold adalah suatu bilangan positif yang kecil sekali mendekati nol, 0.00001 (10-5).Indeks Validitas
Indeks validitas adalah suatu ukuran yang digunakan untuk menentukan jumlah kelompok yang optimal [11]. Pada penelitian ini menggunakan indeks Xie dan Beni(XB). [7] merekomendasikan indeks ini untuk pengelompokan, karena memiliki ketepatan dan kehandalan yang tinggi untuk digunakan sebagai kriteria dalam menentukan jumlah kelompok yang optimum. Kriteria banyak kelompok yang optimum ditunjukkan oleh nilai Indeks Xie dan Beni yang minimum pada lembah pertama. Indeks Xie dan Beni adalah sebagai berikut:
2 1 1 2 ( ) min
.
c n m ik ik i k PI ij i j u d I c n v v
(11)Indeks Pembangunan Manusia (IPM)
Salah satu indikator keberhasilan pembangunan adalah Indeks Pembangunan Manusia (IPM), dimana IPM sebagai indikator modal manusia dalam mencapai kualitas hidup yang lebih baik tergambar melalui komponen pendidikan, ekonomi, dan kesehatan. Penghitungan IPM didasarkan 4 variabel yang memliki satuan pengukuran yang berbeda, terdiri dari: peluang hidup (diukur dengan variabel Angka Harapan Hidup dalam tahun), pendidikan (diukur dengan variabel Angka Melek Huruf dalam persen dan Angka Rata-rata Lama Sekolah dalam tahun), dan hidup layak (diukur dengan variabel paritas daya beli perbulan dalam rupiah).
3. Hasil dan Pembahasan
Data yang digunakan dalam penelitian ini adalah data sekunder yang diperoleh dari Publikasi Badan Pusat Statistik (BPS) 2009 mengenai IPM menurut kabupaten/kota tahun 2008. Komponen-komponen IPM tersebut dipakai sebagai variabel dalam penelitian ini. Variabel tersebut yaitu:
1. X1 = Angka harapan hidup (tahun)/AHH 2. X2= Angka melek huruf (persen)/AMH 3. X3 = Rata-rata lama sekolah (tahun)/MYS
4. X4 = Rata-rata pengeluaran riil per kapita per bulan (ribuan Rp)/PPP
Obyek dari penelitian ini adalah kabupaten/kota di pulau Jawa sebanyak 117 kabupaten/kota, terdiri dari 33 kota dan 84 kabupaten.
Tahapan penelitian adalah sebagai berikut:
a. Melakukan pengelompokan dari c = 2 sampai 10, baik dengan menggunakan FCM dan FCS, serta menentukan faktor fuzzy (weigthing exponent) hasil pengelompokan (m). Pada penelitian ini digunakan m = 2.
b. Menghitung indeks validitas clustering, dengan indeks Xie dan Beni, untuk metode FCM dan FCS.
c. Membandingkan hasil pengelompokan yang terbentuk dari FCM dan FCS dengan jumlah kelompok yang optimum mempunyai nilai indeks validitas Xie dan Beni yang paling minimum untuk setiap metode FCM dan FCS. Sehingga diperoleh jumlah kelompok yang optimum untuk masing-masing metode. Kelompok yang dengan nilai indeks validitas Xie dan Beni yang paling minimum diantara metode FCM dan FCS merupakan jumlah
kelompok yang akan dipilih. Sehingga dapat dilakukan pengelompokan kabupaten/kota berdasarkan variabel IPM dengan menggunakan jumlah kelompok tersebut. Setelah didapatkan kelompok yang optimum dilakukan uji distribusi multivariate normal, uji mean vektor serta uji kovarian matriks. Untuk memilih kelompok yang terbaik digunakan perbandingan antara fungsi objektif, indeks validitas Xie dan Beni serta waktu komputasinya.
Deskripsi variabel penelitian yang digunakan dapat dilihat pada Tabel 1. Berdasarkan Tabel 1 dapat dijelaskan bahwa standar deviasi yang paling tinggi adalah pada variabel X4, ini menunjukkan bahwa variansi data pada variabel tersebut cukup bervariasi, sedangkan standar deviasi yag paling kecil adalah pada variabel X3.
Tabel 1. Statistik Diskriptif Variabel Penelitian
Variabel N Min Max Rata-rata Standar Deviasi
X1 117 60.560 74.430 68.743 2.903
X2 117 64.120 93.010 91.843 6.293
X3 117 3.770 11.420 7.604 1.603
X4 117 588.04 647.03 632.00 9.29
Sebelum proses pengelompokan, dilakukan terlebih dahulu pengujian multivariat normal terhadap variabel penelitian tersebut. Pemeriksaan distribusi multivariat normal dapat dilakukan dengan cara membuat q-q plot dari nilai
d
2j [8]. Jika hasil q-q plot nilai2 j
d
menunjukan ada lebih 50 persen yang memiliki nilai
d
2j
n2;0.05maka keputusan yang diambil adalah gagal menolak H0, yang berarti bahwa data berdistribusi multivariate normal. Hasilpengujian asumsi multivariat normal, menunjukkan bahwa ada 61,53 persen data yang memiliki nilai
d
2j
n2;0.05sehingga dapat disimpulkan bahwa data telah berditribusi multivariat normal,dan data dapat dilakukan proses pengelompokan dengan menggunakan kedua metode tersebut. Dengan data yang telah berdistribusi multivariat normal, maka tahapan berikutnya adalah melakukan pengelompokan dengan mengunakan metode FCM dan metode FCS. Jumlah kelompok yang digunakan sebagai input adalah c = 1 sampai dengan c =10. Dengan melakukan 10 kali pengulangan. Hasil dari ukuran kriteria pengelompokan disajikan pada Tabel 1. Dari Tabel 1, dapat dilihat bahwa nilai fungsi objektif semakin menurun, apabila jumlah kelompok yang inginkan bertambah. Pada jumlah kelompok sama dengan dua, banyaknya iterasi hampir sama pada setiap pengulangan, dengan rata-rata iterasi sebanyak 15,6 iterasi. Demikian juga untuk nilai fungsi objektif yang nilainya relatif sama, yang berarti fungsi objektif ini konvergen pada nilai 54,9181. Nilai indeks validitas Xie dan Beni pada c = 2, pada setiap pengulangan nilai relatif sama, yaitu pada nilai 0,0019. Pada c = 5, jumlah iterasi berbeda pada setiap pengulangan, namun nilai fungsi objektif relatif sama. Nilai indeks validitas Xie dan Beni pada setiap pengulangan menghasilkan nilai yang relatif sama, dengan rata-rata 0,0037. Pada setiap pengulangan, jumlah iterasi pada c = 5 sampai dengan c = 10, mendapatkan hasil yang berbeda satu dengan yang lain. Apabila memperhatikan algoritma FCM, dapat dilihat bahwa FCM, pada tahap awal, inisialisasi derajat keanggotaannya dilakukan secara random.
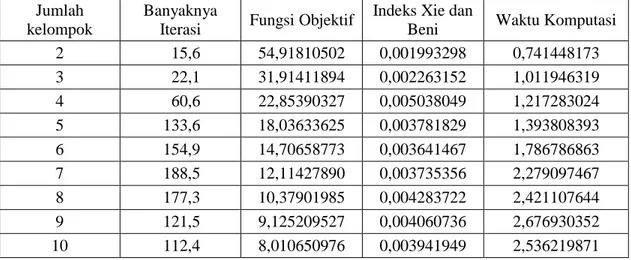
Tabel 2. Rata-rata Iterasi, Fungsi Objektif, Indeks Xie dan Beni, dan Waktu Komputasi, dengan metode FCM
Jumlah kelompok
Banyaknya
Iterasi Fungsi Objektif
Indeks Xie dan
Beni Waktu Komputasi
2 15,6 54,91810502 0,001993298 0,741448173 3 22,1 31,91411894 0,002263152 1,011946319 4 60,6 22,85390327 0,005038049 1,217283024 5 133,6 18,03633625 0,003781829 1,393808393 6 154,9 14,70658773 0,003641467 1,786786863 7 188,5 12,11427890 0,003735356 2,279097467 8 177,3 10,37901985 0,004283722 2,421107644 9 121,5 9,125209527 0,004060736 2,676930352 10 112,4 8,010650976 0,003941949 2,536219871
Penentuan jumlah kelompok yang optimum pada metode FCM, ditunjukkan pada nilai indeks validitas yang minimum pada lembah pertama. Tabel 2 menunjukkan nilai indeks validitas pada jumlah kelompok dua sampai dengan jumlah kelompok sebanyak 4 nilainya semakin meningkat, namun turun secara perlahan, sampai jumlah kelompok sebanyak 6. Sehingga sesuai dengan kreteria di atas bahwa jumlah kelompok mencapai optimum dengan jumlah kelompok sebanyak 6, dimana rata-rata iterasinya 154,90 dan nilai indeks validitas Xie dan Beni pada lembah pertama minimum, sebesar 0,0036.
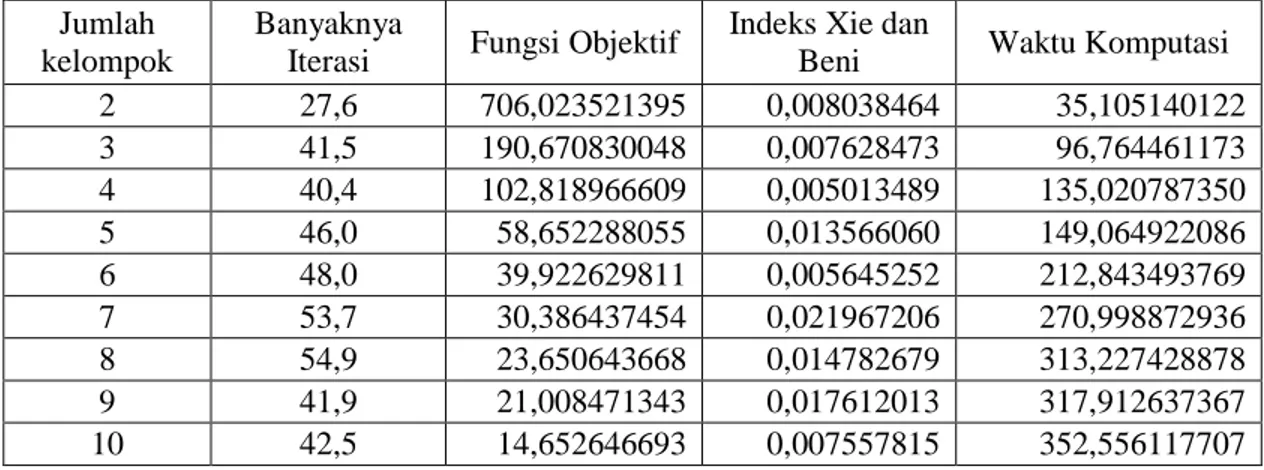
Pada metode FCS juga menggunakan jumlah kelompok sebagai input adalah c = 1 sampai dengan c =10, serta setiap kelompok dilakukan 10 kali pengulangan.Ringkasan hasil dari ukuran kriteria pengelompokan disajikan pada Tabel 2. Pada metode FCS, nilai fungsi objektifnya menunjukkan, bahwa semakin turun apabila jumlah kelompok semakin bertambah, dapat dilihat pada Tabel 2. Setiap penggulangan pada jumlah kelompok c = 2, memberikan hasil yang relatif sama. Namun pada jumlah kelompok c = 3 sampai dengan c = 10, hasil setiap pengulangan, memberikan hasil yang relatif berbeda. Hal ini disebabkan pada tahap inisialisasi awal derajat keanggotaan dilakukan secara random. Pada algoritma FCS juga memperhitungkan radius atau jari-jari pada masing-masing kelompok dalam menghitung jaraknya. Waktu komputasi yang dipakai untuk metode FCS, akan bertambah lebih lama apabila jumlah kelompok ditambahkan. Dengan metode FCM, waktu komputasi lebih cepat apabila dibandingkan dengan metode FCS.
Jumlah kelompok yang optimum pada metode FCS, juga menggunakan nilai indeks validitas Xie dan Beni, yang ditunjukkan pada nilainya yang minimum pada lembah pertama. Tabel 3 menunjukkan nilai indeks validitas pada jumlah kelompok dua sampai dengan jumlah kelompok empat, nilainya semakin menurun, kemudian meningkat pada jumlah kelompok 5 namun turun lagi, sampai jumlah kelompok sebanyak 6. Sehingga sesuai dengan kreteria di atas bahwa jumlah kelompok mencapai optimum dengan jumlah kelompok sebanyak 4, dimana rata-rata iterasinya 40,4 dan nilai indeks validitas Xie dan Beni pada lembah pertama minimum, sebesar 0,0005.
Tabel 3. Rata-rata Iterasi, Fungsi Objektif, Indeks Xie dan Beni, dan Waktu Komputasi, dengan metode FCS
Jumlah kelompok
Banyaknya
Iterasi Fungsi Objektif
Indeks Xie dan
Beni Waktu Komputasi
2 27,6 706,023521395 0,008038464 35,105140122 3 41,5 190,670830048 0,007628473 96,764461173 4 40,4 102,818966609 0,005013489 135,020787350 5 46,0 58,652288055 0,013566060 149,064922086 6 48,0 39,922629811 0,005645252 212,843493769 7 53,7 30,386437454 0,021967206 270,998872936 8 54,9 23,650643668 0,014782679 313,227428878 9 41,9 21,008471343 0,017612013 317,912637367 10 42,5 14,652646693 0,007557815 352,556117707
Tahapan selanjutnya adalah melakukan pengujian perbedaan rata-rata kelompok untuk masing-masing metode, berdasarkan hasil pengolahan didapatkan, dengan menggunakan uji Wilks Lambda untuk kedua metode tersebut. Berdasarkan pengujian yang telah dilakukan pada nilai Wilk’s Lambda (*) untuk metode FCM dengan jumlah kelompok sebanyak 6 kelompok
sebesar 0,0199, dan nilai Chi Squarenya sebesar 434,6743. P-value yang cukup kecil yaitu sebesar 0.000 atau p-value < 0,05, sehingga dapat diputuskan untuk menolak H0 sehingga bisa
dikatakan bahwa terdapat perbedaan rata-rata antar kelompok pada metode FCM yang terbentuk. Untuk metode FCS dengan menggunakan jumlah kelompok yang optimum sebanyak 4 kelompok diperoleh nilai Wilk’s Lambda (*), sebesar 0.7420 dan nilai Chi Squarenya sebesar
33.4216. Nilai p-value yang diperoleh cukup kecil yaitu 0,000 bila dibandingkan dengan derajat kepercayaan atau p-value < 0,05, sehingga diputuskan untuk menolak H0 yang berarti terdapat
perbedaan rata-rata antar kelompok pada metode FCS.
Pengelompokan kabupaten/kota dengan menggunakan metode FCM diperoleh 6 kelompok, sedangkan pengelompokan dengan menggunakan FCS diperoleh 4 kelompok. Untuk mengetahui hasil pengelompokan yang lebih baik dari kedua metode tersebut maka digunakan uji homogenitas. Uji Box’s M digunakan untuk uji homogenitas hasil pengelompokan. Berdasarkan hasil pengolahan didapatkan hasil Uji Box’s M untuk kedua metode tersebut. Dengan metode FCM, hasil uji Box’s M sebesar 62,5243 dengan nilai Chi-square sebesaar 55.1648, sedangkan untuk pengelompokan dengan metode FCS sebesar 30.0946 dengan nilai chi-square 27.6152. Kedua nilai p-value menunjukkan lebih besar dari nilai α= 0,05 yang berarti gagal tolak H0 , maka dapat disimpulkan bahwa matriks varians dan kovarians dari kedua metode
tersebut adalah sama (homogen).
Pada jumlah kelompok 4 dengan menggunakan metode FCM, nilai indeks Xie dan Beni mempunyai selisih sedikit dengan jumlah kelompok yang sama pada FCS. Namun pada nilai fungsi objektif, metode FCM lebih kecil daripada metode FCS, demikian juga dengan waktu komputasinya yang lebih cepat daripada metode FCS. Dengan melihat jumlah kelompok pada metode FCM dengan jumlah kelompok yang sama pada metode FCS yaitu 6 kelompok, dapat dilihat bahwa nilai indeks validitas Xie dan Beni nilainya lebih kecil daripada dengan metode FCS. Demikian juga dengan waktu komputasi yang dibutuhkan semakin cepat. Pada kasus ini metode FCM lebih baik untuk digunakan daripada FCS. Oleh karena itu, hasil pengelompokan
dengan metode fuzzy c-means cluster lebih baik digunakan untuk pengelompokan kabupaten/kota berdasarkan variabel IPM.
Berdasarkan pembahasan sebelumnya interpretasi pengelompokan dilakukan pada hasil pengelompokan dengan menggunakan metode FCM dengan jumlah kelompok sebanyak 6 kelompok. Banyaknya kabupaten/kota anggota kelompok pertama sampai dengan kelompok keenam berturut-turut 28, 25, 8, 29, 12, 15.
Setelah kelompok terbentuk, terhadap seluruh obyek penelitian sebanyak 117 kabupaten/kota diambil rata-rata dari masing-masing variabel pembentuk IPM, yaitu AHH, AMH, MYS, dan PPP
( )
X
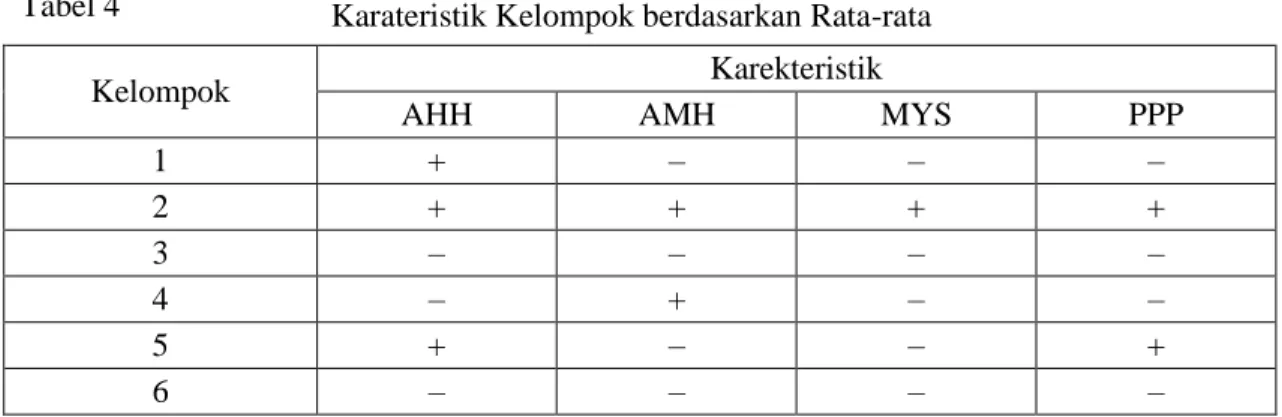
dapat dilihat Tabel 4. Selanjutnya masing-masing kelompok diambil rata-rata untuk variabel AHH, AMH, MYS, dan PPP (Xc). Pada setiap variabel di dalam kelompok diberi tanda, jika (Xc X) adalah tanda + , sedangkan apabila (Xc X)akan diberikan tanda –. Hasil selengkapnya diberikan pada Tabel 4.Dari Tabel 4, dapat kita amati bahwa kelompok 3 dan kelompok 4 mempunyai kesamaan karakteristik. Nilai rata-rata variabel AHH, AMH, MYS, dan PPP di dalam kelompok masih berada di bawah rata-rata tersebut untuk semua kabupaten/kota di pulau Jawa. Apabila dilihat dari nilai rata-rata variabel pada kelompok 6 lebih besar daripada nilai rata-rata variabel pada kelompok 3, kecuali untuk variabel PPP.
Tabel 4 Karateristik Kelompok berdasarkan Rata-rata
Kelompok Karekteristik
AHH AMH MYS PPP
1 + – – – 2 + + + + 3 – – – – 4 – + – – 5 + – – + 6 – – – –
Karakteristik kelompok yang paling berhasil dari kelompok lainnya adalah kelompok ke-2, pada rata-rata nilai variabel-variabel pembentuk IPM merupakan yang tertinggi diantara kelompok lainnya. Pada kelompok ke-5, variabel yang memiliki nilai rata di atas nilai rata-rata di pulau Jawa adalah variabel angka harapan hidup dan paritas daya beli, sehingga variabel yang perlu mendapatkan perhatian adalah variabel pendidikan yaitu angka melek huruf dan rata lamanya sekolah. Kelompok ke-4, variabel yang memiliki nilai rata di atas nilai rata-rata di pulau Jawa hanya pada angka melek huruf, sedangkan variabel lainnya berada di bawah nilai rata-rata di pulau Jawa, yaitu angka harapan hidup, rata-rata lamanya sekolah dan paritas daya beli. Sehingga variabel tersebut yang mendapatkan perhatian untuk pembangunan manusia yang lebih baik. Pada kelompok pertama, hanya variabel angka harapan hidup yang nilai rata-ratanya di atas nilai rata-rata di pulau Jawa, sehingga untuk kelompok ini, variabel yang perlu ditingkatkan adalah variabel angka melek huruf, rata-rata lama sekolah dan paritas daya beli. Kelompok ke-3 dan kelompok ke-6, merupakan kelompok yang semua nilai rata-rata variabelnya di bawah nilai rata-rata di pulau Jawa. Kelompok ke-6 nilai rata-rata variabelnya lebih bagus daripada nilai rata-rata di kelompok pertama. Variabel-variabel pada kelompok
pertama memiliki nilai rata-rata terendah diantara kelompok lainnya.
4. Kesimpulan
Berdasarkan hasil dan pembahasan yang dilakukan dapat diambil kesimpulan bahwa berdasarkan nilai indeks validitas Xie dan Beni yang minimum pada lembah pertama, hasil pengelompokan dengan menggunakan metode fuzzy c-means cluster diperoleh sebanyak 6 kelompok, dengan nilai indeks validitas Xie dan Beni 0,0036. Hasil pengelompokan dengan menggunakan metode fuzzy c-shell cluster diperoleh sebanyak 4 kelompok, dengan nilai indeks validitas Xie dan Beni 0,005. Metode fuzzy c-means cluster memberikan hasil yang lebih baik bila dibandingkan dengan metode fuzzy c-shell cluster, ditunjukkan pada hasil uji homogenitasnya, sehingga fuzzy c-means cluster menghasilkan pengelompokan yang lebih homogen jika dibandingkan dengan metode fuzzy c-shell cluster.
Daftar Pustaka
[1] Abonyi, J. dan Szeifert, (2002), “Supervised Fuzzy Clustering for the Identification of Fuzzy Classifiers”, Journal Elseiver, Vol. 24, 2195-2207
[2] Hoppner, F. dan Klawonn, F., (2004), “Learning Fuzzy Systems – An Objective Function-Approach”,Mathware & Soft Computing, Vol 11, pp.143-162
[3] Dunn, J. (1973). A Fuzzy Relative of the ISODATA Process and Its Use in Detecting Compact well-Separated Cluster. Jurnal of Cybernetic 3 , 32-37.
[4] Bezdek, J. (1981). Pattern Recognition with Fuzzy Objective Function Algorithm. New York: Plenum Press.
[5] Shihab, A. (2000). Fuzzy Clustering Algorithm and Their Application to Medical Image Analysis. Dissertation, University of London, London.
[6] Dave, R. (1992). Generalized Fuzzy C-Shell Clustering and Detection of Circular and Elliptical Boundaries. Pattern Recognition, Vol. 25 No. 7, 713-721
[7] Duo, C., Xue, L., & Du-Wu, C. (2007). An Adaptive Cluster Validiti Index for the Fuzzy C-Means. International Journal of Computer Science and Nework Security 7 No. 2 , 146-156.
[8] Johnson, RA, & Wichern, E. (2002), Applied Multivariate Statistical Analysis, Prentice-Hall, New York
[9] Rencher, A.C. (2002), Methods of Multivariate Analysis, John Wiley and Sons, New York [10] Yu, J., Cheng, Q., & Huang, H. (2004). Analysis of the Weighting Exponent in the
FCM. IEEE Transactions on Systems, Man, and Cybernetics, vol 34, 634-639. [11] Wu, K.-L., & Yang, M.-S. (2005). A Cluster Validity Index for Fuzzy Clustering.
Pattern Recognition Letters , 1275–1291.
[10] Bungker, M.J. dan Miller, J.R. (1996), Definition of Climate Regions in the Northern Plains using an Objective Cluster Modification Technique. Journal of Climate. 9 :130-146.